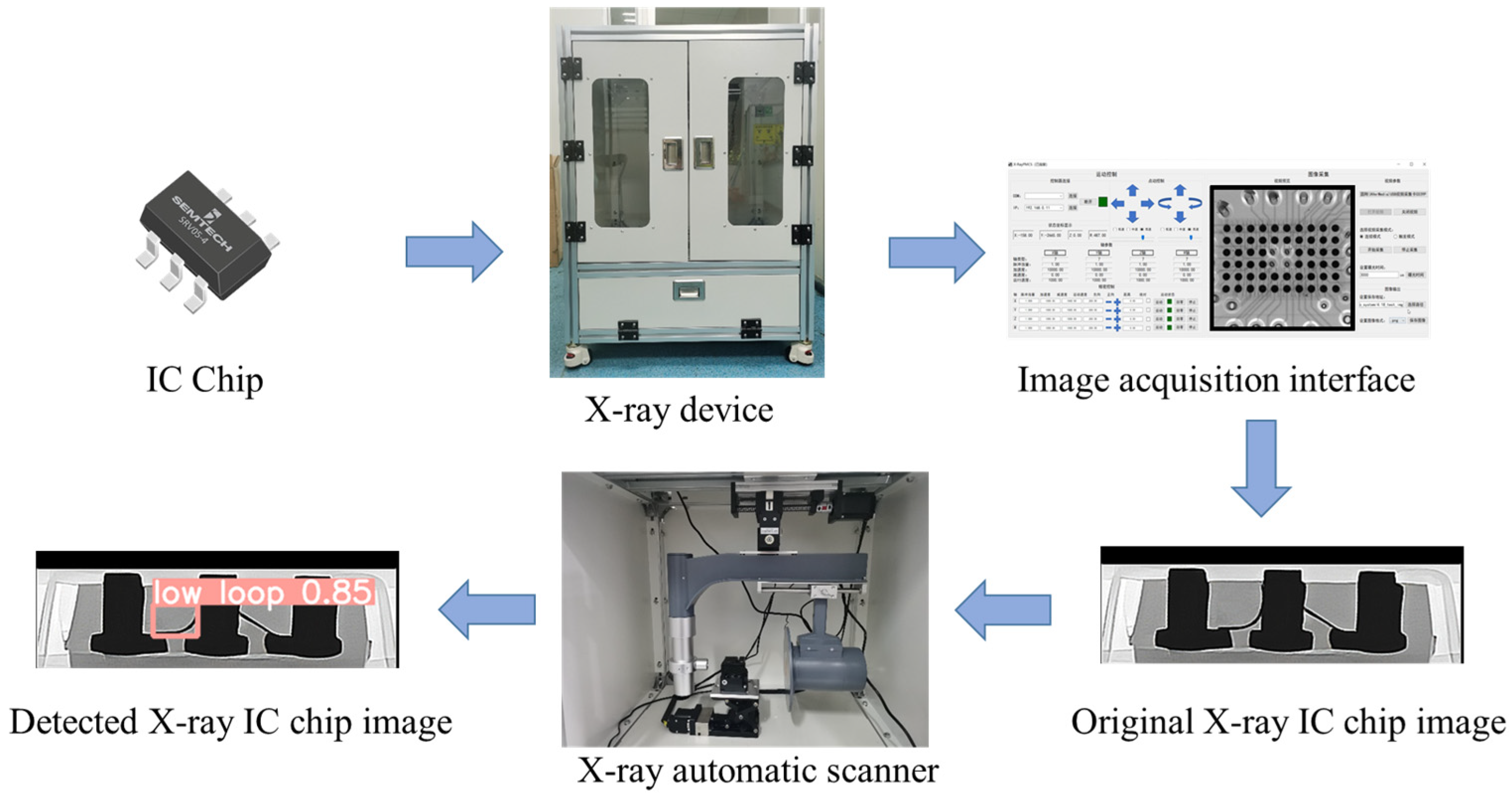
3.2. LMNet for IC Defect Recognition
The LMNet framework, as shown in
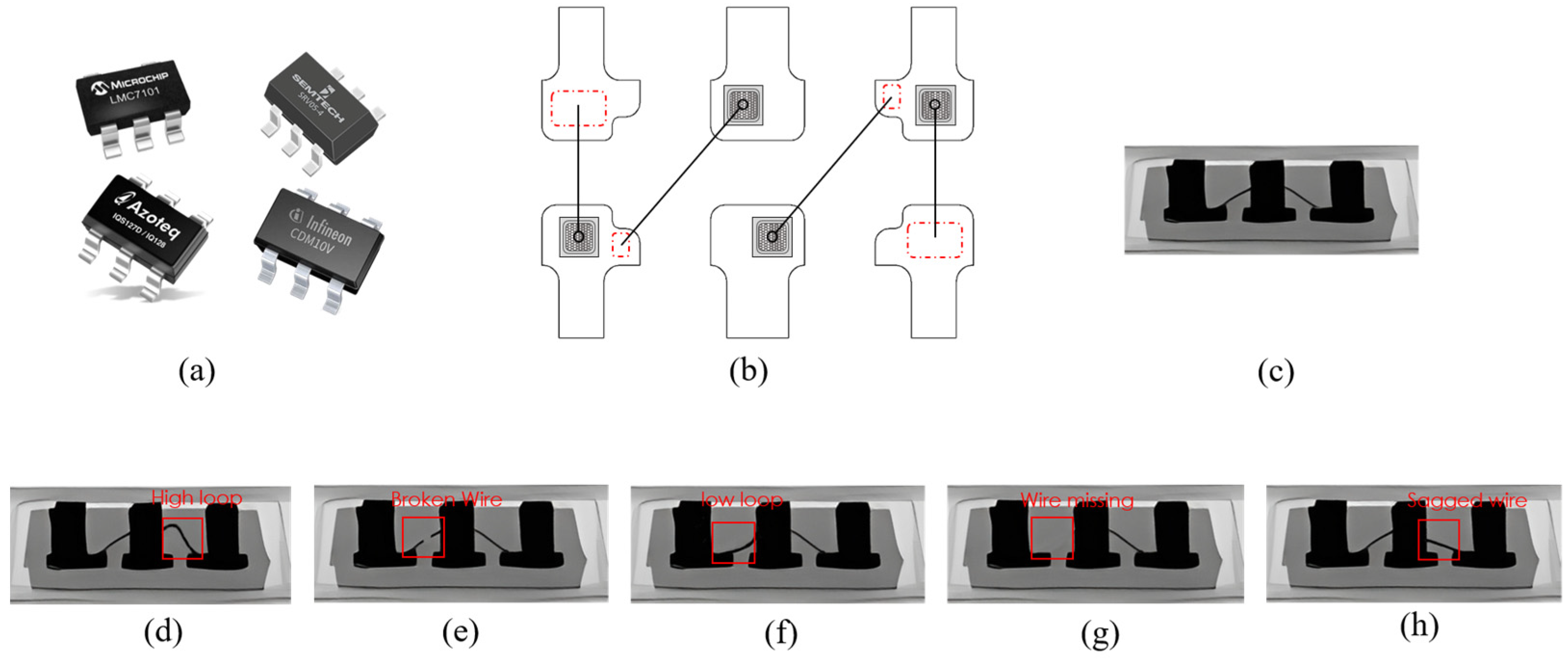
Figure 4, is a modified version of the original YOLOv5 network that is compressed and optimized for our IC defect dataset. In this section, we introduce two key components of the network—the Residual Ghost Convolution (RGC) module and the Spatial Convolution Attention (SCA) module—and provide a detailed description of the LMNet structure.
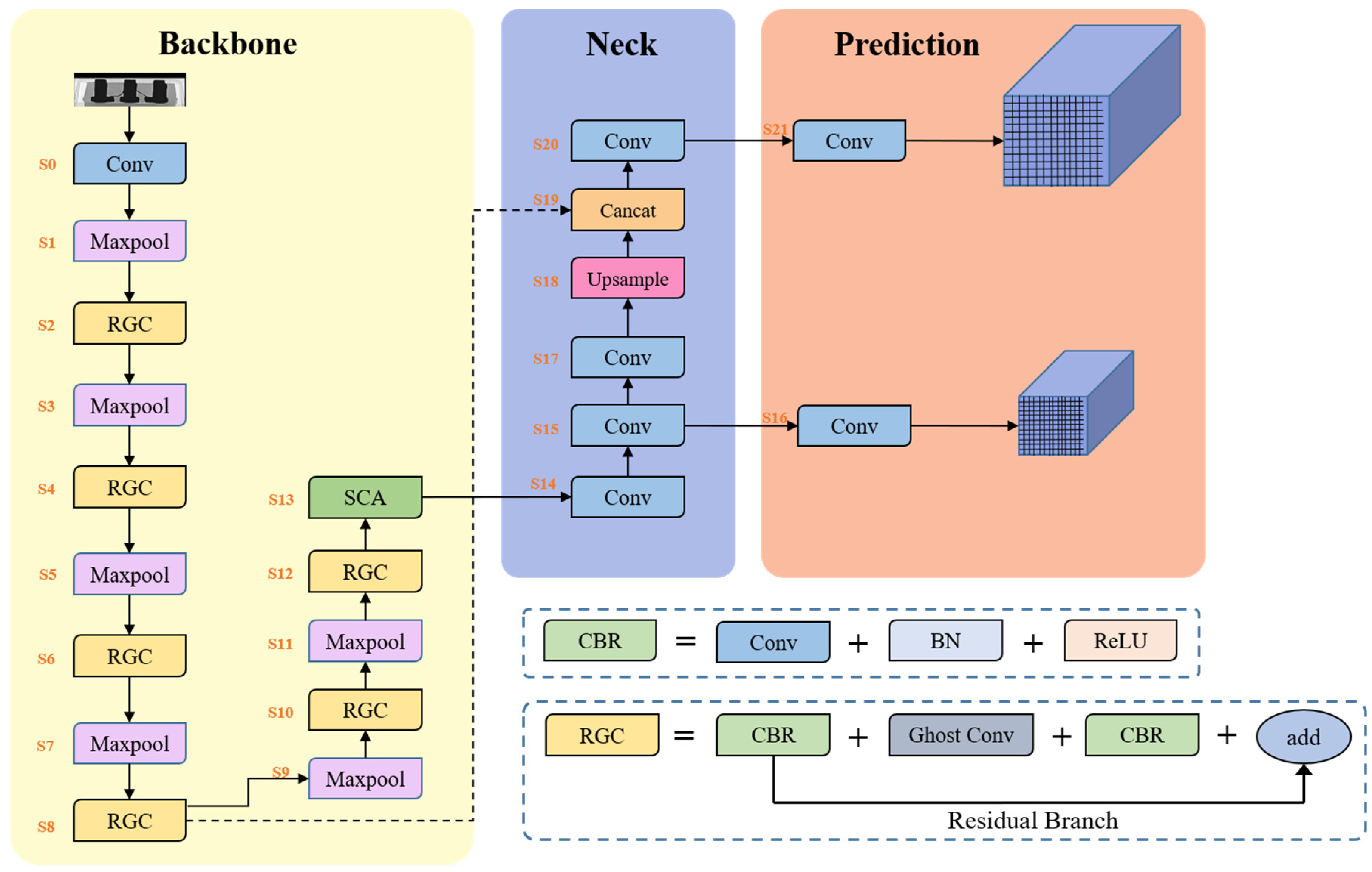
RGC module: The Residual Ghost Convolution module is the basic module of a deep learning network. Efficient representation encoding can make the model better at its corresponding task. Furthermore, feature extraction operations are the main source of parameters and computations. Therefore, the weight of the feature extraction module determines the weight of the entire network. In this paper, we designed the RGC module as shown in
Figure 5; this makes it lightweight, and it has high feature extraction capabilities in relation to the representation learning of X-ray IC images.
The RGC module consists of a 1 × 1 convolution, which increases the number of channels of the input feature map to 2c. To more effectively extract feature information, we needed to map the input data to higher-dimensional space in the intermediate stage. However, this can increase the computational load and memory consumption of the network. To address this issue, we have taken inspiration from GhostNet and introduced Ghost Conv into the feature space expansion process. Ghost Conv helps us to obtain more feature maps in an inexpensive way, thereby reducing memory consumption during intermediate expansion. Additionally, we introduced residual connections in the RGC module to ensure the effective extraction of feature information and improve the stability of the network.
Residual connections can effectively solve a range of problems caused by increases in the network depth, such as gradient disappearance, gradient explosion, and overfitting. We added residual connections to the RGC module to prevent the overfitting caused by the increase in the number of network layers, which effectively improved the stability of the network. Residual connections can be expressed as a superposition of input and nonlinear changes in the input. We defined the input and output of the lth layer as
and
, respectively, and the nonlinear change of the input was defined as
, where
represented the weight parameter of the function
. The residual connection calculation formula is expressed as follows:
Ghost Conv can avoid the redundant computation and convolution filters generated by similar intermediate feature maps, and can achieve a good balance between accuracy and compression. We defined the input feature map as
, where
,
, and
are the height, width, and number of channels of the input feature, respectively. The feature map of
could be generated through a convolution process:
where
represents the convolution operation,
represents the convolution filter, and
,
,
, and
are the number of output channels, kernel size, stride and padding of filter
, respectively. The feature height, width, and number of channels of the output feature map
were
,
, and
, respectively. To simplify the formula, we omitted the bias value.
However, in Ghost Conv, intrinsic feature maps are first generated using traditional convolution. Specifically, the intrinsic map
was generated using traditional convolution:
where the convolution filter used is
. In order to keep the space size consistent with Equation (2), the height value
and the width value
remained unchanged. In order to obtain a feature map with the required number of channels
, Ghost Conv performed a cheap linear operation on each intrinsic feature to generate the required s ghost features, according to the following function:
where
is the
ith intrinsic feature map of
, and
is a linear operation to generate the
jth ghost feature map
. Finally, we obtained
=
. The output feature map was
.
The intermediate expansion stage of the RGC module doubles the output channel compared to the input channel, which effectively increases information retention through higher-dimensional feature maps. However, this operation may consume a significant amount of memory and require much computation. The introduction of Ghost Conv can greatly reduce this burden. The final 1 × 1 convolution reduced the channel count back to the original input dimension of 2c. To ensure network stability during training, we included the input of the expansion operation and the output of the second 1 × 1 convolution unit as a residual branch. This approach reduced network complexity while maintaining stability during training.
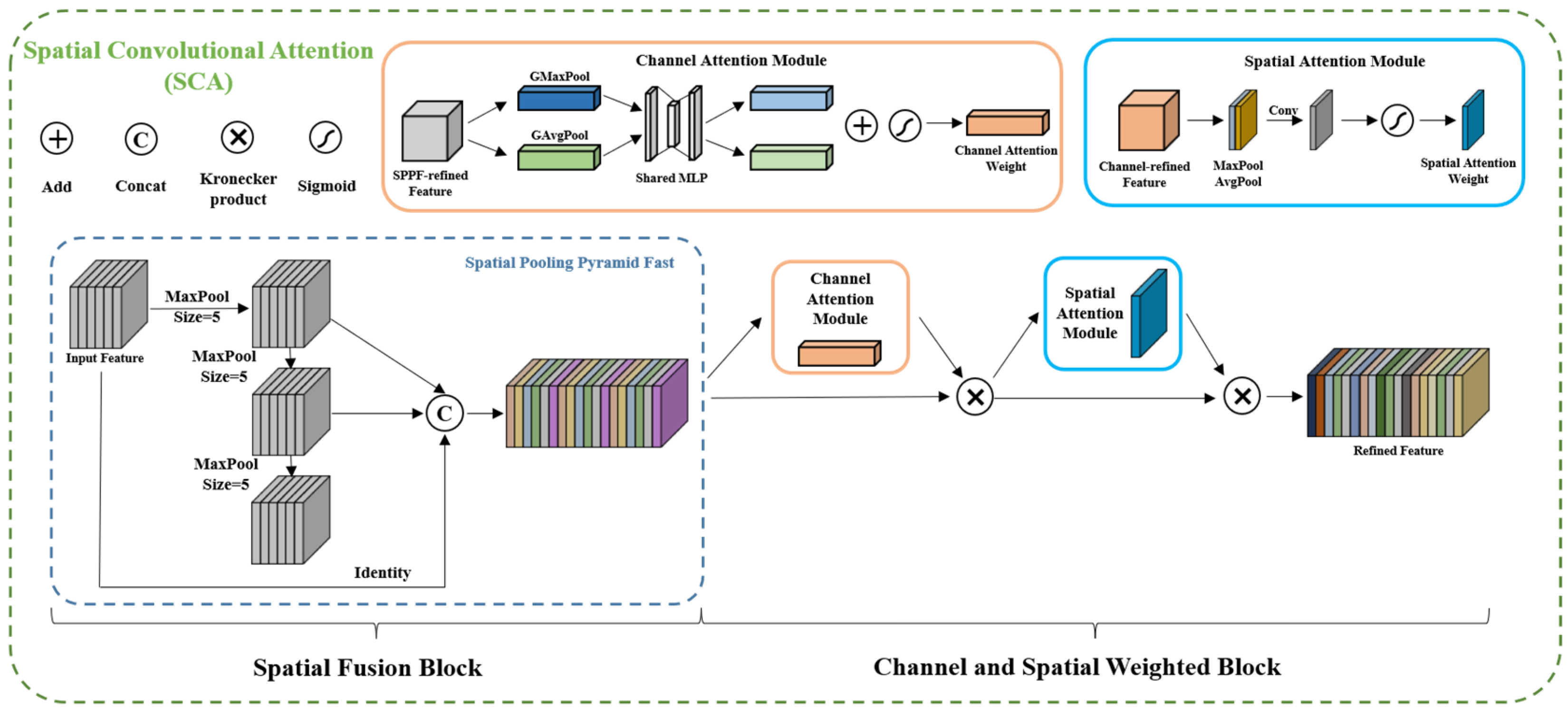
SCA module: To better utilize multi-scale features, we propose a novel SCA module, the structure of which is illustrated in
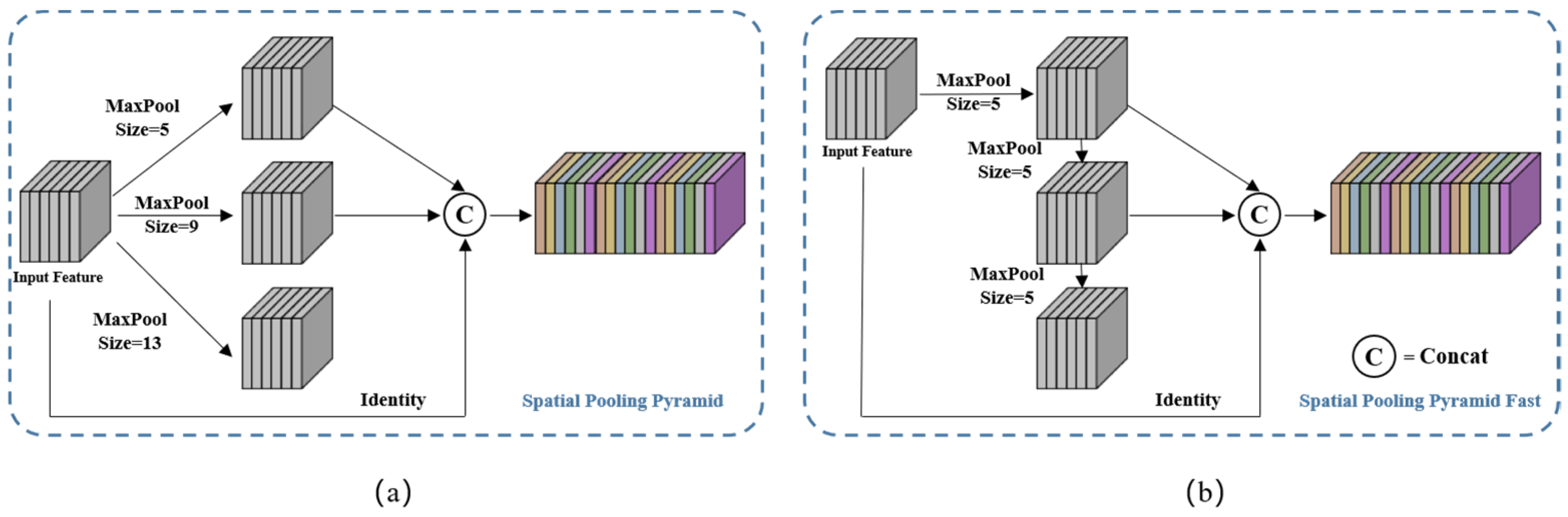
Figure 6. SCA comprises two blocks, spatial scale fusion and attention weighting, and the feature maps are sequentially processed through these blocks. Spatial scale fusion was achieved using Spatial Pyramid Pooling (SPP), which mainly focused on spatial information and consists of four parallel branches: three max-pooling operations (with kernel sizes of 5 × 5, 9 × 9, and 13 × 13) and the input feature map itself. SPP effectively addresses the problem of excessive object scale variation by fusing local and global features. We used an improved version of SPP, called SPPF, based on the author’s work on YOLOv5. SPPF achieved an efficiency improvement of nearly 277.8% compared to SPP. The efficiency gain,
, was calculated using the following formula:
where
is the kernel size of the
-th branch of max pooling in the SPPF module.
Figure 7a,b illustrate the structures of the SPP and SPPF modules, respectively.
The SPPF module was utilized in the spatial scale fusion part of the SCA module, while the attention mechanism module was used in the other part. The attention weighting block acted as an adaptive regulator that learned the importance of each channel’s spatial information, revealing which scale features are more prominent. Whereas multi-scale information is essential to developing effective feature maps, different scales may contribute differently to the results, especially when objects are of similar sizes. In such cases, only one scale may be critical for final prediction. The scale distribution of chip information was more consistent compared to other foreground contents. Therefore, the attention weighting block adaptively weighed different scales during network learning, giving greater weight to more meaningful scale features.
Currently, the most commonly used attention mechanisms are SE, CBAM, and CA modules. Among them, SE is a channel attention module that consists of two operations: squeezing and excitation. This module enables the network to focus on feature channels with greater informative content, while ignoring those with less information. On the other hand, CBAM is a spatial channel attention mechanism module that combines spatial and channel attention. The CA module is a novel approach that addresses the loss of location information caused by global pooling operations. By focusing on the width and height dimensions separately, the spatial coordinate information of the input feature map can be efficiently utilized.
Figure 8 illustrates the structure of the SE, CBAM, and CA modules.
Overall, this paper proposes an SCA module, which integrates more information sources and adaptively weights them based on their importance, thereby improving the contextual representation ability of the feature map. Experimental comparisons show that the CBAM module achieved better results in SCA, and the role of SCA is discussed in detail in
Section 4.1.
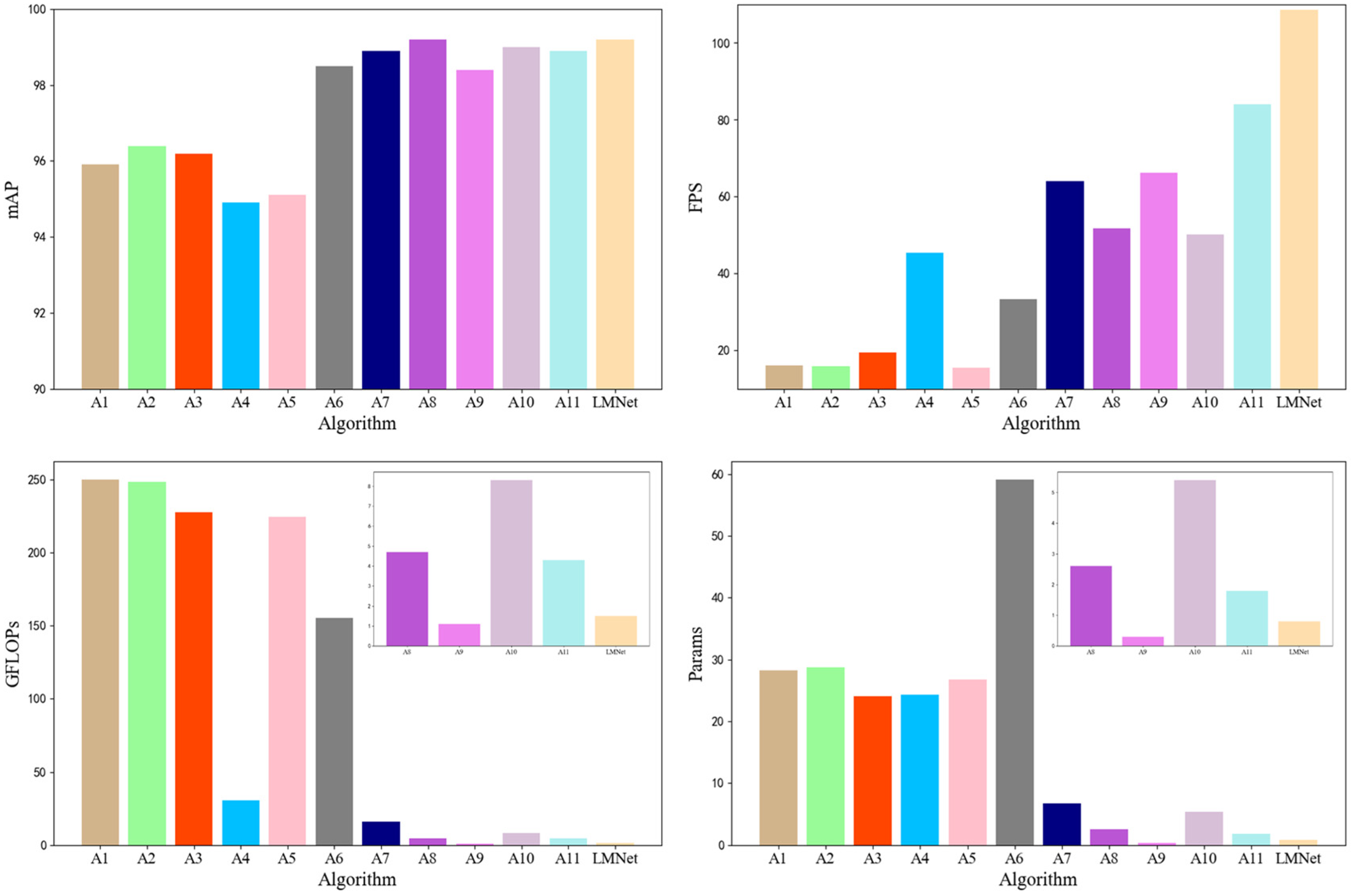
In terms of architecture, we drew inspiration from YOLOv5n and designed an IC chip defect recognition network called LMNet, which is shown in detail in
Table 3. Compared with YOLOv5n, LMNet has fewer network layers and narrower models, resulting in reduced parameters and failures. To obtain a smaller bandwidth backbone, we strictly limited the number of channels in each layer, with almost all layers having fewer than 512 channels. This design strategy makes the network less computationally burdensome for devices. We embedded the RGC module in the backbone for deeper representation learning and efficient feature extraction, and the SCA module was positioned at the end of the backbone to ensure that it processed more meaningful information and could bring the enhanced features closer to the output layer for more accurate recognition results.
To train the LMNet model using the specific argmax shown in Algorithm 1, the resulting weights and features will be organized in .pt files. Subsequently, the LMNet structure and weights can be deployed on the device through the network connectivity.
| Algorithm 1. Proposed Lightweight Framework (LMNET) |
| Input: Ix = X-ray image(input) |
| Parameters: m = model, tr = train, v = valid, te = test, a = argmax (minput-layer, maveragepooling2d, mflatten, mdense, fl = feature-layer, α = learning-rate, es = early stopping, b = dataloader_batch, e = epoch), Ac= accuracy, image-shape = 640, class = Image-label. |
| Output: Pci [Pclass0, …, Pclass8] Predicted class index |
| Preprocessing: |
| if set == training_set:x |
| resize Ix to 512 × 512, crop and resize(Ix) to 640, flipping, normalize pixel to (0, 1), pixels /= 255.0 |
| else: resize Ix to 640, normalize pixels to (0, 1), pixels /= 255.0 |
| Models training: |
| for x = 1 to 300 |
| [tr, v] = partition(tr, v) |
| for y = (tr/b, v/b) |
| if Acv < 99: |
| continue; |
| if Acv is not improving |
| for next 5 epochs, then |
| increase α = α x 0.1: |
| t(m, c, j) = train[m(c), a, tr(x), v(x)] |
| v(m, c, j) = valid[(m(c), a, x), v(x)] |
| unfreeze fl |
| else: |
| call es(m); |
| else: |
| break; |
| end y; |
| end x; |
| te(m(c), a) = [test(m(c), a, te)] |
| Pci[Pclass] = te(m(c), a |


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}