Research on the Parallelization of the DBSCAN Clustering Algorithm for Spatial Data Mining Based on the Spark Platform

Abstract
:
1. Introduction
- (1)
- The traditional parallel-processing platform is expensive and has inferior scalability and fault-tolerance properties, which result in bottlenecks in data transfer.
- (2)
- When dealing with a multi-iterative clustering algorithm such as DBSCAN, Hadoop needs to read and write data frequently from/to the distributed file system. The efficiency of the system decreases as the amount of data increases.
2. Related Works
- (1)
- Parallelization on high-performance cluster platforms. Xu et al. proposed a network-based fast parallel-DBSCAN (PDBSCAN) algorithm for use on cluster systems with master-slave architectures. First, the entire data area is divided into N disjointed data blocks, where each data block is processed by each computing node. After a given data block has been processed, the results are merged on the master node. This parallel algorithm requires extra communication time, where the inefficiencies related to combine the data with the main node data reduce the overall processing efficiency of the algorithm [21]. Based on the data-partition DBSCAN algorithm, Erdem & Gündem used high-performance clusters to improve the efficiency of the algorithm [22]. In these studies, parallel platforms based on high-performance clusters can help to improve the algorithm, but the conventional cluster platform has issues such as poor scalability, bad fault tolerance, etc. The shared architecture is also likely to cause bottlenecks in data transfer.
- (2)
- Parallelization on GPU platforms. Böhm et al. proposed a GPU-based CUDA-DClust parallel algorithm that calculates the distance from the central point to surrounding points using the multi-thread programming model to efficiently query the neighboring data. The results show that the parallel algorithm enhances the overall efficiency with the help of the GPU [23]. However, CUDA-DClust needs to calculate the distance between many unnecessary objects and store them on the device memory. Andrade et al. used the compute unified device architecture (CUDA) on the GPU to accelerate the parallel algorithm [24]. Compared with the serial algorithm, the performance was greatly improved.
- (3)
- Parallelization on Cloud-computing platforms. Dean et al. proposed to take advantage of MapReduce, a large-scale data processing programming model, to enhance the processing efficiency [25]. Böse et al. designed data-mining algorithms based on the MapReduce programming framework, and they demonstrated the feasibility of adopting the MapReduce programming model in data mining [26]. He et al. implemented the MR-DBSCAN algorithm with MapReduce, and achieved good scalability and speedup [27]. Dai et al. divided the data by reducing the number of boundary points, and they used KD-Tree spatial indices to parallelize DBSCAN on Hadoop to improve the performance of the algorithm [28]. Fu et al. studied the parallel DBSCAN clustering algorithm based on Hadoop. The experimental results demonstrated that the proposed algorithm could efficiently process large datasets on commodity hardware and have good scalability [29]. In addition, some researchers studied the parallel implementation of K-Means algorithm on Hadoop to improve the efficiency [30,31]. In these studies, the efficiency of the parallel algorithms were improved on Hadoop, but the results were less than ideal when processing massive spatial datasets [30,31,32]. The reasons for this were: (1) the startup time in MapReduce increased the overall run time of the jobs; (2) the frequent I/O carried out by the Hadoop distributed file system (HDFS) for the intermediate results, due to its fault-tolerance mechanism; and (3) with an increase in the data size, the processing efficiency was significantly decreased [33].
3. DBSCAN Algorithm
3.1. Mathematical Principles of the DBSCAN Algorithm
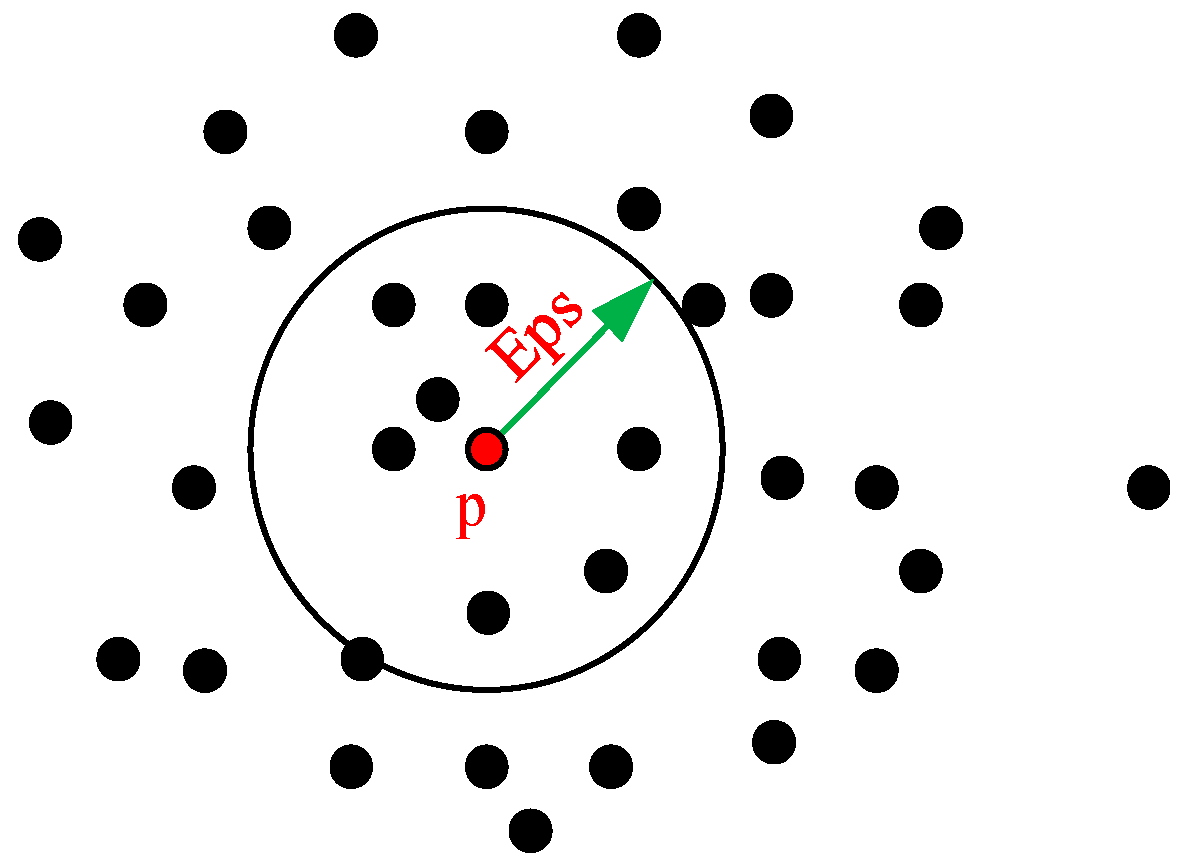
- (1)
- Eps neighboring area: let be the center of a sphere in the dataset . For data within the radius of the object’s area, a collection of points contained in the sphere is . A definition diagram is shown in Figure 1.
- (2)
- Density: at the position of data point in the dataset , the number of points, Num, contained in the neighborhood is its density.
- (3)
- Core point: at the position of data point in the dataset , if the density (Num) in the neighborhood Eps satisfies , it is called a core point.
- (4)
- Border point: at the position of data point in the dataset , if the density in the neighborhood satisfies but it is inside the sphere, it is called a border point.
- (5)
- Noise point: all the objects other than the core and border points in .
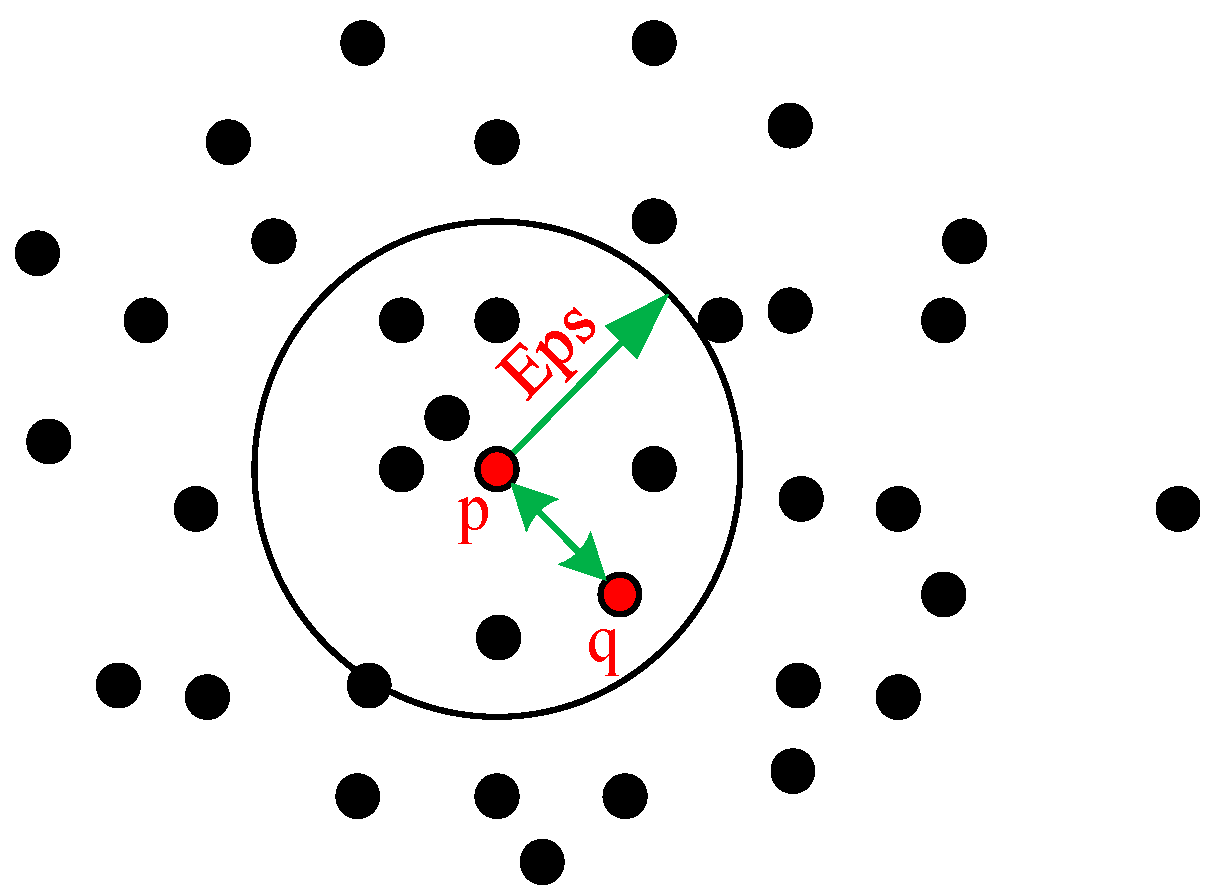
- (6)
- Direct density-reachable: given objects , where there is a core point and this is inside the neighborhood of , it is said that from to is direct density-reachable, i.e., , , as shown in Figure 2.
- (7)
- Density-reachable: given objects , where , , if is directdensity-reachable from , then is density-reachable from . The definition is shown in Figure 3.
- (8)
- Density-connected: given objects , if there is a point that is density-reachable from and , then and are density-connected. The definition is shown in Figure 4.
3.2. Processing Procedure of the DBSCAN Algorithm
- (1)
- All the data objects in dataset are marked as unchecked. Starting from any unchecked data point , mark it as ‘checked’, then check its neighborhood and calculate the number of objects in the neighborhood m. If m satisfies , then create a new cluster , and add to , meanwhile add all the points in the neighborhood to the collection of objects .
- (2)
- For the collection of objects, , if object therein has not been checked, then mark as ‘checked’, and then check its neighborhood and calculate the number of objects in the neighborhood n. If n satisfies , then these objects are added to the object collection. If does not belong to any cluster, then add to .
- (3)
- Repeat step (2), and continue to check object set until it is empty.
- (4)
- Repeat steps (1) to (3). When all the data objects are marked as ‘checked’, the algorithm ends.
| Algorithm 1. DBSCAN algorithm implementation steps. |
| Input Data: Data Set D to be processed Output Data: Cluster that satisfies the Clustering requirements Parameters: Clustering Radius Eps, Minimal number of neighboring points MinPts Main function of the algorithm: DensityCluster(D, Eps, MinPts) { ClusterNum = 0 // Initialize cluster for each unchecked point M in D // Traverse all the unchecked points set M as checked // Mark it checked NeighbourResult = NeighbourSearching(M, Eps) // Search the neighborhood of M if sizeof(NeighbourResult) ≥ MinPts // Mark it as a core and create a cluster ClusterNum = UpdateClusterNum // Expand the cluster expandNeighbourPart(M, NeighbourResult, ClusterNum, Eps, MinPts) else // If it is not a core set M as NOISE // Mark it as noise } Sub function: expandNeighbourPart(M, NeighbourResult, ClusterNum, Eps, MinPts) //cluster expansion function NeighbourSearching(M, Eps) // Neighbor searching …… |
4. Design and Implementation of the DBSCAN Algorithm on the Spark Platform
4.1. Analyzing the Sequential DBSCAN Algorithm
4.2. Parallel Design of the DBSCAN Algorithm
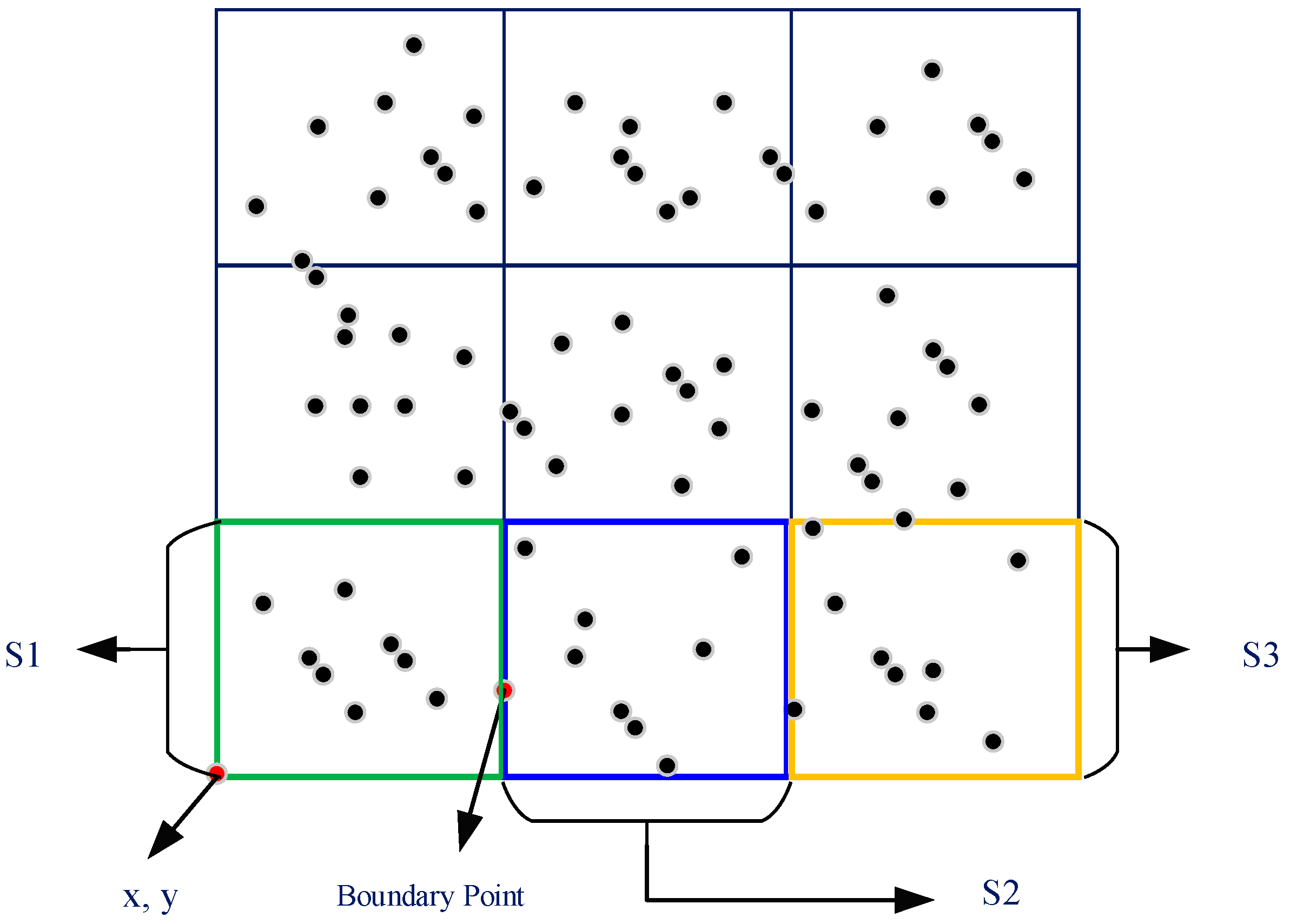
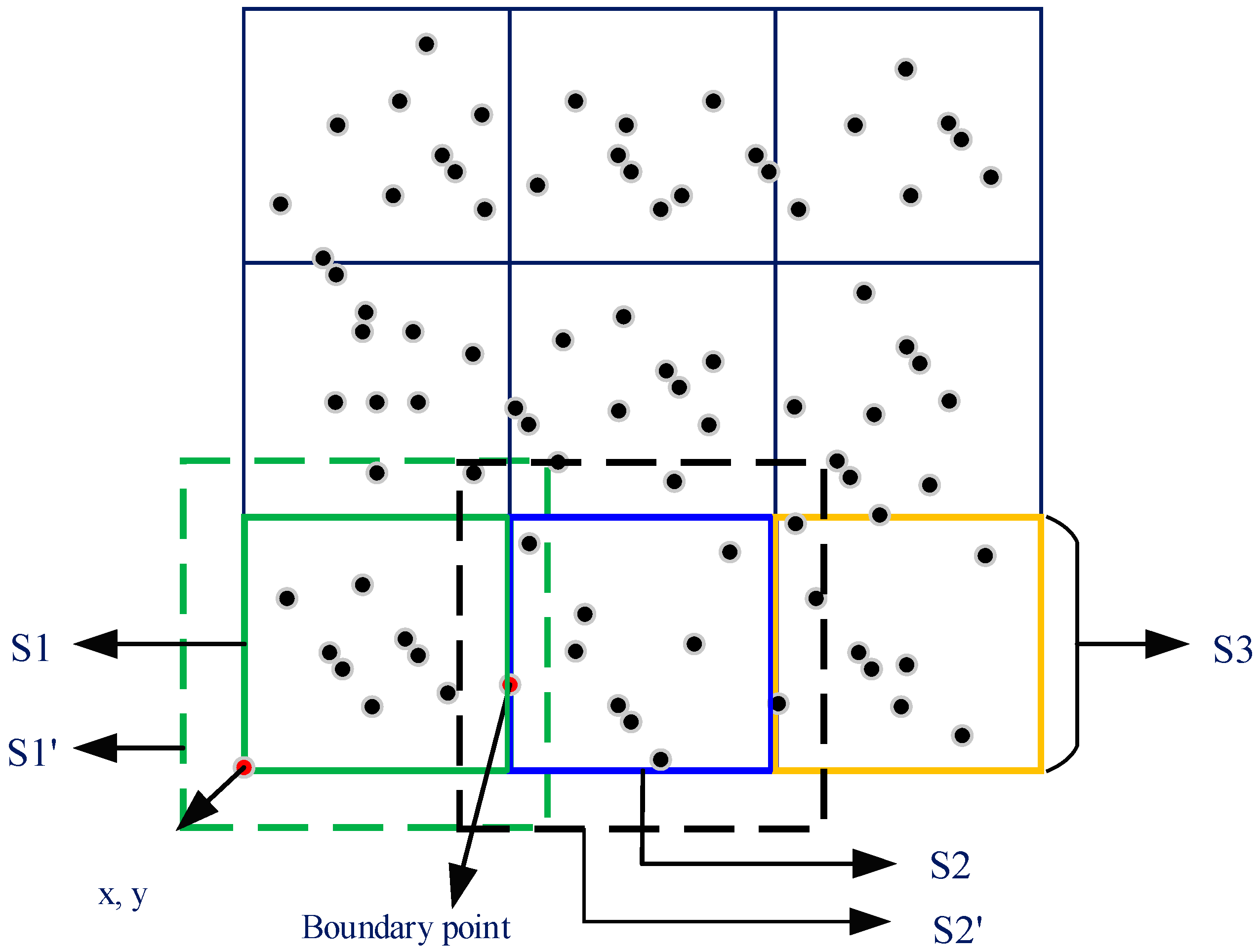
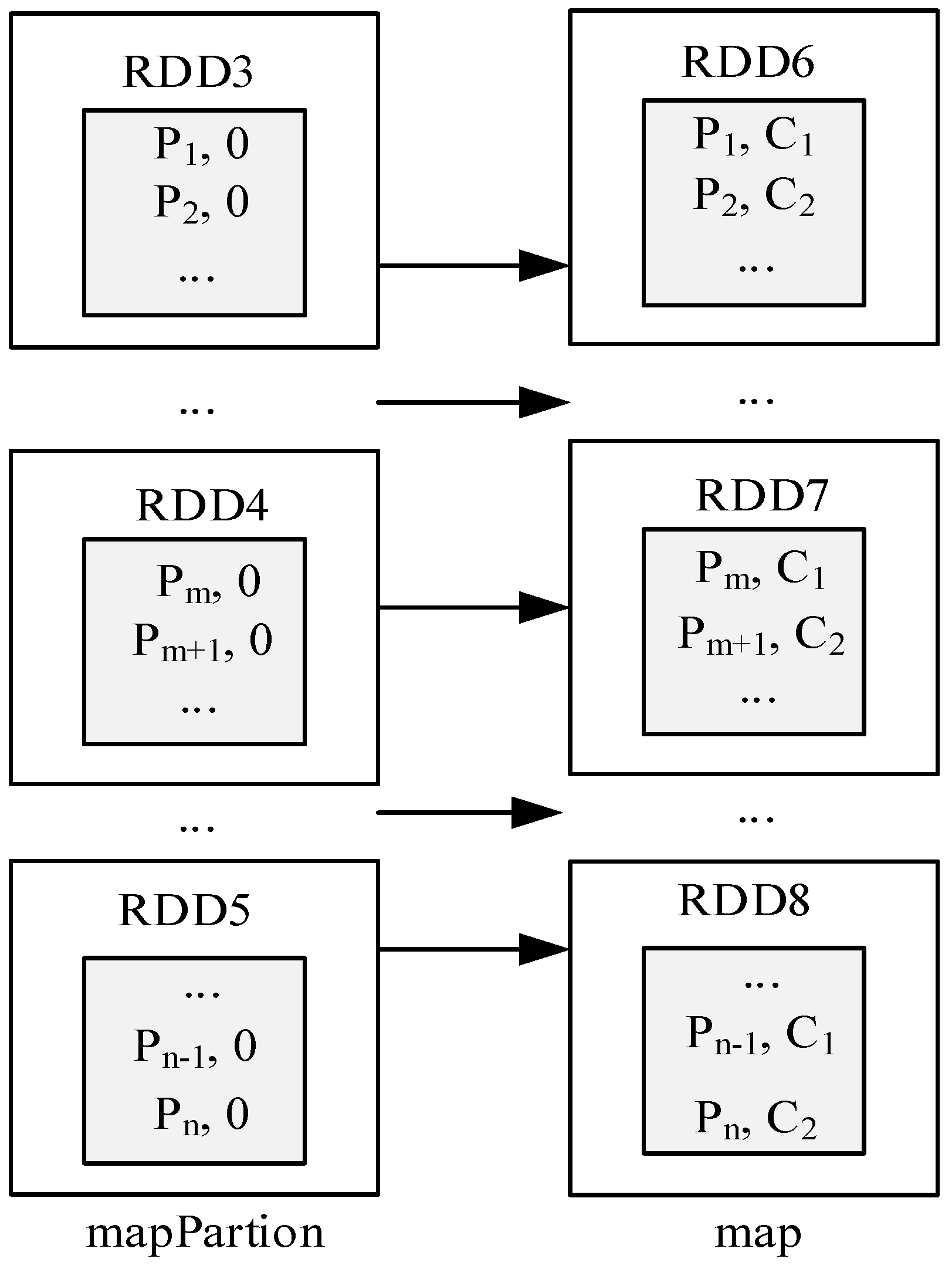
4.2.1. Data Partitioning Stage
4.2.2. Local Clustering Stage
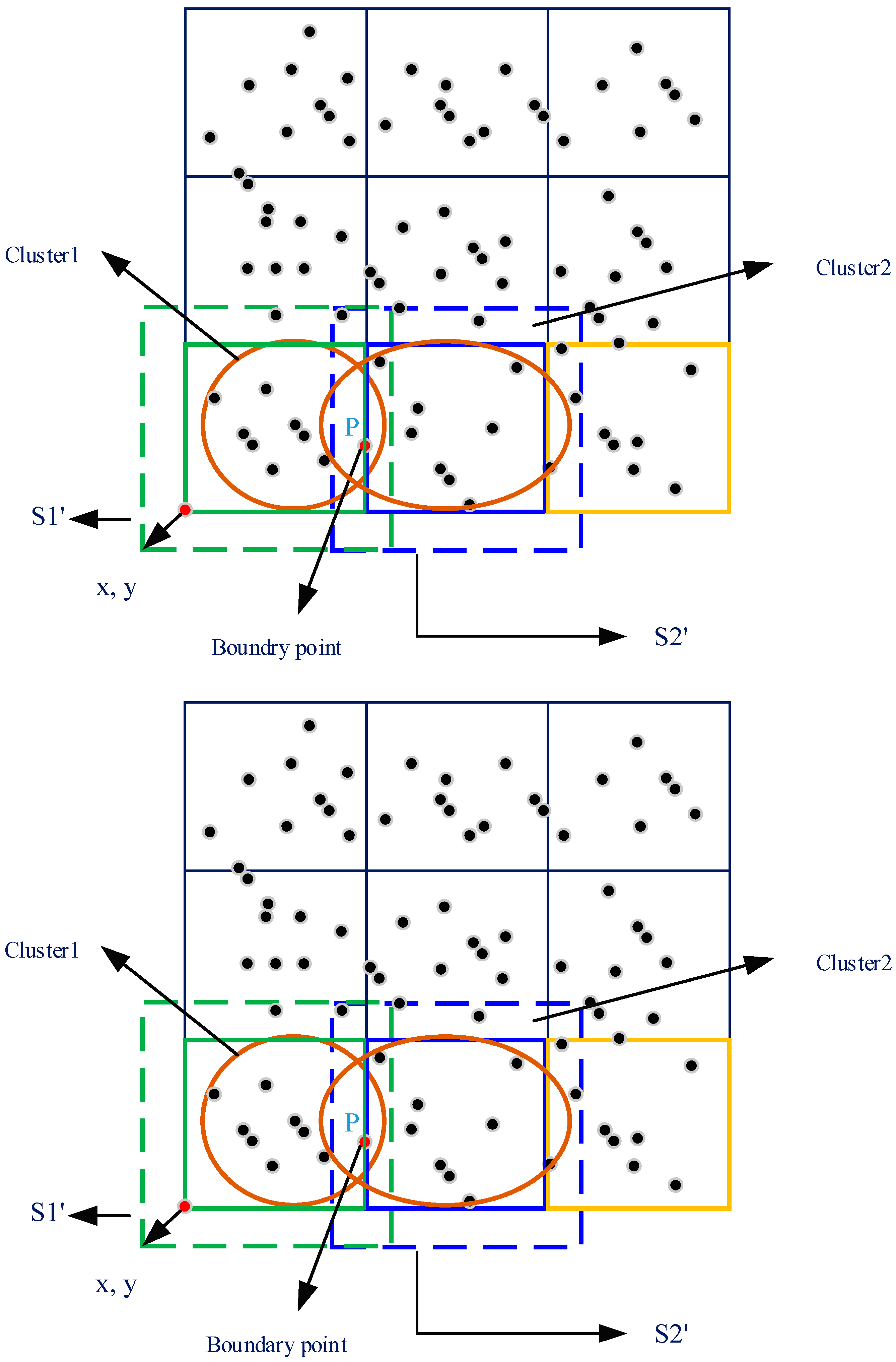
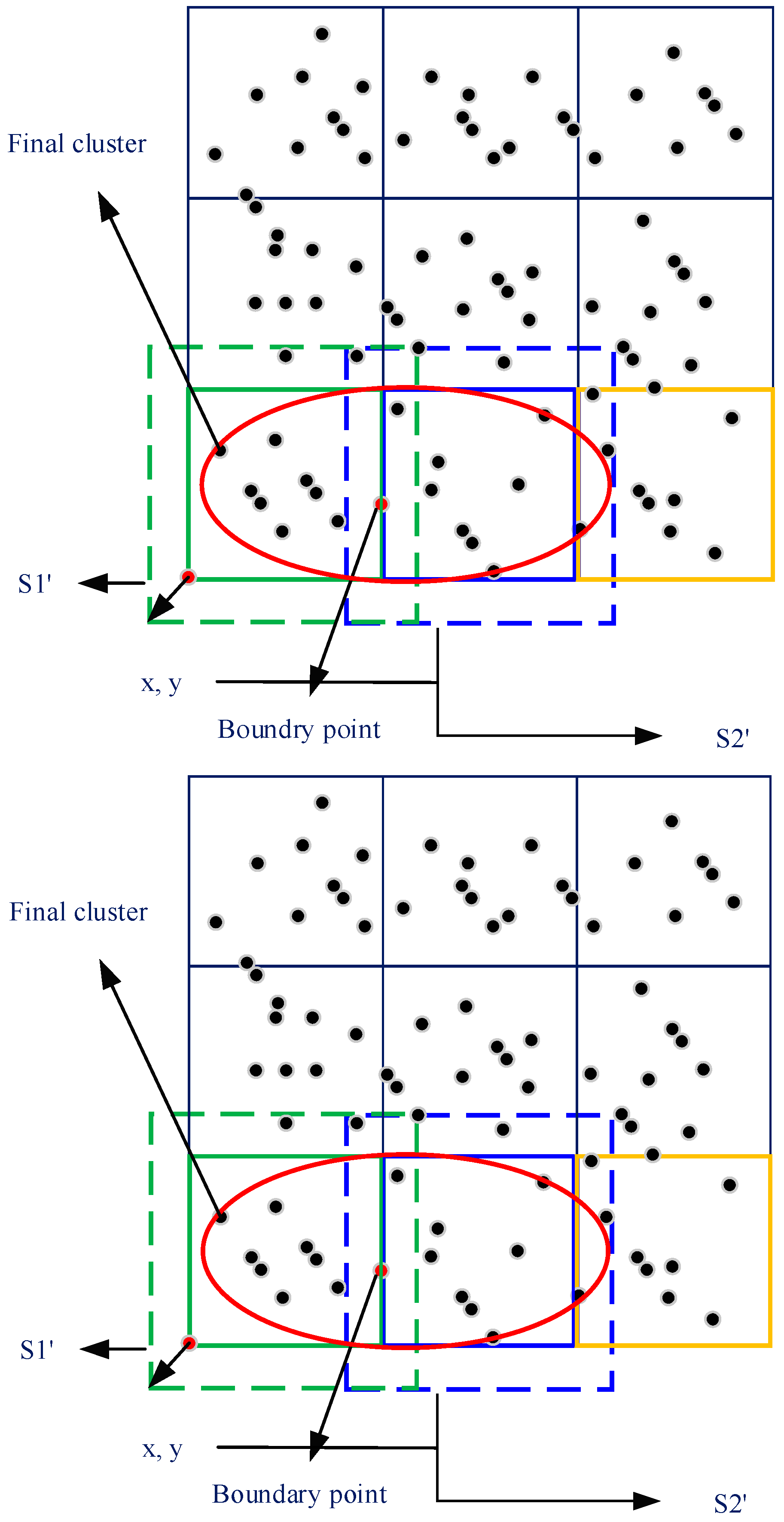
4.2.3. Data Merger Stage
4.2.4. Global Cluster Generation Stage
4.3. Optimizing the Parallel DBSCAN Algorithm on the Single-Node Spark Platform
4.3.1. Optimization Method 1: Optimization of Data Transmission
4.3.2. Optimization Method 2: Serialization Optimizing
4.3.3. Optimization Method 3: Optimization of Resource Parameters
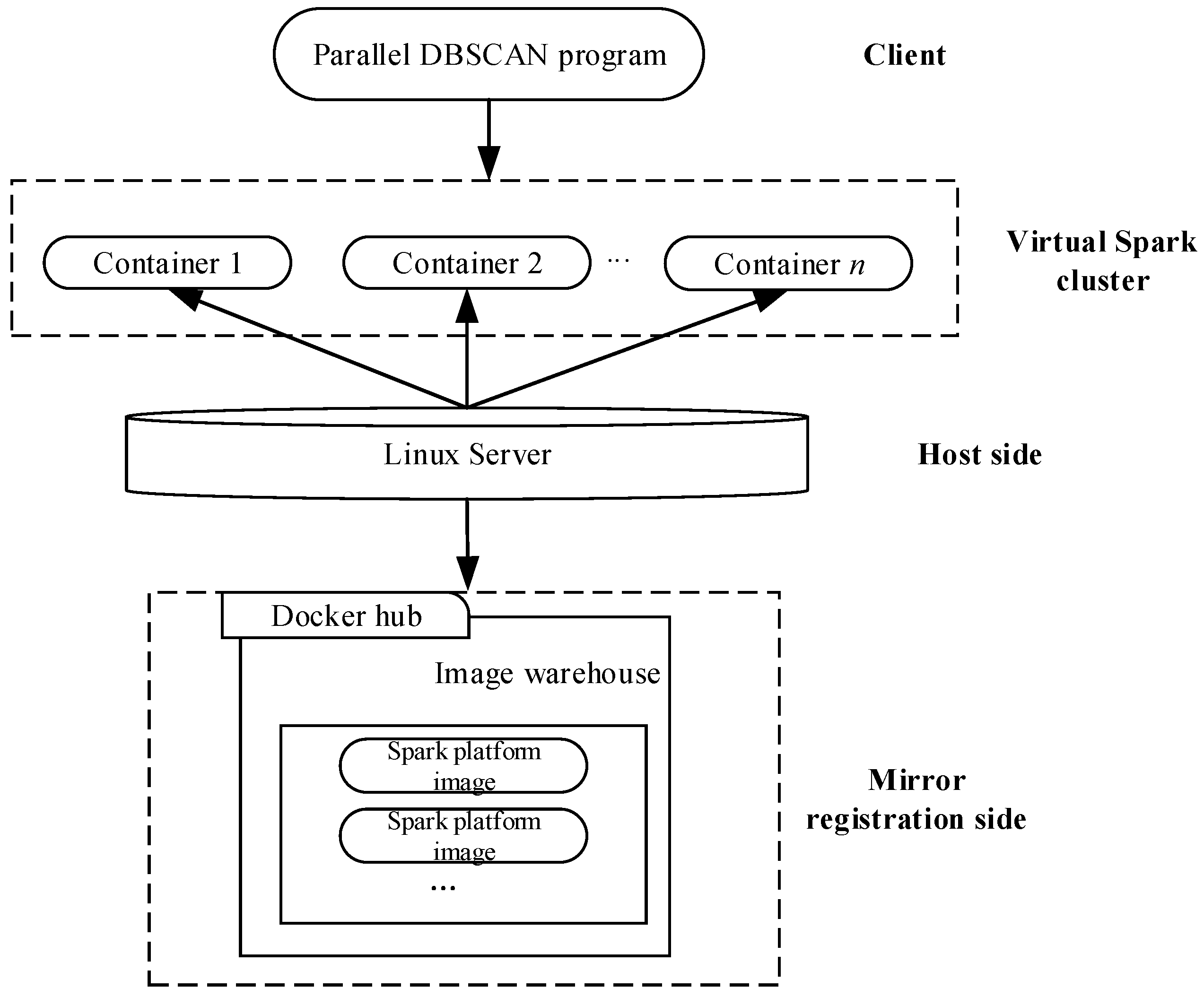
4.4. Implementation of the Parallel DBSCAN Algorithm on a Virtual Spark Cluster
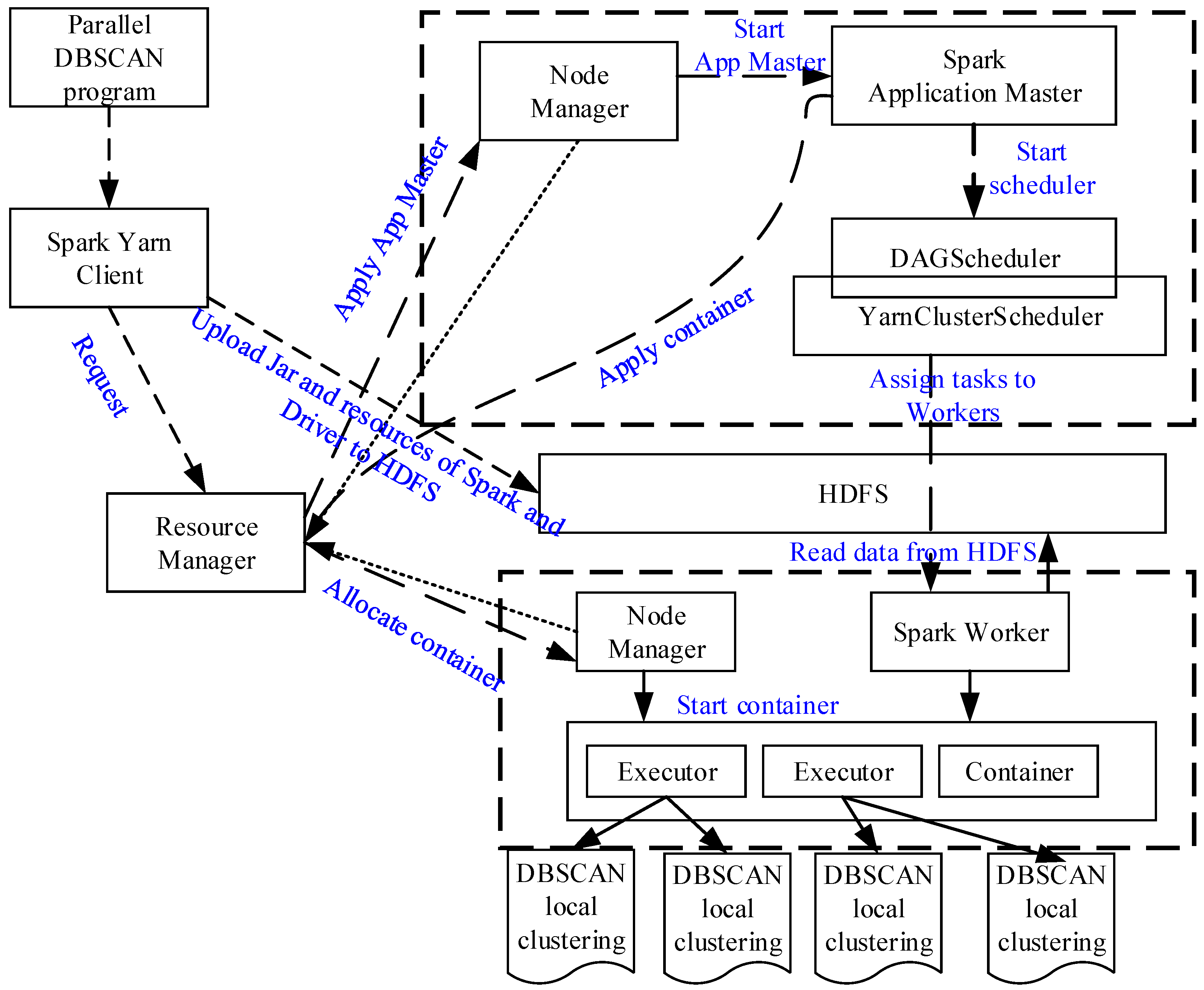
4.5. Implementation of the Parallel DBSCAN Algorithm on the Spark Cluster with Yarn
- (1)
- The Yarn client uploads the DBSCAN application packages to HDFS, and requests a job commit to the Resource Manager to run this task.
- (2)
- Resource Manager responds to the job and requests the Node Manager to create a Spark Application Master and then starts it.
- (3)
- Spark Application Master finds the resource files (the Jar packages, etc.) from the HDFS, and starts DAGscheduler and YARN cluster scheduler to process the initialization operations. Then, the Spark application master will apply the resources from the Resource Manager, and start the respective container through the Node Manager.
- (4)
- Each container contains multiple executors to perform the corresponding tasks simultaneously, and report their state to the Spark Application Master.
4.6. Implementation of the Parallel DBSCAN Algorithm on a Spark Cluster with Mesos
- (1)
- After submitting a DBSCAN processing request through the client side, Spark will generate RDD and Map/Reduce functions, and then transform and generate the corresponding job information. Each job contains multiple tasks, and the job is submitted to the SparkScheduler.
- (2)
- The job sets are sent to the Mesos master node by the SparkScheduler. The Mesos master node performs the corresponding task scheduling to the Mesos slave nodes as the manager, these slave nodes execute the corresponding task in parallel with multiple executors and then return the results. The process of executing the parallel algorithm is shown in Figure 16.
5. Test and Analysis of the Proposed Parallel DBSCAN Algorithm
5.1. Configurations of the Experimental Platforms
5.2. Experimental Data
5.3. Parallel Algorithm Evaluation Index
5.4. Experiment Design
- (1)
- Test the performance of the parallel DBSCAN algorithm based on a single-node Spark platform.
- (2)
- Test the performance of the optimized parallel algorithm based on a single-node Spark platform.
- (3)
- Test the performance of the parallel algorithm based on a virtual Spark cluster.
- (4)
- Obtain the performance of the parallel algorithm based on a physical Spark cluster. The tests were conducted employing both the Mesos and Yarn resources managing modes in turn.
5.5. Experimental Results and Analysis
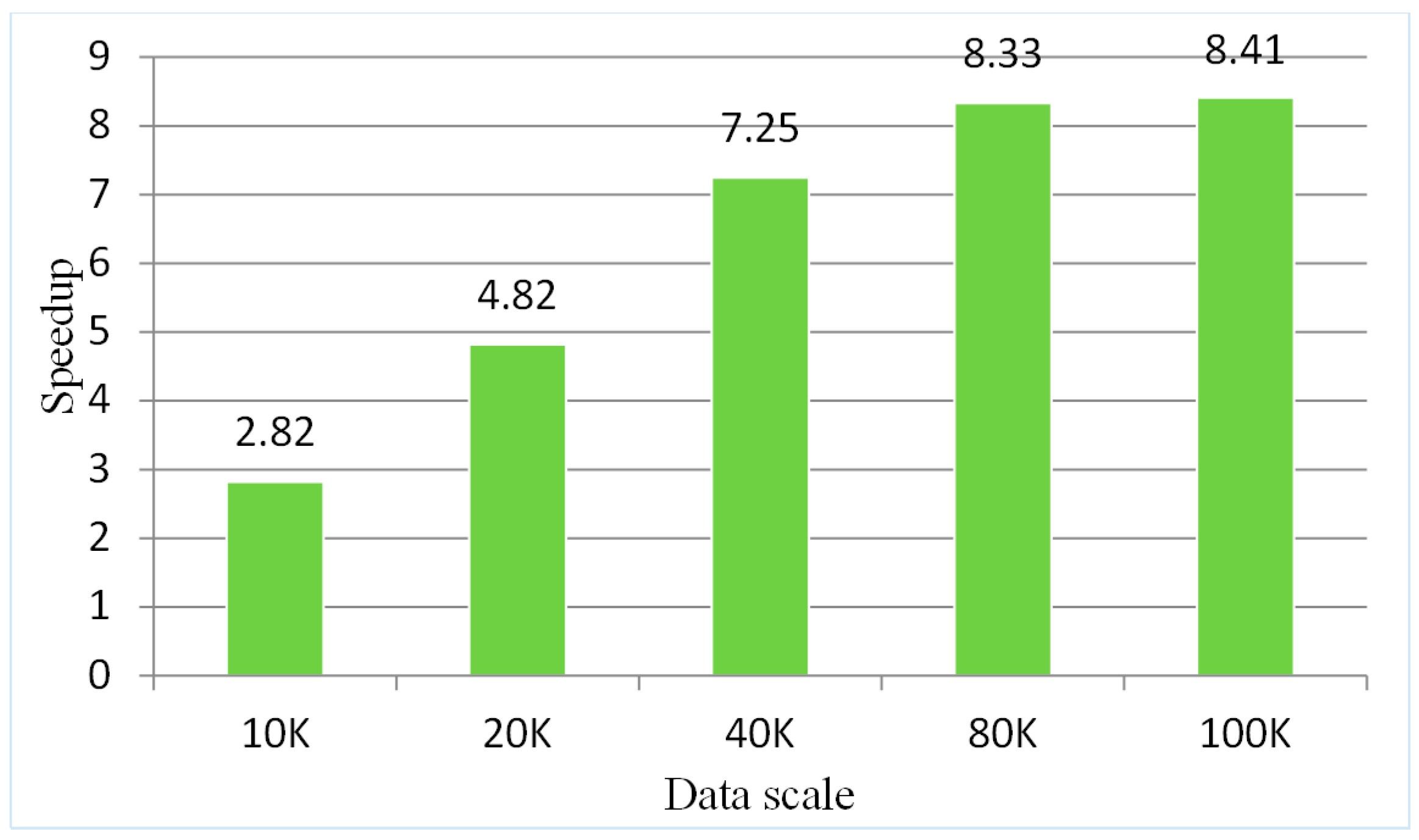
5.5.1. Testing the Parallel Algorithm on a Single-Node Spark Platform
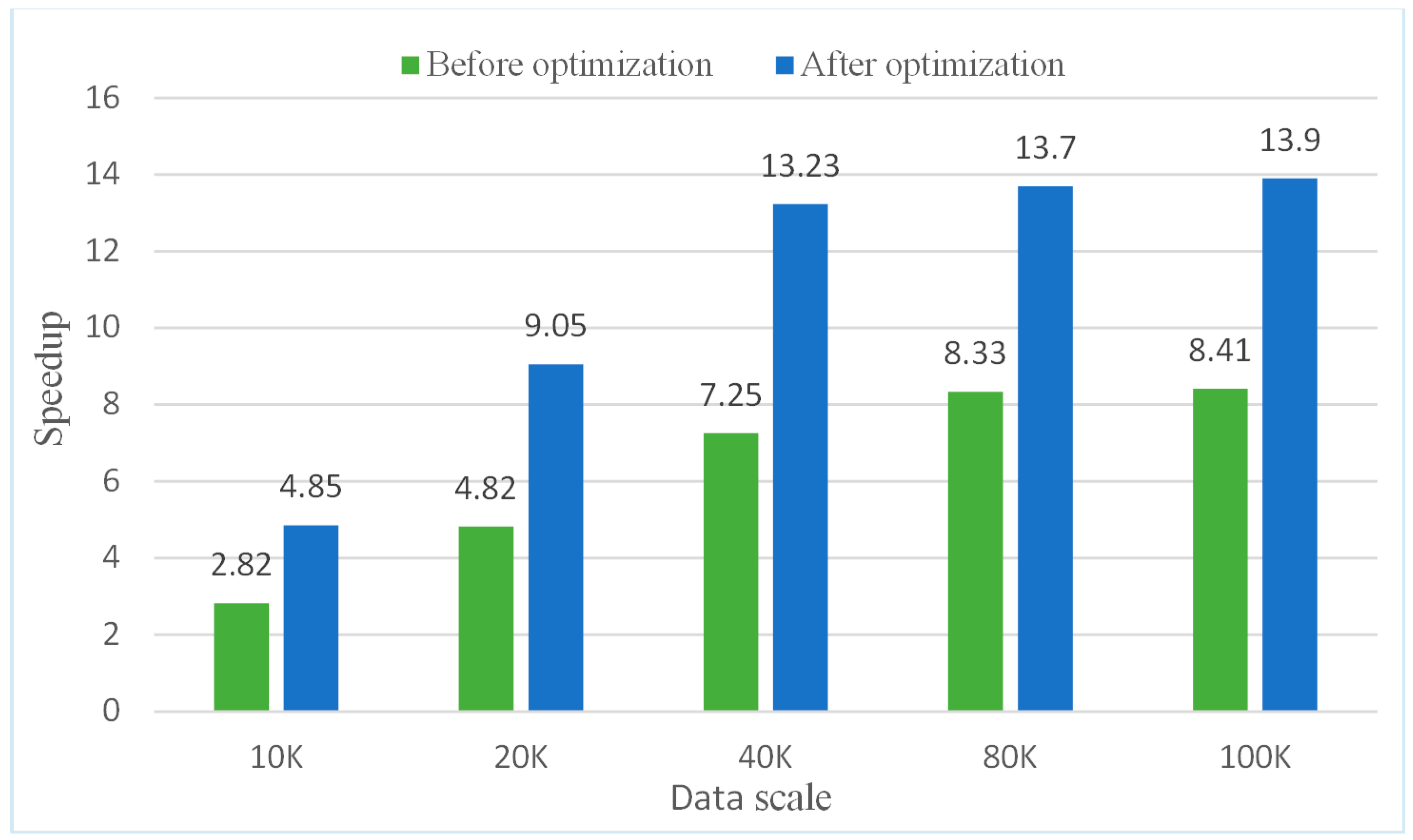
5.5.2. Testing the Optimized Parallel Algorithm on a Single-Node Spark Platform
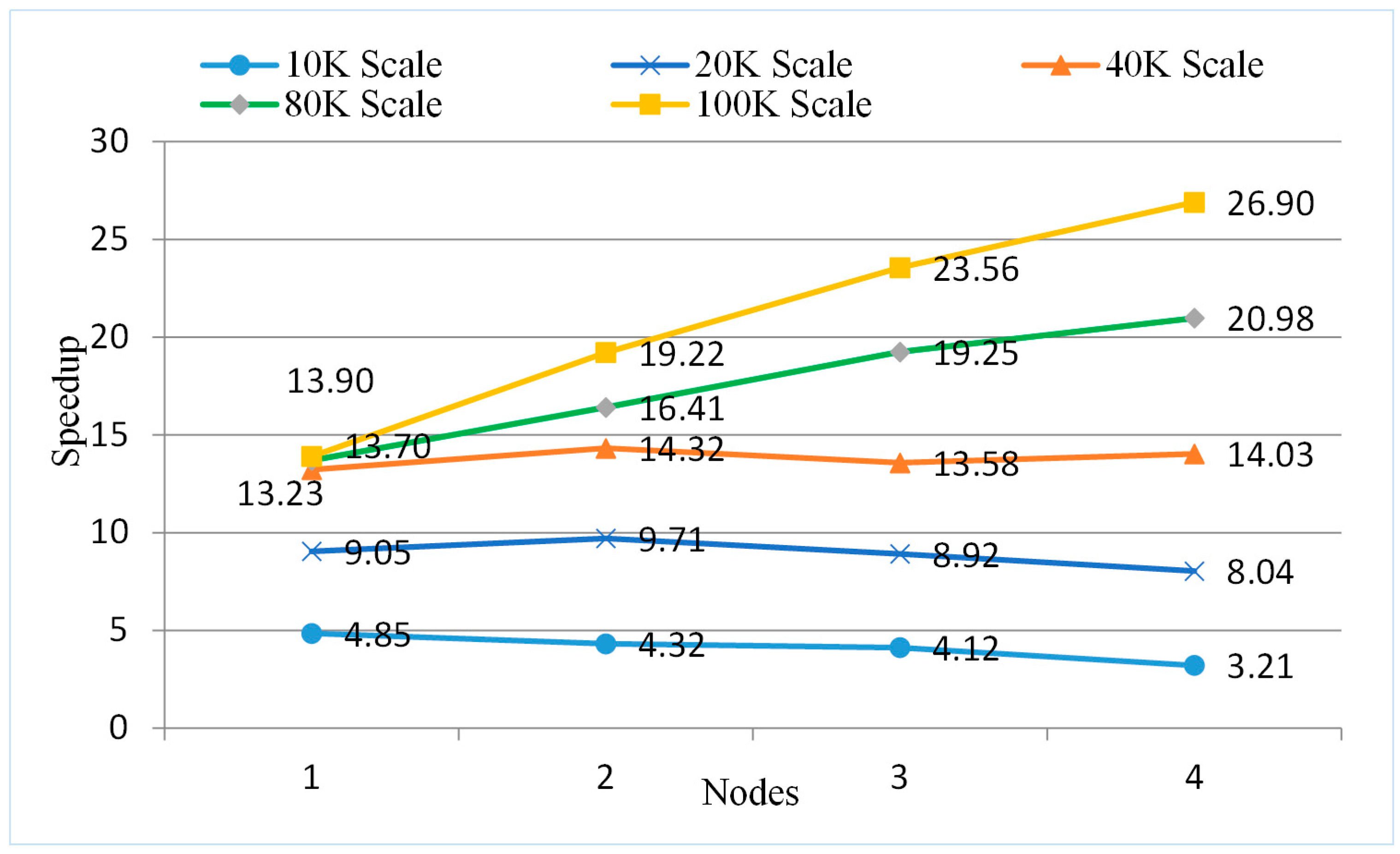
5.5.3. Testing the Parallel Algorithm on a Virtual Spark Cluster Platform
- (1)
- The parallel algorithm has intensive I/O operations, so it requires a higher network-transmission state; however, the virtual cluster built with a single-node server encounters transmission pressure.
- (2)
- The performance of the virtual Spark cluster cannot achieve the same desired effects as a physical Spark cluster.
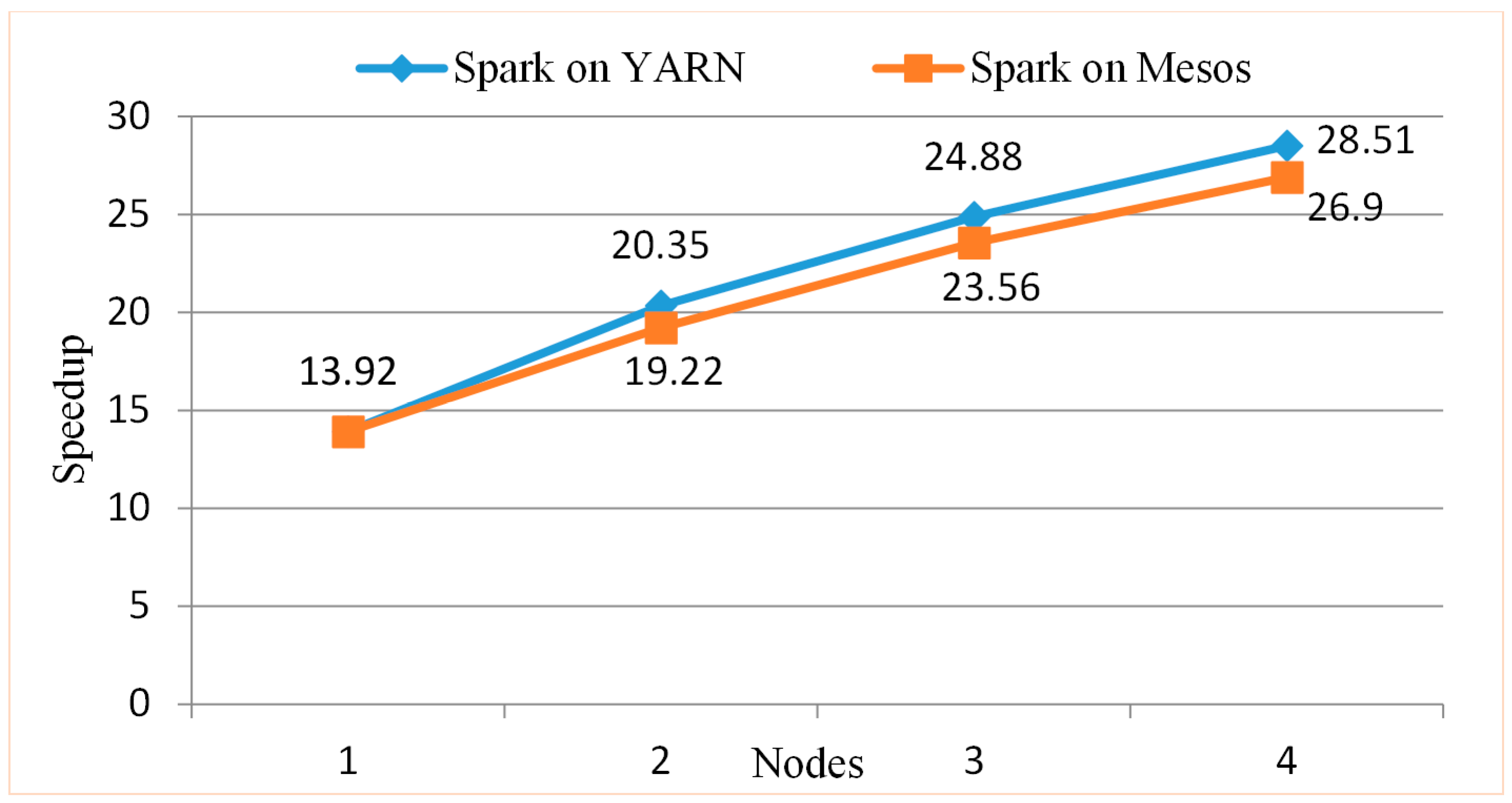
5.5.4. Testing the Parallel Algorithm on a Spark Cluster with the Yarn Resources Manager
5.5.5. Testing the Parallel Algorithm on a Spark Cluster with the Mesos Resources Manager
6. An Urban Congestion Area Discovery Application
6.1. Summary of City Traffic Congestion Area Discovery
6.2. Traffic Congestion Area Discovery Based on the Spark Platform
6.3. Experimental Data and Platform Configuration
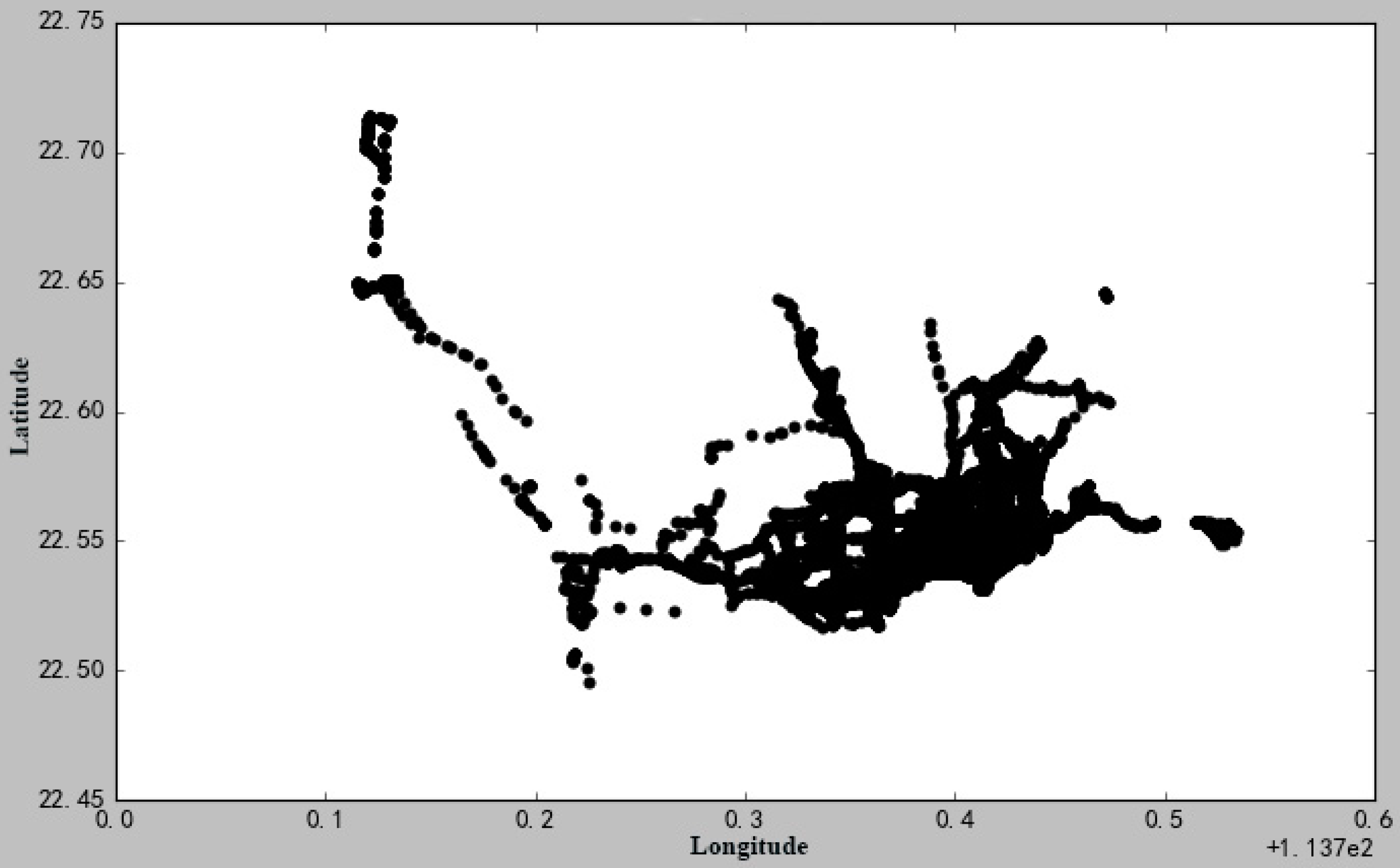
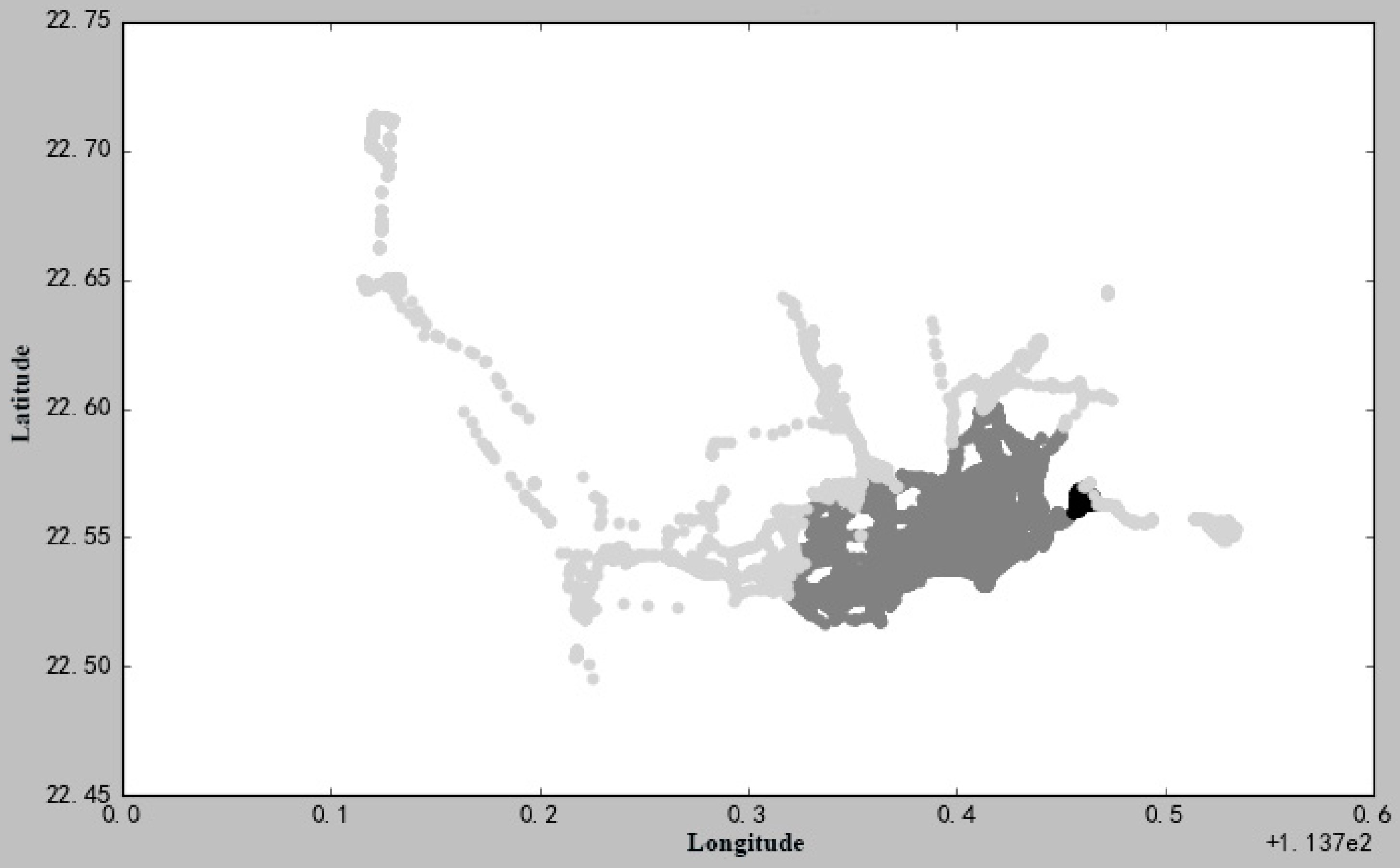
6.4. Experiments and Analysis
7. Conclusions and Future Directions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X.W. A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- He, Y.; Tan, H.; Luo, W.; Mao, H.; Ma, D.; Feng, S.; Fan, J. MR-DBSCAN: A scalable MapReduce-based DBSCAN algorithm for heavily skewed data. Front. Comput. Sci. 2014, 8, 83–99. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. In Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, Philadelphia, PA, USA, 1–3 June 1999; pp. 49–60. [Google Scholar]
- Chen, M.; Gao, X.; Li, H. Parallel DBSCAN with Priority R-tree. In Proceedings of the 2010 2nd IEEE International Conference on Information Management and Engineering, Chengdu, China, 16–18 April 2010; pp. 508–511. [Google Scholar]
- Kryszkiewicz, M.; Lasek, P. TI-DBSCAN: Clustering with DBSCAN by Means of the Triangle Inequality. In Rough Sets and Current Trends in Computing, Proceedings of the 7th International Conference, RSCTC 2010, Warsaw, Poland, 28–30 June 2010; Szczuka, M., Kryszkiewicz, M., Ramanna, S., Jensen, R., Hu, Q., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 60–69. [Google Scholar]
- Owens, J.D.; Luebke, D.; Govindaraju, N.; Harris, M.; Krüger, J.; Lefohn, A.E.; Purcell, T.J. A Survey of General-Purpose Computation on Graphics Hardware. Comput. Graph. Forum 2007, 26, 80–113. [Google Scholar] [CrossRef]
- Wang, L.; Tao, J.; Ranjan, R.; Marten, H.; Streit, A.; Chen, J.; Chen, D. G-Hadoop: MapReduce across distributed data centers for data-intensive computing. Future Gener. Comput. Syst. 2013, 29, 739–750. [Google Scholar] [CrossRef]
- Gan, L.; Fu, H.; Luk, W.; Yang, C.; Xue, W.; Huang, X.; Zhang, Y.; Yang, G. Solving the global atmospheric equations through heterogeneous reconfigurable platforms. ACM Trans. Reconfig. Technol. Syst. 2015, 8, 11. [Google Scholar] [CrossRef]
- Li, L.; Xue, W.; Ranjan, R.; Jin, Z. A scalable Helmholtz solver in GRAPES over large-scale multicore cluster. Concurr. Comput. Pract. Exp. 2013, 25, 1722–1737. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, T.; Ma, Y.; Wang, L.; Liu, D.; Yue, S.; Kolodziej, J. Parallel processing of massive remote sensing images in a GPU architecture. Comput. Inf. 2014, 33, 197–217. [Google Scholar]
- Chen, D.; Li, D.; Xiong, M.; Bao, H.; Li, X. GPGPU-Aided Ensemble Empirical-Mode Decomposition for EEG Analysis during Anesthesia. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1417–1427. [Google Scholar] [CrossRef] [PubMed]
- Bernabé, S.; Lopez, S.; Plaza, A.; Sarmiento, R. GPU Implementation of an Automatic Target Detection and Classification Algorithm for Hyperspectral Image Analysis. IEEE Geosci. Remote Sens. Lett. 2013, 10, 221–225. [Google Scholar] [CrossRef]
- Agathos, A.; Li, J.; Petcu, D.; Plaza, A. Multi-GPU Implementation of the Minimum Volume Simplex Analysis Algorithm for Hyperspectral Unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2281–2296. [Google Scholar] [CrossRef]
- Deng, Z.; Hu, Y.; Zhu, M.; Huang, X.; Du, B. A scalable and fast OPTICS for clustering trajectory big data. Clust. Comput. 2015, 18, 549–562. [Google Scholar] [CrossRef]
- Chen, D.; Li, X.; Wang, L.; Khan, S.U.; Wang, J.; Zeng, K.; Cai, C. Fast and Scalable Multi-Way Analysis of Massive Neural Data. IEEE Trans. Comput. 2015, 64, 707–719. [Google Scholar] [CrossRef]
- Huang, F.; Tao, J.; Xiang, Y.; Liu, P.; Dong, L.; Wang, L. Parallel compressive sampling matching pursuit algorithm for compressed sensing signal reconstruction with OpenCL. J. Syst. Archit. 2017, 72, 51–60. [Google Scholar] [CrossRef]
- Yu, T.; Dou, M.; Zhu, M. A data parallel approach to modelling and simulation of large crowd. Clust. Comput. 2015, 18, 1307–1316. [Google Scholar] [CrossRef]
- Wang, L.; Chen, D.; Liu, W.; Ma, Y.; Wu, Y.; Deng, Z. DDDAS-based parallel simulation of threat management for urban water distribution systems. Comput. Sci. Eng. 2014, 16, 8–17. [Google Scholar] [CrossRef]
- Hu, C.; Zhao, J.; Yan, X.; Zeng, D.; Guo, S. A MapReduce based Parallel Niche Genetic Algorithm for contaminant source identification in water distribution network. Ad Hoc Netw. 2015, 35, 116–126. [Google Scholar] [CrossRef]
- Kim, Y.; Shim, K.; Kim, M.-S.; Sup Lee, J. DBCURE-MR: An efficient density-based clustering algorithm for large data using MapReduce. Inf. Syst. 2014, 42, 15–35. [Google Scholar] [CrossRef]
- Xu, X.; Jäger, J.; Kriegel, H.-P. A Fast Parallel Clustering Algorithm for Large Spatial Databases. Data Min. Knowl. Discov. 1999, 3, 263–290. [Google Scholar] [CrossRef]
- Erdem, A.; Gündem, T.I. M-FDBSCAN: A multicore density-based uncertain data clustering algorithm. Turkish J. Electri. Eng. Comput. Sci. 2014, 22, 143–154. [Google Scholar] [CrossRef]
- Böhm, C.; Noll, R.; Plant, C.; Wackersreuther, B. Density-based clustering using graphics processors. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 661–670. [Google Scholar]
- Andrade, G.; Ramos, G.; Madeira, D.; Sachetto, R.; Ferreira, R.; Rocha, L. G-DBSCAN: A GPU Accelerated Algorithm for Density-based Clustering. Procedia Comput. Sci. 2013, 18, 369–378. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Böse, J.-H.; Andrzejak, A.; Högqvist, M. Beyond online aggregation: Parallel and incremental data mining with online Map-Reduce. In Proceedings of the 2010 Workshop on Massive Data Analytics on the Cloud, Raleigh, NC, USA, 26 April 2010; pp. 1–6. [Google Scholar]
- He, Y.; Tan, H.; Luo, W.; Mao, H.; Ma, D.; Feng, S.; Fan, J. MR-DBSCAN: An Efficient Parallel Density-Based Clustering Algorithm Using MapReduce. In Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems, Tainan, Taiwan, 7–9 December 2011; pp. 473–480. [Google Scholar]
- Dai, B.R.; Lin, I.C. Efficient Map/Reduce-Based DBSCAN Algorithm with Optimized Data Partition. In Proceedings of the 2012 IEEE Fifth International Conference on Cloud Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 59–66. [Google Scholar]
- Fu, Y.X.; Zhao, W.Z.; Ma, H.F. Research on parallel DBSCAN algorithm design based on mapreduce. Adv. Mater. Res. 2011, 301–303, 1133–1138. [Google Scholar] [CrossRef]
- Kumar, A.; Kiran, M.; Prathap, B.R. Verification and validation of MapReduce program model for parallel K-means algorithm on Hadoop cluster. In Proceedings of the 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–8. [Google Scholar]
- Anchalia, P.P.; Koundinya, A.K.; Srinath, N.K. MapReduce Design of K-Means Clustering Algorithm. In Proceedings of the 2013 International Conference on Information Science and Applications (ICISA), Suwon, Korea, 24–26 June 2013; pp. 1–5. [Google Scholar]
- Xu, Z.Q.; Zhao, D.W. Research on Clustering Algorithm for Massive Data Based on Hadoop Platform. In Proceedings of the 2012 International Conference on Computer Science and Service System, Nanjing, China, 11–13 August 2012; pp. 43–45. [Google Scholar]
- Nagpal, A.; Jatain, A.; Gaur, D. Review based on data clustering algorithms. In Proceedings of the 2013 IEEE Conference on Information & Communication Technologies, Thuckalay, India, 11–12 April 2013; pp. 298–303. [Google Scholar]
- Lin, X.; Wang, P.; Wu, B. Log analysis in cloud computing environment with Hadoop and Spark. In Proceedings of the 2013 5th IEEE International Conference on Broadband Network & Multimedia Technology, Guilin, China, 17–19 November 2013; pp. 273–276. [Google Scholar]
- Shukla, S.; Lease, M.; Tewari, A. Parallelizing ListNet training using spark. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 1127–1128. [Google Scholar]
- Lawson, D. Alternating Direction Method of Multipliers Implementation Using Apache Spark; Stanford University: Stanford, CA, USA, 2014. [Google Scholar]
- Biglearn. Available online: http://biglearn.org/2013/files/papers/biglearning2013_submission_7.pdf (accessed on 15 December 2016).
- Wang, B.; Yin, J.; Hua, Q.; Wu, Z.; Cao, J. Parallelizing K-Means-Based Clustering on Spark. In Proceedings of the 2016 International Conference on Advanced Cloud and Big Data (CBD), Chengdu, China, 13–16 August 2016; pp. 31–36. [Google Scholar]
- Jiang, H.; Liu, Z. Parallel FP-Like Algorithm with Spark. In Proceedings of the 2015 IEEE 12th International Conference on e-Business Engineering, Beijing, China, 23–25 October 2015; pp. 145–148. [Google Scholar]
- Jin, F.; Zhang, F.; Du, Z.H.; Liu, R.; Li, R.Y. Spatial overlay analysis of land use vector data based on Spark. J. Zhejiang Univ. 2016, 43, 40–44. [Google Scholar]
- Xie, X.L.; Xiong, Z.; Hu, X.; Zhou, G.Q.; Ni, J.S. On Massive Spatial Data Retrieval Based on Spark. In Web-Age Information Management, Proceedings of the WAIM 2014 International Conference on Web-Age Information Management, Macau, China, 16–18 June 2014; Chen, Y.G., Balke, W.T., Xu, J.L., Xu, W., Jin, P.Q., Lin, X., Tang, T., Hwang, E.J., Eds.; Springer: Cham, Switzerland, 2014; pp. 200–208. [Google Scholar]
- Suchanek, F.; Weikum, G. Knowledge harvesting in the big-data era. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 933–938. [Google Scholar]
- Li, X.Y.; Li, D.R. DBSCAN spatial clustering algorithm and its application in urban planning. Sci. Surv. Mapp. 2005, 30, 51–53. [Google Scholar]
- Nisa, K.K.; Andrianto, H.A.; Mardhiyyah, R. Hotspot clustering using DBSCAN algorithm and shiny web framework. In Proceedings of the 2014 International Conference on Advanced Computer Science and Information System, Jakarta, Indonesia, 18–19 October 2014; pp. 129–132. [Google Scholar]
- Çelik, M.; Dadaşer-Çelik, F.; Dokuz, A.S. Anomaly detection in temperature data using DBSCAN algorithm. In Proceedings of the 2011 International Symposium on Innovations in Intelligent Systems and Applications, Istanbul, Turkey, 15–18 June 2011; pp. 91–95. [Google Scholar]
- Silva, T.L.C.D.; Neto, A.C.A.; Magalhaes, R.P.; Farias, V.A.E.D.; Macêdo, J.A.F.D.; Machado, J.C. Efficient and distributed DBScan algorithm using mapreduce to detect density areas on traffic data. In Proceedings of the 16th International Conference on Enterprise Information Systems, Lisbon, Portugal, 27–30 April 2014; pp. 52–59. [Google Scholar]
- Adiba, M.E.; Lindsay, B.G. Database Snapshots. In Proceedings of the Sixth International Conference on Very Large Data Bases, Montreal, QC, Canada, 1–3 October 1980; pp. 86–91. [Google Scholar]
- Wang, W.; Tao, L.; Gao, C.; Wang, B.F.; Yang, H.; Zhang, Z.A. C-DBSCAN Algorithm for Determining Bus-Stop Locations Based on Taxi GPS Data. In Proceedings of the 10th International Conference on Advanced Data Mining and Applications, Guilin, China, 19–21 December 2014; pp. 293–304. [Google Scholar]
- Liu, C.K.; Qin, K.; Kang, C.G. Exploring time-dependent traffic congestion patterns from taxi trajectory data. In Proceedings of the 2015 2nd IEEE International Conference on Spatial Data Mining and Geographical Knowledge Services (ICSDM), Fuzhou, China, 8–10 July 2015; pp. 39–44. [Google Scholar]
- Chen, X.W.; Lu, Z.H.; Jantsch, A.; Chen, S. Speedup analysis of data-parallel applications on Multi-core NoCs. In Proceedings of the IEEE 8th International Conference on ASIC, Changsha, China, 20–23 October 2009; pp. 105–108. [Google Scholar]
- Ieda, H. Development and management of transport systems. In Sustainable Urban Transport in an Asian Context; Springer: Tokyo, Japan, 2010; pp. 277–335. [Google Scholar]
- Yin, L. The Analysis of Our Urban Transportation Problem and the Research of Road Construction &map Planning Management. In Proceedings of the 2010 International Conference on E-Product E-Service and E-Entertainment, Henan, China, 7–9 November 2010; pp. 1–4. [Google Scholar]
- Shao, Y.; Song, J.H. Traffic Congestion Management Strategies and Methods in Large Metropolitan Area: A Case Study in Shenzhen. Urban Transp. China 2010, 8. [Google Scholar] [CrossRef]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dada Scale | Neighborhood Query Time (T1/s) | Data Reading and Writing Time (T2/s) | Total Running Time (Ts/s) | T1/Ts |
|---|---|---|---|---|
| 10 K | 32.97 | 3.66 | 36.63 | 90.01% |
| 20 K | 128.66 | 13.44 | 142.10 | 90.54% |
| 40 K | 518.15 | 52.25 | 570.40 | 90.84% |
| val data = sc.textFile(src) val parsedData = data.map(s => Vectors .dense(s.split(' ') .map(_.toDouble))) .cache() //RDD conversion is performed by various operators … //The reused boundary area object variables in the clustering process val borderPoint = partitions.map(lambda (key, value): ((key, 0), value)) … |
| val data = sc.textFile(src) val parsedData = data.map(s => Vectors .dense(s.split(' ') .map(_.toDouble))) .cache() // RDD conversion is performed by various operators … //The reused boundary area object variables in the clustering process val borderPoint = partitions.map(lambda (key, value): ((key, 0), value)) //Introduce the broadcast variables val borderShare = vectors.context.broadcast(borderPoint) … |
| // Import the Serialization classes import com.esotericsoftware.kryo.Kryo import org.apache.spark.serializer.KryoRegistrator // Customized serialization classes class MyRegistrator extends KryoRegistrator{ override def registerClasses(kyro: Kyro){ kryo.register(classOf[MyClass1]) kryo.register(classOf[MyClass2]) } } // Codes of the main function object DBSCANApp{ val log = LoggerFactory.getLogger(DBSCANApp.getClass) def main(args: Array[String]) { // Initialize the spark configuration information val conf = new SparkConf().setAppName(s"DBSCANApp(eps=$eps, minPts=$minPts) -> $Output") // Set the serialization class conf.set(“spark.serializer”,” org.apache.spark.serializer.KryoSerializer”) // Introduce the customized serialization classes conf.set(“spark.kryo.registrator”, ”DBSCAN.MyRegistrator ”) val sc = new SparkContext(conf) … } |
| } |
| Tuning Parameters | Function |
|---|---|
| num-executors | Set the specified number of Executor processes to execute the Spark job |
| executor-memory | Set the memory for each Executor process |
| executor-cores | Set the number of CPU cores for each Executor process |
| driver-memory | Set the memory of driver process |
| spark.default.parallelism | Set the number of default tasks |
| spark.storage.memoryFraction | Configure the amount of space used for caching in RDD, which defaults to 0.67 |
| spark.shuffle.memoryFraction | Configure Executor memory scale in shuffle process, which defaults to 0.2 |
| Platform Name | Hardware Configuration | Installed Software | Computing Nodes |
|---|---|---|---|
| Single-node platform | Processors: Intel(R) Xeon(R) E5-2650 v2 @2.60GHz | CentOS 7.0 | 1 |
| Cores: 8 | Spark 1.6.0 | ||
| Memory size: 64G | Java 1.8.0 | ||
| Cache size: 20480KB | Scala 2.10.4 | ||
| Virtual Spark cluster | Processors: Intel(R) Xeon(R) E5-2650 v2 @ 2.60GHz | CentOS 7.0 | 4 virtual node from 1 physical node with Docker software |
| Spark 1.6.0 | |||
| Cores: 8 | Docker 1.8.0 | ||
| Memory size: 64G | Scala 2.10.4 | ||
| Cache size: 20480KB | Java 1.8.0 | ||
| Physical Spark Cluster | Processors: Intel(R) Xeon(R) E5-2650 v2 @2.60GHz | CentOS 7.0 | 4 |
| Spark 1.6.0 | |||
| Cores: 8 | Hadoop 2.6.0 | ||
| Memory size: 64G | Java 1.8.0 | ||
| Cache size: 20480KB | Scala 2.10.4 |
| Data Scales | Clustering Parameters | Sequential Elapsed Time (s) | Parallel Elapsed Time on Single Node Spark Platform (s) |
|---|---|---|---|
| 10 K | (15, 90) | 36.63 | 12.98 |
| 20 K | (15, 90) | 144.10 | 29.89 |
| 40 K | (15, 90) | 570.40 | 78.68 |
| 80 K | (15, 90) | 2281.87 | 273.93 |
| 100 K | (15, 90) | 3815.95 | 453.74 |
| Data Scales | Elapsed Time of the Serial Processing (s) | Elapsed Time of the Parallel Algorithm before Optimization (s) | Elapsed Time of the Parallel Algorithm after Optimization (s) |
|---|---|---|---|
| 10 K | 36.63 | 12.98 | 7.55 |
| 20 K | 144.10 | 29.89 | 15.92 |
| 40 K | 570.40 | 78.68 | 43.12 |
| 80 K | 2281.87 | 273.93 | 166.56 |
| 100 K | 3815.95 | 453.74 | 274.53 |
| Virtual Nodes | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Data Scales | |||||
| 10 K | 7.55 | 15.38 | 16.22 | 17.87 | |
| 20 K | 15.92 | 24.73 | 24.85 | 25.25 | |
| 40 K | 43.12 | 61.46 | 59.27 | 58.00 | |
| 80 K | 166.56 | 190.28 | 188.52 | 186.32 | |
| 100 K | 274.53 | 360.24 | 358.24 | 366.48 | |
| Car No. | Time | ID | wd | Status | v | Angle |
|---|---|---|---|---|---|---|
| YB000H6 | 2011/04/18 00:07:53 | 114.118347 | 22.574850 | 0 | 0 | 0 |
| YB000H6 | 2011/04/18 00:08:01 | 114.118347 | 22.574850 | 0 | 0 | 0 |
| YB000H6 | 2011/04/18 00:08:03 | 114.118347 | 22.574850 | 0 | 2 | 0 |
| YB000H6 | 2011/04/18 00:08:33 | 114.118301 | 22.574301 | 0 | 25 | 4 |
| YB000H6 | 2011/04/18 00:08:39 | 114.118286 | 22.573967 | 0 | 22 | 3 |
| …… | …… | …… | …… | …… | …… | …… |
| Car No. | Time | ID | wd | Status | Velocity | Angle |
|---|---|---|---|---|---|---|
| YB000H6 | 2011/04/18 07:59:52 | 114.150284 | 22.591333 | 0 | 0 | 4 |
| YB000H6 | 2011/04/18 08:04:52 | 114.118301 | 22.589149 | 0 | 16 | 5 |
| YB000H6 | 2011/04/18 08:05:22 | 114.149269 | 22.588949 | 0 | 10 | 5 |
| YB000H6 | 2011/04/18 08:06:22 | 114.149284 | 22.588949 | 0 | 0 | 5 |
| …… | …… | …… | …… | …… | …… | …… |
| Car No. | Longitude | Latitude |
|---|---|---|
| YB000H6 | 114.150284 | 22.591333 |
| YB000H6 | 114.118301 | 22.589149 |
| YB000H6 | 114.149269 | 22.588949 |
| YB000H6 | 114.149284 | 22.588949 |
| YB000H6 | 114.135834 | 22.578899 |
| YB000H6 | 114.115616 | 22.602633 |
| …… | …… | …… |
| Longitude | Latitude | Subordinated Clustering No. |
|---|---|---|
| 114.150284 | 22.591333 | 1 |
| 114.118301 | 22.589149 | 1 |
| 114.149269 | 22.588949 | 1 |
| 114.149284 | 22.588949 | 1 |
| 114.135834 | 22.578899 | 2 |
| 114.115616 | 22.602633 | 0 (noise point) |
| …… | …… | …… |
| Area No. | Longitude | Latitude | Congested Urban Sections |
|---|---|---|---|
| 1 | 114.115838 | 22.585331 | Bujiguan |
| 2 | 114.163884 | 22.605763 | Shawangguan |
| 3 | 113.910531 | 22.552058 | Nantouguan |
| 4 | 114.092502 | 22.55025 | Huaqiangbei Road |
| 5 | 114.132781 | 22.560929 | Dongmenzhong Road |
| 6 | 114.094852 | 22.618864 | Qingshuiqiao |
| 7 | 113.990657 | 22.540561 | Shennan Rd., Huaqiaocheng |
| 8 | 114.243162 | 22.599692 | Shenyan Rd., Yantianganqu |
| 9 | 114.344448 | 22.601422 | YanbaRd., Expressway Entrance |
| 10 | 114.125419 | 22.605532 | Buji Road |
| 11 | 114.289037 | 22.748603 | Shenhui Road |
| 12 | 114.066885 | 22.611871 | Bantian Wuhe Ave. |
| 13 | 114.202285 | 22.558944 | Luosha Rd. |
| 14 | 113.910531 | 22.552058 | #107 National Highway |
| Data Scale | Processing Platform | Selected Algorithm | Elapsed Time (h) |
|---|---|---|---|
| 4000 K (1054 MB) | Single node | Serial DBSCAN Algorithm | Out of memory |
| Spark cluster | Parallel DBSCAN Algorithm based on Spark | 2.2 | |
| 2000 K (500 MB) | Single node | Serial DBSCAN Algorithm | 13 |
| Spark cluster | Parallel DBSCAN Algorithm based on Spark | 0.4 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, F.; Zhu, Q.; Zhou, J.; Tao, J.; Zhou, X.; Jin, D.; Tan, X.; Wang, L. Research on the Parallelization of the DBSCAN Clustering Algorithm for Spatial Data Mining Based on the Spark Platform. Remote Sens. 2017, 9, 1301. https://doi.org/10.3390/rs9121301
Huang F, Zhu Q, Zhou J, Tao J, Zhou X, Jin D, Tan X, Wang L. Research on the Parallelization of the DBSCAN Clustering Algorithm for Spatial Data Mining Based on the Spark Platform. Remote Sensing. 2017; 9(12):1301. https://doi.org/10.3390/rs9121301
Chicago/Turabian StyleHuang, Fang, Qiang Zhu, Ji Zhou, Jian Tao, Xiaocheng Zhou, Du Jin, Xicheng Tan, and Lizhe Wang. 2017. "Research on the Parallelization of the DBSCAN Clustering Algorithm for Spatial Data Mining Based on the Spark Platform" Remote Sensing 9, no. 12: 1301. https://doi.org/10.3390/rs9121301
APA StyleHuang, F., Zhu, Q., Zhou, J., Tao, J., Zhou, X., Jin, D., Tan, X., & Wang, L. (2017). Research on the Parallelization of the DBSCAN Clustering Algorithm for Spatial Data Mining Based on the Spark Platform. Remote Sensing, 9(12), 1301. https://doi.org/10.3390/rs9121301