An Empirical Review of Automated Machine Learning




Abstract
:1. Introduction
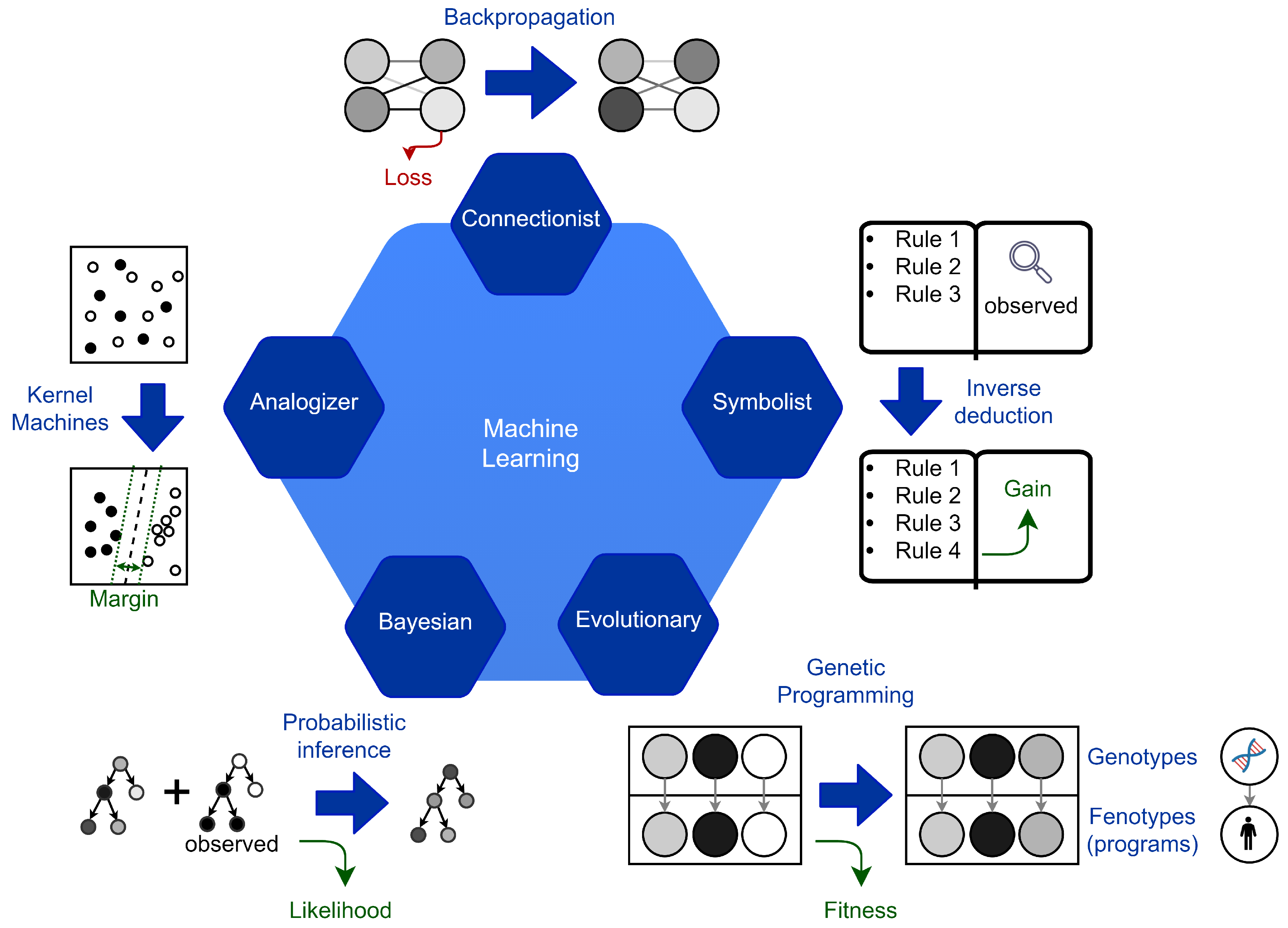
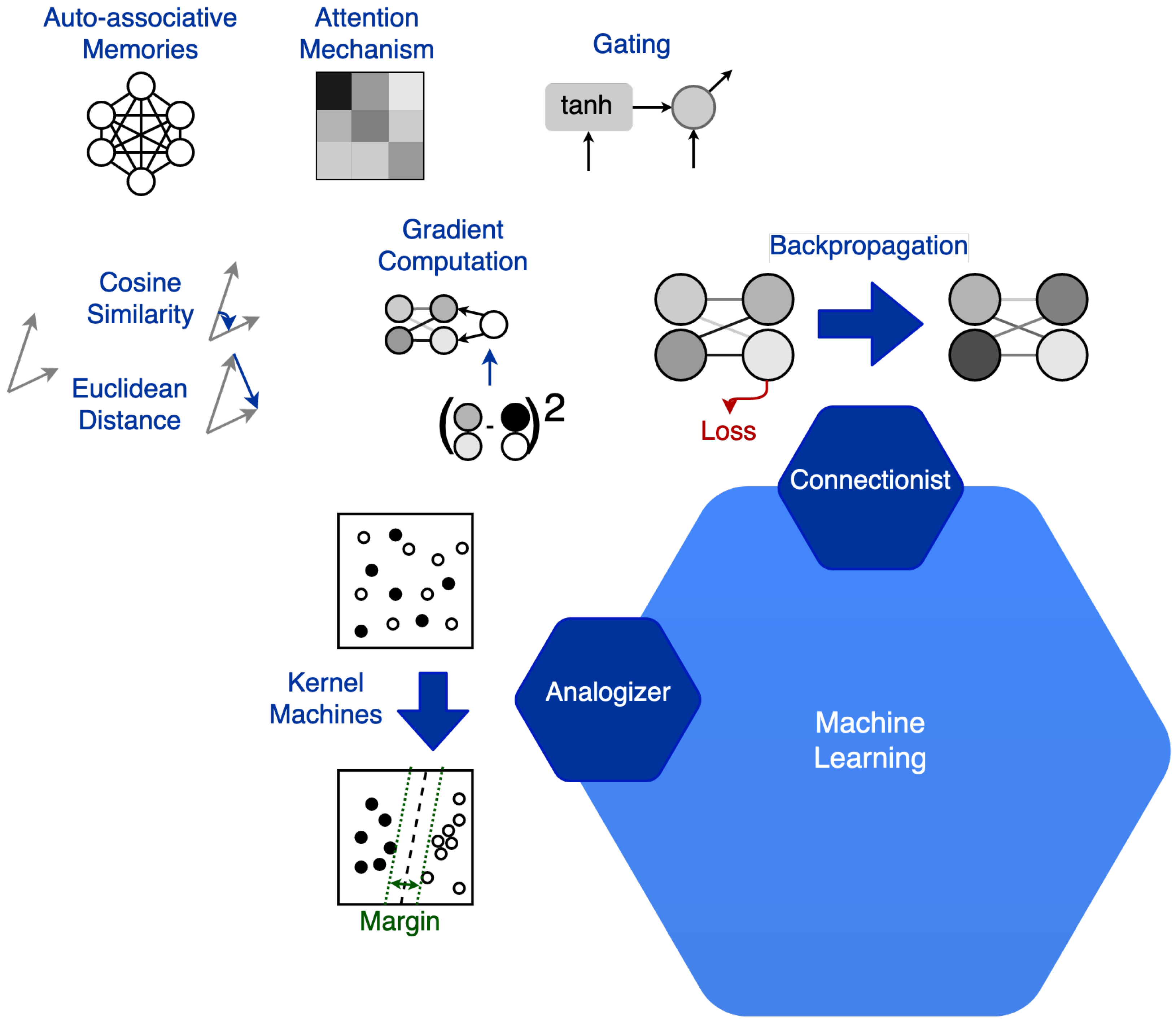
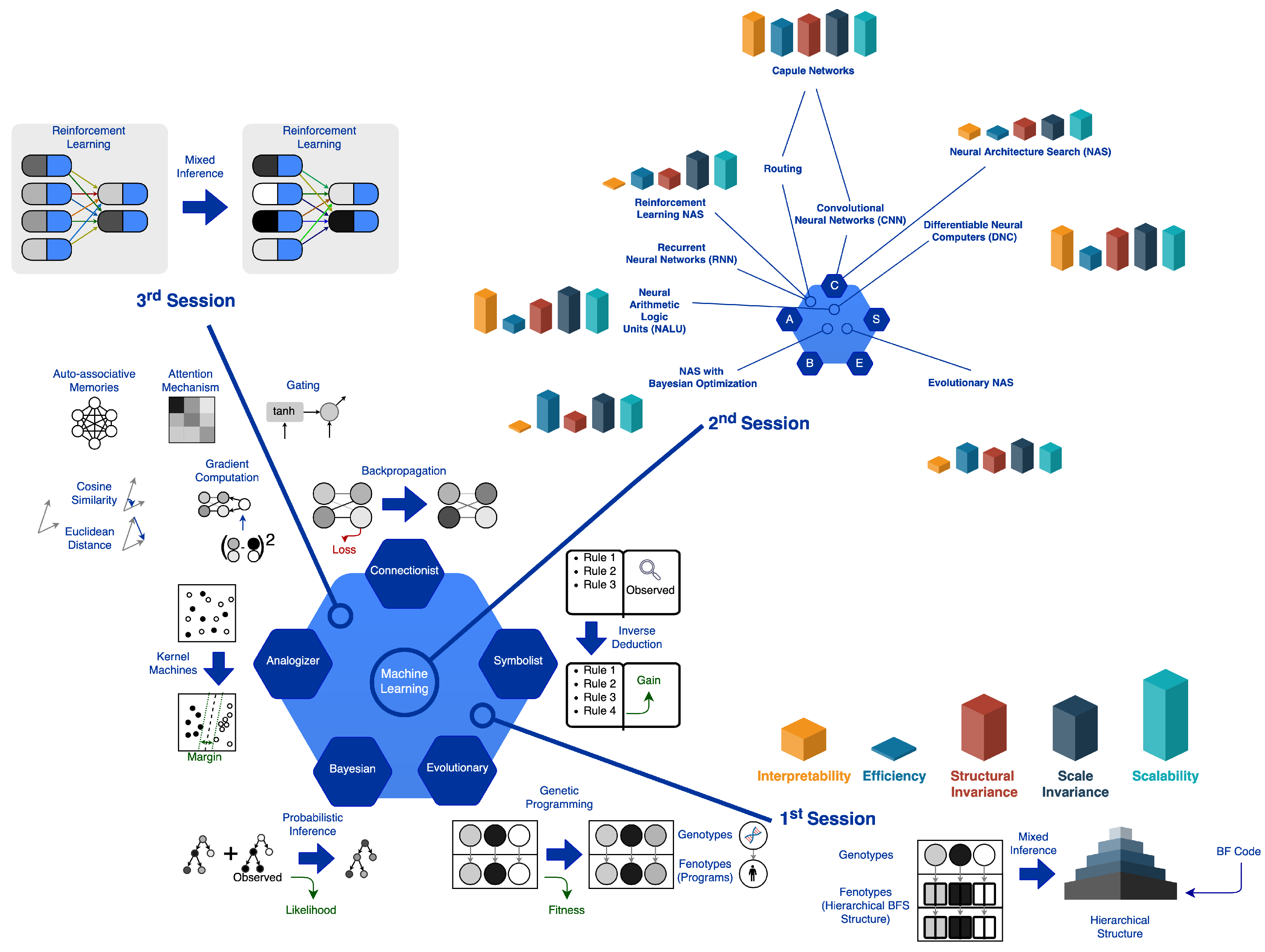
2. Machine Learning Paradigms
3. Related Work
3.1. AutoML Surveys and Reviews
3.2. AutoML Applications
4. The Experimental Path
4.1. First Experimental Session
4.1.1. First Experiment (Genetic Algorithms and BrainF*ck (BF) Language)
4.1.2. Second Experiment (Sequential Model)
- the ‘ character inserts the instruction preceding ’ inside the input tape;
- the * character overwrites the currently pointed cell with the instruction preceding *;
- the ⌃ character removes the currently pointed cell;
- the / character writes the zero value in the currently pointed cell;
- the ; character splits the structures in the definition of a parent architecture;
- the , character splits the building blocks in the definition of a structure;
- the . character splits the code that the block can generate.
4.2. Second Experimental Session
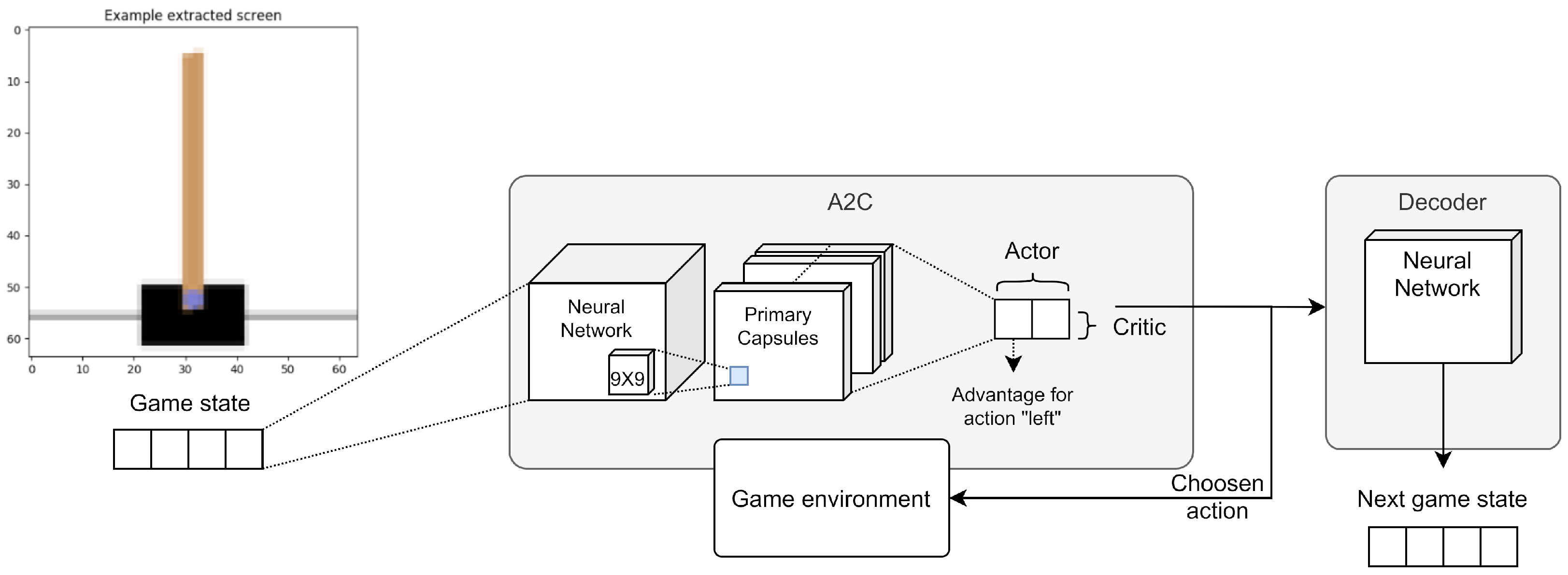
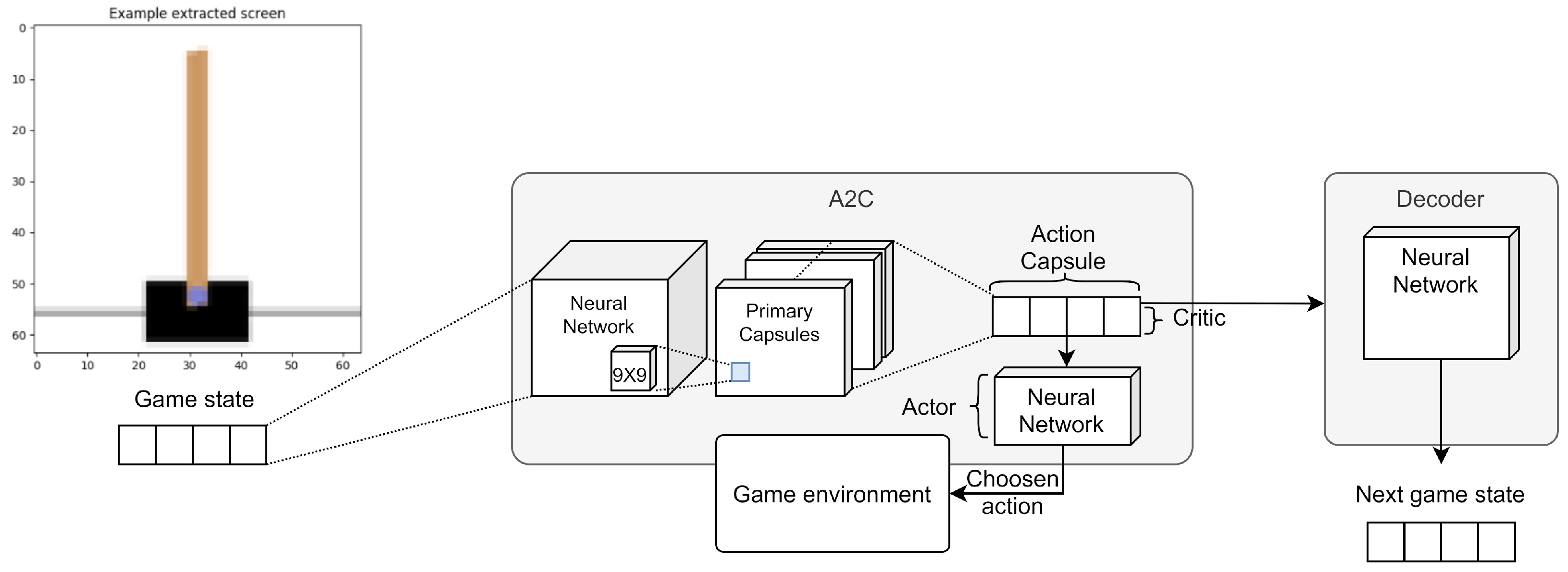
4.3. Third Experimental Session
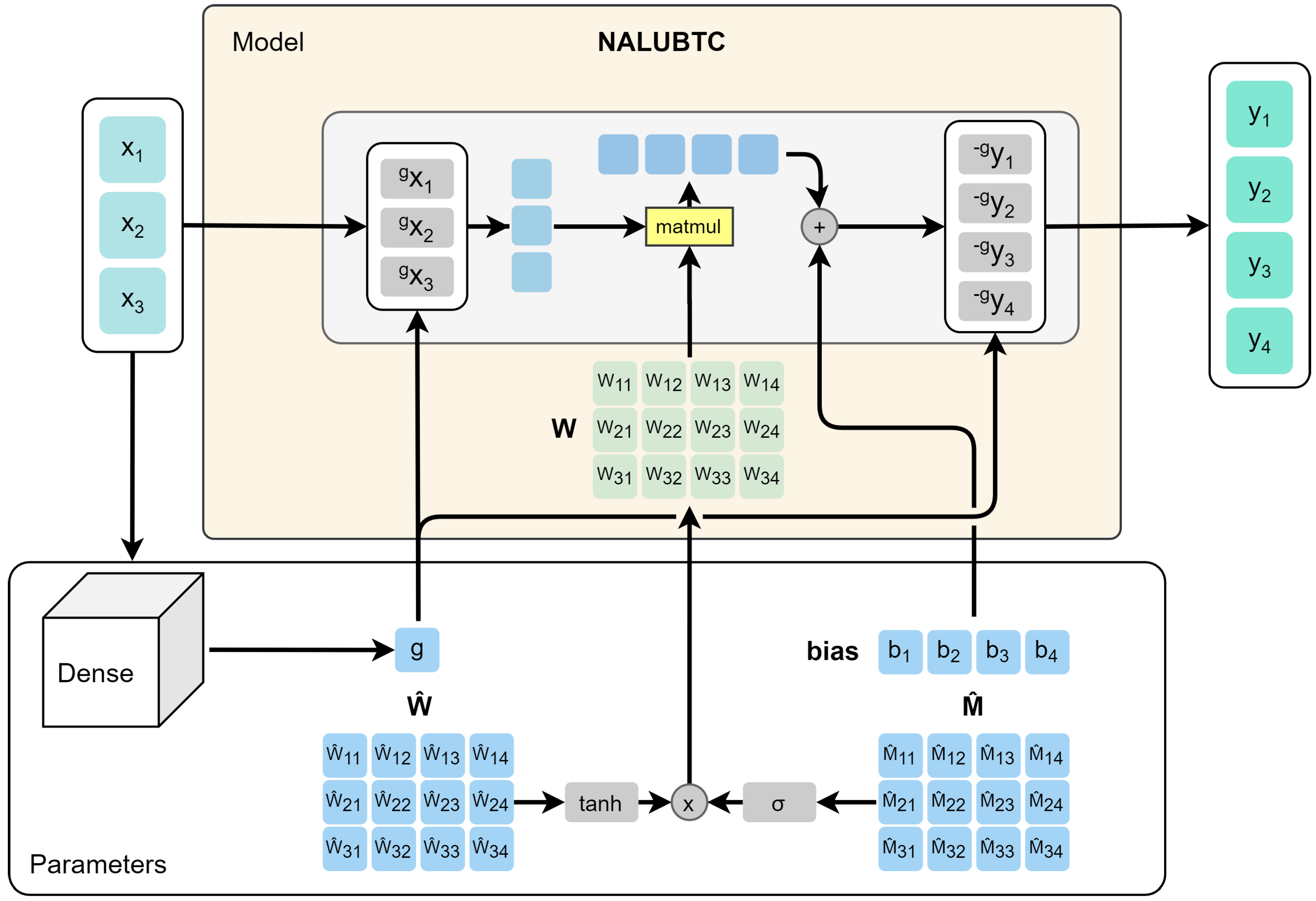
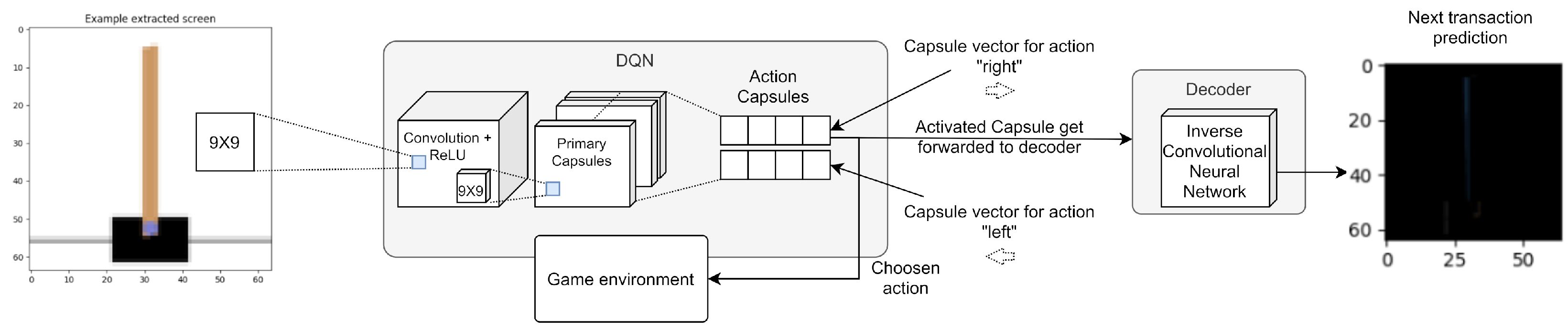
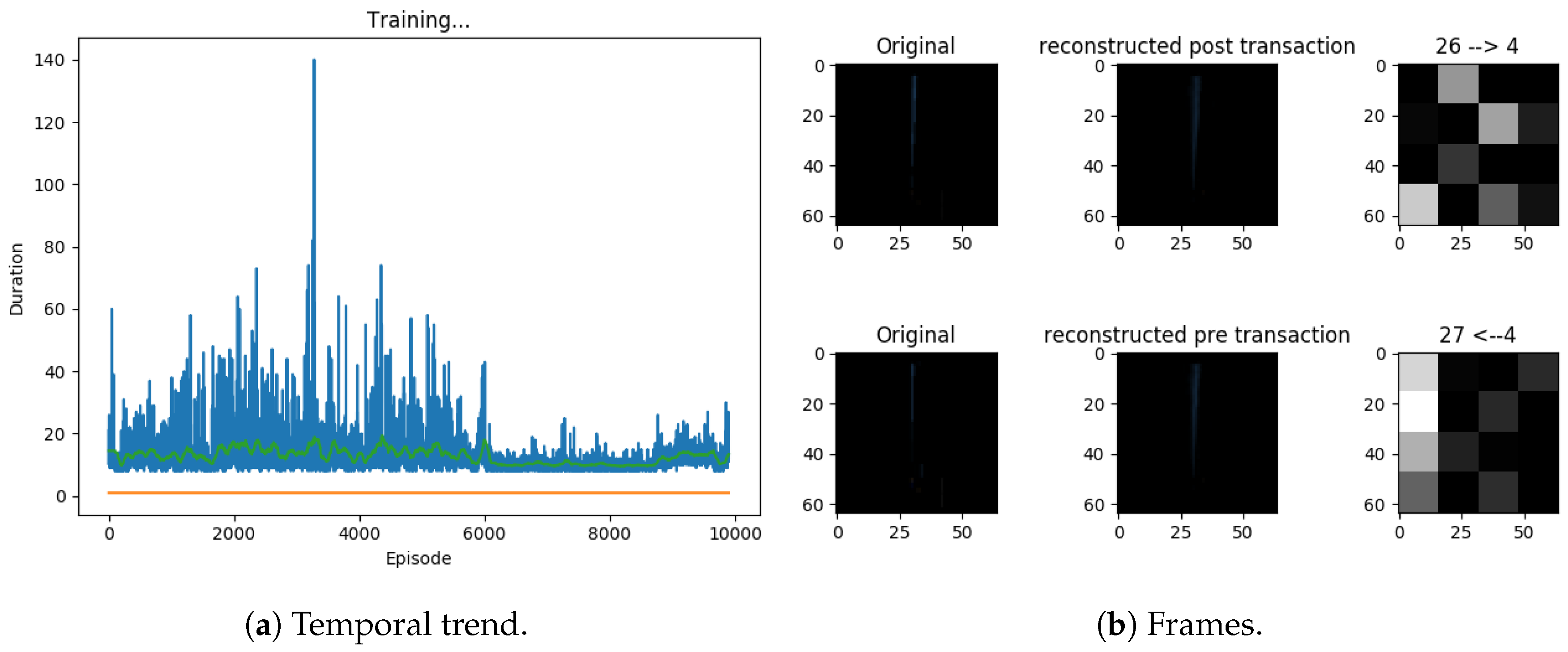
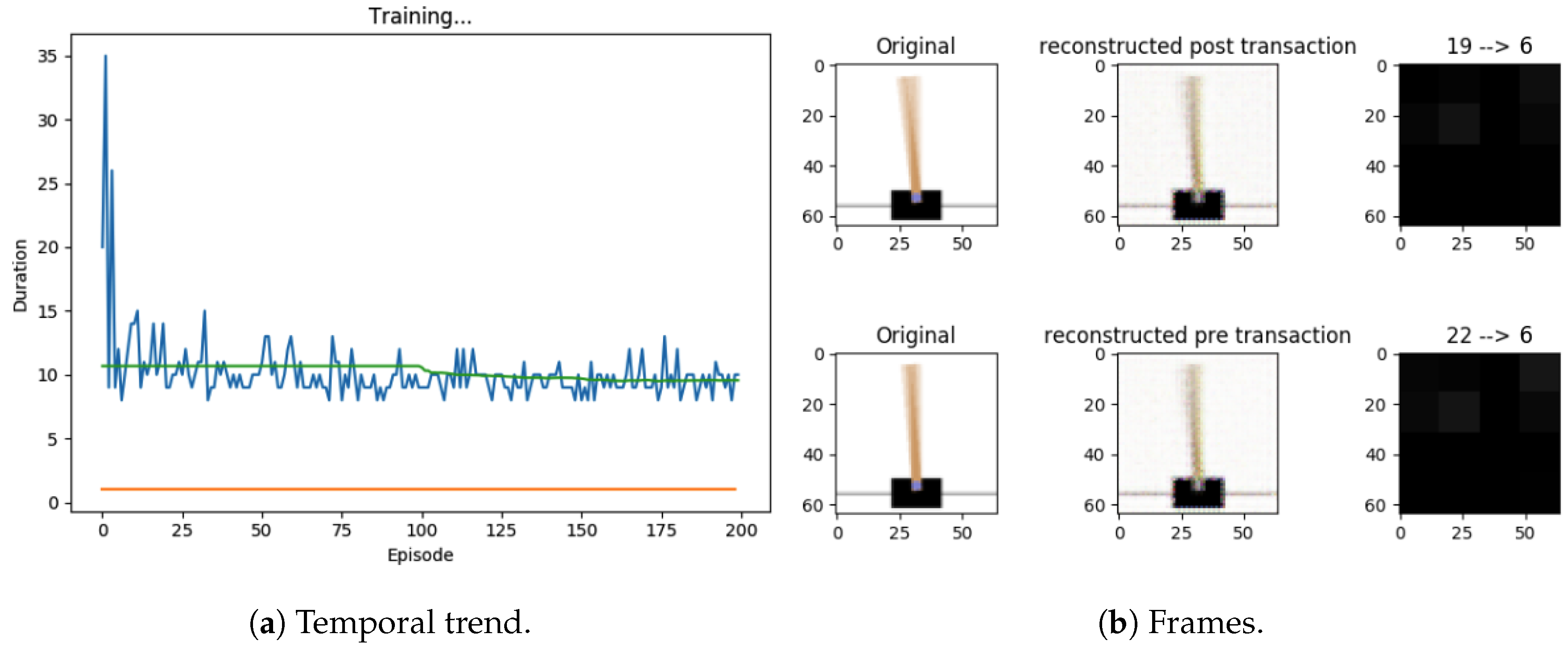
4.3.1. First Experiment
4.3.2. Second Experiment
4.3.3. Third Experiment
5. Empirical Evaluation
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Caldarelli, S.; Feltoni Gurini, D.; Micarelli, A.; Sansonetti, G. A Signal-Based Approach to News Recommendation. In CEUR Workshop Proceedings; CEUR-WS.org: Aachen, Germany, 2016; Volume 1618. [Google Scholar]
- Biancalana, C.; Gasparetti, F.; Micarelli, A.; Miola, A.; Sansonetti, G. Context-aware Movie Recommendation Based on Signal Processing and Machine Learning. In Proceedings of the 2nd Challenge on Context-Aware Movie Recommendation, CAMRa ’11, Chicago, IL, USA, 27 October 2011; ACM: New York, NY, USA, 2011; pp. 5–10. [Google Scholar]
- Onori, M.; Micarelli, A.; Sansonetti, G. A Comparative Analysis of Personality-Based Music Recommender Systems. In CEUR Workshop Proceedings; CEUR-WS.org: Aachen, Germany, 2016; Volume 1680, pp. 55–59. [Google Scholar]
- Sansonetti, G.; Gasparetti, F.; Micarelli, A.; Cena, F.; Gena, C. Enhancing Cultural Recommendations through Social and Linked Open Data. User Model. User-Adapt. Interact. 2019, 29, 121–159. [Google Scholar]
- Sansonetti, G. Point of Interest Recommendation Based on Social and Linked Open Data. Pers. Ubiquitous Comput. 2019, 23, 199–214. [Google Scholar]
- Fogli, A.; Sansonetti, G. Exploiting Semantics for Context-Aware Itinerary Recommendation. Pers. Ubiquitous Comput. 2019, 23, 215–231. [Google Scholar]
- Feltoni Gurini, D.; Gasparetti, F.; Micarelli, A.; Sansonetti, G. Temporal People-to-people Recommendation on Social Networks with Sentiment-based Matrix Factorization. Future Gener. Comput. Syst. 2018, 78, 430–439. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar]
- Yao, Q.; Wang, M.; Escalante, H.J.; Guyon, I.; Hu, Y.; Li, Y.; Tu, W.; Yang, Q.; Yu, Y. Taking Human out of Learning Applications: A Survey on Automated Machine Learning. arXiv 2018, arXiv:1810.13306. [Google Scholar]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [PubMed]
- Hilbert, D. Die grundlagen der mathematik. In Die Grundlagen der Mathematik; Springer: Berlin/Heidelberg, Germany, 1928; pp. 1–21. [Google Scholar]
- Church, A. An Unsolvable Problem of Elementary Number Theory. Am. J. Math. 1936, 58, 345–363. [Google Scholar]
- Turing, A.M. On computable numbers, with an application to the Entscheidungsproblem. Proc. Lond. Math. Soc. 1937, 2, 230–265. [Google Scholar]
- Heekeren, H.R.; Marrett, S.; Ungerleider, L.G. The neural systems that mediate human perceptual decision making. Nat. Rev. Neurosci. 2008, 9, 467–479. [Google Scholar]
- Vaccaro, L.; Sansonetti, G.; Micarelli, A. Automated Machine Learning: Prospects and Challenges. In Proceedings of the Computational Science and Its Applications—ICCSA 2020, Cagliari, Italy, 1–4 July 2020; Springer International Publishing: Cham, Switzerland, 2020; Volume 12252 LNCS, pp. 119–134. [Google Scholar]
- Domingos, P. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World; Basic Books: New York, NY, USA, 2015. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural Architecture Search: A Survey. J. Mach. Learn. Res. 2019, 20, 55:1–55:21. [Google Scholar]
- Fox, G.C.; Glazier, J.A.; Kadupitiya, J.C.S.; Jadhao, V.; Kim, M.; Qiu, J.; Sluka, J.P.; Somogyi, E.T.; Marathe, M.; Adiga, A.; et al. Learning Everywhere: Pervasive Machine Learning for Effective High-Performance Computation. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 422–429. [Google Scholar]
- Meier, B.B.; Elezi, I.; Amirian, M.; Dürr, O.; Stadelmann, T. Learning Neural Models for End-to-End Clustering. In Artificial Neural Networks in Pattern Recognition; Springer International Publishing: Cham, Switzerland, 2018; pp. 126–138. [Google Scholar]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. (Eds.) Automated Machine Learning—Methods, Systems, Challenges; The Springer Series on Challenges in Machine Learning; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Zöller, M.A.; Huber, M.F. Benchmark and Survey of Automated Machine Learning Frameworks. arXiv 2019, arXiv:1904.12054. [Google Scholar]
- Escalante, H.J. Automated Machine Learning—A brief review at the end of the early years. arXiv 2020, arXiv:2008.08516. [Google Scholar]
- Liu, Z.; Xu, Z.; Madadi, M.; Junior, J.J.; Escalera, S.; Rajaa, S.; Guyon, I. Overview and unifying conceptualization of automated machine learning. In Proceedings of the Automating Data Science Workshop, Wurzburg, Germany, 20 September 2019. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212. [Google Scholar] [CrossRef]
- Vanschoren, J. Meta-Learning. In Automated Machine Learning: Methods, Systems, Challenges; Springer International Publishing: Cham, Switzerland, 2019; pp. 35–61. [Google Scholar]
- Feurer, M.; Hutter, F. Hyperparameter Optimization. In Automated Machine Learning: Methods, Systems, Challenges; Springer International Publishing: Cham, Switzerland, 2019; pp. 3–33. [Google Scholar]
- Shawi, R.E.; Maher, M.; Sakr, S. Automated Machine Learning: State-of-The-Art and Open Challenges. arXiv 2019, arXiv:1906.02287. [Google Scholar]
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’13, Chicago, IL, USA, 11–14 August 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 847–855. [Google Scholar]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.; Li, Z.; Chen, X.; Wang, X. A Comprehensive Survey of Neural Architecture Search: Challenges and Solutions. arXiv 2020, arXiv:2006.02903. [Google Scholar]
- Wistuba, M.; Rawat, A.; Pedapati, T. A Survey on Neural Architecture Search. arXiv 2019, arXiv:1905.01392. [Google Scholar]
- Chen, Y.; Song, Q.; Hu, X. Techniques for Automated Machine Learning. arXiv 2019, arXiv:1907.08908. [Google Scholar]
- Frazier, P.I. Bayesian Optimization. In Recent Advances in Optimization and Modeling of Contemporary Problems; PubsOnLine: Catonsville, MD, USA, 2018; Chapter 11; pp. 255–278. [Google Scholar]
- Zöller, M.; Huber, M.F. Survey on Automated Machine Learning. arXiv 2019, arXiv:1904.12054. [Google Scholar]
- Tuggener, L.; Amirian, M.; Rombach, K.; Lorwald, S.; Varlet, A.; Westermann, C.; Stadelmann, T. Automated Machine Learning in Practice: State of the Art and Recent Results. In Proceedings of the 6th Swiss Conference on Data Science (SDS), Bern, Switzerland, 14 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Chung, C.; Chen, C.; Shih, W.; Lin, T.; Yeh, R.; Wang, I. Automated machine learning for Internet of Things. In Proceedings of the 2017 IEEE International Conference on Consumer Electronics, (ICCE-TW), Taipei, Taiwan, 12–14 June 2017; pp. 295–296. [Google Scholar]
- Li, Z.; Guo, H.; Wang, W.M.; Guan, Y.; Barenji, A.V.; Huang, G.Q.; McFall, K.S.; Chen, X. A Blockchain and AutoML Approach for Open and Automated Customer Service. IEEE Trans. Ind. Inform. 2019, 15, 3642–3651. [Google Scholar]
- Di Mauro, M.; Galatro, G.; Liotta, A. Experimental Review of Neural-Based Approaches for Network Intrusion Management. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2480–2495. [Google Scholar] [CrossRef]
- Maipradit, R.; Hata, H.; Matsumoto, K. Sentiment Classification Using N-Gram Inverse Document Frequency and Automated Machine Learning. IEEE Softw. 2019, 36, 65–70. [Google Scholar] [CrossRef] [Green Version]
- Shi, X.; Wong, Y.; Chai, C.; Li, M. An Automated Machine Learning (AutoML) Method of Risk Prediction for Decision-Making of Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 1–10. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Schmidhuber, J. Optimal ordered problem solver. Mach. Learn. 2004, 54, 211–254. [Google Scholar] [CrossRef] [Green Version]
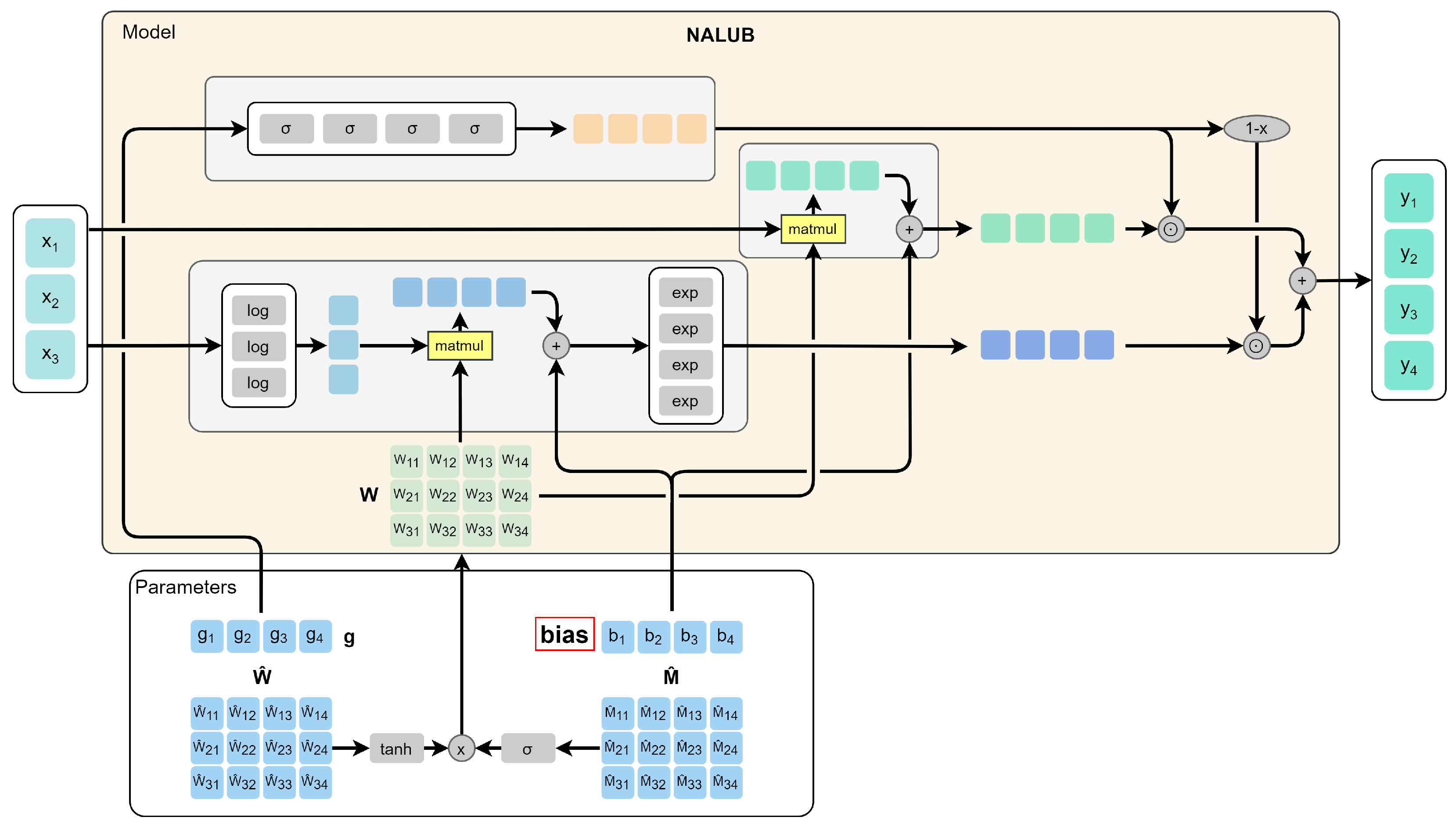
- Trask, A.; Hill, F.; Reed, S.; Rae, J.; Dyer, C.; Blunsom, P. Neural Arithmetic Logic Units. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS), NIPS’18, Montreal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018. [Google Scholar]
- Graves, A.; Wayne, G.; Reynolds, M.; Harley, T.; Danihelka, I.; Grabska-Barwińska, A.; Colmenarejo, S.G.; Grefenstette, E.; Ramalho, T.; Agapiou, J.; et al. Hybrid computing using a neural network with dynamic external memory. Nature 2016, 538, 471–476. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Jin, H.; Song, Q.; Hu, X. Auto-keras: An efficient neural architecture search system. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1946–1956. [Google Scholar]
- Kandasamy, K.; Neiswanger, W.; Schneider, J.; Poczos, B.; Xing, E.P. Neural Architecture Search with Bayesian Optimisation and Optimal Transport. In Advances in Neural Information Processing Systems (NIPS); Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 2016–2025. [Google Scholar]
- Liu, H.; Simonyan, K.; Vinyals, O.; Fernando, C.; Kavukcuoglu, K. Hierarchical Representations for Efficient Architecture Search. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized Evolution for Image Classifier Architecture Search. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; pp. 4780–4789. [Google Scholar]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient neural architecture search via parameter sharing. arXiv 2018, arXiv:1802.03268. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive Neural Architecture Search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 19–35. [Google Scholar]
- Jastrzębski, S.; de Laroussilhe, Q.; Tan, M.; Ma, X.; Houlsby, N.; Gesmundo, A. Neural Architecture Search Over a Graph Search Space. arXiv 2018, arXiv:1812.10666. [Google Scholar]
- Chen, T.Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural ordinary differential equations. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Munich, Germany, 8–14 September 2018; pp. 6571–6583. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 44–51. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- McGill, M.; Perona, P. Deciding how to decide: Dynamic routing in artificial neural networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 2363–2372. [Google Scholar]
- Hassan, H.A.M.; Sansonetti, G.; Gasparetti, F.; Micarelli, A. Semantic-based Tag Recommendation in Scientific Bookmarking Systems. In Proceedings of the ACM RecSys 2018, Vancouver, BC, Canada, 2–7 October 2018; ACM: New York, NY, USA, 2018; pp. 465–469. [Google Scholar]
- Hahn, T.; Pyeon, M.; Kim, G. Self-Routing Capsule Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 7656–7665. [Google Scholar]
- Choi, J.; Seo, H.; Im, S.; Kang, M. Attention routing between capsules. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 1981–1989. [Google Scholar]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents. J. Artif. Intell. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M.A. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Shao, K.; Tang, Z.; Zhu, Y.; Li, N.; Zhao, D. A Survey of Deep Reinforcement Learning in Video Games. arXiv 2019, arXiv:1912.10944. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; A Bradford Book: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing between Capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3859–3869. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the Variance of the Adaptive Learning Rate and Beyond. arXiv 2020, arXiv:1908.03265. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Richardson, M.; Domingos, P. Markov Logic Networks. Mach. Learn. 2006, 62, 107–136. [Google Scholar] [CrossRef] [Green Version]
- Navon, A.; Achituve, I.; Maron, H.; Chechik, G.; Fetaya, E. Auxiliary Learning by Implicit Differentiation. arXiv 2020, arXiv:2007.02693. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Game | Algorithm | Vision | Capsule Routing | Optimization Algorithm | Learning Rate | Number of Episodes | Solved |
|---|---|---|---|---|---|---|---|
| CartPole-v0 | Actor-Critic (AC) | No | No | Adam | 3.00 | 710 | Yes |
| CartPole-v0 | AC | No | Policy | RAdam | 5.00 | 600 | No |
| CartPole-v0 | AC | No | Policy | RAdam | 5.00 | 600 | No |
| CartPole-v0 | AC | No | Policy | Adam | 5.00 | 600 | No |
| CartPole-v0 | AC | No | Policy | Adam | 1.30 | 1420 | Yes |
| CartPole-v0 | AC | No | Policy | Adam | 2.30 | 1000 | Yes |
| CartPole-v0 | AC | No | Policy | Adam | 2.00 | 710 | Yes |
| CartPole-v0 | AC with corrections | No | Policy | Adam | 2.00 | 710 | Yes |
| CartPole-v0 | AC with memory | No | No | Adam | 3.00 | 1000 | Yes |
| CartPole-v0 | AC with memory | No | No | Adam | 1.30 | 820 | Yes |
| CartPole-v0 | AC | Yes | Vision | RAdam | 5.00 | 1000 | No |
| CartPole-v0 | AC | Yes | Vision | RAdam | 1.30 | 1200 | No |
| CartPole-v0 | AC | Yes | Vision | RAdam | 1.30 | 1000 | No |
| CartPole-v0 | AC without policy | No | No | Adam | 3.00 | 2220 | No |
| CartPole-v0 | AC without policy | No | No | Adam | 3.00 | 1190 | Yes |
| CartPole-v0 | AC without policy | No | No | Adam | 5.00 | 1000 | Yes |
| CartPole-v0 | AC without policy | No | No | Adam | 7.00 | 550 | Yes |
| CartPole-v0 | AC | Yes | No | Adam | 3.00 | 1200 | No |
| CartPole-v0 | AC | Yes | No | RAdam | 5.00 | 3090 | No |
| CartPole-v0 | AC | Yes | No | RAdam | 1.30 | 940 | No |
| CartPole-v0 | AC | Yes | No | RAdam | 5.00 | 1050 | No |
| CartPole-v0 | AC | Yes | No | RAdam | 2.00 | 920 | No |
| CartPole-v0 | AC | Yes | No | RMSProp | 2.00 | 1840 | No |
| CartPole-v0 | AC | Yes | No | RMSProp | 5.00 | 1910 | Yes |
| CartPole-v0 | Deep-Q Network | Yes | Vision+Policy | RAdam | 5.00 | 350 | No |
| CartPole-v0 | Deep-Q Network | Yes | No | RMSProp | 0.01 | 1000 | No |
| CartPole-v0 | Deep-Q Network | Yes | No | RMSProp | 0.01 | 1000 | No |
| CartPole-v0 | Deep-Q Network | Yes | No | RMSProp | 0.01 | 10,000 | No |
| Pong-v0 | AC | Yes | No | Adam | 2.00 | 250 | No |
| MountainCar-v0 | AC | No | No | Adam | 2.00 | 14,000 | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vaccaro, L.; Sansonetti, G.; Micarelli, A. An Empirical Review of Automated Machine Learning. Computers 2021, 10, 11. https://doi.org/10.3390/computers10010011
Vaccaro L, Sansonetti G, Micarelli A. An Empirical Review of Automated Machine Learning. Computers. 2021; 10(1):11. https://doi.org/10.3390/computers10010011
Chicago/Turabian StyleVaccaro, Lorenzo, Giuseppe Sansonetti, and Alessandro Micarelli. 2021. "An Empirical Review of Automated Machine Learning" Computers 10, no. 1: 11. https://doi.org/10.3390/computers10010011
APA StyleVaccaro, L., Sansonetti, G., & Micarelli, A. (2021). An Empirical Review of Automated Machine Learning. Computers, 10(1), 11. https://doi.org/10.3390/computers10010011