1. Introduction
In cereal crops, nitrogen (N) is the most important element for maintaining growth status and enhancing grain yield [
1]. Therefore, the real-time, nondestructive and accurate monitoring of the nitrogen (N) concentration in crops has become a key technique for timely diagnosis of problems, precise fertilization and productivity estimation [
2,
3,
4,
5,
6,
7,
8,
9,
10]. Remote sensing has been widely applied in recent decades to determine the biophysical and chemical parameters of crops [
2,
11,
12]. Many forthcoming hyperspectral satellite missions will be dedicated to land and crop monitoring. Hence, there is an urgent need to identify next-generation bio-geophysical variable retrieval algorithms that can be incorporated into an operational processing chain.
Considerable progress has been made using multispectral and hyperspectral data acquired from ground and aerial platforms to estimate the N concentration of crops [
8,
13,
14,
15,
16,
17,
18,
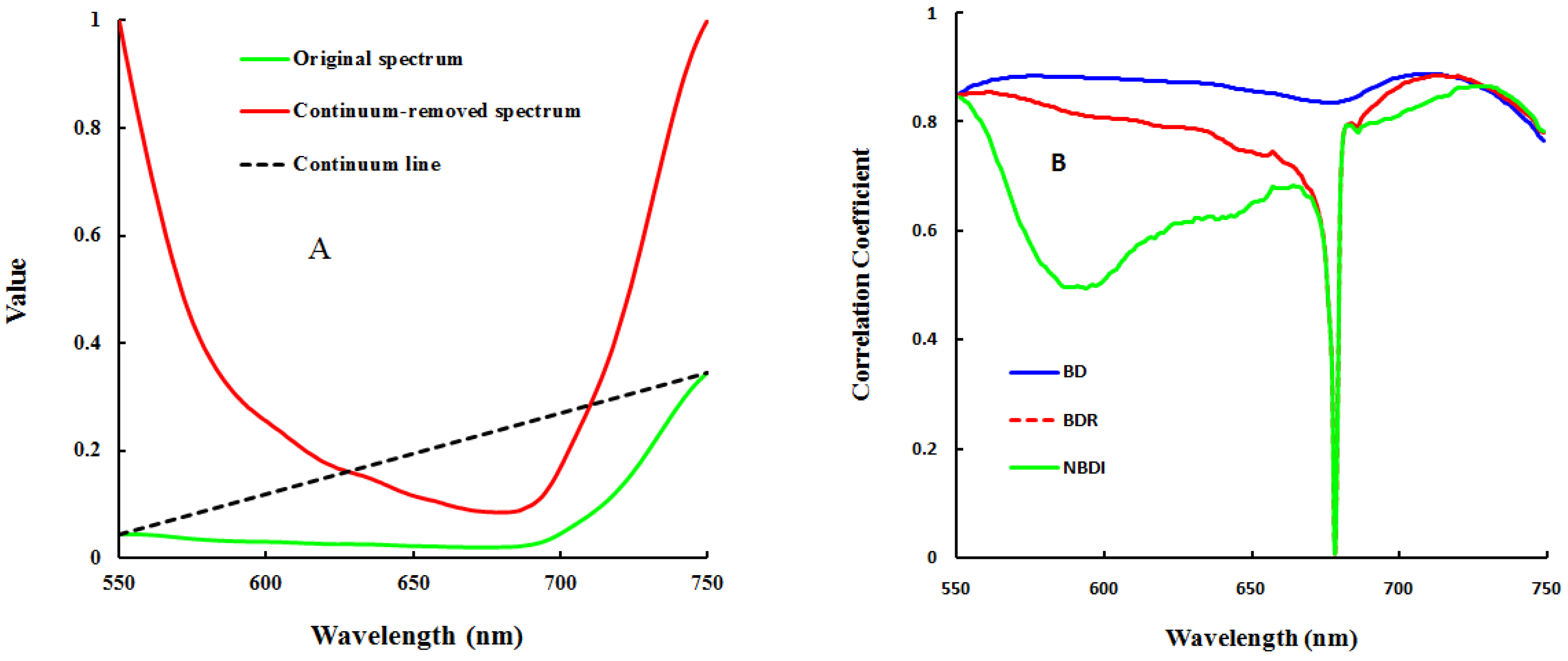
19]. Existing reports indicate that in most previous work, the core wavelengths have first been determined and then used to construct a sensitive spectral index, as in the case of the continuum removal (CR) and the vegetation index (VI) method. The CR method can be used to effectively isolate individual absorption features of interest and estimate the chemical concentration in dried leaves [
20,
21,
22]. However, one must determine the spectral range each time when the CR operation is performed, which results in unstable performance in monitoring of the chemical concentration of crops [
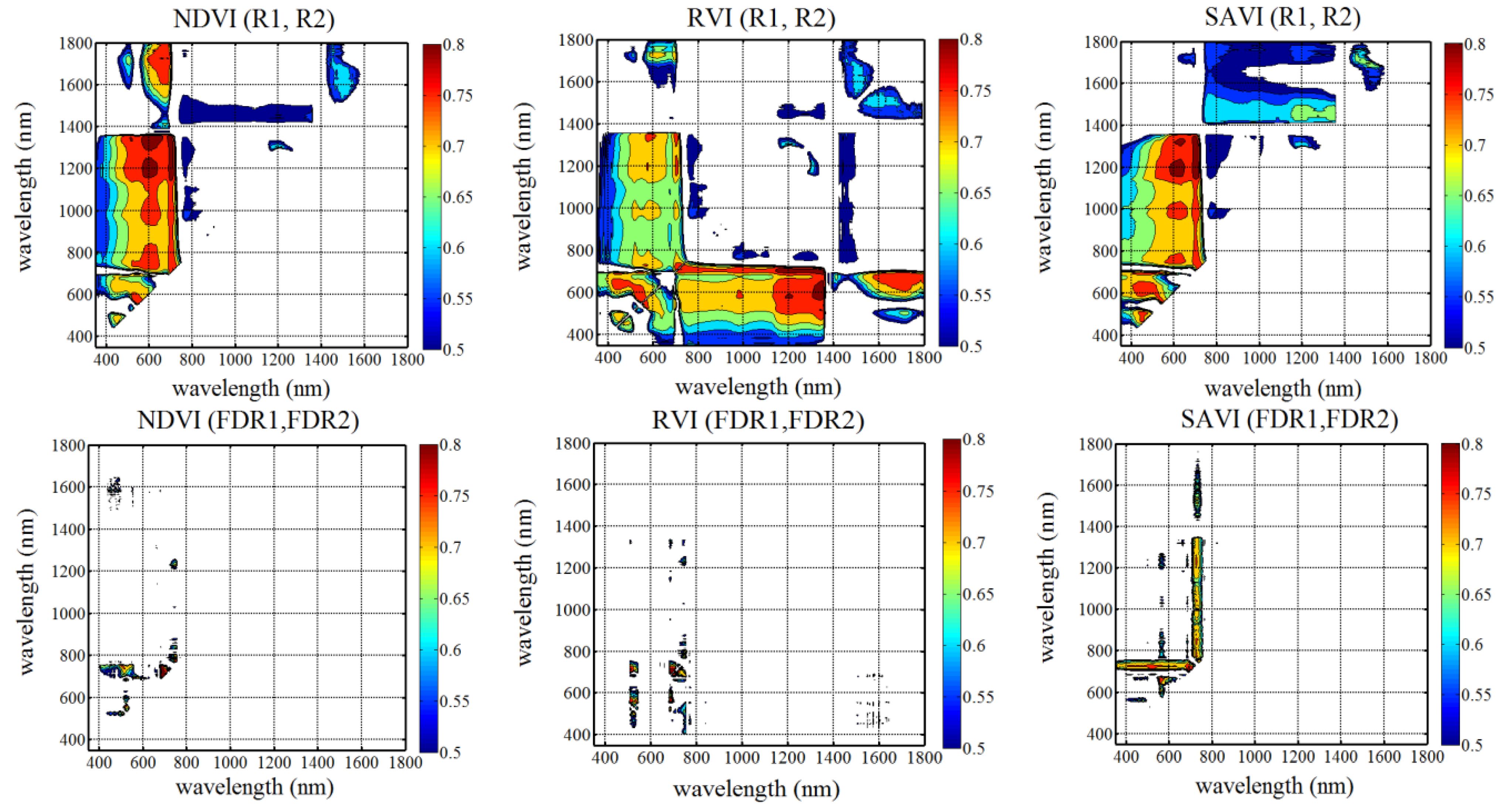
23]. In addition to the CR method, various vegetation indices, such as the Normalized Difference Vegetation Index (NDVI), the Ratio Vegetation Index (RVI), the Soil-Adjusted Vegetation Index (SAVI), Modified Normalized Difference (mND), and the Photochemical Reflectance Index (PRI), have been widely used to characterize chemical concentration of plants because these indices have simple forms and are easy to calculate [
10,
12,
24,
25,
26]. However, most researchers use only a limited number of wavelengths in specific spectral regions to calculate these indices and have not exploited the full spectrum information in hyperspectral data. In addition, many of these vegetation indices are strongly influenced by the soil background, resulting in soil-dependent VI-biophysical relationships. Linear regression models are typically analyzed based on individual input variables of the characteristic wavelength or vegetation index. Therefore, several researchers have suggested that multivariable input parameters should be considered when constructing such linear regressions.
Presently, the commercial instruments that are used to monitor crop N concentrations, such as ASD [
27] and hyperspectral imager, are not suitable for future use on family farms or for individual users because of their high cost and relatively complex operational procedures. A number of other portable devices, such as the SPAD (650 and 940 nm) [
28], can only work on a single leaf each time and therefore cannot be applied to large populations of plants. The LNC models that are currently developed with specific wavelengths on portable devices, such as the GreenSeeker (656 and 770 nm) and the Crop Circle (450,550,650,670,730, and 760 nm) [
29,
30,
31], may not be accurately transferrable among ecological sites and crop varieties. For the development of instruments with lower manufacturing cost and higher accuracy, it is unclear how many input variables should be used and which type of regression algorithms offers the best stability and computational efficiency.
A comprehensive multivariable linear regression could be performed to establish N predictive models for modern crop production. Several studies have addressed various multivariate models, such as stepwise multiple linear regression (SMLR) and partial least squares regression (PLSR) [
5,
16]. The SMLR is likely to suffer from multicollinearity when applied to canopy hyperspectral data [
32,
33]. Grossman
et al. [
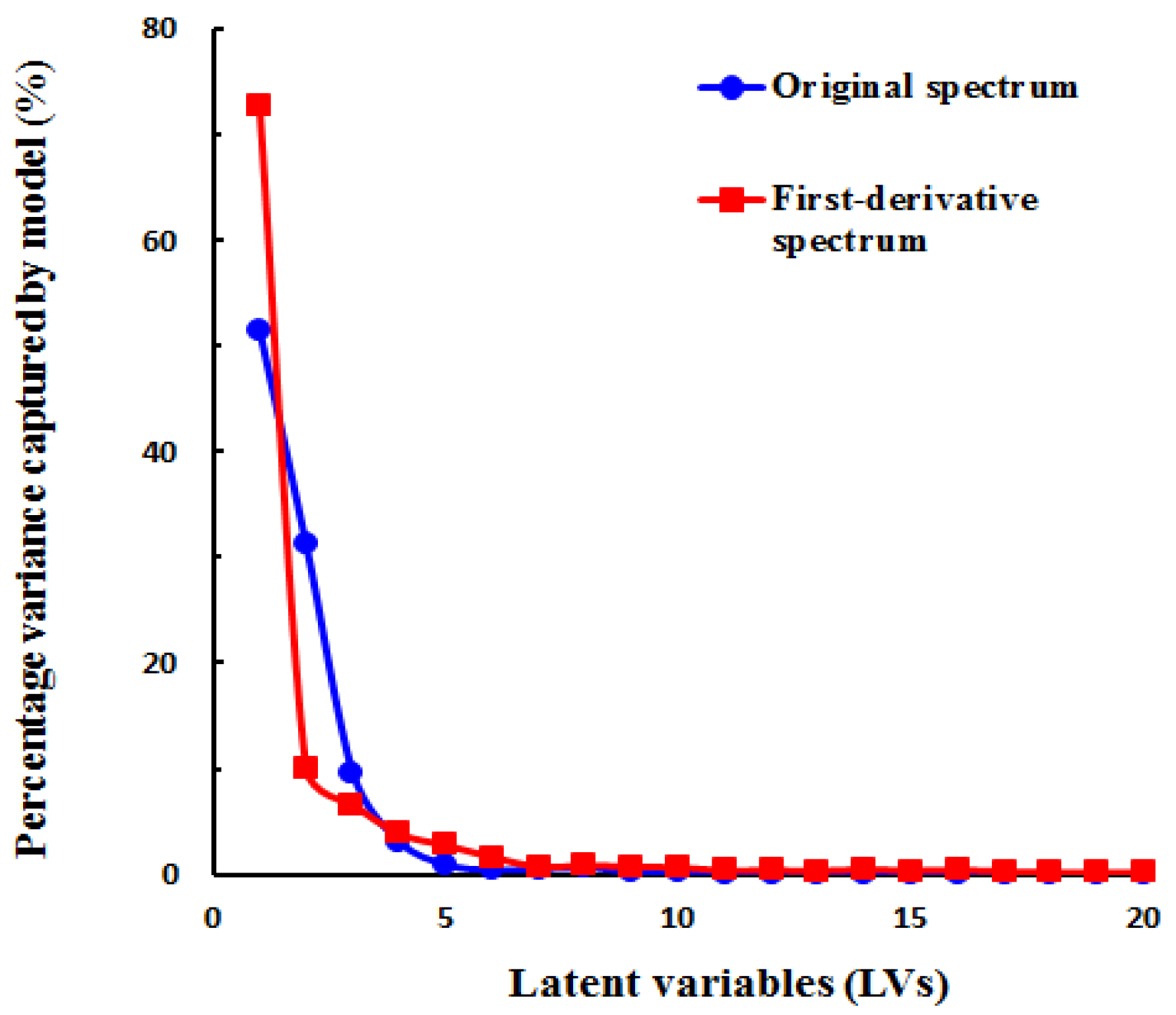
33] have found that the best wavelengths selected with SMLR might not be related to the absorption characteristics of the compounds of interest and do not produce consistent results between datasets. Hence, care should be taken when using SMLR to select wavelengths and estimate N concentration. Alternatively, the PLSR approach has been adopted to reduce the large number of measured collinear spectral variables to a few non-correlated latent variables (LVs), thereby avoiding the potential overfitting problems that are typically associated with SMLR [
16,
33].
A number of spectrometric studies have been undertaken concerning the estimation of the N content of plants using CR, vegetation indices (VIs), SMLR and PLSR [
8,
10,
11,
12,
16,
33,
34]. These approaches use an inconsistent number of wavelengths to estimate the N concentrations or estimate the chlorophyll status. Apart from these linear regression methods, some recent studies have investigated non-linear regression methods from the machine learning field such as artificial neural networks (ANNs) and support vector machines (SVMs) [
34,
35].
To date, the performance, advantages and disadvantages of leaf nitrogen concentration (LNC) estimation for wheat crops using ANN and SVM algorithms remain unclear. Currently, the ANN method is widely used in remote sensing to predict vegetation parameters and crop yields [
6,
34,
35]. However, it inevitably suffers from the overfitting problem. Fortunately, some researchers reported the SVM method resolves the problem of overfitting encountered when analyzing high-dimensional data [
36] and has been used to soil moisture [
37], hourly typhoon rainfall [
38], long-lead stream flows [
39], leaf area index, and leaf chlorophyll density [
40,
41]. These studies have shown that the SVM approach is preferable to the ANN approach for these applications because of its greater generalizability. In addition to the conventional application, ANN and SVM methods should be assessed in a comparative way in terms of their performance and potential for the estimation of wheat LNC.
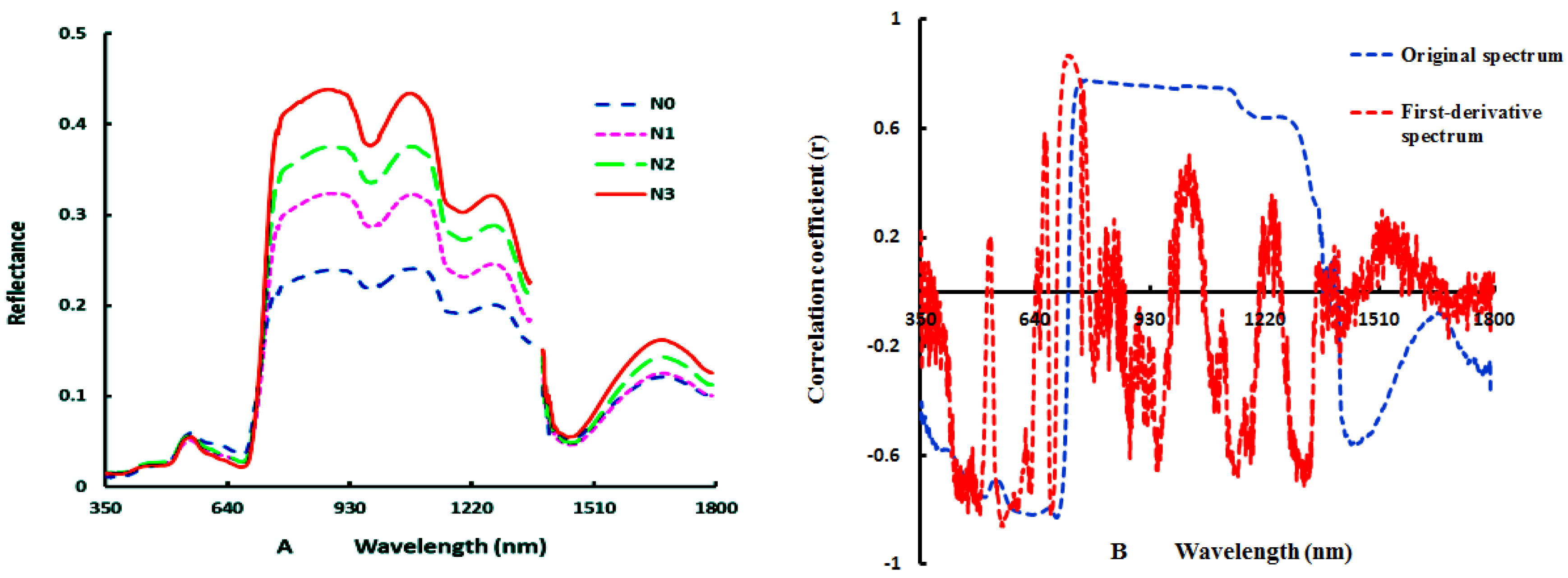
Currently, the first derivative is often used to decompose a mixed spectrum and reduce the noise in the hyperspectral region [
41,
42]. Mauser and Bach [
43] have concluded that derivative spectral indices are very sensitive to LAI. Yoder and Pettigrew-Crosby [
4] have found that first-order derivative spectra are the best predictors of the N and chlorophyll contents of big-leaf maples grown under different fertilization treatments. Johnson and Billow [
44] have examined Douglas fir needles grown using various fertilization treatments and also found the first-order derivatives of the fresh leaf spectra to be strongly correlated with the total N concentration. Many studies have demonstrated the potential of derivative spectra for estimating chemical concentrations of non-crop vegetation types. However, few studies have examined the performance of first-order derivative spectra with respect to the LNC of fresh wheat crop leaves.
To the best of our knowledge, no studies in the literature have provided an evaluation of all these methods and their predictive equations for wheat LNC using a large number of samples accumulated over nine consecutive years of field trial experiments with a total of 821 wide representatively samples. Moreover, previous evaluations have focused on the prediction accuracies and have not reported results on computational efficiency and complex level, which may be a serious problem when using hyperspectral imaging data. To address these research gaps, this study presents the results of a comparative assessment of six retrieval methods applied to in situ measurements acquired over eight years for seven varieties, four eco-sites, and 821 samples. The main objectives were (1) to evaluate the ability and performance of various linear (CR, VIs, SMLR and PLSR) and nonlinear (ANNS and SVMS) regression methods based on the original and first derivative spectra for LNC estimation; and (2) to determine which method, input variable and model could estimate the LNC in winter wheat with higher accuracy, better robustness, less time, and less complexity.
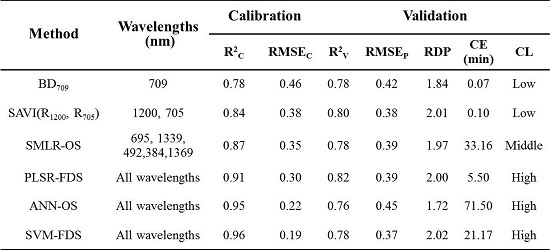
5. Conclusions
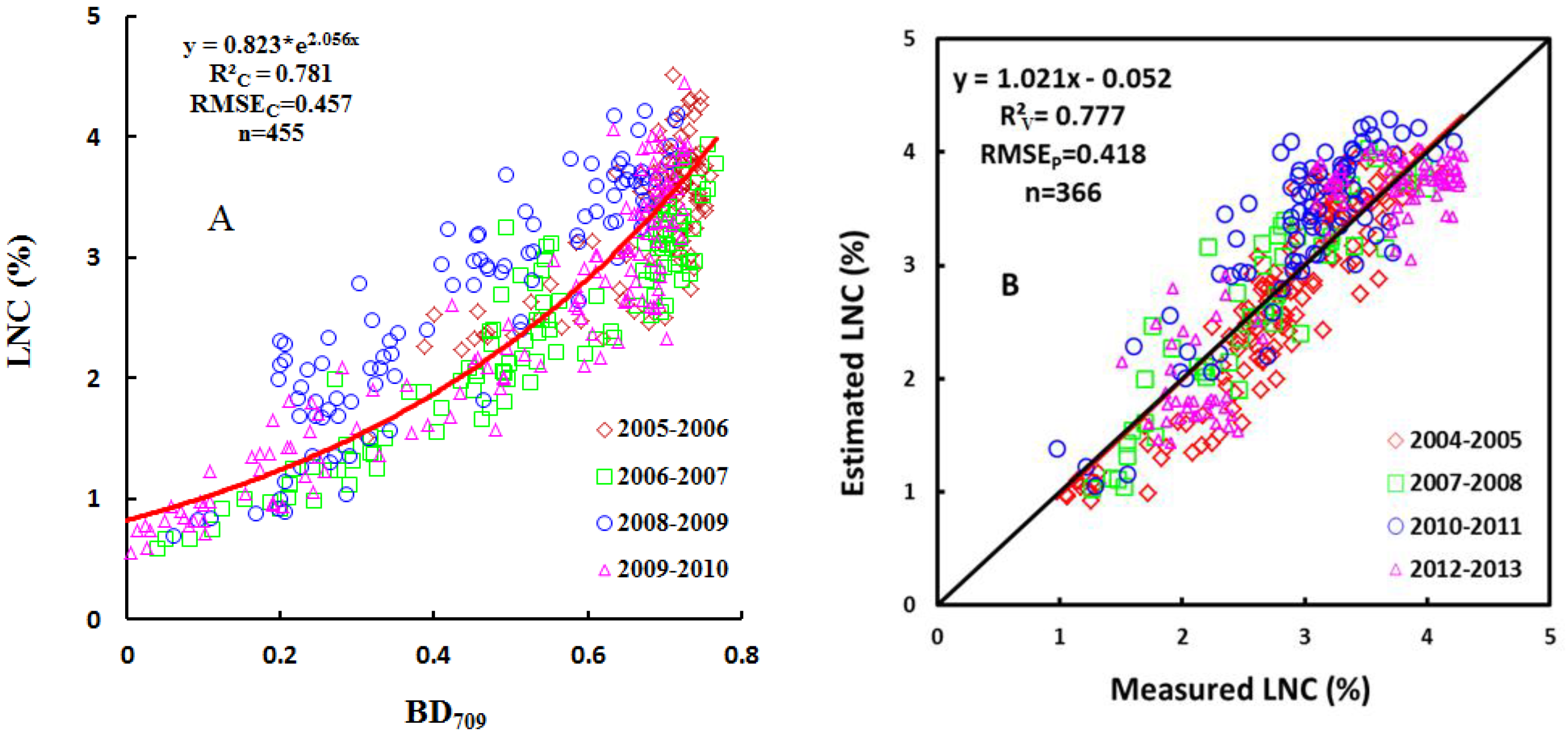
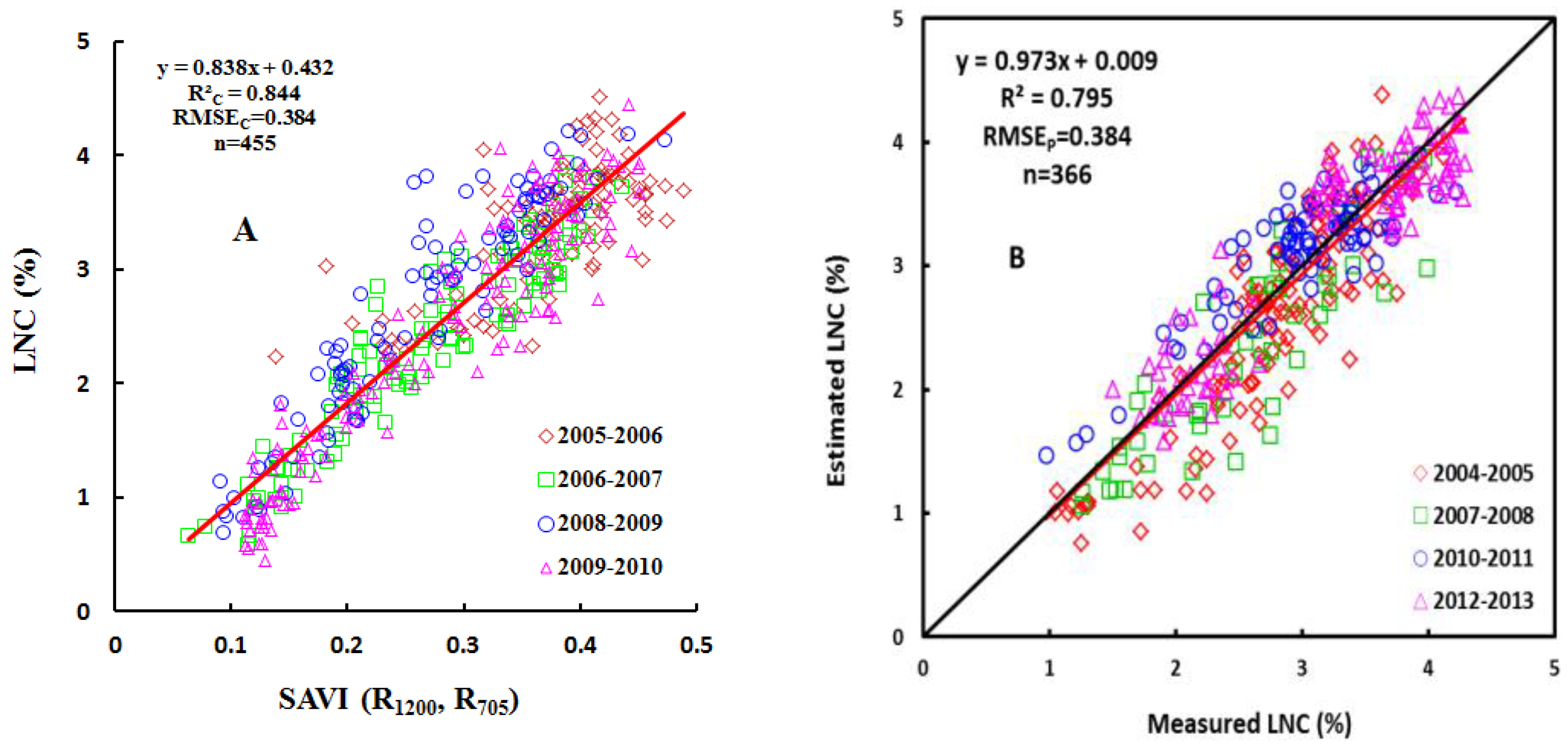
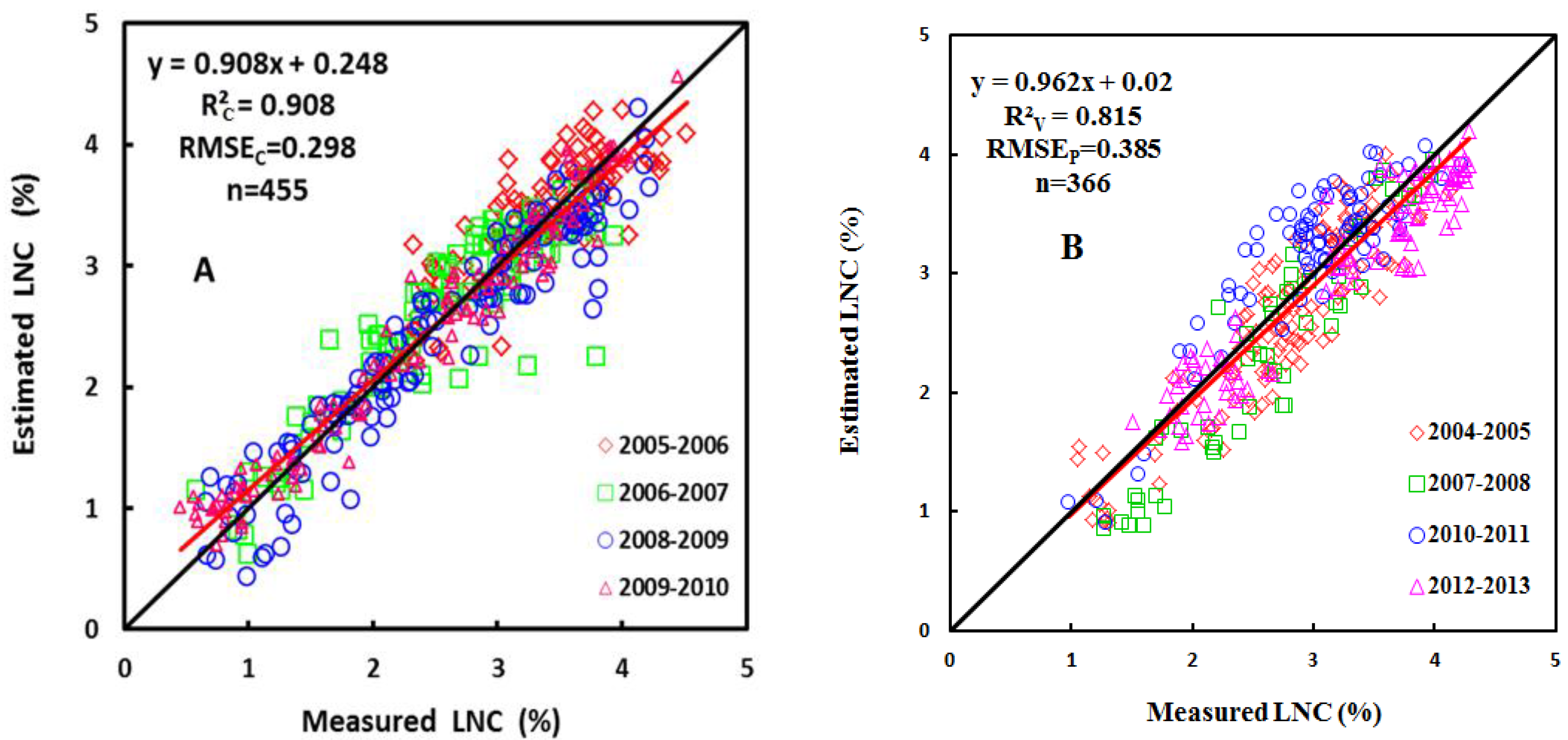
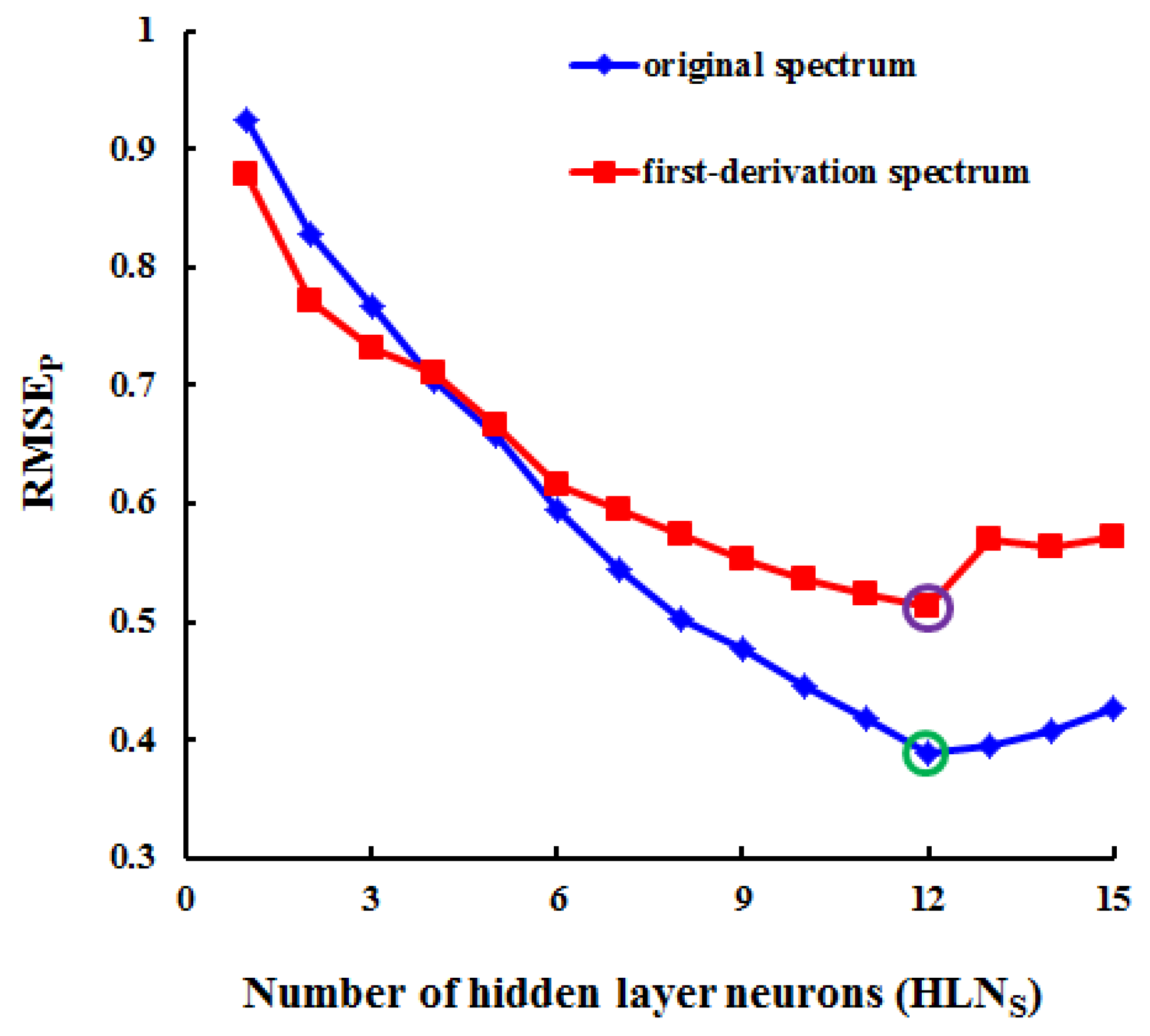
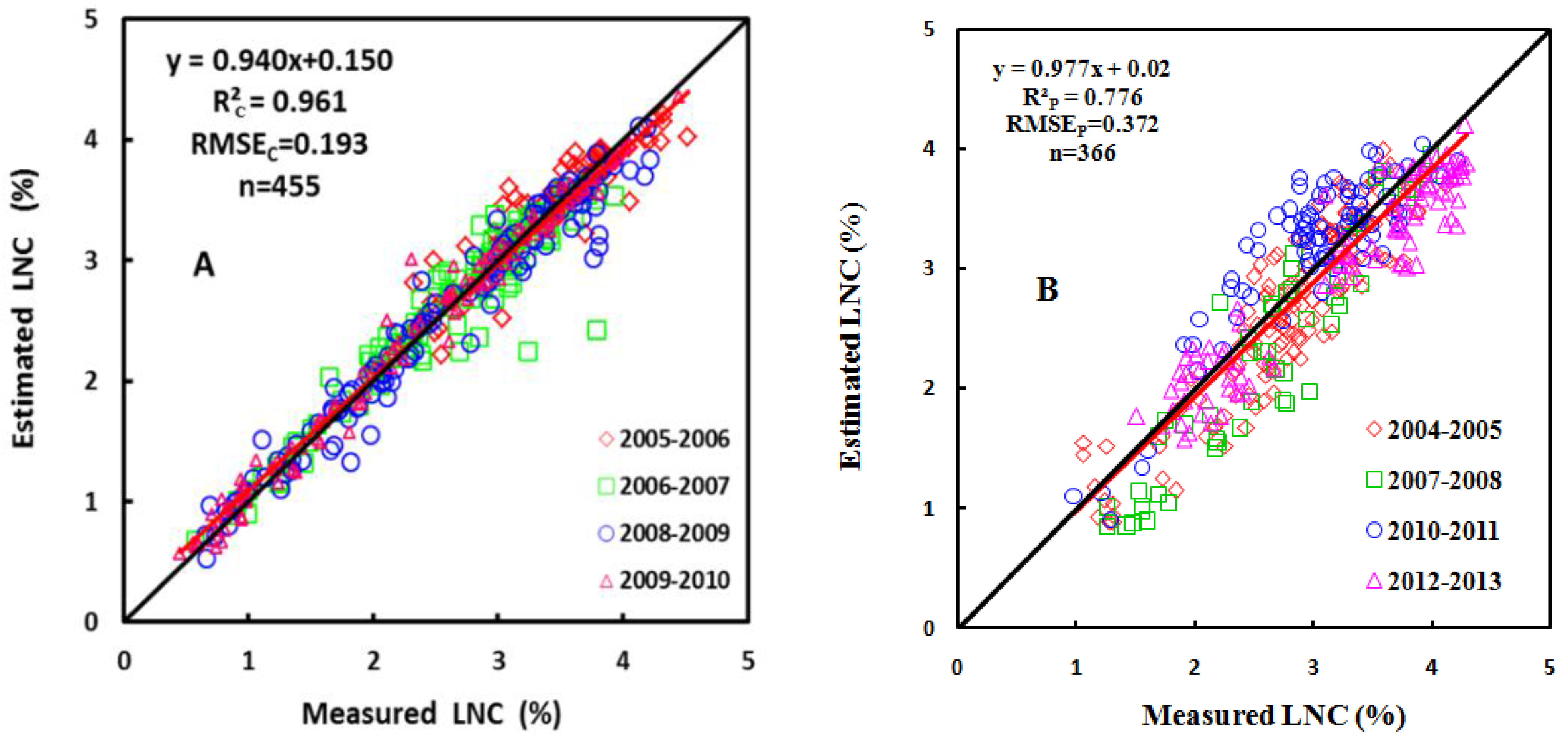
In this study, we demonstrated the performance, advantages, shortcomings, and robustness of six statistical modeling approaches for wheat canopy LNC. The PLSR-FDS, ANN-OS and SVM-FDS methods yield similar accuracies with SVM-FDS as the best if the CE and CL are not considered, however, ANNs and SVMs performed better on calibration set than the validation set which indicate that we should take more caution with the two methods for over-fitting. Except PLS method, the performance for most methods did not enhance when the spectrum were operated by the first derivative. The prediction accuracy was found to be higher when more wavelengths were used, though at the cost of a lower CE. Moreover, the evaluation of the robustness demonstrates that SVMs method may be better suited than the other methods to cope with potential confounding factors for most varieties, ecological site and growth stage. However, when the estimation accuracy, the CE, the number of wavelengths, and the CL of each model are systematically considered for the design of hardware devices, the SAVI(R1200, R705) model is found to be the best option for estimating the LNC in wheat. Although it might generally be preferable to make use of the full spectral resolution, our study demonstrated that even with two spectral bands, it is possible to (locally) obtain very good results. Hence, it remains to be proven that the full wavelength spectrum contains substantially more information than do narrow-band vegetation indices.
The current study focused on the six most widely used algorithms for the considered task. The results of this study are of interest to the remote sensing community for the development of improved inversion schemes for hyperspectral applications concerning other types of vegetation using empirical models, such as mapping important vegetation biophysical properties of other crops. The examples provided in this paper may also serve as illustrations of the advantages and disadvantages of empirical models. Although statistical models have been developed and successfully applied across various growth stages, varieties and eco-sites, the use of these methods is not always possible. Those methods in this paper established for vegetation variable retrieval, which are frequently applied in terrestrial bio-physical products, proving a high potential of hyperspectral measurement in the future. Because our study was performed using a specific dataset, our findings necessarily have certain limitations in applicability. In order to develop accurate, robust and fast model with high reliability, practicability and applicability, the next step should be to confirm these findings for a broader range of species and environments. A simulation experiment based on synthetic spectra generated by physically-based radiative transfer model will be conducted. Physical accuracy estimates are mandatory and should be provided using comprehensive validation datasets collected on more various sites and varieties. Except parametric regression and non-parametric regression, the hybrid methods combine generic capability of physically-based methods with flexible and computationally efficient methods should be tested. What is more, the impact of feature selection and randomly generated noise should be considered to study the stability of the developed statistical models to unfavorable measuring conditions with different sites and varieties in the future. Additionally, the theoretical uncertainties of the biophysical parameter products should be analysis in the study. The associated uncertainty estimates also provide information on the success of transporting a locally trained model to other sites and/or observation conditions, which are not intended to replace true accuracy estimates, but instead provide complementary information.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








