
Distributed Representation for Assembly Code



Abstract
:1. Introduction
2. Related Works
2.1. Representation Learning Model for Assembly Code
2.1.1. Edge Coverage
2.1.2. Random Walks
- RP: A repository containing the assembly functions;
- : Set of sequences generated from the function in the repository RP;
- : Set of instructions contained in the i-th sequence of function ;
- : Set of tokens (operands and opcodes) contained in the j-th instruction of the sequence ;
- : Opcode of instruction ;
- : Set of operands in instruction ;
- : Current target token in instruction .
3. Proposed Method
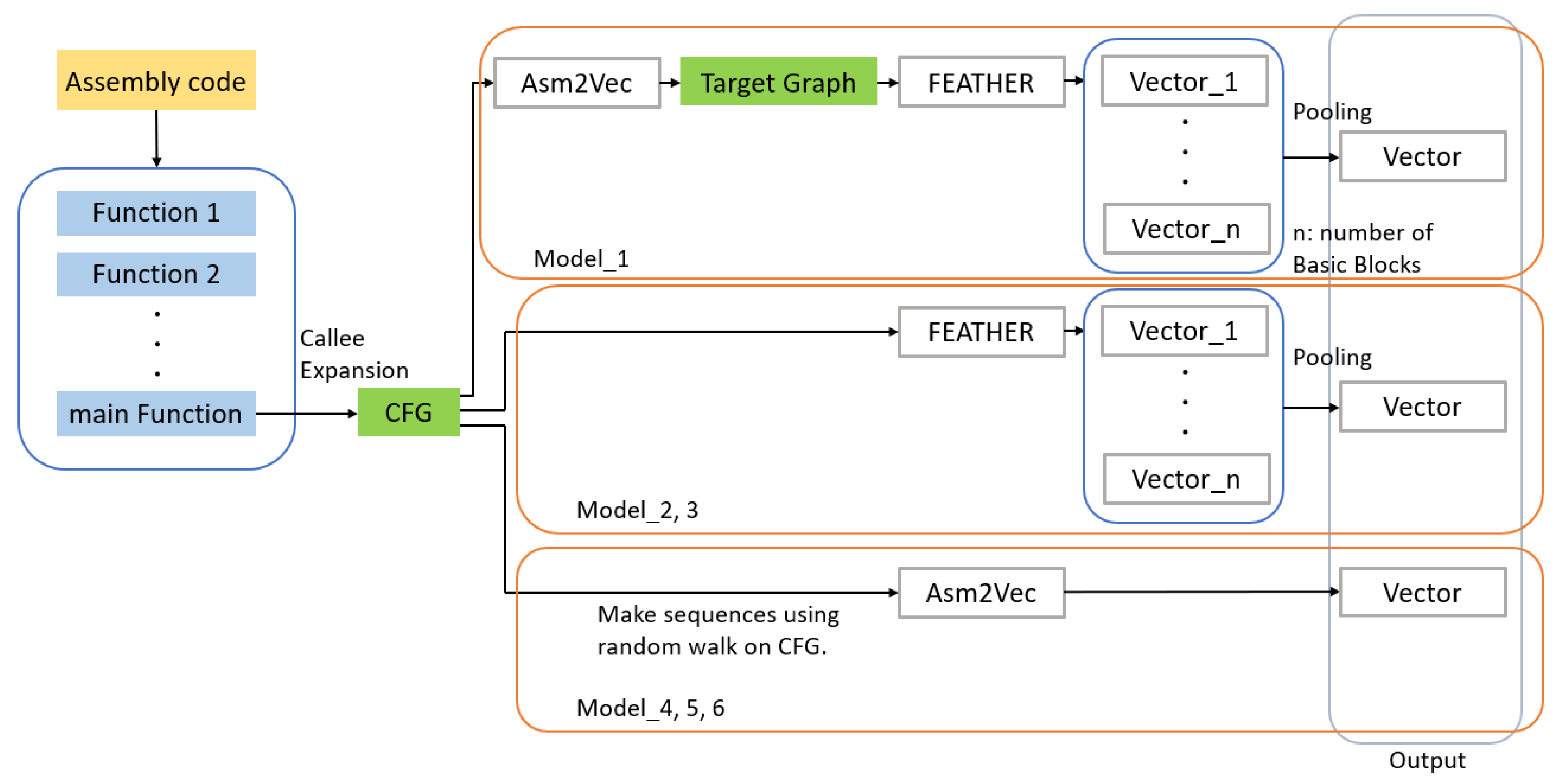
3.1. Overview
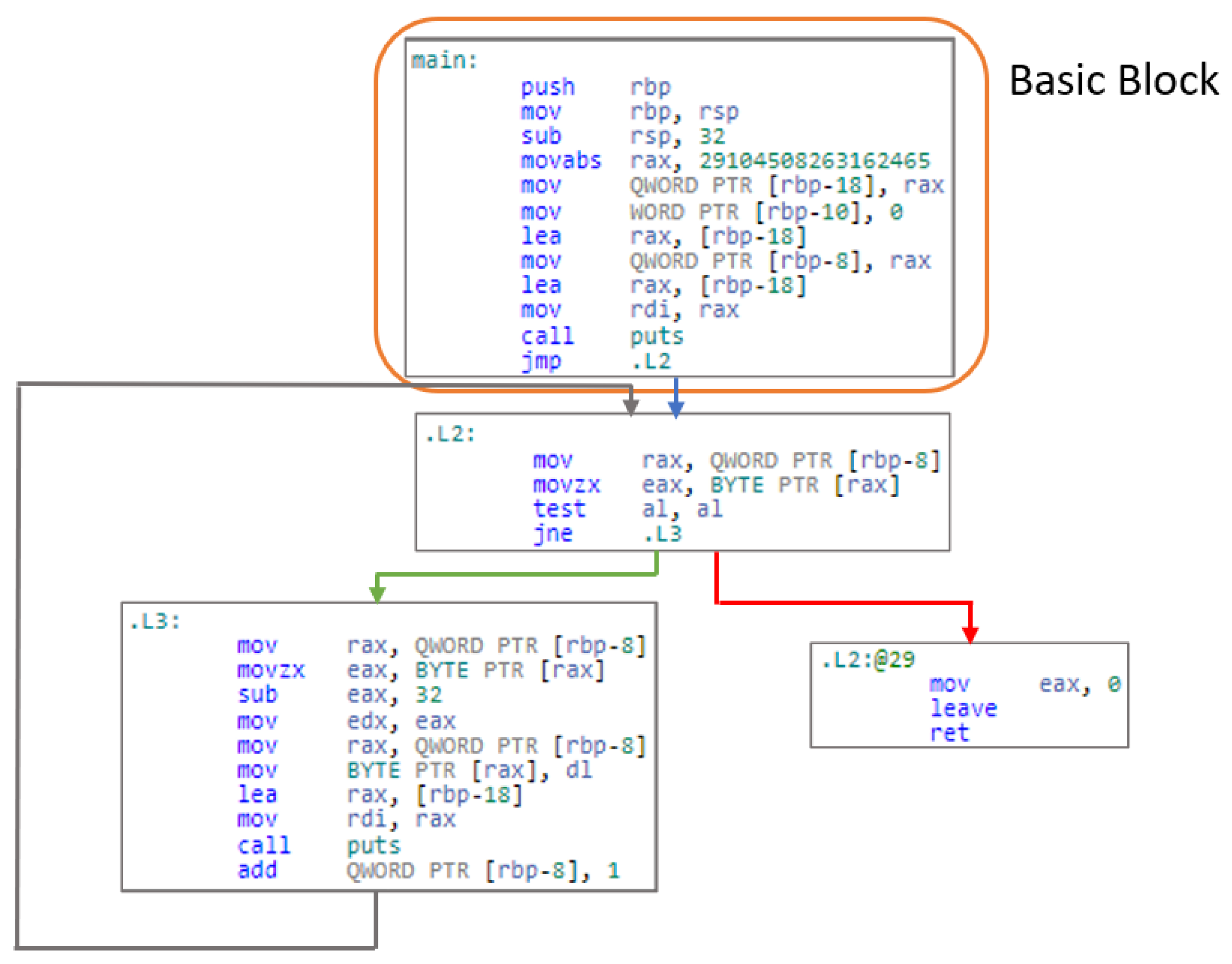
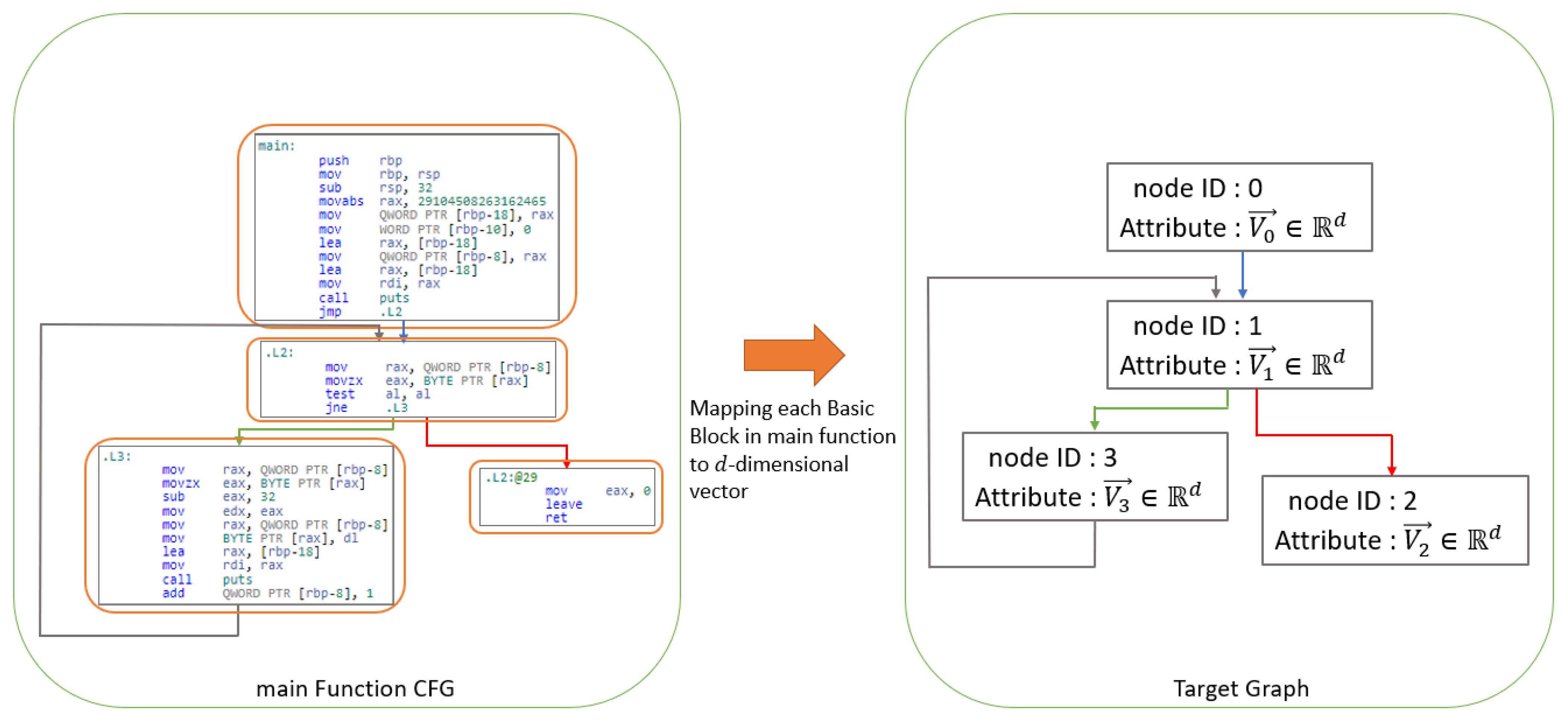
3.2. Generate Target Graph
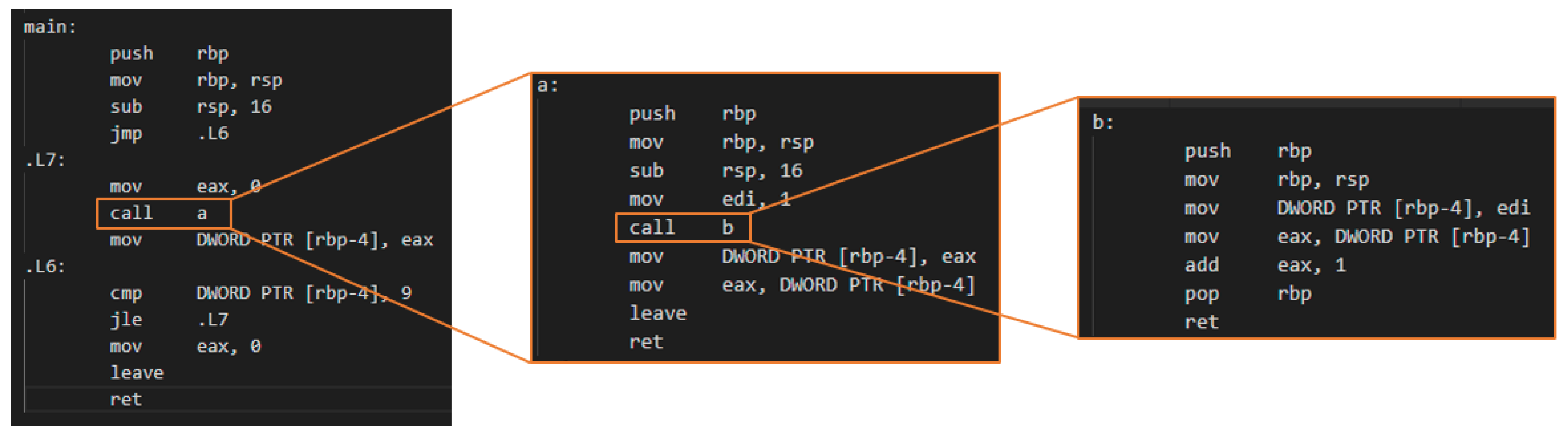
3.2.1. Function Call Expansion of Main Routine (Main Function)
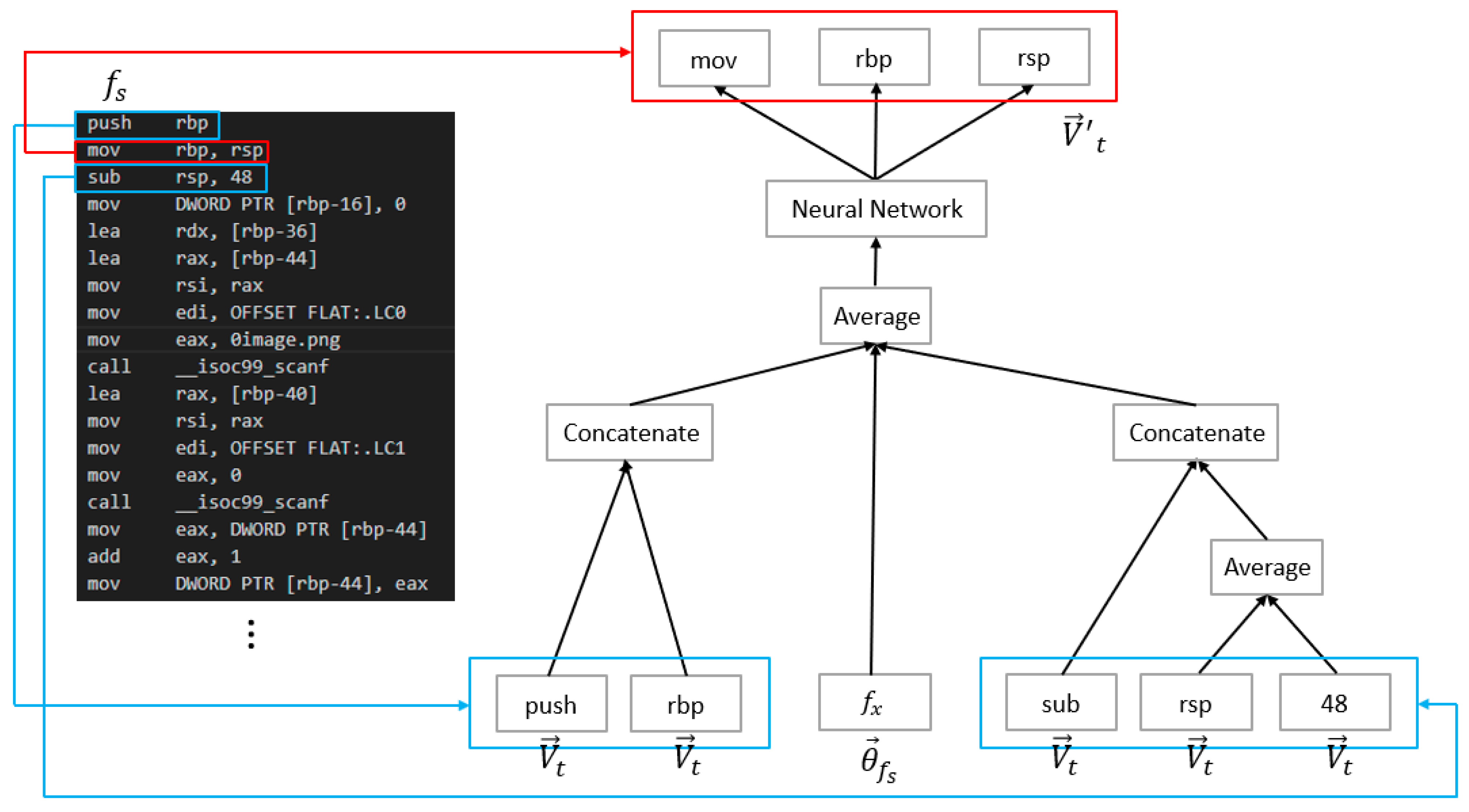
3.2.2. Vector Representation of Each Basic Block of the Main Function
3.3. Graph Embedding Methods
3.3.1. FEATHER
- It is possible to embed three types of information into the hybrid: neighbor node information, structural roles, and node attributes (metadata possessed by the nodes);
- The resulting vector representation of each node can be used as a representation of the entire graph by pooling it with a permutation-invariant function.
3.3.2. Characteristic Functions and Node-Embedding on Graphs in FEATHER
- The real part is an even function and the imaginary part is a radix;
- The range of both parts is ;
- Nodes with different structural roles have different characteristic functions.
- 1.
- Initialize the real part and imaginary part of the embedding (lines 1 and 2);
- 2.
- Repeat for each of the k different node features on a scale up to r (lines 3 and 4);
- 3.
- At the first scale, compute the outer product of the feature under consideration and the corresponding evaluation point vectors (lines 6 and 7);
- 4.
- Take the cosine and sine of (lines 8 and 9);
- 5.
- Using the normalized adjacency matrix, compute the real part and imaginary part of the characteristic function evaluation (lines 10 and 11);
- 6.
- Add matrices to the real and imaginary parts of the embedding (lines 12 and 13);
- 7.
- Once the characteristic function of each feature is evaluated for each scale, concatenate and return the real and imaginary parts of the embedding (lines 14 and 15).
| Algorithm 1: Node-embedding algorithm on FEATHER. |
 |
3.3.3. Pooling of Each Node
4. Experiment and Results
4.1. Experiment Overview
4.2. Experimental Data Sets
- One capital alphabet etter to indicate the solution creator;
- Issue no.;
- Sequential numbers for multiple solutions;
- File extension (.s).
4.3. Used Models
- 1.
- Model_1
- Embedded target: CFG with node attributes;Each node has the following node features:
- Node neighborhood: Normalized adjacent matrix;
- Structural information: Logarithmic transformation of the order of each node and clustering coefficients;
- Node attribute: 400-dimensional (each token: 200 dimensions) representation vector obtained from the corresponding basic block using Asm2Vec (Reduced to 16 dimensions using the Python ibrary Scikit-Learn’s Truncated SVD [27]).
- Embedding method: Pooling on the arithmetic mean after each node embedding using FEATHER;
- Embedded dimension: 4000-dimensional;
- Number of evaluation points : 25;
- Scale of random walk r: 5.
- 2.
- Model_2
- Embedded target: CFG without node attribute;Each node has the following node features:
- Node neighborhood: Normalized adjacent matrix;
- Structural information: Logarithmic transformation of the order of each node and clustering coefficients.
- Embedding method: Pooling on the arithmetic mean after each node embedding using FEATHER;
- Embedded dimension: 500-dimensional;
- Number of evaluation points : 25;
- Scale of random walk r: 5.
- 3.
- Model_3
- Embedded target: CFG without node attribute;Each node has the following node features:
- Node neighborhood: Normalized adjacent matrix;
- Structural information: Logarithmic transformation of the order of each node and clustering coefficients.
- Embedding method: Pooling on the arithmetic mean after each node embedding using FEATHER;
- Embedded dimension: 4000-dimensional;
- Number of evaluation points : 25;
- Scale of random walk r: 40.
- 4.
- Model_4
- Embedded target: Assembly Code;
- Embedding Method: Asm2Vec;
- Embedded dimension: 500-dimensional(each token: 250-dimensional);
- Number of random walks n: 10.
- 5.
- Model_5
- Embedded target: Assembly Code;
- Embedding Method: Asm2Vec;
- Embedded dimension: 4000-dimensional(each token: 2000-dimensional);
- Number of random walks n: 10.
- 6.
- Model_6
- Embedded target: Assembly Code;
- Embedding Method: Asm2Vec;
- Embedded dimension: 500-dimensional (each token: 250-dimensional);
- Number of random walks n: 50.
- : Order of u;
- : Number of triangles formed by connecting u and the edges of adjacent nodes
4.4. Evaluation Index
4.4.1. Precision Measure and Recall Measure
- : Number of pairs of elements with the same abel that are classified into the same cluster as a result of clustering;
- : Number of pairs of elements with different abels that are classified into the same cluster as a result of clustering;
- : Number of pairs of elements with the same abel that are classified into different clusters as a result of clustering.
4.4.2. Normalized Mutual Information
4.4.3. Execution Time
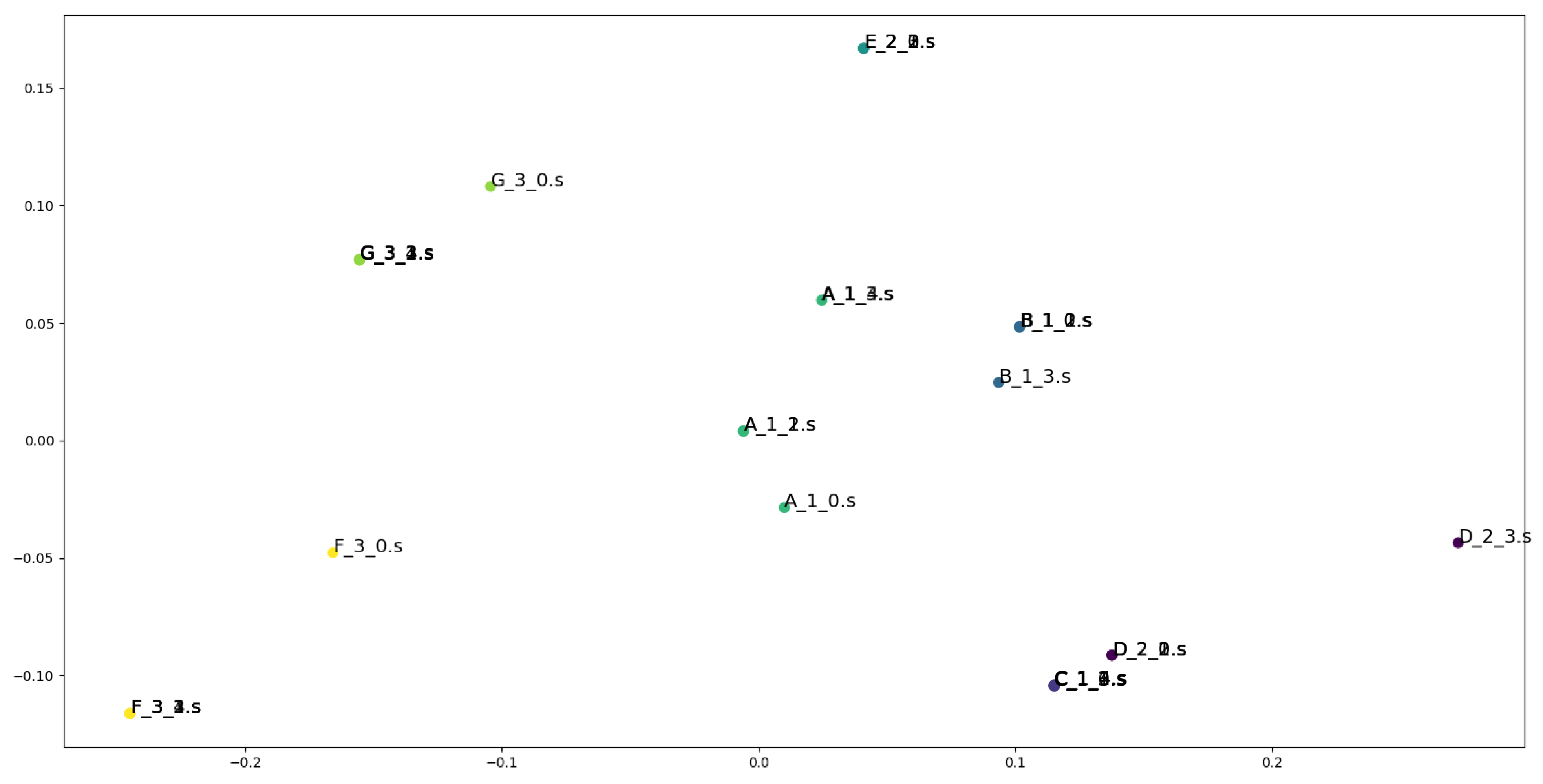
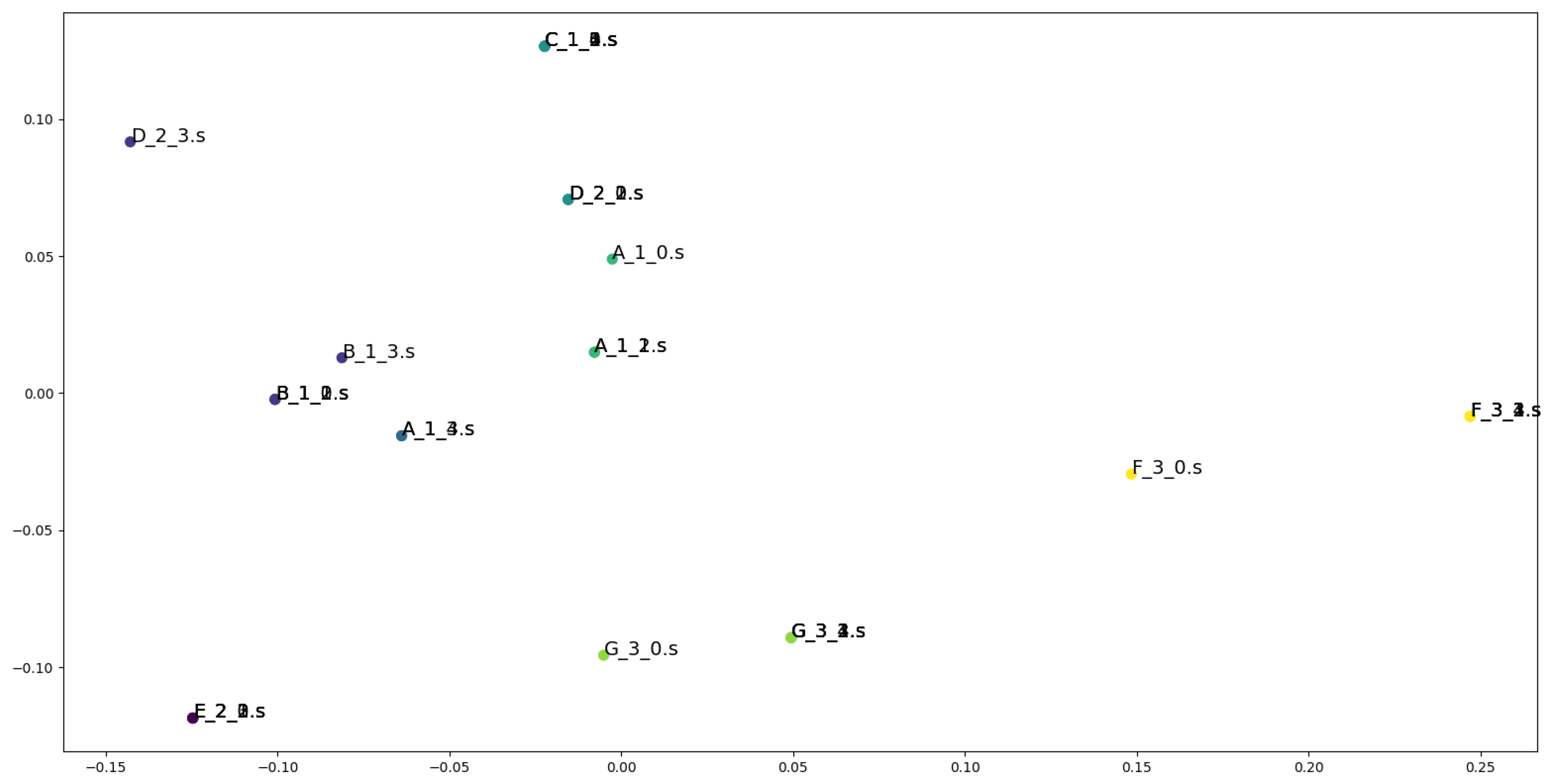
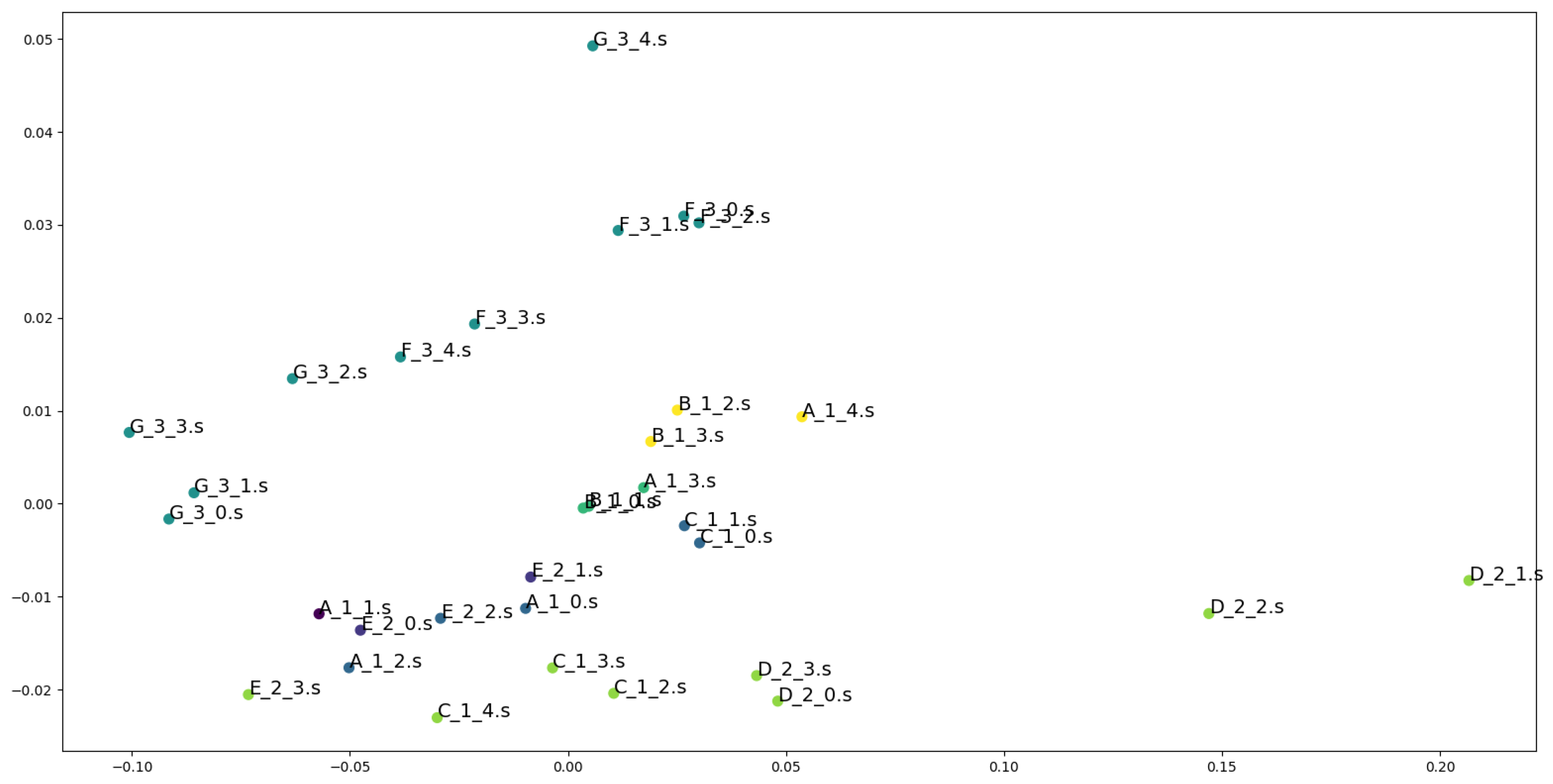
4.5. Results of the Experiments
5. Evaluation and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- M-Trends Report. 2020. Available online: https://www.mandiant.com/sites/default/files/2021-09/mtrends-2020.pdf (accessed on 24 March 2023).
- Yuta, T.; Terada, M.; Matsuki, T.; Kasama, T.; Araki, S.; Hatada, M. Datasets for Anti-Malware Research. SIG Tech. Rep. 2018, 38, 1–8. [Google Scholar]
- Yamamoto, T.; Matsushita, M.; Kamiya, T.; Inoue, K. Similarity Metric CSR Using Code Clone Detection Tool. Softw. Sci. 2001, 101, 25–32. [Google Scholar]
- Okahara, S.; Manabe, Y.; Yamauchi, H.; Monden, A.; Matsumoto, K.; Inoue, K. Experimentally Deriving Probability of Program Piracy based on Length of Code Clone. IEICE Tech. Rep. 2008, 108, 7–11. [Google Scholar]
- Basit, H.A.; Puglisi, S.J.; Smyth, W.F.; Turpin, A. Efficient token based clone detection with flexible tokenization. In Proceedings of the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT International Symposium on Foundations of Software Engineering, Dubrovnik, Croatia, 3–7 September 2007; pp. 513–516. [Google Scholar]
- Selim, G.m.k.; Foo, K.C.; Zou, Y. Enhancing Source-Based Clone Detection Using Intermediate Representation. In Proceedings of the 17th Working Conference on Reverse Engineering, Beverly, MA, USA, 13–16 October 2010; pp. 227–236. [Google Scholar]
- Gode, N.; Koschke, R. Incremental Clone Detection. In Proceedings of the 13th European Conference on Software Maintenance and Reengineering, Kaiserslautern, Germany, 24–27 March 2009; pp. 219–228. [Google Scholar]
- Hummel, B.; Jürgens, E.; Heinemann, L.; Conradt, M. Index-based code clone detection: Incremental, distributed, scalable. In Proceedings of the 26th IEEE International Conference on Software Maintenance, Timisoara, Romania, 12–18 September 2010; pp. 1–9. [Google Scholar]
- Chilowicz, M.; Duris, É.; Roussel, G. Syntax tree finger printing for source code similarity detection. In Proceedings of the 17th IEEE International Conference on Program Comprehension, Vancouver, BC, Canada, 17–19 May 2009; pp. 243–247. [Google Scholar]
- Iwamura, M.; Itoh, M.; Muraoka, Y. Automatic malware classification system based on similarity of machine code instructions. Inf. Process. Soc. Jpn. 2010, 51, 1–11. [Google Scholar]
- Flake, H. Structural Comparison of Executable Objects. In Proceedings of the Detection of Intrusions and Malware and Vulnerability Assessment (DIMVA 2004), Dortmund, Germany, 6–7 July 2004; pp. 161–173. [Google Scholar]
- Kornblum, J. Identifying almost identical files using context triggered piecewise hashing. Digit. Investig. 2006, 3, 91–97. [Google Scholar] [CrossRef]
- Roussev, V.; Quates, C. Content triage with similarity digests: The M57 case study. Digit. Investig. 2012, 9, S60–S68. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NA, USA, 5–10 December 2013. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences anddocuments. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. code2vec: Learning Distributed Representations of Code. Proc. ACM Program. Lang. 2018, 3, 1–29. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online earning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature earning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Nowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Ahmed, N.K.; Rossi, R.; Lee, J.B.; Willke, T.L.; Zhou, R.; Kong, X.; Eldardiry, H. Learning role-based graph embeddings. arXiv 2018, arXiv:1802.02896. [Google Scholar]
- Liao, L.; He, X.; Zhang, H.; Chua, T. Attributed social network embedding. IEEE Trans. Knowl. Data Eng. 2018, 30, 2257–2270. [Google Scholar] [CrossRef]
- Narayanan, A.; Chandramohan, M.; Venkatesan, R.; Chen, L.; Liu, Y.; Jaiswal, S. graph2vec: Learning Distributed Representations of Graphs. arXiv 2017, arXiv:1707.05005. [Google Scholar]
- Ding, S.H.H.; Fung, B.C.M.; Charland, P. Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 19–23 May 2019. [Google Scholar]
- Rozemberczki, B.; Sarkar, R. Characteristic Functions on Graphs: Birds of a Feather, from Statistical Descriptors to Parametric Models. In Proceedings of the CIKM ’20: Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 1325–1334. [Google Scholar]
- DasGupta, A. Characteristic functions and applications. In Probability for Statistics and Machine Learning; Springer: New York, NY, USA, 2011; pp. 292–322. [Google Scholar]
- Kyopuro Tenkei 90 Mon. Available online: https://atcoder.jp/contests/typical90 (accessed on 24 March 2023).
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Halko, N.; Martinsson, P.-G.; Tropp, J.A. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. Siam Rev. 2011, 53, 217–288. [Google Scholar] [CrossRef]
- Banerjee, A.; Krumpelman, C.; Ghosh, J.; Basu, S.; Mooney, R.J. Model-based overlapping clustering. In Proceedings of the KDD ’05: Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 532–537. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A_1_0.s | B_1_0.s | C_1_0.s | D_2_0.s | E_2_0.s | F_3_0.s | G_3_0.s | |
|---|---|---|---|---|---|---|---|
| A_1_0.s | 1.0 | 0.59 | 0.71 | 0.65 | 0.56 | 0.66 | 0.64 |
| A_1_1.s | 0.95 | 0.60 | 0.71 | 0.65 | 0.57 | 0.66 | 0.63 |
| A_1_2.s | 0.93 | 0.60 | 0.71 | 0.65 | 0.57 | 0.66 | 0.63 |
| A_1_3.s | 0.86 | 0.59 | 0.73 | 0.64 | 0.50 | 0.65 | 0.65 |
| A_1_4.s | 0.85 | 0.59 | 0.74 | 0.64 | 0.50 | 0.65 | 0.65 |
| B_1_0.s | 0.59 | 1.0 | 0.58 | 0.60 | 0.51 | 0.56 | 0.55 |
| B_1_1.s | 0.59 | 1.0 | 0.58 | 0.60 | 0.51 | 0.56 | 0.55 |
| B_1_2.s | 0.57 | 0.92 | 0.56 | 0.58 | 0.48 | 0.56 | 0.53 |
| B_1_3.s | 0.57 | 0.88 | 0.55 | 0.57 | 0.49 | 0.53 | 0.53 |
| C_1_0.s | 0.71 | 0.58 | 1.0 | 0.66 | 0.49 | 0.64 | 0.64 |
| C_1_1.s | 0.70 | 0.58 | 0.99 | 0.66 | 0.49 | 0.64 | 0.64 |
| C_1_2.s | 0.72 | 0.58 | 0.98 | 0.66 | 0.50 | 0.64 | 0.64 |
| C_1_3.s | 0.71 | 0.57 | 0.96 | 0.65 | 0.49 | 0.63 | 0.63 |
| C_1_4.s | 0.72 | 0.58 | 0.98 | 0.66 | 0.51 | 0.65 | 0.64 |
| D_2_0.s | 0.65 | 0.60 | 0.66 | 1.0 | 0.50 | 0.61 | 0.61 |
| D_2_1.s | 0.65 | 0.60 | 0.66 | 0.99 | 0.50 | 0.61 | 0.61 |
| D_2_2.s | 0.65 | 0.60 | 0.66 | 0.99 | 0.50 | 0.61 | 0.61 |
| D_2_3.s | 0.65 | 0.59 | 0.65 | 0.97 | 0.51 | 0.61 | 0.60 |
| E_2_0.s | 0.56 | 0.51 | 0.49 | 0.50 | 1.0 | 0.54 | 0.50 |
| E_2_1.s | 0.55 | 0.50 | 0.50 | 0.50 | 0.93 | 0.53 | 0.49 |
| E_2_2.s | 0.55 | 0.50 | 0.50 | 0.50 | 0.93 | 0.54 | 0.49 |
| E_2_3.s | 0.54 | 0.51 | 0.49 | 0.50 | 0.97 | 0.53 | 0.50 |
| F_3_0.s | 0.66 | 0.56 | 0.64 | 0.61 | 0.54 | 1.0 | 0.77 |
| F_3_1.s | 0.67 | 0.56 | 0.64 | 0.60 | 0.55 | 0.98 | 0.79 |
| F_3_2.s | 0.66 | 0.56 | 0.63 | 0.61 | 0.55 | 0.94 | 0.77 |
| F_3_3.s | 0.67 | 0.56 | 0.64 | 0.61 | 0.55 | 0.95 | 0.78 |
| F_3_4.s | 0.67 | 0.56 | 0.64 | 0.61 | 0.55 | 0.95 | 0.78 |
| G_3_0.s | 0.64 | 0.55 | 0.64 | 0.61 | 0.50 | 0.77 | 1.0 |
| G_3_1.s | 0.65 | 0.55 | 0.64 | 0.61 | 0.51 | 0.78 | 0.98 |
| G_3_2.s | 0.65 | 0.56 | 0.63 | 0.61 | 0.50 | 0.76 | 0.95 |
| G_3_3.s | 0.65 | 0.56 | 0.64 | 0.61 | 0.51 | 0.77 | 0.96 |
| G_3_4.s | 0.64 | 0.54 | 0.64 | 0.60 | 0.49 | 0.77 | 0.96 |
| Model_1 | Model_2 | Model_3 | |
|---|---|---|---|
| Embedded target | CFG with node attributes | CFG without node attribute | CFG without node attribute |
| Embedding method | FEATHER | FEATHER | FEATHER |
| Embedded dimension | 4000 | 500 | 4000 |
| Number of evaluation points | 25 | 25 | 25 |
| Scale of random walk | 5 | 5 | 40 |
| Model_4 | Model_5 | Model_6 | |
|---|---|---|---|
| Embedded target | Assembly Code | Assembly Code | Assembly Code |
| Embedding method | Asm2Vec | Asm2Vec | Asm2Vec |
| Embedded dimension | 500 | 4000 | 500 |
| Number of random walks | 10 | 10 | 50 |
| Model_1 | Model_2 | Model_3 | Model_4 | Model_5 | Model_6 | |
|---|---|---|---|---|---|---|
| Precision measure | 0.85 | 0.79 | 0.812 | 0.507 | 0.506 | 0.621 |
| Recall measure | 0.929 | 0.844 | 0.862 | 0.635 | 0.633 | 0.707 |
| Normalized Mutual Information | 0.954 | 0.895 | 0.929 | 0.657 | 0.673 | 0.785 |
| Execution time (s) | 35.239 | 0.0359 | 0.0657 | 153.044 | 462.574 | 774.089 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoshida, K.; Suzuki, K.; Matsuzawa, T. Distributed Representation for Assembly Code. Computers 2023, 12, 222. https://doi.org/10.3390/computers12110222
Yoshida K, Suzuki K, Matsuzawa T. Distributed Representation for Assembly Code. Computers. 2023; 12(11):222. https://doi.org/10.3390/computers12110222
Chicago/Turabian StyleYoshida, Kazuki, Kaiyu Suzuki, and Tomofumi Matsuzawa. 2023. "Distributed Representation for Assembly Code" Computers 12, no. 11: 222. https://doi.org/10.3390/computers12110222
APA StyleYoshida, K., Suzuki, K., & Matsuzawa, T. (2023). Distributed Representation for Assembly Code. Computers, 12(11), 222. https://doi.org/10.3390/computers12110222