1. Introduction
Members of the public, acting as non-expert volunteers, have been involved in scientific research for more than a century [
1] yet the rise of citizen science is a much more recent phenomenon [
2]. At the same time, other initiatives that involve citizens have emerged, which are better described using the term crowdsourcing [
3]. This is defined as the outsourcing of micro-tasks to the public, either for small payments using a platform such as Amazon’s Mechanical Turk [
4], or for other incentives, e.g., helping to find the missing Malaysian airlines plane (MH370) by collectively examining very high resolution satellite imagery over a vast geographical area [
5]. This rise in the active involvement of the public can be attributed to a number of factors including the proliferation of location-enabled mobile devices (which has also led to the term Volunteered Geographic Information (VGI), where citizens are sensors of location-based information [
6]); access to global, very high resolution satellite imagery via Google and Bing; and the development of Web 2.0 technology, which has led to a whole new generation of user-generated content including online mapping and neogeography [
7].
The majority of citizen science applications can be found in the field of ecology, biodiversity and nature conservation [
8], primarily due to the long history of citizen involvement in these domains. Amateur weather stations are another source of data that have been contributed by citizens for decades [
9]. More recent applications include OpenStreetMap (OSM), which is a hugely successful collaborative online mapping initiative [
10], volunteer efforts in disaster response [
11,
12] and environmental monitoring [
13,
14], among others (e.g., see [
8]). However, an area where there is still considerable unrealized potential for crowdsourcing and citizen science is in the collection of in-situ data for the calibration and validation of products derived from Earth Observation (EO) [
15]. Recent examples include Geo-Wiki and VIEW-IT for the interpretation of very high resolution satellite imagery by volunteers for land cover applications [
16,
17,
18] and the iSpex mobile app for validation of in-situ air quality monitoring data and comparison with EO products on aerosol optical thickness, e.g., from MODIS [
19]. There are many other examples of initiatives in which EO-relevant in-situ data are being crowdsourced but which are not yet being exploited for calibration or validation of EO-derived products [
15].
One source of authoritative in-situ data is LUCAS (Land Use Cover Area frame Sample) [
20], which is used for land cover and land use change detection in EU member countries, among many other applications [
21]. In fact, LUCAS represents the only official in-situ dataset available for EU wide validation exercises such as the validation of the European Environment Agency’s (EEA) very high resolution layers and CORINE land cover [
22,
23,
24]. The LUCAS survey, which takes place every three years, is conducted in two stages. In the first stage, a systematic sample with a spacing of 2 km is laid on top of EU member countries, resulting in more than one million points. These are photo-interpreted and then placed into one of seven classes: arable land, permanent crops, grassland, wooded areas, shrubland, bareland, artificial land and water. From this, a smaller sample is drawn and each site is visited by a field surveyor unless the point is above 1500 m or inaccessible. This threshold was originally set at 1000 m in the 2006 and 2009 LUCAS surveys but was changed to 1500 m in the 2012 survey [
25].
In 2015, there were 273,401 samples surveyed by 750 surveyors. Each surveyor followed a published set of protocols for data collection at each sample point [
20]. The simplest part of the protocol is as follows: each point is photographed and then additional photographs are taken in the four cardinal directions away from the point. In addition, the surveyor notes down the land cover and land use from a very detailed, hierarchical classification [
26]. There are several additional tasks associated with the survey protocols, e.g., walking a transect in an easterly direction while noting down changes in land cover and land use, and taking soil samples at certain locations.
If we use only the simple protocol for data collection, then we can consider the following practical research question: can citizens use a mobile application to collect data that could complement and enrich the LUCAS dataset and also provide an additional source of in-situ data for calibration and validation of remotely sensed products or for area estimation? This could be data that are either more densely sampled in a given area or collected more frequently than the LUCAS survey, which takes place every three years, or both. To answer this question, a mobile app called FotoQuest Austria was developed, and a data collection campaign was launched during the summer of 2015. The app is loosely based on the idea of geocaching, but rather than finding treasures at specific locations, players gain points for reaching a location, taking photographs, and documenting the land cover and land use. The app has a serious purpose but includes elements of gamification (i.e., the addition of game elements to existing applications [
27]) to help motivate the volunteers. FotoQuest Austria also has similarities to the very recently released Pokémon GO app, which is played outdoors and also leads players to specific locations to find Pokémon. Gamification has been utilized to help motivate participation in citizen science applications; e.g., the Biotracker app, for contributing phenology data to Project Budburst, has been shown to attract a younger technologically-savvy audience (termed the “Millennials”) by coupling technology with competitive elements such as badges and leaderboards [
28]. The Cropland Capture game has also been successful in attracting players, which have collectively gathered more than 4.5 million classifications on the presence or absence of cropland from very high resolution satellite images and geo-tagged photographs [
29,
30].
The aim of this paper is to compare the results obtained from an application on in-situ crowdsourced data collection against LUCAS results in Austria. The paper is organized as follows.
Section 2 provides an overview of the LUCAS land cover and land use classification, the FotoQuest Austria app and the campaign that was run to collect the data. The data are then described along with the methods by which the data were analyzed. Although the results show reasonable agreement at the highest and most general level of the LUCAS classification, we offer recommendations for how we can further improve the quality of land cover and land use data collected by citizens in the context of LUCAS, including use of the technology to enhance the data collection process in future, planned campaigns.
3. Materials and Methods
3.1. Data Pre-Processing
In order to compare data collected by LUCAS with that from FotoQuest Austria, the first task was to select data corresponding to those quests that coincide with LUCAS 2015 points. The result was 677 overlapping points. Of these, more than 50% were subsequently excluded due to reasons such as being taken before the start date of the campaign, points that were reported as being not visible, and land use or land cover that was reported as unknown, leaving a total of 306 points in common.
Figure 4 shows the location of LUCAS 2015 and FotoQuest Austria points, highlighting those that were used in the analysis. The points shown in green in
Figure 4 are the LUCAS points, of which there are 8844 in total. For the FotoQuest campaign, additional points were then added, densifying the sample, particularly in urban areas (to target urban sprawl) and in wetland areas, which are currently not well mapped in Austria. The total number of unique locations or quests available across Austria was 62,894 or roughly 8 times more than the available LUCAS points. Hence, the LUCAS points are only a sub-sample of the total number of points in the game, which shows how much more in-situ data would potentially be available for calibration and validation of remotely-sensed products if all the locations were visited. The red points shown in
Figure 4 are those that were collected during the FotoQuest Austria campaign while the yellow ones are those that were used in the analysis once some of the data were excluded, as described above.
The database from FotoQuest Austria had one row per entry for each land use or land cover, with all the information from a given location spanning multiple rows. These could come from the same player, describing all land uses and land cover types seen within a radius from the point, but also from several players evaluating the same point. A summary of all the entries per point was done, and this summary statistic was then added to the main database. An agreement response variable was added to reflect agreement between the answers provided for land cover and land use at each location compared to the land cover and land use recorded by the LUCAS surveyor. Agreement was separated into three levels for land cover and two levels for land use, which corresponds to the LUCAS classification system, arranged into a hierarchy as described in
Section 2.1. Thus, there could be agreement at the highest level of land cover or land use (i.e., level 1) or at higher levels (levels 2 and 3) based on how detailed an answer was provided by each player and at each point.
3.2. Statistical Analysis
Confusion matrices between the authoritative LUCAS data and the answers provided by the players were tabulated in order to calculate the overall agreement for land cover and land use at each of the levels of the LUCAS classification and class agreement at level 1. Another important consideration was to understand if the agreement levels differed when the points visited were in areas with a mixture of land cover or land use. For this, a visual inspection of the LUCAS survey pictures and a 20 m radius of the relevant point on satellite imagery from Google Earth was undertaken to identify homogeneous points as shown in
Figure 5. Homogeneous points (hg,
Figure 5a) were those in which all of the photographs and the Google Earth imagery showed the same land cover; potentially homogeneous (pt) is when 2 to 3 of the photographs showed the same land cover but the photographs were taken from a road while heterogeneous (ht,
Figure 5b) means different land cover types shown in the photographs. Overall agreement was calculated separately on these three degrees of homogeneity to see whether this had an influence on the performance of the players.
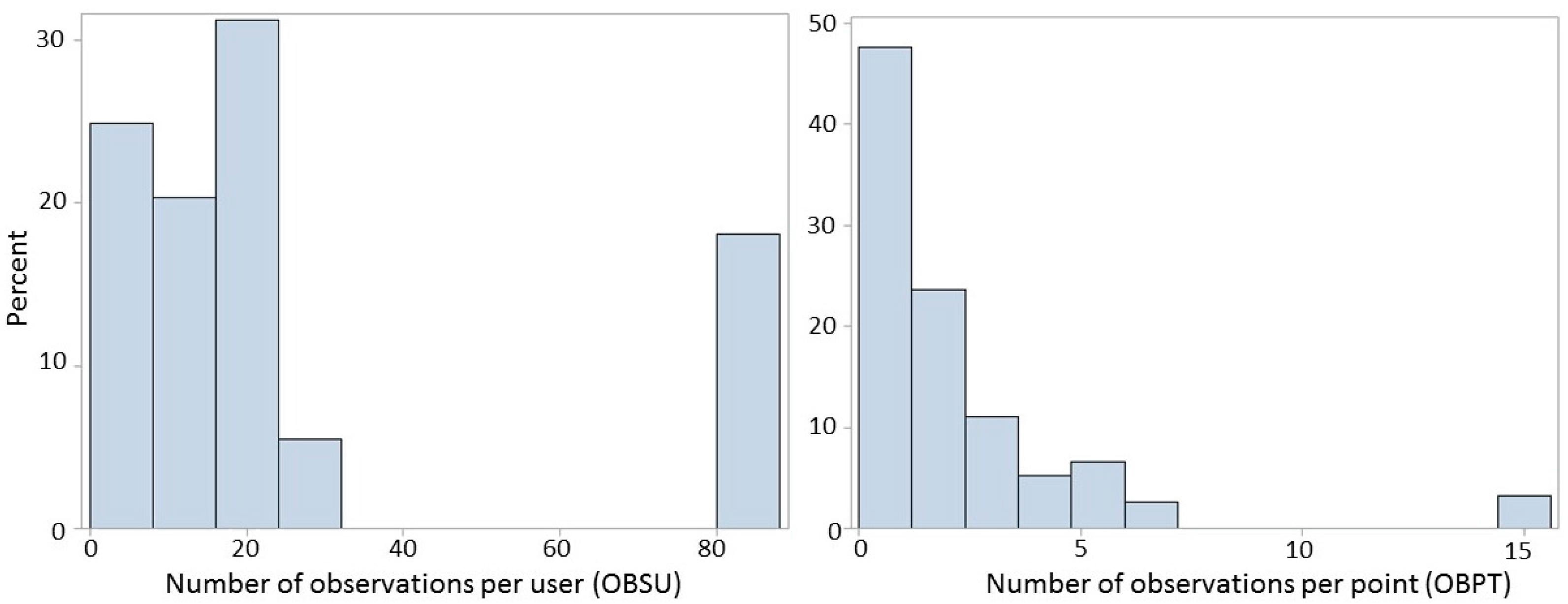
A set of statistical models was then derived to test the agreement between the land cover and land use data from the players in relation to the authoritative LUCAS data, i.e., the response variables, using several possible predictors of the agreement differences. These include the variables radius (RD), which represents the visible distance for a given land use or land cover in meters (4 categories) around the point in FotoQuest, the distance between the actual point and the LUCAS point coordinates (D) and the three levels of homogeneity (HM), i.e., homogeneous, potentially homogeneous and heterogeneous (hg, pt, and ht, respectively). Additionally, since each point could be evaluated several times by different players and each player could have evaluated several points, the total number of observations that each player made (OBSU) as well as the total number of times each point was visited (OBPT) were included as covariates. From a total of 76 players, all visited 25 points on average with the exception of one player who visited 83 points.
Furthermore, random effects for the player and unique point identifications (PLAYER-ID, POINT-ID) were included to deal with lack of independence issues, i.e., several observations made by the same player and several evaluations per point.
Once the predictors were selected, generalized linear mixed models with binomial responses were developed to analyze the agreement at each of the three levels of land cover and two levels of land use. The Laplace estimation method was employed to fit the models using Proc Glimmix, SAS v9.4. Random effects were evaluated using statistical inference for the covariance parameters (significance test based on the ratio of residual likelihoods) via the inclusion of a “covtest glm” statement and the comparison of relative goodness of fit of models with and without these effects. The Akaike Information Criterion (AIC) [
33] reported by the software was used to compare the relative goodness of fit. A general representation of the fixed effects model is given by:
where Y = binomial response indicating overall agreement of FotoQuest Austria data with LUCAS 2015 (yes = 1, no = 0). The double colon separates fixed and random effects.
Since the actual point coordinates were seldom reported in the FotoQuest dataset, observations with values for D were very limited (less than 25%). A univariate model with D as the only predictor was run but no significant effect was found (
p > 0.05). D was consequently excluded from the final multivariate model, which is provided in Equation (2) as:
Moreover, there was one player who visited 83 different points and one location was visited 15 times as shown in
Figure 6. Thus, these extreme observations were also eliminated before fitting the models.
Initial correlation analyses were run between the predictors before entering them in the models in order to control for collinearity. If collinearity was found, the decision on which predictor to choose was made using the Akaike Information Criterion (AIC) as a relative goodness of fit to compare between models with different predictor variables.
Finally, to understand if the power player influenced the agreement with LUCAS, a set of models for all levels of land use and land cover were run but only with a covariate (GR), which identifies whether the player was a power player (PP) (i.e., the person who visited 83 different points) or a regular player (RP). The simplified model is shown in Equation (3):
The results derived from these models (Equation (3)) are purely demonstrative because there was only one power player and therefore all observations coming from this power group are not independent. The results are merely provided to illustrate the differences between the two groups. Most of the models did not converge when POINT-ID was introduced as a random effect due to the low number of observations. The variable PLAYER-ID was evaluated at all times as a random effect.
4. Results
Table 3 shows the agreement values for three different sets of points: overall agreement, agreement at homogeneous points (hg), and agreement at not homogeneous points (pt and hg) for all levels of land cover and land use while the confusion matrices appear in
Table 4 and
Table 5. The overall agreement for land cover and land use at level 1 is similar, i.e., 68%–69%, indicating reasonable performance by the players. For land use at level 2, the agreement drops to 62% while levels 2 and 3 for land cover are much lower, i.e., between 37% and 23%. This indicates that more detailed land use is easier to identify than detailed land cover, which would require, e.g., tree type and crop type identification skills, which many people may not possess. Additionally, clear differences between homogeneous and more heterogeneous points can be observed, where homogeneous points always have higher agreement, ranging from 8% to 30% more.
In the confusion matrices, the results show that artificial land is sometimes confused with Grassland or Woodland or vice versa while Cropland is confused with Grassland at times (
Table 4). For land use, there is some confusion between Agriculture, Residential and Transport classes (
Table 5).
Table 6 and
Table 8 show the overall agreement at all levels for the main land cover and land use classes in LUCAS. The land cover agreement at level 1 is very high for the Artificial Land and Cropland classes, which together cover 44% of the points. The Grassland and Woodland classes have lower agreement, between 60% and 62%, and represent almost 50% of the dataset. Although the agreement shown in these tables does not represent the exact agreement for individual sub-classes at lower levels, which also differ in number inside each main class (e.g.,
Table 1 and
Table 7), it does provide an overall idea of accordance. For the purpose of land cover mapping, these high level classes (level 1) are generally sufficient so we focus mainly on these.
In
Table 7, an example for the main class “Cropland” at level 3 is shown to illustrate the differences between the agreements that exist in different subclasses within a main class. Crops that are relatively easy to recognize, i.e., maize and wheat, have higher agreement than the others, which when averaged out result in around 50% agreement for this level 1 class.
Likewise, there is over 90% land use agreement in the Agriculture land use class and over 70% for the Residential and Forestry classes in level 1 (
Table 8). The Transport land use class has an agreement of ca. 21% but represents only 15% of the points in the database. Other land use classes represent 10% of the sample and have agreements from 53% and lower.
In the land cover model at level 2 (
Table 9), additionally to significant homogeneity (HM) effects (
Table 10), the number of observations per user (OBSU) had a significant effect on agreement, with every additional observation increasing the chances of agreement between FotoQuest and LUCAS by up to 1% (regression coefficient (reg. coeff.) ± standard error (std. err): 0.0055 ± 0.0022).
In the land use model at level 1, apart from significant effects from homogeneity and radius (
Table 10), for every additional observation at a given point, the chances of land use agreement between the two systems increased by 32% (reg. coeff. ± std. err.: 0.2739 ± 0.1010), which is in line with the findings in [
34], i.e., the positional accuracy of road features in OpenStreetMap increased with an increase in the number of contributors. At level 2 in the land use model, significant effects of HM and RD were noted (
Table 9), but also for every additional observation a given player has made, the chances of land use agreement between the two systems increased by 8% (reg. coeff. ± std. err.: 0.0772 ± 0.0265).
On the one hand, there is an overall trend for homogeneous points (hg) to have significantly higher agreement in land use and land cover than heterogeneous points (ht) (HM,
Table 10), with the exceptions of land cover level 2 and 3, where no variable was found to be significant. On the other hand, the trend observed for radius (RD,
Table 10) shows that when the radius reported is large, the agreement in land use is much higher although in some levels there are no significant differences between some adjacent radii.
When comparing the agreement from the one power player with the agreement from all other players (
Table 11), it appears that the power player always has higher agreement, although these differences were not significant, except for land cover level 2, where the power player had significantly higher agreement than the other players. These differences are due to the lower variability existing in this group.
5. Discussion
The results of this first campaign with the FotoQuest Austria app show the willingness and potential of citizens to be involved in collecting data that are of relevance to both LUCAS and for developing training and validation datasets for Earth Observation data, especially when homogeneous points are considered. At present the accuracy is not sufficient for calibration and validation of remotely sensed products. Changes that are currently being implemented in the latest version of the app include improved training, e.g., videos showing the procedures to follow and images of typical land cover/land use as well as recognition of specific crops. We will also use control points where a known stable land cover/use exists and then tell the player whether their answer was correct and why as a form of corrective feedback in future versions. All these new features, together with in-app display of satellite imagery from the surrounding area and a decision tree to aid land cover/land use classification should help to obtain higher accuracies in the future. We will also consider the use of tools from Cognitive Task Analysis (CTA) as outlined in [
35], in particular the use of a walk through, online questionnaires and semi-structured interviews with players as a way of better understanding how they perceive land cover and land use and as ways to improve the training materials and app more generally. At the highest level of the LUCAS classification for both land cover and land use, the overall agreement was ca. 70% and in urban areas and cropland reached ca. 90%. These two main classes are easy to recognize and do not require any training showing that at Level 1, players could perform well without additional training. Some improvements are needed in the recognition of these last two classes, to reduce the confusion between Grassland and Artificial, and for recognition of transport-related land uses. The former may be related to heterogeneity, e.g., are a few trees scattered in a grassy area considered to be Grassland or Woodland, while the latter may require more specialist knowledge. Regarding the confusion between Grassland and Artificial, which one would think should not occur, the issue may again be the heterogeneity of the landscape. When the point falls in a small grassland area (e.g., a park or large garden) which is located within a larger artificial setting or on a road next to a grassy area, the player may have been confused as to which land cover class to choose. From a land cover mapping perspective, the ability to recognize transport-related land uses is less relevant.
When the more detailed classification of land cover from FotoQuest Austria is compared with the authoritative LUCAS data (i.e., levels 2 and 3), the agreement is much lower and hence the performance by the crowd is relatively poor in comparison to level 1. Looking at these more detailed classes (
Section 2.1), it is clear that some specialist knowledge or training is required, e.g., to be able to differentiate between different crop or forest types. For example, at level 3, the overall agreement for crop types was 50%. However, common crop types such as maize and wheat had higher agreement, i.e., around 80%, while others clearly require more specialist knowledge and therefore agreement was much lower. The current version of the app provided no training in land cover or land use recognition and relied only on the knowledge of the individuals taking part in the game. The main reason was to minimize the burden on players as much as possible, given that each quest involved collecting data according to a protocol and there is a tradeoff between how much you can ask individuals to do and the number of participants [
36]. However, it is clear that some training is required if citizens are to be able to accurately classify land cover and land use. This could be in the form of some type of mapping party [
37], a simple online tutorial or providing players with sample images (e.g., different types of trees or crops) in the app, which are displayed when they need to make a decision about level 2 and 3 land cover/land use. A feedback system could also be beneficial [
38] so that players who have problems with the recognition of certain land cover or land use types could learn as they play the game or some type of online chat facility to ask questions about current quests could be added. Finally, the use of tools from CTA could be employed to help improve the training materials and the app more generally.
The radius of homogeneity (as specified by players in the app) and homogeneity in all directions (determined by the LUCAS photographs and satellite imagery) are clearly influencing agreement, resulting in higher values, especially for land use categories. From a remote sensing perspective, the automatic determination of homogeneous points (i.e., radius greater than 25 m), especially those where several players agree, would be beneficial for both training and validating satellite imagery, in particular the most recent Sentinel data or Landsat. Thus, crowdsourcing homogeneous land cover using citizens has the potential to vastly increase the amount in-situ data available, where the lack of ground-based data has already been raised as a key issue by the EEA [
39].
Another result from the analysis is that it makes no apparent difference to the expected agreement if the player is a power player or not. There are some observed differences but these are not significant once other characteristics are controlled for. When exploring other players (excluding power players), the number of observations does have an influence on agreement on level 2 land use and land cover, implying that the collective intelligence of the crowd has a positive effect [
34,
40]. The sliding scale of points was intended to attract players to undertake quests that had not been captured yet. Nevertheless it might be beneficial to leave the maximum point value of 100 on each point until it has been visited a minimum number of times in order to apply some type of majority voting at each location. We could also consider adding additional incentives to the game, e.g., in the style of Pokémon GO, which has demonstrated that individuals are willing to go outside and play a mobile game if the tasks are fun and challenging.
Although the campaign resulted in the collection of 2234 points at 1699 unique locations, the actual number of points used in this analysis was low. This was partly due to the fact that less than half of the points overlapped with LUCAS points, because the game was populated with eight times more points than available in LUCAS, and, of those points collected, another 50% were excluded for various reasons including lack of visibility of the location. Many of these issues have been considered, and the current version of the app, as well as the new campaign FotoQuest Go, which includes LUCAS points across Europe, have already implemented some improvements. For example, newer versions of the app now display a satellite image around the point, which helps the player to compare the surrounding area to what is seen on the imagery. This can serve as useful navigational aid, e.g., by providing alternative routes for reaching points that were previously reported as not visible or unreachable.
The 2015 LUCAS campaign took place in the spring of 2015. The data were finally released more than one year later, since the data needed further processing, i.e., transferred from a paper-based format and for quality assurance checks. A mobile application makes the data collection much easier and the data collected can be processed much faster. The results could also be made available in near real-time. Most significantly, if such gaming approaches were to become more popular and lead to the continual monitoring of land cover and land use by the public, this would provide a constant stream of information that would not only complement LUCAS data but also be useful for land cover calibration and validation.
6. Conclusions
The overall agreement between the land cover and land use data at high level (L1) collected by citizens compared with authoritative data from LUCAS was close to 70%. This value, although not yet high enough to be considered reliable for use in validation, is very encouraging for a first attempt at understanding the willingness of volunteers to survey data in the field and support professional surveys such as LUCAS with crowdsourced data. However, it is clear that some additional training is needed, as well as regular feedback, if citizens are to be able to distinguish between more detailed classes of land cover and land use or to improve their recognition skills over time. Moreover, detailed land use information is extremely valuable. As there was only a small difference in the overall agreement between levels 1 and 2 of the LUCAS land use classification (6%) when compared with data from FotoQuest Austria, this may be a useful source of data for urban planning, particularly in providing information about areas with recent change. Such an app could even be used by planning authorities to direct citizens to potential areas where change is occurring to help update their databases.
The identification of land cover in homogeneous areas is the most useful from a remote sensing perspective, and this was also the easiest for players to identify with an agreement close to 80% for land cover and land use at the highest level of the classification (L1). Rather than gather land cover and land use information at heterogeneous locations, players could simply mark these spots as heterogeneous and move on. Alternatively, they could find nearby homogeneous areas and gather information at these locations instead. This would maximize the information content from the players while making it easier to recognize and classify land cover and land use.
FotoQuest Austria has been extended to Europe and will be used to gather land cover and land use data across multiple EU countries from mid-October 2016. If the app were to become more successful and be used to collect data on a regular basis, then it would provide much more up-to-date data than LUCAS data and at a potentially higher density than the current sample. Ideally, multiple quests at the same point would be undertaken in order to obtain more reliable statistics. Thus, different ways to motivate participation should be a key focus. Crowdsourcing clearly has the potential to contribute to in-situ data collection of relevance to remote sensing but there is a delicate balance between the need for rigor in the data collection protocols and the promotion of public participation, ensuring that the activity remains fun and engaging.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}