Geographical Imputation of Missing Poaceae Pollen Data via Convolutional Neural Networks

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Description
2.2. Methodology
2.3. Experimental Design
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- De Weger, L.A.; Bergmann, K.C.; Rantio-Lehtimaki, A.; Dahl, A.; Buters, J.; Déchamp, C.; Belmonte, J.; Thibaudon, M.; Cecchi, L.; Besancenot, J.P.; et al. Impact of Pollen. In Allergenic Pollen; Sofiev, M., Bergmann, K.C., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 161–215. [Google Scholar] [CrossRef]
- Lake, I.; Jones, N.; Agnew, M.; Goodess, C.; Giorgi, F.; Lynda, H.L.; Semenov, M.; Solmon, F.; Storkey, J.; Vautard, R.; et al. Erratum: “Climate Change and Future Pollen Allergy in Europe”. Environ. Health Perspect. 2018, 126. [Google Scholar] [CrossRef] [PubMed]
- Sabariego, S.; Cuesta, P.; Fernández-González, F.; Pérez-Badia, R. Models for forecasting airborne Cupressaceae pollen levels in central Spain. Int. J. Biometeorol. 2012, 56, 253–258. [Google Scholar] [CrossRef] [PubMed]
- Smith, M.; Emberlin, J. A 30-day-ahead forecast model for grass pollen in north London, UK. Int. J. Biometeorol. 2006, 50, 233–242. [Google Scholar] [CrossRef] [PubMed]
- Silva-Palacios, I.; Fernández-Rodríguez, S.; Durán-Barroso, P.; Tormo-Molina, R.; Maya-Manzano, J.; Gonzalo-Garijo, A. Temporal modelling and forecasting of the airborne pollen of Cupressaceae on the southwestern Iberian peninsula. Int. J. Biometeorol. 2016, 60, 1509–1517. [Google Scholar] [CrossRef]
- Schaber, J.; Badeck, F.W. Physiology-based phenology models for forest tree species in Germany. Int. J. Biometeorol. 2003, 47, 193–201. [Google Scholar] [CrossRef]
- Navares, R.; Aznarte, J. Forecasting the Start and End of Pollen Season in Madrid; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; Chapter 26; pp. 387–399. [Google Scholar]
- Puc, M. Artificial neural network model of the relationship between Betula pollen and meteorological factors in Szczecin (Poland). Int. J. Biometeorol. 2011, 56, 395–401. [Google Scholar] [CrossRef]
- Castellano-Méndez, M.; Aira, M.J.; Iglesias, I.; Jato, V.; González-Manteiga, W. Artificial neural networks as a useful tool to predict the risk level of Betula pollen in the air. Int. J. Biometeorol. 2005, 49, 310–316. [Google Scholar] [CrossRef]
- Iglesias-Otero, M.A.; Fernández-González, M.; Rodríguez-Caride, D.; Astray, G.; Mejuto, J.C.; Rodríguez-Rajo, F.J. A model to forecast the risk periods of Plantago pollen allergy by using ANN methodology. Aerobiologia 2015, 31, 201–211. [Google Scholar] [CrossRef]
- Navares, R.; Aznarte, J. Predicting the Poaceae pollen season: six month-ahead forecasting and identification of relevant features. Int. J. Biometeorol. 2016. [Google Scholar] [CrossRef]
- Navares, R.; Aznarte, J. What are the most important variables for Poaceae airborne pollen forecasting? Sci. Total Environ. 2016, 579, 1161–1169. [Google Scholar] [CrossRef]
- Oteros, J.; Sofiev, M.; Smith, M.; Clot, B.; Damialis, A.; Prank, M.; Werchan, M.; Wachter, R.; Weber, A.; Kutzora, S.; et al. Building an automatic pollen monitoring network (ePIN): Selection of optimal sites by clustering pollen stations. Sci. Total Environ. 2019, 688, 1263–1274. [Google Scholar] [CrossRef]
- Schafer, J.L. Multiple imputation: A primer. Stat. Methods Med. Res. 1999, 8, 3–15. [Google Scholar] [CrossRef] [PubMed]
- Bennett, D. How can I deal with missing data in my study? Aust. N. Z. J. Public Health 2001, 25, 464–469. [Google Scholar] [CrossRef] [PubMed]
- Shepard, D. A Two-dimensional Interpolation Function for Irregularly-spaced Data. In Proceedings of the 23rd ACM National Conference, Las Vegas, NV, USA, 27–29 Auguest 1968; ACM: New York, NY, USA, 1968; pp. 517–524. [Google Scholar] [CrossRef]
- Matheron, G. Principles of geostatistics. Econ. Geol. 1963, 58, 1246–1266. [Google Scholar] [CrossRef]
- Kordon, A.K. Competitive Advantages of Computational Intelligence. In Applying Computational Intelligence: How to Create Value; Springer: Berlin/Heidelberg, Germany, 2010; pp. 233–256. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Makati, Philippines, 2012; pp. 1097–1105. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: Sydney, Australia, 2017; Volume 70, pp. 1243–1252. [Google Scholar]
- Smith, S.W. The Scientist and Engineer’s Guide to Digital Signal Processing; California Technical Publishing: San Diego, CA, USA, 1997. [Google Scholar]
- Nowosad, J. Spatiotemporal models for predicting high pollen concentration level of Corylus, Alnus, and Betula. Int. J. Biometeorol. 2016, 60, 843–855. [Google Scholar] [CrossRef]
- Navares, R.; Aznarte, J.L. Forecasting Plantago pollen: improving feature selection through random forests, clustering, and Friedman tests. Theor. Appl. Climatol. 2019. [Google Scholar] [CrossRef]
- Zewdie, G.K.; Lary, D.J.; Levetin, E.; Garuma, G.F. Applying Deep Neural Networks and Ensemble Machine Learning Methods to Forecast Airborne Ambrosia Pollen. Int. J. Environ. Res. Public Health 2019, 16, 1992. [Google Scholar] [CrossRef]
- Sevillano, V.; Aznarte, J.L. Improving classification of pollen grain images of the POLEN23E dataset through three different applications of deep learning convolutional neural networks. PLoS ONE 2018, 13, e0201807. [Google Scholar] [CrossRef]
- Khanzhina, N.; Putin, E.; Filchenkov, A.; Zamyatina, E. Pollen grain recognition using convolutional neural network. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 25–27 April 2018. [Google Scholar]
- Galán Soldevilla, C.; Cariñanos González, P.; Alcázar Teno, P.; Domínguez Vílches, E. Manual de Calidad y Gestión de la Red Española de Aerobiología; Universidad de Córdoba: Córdoba, Spain, 2007. [Google Scholar]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective, 1st ed.; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Edward Rasmussen, C.; Bousquet, O.; von Luxburg, U.; Rätsch, G. Gaussian Processes in Machine Learning. In Advanced Lectures on Machine Learning: ML Summer; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3176. [Google Scholar] [CrossRef]
- Gamboa, J.C.B. Deep Learning for Time-Series Analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar]
- Rodríguez-Rajo, F.; Frenguelli, G.; Jato, M. Effect of air temperature on forecasting the start of the Betula pollen season at two contrasting sites in the south of Europe (1995–2001). Int. J. Biometeorol. 1983, 47, 117–125. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. arXiv 2016, arXiv:1611.03530. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jato, V.; Rodríguez-Rajo, F.J.; Alcázar, P.; Nuntiis, P.D.; Galán, C.; Mandrioli, P. May the definition of pollen season influence aerobiological results? Aerobiologia 2006, 22, 13–25. [Google Scholar] [CrossRef]
- Peternel, R.; Srnec, L.; Culig, J.; Hrga, I.; Hercog, P. Poaceae pollen in the atmosphere of Zagreb (Croatia), 2002–2005. Grana 2005, 45, 130–136. [Google Scholar] [CrossRef]




{kind=link}
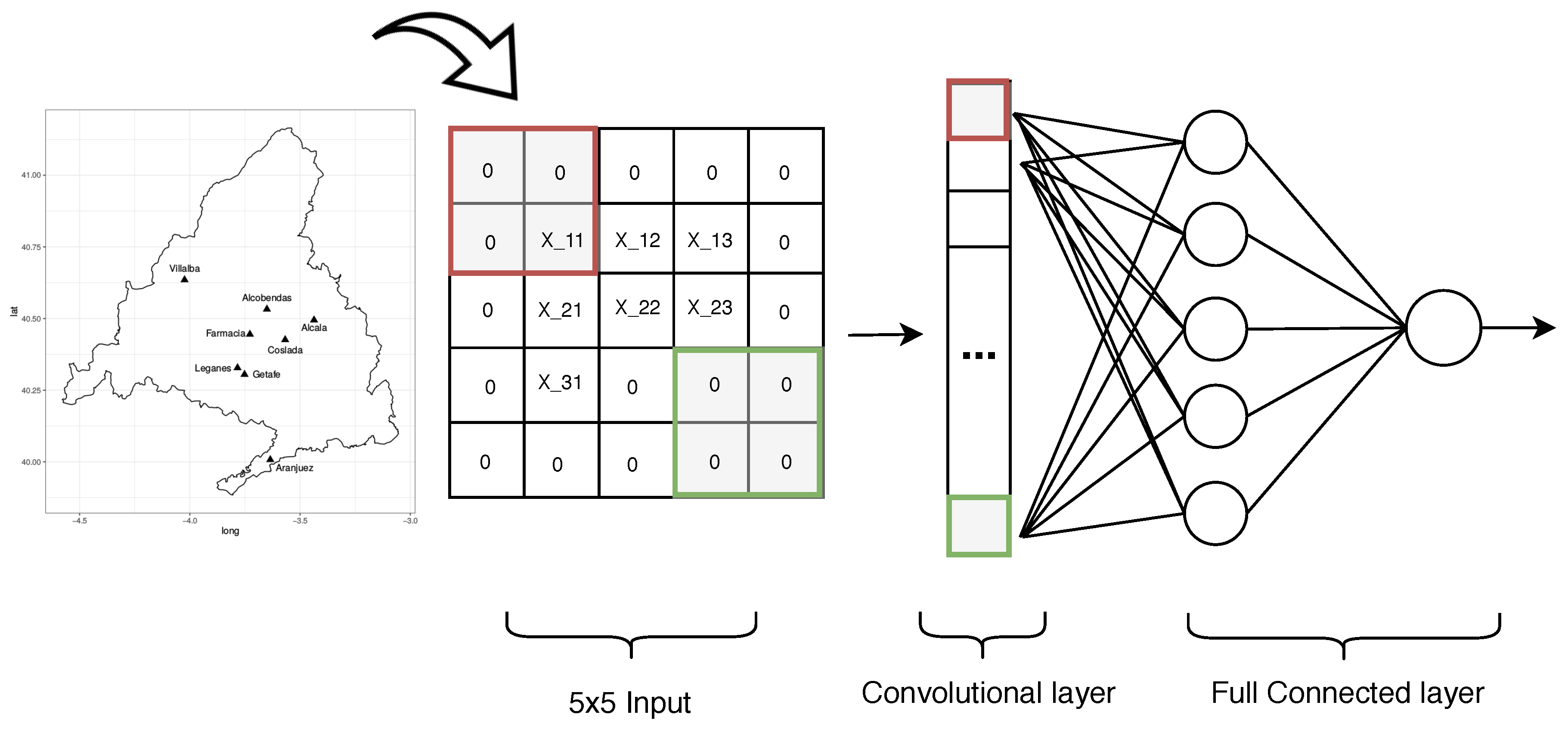{kind=link}
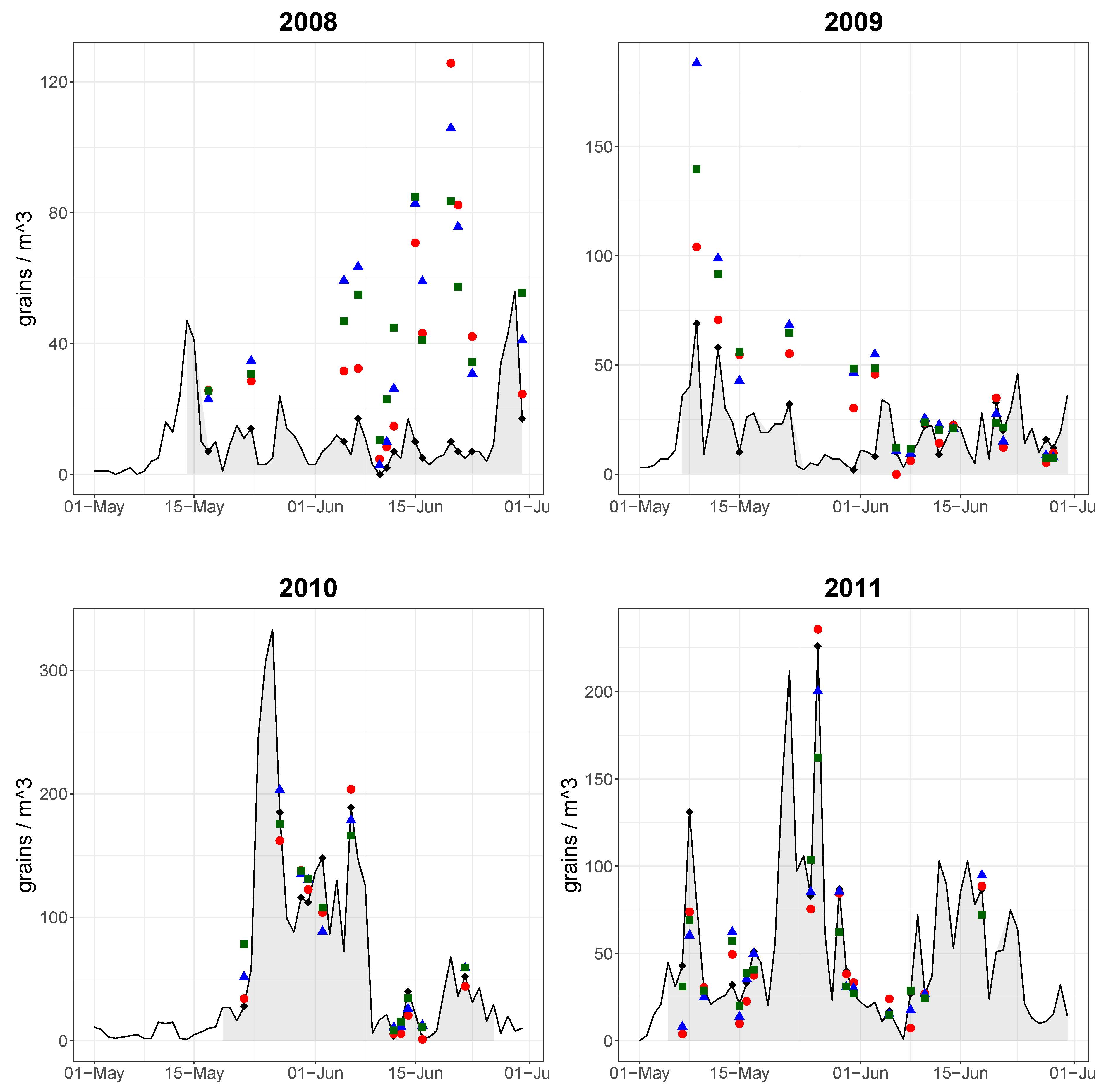{kind=link}
| % of Missing | Peak Season | Off-Peak Season | All | ||||||
|---|---|---|---|---|---|---|---|---|---|
| IDW | GP | CNN | IDW | GP | CNN | IDW | GP | CNN | |
| 10% | 43.97 | 42.44 | 39.89 | 5.36 | 5.07 | 4.53 | 18.02 | 17.41 | 16.46 |
| (5.84) | (8.56) | (5.25) | (0.91) | (1.09) | (0.98) | (2.05) | (3.02) | (2.02) | |
| 20% | 41.55 | 39.69 | 37.35 | 5.76 | 5.24 | 4.80 | 17.26 | 16.43 | 15.42 |
| (3.95) | (4.72) | (4.21) | (1.50) | (1.55) | (1.20) | (1.57) | (1.80) | (1.48) | |
| 30% | 42.79 | 41.50 | 40.14 | 6.45 | 5.92 | 5.40 | 17.87 | 17.24 | 16.60 |
| (3.77) | (4.20) | (4.05) | (0.68) | (0.79) | (1.15) | (1.52) | (1.66) | (1.60) | |
| GP | CNN | |
|---|---|---|
| 10% missing | 243.38 | 17.47 |
| (10.56) | (0.66) | |
| 20% missing | 171.22 | 15.91 |
| (18.00) | (0.64) | |
| 30% missing | 148.12 | 15.55 |
| (24.19) | (1.65) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Navares, R.; Aznarte, J.L. Geographical Imputation of Missing Poaceae Pollen Data via Convolutional Neural Networks. Atmosphere 2019, 10, 717. https://doi.org/10.3390/atmos10110717
Navares R, Aznarte JL. Geographical Imputation of Missing Poaceae Pollen Data via Convolutional Neural Networks. Atmosphere. 2019; 10(11):717. https://doi.org/10.3390/atmos10110717
Chicago/Turabian StyleNavares, Ricardo, and José Luis Aznarte. 2019. "Geographical Imputation of Missing Poaceae Pollen Data via Convolutional Neural Networks" Atmosphere 10, no. 11: 717. https://doi.org/10.3390/atmos10110717
APA StyleNavares, R., & Aznarte, J. L. (2019). Geographical Imputation of Missing Poaceae Pollen Data via Convolutional Neural Networks. Atmosphere, 10(11), 717. https://doi.org/10.3390/atmos10110717