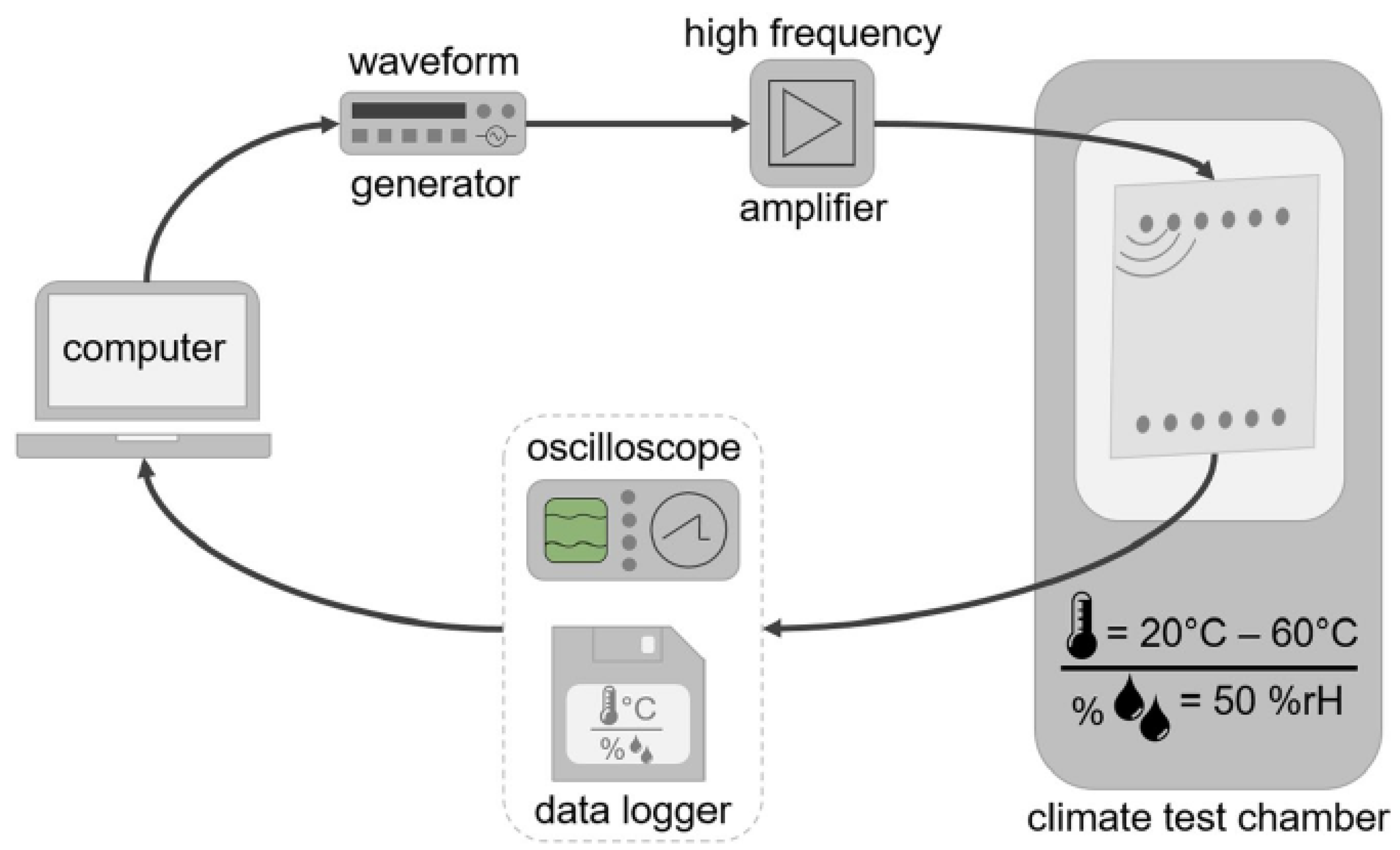
Another observation is that the models trained with the original data exhibit higher errors than the models trained with synthetic data. This applies to the original and the synthetic test sets. It can also be seen that the error of the models trained with synthetic data is approximately the same for both test sets, while the errors for the test sets of the models trained with the original data differ significantly. This suggests that the models trained with synthetic data are not only more accurate but also more stable than the models trained with the original data.
In the following sections, the different ANN architectures and different datasets will be investigated in more detail. For that, the errors of the models trained with synthetically generated data will be analyzed and compared in more detail. With that, it will be shown that models trained with these data have a low mean relative error (MRE). But, for the XANN, outliers occur with a higher deviation from the true damage positions (up to approx. 3% of ), which cannot be observed for the classic ANN. The XANN architecture will be used to examine these outliers and find the reason behind the high deviations.
5.2. XANN
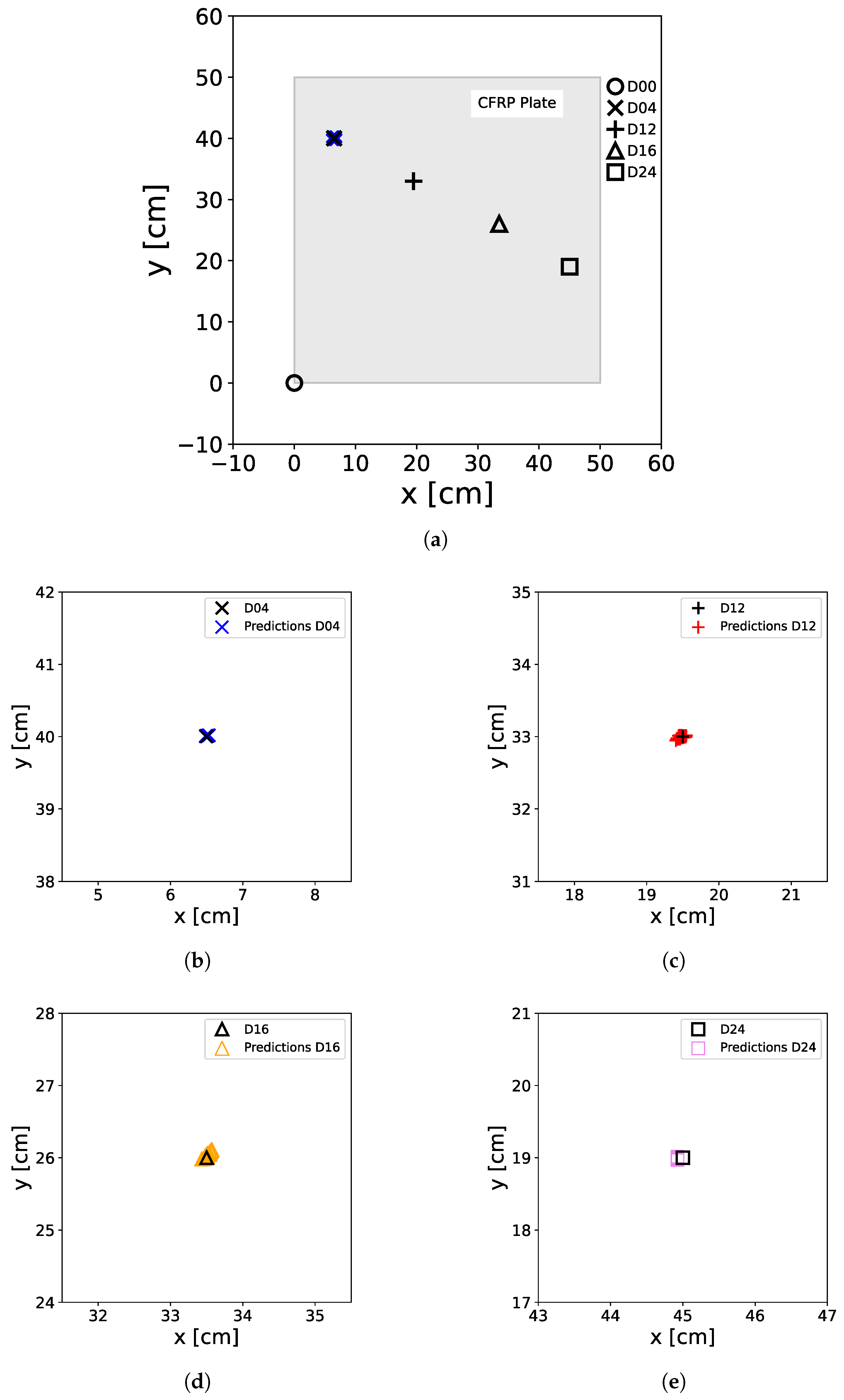
The XANN underwent training and testing following the same procedure as outlined for the ANN. The resulting predictions of the trained XANN can be seen in
Figure 17. The performance is comparable to
Figure 13 and
Figure 16. However, in the zoomed-in images of
Figure 17, it can be observed that the predictions are more scattered around the damage locations compared to the normal ANN. It also shows greater errors. But, also with the XANN, no false predictions could be observed.
Table 5 displays the ER corresponding to the predictions shown in
Figure 17. Remarkably, the errors in the XANN have increased compared to the classic ANN. However, they still fall within an acceptable range, reaching up to
of
. It is noteworthy that the maximum ER deviates more from the mean ER in the XANN models than in the classical ANN models.
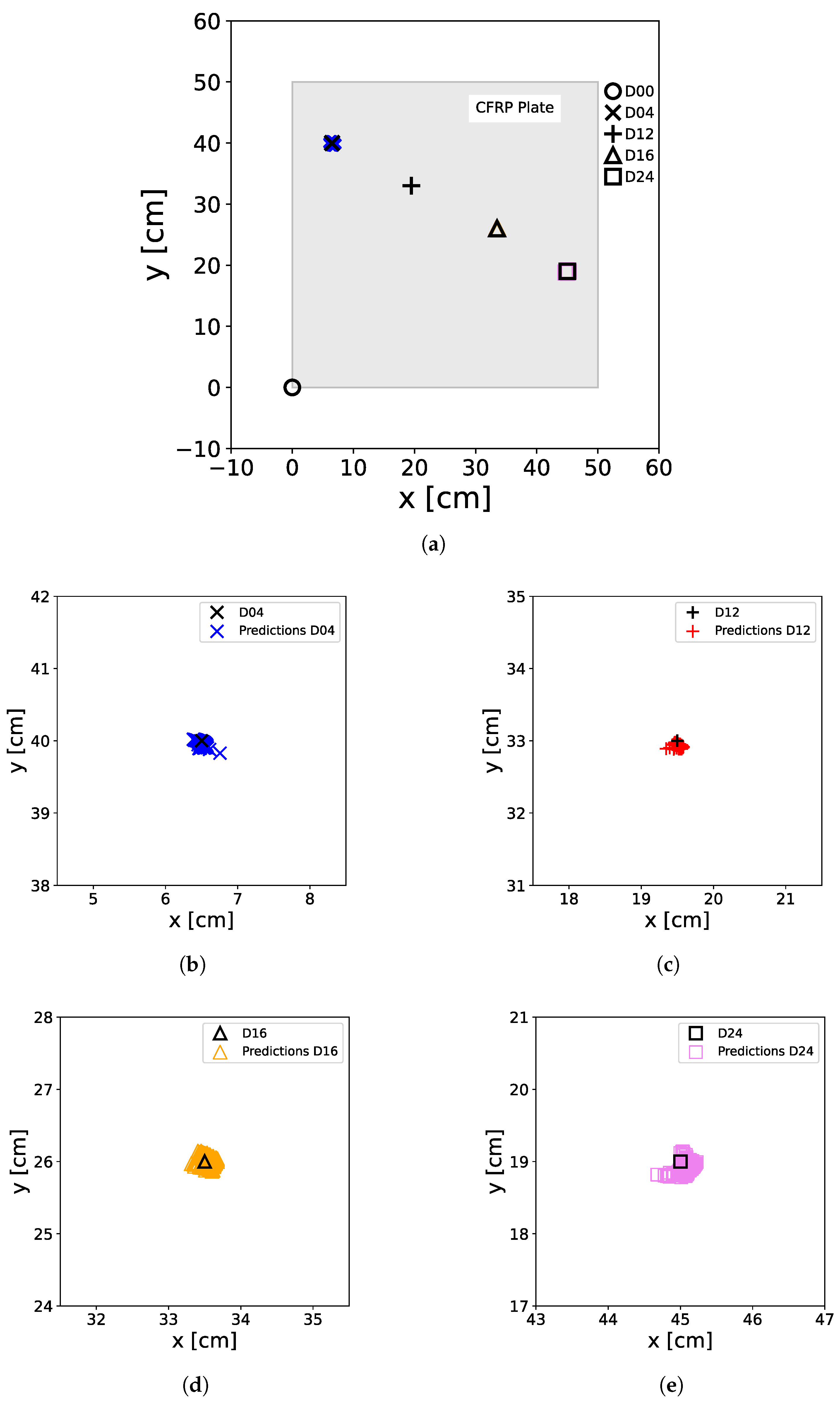
However, to further explore the explanatory capabilities of the XANN, a test set was selected that included 1000 artificially generated feature values. This approach was adopted due to the fact that the initial test set does not encompass the entire spectrum of feature values present in the training set. A comparison between
Figure 5 and
Figure 12 further illustrates this point. By using this test set, it can be demonstrated that the XANN is still able to accurately predict the damage status. The predictions of the XANN for this test set are depicted in
Figure 18. However, in the zoomed-in images of
Figure 18b–e, it can be observed that the distribution of the predictions around the damage positions is more scattered and has a larger error than the predictions in
Figure 13,
Figure 16 and
Figure 17. The error can even be greater than 1 cm, resulting in outliers that are quite far from the point cloud of distributed predictions.
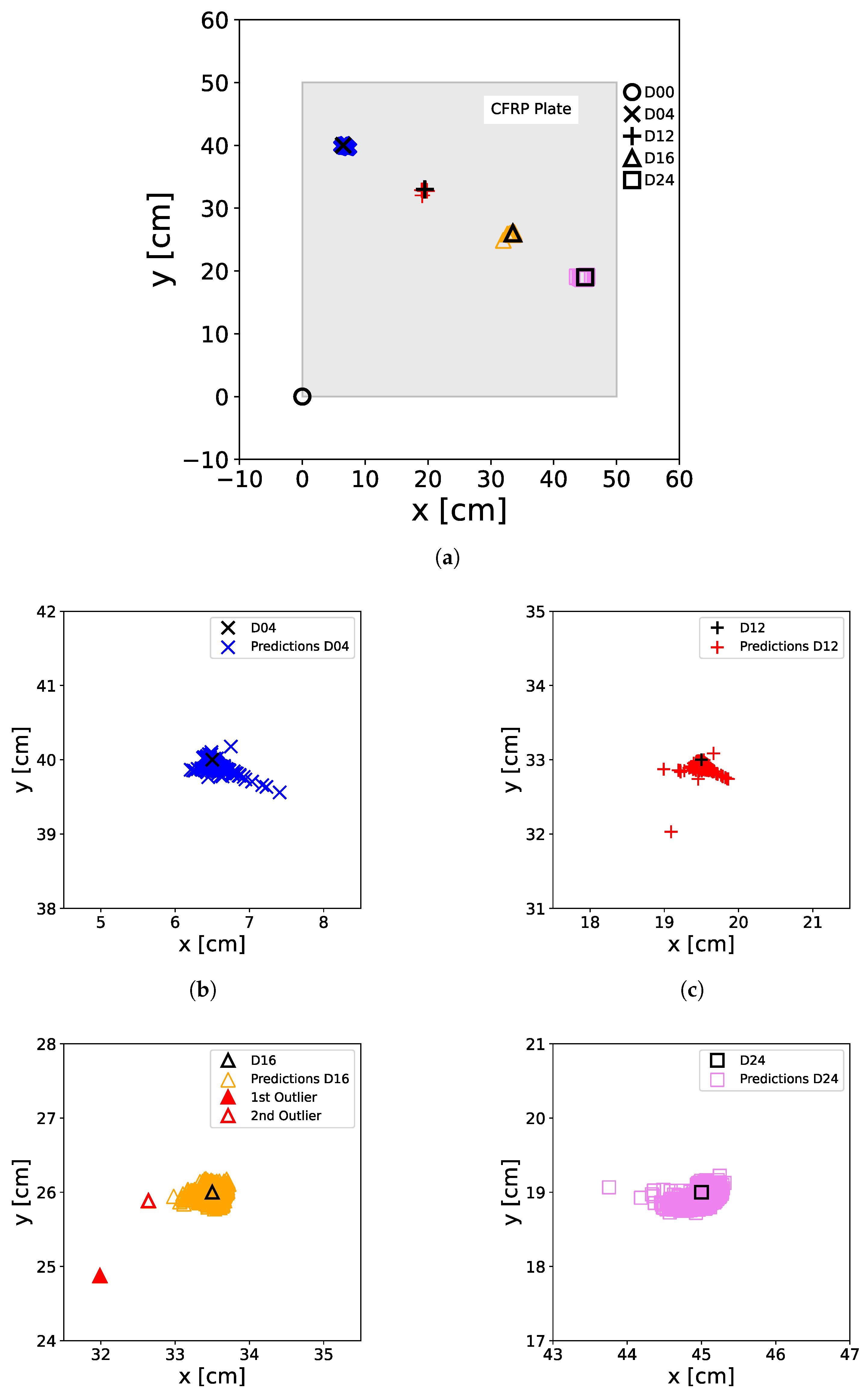
Figure 18d highlights two of these outliers, which will be further examined later. Nonetheless, no false predictions were observed.
Table 6 presents the RE generated by the XANN model when utilizing the sampled data as input. As illustrated in
Figure 18, the errors in this scenario show an increase, attributed to the higher variance present in the input data (compare, e.g.,
Figure 5 with
Figure 12). The maximum error of D16 corresponds to outlier 1 from
Figure 18d and is with approx.
of
, which is much higher than the mean ER of D16. Even outlier 2, with an error of approx.
, is relatively small compared to this.
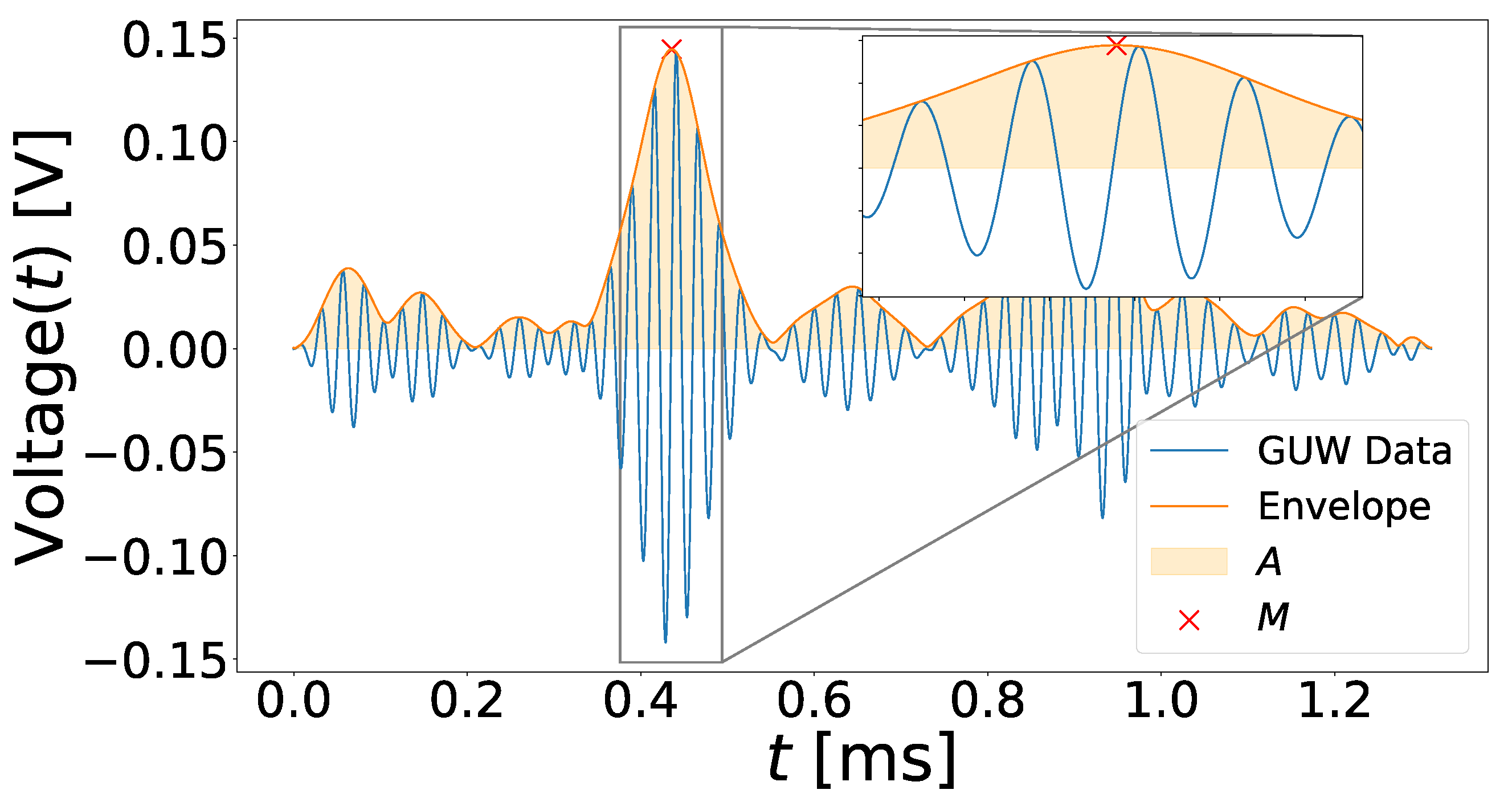
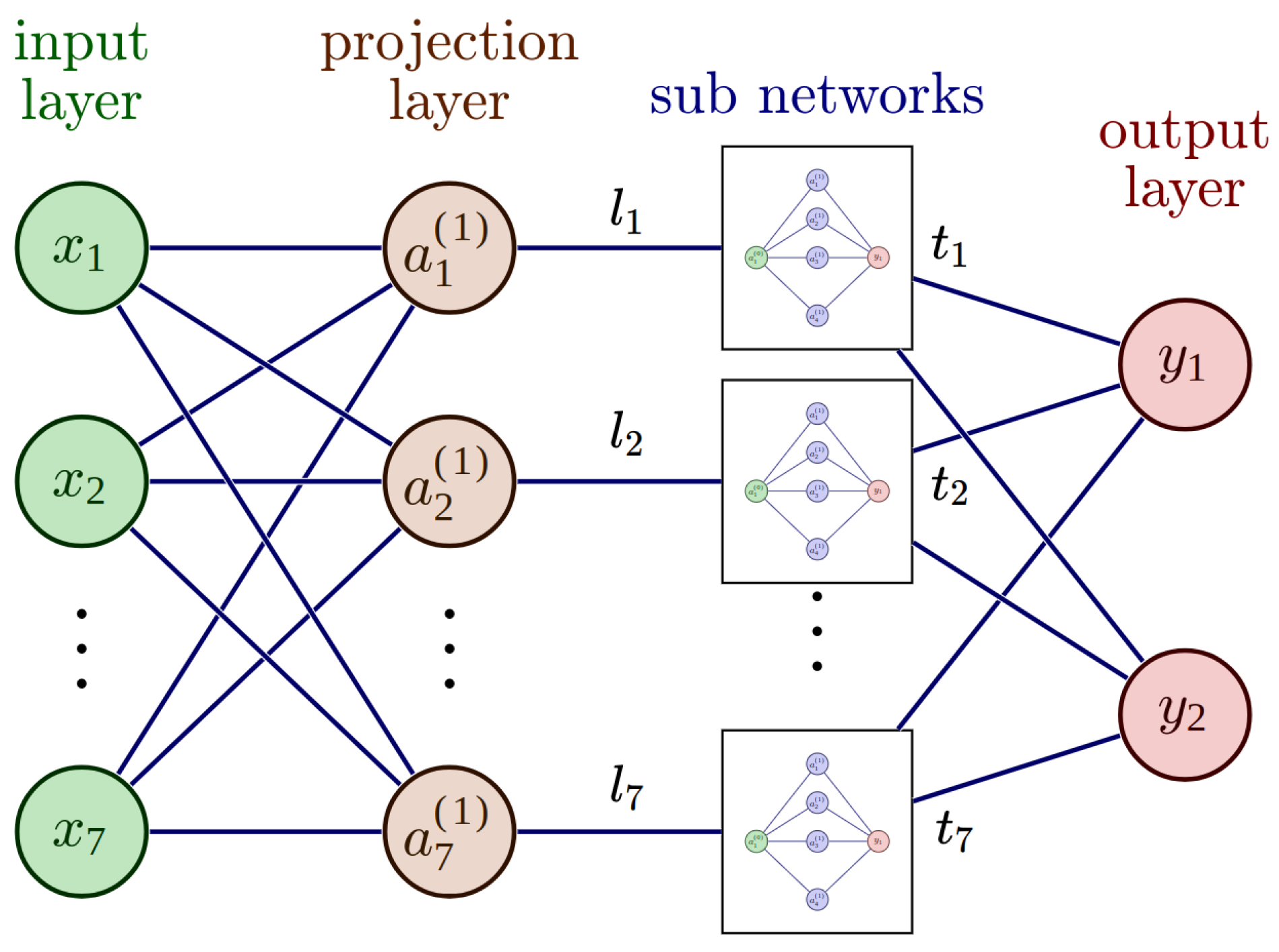
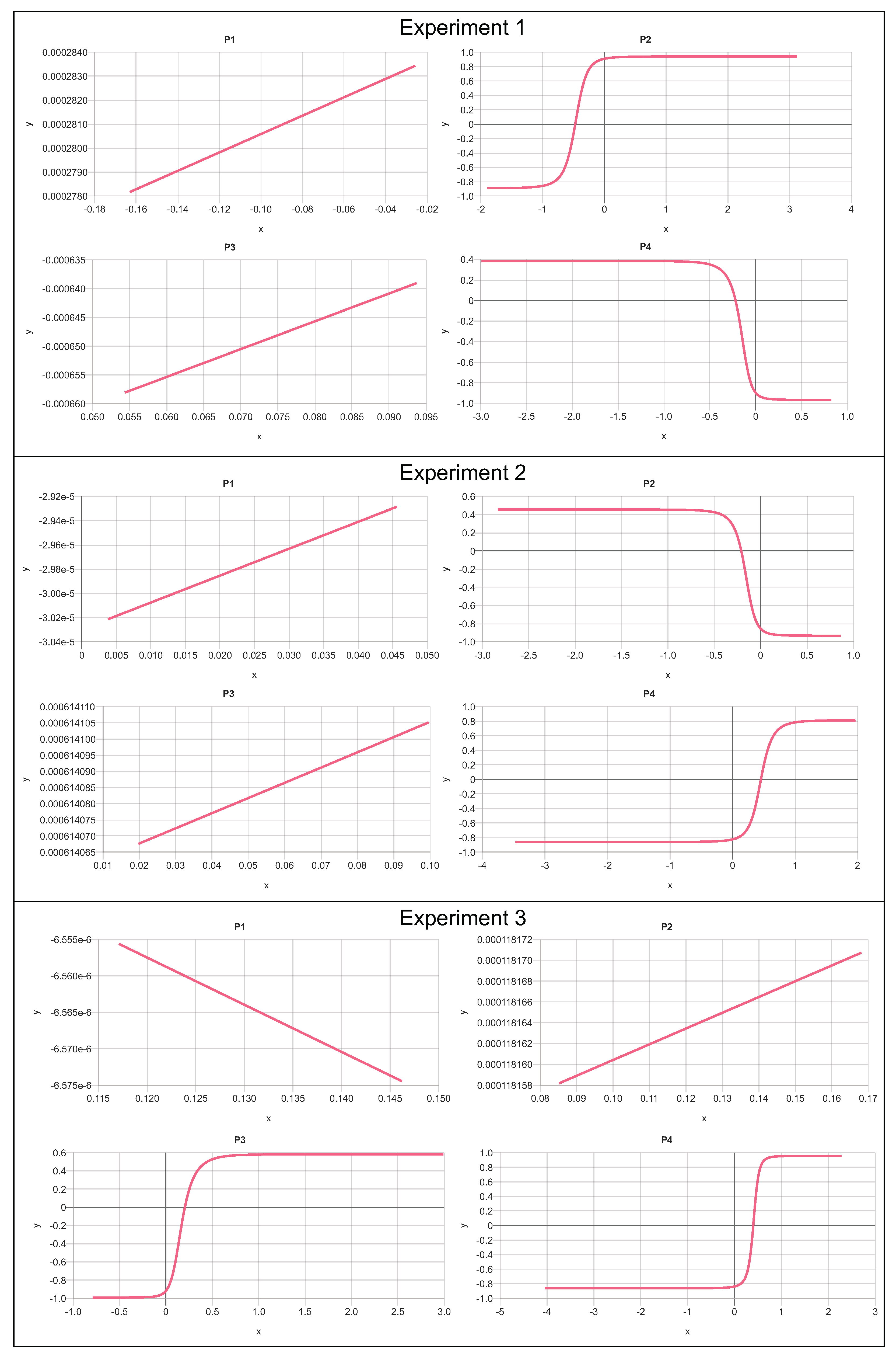
To investigate the XANN model’s explanatory possibilities, the outputs of the subnetworks are studied as functions of their inputs. Since the input of each subnetwork is the output of the corresponding projection node, the input–output relationship can be visualized. For a reasonable visualization of the subtransfer functions, the minimum and maximum values of their inputs were computed. To generate input arrays for each subnetwork that cover the entire relevant value range of the transfer functions, the minimum and maximum were used as boundaries. The generated input arrays consist of 1000 data points and start with the minimum value and increase with every entry until the maximum is reached in the last entry of the array.
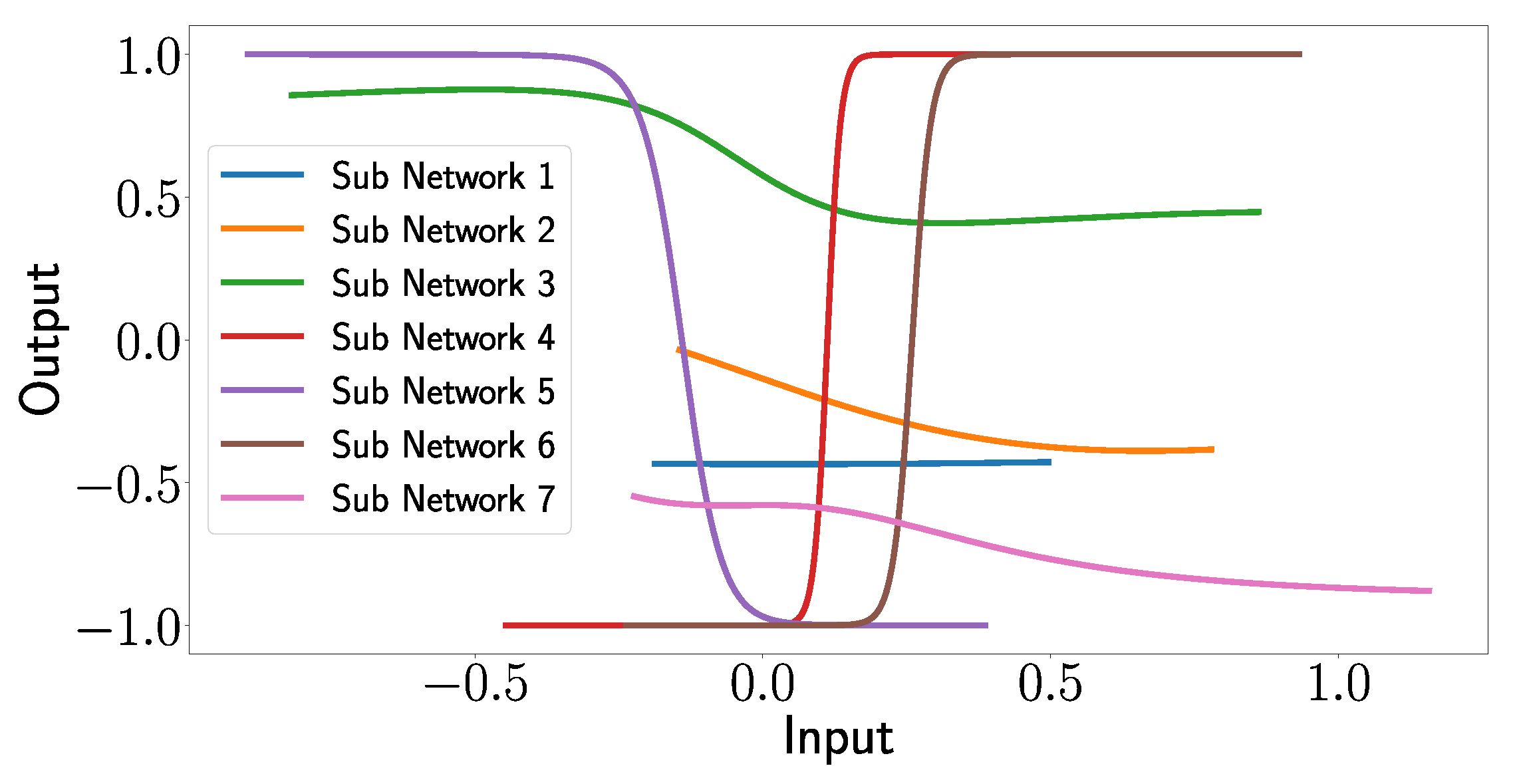
In
Figure 19, the outputs of the subnetworks are plotted as functions of the input arrays, which demonstrates the explanatory capabilities of the XANN. The deeper analysis of the input–output relationship shows an interesting pattern.
One can see that the transfer functions of subnetworks 1, 2, and 7 seem to correspond to a quadratic function (subnetwork 1) or higher-degree polynomials (subnetworks 2 and 3). However, what is more remarkable and interesting is that subnetworks 3, 4, 5, and 6 correspond to shifted tangent hyperbolic and tangent hyperbolic functions multiplied by −1, respectively. This is not surprising since, as mentioned above, the networks use tangent hyperbolic functions as activation functions, whereas the shifts and the multiplication by −1 is probably explained by the learned weights of the nodes in the subnetworks. Later, we will see that the transfer functions of subnetworks 3, 4, 5, and 6 lead to strict separations of the output values with respect to the damage cases.
Given that all output values fall within the range of −1 to 1, it is reasonable to expect that by appropriately weighting the output layer and summing the subnetwork outputs, values between zero and one can be generated. This range corresponds to the scaled positions of the damage labels (ranging from 0.2 to 1), while the damage-free case is represented by the [0,0] position. Thus, the XANN demonstrates its ability to predict the X and Y positions of the damage based on these generated values.
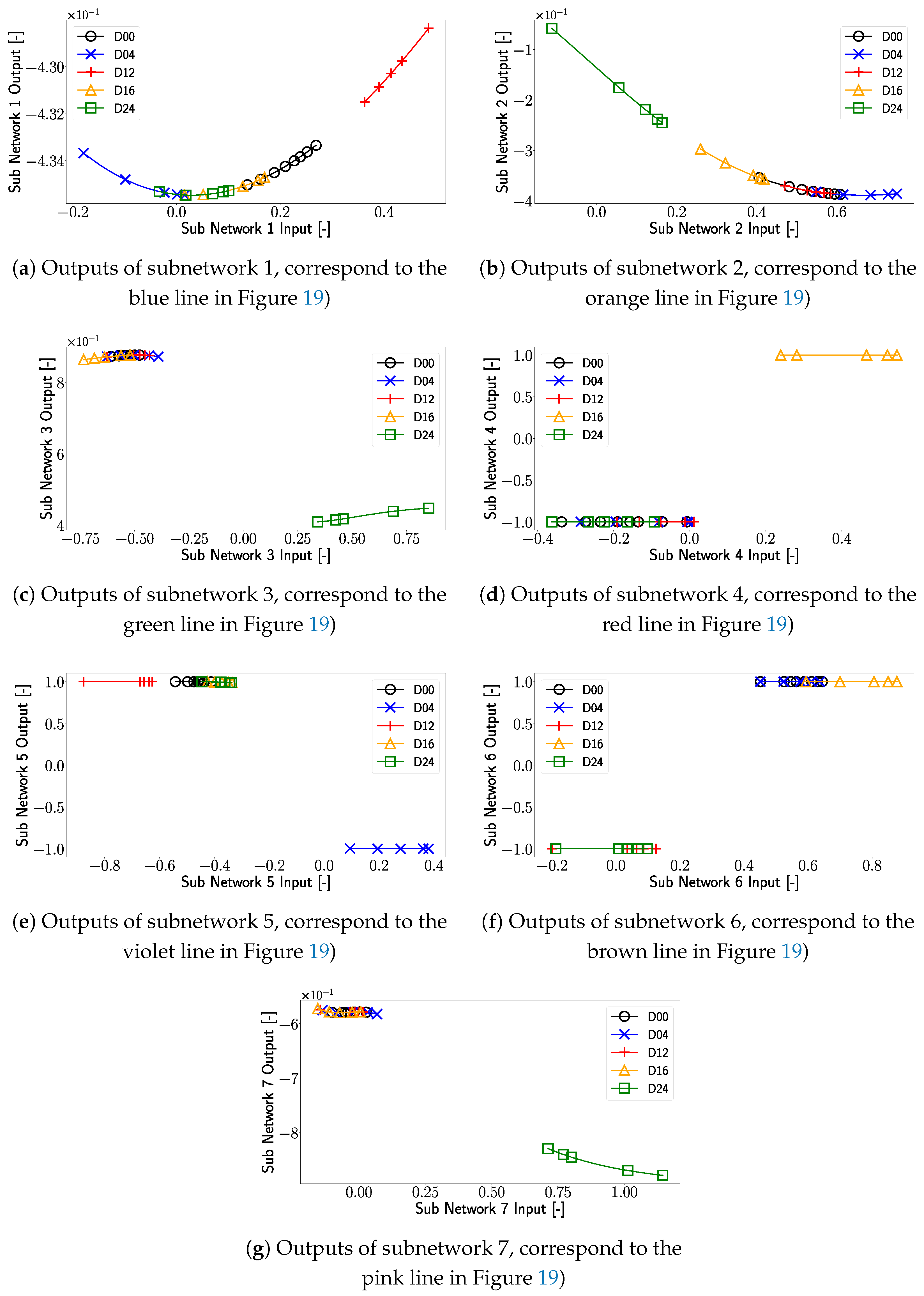
To gain more insights into the decision-making process of the XANN model, the outputs of the subnetworks are investigated with respect to the different damage cases. At first, the test set used in
Figure 5 containing the original data was used as input for the trained subnetworks. Whereby the input features can be related to the corresponding damage cases. The images of these input–output plots are shown in
Figure 18. Note that the range of input and output values differs from subplot to subplot.
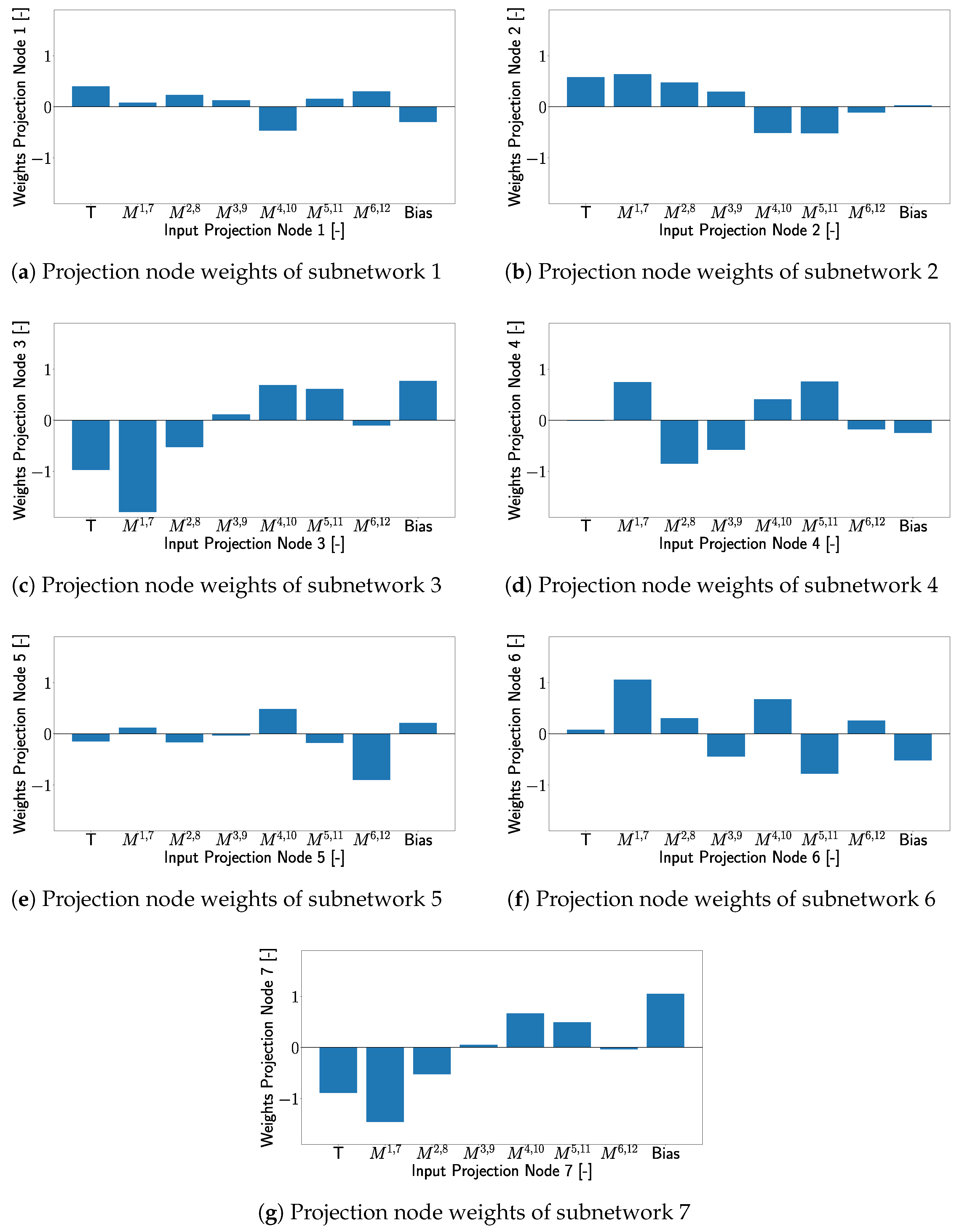
To gain a deeper understanding of the processes in the XANN, the weights of the individual projection layer nodes with respect to the node inputs are listed in Figure 21. Since the individual projection nodes serve as input for the respective subnetworks, this approach allows us to examine the influence of the individual input features on the subnetworks. The subfigures in Figure 21 are arranged in such a way that, e.g., Figure 21a correspond to the weights of the nodes corresponding to the subnetwork from
Figure 20a and so on.
For further investigation, subnetwork 5 will be presented and analyzed as an example in the following. A compressed examination of all the subnetworks can be found as bullet points in
Appendix A.
In
Figure 20e, the outputs of subnetwork 5 are displayed. One can see that the transfer function of subnetwork 5 corresponds to a shifted and negatively multiplied tangent hyperbolic function (violet line in
Figure 20). Taking a closer look at
Figure 20e, one can see that only the linear parts of the tangent hyperbolic function are used, which leads to a clear separation of the different damage cases. To be more precise, a separation of Damage D04 from the other damage cases is realized.
Turning our attention to
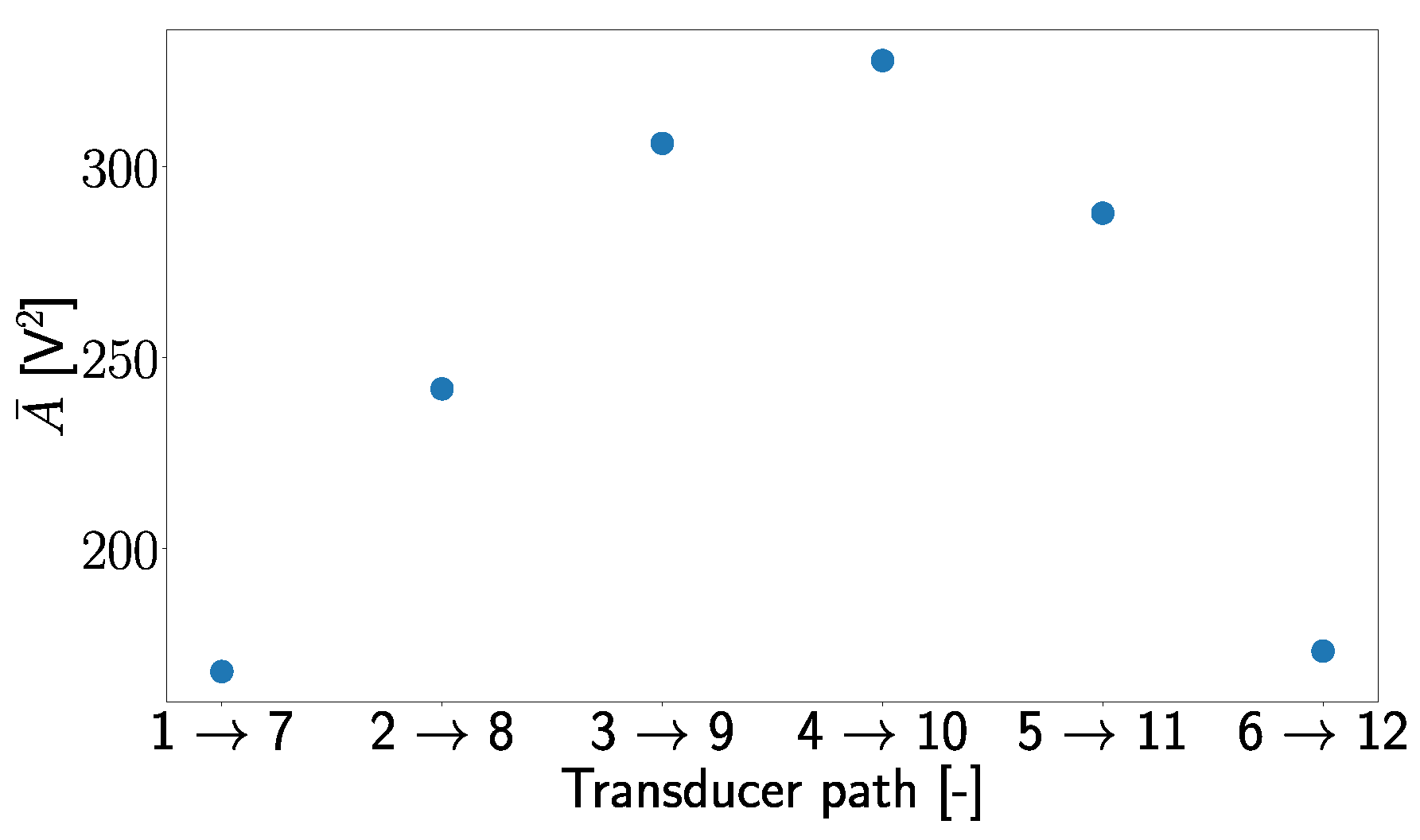
Figure 21e, one can see that transducer path
is the most influential feature for subnetwork 5. Looking at
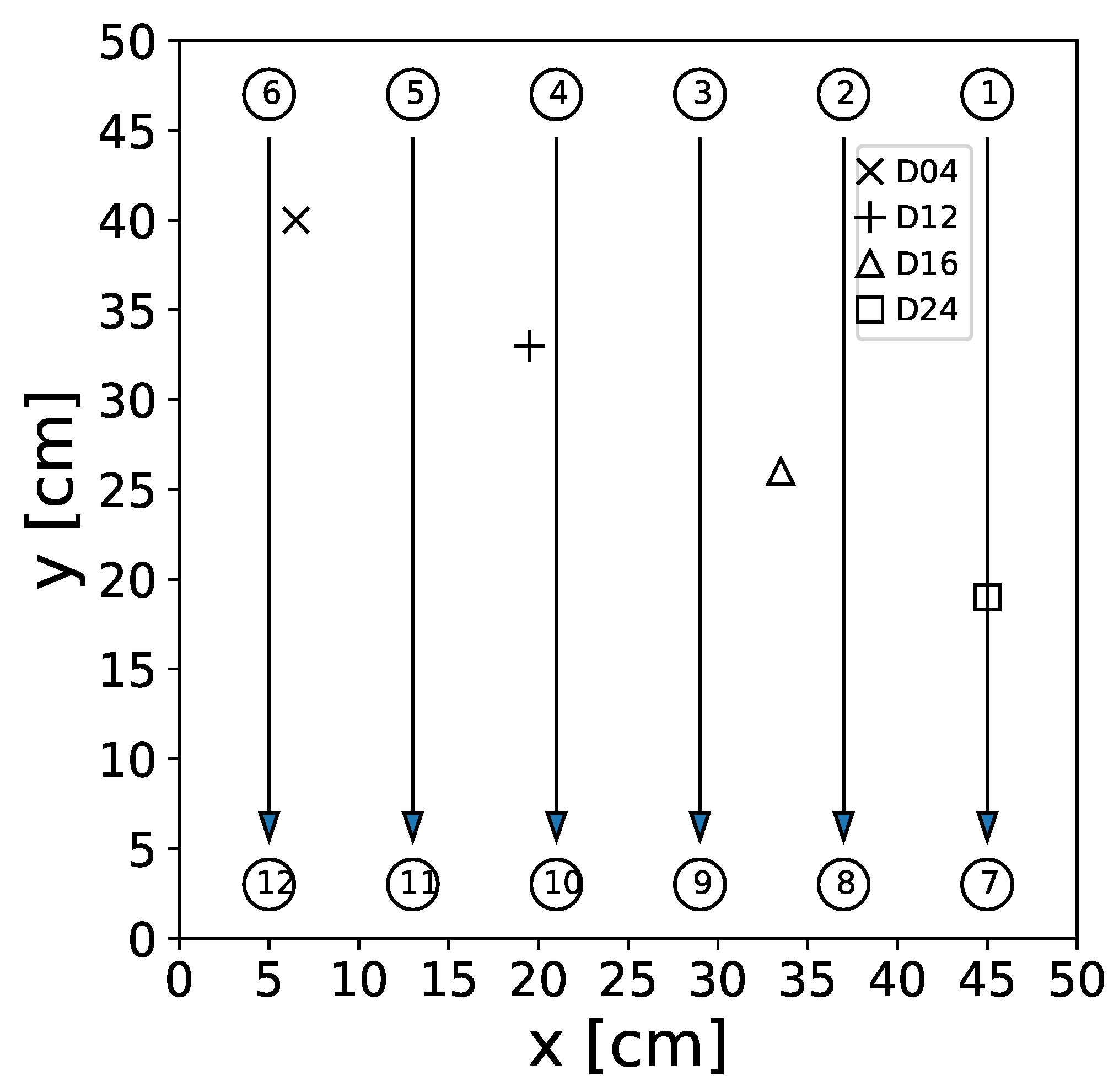
Figure 2, it can be seen that damage D04 is located very close to transducer path
, which results in a significant signal and feature modification in this transducer path due to this damage. Due to this spatial correlation of D04 and path
, subnetwork 5 separates the damage D04 where the signal from transducer path
experiences a change (detects damage) from the cases where no or just small changes are measured in this transducer path (no damage is detected).
This indicates that for transducer path
that influences subnetwork 5 the most, the subnetwork differentiates between damage cases that can be detected from path
and those that cannot be detected from path
. This pattern can be observed in all subnetworks with transfer functions similar to a varied tangent hyperbolic function, where each damage case could be clearly separated in at least one subnetwork from the cases where no damage was detected, as can be seen in
Figure 20c–f. The separation of different damage cases, especially from the undamaged case, relies on the projection layer weights. These weights are important to identify the input features that have the most influence on the subnetwork and thus affects the influence of the transducer paths. Due to this damage, cases that are close to the most influential transducer paths of a subnetwork are more likely to be effectively separated from this subnetwork, as described in more detail in
Appendix A. In cases where the transfer function differs from a varied tangent hyperbolic function, the separation of the damage cases is less distinct and is more like a gradual transition. Similar to the linear transfer functions in
Section 3.2, these transfer functions have only a small impact on XANN’s prediction process.
It should be mentioned here that the shape and forms of the transfer functions of the subnetworks are different for every new trained model, as mentioned before in
Section 3.2. This is due to the fact that for every training, different random initial weights are used, which leads to different influences of the input values on the subnetworks and, therefore, different transfer functions. But, it was shown that for every trained XANN model, some subnetworks applied a varied tangent hyperbolic function as a transfer function, similar to the results in
Section 3.2. In
Figure 22, the subnetwork transfer functions of a newly trained UGW data XANN are shown. As before, these transfer functions are sensitive to the most influential transducer paths and separate the damage cases where the damage was detected from these paths from those that were not detected from these paths. The influence of the inputs on a certain subnetwork is defined by the weights of the projection layer.
By analyzing the overall architecture of the XANN, one can see that the outputs of the subnetworks are used as inputs for the subsequent output layer and that the subnetworks constrain the inputs of the output layer within specific value ranges. It is important to remember that the labels of the x- and y-positions of the damage cases are scaled to values between 0 and 1, with [0,0] denoting the undamaged state and the activation function of the output layer corresponding to the identity function. Due to this, the output layer produces predictions of the damage positions by computing the linear combinations of the subnetwork outputs and their corresponding weights. In
Figure 23, the weights of the output layer are shown, including the bias weights, which are also part of the linear combinations.
In the following example, an approach is executed to gain a more profound understanding of how the output layer refines its predictions
P. For that, in
Table 7, the weight matrix
W of the output layer, and in
Table 8, the rounded example outputs of the subnetworks’ output vector
X for the undamaged case D00, have the bias node set to 1.
Now the following operation is executed:
where the symbol · represents the dot product and
represents the transposed weight matrix, while
X represents the vector of output values from the subnetworks. Using the output values from
Table 8 and the weights from
Table 7, we obtain the following values for the x and y positions:
These values are close to zero, and since no rescaling is performed for the undamaged case D00, this result was expected.
When one takes a closer look at the damage case D04, one can see that, in comparison with the undamaged case D00, only subnetwork 5 (see
Figure 20e) shows a significant change in its outputs for D04. In this subnetwork, the output alters from 1 to −1, while for the other subnetwork, only minimal changes can be observed, so these changes are ignored in the following. This means that by changing the value of subnetwork 5 in
Table 8 from 1 to −1, one should change the prediction of the output layer from D00 to D04. By repeating the operation from Equation (
15) with the new subnetwork 5 value, the following values are obtained:
Following the reverse scaling process, we attain
Looking at
Figure 2, one can see that these values are close to the true damage position of D04. This and the previous example show how the subnetwork outputs and the output layer weights achieve damage position predictions via linear operations.
Similar behavior can be observed in other damage cases. For example, for D12, only for subnetwork 5, the output value has to be changed from 1 to −1; for damage D16, just the output of subnetwork 4 has to be changed to modify the prediction from D00 to the corresponding damage case. For damage case D24, on the other hand, the output of three subnetworks has to be changed, specifically in subnetworks 3, 6, and 7, to switch from a D00 to D24 prediction. Subnetworks 1 and 2 remain unchanged for all damage cases, indicating that these subnetworks just have limited influence on the prediction-making process.
In
Figure 23, it is evident that subnetwork 2 makes almost no contribution to the linear combination in the output layer since the corresponding weights are almost zero.
Figure 20 and
Figure 20a, on the other hand, show that the outputs of subnetwork 1 are for all inputs almost constant, independent of the damage case so that no relevant change in the prediction can result from subnetwork 1.
These observations show that it is possible to gain deep insights into the decision-making process of a trained model with the XANN architecture.
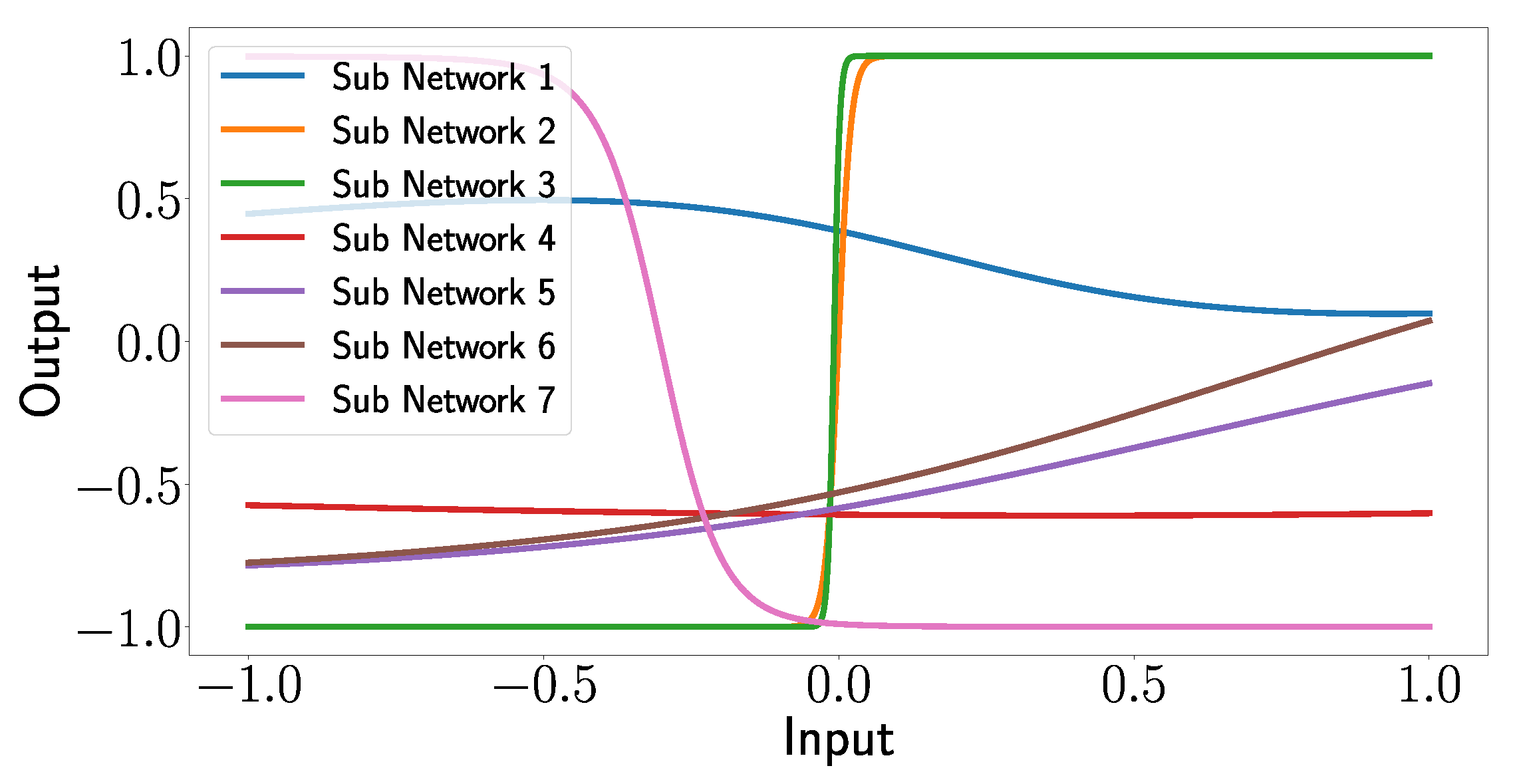
In the next step, we want to investigate how one can use the XANN model to further validate if the artificially generated signal features are valid. For that, the outputs of the subnetworks of the trained XANN model are investigated. In
Figure 24, the subnetwork outputs for the artificially generated signal features with respect to the damage cases are shown. By comparing
Figure 24 with
Figure 20, one can see that both Figures show in general the same pattern, with the difference that in
Figure 24, the range of the inputs, and consequently the output values, are extended. This was expected since the artificially generated data itself has a larger value range than the measured signal features. For instance, in
Figure 24d, this leads to the observation that subnetwork 4 is not only using the linear but also the non-linear part of the transfer function. For D16, the change in the minimum input value from approximately 0.2 in the original dataset to a minimum input value of about 0.14 in the sampled data caused this change. For the damage-free case, the shift is due to the change in the maximum input value from approximately 0 to around 0.1. In
Figure 18a, one can see that this has no effect on the prediction for the damage-free case; however, this could be due to the lack of rescaling for this case. For damage D16, outliers can also be observed in
Figure 18d, highlighted as first and second outliers.
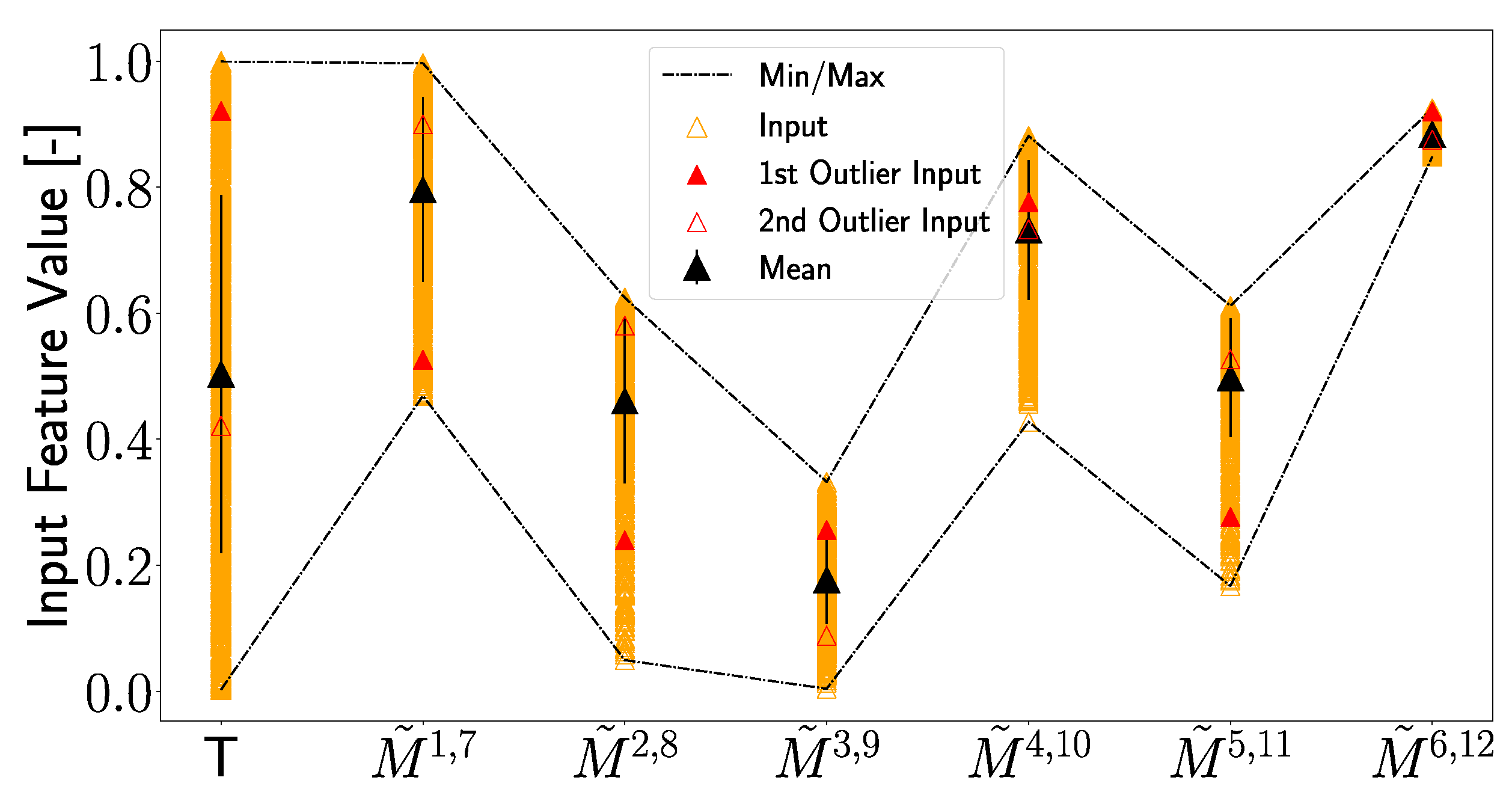
In the next step, it will be investigated if the use of the non-linear components of the transfer function in subnetwork 4 is the reason for these outliers and if any peculiarities in the artificially generated data can be identified that can explain the outliers. In
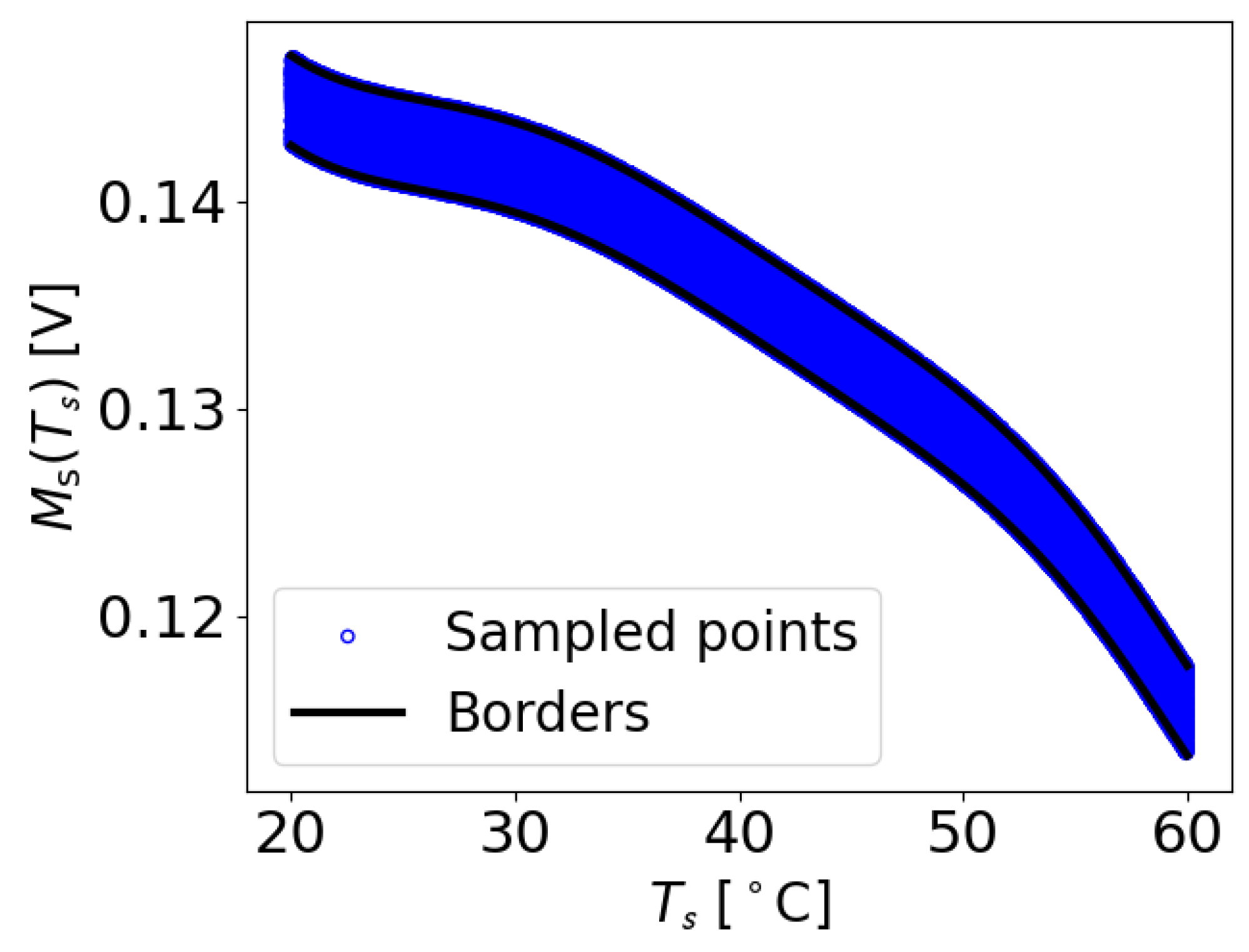
Figure 25, the normalized and scaled input values of each feature are plotted together with the mean input value along with its standard deviation. It can be seen that the input values for the outliers are significantly distant from the mean value in some cases (e.g., for the first outlier at T,
,
, and
) and that these deviations from the mean are larger than the standard deviations. But, it should be pointed out that other input values that do not result in an outlier show similar deviations from the mean value. Also, for other features, the input values of the outliers are quite close to the mean value. These observations indicate that the input features of the outliers do hold any unique position, i.e., they never represent the maximum or minimum input values or stand out in any particular way. Even if one analyzes the input data of the first outlier, which is the largest, no extraordinary position among the input values of transducer paths
and
, which are the closest to D16, can be observed.
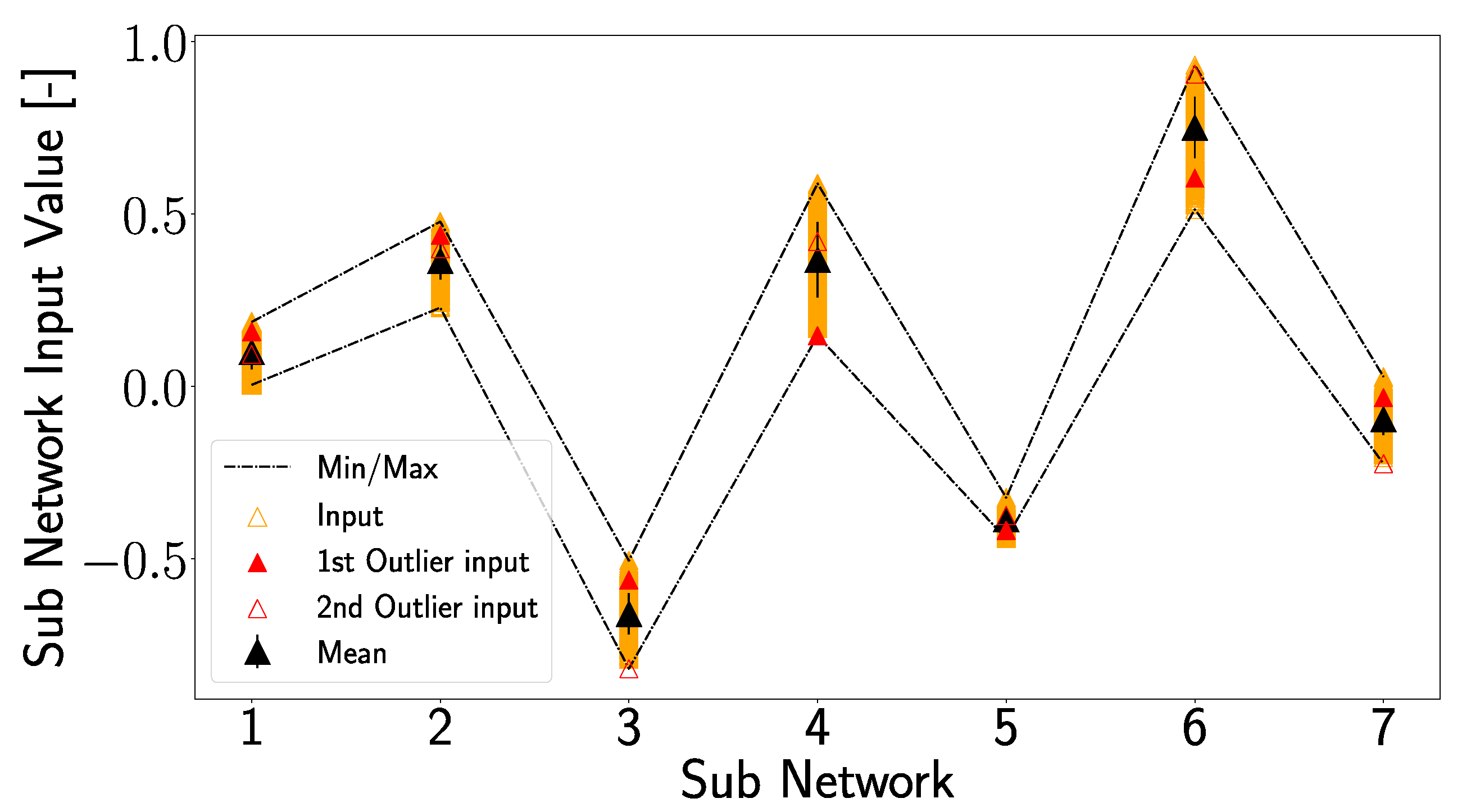
In
Figure 26, which shows the inputs of the subnetworks (corresponding to the inputs in
Figure 20 and
Figure 24), a different picture emerges, so that the input value of the first outlier for subnetwork 4 is the minimum input for subnetwork 4. Due to this, the output value for D16, which is located at the non-linear part of the transfer function (see
Figure 24d), corresponds to the first outlier. But, also for the second outlier, unique positions can be observed since it represents the minimum input value in subnetworks 3 and 7. Particularly interesting is subnetwork 7, where the minimum input value of D16 leads to a significant deviation in the output. Looking at
Figure 23, one can see that subnetwork 7 significantly influences the prediction of the x-position, which could explain why the second outlier deviates so much from the total damage position in the x-direction. The first outlier, on the other hand, shows large deviations in the x- and y-direction due to a similar strong influence of subnetwork 4 in the prediction of both directions; see
Figure 23.
The inputs of the outliers hold no particular characteristics, as shown in
Figure 25. But, on the other hand, the inputs of the outliers lead to significant changes in the subnetwork outputs. This implies that the composition of the outlier inputs represents a special case. Due to the fact that the individual feature values are generated independently, this is comprehensible since it could lead to input configurations that may not occur in reality so that the outputs of the subnetworks were shifted, resulting in a deviating position prediction.
Since the outliers are still quite close to the actual damage positions, it can still be assumed that the artificially generated features are valid. This also means that the assumption that a feature measured at T lies between the boundaries and for each individual transducer path is valid. However, it is necessary to be careful when implementing the artificial generation of values across different paths.
It should be mentioned that the analysis carried out here could also be used to determine at which point a trained model fails when an individual transducer transmits incorrect data, e.g., due to malfunction.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
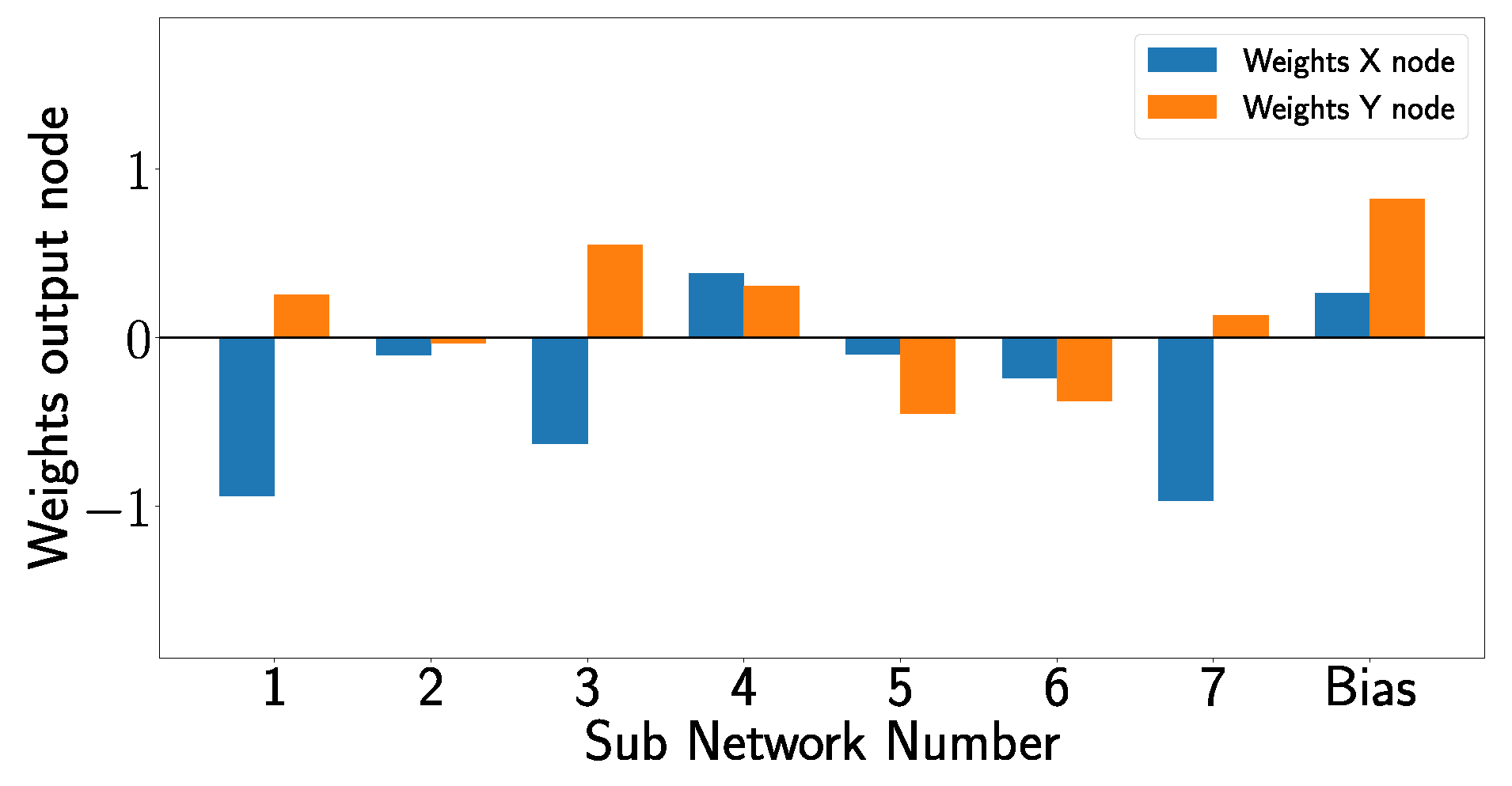{kind=link}
{kind=link}
{kind=link}
{kind=link}