
A Neural Network Model Combining [-2]proPSA, freePSA, Total PSA, Cathepsin D, and Thrombospondin-1 Showed Increased Accuracy in the Identification of Clinically Significant Prostate Cancer

 ,
,  , , ,
, , ,  , , ,
, , ,  and
and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Population
2.2. Determination of Proclarix and PHI
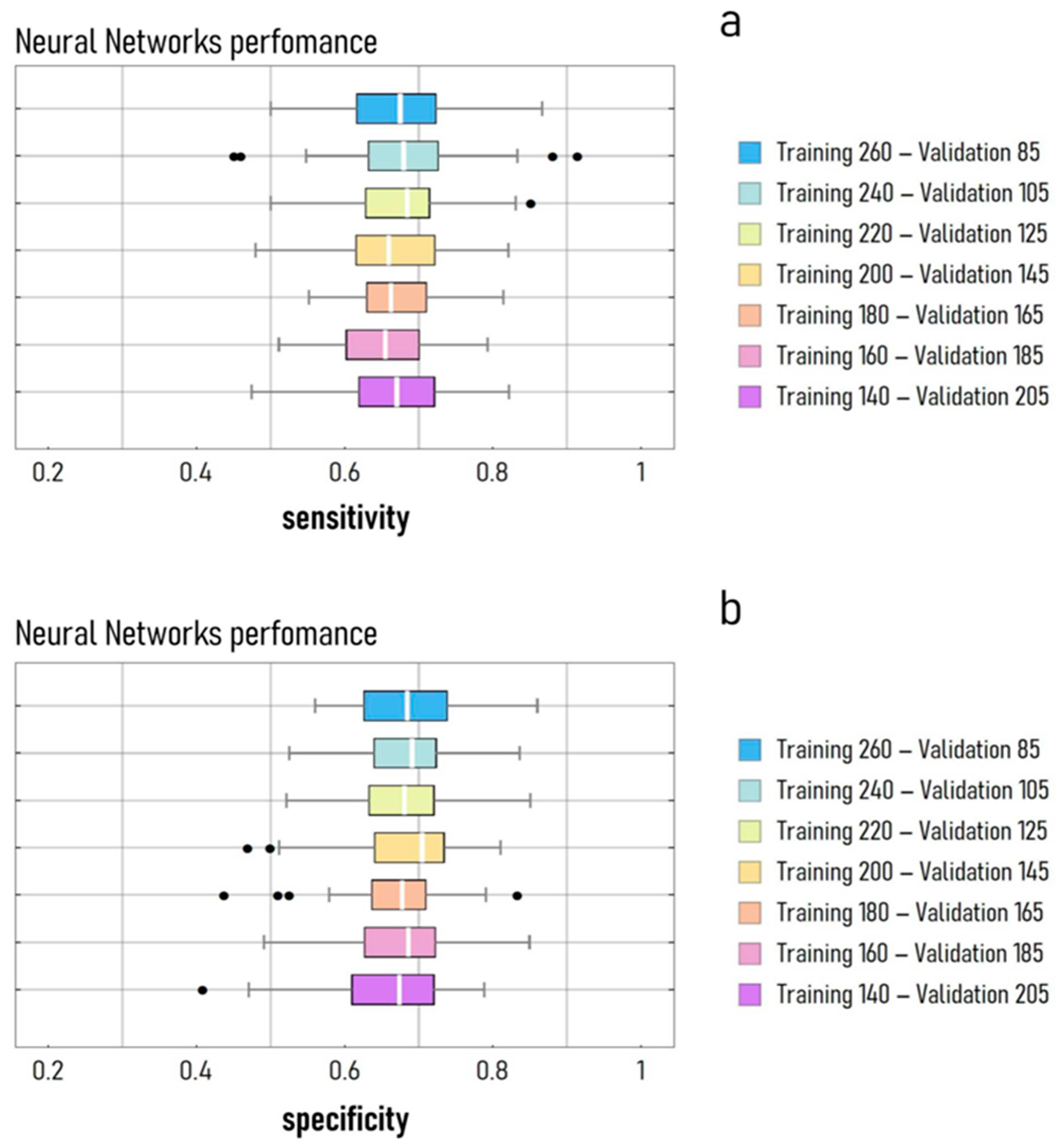
2.3. Neural Networks Design
2.4. Training and Validation of the Neural Network Model
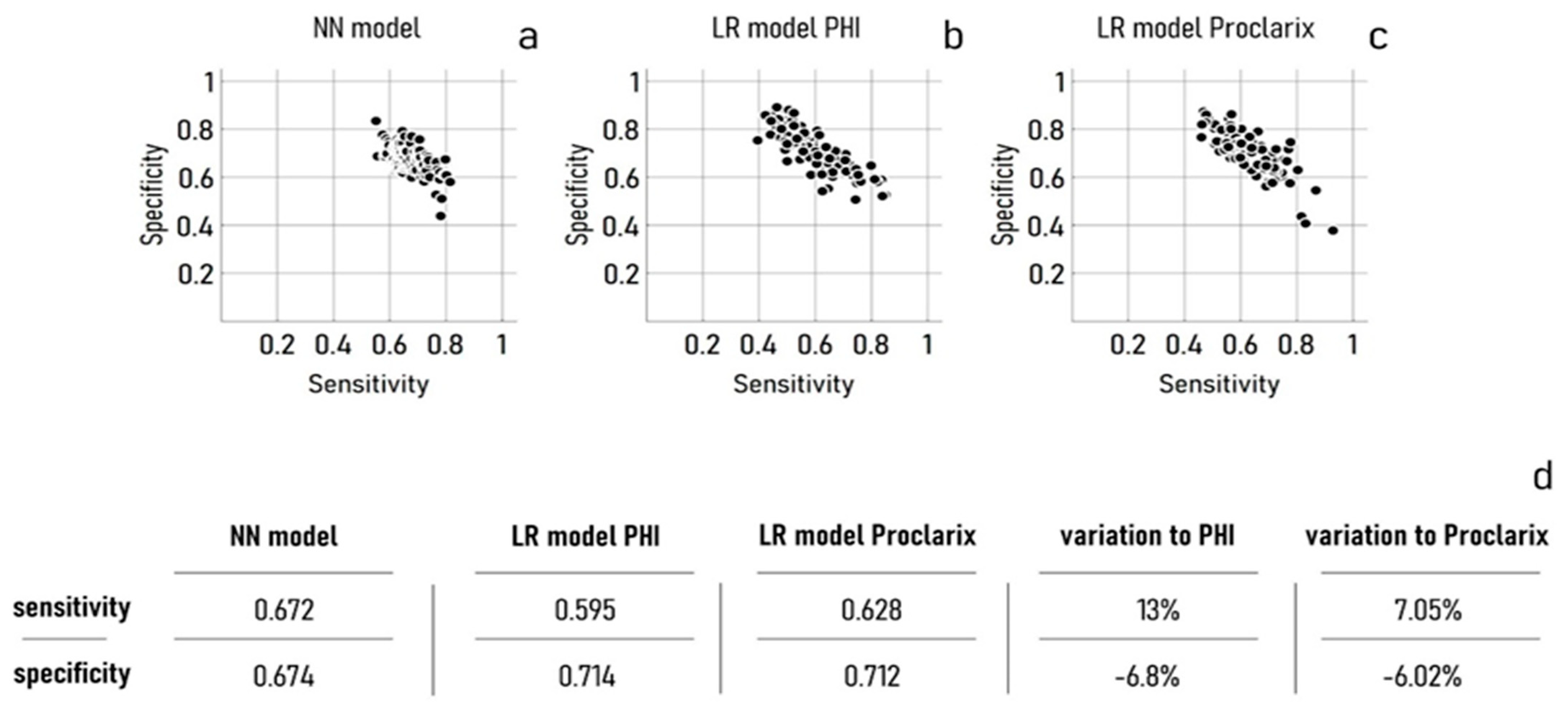
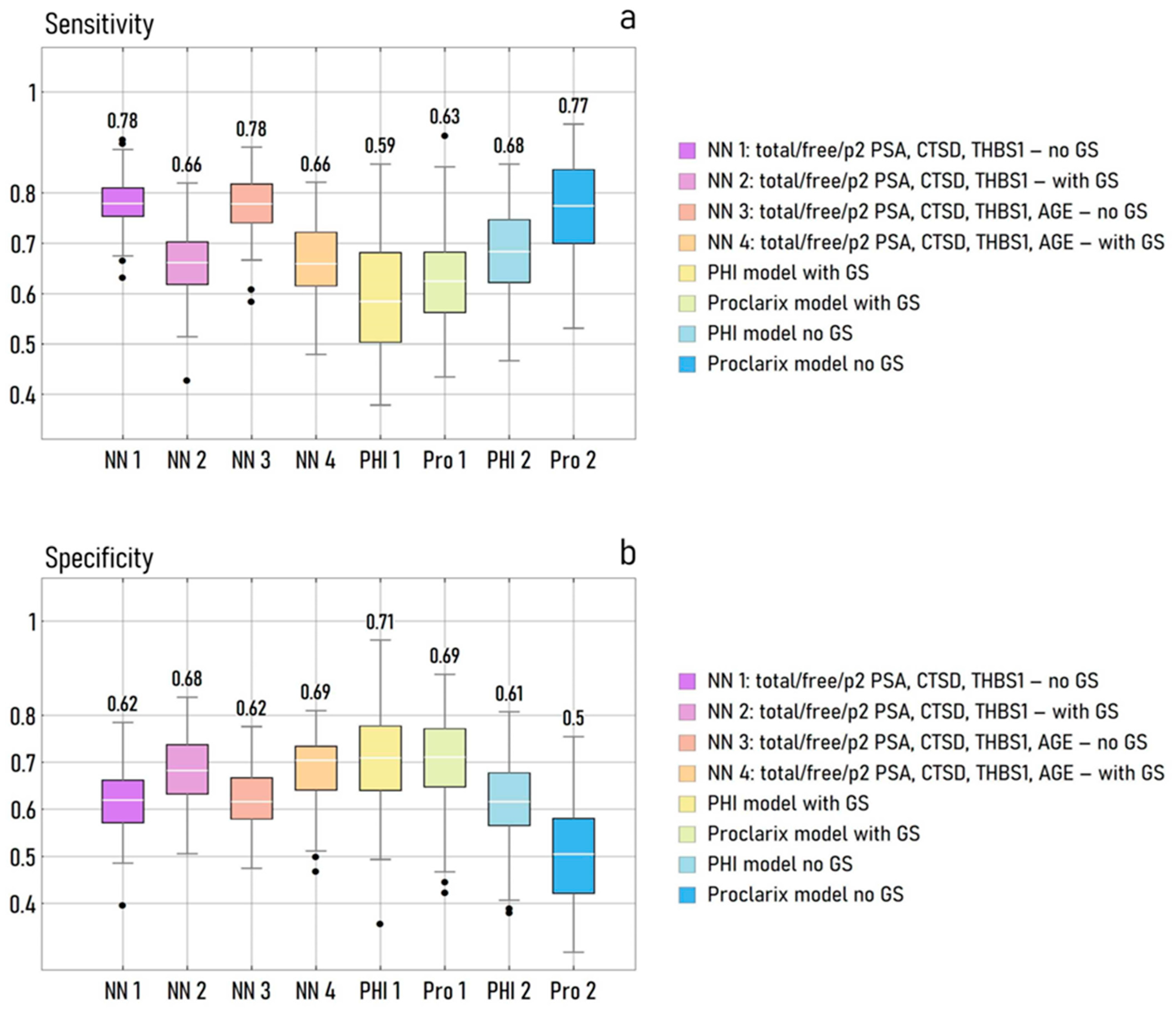
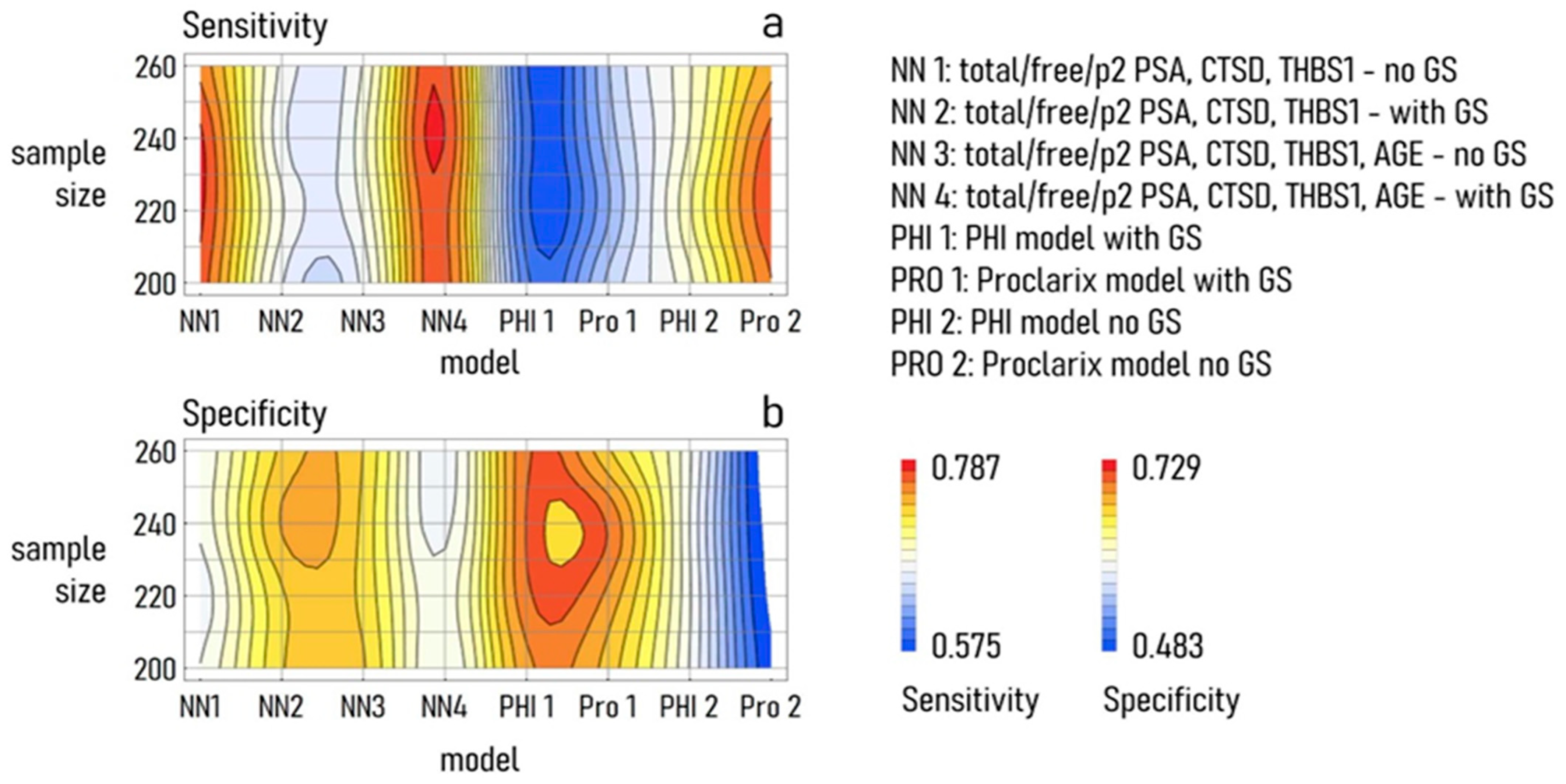
3. Results
The ANN Model Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hugosson, J.; Mansson, M.; Wallstrom, J.; Axcrona, U.; Carlsson, S.V.; Egevad, L.; Geterud, K.; Khatami, A.; Kohestani, K.; Pihl, C.G.; et al. Prostate Cancer Screening with PSA and MRI Followed by Targeted Biopsy Only. N. Engl. J. Med. 2022, 387, 2126–2137. [Google Scholar] [CrossRef] [PubMed]
- Ferro, M.; Lucarelli, G.; de Cobelli, O.; Del Giudice, F.; Musi, G.; Mistretta, F.A.; Luzzago, S.; Busetto, G.M.; Buonerba, C.; Sciarra, A.; et al. The emerging landscape of tumor marker panels for the identification of aggressive prostate cancer: The perspective through bibliometric analysis of an Italian translational working group in uro-oncology. Minerva. Urol. Nephrol. 2021, 73, 442–451. [Google Scholar] [CrossRef] [PubMed]
- Ferro, M.; De Cobelli, O.; Lucarelli, G.; Porreca, A.; Busetto, G.M.; Cantiello, F.; Damiano, R.; Autorino, R.; Musi, G.; Vartolomei, M.D.; et al. Beyond PSA: The Role of Prostate Health Index (phi). Int. J. Mol. Sci. 2020, 21, 1184. [Google Scholar] [CrossRef] [Green Version]
- Steuber, T.; Heidegger, I.; Kafka, M.; Roeder, M.A.; Chun, F.; Preisser, F.; Palisaar, R.J.; Hanske, J.; Budaeus, L.; Schiess, R.; et al. PROPOSe: A Real-life Prospective Study of Proclarix, a Novel Blood-based Test to Support Challenging Biopsy Decision-making in Prostate Cancer. Eur. Urol. Oncol. 2022, 5, 321–327. [Google Scholar] [CrossRef] [PubMed]
- Terracciano, D.; La Civita, E.; Athanasiou, A.; Liotti, A.; Fiorenza, M.; Cennamo, M.; Crocetto, F.; Tennstedt, P.; Schiess, R.; Haese, A.; et al. New strategy for the identification of prostate cancer: The combination of Proclarix and the prostate health index. Prostate 2022, 82, 1469–1476. [Google Scholar] [CrossRef] [PubMed]
- Barabasi, A.L. Network science: Luck or reason. Nature 2012, 489, 507–508. [Google Scholar] [CrossRef]
- Topol, E.J. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef]
- Ferro, M.; Crocetto, F.; Bruzzese, D.; Imbriaco, M.; Fusco, F.; Longo, N.; Napolitano, L.; La Civita, E.; Cennamo, M.; Liotti, A.; et al. Prostate Health Index and Multiparametric MRI: Partners in Crime Fighting Overdiagnosis and Overtreatment in Prostate Cancer. Cancers 2021, 13, 4723. [Google Scholar] [CrossRef]
- Gentile, F.; Ferro, M.; Della Ventura, B.; La Civita, E.; Liotti, A.; Cennamo, M.; Bruzzese, D.; Velotta, R.; Terracciano, D. Optimized Identification of High-Grade Prostate Cancer by Combining Different PSA Molecular Forms and PSA Density in a Deep Learning Model. Diagnostics 2021, 11, 335. [Google Scholar] [CrossRef]
- Gentile, F.; La Civita, E.; Della Ventura, B.; Ferro, M.; Cennamo, M.; Bruzzese, D.; Crocetto, F.; Velotta, R.; Terracciano, D. A Combinatorial Neural Network Analysis Reveals a Synergistic Behaviour of Multiparametric Magnetic Resonance and Prostate Health Index in the Identification of Clinically Significant Prostate Cancer. Clin. Genitourin. Cancer 2022, 20, e406–e410. [Google Scholar] [CrossRef]
- Van Booven, D.J.; Kuchakulla, M.; Pai, R.; Frech, F.S.; Ramasahayam, R.; Reddy, P.; Parmar, M.; Ramasamy, R.; Arora, H. A Systematic Review of Artificial Intelligence in Prostate Cancer. Res. Rep. Urol. 2021, 13, 31–39. [Google Scholar] [CrossRef] [PubMed]
- Boegemann, M.; Stephan, C.; Cammann, H.; Vincendeau, S.; Houlgatte, A.; Jung, K.; Blanchet, J.S.; Semjonow, A. The percentage of prostate-specific antigen (PSA) isoform [-2]proPSA and the Prostate Health Index improve the diagnostic accuracy for clinically relevant prostate cancer at initial and repeat biopsy compared with total PSA and percentage free PSA in men aged </=65 years. BJU Int. 2016, 117, 72–79. [Google Scholar] [CrossRef] [PubMed]
- Perera, M.; Mirchandani, R.; Papa, N.; Breemer, G.; Effeindzourou, A.; Smith, L.; Swindle, P.; Smith, E. PSA-based machine learning model improves prostate cancer risk stratification in a screening population. World J. Urol. 2021, 39, 1897–1902. [Google Scholar] [CrossRef] [PubMed]
- Epstein, J.I.; Egevad, L.; Amin, M.B.; Delahunt, B.; Srigley, J.R.; Humphrey, P.A.; Grading, C. The 2014 International Society of Urological Pathology (ISUP) Consensus Conference on Gleason Grading of Prostatic Carcinoma: Definition of Grading Patterns and Proposal for a New Grading System. Am. J. Surg. Pathol. 2016, 40, 244–252. [Google Scholar] [CrossRef]
- Semjonow, A.; Kopke, T.; Eltze, E.; Pepping-Schefers, B.; Burgel, H.; Darte, C. Pre-analytical in-vitro stability of [-2]proPSA in blood and serum. Clin. Biochem. 2010, 43, 926–928. [Google Scholar] [CrossRef]
- Osses, D.F.; Roobol, M.J.; Schoots, I.G. Prediction Medicine: Biomarkers, Risk Calculators and Magnetic Resonance Imaging as Risk Stratification Tools in Prostate Cancer Diagnosis. Int. J. Mol. Sci. 2019, 20, 1637. [Google Scholar] [CrossRef] [Green Version]
- Gulati, R. Reducing Prostate Cancer Overdiagnosis. N. Engl. J. Med. 2022, 387, 2187–2188. [Google Scholar] [CrossRef]
- Davik, P.; Remmers, S.; Elschot, M.; Roobol, M.J.; Bathen, T.F.; Bertilsson, H. Reducing prostate biopsies and magnetic resonance imaging with prostate cancer risk stratification. BJUI Compass 2022, 3, 344–353. [Google Scholar] [CrossRef]
- Wilt, T.J.; Brawer, M.K.; Jones, K.M.; Barry, M.J.; Aronson, W.J.; Fox, S.; Gingrich, J.R.; Wei, J.T.; Gilhooly, P.; Grob, B.M.; et al. Radical prostatectomy versus observation for localized prostate cancer. N. Engl. J. Med. 2012, 367, 203–213. [Google Scholar] [CrossRef] [Green Version]
- Campistol, M.; Morote, J.; Regis, L.; Celma, A.; Planas, J.; Trilla, E. Proclarix, A New Biomarker for the Diagnosis of Clinically Significant Prostate Cancer: A Systematic Review. Mol. Diagn. Ther. 2022, 26, 273–281. [Google Scholar] [CrossRef]
- Klocker, H.; Golding, B.; Weber, S.; Steiner, E.; Tennstedt, P.; Keller, T.; Schiess, R.; Gillessen, S.; Horninger, W.; Steuber, T. Development and validation of a novel multivariate risk score to guide biopsy decision for the diagnosis of clinically significant prostate cancer. BJUI Compass 2020, 1, 15–20. [Google Scholar] [CrossRef] [PubMed]
- Del Pino-Sedeno, T.; Infante-Ventura, D.; de Armas Castellano, A.; de Pablos-Rodriguez, P.; Rueda-Dominguez, A.; Serrano-Aguilar, P.; Trujillo-Martin, M.M. Molecular Biomarkers for the Detection of Clinically Significant Prostate Cancer: A Systematic Review and Meta-analysis. Eur. Urol. Open. Sci. 2022, 46, 105–127. [Google Scholar] [CrossRef] [PubMed]
- Duffy, M.J. Biomarkers for prostate cancer: Prostate-specific antigen and beyond. Clin. Chem. Lab. Med. 2020, 58, 326–339. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schwarzer, G.; Schumacher, M. Artificial neural networks for diagnosis and prognosis in prostate cancer. Semin. Urol. Oncol. 2002, 20, 89–95. [Google Scholar] [CrossRef]
- Snow, P.B.; Smith, D.S.; Catalona, W.J. Artificial neural networks in the diagnosis and prognosis of prostate cancer: A pilot study. J. Urol. 1994, 152, 1923–1926. [Google Scholar] [CrossRef]
- Munteanu, V.C.; Munteanu, R.A.; Gulei, D.; Schitcu, V.H.; Petrut, B.; Berindan Neagoe, I.; Achimas Cadariu, P.; Coman, I. PSA Based Biomarkers, Imagistic Techniques and Combined Tests for a Better Diagnostic of Localized Prostate Cancer. Diagnostics 2020, 10, 806. [Google Scholar] [CrossRef]
- Kelly, C.J.; Karthikesalingam, A.; Suleyman, M.; Corrado, G.; King, D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 2019, 17, 195. [Google Scholar] [CrossRef] [Green Version]
- Tsao, C.W.; Liu, C.Y.; Cha, T.L.; Wu, S.T.; Sun, G.H.; Yu, D.S.; Chen, H.I.; Chang, S.Y.; Chen, S.C.; Hsu, C.Y. Artificial neural network for predicting pathological stage of clinically localized prostate cancer in a Taiwanese population. J. Chin. Med. Assoc. 2014, 77, 513–518. [Google Scholar] [CrossRef] [Green Version]
- Dejous, C.; Krishnan, U.M. Sensors for diagnosis of prostate cancer: Looking beyond the prostate specific antigen. Biosens. Bioelectron. 2020, 173, 112790. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gentile, F.; La Civita, E.; Ventura, B.D.; Ferro, M.; Bruzzese, D.; Crocetto, F.; Tennstedt, P.; Steuber, T.; Velotta, R.; Terracciano, D. A Neural Network Model Combining [-2]proPSA, freePSA, Total PSA, Cathepsin D, and Thrombospondin-1 Showed Increased Accuracy in the Identification of Clinically Significant Prostate Cancer. Cancers 2023, 15, 1355. https://doi.org/10.3390/cancers15051355
Gentile F, La Civita E, Ventura BD, Ferro M, Bruzzese D, Crocetto F, Tennstedt P, Steuber T, Velotta R, Terracciano D. A Neural Network Model Combining [-2]proPSA, freePSA, Total PSA, Cathepsin D, and Thrombospondin-1 Showed Increased Accuracy in the Identification of Clinically Significant Prostate Cancer. Cancers. 2023; 15(5):1355. https://doi.org/10.3390/cancers15051355
Chicago/Turabian StyleGentile, Francesco, Evelina La Civita, Bartolomeo Della Ventura, Matteo Ferro, Dario Bruzzese, Felice Crocetto, Pierre Tennstedt, Thomas Steuber, Raffaele Velotta, and Daniela Terracciano. 2023. "A Neural Network Model Combining [-2]proPSA, freePSA, Total PSA, Cathepsin D, and Thrombospondin-1 Showed Increased Accuracy in the Identification of Clinically Significant Prostate Cancer" Cancers 15, no. 5: 1355. https://doi.org/10.3390/cancers15051355
APA StyleGentile, F., La Civita, E., Ventura, B. D., Ferro, M., Bruzzese, D., Crocetto, F., Tennstedt, P., Steuber, T., Velotta, R., & Terracciano, D. (2023). A Neural Network Model Combining [-2]proPSA, freePSA, Total PSA, Cathepsin D, and Thrombospondin-1 Showed Increased Accuracy in the Identification of Clinically Significant Prostate Cancer. Cancers, 15(5), 1355. https://doi.org/10.3390/cancers15051355