
A Framework for Large-Area Mapping of Past and Present Cropping Activity Using Seasonal Landsat Images and Time Series Metrics

Abstract
:
1. Introduction
2. Materials and Methods
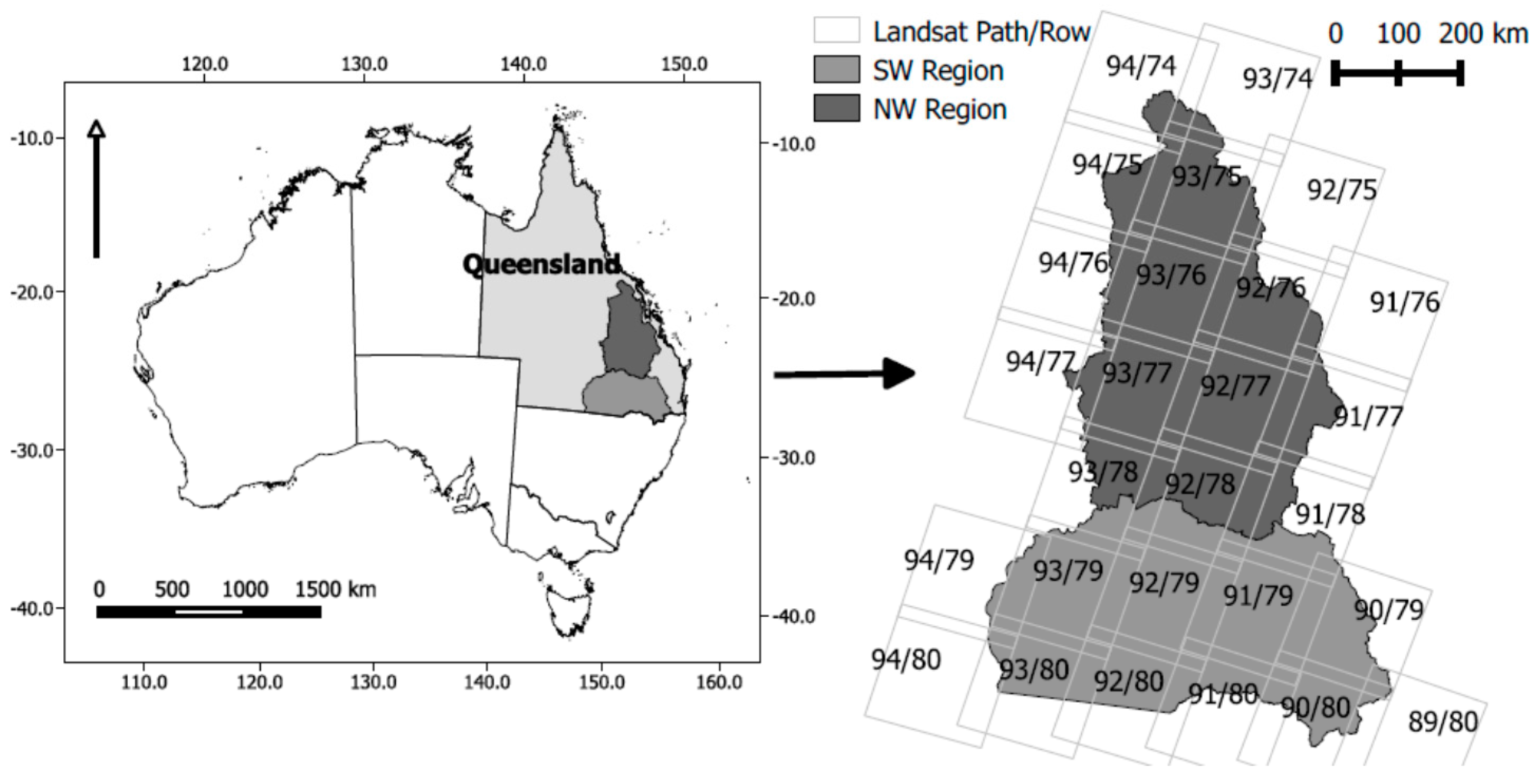
2.1. Study Area and Rationale
2.2. Defining the Growing Seasons
2.3. Satellite Imagery
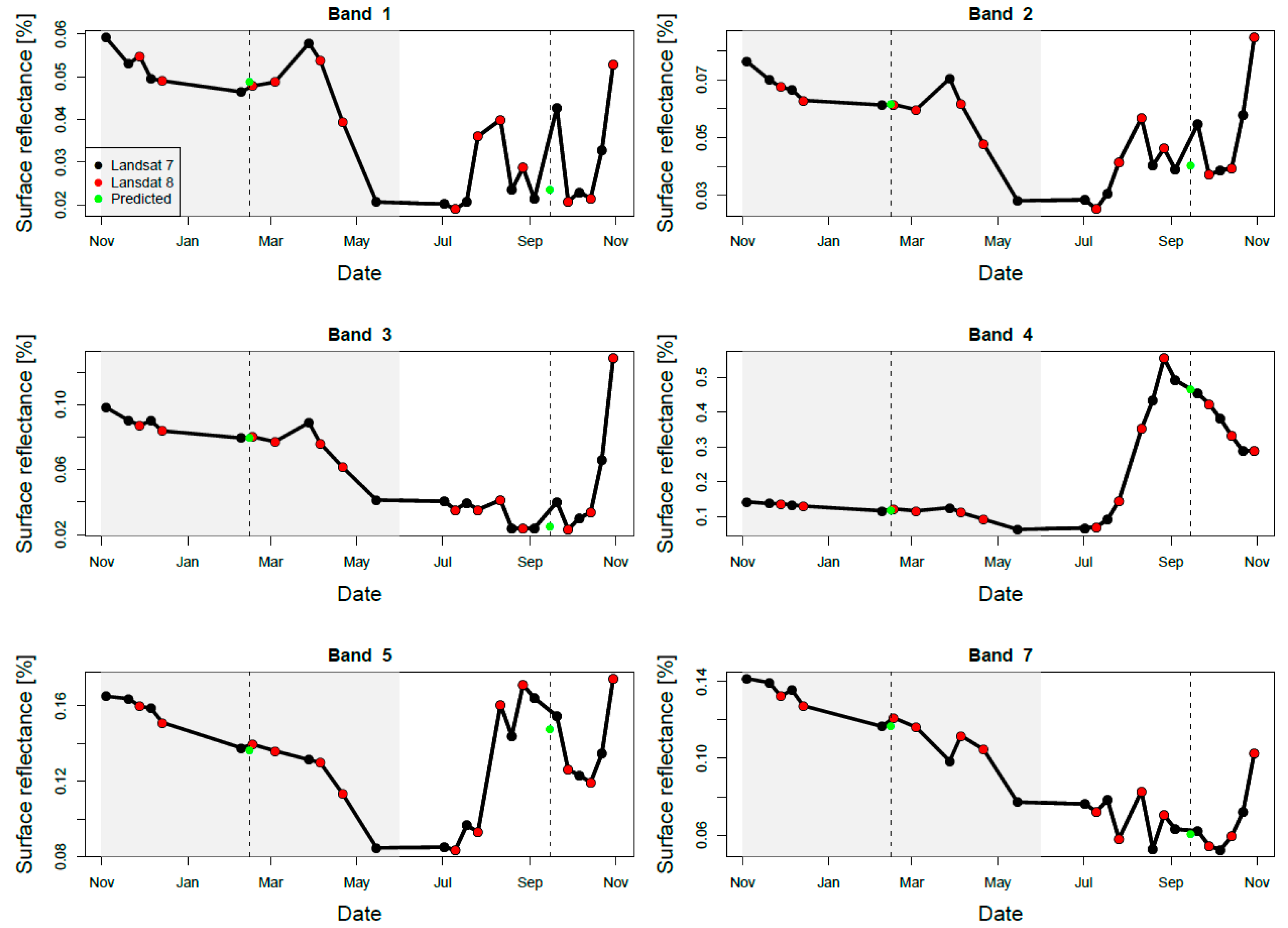
2.4. Synthetic Image Generation and Segmentation
2.5. Classification Variables
2.6. Training and Validation Data
2.7. Image Classification
- Multinominal logistic regression (also called the multinomial logit model) can be used when the dependent variable is categorical, and thus for classification problems [64]. The multinomial logit model (referred to as “Logit” from here on) assumes that dependent variables cannot be perfectly predicted from the independent variables, but that a linear combination of training data can be used to determine the probability of each outcome.
- RF is a method suitable for classification applications that constructs a multitude of decision trees [60,66]. RF is a way of averaging multiple single trees trained on slightly different sub-samples of the training data. This “bootstrapping” step generally leads to a better model performance by reducing the variance without introducing bias. This also means that, while a single tree may be subject to noise in the input data, the average is not (as long as the trees are not correlated). These features of the RF were further explored in an offline analysis: a single RF tree was selected as a classifier, as well as a single RF pruned tree, and a RF trees with Bayesian bagging (single and pruned). The single trees and Bayesian bagging did not result in improved classification accuracy and was not further investigated due to the processing cost. Within the RF classifier was land use “cropping” extracted from QLUMP and used as an a priori variable (as a factor) in the suite of classification approaches (RF + land use).
3. Results
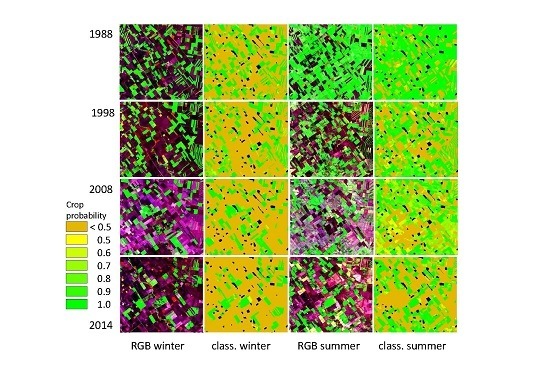
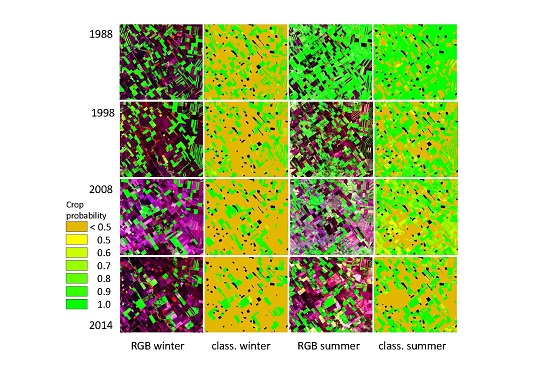
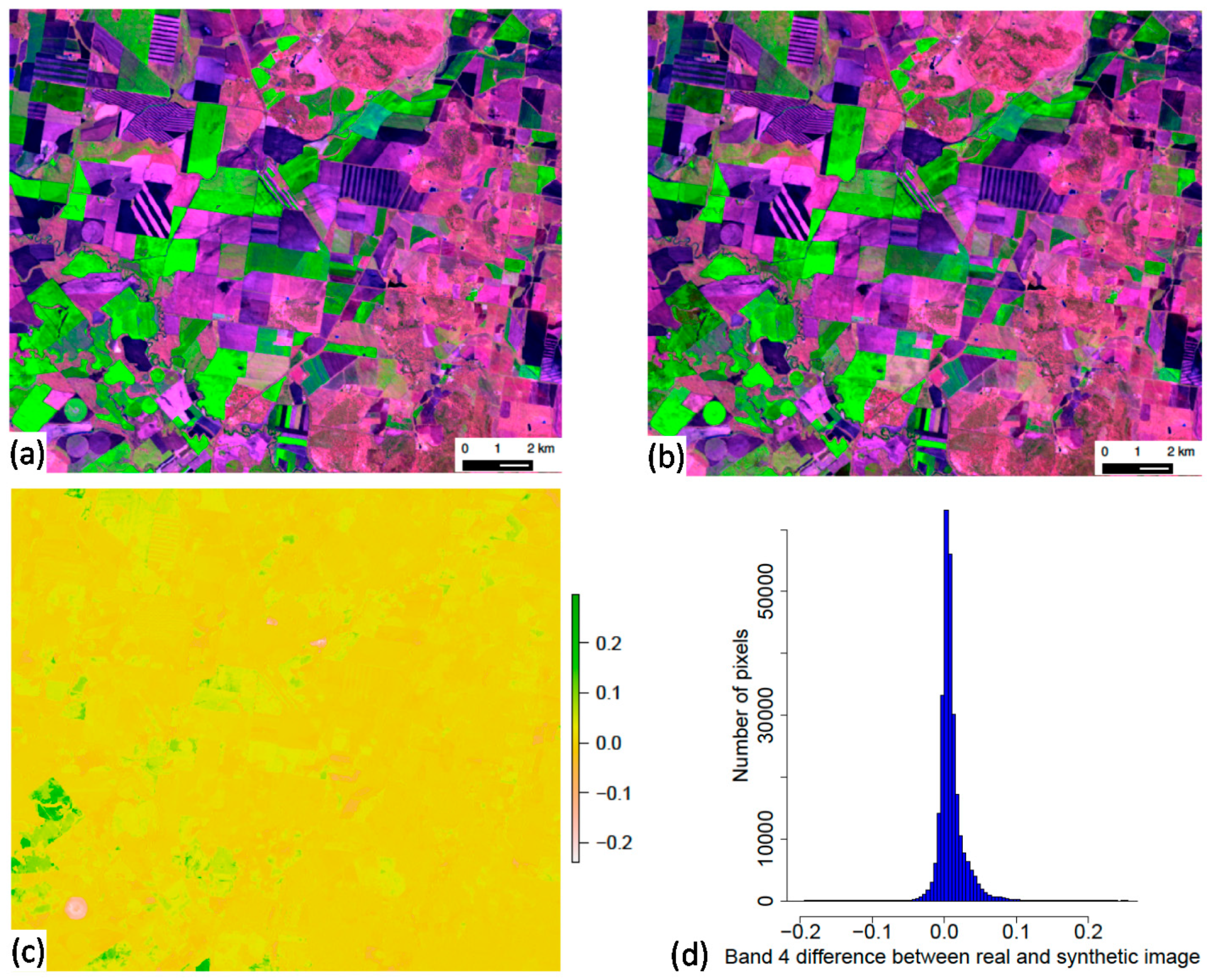
3.1. Synthetic Image Generation
3.2. Image Segmentation
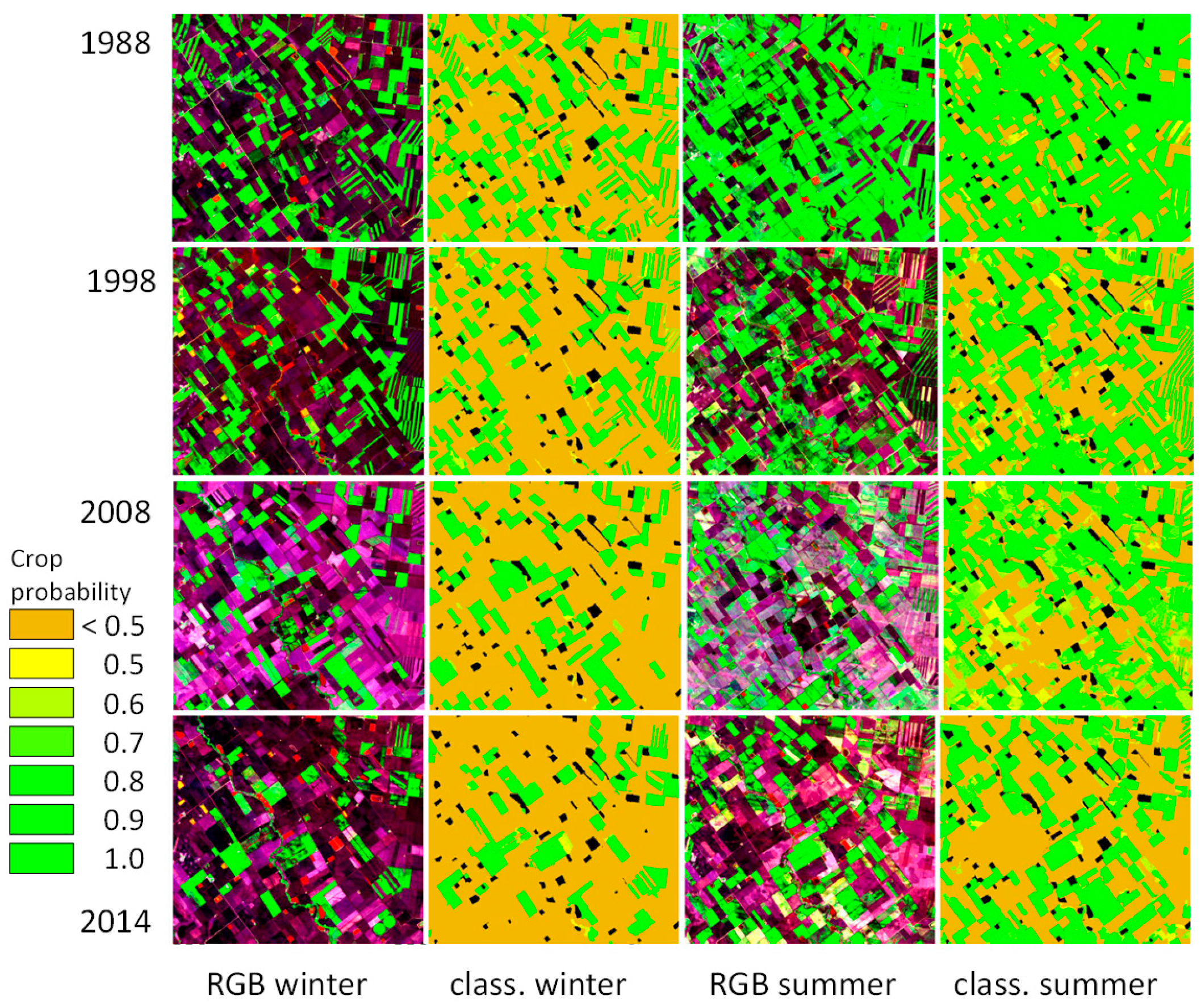
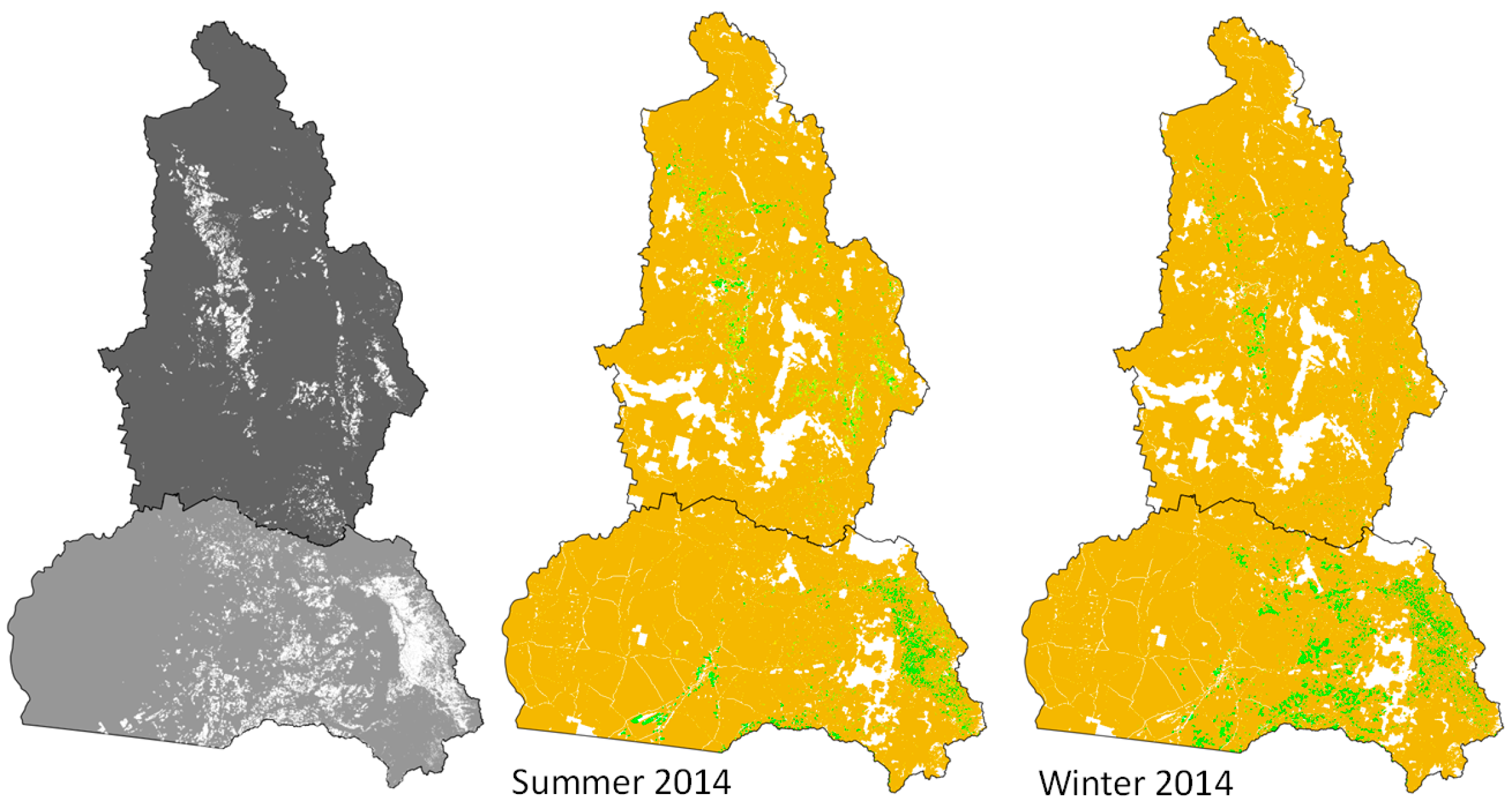
3.3. Classification and Map Accuracies
4. Discussion
4.1. Synthetic Image Generation and Segmentation
4.2. Classification Performance and Map Accuracies
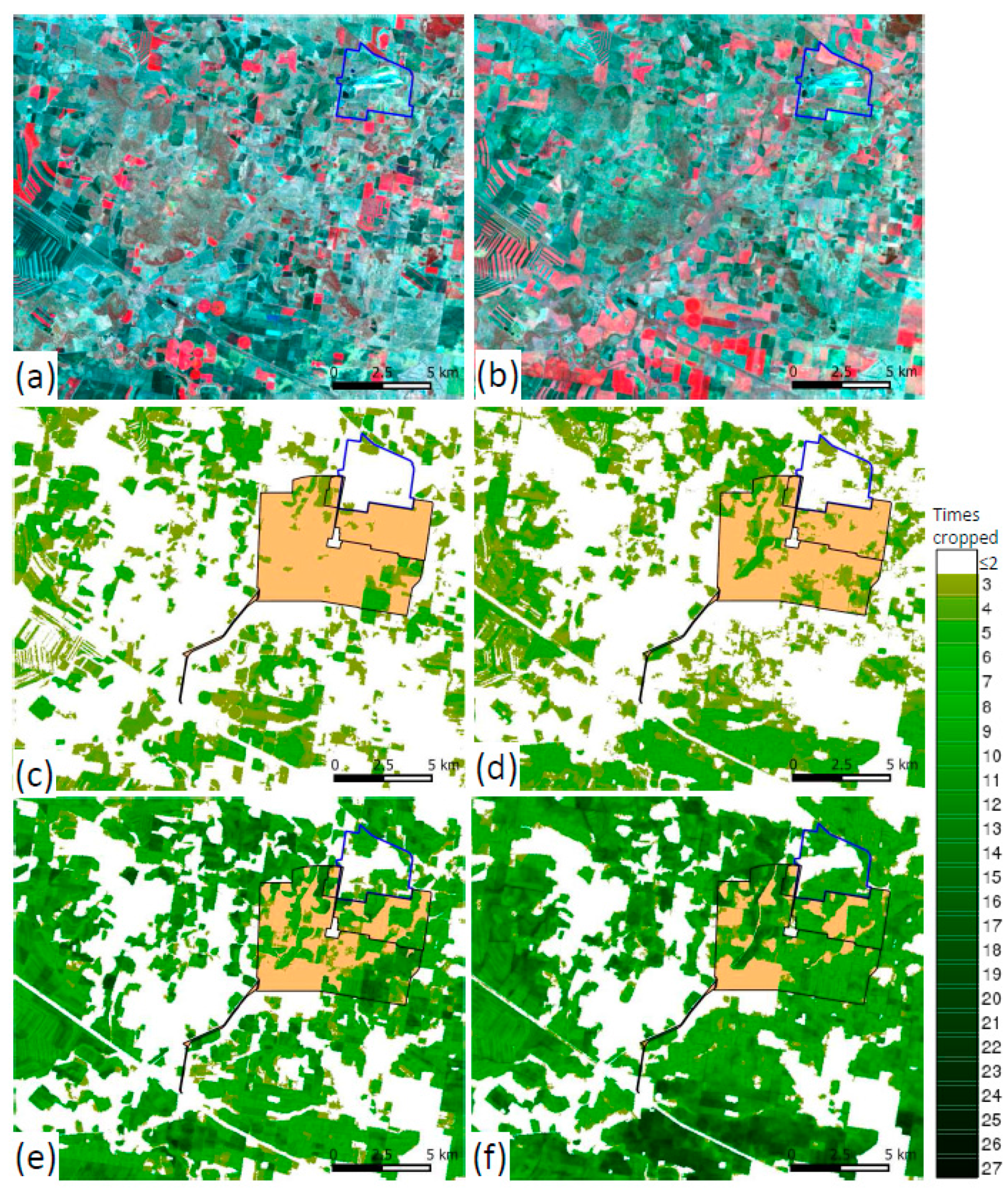
4.3. Future Applications
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

References
- Grassini, P.; van Bussel, L.G.J.; Wart, J.V.; Wolf, J.; Claessens, L.; Yang, H.; Boogaard, H.; de Groot, H.; van Ittersum, M.K.; Cassman, K.G. How good is good enough? Data requirements for reliable crop yield simulations and yield-gap analysis. Field Crops Res. 2015, 177, 49–63. [Google Scholar] [CrossRef] [Green Version]
- Rembold, F.; Atzberger, C.; Savin, I.; Rojas, O. Using Low Resolution Satellite Imagery for Yield Prediction and Yield Anomaly Detection. Remote Sens. 2013, 5, 1704–1733. [Google Scholar] [CrossRef] [Green Version]
- Chipanshi, A.; Zhang, Y.; Kouadio, L.; Newlands, N.; Davidson, A.; Hill, H.; Warren, R.; Qian, B.; Daneshfar, B.; Bedard, F.; et al. Evaluation of the Integrated Canadian Crop Yield Forecaster (ICCYF) model for in-season prediction of crop yield across the Canadian agricultural landscape. Agric. For. Meteorol. 2015, 206, 137–150. [Google Scholar] [CrossRef]
- Atzberger, C. Advances in Remote Sensing of Agriculture: Context Description, Existing Operational Monitoring Systems and Major Information Needs. Remote Sens. 2013, 5, 949–981. [Google Scholar] [CrossRef]
- Foley, J.A.; DeFries, R.S.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K.; et al. Global Consequences of Land Use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef] [PubMed]
- Hilson, G. An overview of land use conflicts in mining communities. Land Use Policy 2002, 19, 65–73. [Google Scholar] [CrossRef]
- Godfray, H.C.J.; Beddington, J.R.; Crute, I.R.; Haddad, L.; Lawrence, D.; Muir, J.F.; Pretty, J.; Robinson, S.; Thomas, S.M.; Toulmin, C. Food Security: The Challenge of Feeding 9 Billion People. Science 2010, 327, 812–818. [Google Scholar] [CrossRef] [PubMed]
- Hansen, M.C.; Defries, R.S.; Townshend, J.R.G.; Sohlberg, R. Global land cover classification at 1 km spatial resolution using a classification tree approach. Int. J. Remote Sens. 2000, 21, 1331–1364. [Google Scholar] [CrossRef]
- Herold, M.; Mayaux, P.; Woodcock, C.E.; Baccini, A.; Schmullius, C. Some challenges in global land cover mapping: An assessment of agreement and accuracy in existing 1 km datasets. Remote Sens. Environ. 2008, 112, 2538–2556. [Google Scholar] [CrossRef]
- Cracknell, A.P. The Advanced Very High Resolution Radiometer; Taylor and Francis: London, UK, 1997. [Google Scholar]
- Schmidt, M.; King, E.A.; McVicar, T.R. Assessing the geometric accuracy of AVHRR data processed with state vector based navigation as implemented in CAPS (Common AVHRR Processing System). Can. J. Remote Sens. 2008, 34, 496–508. [Google Scholar] [CrossRef]
- Justice, C.O.; Townshend, J.R.G.; Kalb, V.L. Representation of Vegetation by Continental Data Sets Derived from NOAA-AVHRR Data. Int. J. Remote Sens. 1991, 12, 999–1021. [Google Scholar] [CrossRef]
- Quarmby, N.A.; Townshend, J.R.G.; Settle, J.J.; White, K.H.; Milnes, M.; Hindle, T.L.; Silleos, N. Linear mixture modelling applied to AVHRR data for crop area estimation. Int. J. Remote Sens. 1992, 13, 415–425. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Cutler, M.E.J.; Lewis, H. Mapping sub-pixel proportional land cover with AVHRR imagery. Int. J. Remote Sens. 1997, 18, 917–935. [Google Scholar] [CrossRef]
- Schmidt, M. Development of A Fuzzy Expert System for Detailed Land Cover Mapping in the Dra Catchment (Morocco) Using High Resolution Satellite Images. Ph.D Thesis, University of Bonn, Bonn, Germany, 2003. [Google Scholar]
- Atzberger, C.; Rembold, F. Mapping the Spatial Distribution of Winter Crops at Sub-Pixel Level Using AVHRR NDVI Time Series and Neural Nets. Remote Sens. 2013, 5, 1335–1354. [Google Scholar] [CrossRef] [Green Version]
- Friedl, M.A.; McIver, D.K.; Hodges, J.C.F.; Zhang, X.Y.; Muchoney, D.; Strahler, A.H.; Woodcock, C.E.; Gopal, S.; Schneider, A.; Cooper, A.; Baccini, A.; Gao, F.; Schaaf, C. Global land cover mapping from MODIS: Algorithms and early results. Remote Sens. Environ. 2002, 83, 287–302. [Google Scholar] [CrossRef]
- Lymburner, L. The National Dynamic Land Cover Dataset; Geoscience Australia: Symonston, Australia, 2011.
- Lobell, D.B.; Asner, G.P. Cropland distributions from temporal unmixing of MODIS data. Remote Sens. Environ. 2004, 93, 412–422. [Google Scholar] [CrossRef]
- Maxwell, S.K.; Sylvester, K.M. Identification of “ever-cropped” land (1984–2010) using Landsat annual maximum NDVI image composites: Southwestern Kansas case study. Remote Sens. Environ. 2012, 121, 186–195. [Google Scholar] [CrossRef] [PubMed]
- Homer, C.G.; Dewitz, J.A.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.D.; Wickham, J.D.; Megown, K. Completion of the 2011 National Land Cover Database for the conterminous United States-Representing a decade of land cover change information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar]
- Genovese, G.; Vignolles, C.; Negre, T.; Passera, G. A methodology for a combined use of normalised difference vegetation index and CORINE land cover data for crop yield monitoring and forecasting. A case study on Spain. Agronomie 2001, 21, 91–111. [Google Scholar] [CrossRef]
- Lesslie, R.; Barson, M.; Smith, J. Land use information for integrated natural resources management—A coordinated national mapping program for Australia. J. Land Use Sci. 2006, 1, 45–62. [Google Scholar] [CrossRef]
- DSITI Queensland Land Use Mapping Program (QLUMP) of the Department of Science, Information Technology and Innovation (DSITI). Available online: https://www.qld.gov.au/environment/land/vegetation/mapping/qlump/ (accessed on 29 May 2015).
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Pringle, M.J.; Schmidt, M.; Muir, J.S. Geostatistical interpolation of SLC-off Landsat ETM+ images. ISPRS J. Photogramm. Remote Sens. 2009, 64, 654–664. [Google Scholar] [CrossRef]
- Wolfe, R.E.; Roy, D.P.; Vermote, E. MODIS land data storage, gridding, and compositing methodology: Level 2 grid. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1324–1338. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Kline, K.; Scaramuzza, P.L.; Kovalskyy, V.; Hansen, M.; Loveland, T.R.; Vermote, E.; Zhang, C. Web-enabled Landsat Data (WELD): Landsat ETM+ composited mosaics of the conterminous United States. Remote Sens. Environ. 2010, 114, 35–49. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and Photographic Infrared Linear Combinations for Monitoring Vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Hansen, M.C.; Egorov, A.; Roy, D.P.; Potapov, P.; Ju, J.; Turubanova, S.; Kommareddy, I.; Loveland, T.R. Continuous fields of land cover for the conterminous United States using Landsat data: first results from the Web-Enabled Landsat Data (WELD) project. Remote Sens. Lett. 2011, 2, 279–288. [Google Scholar] [CrossRef]
- Griffiths, P.; van der Linden, S.; Kuemmerle, T.; Hostert, P. A Pixel-Based Landsat Compositing Algorithm for Large Area Land Cover Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2088–2101. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D.P. Automated crop field extraction from multi-temporal Web Enabled Landsat Data. Remote Sens. Environ. 2014, 144, 42–64. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D.P. Conterminous United States crop field size quantification from multi-temporal Landsat data. Remote Sens. Environ. 2016, 172, 67–86. [Google Scholar] [CrossRef]
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an Operational System for Crop Type Map Production Using High Temporal and Spatial Resolution Satellite Optical Imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E.; Holden, C.; Yang, Z. Generating synthetic Landsat images based on all available Landsat data: Predicting Landsat surface reflectance at any given time. Remote Sens. Environ. 2015, 162, 67–83. [Google Scholar] [CrossRef]
- Müller, H.; Rufin, P.; Griffiths, P.; Barros Siqueira, A.J.; Hostert, P. Mining dense Landsat time series for separating cropland and pasture in a heterogeneous Brazilian savanna landscape. Remote Sens. Environ. 2015, 156, 490–499. [Google Scholar] [CrossRef]
- Devadas, R.; Denham, R.J.; Pringle, M. Support Vector Machine Classification of Object-Based Data for Crop Mapping, Using Multi-Temporal Landsat Imagery. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, XXXIX-B7, 185–190. [Google Scholar] [CrossRef]
- Matton, N.; Canto, G.; Waldner, F.; Valero, S.; Morin, D.; Inglada, J.; Arias, M.; Bontemps, S.; Koetz, B.; Defourny, P. An Automated Method for Annual Cropland Mapping along the Season for Various Globally-Distributed Agrosystems Using High Spatial and Temporal Resolution Time Series. Remote Sens. 2015, 7, 13208–13232. [Google Scholar] [CrossRef]
- DNRM Strategic Cropping Land. Available online: https://www.dnrm.qld.gov.au/land/accessing-using-land/strategic-cropping-land (accessed on 31 July 2015).
- Weston, E.J. The Queensland Environment. In Native Pastures in Queensland; Burrows, W.H., Scalan, J.C., Rutherford, M.T., Eds.; Department of Primary Industries: Brisbane, Australia, 1988; pp. 13–21. [Google Scholar]
- Isbell, R. A brief history of national soil classification in Australia since the 1920s. Soil Res. 1992, 30, 825–842. [Google Scholar] [CrossRef]
- ABS Australian Bureau of Statistics—Value of Agricultural Commodities Produced, Australia, 2013-14. Available online: http://www.abs.gov.au/AUSSTATS/[email protected]/DetailsPage/7121.02013-14?OpenDocument (accessed on 19 September 2015).
- Pringle, M.J.; Denham, R.J.; Devadas, R. Identification of cropping activity in central and southern Queensland, Australia, with the aid of MODIS MOD13Q1 imagery. Int. J. Appl. Earth Obs. Geoinf. 2012, 19, 276–285. [Google Scholar] [CrossRef]
- DSDIP Regional Planning Interest Act. Available online: http://www.statedevelopment.qld.gov.au/infrastructure-and-planning/regional-planning-interests-act.html (accessed on 29 May 2015).
- USGS Earthexplorer. Available online: http://earthexplorer.usgs.gov/ (accessed on 29 May 2015).
- Flood, N. Continuity of Reflectance Data between Landsat-7 ETM+ and Landsat-8 OLI, for Both Top-of-Atmosphere and Surface Reflectance: A Study in the Australian Landscape. Remote Sens. 2014, 6, 7952–7970. [Google Scholar] [CrossRef]
- Frantz, D.; Roder, A.; Udelhoven, T.; Schmidt, M. Enhancing the Detectability of Clouds and Their Shadows in Multitemporal Dryland Landsat Imagery: Extending Fmask. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1242–1246. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Pringle, M.J. Robust prediction of time-integrated NDVI. Int. J. Remote Sens. 2013, 34, 4791–4811. [Google Scholar] [CrossRef]
- Marchant, B.P.; Saby, N.P.A.; Lark, R.M.; Bellamy, P.H.; Jolivet, C.C.; Arrouays, D. Robust analysis of soil properties at the national scale: Cadmium content of French soils. Eur. J. Soil Sci. 2010, 61, 144–152. [Google Scholar] [CrossRef]
- Danaher, T.; Collett, L. Development, Optimisation and Multi-Temporal Application of a Simple Landsat Based Water Index. In Proceedings of the 13th Australasian Remote Sensing and Photogrammetry Conference, Canberra, Australia, 20–24 November 2006.
- Bunting, P.; Clewley, D.; Lucas, R.M.; Gillingham, S. The Remote Sensing and GIS Software Library (RSGISLib). Comput. Geosci. 2014, 62, 216–226. [Google Scholar] [CrossRef]
- Clewley, D.; Bunting, P.; Shepherd, J.; Gillingham, S.; Flood, N.; Dymond, J.; Lucas, R.; Armston, J.; Moghaddam, M. A Python-Based Open Source System for Geographic Object-Based Image Analysis (GEOBIA) Utilizing Raster Attribute Tables. Remote Sens. 2014, 6, 6111–6135. [Google Scholar] [CrossRef]
- Bunting, P.; Gillingham, S. The KEA image file format. Comput. Geosci. 2013, 57, 54–58. [Google Scholar] [CrossRef]
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Paller, M.; Rodriguez, E.; Roth, L.; et al. The Shuttle Radar Topography Mission. Rev. Geophys. 2007, 45. [Google Scholar] [CrossRef]
- Daughtry, C.S.T.; Hunt, E.R., Jr.; Mcmurtrey, J.E., III. Assessing crop residue cover using shortwave infrared reflectance. Remote Sens. Environ. 2004, 90, 126–134. [Google Scholar] [CrossRef]
- Haboudane, D. Hyperspectral vegetation indices and novel algorithms for predicting green LAI of crop canopies: Modeling and validation in the context of precision agriculture. Remote Sens. Environ. 2004, 90, 337–352. [Google Scholar] [CrossRef]
- Lopez Garcia, M.J.; Caselles, V. Mapping burns and natural reforestation using Thematic Mapper data. Geocarto Int. 1991, 1, 31–37. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Burges, C.J.C. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer New York: New York, NY, USA, 2013. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
- Croissant, Y. Estimation of Multinomial Logit Models in R: The Mlogit PACKAGES; Université De La Réunion: Saint-Denis, France, 2012. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth Publishing Company: Belmont, CA, USA, 1984. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by Randomforest. R News 2002, 2, 18–22. [Google Scholar]
- Schmidt, M.; Pringle, M.; Devadas, R.; Denham, R.; Tindall, D. Active Crop Mapping in the Western Queensland Cropping Region [data-set]. Version 1; Queensland Department of Science, Information Technology and Innovation: Brisbane, Australia, 2015; http://dx.doi.org/10.4227/05/555A826AC41DC.
- Schmidt, M.; Pringle, M.; Devadas, R.; Denham, R.; Tindall, D. Active Crop Frequency Mapping in the Western Queensland Cropping Region [data-set]; Queensland Department of Science, Information Technology and Innovation: Brisbane, Australia, 2015; http://dx.doi.org/10.4227/05/555A856191970.
- DSDIP New Acland Coal Mine Stage 3 Project. Available online: http://www.dilgp.qld.gov.au/assessments-and-approvals/new-acland-coal-mine-stage-3-expansion.html (accessed on 1 October 2015).
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Scarth, P.; Röder, A.; Schmidt, M. Tracking Grazing Pressure and Climate Interaction—The Role of Landsat Fractional Cover in Time Series Analysis; Sparrow, B., Bhalia, G., Eds.; Alice Springs Convention Center: Alice Springs, Australia, 2010. [Google Scholar]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar]
- Schmidt, M.; Udelhoven, T.; Gill, T.; Röder, A. Long term data fusion for a dense time series analysis with MODIS and Landsat imagery in an Australian Savanna. J. Appl. Remote Sens. 2012, 6. [Google Scholar] [CrossRef]
- Tewes, A.; Thonfeld, F.; Schmidt, M.; Oomen, R.; Zhu, X.; Dubovyk, O.; Menz, G.; Schellberg, J. Using RapidEye and MODIS Data Fusion to Monitor Vegetation Dynamics in Semi-Arid Rangelands in South Africa. Remote Sens. 2015, 7, 6510–6534. [Google Scholar] [CrossRef]
- Wu, Z. Automated Cropland Classification Algorithm (ACCA) for California Using Multi-sensor Remote Sensing. Photogramm. Eng. Remote Sens. 2014, 80, 81–90. [Google Scholar] [CrossRef]
- Watts, J.D.; Powell, S.L.; Lawrence, R.L.; Hilker, T. Improved classification of conservation tillage adoption using high temporal and synthetic satellite imagery. Remote Sens. Environ. 2011, 115, 66–75. [Google Scholar] [CrossRef]
- Schmidt, M.; Lucas, R.; Bunting, P.; Verbesselt, J.; Armston, J. Multi-resolution time series imagery for forest disturbance and regrowth monitoring in Queensland, Australia. Remote Sens. Environ. 2015, 158, 156–168. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, M.; Thamm, H.-P.; Menz, G. Long term vegetation change detection application in an arid environment using LANDSAT data. In Geoinformation for European Wide Integration; Benes, T., Ed.; Millpress: Kennebunkport, ME, USA, 2003; pp. 145–154. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vegetation Indices, Temporal Variables and Band Ratios | |
|---|---|
| 1 | Normalised Difference Vegetation Index (NDVI) [29] |
| 2 | Modified Chlorophyll Absorption in Reflectance Index (MCARI) [56] |
| 3 | Renormalized Difference Vegetation Index (RDVI) [57] |
| 4 | Triangular Vegetation Index (TVI) [57] |
| 5 | Modified Simple Ratio (MSR) [57] |
| 6 | Normalised Difference Burn Ratio (NDBR) [58] |
| 7 | NDVI seasonal variance (ndviTsVr) |
| 8 | NDVI seasonal minimum (ndviTsMn) |
| 9 | NDVI seasonal maximum (ndviTsMx) |
| 10 | NDVI seasonal coefficient of variation (ndviTsCV) |
| 11 | NDVI seasonal range (ndviTsRng) |
| 12 | NDVI gradient up (first minimum to maximum) (ndviTsGr1) |
| 13 | NDVI gradient down (maximum to second minimum) (ndviTsGr2) |
| 14 | NDVI day of time series maximum (ndviTsDyMx) |
| 15 | b7 − b3/(b7 + b3) (nr73) |
| 16 | b7 − b2/(b7 + b2) (nr72) |
| 17 | b5 − b7/(b5 + b7) (nr57) |
| 18 | b4 − b5/(b4 + b5) (nr45) |
| 19 | b5 − b3/(b5 + b3) (nr53) |
| 20 | b5 − b2/(b5 + b2) (nr52) |
| 21 | b4 − b2/(b4 + b2) (nr42) |
| 22 | b2/b3 (r23) |
| 23 | b4/b3 (r43) |
| Summer | Crop | No-Crop | Crop | No-Crop | Crop | No-Crop |
| Training | Training | Validation | Validation | Total | Total | |
| NW | 280 | 1215 | 58 | 1359 | 338 | 2574 |
| SW | 547 | 732 | 113 | 1245 | 660 | 1977 |
| Winter | Crop | No-Crop | Crop | No-Crop | Crop | No-Crop |
| training | training | validation | validation | total | total | |
| NW | 145 | 1309 | 68 | 1292 | 213 | 2601 |
| SW | 448 | 758 | 181 | 1236 | 629 | 1994 |
| NW Summer | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | Accuracy | C5.0 | SVM | Logit | Random Forest (RF) | RF + landuse | |||||
| Crop | Producer‘s acc. | 0.580 | (0.469, 0.682) | 0.959 | (0.848, 0.992) | 0.734 | (0.606, 0.833) | 0.869 | (0.752, 0.937) | 0.878 | (0.782, 0.936) |
| Crop | User‘s acc. | 0.638 | (0.521, 0.739) | 0.588 | (0.471, 0.694) | 0.588 | (0.471, 0.694) | 0.663 | (0.547, 0.762) | 0.900 | (0.807, 0.952) |
| No-Crop | Producer‘s acc. | 0.954 | (0.933, 0.968) | 0.951 | (0.930, 0.965) | 0.950 | (0.929, 0.964) | 0.959 | (0.939, 0.972) | 0.987 | (0.974, 0.994) |
| No-Crop | User‘s acc. | 0.942 | (0.920, 0.958) | 0.997 | (0.987, 0.999) | 0.973 | (0.956, 0.983) | 0.987 | (0.974, 0.994) | 0.984 | (0.970, 0.992) |
| Overall Acc. | 0.908 | (0.883, 0.927) | 0.951 | (0.932, 0.965) | 0.930 | (0.908, 0.947) | 0.951 | (0.932, 0.965) | 0.975 | (0.959, 0.984) | |
| Kappa | 0.555 | 0.704 | 0.615 | 0.725 | 0.875 | ||||||
| NW Winter | |||||||||||
| Class | Accuracy | C5.0 | SVM | Logit | Random Forest (RF) | RF + landuse | |||||
| Crop | Producer‘s acc. | 0.875 | (0.740, 0.948) | 0.939 | (0.821, 0.984) | 0.893 | (0.774, 0.955) | 0.922 | (0.802, 0.974) | 0.893 | (0.774, 0.955) |
| Crop | User‘s acc. | 0.792 | (0.655, 0.887) | 0.868 | (0.740, 0.940) | 0.943 | (0.833, 0.985) | 0.887 | (0.762, 0.953) | 0.943 | (0.833, 0.985) |
| No-Crop | Producer‘s acc. | 0.983 | (0.968, 0.991) | 0.989 | (0.976, 0.995) | 0.995 | (0.985, 0.998) | 0.991 | (0.978, 0.996) | 0.995 | (0.985, 0.998) |
| No-Crop | User‘s acc. | 0.991 | (0.978, 0.996) | 0.995 | (0.985, 0.998) | 0.991 | (0.978, 0.996) | 0.994 | (0.982, 0.997) | 0.991 | (0.978, 0.996) |
| Overall Acc. | 0.975 | (0.960, 0.985) | 0.986 | (0.972, 0.992) | 0.987 | (0.974, 0.993) | 0.986 | (0.972, 0.992) | 0.987 | (0.974, 0.993) | |
| Kappa | 0.818 | 0.894 | 0.910 | 0.896 | 0.910 | ||||||
| SW Summer | |||||||||||
| Class | Accuracy | C5.0 | SVM | Logit | Random Forest (RF) | RF + landuse | |||||
| Crop | Producer‘s acc. | 0.841 | (0.777, 0.900) | 0.892 | (0.834, 0.933) | 0.922 | (0.868, 0.956) | 0.860 | (0.781, 0.893) | 0.958 | (0.911, 0.981) |
| Crop | User‘s acc. | 0.851 | (0.788, 0.898) | 0.856 | (0.793, 0.903) | 0.885 | (0.826, 0.927) | 0.879 | (0.813, 0.917) | 0.908 | (0.853, 0.945) |
| No-Crop | Producer‘s acc. | 0.941 | (0.913, 0.960) | 0.944 | (0.917, 0.963) | 0.955 | (0.931, 0.972) | 0.952 | (0.923, 0.967) | 0.964 | (0.942, 0.978) |
| No-Crop | User‘s acc. | 0.936 | (0.908, 0.957) | 0.959 | (0.935, 0.975) | 0.970 | (0.950, 0.983) | 0.943 | (0.909, 0.957) | 0.984 | (0.966, 0.993) |
| Overall Acc. | 0.912 | (0.886, 0.933) | 0.930 | (0.906, 0.948) | 0.946 | (0.941, 0.961) | 0.925 | (0.893, 0.939) | 0.963 | (0.944, 0.976) | |
| Kappa | 0.784 | 0.825 | 0.866 | 0.817 | 0.906 | ||||||
| SW Winter | |||||||||||
| Class | Accuracy | C5.0 | SVM | Logit | Random Forest (RF) | RF + landuse | |||||
| Crop | Producer‘s acc. | 0.912 | (0.853, 0.949) | 0.954 | (0.904, 0.979) | 0.954 | (0.904, 0.979) | 0.967 | (0.919, 0.987) | 0.980 | (0.938, 0.994) |
| Crop | User‘s acc. | 0.973 | (0.928, 0.991) | 0.980 | (0.937, 0.994) | 0.980 | (0.937, 0.994) | 0.973 | (0.928, 0.991) | 0.980 | (0.938, 0.994) |
| No-Crop | Producer‘s acc. | 0.991 | (0.975, 0.997) | 0.993 | (0.978, 0.998) | 0.993 | (0.978, 0.998) | 0.991 | (0.975, 0.997) | 0.993 | (0.979, 0.998) |
| No-Crop | User‘s acc. | 0.969 | (0.947, 0.982) | 0.985 | (0.967, 0.993) | 0.985 | (0.967, 0.993) | 0.989 | (0.972, 0.995) | 0.993 | (0.979, 0.998) |
| Overall Acc. | 0.970 | (0.952, 0.981) | 0.983 | (0.968, 0.991) | 0.983 | (0.968, 0.991) | 0.985 | (0.970, 0.992 | 0.990 | (0.977, 0.995) | |
| Kappa | 0.922 | 0.956 | 0.956 | 0.960 | 0.973 | ||||||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schmidt, M.; Pringle, M.; Devadas, R.; Denham, R.; Tindall, D. A Framework for Large-Area Mapping of Past and Present Cropping Activity Using Seasonal Landsat Images and Time Series Metrics. Remote Sens. 2016, 8, 312. https://doi.org/10.3390/rs8040312
Schmidt M, Pringle M, Devadas R, Denham R, Tindall D. A Framework for Large-Area Mapping of Past and Present Cropping Activity Using Seasonal Landsat Images and Time Series Metrics. Remote Sensing. 2016; 8(4):312. https://doi.org/10.3390/rs8040312
Chicago/Turabian StyleSchmidt, Michael, Matthew Pringle, Rakhesh Devadas, Robert Denham, and Dan Tindall. 2016. "A Framework for Large-Area Mapping of Past and Present Cropping Activity Using Seasonal Landsat Images and Time Series Metrics" Remote Sensing 8, no. 4: 312. https://doi.org/10.3390/rs8040312
APA StyleSchmidt, M., Pringle, M., Devadas, R., Denham, R., & Tindall, D. (2016). A Framework for Large-Area Mapping of Past and Present Cropping Activity Using Seasonal Landsat Images and Time Series Metrics. Remote Sensing, 8(4), 312. https://doi.org/10.3390/rs8040312