3.1. Biodiesel Synthesis in a Batch Reactor and Comparison of Analytical Methods
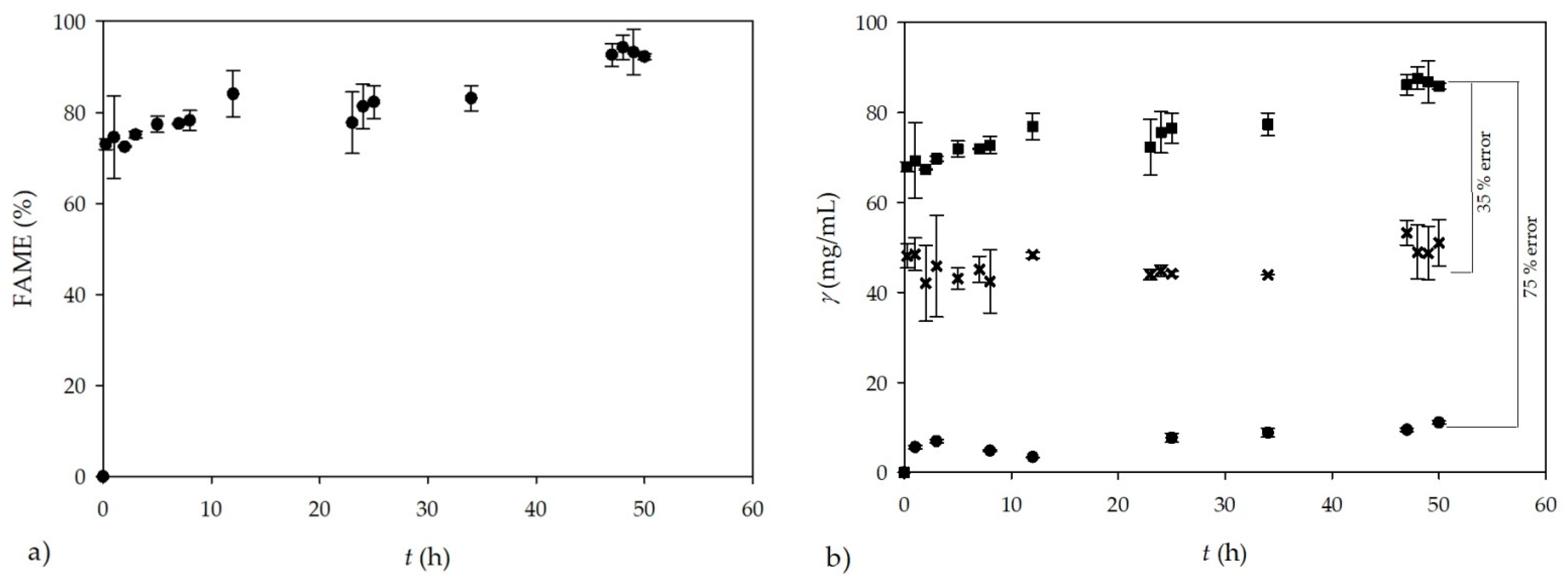
Biodiesel was synthesized in a batch reactor (
V = 250 mL) using sunflower oil and methanol in excess as substrates and the enzyme lipase as the biocatalyst. During the process, the dynamic change of biodiesel yield (% FAME) was monitored and it is presented in
Figure 3a. At the end of the process, successful biodiesel production was performed, resulting in a biodiesel yield of
I = 93 ± 2.5% after 50 h.
Based on the stoichiometry of the reaction and GC measurements of FAME concentration, the theoretical glycerol concentration in collected samples was calculated. The obtained biodiesel yield at the end of the transesterification performed in a batch reactor (
Figure 3a) corresponds to the FAME concentration of
γFAME = 1041.99 ± 1.18 mg/mL, which is consistent with the calculated (theoretical) total glycerol concentration of 93 mg/mL. The obtained results are in accordance with the usual biodiesel production by transesterification, which produce, on average, 1 kg of glycerol per 10 kg of biodiesel. To confirm the theoretical glycerol concentrations calculated based on the GC measurements from FAME, two additional analytical methods were used for
off-line measurement of total glycerol concentration. Usually, the concentration of glycerol produced during biodiesel synthesis by transesterification is monitored by GC and/or UV-VIS spectrophotometric methods, respectively [
9,
10,
16].
Glycerol concentrations obtained by GC and UV-VIS spectrophotometric measurements are shown in
Figure 3b and compared to the calculated theoretical glycerol concentrations. As can be seen from
Figure 3b, the theoretical concentration of total glycerol during the transesterification process was in the range of 70–93 mg/mL. The measurements performed by GC resulted in glycerol concentrations in the range from 45 to 65 mg/mL, which is 35% less than the calculated theoretical value. The reason for this difference is probably the high rate of glycerol precipitation and sedimentation during the collection and preparation of samples for GC analysis, resulting in a significant loss of glycerol in the analyzed sample. The measurements performed by the UV-VIS spectrophotometric method show an even greater deviation (75%) from the theoretical values, as the preparation of samples requires even more steps, resulting in a greater glycerol loss, and consequently leading to greater errors. Based on the presented figures, both
off-line analytical methods were proved to be inadequate for quantifying the total glycerol formed during biodiesel production by transesterification. This was also observed by Gelinski et al. [
34], who reported that the majority of results during glycerol quantification by the UV-VIS method were below the expected level. The main disadvantage of NIR spectroscopy is that it needs to be validated by another technique, which is the basic requirement for NIR spectroscopy to be used independently for measurements in further experiments. In this research, theoretical concentrations of glycerol were used to validate the results of NIR spectroscopy. On the other hand, NIR spectroscopy does not require additional sample preparation, which is the main advantage of this method. Consequently, NIR spectroscopy is less costly and time consuming compared to other analytical methods [
19,
25,
27].
3.2. NIR Spectroscopy for the Measurements of Glycerol Concentration in Model Samples
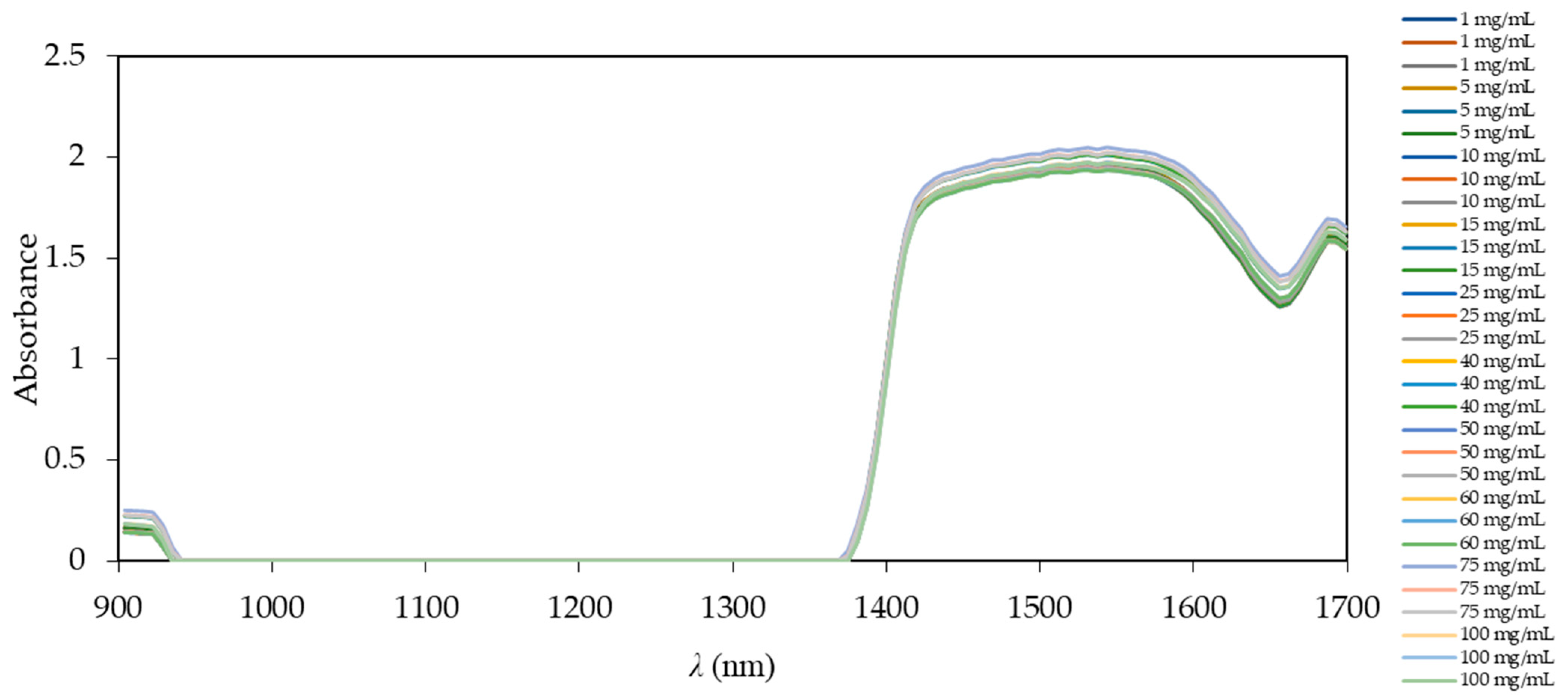
As an alternative to the previously mentioned method, based on calculated theoretical glycerol concentrations, the measurement of glycerol concentration was performed by NIR spectroscopy. The first step was to record the NIR spectra based on the range of different glycerol concentrations. The set of 20 samples performed in triplicate with different glycerol concentrations (model samples) ranging from 0 to 100 mg/mL was prepared to obtain the calibration model for on-line monitoring of biodiesel production by transesterification. Eleven samples performed in triplicate resulting in 33 samples were performed for glycerol concentrations from 0 to 100 mg/mL, and nine samples performed in triplicate resulting in 27 samples were performed for glycerol concentrations from 0 to 0.035 mg/mL.
Model samples were prepared from crude glycerol, diluted in ultra-purified water in the range from 0 to 100 mg/mL. This concentration range was chosen in order to cover all expected glycerol concentrations that could occur during the usual course of the biodiesel production process [
35]. Before NIR measurements, the calibration to dark and light source was performed. The obtained spectra from NIR spectroscopy without any pre-processing for all tested samples are shown in
Figure 4.
Overlapping spectra in
Figure 4 show that there is a region where the spectra do not differ (941–1370 nm), as they are simply different glycerol concentrations in ultra-purified water. The main difference in the spectra can be found in the region below 941 nm and in the region from 1370 to 1700 nm. This region corresponds to the stretching and deformation vibrations of –CH, –CO, and –OH groups present in glycerol. It is also noted that the spectra show significant overlapping and high similarity in shape and intensity. In order to find similarities and differences between samples in this part of the spectrum, further analysis of the main components can be performed without pre-processing of the NIR spectra using the PCA method. This method can reduce a great number of variables (from several hundred to tens) and remove noise [
36]. Nowadays, pre-processing of NIR spectra is commonly used for biodiesel synthesis monitoring using NIR [
34]. Based on our previous experience, the use of pre-processing techniques, such as smoothing, on the first or second derivative can lead to a loss of sometimes vital information [
23,
24]; thus, in this work, we only used raw NIR spectra for further analysis. Factors obtained from PCA analysis of the NIR spectra were further used as inputs for ANNs, in order to monitor
on-line glycerol formation during biodiesel synthesis.
To develop ANNs, it was necessary to select the neural network that could process the obtained data. Even though different ratios for training, test, and validation (50:30:20, 60:20:20, 70:15:15, 70:20:10) were tested on available experimental results, the highest
R2 and the lowest root mean square error (RMSE) was obtained for the 60:20:20 ratio, respectively. In all of the above cases, the data were randomly selected by the software from the obtained theoretical values of glycerol.
Table 1 shows five obtained ANNs (10-13-1, 10-9-1, 10-6-1, 10-8-1, and 10-7-1) and their characteristics. The first number in the network architecture indicates the input of ANN, which, in this case, is the number of factors obtained by the PCA analysis (10), the next number is the number of neurons in the hidden layer, which was set in the range of 6–13, and the last is the number of outputs (glycerol concentration). Based on the
R2 values for training, test, and validation and their errors, the best network was selected. Even though all the proposed neural networks listed in the table have extremely high values, i.e., all values of training accuracy, testing, and validation are greater than 0.9, neural network number 3 was chosen because of the smallest number of neurons in the hidden layer, which provides additional network stability. Furthermore, in the case of the training neural network number 2, and in the case of testing neural networks number 1 and 4, the higher
R2 values are obtained at validation. On the contrary, the selected neural network number 3 has the highest precision value. Moreover, very importantly, this network is characterized by the smallest error.
As mentioned earlier, the 10-6-1 architecture means that there were 10 factors obtained by PCA for the input variables, six neurons were in the hidden layer, and the glycerol concentration was the only output. In this case, the first 10 factors of the PCA analysis, which explained 99% of the variability in the data, were used as inputs for ANN. In this case, ANN that used 60% of the total data for learning, 20% for testing, and 20% for validation, and have 6–13 neurons in the hidden layer, were found to be the most suitable.
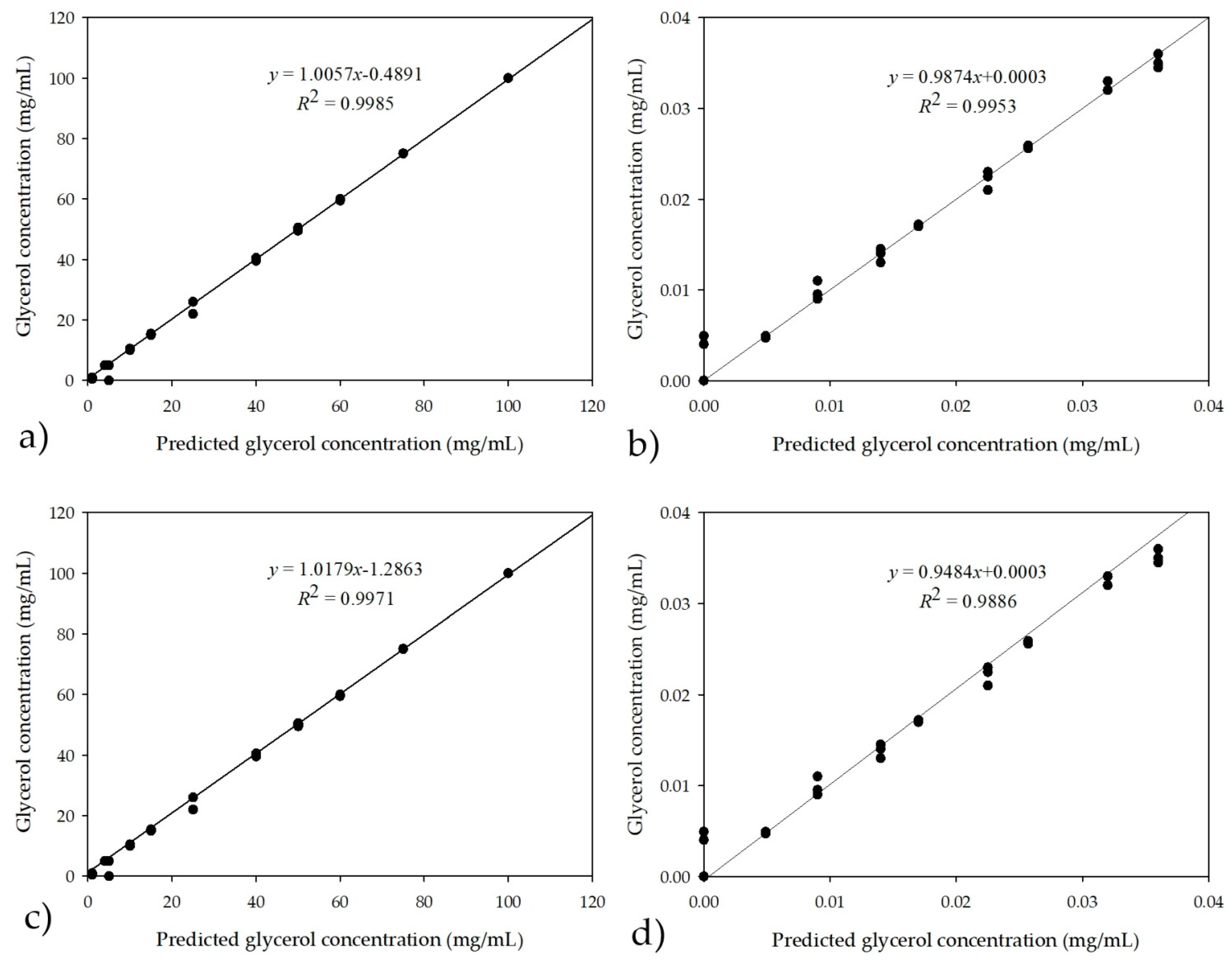
Figure 5a shows the correlation between the prediction of the glycerol concentration using the selected neural network and the experimental values for glycerol concentrations in the model samples ranging from 0 to 100 mg/mL.
To verify that the lower calculated theoretical glycerol concentrations could be determined using an NIR spectrometer, dilutions of the model samples were made and the glycerol concentrations in the samples were in the range of 0–0.03 mg/mL (
Figure 5b). As in the previous case, all concentrations were performed in triplicate and the PCA was performed first from the recorded NIR spectrum data, followed by ANN. The neural networks that had a total data ratio of 60:20:20 randomly selected by the software for training, testing, and validation also performed the best, as was the case of the higher range of glycerol concentrations (0–100 mg/mL). In this case, the neural network which was selected had
R2 values of 0.9996, 0.9974, and 0.9937 for learning, testing, and validation, with errors of 0.0000, 0.0002, and 0.0030, respectively. Because the software randomly selects data for training, testing, and validation based on user-defined ratios, all three samples (triplicates) recorded in a single interval could be used for validation. The main question remains whether this ANN is valid. From
Figure 6a, it is easy to see whether the values of ANN show over-fitting or under-fitting, leading to higher or lower results for the calculated theoretical glycerol. Of course, one must look at the
R2 values and error values to determine if ANN is overtrained or undertrained. When ANN is overtrained, situations such as high
R2 values for training with lowest errors occur, while
R2 values for testing and validation are very low and have high errors. When ANN is undertrained, low
R2 values for training occur with high error values, while high
R2 values for testing or validation are observed with low error values. To avoid selecting triplicate samples from the same time interval by random software generation, one must perform the predictive tests of the ANN model in the Statistica software, with the predictive datasheet showing which samples were used for training, testing, and validation. The other way to avoid this is to use some kind of cross-validation, such as subsampling strategy, for building predictive models. For this purpose, subsampling was performed separately for both ANN (for higher and lower glycerol concentrations) using six neurons in the hidden layer, with the number of subsamples set at five and the subsample in the ratio 60:20:20 using the random subsampling method and the seed for subsampling 1000. In all cases (in this and following cases), the dataset used was exactly the same as for ANNs without subsampling, i.e., the PCA results from the recorded NIR spectra. The results of the five ANNs for the higher glycerol concentrations in terms of
R2 values ranged from 0.9999 to 0.9992 for training, 0.9995 to 0.9926 for testing, and 0.9956 to 0.7500 for validation, with the best results obtained for ANN number 4, which had
R2 values 0.9999, 0.9995, and 0.9956 with errors of 0.0000, 0.0013, and 0.0056 for training, testing, and validation, respectively. For the lower glycerol concentration, five ANNs were identified whose
R2 values ranged from 1.0000 to 0.9526 for training, 0.9982 to 0.8764 for testing, and 0.9968 to 0.2057 for validation, with the best results obtained for ANN, which had
R2 values of 0.9984, 0.9957, and 0.9935 with errors of 0.0000, 0.0000, and 0.0000 for training, testing, and validation, respectively. The results of the subsampling strategy for predicting higher and lower glycerol concentrations are shown in
Figure 5c,d, respectively.
3.3. NIR Spectroscopy for Glycerol Off-Line Monitoring of Real Samples for Experiments Performed in a Batch Reactor
After obtaining a good agreement between the results measured by NIR spectroscopy and the data obtained by prediction of the selected ANN for known glycerol concentrations in model samples, NIR spectroscopy was applied for
off-line analysis of real samples from the biodiesel production process. Biodiesel production was again performed in a batch reactor and the samples were taken out of the reactor at different time intervals. The glycerol concentration was measured in collected samples by GC, UV-VIS spectrophotometry, and NIR spectroscopy by previously described methods. Furthermore, the concentration of FAME was measured in all samples by GC and used to calculate the theoretical glycerol concentration. Triplicate samples were taken at 5 min intervals during the first 60 min and then at 10 min intervals until 90 min with the last samples taken at 120 min, resulting in 51 samples (17 different times × 3 samples per time). Glycerol concentrations obtained by different methods are shown in
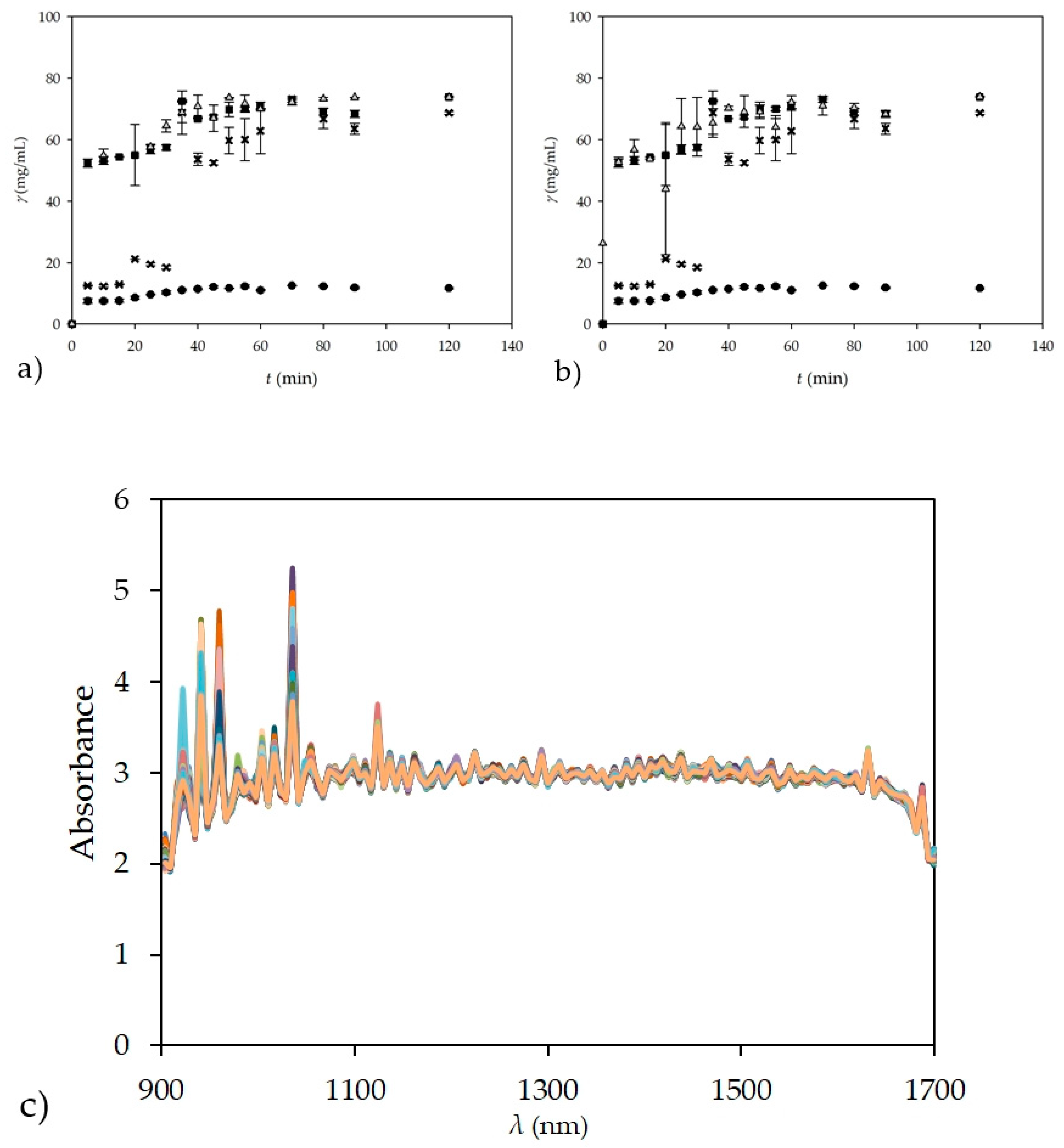
Figure 6a, and the spectra obtained by NIR spectroscopy without pre-processing for all tested samples during the batch experiment are shown in
Figure 6b.
Glycerol concentrations measured by the UV-VIS spectrophotometer again showed the largest deviation from the theoretically calculated glycerol concentration. For measurements performed by GC, the deviations in the glycerol concentration were slightly smaller but still present, probably due to its precipitation and sedimentation during sample preparation and analysis. On the other hand, the glycerol concentrations obtained by NIR spectroscopy coupled with ANN predictions that were performed using theoretical glycerol concentration are practically equal with the calculated theoretical glycerol concentrations; thus, demonstrating the accuracy of the NIR method. For this experiment an ANN model based on calculated theoretical values was performed with the best prediction of experimental values for ANN that had architecture 10-9-1. As in the previous case, the data ratio was 60:20:20, with data randomly selected by software, for training, testing, and validation. R2 values of 0.9733, 0.9482, and 0.9412 were obtained for training, testing, and validation with error values of 0.0059, 0.0203, and 0.0098, respectively. The main reason for the accuracy of the NIR method, among other reasons, is probably the fact that the glycerol concentration was measured directly in the sample, without the need to prepare the sample before the analysis itself.
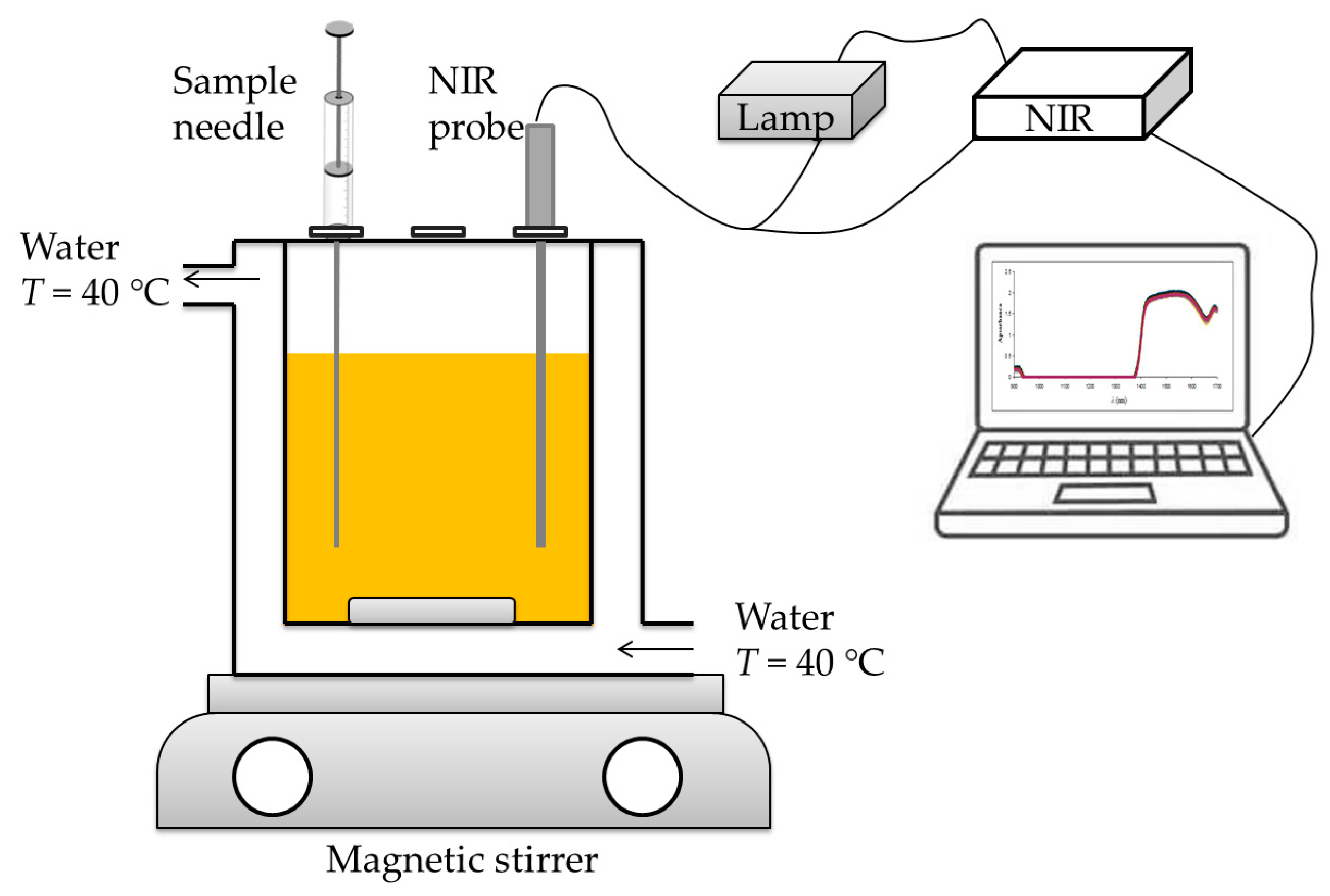
As shown in
Figure 1, an NIR probe was inserted into the reactor for the batch process. From the comparison of
Figure 4 and
Figure 6c, it is clear that the spectra of glycerol in ultra-purified water are significantly different from the spectra obtained in batch measurements. The reason for this is the much more complex system in the batch reactor due to all the components present, such as the edible sunflower oil, methanol, buffer, enzyme, FAME, and glycerol. The replacement of ultra-purified water with vegetable oil adds additional peaks, as does the addition of the enzyme and any other component, resulting in such a difference not only in the 941–1370 nm range, which showed no difference with ultra-purified water, but also in the intensity of the NIR spectra. Some might argue that the spectra might also contain some kind of noise effect, and the best way to deal with noise is to first smooth the spectra to avoid this. However, the goal of this work was to get the best out of the unmodified spectra, i.e., with any additional pre-processing, and thus, test not only the ability of the NIR instrument, but also the ability of the ANN to work with such complex data. In addition, noise could easily affect the ANN, since learning from data with noise sometimes yields high
R2 values for training, but the final result in validation is not as high as the results obtained in this experiment. As in the previous case with different concentration ranges of glycerol concentrations, subsampling of the data was performed for ANN, which, in this case, had nine neurons in the hidden layer, with the number of subsamples set to five, and the size of the subsamples in the ratio 60:20:20 using the random subsampling method and the seed for subsampling 1000. The most suitable network was network number 3, with
R2 values of 0.9785, 0.8968, and 0.8348 with errors having values of 0.0063, 0.0074, and 0.2511 for training, testing, and validation, respectively. These results are shown in
Figure 6b. In this case, it is clear that network selection without cross-validation can lead to better results, as one can select the one with the highest
R2 values from hundreds of different ANNs. This can sometimes be misleading, especially in cases with smaller datasets. In these cases, subsampling can provide much more reliable results; although they may not be as successful in terms of
R2 values, they ensure the right kind of ANN validation.
3.4. On-Line Measurements of the Glycerol Concentration by NIR Spectroscopy in a Batch Reactor and in a Microreactor
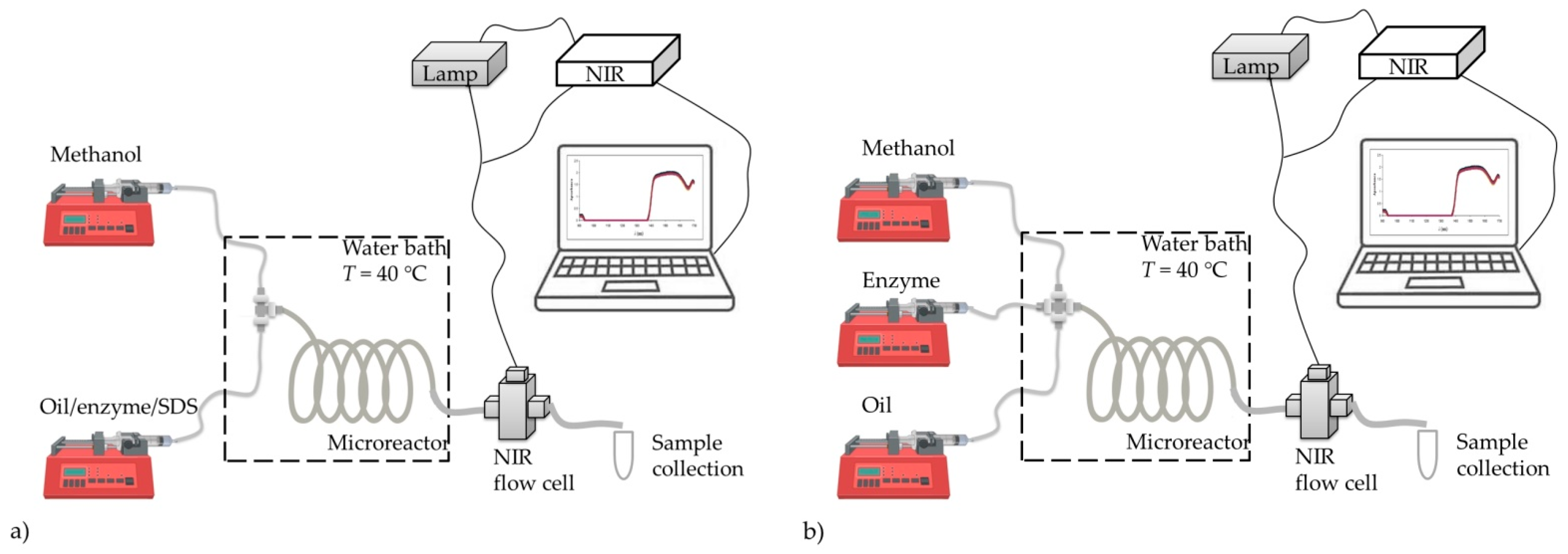
Considering the successfully performed off-line measurements of the glycerol concentration by NIR spectroscopy, on-line measurements of glycerol concentrations in a batch reactor and in a microreactor were performed during the course of the transesterification process. During the batch experiment, the probe was immersed in the reactor throughout the process, and spectra were recorded every five minutes for the first 60 min, followed by 10 min recording intervals up to 90 min, and the last spectra was recorded after 120 min resulting in 51 samples (17 different times × 3 samples per time). In order to prevent outside light interference, the reactor was enveloped with aluminum foil. For the experiment performed in a microreactor, the output stream was connected to the covered flow cell of the NIR spectroscope; thus, preventing any interference of outside light source. As a result, the reaction medium in the outlet stream of the microreactor could be analyzed on-line with NIR spectroscopy.
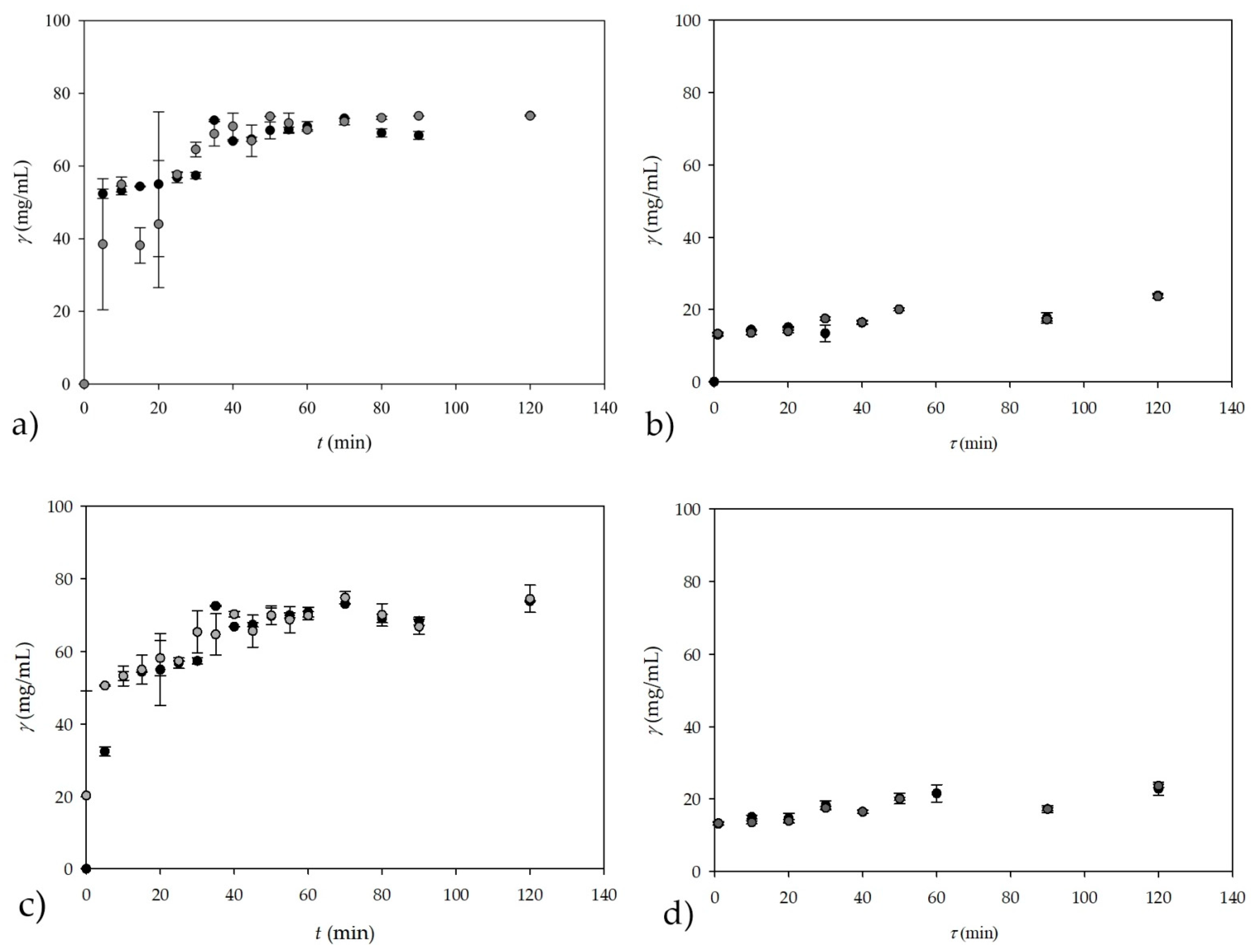
A comparison of the calculated theoretical values of the glycerol concentration and the glycerol concentration measured
on-line by NIR spectroscopy are shown in
Figure 7a for the experiment conducted in a batch reactor.
Obviously, a good agreement between the glycerol concentrations measured by on-line NIR spectroscopy and the calculated theoretical values was obtained.
Considering the successfully performed
on-line measurements in a batch reactor, the possibility of
on-line measurements of the glycerol concentration in the continuous reaction system, i.e., in the PTFE coil microreactor with three inlets, was also investigated. The corresponding results are shown in
Figure 7b. The experiment in the +-shaped microreactor was performed for eight different residence times, resulting in 24 samples (triplicate samples for each residence time), and the spectra of the samples showed the same trend as those shown in
Figure 6b for the batch reactor. To obtain a larger dataset, the data from the batch reactor (17 samples in triplicate, resulting in 51 samples) and the data from the +-shaped microreactor (24 samples) were combined, resulting in a matrix of 75 samples x 795 wavelengths, which was later used for ANN modeling, after PCA was performed. The reason for coupling data from different experiments was to test if it is possible to monitor glycerol concentration in different systems. As in the experiment conducted in a batch reactor, the
on-line measurement of the glycerol concentration by NIR spectroscopy shows very good agreement with the theoretically calculated values of the glycerol concentration.
The best ANN model that was used for both experiments was obtained once again with ANN that had a 60:20:20 ratio of randomly selected data by software for training, testing, and validation with an ANN structure of 10-6-1.
R2 values of 0.9886, 0.9735, and 0.9375 with errors of 0.0013, 0.0036, and 0.0111 were obtained for training, testing, and validation, respectively. In addition, ANN model 4, obtained from performing ANNs with five subsamples and the subsample size in the ratio of 60:20:20 with six neurons in the hidden layer, also provided very promising results with
R2 values of 0.9868, 0.9588, and 0.9026 for training, testing, and validation, respectively, with corresponding errors of 0.0031, 0.0042, and 0.1628. The results of the subsampling ANN model are shown in
Figure 7c for the batch reactor and in
Figure 7d for the +-shaped microreactor. This is further evidence that NIR spectroscopy is a good method for measuring glycerol concentration in a batch reactor and in a continuous microreactor by means of
off-line and
on-line measurements.
Based on the good results obtained with NIR, on the basis of
on-line measurements of the glycerol concentration for experiments performed in a PTFE coil microreactor with three inlets, an additional two experiments were conducted in a different microreactor configuration, namely, in a microreactor with two inlets. In this experiment, the first inlet stream consisted of methanol and the second inlet stream consisted of the emulsion formed from oil and an enzyme dissolved in a buffer with the addition of an emulsifier (SDS). In one of our previous works [
4], we demonstrated that if a large excess of methanol was used (oil to methanol molar ratio 1:90) the reaction can be shifted towards product formation. Consequently, higher yields will be achieved in comparison to processes with the stoichiometric ratio of substrates for the same residence time. Such methanol excess is not possible in a batch process because the enzyme is significantly inhibited by higher methanol concentrations. Namely, lipase-catalysed biodiesel production is only possible in systems where the lipase is somehow protected from the high methanol content. This could be realized in a microreactor equipped with three inlets in which enzyme, methanol, and oil are fed as separate streams, or in a microreactor equipped with two inlets in which the mixture of the enzyme and oil is fed as one stream while methanol is fed separately. In those microreactor systems, the enzyme was not in direct contact with the methanol and the reaction occurred only at the surface of phases. Having in mind that the
on-line measurement of glycerol concentration by NIR spectroscopy during the transesterification reaction in a +-shaped microreactor is successfully performed (
Figure 7b), additional experiments were performed in a T-shaped microreactor to show the applicability of NIR spectroscopy for measurements of the glycerol concentration in a different microreactor configuration. Additionally, different oil to methanol ratios were also tested in order to investigate the influence of different concentration profiles on the reliability of NIR spectroscopy (
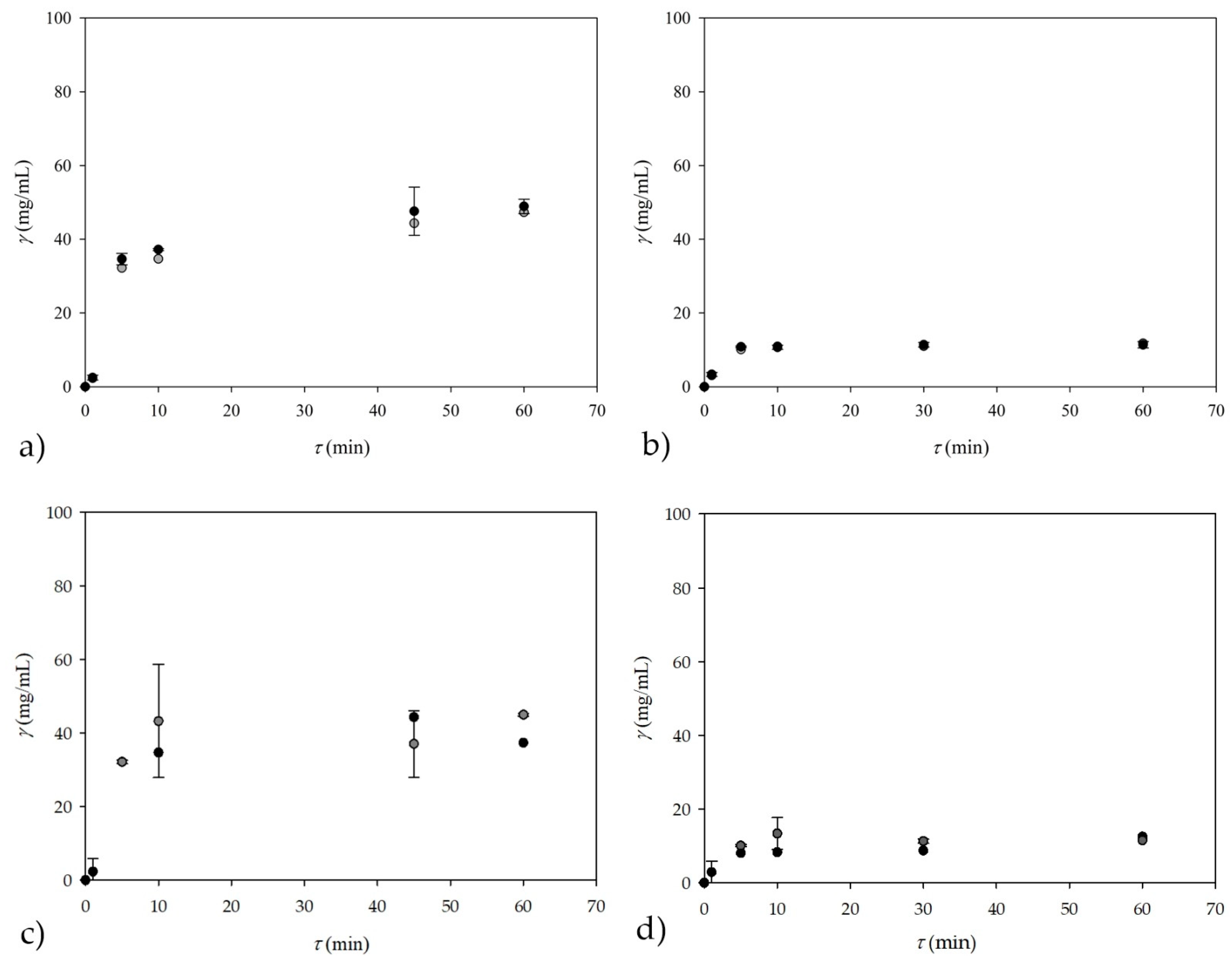
Figure 8a,b). In the transesterification reaction performed in a T-shaped microreactor, NIR spectroscopy could also be influenced by the presence of the emulsifier needed for the preparation of a stable emulsion of oil and lipase (one of the two inlet streams).
For this,
on-line NIR spectroscopy measurements coupled with an ANN (with the architecture of 10-13-2 and the 60:20:20 ratio for training, testing, and validation) prediction model were compared with theoretical glycerol concentrations for the experiment performed in a microreactor with two inlets (
Figure 8a,b). For this experiment, theoretical glycerol values from previous microreactor experiment (
Figure 7b) coupled with new data for theoretical glycerol values obtained in two experiments with a T-shaped microreactor were used for later modeling. To perform the ANN analysis, a data matrix was first created consisting of 27 samples from
Figure 7b, 18 samples from
Figure 8a, and 18 samples from
Figure 8b, followed by PCA prior to ANN modeling. As in the previous cases, the first 10 factors from PCA were used as input variables for the ANN, resulting in a data matrix of 63 samples and 10 factors with, in this case, two output variables (glycerol concentration and residence time) to simultaneously test whether it was possible to predict not only glycerol concentration but also residence time.
It can be seen from the ANN architecture that there were two outputs in this case, the first one being glycerol concentration, and the other being residence time. Results for this ANN in terms of R2 values were 0.9999, 0.9746, and 0.9408 with errors of 0.0000, 0.0053, and 0.1531, for training, testing, and validation, respectively, which was combined for glycerol concentration and residence time.
Since this ANN is a combination of two outputs, for the first output (glycerol concentration), R2 values for training, testing, and validation were 0.9999, 0.9495, and 0.9463, while for the residence time, R2 values for training, testing, and validation were 0.9999, 0.9996, and 09354.
In the case of the subsampling strategy (
Figure 8c,d), which was performed with five subsamples and a subsample size ratio of 60:20:20 with 13 neurons in the hidden layer, the results were lower in terms of
R2 values for training, testing, and validation, resulting in values of 0.9997, 0.9836, and 0.9051 with errors of 0.0002, 0.0089, and 0.1202, respectively. Although the difference is not that great in term of values for validation in both cases, noticeable difference can be seen when looking at the results for the first output (glycerol concentration), where
R2 values of 0.9999, 0.9713, and 0.8146 were obtained for training, testing, and validation; thus, presenting a problem, which is most probably caused from working with smaller datasets. The results for time were, in the second case, much better with the
R2 values of 0.9996, 0.9959, and 0.9956 for training, testing, and validation.
Although the theoretical glycerol concentrations in the second case (subsampling strategy) is a bit lower than expected, with additional data from the future experiments, glycerol concentration and residence times correlated with on-line NIR measurements could have potential applicability of ANN model simulations for on-line estimations of glycerol concentrations and/or residence time during continuous biodiesel production in a microreactor by means of transesterification. These results show that on-line NIR measurements are applicable in systems with different configurations and for experiments performed at different concentrations of reactants and other components of the reaction mixture, without the need for any adjustments.
3.5. On-Line Measurement of Glycerol Concentrations—Prediction by ANN Based on NIR Spectroscopy
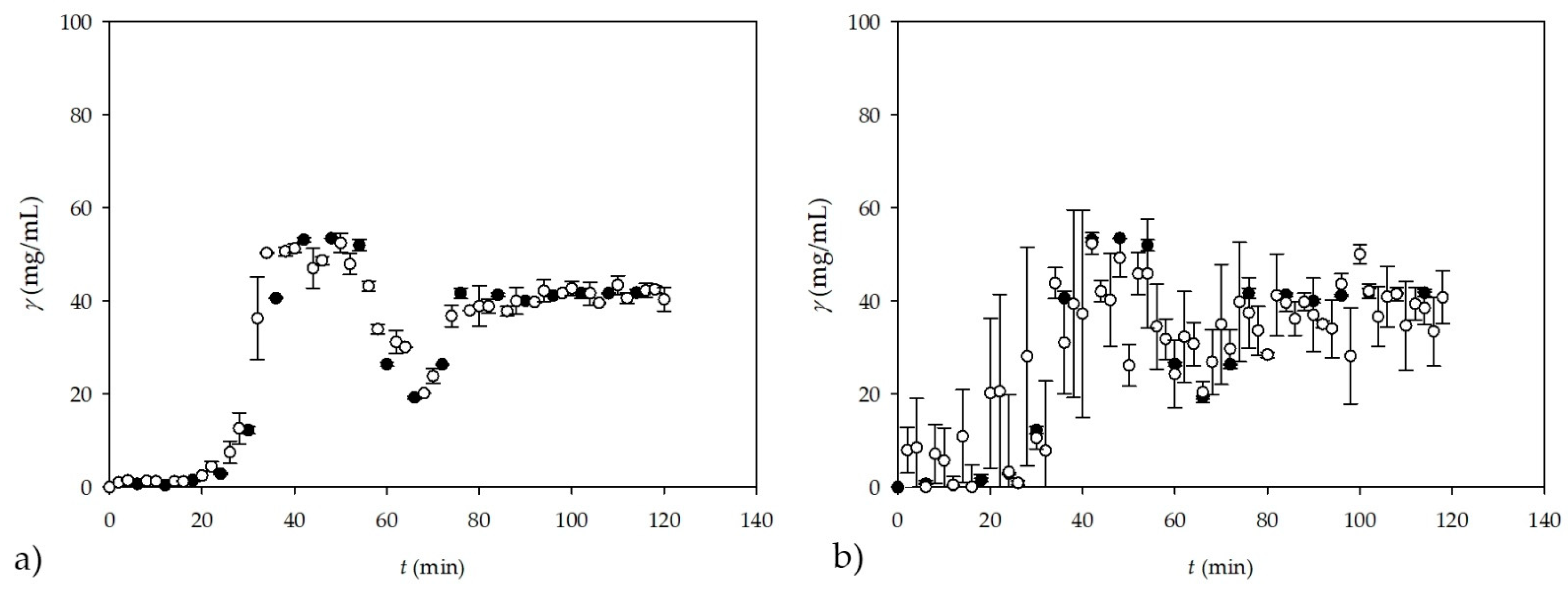
In order to further investigate NIR spectroscopy potential, an additional experiment was performed in a microreactor for two different concentrations of oil in the inlet stream (described in
Section 2.2.9). For this purpose, the ANN model was developed based only on the calculated theoretical values of glycerol and the recorded NIR spectra for those samples were developed. Although the NIR spectra were recorded every 2 to 4 min, each sample was recorded in triplicate because each sample can be recorded within 10 s, allowing more accurate predictions. In this case, 53 samples were recorded in triplicate, resulting in a total of 159 samples. On the GC, glycerol concentration was measured in 60 samples, leaving 99 samples that were recorded by NIR spectroscopy only. As in the previous cases, PCA was first performed for all 159 samples followed by ANN. Furthermore, the first 10 factors obtained by PCA were used as inputs, while the theoretical glycerol concentration was used as the output variable for ANN. This was only the case for known glycerol concentrations obtained by GC measurements, while all other concentrations were predicted by ANN. The software randomly divided the data into training, testing, and validation in a 60:20:20 ratio. Obtained ANN consisted of 10 input layers (the first 10 PCA factors that were derived from theoretical values of glycerol), 13 neurons in the hidden layer, and an output layer, representing the glycerol concentration, with
R2 values of 0.9781, 0.9761, and 0.9530 and errors of 0.0042, 0.0097, and 0.0160 for training, testing, and validation, respectively. This ANN was used to predict theoretical glycerol concentrations recorded only by NIR spectroscopy, meaning that the predicted values were not measured by GC or any other method. The results of the ANN predictions of glycerol concentrations are shown in
Figure 9a. The results of the subsampling strategy, in which the number of subsamples was set to five and the subsample was set to a 60:20:20 ratio with 13 neurons in the hidden layer, are shown in
Figure 9b. In this case
R2 values were 0.9853, 0.9437, and 0.8811 for training, testing, and validation with corresponding errors of 0.0045, 0.0179, and 0.0700. When looking at both figures, it is clear that for this kind of prediction much more data will be needed for the training and testing of ANNs in order to make suitable validations and predictions.
It can be observed that the ANN predictions based on the NIR spectra are in accordance with the experimental data and the highest values are observed when both steady states are achieved around 48 and 100 min, respectively. The ANN predictions describe very well the change in glycerol concentration that happened when the oil concentration in the inlet stream was reduced. In addition to the dynamic change, the values obtained by the ANN predictions also describe the steady state part of the process (
Figure 9). Moreover, regardless of the different dynamics of sampling (for
off-line measurements) and recording the NIR spectrum (for
on-line measurements), there is a clear correspondence between the results of
on-line and
off-line measurements.
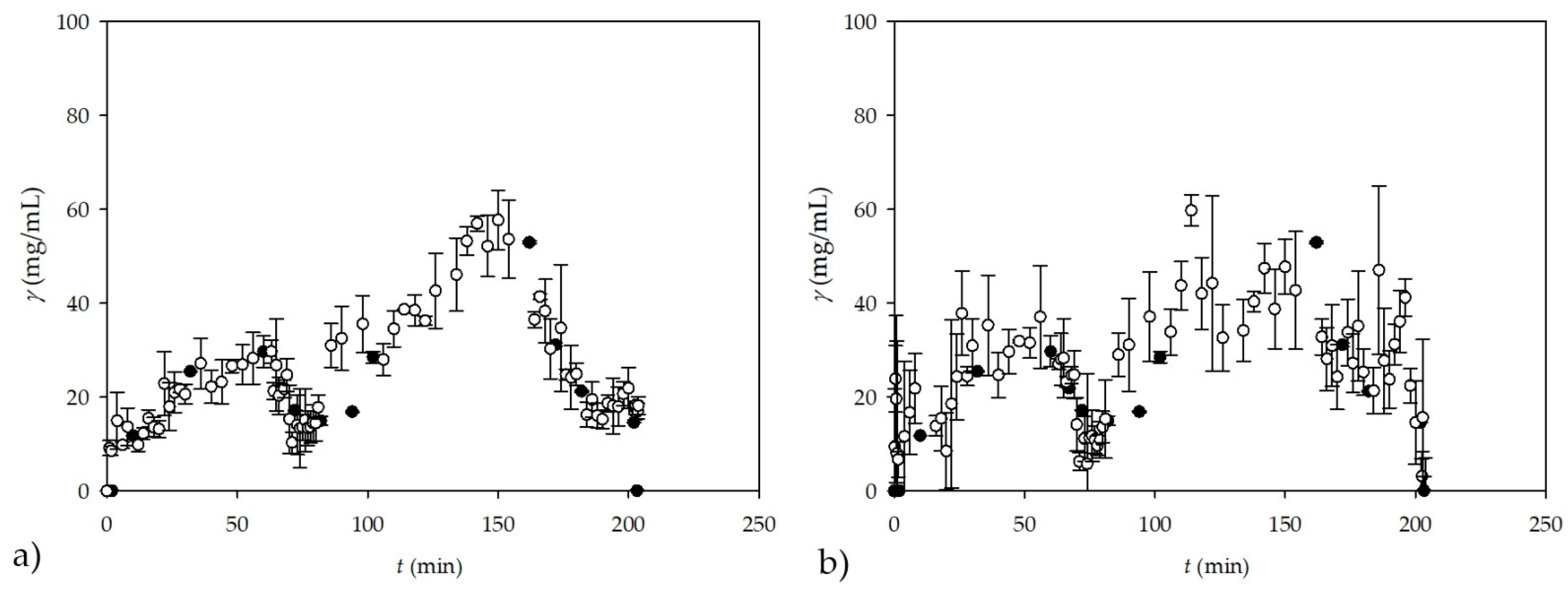
The second experiment, evaluating the ANN prediction of the NIR spectra, was performed with different residence times, which were changed frequently, before the steady state was established. The same principle as in the previous experiment was applied to find an ANN suitable for explaining the calculated theoretical values of the glycerol data. In this experiment, 90 samples were recorded in triplicate, resulting in a total of 270 samples. On GC, the glycerol concentration was measured for 51 samples, leaving 219 samples that were recorded by NIR spectroscopy only. As in the previous cases, PCA was first performed for all samples before ANN modeling. Again, ANN was performed for samples with known glycerol concentrations, which was used to predict other concentrations recorded by NIR spectroscopy only. The result was an ANN that had a separation of data into training, testing, and validation in ratio of 60:20:20, respectively. This time, the ANN consisted of 10 input layers (the first 10 PCA factors), 10 neurons in the hidden layer, and one output layer (glycerol concentration), with
R2 values of 0.9719, 0.9733, and 0.9525 for training, testing, and validation, respectively. The results of ANN predictions of glycerol concentration during frequent changes of residence times are presented in
Figure 10a. As in previous experiments, there is a clear agreement between
off-line and
on-line measurements, regardless of the different sampling times. From the
Figure 10b it is visible that, once again, when working with some sort of cross-validation, results vary a bit from
Figure 10a. Again, a subsampling strategy with five subsamples and a subsample size ratio of 60:20:20 was used with, in this case, 10 neurons in the hidden layer, and
R2 values of 0.9785, 0.9574, and 0.9221 were obtained with errors of 0.0041, 0.0158, and 0.0217 for training, testing, and validation, respectively.
As for the previous experiment, where NIR spectra were also recorded in triplicate, a good trend of ANN predictions based on experimentally measured data is observed. It is also noticeable that this experiment was more dynamic as the residence times were changed frequently before the steady state was achieved. Although the ANN predictions for this experiment prove that NIR spectroscopy could be used as a potential
on-line measurement method, a lot of work is still needed. Most importantly, a database of NIR spectra and GC measurements for all steady states needs to be created for this type of experiment to predict each transition state and glycerol concentration during that period. Nevertheless, in further experiments, additional data should be generated, which will enable the prediction of glycerol concentrations during any change in flow regime in a microreactor. Furthermore, as demonstrated in the work of Westad and Marini [
37], some sort of cross-validation is needed when working with this kind of data; especially with ANNs that have less than a few hundreds or thousands of samples. As presented in this work, there is a clear difference between randomly selecting ANNs that had the highest
R2 values and some kind of cross-validation that is needed in this case.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}