1. Introduction
In the medical domain, the localization and determination of a disease’s extension can be a major advantage for the treatment. Ever since imaging modalities became available for cancer therapy, the precise delineation of organs and target volumes has been of great interest. The manual generation of these contours is thereby often time-consuming, requires intensive prior training and often lacks consistency between observers, especially for target volumes [
1,
2]. Because of the importance of available contour annotations in the clinical routine, a lot of research has been conducted in this area. Widespread early approaches that were used to automate medical-image segmentation were atlas-based methods [
3,
4,
5]. For this, reference images were first contoured to build the atlas. These atlas images were then registered onto the new image while the same deformation field was applied to the atlas’ contours, resulting in a segmentation of the new image. While this approach proved to be successful in terms of manual labor reduction [
6,
7], it showed drawbacks in regard to individual segmentation quality, when the image quality or the individual anatomy deviated from the atlas.
With the increase in deep-learning (DL) methods that are capable of accurate contouring, the automatization of segmentation (auto-segmentation) has been applied in more and more of the areas in which medical images are analyzed. The most popular network architecture for automatic medical-image segmentation is the U-Net, which was introduced by Ronneberger et al. [
8]. The deployment of this architecture in a framework with self-configuring hyperparameters, the nnU-Net [
9], increased the accuracy and accessibility of DL-based segmentation methods. With the nnU-Net, it is possible to train a State-of-the-Art deep-learning model for medical-image segmentation tasks on custom data-label pairs, eliminating the need to explore task-specific hyperparameter settings.
While, at first, DL methods were optimized to predict single volumes of interest, the importance of models for multi-organ segmentation has increased [
10,
11]. Recently, the TotalSegmentator Version 2 toolkit was released under the URL
https://github.com/wasserth/TotalSegmentator (accessed on 31 October 2023). The TotalSegmentator is a ready-trained open-access toolkit for the auto-segmentation of 117 anatomical structures in the whole body, which is based on the nnU-Net framework [
11].
Multi-label-segmentation models have been shown to be beneficial for the segmentation accuracy of individual organs and for the robustness of the DL methods when compared to single-label models [
12]. Currently, most multi-organ-segmentation models are trained on sparse labels (i.e., most voxels of an image are not labeled), due to missing dense annotations in the available medical-image data sets. In aiming to increase segmentation accuracy, the dense segmentation of the human body is necessary, i.e., the segmentation of every anatomical structure and its substructures. Gare et al. [
13] showed that for ultrasound images dense pixel labeling improves disease classification when compared to models trained on only sparsely labeled images.
DL-based auto-segmentation enhances different tasks that need medical-image segmentation. Enhancements can be in the form of improved standardization, time savings or refined precision. Relevant tasks can be found in the realm of radiology, surgery [
14] and radiotherapy. It also facilitates research fields like biomechanical modeling [
15] and generation of synthetic medical-image data sets [
16], which, in turn, improve the results in clinical applications. Nevertheless, the main application of automatic medical-image-segmentation methods lies within cancer diagnosis and treatment planning [
17]. In cancer therapy, common auto-segmentation tasks are the segmentation of organs at risk (OARs) [
18,
19], target volumes [
20,
21,
22,
23] and metastases [
24]. For example, Nikolov et al. [
19] trained a DL-based auto-segmentation model that delineates 21 OARs achieving expert-level performance in the head and neck area.
In the field of radiation therapy, the exact contouring of OARs as well as target volumes is of major importance for the treatment outcome. Only with the precise delineation of target volumes and OARs, optimal tumor control can be achieved while adjacent healthy tissues are preserved. This significance is particularly pronounced in the head and neck region, where anatomical structures exhibit close spatial proximity paired with high anatomical flexibility. Target volumes as well as OARs are delineated by experts on the planning CT scans. These volumes are the basis for the objective function in the optimization of the radiation treatment plan.
Different target volumes are defined in radiotherapy. Following [
25], the gross target volume is the visible and palpable, most inner tumor extension. It is surrounded by the clinical target volume (CTV) which comprises tissue that is potentially infiltrated by microscopic tumor cells. The CTV can itself be subdivided into the primary CTV and the nodal CTV. The primary CTV is drawn as a margin of 0.5–1 cm around the gross target volume, while the nodal CTV follows the lymphatic pathways and includes all areas that are found to harbor microscopic tumor cells with a probability of 10% or more [
26,
27,
28]. The outermost target volume is the planning target volume which surrounds the union of all former mentioned target volumes and compensates for beam parameter uncertainties, patient placement errors, organ fluctuations and other motion-induced variance [
29].
The extension of the CTV is not visible with modern imaging techniques, since it comprises normal tissues infiltrated by microscopic tumor cells. The definition of its outline is rather based on recurrence studies and thus, empirically built clinical experience [
30,
31]. This makes the delineation of CTVs a difficult task for clinicians that need many years of training [
32]. Its complexity is not only visible in the training needed to perform this task, but also in the time needed to produce acceptable delineations and in their resulting divergence. Given the same CT scan, the manual CTV delineations of different experts show a large inter- and intra-observer variability of up to 200% difference in volume [
1].
The quality of manual labels heavily affects the training and thus, the prediction accuracy of supervised learning methods. The inconsistent manual delineations of CTVs have a negative impact on the auto-segmentation of target volumes [
33,
34]. For that, researchers in this field focus on curating consistent data sets by executing extensive peer-reviews on the process of manual contouring or incorporating contours of only a minimum number of clinical experts, or institutes [
21,
22,
23]. For CTV delineation, the predicted labels are reported to still need intensive pre- and post-processing [
35,
36,
37,
38] and they are not easily adaptable to changes in segmentation standards or patient-individual requirements. All this is done, aiming for improved spatial conformance of the predicted contour with manual delineation, while knowing that manual delineations are not well standardized.
Not only the comparison to labels that are highly dependent on the expert that generated the label, but also recent studies on evaluation metrics raise critiques on the current state-of-the-art. Reinke et al. [
39] point out that the measurements of pure spatial overlap (i.e., the DICE) do not necessarily quantify the actual quality of interest in medical image segmentation tasks. For the delineation of CTVs the quality of interest that should be measured is the conformance of the CTV delineation with the expert guidelines.
To overcome the variety in CTV delineation, the detailed clinical knowledge about the extension of the CTVs is collected in international consensus expert guidelines including head and neck treatments [
27,
28]. These expert guidelines provide a commonly accepted delineation scheme for the CTVs in a rule-based manner and thus, standardize their segmentation. As one example, Grégoire et al. [
27] focus on the delineation of nodal CTV in the head and neck area. In these expert guidelines, the nodal CTV is subdivided into ten levels with some additional subdivisions. The extent of each single level is described by bordering anatomical structures. Thus, the expert guidelines convert the difficult problem of delineating the extent of cancerous infiltration which is not visible in CT scans, in a contouring task of anatomical structures. The selection of levels that should be irradiated is based on the location of the primary tumor.
In summary, the current status quo for automatic CTV delineation is to optimize a metric that measures spatial conformance with unreliable manual labels that impair the training of supervised learning methods. The inconsistency of the manual labels result from the diverse character of cancer growth and the missing contrast to surrounding tissues. The international consensus expert guidelines are based on the combination of anatomical boundaries for which more consistent segmentations are expected. Thus, we advocate the exploitation of written-down human knowledge-based expert guidelines as ground truth for the CTV delineation overcoming the dependence on inconsistent manual labels and solely focusing on commonly agreed standards.
Oriented towards the goal of evaluating guideline conformance of CTV delineations, in this study, the 71 most important anatomical structures mentioned in the expert guidelines have been chosen for an auto-segmentation task. For that, all 71 structures have been manually delineated, and used to train nnU-Net models for auto-segmentation. The predictions for 18 unseen data sets are evaluated against the manual labels as well as segmentations generated by the TotalSegmentator, and compared to previously reported segmentation results. So far, studies on the segmentation of anatomical structures have only published results on a small subset of the necessary 71 anatomical structures. The existent results are widely distributed over multiple unrelated publications.
In this study, 48 of our 71 anatomical structures are automatically segmented for the first time. For the remaining structures, our model provides improved or comparable segmentations. We evaluate the segmentation accuracy between different tissue types and reasons for why some structures are more difficult for an auto-segmentation task. Finally, the impact of the segmentation accuracy for the construction of CTV delineation according to the expert guidelines is discussed. Our results indicate that the automatic application of delineation rules given in the expert guidelines is feasible without any restraint.
2. Materials and Methods
2.1. Image Properties of the Data Set
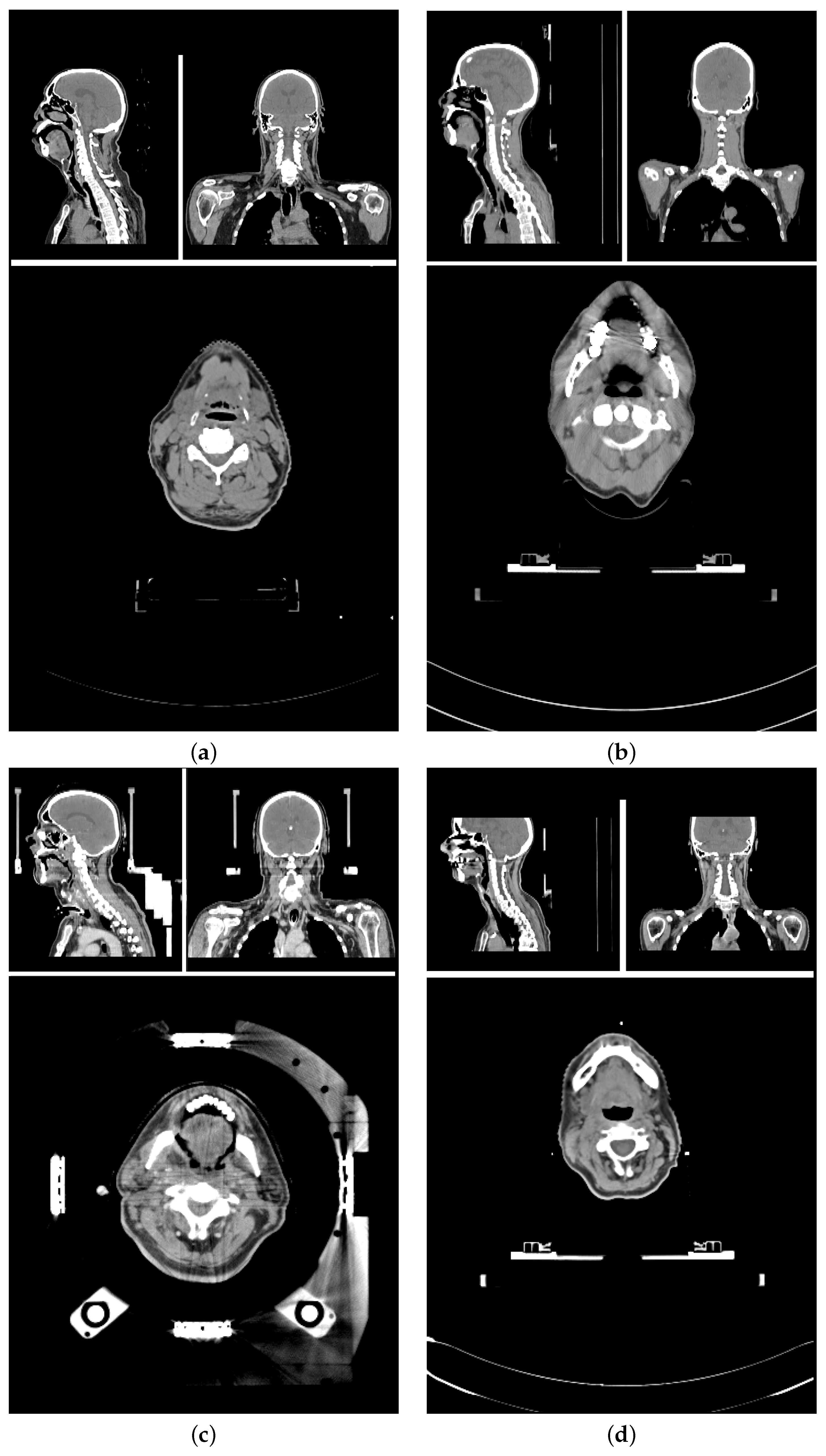
The planning CT scans for this study were aggregated from four different study cohorts.
Figure 1 shows an exemplary CT scan of each cohort. All patients received radiotherapy for head and neck cancer. For each patient, there was exactly one planning CT scan considered in this study. Each CT scan consists of 90 to 220 single slices (mean: 141 ± 24) of 512 × 512 voxels each. The voxel size ranged from 0.98 × 0.98 × 2
to 1.27 × 1.27 × 3
.
The training data set and test data set are mutually exclusive. The
training data set (86 scans) included (a) 84 in-house HNC patients from three different cohorts (varying setup, positioning, devices, and protocols) [
43,
44], and (b) 2 open access HNC data sets [
40,
41,
42]. The
test data set (18 scans) is curated from the same three study cohorts (14, and 4 scans, respectively). The patient selection for the test data set was based on available meta-information to best represent the variety of the data cohorts. Factors for the selections were study cohort, location of the primary tumor, gender, presence of a tracheostoma, size of nCTV, estimated age and weight of the patient.
2.2. Label Selection and Generation of the Manual Labels
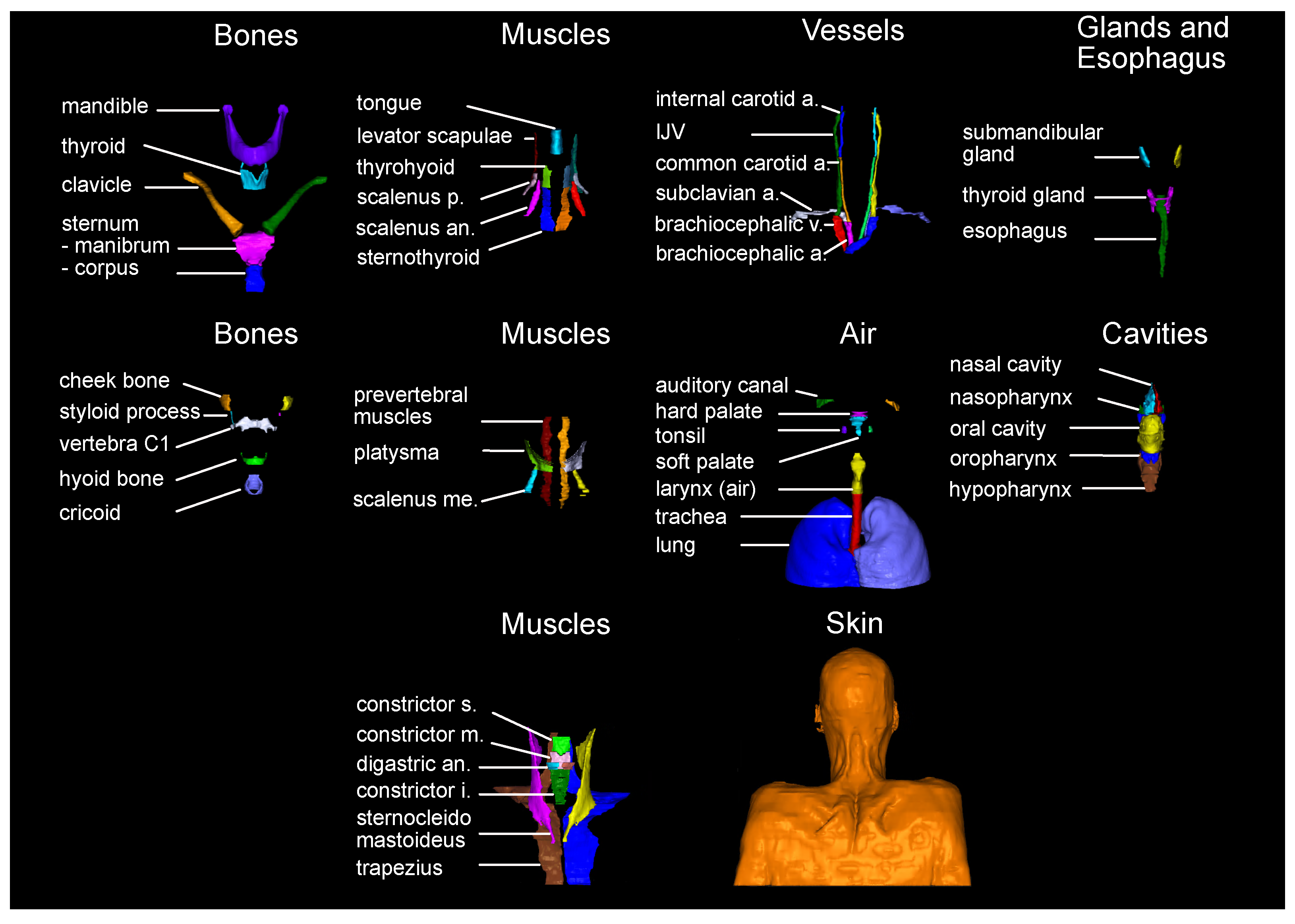
The 71 structures were chosen based on their number of occurrence in the Grégoire et al. [
27] expert guidelines. The resulting set of anatomical structures is visualized in
Figure 2. Manual labels of the 71 anatomical structures were generated for all 104 CT scans by six different trained observers on a Wacom Cintiq 24HD Display in RayStation 8B(R) SP1. The observers were following a standard operation procedure for the delineations that included (a) the unambiguous definition of the structures’ extent (e.g., mandible without teeth), (b) windowing, and (c) spatial restrictions based on other anatomical structures (mostly cranial and caudal). The whole standard operation procedure can be found in
Appendix A.1. Each data set was at least once reviewed and if necessary adjusted by one of the other observers before it was accepted for the study.
For one patient data set, 41 selected structures were segmented a second time by one of the trained observers who was not involved in the initial segmentation or the review of this patient. Based on those two sets of contours, the inter-observer variability was approximately assessed.
Caused by the field of view of our CT scans, the esophagus, the sternum (corpus and manubrium), the lobes of the lung, the trachea, the trapezius muscles, the brachiocephalic veins, and the skin are never or not always completely present on our patient scans, but cut off on the caudal edge of the scan. The sternum corpus is sometimes not present at all. Further, in cases where the patients were post-operatively irradiated, or the extension of the primary tumor distorted surrounding anatomical structures, the respective missing anatomical structures were not segmented. In total, there were 30 anatomical structures missing. Fifteen of those structures cumulated in two test patients (#8, #7), and three other patients had at least two missing structures. Nine of the 18 test patients were not missing any structure and thus, had the full set of 71 anatomical structures manually segmented.
2.3. Network Training and Label Prediction
For the automatic segmentation, the nnU-Net framework Version 1 was chosen and trained with one adaption to the default parameters: mirroring was removed from the data augmentation to keep the left-right orientation of the patients consistent during training. The final training data set provided for the nnU-Net training was generated by mirroring all 86 training data sets. Left and right instances of anatomical structures were then swapped back for left-right consistency after mirroring.
Since in the nnU-Net Version 1, a network can only be trained for non-overlapping structures, the labels of all 71 anatomical structures were subdivided into three non-overlapping, disjoint subsets, containing (a) the labels for all bones, muscles, vessels, air-related structures, glands and the esophagus (#64), (b) the labels for all cavities (i.e., hypopharynx, left and right nasal cavity, nasopharynx, oral cavity, and oropharynx), and (c) the skin label. According to the author, nnU-Net Version 2 has no accuracy advantages over its Version 1 [
45].
Following the nnU-Net’s five-fold cross-validation standard, for all three subsets there were five 3D full-resolution models trained with the trainer V2. Fold 1 and fold 2 were using 137 data sets for training and 35 data sets for validation, while fold 3–5 were using 138 data sets for training and 34 data sets for validation. Each fold was trained for 1000 epochs. The predictions were made for all 18 previously unseen test data sets in the nnU-Net’s default 5-heads manner. No postprocessing was applied.
All computations were executed using the nnU-Net Version 1.7.0 with Python Version 3.9.7, PyTorch 1.10.2 with CUDA Version 11.3.1. Training and predictions were executed on a computer with an AMD Ryzen™ 9 3900X Processor, 128 GB RAM, with an NVIDIA GeForce RTX 3090, and 24 GB VRAM.
For 16 of our anatomical structures, segmentations can also be retrieved by using the pre-trained TotalSegmentator toolkit. We employed the TotalSegmentator as Python library on our 18 test patients with default configurations. The predictions generated by the TotalSegmentator were run on a computer with an Intel® Core™ i7 Processor, 64 GB RAM, with an NVIDIA GeForce RTX 2070, and 8 GB VRAM.
2.4. Evaluation of Predicted Labels
We assess the similarity and distance between two distinct labels of the same structure through three metrics: (a) their volumetric overlap, measured using the Sørensen–Dice coefficient (DICE) [
46,
47], (b) the distance between both contours, evaluated by the Hausdorff distance (HD) [
48] and (c) the fraction of deviation larger than 2 mm, quantified using the surface DICE (sDICE) as defined in Nikolov et al. [
19]. For the evaluation of the HD we chose the 95th percentile (HD (95)). Choosing a margin of 2 mm is based on the clinical practice in photon radiation therapy to intervene when deviations are in the order of 2 mm or larger. The sDICE (2 mm) is considered to indicate the correction effort needed for the predicted CTVs. This selection of metrics is consistent with the metrics reloaded framework [
39] accessible under the URL
https://metrics-reloaded.dkfz.de/ (accessed on 20 October 2023). Structures that are not present in the manual labels, in the predicted labels or both sets of labels are left out in the analyses. For the calculation of all metrics, the library surface-distance-based-measures Version 0.1 was used.
4. Discussion
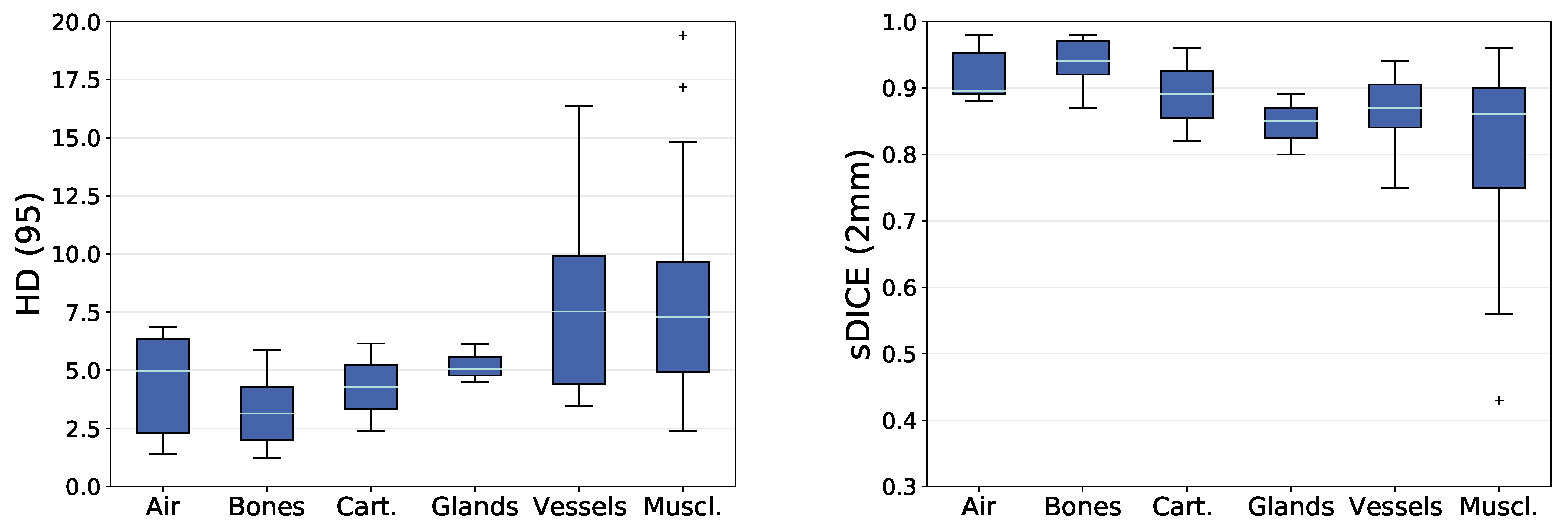
When comparing the grouped DICEm between tissue types, groups with good contrast on CT scans like air-related structures and bones show an increased accuracy when compared to other groups. Noticeably, the variation in DICEm is the largest for the group of muscles. First, this group has the largest number of different anatomical instances. Further, the contrast of soft tissues on CT scans is not sufficient to identify most muscles completely. Finally, the group of muscles is also the most diverse group ranging from structures with an average volume of 550 voxels (digastric muscle) to 55,000 voxels (trapezius muscle).
4.1. Reasons for Impaired Prediction Accuracy
We have visually analyzed cases of impaired prediction accuracy for highlighted anatomical structures from before. Typical deviations occur at the transition between related structures (e.g., between the superior, the middle and the inferior constrictor muscles), or at the beginning and ending of elongated structures (e.g., the final cranial slice of the internal carotid artery). DICE values are sometimes low for thin structures although the sDICE (2 mm) is high. This is because small deviations of thin structures can lead to a large decrease in overlap and cause large changes in DICE, which does not tolerate any type of deviation. The sDICE (2 mm) instead allows deviations smaller than 2 mm. Non-systematic segmentation errors originate from largely deviating manual labels, which are cause by metal artifacts (e.g., for the tongue) or insufficient soft tissue contrast (e.g., for the platysma muscle). In the following section, reasons for impaired prediction accuracy are discussed for every prior identified anatomical structure, for that the automatic prediction resulted in a below Q1 (or above Q3) evaluation metric.
The visual analysis of cases in which the
internal carotid artery (ICA) shows especially low DICE and sDICE on both sides, results in four common reasons for deviations between the manual segmentation and its prediction: (a) the ICA is a thin structure, (b) the transition between internal carotid artery and common carotid artery varies, (c) the final slice, on which the ICA occurs cranially varies, and (d) due to metal in the mouth, CT artifacts occur in this area.
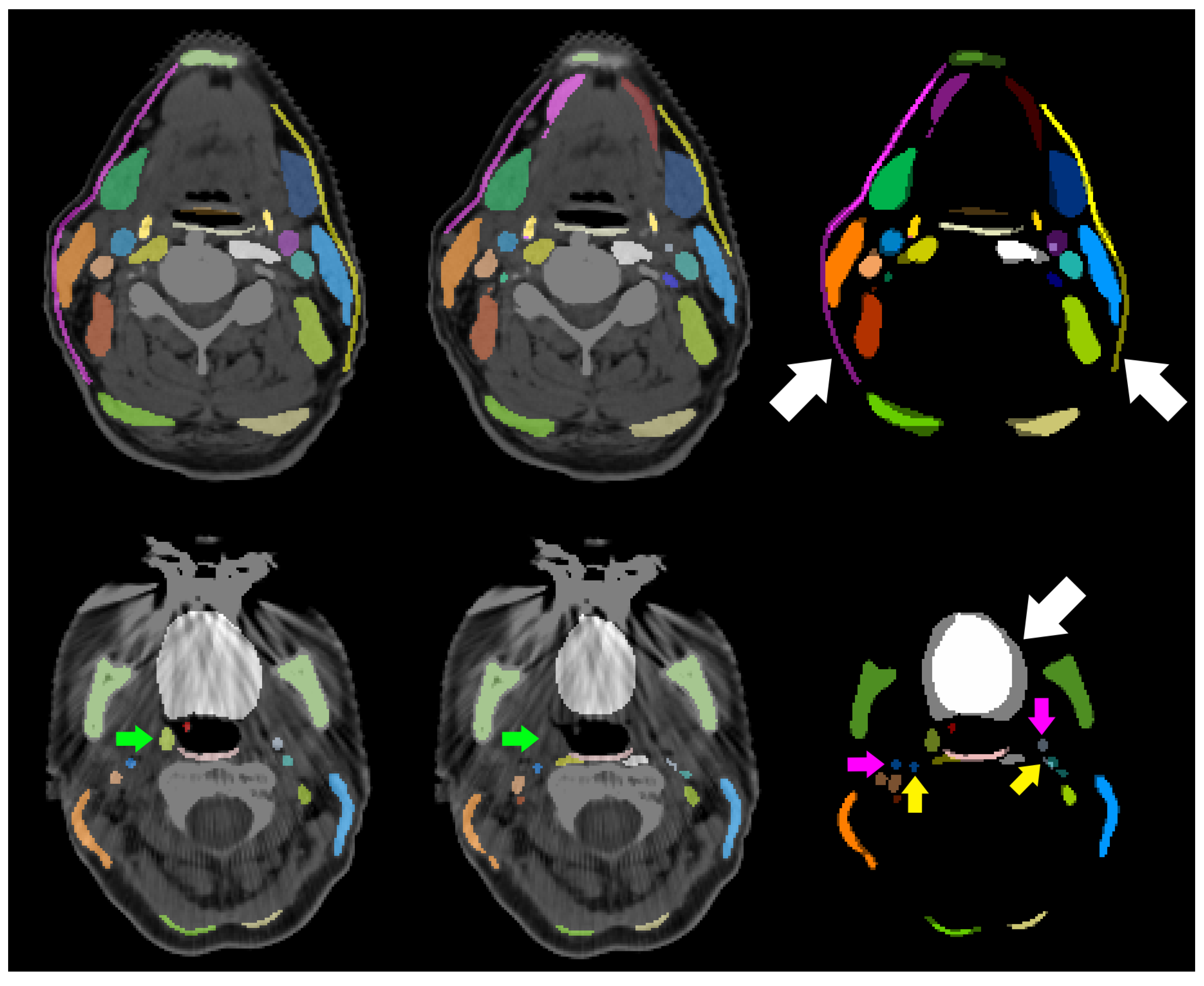
Figure 5 shows the deviation between manual and predicted segmentation of the ICA due to inconsistent decision on the most cranial slice and the bottom row of
Figure 6 shows metal artifacts.
For the subclavian artery similar reasons are resulting in small DICEm and sDICEm: (a) the subclavian artery is a thin structure, (b) the transition between the right subclavian artery and the brachiocephalic artery varies, and (c) the lateral extension varies.
The visual analysis of the superior constrictor muscles and middle constrictor muscles also results in clear confusion at the area of transition between both structures, as well as the transition between the middle and the inferior constrictor muscles. This observation is supported by the above-median performance of their combination (i.e., constrictors (s., m., i.)). Training their combination, and differentiating the substructures in a rule-based post-processing, might be beneficial to the auto-segmentation of the constrictor muscles and similar cases.
The digastric muscles and the posterior scalene muscles show an (almost) below Q1 performance in DICEm and sDICEm with large standard deviations amongst test patients. DICE values range from [0–0.83] for the digastric muscles and [0–0.71 (0.81)] for the posterior scalene muscles. sDICE values deviate by more than 0.68 (digastric muscles) and 0.85 (posterior scalene muscles) between minimum and maximum. All predictions show greater accordance with the manual labels than the segmentations generated by the second observer (high inter-observer variability).
The tongue has an above-median DICEm, but a noticeable low sDICEm. Since the tongue is a theoretically easy to locate structure of above-average volume, the DICEm does only marginally indicate problems with its segmentation. The sDICEm signals inconsistencies in the precise outline of the tongue. Reasons are metal artifacts that occur predominantly in the area of the mouth which impair the precise segmentation of the tongue.
The right platysma muscle is an outlier in HDm. The analysis of individual cases shows a deviation of the manual labels in the frontal-dorsal direction and the cranial-caudal direction. Since the platysma muscle is a thin cutaneous muscle, it is sometimes barely visible in its most frontal and most dorsal extension. Thus, the network is trained on only a few extended examples. Auto-segmentations depict only the mostly visible inner extension of the platysma muscles.
4.2. Inter-Observer Variability, and Tracheostomy Analysis
The anatomical structures with an inter-observer variability outside the 3
interval around the mean in any of the three metrics or a value below the Q1 in DICE
m or sDICE
m or above the Q3 in HD
m were visually analyzed. Two systematic reasons are found that explain deviations. First, the lateral extension of the subclavian artery was inconsistent. Second, muscular structures were systematically segmented wider by one observer than by the other. This holds for the prevertebral muscles, the sternocleidomastoid muscles, the trapezius muscles and the digastric muscles. The deviation between all scalene muscles and the tonsils did not follow systematic reasons. Those structures are barely or not visible in the planning CT scans.
Figure 6 shows this for the tonsil (green arrows). This results in largely deviating contours between both observers as visualized in the right column of
Figure 7. No unambiguous reason can be given for the right internal carotid artery. As it is a thin structure that is difficult to segment, deviations occur in some central slices, while its left counterpart is much better aligned between both observers. No clear difference is visible between both sides of the patient CT scan.
Although the DL-models were trained on a distinct amount of patient data sets with tracheostomy, leaving out those patients from the analysis improves seventeen selected structures noticeably in almost all of the three metrics. Analyzing the deviation of the DICEm and the sDICEm for all other anatomical structures shows almost no change. Most of the 17 structures are in close proximity to the tracheostomy or the distortions in the larynx caused by tracheostomy.
4.3. Comparison to TotalSegmentator
Most anatomical structures that are automatically segmented by the TotalSegmentator framework (TS) are very similar to our own generated segmentations. For those structures that are deviating noticeable there is a common reason when analyzing the segmentations visually.
Figure 5 includes the 3D comparison of those structures. The most common reason is the disagreement in the starting and ending position of elongated structures like the common carotid artery, the trachea, and the subclavian artery. Our manual segmentations for the common carotid arteries ends cranially at the artery’s bifurcation. Although caudally starting very similarly, the segmentations of the TS end approximately half way to the artery’s bifurcation, close to the cranial edge of the esophagus and the trachea. For the trachea, our manual labels exclude the bronchi, while the TS predicted segmentations include the right and left primary bronchi. Our manual labels for the subclavian artery exceed the TS generated labels laterally.
Deviations in the auto-segmentation of the thyroid gland result from patient-individual differences, rather than a systematic difference in the definition. Especially in patients that are equipped with a tracheostoma, the TS predictions deviate more from the manual segmentations than our own predictions. It might be, that in the training data set on which the TS model was trained, there were less or no patient data with a tracheostoma.
4.4. Impact on CTV Delineation
The delineation of CTVs should be targeted for auto-segmentation using DL algorithms. Following the international consensus guidelines of Grégoire et al. [
27]. This study can be the basis for improved standardization and reduced workload. In the following section, the implications are analyzed that the prior described systematic deviations in the auto-segmentations of anatomical structures have on the clinical target volume delineation when following Grégoire et al. [
27].
The predicted contour of the
internal carotid artery (ICA) deviates caudally when transitioning into the common carotid artery (CCA) and its final slice cranially, as well as due to metal artifacts. Within the expert guidelines [
27], the ICA is needed as the medial edge of Level II, the lateral edge of Level VIIa, and the medial edge of the Level VIIb. All these levels are transitioning into each other and the precise boundary becomes only relevant if some, but not all of these levels are irradiated. Since Level II begins caudally approximately where the CCA and ICA are transitioning, one might add the CCA as boundary into the rules when automating the delineation of Level II. The cranial edge of Level II is given by either the lateral process of C1 which the ICA always exceeds, or Level VIIb. The cranial edge of Level VIIb is the base of skull (jugular foramen) which the ICA reaches in all our test patients. Thus, the deviations introduced by the auto-segmentation of the ICA do not affect the CTVs’ delineation.
The predicted contour of the
subclavian artery (SuA) deviates laterally and in its transition to the brachiocephalic artery. Within the expert guidelines [
27], the SuA is needed as the posterior edge of the Level IVb. Caudally, this posterior boundary is cumulating both, the SuA and the brachiocephalic artery, such that their transition does not affect the delineation of the CTV. Also cranially, the lateral deviation of the SuA’s segmentation does not affect the posterior edge of the Level IVb. This is, because the SuA’s extension always exceeds the necessary boundary of Level IVb.
The predicted contour of the
inferior, middle and superior constrictor muscles (CM) deviates caudally and cranially at the transitions between each other. Within the expert guidelines [
27], the CM is needed as the anterior edge of Level VIIa which is bordering the superior or middle pharyngeal constrictor muscle. This boundary is cumulating both, the superior and middle CM, such that their transition does not affect the delineation of the CTV.
The predicted contour of the
platysma muscle (PM) deviates in frontal and dorsal direction as well as in cranial and caudal direction. Within the expert guidelines [
27], the PM is needed as caudal edge of Level Ia and Ib, lateral edge of Level Ib and Level V, and anterior edge of Level VIa. The caudal edge of Level Ia required sufficient delineations of the PM in its central regions which is shown consistently. The caudal edge of Level Ib is described by a plane independent of the PM. The PM only cuts this plane as it is the lateral border of Level Ib. For this, the central parts of the PM are relevant. Those are well-predicted. In the boundary descriptions of Level V and Level VIa, the skin is given as an alternative edge. Since the PM is a thin cutaneous muscle, the expert guidelines already account for its potential invisibility. In this case, there will be no further implications for the CTV delineation than the irradiation of the PM itself.
The predicted contour of the
anterior belly of the digastric muscle (aDM) deviates unsystematically. Within the expert guidelines [
27], the aDM is needed as caudal and lateral edge of Level Ia, and medial edge of Level Ib. For the caudal edge of Level Ia the aDM is not the primary boundary, but a substitute for the PM if the PM is not visible. Due to inconsistent delineations of the sDM, substituting the PM in this case might cause deviations in the caudal boundary of Level Ia. Nevertheless, as discussed before, the PM is often delineated well in the discussed region. Visually analyzing the data, as lateral edge of Level Ia, often the mandible is chosen. Further, as medial edge of Level Ib, often the Level Ia is chosen. Thus, the delineations we got from the clinics do not always spare the aDM. With our inconsistent delineations, we cannot improve this situation and spare the aDM reliably. No solution can be provided for cases in which Level Ib is irradiated while Level Ia is not.
The predicted contour of the
posterior scalene muscle (pSM) deviates unsystematically. Within the expert guidelines [
27], the scalene muscles are needed as medial edge of Level II, Level III, Level IVa, Level V, Level Vc, posterior edge of Level IVa, and lateral edge of Level IVb. Although not specified precisely, the visual analysis shows that most boundaries are given by the anterior scalene muscle. The pSM potentially plays a role in delineating the medial edge of Level V caudally. Here, the confusion between different scalene muscles does not affect CTV delineation, but the pSM could be unintentionally irradiated if contoured erroneously.
The predicted contour of the
tongue and the
tonsils deviate unsystematically due to metal artefacts and missing soft tissue contrast. Since both structures are not used as a boundary definition, but only as selection criterion for nodal levels in the expert guidelines [
27], the CTV delineation is not affected by distortions of these two structures.
4.5. Limitations and Future Research Directions
In our study, we segmented 71 anatomical structures. With additional tools like the TotalSegmentator, the set of structures can be further extended. Nevertheless, even including multiple models, there are still anatomical structures that are segmented neither previously nor in this study. Thus, the dense segmentation of all anatomical structures in the human body is still an issue. Future research should focus on bringing different segmentation models together to generate data sets with dense labels so that the observed positive effects of dense annotations can be exploited.
For this, the large inter-observer variability indicates upcoming problems related to this topic. In our opinion, better agreement of structures’ definitions should be reached, before dense annotations can be generated expediently. Their precise delineation could be supported by additional multi-modal images. We suggest to use MRI scans which have better soft tissue contrast in addition CT scans for the segmentation of soft tissue structures.
Not all necessary structures are covered for the auto-segmentation of all CTV levels in the head and neck area. Structures like the posterior belly of the digastric muscle, the mylo-hyoid muscle, the transversal cervical vessel and the infrahyoid (strap) muscles are missing for completeness. Further, some segmented structures do not lead to sufficient prediction accuracy to be spared (e.g., the anterior belly of the digastric muscles). Completing the prerequisites for generating a guideline conform CTV automatically, additional manual labels need to be generated on which new models can be trained for their auto-segmentation. Improvements for the anterior belly of the digastric muscles and the platysma muscle are expected from the use of additional MRI scans.
Although our training data set was very diverse, the number of training and test samples was too low to train the models to identify each image feature and each patient condition. Thus, patients with tracheostomy led to worse segmentation accuracies. The same might hold for postoperative patients, different stages of contrast agents, or different resolutions of CT scans. Additional data sets might improve the results on underrepresented image features.
In the future, we aim to construct guideline conform CTV delineations by extracting the necessary anatomical boundaries from the generate labels of the presented 71 anatomical structures. These boundaries can be combined following the expert guidelines to form all of the ten levels in the head and neck area which are selected for radiation therapy dependent on the location of the primary tumor. All discussed segmented anatomical structures show sufficient accuracy for this method of CTV generation. Thus, the automatization of CTV delineation becomes independent of inconsistent training and test labels, while providing the desired standardization and becoming more easy to adapt to changes in the guidelines than common segmentation methods.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






