3.3. Experimental Results
Table 3 provides the results of the baseline breast tumor detection models based on the Faster R-CNN, RetinaNet, YOLOv5, YOLOv7, and YOLOv8 architectures. These models were trained on a dataset that included horizontally flipped versions of the original DBT images.
Based on the results, it was observed that the Faster R-CNN architecture outperformed the other baseline models in the detection of breast lesions. This superiority was attributed to the region proposal network (RPN), which facilitated Faster R-CNN in generating Region of Interest (ROI) proposals more efficiently compared to other methods. Furthermore, RetinaNet demonstrated promising results, outperforming all YOLO-based breast tumor detection models across all evaluation metrics.
However, it is worth noting that the YOLO architectures possessed an advantage in terms of speed and simplicity, as they could directly predict both bounding boxes and class probabilities from entire breast DBT images in a single pass. In contrast, the RetinaNet architectures involved an additional step of classifying proposal regions before predicting the bounding boxes and class probabilities for each region. This additional step enhanced the precision of the RetinaNet architecture but also made it slower and more complex.
In summary, these findings suggest that the Faster R-CNN and RetinaNet object detection architectures may be better suited for DBT images, with Faster R-CNN showcasing top performance and RetinaNet offering enhanced precision despite increased complexity.
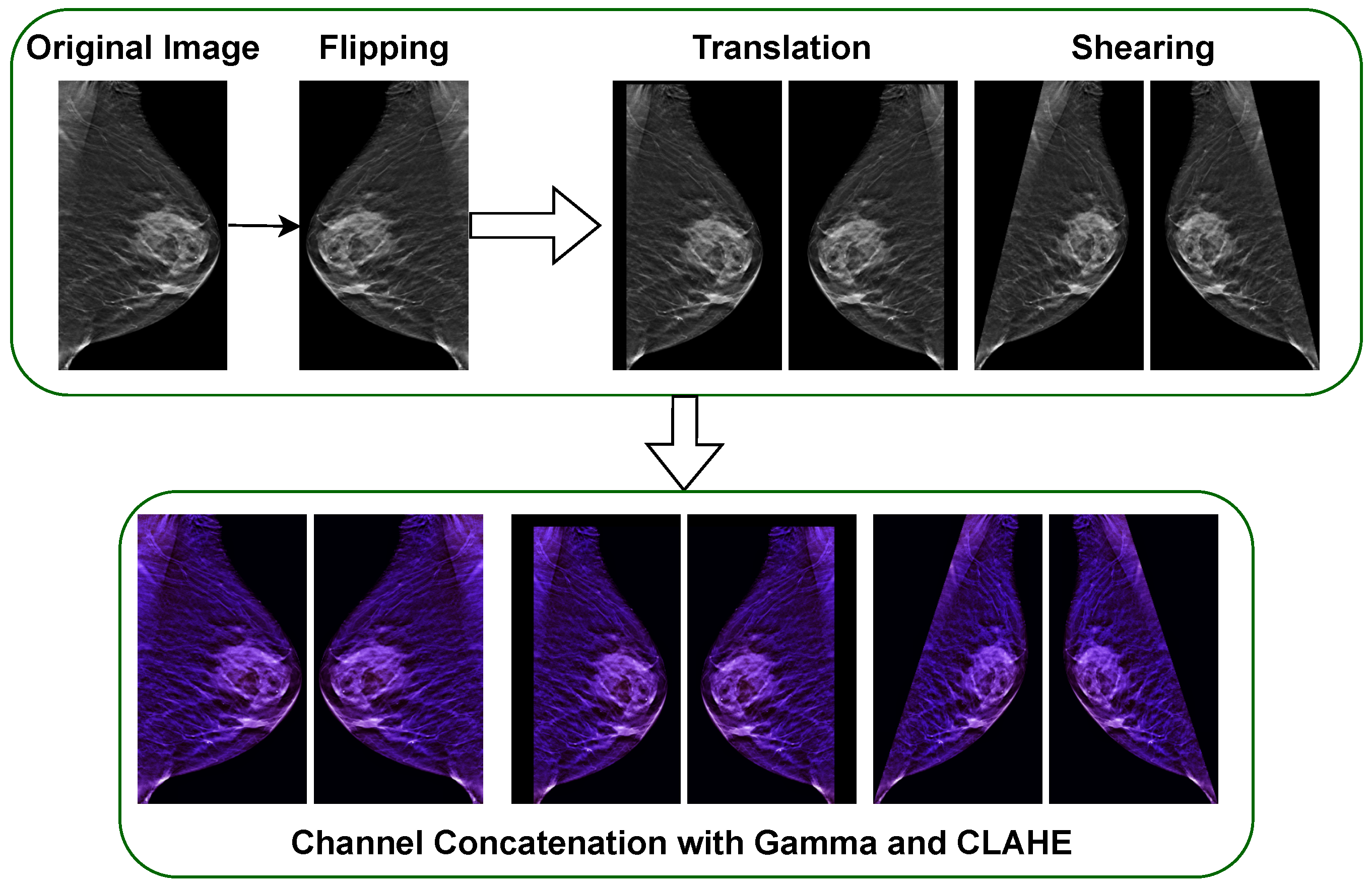
Table 4 tabulates the results of the breast tumor detection models based on the Faster R-CNN, RetinaNet, YOLOv5, and YOLOv7 architectures with the Ch-Rep data augmentation technique.
Comparing the values in
Table 4 to those in
Table 3, it can be concluded that utilizing the Ch-Rep training set for deep learning-based detectors can result in significant enhancements across all metrics for all the evaluated models. Specifically, the Faster R-CNN-based IBTD model demonstrated an increased detection accuracy of 3%, accompanied by notable improvements in precision, true positive rate (TPR), and F1-score, which rose by 6%, 3%, and 3%, respectively. Similarly, the RetinaNet-based IBTD model exhibited a remarkable 13% surge in detection accuracy, with its TPR experiencing a substantial boost of 34%. These improvements led to a notable 25% enhancement in F1-score by reducing the number of false negatives.
In contrast, the YOLO-based IBTD models achieved a lower detection accuracy, registering figures of 62.79%, 63.91%, and 60.74% for versions 5, 7, and 8, respectively. Nonetheless, they consistently outperformed their baseline models, indicating that an increase in the number of training samples can significantly enhance their detection performance.
Table 5 presents the results of the breast tumor detection models with the Ch-Conc data augmentation technique.
Upon examination of
Table 5 in conjunction with
Table 3 and
Table 4, it became evident that the Ch-Conc data augmentation method can outperform both the Ch-Rep data augmentation method and the baseline models, even with a smaller set of training samples. This serves as a clear indication that the proposed Ch-Conc data augmentation method enhances the quality of the generated DBT images by incorporating valuable features and information, ultimately leading to heightened detection accuracy.
For instance, the Faster R-CNN-based IBTD model achieved a detection accuracy that was 4% higher than that obtained using the Ch-Rep method and 7% superior to the baseline model. Furthermore, this model exhibited precision and recall rates of 93.75% and 70.31%, respectively, resulting in a substantial 8% improvement in the F1-score in comparison to the baseline.
Upon analyzing the RetinaNet-based IBTD model, it becomes evident that the detection accuracy has improved by 14% compared to the baseline model, surpassing the 13% increase achieved with the Ch-Rep data augmentation technique. Although the precision was slightly lower than that of the baseline IBTD models at 86.54%, the RetinaNet-based IBTD model achieved a notably higher true positive rate (TPR) at 70.31%. This led to a substantial improvement in the F1-score, which increased by 27% compared to the baseline model and by 2% compared to the Ch-Rep method.
Transitioning to the YOLO-based IBTD models, it is apparent that the YOLOv5-based IBTD model has achieved an increased accuracy of 68.18%, which is 6% higher than the accuracy obtained using the Ch-Rep data augmentation technique. The YOLOv5-based IBTD model has also exhibited improvements in TPR and F1-score. In addition, YOLOv8 demonstrated better accuracy with a 4% and 8% increase compared to the baseline and Ch-Rep, respectively, while showing improvements in both TPR and F1-score.
However, the YOLOv7-based IBTD model outperformed the baseline model but achieved lower performance than the Ch-Rep data augmentation technique. This indicates that the number of training samples significantly impacts the performance of the YOLOv7-based IBTD model.
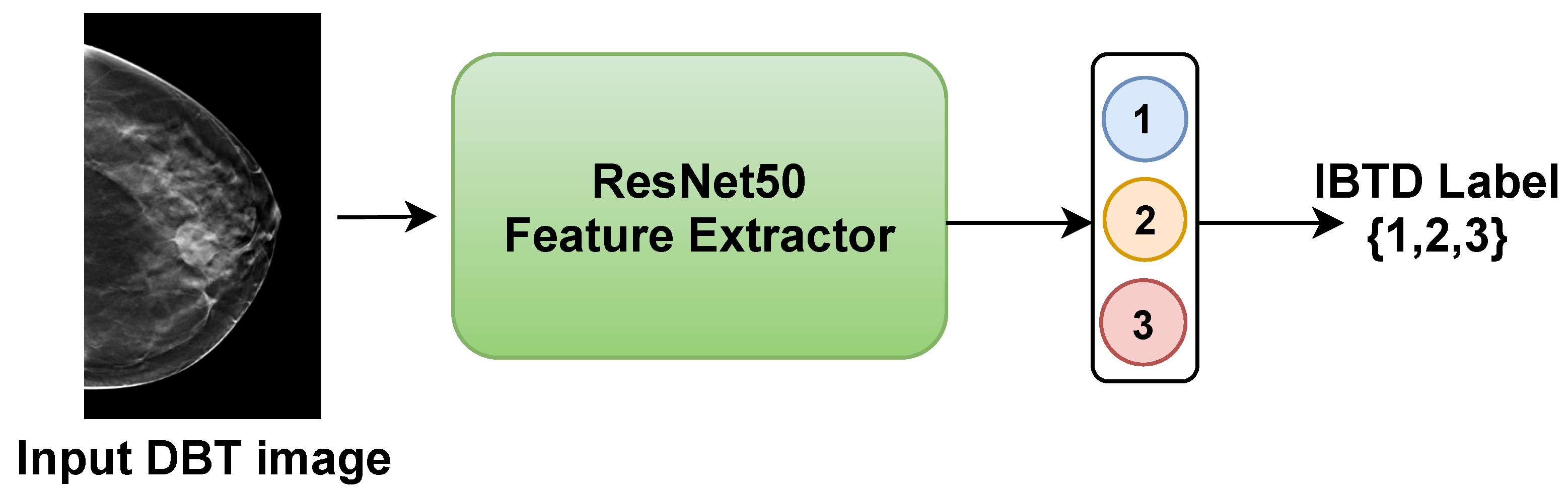
Based on the analysis above, it can be inferred that the utilization of the Ch-Conc augmentation technique can result in significant improvements in breast lesion detection compared to Ch-Rep. Furthermore, the IBTD models based on the Faster R-CNN, RetinaNet, and YOLOv5 object detection architectures exhibited promising detection accuracy. Therefore, we chose these models to construct the proposed ensemble.
Figure 8 presents the visual representation of the detection models trained using the Ch-Conc approach with the Grad-CAM technique. The image is highlighted in red for pixels that highly contribute to detecting tumors and blue for pixels with minimal impact on the detector’s decisions. The fifth column displays the most accurate detection outcomes, with the Faster-RCNN-based IBTD model output box highlighted in red, the RetinaNet-based IBTD model output box in green, and the YOLOv5-based IBTD model output box in yellow.
For the DBT image in the top row, which shows a small tumor situated at the left edge of the image, the Faster R-CNN-based IBTD model exhibits an appropriate activation response, whereas the RetinaNet-based IBTD and YOLOv5-based IBTD fail to detect the tumor accurately. In the second row, the RetinaNet-based IBTD model successfully detects a tumor with an irregular shape, whereas the Faster R-CNN-based IBTD model produces a false positive response covering a large area, and YOLOv5-based IBTD fails to detect the tumor at all. Finally, in the third row, with a large and circular tumor, only the YOLOv5-based IBTD detector produces an accurate activation for the tumor, while RetinaNet-based IBTD fails entirely and Faster R-CNN yields false positive results.
After carefully examining the results of the various IBTD detectors, we found that each one excels at identifying tumors with well-defined boundaries. However, when it comes to detecting tumors with fuzzy borders and low contrast, some detectors could not identify them accurately. Therefore, ensembling these individual IBTD detectors is a powerful technique in order to obtain better detection results by taking advantage of the excellence of each detector.
Table 6 presents the breast tumor detection results of the proposed ensemble method compared to the two most common object detection ensemble methods, including non-maximum suppression (NMS) [
20] and weighted boxes fusion (WBF) [
21].
The NMS technique [
20] is a post-processing technique commonly used in object detection tasks to eliminate duplicate or redundant bounding boxes generated by the detection model. In an ensemble setting, NMS can be applied to merge the output of multiple object detection models into a final set of non-overlapping bounding boxes. This was achieved by first sorting the bounding boxes according to their detection confidence scores, then iterating through the boxes in decreasing order of confidence and discarding any boxes that have an intersection-over-union (IoU) overlap greater than a predefined threshold with higher-scoring boxes. The Weighted Box Fusion (WBF) ensemble technique [
21] is a popular post-processing technique used in object detection tasks to combine the outputs of multiple detection models into a final set of non-overlapping bounding boxes. Unlike NMS, which simply selects the highest-scoring box and discards the rest, WBF assigns weights to each box based on its detection confidence and its intersection-over-union (IoU) overlap with other boxes. The final box for each object is then computed as a weighted average of the individual boxes, with the weights proportional to the product of their confidence and their IoU overlaps. WBF has been shown to be effective in reducing false positives and increasing the recall of object detection models, especially in cases where individual models have different strengths and weaknesses. However, it requires more computational resources than NMS and may be less suitable for real-time applications.
After analyzing the experimental results, we found that using ensemble methods led to a slight improvement in accuracy of around 1–3% compared to the top-performing individual models. However, our proposed method outperformed the other techniques and achieved an impressive accuracy of 86.72%. Additionally, our approach achieved an F1 score of 84.96%, indicating that it can accurately detect breast tumors with minimal false positive and false negative samples. This significant performance improvement resulted in a 5% increase in the F1 score compared to the best individual detector.
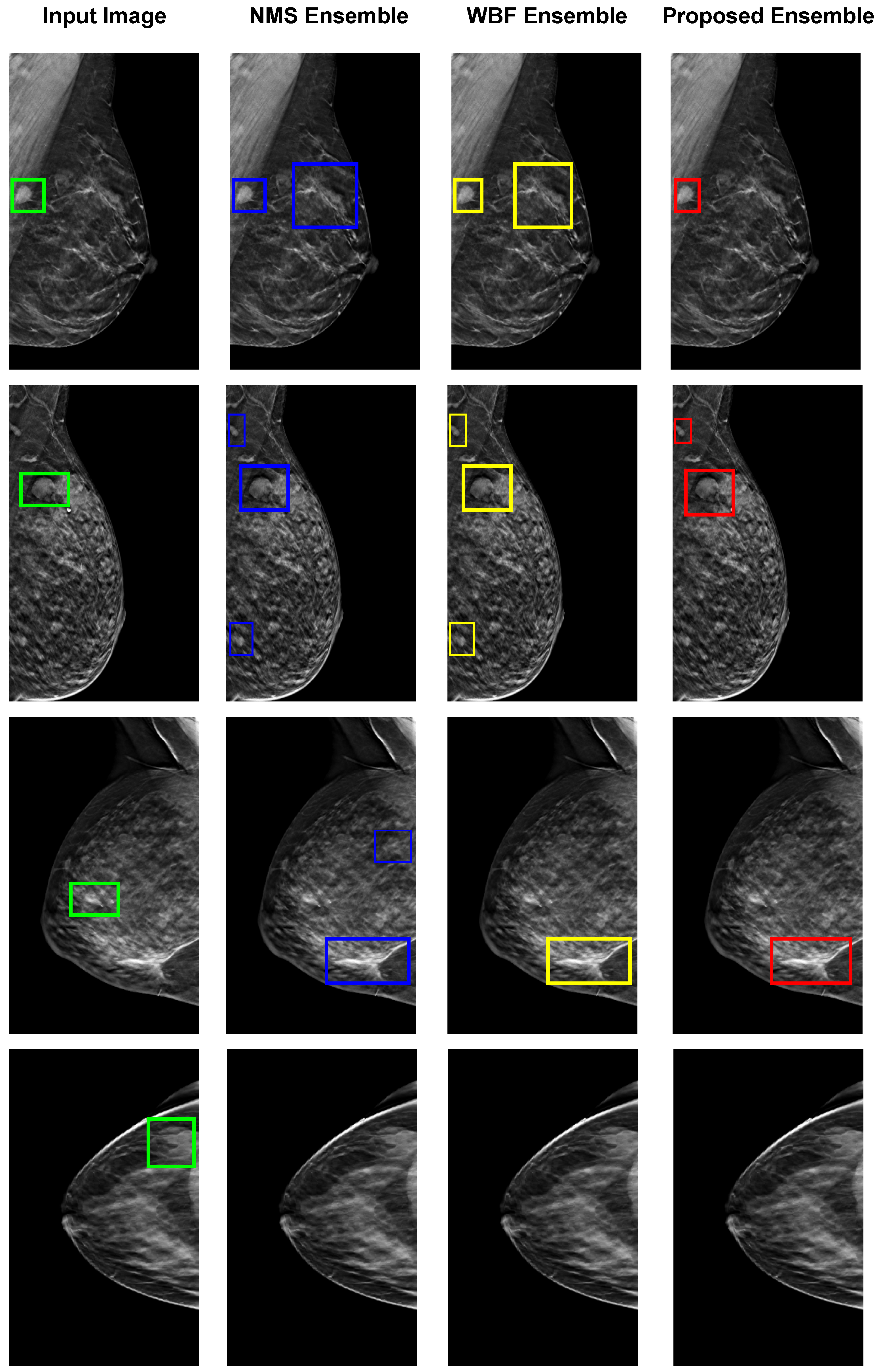
Figure 9 illustrates the four examples of images of breast tumor detection using different ensemble methods, including NMS, WBF, and the proposed ensemble. The top row demonstrates that the proposed ensemble method only accurately detects the tumor with dense, bright tissue region compared to the given input images. However, the other ensemble NMS and WBF methods produce false positives by detecting the fuzzy boundaries of healthy tissues. The proposed ensemble method is effective in such cases, relying on the best detection model for each input image. The second and third rows show false positive results from all individual models, which affect both NMS and WBF methods, but the proposed ensemble has minimal false positives. In the last rows, none of the individual detection models produce correct detections, resulting in no outputs from the ensemble methods. The proposed technique shows some limitations for these specific cases but is performed better than the others.
3.4. Analyzing the Complexity of the Proposed Method
The proposed ensemble approach not only excels in detection accuracy but also boasts a competitive edge in terms of computational complexity when juxtaposed with alternative ensemble methods. In the case of NMS and WBF ensemble strategies, the generation of tumor bounding boxes necessitates the activation of all individual detection models (IBTDs) before constructing the ensemble outcome. To elucidate, all three IBTD models must be executed to procure bounding boxes, which are subsequently subjected to NMS and WBF for ensemble formation, culminating in the final breast tumor detection outcome. Contrary to existing ensemble techniques such as NMS and WBF, our proposed ensemble mechanism distinguishes itself by selecting a singular IBTD model for tumor bounding box generation with every input DBT image. Consequently, the throughput of our approach surpasses that of the other evaluated methods.
Importantly, the computational complexity of the ensemble breast tumor detection model escalates with the augmentation of parameters within individual breast tumor detection models. Within our study, individual models founded on Faster-RCNN, RetinaNet, and YOLO deep learning architectures encompass 43 million, 36 million, and 7 million parameters, respectively. Employing NMS and WBF entails the simultaneous operation of Faster-RCNN, RetinaNet, and YOLO tumor detection models, leading to a cumulative computational complexity approximating the summation of the three models’ parameters—equivalent to 86 million parameters.
In contrast, our proposed ensemble technique requires the activation of only one among Faster-RCNN, RetinaNet, and YOLO tumor detection models, along with the parameters of ResNet50 (24 million parameters). In the optimal scenario for a given DBT image, our ensemble opts for the YOLO-based tumor detection model, resulting in a computational complexity totaling 31 million parameters. In a less favorable case, our ensemble selects the Faster-RCNN-based tumor detection model (the most resource-intensive), contributing to a total computational complexity of 67 million parameters.
3.5. Evaluating the Proposed Method on the Breast Mammography Modality
To further corroborate the efficacy of the proposed ensemble approach, we conducted evaluations using another breast imaging modality, namely breast mammography. Our assessment focused on the performance of the proposed method using the INbreast dataset [
28]. It contains a total of 410 images from 115 women. It is a valuable resource for research that focuses on mammogram images for breast cancer detection and diagnosis and has been used in several studies to develop and evaluate new methods for breast cancer imaging, including computer-aided detection (CAD) systems.
Table 7 presents the evaluation results of the individual baseline models based on Faster-RCNN, RetinaNet, and YOLOv5, the ensemble methods (NMS and WBF), and the proposed ensemble method for the INbreast dataset.
The proposed ensemble technique exhibited marked superiority over all examined ensemble methods, thereby elevating detection accuracy beyond the capabilities of baseline models. It is noteworthy that conventional ensemble methods (NMS and WBF) proved incapable of augmenting detection performance due to the adverse impact of false positives from individual models on the final ensemble outcomes. However, our ensemble approach outperformed these conventional methods, highlighting the efficacy of model selection tailored to each input DBT image. Our ensemble method achieved an accuracy of 88.64%, surpassing the top-performing RetinaNet model (best baseline) by a margin of two percentage points. Additionally, it attained an f1-score of 87.81%, marking a remarkable 12% advancement over the WBF ensemble technique.
One of the limitations of this study is the reliance on the DBTex challenge dataset, the only publicly accessible database for Digital Breast Tomosynthesis (DBT) images, which poses constraints on the model’s generalizability due to its relatively limited size and diversity. In addition, the quality of annotations within the dataset could influence the model’s performance, yet details about the annotation process, such as inter-rater reliability and quality control measures, are not provided.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}