1. Introduction
Determining the position of a person is required in many applications, such as first responders, mine workers and indoor civilians. A global navigation satellite system (GNSS) is essential for outdoor navigation. However, GNSS signals are unavailable indoors for attenuation and creation of multiple paths. Many technologies, including ultrawideband (UWB) [
1], WiFi [
2], radio frequency identification (RFID) [
3], inertial navigation [
4,
5,
6], etc., have been studied for indoor navigation. Unlike outdoor navigation, no single approach has been shown to be most suitable for the majority of applications [
7]. UWB, WiFi and RFID are infrastructure-dependent technology and in non-line-of-sight conditions, they suffer great errors in localization. Inertial navigation systems (INS) are self-contained, because they do not receive or transmit any signals. Low-cost micro-electromechanical systems (MEMS) sensors suit the requirement for consumer applications with a low cost, such as pedestrian navigation [
8]. However, the errors of low-cost MEMS-based pedestrian navigation systems (PNS) will accumulate due to bias and noise in measurement. Although the zero-velocity update (ZUPT) method is intended to restrict positional errors, this technology cannot correct the azimuth error. Due to the inability to observe the yaw error, the heading drift becomes the main factor that causes the estimated positional error.
In order to reduce yaw error, several methods are used. Map matching proposed by the authors of [
9,
10,
11,
12] show great improvement in estimating positions. In a study [
9], Cardinal Heading Aided for Inertial Navigation System (CHAIN) is employed to mitigate heading drift. The algorithm uses the simple notion that users are likely to walk in one of four cardinal headings. In another study [
10], a confidence of CHAIN is utilized to update the weight of particles. The approach reduces the number of particles and improves the performance of the system. In another study [
11], this update in weight is assigned by the discrete dominant direction (DDD) rule and human behavior. Eight directions are employed according to the Gaussian distribution. In [
12], only the building outline is needed for filtering particles to improve the accuracy. Particle filters need to compute the posterior density
by a set of weighted particles, where
is the real state (e.g., the location of a person), while
and
are the observation variables. Checking the compliance of every particle against the map constraints increases the computational cost of this algorithm.
The conditional random fields (CRFs) were applied to pedestrian indoor navigation by Xiao et al. [
13] and Bataineh [
14]. Both of them have good performance. The algorithm has two advantages. Firstly, the computation is efficient. Secondly, it can capture arbitrary constraints between observations. In a study [
13], the map is divided into identical squares with edge lengths of
, which is set as the narrowest corridor in most buildings (e.g., 0.8 m). Two feature functions were used. One describes the relationship of the orientation and length of two observations in two consecutive states. Another involves the rotation of observation
by a pre-defined degree. The third feature function is optional, which takes the received signal strength (RSS) fingerprint data into account. The fourth feature function can also be added to the model if the building is equipped with cameras or other sensors. Extensive experiments show that this method outperforms state-of-the-art approaches, such as hidden Markov model (HMM) and particle filters. In [
14], the length of cell size was set as 1 m through the experiments, while a buffer size of 2 cells was used for transitions to the neighboring cells. Only one feature function is used, which is based on the distance between the observed and the candidate states. However, another technique called improved heuristic drift elimination (iHDE) [
15] is also used to reduce heading errors. The experiments show that the CRF + iHDE algorithm is superior to the sole iHDE algorithm. In [
13], a distance of 200 m was tested for different types of cell phones, while 352 m was tested on wrist-worn inertial measurement units in another study [
14]. In [
14], only 25 states were chosen for every observation, while in another study [
13], the vertices in the whole indoor map are chosen as states for one observation. Although the former is more computationally effective, it can only correct distance errors less than 3 m. The latter can correct errors as large as the whole indoor distance in theory.
The map-matching technique based on conditional random fields described in this paper aims to decrease the number of states for every observation and to improve the accuracy of the system. The pre-defined states are squares with edge lengths of = 0.8. Only four states are chosen for each observation. The observations are chosen as positions from INS. The next position is obtained from fixed length intervals (i.e., 0.8 m), instead of being based on step length or same time intervals.
2. System Description
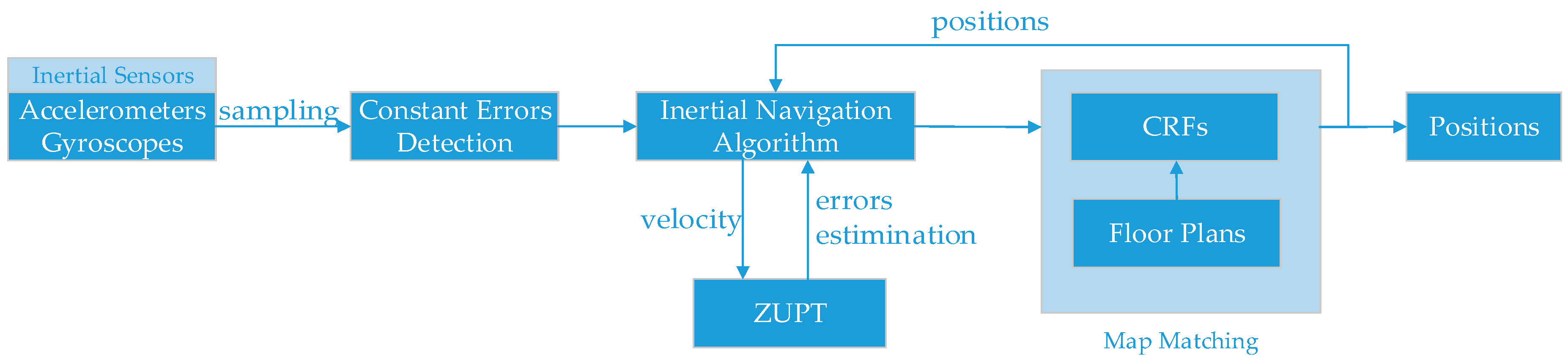
The system architecture is described in
Figure 1. Inertial sensors, including three accelerometers and three gyroscopes, are used to determine locations. As magnetometers are susceptible to disturbance, we do not use them to obtain the system heading. Generally speaking, the whole system consists of 5 sections. The first part involves the data sampling from inertial sensors, which is conducted every 0.01 s by computers. The second part involves the constant errors detection algorithm, with the gyroscope constant errors detected in this stage. The third part is inertial navigation algorithm, which is based on traditional inertial navigation equation [
16]. The fourth part is the ZUPT algorithm, which has already been detailed in [
16]. The fifth part is the CRFs-based map matching method. There is feedback between CRFs and inertial navigation algorithm.
2.1. Detection of Constant Errors
As constant errors of gyroscopes have an enormous effect on the accuracy of the system, these errors cannot be estimated by the Kalman filter used in the ZUPT stage, which was described in detail in study [
16]. Therefore, some methods must be performed to deal with this problem. We propose a simple but very useful technique to estimate the errors. When the system is strapped onto a user’s shoe, it is very convenient for the user to stand still for a while. In our experiments, we require the minimum time intervals are 6 s. During these time intervals, if the standard deviation of the gyroscopes is lower than a threshold value, the mean values of the outputs of the gyroscopes can be roughly recognized as constant errors. When the user begins to move around, the constant errors should be subtracted from the outputs of the gyroscopes. We call this process “the constant errors detection”. The constant errors that are not estimated will cause heading errors and will eventually affect the positional errors, which will be corrected by the proposed CRFs algorithm.
2.2. Inertial Navigation Algorithm
To calculate a pedestrian’s position, three basic navigation equations are used. Those are velocity, attitude and position differential equations.
where
is the transformation matrix from the
b frame to the
n frame and
is the specific force in the body frame. The body frame is defined as a right-handed
Cartesian coordinate system (
means forward,
means left,
means upward). The navigation frame is defined as east-north-up (ENU). We use the subscripts b (body) and n (navigation) to denote the project of a vector in a corresponding frame.
represents the angular rate of the body frame relative to the navigation frame.
represents the cross product matrix of
.
is the sampling period.
2.3. ZUPT
When a person is walking, his/her foot will usually stay on the ground for approximately 0.1–0.3 s. We call these gaps the zero-velocity intervals. If the errors can be compensated during those periods, the accuracy of the foot-mounted pedestrian system can be improved greatly. In study [
16], we detailed how to detect these intervals and verified the sensor bias errors, attitude errors and positional errors. Speed of a pedestrian is used to detect the zero velocity intervals, also the hidden Markov model was employed to identify acceleration intervals, deceleration intervals and zero velocity intervals. This method can perform well in various motion models. The performance of the system can be highly improved by these techniques. However, the heading error cannot be observed and cannot be estimated, which makes it the main error that affects the accuracy of the system. Therefore, we propose the CRFs-based map-matching method.
2.4. Linear-Chain CRFs
CRFs [
17] are undirected probabilistic models used to compute the probability
of a possible output
when given the input
. A special form of CRF is known as a linear chain structure. In that case, the output variables are modeled as a sequence. Therefore, the conditional probability
can be written as:
where
is the number of factors. We noted that there are
observation variables, because
and
are connected in one factor. Each factor
relates to a potential function that incorporates different features
of the required part of the input and output.
can also be written as:
is called the normalization factor, which is calculated as follows:
The summarization is conducted for all possible output sequences and the normalization factor ensures that
is a probability measure. Equations (6) and (7) form a linear-chain CRF. Given the input vectors
and the potential function
, we need to find the most likely hidden states
as follows:
In Equation (8), we only need to compute the non-normalized probability. This can greatly reduce the computational complexity. The Viterbi algorithm [
18] provides a good way to compute the most probable values in Equation (8).
The steps of Viterbi algorithm can be simply summarized as follows:
- (1)
Initialization: Compute the non-normalized probability of the first position for all states, where
is the number of states.
- (2)
Recursion: Compute and find the biggest the non-normalization probability to the position
over all states
, at the same time record the state label
that has the largest value.
- (3)
When
, find the largest
and record the terminal track state label
.
- (4)
Calculate the final output sequence as follows:
The complexity of the algorithm is .
2.5. Map Pre-Processing
To use CRFs, we need to define states and feature functions for every observation. However, indoor maps should be processed to get discrete states before this. The obtained indoor maps are in an image format, which is not suitable for the map-matching algorithm. First, we use a software called MapInfo to convert the image into a digital format. After this, the map is divided by a set of square cells, with the vertices being possible states. We get the vertices using the following equations:
where
and
are given as initial positions in the digital map.
If the vertices are too close to the wall, they are no longer considered as states. In this paper, we set the threshold value as 0.2 ×
a (
a is the square length). If the distance between a vertex and the wall is smaller than 0.2 ×
a, the vertex is removed. We should bear in mind that there are some restrictions between states. For example, if the edge between two vertices crosses a wall, the states cannot transition from one vertex to another. A higher accuracy will be obtained if more time is spent on the map processing stage.
Figure 2 shows states in the Economics and Management Building in Beijing University of Technology, with the edge length of a square cell being 0.8 m.
2.6. Definition of States and Choice of Observations
CRF models use a set of input observations, such as positions and headings, to predict hidden variables. The predicted trajectories are located exactly on one of the states. In this step, we should determine what observations can be used in CRFs and how to choose hidden states for each observation.
The hidden states for observations based on step length should consider that step length is not same for different individuals and even a same person will have different step lengths at different walking speeds. In [
13], a buffer size is chosen for every observation. However, knowing that ZUPT has already estimated the accelerometer errors, the length from one position to another position is quite accurate. The errors left uncorrected are gyroscope drifts and azimuth errors. We can use this characteristic to further reduce the number of hidden states for every observation.
The observations are chosen as positions that are a fixed length from each other. The equation is shown as follows:
where
and
are two positions;
represents the
coordinate in position
;
represents the
coordinate in position
;
represents the
coordinate in
position; and
represents the
coordinate in position
. Supposing that
is the last observation, if the distance between the position
and
is equal to
,
is chosen as the next observation.
is equal to the edge length between two consecutive states.
We must emphasize that the observations are not chosen as step lengths. differs from step length the majority of the time.
When the observations are determined above, hidden states are simply chosen as the nearest 4 vertices around every observation.
2.7. Definition of Feature Functions
A feature function defines the extent to which the observation supports two consecutive states. A high value of the feature function indicates stronger support [
13]. As the length of the positions is used to choose observations, the feature function is selected as the orientation of two consecutive observations:
where
is the orientation variance of two consecutive observations and we set
= 22.5°in our INS system.
is the orientation of the edge between states
and
, while
is the orientation of two consecutive observations. This is the only feature function used in CRFs.
Therefore, Equation (8) can be rewritten as:
A sliding window is used to select the most probable states and the length of the window is set as 2.4 m. Therefore, four positions () need to be estimated using CRF algorithm in every window, with the window sliding 0.8 m.
2.8. Feedback Technique
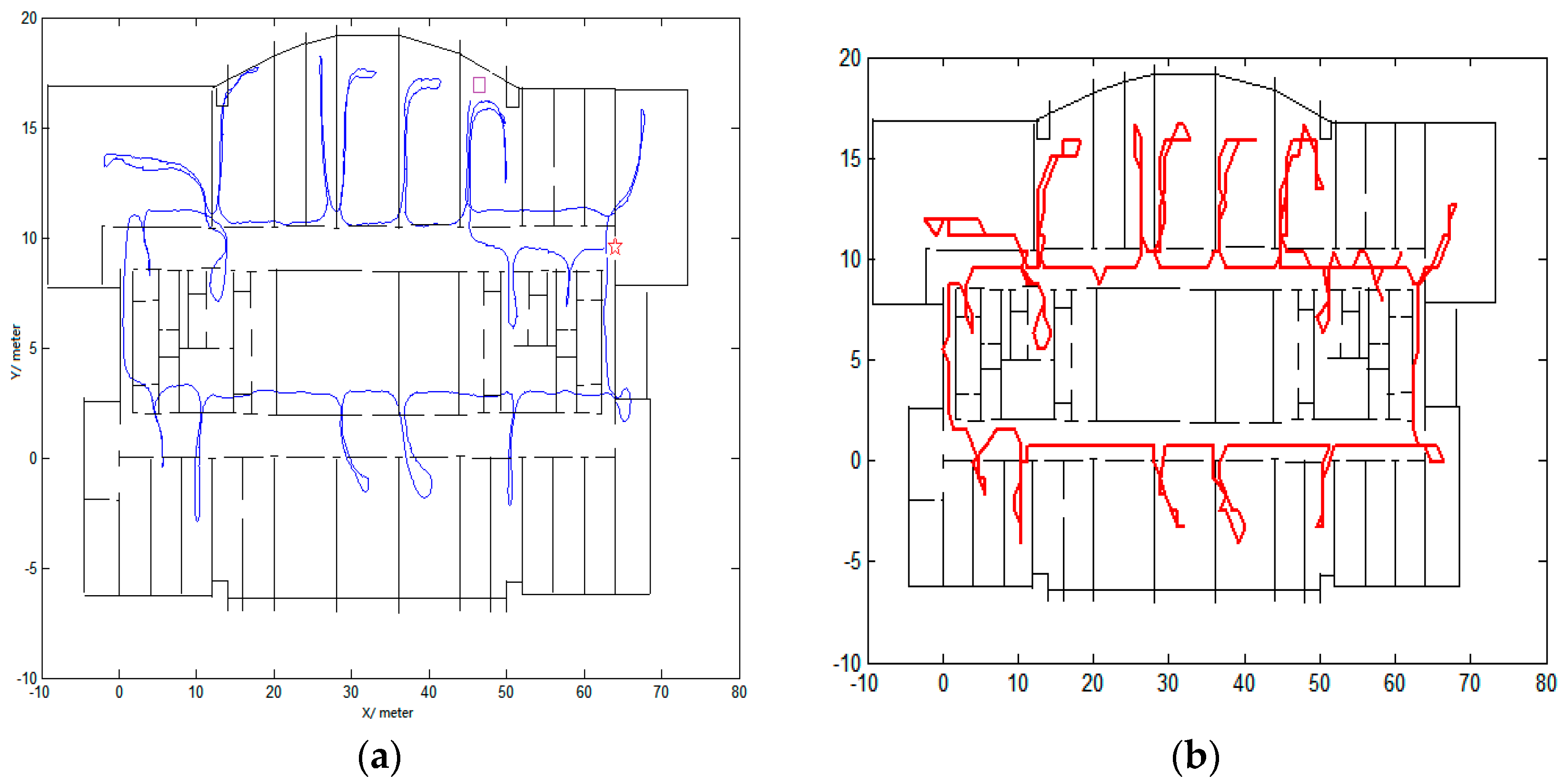
Another technique employed in this paper is the feedback of the output sequence of CRFs to the inertial navigation algorithm to obtain more accurate positions as shown in
Figure 1. The output sequence of CRFs is the estimated positions, denoted as
and
, which feedback to inertial navigation algorithm to replace the raw positions from inertial navigation algorithm, and the subsequent positions are recalculated from these estimated positions:
where
means
coordinate in position
.
means
coordinate in position
. Experiments in
Section 3 will show the effect.

{kind=link}
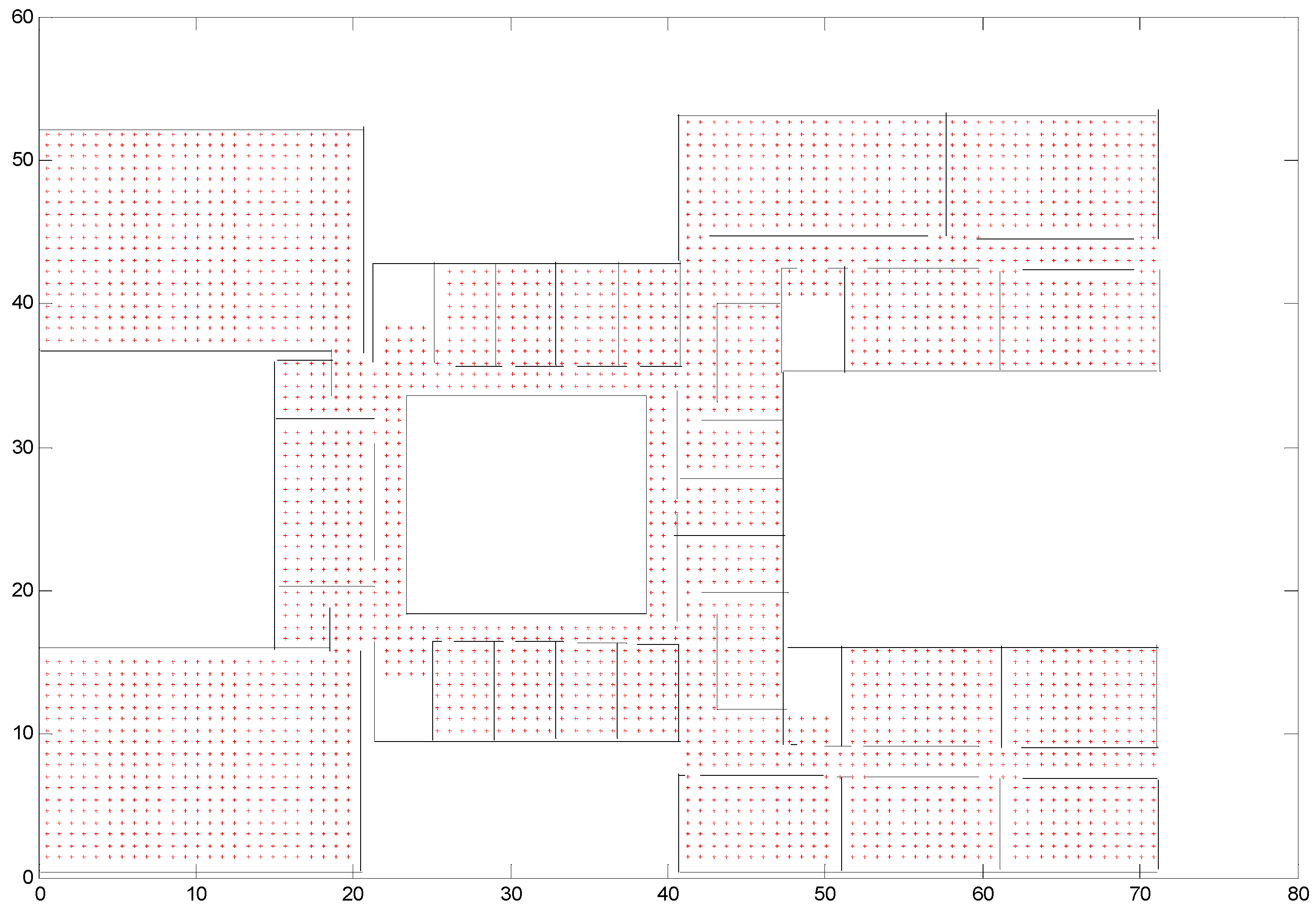{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






