
Multiclass AI-Generated Deepfake Face Detection Using Patch-Wise Deep Learning Model

 , , ,
, , ,  , and
, and 
Abstract
:1. Introduction
- Our primary contribution lies in being the first to address this problem as a multi-classification task. No prior work has tackled this specific aspect, and our study represents a pioneering effort in this area. By approaching deepfake detection through the lens of multi-classification, we aim to enhance the accuracy and efficacy of identifying and categorizing deepfake content, thereby advancing the field’s understanding and capabilities in combating this evolving challenge.
- We have compiled and curated our dataset specifically for multiclass deepfake identification. This dataset is carefully designed to facilitate the training and evaluation of our deepfake detection model, allowing us to explore the complexities of multiclass classification and improve the accuracy of deepfake identification.
- The proposed fine-tuned ViT model exhibits superior performance to state-of-the-art deepfake identification models.
- Following an extensive analysis, our research firmly establishes the remarkable robustness and generalizability of the proposed method, surpassing numerous state-of-the-art techniques. The findings validate the effectiveness and reliability of our approach in the field of deepfake detection.
2. Related Works
- Attention Mechanism: ViT models utilize self-attention mechanisms, which allow them to capture long-range dependencies within an image. This is crucial for detecting subtle inconsistencies and artifacts that might be present in deepfake images. Deepfake generation often involves stitching or blending different parts of images, and attention mechanisms can help identify these anomalies.
- Global Context: Classic CNNs are great at pulling out details from specific areas, whereas ViT models take in the complete image as a sequence of patches, allowing them to grasp the global context. This difference can be beneficial for deepfake detection, as it lets the model scrutinize the overall structure and consistency of an image.
- Robustness to Manipulations: ViT models might exhibit increased robustness to common manipulation techniques used in deepfake generation. Their attention mechanisms can potentially make them more resistant to simple modifications like noise addition or small alterations in pixel values.
- Interpretable Attention Maps: ViT models generate attention maps that indicate which parts of an image are considered the most important for making predictions. These maps could provide insights into how the model distinguishes between real and deepfake images, aiding in understanding and improving the model’s decision-making process.
3. Proposed Methodology
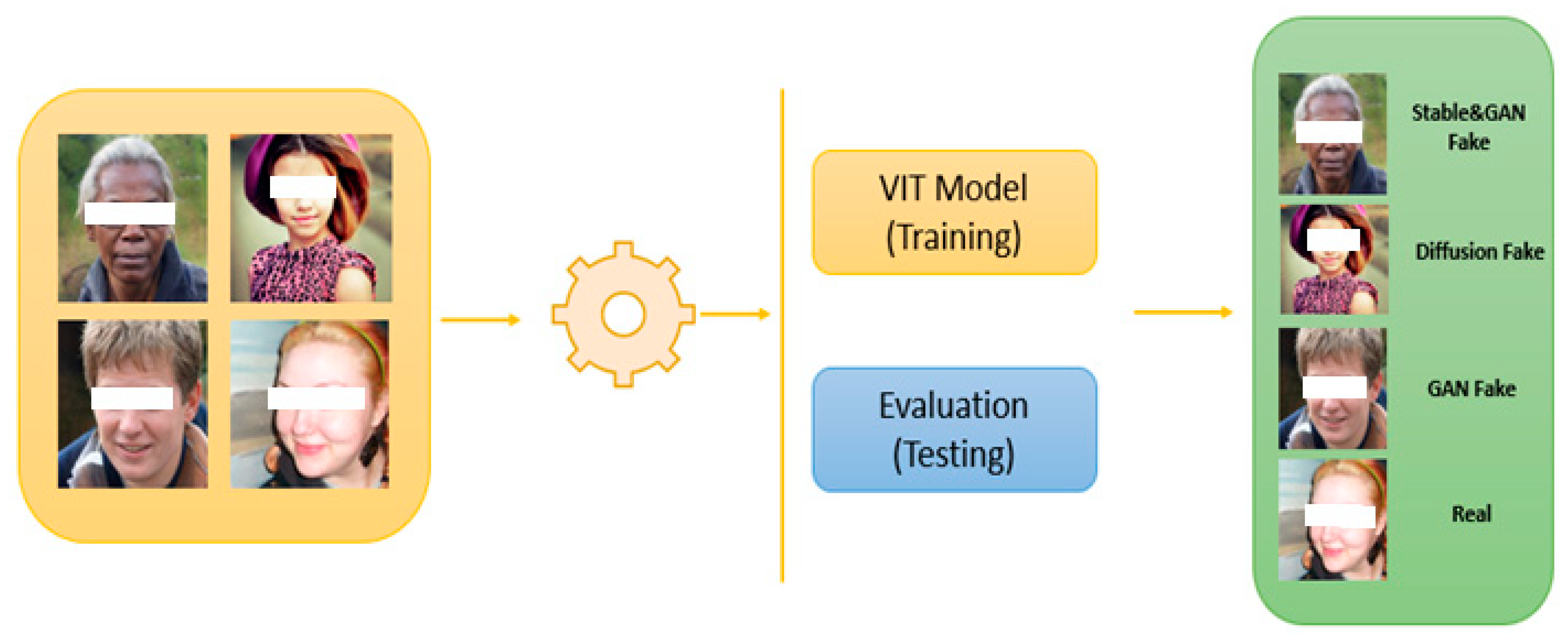
3.1. Dataset
- Real Images: We considered Kaggle [34] for real images; due to the limitation of computation power, we considered 10K images from this source.
- Online Source: We obtained GAN-based fake images from an online source [35]. This source consistently provides new fake images with each visit, enabling us to access a diverse and up-to-date dataset for our analysis and experimentation.
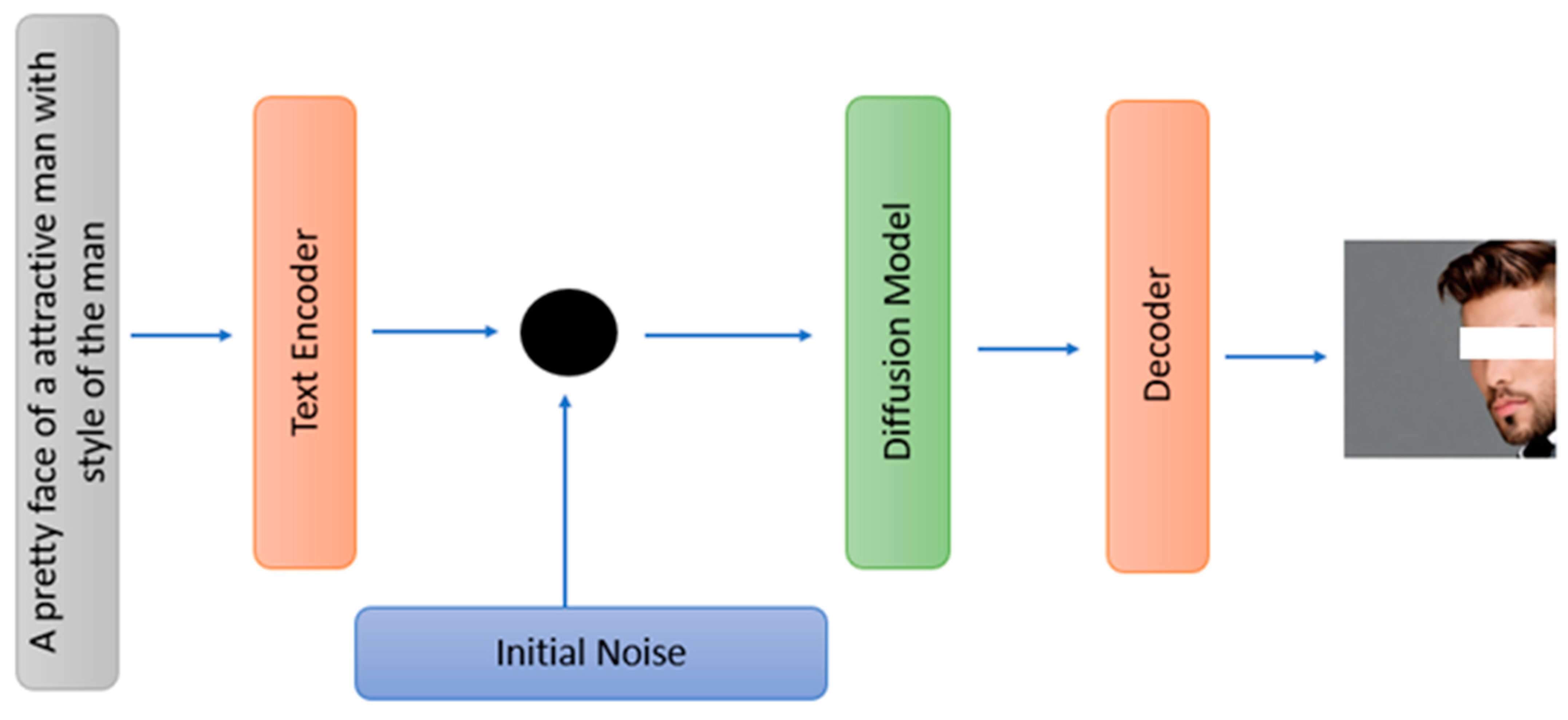
- Stable Diffusion: In this study, we curated a dataset focused on Stable Diffusion, specifically in the context of text-to-image conversion. Stable Diffusion text-to-image conversion involves a method for consistently generating high-quality images from textual descriptions. The primary objective is to create realistic and cohesive images that faithfully represent the provided textual descriptions. This approach utilizes advanced machine learning models and deep learning techniques to achieve this goal. The process of Stable Diffusion text-to-image conversion typically encompasses several key steps, including text encoding, image synthesis, and refinement. During text encoding, the textual descriptions transform into a format compatible with processing by the image synthesis model. Techniques such as word embeddings or attention mechanisms may be employed to capture the semantic meaning of the text. Following this, the image synthesis model utilizes the encoded text to produce a corresponding image, as illustrated in Figure 1. The image synthesis process is geared towards capturing the visual details and context outlined in the text description. To ensure stability and consistency in the image generation process, regularization techniques and control mechanisms may be incorporated. Stable Diffusion text-to-image conversion has various applications, including creative content generation, virtual world creation, and multimedia production. As this technology continues to advance, the generation of fake content and the potential for misuse of such tools are steadily increasing. This trend poses significant challenges and concerns in various domains, such as disinformation campaigns, image manipulation, and privacy breaches. Stable Diffusion based on the conditional Latent Diffusion Model (LDM) and the equation of LDM concerning conditional image pairs can be seen in Equation (1) [36]. In Equation 1, models can be understood as a series of equally weighted denoising autoencoders, denoted as for t = 1...T. These autoencoders are trained to predict a denoised version of their input, where represents a noisy version of the input x.
- StyleGAN2 encoding of Stable Diffusion: This dataset is available on Kaggle [37] with the name Synthetic Faces High Quality (SFHQ). This dataset comprises high-quality 1024 × 1024 curated face images. It was created through a multi-step process. Firstly, a significant number of “text to image” generations were generated, primarily using Stable Diffusion v2.1, along with some from Stable Diffusion v1.4 models. Subsequently, a set of photo-realistic candidate images was generated by encoding these images into the latent space of StyleGAN2 and applying a small manipulation to enhance each image into a high-quality, photo-realistic candidate. This process ensured that the dataset contained diverse and visually appealing face images, enabling us to conduct comprehensive and accurate analyses in our research. The styleGAN2 is mathematically based on a generator network (G), mapping vector (F), noise vector (z), conditional vector (), and style vector (s) to produce the synthesized image; see Equation (2) that is used to synthesize the image x.
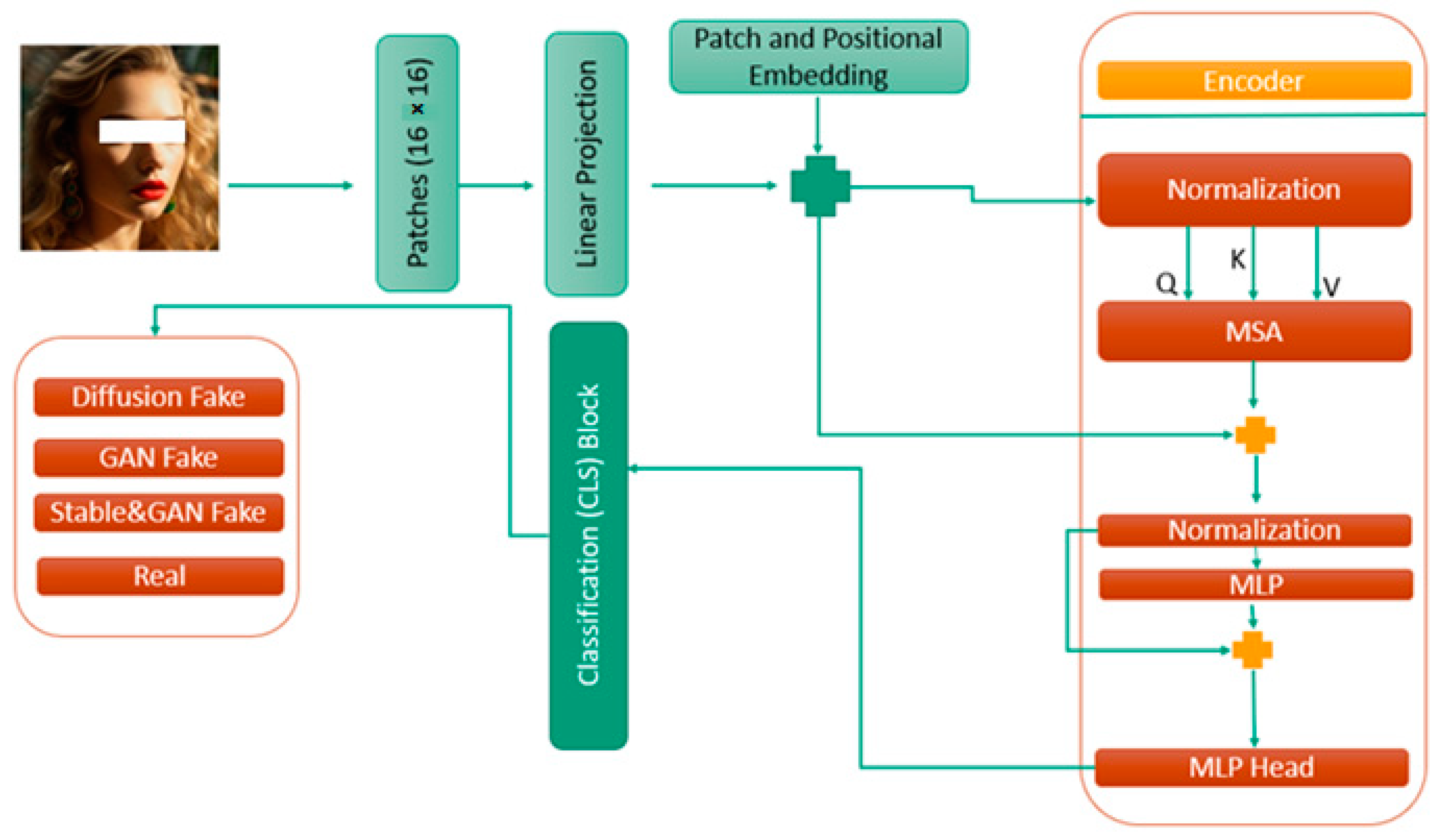
3.2. ViT Architecture
- Patch Embedding: The image patches () are linearly projected to an embedding space by a linear transformation Wpatch (see Equation (5)).
- Positional Embedding: Each patch embedding () is augmented with positional information ( to capture spatial relationships. These positional embeddings are added to the patch embeddings (see Equation (6)).
- Transformer Encoder: The transformer encoder processes the positional embeddings Epos. This encoder comprises several layers, each incorporating self-attention mechanisms and feedforward neural networks. The result of this encoding is a collection of contextualized embeddings, as depicted in Equation (6). Equation (7), (), represents the output representations or embeddings produced by the Transformer encoder for each position in the input sequence.
- Classification Head: The final contextualized embeddings Z are used for downstream tasks. In classification tasks, a classification head takes the average or a specific token’s embedding (e.g., classification token) from Z and passes it through one or more fully connected layers to make predictions.
3.3. ViT Hyper-Parameters
3.4. CNN Architecture-Based Pretrained Models
4. Experiment Results and Discussion
4.1. Evaluation Metrics
- Accuracy: Accuracy is a metric that assesses the overall correctness of the model’s predictions. It calculates the proportion of correctly classified samples out of the total samples. While accuracy is a crucial evaluation measure, it may not be sufficient in certain scenarios, such as imbalanced datasets or cases where different types of errors have varying consequences. In such situations, additional evaluation metrics may be necessary to provide a more comprehensive understanding of the model’s performance and capabilities.
- Precision: Precision (P) is a metric that evaluates a model’s capability to correctly identify positive samples among the predicted positive samples. It calculates the proportion of true positive predictions to the total number of positive predictions (which includes both true positives and false positives). Precision provides valuable insights into how accurately the model detects and classifies positive instances, making it an essential measure in many classification tasks.
- Recall: Recall (R), alternatively termed sensitivity or the true positive rate, gauges the model’s ability to accurately recognize positive samples within the total pool of actual positive samples. It is computed as the ratio of true positives to the sum of true positives and false negatives. Recall signifies the model’s effectiveness in comprehensively capturing positive instances, rendering it a crucial assessment metric in classification tasks.
- F1 Score: The F1 score is computed as the harmonic mean of precision (P) and recall (R), providing a single statistic that balances the two metrics. This makes it particularly useful when dealing with imbalanced class distributions or scenarios where equal emphasis is placed on both types of errors. The F1 score ranges from 0 to 1, with 1 representing the best possible performance of the model. By incorporating both precision and recall, the F1 score offers a comprehensive evaluation of the model’s overall effectiveness in classification tasks.
4.2. Results and Discussion
- Our proposed model weights will be downloaded.
- Install the necessary libraries.
- Extract the model weights that are in the RAR file and load the model.
- Upload an image to Google Colab and set the path in the “img” variable.
- Run the “Prediction” cell to get the class.
4.2.1. Comparison with CNN-Based Pretrained Architectures
4.2.2. Comparison with the Literature Contributions
4.2.3. Implications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TP | True Positive |
| FP | False Positive |
| TN | True Negative |
| TP | True Positive |
| FN | False Negative |
| ViT | Vision Transformer |
| DARPA | Defense Advanced Research Projects Agency |
| GAN | Generative Adversarial Networks |
| ML | Machine Learning |
| DL | Deep Learning |
| CNN | Convolutional Neural Network |
| AI | Artificial Intelligence |
| E | Embeddings |
| Pos | Positional |
References
- Rafique, R.; Gantassi, R.; Amin, R.; Frnda, J.; Mustapha, A.; Alshehri, A.H. Deep fake detection and classification using error-level analysis and deep learning. Sci. Rep. 2023, 13, 7422. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Zhang, C.; Zheng, S.; Zhang, M.; Qamar, M.; Bae, S.-H.; Kweon, I.S. A Survey on Audio Diffusion Models: Text To Speech Synthesis and Enhancement in Generative AI. 2023. Available online: http://arxiv.org/abs/2303.13336 (accessed on 10 August 2023).
- Wu, X.; Xu, K.; Hall, P. A survey of image synthesis and editing with generative adversarial networks. Tsinghua Sci. Technol. 2017, 22, 660–674. [Google Scholar] [CrossRef]
- Wojewidka, J. The deepfake threat to face biometrics. Biom. Technol. Today 2020, 2020, 5–7. [Google Scholar] [CrossRef]
- van der Sloot, B.; Wagensveld, Y. Deepfakes: Regulatory challenges for the synthetic society. Comput. Law Secur. Rev. 2022, 46, 105716. [Google Scholar] [CrossRef]
- Gregory, S. Deepfakes, misinformation and disinformation and authenticity infrastructure responses: Impacts on frontline witnessing, distant witnessing, and civic journalism. Journalism 2021, 23, 708–729. [Google Scholar] [CrossRef]
- AI Deepfake Videos: The Growing Concerns and Potential Harm—DevX. Available online: https://www.devx.com/news/ai-deepfake-videos-the-growing-concerns-and-potential-harm/ (accessed on 9 August 2023).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Available online: https://proceedings.neurips.cc/paper_files/paper/2014/hash/5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html (accessed on 11 July 2023).
- How Deepfakes Deceptions are Affecting Businesses. Available online: https://shuftipro.com/blog/how-deepfakes-deceptions-are-affecting-businesses/ (accessed on 9 August 2023).
- The Dangers of Deepfakes—A Cybersecurity Perspective—IPV Network. Available online: https://ipvnetwork.com/the-dangers-of-deepfakes-a-cybersecurity-perspective/ (accessed on 9 August 2023).
- Diakopoulos, N.; Johnson, D. Anticipating and Addressing the Ethical Implications of Deepfakes in the Context of Elections. New Media Soc. 2020, 23, 2072–2098. [Google Scholar] [CrossRef]
- Nguyen, Q.V.H.; Nguyen, D.T.; Nguyen, D.T.; Huynh-The, T.; Nahavandi, S.; Nguyen, T.T.; Pham, Q.-V.; Nguyen, C.M. Deep learning for deepfakes creation and detection: A survey. Comput. Vis. Image Underst. 2022, 223, 103525. [Google Scholar] [CrossRef]
- Tampubolon, M. Digital Face Forgery and the Role of Digital Forensics. Int. J. Semiot. Law 2023, 1–15. [Google Scholar] [CrossRef]
- Passos, L.A.; Jodas, D.; da Costa, K.A.P.; Júnior, L.A.S.; Rodrigues, D.; Del Ser, J.; Camacho, D.; Papa, J.P. A Review of Deep Learning-based Approaches for Deepfake Content Detection. arXiv 2022, arXiv:2202.06095. [Google Scholar]
- Media Forensics. Available online: https://www.darpa.mil/program/media-forensics (accessed on 9 August 2023).
- Facebook, Microsoft Back Contest to Better Detect Deepfakes|WIRED. Available online: https://www.wired.com/story/facebook-microsoft-contest-better-detect-deepfakes/ (accessed on 9 August 2023).
- Akhtar, Z.; Mouree, M.R.; Dasgupta, D. Utility of Deep Learning Features for Facial Attributes Manipulation Detection. In Proceedings of the 2020 IEEE International Conference on Humanized Computing and Communication with Artificial Intelligence (HCCAI), Irvine, CA, USA, 21–23 September 2020; pp. 55–60. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. 2016. Available online: https://arxiv.org/abs/1602.07360v4 (accessed on 12 July 2023).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; Available online: https://arxiv.org/abs/1409.1556v6 (accessed on 12 July 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Agarwal, S.; Varshney, L.R. Limits of Deepfake Detection: A Robust Estimation Viewpoint. 2019. Available online: https://arxiv.org/abs/1905.03493v1 (accessed on 9 August 2023).
- Akhtar, Z.; Dasgupta, D. A Comparative Evaluation of Local Feature Descriptors for DeepFakes Detection. Available online: https://ieeexplore.ieee.org/abstract/document/9033005/ (accessed on 11 July 2023).
- Bekci, B.; Akhtar, Z.; Ekenel, H.K. Cross-Dataset Face Manipulation Detection. In Proceedings of the 2020 28th Signal Processing and Communications Applications Conference (SIU), Gaziantep, Turkey, 5–7 October 2020; pp. 1–4. [Google Scholar]
- Li, Y.; Chang, M.-C.; Lyu, S. In Ictu Oculi: Exposing AI Created Fake Videos by Detecting Eye Blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Eyebrow Recognition for Identifying Deepfake Videos|IEEE Conference Publication|IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/9211068/authors#authors (accessed on 12 July 2023).
- Patel, M.; Gupta, A.; Tanwar, S.; Obaidat, M.S. Trans-DF: A Transfer Learning-based end-to-end Deepfake Detector. In Proceedings of the 2020 IEEE 5th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 30–31 October 2020; pp. 796–801. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. How do the hearts of deep fakes beat? deep fake source detection via interpreting residuals with biological signals. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September—1 October 2020; pp. 1–10. [Google Scholar]
- Yang, J.; Xiao, S.; Li, A.; Lu, W.; Gao, X.; Li, Y. MSTA-Net: MSTA-Net: Forgery detection by generating manipulation trace based on multi-scale self-texture attention. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4854–4866. [Google Scholar] [CrossRef]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. Available online: https://openaccess.thecvf.com/content/CVPR2021/html/Zhao_Multi-Attentional_Deepfake_Detection_CVPR_2021_paper.html?ref=https://githubhelp.com (accessed on 12 July 2023).
- Wang, J.; Wu, Z.; Ouyang, W.; Han, X.; Chen, J.; Jiang, Y.-G.; Li, S.-N. M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection. In Proceedings of the ICMR’22: International Conference on Multimedia Retrieval, Newark, NJ, USA, 27–30 June 2022. [Google Scholar]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A Survey of Visual Transformers. Available online: https://ieeexplore.ieee.org/abstract/document/10088164/ (accessed on 9 August 2023).
- k Real and Fake Faces|Kaggle. Available online: https://www.kaggle.com/datasets/xhlulu/140k-real-and-fake-faces (accessed on 12 July 2023).
- thispersondoesnotexist.com (1024 × 1024). Available online: https://thispersondoesnotexist.com/ (accessed on 12 July 2023).
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 10674–10685. [Google Scholar]
- Synthetic Faces High Quality (SFHQ) Part 4|Kaggle. Available online: https://www.kaggle.com/datasets/selfishgene/synthetic-faces-high-quality-sfhq-part-4 (accessed on 2 August 2023).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 2020. Available online: https://arxiv.org/abs/2010.11929v2 (accessed on 12 May 2023).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Performance Metrics: Confusion matrix, Precision, Recall, and F1 Score|by Vaibhav Jayaswal|Towards Data Science. Available online: https://towardsdatascience.com/performance-metrics-confusion-matrix-precision-recall-and-f1-score-a8fe076a2262 (accessed on 21 December 2023).
- Gandhi, A.; Jain, S. Adversarial Perturbations Fool Deepfake Detectors. Available online: https://ieeexplore.ieee.org/abstract/document/9207034/ (accessed on 13 July 2023).
- Hu, S.; Li, Y.; Lyu, S. Exposing GaN-generated faces using inconsistent corneal specular highlights. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2500–2504. [Google Scholar]
- Yousaf, B.; Usama, M.; Sultani, W.; Mahmood, A.; Qadir, J. Fake visual content detection using two-stream convolutional neural networks. Neural Comput. Appl. 2022, 34, 7991–8004. [Google Scholar] [CrossRef]
- Lyu, S. DeepFake Detection. In Advances in Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2022; pp. 313–331. [Google Scholar] [CrossRef]
- Huang, B.; Wang, Z.; Yang, J.; Ai, J.; Zou, Q.; Wang, Q.; Ye, D. Implicit Identity Driven Deepfake Face Swapping Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 4490–4499. [Google Scholar]
- Raza, A.; Munir, K.; Almutairi, M. A Novel Deep Learning Approach for Deepfake Image Detection. Appl. Sci. 2022, 12, 9820. [Google Scholar] [CrossRef]
- Arshed, M.A.; Alwadain, A.; Ali, R.F.; Mumtaz, S.; Ibrahim, M.; Muneer, A. Unmasking Deception: Empowering Deepfake Detection with Vision Transformer Network. Mathematics 2023, 11, 3710. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real | GAN_Fake | Diffusion Fake | Stable&GAN Fake |
|---|---|---|---|
 |  |  |  |
| Parameters | Values |
|---|---|
| Transformer Encoder Hidden Layers | 12 |
| Hidden Layer Activation | Gelu |
| Channels | 3 |
| Patches | 16 × 16 |
| Balanced | True |
| Learning Rate | 2 × 10−5 |
| Epochs | 5 |
| Dataset | Diffusion_Fake | GAN_Fake | Real | Stable&GAN_Fake | Total |
|---|---|---|---|---|---|
| Train | 7203 | 7192 | 7203 | 7204 | 28,802 |
| Validation | 1800 | 1798 | 1800 | 1800 | 7198 |
| Test | 997 | 1010 | 997 | 996 | 4000 |
| Class Name | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| Diffusion_Fake | 1.0000 | 1.0000 | 1.0000 | 997 |
| GAN_Fake | 1.0000 | 0.9960 | 0.9980 | 1010 |
| Real | 1.0000 | 1.0000 | 1.0000 | 997 |
| Stable&GAN_Fake | 0.9960 | 1.0000 | 0.9980 | 996 |
| Images | Predicted | Actual |
|---|---|---|
 | GAN_Fake | GAN_Fake |
 | Diffusion_Fake | Diffusion_Fake |
 | Stable&GAN_Fake | Stable&GAN_Fake |
 | Real | Real |
 | Diffusion_Fake | Real |
| Model | Train Accuracy | Validation Accuracy | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
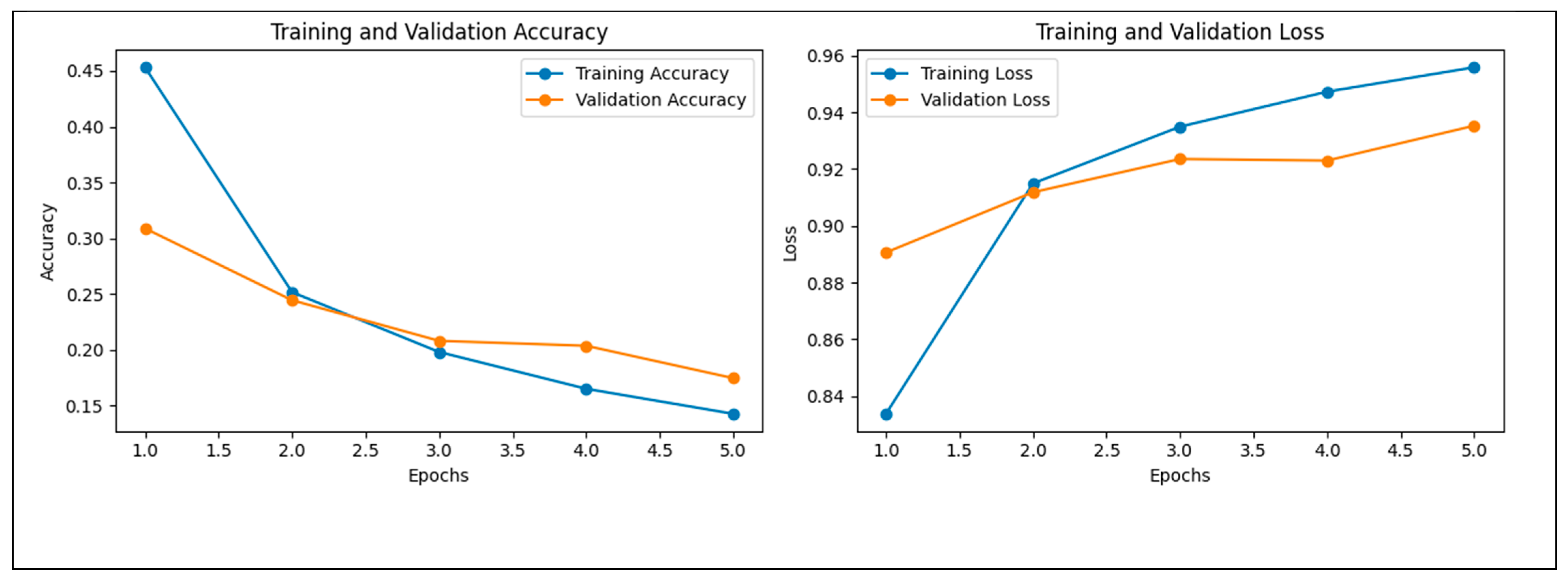
| ResNet-50 | 0.77 | 0.78 | 0.77 | 0.80 | 0.77 | 0.78 |
| VGG-16 | 0.95 | 0.93 | 0.94 | 0.94 | 0.94 | 0.94 |
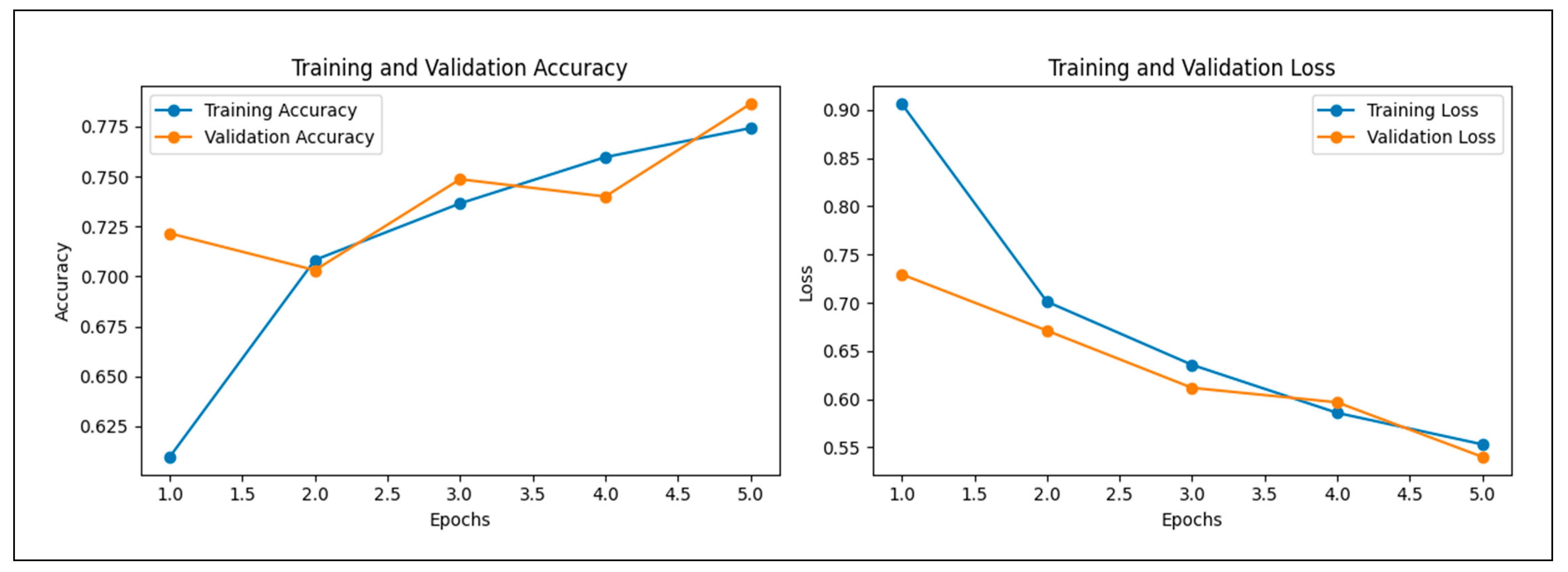
| Proposed | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Authors | Methodology | Dataset | Classes | Accuracy (%) |
|---|---|---|---|---|
| (Gandhi et al., 2020) [41] | Pretrained ResNet Model | 10,000 Images | 2 | 94.75% |
| (Hu et al., 2021) [42] | Highlights of Corneal Specular | 1000 Images | 2 | 90.48% |
| (Yousaf et al., 2022) [43] | CNN Based on Two Stream | 11,982 Images | 2 | 90.65% |
| (Haung et al., 2022) [45] | Implicit Identity-Driven Framework employing Explicit Identity Contrast (EIC) and Implicit Identity Exploration (IIE) losses | 10,000 videos DeepFakesofFF++(C23) and FaceShifter | 2 | 67.99–88.21% |
| (Raza et al., 2022) [46] | Hybrid (VGG16 and CNN) | 2041 Images | 2 | 94% |
| (Arshed et al., 2023) [47] | Transformer | 100,000 Images | 2 | 99.5–100% |
| Proposed (Experiment 1) | ResNet-50 | 40,000 Images | 4 | 77% |
| Proposed (Experiment 2) | VGG-16 | 40,000 Images | 4 | 94% |
| Proposed (Experiment 3) | ViT | 40,000 Images | 4 | 99.90% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arshed, M.A.; Mumtaz, S.; Ibrahim, M.; Dewi, C.; Tanveer, M.; Ahmed, S. Multiclass AI-Generated Deepfake Face Detection Using Patch-Wise Deep Learning Model. Computers 2024, 13, 31. https://doi.org/10.3390/computers13010031
Arshed MA, Mumtaz S, Ibrahim M, Dewi C, Tanveer M, Ahmed S. Multiclass AI-Generated Deepfake Face Detection Using Patch-Wise Deep Learning Model. Computers. 2024; 13(1):31. https://doi.org/10.3390/computers13010031
Chicago/Turabian StyleArshed, Muhammad Asad, Shahzad Mumtaz, Muhammad Ibrahim, Christine Dewi, Muhammad Tanveer, and Saeed Ahmed. 2024. "Multiclass AI-Generated Deepfake Face Detection Using Patch-Wise Deep Learning Model" Computers 13, no. 1: 31. https://doi.org/10.3390/computers13010031
APA StyleArshed, M. A., Mumtaz, S., Ibrahim, M., Dewi, C., Tanveer, M., & Ahmed, S. (2024). Multiclass AI-Generated Deepfake Face Detection Using Patch-Wise Deep Learning Model. Computers, 13(1), 31. https://doi.org/10.3390/computers13010031