
Functional Data Analysis for Imaging Mean Function Estimation: Computing Times and Parameter Selection


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Functional Data Analysis
1.2. Applicability of FDA to Imaging Data
1.3. Objectives
2. Materials and Methods
2.1. Imaging Data
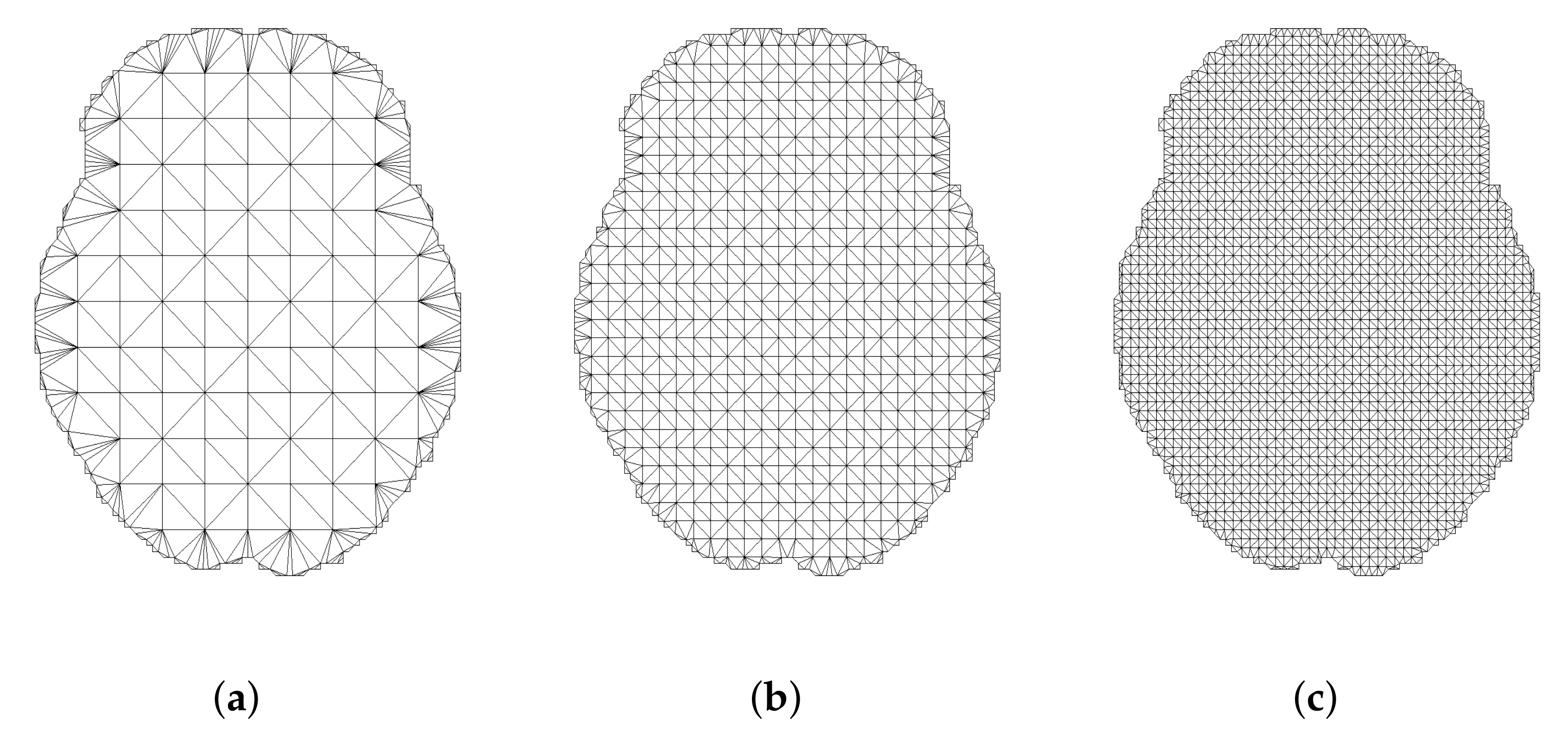
2.2. Delaunay Triangulations
2.3. Mean Function and SCC for One-Group Setup
2.4. Mean Function and SCC for Two-Group Setup
3. Results
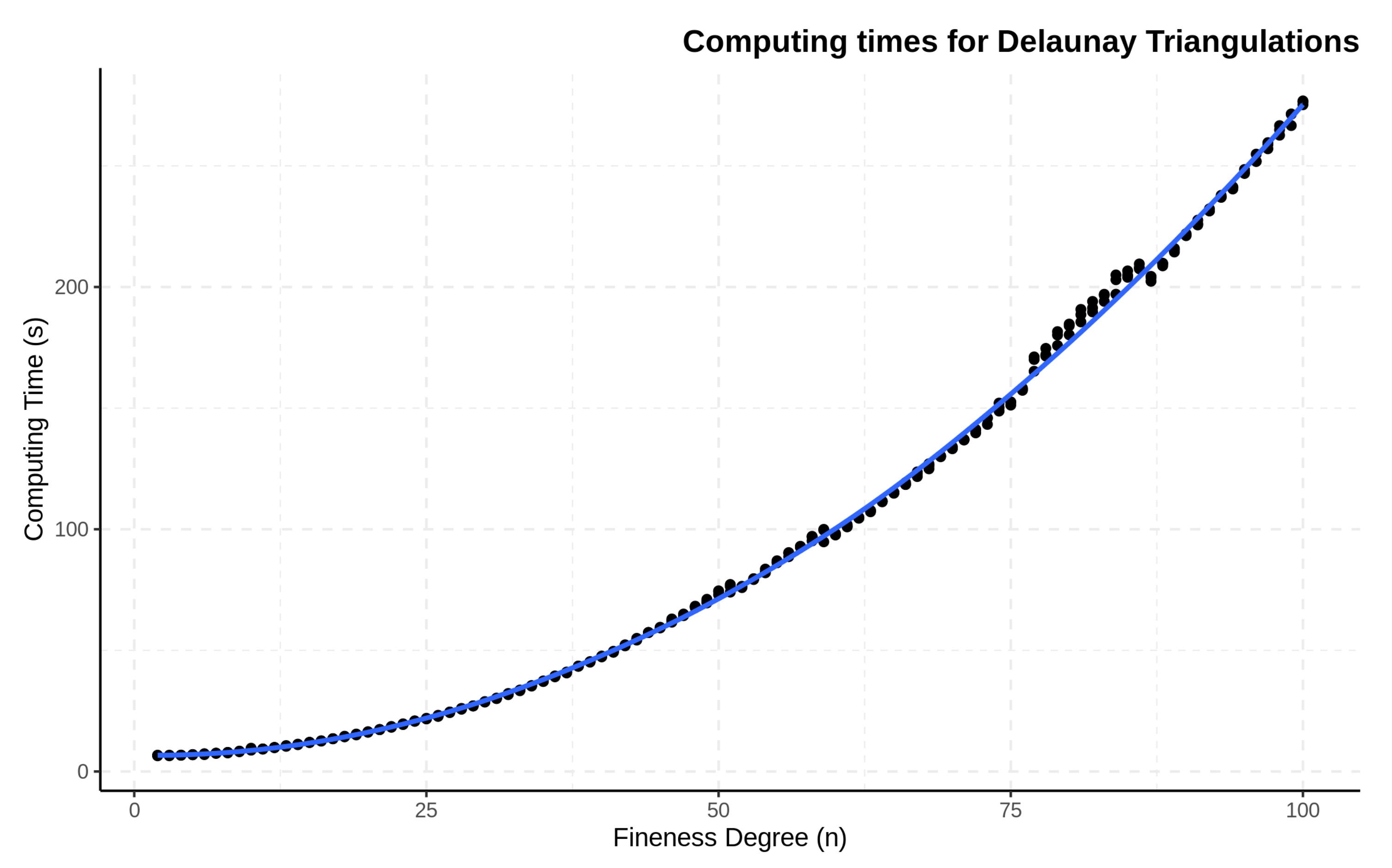
3.1. Delaunay Triangulations
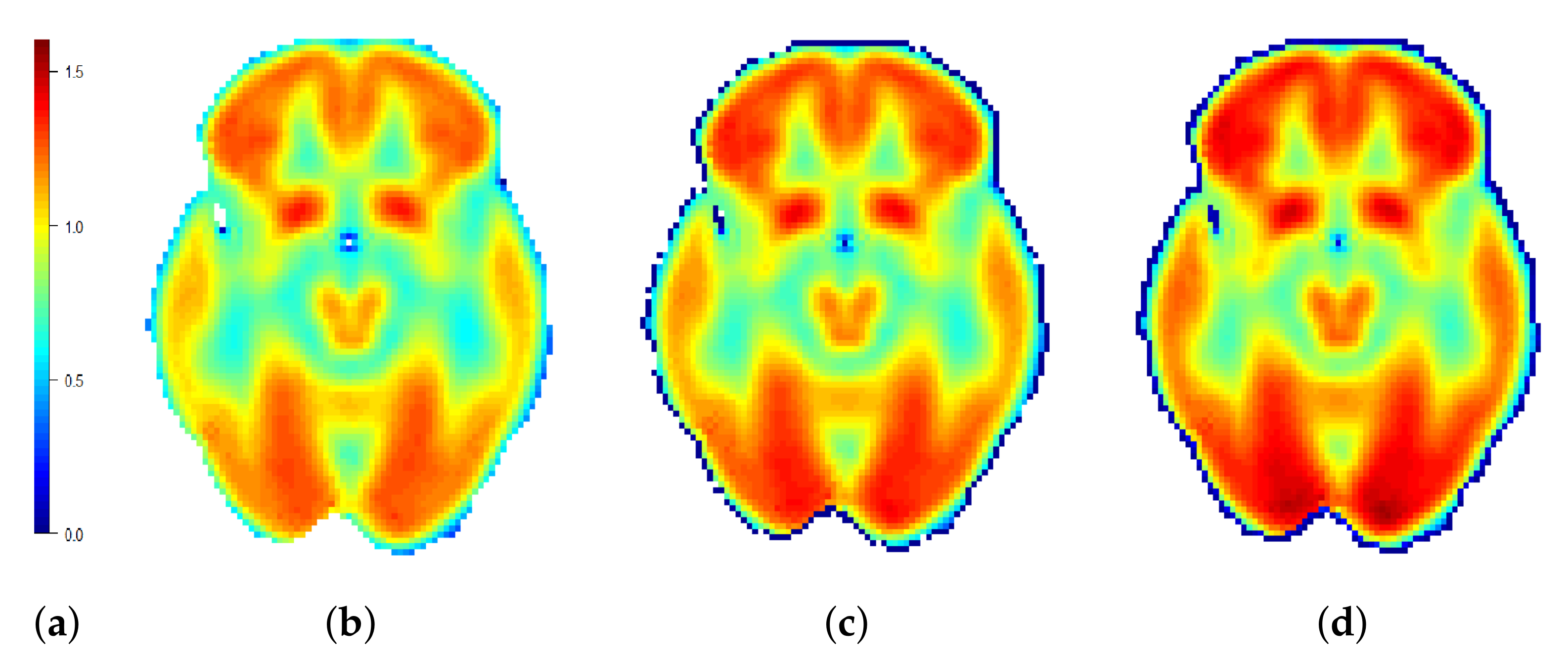
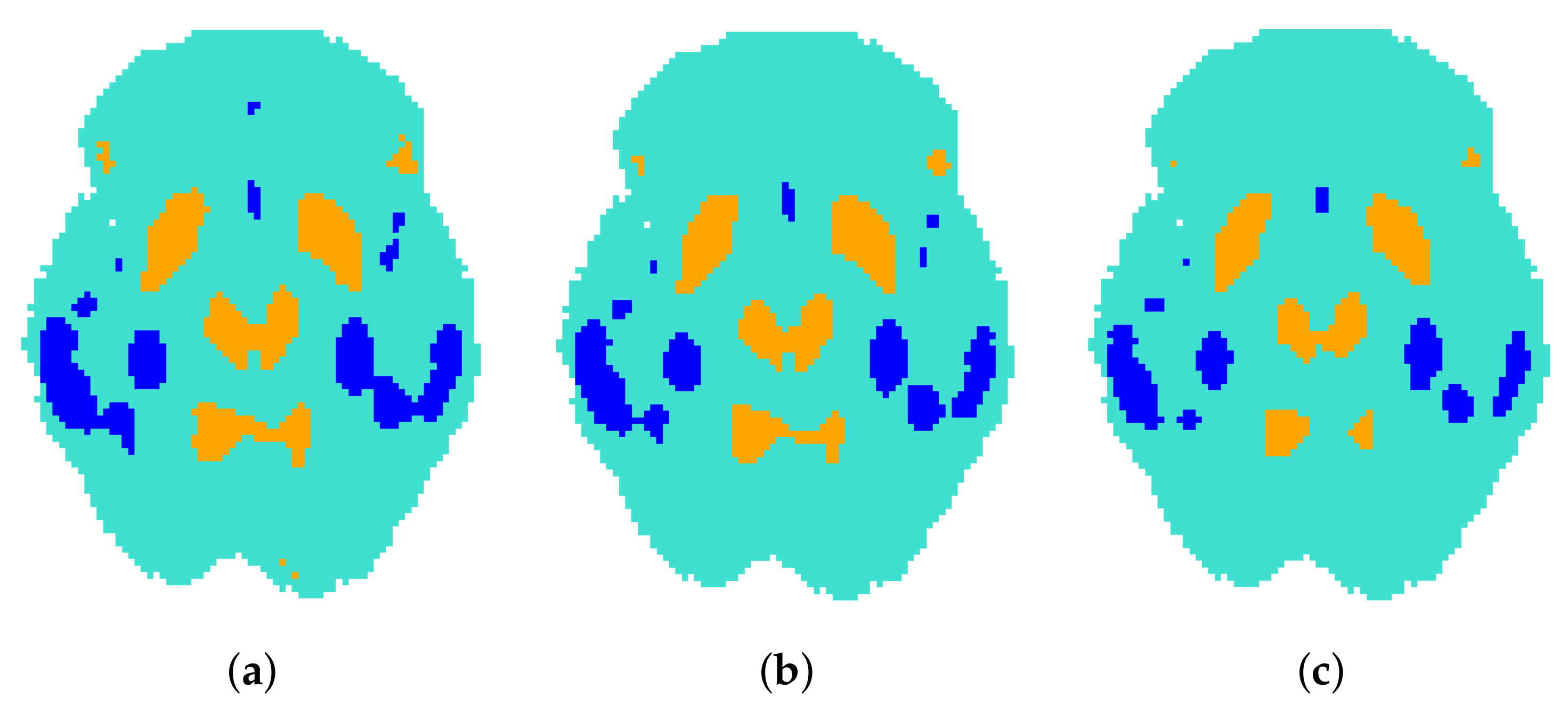
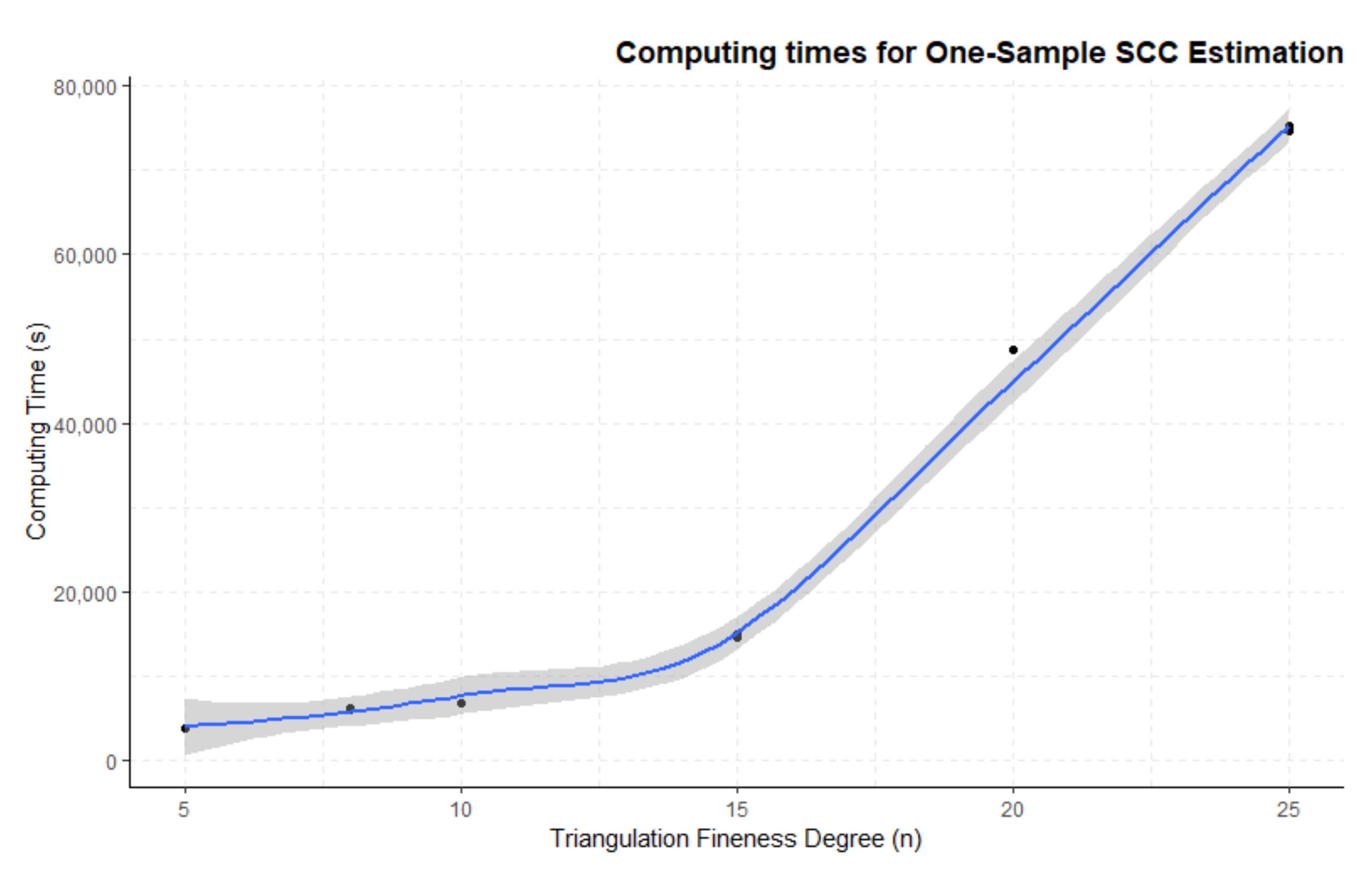
3.2. One-Group Mean Function and SCC Estimation
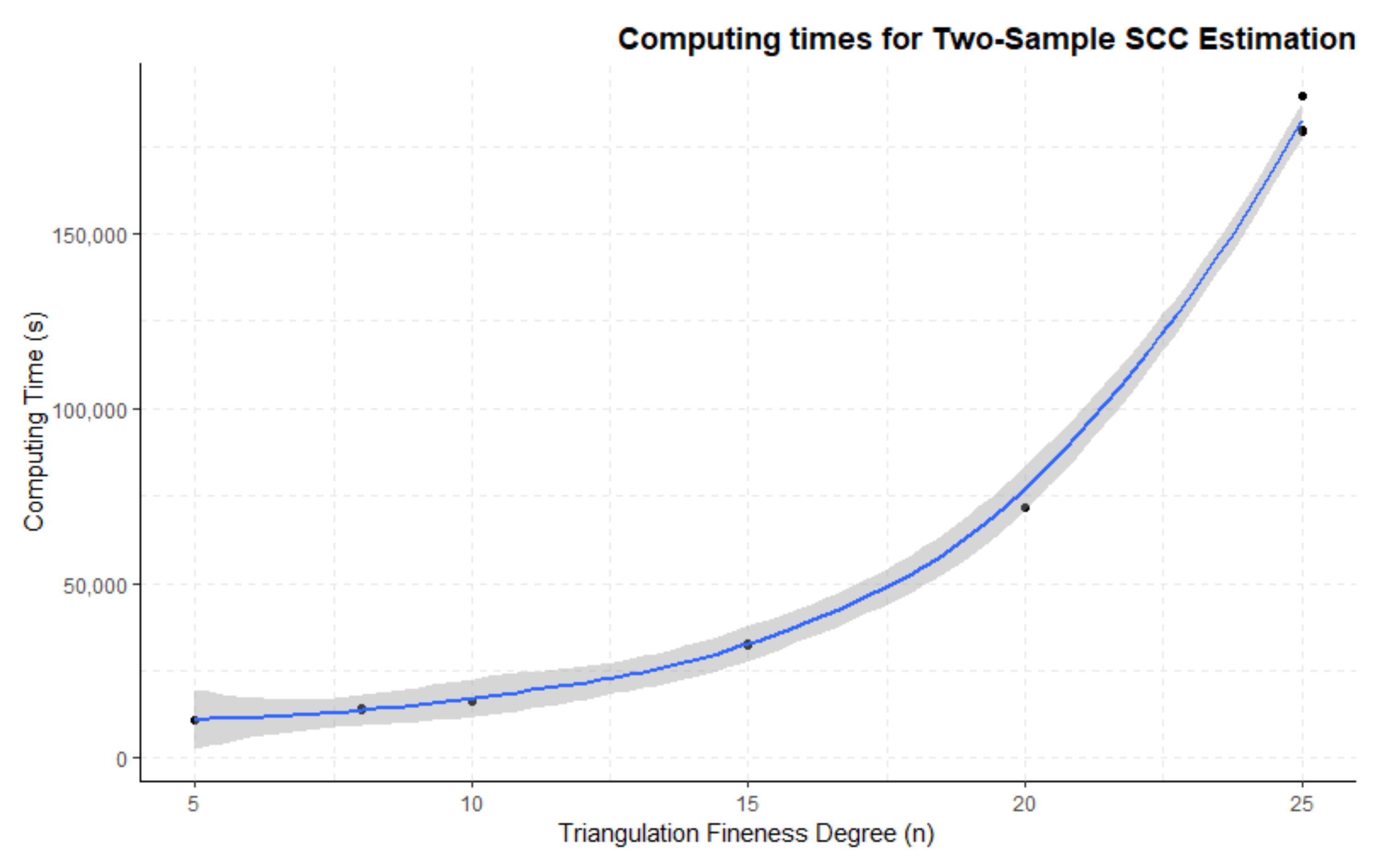
3.3. Two-Group Mean Function and SCC Estimation
4. Discussion
5. Computer Specifications
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FDA | Functional Data Analysis |
| SCC | Simultaneous Confidence Corridor |
| PET | Positron Emissionn Tomography |
| 18F-FDG | 18-Fluorodeoxyglucose |
| AD | Alzheimer’s Disease |
| SPM | Statistical Parametric Mapping |
References
- Ramsay, J.O. Functional data analysis. In Encyclopedia of Statistical Sciences; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 4. [Google Scholar] [CrossRef]
- Wang, J.-L.; Chiou, J.-M.; Müller, H.-G. Functional data analysis. Annu. Rev. Stat. Appl. 2016, 3, 257–295. [Google Scholar] [CrossRef] [Green Version]
- Worsley, K.J.; Taylor, J.E.; Tomaiuolo, F.; Lerch, J. Unified univariate and multivariate random field theory. NeuroImage 2004, 23, S189–S195. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, G.; Wang, L.; Ogden, R.T. Simultaneous confidence corridors for mean functions in functional data analysis of imaging data. Biometrics 2020, 76, 427–437. [Google Scholar] [CrossRef] [PubMed]
- Lai, M.J.; Wang, L. Bivariate Spline over Triangulation, R Package Version 0.1.0; R Core Team: Vienna, Austria, 2019.
- Degras, D.A. Simultaneous confidence bands for nonparametric regression with functional data. Stat. Sin. 2011, 21, 1735–1765. [Google Scholar] [CrossRef] [Green Version]
- Arias-López, J.A.; Cadarso-Suárez, C.; Aguiar-Fernández, P. Computational Issues in the Application of Functional Data Analysis to Imaging Data. In Computational Science and Its Applications—ICCSA 2021, Proceedings of the 21st International Conference, Cagliari, Italy, 13–16 September 2021; Gervasi, O., Murgante, B., Misra, S., Garau, C., Blečić, I., Taniar, D., Apduhan, B.O., Rocha, A.M.A.C., Tarantino, E., Torre, C.M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 630–638. [Google Scholar] [CrossRef]
- López-González, F.J.; Silva-Rodríguez, J.; Paredes-Pacheco, J.; Niñerola-Baizán, A.; Efthimiou, N.; Martín-Martín, C.; Moscoso, A.; Ruibal, Á.; Roé-Vellvé, N.; Aguiar, P. Intensity normalization methods in brain FDG-PET quantification. NeuroImage 2020, 222, 117229. [Google Scholar] [CrossRef] [PubMed]
- Mueller, S.G.; Weiner, M.W.; Thal, L.J.; Petersen, R.C.; Jack, C.R.; Jagust, W.; Trojanowski, J.Q.; Toga, A.W.; Beckett, L. Ways toward an early diagnosis in Alzheimer’s disease: The Alzheimer’s Disease Neuroimaging Initiative (ADNI). Alzheimer’s Dement. 2005, 1, 55–66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Penny, W.D.; Friston, K.J.; Ashburner, J.T.; Kiebel, S.J.; Nichols, T.E.; Klebel, S.J.; Nichols, T.E. Statistical Parametric Mapping: The Analysis of Functional Brain Images; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Lai, M.J.; Wang, L. Triangulation: Triangulation in 2D Domain, R Package Version 0.1.0; R Core Team: Vienna, Austria, 2020.
- Wang, Y.; Wang, G.; Wang, L. ImageSCC: SCC for Mean Function of Imaging Data, R Package Version 0.1.0; R Core Team: Vienna, Austria, 2020.






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arias-López, J.A.; Cadarso-Suárez, C.; Aguiar-Fernández, P. Functional Data Analysis for Imaging Mean Function Estimation: Computing Times and Parameter Selection. Computers 2022, 11, 91. https://doi.org/10.3390/computers11060091
Arias-López JA, Cadarso-Suárez C, Aguiar-Fernández P. Functional Data Analysis for Imaging Mean Function Estimation: Computing Times and Parameter Selection. Computers. 2022; 11(6):91. https://doi.org/10.3390/computers11060091
Chicago/Turabian StyleArias-López, Juan A., Carmen Cadarso-Suárez, and Pablo Aguiar-Fernández. 2022. "Functional Data Analysis for Imaging Mean Function Estimation: Computing Times and Parameter Selection" Computers 11, no. 6: 91. https://doi.org/10.3390/computers11060091
APA StyleArias-López, J. A., Cadarso-Suárez, C., & Aguiar-Fernández, P. (2022). Functional Data Analysis for Imaging Mean Function Estimation: Computing Times and Parameter Selection. Computers, 11(6), 91. https://doi.org/10.3390/computers11060091