1. Introduction
Lithium-ion batteries (LIBs) have garnered widespread adoption across various industries, including electric vehicles, portable electronics, the aerospace industry, submarines, and more. This is attributed to their remarkable advantages, including their increased energy density, elevated output voltage, minimal self-discharge, absence of memory effects, broad operational range, and eco-friendliness. Since their initial introduction, these advantages have firmly established LIBs as the preferred energy storage solution [
1]. As the emphasis on environmental preservation continues to grow, many individuals are opting for energy-powered vehicles. When choosing such vehicles, two critical considerations come to the forefront: their range and safety features. However, it is essential to recognize that the chemistry of LIBs degrades over time, presenting a range of significant challenges [
2]. Efficiently projecting the RUL of LIBs and providing preventive maintenance guidance to mitigate the risks associated with overcharging and discharging are imperative tasks. This critical endeavor is essential for upholding the security and dependability of the system and integrity of LIBs [
3]. The reserve RUL estimates how old a battery is and how many cycles of charging and discharging it can withstand before failing in a given circumstance. Typically, a battery’s rated capacity is conservatively established between 70% to 80% of its failure threshold (FT) [
4]. Prompt battery replacement becomes essential once the capacity reaches the FT. Failure to do so can result in LIB malfunction, jeopardizing energy storage equipment and even giving rise to catastrophic incidents [
5]. Because battery capacity and RUL are closely correlated, most current RUL prediction techniques concentrate on predicting changes in LIB capacity. Enhancing the precision of RUL prediction for LIBs facilitates proactive maintenance approaches [
6]. The degradation of a battery during a charge–discharge cycle is promptly evident through a reduction in battery capacity. To analyze battery performance deterioration and predict the RUL of LIBs, capacity is a direct indicator of health. The RUL can be described as follows in Equation (
1):
The term “total available cycles” refers to a predefined number of charge–discharge cycles that a battery can endure, while the current cycle represents the ongoing charge–discharge cycle of the battery at a specific moment. Equation (
1) calculates the remaining charge–discharge cycles that the battery can undergo before reaching its intended end of life. This calculation is based on the initial estimation of the total available cycles and the current usage [
7]. The three main methods used to project the RUL of LIBs at this time are mechanism-based approaches, data-driven prediction techniques, and integrated prediction methodologies [
8]. RUL prediction strategies are grounded in mechanism models such as the equivalent circuit process [
9] and empirical degradation model method [
10], which offer precise RUL forecasts under relatively stable external circumstances. However, these models’ accuracy can be susceptible to variations in external conditions. Employing historical feature data, the data-driven method of RUL prediction determines the correlations between battery characteristics and RUL. Techniques such as relevance vector machines (RVM)s [
11] and neural networks (NNs) [
12] belong to this category, and they have demonstrated remarkable flexibility and gained widespread adoption. A long short-term memory (LSTM) network optimized using an improved sparrow search algorithm (ISSA) was used to present a novel RUL prediction approach. Using the ISSA, hyperparameters that impacted prediction accuracy were tuned. Comparative tests revealed that the suggested process worked better than others, such as the SVR, CNN, RNN, and LSTM, thus enabling improved battery consumption [
13].
A highly adaptable and resilient RUL prediction strategy was developed, and the method utilized multi-kernel RVMs that were optimized with the gray wolf optimizer to predict aging features for RUL prediction. In order to use complementary in ensemble empirical mode decomposition and, that the quantifiable and historical aging characteristics were split into high- and low-frequency signals. An LSTM NN and a feedforward neural network (FNN) were then used to model and forecast these signals with changing frequency, respectively [
14]. The extensive utilization of deep-learning neural networks, particularly the LSTM NN, excels in accurately forecasting battery capacity and RUL, making it a valuable tool for measuring battery aging data. Its proficiency in storing and updating information over extended periods without encountering the vanishing gradient issue significantly contributes to its elevated prediction precision. Chinomona et al. [
15] employed a forward-selection LSTM technique. The approach adeptly extracted an optimal feature subset from raw signals by filtering out irrelevant features. Park et al. [
16] presented a many-to-one LSTM structure to correctly predict the RUL for LIBs. In their study, a data-driven ELM neural network model was employed to address the challenging task of predicting the RUL of LIBs. An ELM neural network was used for passive mapping to transform the problem into a high-dimensional space, and random input weights and thresholds were introduced [
17]. The sliding time window technique was employed to process input data samples to capture valuable feature information from the input data and predict the RUL. These feature-rich data were then leveraged to make RUL predictions. Within the domain of RUL prediction, the LSTM NN, a notable improvement over traditional recurrent NNs, plays a pivotal role. In this context, the RUL prediction method developed by [
18] is a noteworthy contribution.
Batteries are essential for many contemporary technologies, including electric cars, renewable energy sources, and portable electronics. Ensuring their reliable performance and longevity is paramount to the functionality and sustainability of these applications. Predicting the RUL of batteries has emerged as a critical challenge, as it allows for proactive maintenance and replacement strategies, ultimately reducing downtime and operational costs. Conventional RUL prediction methods have traditionally relied on statistical and physics-based models. While effective to some extent, these methods often struggle to capture the complex and nonlinear behaviors exhibited by batteries, particularly when confronted with diverse operational conditions and varying usage patterns. In this study, we address and confront two fundamental challenges. Firstly, our goal is to improve LIB RUL prediction accuracy. This goal unites researchers in the pursuit of the most precise results. Secondly, we grapple with the challenge of optimizing the overall execution time of our hybrid method. This process encompasses various tasks, including data extraction, formatting, model training, validation, and performance computation, all of which can be time-consuming. Given the complexity of our hybrid approach, it is essential to streamline these operations to achieve quicker and more efficient RUL predictions. These two issues serve as the foundation for our research, which aims to increase the accuracy and effectiveness of RUL prediction for LIBs.
We developed the CNN-GRU approach to address these challenges; this was designed to combine CNN and GRU architectures. In this study, we address the pressing need for more accurate predictions of the RUL of LIBs. These batteries play a crucial role in various industries, and ensuring their reliability and efficiency is paramount. However, existing methods have limitations in their ability to accurately estimate RUL. To overcome these limitations, we harness data-driven approaches, capitalizing on the power of machine learning techniques, which have gained increasing attention in recent years due to their potential to significantly enhance RUL predictions. Notably, the integration of deep learning architectures has brought about innovation in this field. Deep learning models, such as CNNs, have demonstrated remarkable capabilities in uncovering intricate data patterns and relationships, particularly in multi-dimensional data. This makes them exceptionally well suited for extracting crucial information from various battery parameters, including V, I, and T. Simultaneously, RNNs, including LSTM and GRU, have demonstrated their efficacy in simulating temporal relationships in sequential data. Our research presents a fresh and groundbreaking method for predicting battery RUL. We combine the best features of CNNs and GRUs into a hybrid architecture with the intention of drastically improving the precision and efficacy of RUL predictions. This innovative CNN-GRU hybrid model concurrently extracts spatial and temporal features from multi-channel charging profiles. While CNNs capture spatial information from V, I, and T data streams, the GRU model captures the time-dependent patterns associated with battery capacity. To validate the effectiveness of our method, we conducted extensive experiments using NASA’s battery datasets.
The main contributions of this article are summarized as follows:
We introduce a hybrid deep learning model for accurate battery RUL prediction by combining CNN and GRU architectures.
Our model utilizes the parallel processing of multiple measurable datasets (V, I, T, and capacity) with the CNN and GRU to extract relevant features.
The CNN captures spatial information from multi-channel charging profiles, while the GRU focuses on time-dependent data derived from previous capacity profiles.
Our extensive experiments demonstrate a significant improvement in precision for the estimation of the remaining charge and prediction of the RUL using our model.
We provide a comparative analysis of our RUL prediction results with those from relevant studies in the literature.
The remainder of this paper is structured as follows:
Section 2 delves into the related work concerning the RUL prediction model.
Section 3 elaborates on the proposed methodology. We provide details about the dataset in
Section 4, and
Section 5 is dedicated to presenting experimental results and discussions. Lastly, we conclude the paper and outline potential future research directions.
3. Methodology
In this section, we present our innovative methodology for precise RUL prediction in LIBs. Our approach consists of a carefully structured process designed to maximize prediction accuracy and robustness. The first phase of our methodology begins with rigorous data preprocessing to ensure the quality of the input data. This phase addresses data anomalies, removes outliers, handles missing values, and normalizes the dataset. The second phase involves selecting input features, including voltage (V), I, T, and capacity. These choices are rooted in their fundamental significance for battery behavior. Voltage is a vital indicator of electrochemical reactions within the battery, reflecting variations in energy output. Current, representing the flow of energy, plays an essential role in understanding the dynamic state of a battery. Temperature, another crucial factor, directly impacts a battery’s aging process, influencing its overall health. Lastly, capacity characterizes a battery’s energy storage capabilities and its ability to maintain charge. In the third step, our methodology leverages a hybrid model combining a CNN and GRU. This decision was made because it is necessary to record temporal and geographical relationships in the battery data. Parallel CNN branches are used for each input feature (V, I, T) to capture spatial information independently.
Simultaneously, a GRU layer models the temporal dependencies in capacity data, which are inherently related to time-dependent behavior. The fourth phase divides the preprocessed data into training, validation, and testing sets. This division ensures that the model is effectively trained on historical data, validated for robustness, and rigorously tested for predictive accuracy. The selected model architecture is fine-tuned and trained using preprocessed data during training. This process enables the models to capture intricate patterns in battery behavior, further enhancing the predictive capabilities. Our trained models estimate and evaluate the battery’s RUL in the final phase. We evaluate the precision and dependability of our predictions using specialized error measures designed for RUL prediction tasks. The process begins with step 1, battery data, where essential information related to the batteries is gathered. In step 2, data preprocessing, this collected data undergoes cleaning and organization. In step 3, train model for RUL estimation, the preprocessed data is utilized to train a model capable of estimating the batteries’ remaining useful life (RUL). The final step, step 4, method evaluation, involves evaluating the model’s performance to determine its effectiveness in predicting battery life. These four steps provide a structured workflow for managing battery data and estimating RUL, as shown in
Figure 2, which illustrates the overall framework of the proposed approach.
3.1. Theoretical Background of the Study
Before delving into the core of our study, it is essential to lay a strong theoretical foundation. In this section, we will elucidate the essential ideas and architectures that form the basis of our research. We will explore CNNs, LSTM, and GRUs. Additionally, we will present the proposed framework models, including their hybrid variations: CNN-LSTM and CNN-GRU.
3.1.1. Convolutional Neural Network Model
CNNs are a potent class of neural networks that are highly renowned for their proficiency in various deep-learning applications. They are a specific type of feedforward neural network (FNN). The architecture of CNNs comprises convolutional and pooling layers, which are particularly adept at extracting pertinent features from data. Subsequently, one or more fully connected layers come into play, and these features are leveraged to make predictions. During the training process, the CNN acquires the ability to correlate the extracted features with the appropriate labels. This achievement is unlocked through iterative mechanisms such as backpropagation and optimization [
50,
51]. A typical CNN comprises several essential layers, including the input, convolutional, pooling, fully connected, and output layers. These networks are widely used in various deep-learning tasks. CNNs are designed to operate on multi-dimensional input feature vectors. The convolutional layers play a crucial role in identifying intrinsic relationships within the data by extracting feature maps. These feature maps are then processed through pooling layers, which perform subsampling to reduce network complexity and prevent overfitting. The convolutional kernel operates on the width of the convolution development, further improving the extraction of relevant feature information. Finally, the fully connected layers integrate the processed data following the convolution and pooling stages. These merged data are subsequently fed into the final layers of the network, often including a fully connected or recurrent layer for making predictions, as shown in
Figure 3, which is a basic CNN architecture.
Figure 2.
Workflow of the proposed approach.
Figure 2.
Workflow of the proposed approach.
3.1.2. LSTM Model
Due to the nature of the data collected from LIBs, which involve charging and discharging cycles and are essentially time-series data, using an RNN is a reasonable choice for processing such sequences while leveraging internal memory. RNNs are equipped with internal feedback and feedforward connections among their processing units, allowing them to handle sequential information. However, it is important to note that RNNs have limitations, particularly when dealing with long sequences. They can only store a portion of a sequence, which can lead to reduced accuracy when dealing with longer sequences [
52]. In this context, where LIB data sequences are relatively lengthy and consist of numerous time series, LSTM networks are preferred over traditional RNNs. LSTM is a specialized type of RNN designed to overcome the challenge of handling long-distance dependencies in sequences. LSTM networks are particularly effective at capturing and learning from sequences with extended context, making them well-suited for tasks involving time dependencies. For instance, LSTM models can effectively model how a battery’s capacity changes over time during discharging profiles. One key feature of LSTM is its ability to maintain a certain level of correlation between hidden-layer nodes. When the network receives sequential data, the hidden-layer nodes’ computations rely on both the current input and the activation levels of the nodes from earlier time steps. When processing sequences that are input-related for LIBs, the LSTM network layer processes both the output and hidden-layer sequences. This allows it to efficiently identify intricate patterns and dependencies in the data. The input gate, forgetting gate, and output gate are the three gates that allow the LSTM to function. Together, these gates enable the data to write, read, and maintain long-term dependencies.
Figure 4 depicts the layout of the LSTM abstraction network.
3.1.3. Gated Recurrent Unit Model
The development of RNNs—particularly LSTM networks—successfully addresses a critical issue faced by fully connected neural networks. The problem is that fully connected networks tend to experience data loss in either space or time, which results in challenges related to vanishing and exploding gradients. These two issues, known as vanishing and exploding gradients, were effectively resolved by introducing the concept of gates in the LSTM network. Input, output, and forgetting gates are components of an LSTM network that regulate and control information flow. This innovation allows LSTM to capture and learn from sequences with long-range dependencies, addressing the challenges associated with data loss. Another noteworthy advancement in this context is the GRU, which can be considered an enhanced version of the LSTM model. The GRU retains the training effectiveness of LSTM while streamlining the network’s topology and reducing the number of training parameters. This makes the GRU a more efficient choice for handling sequential data such as LIB charging and discharging profiles. A single step of the GRU update equations is shown in
Figure 5; at the core of this architecture are two crucial gates: the update gate
and the reset gate
. These gates play pivotal roles in regulating information flow and capturing temporal dependencies within the data.
The update gate combines the functions of the forgetting and input gates in traditional recurrent networks. It determines what information to retain from the previous state and what new information to add. The formula for
is shown in Equation (
2):
where
is the update gate at time step
t in a GRU model that determines how much of the previous hidden state to retain and how much new information to incorporate
. The activation function squeezes values between 0 and 1, controlling information flow.
is the weight matrix for the update gate, and it influences the importance of input
and the prior hidden state
.
is a concatenation of the current input
and previous hidden state
to form the update gate’s input.
is a bias term that shifts the sigmoid’s decision boundary to fine-tune the gate’s behavior in Equation (
2).
The reset gate, represented by
, is another integral component of our architecture. When calculating the present state, it sets the amount of the prior condition that should be erased or reset. By modulating the memory resetting,
allows the network to selectively keep or discard details from previous time steps and capture relevant patterns and dependencies in the data. The formula for
is as follows:
where
(the reset gate) defines how much of the last hidden state
to reset or forget when computing the new hidden state at time step
t based on the current input
. The sigmoid activation function
squashes the weighted sum of the input and previous hidden state, ensuring that
takes values between 0 and 1, thus controlling the amount of reset involved in Equation (
3).
3.1.4. CNN-LSTM Model
Our battery RUL prediction methodology uses a hybrid deep model that combines a CNN and an LSTM network in a data-driven manner. In order to extract characteristics from several quantifiable data sources, such as voltage, current, temperature, and capacity, these two components operate in parallel, as shown in
Figure 6. The CNN focuses on extracting features from multi-channel charging profiles, while the LSTM specializes in capturing features from historical capacity data associated with discharging profiles while considering their time-dependent nature.
3.1.5. CNN-GRU Model
The CNN-GRU architecture is a powerful fusion of CNNs and GRUs that is meticulously designed for complex data analysis tasks. This hybrid model seamlessly combines the spatial feature extraction capabilities of CNNs with the temporal dependency modeling strengths of GRUs. In the context of battery RUL prediction, CNNs play a pivotal role in extracting essential spatial features from various input data sources, such as V, I, T, and capacity. These extracted features are then seamlessly integrated into the GRU layer, which excels in capturing temporal relationships and historical capacity data. The overall framework of the CNN-GRU model suggested in this research consists of four key layers: the input, CNN, GRU, and output layers. The process begins with the CNN layer, which extracts essential information related to lithium battery health factors by mining the natural correlations between feature quantities and lithium battery capacity. Following this, the pooling layer conducts computations by utilizing convolution kernels to extract additional feature data and broaden the scope of the convolution results. The preprocessed lithium battery data are then passed into the GRU network for optimization training through a fully connected layer. Within the GRU layer, the model learns the underlying patterns and internal variability, which are crucial for making accurate predictions. Finally, the output layer generates valuable predictions related to lithium battery capacity, providing valuable insights into the battery’s RUL. This comprehensive architecture enables accurate RUL predictions for LIBs to the benefit of various applications and industries. The hybrid RUL prediction model was constructed using a CNN-GRU channel attention mechanism, as shown in
Figure 7.
4. Data Description
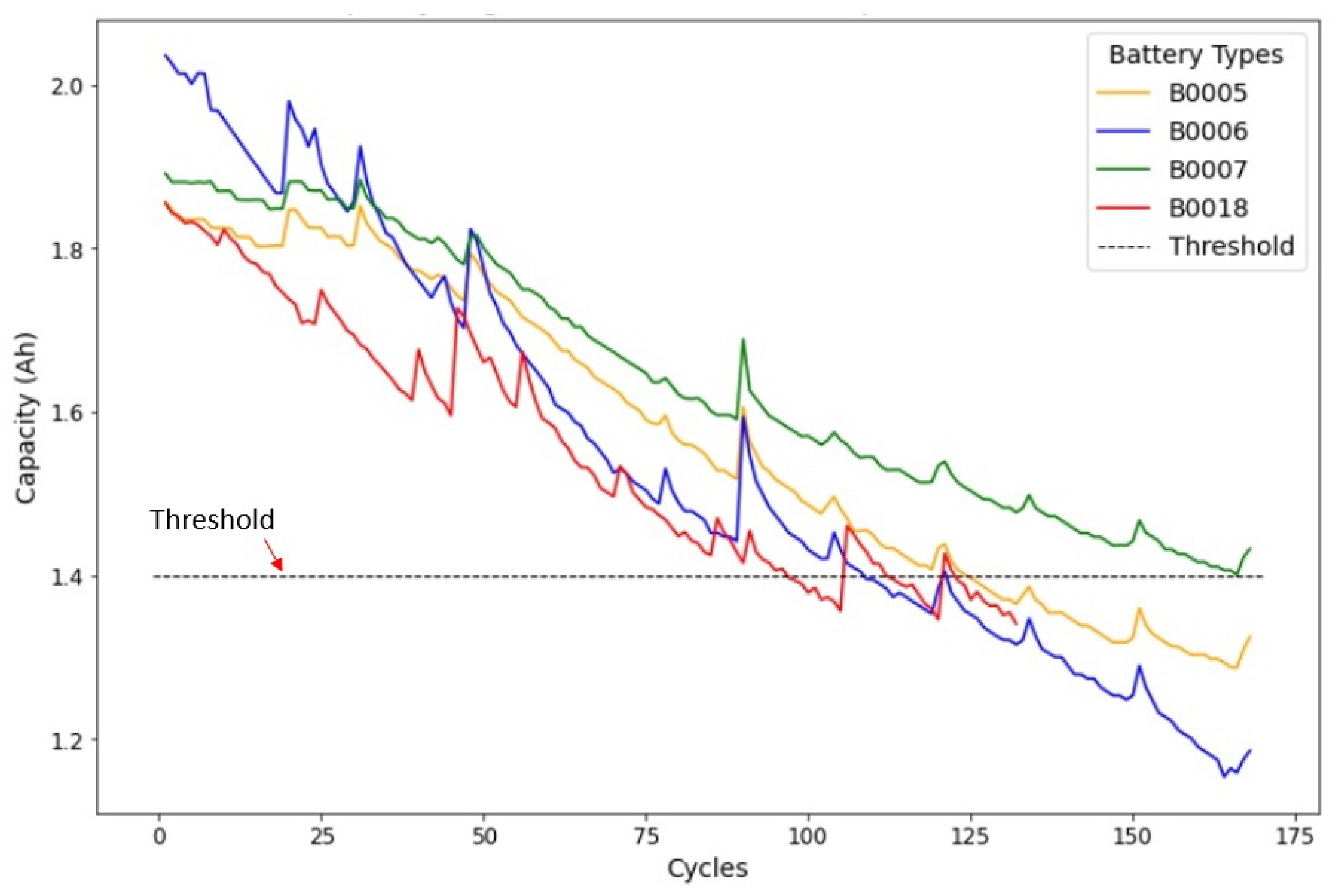
Our study commences with an introductory examination of the dataset in [
53], which encompasses four LIBs, namely, B0005, B0006, B0007, and B0018. These batteries have undergone a series of charge, discharge, and impedance operations. The impedance analysis was conducted using electrochemical impedance spectroscopy (EIS) across varying frequencies. Consecutive charge and discharge cycles have led to the expedited aging of the batteries, and this aging process was reflected in the evolving internal battery parameters, as unveiled by the impedance measurements. The selection criteria were their initial state of health (SoH), capacity, and model name. There were two thorough steps in the billing procedure. The end-of-life (EoL) criterion was reached, which signified a 30% capacity decline from the initial rated capacity of 2 ampere-hours (Ahr) to 1.4 Ahr. At that point, the studies were terminated. These datasets hold valuable potential for forecasting the residual charge (within a designated discharge cycle) and the batteries’ RUL. This study’s dataset included aging data for 18,650 lithium cobalt oxide batteries with a 2 Ah capacity, which were generously provided by NASA. The analysis focused on the cycling behavior of four specific lithium batteries, and all analyses were conducted at room temperature. The results of this analysis unveiled the capacity decay curves for B0005, B0006, B0007, and B0018 at a temperature of 24 °C, as illustrated in
Figure 8.
4.1. Charge, Discharge and Impedance Profiles
The charge profiles exhibited striking consistency across all battery tests, offering a clear window into the intricate behaviors of the system. The charging procedure was meticulously executed, commencing with a stable power input through a constant current (CC) mode, which was precisely set at 1.5 A. This phase persisted until the battery voltage reached its highest point, peaking at 4.2 V. A transition occurred, moving into a constant voltage (CV) mode. This mode was maintained until the charge current gently diminished to a mere 20 mA. In contrast, the discharge phase presented an array of diversity, with each battery showcasing its distinctive characteristics. The discharge process was meticulously regulated by a controlled CC regimen, spanning a range from 1 A to 4 A, which was tailored to the specific battery under investigation. This discharge process persisted until the battery voltage gracefully descended to well-defined thresholds: 2.7 V, 2.5 V, 2.2 V, and 2.5 V. These distinct thresholds illuminated the batteries’ unique resilience and performance attributes as they navigated the discharge process, offering insights into their behaviors across various energy levels. Furthermore, the impedance measurements furnished a multifaceted understanding of battery dynamics, transcending the boundaries of voltage and current.
The batteries’ internal responses came to life by deploying EIS across frequencies. These measurements uncovered intricate electrochemical processes and material behaviors within the battery systems. Impedance measurements were conducted using EIS with a frequency sweep spanning from 0.1 Hz to 5 kHz. The experiments were concluded when the batteries met specific EoL criteria. For instance, one criterion involved a 30% reduction in rated capacity, declining from 2 Ampere-hours (Ahr) to 1.4 Ahr. Additionally, alternative stopping criteria were employed, including a 20% reduction in a rated capacity.
Table 2 presents a summary of the experimental specifications for the battery dataset, including the various charging, discharging, and impedance modes.
4.2. Data Preprocessing
Data preprocessing is essential for predicting the RUL of LIBs. This critical phase includes key techniques that enhance the quality of input data, directly impacting the RUL prediction accuracy. Handling missing values is crucial, as sensor-read gaps (V, I, T, capacity) can disrupt data continuity. Imputing missing values—often by using mean or median imputation methods—ensures data integrity and more precise predictions. Outliers represent extreme deviations or anomalies in the data, introducing unwanted noise during model training. Removing these outliers improves model performance and enables accurate pattern learning in LIB RUL prediction. Also, normalization is a critical step because LIB data come from diverse sensors with varying units and scales. Normalization standardizes these features to a consistent range (usually between 0 and 1), preventing any single feature from dominating the model’s learning process. This facilitates more efficient model convergence and enhances prediction accuracy.
5. Experimental Results and Discussion
This section is divided into three main components; the first part encompasses the evaluation criteria and system configuration of the RUL prediction model. The second part presents the prediction results and comprehensively discusses the RUL prediction model. Finally, the third part provides a summary of the suggested technique.
5.1. Evaluation Criteria and System Configuration
During the model training phase, the CNN network employs the same convolution technique while utilizing 8, 16, and 32 convolution kernels in three convolution layers and one pooling layer. Every battery dataset was first divided into testing and training sets, with a data split of 20% and 80%, respectively. Batteries were combined in many ways for testing, validation, and training, and three situations were employed in our investigation. For example, in scenario 1, battery B0006 and battery B0007 were used as a training set, while battery B0005 was employed for validation, and battery B0018 served as the testing set. Similarly, in scenario 2, battery B0005 and battery B0006 constituted the training sets, with battery B0007 being used for validation and battery B0018 being used as the testing set. This approach allowed the model’s performance to be comprehensively evaluated across different battery datasets and configurations, with the same process being followed for all battery data. To emphasize the comprehensive validation of the experiment, we employed the following four evaluation criteria to assess the CNN-GRU model’s performance in predicting the RUL.
In Equation (
4), the mean absolute error (MAE), for which a lower value indicates superior prediction performance, is expressed as follows:
In Equation (
5), the root mean square error (RMSE), for which a lower value signifies superior prediction performance, is expressed as follows:
In Equation (
6), the mean absolute percentage error (MAPE) provides a meaningful way to assess prediction accuracy, particularly when understanding the relative error is crucial, and lower MAPE values indicate better prediction performance.
In Equation (
7), the mean squared error (MSE) is valuable for assessing prediction accuracy and places a higher weight on more significant errors due to the squaring operation. However, it is sensitive to outliers because it works with squared values. Lower MSE values indicate better prediction performance, with zero representing a perfect match between the predicted and actual values.
These metrics are frequently employed in prediction issues in Equations (
4) to (
7), which represent the MSE, RMSE, MAE, and mean absolute MAPE calculations, respectively. Here, M is the data size, and we denote the predicted capacity of a battery as
and the actual capacity as
; additionally, we employed another proposed model to assess and compare its performance with that of the proposed method.
5.2. Performance of the Proposed Framework
The following tables and figures present the LIBs’ life prediction results based on four approaches—GRU, LSTM, CNN-LSTM, and CNN-GRU—for the battery dataset. In scenario 1 (Train) in
Table 3, we assessed the prediction accuracy of four different models. The MAE for LSTM was 0.037, with an MSE of 0.002, MAPE of 0.024, and a root RMSE of 0.045. For the GRU, the MAE was 0.024, the MSE was 0.0009, the MAPE was 0.015, and the RMSE was 0.030. CNN-LSTM had an MAE of 0.029, an MSE of 0.001, a MAPE of 0.020, and an RMSE of 0.040. Lastly, CNN-GRU resulted in an MAE of 0.069, an MSE of 0.006, a MAPE of 0.047, and an RMSE of 0.079. These results offer valuable insights into the performance of the models in scenario 1 (Train), enabling a comprehensive comparison of their prediction accuracy.
In scenario 1 in
Table 4, we compared the prediction accuracy of the four different models (GRU, LSTM, CNN-LSTM, and CNN-GRU). The MAE for LSTM was 0.043, with an MSE of 0.002, a MAPE of 0.028, and an RMSE of 0.049. For the GRU, the MAE was 0.038, the MSE was 0.001, the MAPE was 0.024, and the RMSE was 0.043. CNN-LSTM had an MAE of 0.055, an MSE of 0.004, a MAPE of 0.035, and an RMSE of 0.067. Lastly, CNN-GRU resulted in an MAE of 0.078, an MSE of 0.008, a MAPE of 0.053, and an RMSE of 0.091. These results provide insights into the comparative performance of these models in scenario 1 (Test), with lower values indicating better prediction accuracy.
Figure 9 provides a visual comparison of the predictive performance of the four models (GRU, LSTM, CNN-LSTM, and CNN-GRU) concerning the discharge capacity (Ah) prediction across multiple cycles in scenario 1; the x-axis shows cycle counts, while the y-axis represents discharge capacity values. The lines correspond to model predictions; the blue line is for LSTM, green is for GRU, magenta is for CNN-LSTM, and cyan is for CNN-GRU, while the black line showing “True” represents the actual data. This graphical representation facilitates the assessment of how these models predict discharge capacity throughout the cycles in scenario 1.
Table 5 compares the prediction accuracy for four distinct models—LSTM, GRU, CNN-LSTM, and CNN-GRU—in scenario 2 (Train). These models are evaluated using key performance metrics, including the MAE, MSE, MAPE, and RMSE. The findings reveal that LSTM achieved an MAE of 0.015, an MSE of 0.0004, an MAPE of 0.009, and an RMSE of 0.020. The GRU demonstrated an MAE of 0.020, an MSE of 0.0007, an MAPE of 0.011, and an RMSE of 0.027. CNN-LSTM attained an MAE of 0.030, an MSE of 0.001, a MAPE of 0.019, and an RMSE of 0.037, while CNN-GRU recorded an MAE of 0.023, an MSE of 0.0008, a MAPE of 0.014, and an RMSE of 0.028. This comprehensive assessment provides valuable insights into these models’ predictive capabilities in scenario 2 (Train) and shows how informed decisions can be made when selecting models for similar predictions.
Table 6 provides a comprehensive comparison of the prediction accuracy for the four distinct models in scenario 2 (Test). The evaluation was based on key performance metrics. LSTM yielded an MAE of 0.034, an MSE of 0.0017, an MAPE of 0.021, and an RMSE of 0.042. The GRU exhibited an MAE of 0.026, an MSE of 0.001, an MAPE of 0.016, and an RMSE of 0.036. CNN-LSTM demonstrated an MAE of 0.039, an MSE of 0.002, a MAPE of 0.024, and an RMSE of 0.050. Finally, CNN-GRU recorded an MAE of 0.050, an MSE of 0.004, a MAPE of 0.030, and an RMSE of 0.067. The model also consistently demonstrated superior performance across the critical evaluation metrics in scenario 2 (Test).
In
Figure 10, we visually compare the predictive performance of the four deep learning models for discharge capacity (Ah) prediction over multiple cycles in scenario 3. The x-axis tracks the cycle counts, while the y-axis shows the discharge capacity values. The lines represent model predictions: blue for LSTM, green for GRU, magenta for CNN-LSTM, and cyan for CNN-GRU; in addition, the black line for True represents the actual observations. This visualization helps assess how these models predicted discharge capacity throughout the cycles.
Table 7 provides a comprehensive assessment of the prediction accuracy of the four distinct models for the training dataset in scenario 3. In this scenario, it became evident that the GRU model consistently outperformed the other models, showcasing its remarkable predictive capabilities. The GRU model achieved the lowest values for the key performance metrics. The GRU model attained the lowest MAE, indicating its minimal prediction errors. Furthermore, it exhibited the lowest MSE, signifying its superior precision in prediction. The MAPE metric, which measured prediction accuracy in terms of percentage, was also the lowest for the GRU model, underscoring its reliability in forecasting. Finally, the RMSE value, which represented the standard deviation of prediction errors, was the smallest for the GRU model, reaffirming its consistency and accuracy. Hence, based on the results presented in
Table 7, the GRU model emerged as the optimal choice for predictive tasks within the training environment of scenario 3.
Table 8 provides a comprehensive assessment of the prediction accuracy for the four distinct models in scenario 3 (Test). The table details the key performance metrics, including MAE, MSE, MAPE, and RMSE, for each model tested in scenario 3. These metrics are crucial for evaluating predictive capabilities, with lower values indicating better prediction accuracy. Notably, the CNN-GRU model consistently outperformed the other models in all metrics. It achieved the lowest MAE, reflecting precise predictions with minimal absolute errors. The CNN-GRU model also recorded the lowest MSE, demonstrating exceptional accuracy in prediction tasks. Moreover, it exhibited the lowest MAPE, indicating reliable predictions that were closely aligned with the actual values, and it had the smallest RMSE, affirming its consistent and precise performance in forecasting outcomes. These metrics collectively highlight the CNN-GRU model’s superior predictive capabilities compared to those of the other models across all evaluated criteria.
Figure 11 visually presents the predictive performance of various deep learning models, including LSTM, GRU, CNN with LSTM (CNN-LSTM), and CNN with GRU (CNN-GRU), in predicting the discharge capacity in Ampere-hours (Ah) over multiple cycles, as observed in scenario 3. The x-axis represents the cycle number, which reflects the temporal progression of the data. The y-axis displays the discharge capacity (Ah) values. The figure includes several lines: a blue line (LSTM-prediction) for the LSTM model’s predictions, a green line (GRU-prediction) for the GRU model’s forecasts, a magenta line (CNN-LSTM-prediction) for predictions from the CNN-LSTM model, and a cyan line (CNN-GRU-prediction) for predictions from the CNN-GRU model. The black line labeled ’True’ represents the actual observed discharge capacity values.
Table 9 comprehensively compares various RUL prediction models for LIBs. The table assesses the performance of these models based on four key evaluation metrics. Notably, our proposed CNN-GRU hybrid model stands out, demonstrating exceptional performance with significantly lower values for MAE, MSE, MAPE, and RMSE compared to those of alternative models. This comprehensive evaluation highlights the remarkable accuracy of our CNN-GRU model in estimating LIBs’ RUL compared to other models. The success of the CNN-GRU model can be attributed to its effective feature extraction from diverse data sources, including V, I, T, and capacity. Additionally, the use of the GRU over LSTM and other recurrent networks enhances the model’s ability to capture long-term dependencies in sequential data. This superior performance establishes our hybrid model as the preferred choice for LIB RUL prediction.
5.3. Summary and Discussion
LIBs are pivotal in numerous sectors, including those of electric vehicles, the aerospace industry, and industrial production. Accurate RUL prediction for LIBs is essential for prolonging battery lifespan, ensuring equipment safety, maintaining operational stability, streamlining maintenance, and enhancing cost efficiency. Our study highlights the importance of selecting the right deep learning model that is tailored to specific training and testing scenarios. In our research, LSTM demonstrated effectiveness in scenario 1, while the GRU model excelled in scenario 2. However, the CNN-GRU model truly stood out in scenario 3. Furthermore, our study introduced an advanced prediction model based on the CNN-GRU architecture. This novel model significantly improved the accuracy of LIB life prediction, surpassing the performance of LSTM, GRU, and even the CNN-GRU model. These findings emphasize the potential for more precise and reliable battery life predictions, offering substantial benefits across various application domains. Our research underscores the critical role of model selection in deep-learning-based RUL prediction and demonstrates how tailored choices can optimize predictive outcomes for LIBs in diverse scenarios. The proposed CNN-GRU model, with its superior predictive capabilities, represents a promising advancement in this field. It excels at capturing long-term dependencies in sequential data, effectively adapts to various operational settings, and consistently outperforms other models in crucial evaluation metrics. These qualities collectively make it the preferred choice for industries seeking reliable and precise LIB management and maintenance strategies.
6. Conclusions and Future Work
This study presents the key perspectives, contributions, and most significant quantitative results from our research on predicting the RUL of LIBs. Our primary contribution lies in the introduction of an innovative hybrid deep learning model that seamlessly integrates CNN and GRU architectures. This model excels at extracting intricate features from diverse data sources, including V, I, T, and capacity, significantly enhancing prediction accuracy. The model’s architecture, which features parallel CNN layers that separately process individual input features, sets the stage for improved predictions. Furthermore, our model outperforms alternative models, including LSTM, GRU, and CNN-LSTM, with a specific focus on the CNN-GRU model. Rigorous evaluations across three scenarios confirmed the model’s efficacy, resulting in noteworthy reductions in key evaluation metrics, including the RMSE, MSE, MAE, and MAPE. In this study, our proposed method boasted an MAE of 0.041, MSE of 0.002, MAPE of 0.026, and RMSE of 0.048, indicating its high prediction accuracy and excellent performance compared to those of other methods. These results underscore the model’s superior predictive capabilities. In our future work, we will delve into the impact of temperature variations on battery RUL predictions. This research will involve conducting experiments at various operating temperatures to gain a better understanding of the battery’s performance under different environmental conditions. Additionally, we will focus on optimizing our methodology while ensuring efficiency. We will explore advanced optimization techniques to strike a balance between model accuracy and computational efficiency, ensuring that our predictions remain of a high quality without compromising processing time. Moreover, our research will emphasize the improvement of the model’s generalization capabilities. By addressing these areas in our future work, we aim to uphold our overarching goal of enhancing the safety and reliability of energy storage systems.
The table of abbreviations below shows the primary notations employed in the proposed approach.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}