
Requirement Change Prediction Model for Small Software Systems

 , , and
, , and
Abstract
:1. Introduction
- -
- Performing a detailed literature review and deriving the requirement variables that support the prediction model for acquiring the probability of changes.
- -
- Defining the core requirement variables with the consultation of experts and weighting techniques.
- -
- Developing a refined dataset with the help of a questionnaire. This questionnaire was given to stakeholders, developers, and experts to acquire their knowledge of the set of requirements.
- -
- Developing a prediction model in the Bayesian network with nodes and arcs to predict the probability of changes in software requirements. Nodes are the core variables with the conditional probabilities acquired by the dataset.
- -
- The proposed algorithm includes a variable elimination method for predicting requirement changes in the specification document. This algorithm takes the Bayesian network conditional probabilities as an input and provides the probability of revisions in the requirement document.
- -
- Evaluation of the proposed model by comparing it with the existing models in terms of the accuracy and validity of this model.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Variables | Description |
|---|---|---|
| Project/Estimation Group | Ambiguity | Sometimes the requirements are not understandable and provide double meanings that may cause changes [20]. |
| Cost and schedule | Project cost is the money needed to complete the project [21]. The schedule is the time allocated by the project managers for managing requirements [22]. | |
| Specificity | Specificity deals with the meanings of the requirement. It demonstrates that all of the people have the same interpretation of the requirement statement [23]. | |
| Quality | Requirement changes affect the quality. It is necessary to ensure that the system’s quality meets the standards [24]. | |
| Technological needs | Sometimes the consideration of new technology for the software development may cause changes [25]. | |
| Consistency | It describes that the requirements are presented in a detailed way and serve the intended purpose [26]. | |
| Dependencies | It interprets the unexpected relationships between requirements. The requirement may depend on another variable not specified in the requirements document [27]. | |
| Reusability | It interprets whether the particular requirement can be reused. If it is reused from repository, then the number of repetitions will be counted [28]. | |
| Management Group | Completeness | It describes that the requirement carry comprehensive meanings, and no information is left behind [23]. |
| Commitment | It interprets that requirement needs further communication for acceptance [29]. | |
| Developer skills | Developer skills play an important role in the timely completion of software. If the developers are skilled, then when changes occur during the development phase, they can easily manage them [30]. | |
| Variability | Requirement changes are natural processes and can occur at any project phase. These are necessary to manage because it affects the complete development process, cost, schedule design, and implementation [31]. | |
| Verification | When requirement changes occur, it is necessary to verify whether these changes reflect the intended purpose or not [32]. | |
| Expert knowledge | After a requirement change, experts are needed to decide on how the changes will be integrated into the system [33]. | |
| SRS document revisions | The SRS document provides an overall description of the system, its purpose, revisions, and its requirement specifications [34]. | |
| Stakeholder expertise | Requirement changes frequently occur due to the incompetentency of stakeholders because they provide the system’s requirements [35]. |
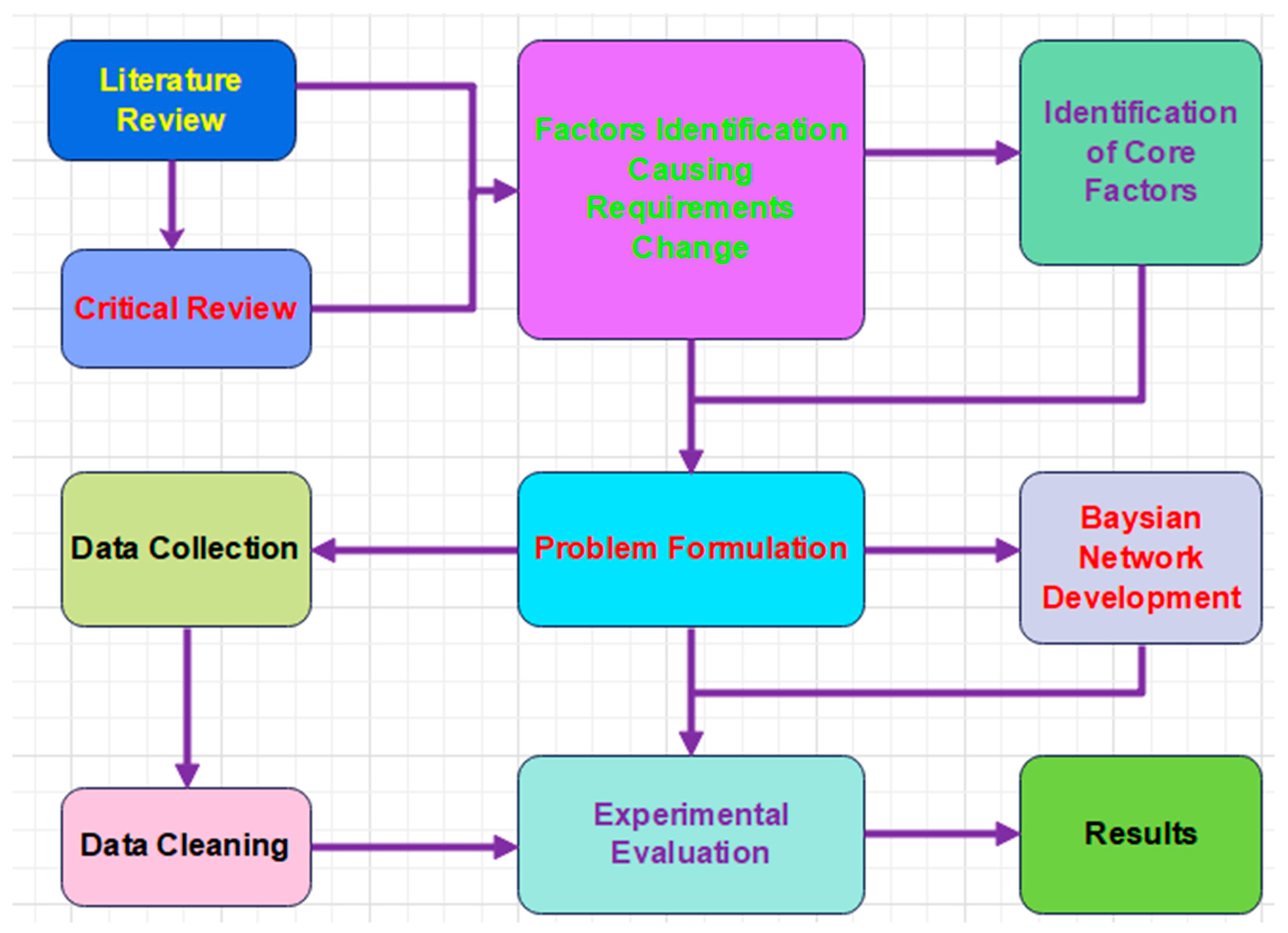
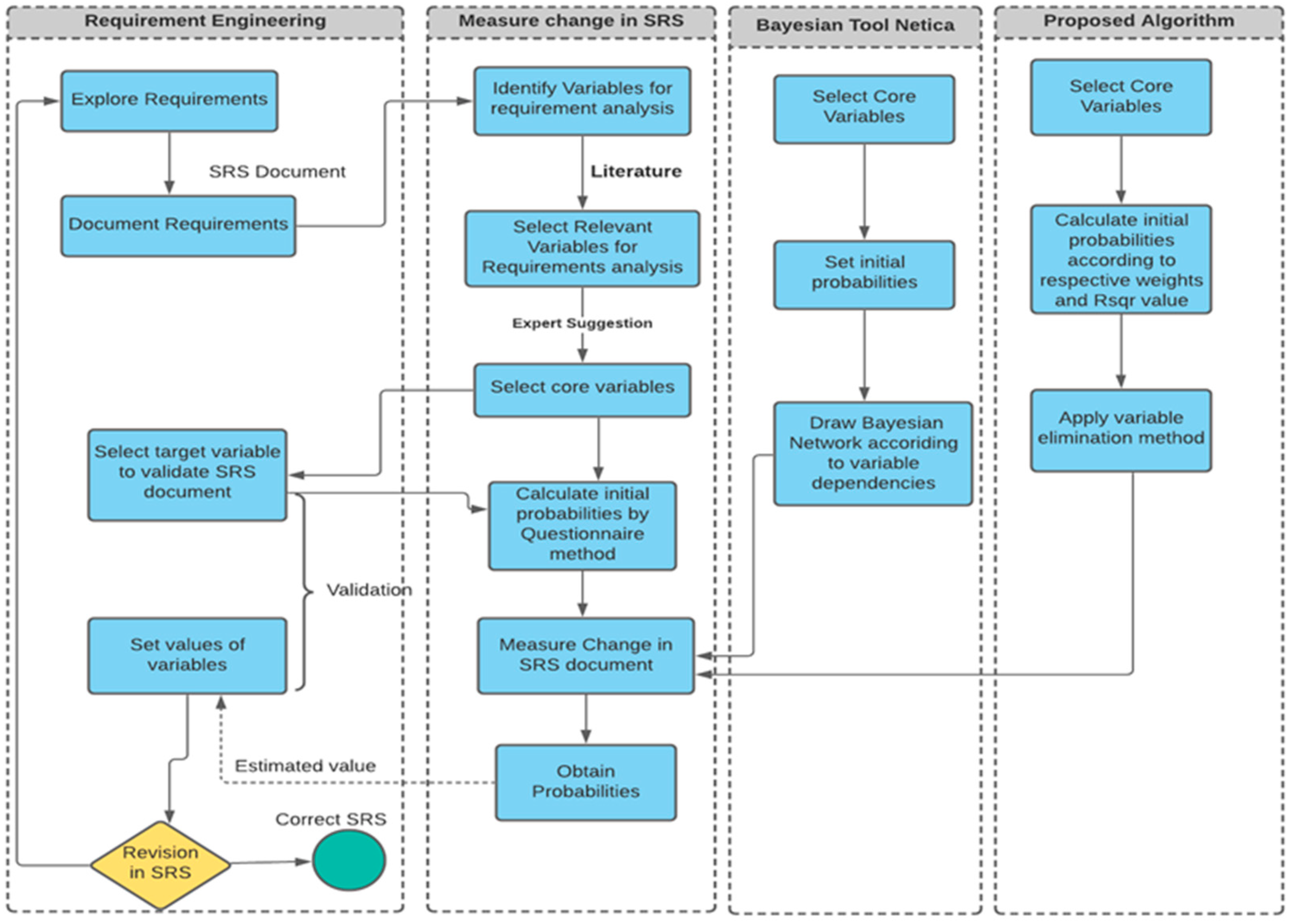
3. Proposed Approach
3.1. Data Collection
3.2. Data Analysis
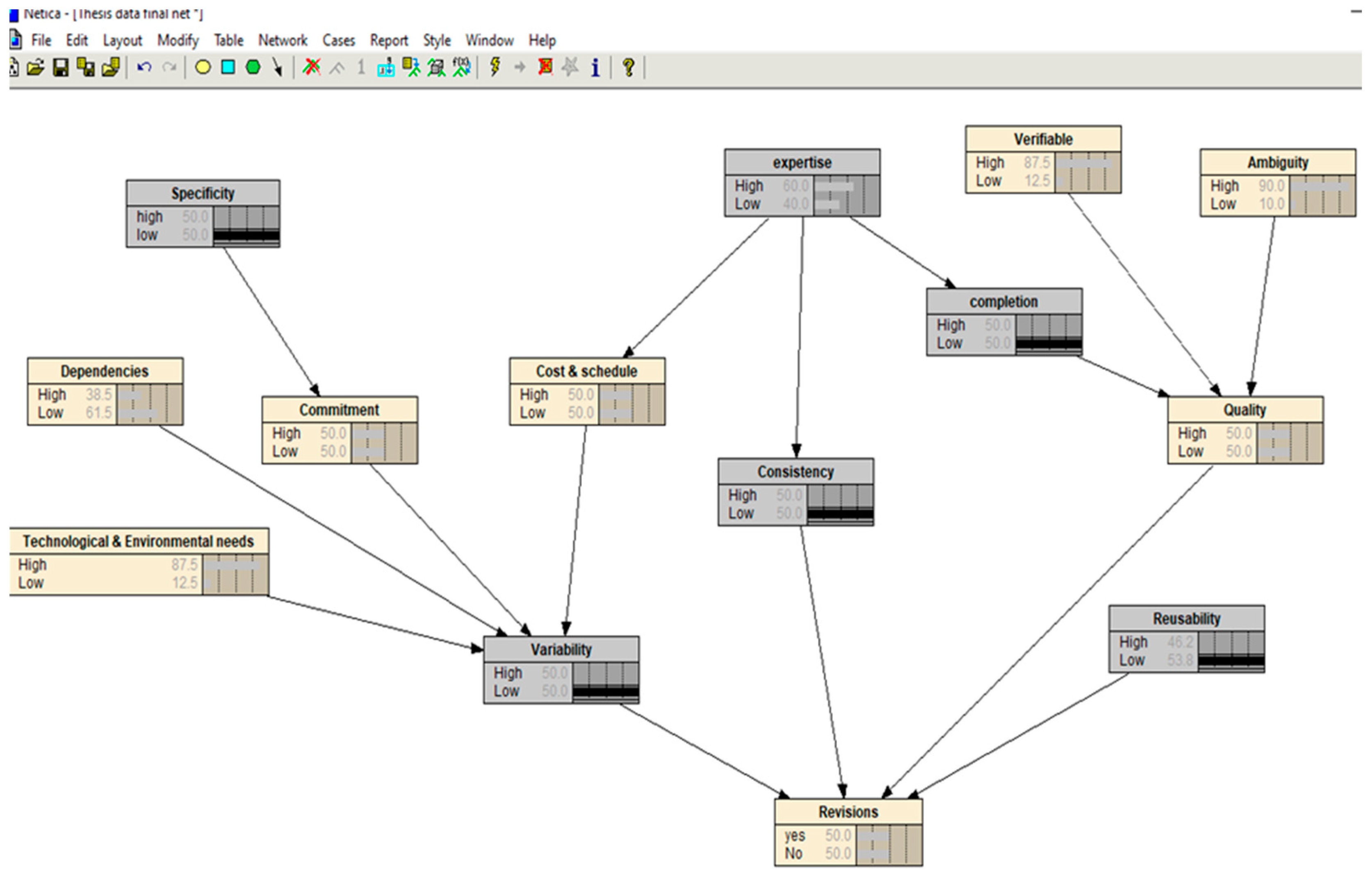
3.3. Bayesian Network Construction with Netica
3.4. Proposed Prediction Model
Variable Elimination Algorithm
| Algorithm 1 | Variable elimination algorithm | |||
| Input data: | ||||
| φ: Set of factors. | ||||
| F: Stack having an active list of factors. | ||||
| Z: Set of variables to be eliminated. | ||||
| K: Number of selected routes. | ||||
| Step 1. | Zi to Zk shows the order of variables. | |||
| For (i = 1; i ≤ k; i++) | ||||
| F←Sum-Product Eliminate Var (F, Zi); | ||||
| End for | ||||
| Step 2. | Subroutine sum over the product of all variable factors to eliminate and return the new factor. | |||
| φ * ← ∏ φ ∈ F (φ) | ||||
| Return φ * | ||||
| Procedure Sum-product eliminate Var () | ||||
| F′ = define all terms having argument Zi (variable to be eliminated) | ||||
| F′ ← {φ ∈ F: Z ∈ scope[φ]} | ||||
| F″ = remaining stack elements | ||||
| F″ = F-F’ | ||||
| Step 3. | Take the product of all factors in F′. | |||
| ψ ← ∏φ ∈ F′ φ | ||||
| Step 4. | Take the sum of products by eliminating Z. | |||
| T = new factor | ||||
| T ← ∑Z ψ | ||||
| Step 5. | Join the T with the remaining stack F″. | |||
| return F″ ∪ {T} | ||||
| Step 6. | End. | |||
3.5. Proposed Prediction Algorithm
| Algorithm 2 | Proposed prediction algorithm | ||
| Step 1. | Def Proposed Algorithm (cond_Prob) | ||
| { | |||
| Vi = initial variable | |||
| Vn = Total number of variables | |||
| While (Vi ≤ Vn) | |||
| { | |||
| Step 2. | If (Vi € Stakeholder. Dataset & Vi. RSquare Value > 1 & ≤100) | ||
| Cond_Prob1 = VI. Data*0.3*RSquare Value | |||
| Else | |||
| if (Vi € Developer. Dataset & Vi. RSquare Value >1 & ≤100) | |||
| Cond_Prob2= Vi. Data*0.2*RSquare Value | |||
| Else (Vi € Expert. Dataset & Vi. RSquare Value >1 & ≤100) | |||
| Cond_Prob3= Vi. Data*0.5*RSquare Value | |||
| FinalCond_Prob = merge (Cond_Prob1, Cond_Prob2, Cond_Prob3) | |||
| Step 3. | While (FinalCond_Probi ≤ FinalCond_Prob n) | ||
| { | |||
| F = Make Factors (FinalCond_Probi) | |||
| { | |||
| Step 4. | Variable Elimination (F, Vi); | ||
| Step 5. | Return cond_Prob; | ||
| Step 6. | End. | ||
3.6. Process Model
- Measuring the posterior probability of target variables, e.g., revisions upon the effect of all of the core variables in the network.
- Measuring the posterior probability of the target variable in different scenarios, e.g., by making the individual variable evidence value high or low.
4. Evaluation Measures
4.1. Performance Evaluation
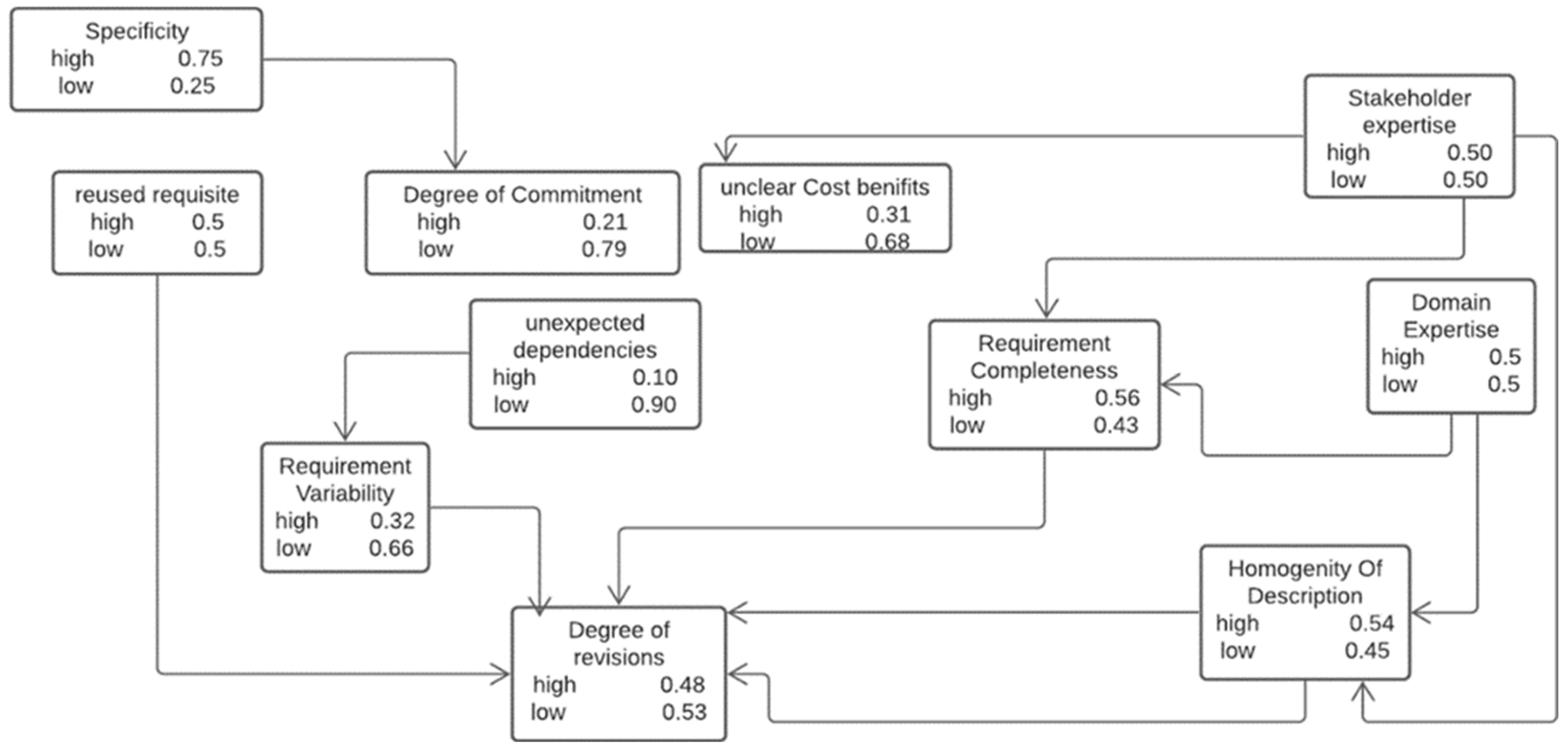
4.1.1. Bayesian Network of Proposed Work
4.1.2. Bayesian Network of del Sagrado et al. [13]
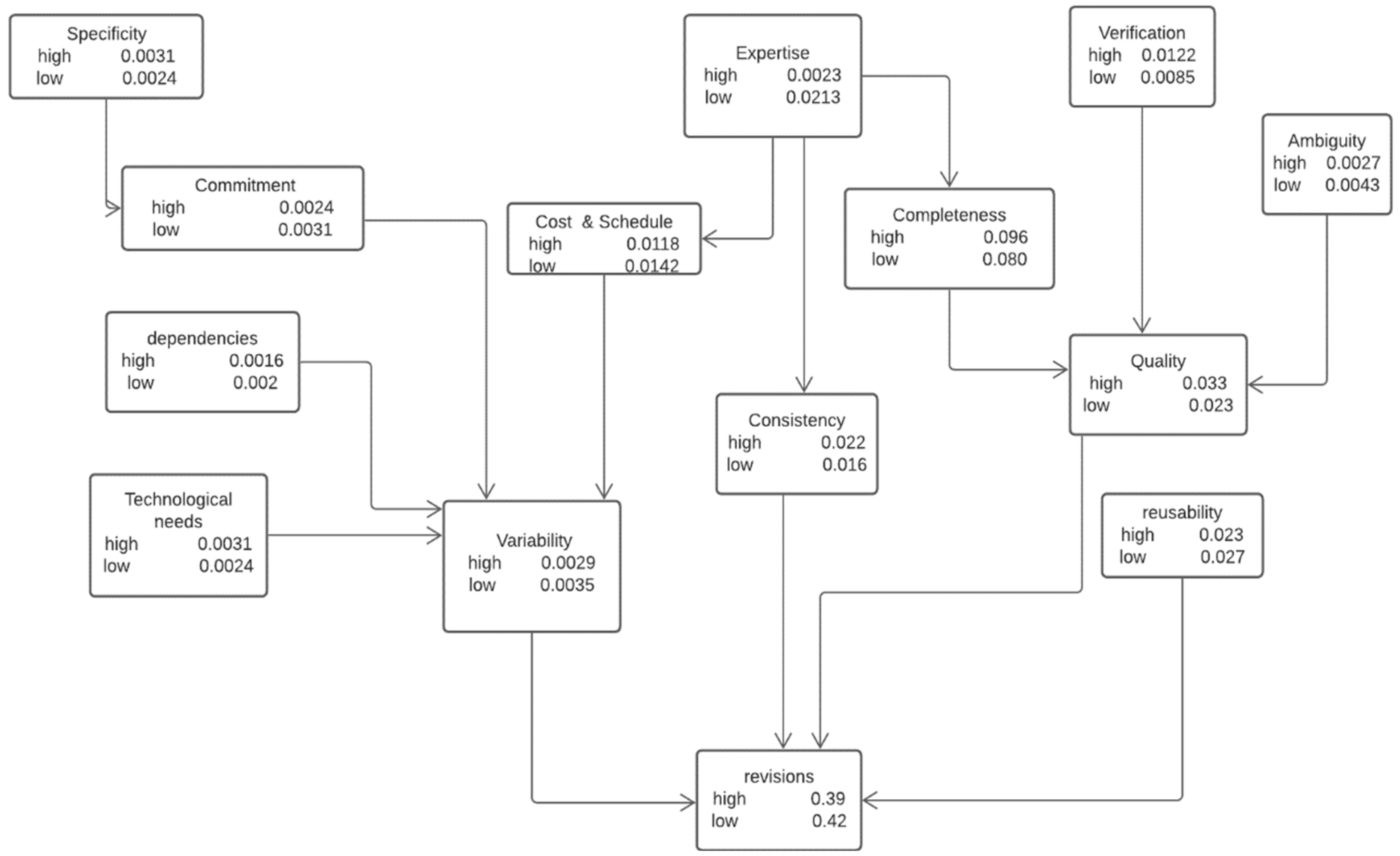
4.1.3. Sensitivity Analysis
4.2. Accuracy Measurement
4.3. Experimental Results and Discussion
- Scenario 1: Specificity = High, Expertise = High, Verification = High, Ambiguity = Low, Dependency = Low, Technology = High, Completeness = High, Reusability = High, Commitment = High, Cost and Schedule = Low, Consistency = High, Quality = High, Variability = Low, Revisions = Low.
- Scenario 2: Specificity = Low, Expertise = Low, verification = Low, Ambiguity = High, Dependency = High, Technology = Low, completeness = Low, Reusability = Low, Commitment = Low, Cost and Schedule = High, Consistency = High, Quality = High, Variability = High, Revisions = High.
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ciancarini, P.; Farina, M.; Okonicha, O.; Smirnova, M.; Succi, G. Software as Storytelling: A Systematic Literature Review. Comput. Sci. Rev. 2023, 47, 100517. [Google Scholar] [CrossRef]
- Shwetha, A.N.; Sumathi, R.; Prabodh, C.P. A Survey on Mobile Application Development Models. In Mobile Application Development: Practice and Experience; Springer Nature Singapore: Singapore, 2023; pp. 1–9. ISBN 9789811968921. [Google Scholar]
- Lin, B.; Cassee, N.; Serebrenik, A.; Bavota, G.; Novielli, N.; Lanza, M. Opinion Mining for Software Development: A Systematic Literature Review. ACM Trans. Softw. Eng. Methodol. 2022, 31, 1–41. [Google Scholar] [CrossRef]
- Mihelič, A.; Vrhovec, S.; Hovelja, T. Agile Development of Secure Software for Small and Medium-Sized Enterprises. Sustainability 2023, 15, 801. [Google Scholar] [CrossRef]
- Thota, M.K.; Shajin, F.H.; Rajesh, P. Survey on Software Defect Prediction Techniques. Int. J. Appl. Sci. Eng. 2020, 17, 331–344. [Google Scholar]
- Yang, Y.; Xia, X.; Lo, D.; Bi, T.; Grundy, J.; Yang, X. Predictive Models in Software Engineering: Challenges and Opportunities. ACM Trans. Softw. Eng. Methodol. 2022, 31, 1–72. [Google Scholar] [CrossRef]
- Baham, C.; Hirschheim, R. Issues, Challenges, and a Proposed Theoretical Core of Agile Software Development Research. Inf. Syst. J. 2022, 32, 103–129. [Google Scholar] [CrossRef]
- Karagiannis, D. Conceptual Modelling Methods: The AMME Agile Engineering Approach. In Domain-Specific Conceptual Modeling; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–21. ISBN 9783030935467. [Google Scholar]
- Yang, Y.; Xia, X.; Lo, D.; Grundy, J. A Survey on Deep Learning for Software Engineering. ACM Comput. Surv. 2022, 54, 1–73. [Google Scholar] [CrossRef]
- Khaliq, Z.; Farooq, S.U.; Khan, D.A. Artificial Intelligence in Software Testing: Impact, Problems, Challenges and Prospect. arXiv 2022, arXiv:2201.05371. [Google Scholar]
- Huang, Y.-S.; Chiu, K.-C.; Chen, W.-M. A Software Reliability Growth Model for Imperfect Debugging. J. Syst. Softw. 2022, 188, 111267. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, L.; Lian, X.; Gao, X.; Lv, H.; Shi, L. ReqGen: Keywords-Driven Software Requirements Generation. Mathematics 2023, 11, 332. [Google Scholar] [CrossRef]
- del Sagrado, J.; del Águila, I.M. Stability Prediction of the Software Requirements Specification. Softw. Qual. J. 2018, 26, 585–605. [Google Scholar] [CrossRef]
- Park, S.; Maurer, F.; Eberlein, A.; Fung, T.-S. Requirements Attributes to Predict Requirements Related Defects. In Proceedings of the 2010 Conference of the Center for Advanced Studies on Collaborative Research—CASCON ’10, Toronto, ON, Canada, 1–4 November 2010; ACM Press: New York, NY, USA, 2010. [Google Scholar]
- Hein, P.H.; Voris, N.; Morkos, B. Predicting Requirement Change Propagation through Investigation of Physical and Functional Domains. Res. Eng. Des. 2018, 29, 309–328. [Google Scholar] [CrossRef]
- Arora, C.; Sabetzadeh, M.; Goknil, A.; Briand, L.C.; Zimmer, F. Change Impact Analysis for Natural Language Requirements: An NLP Approach. In Proceedings of the 2015 IEEE 23rd International Requirements Engineering Conference (RE), Ottawa, ON, Canada, 24–28 August 2015; IEEE: New York, NY, USA, 2015; pp. 6–15. [Google Scholar]
- Yadav, H.B.; Yadav, D.K. Early Software Reliability Analysis Using Reliability Relevant Software Metrics. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 2097–2108. [Google Scholar] [CrossRef]
- Bano, M. Addressing the Challenges of Requirements Ambiguity: A Review of Empirical Literature. In Proceedings of the 2015 IEEE Fifth International Workshop on Empirical Requirements Engineering (EmpiRE), Ottawa, ON, Canada, 24 August 2015; IEEE: New York, NY, USA, 2015; pp. 21–24. [Google Scholar]
- Zheng, W.; Shen, T.; Chen, X.; Deng, P. Interpretability Application of the Just-in-Time Software Defect Prediction Model. J. Syst. Softw. 2022, 188, 111245. [Google Scholar] [CrossRef]
- Wakimoto, M.; Morisaki, S. Goal-Oriented Software Design Reviews. IEEE Access 2022, 10, 32584–32594. [Google Scholar] [CrossRef]
- Butt, S.A.; Khalid, A.; Ercan, T.; Ariza-Colpas, P.P.; Melisa, A.-C.; Piñeres-Espitia, G.; De-La-Hoz-Franco, E.; Melo, M.A.P.; Ortega, R.M. A Software-Based Cost Estimation Technique in Scrum Using a Developer’s Expertise. Adv. Eng. Softw. 2022, 171, 103159. [Google Scholar] [CrossRef]
- Rath, A.K. Fundamentals of Software Engineering: Designed to Provide an Insight into the Software Engineering Concepts (English Edition); BPB Publications: New Delhi, India, 2020; ISBN 9789388511773. [Google Scholar]
- Devanbu, P.; Dwyer, M.; Elbaum, S.; Lowry, M.; Moran, K.; Poshyvanyk, D.; Ray, B.; Singh, R.; Zhang, X. Deep Learning & Software Engineering: State of Research and Future Directions. arXiv 2020, arXiv:2009.08525. [Google Scholar]
- Bibiano, A.C.; Uchôa, A.; Assunção, W.K.G.; Tenório, D.; Colanzi, T.E.; Vergilio, S.R.; Garcia, A. Composite Refactoring: Representations, Characteristics and Effects on Software Projects. Inf. Softw. Technol. 2023, 156, 107134. [Google Scholar] [CrossRef]
- Zorzetti, M.; Signoretti, I.; Salerno, L.; Marczak, S.; Bastos, R. Improving Agile Software Development Using User-Centered Design and Lean Startup. Inf. Softw. Technol. 2022, 141, 106718. [Google Scholar] [CrossRef]
- Laplante, P.A.; Kassab, M. Requirements Engineering for Software and Systems, 4th ed.; Auerbach: London, UK, 2022; ISBN 9781000593792. [Google Scholar]
- Hou, F.; Jansen, S. A Systematic Literature Review on Trust in the Software Ecosystem. Empir. Softw. Eng. 2023, 28, 8. [Google Scholar] [CrossRef]
- Kadebu, P.; Sikka, S.; Tyagi, R.K.; Chiurunge, P. A Classification Approach for Software Requirements towards Maintainable Security. Sci. Afr. 2023, 19, e01496. [Google Scholar] [CrossRef]
- Sur, T.; Jaisswal, A.; Vinayakarao, V. Mathematical Expressions in Software Engineering Artifacts. In Proceedings of the Proceedings of the 6th Joint International Conference on Data Science & Management of Data (10th ACM IKDD CODS and 28th COMAD), Mumbai, India, 4–7 January 2023; ACM: New York, NY, USA, 2023. [Google Scholar]
- Laato, S.; Mäntymäki, M.; Islam, A.K.M.N.; Hyrynsalmi, S.; Birkstedt, T. Trends and Trajectories in the Software Industry: Implications for the Future of Work. Inf. Syst. Front. 2022, 25, 929–944. [Google Scholar] [CrossRef]
- Horcas, J.M.; Pinto, M.; Fuentes, L. Empirical Analysis of the Tool Support for Software Product Lines. Softw. Syst. Model. 2023, 22, 377–414. [Google Scholar] [CrossRef]
- Weder, B.; Barzen, J.; Leymann, F.; Vietz, D. Quantum Software Development Lifecycle. In Quantum Software Engineering; Springer International Publishing: Cham, Switzerland, 2022; pp. 61–83. ISBN 9783031053238. [Google Scholar]
- Akbar, M.A.; Smolander, K.; Mahmood, S.; Alsanad, A. Toward Successful DevSecOps in Software Development Organizations: A Decision-Making Framework. Inf. Softw. Technol. 2022, 147, 106894. [Google Scholar] [CrossRef]
- Nandakumar, R. Quantitative Quality Score for Software. In Proceedings of the 15th Innovations in Software Engineering Conference, Gandhinagar, India, 24–26 February 2022; ACM: New York, NY, USA, 2022. [Google Scholar]
- Gutfleisch, M.; Klemmer, J.H.; Busch, N.; Acar, Y.; Sasse, M.A.; Fahl, S. How Does Usable Security (Not) End up in Software Products? Results from a Qualitative Interview Study. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 23–25 May 2022; IEEE: New York, NY, USA, 2022; pp. 893–910. [Google Scholar]
- Xiang, Y.; Loker, D. Trans-Causalizing NAT-Modeled Bayesian Networks. IEEE Trans. Cybern. 2022, 52, 3553–3566. [Google Scholar] [CrossRef] [PubMed]





| Variables | Missing Values | Mean | Median | Mode | Standard Deviation | Variance | Range |
|---|---|---|---|---|---|---|---|
| Specificity | 1 | 2.7061 | 2.8 | 2.45 | 0.62 | 0.387 | 2.45 |
| Consistency | 2 | 2.7595 | 2.9 | 3.27 | 0.70 | 0.501 | 3.00 |
| Completion | 3 | 2.7965 | 2.8 | 2.00 | 0.66 | 0.448 | 2.45 |
| Ambiguity | 3 | 2.6476 | 2.60 | 2.00 | 0.71 | 0.509 | 2.82 |
| Commitment | 1 | 2.727 | 2.70 | 2.73 | 0.50 | 0.374 | 2.09 |
| Expertise | 3 | 2.7993 | 2.95 | 3.00 | 0.62 | 0.448 | 2.36 |
| Quality | 2 | 2.8282 | 2.90 | 2.09 | 0.61 | 0.359 | 2.19 |
| Reusability | 3 | 2.7730 | 2.79 | 3.36 | 0.66 | 0.380 | 2.36 |
| Dependency | 0 | 2.5329 | 2.58 | 2.00 | 0.59 | 0.343 | 2.55 |
| Variability | 2 | 2.5620 | 2.54 | 2.00 | 0.61 | 0.383 | 2.18 |
| Cost and schedule | 4 | 2.6354 | 2.8 | 2.00 | 0.66 | 0.340 | 2.82 |
| Verification | 2 | 2.7694 | 2.74 | 3.00 | 0.69 | 0.486 | 2.82 |
| Technological needs | 2 | 2.7830 | 2.75 | 3.09 | 0.66 | 0.445 | 2.55 |
| Independent Variables | Dependent Variables | R Square | Adjusted R Square | Co-Variance | Significant Value |
|---|---|---|---|---|---|
| Specificity | Commitment | 0.037 | 0.022 | 0.006 | 0.001 |
| Expertise | Consistency | 0.097 | 0.084 | 0.006 | 0.001 |
| Completeness | Quality | 0.067 | 0.054 | 0.010 | 0.001 |
| Ambiguity | Quality | 0.018 | 0.003 | 0.010 | 0.001 |
| Verification | Quality | 0.098 | 0.085 | 0.010 | 0.001 |
| Dependency | Variability | 0.010 | 0.014 | 0.016 | 0.001 |
| Technology | Variability | 0.016 | 0.001 | 0.024 | 0.001 |
| Expertise | Cost and schedule | 0.075 | 0.061 | 0.012 | 0.004 |
| Expertise | Completeness | 0.462 | 0.454 | 0.009 | 0.013 |
| Variables | Low State Old Conditional Probability of Revisions | Low State New Conditional Probability of Revisions | High State Old ConditionalProbability of Revisions | High State New Conditional Probability of Revisions |
|---|---|---|---|---|
| Quality | 0.42 | 0.41 | 0.45 | 0.45 |
| Reusability | 0.42 | 0.41 | 0.45 | 0.46 |
| Consistency | 0.42 | 0.41 | 0.45 | 0.45 |
| Variability | 0.42 | 0.38 | 0.45 | 0.62 |
| Models | Mean Values of Estimated Results | Mean Magnitude Relative Error (MMRE) | Root Mean Square Error (RMSE) |
|---|---|---|---|
| Proposed model | 0.465 | 0.0042 | 0.026 |
| del Sagrado et al. [13] model | 0.435 | 0.0052 | 0.032 |
| Variables | Probability Value | Probability (Revisions) | Probability Value | Probability (Revisions) |
|---|---|---|---|---|
| Specificity | High | 0.44 | Low | 0.45 |
| Expertise | High | 0.44 | Low | 0.45 |
| Verifiable | High | 0.44 | Low | 0.45 |
| Ambiguity | High | 0.45 | Low | 0.44 |
| Dependency | High | 0.45 | Low | 0.44 |
| Technology | High | 0.44 | Low | 0.45 |
| Completeness | High | 0.44 | Low | 0.45 |
| Reusability | High | 0.44 | Low | 0.45 |
| Commitment | High | 0.45 | Low | 0.44 |
| Cost and schedule | High | 0.45 | Low | 0.44 |
| Consistency | High | 0.44 | Low | 0.45 |
| Quality | High | 0.43 | Low | 0.44 |
| Variability | High | 0.42 | Low | 0.45 |
| Variables | Probability Value | Probability (Revision) | Probability Value | Probability (Revisions) |
|---|---|---|---|---|
| Specificity | High | 0.49 | Low | 0.52 |
| Stakeholder expertise | High | 0.49 | Low | 0.52 |
| Unexpected dependencies | High | 0.52 | Low | 0.49 |
| Requirement completeness | High | 0.49 | Low | 0.52 |
| Reused requisite | High | 0.49 | Low | 0.52 |
| Degree of commitment | High | 0.52 | Low | 0.49 |
| Unclear cost and benefits | High | 0.52 | Low | 0.49 |
| Homogeneity | High | 0.49 | Low | 0.52 |
| Requirement variability | High | 0.43 | Low | 0.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fatima, R.; Zeshan, F.; Ahmad, A.; Hamid, M.; Filali, I.; Alhussan, A.A.; Abdallah, H.A. Requirement Change Prediction Model for Small Software Systems. Computers 2023, 12, 164. https://doi.org/10.3390/computers12080164
Fatima R, Zeshan F, Ahmad A, Hamid M, Filali I, Alhussan AA, Abdallah HA. Requirement Change Prediction Model for Small Software Systems. Computers. 2023; 12(8):164. https://doi.org/10.3390/computers12080164
Chicago/Turabian StyleFatima, Rida, Furkh Zeshan, Adnan Ahmad, Muhamamd Hamid, Imen Filali, Amel Ali Alhussan, and Hanaa A. Abdallah. 2023. "Requirement Change Prediction Model for Small Software Systems" Computers 12, no. 8: 164. https://doi.org/10.3390/computers12080164
APA StyleFatima, R., Zeshan, F., Ahmad, A., Hamid, M., Filali, I., Alhussan, A. A., & Abdallah, H. A. (2023). Requirement Change Prediction Model for Small Software Systems. Computers, 12(8), 164. https://doi.org/10.3390/computers12080164