Multi-Path Dilated Residual Network for Nuclei Segmentation and Detection

 , and
, and
Abstract
:1. Introduction
2. Related Work
3. Method
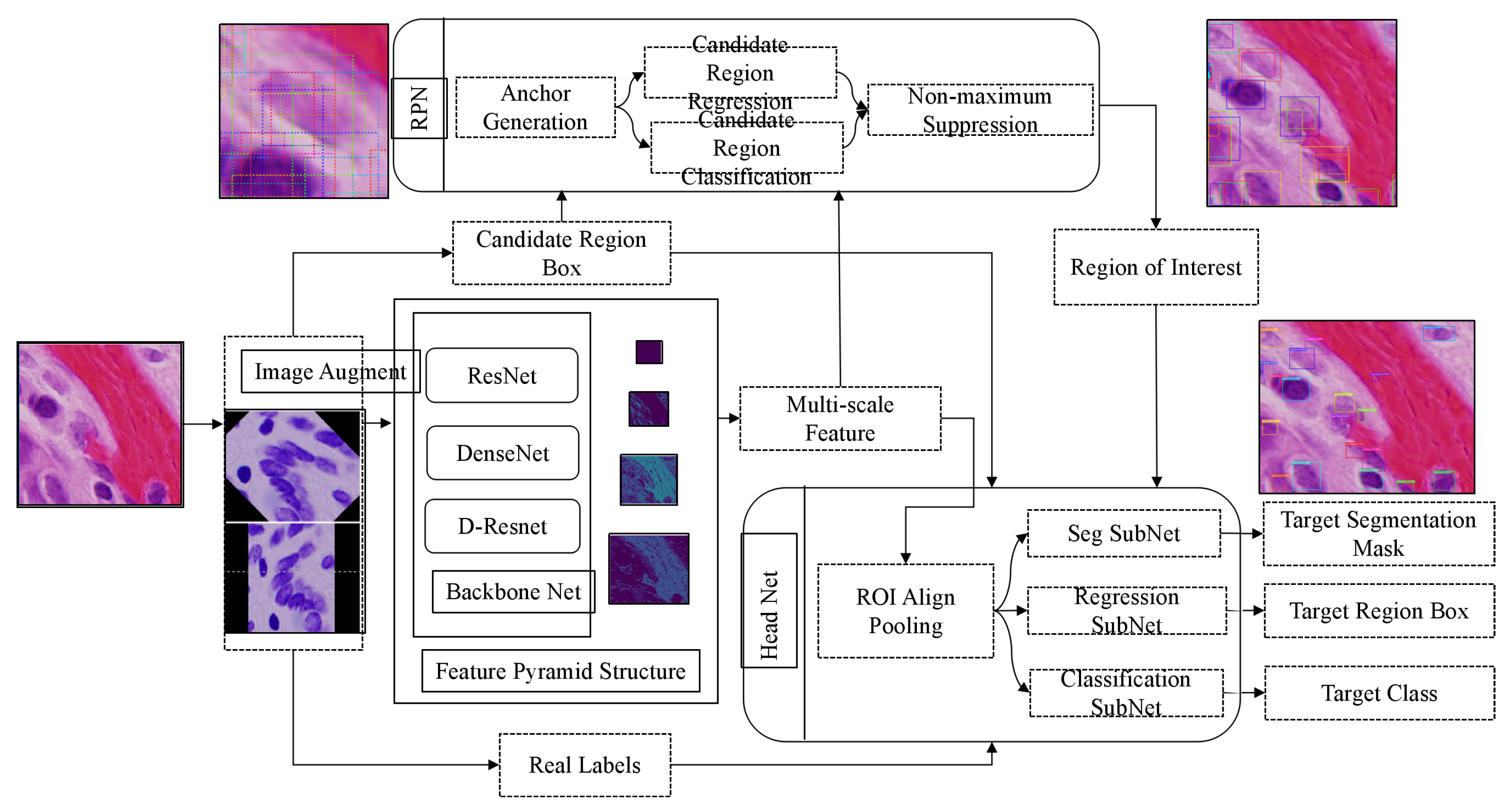
3.1. Framework
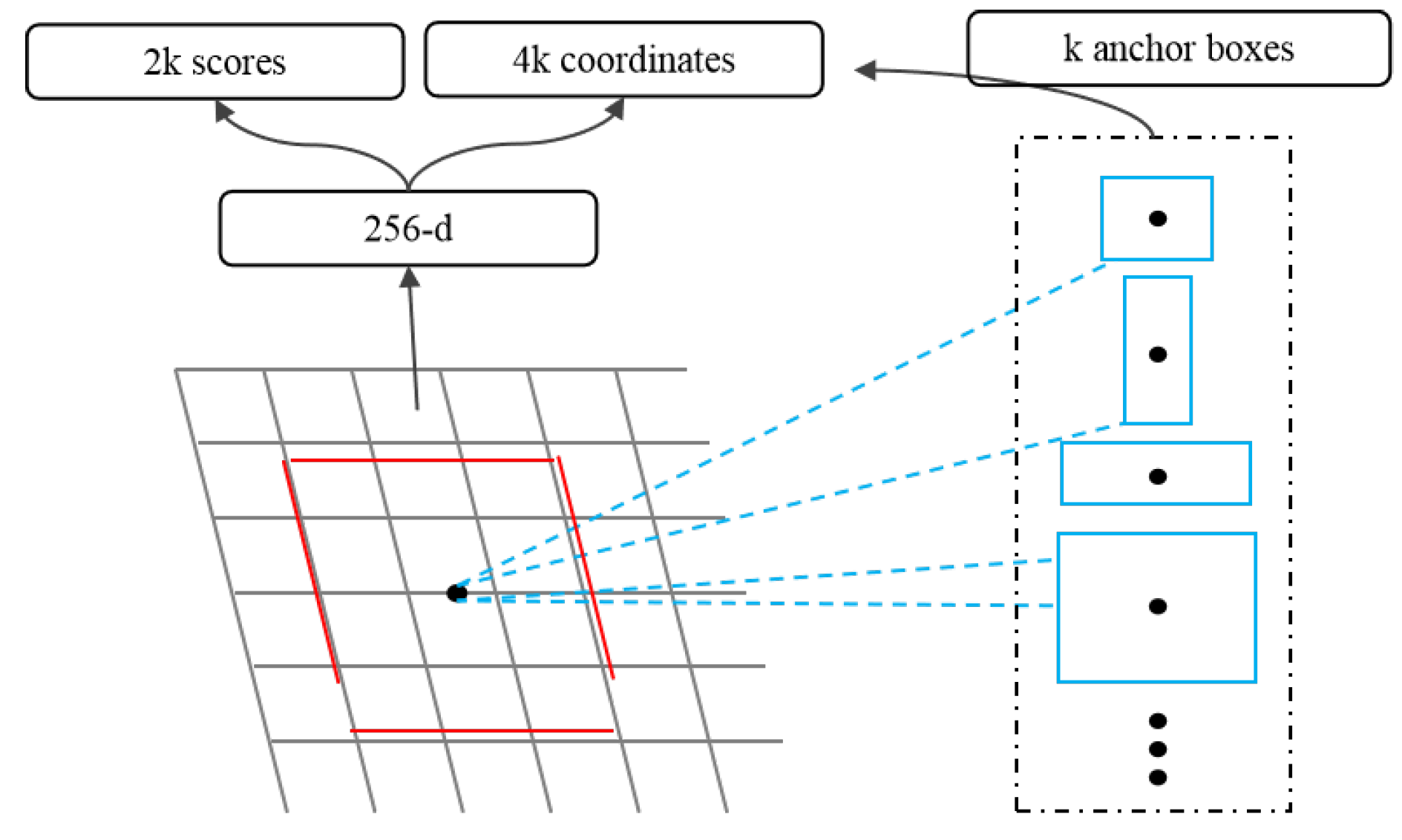
3.2. Region Proposal Network
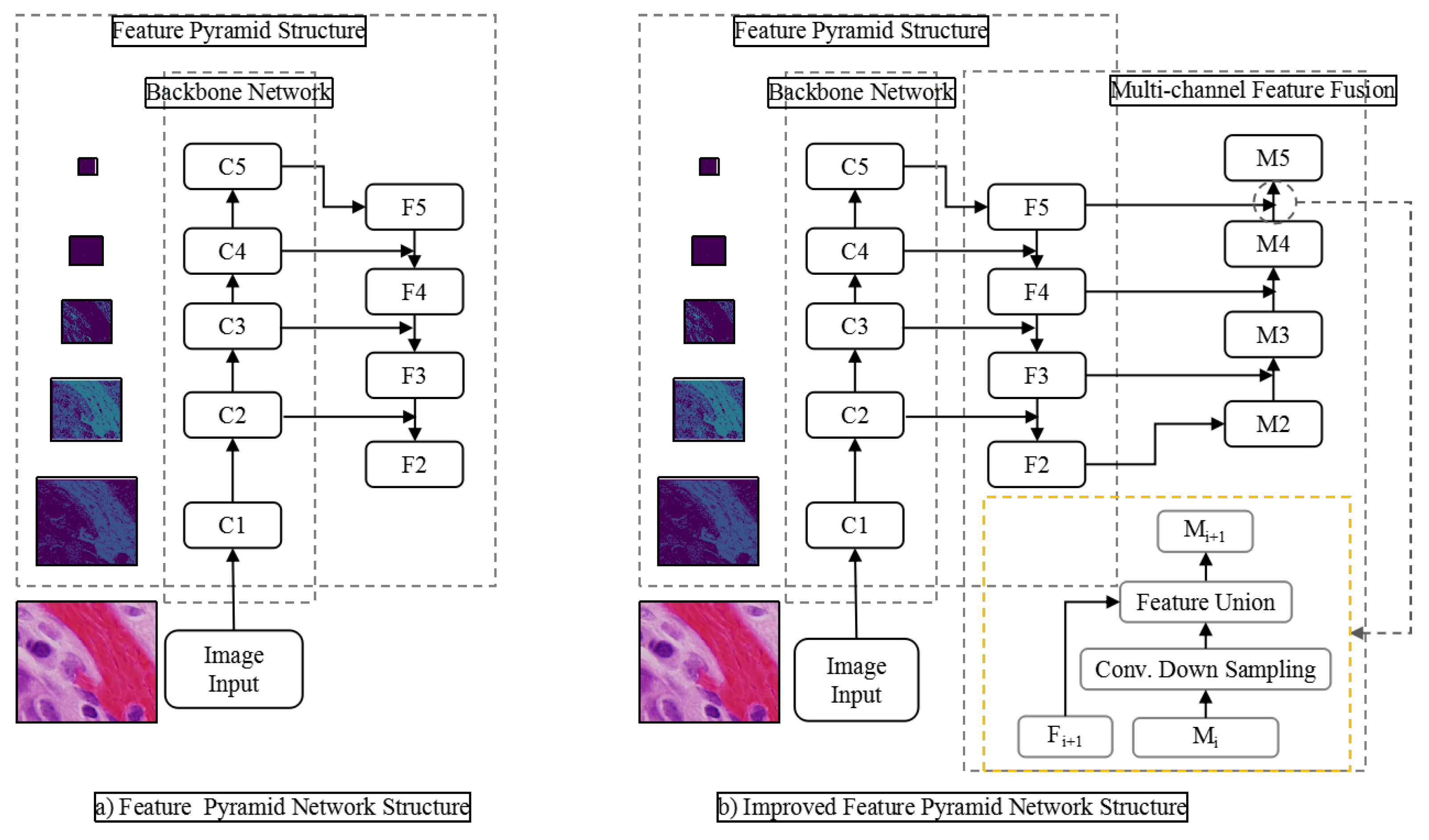
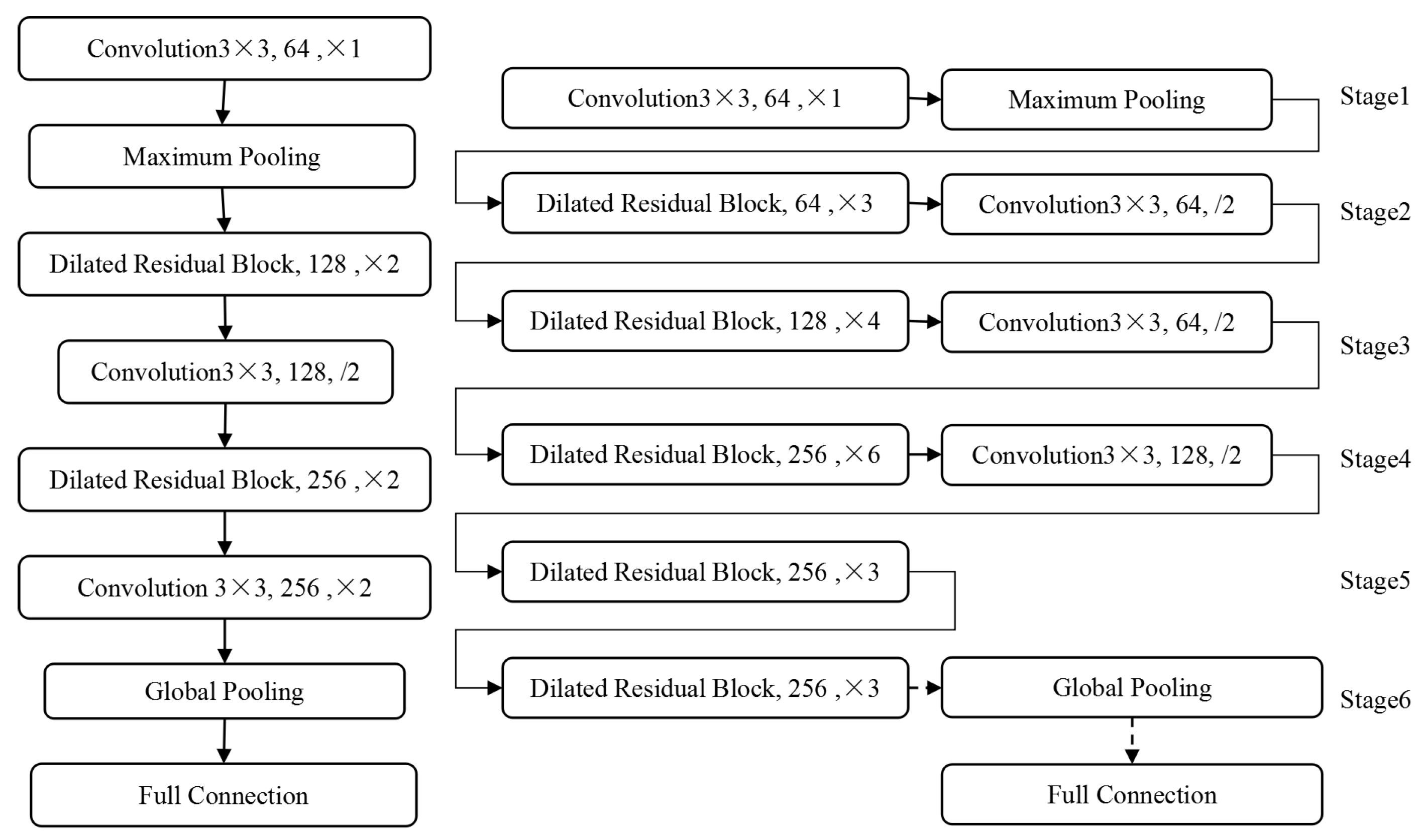
3.3. Feature Extraction
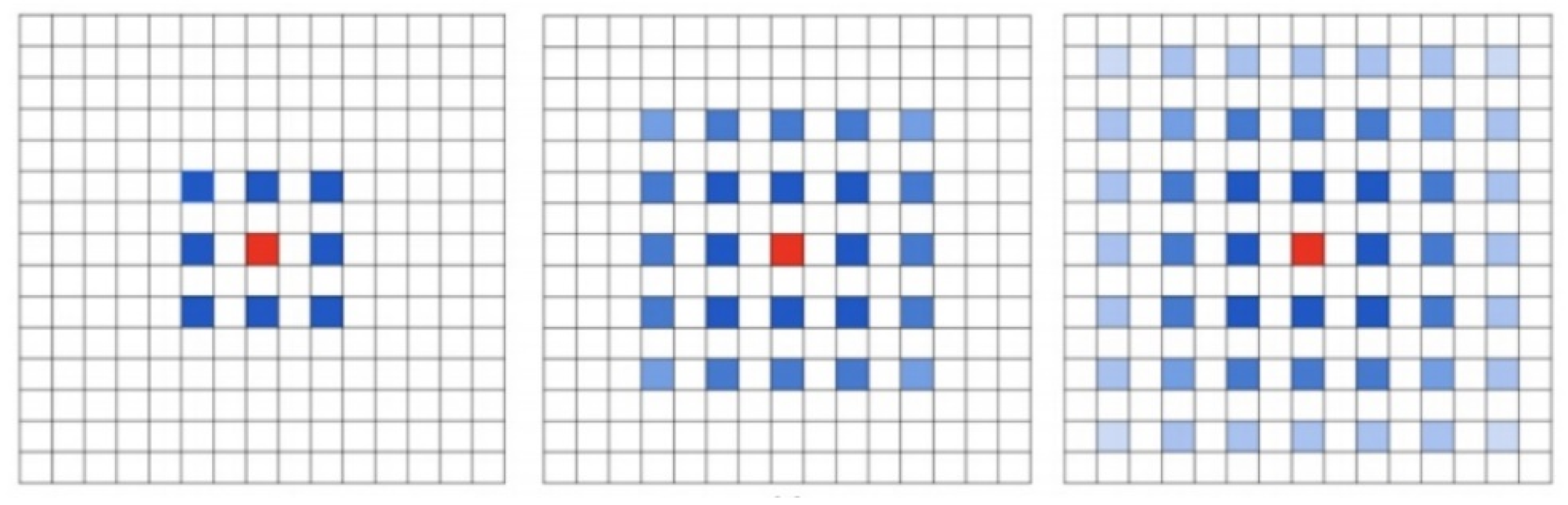
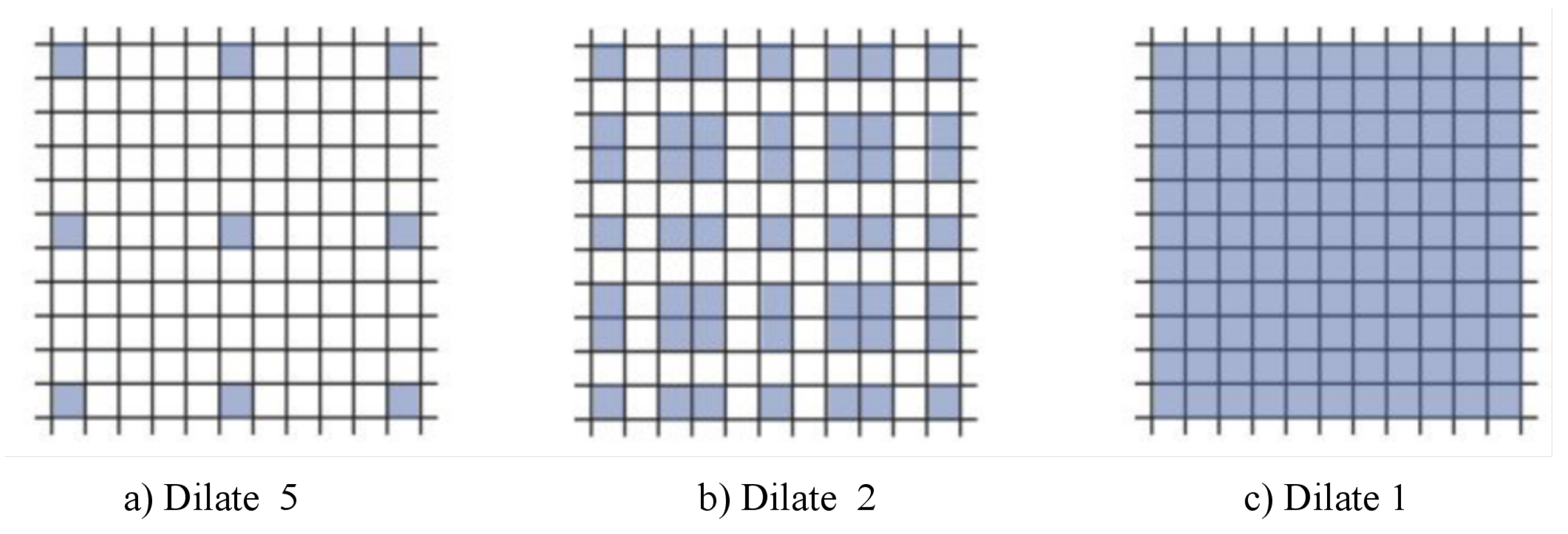
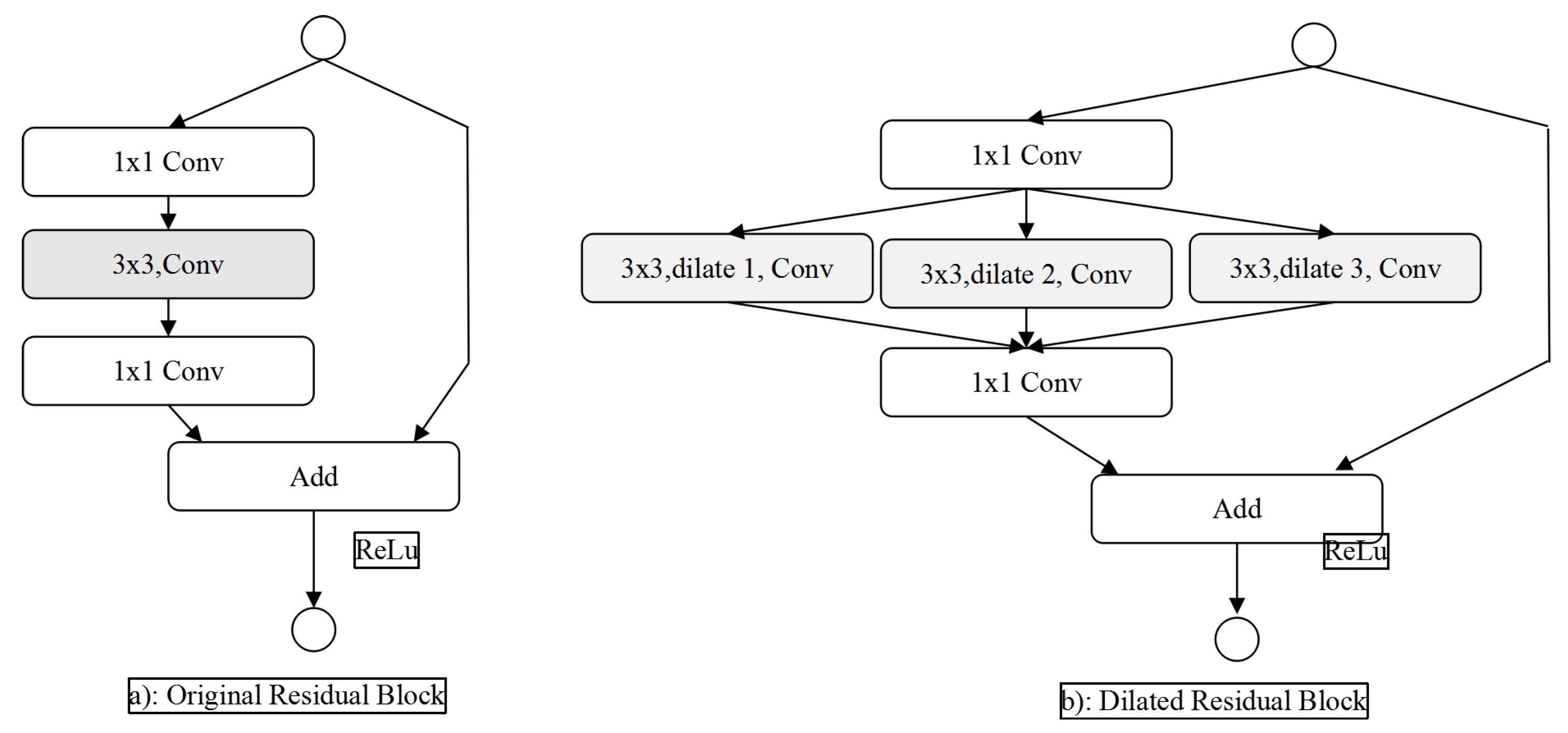
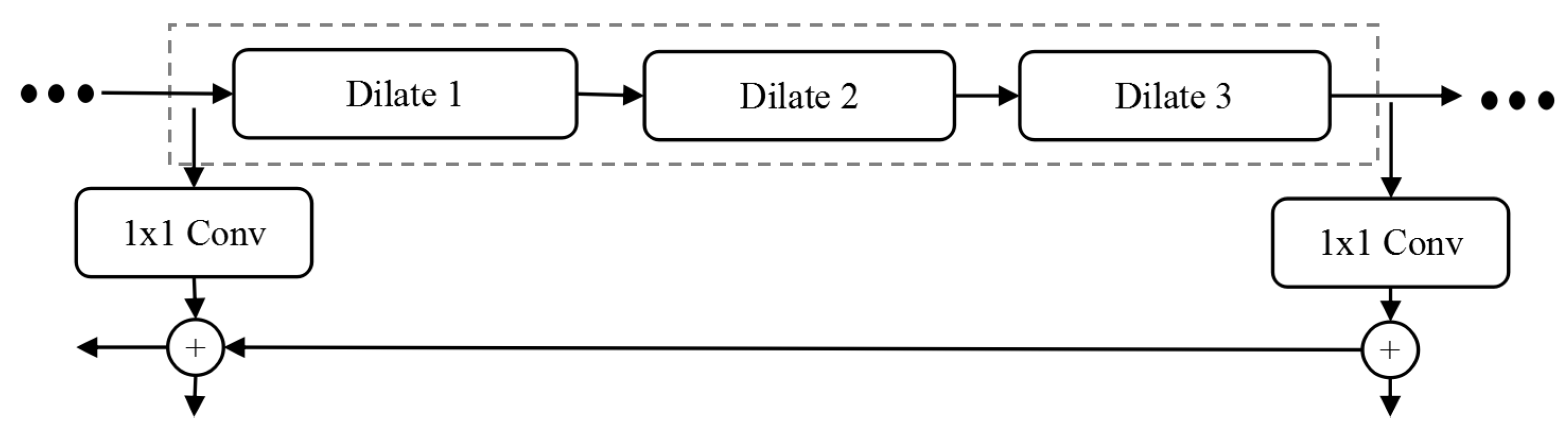
3.4. Dilated Residual Network
3.5. Design of Dilated Residual Network
3.6. The Layer of Softmax
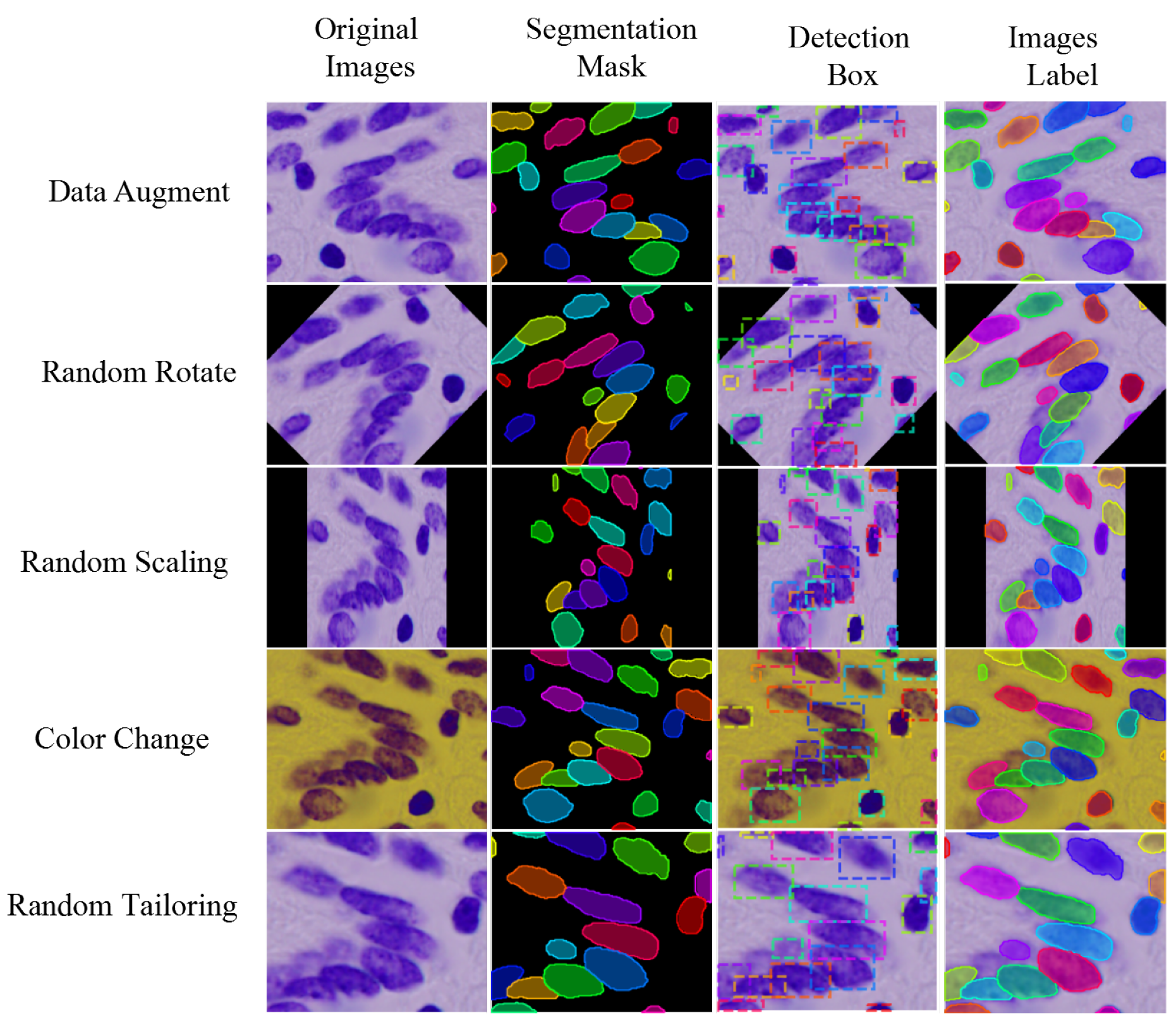
4. Experiments
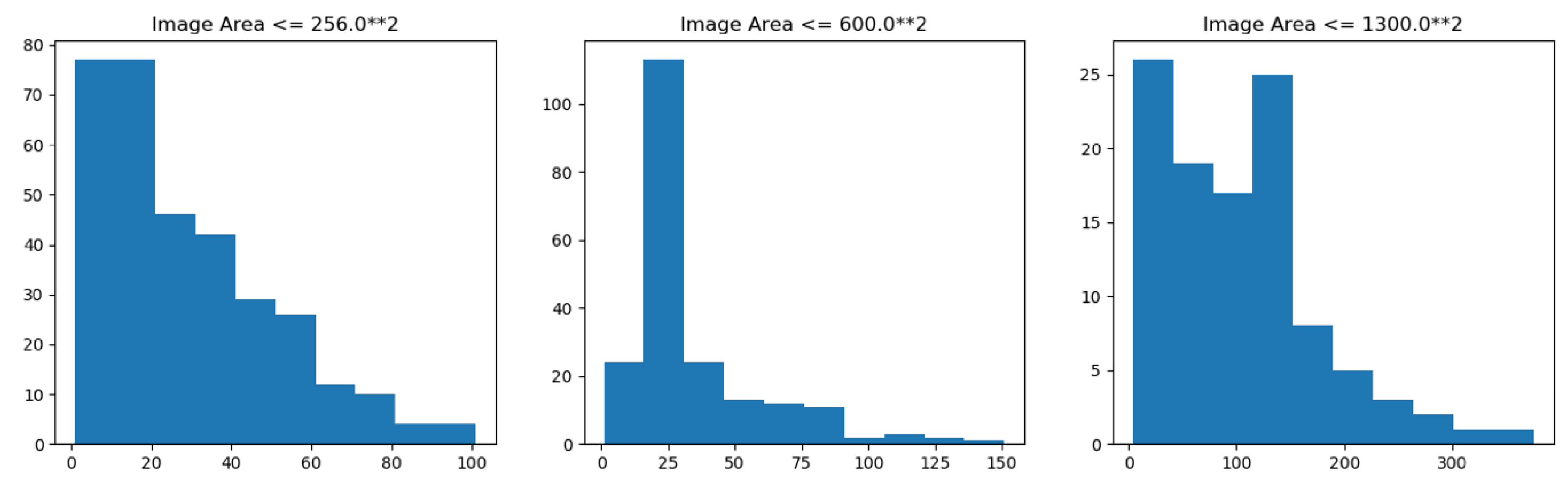
4.1. Data Sets
4.2. Experimental Configuration and Metrics
4.3. Evaluation Indicators
| Algorithm 1 AJI computation |
| Require: A series of images containing real annotations and predictive segmentation results; is indexed by i for each real nucleus; Each prediction segmentation result is indexed by k; Ensure: AJI Score 1: Initialize the number of intersections and union between the real labeled area and the predicted segmentation result area, and count them 2: 3: for all do 4: 5: Refresh the counting: 6: Mark 7: end for 8: for all do 9: 10: Refresh the counting: 11: Mark 12: end for 13: |
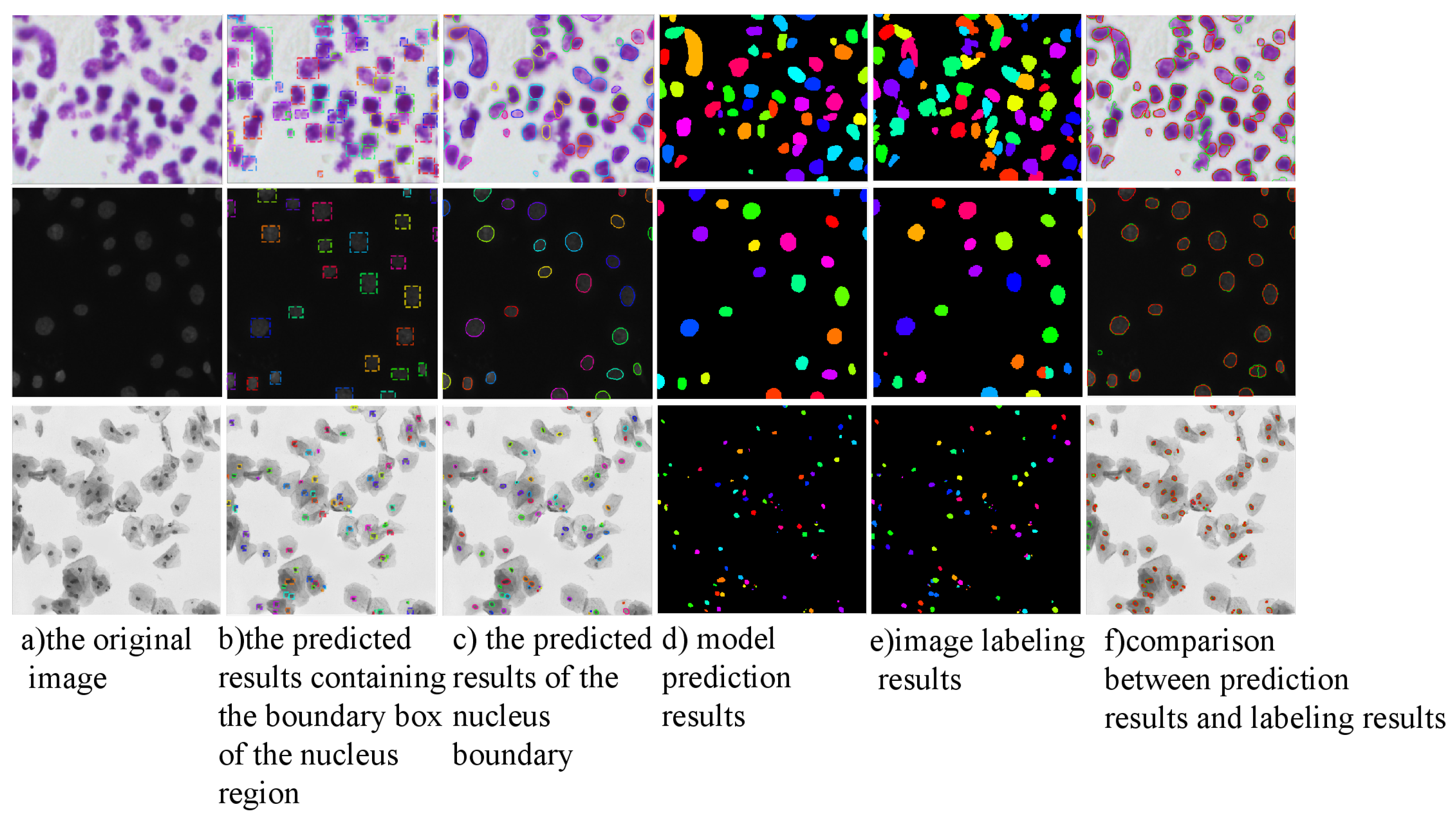
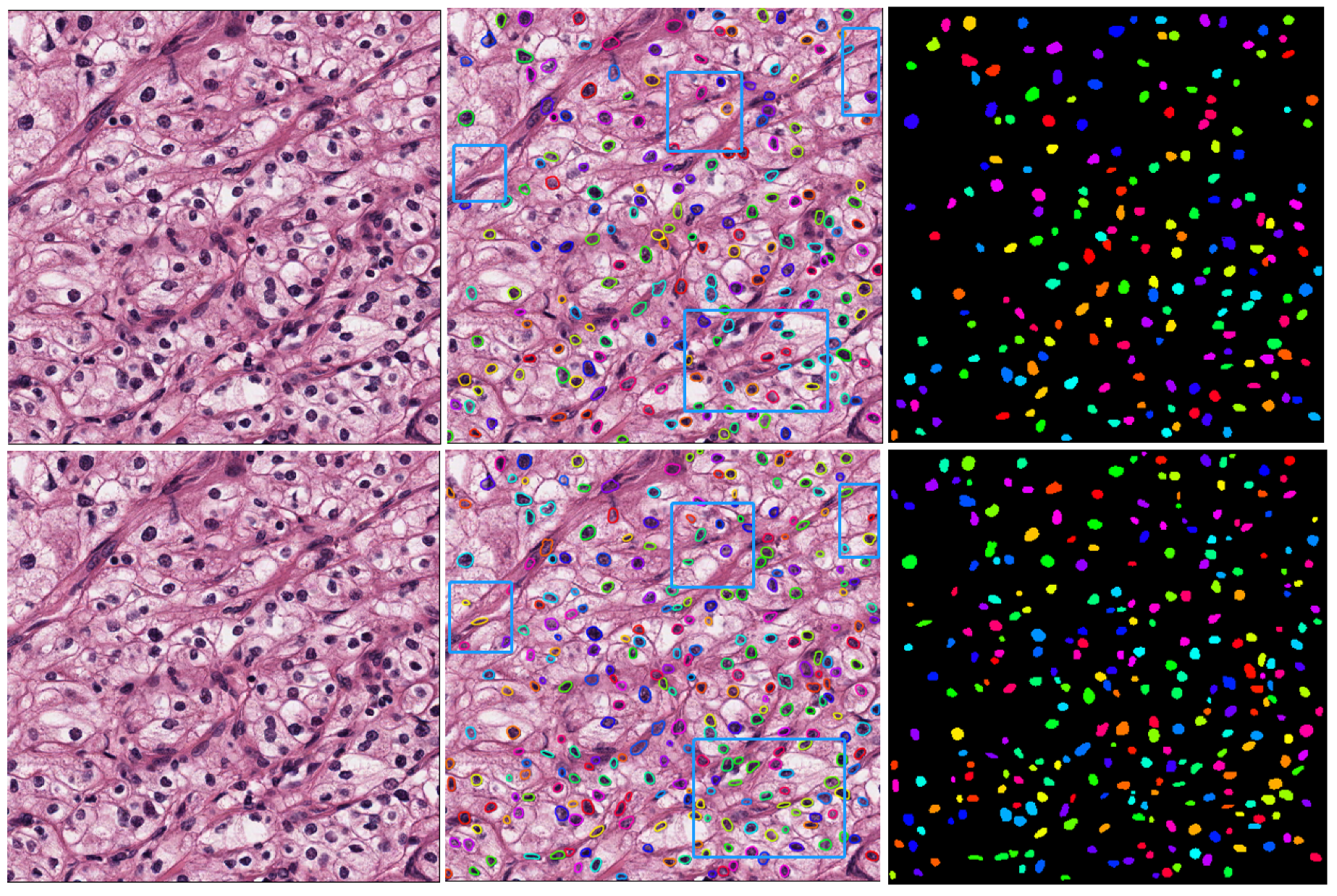
4.4. Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gervais, M.L.; Henry, P.C.; Saravanan, A.; Burry, T.N.; Gallie, B.L.; Jewett, M.A.S.; Hill, R.P.; Evans, A.J.; Ohh, M. Nuclear e-cadherin and vhl immunoreactivity are prognostic indicators of clear-cell renal cell carcinoma. Lab. Investig. 2007, 87, 1252–1264. [Google Scholar] [CrossRef] [PubMed]
- Fatakdawala, H.; Xu, J.; Basavanhally, A.; Bhanot, G.; Ganesan, S.; Feldman, M.; Tomaszewski, J.E.; Madabhushi, A. Expectation maximization driven geodesic active contour with overlap resolution (emagacor): Application to lymphocyte segmentation on breast cancer histopathology. IEEE Trans. Biomed. Eng. 2010, 57, 1676–1689. [Google Scholar] [CrossRef] [PubMed]
- Kachouie, N.N.; Fieguth, P.; Gamble, D.; Jervis, E.; Ezziane, Z.; Khademhosseini, A. Constrained watershed method to infer morphology of mammalian cells in microscopic images. Cytometry Part A 2010, 77, 1148–1159. [Google Scholar] [CrossRef] [PubMed]
- Basavanhally, A. Automated Image-Based Detection and Grading of Lymphocytic Infiltration in Breast Cancer Histopathology. Ph.D. Thesis, Rutgers University-Graduate School, New Brunswick, NJ, USA, 2010. [Google Scholar]
- Cireşan, D.C.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Mitosis detection in breast cancer histology images with deep neural networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2013), Nagoya, Japan, 22–26 September 2013; pp. 22–26. [Google Scholar]
- Ertosun, M.G.; Rubin, D.L. Automated grading of gliomas using deep learning in digital pathology images: A modular approach with ensemble of convolutional neural networks. In Proceedings of the AMIA Annual Symposium, San Francisco, CA, USA, 14–18 November 2015. [Google Scholar]
- Xu, J.; Luo, X.; Wang, G.; Gilmore, H.; Madabhushi, A. A deep convolutional neural network for segmenting and classifying epithelial and stromal regions in histopathological images. Neurocomputing 2016, 191, 214–223. [Google Scholar] [CrossRef] [PubMed]
- Sirinukunwattana, K.; Pluim, J.P.W.; Chen, H.; Qi, X.; Heng, P.A.; Guo, Y.B.; Wang, L.Y.; Matuszewski, B.J.; Bruni, E.; Sanchez, U.; et al. Gland segmentation in colon histology images: The glas challenge contest. Med. Image Anal. 2016, 35, 489–502. [Google Scholar] [CrossRef] [PubMed]
- Ojala, T.; Pietikainen, M.; Harwood, D. Performance Evaluation of Texture Measures with Classification Based on Kullback Discrimination of Distributions. In Proceedings of the 12th International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994; Volume 1, pp. 582–585. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Tampa, FL, USA, 5–8 December 1988; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask RCNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, E.K.; Li, Y.; Ye, Y.; Yiu, S.M.; Hui, L.C. A Dynamic Trust Framework for Opportunistic Mobile Social Networks. IEEE Trans. Netw. Serv. Manag. 2018, 15, 319–329. [Google Scholar] [CrossRef]
- Wang, S.; Wang, E.K.; Li, X.; Ye, Y.; Lau, R.Y.; Du, X. Multi-view learning via multiple graph regularized generative model. Knowl.-Based Syst. 2017, 121, 153–162. [Google Scholar] [CrossRef]
- Guan, J.; Wang, E. Repeated review based image captioning for image evidence review. Signal Process. Image Commun. 2018, 63, 141–148. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lu, H.; Xu, J.; Liu, L.; Zhou, C.; Zhou, X.; Zhang, Z. Nuclear Segmentation of Clear Cell Renal Cell Carcinoma based on Deep Convolutional Neural Networks. J. Biomed. Eng. Res. 2017, 36, 340–345. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Kumar, N.; Verma, R.; Sharma, S.; Bhargava, S.; Vahadane, A.; Sethi, A. A Dataset and a Technique for Generalized Nuclear Segmentation for Computational Pathology. IEEE Trans. Med. Imaging 2017, 36, 1550–1560. [Google Scholar] [CrossRef] [PubMed]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ogan | Desease | Number of Images (piece) | Mark of Nuclei (number) |
|---|---|---|---|
| Breast | Invasive breast cancer | 6 | 2213 |
| Kidney | Clear cell carcinoma of kidney | 6 | 5577 |
| Lung | Squamous cell carcinoma of lung, Lung adenocarcinoma | 6 | 2743 |
| Prostate | Prostate adenocarcinoma | 6 | 2400 |
| Bladder | Bladder urothelial carcinoma | 2 | 743 |
| Colon | Colonic adenocarcinoma | 2 | 726 |
| Stomach | Gastric adenocarcinoma | 2 | 2556 |
| Total | - | 30 | 16,958 |
| Parameter | Value |
|---|---|
| Learning Rate | 0.0001, 0.00001, 0.000001 |
| Epochs | 20, 40, 75 |
| Optimization | amsgrad |
| GradientClipNorm | 5.0 |
| Project | Configuration |
|---|---|
| OS | Linux | Ubuntu 16.04 LTS |
| CPU | Intel Core i7-6800K @ 3.40 GHz |
| GPU | 2*NVIDIA GeForce GTX 1080 (8G Graphic Memory) |
| Memory | 48G Mem + 64G Swap |
| Harddisk | 2T |
| Development Language | Python 3 |
| Deep Learning Framework | TensorFlow, Keras, Pytorch |
| Normalization Method | BN (Training) | BN (No Training) | GN (Training) |
|---|---|---|---|
| Batch Size 1 | 0.3442 | 0.4191 | 0.4514 |
| Batch Size 2 | 0.3707 | 0.4243 | 0.4527 |
| Backbone Net | ResNet50 | ResNet101 | DenseNet121 | D-ResNet64 |
|---|---|---|---|---|
| Epoch | 20 | 25 | 25 | 30 |
| Training error | 1.83 | 1.08 | 0.91 | 1.25 |
| Test error | 2.05 | 1.74 | 1.56 | 1.37 |
| Model | AJI (Gray) | AJI (ALL) |
|---|---|---|
| SVM | 0.0656 | 0.0653 |
| Random Forest | 0.1716 | 0.1247 |
| Logistic Regression (LR) | 0.4815 | 0.3444 |
| UNet + Morphology Postprocessing | 0.4785 | 0.3647 |
| ResNet50 + Mask RCNN | 0.5560 | 0.4527 |
| ResNet101 + Mask RCNN | 0.6094 | 0.5155 |
| DenseNet121 + Mask RCNN | 0.5681 | 0.4791 |
| ResNet50 + Mask SSD[34] | 0.5819 | 0.4763 |
| UNet + Deep Watershed Transform[57] | 0.6308 | 0.5016 |
| D-ResNet + Mask RCNN (Our) | 0.6077 | 0.5249 |
| D-ResNet + Mask RCNN + PA(Our) | 0.6145 | 0.5440 |
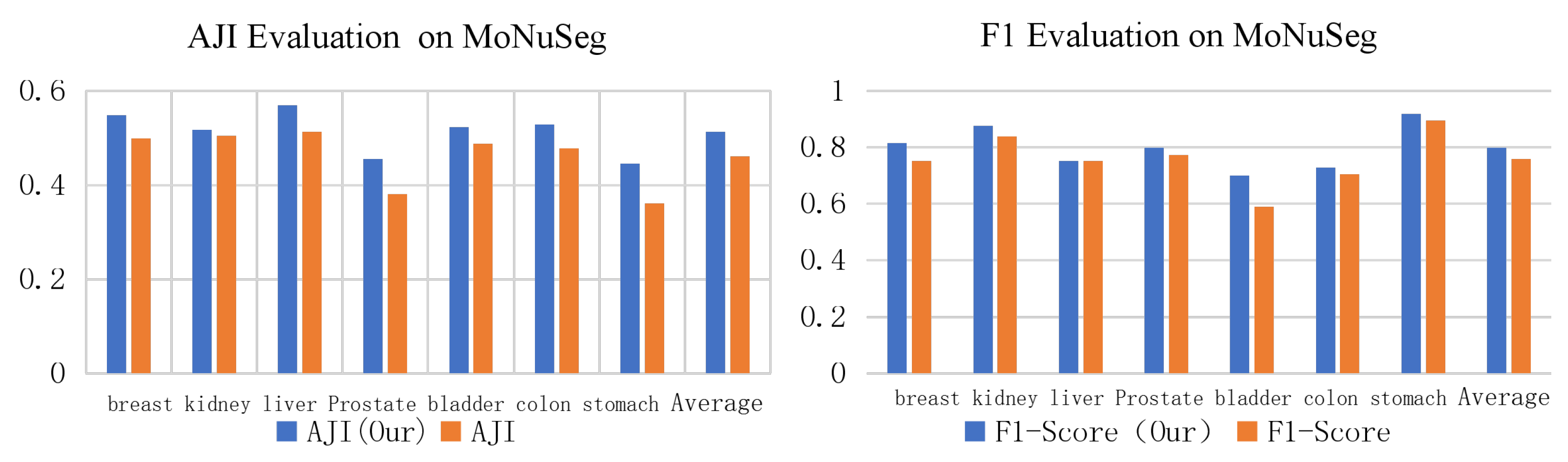
| Organ | AJI (Ours) | AJI (ALL) | F1-Score (Our) | F1-Score |
|---|---|---|---|---|
| Breast | 0.5486 | 0.4993 | 0.8167 | 0.7532 |
| Kidney | 0.5175 | 0.5051 | 0.8768 | 0.8386 |
| Liver | 0.5692 | 0.5137 | 0.7532 | 0.7524 |
| Prostate | 0.4561 | 0.3804 | 0.7984 | 0.7731 |
| Bladder | 0.5234 | 0.4876 | 0.7009 | 0.5894 |
| Colon | 0.5291 | 0.4783 | 0.7293 | 0.7057 |
| Stomach | 0.4456 | 0.3618 | 0.9187 | 0.8962 |
| Average | 0.5128 | 0.4609 | 0.7991 | 0.7584 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, E.K.; Zhang, X.; Pan, L.; Cheng, C.; Dimitrakopoulou-Strauss, A.; Li, Y.; Zhe, N. Multi-Path Dilated Residual Network for Nuclei Segmentation and Detection. Cells 2019, 8, 499. https://doi.org/10.3390/cells8050499
Wang EK, Zhang X, Pan L, Cheng C, Dimitrakopoulou-Strauss A, Li Y, Zhe N. Multi-Path Dilated Residual Network for Nuclei Segmentation and Detection. Cells. 2019; 8(5):499. https://doi.org/10.3390/cells8050499
Chicago/Turabian StyleWang, Eric Ke, Xun Zhang, Leyun Pan, Caixia Cheng, Antonia Dimitrakopoulou-Strauss, Yueping Li, and Nie Zhe. 2019. "Multi-Path Dilated Residual Network for Nuclei Segmentation and Detection" Cells 8, no. 5: 499. https://doi.org/10.3390/cells8050499
APA StyleWang, E. K., Zhang, X., Pan, L., Cheng, C., Dimitrakopoulou-Strauss, A., Li, Y., & Zhe, N. (2019). Multi-Path Dilated Residual Network for Nuclei Segmentation and Detection. Cells, 8(5), 499. https://doi.org/10.3390/cells8050499