
A Review of Omics Technologies and Bioinformatics to Accelerate Improvement of Papaya Traits


Abstract
:1. Introduction
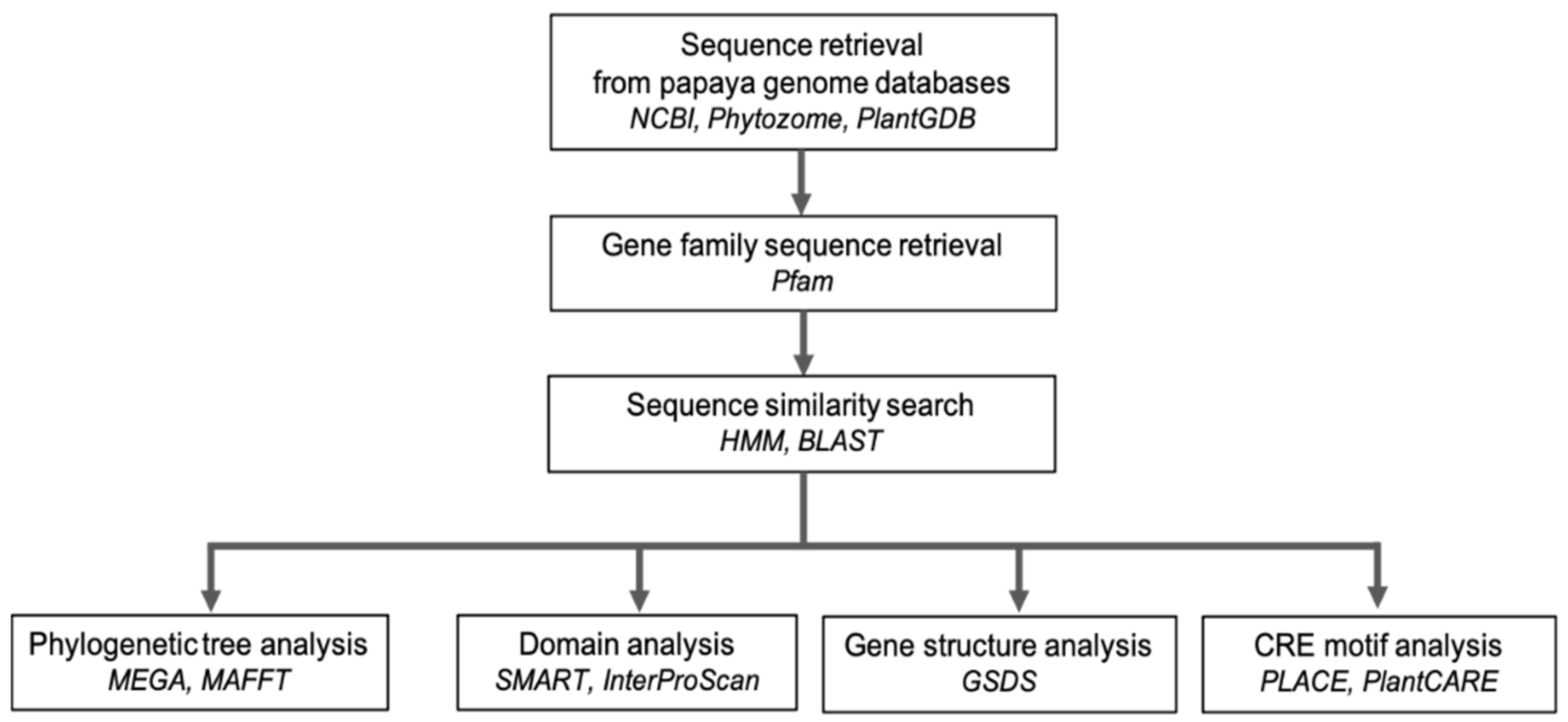
2. The Role of Bioinformatics in Analysing Omics Data
Comparative Genomics Analysis of Carica papaya
3. Application of Omics Technologies in Carica papaya
3.1. Genomics and Molecular Markers
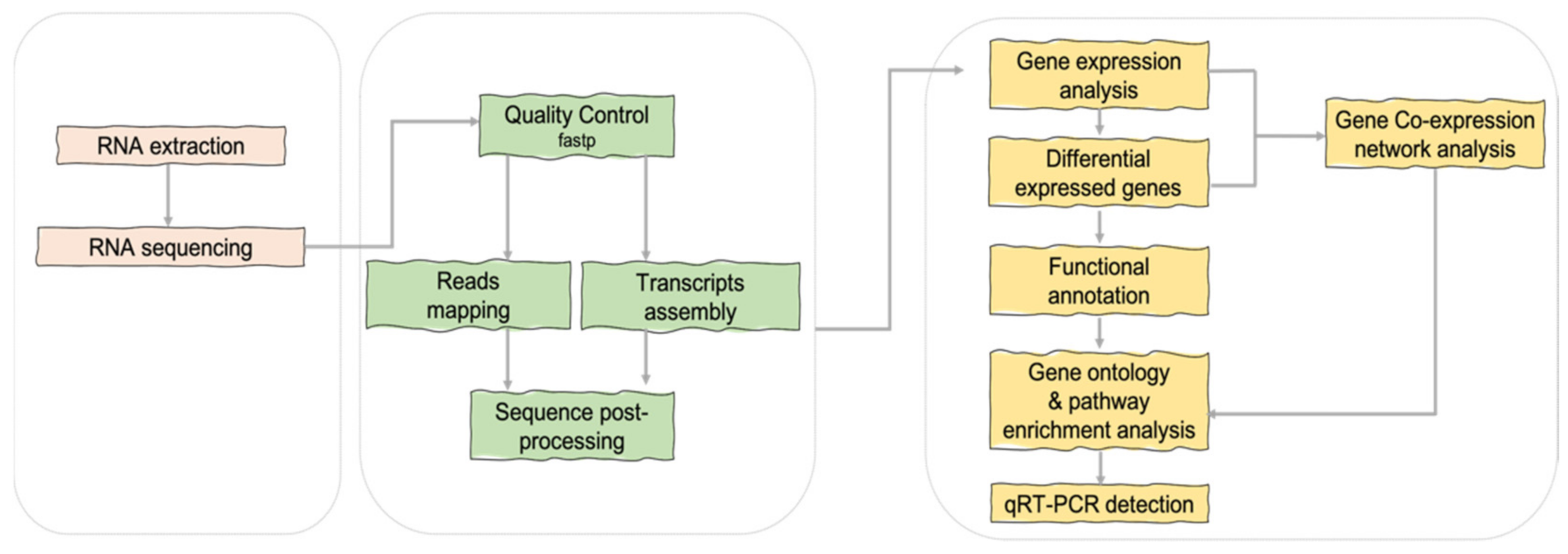
3.2. Transcriptomics
3.3. Proteomics
3.4. Metabolomics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Omics Platform | Traits/Conditions | Descriptions | Approach | Reference |
|---|---|---|---|---|
| Genomics | - | Whole-genome sequences of papaya cultivar SunUp. Development of first papaya reference genome sequences. | Whole-genome shotgun Sanger sequencing | [2] |
| - | Whole-genome resequencing of papaya cultivars Eksotika and Sekaki to identify putative SNPs. The identified SNPs between Eksotika and Sekaki located in genes of interest could be suggested for validation using a genotyping platform. | Whole-genome resequencing using Illumina HiSeq2000 (Illumina Inc., CA, USA) and bioinformatic analysis | [58] | |
| - | Whole-genome resequencing of papaya cultivar SunUp (transgenic) and Sunset (nontransgenic) to identify SNPs and InDels, and used in comparing transgenic and nontransgenic papaya. The identified SNPs and InDels that were located in high-impact genes could be applied in marker-assisted PRSV disease-resistance breeding in papaya. | Whole-genome resequencing using Illumina HiSeq2000 (Illumina Inc., CA, USA) and bioinformatic analysis | [59] | |
| - | Whole-genome resequencing of wild-type and cultivated papaya to detect structural variations in papaya, and used in understanding the process of papaya domestication. | Whole-genome resequencing using Illumina HiSeq2500 (Illumina Inc., CA, USA) and bioinformatic analysis | [65] | |
| Ripening | Gene-based SSR marker development focusing on genes related to fruit ripening. | Bioinformatics and genotyping | [61] | |
| Polymorphic SSR marker development for marker-assisted breeding in papaya. | Whole-genome resequencing using Illumina HiSeq4000 (Illumina Inc., Foster City, CA, USA), bioinformatics, and genotyping | [62] | ||
| Genome-wide identification of SNPs and InDels using whole-genome resequencing of two papaya cultivars, namely Sekati and JS-12. The SNPs that were located in RRGs are potential SNPs to be converted in PCR markers, and could be applied in papaya genetic mapping and diversity studies, as well as marker-assisted selection. | Whole-genome resequencing using Illumina Miseq (Illumina Inc., Foster City, CA, USA) | [64] | ||
| Abiotic stress | Genome-wide analysis of basic helix–loop–helix (bHLH) transcription factors. Candidate bHLH genes that might be responsible for abiotic stress. | Comparative genomics and quantitative real-time PCR (qRT-PCR) | [31] | |
| Disease resistance | Genome-wide analysis of NBS resistance gene family. Candidate resistance (R) genes potentially responsible for disease-resistance mechanism. | Comparative genomics and quantitative real-time PCR (qRT-PCR) | [24] | |
| Disease resistance | Genome-wide analysis of NPR1 family. Candidate pathogenesis-related genes that might be responsible for a disease-resistance mechanism. | Comparative genomics and quantitative real-time PCR (qRT-PCR) | [32] | |
| Ripening | Genome-wide analysis of SQUAMOSA promoter binding protein-like gene family in papaya. Candidate ripening- and development-related genes. | Comparative genomics and quantitative real-time PCR (qRT-PCR) | [33] | |
| Ripening | Genome-wide analysis of Aux/IAA gene family. Candidate ripening-related genes in papaya. | Comparative genomics and quantitative real-time PCR (qRT-PCR) | [34] | |
| Flower development | Genome-wide analysis of auxin response factor (ARF) family genes related to flower and fruit development in papaya. Candidate genes related to flower and fruit development. | Comparative genomics and Quantitative real-time PCR (qRT-PCR) | [35] | |
| Transcriptomics | Drought tolerance | Coexpression network analysis to identify genes and transcription factors related to abiotic stress. | Transcriptome sequencing using Illumina NextSeq500 (Illumina Inc., Foster City, CA, USA) and coexpression network analysis | [73] |
| Ripening mechanism | Identification of potential regulatory genes during papaya ripening underlying 1-MCP treatment. | Transcriptome sequencing using Hiseq Xten (Illumina Inc., Foster City, CA, USA) | [74] | |
| Fruit colouration | Identification of potential TF regulating the carotenoid biosynthetic pathway. | Transcriptome sequencing using Illumina HiSeq2500 | [75] | |
| Sex determination | Differential expressed genes in sex determination of papaya, in male-to-hermaphrodite and male flowers. | (Illumina Inc., Foster City, CA, USA) Transcriptome sequencing using Illumina HiSeq2500 (Illumina Inc., Foster City, CA, USA) | [76] | |
| Disease resistance | Identification of disease-resistance genes in PRSV-resistant and susceptible cultivars. | Transcriptome sequencing using Illumina HiSeq2500 (Illumina Inc., Foster City, CA, USA) | [78] | |
| Disease resistance | Identification of stress-response genes and nutrient upregulated genes in tolerance mechanism of papaya sticky disease. | Transcriptome sequencing using Illumina HiSeq2000 (Illumina Inc., Foster City, CA, USA) | [79] | |
| Proteomics | Ripening mechanism | Comparative proteomic analysis of climacteric and preclimacteric papaya cultivars. | 2-DGE and LC-MS/MS | [83] |
| Ripening mechanism | Differentially expressed proteins during papaya ripening. | 2-DGE and QTRAP hybrid tandem mass spectrometer | [84] | |
| Ripening mechanism | Differentially accumulated proteins (DAPs) during papaya ripening. | HPLC and LC-MS/MS | [85] | |
| Disease mechanism | Identification of differentially expressed proteins in healthy and PMev disease leaf samples in the Golden cultivar. Metabolism-related proteins were downregulated, and stress-responsive proteins were upregulated. | MALDI-TOF-MS/MS and DIGE/LC-IonTrap-MS/MS | [86] | |
| Disease mechanism | Differentially expressed proteins of compatible reaction between Eksotika papaya and E. mallotivora | iTRAQ mass spectrometry | [87] | |
| Disease mechanism | Protein expression between PMeV-infected preflowering C. papaya and control plants | LC-MS/MS-based label-free proteomics | [88] | |
| Metabolomics | Fruit ripening | Comparative analysis of metabolite profiling between Eksotika and Sekaki cultivars. | GC-MS | [93] |
| Fruit ripening | Profiling analysis of bioactive and volatile compounds in two papaya cultivars, namely Sel-42 and Tainung. | HPLC-ESI-MS/MS | [94] | |
| Fruit ripening | Comparative profiling of carotenoids and volatile in yellow and red flashed between Sui huang and Sui hong cultivars. | HPLC-ApCI-MS | [95] | |
| Fruit ripening | Identification of genes and metabolites regulating fruit ripening and softening in papaya cultivar Suiyou-2. | Transcriptome sequencing using Illumina Hiseq Xten (Illumina Inc., Foster City, CA, USA) and metabolomics profiling using HPLC-ESI-MS/MS | [103] | |
| Chilling injury | Elucidating of primary metabolites and volatile changes in papaya peel in response to chilling stress. | GC-MS /MS | [97] | |
| Bioactive properties | Metabolite profiling in papaya leaves. | UPLC-ESI-MS and GC-MS/MS | [98,99,100] |
4. Future Perspective
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Food and Agriculture Organization. Major Tropical Fruits, Market Review; Food and Agriculture Organization: Rome, Italy, 2020; pp. 1–5. [Google Scholar]
- Ming, R.; Yu, Q.; Moore, P.H.; Paull, R.E.; Chen, N.J.; Wang, M.L.; Zhu, Y.J.; Schuler, M.A.; Jiang, J.; Paterson, A.H. Genome of papaya, a fast growing tropical fruit tree. Tree Genet. Genomes 2012, 8, 445–462. [Google Scholar] [CrossRef]
- Chan, Y. Breeding papaya (Carica papaya L.). In Breeding Plantation Tree Crops. Tropical Species, 1st ed.; Jain, S.M., Priyadarshan, P.M., Eds.; Springer: New York, NY, USA, 2009; Volume 1, pp. 121–159. [Google Scholar]
- Plant Variety Protection Malaysia. Available online: http://pvpbkkt.doa.gov.my/ (accessed on 10 June 2021).
- Ogata, T.; Yamanaka, S.; Shoda, M.; Urasaki, N.; Yamamoto, T. Current status of tropical fruit breeding and genetics for three tropical fruit species cultivated in Japan: Pineapple, mango, and papaya. Breed. Sci. 2016, 66, 69–81. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Storey, W.B. Genetics of papaya. J. Hered. 1953, 44, 70–78. [Google Scholar] [CrossRef]
- Tamaki, M.; Urasaki, N.; Motomura, K.; Nakamura, I.; Adaniya, S. Shortening the breeding cycle of papaya (Carica papaya L.) by culturing embryos treated with ethrel. Plant Cell Tissues Organ Cult. 2011, 106, 225–233. [Google Scholar] [CrossRef]
- Dhekney, S.A.; Kandel, R.; Bergey, D.R.; Sitther, V.; Soorianathasundaram, K.; Litz, R.E. Advances in papaya biotechnology. Biocatal. Agric. Biotechnol. 2016, 5, 133–142. [Google Scholar] [CrossRef]
- Vos, C.; Arancon, N. Soil and plant nutrient management and fruit production of papaya (Carica papaya) in Keaau, Hawaii. J. Plant Nutr. 2019, 43, 384–395. [Google Scholar] [CrossRef]
- Cruz, A.F.; de Oliveira, B.F.; de Carvalho Pires, M. Optimum Level of Nitrogen and Phosphorus to Achieve Better Papaya (Carica papaya var. Solo) Seedlings Growth and Mycorrhizal Colonization. Int. J. Fruit Sci. 2019, 17, 1–11. [Google Scholar] [CrossRef]
- Fallas-Corralesa, R.G.; van der Zee, S.E.A.T.M. Diagnosis and management of nutrient constraints in papaya. In Fruit Crops: Diagnosis and Management of Nutrient Constraints, 1st ed.; Srivastava, A.K., Hu, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; Volume 1, pp. 607–628. [Google Scholar]
- Santos, E.M.C.; Cavalcante, Í.H.L.; da Silva Junior, G.B.; Albano, F.G. Impact of nitrogen and potassium nutrition on papaya (pawpaw) fruit quality. Biosci. J. Uberlândia 2015, 31, 1341–1348. [Google Scholar] [CrossRef] [Green Version]
- Dinesh, M.R.; Reddy, B.M.C. Physiological Basis of Growth and Fruit Yield Characteristics of Tropical and Sub-tropical Fruits to Temperature. In Tropical Fruit Tree Species and Climate Change; Sthapit, S.R., Scherr, S.J., Eds.; Bioversity International: Rome, Italy, 2012; Volume 1, pp. 45–70. [Google Scholar]
- Salinas, I.; Hueso, J.J.; Cuevas, J. Active Control of Greenhouse Climate Enhances Papaya Growth and Yield at an Affordable Cost. Agronomy 2021, 11, 378. [Google Scholar] [CrossRef]
- Ramírez, A.G.; Rodríguez, L.M.P.; Erosa, F.E.; Fuentes, G.; Santamaría, J.M. Identification of the SHINE clade of AP2/ERF domain transcription factors genes in Carica papaya; Their gene expression and their possible role in wax accumulation and water deficit stress tolerance in a wild and a commercial papaya genotypes. Environ. Exp. Bot. 2021, 183, 104341. [Google Scholar] [CrossRef]
- Shiratake, K.; Suzuki, M. Omics studies of citrus, grape and rosaceae fruit trees. Breed. Sci. 2016, 66, 122–138. [Google Scholar] [CrossRef] [Green Version]
- Ali, M.W.; Borrill, P. Applying genomic resources to accelerate wheat biofortification. Heredity 2020, 125, 386–395. [Google Scholar] [CrossRef]
- Roorkiwal, M.; Jain, A.; Kale, S.M.; Doddamani, D.; Chitikineni, A.; Thudi, M.; Varshney, R.K. Development and evaluation of high-density Axiom®CicerSNP Array for high-resolution genetic mapping and breeding applications in chickpea. Plant Biotechnol. J. 2018, 16, 890–901. [Google Scholar] [CrossRef] [Green Version]
- Raza, A.; Tabassum, J.; Kudapa, H.; Varshney, R.K. Can omics deliver temperature resilient ready-to- grow crops? Crit. Rev. Biotechnol. 2021, 1–24. [Google Scholar] [CrossRef]
- Fitch, M.M.M.; Manshardt, R.M.; Gonsalves, D.; Slightom, J.L.; Sanford, J.C. Virus Resistant Papaya Plants Derived from Tissues Bombarded with the Coat Protein Gene of Papaya Ringspot Virus. Bio Technol. 1992, 10, 1466–1472. [Google Scholar] [CrossRef]
- Ming, R.; Hou, S.; Feng, Y.; Yu, Q.; Dionne-Laporte, A.; Saw, J.H.; Senin, P.; Wang, W.; Ly, B.V.; Lewis, K.L.T.; et al. The draft genome of the transgenic tropical fruit tree papaya (Carica papaya Linnaeus). Nature 2008, 452, 991–996. [Google Scholar] [CrossRef] [Green Version]
- Sondur, S.N.; Manshardt, R.M.; Stiles, J.I. A genetic map of papaya based on random amplified polymorphic DNA markers. Theor. Appl. Genet. 1996, 93, 547–553. [Google Scholar] [CrossRef]
- Chen, C.; Yu, Q.; Hou, S.; Li, Y.; Eustice, M.; Skelton, R.L.; Veatch, O.; Herdes, R.E.; Diebold, L.; Saw, J.; et al. Construction of a sequence-tagged high-density genetic map of papaya for comparative structural and evolutionary genomics in Brassicales. Genetics 2007, 177, 2481–2491. [Google Scholar] [CrossRef] [Green Version]
- Porter, B.W.; Paidi, M.; Ming, R.; Alam, M.; Nishijima, W.T.; Zhu, Y.J. Genome-wide analysis of Carica papaya reveals a small NBS resistance gene family. Mol. Genet. Genom. 2009, 281, 609–626. [Google Scholar] [CrossRef]
- Yu, Q.; Tong, E.; Skelton, R.L.; Bowers, J.E.; Jones, M.R.; Murray, J.E.; Hou, S.; Guan, P.; Acob, R.A.; Luo, M.C.; et al. A physical map of the papaya genome with integrated genetic map and genome sequence. BMC Genom. 2009, 10, 371. [Google Scholar] [CrossRef] [Green Version]
- Chávez-Pesqueira, M.; Núñez-Farfán, J. Domestication and genetics of papaya: A review. Front. Ecol. Evol. 2017, 5. [Google Scholar] [CrossRef] [Green Version]
- Palei, S.; Dash, D.K.; Rout, G.R. Biology and biotechnology of papaya, an important fruit crop of tropics: A review. Vegetos 2018, 31, 1–15. [Google Scholar] [CrossRef]
- Marsh, J.I.; Hu, H.; Gill, M.; Batley, J.; Edwards, D. Crop breeding for a changing climate: Integrating phenomics and genomics with bioinformatics. Theor. Appl. Genet. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Ellegren, H. Comparative genomics and the study of evolution by natural selection. Mol. Ecol. 2008, 17, 4586–4596. [Google Scholar] [CrossRef]
- Morrell, P.L.; Buckler, E.S.; Ross-Ibarra, J. Crop genomics: Advances and applications. Nat. Rev. Genet. 2012, 13, 85–96. [Google Scholar] [CrossRef]
- Yang, M.; Zhou, C.; Yang, H.; Kuang, R.; Huang, B.; Wei, Y. Genome-wide analysis of basic helix-loop-helix transcription factors in papaya (Carica papaya L.). PeerJ 2020, 8, e9319. [Google Scholar] [CrossRef]
- Praza-Echeverria, S.; Santamaría, J.M.; Fuentes, G.; De los Angeles Menéndez-Cerón, M.; Vallejo-Reyna, M.A.; Herrera-Valencia, V.A. The NPR1 family of transcription cofactors in papaya: Insights into its structure, phylogeny and expression. Genes Genom. 2012, 34, 379–390. [Google Scholar] [CrossRef]
- Liu, K.; Yuan, C.; Feng, S.; Zhong, S.; Li, H.; Zhong, J.; Shen, C.; Liu, J. Genome-wide analysis and characterization of Aux/IAA family genes related to fruit ripening in papaya (Carica papaya L.). BMC Genom. 2017, 18, 1–12. [Google Scholar] [CrossRef]
- Xu, Y.; Xu, H.; Wall, M.M.; Yang, J. Roles of transcription factor SQUAMOSA promoter binding protein-like gene family in papaya (Carica papaya) development and ripening. Genomics 2020, 112, 2734–2747. [Google Scholar] [CrossRef]
- Liu, K.; Yuan, C.; Li, H.; Lin, W.; Yang, Y.; Shen, C.; Zheng, X. Genome-wide identification and characterization of auxin response factor (ARF) family genes related to flower and fruit development in papaya (Carica papaya L.). BMC Genom. 2015, 16, 901. [Google Scholar] [CrossRef] [Green Version]
- Amin, M.N.; Bunawan, H.; Redzuan, R.A.; Jaganath, I.B.S. Erwinia mallotivora sp., a new pathogen of papaya (Carica papaya) in peninsular Malaysia. Int. J. Mol. Sci. 2011, 12, 39–45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Purcifull, D.E.; Edwardson, J.R.; Hiebert, E.; Gonsalves, D. Papaya Ringspot Virus. In CMI/AAB Description of Plant Viruses; Coronel, R.E., Ed.; Wageningen University: Wageningen, The Netherlands, 1984; Volume 2. [Google Scholar]
- Maciel-Zambolim, E.; Kunieda-Alonso, S.; Matsuoka, K.; De Carvalho, M.G.; Zerbini, F.M. Purification and some properties of Papaya meleira virus, a novel virus infecting papayas in Brazil. Plant Pathol. 2003, 52, 389–394. [Google Scholar] [CrossRef]
- National Center for Botechnology Information (NCBI). Available online: https://ftp.ncbi.nlm.nih.gov/genomes/all/annotation_releases/3649/100/GCF_000150535.2_Papaya1.0/ (accessed on 29 May 2021).
- Duvick, J.; Fu, A.; Muppirala, U.; Sabharwal, M.; Wilkerson, M.D.; Lawrence, C.J.; Lushbough, C.; Brendel, V. PlantGDB: A resource for comparative plant genomics. Nucleic Acids Res. 2008, 36, 959–965. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J.; Mitros, T.; Dirks, W.; Hellsten, U.; Putnam, N.; et al. Phytozome: A comparative platform for green plant genomics. Nucleic Acids Res. 2012, 40, D1178–D1186. [Google Scholar] [CrossRef]
- Yates, A.; Akanni, W.; Amode, M.R.; Barrell, D.; Billis, K.; Carvalho-Silva, D.; Cummins, C.; Clapham, P.; Fitzgerald, S.; Gil, L.; et al. Ensembl 2016. Nucleic Acids Res. 2016, 44, D710–D716. [Google Scholar] [CrossRef]
- Van Bel, M.; Diels, T.; Vancaester, E.; Kreft, L.; Botzki, A.; Van De Peer, Y.; Coppens, F.; Vandepoele, K. PLAZA 4.0: An integrative resource for functional, evolutionary and comparative plant genomics. Nucleic Acids Res. 2018, 46, 1190–1196. [Google Scholar] [CrossRef]
- Prakash, A.; Jeffryes, M.; Bateman, A.; Finn, R.D. The HMMER Web Server for Protein Sequence Similarity Search. Curr. Protoc. Bioinform. 2017, 60, 3.15.1–3.15.23. [Google Scholar] [CrossRef]
- Altschul, S.F.; Gertz, E.M.; Agarwala, R.; Schäffer, A.A.; Yu, Y.K. PSI-BLAST pseudocounts and the minimum description length principle. Nucleic Acids Res. 2009, 37, 815–824. [Google Scholar] [CrossRef] [Green Version]
- Jones, P.; Binns, D.; Chang, H.Y.; Fraser, M.; Li, W.; McAnulla, C.; McWilliam, H.; Maslen, J.; Mitchell, A.; Nuka, G.; et al. InterProScan 5: Genome-scale protein function classification. Bioinformatics 2014, 30, 1236–1240. [Google Scholar] [CrossRef] [Green Version]
- El-Gebali, S.; Mistry, J.; Bateman, A.; Eddy, S.R.; Luciani, A.; Potter, S.C.; Qureshi, M.; Richardson, L.J.; Salazar, G.A.; Smart, A.; et al. The Pfam protein families database in 2019. Nucleic Acids Res. 2019, 47, D427–D432. [Google Scholar] [CrossRef]
- Letunic, I.; Bork, P. 20 years of the SMART protein domain annotation resource. Nucleic Acids Res. 2018, 46, D493–D496. [Google Scholar] [CrossRef]
- Higo, K.; Ugawa, Y.; Iwamoto, M.; Korenaga, T. Plant cis-acting regulatory DNA elements (PLACE) database: 1999. Nucleic Acids Res. 1999, 27, 297–300. [Google Scholar] [CrossRef] [Green Version]
- Lescot, M.; Déhais, P.; Thijs, G.; Marchal, K.; Moreau, Y.; Van De Peer, Y.; Rouzé, P.; Rombauts, S. PlantCARE, a database of plant cis-acting regulatory elements and a portal to tools for in silico analysis of promoter sequences. Nucleic Acids Res. 2002, 30, 325–327. [Google Scholar] [CrossRef]
- Hu, B.; Jin, J.; Guo, A.Y.; Zhang, H.; Luo, J.; Gao, G. GSDS 2.0: An upgraded gene feature visualization server. Bioinformatics 2015, 31, 1296–1297. [Google Scholar] [CrossRef] [Green Version]
- Thompson, J.D.; Gibson, T.J.; Higgins, D.G. Multiple Sequence Alignment Using ClustalW and ClustalX. Curr. Protoc. Bioinform. 2003, 2.3.1–2.3.22. [Google Scholar] [CrossRef]
- Katoh, K.; Misawa, K.; Kuma, K.I.; Miyata, T. MAFFT: A novel method for rapid multiple sequence alignment based on fast Fourier transform. Nucleic Acids Res. 2002, 30, 3059–3066. [Google Scholar] [CrossRef] [Green Version]
- Kumar, S.; Stecher, G.; Li, M.; Knyaz, C.; Tamura, K. MEGA X: Molecular evolutionary genetics analysis across computing platforms. Mol. Biol. Evol. 2018, 35, 1547–1549. [Google Scholar] [CrossRef]
- Aizat, W.M.; Ismail, I.; Noor, N.M. Recent Development in Omics Studies. In Omics Applications for Systems Biology, 1st ed.; Aizat, W., Goh, H.H., Baharum, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 1102, pp. 1–9. [Google Scholar] [CrossRef]
- Scossa, F.; Alseekh, S.; Fernie, A.R. Integrating multi-omics data for crop improvement. J. Plant Physiol. 2021, 257, 1–16. [Google Scholar] [CrossRef]
- Choi, H.K. Translational genomics and multi-omics integrated approaches as a useful strategy for crop breeding. Genes Genom. 2019, 41, 133–146. [Google Scholar] [CrossRef] [Green Version]
- Zainal-Abidin, R.; Abu-Bakar, N.; Yusof, M.M.F.; Abdullah, N. Sequence information on single nucleotide polymorphism (SNP) through genome sequencing analysis of Carica papaya variety Eksotika and Sekaki. J. Trop. Agric. Food Sci. 2016, 44, 219–228. [Google Scholar]
- Fang, J.; Fang, J.; Fang, J.; Fang, J.; Wood, A.M.; Chen, Y.; Chen, Y.; Yue, J.; Ming, R.; Ming, R. Genomic variation between PRSV resistant transgenic SunUp and its progenitor cultivar Sunset. BMC Genom. 2020, 21. [Google Scholar] [CrossRef]
- Nadeem, M.A.; Nawaz, M.A.; Shahid, M.Q.; Doğan, Y.; Comertpay, G.; Yıldız, M.; Hatipoğlu, R.; Ahmad, F.; Alsaleh, A.; Labhane, N.; et al. DNA molecular markers in plant breeding: Current status and recent advancements in genomic selection and genome editing. Biotechnol. Biotechnol. Equip. 2018, 32, 261–285. [Google Scholar] [CrossRef] [Green Version]
- Vidal, N.M.; Grazziotin, A.L.; Ramos, H.C.C.; Pereira, M.G.; Venancio, T.M. Development of a gene-centered SSR atlas as a resource for papaya (Carica papaya) marker-assisted selection and population genetic studies. PLoS ONE 2014, 9, e112654. [Google Scholar] [CrossRef] [Green Version]
- Nantawan, U.; Kanchana-udomkan, C.; Drew, R.; Ford, R. Development of polymorphic simple sequence repeat (SSR) markers from genome re-sequencing of Carica papaya L. ‘Sunrise Solo’ and ‘RB2′ for marker-assisted breeding. Acta Hortic. 2018, 1205, 687–695. [Google Scholar] [CrossRef] [Green Version]
- Saxena, R.K.; Edwards, D.; Varshney, R.K. Structural variations in plant genomes. Brief. Funct. Genom. Proteom. 2014, 13, 296–307. [Google Scholar] [CrossRef] [Green Version]
- Bohry, D.; Ramos, H.C.C.; dos Santos, P.H.D.; Boechat, M.S.B.; Arêdes, F.A.S.; Pirovani, A.A.V.; Pereira, M.G. Discovery of SNPs and InDels in papaya genotypes and its potential for marker assisted selection of fruit quality traits. Sci. Rep. 2021, 11, 292. [Google Scholar] [CrossRef]
- Liao, Z.; Zhang, X.; Zhang, S.; Lin, Z.; Zhang, X.; Ming, R. Structural variations in papaya genomes. BMC Genom. 2021, 22, 335. [Google Scholar] [CrossRef]
- Collard, B.C.Y.; Jahufer, M.Z.Z.; Brouwer, J.B.; Pang, E.C.K. An introduction to markers, quantitative trait loci (QTL) mapping and marker-assisted selection for crop improvement: The basic concepts. Euphytica 2005, 142, 169–196. [Google Scholar] [CrossRef]
- Deputy, J.C.; Ming, R.; Ma, H.; Liu, Z.; Fitch, M.M.M.; Wang, M.; Manshardt, R.; Stiles, J.I. Molecular markers for sex determination in papaya (Carica papaya L.). Theor. Appl. Genet. 2002, 106, 107–111. [Google Scholar] [CrossRef]
- Blas, A.L.; Yu, Q.; Veatch, O.J.; Paull, R.E.; Moore, P.H.; Ming, R. Genetic mapping of quantitative trait loci controlling fruit size and shape in papaya. Mol. Breed. 2012, 29, 457–466. [Google Scholar] [CrossRef]
- Nantawan, U.; Kanchana-Udomkan, C.; Bar, I.; Ford, R. Linkage mapping and quantitative trait loci analysis of sweetness and other fruit quality traits in papaya. BMC Plant Biol. 2019, 19, 449. [Google Scholar] [CrossRef] [PubMed]
- Tao, Y.; Zhao, X.; Mace, E.; Henry, R.; Jordan, D. Exploring and Exploiting Pan-genomics for Crop Improvement. Mol. Plant 2019, 12, 156–169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neik, T.X.; Amas, J.; Barbetti, M.; Edwards, D.; Batley, J. Understanding host–pathogen interactions in brassica napus in the omics era. Plants 2020, 9, 1336. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Gerstein, M.; Snyder, M. RNA-Seq: A revolutionary tool for transcriptomics. Nat. Rev. Genet. 2009, 10, 57–63. [Google Scholar] [CrossRef]
- Gamboa-Tuz, S.D.; Pereira-Santana, A.; Zamora-Briseño, J.A.; Castano, E.; Espadas-Gil, F.; Ayala-Sumuano, J.T.; Keb-Llanes, M.Á.; Sanchez-Teyer, F.; Rodríguez-Zapata, L.C. Transcriptomics and co-expression networks reveal tissue-specific responses and regulatory hubs under mild and severe drought in papaya (Carica papaya L.). Sci. Rep. 2018, 8, 14539. [Google Scholar] [CrossRef]
- Zhu, X.; Ye, L.; Ding, X.; Gao, Q.; Xiao, S.; Tan, Q.; Huang, J.; Chen, W.; Li, X. Transcriptomic analysis reveals key factors in fruit ripening and rubbery texture caused by 1-MCP in papaya. BMC Plant Biol. 2019, 19, 1–23. [Google Scholar] [CrossRef]
- Shen, Y.H.; Lu, B.G.; Feng, L.; Yang, F.Y.; Geng, J.J.; Ming, R.; Chen, X.J. Isolation of ripening-related genes from ethylene/1-MCP treated papaya through RNA-seq. BMC Genom. 2017, 18, 1–13. [Google Scholar] [CrossRef]
- Lin, H.; Liao, Z.; Zhang, L.; Yu, Q. Transcriptome analysis of the male-to-hermaphrodite sex reversal induced by low temperature in papaya. Tree Genet. Genomes 2016, 12, 94. [Google Scholar] [CrossRef]
- Zhou, P.; Zhang, X.; Fatima, M.; Ma, X.; Fang, H.; Yan, H.; Ming, R. DNA methylome and transcriptome landscapes revealed differential characteristics of dioecious flowers in papaya. Hortic. Res. 2020, 7, 81. [Google Scholar] [CrossRef]
- Fang, J.; Lin, A.; Qiu, W.; Cai, H.; Umar, M.; Chen, R.; Ming, R. Transcriptome profiling revealed stress-induced and disease resistance genes up-regulated in PRSV resistant transgenic papaya. Front. Plant Sci. 2016, 7, 855. [Google Scholar] [CrossRef] [Green Version]
- Madroñero, J.; Rodrigues, S.P.; Antunes, T.F.S.; Abreu, P.M.V.; Ventura, J.A.; Fernandes, A.A.R.; Fernandes, P.M.B. Transcriptome analysis provides insights into the delayed sticky disease symptoms in Carica papaya. Plant Cell Rep. 2018, 37, 967–980. [Google Scholar] [CrossRef]
- Tian, T.; Liu, Y.; Yan, H.; You, Q.; Yi, X.; Du, Z.; Xu, W.; Su, Z. AgriGO v2.0: A GO analysis toolkit for the agricultural community, 2017 update. Nucleic Acids Res. 2017, 45, W122–W129. [Google Scholar] [CrossRef]
- Ge, S.X.; Jung, D.; Yao, R. ShinyGO: A graphical gene-set enrichment tool for animals and plants. Bioinformatics 2020, 36, 2628–2629. [Google Scholar] [CrossRef]
- Aslam, B.; Basit, M.; Nisar, M.A.; Khurshid, M.; Rasool, M.H. Proteomics: Technologies and their applications. J. Chromatogr. Sci. 2017, 55, 182–196. [Google Scholar] [CrossRef] [Green Version]
- Nogueira, S.B.; Labate, C.A.; Gozzo, F.C.; Pilau, E.J.; Lajolo, F.M.; Oliveira do Nascimento, J.R. Proteomic analysis of papaya fruit ripening using 2DE-DIGE. J. Proteom. 2011, 75, 1428–1439. [Google Scholar] [CrossRef]
- Huerta-Ocampo, J.Á.; Osuna-Castro, J.A.; Lino-López, G.J.; Barrera-Pacheco, A.; Mendoza-Hernández, G.; De León-Rodríguez, A.; Barba de la Rosa, A.P. Proteomic analysis of differentially accumulated proteins during ripening and in response to 1-MCP in papaya fruit. J. Proteom. 2012, 75, 2160–2169. [Google Scholar] [CrossRef]
- Jiang, B.; Ou, S.; Xu, L.; Mai, W.; Ye, M.; Gu, H.; Zhang, T.; Yuan, C.; Shen, C.; Wang, J.; et al. Comparative proteomic analysis provides novel insights into the regulation mechanism underlying papaya (Carica papaya L.) exocarp during fruit ripening process. BMC Plant Biol. 2019, 19. [Google Scholar] [CrossRef]
- Rodrigues, S.P.; Ventura, J.A.; Aguilar, C.; Nakayasu, E.S.; Almeida, I.C.; Fernandes, P.M.B.; Zingali, R.B. Proteomic analysis of papaya (Carica papaya L.) displaying typical sticky disease symptoms. Proteomics 2011, 11, 2592–2602. [Google Scholar] [CrossRef]
- Abu Bakar, N.; Badrun, R.; Shaharuddin, N.A.; Labuh, R. iTRAQ Proteins Analysis of Early Infected Papaya Plants with Papaya Dieback Pathogen. Asian J. Plant Biol. 2015, 3, 1–7. [Google Scholar]
- Abu Bakar, N.; Badrun, R.; Rozano, L.; Ahmad, L.; Raih, M.M.; Tarmizi, A.A. Identification and validation of putative Erwinia mallotivora effectors via quantitative proteomics and Real Time Analysis. J. Agric. Food. Technol. 2017, 7, 10–21. [Google Scholar]
- Soares, E.A.; Werth, E.G.; Madroñero, L.J.; Ventura, J.A.; Rodrigues, S.P.; Hicks, L.M.; Fernandes, P.M.B. Label-free quantitative proteomic analysis of pre-flowering PMeV-infected Carica papaya L. J. Proteom. 2016, 151, 275–283. [Google Scholar] [CrossRef] [PubMed]
- Vizcaíno, J.A.; Deutsch, E.W.; Wang, R.; Csordas, A.; Reisinger, F.; Ríos, D.; Dianes, J.A.; Sun, Z.; Farrah, T.; Bandeira, N.; et al. ProteomeXchange provides globally coordinated proteomics data submission and dissemination. Nat. Biotechnol. 2014, 32, 223–226. [Google Scholar] [CrossRef] [PubMed]
- Kusano, M.; Yang, Z.; Okazaki, Y.; Nakabayashi, R.; Fukushima, A.; Saito, K. Using metabolomic approaches to explore chemical diversity in rice. Mol. Plant 2015, 8, 58–67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Okazaki, Y.; Saito, K. Integrated metabolomics and phytochemical genomics approaches for studies on rice. Gigascience 2016, 5, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Sanimah, S.; Sarip, J. Metabolomic analysis of Carica papaya variety Eksotika and Sekaki. J. Trop. Agric. Food Sci. 2015, 43, 103–117. [Google Scholar]
- Kelebek, H.; Selli, S.; Gubbuk, H.; Gunes, E. Comparative evaluation of volatiles, phenolics, sugars, organic acids and antioxidant properties of Sel-42 and Tainung papaya varieties. Food Chem. 2015, 173, 912–919. [Google Scholar] [CrossRef]
- Jing, G.; Li, T.; Qu, H.; Yun, Z.; Jia, Y.; Zheng, X.; Jiang, Y. Carotenoids and volatile profiles of yellow- and red-fleshed papaya fruit in relation to the expression of carotenoid cleavage dioxygenase genes. Postharvest Biol. Technol. 2015, 109, 114–119. [Google Scholar] [CrossRef]
- Santana, L. Nutraceutical Potential of Carica papaya in Metabolic syndrome. Nutrients 2019, 5, 1608. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.; Li, Z.; Chen, X.; Yun, Z.; Li, T.; Jiang, Y. Comparative metabolites profiling of harvested papaya (Carica papaya L.) peel in response to chilling stress. J. Sci. Food Agric. 2019, 99, 6868–6881. [Google Scholar] [CrossRef]
- Gogna, N.; Hamid, N.; Dorai, K. Metabolomic profiling of the phytomedicinal constituents of Carica papaya L. leaves and seeds by 1H NMR spectroscopy and multivariate statistical analysis. J. Pharm. Biomed. Anal. 2015, 115, 74–85. [Google Scholar] [CrossRef]
- Harini, R.S.; Saivikashini, A.; Keerthana, G. Profiling metabolites of Carica papaya Linn. variety CO7 through GC-MS analysis. J. Pharmacogn. Phytochem. 2016, 5, 200–203. [Google Scholar]
- Vuong, Q.V.; Hirun, S.; Roach, P.D.; Bowyer, M.C.; Phillips, P.A.; Scarlett, C.J. Effect of extraction conditions on total phenolic compounds and antioxidant activities of Carica papaya leaf aqueous extracts. J. Herb. Med. 2013, 3, 104–111. [Google Scholar] [CrossRef]
- Oikawa, A.; Otsuka, T.; Nakabayashi, R.; Jikumaru, Y.; Isuzugawa, K.; Murayama, H.; Saito, K.; Shiratake, K. Metabolic profiling of developing pear fruits reveals dynamic variation in primary and secondary metabolites, including plant hormones. PLoS ONE 2015, 10, 1–18. [Google Scholar] [CrossRef]
- Yun, Z.; Li, T.; Gao, H.; Zhu, H.; Gupta, V.K.; Jiang, Y. Integrated transcriptomic, proteomic and metabolomics analysis reveals peel ripening of harvested banana under natural condition. Biomolecules 2019, 9, 167. [Google Scholar] [CrossRef] [Green Version]
- Zheng, S.; Hao, Y.; Fan, S.; Cai, J.; Chen, W.; Li, X.; Zhu, X. Metabolomic and transcriptomic profiling provide novel insights into fruit ripening and ripening disorder caused by 1-MCP treatments in papaya. Int. J. Mol. Sci. 2021, 22, 916. [Google Scholar] [CrossRef]
- Alcalá-Briseño, R.I.; Casarrubias-Castillo, K.; López-Ley, D.; Garrett, K.A.; Silva-Rosales, L. Network analysis of the papaya orchard virome from two agroecological regions of Chiapas, Mexico. mSystems 2020, 5, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Benes, B.; Guan, K.; Lang, M.; Long, S.P.; Lynch, J.P.; Marshall-Colón, A.; Peng, B.; Schnable, J.; Sweetlove, L.J.; Turk, M.J. Multiscale computational models can guide experimentation and targeted measurements for crop improvement. Plant J. 2020, 103, 21–31. [Google Scholar] [CrossRef]
- Li, Y.H.; Zhou, G.; Ma, J.; Jiang, W.; Jin, L.G.; Zhang, Z.; Guo, Y.; Zhang, J.; Sui, Y.; Zheng, L.; et al. De novo assembly of soybean wild relatives for pan-genome analysis of diversity and agronomic traits. Nat. Biotechnol. 2014, 32, 1045–1052. [Google Scholar] [CrossRef] [Green Version]
- Golicz, A.A.; Bayer, P.E.; Barker, G.C.; Edger, P.P.; Kim, H.R.; Martinez, P.A.; Chan, C.K.K.; Severn-Ellis, A.; McCombie, W.R.; Parkin, I.A.P.; et al. The pangenome of an agronomically important crop plant Brassica oleracea. Nat. Commun. 2016, 7, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Kaur, N.; Alok, A.; Shivani; Kaur, N.; Pandey, P.; Awasthi, P.; Tiwari, S. CRISPR/Cas9-mediated efficient editing in phytoene desaturase (PDS) demonstrates precise manipulation in banana cv. Rasthali genome. Funct. Integr. Genom. 2018, 18, 89–99. [Google Scholar] [CrossRef]
- Charrier, A.; Vergne, E.; Dousset, N.; Richer, A.; Petiteau, A.; Chevreau, E. Efficient targeted mutagenesis in apple and first time edition of pear using the CRISPR-Cas9 system. Front. Plant Sci. 2019, 10, 40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Wang, S.; Li, D.; Zhang, Q.; Li, L.; Zhong, C.; Liu, Y.; Huang, H. Optimized paired-sgRNA/Cas9 cloning and expression cassette triggers high-efficiency multiplex genome editing in kiwifruit. Plant Biotechnol. J. 2018, 16, 1424–1433. [Google Scholar] [CrossRef] [PubMed] [Green Version]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zainal-Abidin, R.-A.; Ruhaizat-Ooi, I.-H.; Harun, S. A Review of Omics Technologies and Bioinformatics to Accelerate Improvement of Papaya Traits. Agronomy 2021, 11, 1356. https://doi.org/10.3390/agronomy11071356
Zainal-Abidin R-A, Ruhaizat-Ooi I-H, Harun S. A Review of Omics Technologies and Bioinformatics to Accelerate Improvement of Papaya Traits. Agronomy. 2021; 11(7):1356. https://doi.org/10.3390/agronomy11071356
Chicago/Turabian StyleZainal-Abidin, Rabiatul-Adawiah, Insyirah-Hannah Ruhaizat-Ooi, and Sarahani Harun. 2021. "A Review of Omics Technologies and Bioinformatics to Accelerate Improvement of Papaya Traits" Agronomy 11, no. 7: 1356. https://doi.org/10.3390/agronomy11071356
APA StyleZainal-Abidin, R. -A., Ruhaizat-Ooi, I. -H., & Harun, S. (2021). A Review of Omics Technologies and Bioinformatics to Accelerate Improvement of Papaya Traits. Agronomy, 11(7), 1356. https://doi.org/10.3390/agronomy11071356