
Japanese Translation and Validation of Genomic Knowledge Measure in the International Genetics Literacy and Attitudes Survey (iGLAS-GK)

 ,
,  , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Instruments
2.2. Participants
2.3. Measure
2.4. Identification of Unreliable Responses
2.5. Statistical Analysis
2.5.1. Item Analysis
2.5.2. Ceiling and Floor Effects
2.5.3. Test–Retest
2.5.4. Confirmation of Factor Structure
2.5.5. Significance Level and Analysis Tools
2.6. Ethical Considerations
3. Results
3.1. Content Validity
3.2. Participants
3.3. Item Analysis
3.4. Number of Factors and Inter-Factor Correlations
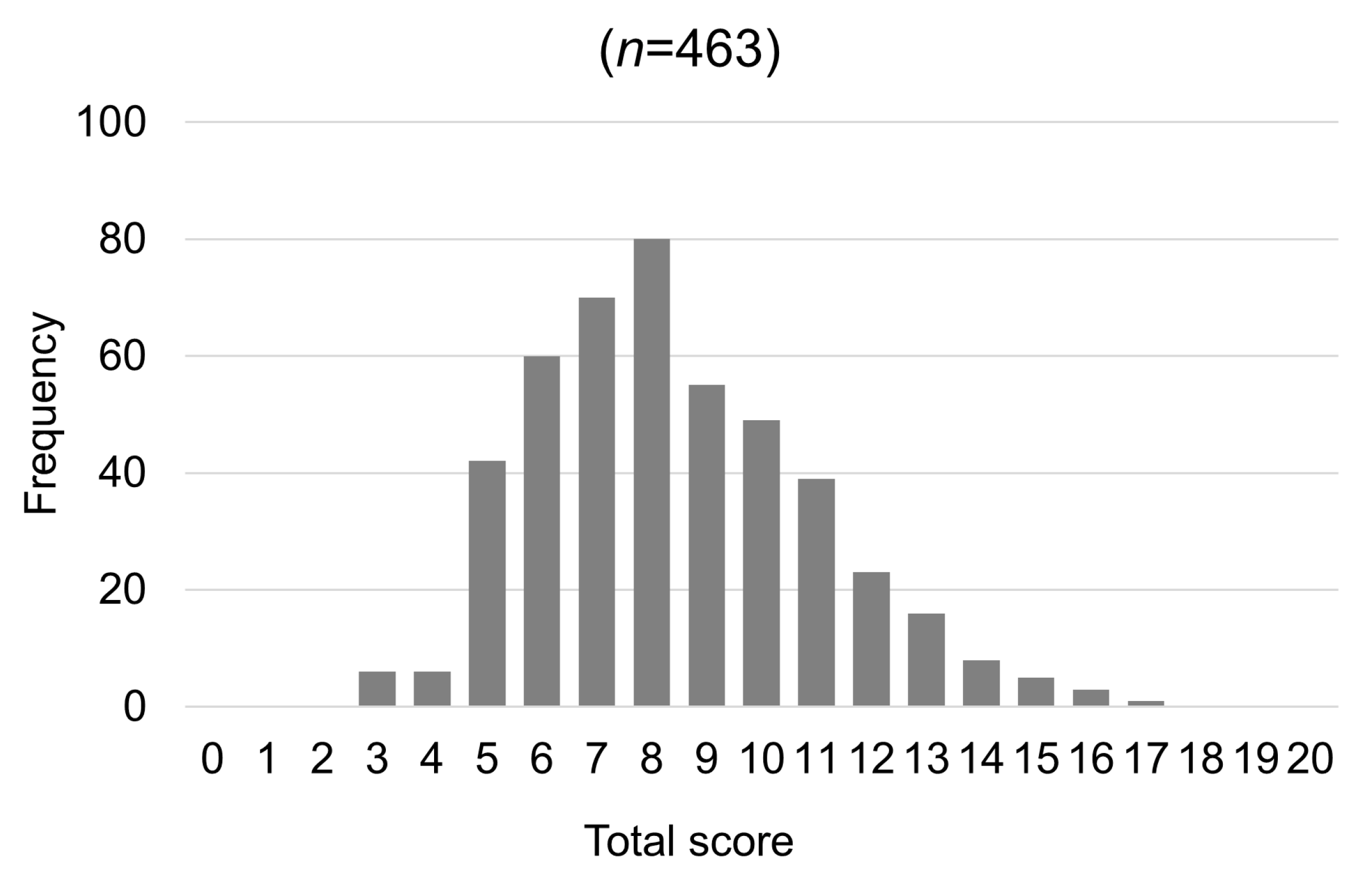
3.5. Summary Statistics of the 20 Items
3.6. Test–Retest Reliability
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Christensen, K.; Murray, J.C. What genome-wide association studies can do for medicine. N. Engl. J. Med. 2007, 356, 1094–1097. [Google Scholar] [CrossRef] [Green Version]
- Guttmacher, A.E.; Collins, F.S. Welcome to the genomic era. N. Engl. J. Med. 2003, 349, 996–998. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Läll, K.; Mägi, R.; Morris, A.; Metspalu, A.; Fischer, K. Personalized risk prediction for type 2 diabetes: The potential of genetic risk scores. Genet. Med. 2017, 19, 322–329. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khera, A.V.; Chaffin, M.; Aragam, K.G.; Haas, M.E.; Roselli, C.; Choi, S.H.; Natarajan, P.; Lander, E.S.; Lubitz, S.A.; Ellinor, P.T.; et al. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat. Genet. 2018, 50, 1219–1224. [Google Scholar] [CrossRef]
- Inouye, M.; Abraham, G.; Nelson, C.P.; Wood, A.M.; Sweeting, M.J.; Dudbridge, F.; Lai, F.Y.; Kaptoge, S.; Brozynska, M.; Wang, T.; et al. Genomic risk prediction of coronary artery disease in 480,000 adults: Implications for primary prevention. J. Am. Coll. Cardiol. 2018, 72, 1883–1893. [Google Scholar] [CrossRef] [PubMed]
- Elliott, J.; Bodinier, B.; Bond, T.A.; Chadeau-Hyam, M.; Evangelou, E.; Moons, K.G.M.; Dehghan, A.; Muller, D.C.; Elliott, P.; Tzoulaki, I. Predictive accuracy of a polygenic risk score-enhanced prediction model vs. a clinical risk score for coronary artery disease. JAMA 2020, 323, 636–645. [Google Scholar] [CrossRef]
- Hachiya, T.; Hata, J.; Hirakawa, Y.; Yoshida, D.; Furuta, Y.; Kitazono, T.; Shimizu, A.; Ninomiya, T. Genome-wide polygenic score and the risk of ischemic stroke in a prospective cohort: The Hisayama study. Stroke 2020, 51, 759–765. [Google Scholar] [CrossRef]
- Ashida, S.; Goodman, M.; Pandya, C.; Koehly, L.M.; Lachance, C.; Stafford, J.; Kaphingst, K.A. Age differences in genetic knowledge, health literacy and causal beliefs for health conditions. Public Health Genom. 2011, 14, 307–316. [Google Scholar] [CrossRef] [Green Version]
- Milo Rasouly, H.; Cuneo, N.; Marasa, M.; Demaria, N.; Chatterjee, D.; Thompson, J.J.; Fasel, D.A.; Wynn, J.; Chung, W.K.; Appelbaum, P.; et al. GeneLiFT: A novel test to facilitate rapid screening of genetic literacy in a diverse population undergoing genetic testing. J. Genet Couns. 2021, 30, 742–754. [Google Scholar] [CrossRef]
- Langer, M.M.; Roche, M.I.; Brewer, N.T.; Berg, J.S.; Khan, C.M.; Leos, C.; Moore, E.; Brown, M.; Rini, C. Development and validation of a genomic knowledge scale to advance informed decision-making research in genomic sequencing. MDM Policy Pract. 2017, 2, 2381468317692582. [Google Scholar] [CrossRef]
- Carver, R.B.; Castéra, J.; Gericke, N.; Evangelista, N.A.M.; El-Hani, C.N. Young adults’ belief in genetic determinism, and knowledge and attitudes towards modern genetics and genomics: The PUGGS questionnaire. PLoS ONE 2017, 12, e0169808. [Google Scholar] [CrossRef] [Green Version]
- Hooker, G.W.; Peay, H.; Erby, L.; Bayless, T.; Biesecker, B.B.; Roter, D.L. Genetic literacy and patient perceptions of IBD testing utility and disease control: A randomized vignette study of genetic testing. Inflamm. Bowel Dis. 2014, 20, 901–908. [Google Scholar] [CrossRef] [Green Version]
- Ishiyama, I.; Nagai, A.; Muto, K.; Tamakoshi, A.; Kokado, M.; Mimura, K.; Tanzawa, T.; Yamagata, Z. Relationship between public attitudes toward genomic studies related to medicine and their level of genomic literacy in Japan. Am. J. Med. Genet. A 2008, 146A, 1696–1706. [Google Scholar] [CrossRef]
- Jallinoja, P.; Aro, A.R. Knowledge about genes and heredity among Finns. New Genet. Soc. 1999, 18, 101–110. [Google Scholar] [CrossRef]
- Furr, L.A.; Kelly, S.E. The genetic knowledge index: Developing a standard measure of genetic knowledge. Genet. Test. 1999, 3, 193–199. [Google Scholar] [CrossRef] [PubMed]
- Chapman, R.; Likhanov, M.; Selita, F.; Zakharov, I.; Smith-Woolley, E.; Kovas, Y. Genetic Literacy and Attitudes Survey (iGLAS): International population-wide assessment instrument. Eur. Proc. Soc. Behav. Sci. 2017, 33, 45–66. [Google Scholar] [CrossRef]
- The Establishment of the Accessible Genetics Consortium (TAGC). The International Genetic Literacy and Attitudes Survey. Available online: https://tagc.world/iglas/ (accessed on 12 August 2022).
- Chapman, R.; Likhanov, M.; Selita, F.; Zakharov, I.; Smith-Woolley, E.; Kovas, Y. New literacy challenge for the twenty-first century: Genetic knowledge is poor even among well educated. J. Community Genet. 2019, 10, 73–84. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Browner, W.S.; Newman, T.B.; Hulley, S.B. Estimating sample size and power: Applications and examples. In Designing Clinical Research; Hulley, S.B., Cummings, S.R., Browner, W.S., Grady, D.G., Newman, T.B., Eds.; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2013; pp. 55–83. [Google Scholar]
- Bowling, B.V.; Acra, E.E.; Wang, L.; Myers, M.F.; Dean, G.E.; Markle, G.C.; Moskalik, C.L.; Huether, C.A. Development and evaluation of a genetics literacy assessment instrument for undergraduates. Genetics 2008, 178, 15–22. [Google Scholar] [CrossRef] [Green Version]
- Oppenheimer, D.M.; Meyvis, T.; Davidenko, N. Instructional manipulation checks: Detecting satisficing to increase statistical power. J. Exp. Soc. Psychol. 2009, 45, 867–872. [Google Scholar] [CrossRef]
- Aust, F.; Diedenhofen, B.; Ullrich, S.; Musch, J. Seriousness checks are useful to improve data validity in online research. Behav. Res. Methods 2013, 45, 527–535. [Google Scholar] [CrossRef] [Green Version]
- Hambleton, R.K.; Jones, R.W. Comparison of classical test theory and item response theory and their applications to test development. Educ. Meas. 1993, 12, 38–47. [Google Scholar] [CrossRef]
- Statistics Bureau. Ministry of Internal Affairs and Communications. The 2020 Population Census (Japan) [Internet]. Available online: https://www.stat.go.jp/english/data/kokusei/2020/summary.html (accessed on 12 August 2022).
- Yamamoto, K.; Hachiya, T.; Fukushima, A.; Nakaya, N.; Okayama, A.; Tanno, K.; Aizawa, F.; Tokutomi, T.; Hozawa, A.; Shimizu, A. Population-based biobank participants’ preferences for receiving genetic test results. J. Hum. Genet. 2017, 62, 1037–1048. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Robert, M.; Kaplan, D.P.S. Psychological Testing: Principles, Applications, and Issues, 9th ed.; Cengage Learning: Boston, MA, USA, 2017. [Google Scholar]
- Madrid-Valero, J.J.; Chapman, R.; Bailo, E.; Ordoñana, J.R.; Selita, F.; Kovas, Y.; Gregory, A.M. What Do People Know About the Heritability of Sleep? Behav. Genet. 2021, 51, 144–153. [Google Scholar] [CrossRef] [PubMed]
- Visscher, P.M.; Hill, W.G.; Wray, N.R. Heritability in the Genomics Era–Concepts and Misconceptions. Nat. Rev. Genet. 2008, 9, 255–266. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
| Question | Item Difficulty (%) | Good–Poor Analysis | Factor Analysis b | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Total | Lower (n = 184) | Middle (n = 135) | Upper (n = 144) | Subtraction (Upper-Lower) | p Value a | 95% CI | Factor Loading | Communality | |||||||
| F1 | F2 | F3 | F4 | F5 | F6 | ||||||||||
| Q1 † | What is a genome? | 36.1 | 21.2 | 38.5 | 52.8 | 31.6 | <0.001 *** | [21.5, 41.6] | 0.00 | 0.10 | 0.13 | 0.11 | 0.12 | 0.05 | 0.07 |
| Q2 † | Which of the following 4 letter groups represent the base units of DNA? | 42.5 | 21.2 | 43.7 | 68.8 | 47.6 | <0.001 *** | [38.0, 57.2] | −0.05 | 0.00 | −0.03 | 0.61 | 0.19 | −0.02 | 0.45 |
| Q3 † | How many copies of each gene do we have in each autosome cell? | 21.6 | 11.4 | 19.3 | 36.8 | 25.4 | <0.001 *** | [16.3, 34.5] | 0.18 | 0.06 | −0.01 | 0.36 | −0.08 | −0.08 | 0.15 |
| Q4 † | People differ in the amount of DNA they share. How much of this differing DNA do siblings usually share? | 44.7 | 28.8 | 46.7 | 63.2 | 34.4 | <0.001 *** | [24.1, 44.6] | 0.02 | −0.36 | 0.00 | 0.26 | 0.03 | 0.03 | 0.20 |
| Q5 † | What is the main function of all genes? | 68.5 | 52.2 | 69.6 | 88.2 | 36.0 | <0.001 *** | [27.1, 45.0] | −0.01 | −0.02 | 0.01 | 0.02 | 0.99 | −0.02 | 1.00 |
| Q6 † | On average, how much of their total DNA is the same in two people selected at random? | 14.3 | 13.6 | 13.3 | 16.0 | 2.4 | 0.544 | [−5.4, 10.2] | −0.01 | 1.00 | −0.01 | 0.00 | −0.04 | −0.04 | 1.00 |
| Q7 ‡ | Genetic contribution to the risk for developing Schizophrenia comes from: | 57.2 | 46.7 | 55.6 | 72.2 | 25.5 | <0.001 *** | [15.2, 35.8] | 0.77 | −0.08 | −0.08 | 0.02 | −0.04 | 0.03 | 0.63 |
| Q8 † | In humans, DNA is packaged into how many pairs of chromosomes? | 40.0 | 26.1 | 37.0 | 60.4 | 34.3 | <0.001 *** | [24.1, 44.5] | −0.23 | 0.12 | 0.02 | 0.34 | 0.19 | 0.08 | 0.28 |
| Q9 † | An epigenetic change is: | 33.3 | 28.8 | 32.6 | 39.6 | 10.8 | 0.040 * | [0.5, 21.1] | −0.23 | −0.05 | −0.02 | 0.01 | 0.19 | −0.21 | 0.13 |
| Q10 † | Approximately how many genes does the human DNA code contain? | 17.7 | 12.5 | 8.9 | 32.6 | 20.1 | <0.001 *** | [11.1, 29.2] | 0.07 | 0.22 | −0.10 | 0.40 | −0.09 | 0.11 | 0.23 |
| Q11 ‡ | Genetic contribution to the risk for developing Autism comes from: | 56.4 | 46.2 | 52.6 | 72.9 | 26.7 | <0.001 *** | [16.5, 36.9] | 1.00 | 0.04 | 0.02 | −0.01 | 0.02 | −0.02 | 1.00 |
| Q12 † | What are polymorphisms? | 49.9 | 32.1 | 53.3 | 69.4 | 37.3 | <0.001 *** | [27.3, 47.5] | 0.06 | 0.03 | 0.24 | 0.23 | 0.03 | 0.32 | 0.23 |
| Q13 † | The DNA sequence in two different cells, for example a neuron and a heart cell, of one person, is: | 21.0 | 13.0 | 16.3 | 35.4 | 22.4 | <0.001 *** | [13.2, 31.6] | 0.14 | 0.47 | 0.15 | 0.05 | 0.12 | 0.06 | 0.27 |
| Q14 † | Non-coding DNA describes DNA that: | 36.5 | 14.7 | 42.2 | 59.0 | 44.3 | <0.001 *** | [34.8, 53.9] | 0.13 | −0.11 | 0.10 | 0.48 | 0.19 | 0.05 | 0.34 |
| Q15 ‡ | Can dog breeding be considered a form of gene engineering? | 49.2 | 32.6 | 47.4 | 72.2 | 39.6 | <0.001 *** | [29.6, 49.6] | −0.04 | −0.06 | 0.34 | 0.11 | 0.11 | −0.22 | 0.23 |
| Q16 † | Which of the mentioned below is a method for gene editing: | 28.7 | 20.7 | 26.7 | 41.0 | 20.3 | <0.001 *** | [10.4, 30.3] | −0.08 | −0.05 | 0.02 | 0.53 | −0.35 | −0.07 | 0.35 |
| Q17 ‡ | Can we fully predict a person’s behaviour from examining their DNA sequence? | 87.7 | 84.2 | 86.7 | 93.1 | 8.9 | 0.014 * | [2.1, 15.5] | −0.01 | −0.02 | 0.00 | −0.01 | −0.01 | 1.00 | 1.00 |
| Q18 ‡ | At present in many countries, new born infants are tested for certain genetic traits. | 47.1 | 31.0 | 48.1 | 66.7 | 35.7 | <0.001 *** | [25.5, 45.9] | 0.02 | −0.02 | 0.55 | −0.05 | 0.02 | −0.16 | 0.34 |
| Q19 ‡ | Some of the genes that relate to dyslexia also relate to ADHD: | 71.3 | 50.5 | 80.7 | 88.9 | 38.4 | <0.001 *** | [29.5, 47.2] | −0.02 | 0.01 | 1.00 | 0.00 | −0.01 | 0.03 | 1.00 |
| Q20 † | If a report states ‘the heritability of insomnia is approximately 30%,’ what would that mean? | 17.1 | 11.4 | 21.5 | 20.1 | 8.7 | 0.029 * | [0.7, 16.7] | 0.08 | −0.47 | 0.10 | 0.01 | −0.28 | −0.16 | 0.36 |
| Mean (SD) | Percent of variance (%) | ||||||||||||||
| 42.0 (19.7) | 29.9 (18.4) | 42.0 (21.3) | 57.5 (22.4) | 9.0 | 8.4 | 7.9 | 7.3 | 7.2 | 6.5 | ||||||
| Mean † (SD) | Cumulative variance (%) | ||||||||||||||
| 33.7 (15.1) | 22.0 (11.2) | 33.5 (17.1) | 48.8 (20.5) | 9.0 | 17.4 | 25.3 | 32.6 | 39.8 | 46.3 | ||||||
| Mean ‡ (SD) | |||||||||||||||
| 61.5 (15.4) | 48.6 (19.2) | 61.9 (17.3) | 77.7 (10.6) | ||||||||||||
| Characteristic | Study 1 (n = 463) | Study 2 (n = 48) |
|---|---|---|
| Sex | ||
| Male | 234 (50.5) | 21 (43.8) |
| Female | 229 (49.5) | 27 (56.3) |
| Age | ||
| 20–29 | 81 (17.5) | 7 (14.6) |
| 30–39 | 87 (18.8) | 10 (20.8) |
| 40–49 | 92 (19.9) | 7 (14.6) |
| 50–59 | 96 (20.7) | 10 (20.8) |
| 60–69 | 107 (23.1) | 14 (29.2) |
| Average | 46.0 | 47.5 |
| Educational background | ||
| Junior high school | 8 (1.7) | 2 (4.2) |
| Senior high school or its equivalent | 121 (26.1) | 12 (25.0) |
| Vocational school or technical college | 93 (20.1) | 6 (12.5) |
| Bachelor’s degree | 212 (45.8) | 25 (52.1) |
| Master’s degree | 20 (4.3) | 3 (6.3) |
| Doctoral degree | 9 (1.9) | 0 (0.0) |
| Occupation | ||
| Company employee (full-time) | 165 (35.6) | 15 (31.3) |
| Homemaker | 78 (16.8) | 9 (18.8) |
| Unemployed | 69 (14.9) | 9 (18.8) |
| Part-time work | 48 (10.4) | 5 (10.4) |
| Company employee (temporary staff) | 23 (5.0) | 2 (4.2) |
| Self-employed | 20 (4.3) | 0 (0.0) |
| Student | 14 (3.0) | 1 (2.1) |
| Freelancer | 11 (2.4) | 2 (4.2) |
| Manager/Executive | 10 (2.2) | 0 (0.0) |
| Physician/medical personnel | 8 (1.7) | 2 (4.2) |
| Public employee (excluding faculty/staff) | 8 (1.7) | 1 (2.1) |
| Other | 9 (1.9) | 2 (4.2) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoshida, A.; Tokutomi, T.; Fukushima, A.; Chapman, R.; Selita, F.; Kovas, Y.; Sasaki, M. Japanese Translation and Validation of Genomic Knowledge Measure in the International Genetics Literacy and Attitudes Survey (iGLAS-GK). Genes 2023, 14, 814. https://doi.org/10.3390/genes14040814
Yoshida A, Tokutomi T, Fukushima A, Chapman R, Selita F, Kovas Y, Sasaki M. Japanese Translation and Validation of Genomic Knowledge Measure in the International Genetics Literacy and Attitudes Survey (iGLAS-GK). Genes. 2023; 14(4):814. https://doi.org/10.3390/genes14040814
Chicago/Turabian StyleYoshida, Akiko, Tomoharu Tokutomi, Akimune Fukushima, Robert Chapman, Fatos Selita, Yulia Kovas, and Makoto Sasaki. 2023. "Japanese Translation and Validation of Genomic Knowledge Measure in the International Genetics Literacy and Attitudes Survey (iGLAS-GK)" Genes 14, no. 4: 814. https://doi.org/10.3390/genes14040814
APA StyleYoshida, A., Tokutomi, T., Fukushima, A., Chapman, R., Selita, F., Kovas, Y., & Sasaki, M. (2023). Japanese Translation and Validation of Genomic Knowledge Measure in the International Genetics Literacy and Attitudes Survey (iGLAS-GK). Genes, 14(4), 814. https://doi.org/10.3390/genes14040814