1. Introduction
Nowadays, the use of the Internet, in general, and reliance on cloud-based resources is growing at an exponential rate. Operations are concentrating on their core businesses while transferring their information technology (IT) services to the cloud. Many more factors encourage businesses to use internet-based offerings. Likewise, malicious traffic has increased at a rapid rate [
1]. Today’s cyberattacks are becoming more diversified and broad. The purpose of these assaults is to obtain unauthorized access to remote data or to create service interruptions for consumers. These attacks have a tremendous influence not only on the economy and finances of a country but also at the national level, in addition to cultural security [
2,
3]. Therefore, such assaults should be prevented from both inside and outside as well as from governmental and private institutions [
4,
5,
6]. As a result, it is critical to rely on automated powerful systems for quickly and reliably identifying threats. Interestingly, intrusion detection systems (IDS) have been considered an excellent solution to further boosting the security level of a system [
7].
IDS is a type of security software that observes network traffic and gives warnings once an unusual behavior is discovered [
8]. Generally, there are two kinds of IDS: host-based intrusion detection systems (HIDS) and network-based intrusion detection systems (NIDS) [
9]. HIDS, known as a passive component, focuses on a single machine [
10]. On the other hand, NIDS, known as an active component, is used to analyze network packets as well as to monitor and safeguard a system from network risks [
9]. The focus of this research was on NIDS, since the proposed IDS analyzes the flow of data among computers, such as network traffic, detects unusual behavior, and defends nodes from complex assaults.
Machine learning (ML) algorithms are frequently employed in network security to further enhance the capabilities of an IDS in identifying attacks due to the nature of its learning abilities. They have shown outstanding performance as powerful and successful defense mechanisms [
11]. However, the adoption of ML in this domain poses severe challenges to cyber defense, with adversarial machine learning (AML) assaults being one of the most critical [
12]. AML has lately arisen as a serious threat to the success of such systems. An adversarial attacker can weaken network protection by exploiting flaws in the ML methods. By generating small disturbances into network traffic, attackers can utilize the vulnerability and cause NIDS to damage [
13]. The fabrication of samples is meant to disrupt the ML algorithm by eliciting outcomes favorable to the attacker, which is one of the malevolent behaviors. In the cyber security area, these flaws are crucial, since an undetected intrusion may compromise an entire enterprise [
14]. Therefore, it is essential to develop ML-based approaches that can protect the systems from adversarial attacks.
Among different ML algorithms, generative adversarial networks (GANs) have been extensively leveraged with adversarial attacks. A GAN is a type of deep learning techniques in which two neural networks compete against each other in a two-player game. It has demonstrated the advantage of ML in producing higher-dimensional data, such as images, audio, and text, since it was initially released in 2014 [
15]. Many research papers have employed GANs to either enhance IDS or to design novel attack instances such as generating adversarial malware samples [
16,
17]. However, there are only a few works on GAN-based intrusion detection [
18].
GAN-based adversarial training (AT) can be utilized as a defense mechanism. AT methods inject adversarial examples (AEs) into the training data to make sure that the machine learning technique imparts adversarial perturbations as much as possible [
18]. Therefore, they enhance the generalization and resilience of the machine learning techniques, since these models are trained on clean and adversarial examples [
19]. In AT, AEs are generated by GANs and then added to the clean dataset [
20]. This approach shows that the added AEs elevated the accuracy of the trained model by approximately 10% [
20]. However, as the same GAN model is used during the training (i.e., defending) and testing (i.e., attacking), the accuracy will go down once the proposal tests with different attack models. Further, the size of the epochs utilized in [
20] was only 100, which is not sufficient to generate strong AEs.
To overcome the aforementioned shortcomings, we present a GAN-based approach for the adversarial training of ML models against AEs generated using a black-box attack, namely, the zeroth order optimization (ZOO) attack. Then, we evaluated the resilience of the designed system by presenting the ZOO black-box attack method to define adversarial perturbation in the data network. Note that an opponent did not have access to the specifics of the ML-based IDS, which made the experiment more realistic, and we took this into consideration during the implementation of the ZOO attack. Our finding was that the employment of a GAN as a defensive strategy makes ML-based IDS more resilient to previously unseen and unknown adversarial perturbations.
1.1. Motivation
Over the years, computer networks have grown swiftly, contributing greatly to social and economic progress. However, compared to other sectors, network security applications of ML confront a significant concern regarding active adversarial attacks [
21,
22]. This happens due to the adversarial nature of ML applications in network security. In a battle among both attackers and defenders that may be described as an arms competition, ML systems are continually probed by adversaries with inputs that are specifically meant to evade the system and generate a false prediction. Furthermore, malicious attacks have become more common, and ML models’ defense and resistance against them must be addressed. Several studies in text and image recognition fields have looked at the danger and provided viable countermeasures. Unfortunately, not much research on the NIDS sector that addresses the problems of adversarial attacks has been undertaken [
12]. In addition, the learning model and dataset quality are both closely connected to the efficiency of the IDS. Many researches have been dependent on datasets that have significant shortcomings such as simulated traffic (i.e., not from an actual production network), anonymity, redundancy, and outdated attack traffic, e.g., denial of service (DDoS) [
20,
23]. Other studies have concentrated on the adversary knowledge factor, such as white-box attacks, and shown that such attacks are strong in targeting a system under the assumption that opponents have full access and knowledge of the classifier [
24,
25]. In practice, having such an ability by an attacker seems to be elusive. It has been proven that a GAN is a very serious and powerful attack compared with other existing attacks [
26]. Contrary to white-box attacks, GAN-based black-box attacks are considered weak, as attackers have no knowledge or only have superficial information about the victim classifier. A GAN-based adversarial ML attack has been proposed and validated on a black-box IDS, and it turned out that GAN is a powerful technology for bypassing an IDS due to the fact of its potential to generate data that have a similar distribution to the original dataset [
20]. In general, there is a lack of research studies investigating and evaluating the effectiveness of existent adversarial defensive mechanisms. Accordingly, it is necessary to ensure the resilience of the proposed methods against adversarial attacks and to pay more attention to proposing attack-agnostic defense mechanisms that address the increasing variety of adversarial attacks, rather than focusing only on a narrow range of attacks [
27]. Therefore, the above reasons served as motivation to propose the main contribution in this paper.
1.2. The Contribution of the Paper
The major contribution of this paper is as follows:
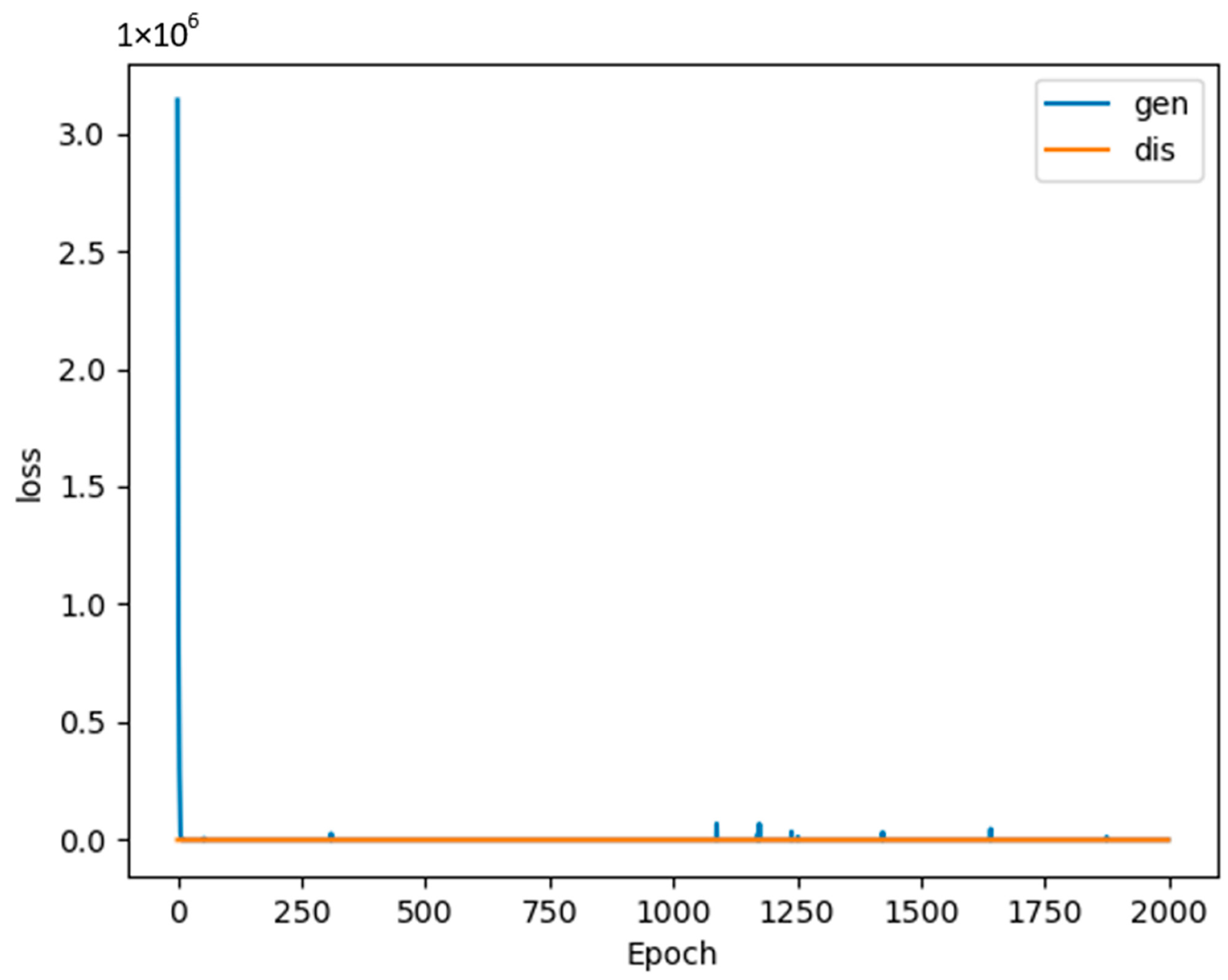
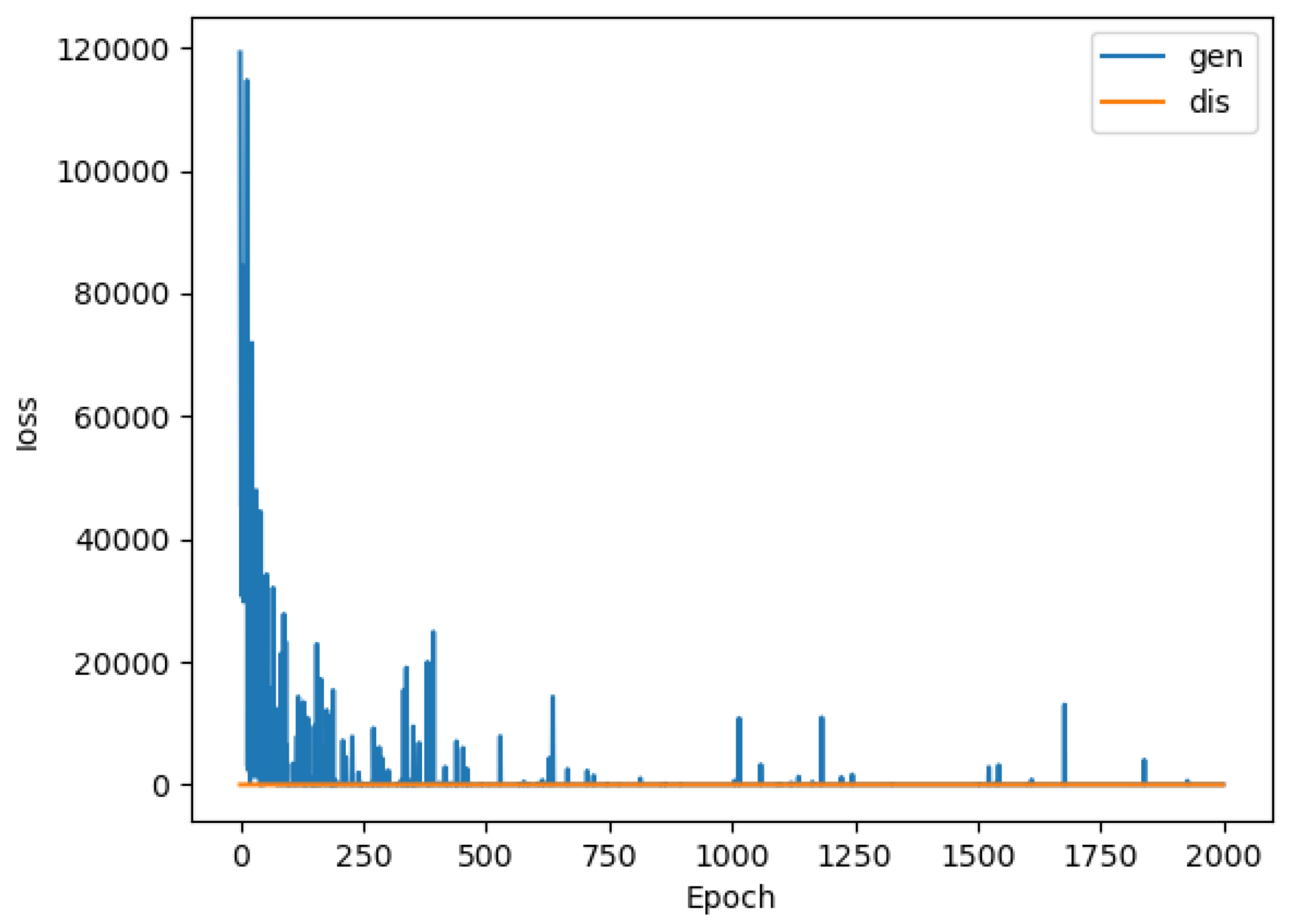
We used a GAN to generate strong adversarial examples, for the first time, from the CSE-CIC-IDS2018 dataset, which was introduced by the Canadian Institute of Cybersecurity (CIC), called the Communications Security Establishment and CIC 2018 (CSE-CIC-IDS2018) Dataset. The strong adversarial examples are generated using a GAN with 2000 epochs;
We designed a defensive model for NIDS-based random forest classifier and enhanced the proposed model using GAN-based adversarial training, where the generated adversarial examples are used for training the model and measuring the model resistance in two phases. The first phase was utilized to train the proposed technique on a non-crafted dataset, and the second phase was related to improving the robustness and accuracy of the first phase by retraining the proposed model on a combined dataset that included a non-crafted dataset, generated dataset from a GAN;
Our proposal was further improved by carefully training our model with valuable features selected by PCA with the generated adversarial examples;
We implemented a black-box-based ZOO attack to evaluate the resistance of the proposed random forest model in which this attack was capable of generating adversarial examples that the model had never seen before.
To the best of our knowledge, there is no recent work concentrated mainly on the improvement of ML-based IDS as a defense model and evaluating the resilience of the model by thwarting new unseen attacks.
The remainder of this paper is structured as follows:
Section 2 tackles, in brief, the random forest model, GAN-based defense technique, black-box-based ZOO attack, and feature reduction methods.
Section 3 tackles the curriculums of related work including adversarial attack and defense techniques. Our proposed methodology is described in detail in
Section 4. The experimental setup and results of the proposal are illustrated in
Section 5. A comparison with other prior work is given in
Section 6. Finally, we provide the conclusion in
Section 7.
2. Background
In this section, we present the fundamentals of the random forest classifier and explain the GAN architecture in detail. Afterward, we describe the realistic threat model scenario, ZOO attack, which was considered in our work, and then we explain the current feature selection and reduction methods.
2.1. Random Forest (RF) Classifier
RF is one of the most powerful methods employed to solve classification and regression issues in machine learning. It is a class of supervised classification algorithms. The random forest requires two steps: one is to tune the random forest configuration, and the other is to predict the incoming results obtained from step one [
28]. The random forest algorithm is implemented based on building multiple decision trees; each one represents a classifier. Every tree in the forest is sampled from the original dataset to create a sub-dataset. Then, subsets of data are placed in each decision tree, and each decision tree produces results. The result of the final decision is determined via a vote by all decision trees. A tree does not select all the features, instead only some features are randomly chosen; then, from the chosen features, only the optimal features are selected. Because of this randomness, its variance decreases, and a better overall classification model is also produced [
29].
2.2. GAN-Based Defense Methodology
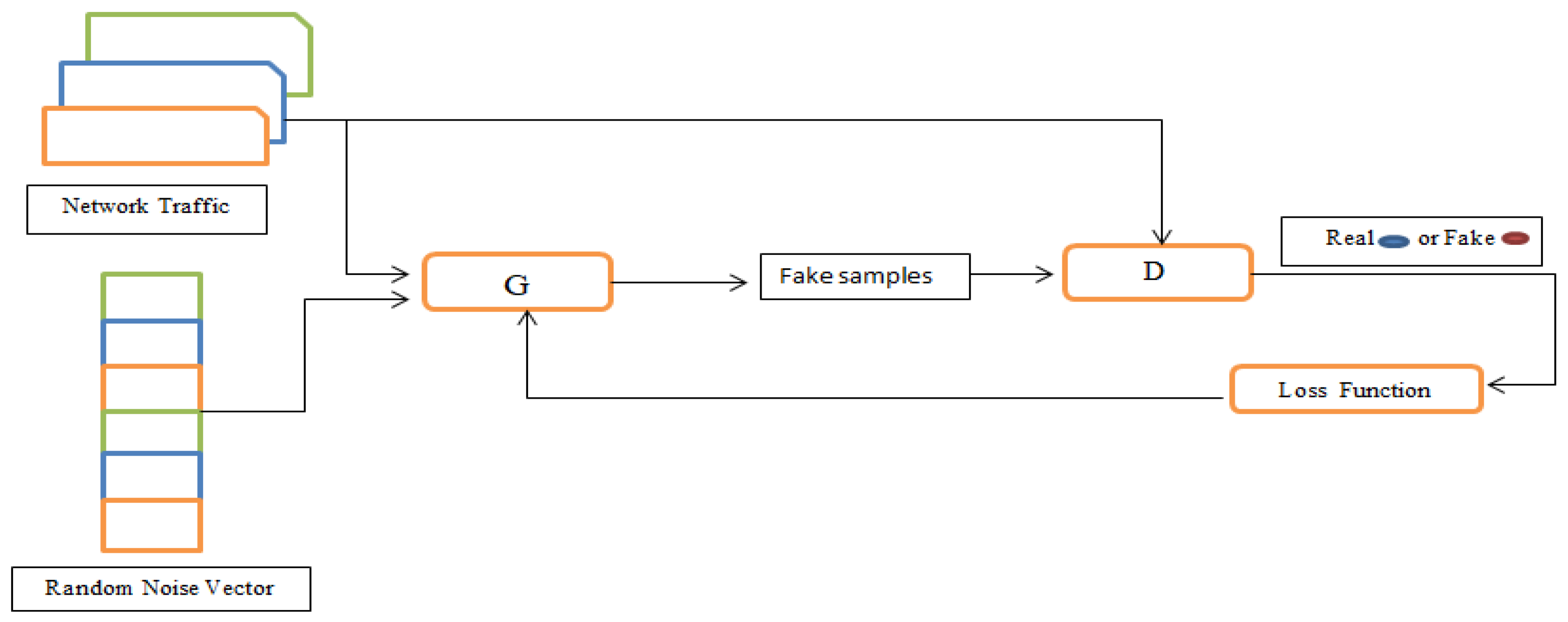
A GAN is a deep learning approach that is composed of two NNs, each one against the other in a game setting as shown in
Figure 1 [
30]. It has been studied in depth in the field of security, as a GAN is capable of generating new unseen threats. The usage of a GAN as a defense mechanism renders the model more robust against future attacks. The main objective of a GAN is to detect unknown or unseen attacks and protect systems from various vulnerabilities [
18]. In a zero sum game context, a GAN has two NNs competing against each other. One is leveraged for producing regression and labeled as a generator (
G), while the second is labeled as a discriminator (
D). Usually, the purpose of the generator is to take random noise (
V) as input, transform it using the NNs, and create false instances, whereas the aim of the discriminator is to use a NN to separate the infected data generated via the generator from the actual one [
31,
32]. When the process reaches equilibrium, the discriminator is unable to recognize between real and bogus data. The generator, therefore, accepts random noise (
V) as input and produces actual instances as output. That is to say, the generator has found how the data is distributed [
26,
33]. The adversarial loss for both
G and
D is given in Equations (1) and (2), respectively [
34].
In the above equations, S refers to the data collected from the generator and leveraged to train the discriminator, while the variable E is the expected volume of the produced data that is indicated to be an attack or benign. Bbenign is a variable for the benign data, and Battack is the attack data.
2.3. Black-Box-Based ZOO Attack
The ZOO-attack-based method was first introduced in [
35] to generate adversarial examples (AEs). Note that white-box-attack-based methods differ from black-box attacks, as black-box methods do not rely on the gradient information of the target model. The black-box attack process represents a targeted misclassification by which the data are crafted to generate AEs. The generation of such examples relies on the modification of optimization parameters and on a conjecture of confidence, rather than the gradation. When an attacker generates these examples, he or she utilizes them to violate IDS [
36]. In this paper, the threat model settings assume an attacker only queries the model for relevant labels and has no access to the IDS model, including its hyperparameters. The goal of such an attacker is to generate AEs that are hard to detect via the IDS model, and this makes the model vulnerable to many threats.
2.4. Reduction Techniques
To further increase the IDS model’s resilience, the most valuable features should be extracted from the collected dataset. This will also help to decrease the data’s dimensions and the model’s complexity. Such a method is known as a reduction method in which only valuable features are chosen during the classification. In this work, two reduction techniques, known as “PCA” and “RFE”, are tackled in the following.
Principle component analysis (PCA) is widely employed to extract preferable features and compress them, in which the dimensions of the feature are reduced. Note that this also leads to the diminishment of the computational time and the model’s complexity. The subsets of the feature set are extracted via PCA, and this helps diminish the search range [
37]. In fact, the general usage of PCA is to extract important features for traffic analysis [
38];
Recursive feature elimination (Rfe) is utilized to select some valuable features out of all of the features in the dataset. Only features with high ranking are selected, and reset features (e.g., those with low ranks) are eliminated one by one. Rfe technique removes duplicated features and extracts only preferable and valuable features from all dataset features. The goal of Rfe is to choose the best subsets of valuable features [
10].
4. Proposed Research Methodology
In this section, we present in detail our proposed technique’s structure, the dataset’s preparation and preprocessing, and the evaluation metrics.
4.1. Model Structure
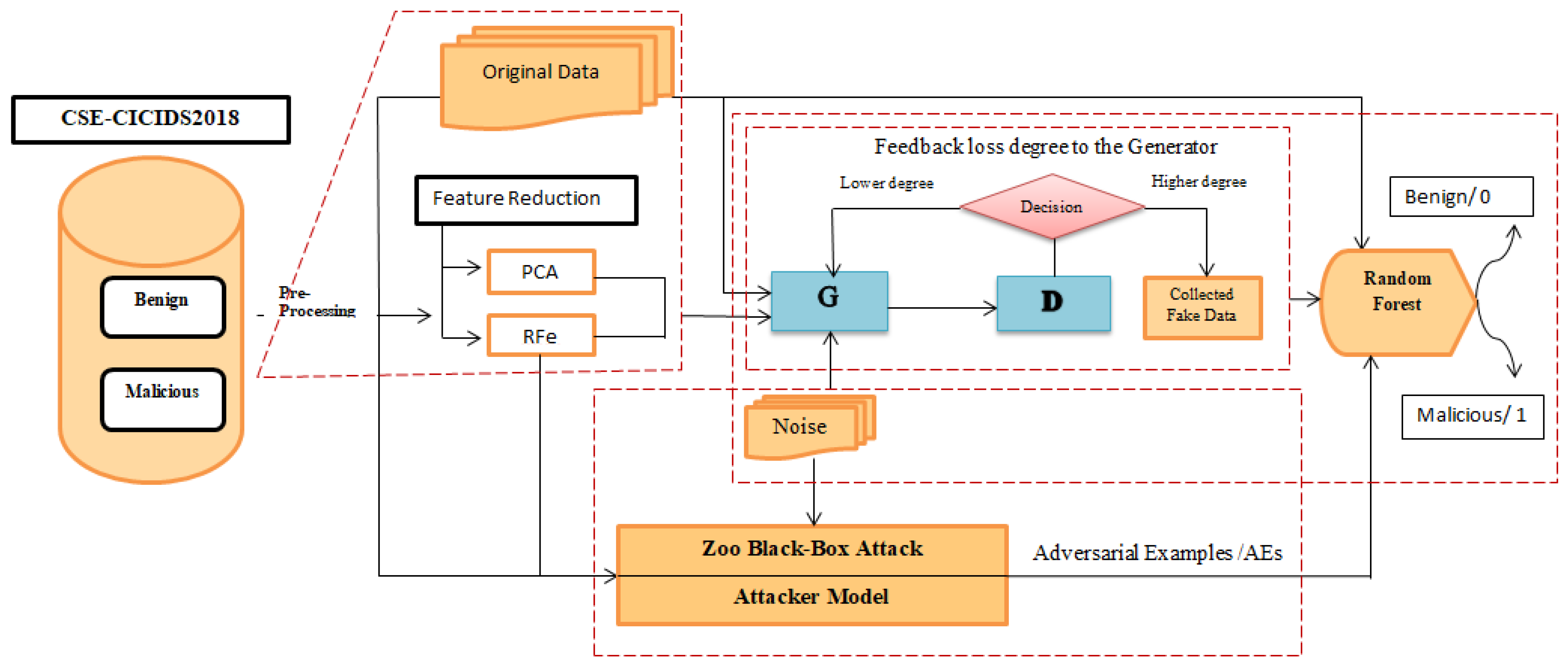
A framework diagram of the proposed model is demonstrated in
Figure 2. It consists of three main parts. The first part is data preprocessing, which is used to prepare the original data for the ML models and apply feature reduction methods to improve the accuracy and reduce the complexity. Specifically, we used PCA and RFE to reduce the data’s dimensions by selecting only the relevant features that are needed for the classification task. The second part is the defender model, which consists of the classifier model and the GAN model. The classifier is an ML model used for binary classification. The GAN model aims to generate adversarial examples (AEs) from the original dataset using arbitrary latent vector (noise vector) and retrain our classifier on the new dataset (original and synthetic dataset) to make it more resistant and powerful against known and unknown attacks in the future. The last part, i.e., the attacker model, is a black-box attack method. This model generates new AEs that aim to evade the detection system, the defender model, and influence on the predictions of the classifier to determine its robustness.
4.2. Dataset
The CSE-CIC-IDS2018 is an intrusion detection dataset created by the Communications Security Establishment and Canadian Institute for Cybersecurity on AWS (Amazon Web Services), located at Fredericton, Canada, in 2018 [
46]. The IDS2018 is the updated version of the IDS2017 dataset and the latest and most comprehensive intrusion dataset, collected for launching real attacks, which is publicly available. The dataset includes the necessary standards for the attack dataset and contains many different kinds of attacks. This dataset also comprises network traffic, system logs, and 80 features [
47]. To better model the attacks, a topology with a machine diversity similar to real-world networks was created [
48]. The infrastructure of the network included 50 attacker machines, 420 victim machines, and 30 servers. The details of the dataset’s features are provided in
Table 1.
Figure 2.
The overall framework of our proposal.
Figure 2.
The overall framework of our proposal.
The intrusions in the CSE-CICIDS2018 dataset were normalized into two kinds, namely, benign and malicious. The number of benign and malicious network traffics is given in
Table 2.
4.3. Data Preprocessing
The CSE-CICIDS2018 dataset consists of over 1,000,000 records. The dataset consists of the original traffic in the packet capture (pcap) files, the logs, the preprocessed labels, and the feature-selected comma-separated values (CSV) files. The CSV files are categorized into two classes benign (class-0) and malicious (class-1). The dataset does not contain blanks or errors. Therefore, we applied some preliminary data processing procedures which are presented as follows:
Numerical standardization: To provide data consistency, the data were standardized using the technique of obtaining the Z-Score in which the standard deviation was set to 1, and the average value of each feature was set to 0.
Outliers: We deleted two features (i.e., the timestamp (date and time) and Fwd packets features) from the CSE-CIC-IDS2018 dataset, because they have a neglected influence on the model training. Therefore, the total number of features was 78.
Replacement of default values: In the leveraged dataset, the packet length Std feature has a value of infinity. We fixed this by changing its value to 0 in the database.
For all the experiments in
Section 5, 75% of the dataset was employed to train the ML model, and the remaining 25% was employed to test the model. However, 70% of the dataset was used to train the GAN model, and the remaining 30% was used to test the model.
4.4. Evaluation Metrics
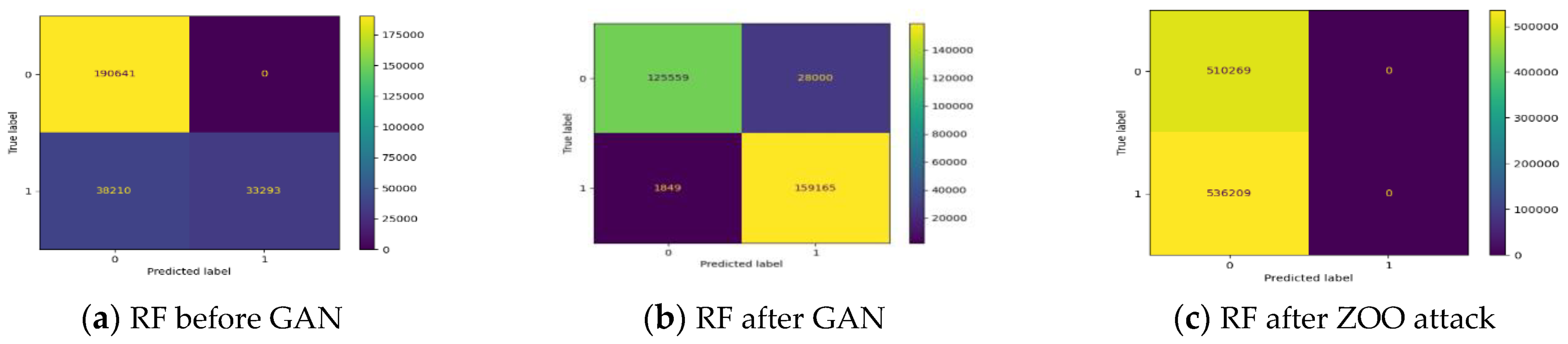
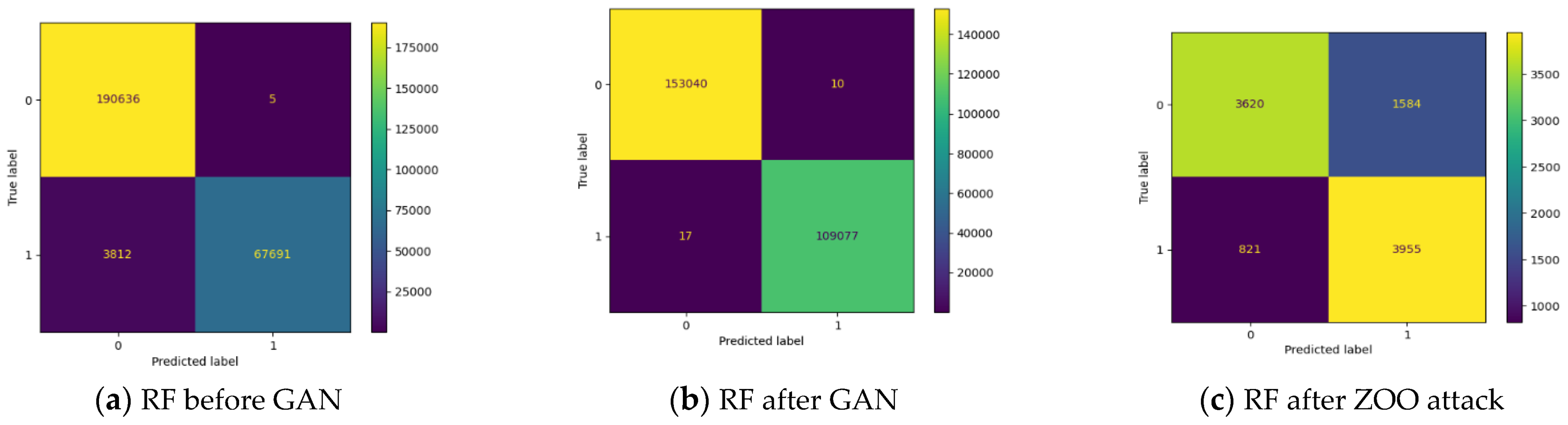
There are several classification metrics for IDS. The confusion matrix (CM) of a two-class classifier was used to compute the performance metrics because, in our work, the experiments were conducted broadly to distinguish between malicious and normal records. The abbreviations of the CM are as follows:
TP: Normal events are correctly classified by the model;
TN: Malicious attacks are successfully identified by the model;
FP: Normal events are incorrectly distinguished to be an anomaly;
FN: Malicious attacks are incorrectly recognized via the model as a normal event.
The performance of our classifier model could be obtained via the following standards: accuracy (AC), precision (PC), recall (RC), F1-score, AUC-ROC, and MSE.
ACC: The proportion of all predicted instances, including normal or abnormal, that is correctly predicted by the IDS. It is one of the longest-used metrics to measure IDS performance, and it can be very useful when the classes are imbalanced.
Precision: The ratio of normal records that are correctly identified by the IDS to all records that the IDS identified as normal.
Recall: The percentage of all normal records correctly identified by IDS.
F1-score: The balance between precision and Recall, and it is expressed as the harmonic mean of the two metrics.
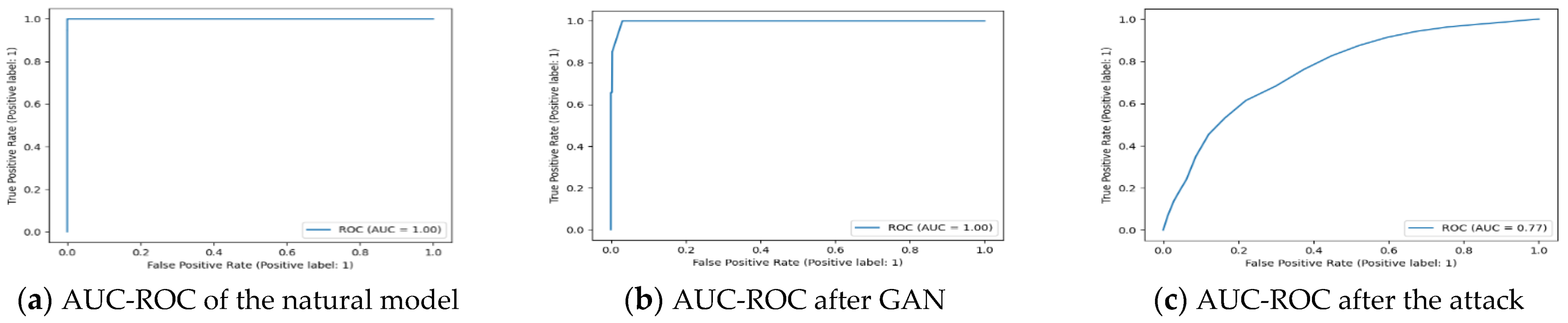
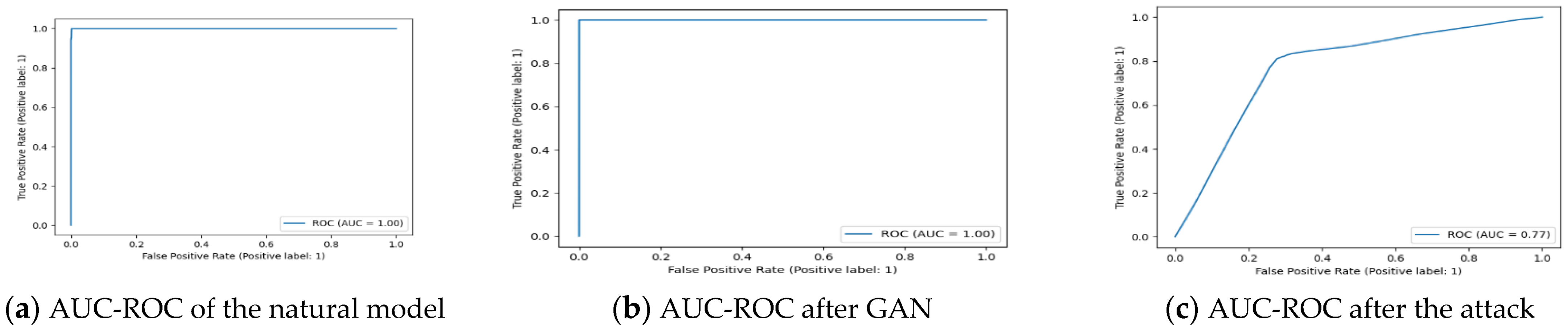
AUC-ROC: This indicates how much or to what extent a machine learning model is capable of detecting or classifying various categories of scenarios as we intended.
MSE: This is the average squared error between the model’s predictions and the actual outcomes.
6. Comparison with Previous Studies
In this section, we compare our proposed ML-based IDS with state-of-the-art ML/DL-based IDS that only evaluate the model’ performance without measuring the model resistance. Each of the prior work was implemented with different methods (e.g., some of them used a single model and others used multiple models) on same dataset. The results show that our proposal offers better accuracy compared to other existing works as shown in
Table 9. It is worth mentioning that we did not compare our work with work that handled class imbalance issues by modifying the original dataset (e.g., the work in [
47,
49]), because it was beyond the scope of this paper, and it could be a complement to our proposed model. Although DL has been proven to be effective in the field of NIDS, our proposed ML model achieved better results. This might be because DL algorithms deal very well with complex tasks that require discovering relationships among a large number of different features. However, our experimental results show that reducing the number of features of our targeted task led to improving the overall accuracy. In addition, a recent study showed that using such techniques (i.e., using PCA to minimize the dimensionality of the dataset) with IDS reduced the performance of the model.
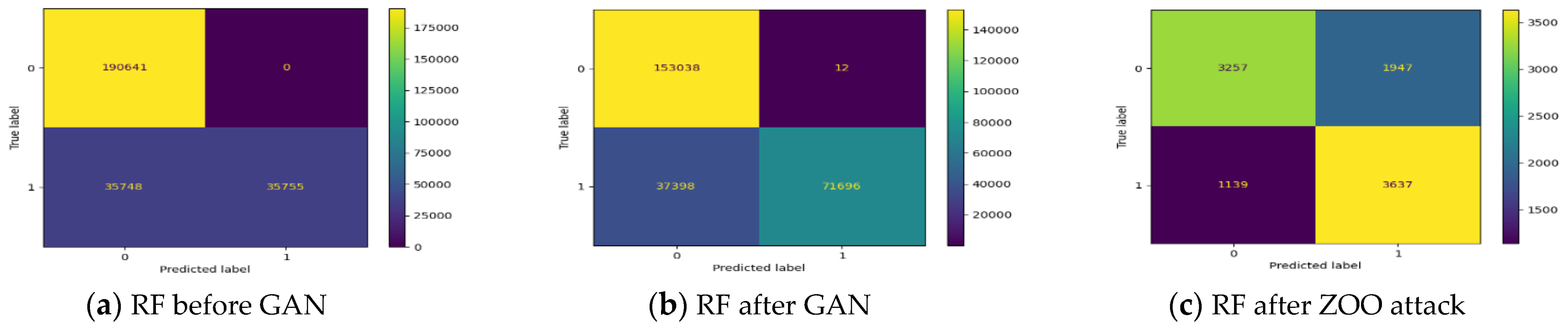
We compared our work with a related work [
20] to measure the proposed model resistance against different attacks, where they used GAN as a defense method based on adversarial training. The test was conducted before and after applying GAN and ZOO attacks with and without applying adversarial training. Our model outperformed the work in [
20] in all testing stages when these two attacks were applied as shown in
Table 10. We obtained better results due to the technique used for feature selection and number of epochs. Specifically, we used PCA for feature selection instead of dividing the features into functional and nonfunctional as done in [
20]. Moreover, since the epochs used in [
20] were only 100, this would not be enough to generate sufficiently strong fake samples for training the model effectively. To address this dilemma and generate strong samples, we increased the number of epochs to 2000.



 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}