An End-to-End Image-Based Automatic Food Energy Estimation Technique Based on Learned Energy Distribution Images: Protocol and Methodology


Abstract
:1. Introduction
2. Methods
2.1. Image-to-Energy Data Set
2.2. Generative Adversarial Networks (GAN)
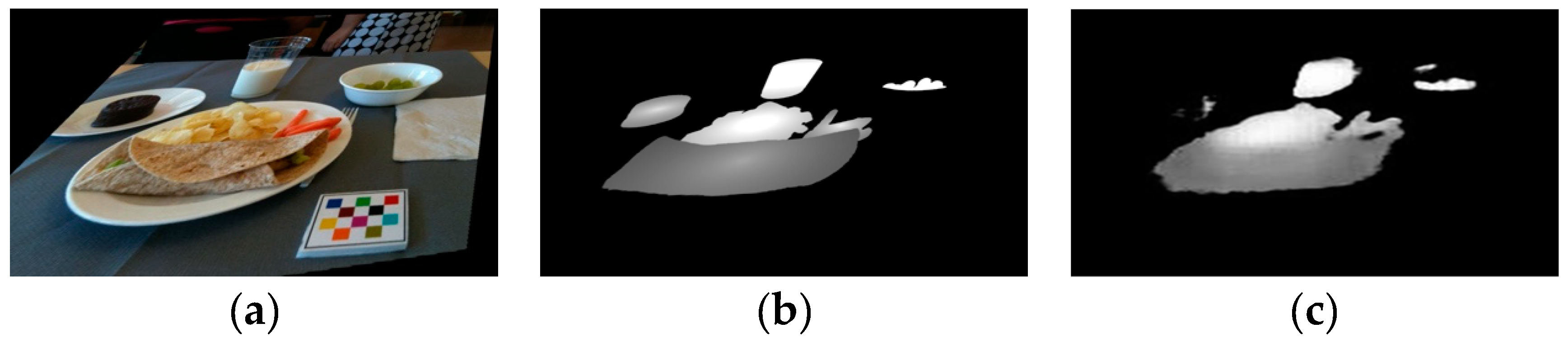
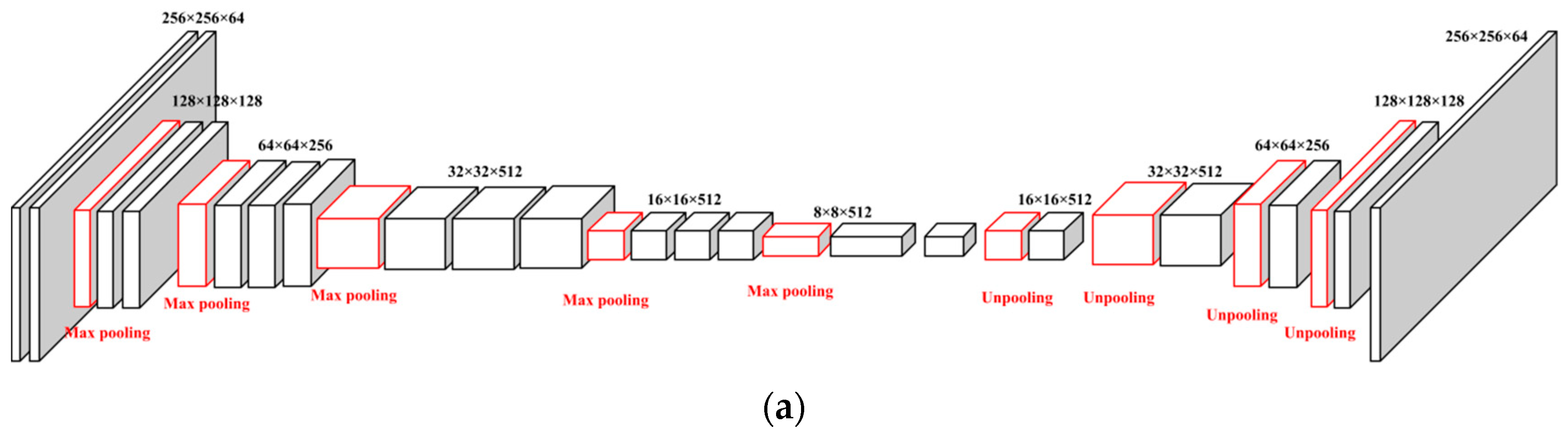
2.3. The Use of Conditional GAN (cGAN) for Image Mappings
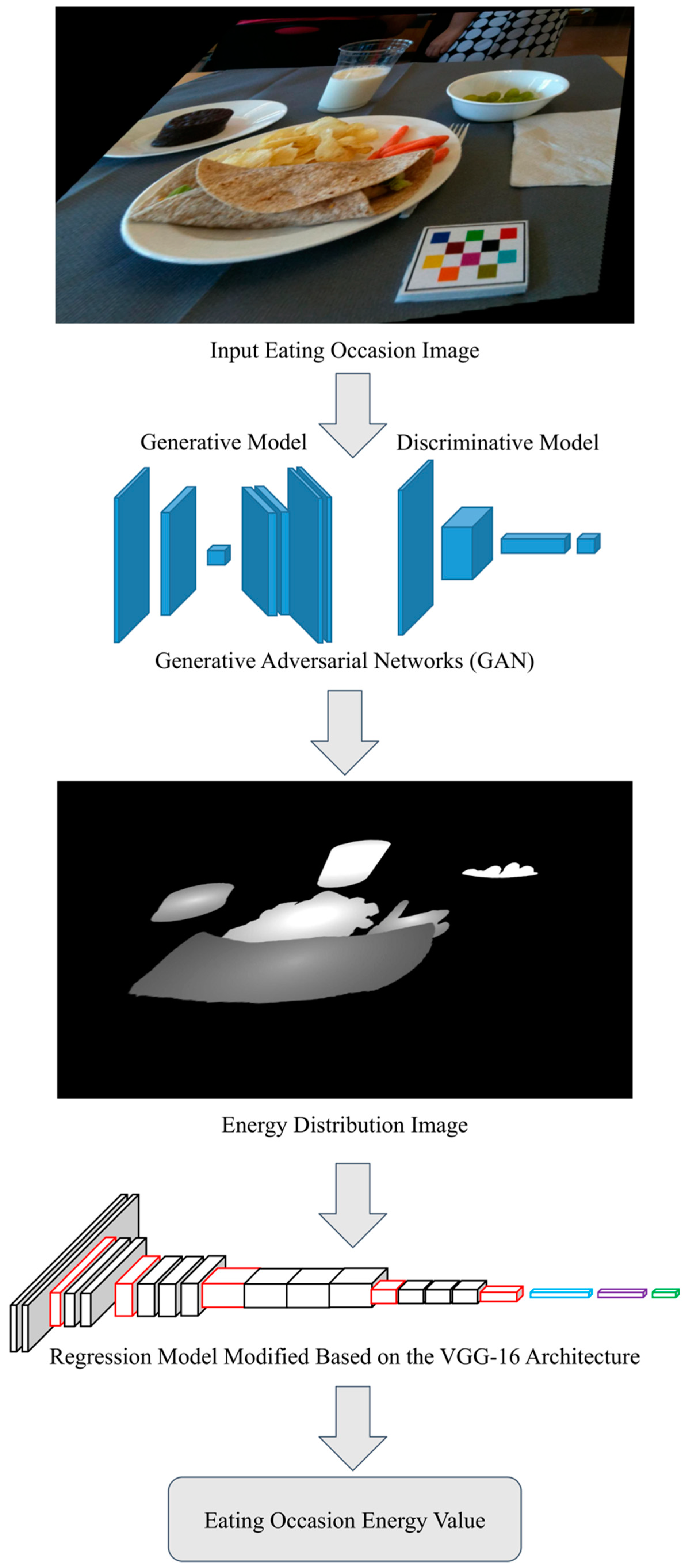
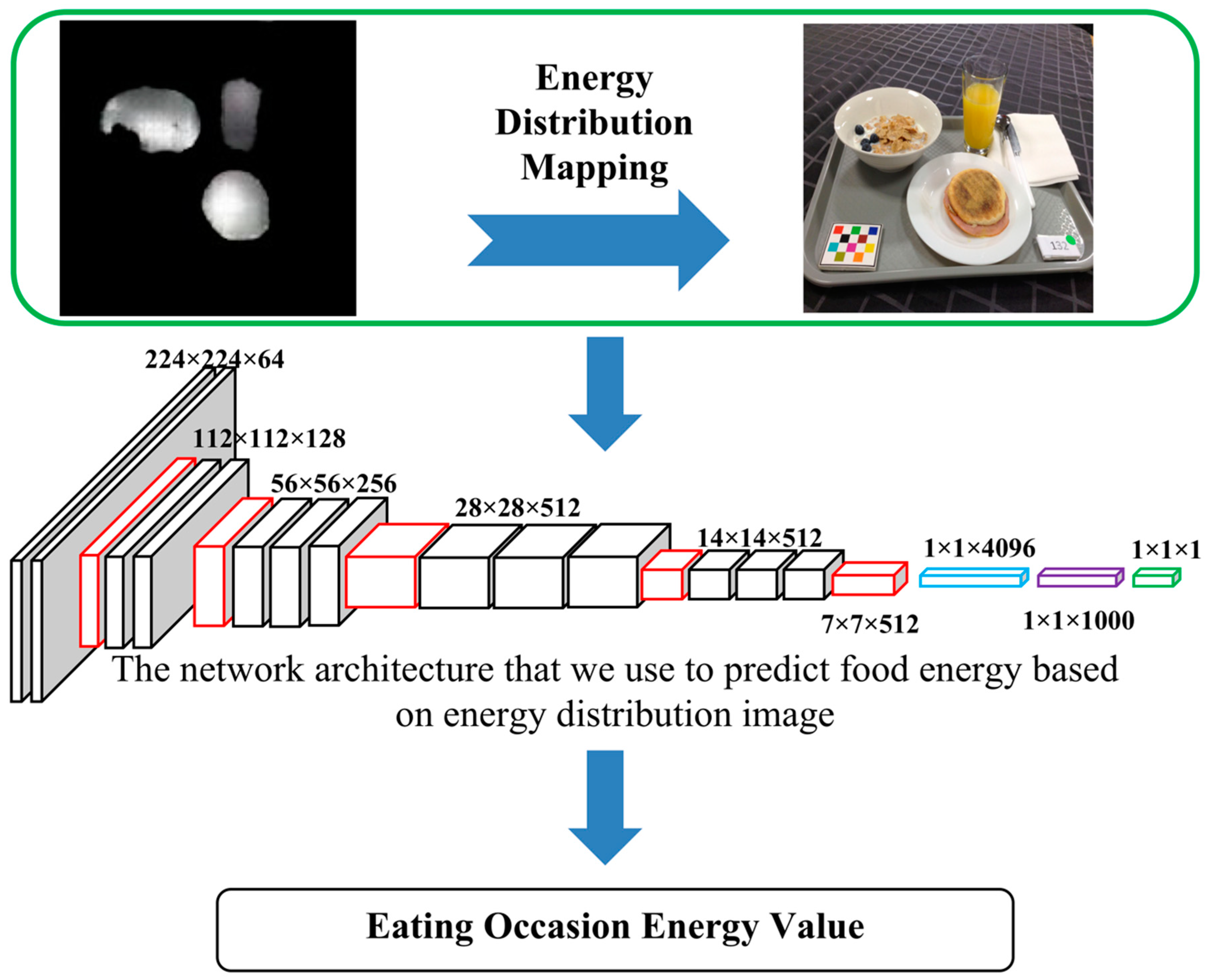
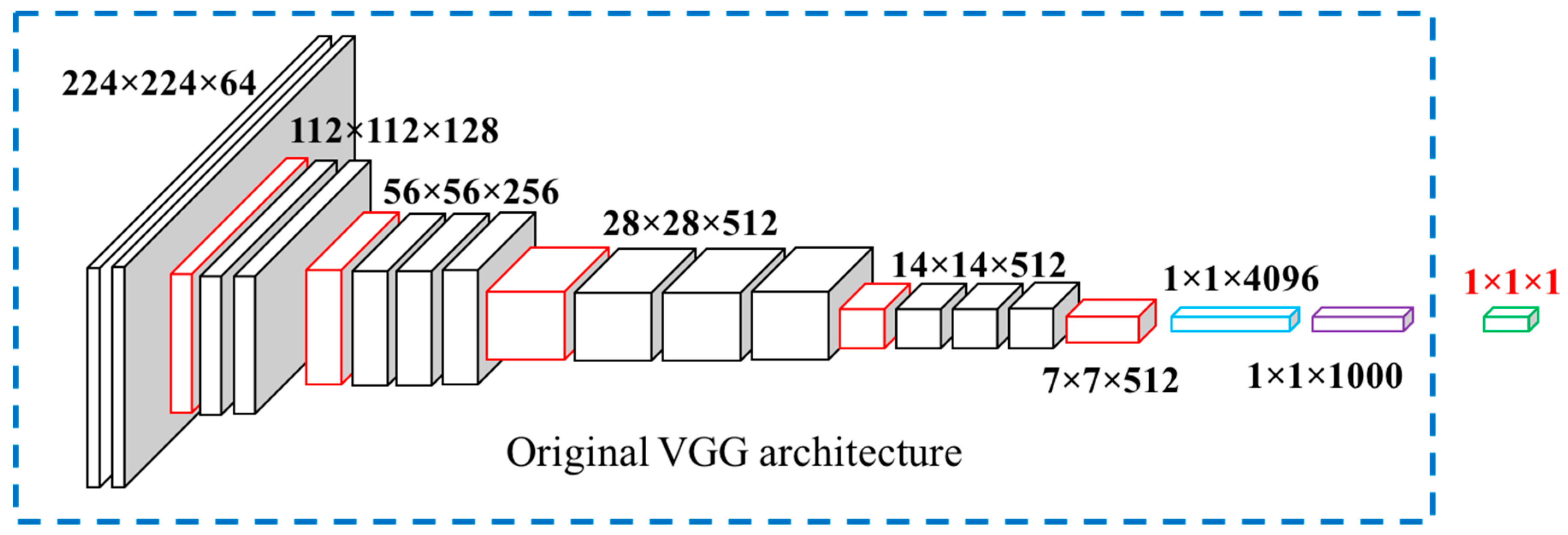
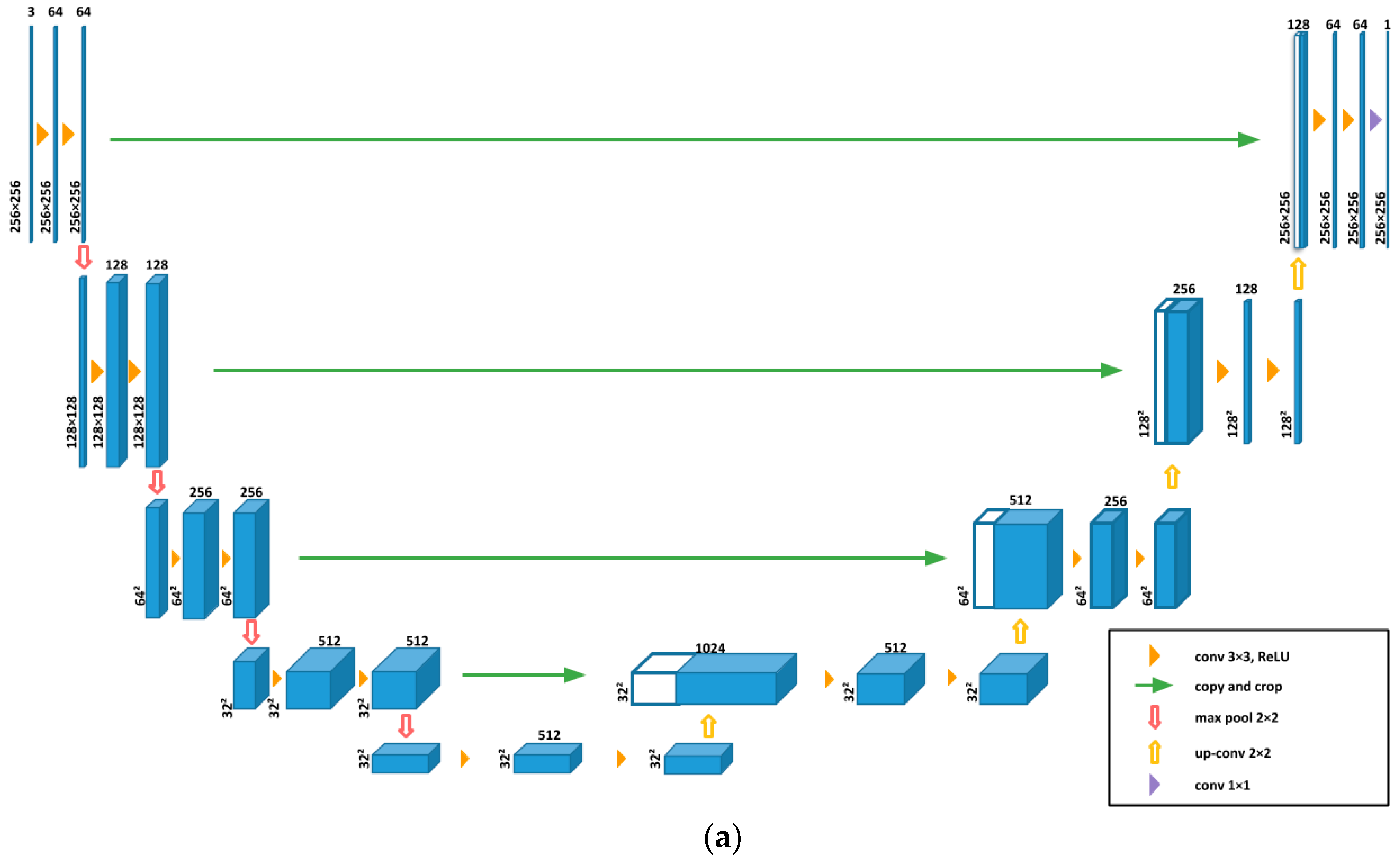
2.4. Food Energy Estimation Based on Energy Distribution Images
3. Experimental Results
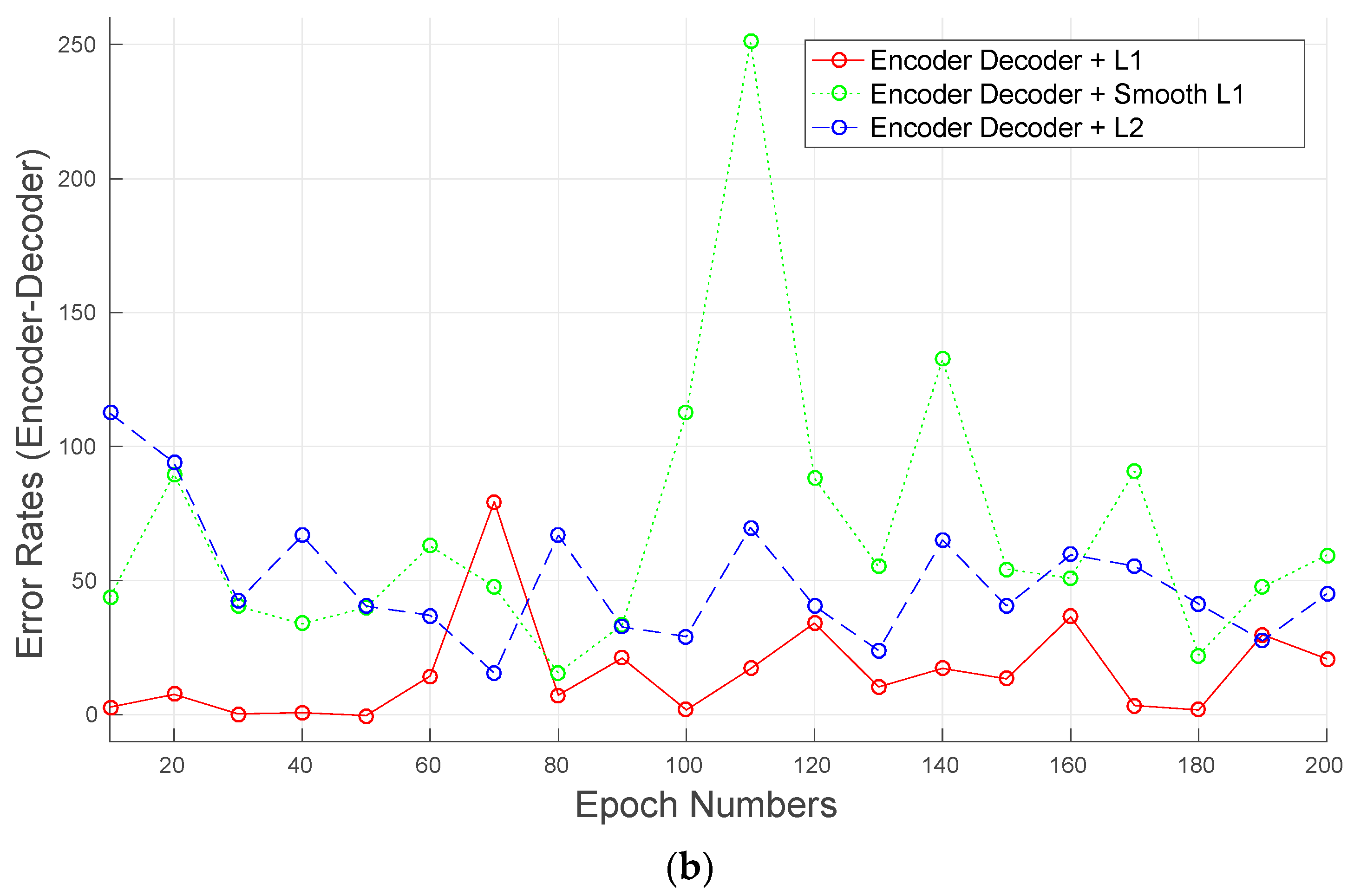
3.1. Learning Image-to-Energy Mappings
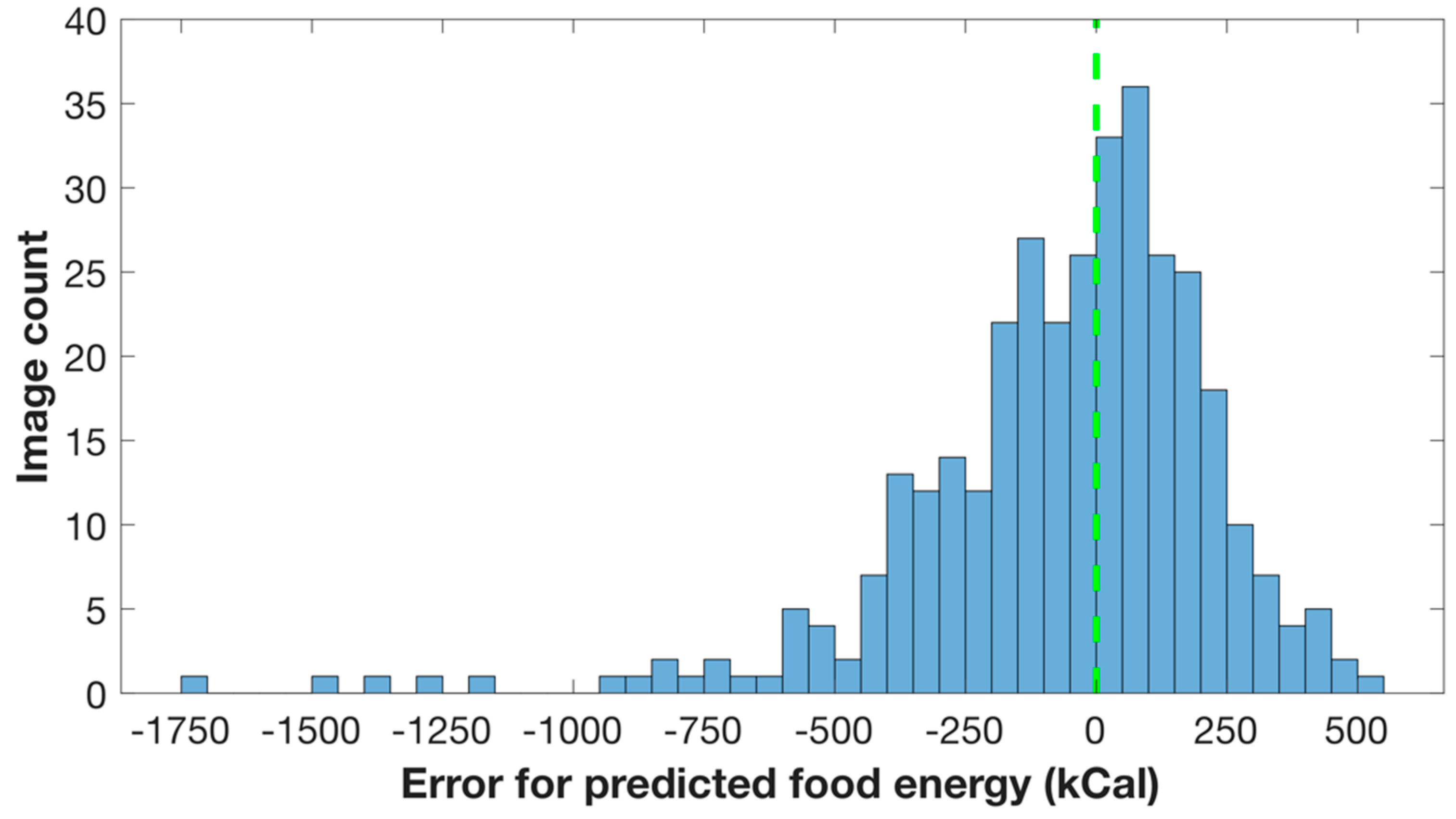
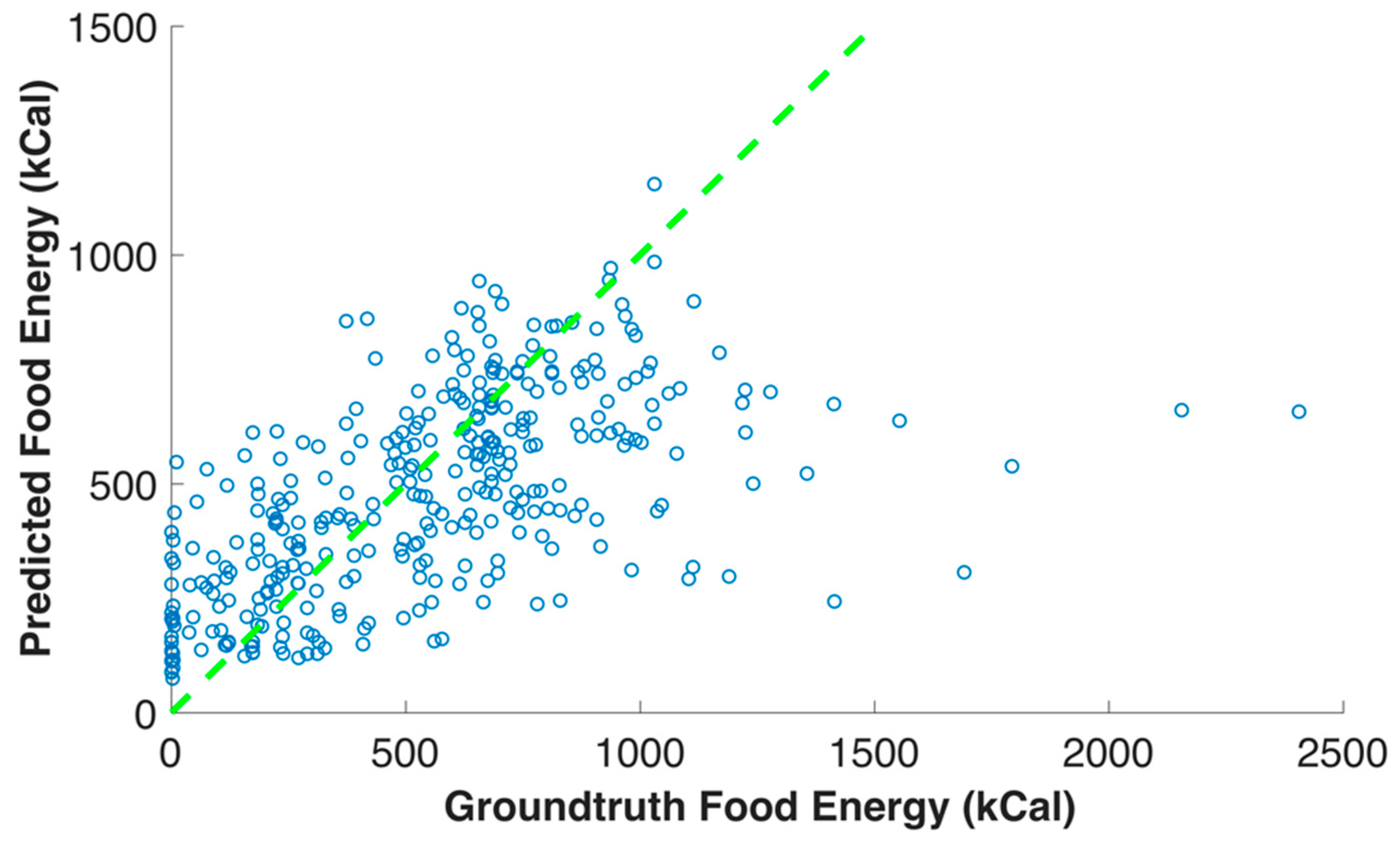
3.2. Food Energy Estimation Based on Energy Distribution Images
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liese, A.D.; Krebs-Smith, S.M.; Subar, A.F.; George, S.M.; Harmon, B.E.; Neuhouser, M.L.; Boushey, C.J.; Schap, T.E.; Reedy, J. The Dietary Patterns Methods Project: Synthesis of Findings across Cohorts and Relevance to Dietary Guidance. J. Nutr. 2015, 145, 393–402. [Google Scholar] [CrossRef] [PubMed]
- Harmon, B.E.; Boushey, C.J.; Shvetsov, Y.B.; Reynolette Ettienne, J.R.; Wilkens, L.R.; Marchand, L.L.; Henderson, B.E.; Kolonel, L.N. Associations of key diet-quality indexes with mortality in the Multiethnic Cohort: The Dietary Patterns Methods Project. Am. J. Clin. Nutr. 2015, 587–597. [Google Scholar] [CrossRef] [PubMed]
- Boushey, C.J.; Spoden, M.; Zhu, F.M.; Delp, E.J.; Kerr, D.A. New mobile methods for dietary assessment: Review of image-assisted and image-based dietary assessment methods. Proc. Nutr. Soc. 2017, 76, 283–294. [Google Scholar] [CrossRef] [PubMed]
- Six, B.; Schap, T.; Zhu, F.; Mariappan, A.; Bosch, M.; Delp, E.; Ebert, D.; Kerr, D.; Boushey, C. Evidence-based development of a mobile telephone food record. J. Am. Diet. Assoc. 2010, 110, 74–79. [Google Scholar] [CrossRef] [PubMed]
- Howes, E.; Boushey, C.J.; Kerr, D.A.; Tomayko, E.J.; Cluskey, M. Image-based dietary assessment ability of dietetics students and interns. Nutrients 2017, 9, 114. [Google Scholar] [CrossRef]
- Williamson, D.A.; Allen, R.; Martin, P.D.; Alfonso, A.J.; Gerald, B.; Hunt, A. Comparison of digital photography to weighed and visual estimation of portion sizes. J. Am. Diet. Assoc. 2003, 103, 1139–1145. [Google Scholar] [CrossRef]
- Zhu, F.; Bosch, M.; Woo, I.; Kim, S.; Boushey, C.; Ebert, D.; Delp, E.J. The Use of Mobile Devices in Aiding Dietary Assessment and Evaluation. IEEE J. Sel. Top. Signal Process. 2010, 4, 756–766. [Google Scholar] [CrossRef]
- Zhu, F.; Bosch, M.; Khanna, N.; Boushey, C.; Delp, E. Multiple Hypotheses Image Segmentation and Classification with Application to Dietary Assessment. IEEE J. Biomed. Health Inform. 2015, 19, 377–388. [Google Scholar] [CrossRef]
- Kitamura, K.; Yamasaki, T.; Aizawa, K. FoodLog: Capture, Analysis and Retrieval of Personal Food Images via Web. In Proceedings of the ACM Multimedia Workshop on Multimedia for Cooking and Eating Activities, Beijing, China, 23 October 2009; pp. 23–30. [Google Scholar]
- Joutou, T.; Yanai, K. A Food Image Recognition System with Multiple Kernel Learning. In Proceedings of the IEEE International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; pp. 285–288. [Google Scholar]
- Kong, F.; Tan, J. DietCam: Automatic dietary assessment with mobile camera phones. Pervasive Mob. Comput. 2012, 8, 147–163. [Google Scholar] [CrossRef]
- Meyers, A.; Johnston, N.; Rathod, V.; Korattikara, A.; Gorban, A.; Silberman, N.; Guadarrama, S.; Papandreou, G.; Huang, J.; Murphy, K.P. Im2Calories: Towards an Automated Mobile Vision Food Diary. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1233–1241. [Google Scholar]
- Chen, H.; Jia, W.; Li, Z.; Sun, Y.; Sun, M. 3D/2D model-to-image registration for quantitative dietary assessment. In Proceedings of the IEEE Annual Northeast Bioengineering Conference, Philadelphia, PA, USA, 16–18 March 2012; pp. 95–96. [Google Scholar]
- Pouladzadeh, P.; Shirmohammadi, S.; Almaghrabi, R. Measuring Calorie and Nutrition from Food Image. IEEE Trans. Instrum. Meas. 2014, 63, 1947–1956. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, Q.; Siddiquie, B.; Divakaran, A.; Sawhney, H. Snap-n-Eat Food Recognition and Nutrition Estimation on a Smartphone. J. Diabetes Sci. Technol. 2015, 9, 525–533. [Google Scholar] [CrossRef]
- Aizawa, K.; Maruyama, Y.; Li, H.; Morikawa, C. Food Balance Estimation by Using Personal Dietary Tendencies in a Multimedia Food Log. IEEE Trans. Multimed. 2013, 15, 2176–2185. [Google Scholar] [CrossRef]
- Fang, S.; Liu, C.; Zhu, F.; Delp, E.; Boushey, C. Single-View Food Portion Estimation Based on Geometric Models. In Proceedings of the IEEE International Symposium on Multimedia, Miami, FL, USA, 14–16 December 2015; pp. 385–390. [Google Scholar]
- Fang, S.; Zhu, F.; Jiang, C.; Zhang, S.; Boushey, C.; Delp, E. A Comparison of Food Portion Size Estimation Using Geometric Models and Depth Images. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 26–30. [Google Scholar]
- Fang, S.; Zhu, F.; Boushey, C.; Delp, E. The use of co-occurrence patterns in single image based food portion estimation. In Proceedings of the IEEE Global Conference on Signal and Information Processing, Montreal, QC, Canada, 14–16 November 2017; pp. 462–466. [Google Scholar]
- USDA Food and Nutrient Database for Dietary Studies, 1.0; Agricultural Research Service, Food Surveys Research Group: Beltsville, MD, USA, 2004.
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Wang, T.; Liu, M.; Zhu, J.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. arXiv 2017, arXiv:1711.11585. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Silberman, N.; Kohli, P.; Hoiem, D.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Ege, T.; Yanai, K. Image-Based Food Calorie Estimation Using Knowledge on Food Categories, Ingredients and Cooking Directions. In Proceedings of the Workshops of ACM Multimedia on Thematic, Mountain View, CA, USA, 23–27 October 2017; pp. 367–375. [Google Scholar]
- Abdulnabi, A.H.; Wang, G.; Lu, J.; Jia, K. Multi-Task CNN Model for Attribute Prediction. IEEE Trans. Multimed. 2015, 17, 1949–1959. [Google Scholar] [CrossRef]
- Fang, S.; Shao, Z.; Mao, R.; Fu, C.; Delp, E.J.; Zhu, F.; Kerr, D.A.; Boushey, C.J. Single-view food portion estimation: Learning image-to-energy mappings using generative adversarial networks. In Proceedings of the IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 251–255. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Boushey, C.J.; Spoden, M.; Delp, E.J.; Zhu, F.; Bosch, M.; Ahmad, Z.; Shvetsov, Y.B.; DeLany, J.P.; Kerr, D.A. Reported energy intake accuracy compared to doubly labeled water and usability of the mobile food record among community dwelling adults. Nutrients 2017, 9, 312. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Liu, M.; Breuel, T.; Kautz, J. Unsupervised Image-to-Image Translation Networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Xu, C.; He, Y.; Khanna, N.; Boushey, C.J.; Delp, E.J. Model-based food volume estimation using 3D pose. In Proceedings of the IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 2534–2538. [Google Scholar]
- Xu, C.; Zhu, F.; Khanna, N.; Boushey, C.J.; Delp, E.J. Image enhancement and quality measures for dietary assessment using mobile devices. In Proceedings of the SPIE 8296, Computational Imaging X, Burlingame, CA, USA, 22–26 January 2012. [Google Scholar]
- Hartley, R.I.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 231–241. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Breakfast | Lunch | Dinner |
|---|---|---|
| Bagel | Apple | Apple |
| Banana | Bagel | Banana |
| English muffin | Carrot | Broccoli |
| Grape | Celery | Celery |
| Margarine | Cherry | Cherry |
| Mayonnaise | Chicken wrap | Doritos |
| Milk | Chocolate chip | Fruit cocktail |
| Orange | Ding Dong | Garlic bread |
| Orange juice | Doritos | Garlic toast |
| Pancake | Grape | Grape |
| Peanut butter | Ham sandwich | Lasagna |
| Ranch dressing | Mashed potato | Margarine |
| Saltines | Mayonnaise | Mashed potato |
| Sausage | Milk | Mayonnaise |
| Strawberry | Mustard | Milk |
| Syrup | No fat dressing | Muffin |
| Water | Noodle soup | Orange |
| Wheaties | Peas | Peas |
| Yogurt | Pizza | Ranch dressing |
| Potato | Rice crispy bar | |
| Potato chip | Salad mix | |
| Ranch dressing | Strawberry | |
| Salad mix | String cheese | |
| Saltines | Tomato | |
| Snicker doodle | Water | |
| Strawberry | Watermelon | |
| String cheese | Wheat bread | |
| Tea | Yogurt | |
| Tomato | ||
| Water | ||
| Watermelon | ||
| Yogurt |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, S.; Shao, Z.; Kerr, D.A.; Boushey, C.J.; Zhu, F. An End-to-End Image-Based Automatic Food Energy Estimation Technique Based on Learned Energy Distribution Images: Protocol and Methodology. Nutrients 2019, 11, 877. https://doi.org/10.3390/nu11040877
Fang S, Shao Z, Kerr DA, Boushey CJ, Zhu F. An End-to-End Image-Based Automatic Food Energy Estimation Technique Based on Learned Energy Distribution Images: Protocol and Methodology. Nutrients. 2019; 11(4):877. https://doi.org/10.3390/nu11040877
Chicago/Turabian StyleFang, Shaobo, Zeman Shao, Deborah A. Kerr, Carol J. Boushey, and Fengqing Zhu. 2019. "An End-to-End Image-Based Automatic Food Energy Estimation Technique Based on Learned Energy Distribution Images: Protocol and Methodology" Nutrients 11, no. 4: 877. https://doi.org/10.3390/nu11040877
APA StyleFang, S., Shao, Z., Kerr, D. A., Boushey, C. J., & Zhu, F. (2019). An End-to-End Image-Based Automatic Food Energy Estimation Technique Based on Learned Energy Distribution Images: Protocol and Methodology. Nutrients, 11(4), 877. https://doi.org/10.3390/nu11040877