1. Introduction
Cancer is one of the most serious health concerns that threaten the health and lives of individuals [
1]. The mortality rate and incidence of breast cancer seem to be increasing in recent times. Early precise diagnosis is considered to be a key to enhancing the chances of survival. The primary step in initial diagnosis is a mammogram, but it can be difficult to identify tumors in dense breast tissue, and X-ray radiation imposes a risk to the radiologist’s and the patient’s health [
2]. The precise diagnosis of breast cancer requires skilled histopathologists, as well as large amounts of effort and time for task completion. Furthermore, the diagnosis outcomes of various histopathologists are not the same, because they mainly depend on the former knowledge of each histopathologist [
3]. The average diagnosis precision is just 75%, which leads to low consistency in diagnoses. The term histopathology can be defined as the process of detailed evaluation and microscopic inspection of biopsy samples carried out by a pathologist or expert to learn about cancer growth in tissues or organs [
4]. Common histopathological specimens have more structures and cells that can be dispersed and surrounded haphazardly by distinct types of tissues [
5]. The physical analysis of historic pictures, along with the visual observation of such images, consumes time. This necessitates expertise and experience. In order to raise the predictive and analytical capabilities of histopathological images, the utility of computer-based image analysis represents an effective method [
6]. This form of analysis is even efficient for histopathological images because it renders a dependable second opinion for consistent study, which increases output. This could aid in curtailing the time it takes to identify an issue. Thus, the burden on pathologists and the death rate can be minimized [
7].
Today, machine learning (ML) is fruitfully enforced in text classification, image recognition, and object recognition. With the progression of computer-aided diagnosis (CAD) technology, ML is effectively implemented in breast cancer diagnosis [
8]. Histopathological image classification related to conventional ML techniques and artificial feature extraction demands a manual model of features; however, it does not need an apparatus with more efficiency, and it has benefits in the computing period [
9]. However, histopathological image classification related to deep learning (DL), particularly convolutional neural networks (CNNs), frequently needs a large number of labelled training models, whereas the labelled data are hard to gain [
10]. The labeling of lesions is laborious and time-consuming work, even for professional histopathologists.
This study develops an arithmetic optimization algorithm with deep-learning-based histopathological breast cancer classification (AOADL-HBCC) technique for healthcare decision making. The presented AOADL-HBCC technique mainly aims to recognize the presence of breast cancer in HIs. At the primary level, the AOADL-HBCC technique employs noise removal based on median filtering (MF) and a contrast enhancement process. In addition, the presented AOADL-HBCC technique applies an AOA with a SqueezeNet model to derive feature vectors. Finally, a deep belief network (DBN) classifier with an Adamax hyperparameter optimizer is applied for the breast cancer classification process. In order to exhibit the enhanced breast cancer classification results of the AOADL-HBCC approach, a wide range of simulations was performed.
2. Related Works
Shankar et al. [
11] established a new chaotic sparrow search algorithm including a deep TL-assisted BC classification (CSSADTL-BCC) technique on histopathological images (HPIs). The projected technique mostly concentrated on the classification and detection of BC. To realize this, the CSSADTL-BCC system initially carried out a Gaussian filter (GF) system for eradicating the presence of noise. In addition, a MixNet-oriented extracting feature system was utilized for generating a suitable group of feature vectors. Furthermore, a stacked GRU (SGRU) classifier system was utilized for allotting classes. In [
12], TL and deep extracting feature approaches were employed that adjusted a pretraining CNN system to the current problem. The VGG16 and AlexNet methods were considered in the projected work for extracting features and AlexNet was employed for additional finetuning. The achieved features were then classified by SVM.
Khan et al. [
13] examined a new DL infrastructure for the classification and recognition of BC from breast cytology images utilizing the model of TL. Generally, DL infrastructures demonstrated that certain problems were accomplished in isolation. In the presented structure, features in images were extracted employing pretrained CNN infrastructures such as ResNet, GoogLeNet, and VGGNet that are provided as fully connected (FC) layers to classify benign and malignant cells employing an average pooling classifier. In [
14], a DL-related TL system was presented for classifying histopathological images automatically. Two famous and present pretrained CNN techniques, DenseNet161 and ResNet50, were trained as well as tested via grayscale and color images.
Singh et al. [
15] examined a structure dependent upon the concept of TL for addressing this problem and concentrated their efforts on HPI and imbalanced image classifiers. The authors utilized common VGG19 as the base method and complemented it with different recent approaches for improving the entire efficiency of the technique. In [
16], the conventional softmax and SVM-classifier-related TL systems were estimated for classifying histopathological cancer images in a binary BC database and a multiclass lung and colon cancer database. For achieving optimum classifier accuracy, a procedure that assigns an SVM technique to an FC layer of softmax-related TL techniques was presented. In [
17], the authors’ concentration on BC in HPI was attained by utilizing microscopic scans of breast tissues. The authors proposed two integrated DCNNs for extracting well-known image features utilizing TL. The pretrained Xception and Inception techniques were utilized in parallel. Afterwards, feature maps were integrated and decreased by dropout before they provided the final FC layer to classify.
3. The Proposed Model
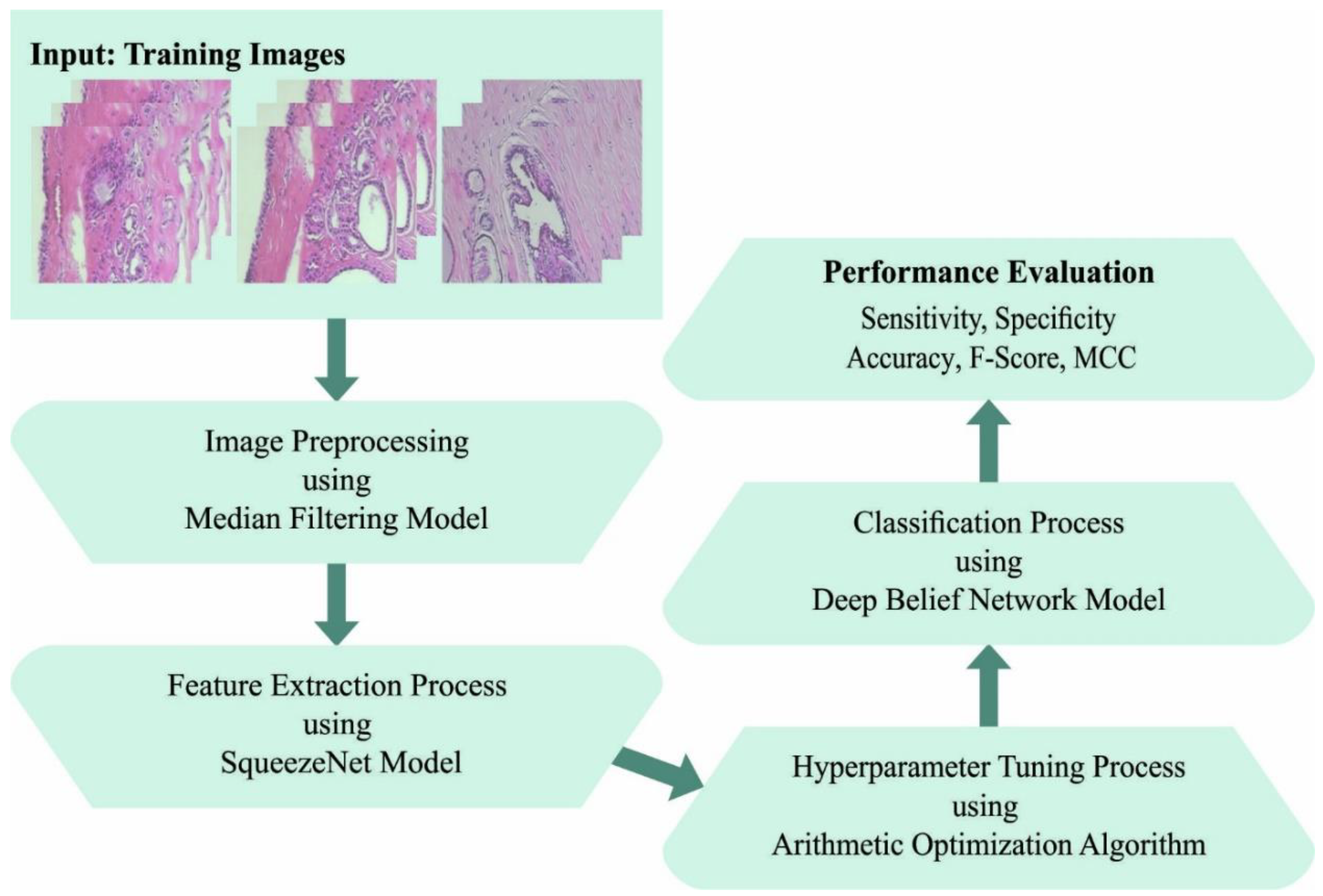
In this work, an automated breast cancer classification method, named the AOADL-HBCC technique, was developed using HIs. The presented AOADL-HBCC technique mainly aims to recognize the presence of breast cancer in HIs. It encompasses a series of processes, namely SqueezeNet feature extraction, AOA hyperparameter tuning, DBN classification, and an Adamax optimizer.
Figure 1 shows a block diagram of the AOADL-HBCC mechanism.
3.1. Design of AOA with SqueezeNet Model
In this study, the presented AOADL-HBCC technique utilized an AOA with a SqueezeNet model to derive feature vectors. Presently, GoogLeNet, ResNet, VGG, AlexNet, etc., are signature techniques of DNN [
18]. However, deep networks might lead to remarkable performance; this method is trained and recognition speed is reduced. Since the residual architecture does not enhance the module variable, the complexity of the trained degradation and gradient disappearance is effectively mitigated, and the convergence efficacy of the module is improved. Thus, the SqueezeNet architecture was applied as a backbone network to extract features.
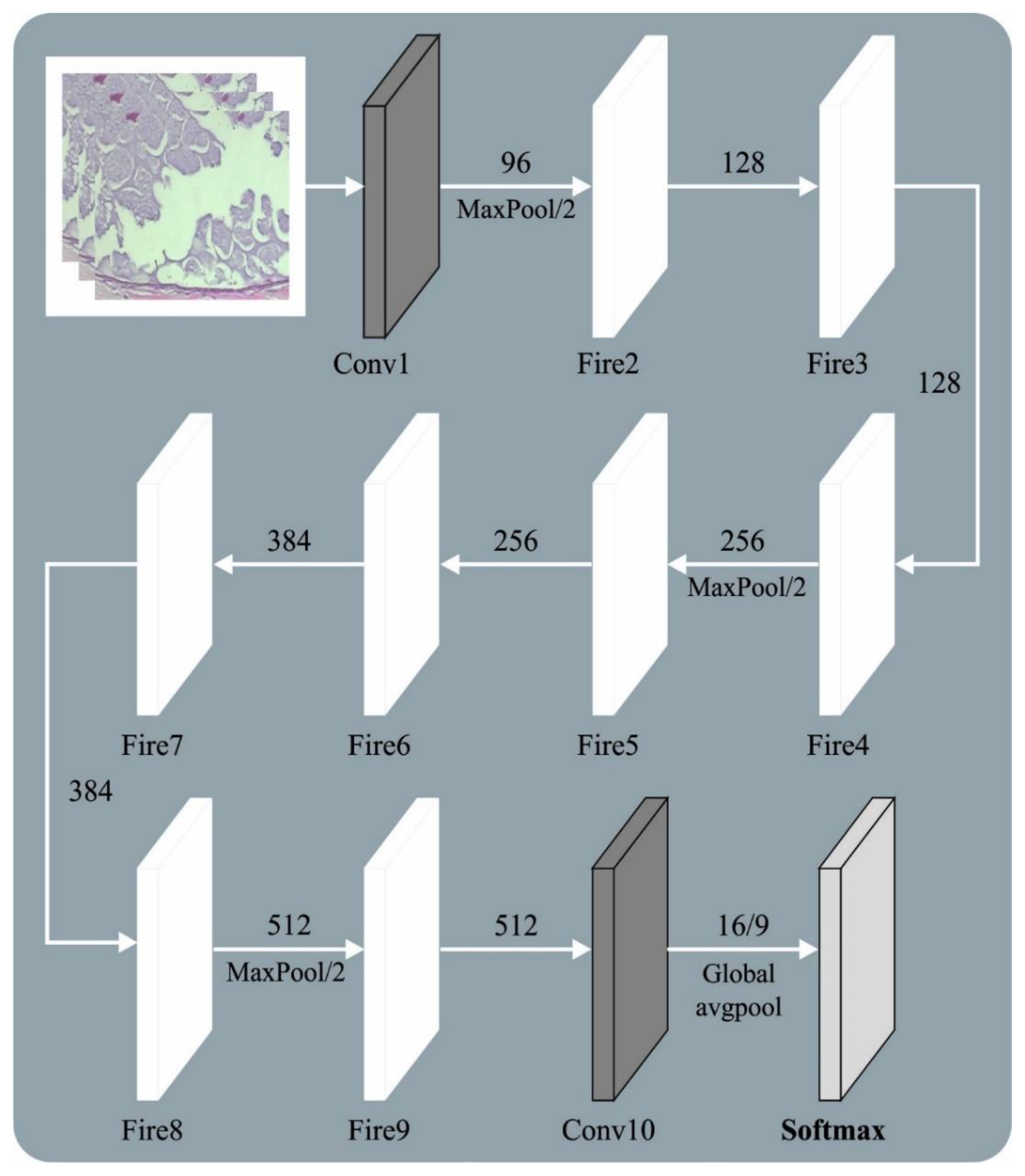
Figure 2 showcases the framework of the SqueezeNet method.
Compared with AlexNet and VGGNet, the SqueezeNet architecture has a smaller number of parameters. The fire module was the primary approach from SqueezeNet. This approach was classified into expand and squeeze structures. The squeeze encompasses convolutional kernels. The expand layer includes and convolutional kernels. The number of convolutional kernels is and the number of convolutional kernels is The model must satisfy . Thus, convolution is added to each inception module, the number of input networks and the convolutional kernel variable are decreased, and the computation difficulty is reduced. Lastly, a convolutional layer is added to enhance the number of channels and feature extraction. SqueezeNet changes convolution with a convolutional layer to reduce the variable count to one-ninth. Image feature extraction depends on a shared convolutional layer. The lowest-level features, such as edges and angles, are detached from the basic network. The higher-level features explain that the target form is eliminated at the highest level. For demonstrating the ship target on scale, the FPN was determined to extend the backbone network; viz., it was especially efficient in the detection of smaller targets. The topmost-level feature of FPN architecture is integrated with basic features by up-sampling via each layer predicting the feature map.
To adjust the hyperparameters of the SqueezeNet method, an AOA was implemented in this work. The AOA starts with a number of arbitrary populations of objects as candidates (immersed objects) [
19]. Here, the object was initialized through arbitrary location from the fluid. The initial location of each object was accomplished as follows:
In this expression,
describes the
object from a population with
objects, along with
and
, which indicate the upper and lower boundaries of the solution space, respectively. In addition, the following indicates the location, AOA initialized density (
D), acceleration (
A), and volume (
V), to
ith object numbers:
Next, the cost value of the candidate is evaluated and stored as
, or
, based on the population. Then, the candidate is upgraded through the parameter model as follows:
In this case,
and
denote the density and volume, respectively, associated with the best object initiated before, and
indicates the arbitrary number that is uniformly distributed. The AOA applies a transfer operator (
TF) to reach exploration–exploitation:
In Equation (7),
slowly steps up from the period still accomplishing 1, and
and
indicate the iteration value and maximal iteration count, respectively. Likewise, a reduction factor of (
d) density is used to offer a global–local search:
In Equation (8),
is reduced with time that offers the ability to converge. This term renders a proper trade-off between exploitation and exploration. The exploration was stimulated on the basis of collision among objects. When
, a random material (mr) was preferred for upgrading acceleration of the object to
iteration:
Here,
,
and
denote the acceleration, volume, and density of the
object. The exploitation was stimulated based on no collision among objects. When
, the object is then upgraded as follows:
where
indicates the optimal object acceleration. The subsequent step to normalize acceleration for assessing alteration percentage is as follows:
Here,
refers to the percentage of steps, and
and
correspondingly imply the normalized limit that is fixed to 0.1 and 0. 9, respectively. When
, the location of the
ith object to the succeeding round is accomplished as follows:
In Equation (12),
denotes the constant corresponding to 2. In addition, when
, the location of the object is upgraded:
In this expression,
denotes a constant number corresponding to 6.
enhances with time from a range
and obtains a determined percentage in the best location. This percentage slowly enhances to diminish the variance among optimum and present locations to offer an optimal balance between exploration and exploitation.
shows the flag for changing the motion path as
while
Finally, the value of each object was assessed through a cost function and returned the optimal solution once the end state was satisfied.
The AOA method extracts a fitness function (FF) to receive enhanced classifier outcomes. It sets a positive value that signifies the superior outcome of the candidate’s solutions. In this work, the minimized classifier error rate is indicated as the FF, as provided in Equation (16).
3.2. Breast Cancer Classification Using Optimal DBN Model
Finally, an Adamax optimizer with the DBN method was applied for the breast cancer classification process (Algorithm 1). A DBN is a stack of RBM, excluding the primary RBM that has an undirected connection [
20]. Significantly, this network architecture creates DL possibilities and reduces training complexity. The simple and effective layer-wise trained method was developed for DBN by Hinton. It consecutively trains layers and greedily trains by tying the weight of unlearned layers, applying CD to learn the weight of a single layer and iterating until all the layers are trained. Then, the network weight was finetuned through a two-pass up-down model, and this illustrates that the network learned without pretraining, since this phase implemented as regular and assisted with the supervised optimized problem. The energy constrained from the directed approach was calculated where the maximal energy was upper-bounded and accomplished equivalence, whether the network weight was tied or not, as follows:
Then, iteratively learning the weight of the network, the up-down approach was used to finetune the network weight. The wake-sleep approach is an unsupervised algorithm applied to train NNs from two phases: the “wake” phase was implemented on the feedforward path to compute weight and the “sleep” phase was executed on the feedback path. The up-down approach was executed to network for decreasing underfit that could usually be detected by a greedily trained network. Particularly in the primary phase, the weight on the directed connection was from named parameters or generative weight that can be adjusted by updating the weight utilizing CD, calculating the wake-phase probability, and sampling the states. Then, the prior layer was stochastically stimulated with top-down connections called inference weights or parameters. The sleep-stage probability was calculated, the state was sampled, and the result was estimated.
For optimizing the training efficacy of the DBN, the Adamax optimizer was employed for altering the hyperparameter values [
21]:
where
In this expression, η denotes the learning rate,
represents the weight at
step,
indicates the cost function, and
specifies the gradient of the
weight variable.
is exploited to select the data needed for the old upgrade, where
and
represent the first and second moments.
| Algorithm 1. Pseudocode of Adamax |
: Rate of Learning
, ,1): Exponential decomposing value to moment candidate
: The cost function with variable
: Primary parameter vector
(Apply time step)
while does not converge apply
end while
displaying (end variable) |
4. Experimental Validation
This section examines the breast cancer classification results of the AOADL-HBCC model on a benchmark dataset [
22]. The dataset holds two sub-datasets, namely the 100× dataset and the 200× dataset, as represented in
Table 1.
Figure 3 illustrates some sample images.
The proposed model was simulated using Python 3.6.5 tools on PC i5-8600k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1 TB HDD. The parameter settings were given as follows: learning rate: 0.01, dropout: 0.5, batch size: 5, epoch count: 50, and activation: ReLU.
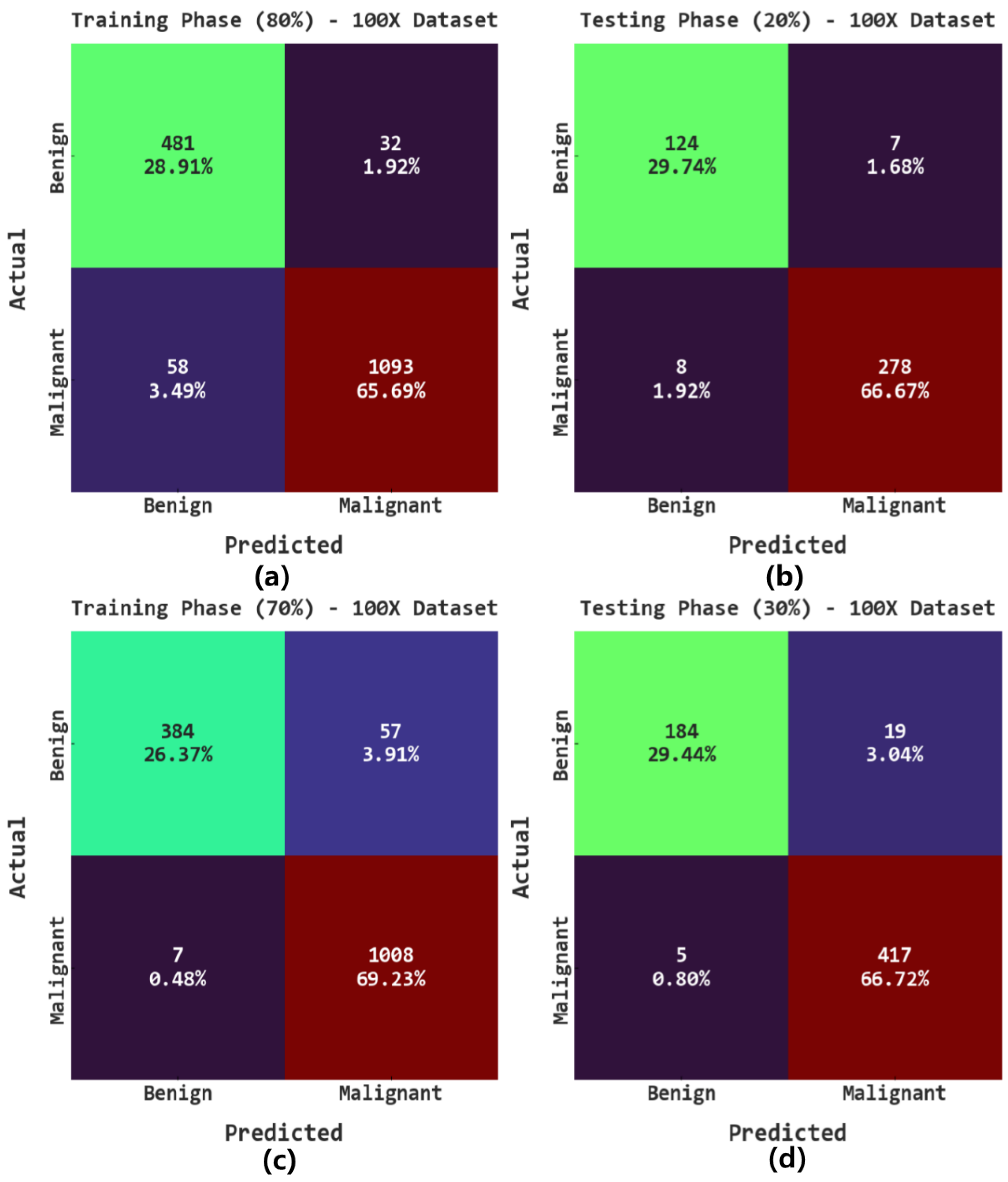
The confusion matrices of the AOADL-HBCC model on the 100× dataset are reported in
Figure 4. This figure implies the AOADL-HBCC method proficiently recognized and sorted the HIs into malignant and benign classes in all aspects.
Table 2 reports the overall breast cancer classification outcomes of the AOADL-HBCC method on the 100× database. The outcomes indicate that the AOADL-HBCC approach recognized both benign and malignant classes proficiently. For example, in the 80% TR database, the AOADL-HBCC method revealed an average
of 94.59%,
of 94.36%,
of 94.36%,
of 93.75%, and MCC of 87.55%. Simultaneously, in the 20% TS database, the AOADL-HBCC method exhibited an average
of 96.40%,
of 95.93%,
of 95.93%,
of 95.83%, and MCC of 91.67%. Concurrently, in the 70% TR database, the AOADL-HBCC approach displayed an average
of 95.60%,
of 93.19%,
of 93.19%,
of 94.62%, and MCC of 89.56%.
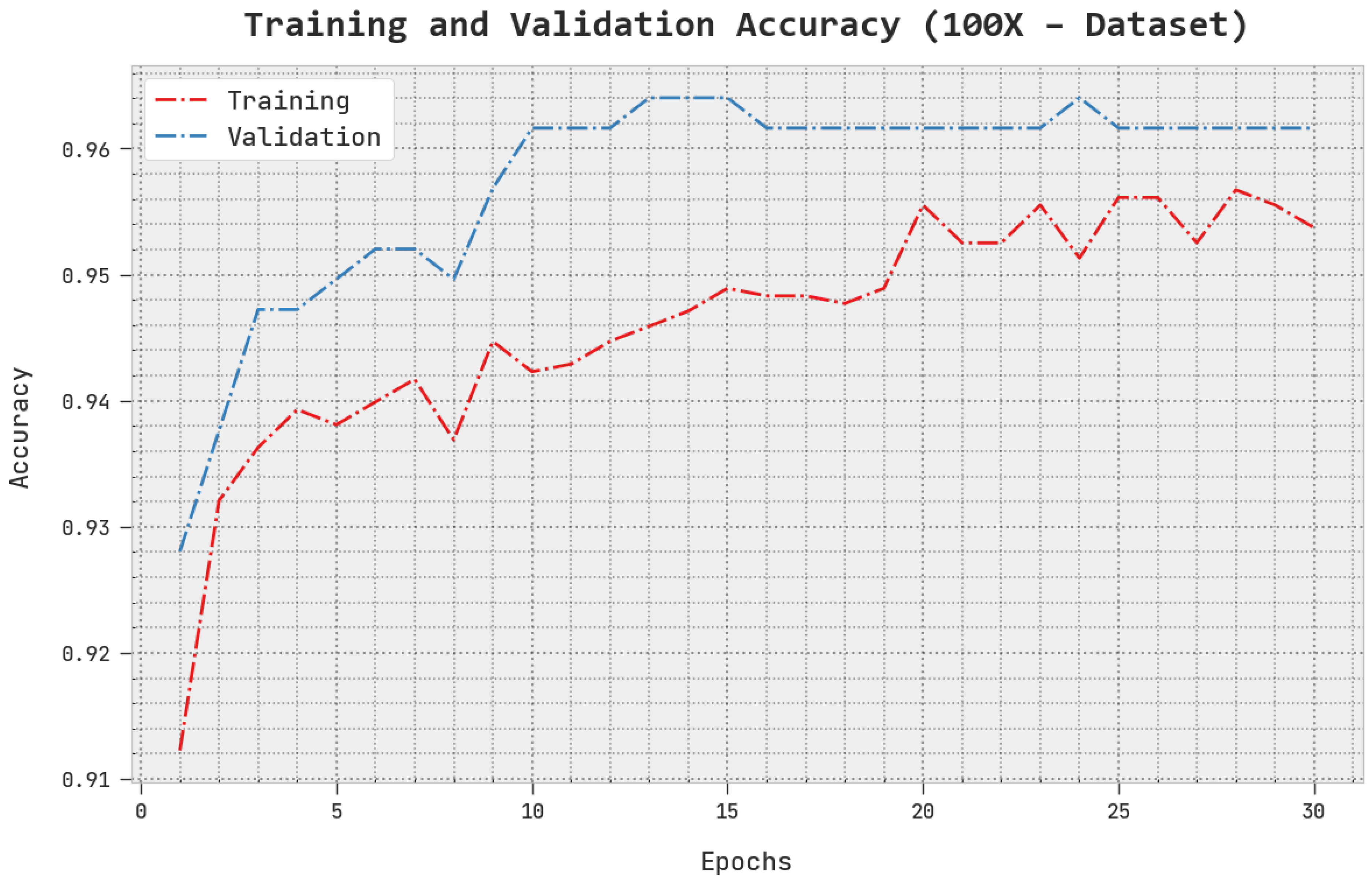
The TACC and VACC of the AOADL-HBCC technique under the 100× dataset are inspected on BCC performance in
Figure 5. This figure indicates that the AOADL-HBCC method displayed enhanced performance with increased values of TACC and VACC. It is noted that the AOADL-HBCC algorithm gained maximum TACC outcomes.
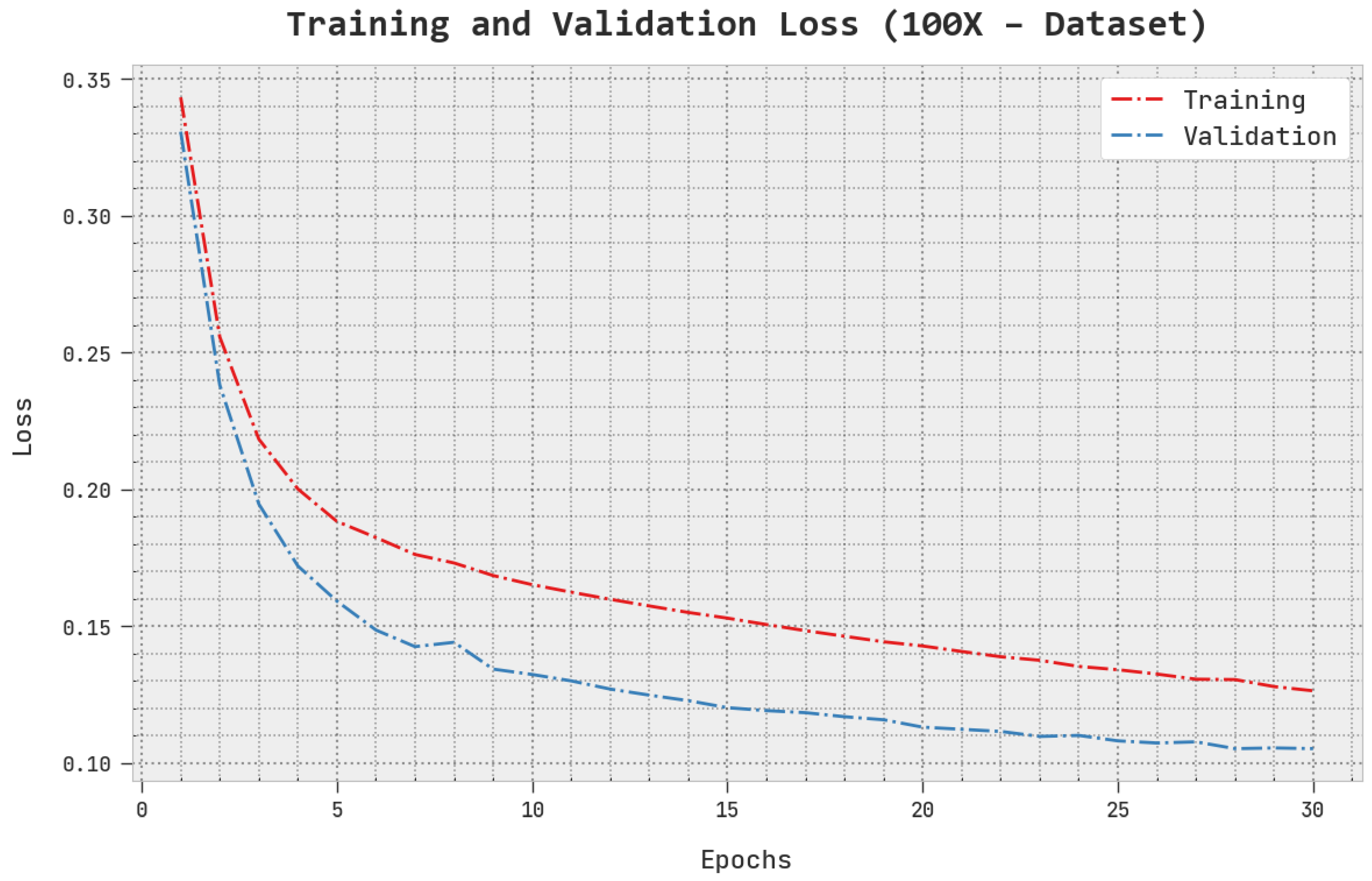
The TLS and VLS of the AOADL-HBCC approach under the 100× dataset are tested on BCC performance in
Figure 6. This figure shows that the AOADL-HBCC method exhibited better performance with minimal values of TLS and VLS. It is noted the AOADL-HBCC approach resulted in reduced VLS outcomes.
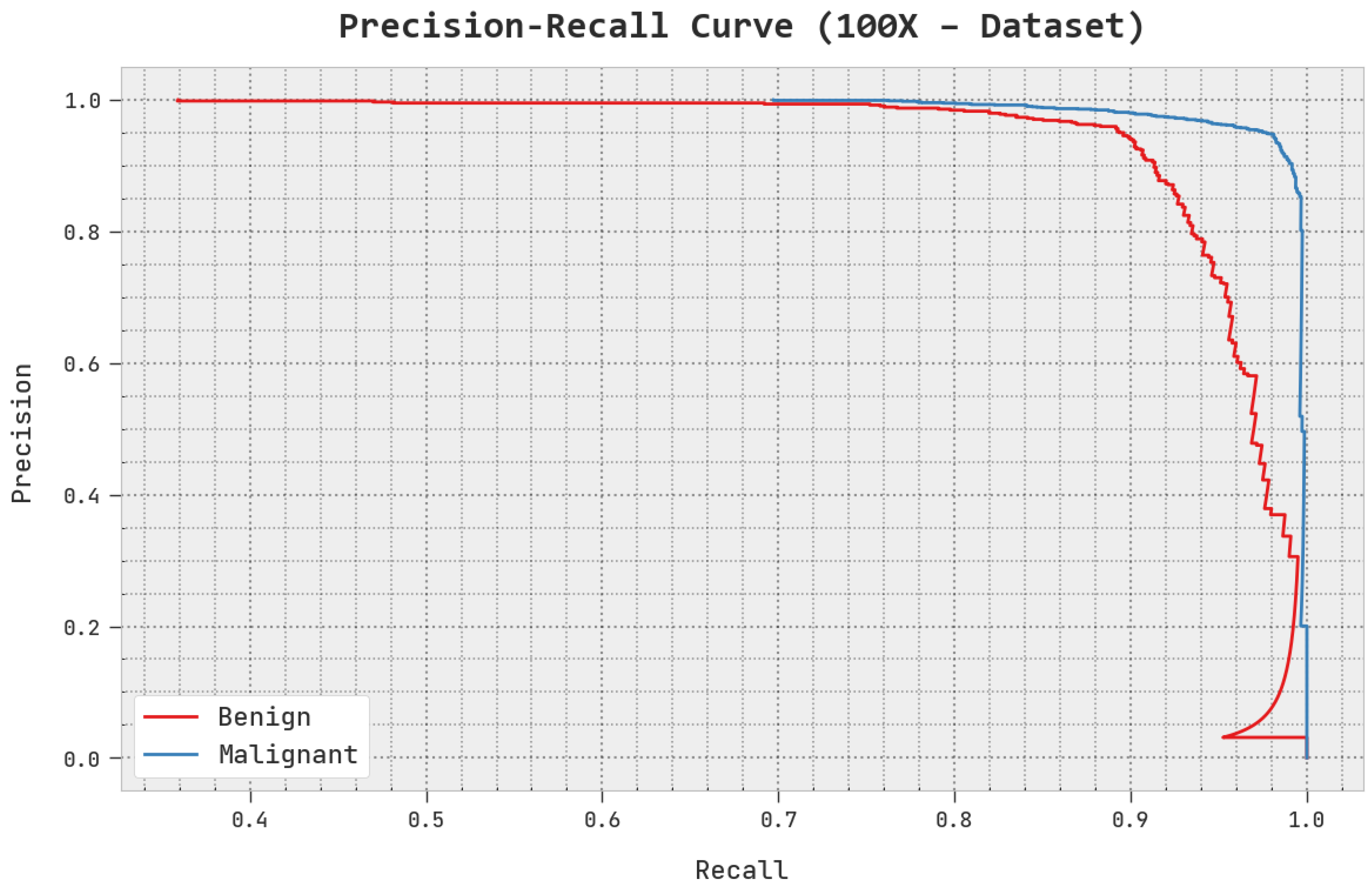
A clear precision–recall investigation of the AOADL-HBCC methodology under the test database is given in
Figure 7. This figure exhibits that the AOADL-HBCC system enhanced precision–recall values in every class label.
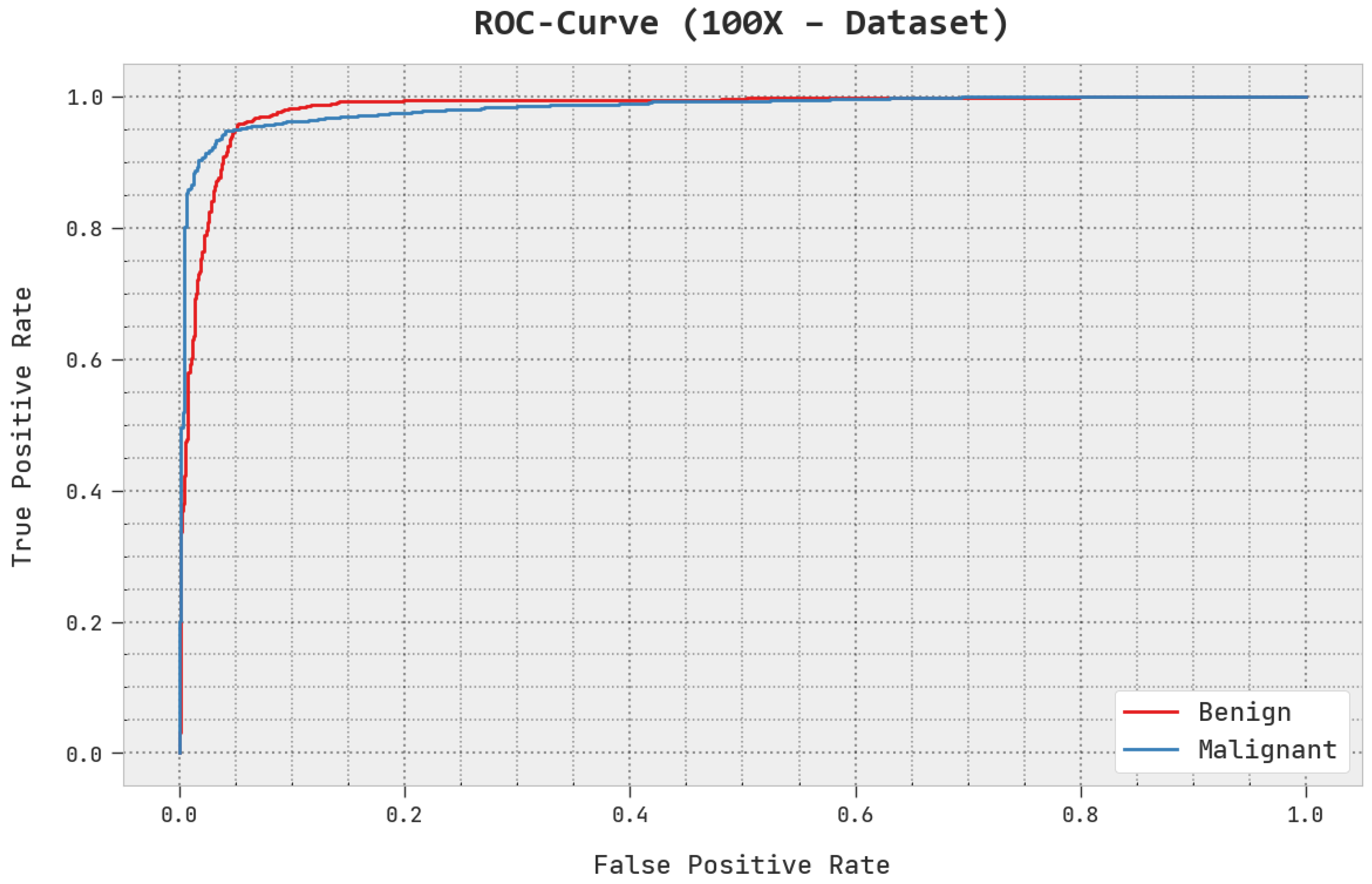
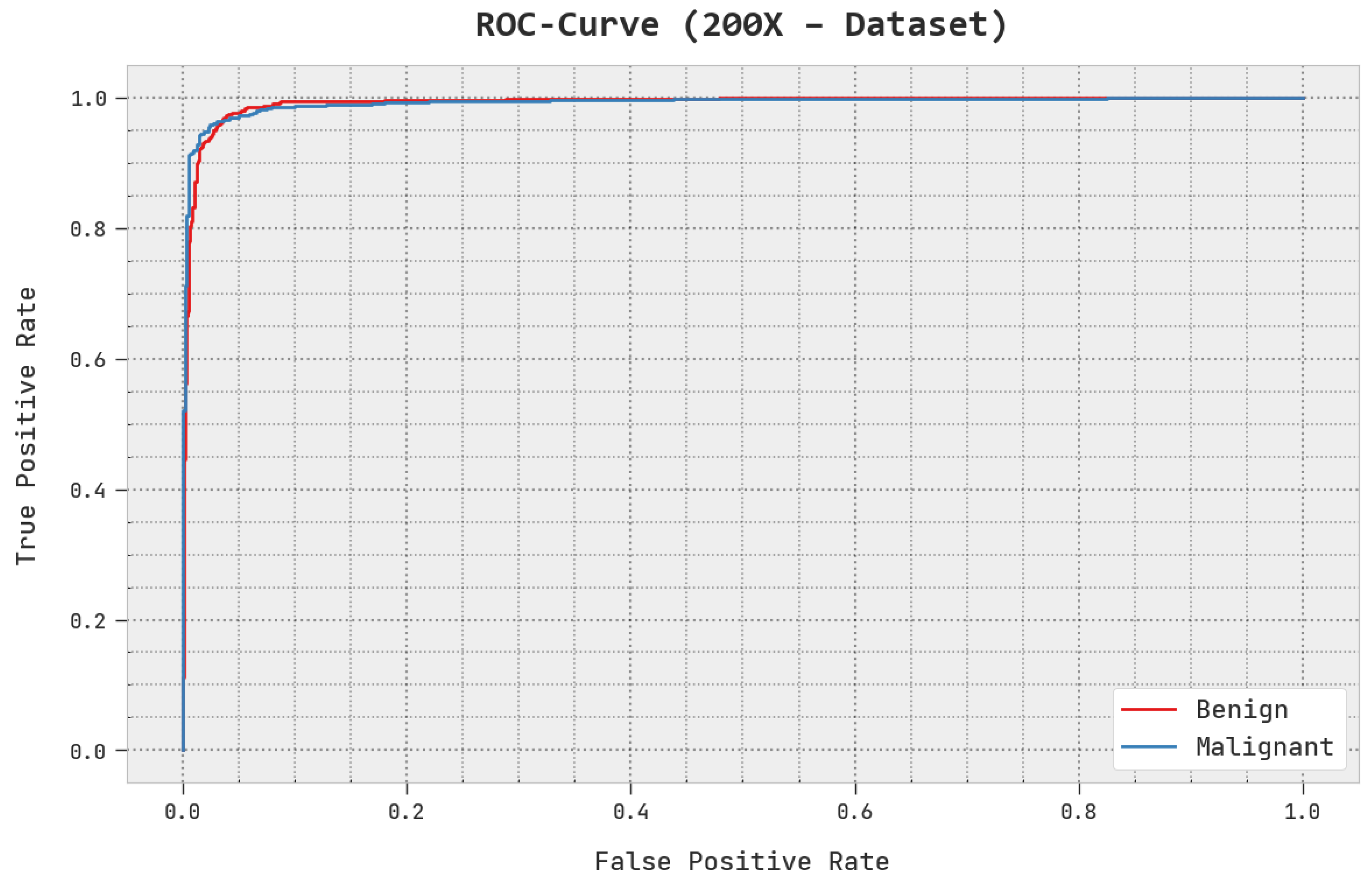
A brief ROC analysis of the AOADL-HBCC approach under the test database is shown in
Figure 8. The fallouts show that the AOADL-HBCC methodology exhibited its capacity in classifying different classes in the test database.
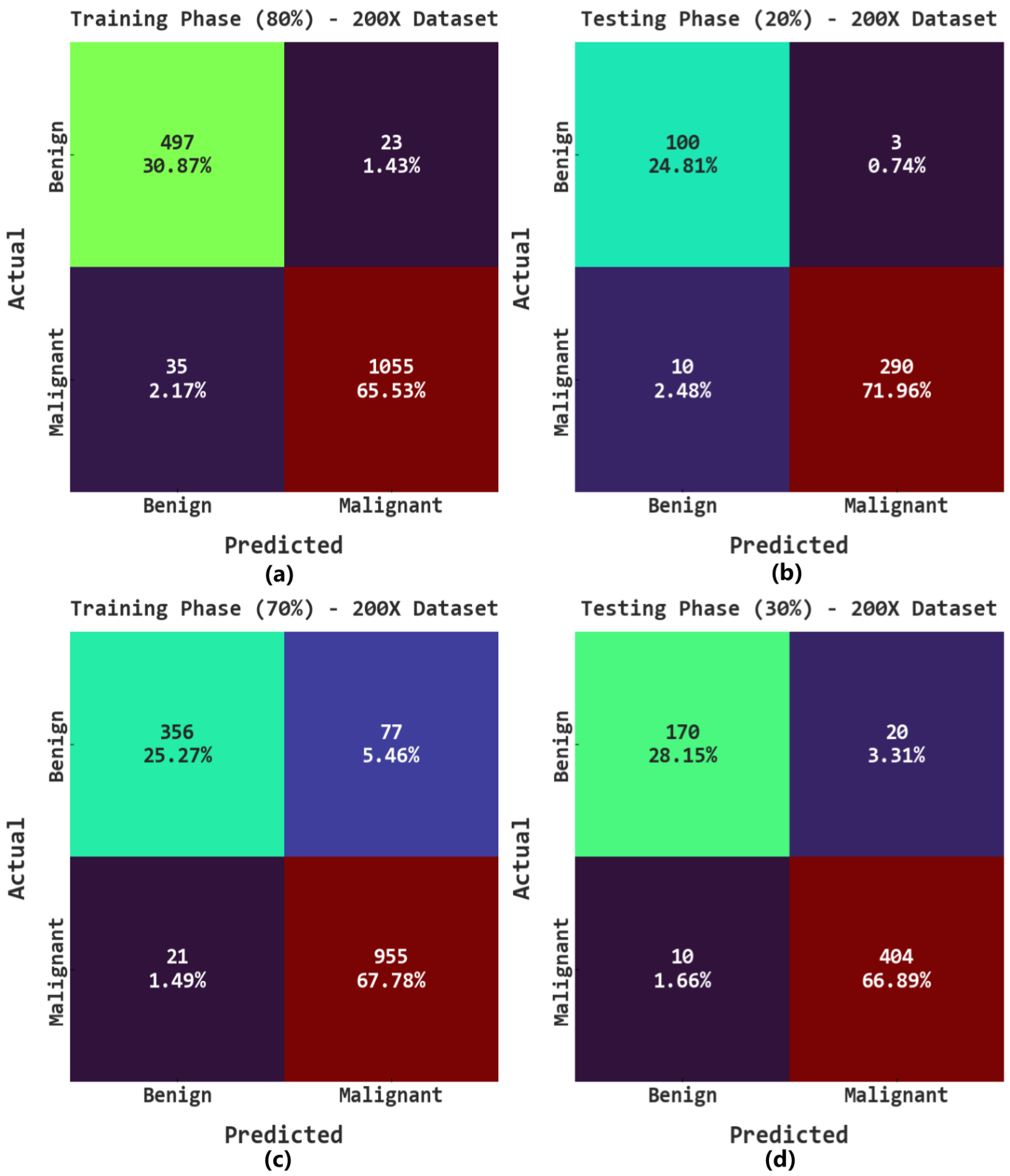
The confusion matrices of the AOADL-HBCC approach on the 200× database are given in
Figure 9. This figure indicates that the AOADL-HBCC approach proficiently recognized and sorted the HIs into malignant and benign classes in every aspect.
Table 3 shows the overall breast cancer classification results of the AOADL-HBCC approach on the 200× dataset. The results indicate that the AOADL-HBCC model recognized both benign and malignant classes proficiently. For example, in the 80% TR database, the AOADL-HBCC technique exhibited an average
of 96.40%,
of 96.18%,
of 96.18%,
of 95.91%, and MCC of 91.83%. Concurrently, in the 20% TS database, the AOADL-HBCC approach displayed an average
of 96.77%,
of 96.88%,
of 96.88%,
of 95.85%, and MCC of 91.80%. Simultaneously, in the 70% TR database, the AOADL-HBCC technique displayed an average
of 93.04%,
of 90.03%,
of 90.03%,
of 91.51%, and MCC of 83.45%.
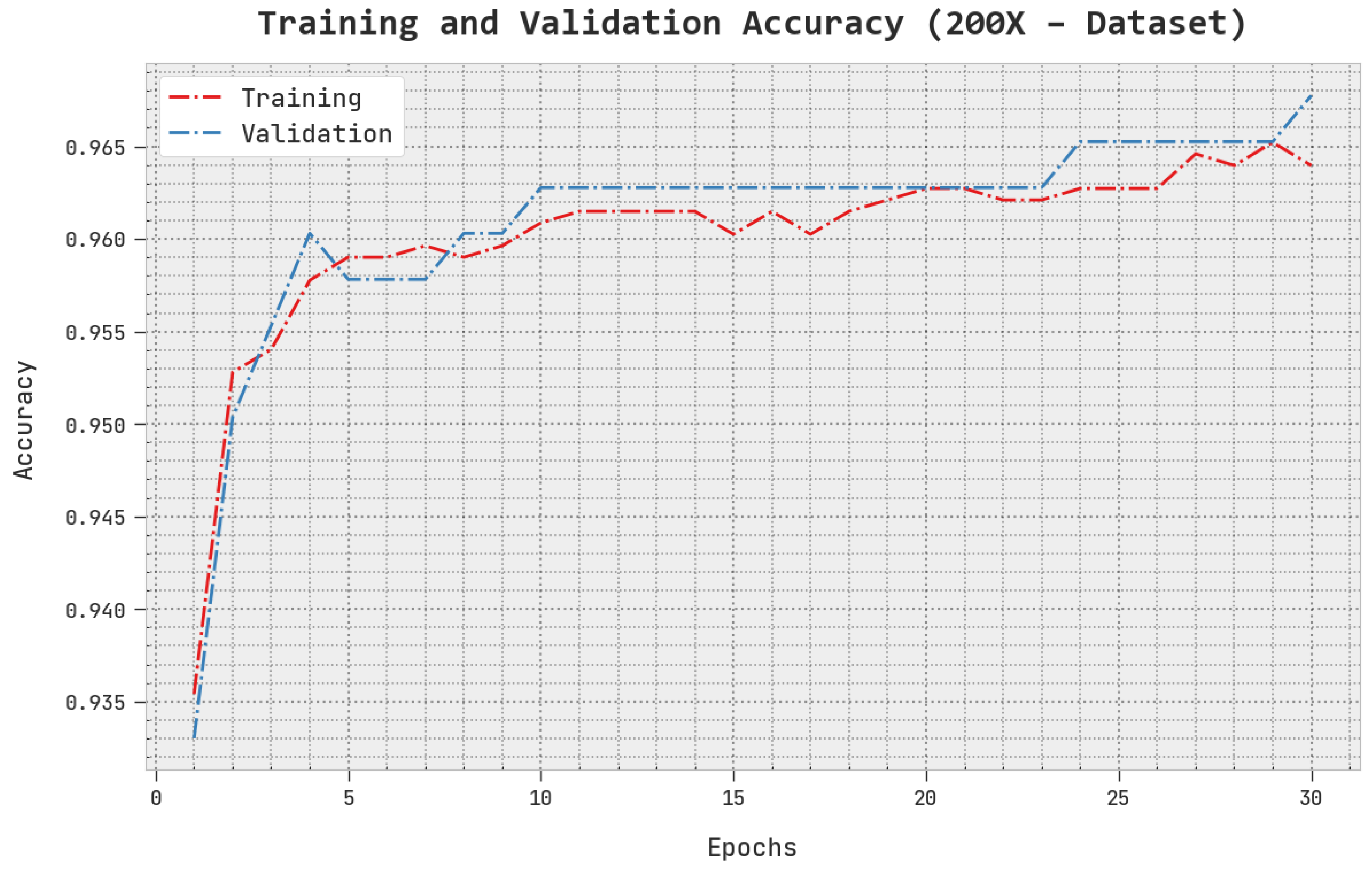
The TACC and VACC of the AOADL-HBCC method under the 200× dataset are inspected on BCC performance in
Figure 10. This figure shows that the AOADL-HBCC methodology displayed enhanced performance with increased values of TACC and VACC. It is noted that the AOADL-HBCC technique attained maximum TACC outcomes.
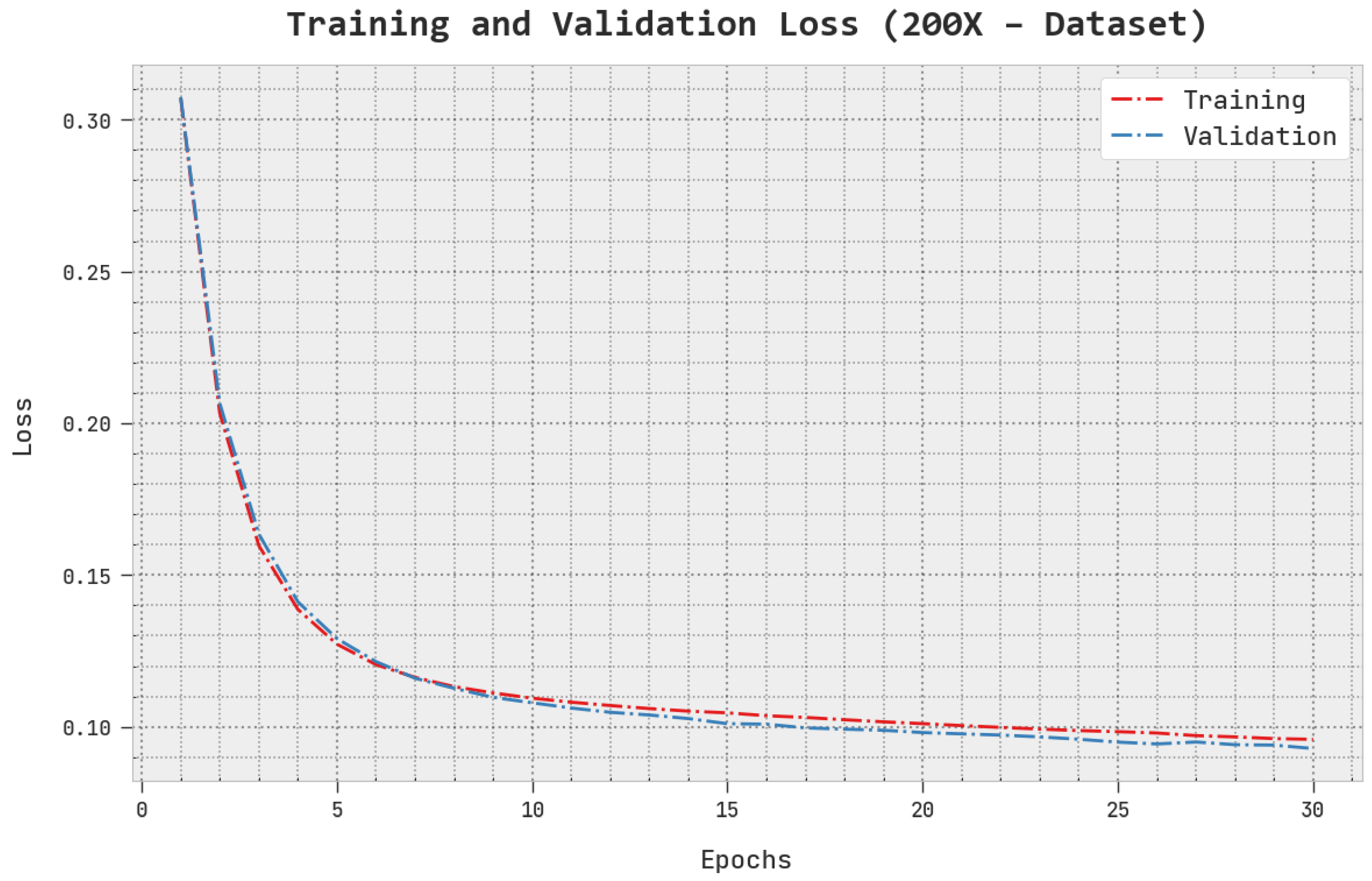
The TLS and VLS of the AOADL-HBCC approach under the 200× dataset are tested on BCC performance in
Figure 11. This figure indicates that the AOADL-HBCC methodology revealed superior performance with minimal values of TLS and VLS. It is noted that the AOADL-HBCC method resulted in reduced VLS outcomes.
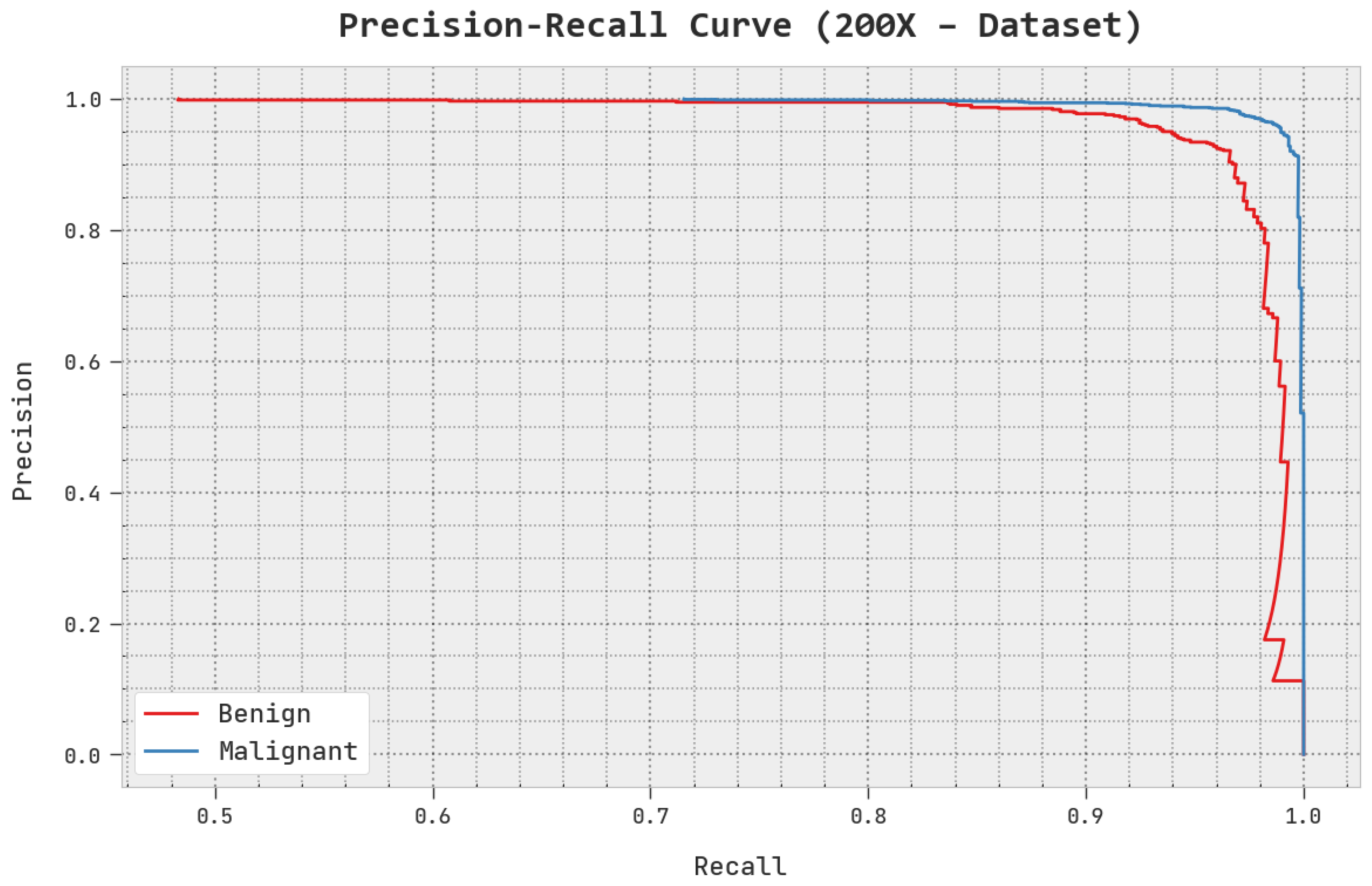
A clear precision–recall inspection of the AOADL-HBCC methodology under the test database is shown in
Figure 12. This figure indicates that the AOADL-HBCC method enhanced precision–recall values in every class label.
A brief ROC study of the AOADL-HBCC system under the test database is given in
Figure 13. The outcomes exhibited by the AOADL-HBCC method reveal its ability in classifying different classes in the test database.
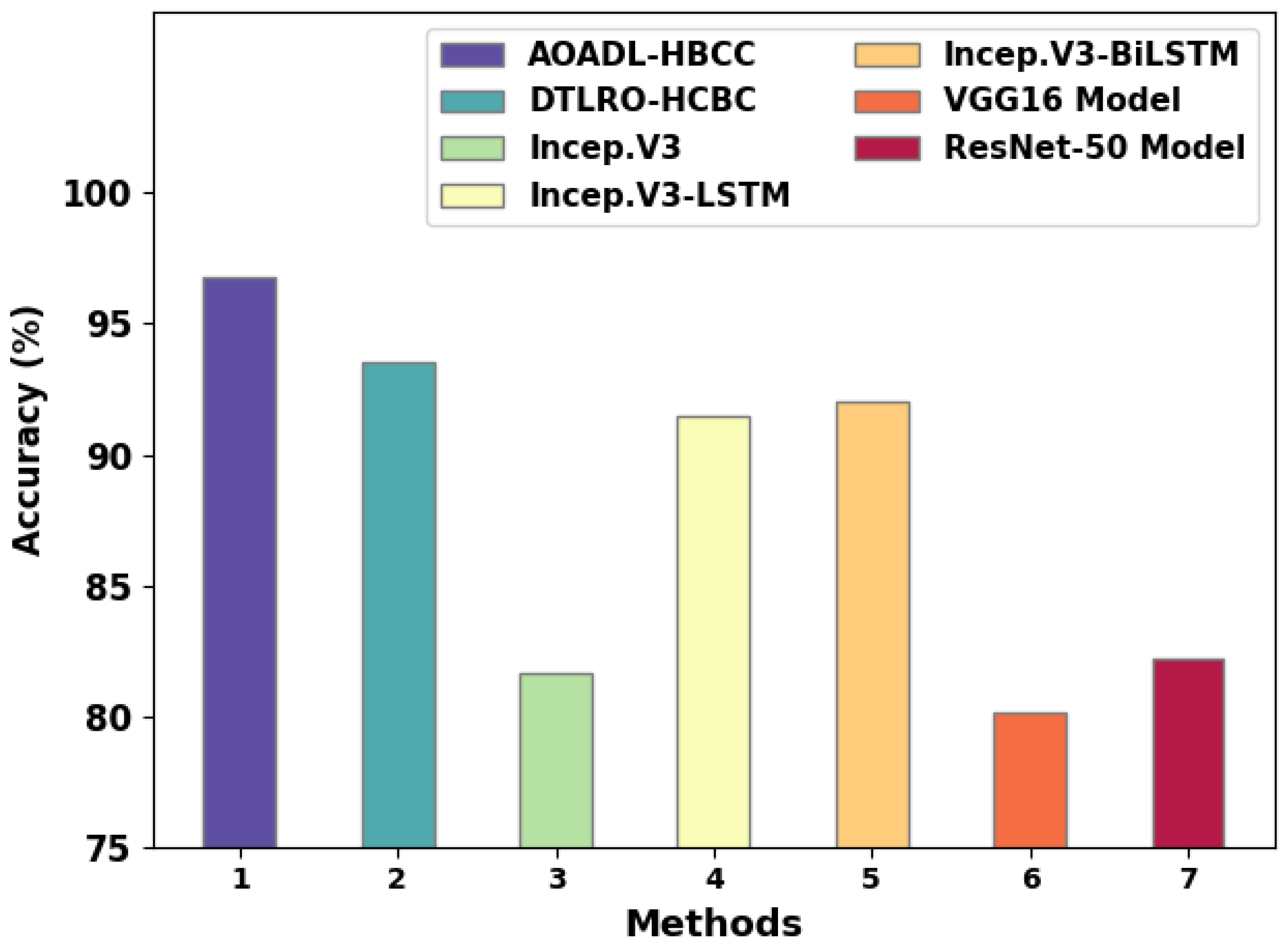
A detailed comparative study of the AOADL-HBCC model with recent DL models is reported in
Table 4 and
Figure 14 [
23]. The simulation values representing the Incep. V3, VGG16, and ResNet-50 models reported lower
of 81.67%, 80.15%, and 82.18%, respectively. Next, the Incep. V3-LSTM and Incep. V3-BiLSTM models attained reasonable
of 91.46% and 92.05%, respectively.
Although the DTLRO-HCBC model reached near-optimal of 93.52%, the AOADL-HBCC model gained maximum of 96.77%. These results ensured the enhanced outcomes of the AOADL-HBCC model over other models.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}