
Developing a Novel Hierarchical VPLS Architecture Using Q-in-Q Tunneling in Router and Switch Design




Abstract
:1. Introduction
- Proposed a novel H-VPLS architecture that integrates FRR as the control plane and VPP as the data plane for router and switch design.
- Developed VPLS via Q-in-Q tunneling, which significantly enhances traffic engineering.
- Conducted a thorough review of existing VPLS configuration scenarios.
- Demonstrated that VPP and FRR provide transparent multipoint-to-multipoint services and interoperability with other vendors’ products using VPLS.
2. Preliminary
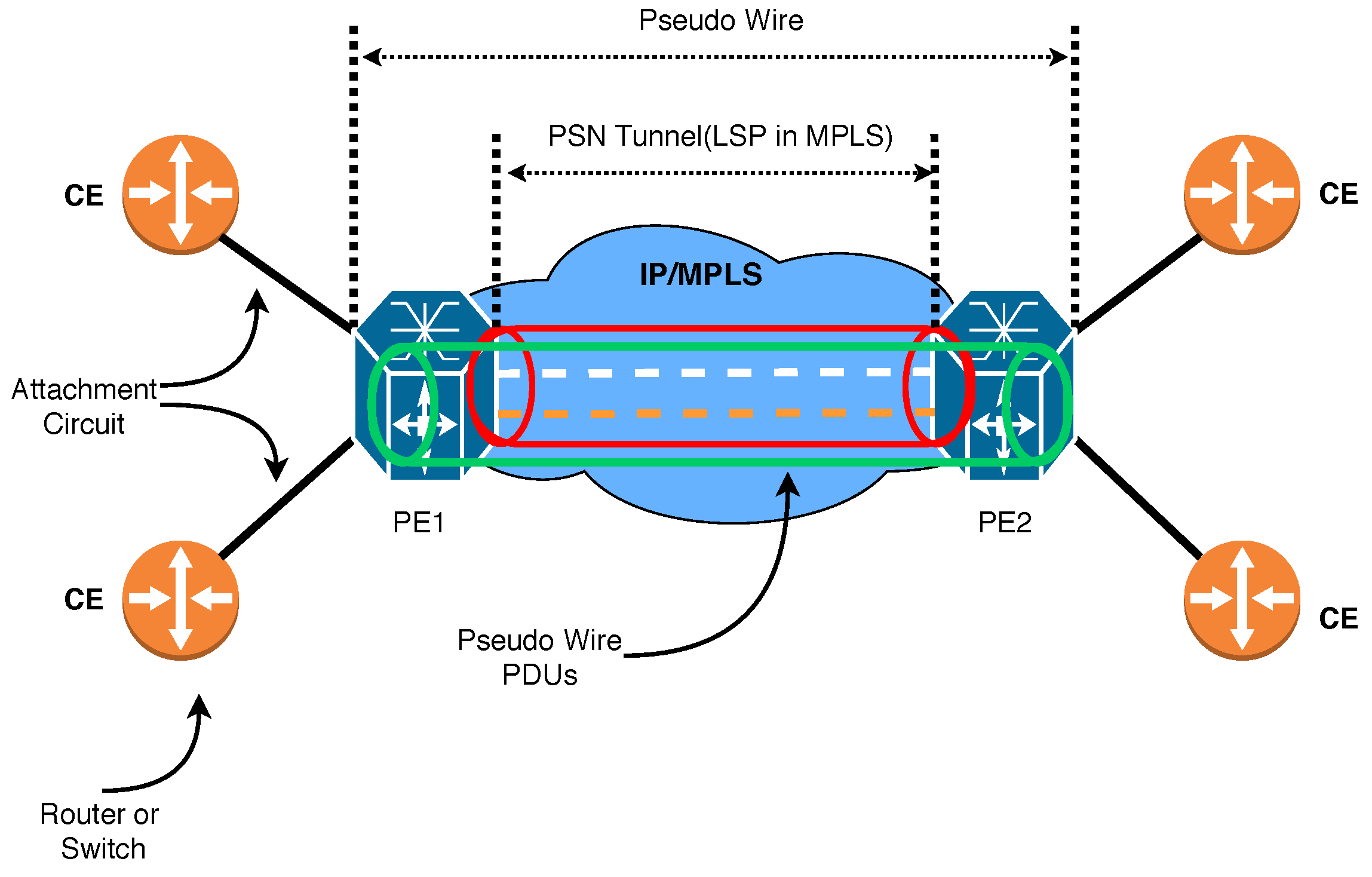
2.1. VPLS Description
- Customer Site
- Customer Edge device or simply CE: Customer network which is directly connected to the ISP.
- Provider Edge device or simply PE: This connects one or multiple CEs to the ISP. PE is responsible for converting IP to MPLS packets.
- Virtual Switch Instances or simply VSI: This is an ethernet bridge function entity of a VPLS instance on a PE. It forwards Layer 2 frames based on MAC addresses and VLAN tags.
- Network Provider device or simply P: ISP’s devices inside the core network which runs MPLS.
- PW signaling or simply PW: This is a bidirectional virtual connection between VSIs on two PEs. It consists of two unidirectional MPLS virtual circuits.
- Attachment Circuit or simply AC: The connection between CE and PE.
- The tunnel is a direct channel between PEs for data transmission. In this work, we use an MPLS tunnel.
2.2. Existing VPLS Models
- Full mesh [40]: In this model, as shown in Figure 3, we apply a PW from each Provider Edge (PE) router to those of other PEs. To prevent Loop in this model, the Split horizon in layer 2 is run. A disadvantage of this model is that it will cause PW redundancy as the complexity of the network grows. Therefore, we see less implementation in practice.
- Hub and Spoke [40]: In this model, as shown in Figure 4, instead of having PW between all PE routers, PW is inserted between all PE routers with a central P router. The advantages of this model are the simplicity and lower number of PW required. Also, since there is no Redundant path, it makes a loop-free connection. The drawback of this model is the single point of failure because if the central router fails, all VPLS communications will fail. Therefore, this model is not implemented in the real world.
- Partial Mesh [40]: This model, as shown in Figure 5, was created to add Redundancy to the Hub and Spoke model. Due to the structure of this model, we must disable the Split horizon, but due to having the Redundant path, we must activate Spanning Tree Protocol (STP). Since providers do not want to run STP on the network core, this model is also less common in practice.
- H-VPLS with MPLS Access Network [40]: In this model, as shown in Figure 6, the network is divided into two parts, Top Tier with Full mesh, and Bottom Tier with Hub and Spoke. This architecture will reduce the number of PWs and will be a hierarchical model. The disadvantage of this model is the single point of failure. Since each of the U-PE routers is connected to the Top Tier network with a link, if this connection is corrupted or disconnected, the entire Bottom Tier connection of the Top Tier network will be disconnected.
- H-VPLS with Q-in-Q Access Network: In the H-VPLS model proposed by the authors of reference [40], the Provider network is partitioned into ethernet-based islands, as depicted in Figure 7. These islands are interconnected using MPLS. Specifically, in the Bottom Tier of this architecture, PW Q-in-Q is utilized as the type of PW. The advantages of this topology, including easy availability through ethernet and hierarchical backing via Q-in-Q access, scalable customer VLANs (4K × 4K), and supporting 4K customers per access domain, have encouraged us to implement this model.
3. Related Works
4. Proposed Architecture
4.1. Our Data Plane: VPP
4.2. Our Control Plane: FRR
4.3. Overall Design Architecture
4.4. Implementation Phase
- Ldpd(): This function enables LDP on all active MPLS interfaces. LDP is used for distributing labels between PE routers and establishing LPSs in MPLS networks.
- L2vpn(): This function is responsible for creating, deleting, and updating PWs. PWs are used to provide point-to-point connectivity between two CE devices over a service provider’s MPLS network. L2VPN is a technology that enables the transport of Layer 2 traffic between different locations over an MPLS network.
- Ldpe(): This function sends hello packages periodically and creates sessions with other LDP neighbors. LDP neighbors are routers that are directly connected and exchange label information with each other. The hello packages are used to discover and establish LDP sessions with other routers.
- Lde(): This function is responsible for the distribution of marked labels. When an LSP is established between two routers, labels are assigned to the traffic that is being transported over the MPLS network. The LDE (Label Distribution Entity) is responsible for distributing these labels to other routers in the network.
- ldpd.c: This file contains the main function for the LDP daemon. It sets up the LDP protocol, initializes the LDP database, and starts the LDP event loop.
- ldp_interface.c: This file contains the code for managing LDP interfaces. It handles interface events, such as interface up/down, and enables LDP on active MPLS interfaces.
- ldp_l2vpn.c: This file contains the code for managing Layer 2 VPNs. It handles the creation, deletion, and updating of PWs, and also manages the L2VPN database.
- ldp_ldp.c: This file contains the code for managing LDP sessions and exchanging label information with other LDP routers. It implements the LDP protocol and handles LDP messages.
- ldp_label.c: This file contains the code for managing LDP labels. It handles label distribution, label assignment, and label retention.
| Algorithm 1 LDP _l2vpn_PWtype () |
Require: Enable L2vpn
|
| Algorithm 2 l2vpn_PW () |
|
| Algorithm 3 Ldpd () |
|
- Creation of l2 tunnel using the VppMPLSTunnelInterface algorithm;
- Addressing routes using VppMplsRoute;
- Bridge-domain using structured set_l2_bridge;
- Obtain the packages and address them;
- Packet encapsulation methods;
- Learning and forwarding part;
- The stream section of the packages in each direction;
- Disable Bridge domain after finishing work.
| Algorithm 4 VppMPLSTSTunnelInterface (VppInterface): |
|
- 1:
- {comment: # from vnet / vnet / mpls / mpls _types.h}
- 2:
- MPLS_IETF_MAX_LABEL = 0xfffff
- 3:
- MPLS_LABEL_INVALID = MPLS_IETF_MAX_LABEL + 1
| Algorithm 5 VppMplsRoute(VppObject): |
|
5. Simulation Results
5.1. Lightweight Design and Test
- The R1 and R2 router configuration are illustrated in Figure 14;
- Configurations for Rahyab router: The settings for the above scenario Figure 13 are given for each router as follows:1. Enable IP forwarding feature in Linux operating system that can be applied to both versions of IP.2. Enable MPLS on each interface.3. Define a new bridge and PW in the kernel.4. Enable bridge and PW.5. Connect the bridge and PW created in the previous section to the ethernet link. It is worth mentioning that the settings for steps 1 to 5 are done in the Command Line environment of Linux, and these settings are the same for all Rahyab routers.6. Turn on and give IP addresses to the interfaces, enable OSPF and MPLS, and perform configurations related to each of them (these are not explained in this document because they are thoroughly explained in other documents).7. Enable VPLS on PE routers (routers 1 and 3 in Figure 13). As a result of running the command, the following commands are activated under VPLS, and the interface ens32 and PW mpw0 are recognized as its members. By determining the address of the router connected to the other end of PW, the VPLS neighborhood of the current router is determined.


5.2. Practical Design and Test
- A general routing protocol must be run in order for the routers to be reachable. We chose Open Shortest Path First (OSPF) as a dynamic routing protocol and ran it on PE1, PE2, PE3, and P routers. In this experiment, routers can reach each other by their associated router-id.
- MPLS and LDP should be configured correctly. MPLS and LDP are used for labeling packets and the distribution of the labels of each router, respectively. At this point in time, routers can reach other routers via MPLS labels rather than IP addresses.
- In this step, VPLS configuration must be applied on PE1, PE2, PE3, and also Q-in-Q tunnel. Moreover, switches should be configured in trunk mode and access VLAN mode as shown in Figure 16.
5.3. Measurements and Quantitative Outputs
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vallet, J.; Brun, O. Online OSPF weights optimization in IP networks. Comput. Netw. 2014, 60, 1–12. [Google Scholar] [CrossRef]
- Bocci, M.; Cowburn, I.; Guillet, J. Network high availability for ethernet services using IP/MPLS networks. IEEE Commun. Mag. 2008, 46, 90–96. [Google Scholar] [CrossRef]
- Ben-Yacoub, L.L. On managing traffic over virtual private network links. J. Commun. Netw. 2000, 2, 138–146. [Google Scholar] [CrossRef]
- Sajassi, A. Comprehensive Model for VPLS. US Patent 8,213,435, 3 July 2012. [Google Scholar]
- Liyanage, M.; Ylianttila, M.; Gurtov, A. Improving the tunnel management performance of secure VPLS architectures with SDN. In Proceedings of the 2016 13th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2016; pp. 530–536. [Google Scholar]
- Liyanage, M.; Ylianttila, M.; Gurtov, A. Fast Transmission Mechanism for Secure VPLS Architectures. In Proceedings of the 2017 IEEE International Conference on Computer and Information Technology (CIT), Helsinki, Finland, 21–23 August 2017; pp. 192–196. [Google Scholar]
- Filsfils, C.; Evans, J. Engineering a multiservice IP backbone to support tight SLAs. Comput. Netw. 2002, 40, 131–148. [Google Scholar] [CrossRef]
- Bensalah, F.; El Kamoun, N. A novel approach for improving MPLS VPN security by adopting the software defined network paradigm. Procedia Comput. Sci. 2019, 160, 831–836. [Google Scholar] [CrossRef]
- Martini, L.; Rosen, E.; El-Aawar, N.; Heron, G. Encapsulation Methods for Transport of Ethernet over MPLS Networks. RFC4448, April 2006. Available online: https://www.rfc-editor.org/rfc/rfc4448 (accessed on 8 August 2023).
- Gaur, K.; Kalla, A.; Grover, J.; Borhani, M.; Gurtov, A.; Liyanage, M. A survey of virtual private LAN services (VPLS): Past, present and future. Comput. Netw. 2021, 196, 108245. [Google Scholar] [CrossRef]
- Hernandez-Valencia, E.J.; Koppol, P.; Lau, W.C. Managed virtual private LAN services. Bell Labs Tech. J. 2003, 7, 61–76. [Google Scholar] [CrossRef]
- Lasserre, M.; Kompella, V. IETF RFC 4762: Virtual Private LAN Service (VPLS) Using Label Distribution Protocol (LDP) Signaling. 2007. Available online: https://www.rfc-editor.org/rfc/rfc4762.html (accessed on 8 August 2023).
- Biabani, M.; Yazdani, N.; Fotouhi, H. REFIT: Robustness Enhancement Against Cascading Failure in IoT Networks. IEEE Access 2021, 9, 40768–40782. [Google Scholar] [CrossRef]
- Wirtgen, T.; Dénos, C.; De Coninck, Q.; Jadin, M.; Bonaventure, O. The Case for Pluginized Routing Protocols. In Proceedings of the 2019 IEEE 27th International Conference on Network Protocols (ICNP), Chicago, IL, USA, 8–10 October 2019; pp. 1–12. [Google Scholar]
- Liyanage, M.; Ylianttila, M.; Gurtov, A. Enhancing security, scalability and flexibility of virtual private LAN services. In Proceedings of the 2017 IEEE International Conference on Computer and Information Technology (CIT), Helsinki, Finland, 21–23 August 2017; pp. 286–291. [Google Scholar]
- Di Battista, G.; Rimondini, M.; Sadolfo, G. Monitoring the status of MPLS VPN and VPLS based on BGP signaling information. In Proceedings of the 2012 IEEE Network Operations and Management Symposium, Maui, HI, USA, 16–20 April 2012; pp. 237–244. [Google Scholar]
- Liyanage, M.; Ylianttila, M.; Gurtov, A. Software defined VPLS architectures: Opportunities and challenges. In Proceedings of the 2017 IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Montreal, QC, Canada, 8–13 October 2017; pp. 1–7. [Google Scholar]
- The FRRouting Community. Available online: https://frrouting.org/ (accessed on 18 June 2020).
- Minei, I.; Marques, P.R. Automatic Traffic Mapping for Multi-Protocol Label Switching networks. U.S. Patent 10,193,801, 29 January 2019. [Google Scholar]
- Andersson, L. Technical Report, LDP Specification, RFC 5036. Minei, I., Thomas, B., Eds.; 2007. Available online: https://dl.acm.org/doi/abs/10.17487/RFC5036 (accessed on 8 August 2023).
- Stoll, D.; Thomas, W.; Belzner, M. The role of pseudo-wires for layer 2 services in intelligent transport networks. Bell Labs Tech. J. 2007, 12, 207–220. [Google Scholar] [CrossRef]
- Kaushalram, A.S.; Budiu, M.; Kim, C. Data-Plane Stateful Processing Units in Packet Processing Pipelines. U.S. Patent 10,523,764, 31 December 2019. [Google Scholar]
- Vector Packet Processing (VPP) Platform. Available online: https://wiki.fd.io/view/VPP (accessed on 18 June 2020).
- Linguaglossa, L.; Rossi, D.; Pontarelli, S.; Barach, D.; Marjon, D.; Pfister, P. High-Speed Data Plane and Network Functions Virtualization by Vectorizing Packet Processing. Comput. Netw. 2019, 149, 187–199. [Google Scholar] [CrossRef]
- Daly, J.; Bruschi, V.; Linguaglossa, L.; Pontarelli, S.; Rossi, D.; Tollet, J.; Torng, E.; Yourtchenko, A. Tuplemerge: Fast software packet processing for online packet classification. IEEE/ACM Trans. Netw. 2019, 27, 1417–1431. [Google Scholar] [CrossRef]
- Shukla, S.K. Low power hardware implementations for network packet processing elements. Integration 2018, 62, 170–181. [Google Scholar]
- Data Plane Development Kit. Available online: http://dpdk.org (accessed on 18 June 2020).
- Zhang, T.; Linguaglossa, L.; Gallo, M.; Giaccone, P.; Rossi, D. FloWatcher-DPDK: Lightweight line-rate flow-level monitoring in software. IEEE Trans. Netw. Serv. Manag. 2019, 16, 1143–1156. [Google Scholar] [CrossRef]
- IEEE Std 802.1 Q-2011; IEEE Standard for Local and Metropolitan Area Networks—Media Access Control (MAC) Bridges and Virtual Bridge Local Area Networks. IEEE SA: Piscataway, NJ, USA, 2011; Volume 31, p. 1365.
- Barach, D.; Linguaglossa, L.; Marion, D.; Pfister, P.; Pontarelli, S.; Rossi, D. High-speed software data plane via vectorized packet processing. IEEE Commun. Mag. 2018, 56, 97–103. [Google Scholar] [CrossRef]
- Liyanage, M.; Ylianttila, M.; Gurtov, A. Secure hierarchical VPLS architecture for provider provisioned networks. IEEE Access 2015, 3, 967–984. [Google Scholar] [CrossRef]
- Standard IETF RFCs. Available online: https://www.ietf.org/standards/rfcs/ (accessed on 18 June 2020).
- Martini, L. ÂIANA Allocations for Pseudo Wire Edge to Edge Emulation (PWE3) Â. Technical Report, RFC 4446. 2006. Available online: https://datatracker.ietf.org/doc/html/rfc4446 (accessed on 8 August 2023).
- Martini, L.; Rosen, E.; El-Aawar, N.; Smith, T.; Heron, G. RFC 4447: Pseudowire Setup and Maintenance Using the Label Distribution Protocol (LDP). The Internet Society. 2006. Available online: https://www.rfc-editor.org/rfc/rfc8077 (accessed on 8 August 2023).
- Bryant, S.; Swallow, G.; Martini, L.; McPherson, D. Pseudowire Emulation Edge-to-Edge (PWE3) Control Word for Use over an MPLS PSN. IETF RFC4385. 2006. Available online: https://patents.google.com/patent/US10523764B2/en?oq=US+Patent+10%2c523%2c764 (accessed on 8 August 2023).
- Cisco. Available online: https://www.cisco.com/ (accessed on 18 June 2020).
- Nexcom. Available online: https://www.nexcom.com/ (accessed on 18 June 2020).
- Manzoor, A.; Hussain, M.; Mehrban, S. Performance Analysis and Route Optimization: Redistribution between EIGRP, OSPF & BGP Routing Protocols. Comput. Stand. Interfaces 2020, 68, 103391. [Google Scholar]
- Holterbach, T.; Bü, T.; Rellstab, T.; Vanbever, L. An open platform to teach how the internet practically works. ACM SIGCOMM Comput. Commun. Rev. 2020, 50, 45–52. [Google Scholar] [CrossRef]
- Tiso, J.; Hutton, K.T.; Teare, D.; Schofield, M.D. Designing Cisco Network Service Architectures (ARCH): Foundation Learning Guide; Cisco Press: Indianapolis, IN, USA, 2011. [Google Scholar]
- Dong, X.; Yu, S. VPLS: An effective technology for building scalable transparent LAN services. In Network Architectures, Management, and Applications II, Proceedings of the Asia-Pacific Optical Communications, Beijing, China, 7–11 November 2004; SPIE Digital Library: Bellingham, WA, USA, 2005; Volume 5626, pp. 137–147. [Google Scholar]
- Xia, W.; Wen, Y.; Foh, C.H.; Niyato, D.; Xie, H. A survey on software-defined networking. IEEE Commun. Surv. Tutor. 2014, 17, 27–51. [Google Scholar] [CrossRef]
- Ahmad, I.; Namal, S.; Ylianttila, M.; Gurtov, A. Security in software defined networks: A survey. IEEE Commun. Surv. Tutor. 2015, 17, 2317–2346. [Google Scholar] [CrossRef]
- Palmieri, F. VPN scalability over high performance backbones evaluating MPLS VPN against traditional approaches. In Proceedings of the Eighth IEEE Symposium on Computers and Communications—ISCC 2003, Kiris-Kemer, Turkey, 30 June–3 July 2003; pp. 975–981. [Google Scholar]
- Rekhter, Y.; Li, T.; Hares, S. A Border Gateway Protocol 4 (BGP-4). Technical Report. 2006. Available online: https://www.rfc-editor.org/rfc/rfc4271 (accessed on 8 August 2023).
- Khandekar, S.; Kompella, V.; Regan, J.; Tingle, N.; Menezes, P.; Lassere, M.; Kompella, K.; Borden, M.; Soon, T.; Heron, G.; et al. Hierarchical Virtual Private LAN Service; Internet Draft; IETF: Wilmington, DE, USA, 2002. [Google Scholar]
- Martini, L.; Sajassi, A.; Townsley, W.M.; Pruss, R.M. Scalable Virtual Private Local Area Network Service. U.S. Patent 7,751,399, 6 July 2010. [Google Scholar]
- Chiruvolu, G.; Ge, A.; Elie-Dit-Cosaque, D.; Ali, M.; Rouyer, J. Issues and approaches on extending Ethernet beyond LANs. IEEE Commun. Mag. 2004, 42, 80–86. [Google Scholar] [CrossRef]
- López, G.; Grampín, E. Scalability testing of legacy MPLS-based Virtual Private Networks. In Proceedings of the 2017 IEEE URUCON, Montevideo, Uruguay, 23–25 October 2017; pp. 1–4. [Google Scholar]
- Dunbar, L.; Mack-Crane, T.B.; Hares, S.; Sultan, R.; Ashwood-Smith, P.; Yin, G. Virtual Layer 2 and Mechanism to Make Iit Scalable. U.S. Patent 9,160,609, 13 October 2015. [Google Scholar]
- Fahad, M.; Khan, B.M.; Bilal, R.; Young, R.C.; Beard, C.; Zaidi, S.S.H. Multibillion packet lookup for next generation networks. Comput. Electr. Eng. 2020, 84, 106612. [Google Scholar] [CrossRef]
- Valenti, A.; Pompei, S.; Matera, F.; Beleffi, G.T.; Forin, D. Quality of service control in Ethernet passive optical networks based on virtual private LAN service technique. Electron. Lett. 2009, 45, 992–993. [Google Scholar] [CrossRef]
- Peter, S.; Li, J.; Zhang, I.; Ports, D.R.; Woos, D.; Krishnamurthy, A.; Anderson, T.; Roscoe, T. Arrakis: The operating system is the control plane. ACM Trans. Comput. Syst. (TOCS) 2015, 33, 1–30. [Google Scholar] [CrossRef]
- Quagga Is a Routing Software Suite. Available online: https://www.quagga.net/ (accessed on 18 June 2020).
- Lim, L.K.; Gao, J.; Ng, T.E.; Chandra, P.R.; Steenkiste, P.; Zhang, H. Customizable virtual private network service with QoS. Comput. Netw. 2001, 36, 137–151. [Google Scholar]
- Dhaini, A.R.; Ho, P.H.; Jiang, X. WiMAX-VPON: A framework of layer-2 VPNs for next-generation access networks. IEEE/OSA J. Opt. Commun. Netw. 2010, 2, 400–414. [Google Scholar] [CrossRef]
- Ixia Tester. Available online: https://www.ixiacom.com/solutions/network-test-solutions (accessed on 18 June 2020).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specifications | Value |
|---|---|
| OS | Ubuntu 22.04.2 LTS |
| FRR | 7.0 stable |
| Vector Packet Processing | 19.08 |
| Plugin | VPP Sandbox/router |
| Hardware | Nexcom NSA 7136 |
| CPU | Dual Intel® Xeon® Processor E5-2600 v4 |
| Number of Cores | 32 |
| RAM | 96 |
| Number of Interfaces | 16 (1 Gbps ) and 6 (10 Gbps) |
| Tester | Ixia |
| Emulator | Gns3 |
| Cisco routers | 7600 Series |
| Cisco switches | Catalyst 3750-X Series |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biabani, M.; Yazdani, N.; Fotouhi, H. Developing a Novel Hierarchical VPLS Architecture Using Q-in-Q Tunneling in Router and Switch Design. Computers 2023, 12, 180. https://doi.org/10.3390/computers12090180
Biabani M, Yazdani N, Fotouhi H. Developing a Novel Hierarchical VPLS Architecture Using Q-in-Q Tunneling in Router and Switch Design. Computers. 2023; 12(9):180. https://doi.org/10.3390/computers12090180
Chicago/Turabian StyleBiabani, Morteza, Nasser Yazdani, and Hossein Fotouhi. 2023. "Developing a Novel Hierarchical VPLS Architecture Using Q-in-Q Tunneling in Router and Switch Design" Computers 12, no. 9: 180. https://doi.org/10.3390/computers12090180
APA StyleBiabani, M., Yazdani, N., & Fotouhi, H. (2023). Developing a Novel Hierarchical VPLS Architecture Using Q-in-Q Tunneling in Router and Switch Design. Computers, 12(9), 180. https://doi.org/10.3390/computers12090180