
A Real Time Arabic Sign Language Alphabets (ArSLA) Recognition Model Using Deep Learning Architecture

Abstract
:1. Introduction and Motivation
2. Related Works
- (1)
- There are many works suggesting the use of a special hardware device to read hand signs which is considered an extra burden and an added expense. These solutions will not be available to everyone.
- (2)
- Related works that have been developed based on machine learning, or image processing algorithms, are dependent on implementing feature extraction techniques. Hence, the quality of extracted results is completely subject to the selected features which could possibly be an imperfect selection.
- (3)
- Related works that have been developed based on CNN neglect well known CNN architectures. Developing a solution based on Ad hoc CNN architecture is doubted on solution credibility, as new CNN architecture should be tested and validated in different environments and situations.
- (4)
- The works that dealt with ArSL suffer from scalability issues. Not all words can be covered due to the vast amount of words used in sign language.
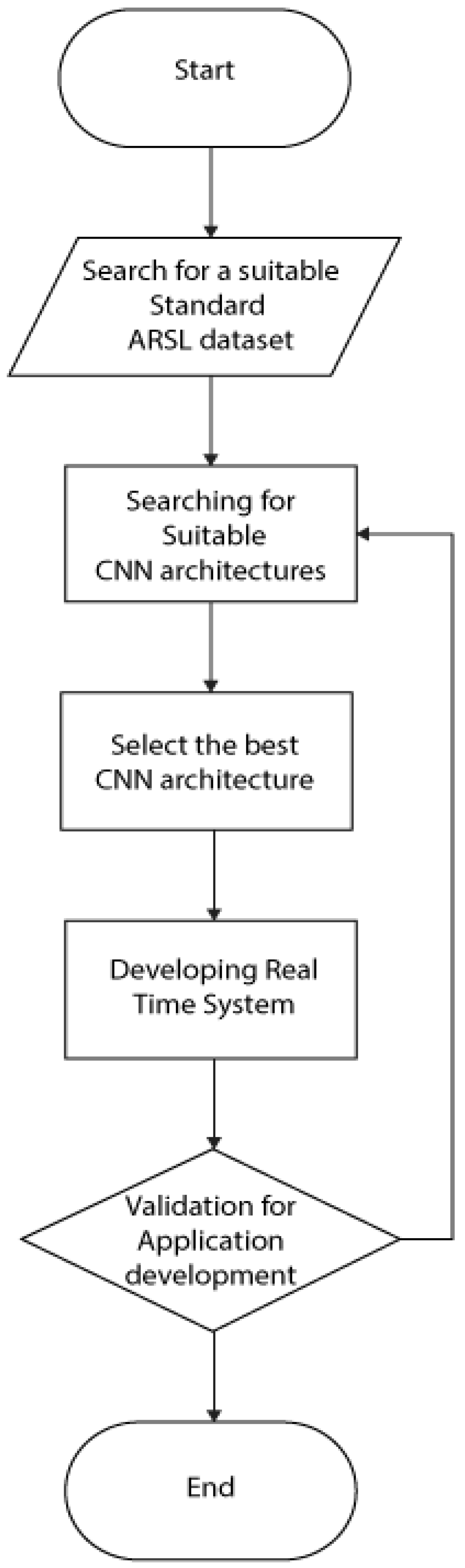
3. Methodology
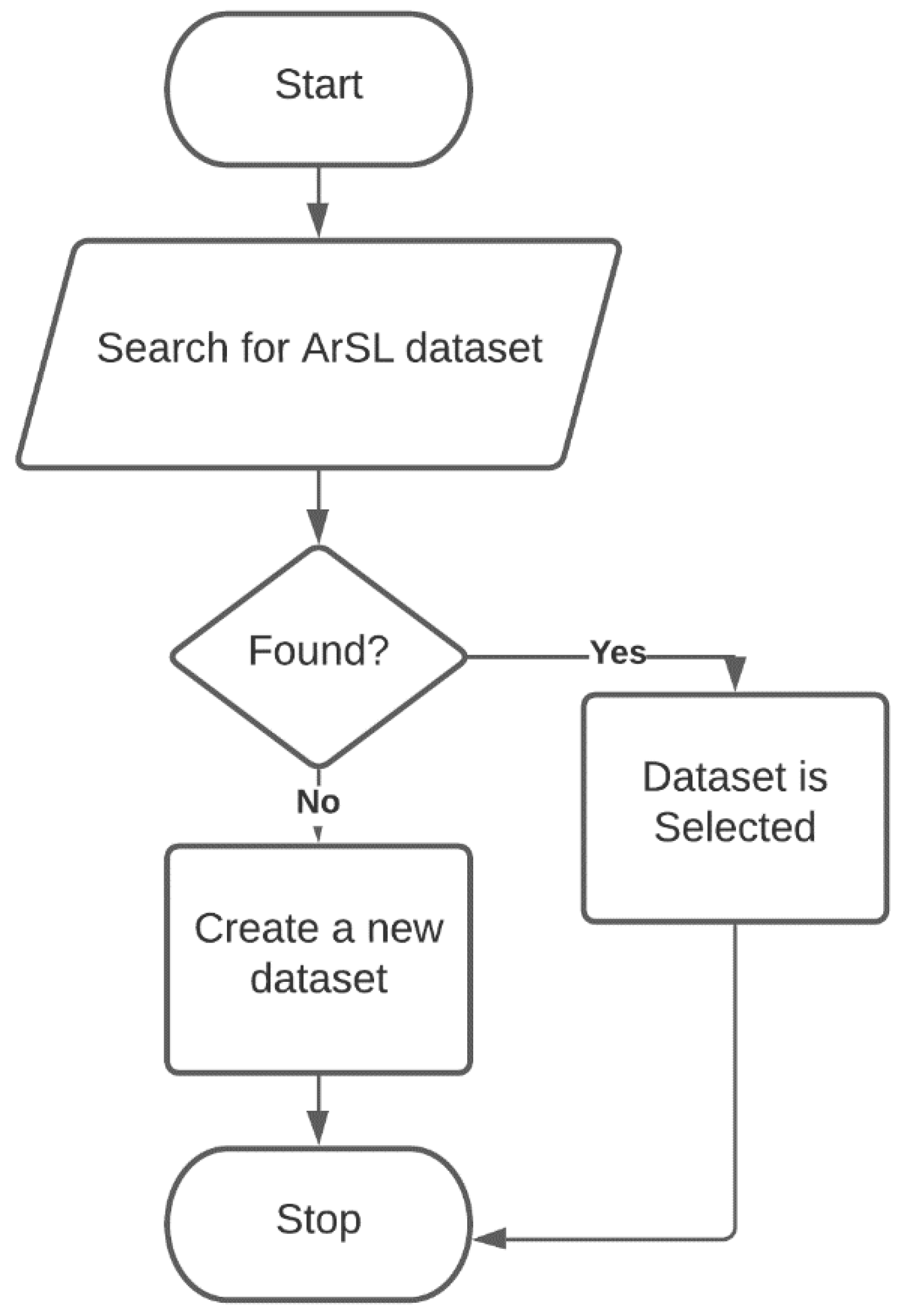
3.1. Search for a Suitable Standard ArSLA Dataset
- (1)
- Dataset for ArSLA. This means the dataset should contain all Arabic alphabetics letters.
- (2)
- The dataset should consist of static images.
- (3)
- The dataset should be a standard dataset which means the selected dataset has been involved in public research with published results.
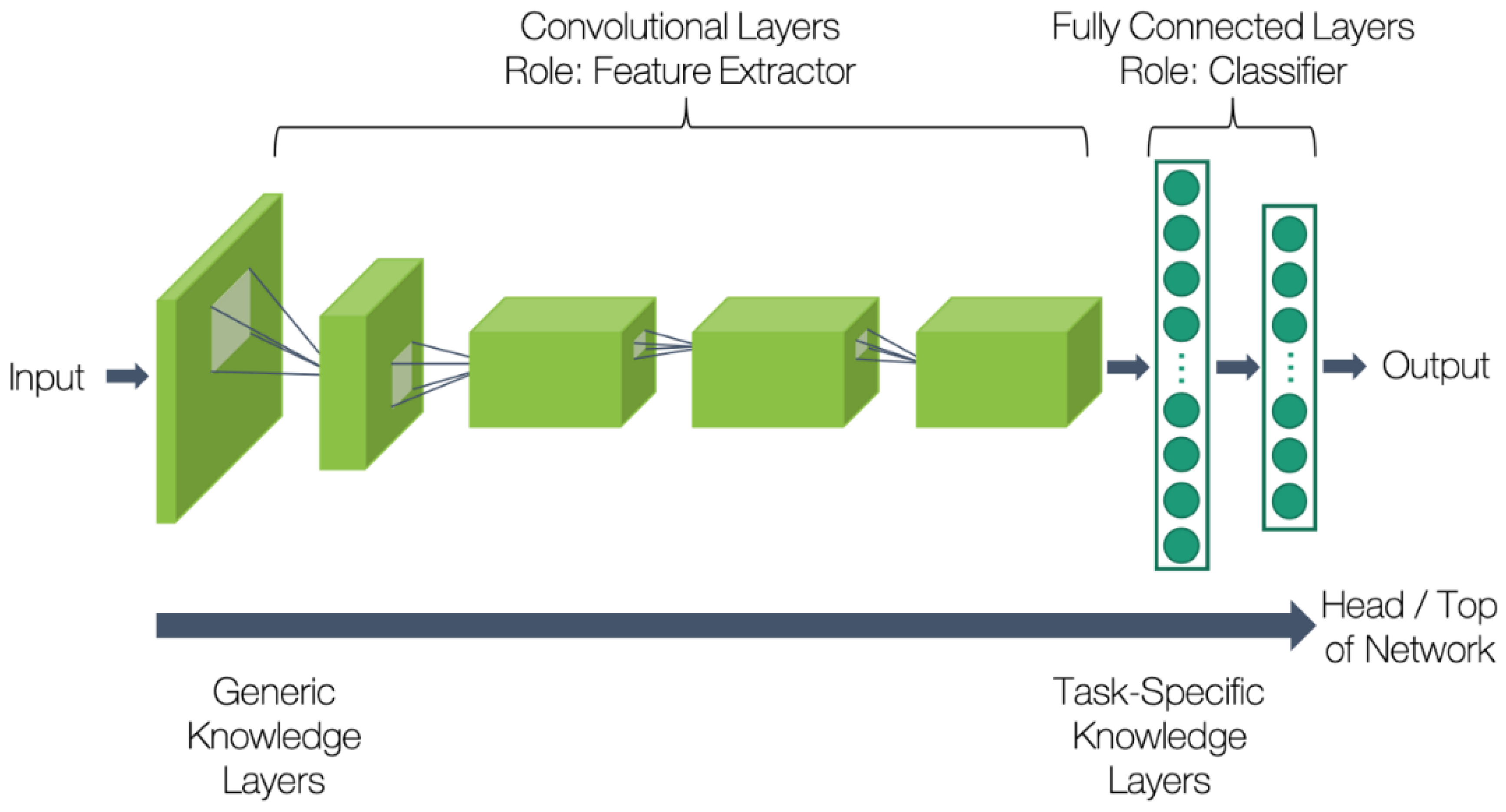
3.2. Search for Suitable CNN Architectures
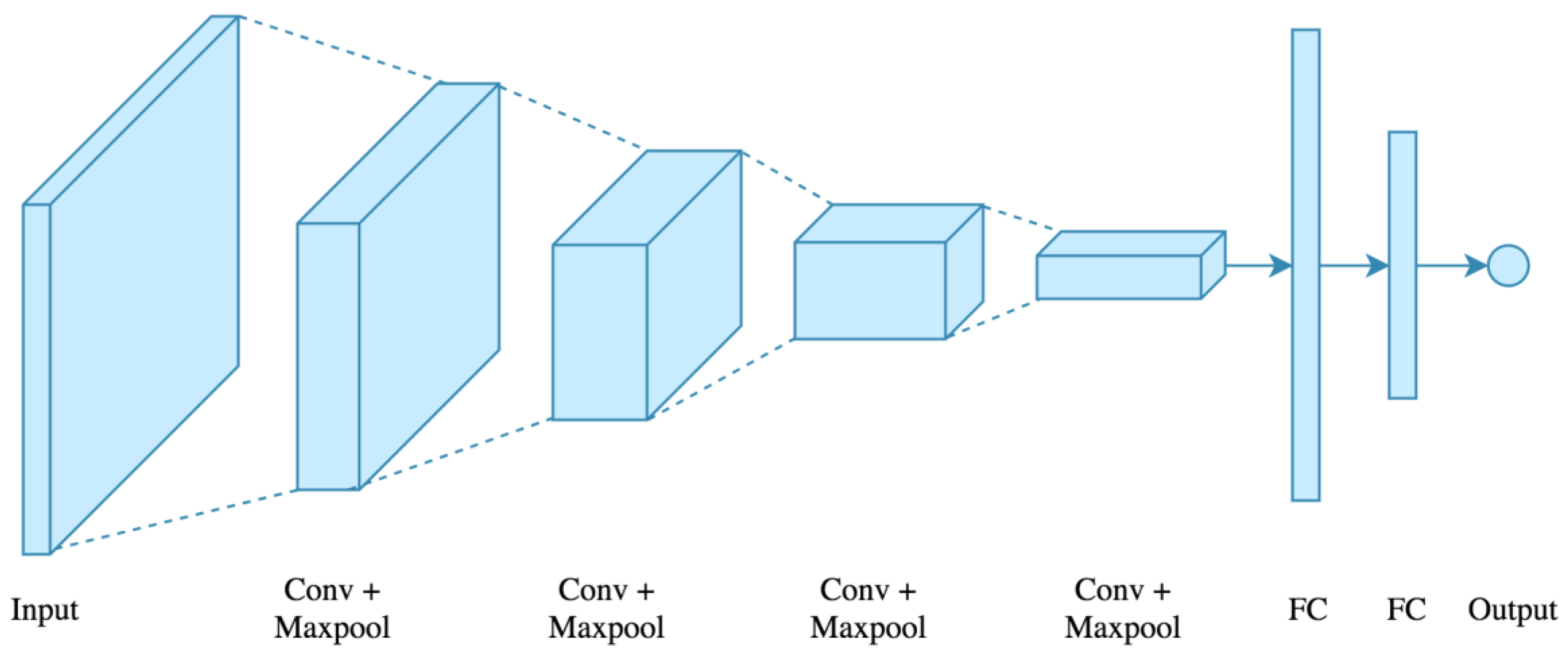
- Convolutional Layers: A grid that provides input to each gate. Each gate’s weights are connected so that each gate recognizes the same feature. There are various sets of gates similar to this, organized in multiple channels (layers) to learn different aspects.
- Pooling Layers: This works as a down--sampling layer by reducing the number of gates. Each of the “k × k” input grid gates are usually reduced to a single cell/gate by choosing the maximum input value or the average of all inputs. The layer is scanned with a tiny k grid and a stride is chosen so that the grid covers the layer without overlapping.
- Fully linked Layers: Each gate’s output is connected to the input of the next layer’s gate. (Also referred to as auto encoder levels). These transform a vectorized version of the input into a normalized vectorized output. The output vector is a set of probabilities that serve as the classification signature.
- Convolution Layers: Consider 1D convolution, suppose the input vector is f and the kernel is g whose length is m. The following equation shows the center of kernel shifted and multiplied.
- 5.
- Pooling Layers: Pooling layers are down-sampling layers combining the output of layers to a single neuron. If we denote k as the kernel size (now assume kernel is squared), Dn as number of kernel windows, and Zs as stride to develop pooling layers, then the output dimension of the pooling layer will be (suppose we have H1 × W1 × D1 input) as has been denoted be the following equation:
- Max-pooling
- Average Pooling
- L2 norm Pooling
- 6.
- Fully Connected Dense Layers: After the pooling layers, pixels of pooling layers are stretched to a single column vector. These vectorized and concatenated data points are fed into dense layers, known as fully connected layers for the classification. In some cases, the output layer of a deep network uses a soft max procedure. Similar to logistic regression: Given n vectors {x1, x2,…,xn} with labels {l1, l2,…,ln}, where li ∈ {0, 1} (as a binary classification task). With a weight vector w one can define by the following equation:
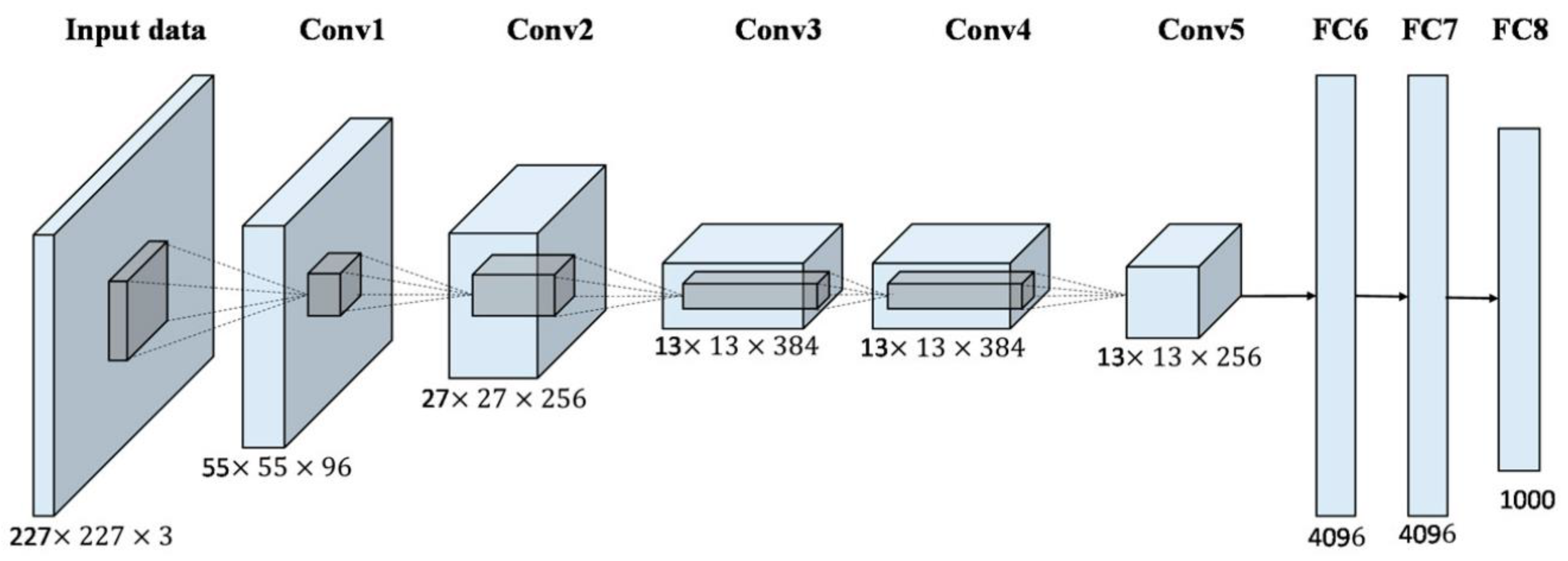
3.2.1. AlexNet
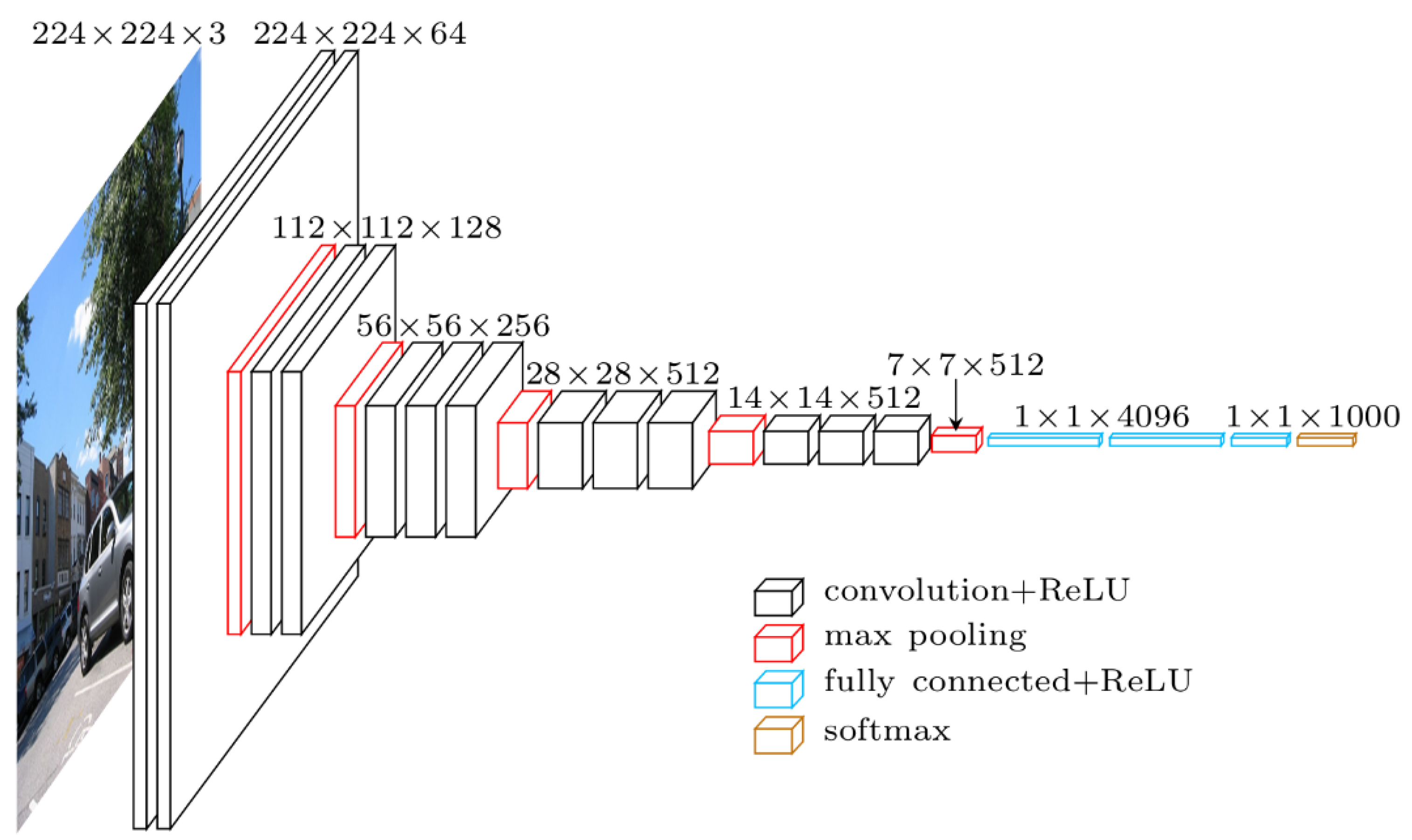
3.2.2. VGG16
3.2.3. ResNet
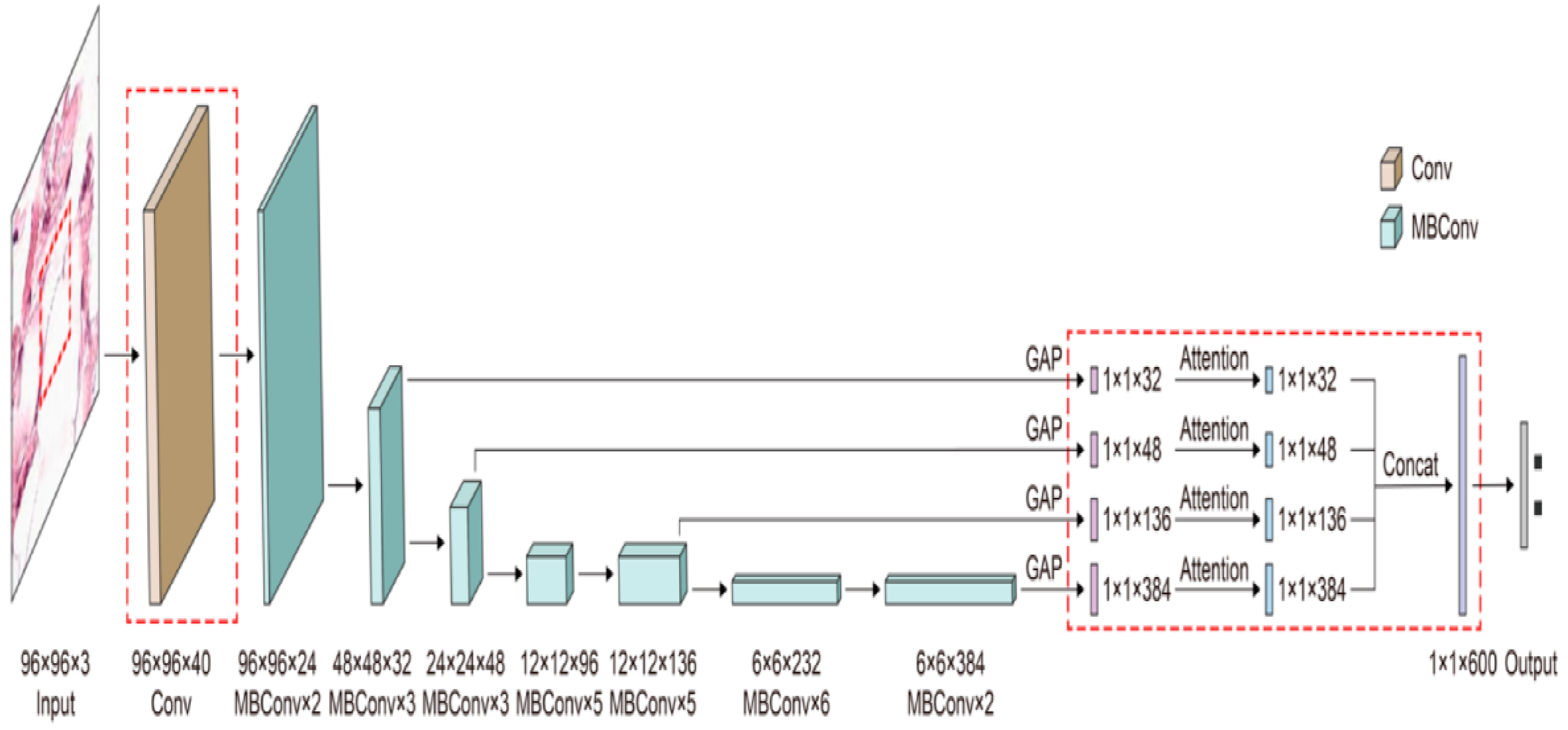
3.2.4. EfficientNet
3.3. Select the Best CNN Architecture
- (1)
- Preparing and resizing the dataset images to be ready for insertion into the selected four CNN architectures.
- (2)
- Labeling the dataset images to be ready for the classification process. The Appendix A shows a snapshot of the software code for labeling the dataset images and for preparing the dataset for experiments.
- (3)
- Split dataset images in two sets, training and testing sets.
- (4)
- Define the epochs and batch size where the epoch specifies the number of times the CNN accepts whole training data, i.e., the epoch is equal to one forward pass and one backward pass for all training samples. On the other hand, the batch size specifies the number of training samples we use in one forward pass and one backward pass [28]. The following parameters are defined in this step: epochs = 30; batch_size = 32. Due to limitation of this paper size, only the results of last five epoch are presented. In this step, image Augmentation was also implemented to avoid overfitting problem.
- (5)
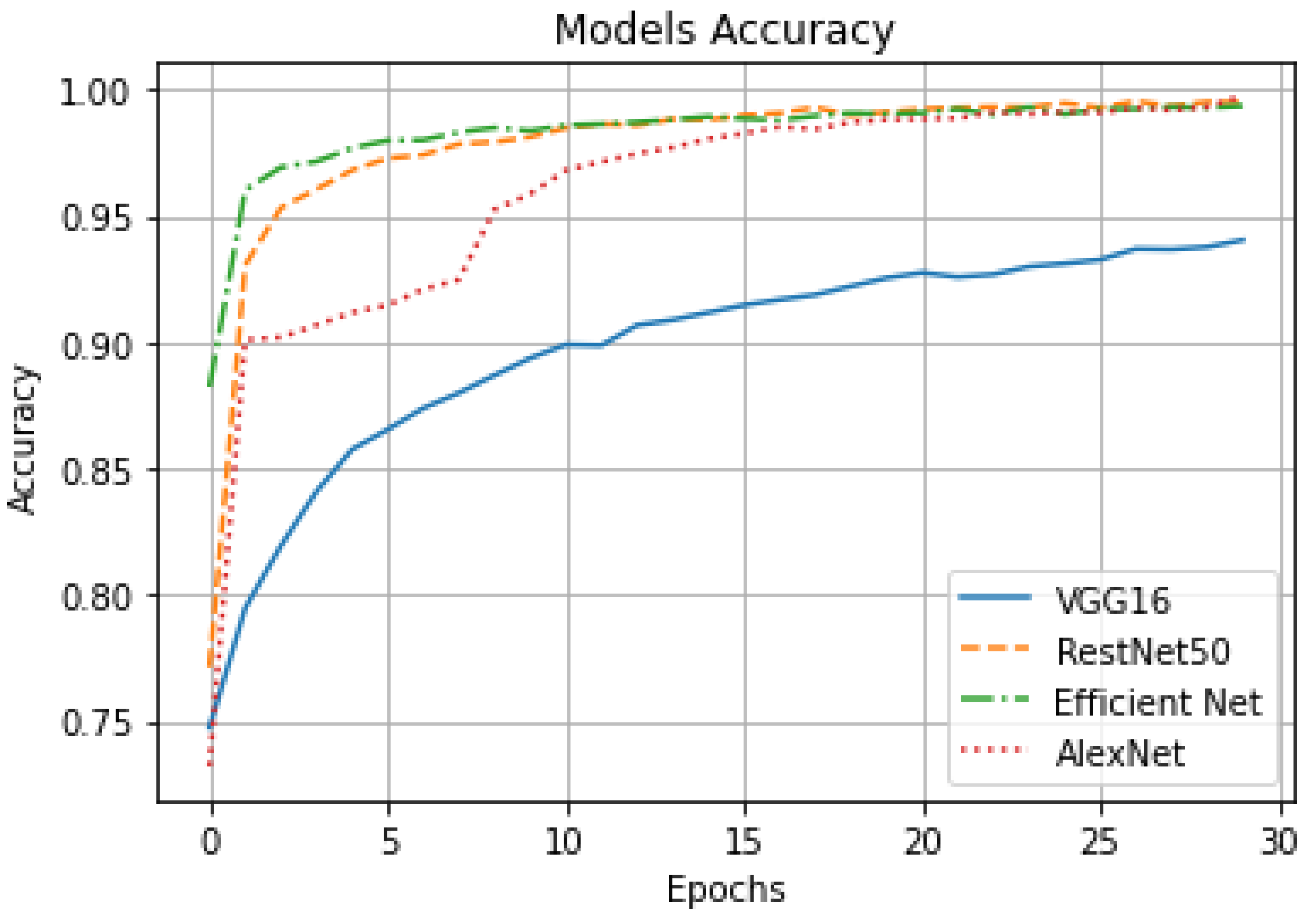
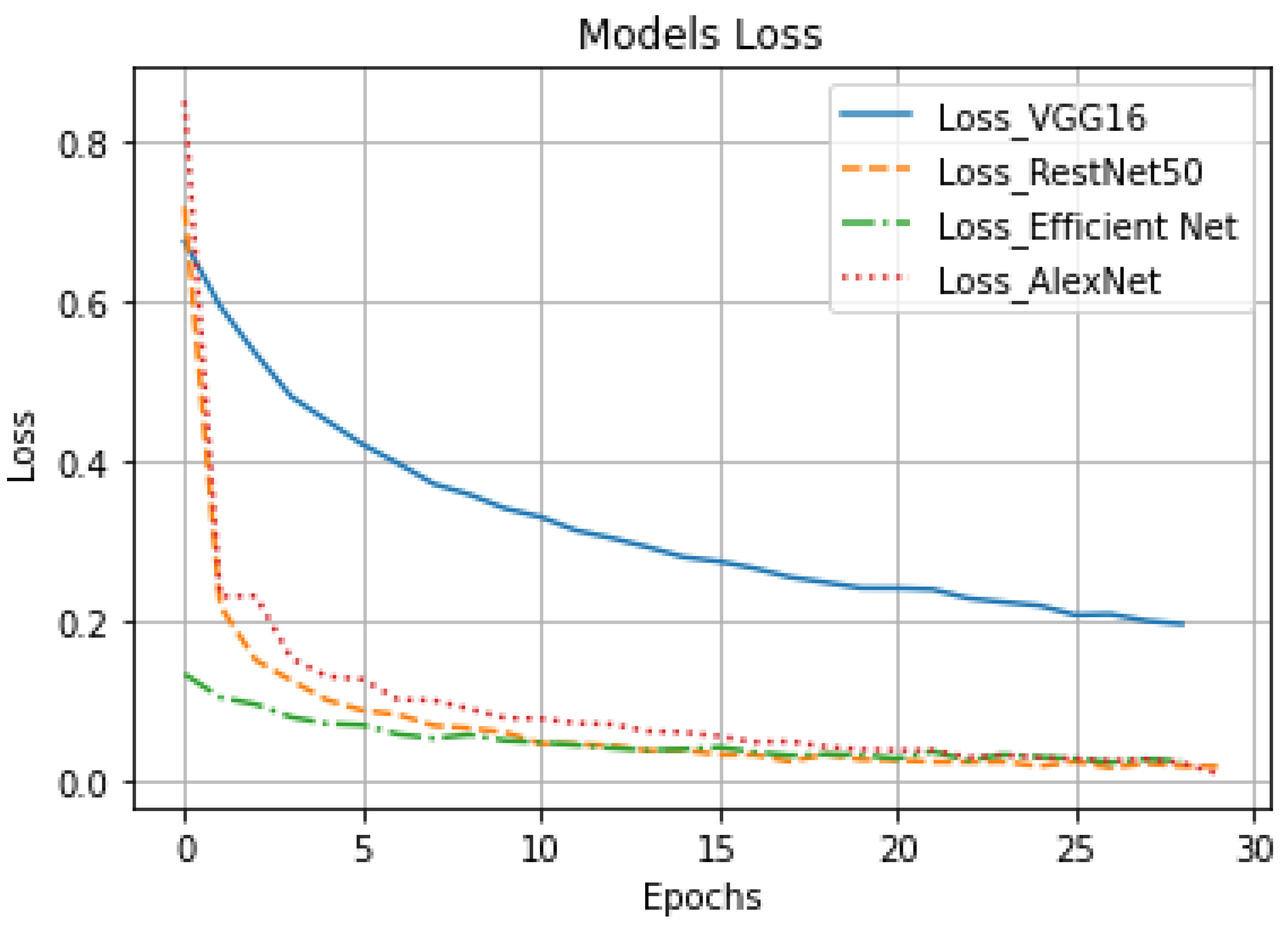
- Run the four CNN architectures where categorical cross-entropy loss [29] is typically used in a multiclass classification setting in which the outputs are interpreted as predictions of class membership probabilities. The output of this experiment step is defining classification accuracy for each CNN architecture. Table 1 shows the hyperparameters for experiments. Table 2 shows the accuracy results that have been generated from the conducted experiments.
4. Developing Real Time ArSLA Recognition Model Using AlexNet Deep Learning Architecture
| Algorithm 1. Algorithm of gestures technique that has been implemented in this model |
| # video capture Set: cap = cv2.VideoCapture(0) while True: read frame # Simulating mirror image frame = cv2.flip(frame, 1) # Coordinates of the ROI x1 = int(0.5*frame.shape [1]) y1 = 10 x2 = frame.shape [1]-10 y2 = int(0.5*frame.shape [1]) # Drawing the ROI # The increment/decrement by 1 is to compensate for the bounding box cv2.rectangle(frame, (x1 − 1, y1 − 1), (x2 + 1, y2 + 1), (255, 0, 0), 1) # Extracting the ROI roi = frame [y1:y2, x1:x2] # Resizing the ROI so it can be fed to the model for prediction roi = resize image (roi, (64, 64)) roi = Color CTV (roi, cv2.COLOR_BGR2GRAY) _, image = cv2.threshold(roi, 120, 255, cv2.THRESH_BINARY) Show image(image) |
| Algorithm 2. Algorithm of testing the model by single image |
| Set path: Img = convert to gray(path) print(path) letter = path.split(letter) print(letter) num = transform(letter) print(num) img = reshape image(1, 227, 227, 3) pred_y = model1.predict(img) print(np.argmax(pred_y)) calculate test loss test accuracy = model1.evaluate(img, num) print(test accuracy) |
5. Discussion and Conclusions
- (1)
- The proposed model is accessible to everyone as no additional or special equipment was used and only a PC or laptop camera is required.
- (2)
- The process of feature extraction is built into the Alexnet architecture which produces high accuracy. This feature extraction is completely independent of human intervention which in turn makes it free from human error factors.
- (3)
- The recognition systems developed based on deep learning architectures exhibit a good reputation and produce results with high accuracy. In light of this, the best deep learning (CNN) architectures (according to the literature) were tested by a real and trusted ArSL dataset, then based on the test’s results the best CNN architecture were chosen for developing the real-time recognition system. The proposed model was not built from scratch, but rather from the latest findings of researchers in this field, which enabled it to benefit from the accumulated experiences. Table 4 summarizes related works by focusing on training accuracy. In our proposed model, the training accuracy for AlexNet is 99.75% (see Table 2). For the training accuracy that is better than the highest value in related works, see Table 4. For the sake of transparency, we have additionally presented the validation accuracy (testing accuracy) which is 94.81%.
- (4)
- The proposed model was developed with the complete Arabic alphabet which allows users to write full articles using ArSLA in real time.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Rastgoo, R.; Kiani, K.; Escalera, S. Sign Language Recognition: A Deep Survey. Expert Syst. Appl. 2020, 164, 113794. [Google Scholar] [CrossRef]
- Mirdehghan, M. Persian, Urdu, and Pashto: A comparative orthographic analysis. Writ. Syst. Res. 2010, 2, 9–23. [Google Scholar] [CrossRef]
- El-Bendary, N.; Zawbaa, H.M.; Daoud, M.S.; Hassanien, A.E.; Nakamatsu, K. ArSLAT: Arabic Sign Language Alphabets Translator. In Proceedings of the 2010 International Conference on Computer Information Systems and Industrial Management Applications (CISIM), Krakow, Poland, 8–10 October 2010; pp. 590–595. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Tharwat, A.; Gaber, T.; Hassanien, A.E.; Shahin, M.K.; Refaat, B. Sift-based arabic sign language recognition system. In Afro-European Conference for Industrial Advancement, Proceedings of the First International Afro-European Conference for Industrial Advancement AECIA 2014, Addis Ababa, Ethiopia, 17–19 November 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 359–370. [Google Scholar]
- Halawani, S.M.; Zaitun, A.B. An avatar based translation system from Arabic speech to Arabic sign language for deaf people. Inter. J. Inf. Sci. Educ. 2012, 2, 13–20. [Google Scholar]
- Mohandes, M.; Aliyu, S.; Deriche, M. Arabic sign language recognition using the leap motion controller. In Proceedings of the 2014 IEEE 23rd International Symposium on Industrial Electronics (ISIE), Istanbul, Turkey, 1–4 June 2014; pp. 960–965. [Google Scholar]
- ElBadawy, M.; Elons, A.S.; Howida, A.; Shedeed, H.A.; Tolba, M.F. Arabic sign language recognition with 3d convolutional neural networks. In Proceedings of the 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 66–71. [Google Scholar]
- Alzohairi, R.; Alghonaim, R.; Alshehri, W.; Aloqeely, S.; Alzaidan, M.; Bchir, O. Image based Arabic sign language recognition system. Int. J. Adv. Comput. Sci. Appl. 2018, 9. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, N.B.; Selim, M.M.; Zayed, H.H. An Automatic Arabic Sign Language Recognition System (ArSLRS). J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 470–477. [Google Scholar] [CrossRef]
- Deriche, M.; Aliyu, S.O.; Mohandes, M. An Intelligent Arabic Sign Language Recognition System Using a Pair of LMCs With GMM Based Classification. IEEE Sens. J. 2019, 19, 8067–8078. [Google Scholar] [CrossRef]
- Hassan, M.; Assaleh, K.; Shanableh, T. Multiple Proposals for Continuous Arabic Sign Language Recognition. Sens. Imaging 2019, 20. [Google Scholar] [CrossRef] [Green Version]
- Gangrade, J.; Bharti, J. Real time sign language recognition using depth sensor. Int. J. Comput. Vis. Robot. 2019, 9, 329. [Google Scholar] [CrossRef]
- Kamruzzaman, M.M. Arabic Sign Language Recognition and Generating Arabic Speech Using Convolutional Neural Network. Wirel. Commun. Mob. Comput. 2020, 2020, 3685614. [Google Scholar] [CrossRef]
- Mustafa, M. A study on Arabic sign language recognition for differently abled using advanced machine learning classifiers. J. Ambient. Intell. Human Comput. 2020, 12, 4101–4115. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Piekarski, M.; Jaworek-Korjakowska, J.; Wawrzyniak, A.I.; Gorgon, M. Convolutional neural network architecture for beam instabilities identification in Synchrotron Radiation Systems as an anomaly detection problem. Measurement 2020, 165, 108116. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Koonce, B. EfficientNet. In Convolutional Neural Networks with Swift for Tensorflow; Apress: Berkeley, CA, USA, 2021; pp. 109–123. [Google Scholar]
- Valueva, M.; Nagornov, N.; Lyakhov, P.; Valuev, G.; Chervyakov, N. Application of the residue number system to reduce hardware costs of the convolutional neural network implementation. Math. Comput. Simul. 2020, 177, 232–243. [Google Scholar] [CrossRef]
- Zanna, L.; Bolton, T. Data-Driven Equation Discovery of Ocean Mesoscale Closures. Geophys. Res. Lett. 2020, 47, e2020GL088376. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning. Scholarpedia 2015, 10, 32832. [Google Scholar] [CrossRef] [Green Version]
- Rezende, E.; Ruppert, G.; Carvalho, T.; Theophilo, A.; Ramos, F.; Geus, P.D. Malicious software classification using VGG16 deep neural network’s bottleneck features. In Information Technology-New Generations; Springer International Publishing: Cham, Switzerland, 2018; pp. 51–59. [Google Scholar]
- Lin, H.; Jegelka, S. Resnet with one-neuron hidden layers is a universal approximator. Advances in neural information processing systems. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 3–8 December 2018; Volume 31. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef]
- Gordon-Rodriguez, E.; Loaiza-Ganem, G.; Pleiss, G.; Cunningham, J.P. Uses and abuses of the cross-entropy loss: Case studies in modern deep learning. In Proceedings of the “I Can’t Believe It’s Not Better!” at NeurIPS Workshops, PMLR, Virtual, 12 December 2020. [Google Scholar]
- Kaura, H.K.; Honrao, V.; Patil, S.; Shetty, P. Gesture controlled robot using image processing. Int. J. Adv. Res. Artific. Intell. 2013, 2. [Google Scholar] [CrossRef] [Green Version]
- Nasir, V.; Sassani, F. A review on deep learning in machining and tool monitoring: Methods, opportunities, and challenges. Int. J. Adv. Manuf. Technol. 2021, 115, 2683–2709. [Google Scholar] [CrossRef]
- Abiyev, R.H.; Arslan, M.; Idoko, J.B. Sign Language Translation Using Deep Convolutional Neural Networks. KSII Trans. Internet Inf. Syst. 2020, 14, 631–653. [Google Scholar] [CrossRef]
- Youssif, A.A.; Aboutabl, A.E.; Ali, H.H. Arabic sign language (ArSL) recognition system using hmm. Int. J. Adv. Comput. Sci. Appl. 2011, 2. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | VGG16 Value | RestNet50 Value | EffecientNet Value | AlexNet Value |
|---|---|---|---|---|
| Initial learning rate | 0.001 | 0.001 | 0.001 | 0.001 |
| Activation function | Categorical Cross Entropy | Categorical Cross Entropy | Categorical Cross Entropy | Categorical Cross Entropy |
| Number of epochs | 30 | 30 | 30 | 30 |
| Batch size | 32 | 32 | 32 | 32 |
| Optimizer | ADAM | ADAM | ADAM | ADAM |
| Weight initialization | Xavier initialization | Xavier initialization | Xavier initialization | Xavier initialization |
| Learning rate decay (λ) | 0.0002 | 0.0002 | 0.0002 | 0.0002 |
| Momentum | 0.9 | 0.9 | 0.9 | 0.9 |
| Model | Epoch | Train Loss | Train Accuracy (%) | Valid Loss | Valid Acc (%) |
|---|---|---|---|---|---|
| VGG16 | 26 | 0.2187 | 93.27 | 0.5936 | 82.30 |
| 27 | 0.2069 | 93.70 | |||
| 28 | 0.2077 | 93.68 | |||
| 29 | 0.1996 | 93.77 | |||
| 30 | 0.1957 | 94.05 | |||
| RestNet50 | 26 | 0.0235 | 99.29 | 0.5688 | 89.83 |
| 27 | 0.0157 | 99.55 | |||
| 28 | 0.0212 | 99.35 | |||
| 29 | 0.0175 | 99.52 | |||
| 30 | 0.1021 | 96.76 | |||
| EffecientNet | 26 | 0.0290 | 99.24 | 0.5481 | 86.56 |
| 27 | 0.0269 | 99.24 | |||
| 28 | 0.0225 | 99.32 | |||
| 29 | 0.0265 | 99.29 | |||
| 30 | 0.0239 | 99.37 | |||
| AlexNet | 26 | 0.0269 | 99.10 | 0.2004 | 94.81 |
| 27 | 0.0242 | 99.28 | |||
| 28 | 0.0265 | 99.19 | |||
| 29 | 0.0216 | 99.32 | |||
| 30 | 0.0085 | 99.75 |
| # | Letter Name in English Script | Letter Name in Arabic Script | # of Images | # | Letter Name in English Script | Letter Name in Arabic Script | # of Images |
|---|---|---|---|---|---|---|---|
| 1 | Alif | أَلِف)أ) | 1672 | 17 | Zā | ظَاء)ظ) | 1723 |
| 2 | Bā | بَاء) ب) | 1791 | 18 | Ayn | عَين)ع) | 2114 |
| 3 | Tā | أتَاء) ت) | 1838 | 19 | Ghayn | غَين)غ) | 1977 |
| 4 | Thā | ثَاء) ث) | 1766 | 20 | Fā | فَاء)ف) | 1955 |
| 5 | Jīm | جِيمْ) ج) | 1552 | 21 | Qāf | قَاف) ق) | 1705 |
| 6 | Hā | حَاء) ح) | 1526 | 22 | Kāf | كَاف)ك) | 1774 |
| 7 | Khā | خَاء) خ) | 1607 | 23 | Lām | لاَمْ)ل) | 1832 |
| 8 | Dāl | دَالْ) د) | 1634 | 24 | Mīm | مِيمْ)م) | 1765 |
| 9 | Dhāl | ذَال) ذ) | 1582 | 25 | Nūn | نُون)ن) | 1819 |
| 10 | Rā | رَاء) ر) | 1659 | 26 | Hā | هَاء)ه) | 1592 |
| 11 | Zāy | زَاي) ز) | 1374 | 27 | Wāw | وَاو)و) | 1371 |
| 12 | Sīn | سِينْ) س) | 1638 | 28 | Yā | يَا) ئ) | 1722 |
| 13 | Shīn | شِينْ) ش) | 1507 | 29 | Tāa | ة)ة) | 1791 |
| 14 | Sād | صَادْ)ص) | 1895 | 30 | Al | ال)ال) | 1343 |
| 15 | Dād | ضَاد)ض) | 1670 | 31 | Laa | ﻻ)ﻻ) | 1746 |
| 16 | Tā | طَاء)ط) | 1816 | 32 | Yāa | يَاء) يَاء) | 1293 |
| # | Ref | Year | Device | Language | Features | Technique | Training Accuracy |
|---|---|---|---|---|---|---|---|
| 1 | [9] | 2017 | Camera | 25 Arabic words | Image pixels | CNN | 90% |
| 2 | [12] | 2019 | dual Leap Motion Controllers | 100 Arabic words | N geometric parameters | LDA | 88% |
| 3 | [14] | 2019 | Kinect sensor | 35 Indian sign | Distances, angles, and velocity involving upper body joints | Multi-class support vector machine classifier | 87.6% |
| 4 | [11] | 2018 | Single camera | 30 Arabic words | Segmented image | Euclidean distance classifier | 83% |
| 5 | [32] | 2020 | Single camera | 24 English letters | Image pixels | Inception v3 plus Support Vector Machine (SVM) | 92.21% |
| 6 | [16] | 2020 | Single camera | 28 Arabic letters | Image pixels | CNN | 97.82% |
| 7 | [6] | 2015 | Glove | 30 Arabic letters | invariant features | ResNet-18 | 93.4% |
| 8 | [33] | 2011 | Single camera | 20 Arabic words | Edge detection and contours tracking | HMM | 82.22% |
| 9 | [13] | 2019 | Camera | 40 Arabic sign language words | Thresholder image differences | HMM | 94.5% |
| 10 | [10] | 2018 | Camera | 30 Arabic letters | FFT | HOG and SVM | 63.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsaadi, Z.; Alshamani, E.; Alrehaili, M.; Alrashdi, A.A.D.; Albelwi, S.; Elfaki, A.O. A Real Time Arabic Sign Language Alphabets (ArSLA) Recognition Model Using Deep Learning Architecture. Computers 2022, 11, 78. https://doi.org/10.3390/computers11050078
Alsaadi Z, Alshamani E, Alrehaili M, Alrashdi AAD, Albelwi S, Elfaki AO. A Real Time Arabic Sign Language Alphabets (ArSLA) Recognition Model Using Deep Learning Architecture. Computers. 2022; 11(5):78. https://doi.org/10.3390/computers11050078
Chicago/Turabian StyleAlsaadi, Zaran, Easa Alshamani, Mohammed Alrehaili, Abdulmajeed Ayesh D. Alrashdi, Saleh Albelwi, and Abdelrahman Osman Elfaki. 2022. "A Real Time Arabic Sign Language Alphabets (ArSLA) Recognition Model Using Deep Learning Architecture" Computers 11, no. 5: 78. https://doi.org/10.3390/computers11050078
APA StyleAlsaadi, Z., Alshamani, E., Alrehaili, M., Alrashdi, A. A. D., Albelwi, S., & Elfaki, A. O. (2022). A Real Time Arabic Sign Language Alphabets (ArSLA) Recognition Model Using Deep Learning Architecture. Computers, 11(5), 78. https://doi.org/10.3390/computers11050078