
Loss of CHGA Protein as a Potential Biomarker for Colon Cancer Diagnosis: A Study on Biomarker Discovery by Machine Learning and Confirmation by Immunohistochemistry in Colorectal Cancer Tissue Microarrays

 , , and
, , and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Patients’ Information
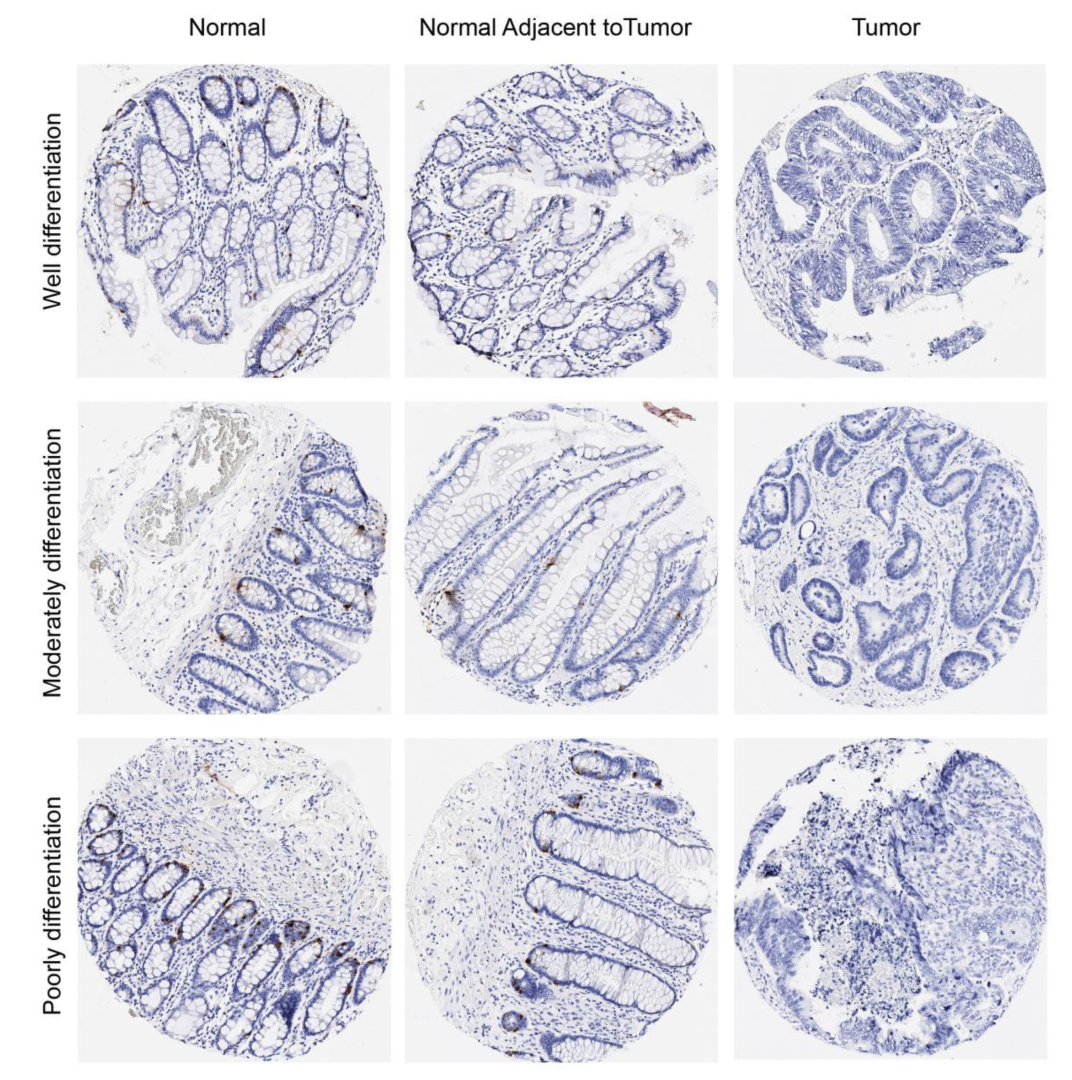
2.2. The Measurements of CHGA Expression by IHC
2.3. Data Collection
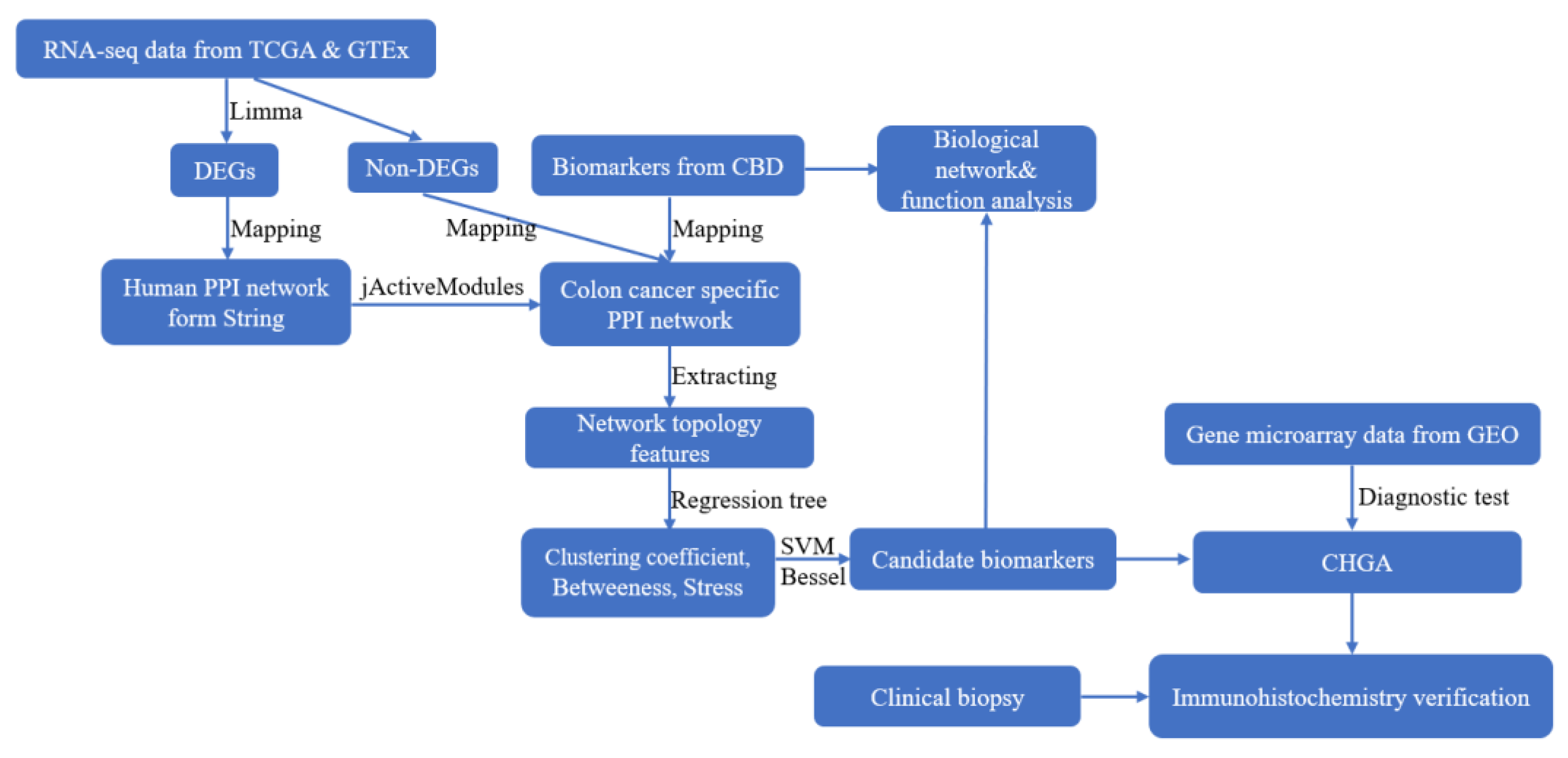
2.4. Colon Cancer Specific PPI Network Construction
2.5. Prediction Model Construction
2.6. ROC Test for the Predicted Biomarkers
2.7. PPI Network and Biological Function Analysis
2.8. Multiple Biomarkers Identification
3. Results
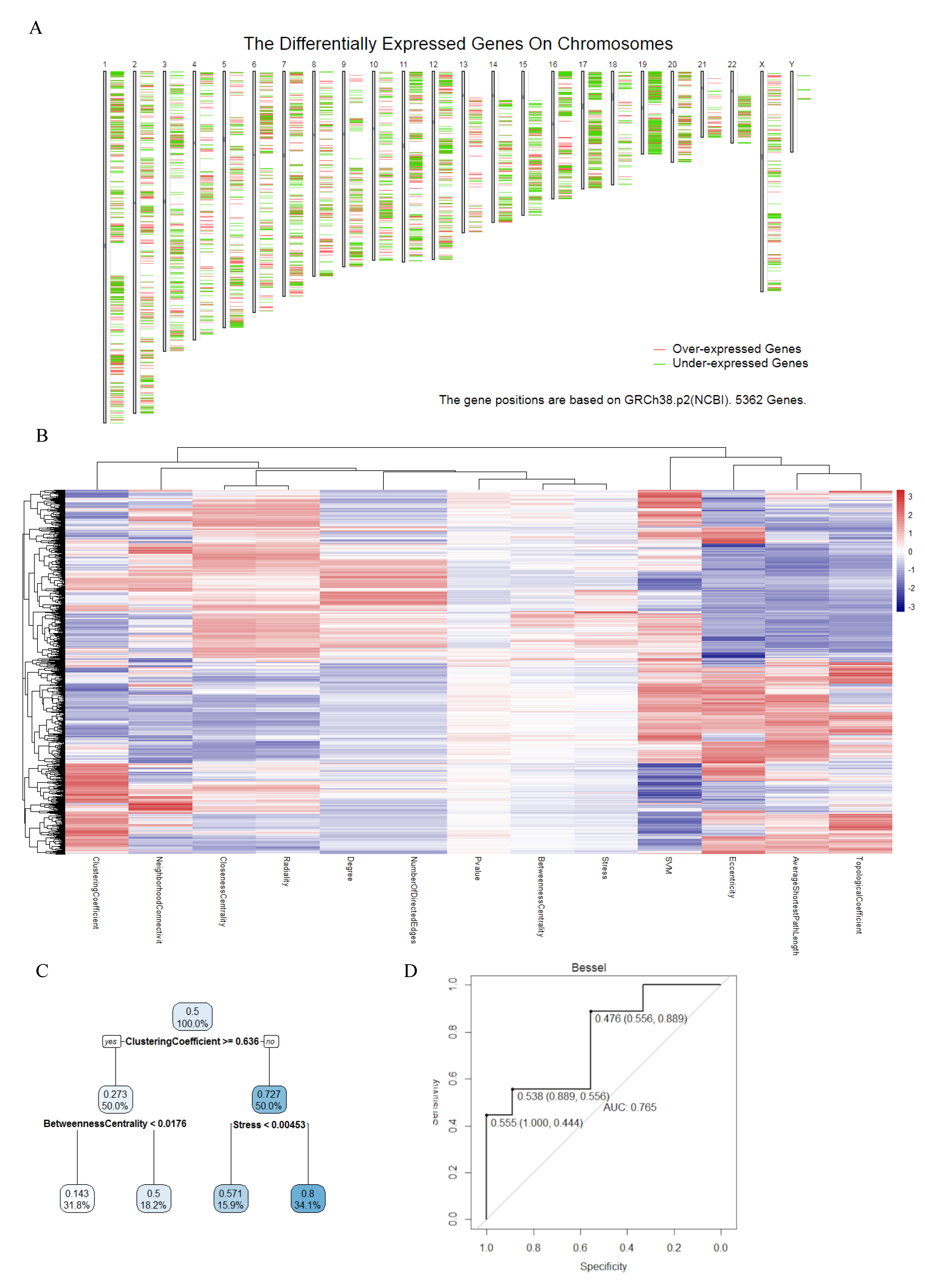
3.1. Colon Cancer Specific Protein-Protein Interaction Network (CCS-PPIN)
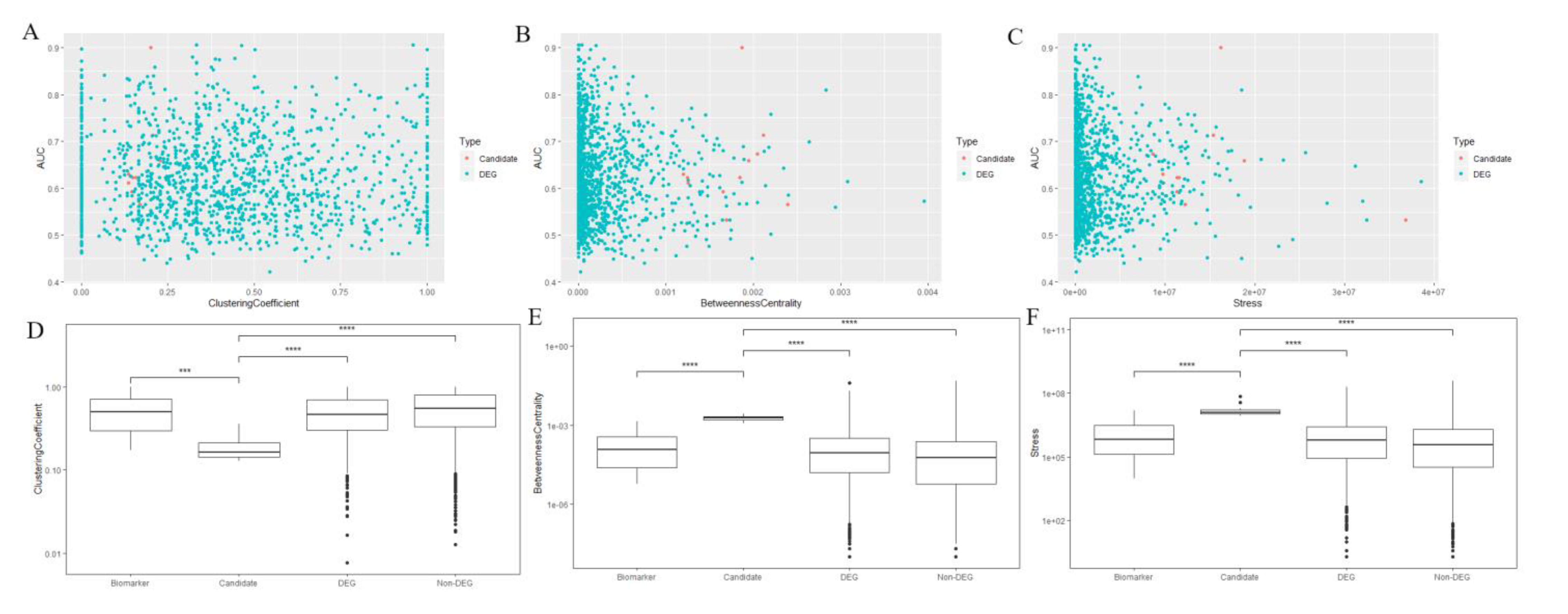
3.2. Machine Learning Based Biomarker Prediction
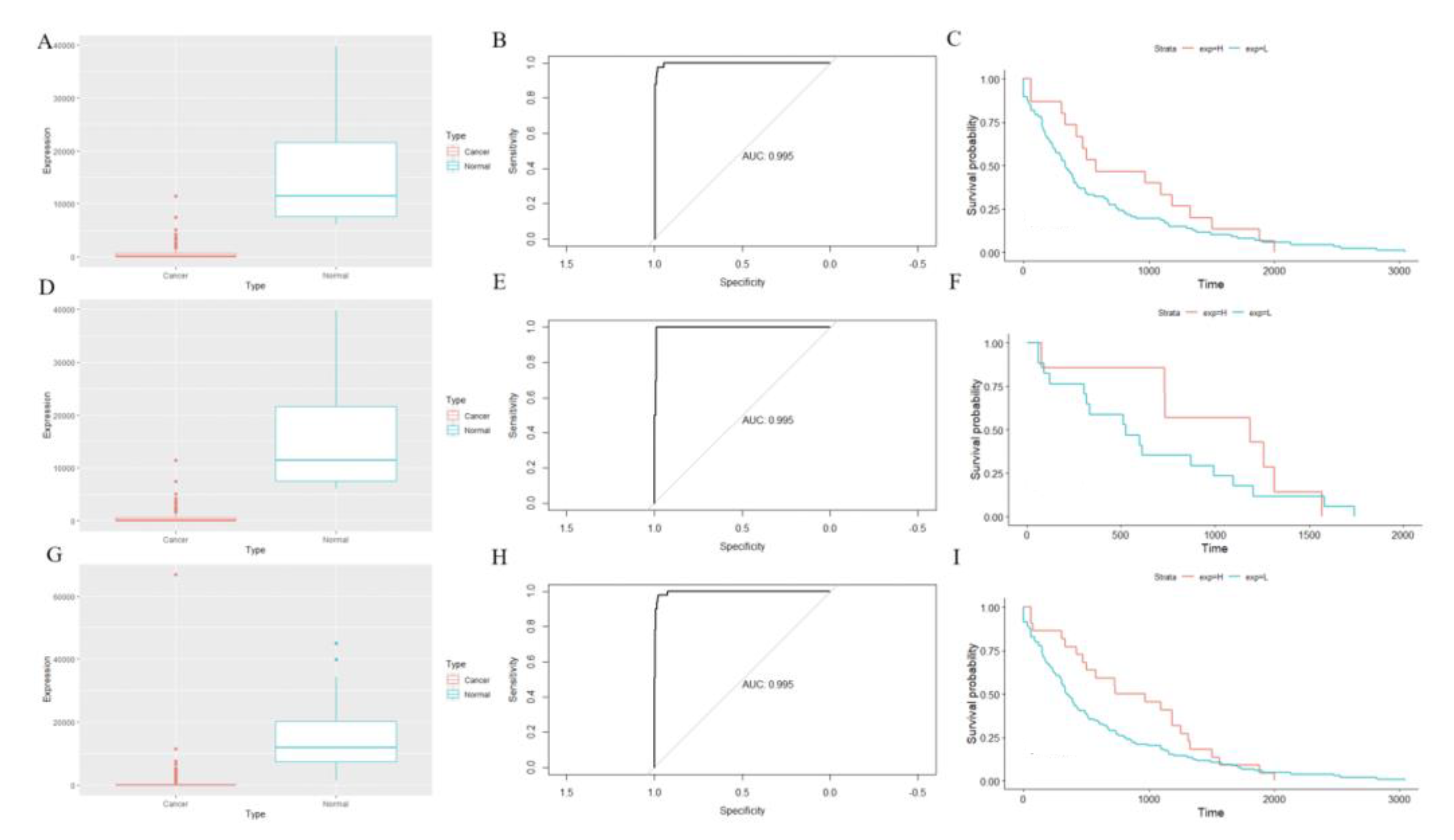
3.3. Verification of Predicted Biomarkers
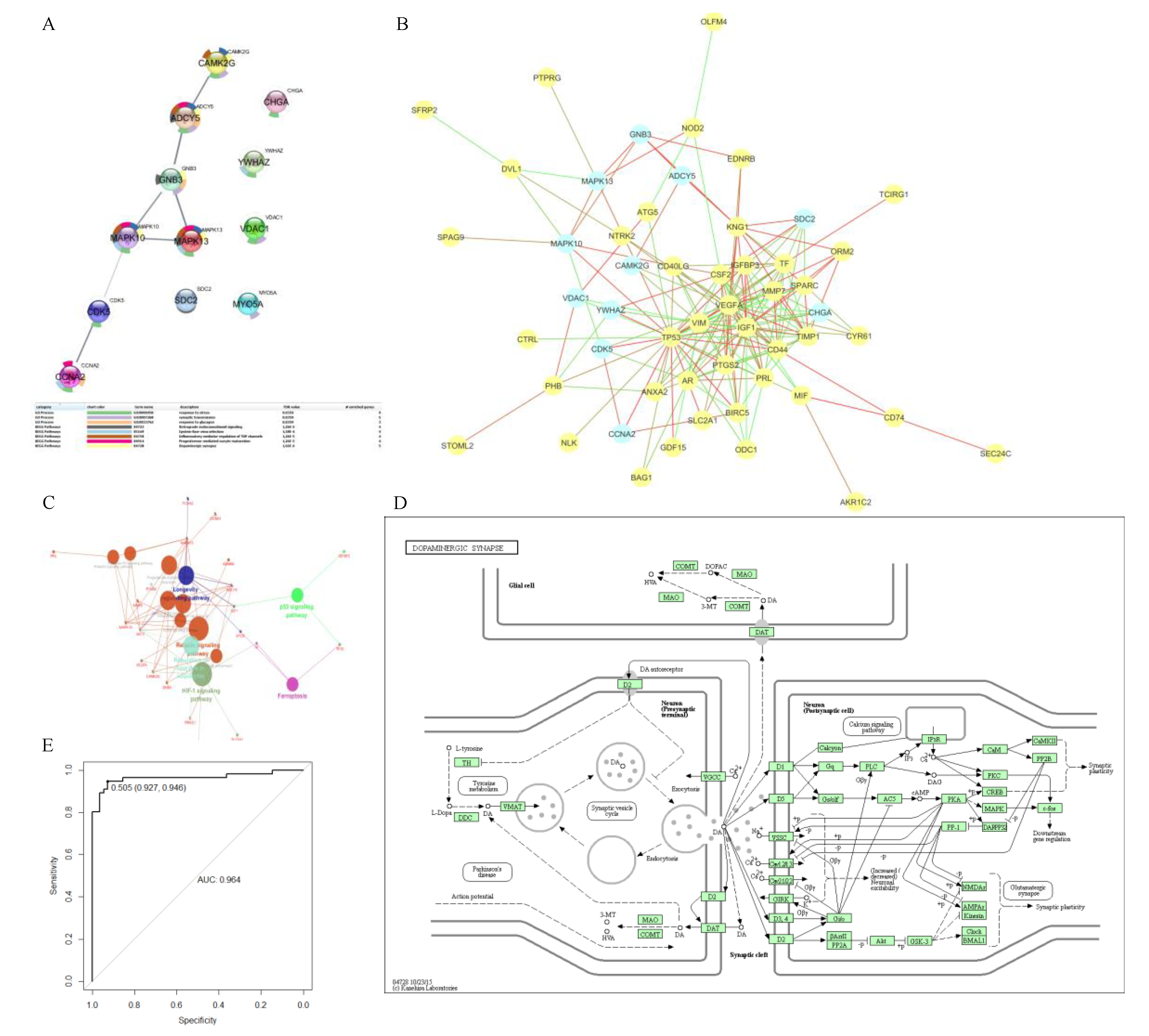
3.4. PPI Network and Biological Function Analysis for Predicted Biomarkers
3.5. Relationship for Reported and Predicted Biomarkers on PPI Network and Biological Function
3.6. Identification of Multiple Biomarker
3.7. Verification for CHGA
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cancer Genome Atlas Network. Comprehensive molecular characterization of human colon and rectal cancer. Nature 2012, 487, 330–337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Siegel, R.L.; Miller, K.D.; Goding Sauer, A.; Fedewa, S.A.; Butterly, L.F.; Anderson, J.C.; Cercek, A.; Smith, R.A.; Jemal, A. Colorectal cancer statistics, 2020. CA Cancer J. Clin. 2020, 70, 145–164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brenner, H.; Kloor, M.; Pox, C.P. Colorectal cancer. Lancet 2014, 383, 1490–1502. [Google Scholar] [CrossRef]
- Dekker, E.; Tanis, P.J.; Vleugels, J.L.A.; Kasi, P.M.; Wallace, M.B. Colorectal cancer. Lancet 2019, 394, 1467–1480. [Google Scholar] [CrossRef]
- Weitz, J.; Koch, M.; Debus, J.; Höhler, T.; Galle, P.R.; Büchler, M.W. Colorectal cancer. Lancet 2005, 365, 153–165. [Google Scholar] [CrossRef]
- Vacante, M.; Borzi, A.M.; Basile, F.; Biondi, A. Biomarkers in colorectal cancer: Current clinical utility and future perspectives. World J. Clin. Cases 2018, 6, 869–881. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Sun, X.; Cao, Y.; Ye, B.; Peng, Q.; Liu, X.; Shen, B.; Zhang, H. CBD: A biomarker database for colorectal cancer. Database 2018, 2018, bay046. [Google Scholar] [CrossRef] [Green Version]
- Yiu, A.J.; Yiu, C.Y. Biomarkers in Colorectal Cancer. Anticancer Res. 2016, 36, 1093–1102. [Google Scholar]
- Hisada, Y.; Mackman, N. Cancer-associated pathways and biomarkers of venous thrombosis. Blood 2017, 130, 1499–1506. [Google Scholar] [CrossRef]
- Wang, H.; Li, X.; Zhou, D.; Huang, J. Autoantibodies as biomarkers for colorectal cancer: A systematic review, meta-analysis, and bioinformatics analysis. Int. J. Biol. Markers 2019, 34, 334–347. [Google Scholar] [CrossRef] [Green Version]
- Rotte, A. Combination of CTLA-4 and PD-1 blockers for treatment of cancer. J. Exp. Clin. Cancer Res. 2019, 38, 255. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://www.cancer.org/cancer/colon-rectal-cancer/about/what-is-colorectal-cancer.html (accessed on 8 April 2020).
- Takeda, A.; Shimada, H.; Nakajima, K.; Yoshimura, S.; Suzuki, T.; Asano, T.; Ochiai, T.; Isono, K. Serum p53 antibody as a useful marker for monitoring of treatment of superficial colorectal adenocarcinoma after endoscopic resection. Int. J. Clin. Oncol. 2001, 6, 45–49. [Google Scholar] [CrossRef] [PubMed]
- Bouzourene, H.; Gervaz, P.; Cerottini, J.-P.; Benhattar, J.; Chaubert, P.; Saraga, E.; Pampallona, S.; Bosman, F.; Givel, J.-C. p53 and Ki-ras as prognostic factors for Dukes’ stage B colorectal cancer. Eur. J. Cancer 2000, 36, 1008–1015. [Google Scholar] [CrossRef]
- Cho, D.Y.; Kim, Y.A.; Przytycka, T.M. Chapter 5: Network biology approach to complex diseases. PLoS Comput. Biol. 2012, 8, e1002820. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sun, X.F.; Shen, B.; Zhang, H. Potential Applications of DNA, RNA and Protein Biomarkers in Diagnosis, Therapy and Prognosis for Colorectal Cancer: A Study from Databases to AI-Assisted Verification. Cancers 2019, 11, 172. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhang, H.; Shen, B.; Sun, X.F. Chromogranin-A Expression as a Novel Biomarker for Early Diagnosis of Colon Cancer Patients. Int. J. Mol. Sci. 2019, 20, 2919. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhang, H.; Shen, B.; Sun, X.F. Novel MicroRNA Biomarkers for Colorectal Cancer Early Diagnosis and 5-Fluorouracil Chemotherapy Resistance but Not Prognosis: A Study from Databases to AI-Assisted Verifications. Cancers 2020, 12, 341. [Google Scholar] [CrossRef] [Green Version]
- Szklarczyk, D.; Gable, A.L.; Lyon, D.; Junge, A.; Wyder, S.; Huerta-Cepas, J.; Simonovic, M.; Doncheva, N.T.; Morris, J.H.; Bork, P.; et al. STRING v11: Protein-protein association networks with increased coverage, supporting functional discovery in genome-wide experimental datasets. Nucleic Acids Res. 2019, 47, D607–D613. [Google Scholar] [CrossRef] [Green Version]
- Larrañaga, P.; Calvo, B.; Santana, R.; Bielza, C.; Galdiano, J.; Inza, I.; Lozano, J.A.; Armañanzas, R.; Santafé, G.; Pérez, A.; et al. Machine learning in bioinformatics. Brief. Bioinform. 2006, 7, 86–112. [Google Scholar] [CrossRef] [Green Version]
- Bruno Stecanella. Support Vector Machines (SVM) Algorithm Explained. Available online: https://monkeylearn.com/blog/introduction-to-support-vector-machines-svm/ (accessed on 24 March 2020).
- Liu, W.-T.; Wang, Y.; Zhang, J.; Ye, F.; Huang, X.-H.; Li, B.; He, Q.-Y. A novel strategy of integrated microarray analysis identifies CENPA, CDK1 and CDC20 as a cluster of diagnostic biomarkers in lung adenocarcinoma. Cancer Lett. 2018, 425, 43–53. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, M.; Zhu, H.; Xu, J. A 15-gene signature for prediction of colon cancer recurrence and prognosis based on SVM. Gene 2017, 604, 33–40. [Google Scholar] [CrossRef] [PubMed]
- Cun, Y.; Frohlich, H. Network and data integration for biomarker signature discovery via network smoothed T-statistics. PLoS ONE 2013, 8, e73074. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baumgartner, C.; Osl, M.; Netzer, M.; Baumgartner, D. Bioinformatic-driven search for metabolic biomarkers in disease. J. Clin. Bioinform. 2011, 1, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, N.; Cui, W.; Jiang, X.; Zhang, Z.; Gnosa, S.; Ali, Z.; Jensen, L.; Jönsson, J.-I.; Blockhuys, S.; Lam, E.W.-F.; et al. The Critical Role of Dysregulated RhoB Signaling Pathway in Radioresistance of Colorectal Cancer. Int. J. Radiat. Oncol. Biol. Phys. 2019, 104, 1153–1164. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.-M.; Mi, Y.-S.; Yu, F.-D.; Han, Y.; Liu, X.-S.; Lu, S.; Zhang, Y.; Zhao, S.-L.; Ye, L.; Liu, T.-T.; et al. SERPINA4 is a novel independent prognostic indicator and a potential therapeutic target for colorectal cancer. Am. J. Cancer Res. 2016, 6, 1636–1649. [Google Scholar] [PubMed]
- Helman, L.J.; Ahn, T.G.; Levine, M.; Allison, A.; Cohen, P.S.; Cooper, M.J.; Cohn, D.V.; A Israel, M. Molecular cloning and primary structure of human chromogranin A (secretory protein I) cDNA. J. Biol. Chem. 1988, 263, 11559–11563. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, H.; Zhou, Z.G.; Yan, H.; Adell, G.; Sun, X.F. Biological function and prognostic significance of peroxisome proliferator-activated receptor delta in rectal cancer. Clin. Cancer Res. 2011, 17, 3760–3770. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gunay, F.S.D.; Kırmızı, B.A.; Ensari, A.; İcli, F.; Akbulut, H. Tumor-associated Macrophages and Neuroendocrine Differentiation Decrease the Efficacy of Bevacizumab Plus Chemotherapy in Patients with Advanced Colorectal Cancer. Clin. Colorectal Cancer 2019, 18, e244–e250. [Google Scholar] [CrossRef] [PubMed]
- Siegel, R.L.; Miller, K.D.; Jemal, A. Cancer statistics, 2020. CA Cancer J. Clin. 2020, 70, 7–30. [Google Scholar] [CrossRef]
- Barabasi, A.L.; Gulbahce, N.; Loscalzo, J. Network medicine: A network-based approach to human disease. Nat. Rev. Genet. 2011, 12, 56–68. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Biopsy (n = 22) | Primary Tumor (n = 55) | Metastatic Lymph Node (n = 22) | Adjacent Normal Mucosa (n = 46) | Distant Normal Mucosa (n = 53) |
|---|---|---|---|---|---|
| Sex | |||||
| Male | 10 | 27 | 12 | 23 | 27 |
| Female | 12 | 28 | 10 | 23 | 26 |
| Age | |||||
| ≤70 years | 14 | 23 | 8 | 19 | 23 |
| >70 years | 8 | 32 | 14 | 27 | 30 |
| Primary tumor location | |||||
| Colon | 11 | 44 | 18 | 37 | 43 |
| Rectum | 11 | 11 | 4 | 9 | 10 |
| TNM stage | |||||
| I | 4 | 7 | 0 | 6 | 7 |
| II | 10 | 13 | 0 | 11 | 14 |
| III | 8 | 30 | 20 | 24 | 27 |
| IV | 0 | 5 | 2 | 5 | 5 |
| Differentiation | |||||
| Well | 2 | 5 | 1 | 4 | 5 |
| Moderately | 16 | 36 | 17 | 31 | 32 |
| Poorly | 4 | 14 | 4 | 11 | 16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhang, H.; Fan, C.; Hildesjö, C.; Shen, B.; Sun, X.-F. Loss of CHGA Protein as a Potential Biomarker for Colon Cancer Diagnosis: A Study on Biomarker Discovery by Machine Learning and Confirmation by Immunohistochemistry in Colorectal Cancer Tissue Microarrays. Cancers 2022, 14, 2664. https://doi.org/10.3390/cancers14112664
Zhang X, Zhang H, Fan C, Hildesjö C, Shen B, Sun X-F. Loss of CHGA Protein as a Potential Biomarker for Colon Cancer Diagnosis: A Study on Biomarker Discovery by Machine Learning and Confirmation by Immunohistochemistry in Colorectal Cancer Tissue Microarrays. Cancers. 2022; 14(11):2664. https://doi.org/10.3390/cancers14112664
Chicago/Turabian StyleZhang, Xueli, Hong Zhang, Chuanwen Fan, Camilla Hildesjö, Bairong Shen, and Xiao-Feng Sun. 2022. "Loss of CHGA Protein as a Potential Biomarker for Colon Cancer Diagnosis: A Study on Biomarker Discovery by Machine Learning and Confirmation by Immunohistochemistry in Colorectal Cancer Tissue Microarrays" Cancers 14, no. 11: 2664. https://doi.org/10.3390/cancers14112664
APA StyleZhang, X., Zhang, H., Fan, C., Hildesjö, C., Shen, B., & Sun, X. -F. (2022). Loss of CHGA Protein as a Potential Biomarker for Colon Cancer Diagnosis: A Study on Biomarker Discovery by Machine Learning and Confirmation by Immunohistochemistry in Colorectal Cancer Tissue Microarrays. Cancers, 14(11), 2664. https://doi.org/10.3390/cancers14112664