1. Introduction
Classification is a typical machine-learning task that aims to classify set of samples into predefined classes. Each sample represents a given entity with d observed features. More formally, if the samples belong to k different classes (labeled ), the goal is to build a model based on a sample set and their corresponding class labels , where , , which can be used to predict a class label of an sample. The set of samples and their corresponding labels used to build the model are called a training data set. If there are only two classes (), then the problem is a binary classification problem. If the size of the classes differs significantly, the set containing all the samples of the smaller class is called the minority set, and the set containing all the samples of the larger class is called the majority set.
The classical classification algorithms, such as the Naive Bayes, linear SVM and Random Trees, were designed for balanced data sets. If the class distribution is uneven, the models built on the data set usually favor the larger class. Data imbalance must also be taken into account in model evaluation as an inappropriate metric may provide a completely misleading result about the performance of a classifier [
1].
We can easily understand the problem by imagining a simple classification task where the samples, represented by triangles and circles, have to be classified into the Triangle class and the Circle class, respectively. The training data set that can be used to build the model has 1000 samples, 990 circles and only 10 triangles. If we consider a trivial classifier that predicts the Circle label for each sample, it would make a good decision for 99% of the samples in the data set; however, in practice, the classifier is completely useless.
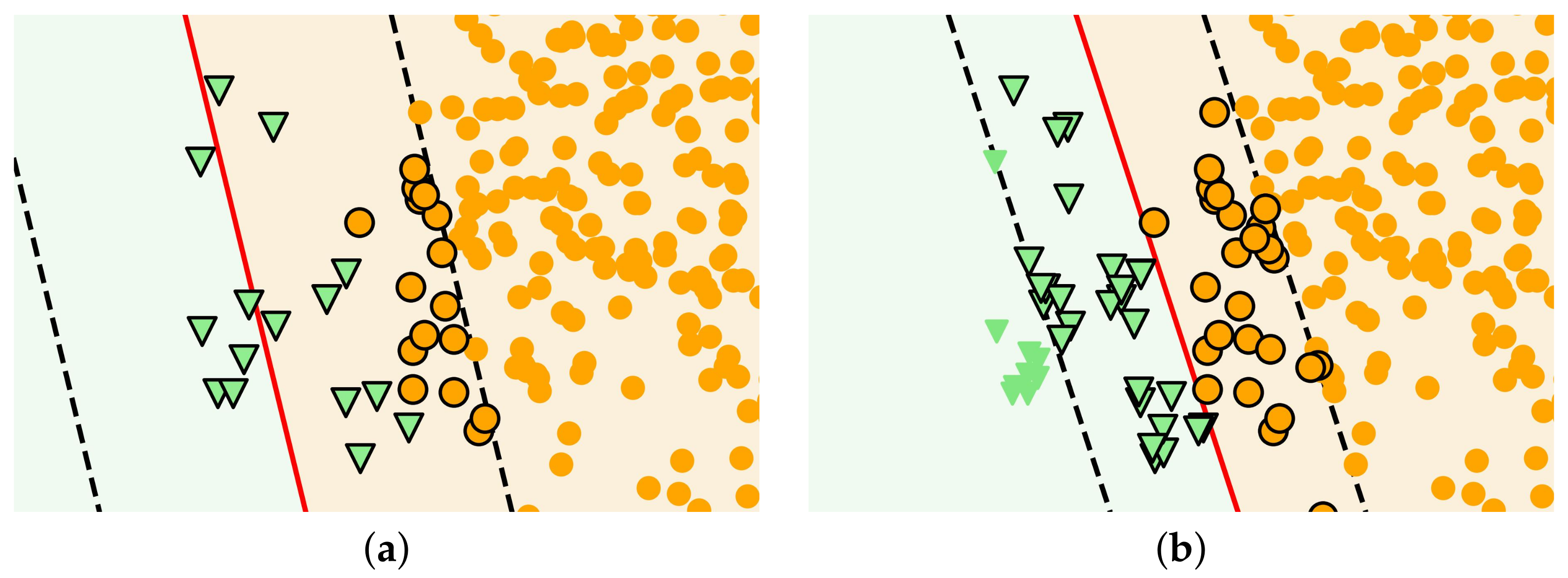
A less extreme example is shown in
Figure 1a. We built a model with a linear SVM on the data set with 200 circles and 15 triangles. The red line indicates the decision boundary for separating samples belonging to different classes. If a sample to be classified falls to the left of the red line, the classifier will classify it as a triangle—otherwise, as a circle. One can readily see that the location of the decision boundary favors the classification of circles to the detriment of triangles. However, on a less imbalanced version of the data set, the classifier was able to find a good decision boundary (
Figure 1b).
We can also observe in
Figure 1 that the samples far from the decision boundary can be classified correctly even by the worse classifier. These easily classifiable samples are commonly referred to as
safe samples. However, some of the samples near the boundary would be classified differently based on the two models. These samples may play an important role in the construction of the model; however, they are
in danger of misclassification as they are very similar to some samples of the other class.
Imbalanced learning has been a focus of interest for two decades, and there are several learning problems in practice where the distribution of classes is skewed (e.g., spam filtering [
2], fault detection [
3,
4], disease risk prediction [
5], cancer diagnosis [
6], dynamic gesture recognition [
7,
8], activity monitoring [
9] and online activity learning [
10]).
We can handle the problem of imbalanced data at the algorithm level, whose best-known representatives are perhaps the cost-sensitive methods. The concept behind them is simple, the misclassification of minority samples costs more (entails a higher penalty) than the misclassification of majority ones [
11]. If large amounts of imbalanced data need to be classified, the use of some cost-sensitive deep-learning methods should also be considered [
12].
In contrast to the previous approach, data-level algorithms address the root of the problem by changing the number and/or distribution of data before applying general classifiers. For binary classification problems, this can be accomplished by oversampling the smaller class or undersampling the larger one, and hybrid solutions also exist that combine under- and oversampling [
1,
13]. All three approaches can also be found in the field of deep learning to handle large amounts of imbalanced data [
14].
One of the advantages of oversampling is that it preserves the information in the data. In addition, oversampling usually reduces the proportion of samples that are difficult to classify and increases the proportion of the safe samples in the data set, while undersampling tends to remove safe samples from the data set preserving the samples that are difficult to classify. This means that the classification with oversampled data sets is likely to be more efficient than using undersampled ones [
15].
In the rest of this paper, we focus primarily on the oversampling algorithms (excluding deep-learning-based solutions). Of the many oversampling algorithms in the literature, it is perhaps worth highlighting that, historically, the algorithm of SMOTE released in 2002 [
16]. The SMOTE attempts to add synthetic samples to the minority set that are similar to but not duplicates of the minority samples.
To achieve this goal, each synthetic sample is generated by interpolating a randomly selected minority sample (
seed) and one of its
k nearest minority neighbors (
co-seed and
pair). We can already see the advantage of using SMOTE because the original Circle–Triangle data set (
Figure 1a) was oversampled by SMOTE to make a more balanced version (
Figure 1b).
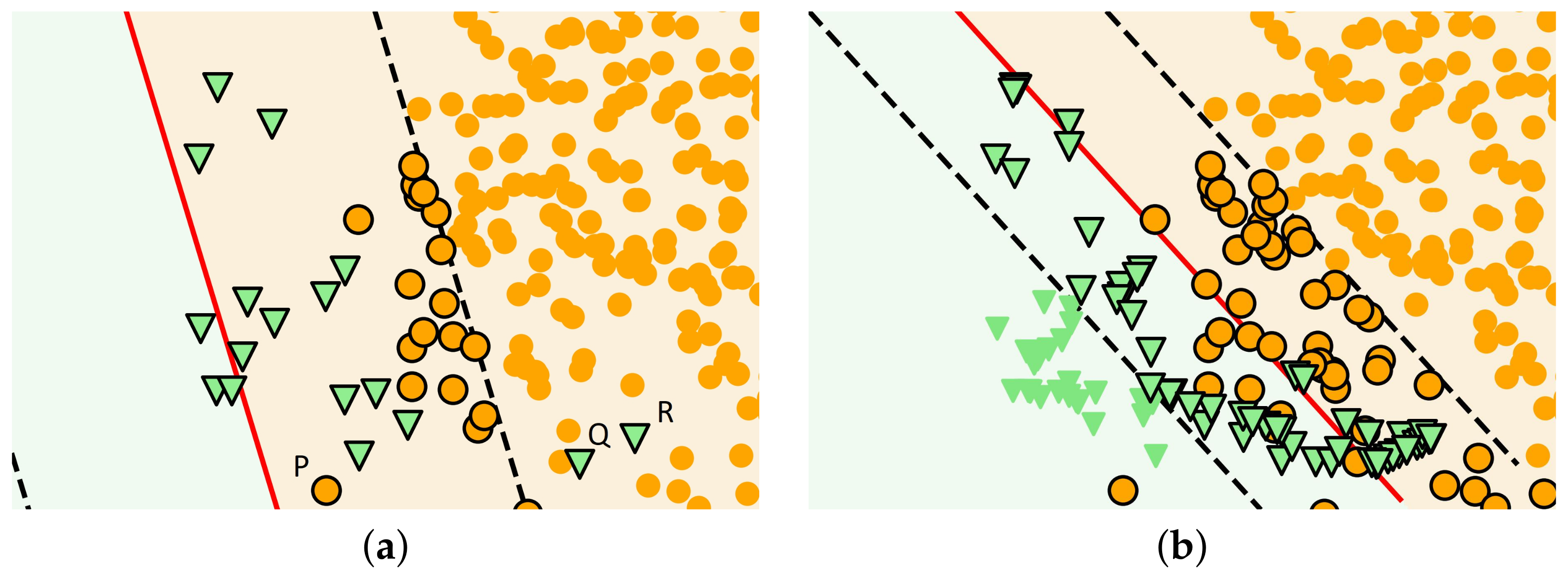
Nevertheless, SMOTE also has certain disadvantages: it selects samples as seeds that are important (e.g., a sample close to the decision boundary), irrelevant (e.g., a sample far to the decision boundary) and misleading (e.g., noise) for classification with equal probability, and the situation is similar for the selection of co-seeds. To provide a clear picture of the problem, we have supplemented the Circle–Triangle data set with three noise samples denoted by P, Q and R (
Figure 2a), and then the data set was oversampled by SMOTE to a similar extent as before.
If we compare
Figure 1a to
Figure 2a, we can see that the decision boundary has shifted due to noise. Furthermore,
Figure 2b shows, that, as a result of oversampling, plenty of new samples appeared around Q and R, thus, increasing the degree of overlap between classes. Moreover, these samples misled the classifier, because they belong to the Triangle class but they are similar to circles.
Over the years, more than a hundred SMOTE variants have been published to overcome the drawbacks of the original version. The interested reader can find more about the SMOTE algorithm, including the several variants in an excellent summary in the literature [
17]. It covers current challenges, such as handling streamed data or using semi-supervised learning.
The following section provides a brief overview of oversampling methods. Then, in
Section 3, we introduce our ModularOverSampler, which was designed taking into account the common features and differences of the methods found in the literature.
Section 4 provides a detailed description of the experimental process and the results. In
Section 5, we discuss the limitations of our method and suggest some directions for further research. Finally, conclusions are drawn in
Section 6.
2. Related Work
Although there are plenty of oversamplers that have been published in the literature, the theoretical considerations behind them, often based on a priori assumptions, serve the same purpose—to ensure that the distribution and locations of the generated samples are adequate to improve the samples classification. A rough structural pattern is also recognizable in a fairly large proportion of the published algorithms; however, by further refining the structure, the diversity of the procedures becomes visible. During the review of the literature, we present the possible structural steps and their role, mentioning some typical implementation methods (strategies) as this supports our concept, which is described in a later section.
Some of the oversamplers start with noise filtering to permanently remove samples considered to be noise from the data set [
18,
19]. Using the filtered data set, we may obtain a clearer picture of which samples are at the decision boundary, where minority samples are in danger of misclassification. However, a noise filter is rarely applied to the minority set, because there is a danger that too many minority samples will be removed, thereby, increasing the degree of imbalance.
In addition, the minority set sometimes really consists of only a few samples because there are problems where the event to be observed is rare (e.g., fault detection [
3], bankruptcy prediction [
20]). The deletion of samples is only acceptable in very justified cases. For example, an isolated sample can be deleted from the minority class [
18] if the overlap of classes is moderate. Samples representing noise and outliers can also be deleted [
19].
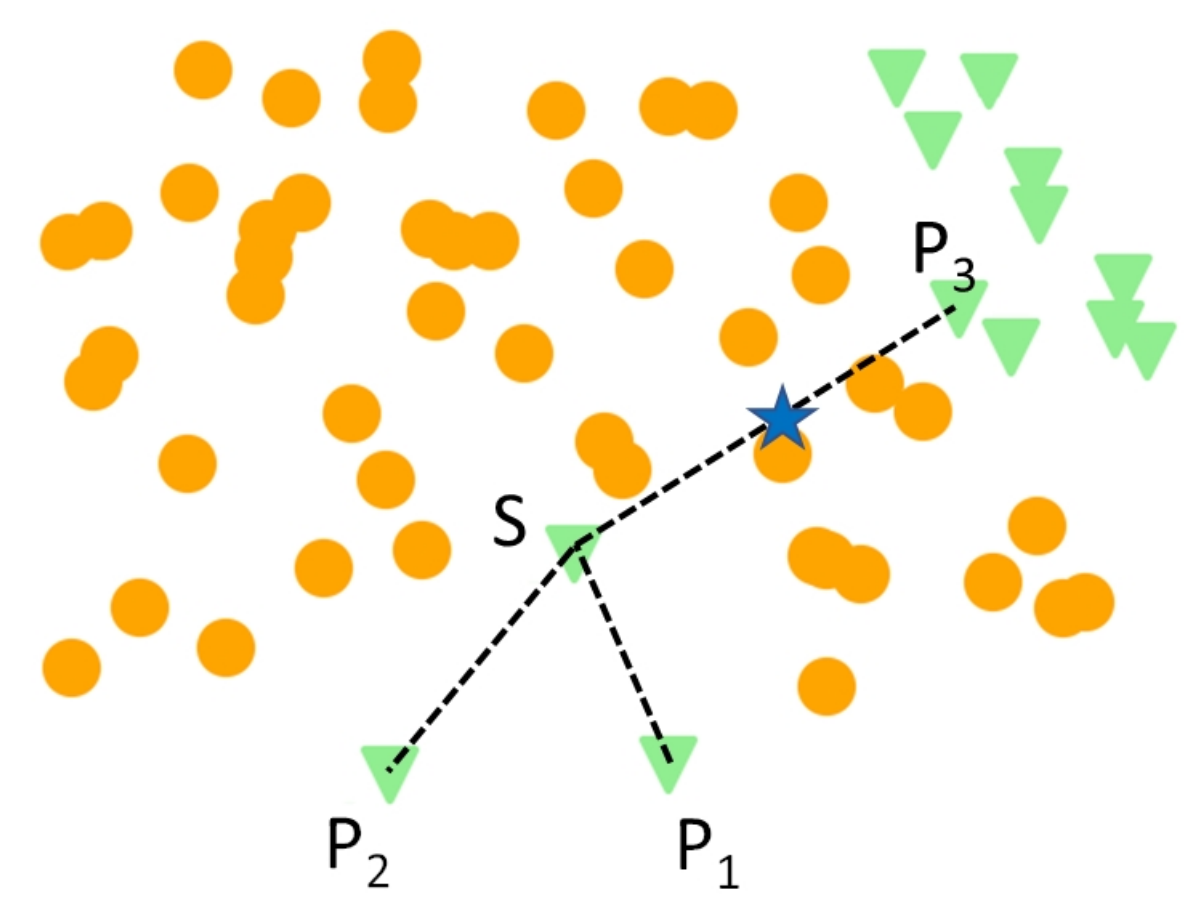
Another typical step is clustering [
21], which can be used to delimit the part of the feature space where it is not worth generating samples. Placing the synthetic samples inside the clusters of the minority set helps to avoid the errors illustrated in
Figure 3 [
22]. The clustering also paves the way for distinguishing samples that are considered important or insignificant for the learning process.
For example, it may reveal the outliers and the isolated samples (possible noise samples), and thus we can exclude them from the further sampling process [
23,
24,
25], and some procedures determine which samples are in danger of misclassification and which ones are safe based on the composition of the clusters, assuming that the decision boundary passes through clusters containing both minority and majority samples [
26]. Instead of general-purpose clustering, many procedures determine the set of samples that are in danger, the set of the safe samples and the set of the noise samples based on the examination of the small environment of the samples (e.g., their
k-nearest neighbors) [
18,
27,
28,
29].
Furthermore, with this, we have reached the next typical step, which is to weight the minority samples according to their importance. At this point, different approaches can be found in the literature because the assessment of the importance of samples varies from method to method. Some oversamplers consider all the minority samples equally important [
20,
30], while others exclude samples labeled for noise [
24]. Contradictory strategies can also be found in algorithms.
For example, there are methods that assign a higher weight to samples near the decision boundary [
31] than to samples that are far away (including the case where only boundary samples can become seeds [
18]); however, for example, the Safe-Level-SMOTE generates samples near to the safe samples [
32]. Furthermore, while many oversamplers ignore data samples in clusters that are too small, there is a method that assigns the largest weights to these minority samples assuming that they are not noises but rare samples [
33].
The next step is to choose the seed samples. The selection is mostly made randomly from the samples of the minority set. The distribution of the selection can be uniform or weighted, as described in the previous paragraph.
The synthetic samples can be generated around the selected seeds [
34,
35]; however, most oversamplers select another sample (called a pair or co-seed) to each seed and create the new samples based on these samples. The most popular method to generate new samples is to interpolate the seeds and their pairs. Typically, the co-seeds are selected randomly from the
k minority nearest neighbors of the seeds [
20,
23,
36] or from the minority samples of the seeds cluster [
37]. Although the seeds and their pairs are usually selected from the same cluster, borderline minority seeds can be strengthened if the new samples are created between them and the safe samples [
38]. There are some methods that select the co-seeds from the majority set; however, this solution is not common [
39].
Sample generation is not always the last step, while some methods reject samples generated in the wrong place during sample generation [
26], others apply post-filtering on the oversampled data set [
23,
36,
40]. The second strategy allows us to make a decision about removing or preserving the samples by seeing the modified version of the dataset that already includes the new synthetic samples. In this case, the sample removal is not limited to the newly generated samples.
3. Methodology
Researchers who require imbalanced data sets now have more than a hundred oversampling algorithms to choose from, and the increase in the number of samplers has not stopped in recent years. With this in mind, we have developed a new algorithm because it motivated us to create a generic sampler that can be well adapted to various databases.
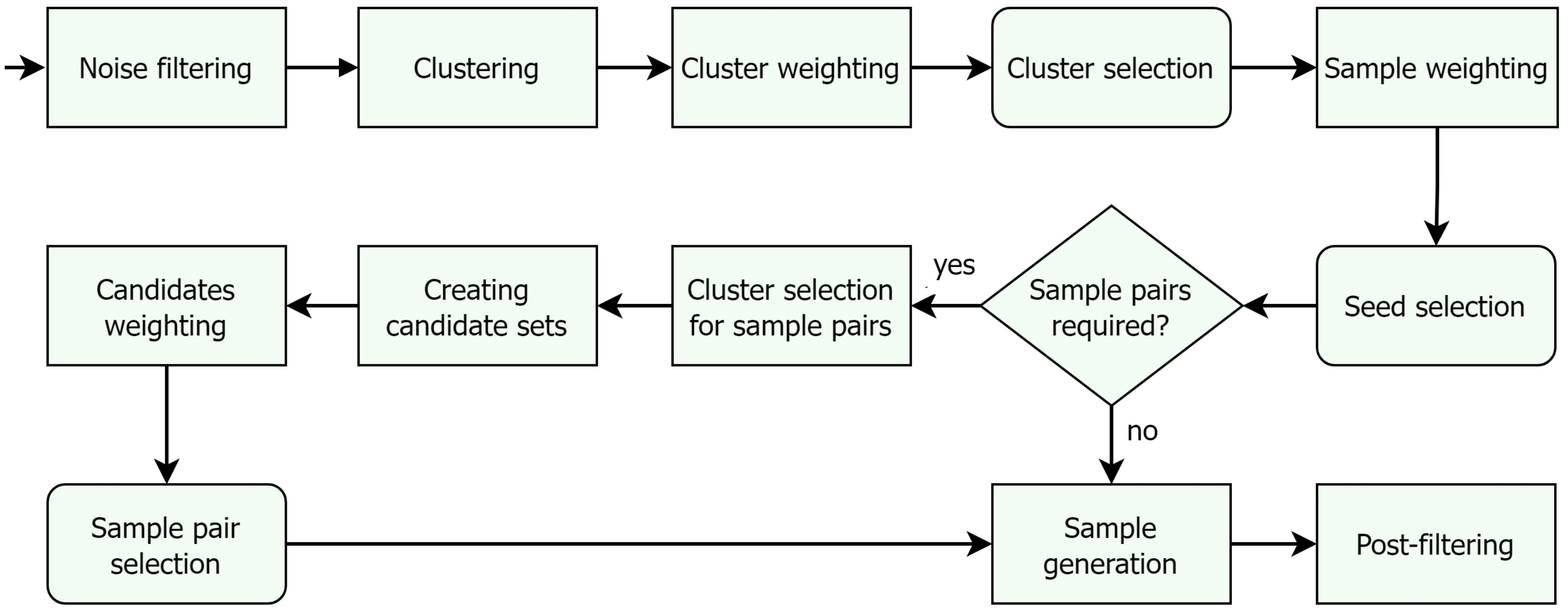
The proposed method utilizes many ideas from other samplers yet differs fundamentally from previously published solutions due to its modular structure. The main steps are shown in
Figure 4. The method consists of a few more steps than we mentioned in the previous section because we have broken down certain steps into smaller ones for flexibility.
For most of the steps, we have defined different strategies which determine the specific methods of performing the steps. (These are described in detail later in this section). Our oversampler can be parameterized with these strategies. The non-round rectangles in
Figure 4 indicate interchangeable modules that are swapped according to the strategies passed as parameters. This structure allows us to fundamentally modify the sampling process via parametrization.
Among the strategies, there are some that cannot be used together. The combination of parameters that assigns exactly one strategy to each interchangeable module and these strategies can be used together is called meaningful parameter combination or path. The algorithm is completed with an optimization step that selects the appropriate one from the paths for the data set to be sampled. We recommend cross-validation for this purpose.
3.1. Noise Filtering
As mentioned in
Section 2, only a few methods attempt to remove the noise samples of the minority set permanently due to the risk of information loss. We also limited the noise removal to the majority set defining the noise with the Edited Nearest Neighbors (ENN) rule [
30], which considers a sample as noise if the majority of its
k-nearest neighbors (kNN) belong to another class. Similar solutions can be found in [
41].
In this step, the noise removal algorithm can be used with and , and as a third option, we made it possible to skip the noise filtering step. We will refer to the three strategies as , and NoFilter.
3.2. Clustering
We mentioned in
Section 2 that there may be different intentions behind the clustering step. Accordingly, the following strategies are defined:
In the rest of the algorithm description, we denote the resulting clusters by S, the set of purely minority clusters by , the set of purely majority clusters by and the set of mixed clusters by . Furthermore, the size of cluster or set c are denoted by .
3.3. Cluster Weighting
In this step, the clusters can be given weight according to their importance. A normalized version of the weight of the cluster determines the probability of randomly selecting a seed from that cluster. For normalization, the weight of a cluster is divided by the sum of the weights of the clusters. By assigning zero weight, we can completely exclude clusters from the seed selection process. Four weighting strategies are defined: CW_Uniform, CW_BySize, CW_Border, CW_ByInsideEnemy. With the CW_Uniform strategy, we can assign the same positive weight to each cluster with at least one minority sample, creating the possibility that nearly the same number of seeds are selected from these clusters.
As a result, samples of the smaller clusters are expected to be involved in generating more synthetic samples than samples of the larger clusters, therefore, it reduces imbalance within the minority class but does not fully balance the clusters as the solution of Jo and Japkowicz [
33]. The
CW_BySize calculates the weight of clusters with at least one minority sample based on their size. More formally, the weight of a cluster
is
All other clusters are given zero weight. If only pure clusters were generated in the previous step, this method ensures that all minority samples have the same chance of being selected as seed. If there are mixed clusters, their minority samples will have a higher chance of becoming a seed than the minority samples of other clusters. A similar solution can be found in [
22]. (To avoid redundant paths, this weighting strategy is not used with the
MinMaj clustering).
The CW_Border strategy assigns weight of 1 to the BORDER cluster and 0 to all others. As a result, only minority samples with a majority neighbor are selected as seeds. Clearly, this weighting only makes sense if BorderSafeNoise clustering was used in the previous step. The CW_ByInsideEnemy as its name implies, assigns high weight to the mixed clusters in which the number of majority samples is high relative to minority samples. Pure clusters receive zero weights.
For a
, the weight is
This strategy is used only in combination with and BorderSafeNoise.
3.4. Cluster Selection
Using the normalized weights (probability values), we randomly select clusters by replacement. In a later step, we will select the seeds from these clusters. We attempted to achieve completely balanced classes, thus is the difference between the number of majority samples and the number of minority samples after the noise filtering step.
3.5. Sample Weighting
This step determines the probability of selecting a sample as a seed. Weighting is performed per cluster and majority samples are automatically given a weight of 0, therefore they cannot become seeds. After determining the weights of the samples, normalization is performed by dividing the weights by the total weight of the samples of their own cluster.
For this step, we defined two weighing strategies: SW_Uniform, SW_kNN.
With the
SW_Uniform all minority samples within a cluster are given the same weight. If
x is a minority sample of a
c cluster, the weight assigned to it is
The
SW_kNN follows in the footsteps of those samplers which attempt to create synthetic samples similar to those minority samples that are in danger for correct classification [
18,
31]. The danger level of a sample is often calculated based on the number of majority samples (enemies) among the sample’s
k-nearest neighbors.
The variant used in this study determines the weight of a minority sample
x according to the following formula:
where
is the five nearest neighbors of
x.
3.6. Seed Selection
To create a multiset of seed samples, we select as many samples from each cluster as the number of times the cluster was previously selected. The sample selection is made randomly with replacement based on the normalized weights (probabilities) that were calculated in the previous step.
3.7. Cluster Selection for Sample Pairs
As the flowchart shows, our oversampler supports sample generation based on a single sample (seed) and based on two samples (a seed and its pair). In the latter case, we need to select a cluster for each seed from which its pair can be selected. These clusters are called the cluster pair of seeds. We have defined the following strategies for this step.
CPM_MINOR: The least restrictive strategy, the MINOR cluster are the cluster pair of each seed.
CPM_SAFE: With this method the minority samples of the SAFE cluster are the cluster pairs of each seed. It can only be used in combination with
BorderSafeNoise clustering. As a result, minority samples in danger of misclassification are associated with safe samples, and thus the generated synthetic samples can strengthen the position of the seeds without deteriorating the position of the majority samples around them [
38].
CPM_SelfCluster: Using this method, the cluster pair of a seed is the set of minority samples of its own cluster, including the case when both the seed and its pair are taken from the BORDER cluster. This option was motivated by the SOI_C [
22].
3.8. Creating Candidate Sets
The purpose of this step is to determine a set of pair candidates for each seed using the output of the previous step. In the simplest case (CS_ALL), we keep all the sample and the candidate set(s) is(are) the output of the previous step.
The second option,
CS_kNN, covers a popular approach, when the pairs of the seeds are from the seeds’ nearest neighbors (See, e.g., SMOTE [
16], Lee [
43]). During the tests, the five nearest neighbors of a seed formed its candidate set, and the nearest neighbors were selected from the pair cluster of the seed.
The third option,
CS_ClusterCenter, allows us to examine a less common solution where cluster centers are used in some way to create new synthetic samples (e.g., AHC [
44], SMMO [
45]). In our case, a candidate set assigned to a seed consists of a single artificial sample that represents the center of the cluster pair of the seed.
3.9. Candidate Weighting
At this point in the process, we assign weights to each sample of the candidate set(s) to determine how likely a sample to be selected as a pair of a certain seed. In this step, we examined the following options. Normalization of weights is performed per candidate set.
SPW_Uniform: operates in a manner analogous to the SW_Uniform. Of course, instead of clusters, this time we are working with the sets of candidates. After CS_ClusterCenter only this option is allowed.
SPW_kNN: works analogously to the
SW_kNN presented in
Section 3.5. Candidates in danger are given higher weight than others.
SPW_SeedPairDistance: These method gives higher weights to the candidates near the seeds than those away from them. The idea appears for, e.g., in [
36] accomplished by using weighted kNN in the pair selection. It is suitable for reducing the occurrence of the type of error shown in
Figure 4. Considering an
seed and an
pair belonging to the candidate set (
D) of
the weight for the
can be calculated as
where
is a distance function. We used the Minkowski distance with
p = 1 and
p = 2 parameterization during the test. The former one corresponds to Manhattan distance, the latter one to the Euclidean distance. The two version of the strategies are denoted by
SPW_SeedPairDistance and
SPW_SeedPairDistance.
Considerable evidence can be found in the literature that the meaningfulness of the
norm worsens with increasing dimensionality for higher values of
k [
46].
3.10. Sample Pairs Selection
For each seed, as many pairs are randomly selected by replacement from their candidate sets as the number of times the seed is in the seeds’ multiset (except in cases where a candidate set is empty). Candidates are picked according to the normalized weights specified in the previous step.
3.11. Sample Generation
If generation is based only on seeds, the samples are generated applying the oversampling part of the ROSE [
35]. Essentially, a new sample is generated in the neighborhood of a seed. The diameter of this neighborhood is determined by a so-called smoothing matrix. The location of the new sample in the neighborhood is based on a given probability density function. If the probability density function is Gaussian, the generated samples can be considered like Gaussian-jitters of the seed. Interested reader can find more details in [
35].
If both seeds and pairs are available, the new samples are determined by linear interpolation which is one of the most commonly used solution: , where is a random number selected from a standard uniform distribution, x is a seed, and y is a pair sample. At this point, we expand the minority set with the new samples.
3.12. Post-Filtering
The role of the post-filter is to remove samples generated in the wrong place to smooth the decision boundary and sometimes to remove irrelevant samples (undersampling). For this step, the choices were two different noise filters (, PF_IPF) and skipping the step (NoFilter).
: It works analogously to ; however, this time we remove the noise sample from the minority set.
PF_IPF: The Iterative Partitioning Filter (IPF) [
47] removes samples from the data set that cannot be consistently classified into the appropriate class by the classifiers built on different folds of the data set. The procedure ends if the quotient of the number of detected noises and the size of the original database remains below
p for
k consecutive steps. We set the value of
p to 0.01 and the number of folds to 5 and decision tree was used as a classifier. The SMOTE-IPF [
23]. It can delete both minority and majority samples.
4. Results and Discussion
To measure the performance of our method and to compare it with other ones, we performed two experiments. In the first part of this section, we provide details of the evaluation process, which was carried out in the same way in both cases.
4.1. Oversamplers
In the field of oversamplers, Kovács published the largest comparative analysis in 2019, ranking 85 methods based on a well-defined test [
48]. According this analysis, the top 10 out of 85 oversamplers are the Polynomial fitting SMOTE [
49], ProWSyn [
50], SMOTE-IPF [
23], Lee [
43], SMOBD [
51], G-SMOTE [
52], CCR [
53], LVQ-SMOTE [
54], Assembled-SMOTE [
38], SMOTE-TomekLinks [
36]). We involved these methods in the tests and the SMOTE based on its prevalence. Interestingly, these samplers work with quite a different approach.
However, there are three procedures among them that just complement the SMOTE with a post-filtering step, the SMOTE-IPF, SMOTE-TomekLink and Lee’s method. Furthermore, in addition to these samplers, the CCR and the SMOBD also deal with the issue of noise.
Due to the design of the proposed method, it should also be mentioned that the Polynomial Fitting SMOTE, whose sampling strategy can be completely changed by modifying its parameters achieved the best overall score.
4.2. Data
For both tests, we used databases from the Knowledge Extraction based on Evolutionary Learning Repository [
55] and the UCI Machine Learning Repository [
56]. The multi-class classification problems were transformed into binary classification problems, therefore these data sets are related.
4.3. Evaluation Metrics
It is the responsibility of the samplers to properly prepare the databases for classification, thus their efficiency is determined by the performance of the classifiers on the sampled data set.
To measure the performance of the classification, the accuracy (Acc),
the F1-score
the G-mean score
and the area under the ROC curve (AUC) were used. The latter can be estimated using the trapezoidal-rule. In the formulas,
and
denote the number of the correctly classified positive and negative samples, respectively, and
and
denote the number the misclassified positive and negative samples, respectively. Traditionally, the minority samples are the positive ones. It is worth noting that the accuracy is only slightly affected by the correct or incorrect classification of the minority samples if the data set is highly imbalanced. The other three metrics are less sensitive to the difference of the class sizes.
4.4. Classifiers
As the effectiveness of the oversamplers is not measured per se, the result obtained may depend on the classifiers involved in the tests. To give a fair chance to all samplers, we used four classifiers operating on different principles, namely a linear support vector machine (SVM), a k-nearest neighbors classifier (kNN), a decision tree (CART) and a feed-forward neural network (MLP), and each classifier was run with multiple parametrizations, mainly following the methodology proposed by Kovács [
48].
For the C regularization parameter of the SVM values 1, 5 and 10 were used, the kNN were run with k = 3, 5 and 7 without weighting and with inverse distance weighting. The CART was used with Gini-impurity and entropy. The height of the tree could be 2, 3 and unlimited. The MLP were applied on the data sets with RELU and logistic activation function and only one hidden layer. The number of the nodes were 10%, 50% or 100% of the input features.
4.5. Evaluation
To evaluate the performance of the oversampler–classifier pairs we used five-fold cross-validation with three repeats with the smote-variants Python package [
56], which guarantees that all the oversamplers are evaluated on the same set of samples during cross-validation, and folds contain a similar proportion of minority and majority samples as the original data set. An oversampled version of the currently selected fold is used to train the classifiers, while testing is done on the original version of the remaining folds.
The different instances of the classifiers and samplers usually provide different results on the same data set depending on their parameters. The highest achieved AUC, F1, G and Acc values are selected as the result of a sampler–classifier pair assuming that users of the methods would also aim to select the best parameterization. Since this step can be considered as parameter optimization, we did not apply a separate optimization step to our method.
The total performance of an oversampler–classifier pair was calculated by averaging the results obtained on the databases.
4.6. Experiment 1
The goal of this test was to verify that the paths of the proposed method are sufficiently diverse to find a suitable one for different data sets. We involved 80 data sets in this experiment, which most important properties are summarized in
Table A1.
Our oversampler was tested with the meaningful parameter combinations (paths). For the other methods, we used the parameter combinations provided by the smote-variants package. (These combinations were specified based on the descriptions of the implemented procedures, sometimes supplemented with additional reasonable ones). If it was supported by the algorithm, complete balancing of the data sets was requested.
By performing the test as described in
Section 4.5, if the ModularOverSampler achieves the highest scores, it means that there is a path that provides the same or better performance than the best of the other samplers in the comparison. The first table shows the number of the data sets on which the different sampler–classifier pairs achieved first place (
Table 1). The results without sampling are also provided.
The results support the assumption that the oversamplers should be adapted to the database being sampled. A different effect of sampling strategies can also be observed in
Figure A1 through a database with few minority samples. Comparing
Figure A1b,c and
Figure A1d–f, we can see that, the kNN-based pair selection strictly narrows the space where new samples can be placed compared to cluster-based solutions, because the same seeds are involved in generating many synthetic samples.
It is easy to see that if the degree of imbalance is smaller, the distribution of the samples will not be so distorted. We can also observe that if the minority samples are not grouped on one side of the majority set, oversampling the border set can increase overlap between classes (
Figure A1f). In such a situation, the pair selection should be limited to a smaller environment of the seeds.
The ModularOverSampler provides us more options than ever before to find a sampler that fit the databases. Although there are some paths that simulate the effect of other oversamplers (for example, the path used to create
Figure A1b,c is equivalent to the SMOTE and SMOTE-ENN [
36]), several paths actually represent new strategies for sampling, as the number of different paths exceeds the number of existing oversamplers.
However, it must be acknowledged that given the performance of today’s PCs, it is not yet viable to examine thousands of parameter combinations to sample a data set. Especially if one wants to further reduce the risk of over-fitting by increasing the number of folds or the number of repetitions. The other remark we need to make here in the name of fairness is that the role of chance in sampling procedures is not negligible. If there is no significant difference in the number of parameters of the samplers, we may assume that none of the samplers gains too much with this effect; however, our method has advantage in this point of view.
To address these issues, we performed another experiment with the limited number of parameters.
4.7. Experiment 2
The aim of the second experiment was to compare the performance of a practical version of our sampler with the other samplers. For the experiment, we formed two completely independent sets, a training and a test sets from the data sets, taking into account the relationship between the different databases. The training set, which contained 50 databases (
Table A2), was used to reduce the number of paths. There are many related databases in it, undoubtedly not the most suitable for path selection; however, this was the cost of including more diverse (e.g., topic, number of samples, number of attributes, imbalance ratio) data sets in the test set (
Table A3).
For each data set, we determined which parameterization of our oversampler has the best impact on the classifiers. Again, we used AUC, F1, G-score and Acc. Thus, a total of 800 paths were obtained as a result: 50 databases × 4 classifiers × 4 scores. Then, we selected the 35 paths that were most frequently appeared in the results (
Table A4). Finally, we examined the performance of the proposed method using the selected paths as parameters. Testing was performed in the same manner as the previous test. The results are shown in (
Table 2).
The table shows that the kNN classifier combined with the ProWSyn achieved a higher G value than combined with our method, but in all other cases our method achieved a better score than the others, and these results are no longer based on a large number of parameter combinations but on the use of different strategies.
To determine which classifiers and metrics the differences can be considered statistically significant, we performed statistical tests. First, a nonparametric Friedman test was used. As a null hypothesis, we assumed that the effect (on the performance of the classification) of all samplers was the same, which could be rejected with a 95% confidence level. Based on these, it makes sense to do more research to see if there is a significant difference between the effect of the proposed method and the other ones. To do this, we performed Holm–Bonferroni tests. Based on the results in
Table A5, we can conclude that, in many cases, there are significant differences between the effects of our method and the others.
The results suggest that our method may be a safe choice for data preparation for any classifier involved in the test. We can expect similar result using before MLP or DTree and better results using before SVM or kNN than we can expect from other methods. If, for some reason, the runtime of the method is important, the use of another well-performing method, e.g., Polynom-fit-SMOTE or ProWSyn is recommended. For kNN and SVC classifiers, one may also want to consider the CCR.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




