1. Introduction
Fine particulate matter PM
, with an aerodynamic diameter less than
micrometers, has been associated with cardiovascular disease leading to mortality [
1,
2,
3,
4]. Inhaling PM
has been associated with asthma, chronic bronchitis, irregular heartbeat, heart attack, premature death, lung disorder [
2,
5] and cancer [
6,
7]. PM
is a heterogeneous mixture of various chemical species with a variable size distribution and mixing states, which are influenced by emissions, atmospheric chemistry, and meteorology [
8,
9]. PM
emissions combined with adverse meteorological conditions can significantly deteriorate air quality [
10,
11,
12,
13], affect visibility [
4,
14,
15,
16,
17,
18], and impact health. It is directly emitted in the atmosphere from various natural and anthropogenic sources, including biomass burning, combustion of fossil fuels, and dust, and it is formed through secondary formation from emitted precursor gases.
It has been suggested that central monitors cannot capture the spatial variability that exists at the urban scale and can thereby introduce error in health models. In one such study, Goldman et al. (2010) found that the use of the data from a central monitoring site in Atlanta, GA, introduced errors while estimating exposures; they further suggested that several other studies have underestimated exposures by not accounting for spatial variability. In one of their health studies, Wilson et al. (2007) showed that a variation in cardiovascular mortality rates is associated with PM
, with respect to the geographical distance from the central monitoring sites. Spatiotemporal variation has, therefore, become a matter of concern for environmental scientists, health researchers, public health officials, and the public [
19,
20]. These studies were conducted on 24-h integrated PM
over several years to investigate both seasonal variation and yearly trends and suggest that the variability is attributable to the meteorology and topography of the study area as well as local conditions such as vehicular emissions, traffic flow patterns, and emissions from residential sources as well as local businesses such as restaurants, etc. In another study, conducted in Birmingham, Alabama, Balanchard et al. (2014) work showed that regional-scale air pollution and local emissions from mobile sources, industrial facilities, and residential communities and complex dispersion patterns of PM
resulted in spatiotemporal variation. Additionally, other factors such as measurement errors and differences in the behavior of PM
constituents contributed to spatiotemporal variation [
21]. In addition, PM
concentrations are closely related to temperature, wind speed, and precipitation [
22,
23,
24]. For example, warmer temperatures and changes in precipitation can impact wildfire emissions in North America, and an increase in temperature can lead to higher biogenic emissions, which are important precursor of secondary organic aerosols (SOAs) [
5]. Higher temperature increases sulfate concentrations and SOAs due to increased
and VOC oxidation [
25], a decrease in semivolatile aerosols due to evaporation [
25,
26,
27], and an increase in the emissions of biogenic VOCs from vegetation. The production of the hydroxyl (OH) radical and hydrogen peroxide (
) could be enhanced by higher relative humidity (RH) [
26]. Additionally, the changes in wind speed and mixing height have a strong influence on PM
[
28]. Meteorological parameters are strongly correlated, resulting in strong interrelationships. For example, boundary layer height is dependent on surface temperature or the relationship between surface temperature and radiation makes it difficult to analyze the effects of individual parameters. The nature of these effects can vary for different air sheds and across seasons and complicate the understanding of local PM
concentrations due to individual meteorological parameters.
Although statistical models do not account for atmospheric processes, they are an important tool to quantify the pollutant sensitivities of individual meteorological parameters [
29,
30]. One statistical method, principal component analysis (PCA), can be used to separate interrelationships into statistically independent basic components [
9]. PCA results can be used in regression analysis to address collinearity and in exploring the relationship among the independent variables, a method known as principal component regression (PCR). For example, early morning (AM) and previous evening (PM) forecasts were evaluated using PCR to quantify the sensitivity of PM
to prescribed burning activity and meteorological variables [
31]. Sabah et al. (2005) used multiple linear regression and PCR methods to predict the concentration of ozone in the atmosphere [
9]. Schlink et al. (2003) proposed a computational method combining principal component analysis (PCA) and artificial neural networks ANN) to compare air quality and meteorological data and to forecast the concentrations of environmental parameters of interest (air pollutants) in urban areas in Finland and Greece [
30]. In their work multivariate statistical methods were employed to predict the annual and seasonal indoor concentrations of
and PM
. Leung et al. (2018) studied the relationships of PM
with local meteorology and synoptic weather patterns in different regions of China using a combination of multivariate statistical methods [
26].
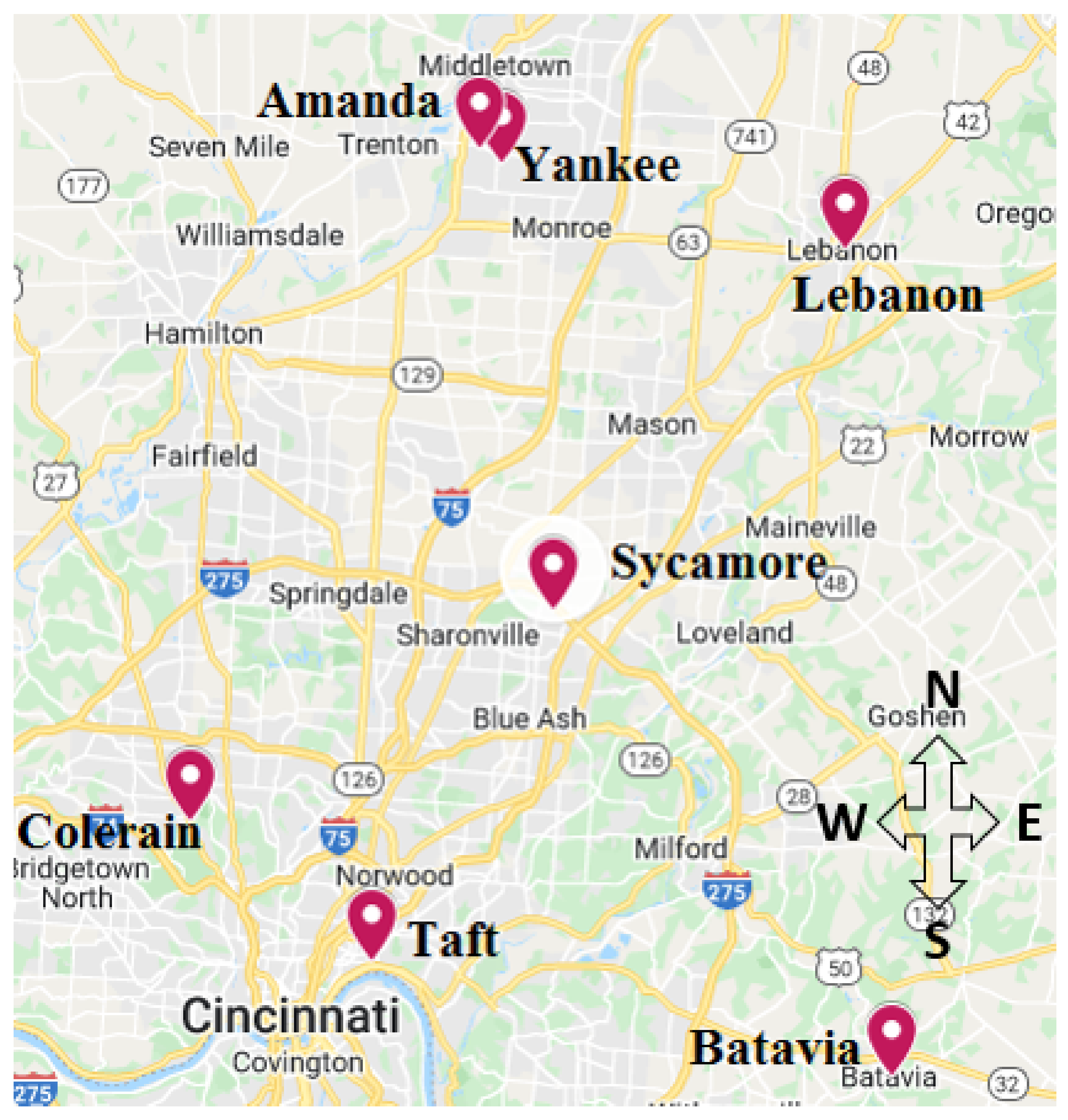
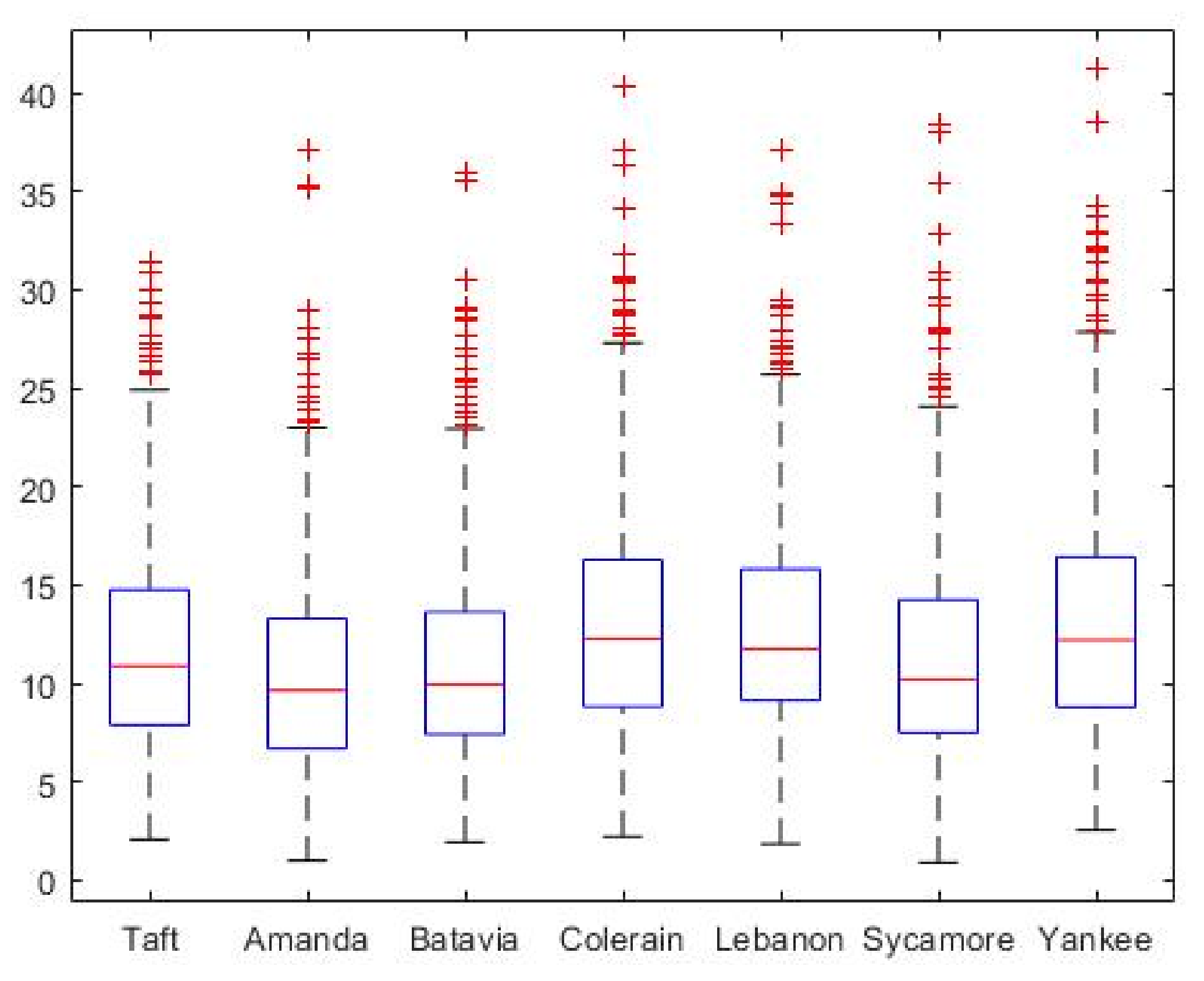
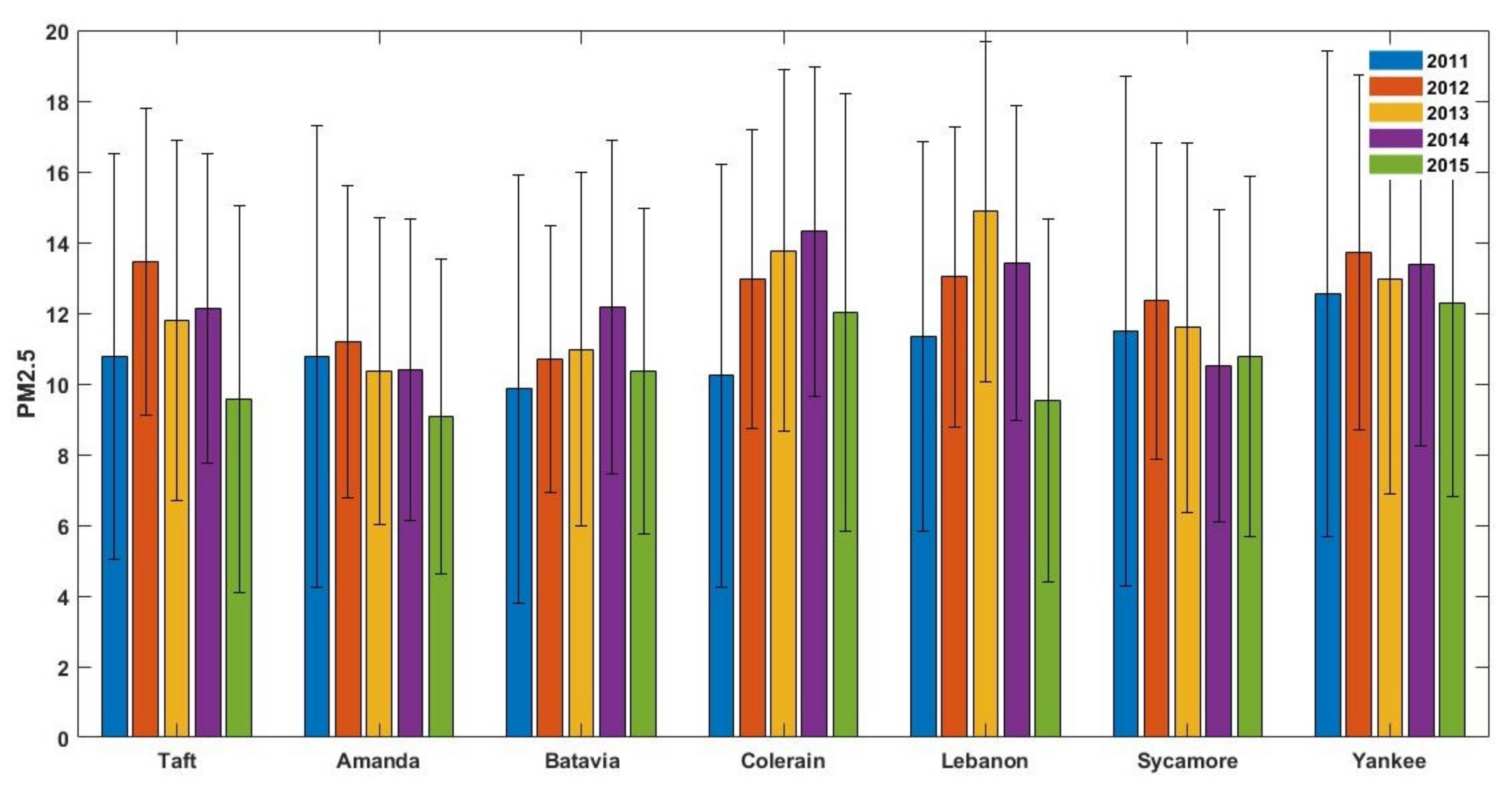
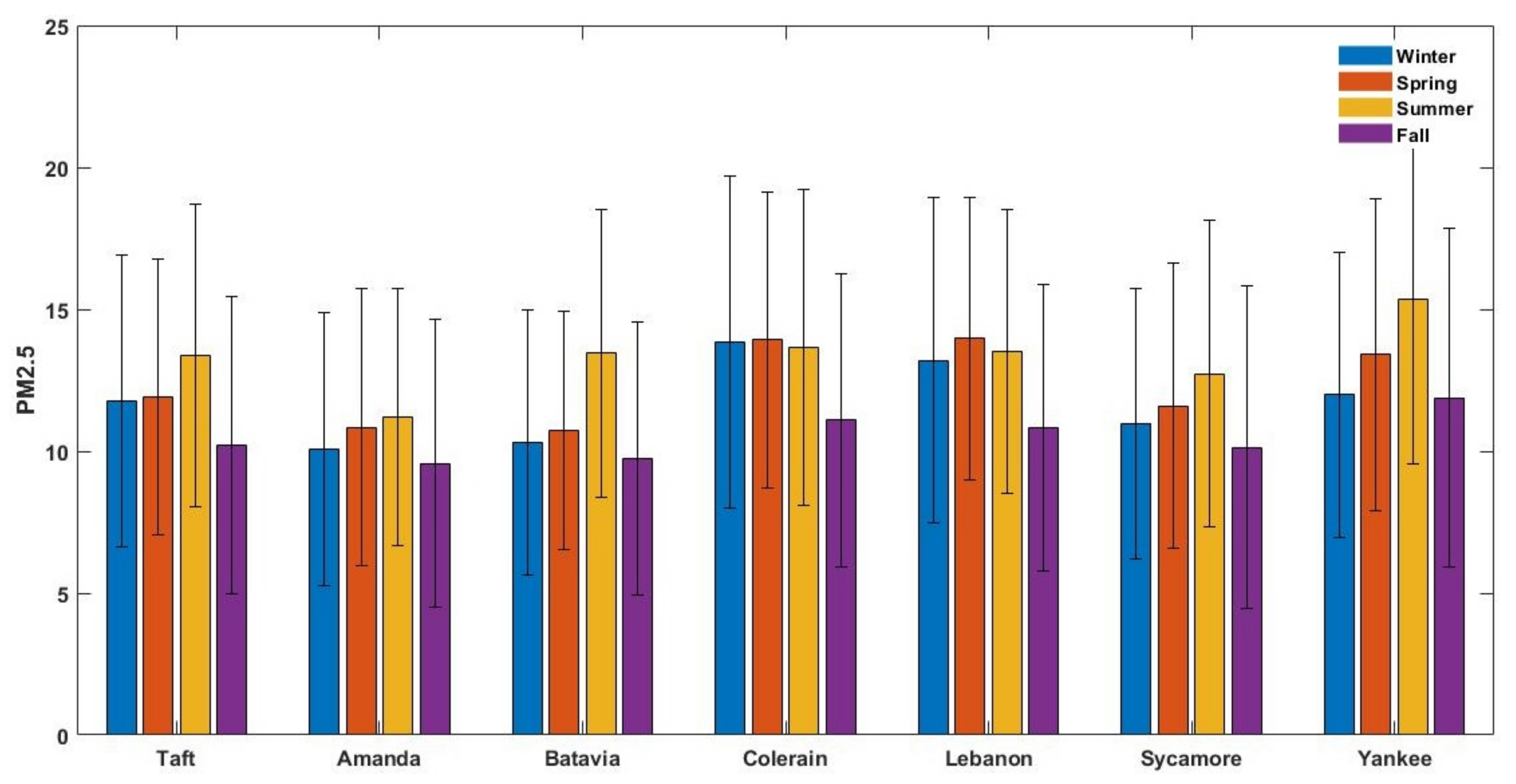
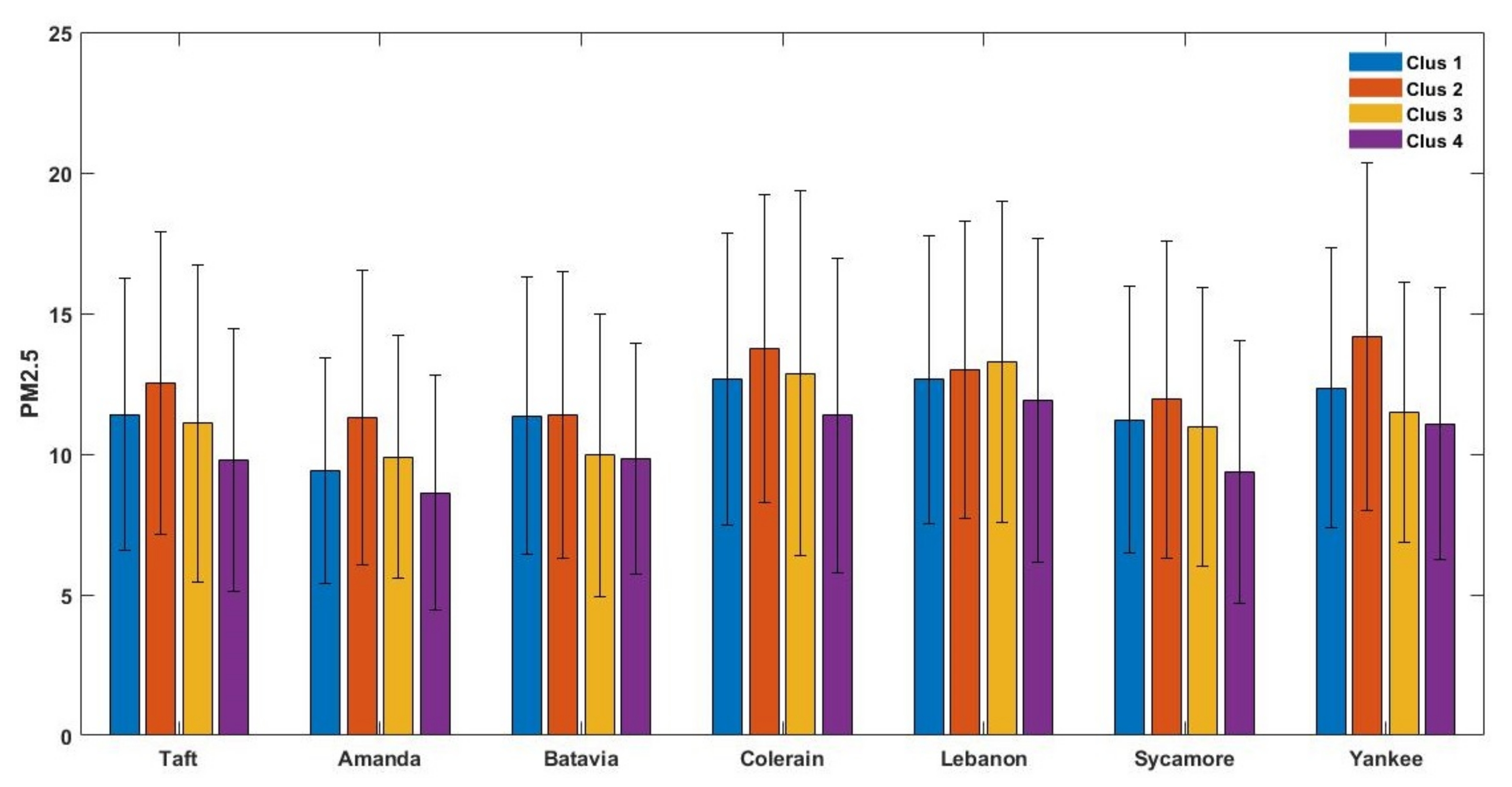
The present work quantifies the spatiotemporal variation of daily (24 h average) PM
in the greater Cincinnati metropolitan area and PM
sensitivities to meteorological parameters. Five years of PM
and meteorological data were collected from the EPA CSN network and the North American Regional Reanalysis (NARR), respectively. The study area includes seven sites (Amanda, Batavia, Colerain, Lebanon, Sycamore, Taft, and Yankee) that measure PM
using continuous monitors (
Figure 1). A unique contribution from this work is that meteorology can be grouped by k-means clustering as opposed to seasons. We also evaluated the applicability to fit PM
using the gamma distribution [
32,
33]. Principal components analysis (PCA) was used to determine the most important meteorological parameters for use in multivariate regression, which was used to quantify PM
sensitivities to the local meteorology in Cincinnati. This work lays the foundation to develop PM
forecast models using the techniques developed in this work.
2. Materials and Methods
2.1. Meteorological Data
Daily 24-h mean meteorological data were obtained using the North American Regional Reanalysis (NARR). The data consists of the following meteorological parameters for five years from August 2011 to December 2015: wind direction (WD), wind speed (WS), solar radiation (SR), relative humidity (RH), outdoor temperature (OT, K), visibility (VIS, km), planetary boundary height (HPBL, m), precipitation rate (PRATE, kg/m/s), accumulated total precipitation (APCP, kg/m), barometric pressure (BP, Pa), UWND.10 m’: Horizontal-wind speed at 10 m (m/s), VWND.10 m’: Vertical-wind at 10 m (m/s). The NARR dataset covers the entire study area, and as a result all sites in the study use the same meteorological data.
2.2. Continuous Particulate Matter Data Completeness
Hourly PM data from August 2011 to December 2015 (1797 days) were obtained from the Southwest Ohio Air Quality Agency (SWOAQA) and processed to remove negative and unreported values for all seven monitoring sites. In addition, days with less than 75% hourly data were considered incomplete and also removed. The processed data resulted in 958 days for which data were available for all seven sites.
2.3. Study Sites
The monitoring network is spread across five counties: Hamilton, Butler, Clermont, Clinton, and Warren, which constitute the five-county Cincinnati metropolitan area (
Figure 1). The monitoring network consists of 18 sites, out of which seven operate three types of continuous PM
samplers (
Table 1). These sites are operated and maintained by the SWOAQA and follow monitoring protocols established by the USEPA. The instruments used are the Tapered Element Oscillating Microbalance (TEOM), the Met-One Beta Attenuation Mass Monitor (BAM), and the Synchronized Hybrid Ambient Real Time Particulate (SHARP) monitors, which are all accepted as federal equivalent methods (FEMs). The TEOM is very sensitive to the ambient relative humidity, which causes a change in its oscillation frequency and can lead to both positive and negative artifacts [
34]. Batavia uses a TEOM to collect concentrations and is more susceptible to error than instruments using beta-attenuation. BAM works on the principle of beta ray attenuation to measure airborne particulate concentration, and therefore the instrumental error is minimal. SHARP combines the speed of light scattering nephelometry with the accuracy of beta attenuation technology for continuous
and PM
measurements.
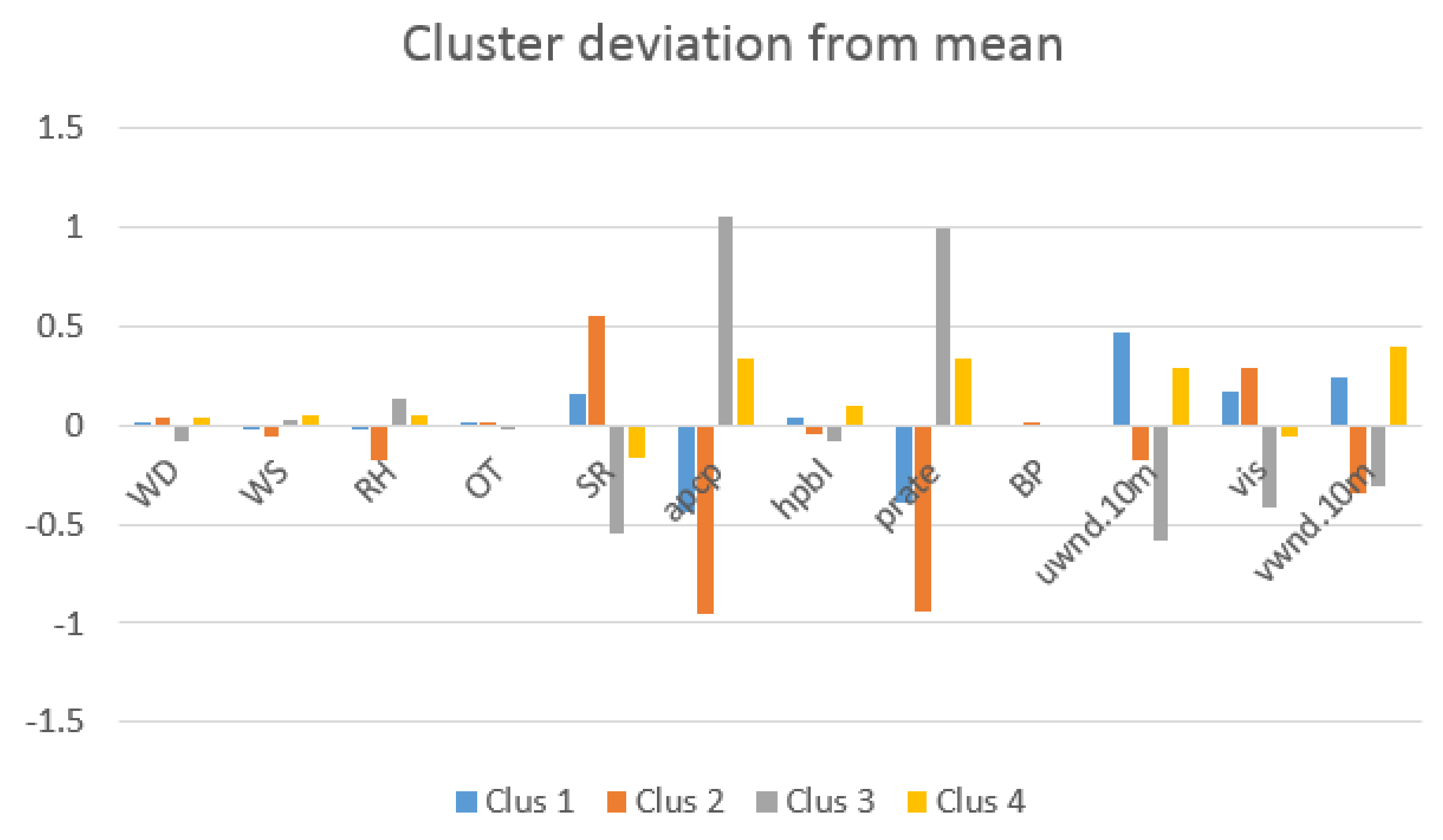
2.4. Clustering Analysis- K-Means Clustering
Clustering is a technique used to separate data into similar groups. Clustering methods vary depending on the distance measure, cluster evaluation criteria, and data type (real or binary data). Commonly used clustering principles are centroid-based, hierarchical, density-based, and graph-based clustering. A variety of distance measures, such as variants of Euclidean distance, Manhattan distance, Mahalanobis distance, cosine distance, and correlation measure can be used in determining the similarity of the data samples. Different cluster evaluation metrics include sum of squared error (SSE), cohesion, and entropy.
In this work, K-means, a widely used center-based clustering algorithm, was chosen. Euclidean distance and SSE were used to determine the similarity of data and evaluate clusters, respectively. K-means determines the members of a cluster such that the members have minimum Euclidean distances from the cluster center, relative to the other cluster centers. A heuristic-based method known as the elbow method was used to determine the optimal number of clusters [
35,
36]. K-means clustering was applied to the NARR data set using the “kmeans ()” function in Matlab (Mathworks, 2019).
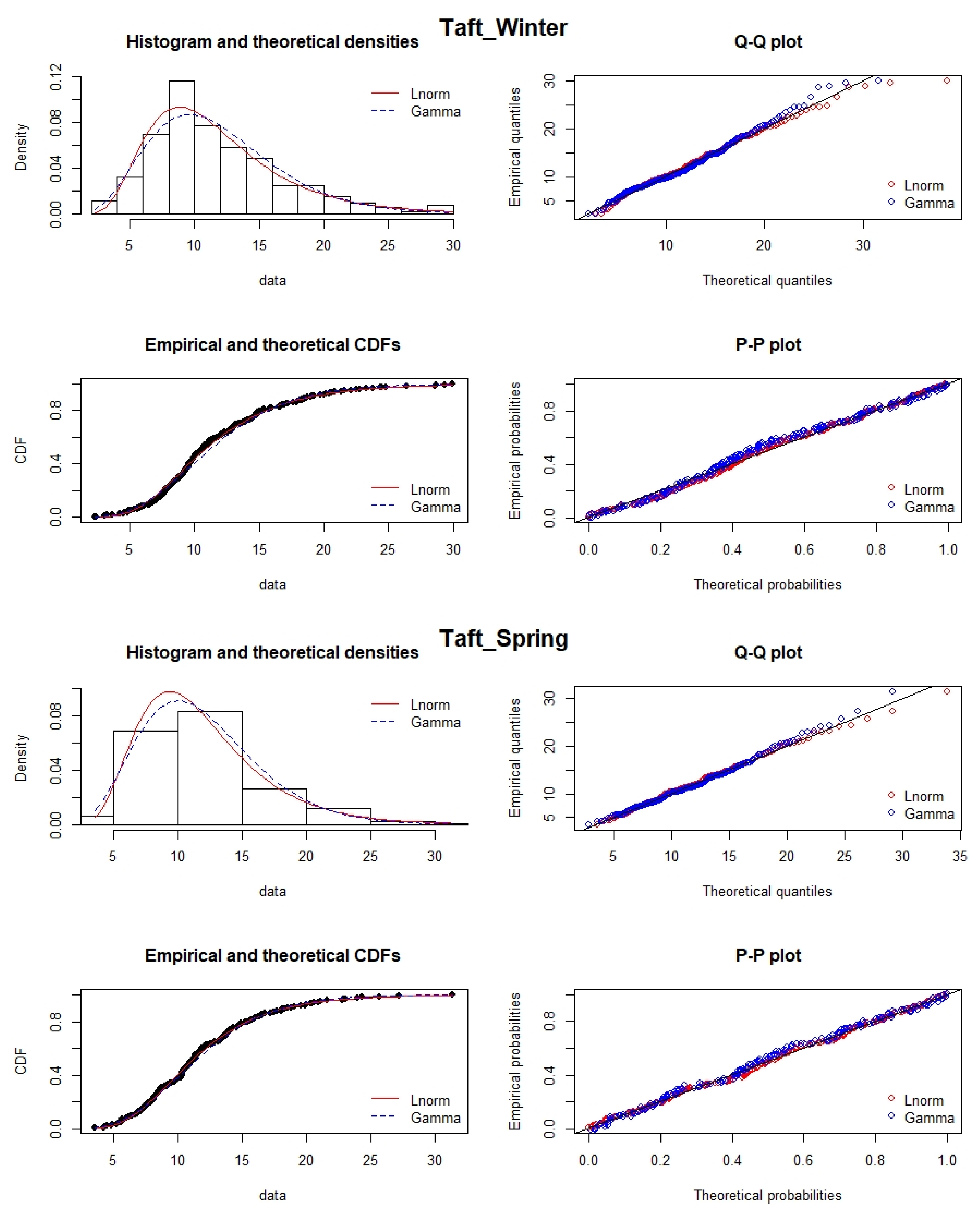
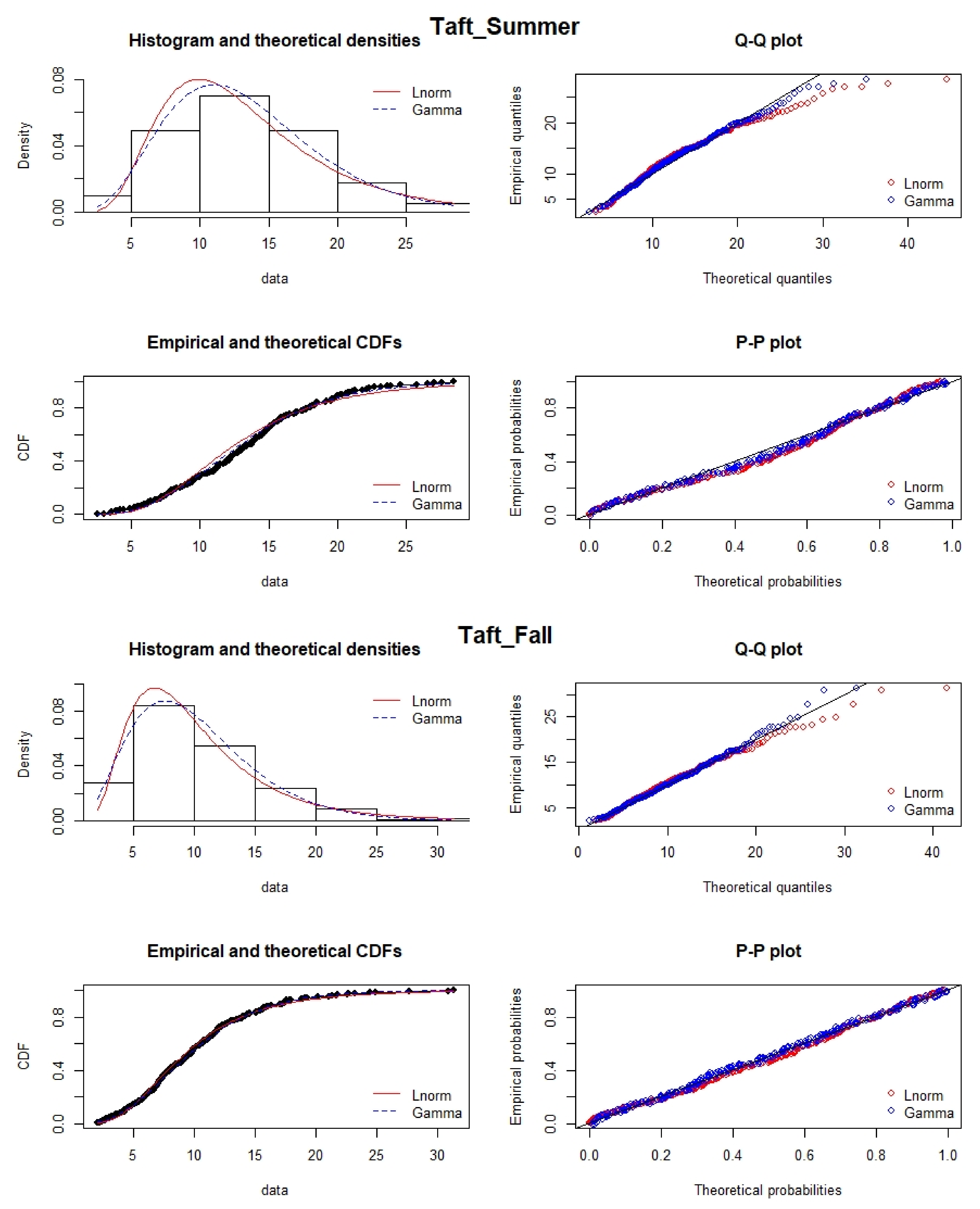
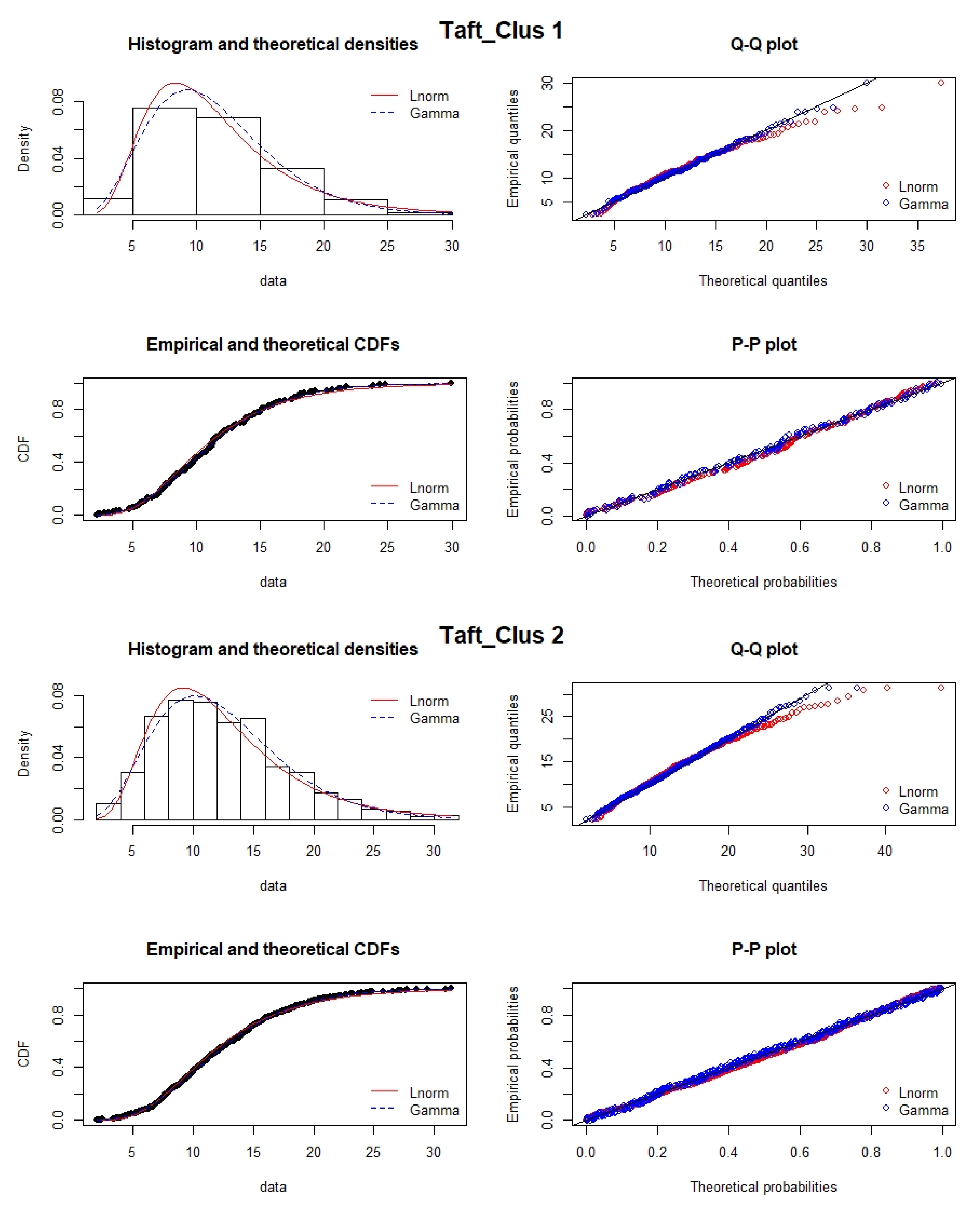
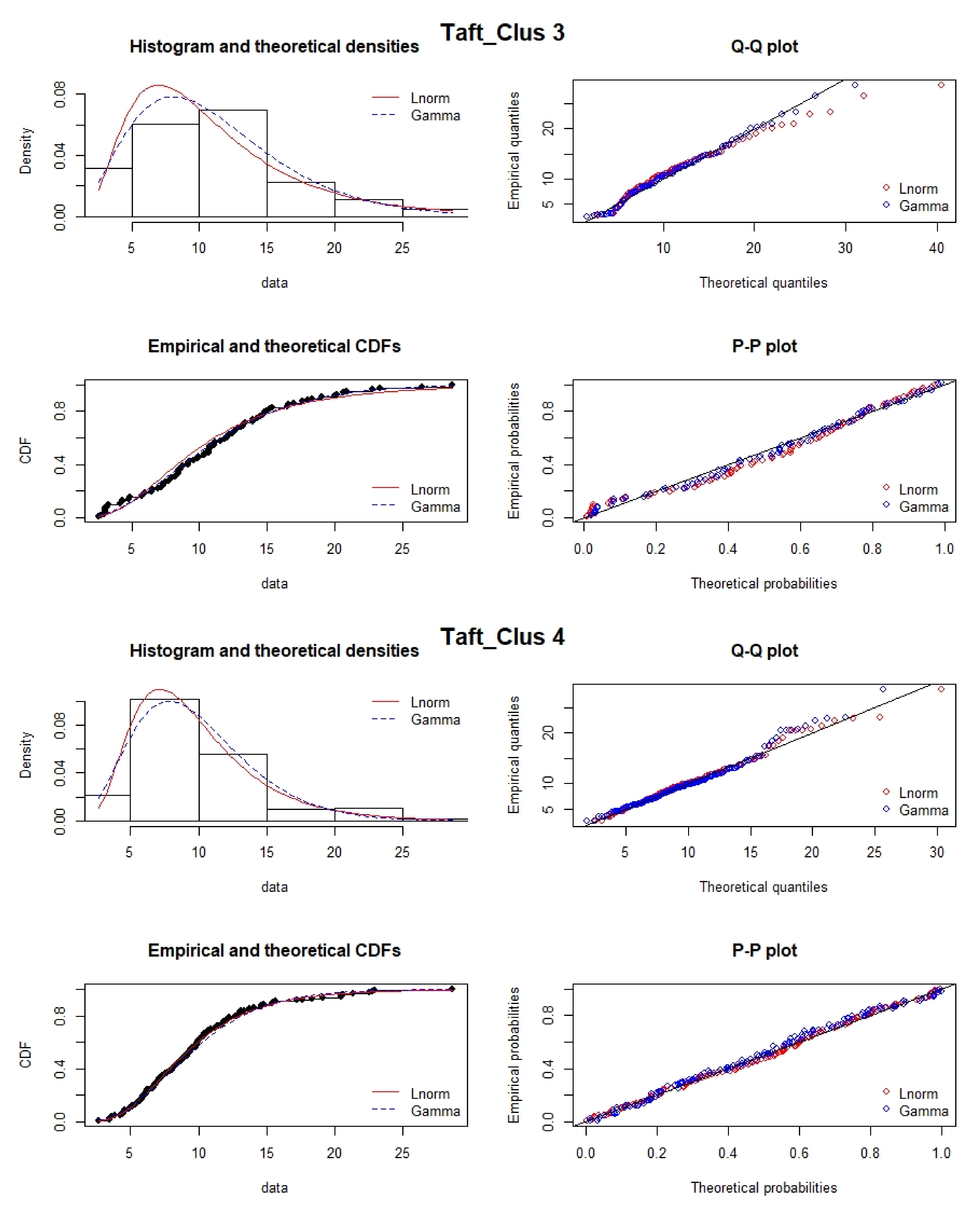
2.5. Distribution Fitting: Lognormal vs. Gamma
Air pollution data are assumed to be lognormally distributed. However, it has been suggested that uncertainties of source impacts quantified by source apportionment models follow an inverse gamma distribution [
37]. Here, we evaluated the use of fitting PM
data using the gamma distribution, given that the gamma, like the lognormal, can be used to fit data with right tailed distributions. The Kolmogorov–Smirnov (KS) test is one such method that compares the maximum separation between the experimental cumulative frequency (
) and the CDF of an assumed theoretical distribution (
). It quantifies a critical value to determine how well the underlying data distribution matches the target distribution [
38]. The limitation of the KS test is that the determination of the critical value is distribution-free. The null hypothesis is satisfied if
where
is the critical value at the 5% significance level.
In this work, PM data for the entire data set for four clusters and seasons were fitted to lognormal and gamma distributions, and the KS-Test was applied to check the satisfiability of the null hypothesis. The null hypothesis is satisfied if the computed KS statistic is less than the critical value.
2.6. Principal Component Analysis
PCA is a method that is often used to reduce the dimensionality of large datasets, by transforming a multidimensional data matrix into orthogonal components. The first step in PCA is to standardize the data matrix so that all variables have a mean of 0 and standard deviation of 1. Singular value decomposition is applied next to determine the principal components that are the eigenvectors of the dispersion matrix. The eigenvectors are orthonormal, and the resulting Z scores are orthogonal, which has the net effect of removing collinearity within the data matrix [
31].
2.7. Multiple Linear Regression
Multiple linear regression is used to model a relationship between two or more predictor variables and a response variable by fitting a linear equation to the observed data. In this work, meteorological parameters used to predict PM (response variable) were determined using PCA results.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}