1. Introduction
Surface maximum air temperature plays an important role in people’s life, climate prediction, [
1] and hydrologic forecasting, etc. [
2]. Therefore, reliable forecasts of maximum air temperatures are essential to prevent heat-related disasters, efficiently mitigate the damages caused by high-temperature disasters and appropriately respond to them [
3]. Deviations usually exist in the prediction of near-surface elements from numerical models due to complex factors such as atmospheric dynamic processes, physical processes, local topography and geomorphology. In particular, the deviation between the prediction and observation of daily maximum temperature is relatively larger when the weather changes drastically [
4]. Therefore, it is still a challenge to realize refined and accurate forecasts for daily maximum temperature. Numerical weather prediction (NWP) models predict surface air temperature by using an atmospheric system containing complex dynamics and land-atmosphere-ocean coupling. In the last 50 years, the NWP has achieved great success with the development of computer technology, modeling techniques and observations [
5,
6]. However, due to the imperfection of initial values, assimilation methods, systematic errors and physical processes in the model, the uncertainties of the atmosphere cannot be thoroughly described [
7,
8], resulting in inevitable errors of numerical predictions. Hence, there is relatively limited space to enhance the NWP by improving the physical processes in numerical models or increasing the spatial resolutions. In order to reduce these model biases and further improve the accuracy of numerical model prediction products, various post-processing methods have been developed to correct the errors of NWP models [
9,
10]. In the early years, the most common post-processing methods included the perfect prediction method (PPM) [
11], the model output statistics (MOS) method [
12], the Kalman filter (KF) [
13], decaying average method, Bayesian model averaging (BMA) [
14], frequency matching method and scoring optimization correction method, etc. These methods have been widely used and achieved good results. Specifically, as an objective weather forecast technology, the MOS method has been widely used in the correction of prediction errors for surface wind, precipitation probability and maximum temperature, and formed the operational forecasts [
15].
The MOS method establishes a regression model between the observation data and model outputs, which uses the statistical relationship to transform a single-valued model forecast into another single-valued model forecast for more accurate forecasts. However, due to the prediction errors in NWP model outputs [
10,
12,
16], the established equation for error correction based on the statistical relations will also produce errors. Therefore, the effect of bias correction using the MOS method will be limited. As each numerical prediction model is continuously updated, it will invalidate a large number of historical model output data used in the MOS method, leading to the failure of MOS to obtain the latest observation features, which is another limitation of this method. Moreover, some statistical correction methods require certain statistical assumptions. For example, the BMA method assumes prior probability, and different prior probability assumptions of BMA will lead to different or even opposite results. In a word, different statistical models have their own limitations. The available weather forecast is generally limited to within about 10 days due to the chaos in the atmosphere, and the effect of error correction for both traditional and new techniques will be weakened with the extension of leading time.
In recent years, studies have shown that compared with the traditional statistical post-processing technology, the artificial intelligence-based post-processing technology in medium-term numerical prediction model has own advantage in that it is a data-driven method. This technology can implicitly extract the spatio-temporal variations of nonlinear and multi-scale physical relationships from multi-source data, thus significantly enhancing the level of medium- and short-term weather forecasts [
17,
18,
19,
20]. Machine learning approaches can handle a large number of input variables because they are not sensitive to the multi-collinearity of the input variables [
21]. In addition, machine learning can be used to establish a model that works for multiple stations, unlike MOS and KF that require bias correction to build a model for each station. Rasp et al. [
17] applied the ANN to the post-processing of ensemble forecasts, and conducted a case study on the 2-m temperature prediction at German surface stations. The results show that the neural network method performs significantly better than the post-processing methods such as the ensemble MOS (EMOS) and quantile regression forests etc., and it is more computationally efficient. In addition, the temporal convolutional network (TCN) is also an emerging network structure suitable for time series [
22], and Hewage et al. [
23] proposed a lightweight data-driven weather forecasting model by using the TCN. Han et al. [
24] transformed the forecast correction problem into an image-to-image translation problem in the field of computer vision. They applied the CU-net (Component Unmixing Network) architecture to the gridded forecasts of 2-m temperature, 2-m relative humidity, 10-m wind speed and 10-m wind direction from the European Centre for Medium-Range Weather Forecasts Integrated Forecasting System (ECMWF-IFS) for error correction, and achieved significant correction performance. The model output machine learning (MOML), a post-processing method for gridded temperature forecasts, matches NWP forecasts against observations through a regression function and shows a better numerical performance than the ECMWF model and MOS, especially in the winter of Beijing [
19]. However, a weakness of MOML is the intricate pre-processing associated with feature engineering. Chen et al. [
25] proposed an end-to-end post-processing method based on a deep convolutional neural network, which directly learns the mapping relationship between the model predicted field and the observed temperature field and obtains relatively accurate temperature predictions. Recently, Zhao et al. [
26] applied a fully connected neural network model with embedded layers for prediction of daily maximum air temperature, reducing the overall root mean square error (RMSE) of the ECMWF-IFS model from 2.746 °C to 1.433 °C.
Due to the complex atmosphere-surface interaction, a single machine learning method is unable to consistently and effectively remove the bias in the NWP model. In fact, the different regressor in machine learning can significantly affect performance of the prediction [
27,
28,
29,
30]. Single machine learning models, especially the deep learning networks, suffer from the “bias-variance” trade-off [
31], and the ensemble machine learning can be an effective way to address this issue. A successful way to reduce the high variance of neural network models is to train multiple models instead of a single model and integrate the predictions of these models, i.e., integration learning. Integration learning not only reduces the variance of predictions, but also yields better predictions than any single model.
Recently, several researchers have attempted to improve the performance of the forecasting by combination (i.e., ensemble) of the diversified machine learning [
32,
33,
34]. The random forest, support vector regression and ANN, as well as the multiple-model ensemble (MME) were employed to improve the forecast bias of daily maximum temperature in Seoul from the Local Data Assimilation and Prediction System model outputs [
21]. Chen et al. [
35] applied linear regression models to integrate the ANN and the long short-term memory-full convolutional network (LSTM-FCN) to reduce prediction bias of 2-m temperature at 301 weather stations in mainland China. These experiments have all demonstrated that combining different machine learning models can improve the forecast performance by overcoming the drawbacks of each individual classifier. However, the complexity of the neural networks used in these studies was limited, and the ensemble methods used were relatively simple.
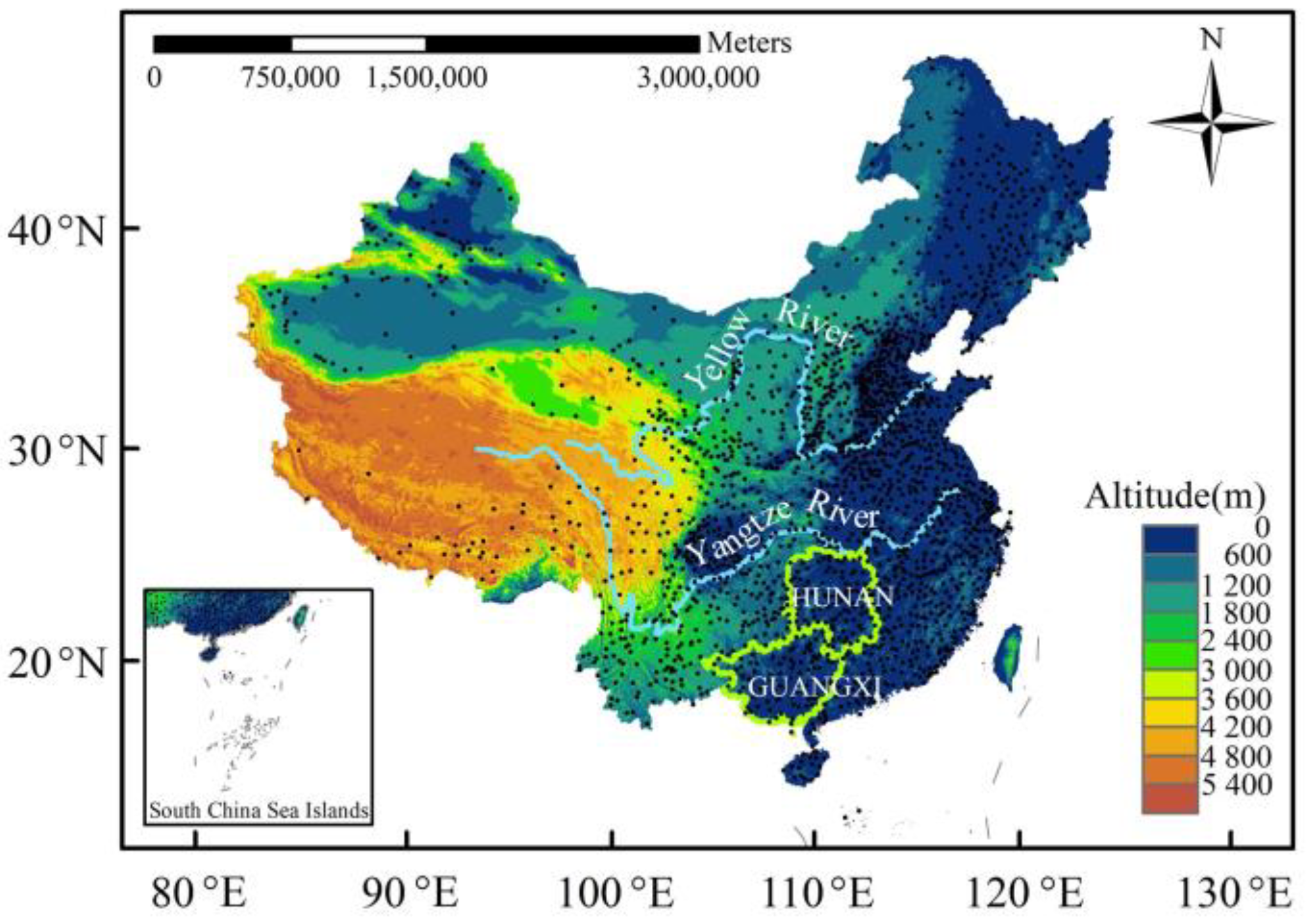
Here, we used the cross-validation method to determine the model hyperparameters, used the mean absolute error (MAE) as the loss function, and used the early stop method to train the model to demonstrate how to use the stacked generalization technology to integrate different types of neural networks. The proposed integrated neural networks are used in the post-processing of daily maximum air temperature forecasting within a neural network framework to reduce the forecast bias of individual neural network models. The daily maximum air temperature forecasting method established in this study will fill the gap that the ECMWF-IFS model output only has 2 m temperature forecast and no daily maximum temperature forecast. Specifically, we explore a case study of daily maximum temperature forecast for 1 January–31 December 2020. We compare the forecast capability between the integrated neural network and the individual neural network, and also compare the forecast capability between the neural network model and the statistical post-processing model. Our ultimate goal is to propose an effective, reliable, and robust ensemble neural network model.
The rest of this paper is organized as follows. The study area and data are briefly described in
Section 2.
Section 3 introduces the methodology, including the machine learning algorithms, data processing, specified evaluation metrics and experimental schemes.
Section 4 presents the results. Finally, the discussions and conclusions are given in
Section 5.
3. Methods
3.1. Construction of Ensemble Neural Network Model
Due to the randomness of initial weight parameters, neural network models generally have high variances. Using ensemble models can effectively reduce the variance and enhance the model generalization ability [
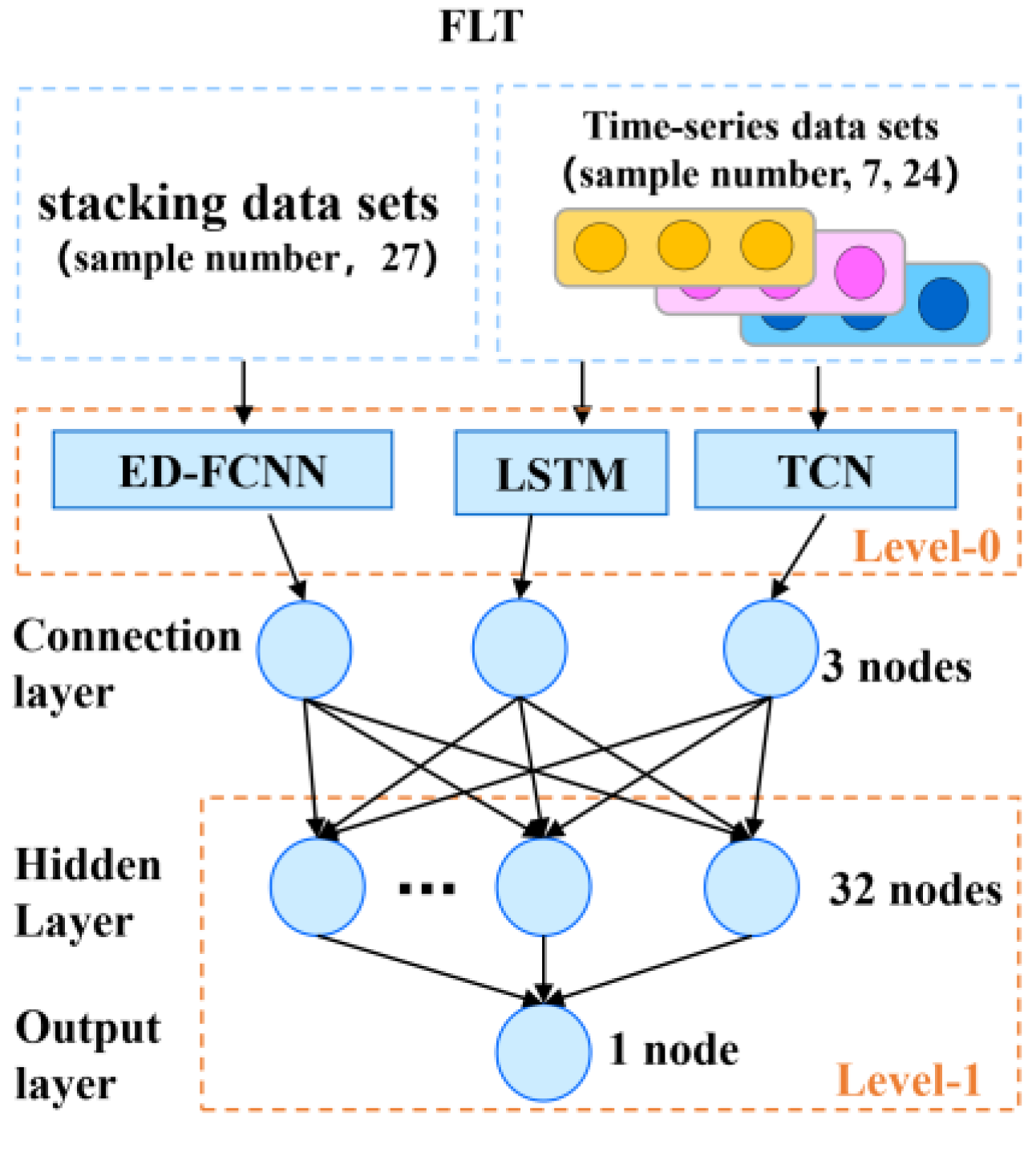
36]. Stacked generalization method is one of the effective methods to construct ensemble models. By integrating multiple models, a better generalization performance can be obtained compared with a single model. Deep learning is a powerful tool to deal with complex nonlinear problems and has started to play a role in weather forecasting. However, the accuracy and dependence of neural network model depend on the different types of neural network adopted, the input features, the methods of feature processing, the addition of auxiliary variables and the hyperparameter settings of the model, which are often required to be selected and designed by the model designer according to the object of modeling prediction. In this study, an ensemble neural network model is constructed based on three neural network models of the ED-FCNN, the LSTM and the TCN by using the stacking ensemble technique (hereafter referred to as the FLT). Usually, the stacking method is divided into the following two levels. Leve-0 trains several different machine learning models to obtain the predictions of each model for the target separately. Leve-1 takes the output result of each model trained in level-0 as the input element and then trains a new model as a level-1, and the output of the level-1 is taken as the final forecast.
In order to reduce the variance of a single neural network model, in this study, as shown in the
Figure 2, the ensemble learning FLT model is proposed, which consisted of ED-FCNN, LSTM and TCN by using a stacking approach. The first level of ensemble learning takes the ED-FCNN, LSTM and TCN as the Level-0 models, and the second level uses the fully connected neural network (FCNN) as the Level-1. The FCNN is selected in this paper as the Level-1 model because the FCNN has the characteristics of multiple inputs, so it can process multiple neural networks in the Level-0 sub-network, and then learn how to best integrate the predictions from each sub-neural network model, and it allows the stacked ensemble model to be regarded as a single large model.
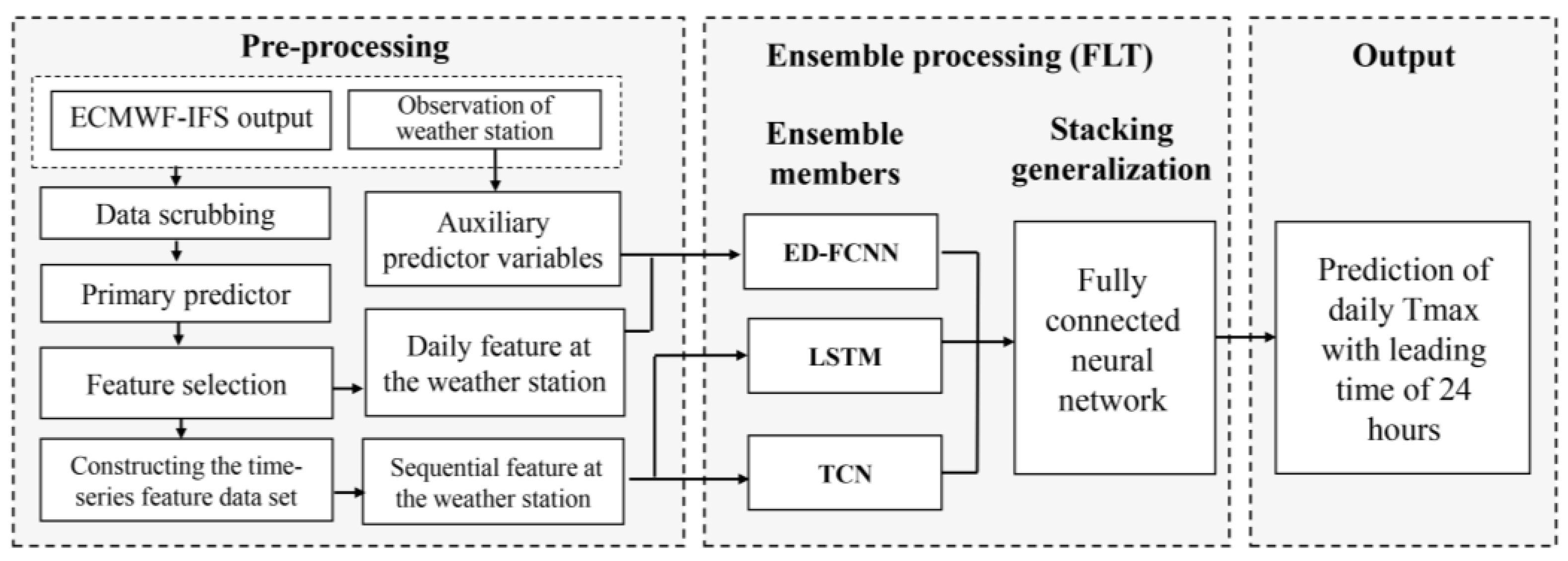
Figure 3 is the flow chart of this study.
One of the sub-neural network models at level-0 of the integrated neural network FLT model in this study is ED-FCNN, which is a fully connected neural network with embedding layer. Spatial and temporal information in the features need to be input into the integrated model FLT. In order to process multi-category variables and integrate the spatio-temporal information into the neural network, a fully connected neural network with an embedding layer is induced in this study, namely, ED-FCNN [
26], which can be adapted to general regression tasks and does not require the data to have a temporal sequence relationship. For the ED-FCNN, the input features are numbered 1 to 27 in
Table 2, which are forecast factors of the ECMWF-IFS model after feature selection, the auxiliary variables and time lagged variables. The input data of all stations is stacked in the ED-FCNN. As these data are in obvious chronological order, the flags of the season and month to identify the temporal information in the data sample are added when constructing the input feature data set for the ED-FCNN. There are two input layers for the ED-FCNN. The first input layer transmits three categorical variables of station number, month and season, where the station number and month are transmitted into the embedded layer after the process of label encoding, and the variable of season is processed by the one-hot encoding. The second input layer passes various meteorological factors and other features, and finally the connection layer connects all the above features.
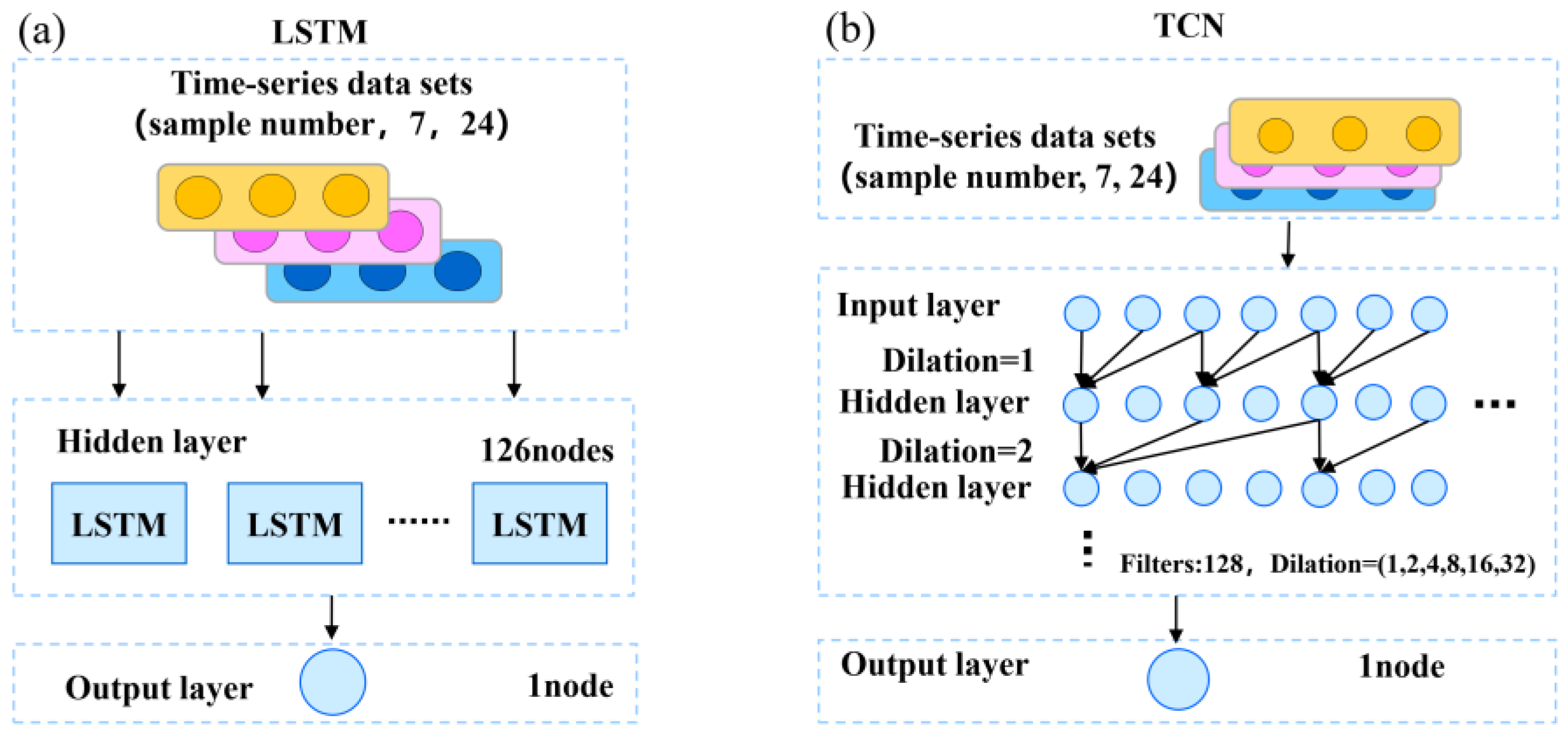
The other two sub-neural network models at level-0 of the integrated neural network FLT model are Long Short-Term Memory Network (LSTM) (
Figure 4a) and Temporal Convolutional Network (TCN) (
Figure 4b), respectively. The LSTM is a kind of RNNs, which is specifically used to deal with time series. Compared with the ordinary structure of RNN, LSTM can solve problems such as the long-term dependence of sequence and gradient vanishing. LSTM is also composed of the input layer, hidden layer and output layer. A unique gating mechanism is added to the LSTM cell in the hidden layer, and the information will be updated when the information passes through the LSTM cell. The TCN, is a neural network architecture proposed by Bai in 2017 [
22]. It migrates the convolutional neural network (CNN) to time-series applications and mainly applies one-dimensional convolution. Compared with the LSTM and other RNNs neural networks, TCN has the advantage of large-scale parallel processing. It further integrates the technologies of causal convolutions, dilated convolutions and residual connections on the basis of one-dimensional convolution [
22]. The causal convolution mainly ensures that the future information will not be leaked during the prediction, which is in line with the characteristics of time-series prediction.
For LSTM and TCN constructed in this study, the time-series data set with a fixed form should be constructed as the model input, and the shape of the input array includes the batch size, time-series length and feature number. The steps of constructing the time-series data set are as follows. Firstly, the feature factors for the time-series data set are selected. Considering the structural features of LSTM and TCN, the input feature factors are numbered 1 to 24 in
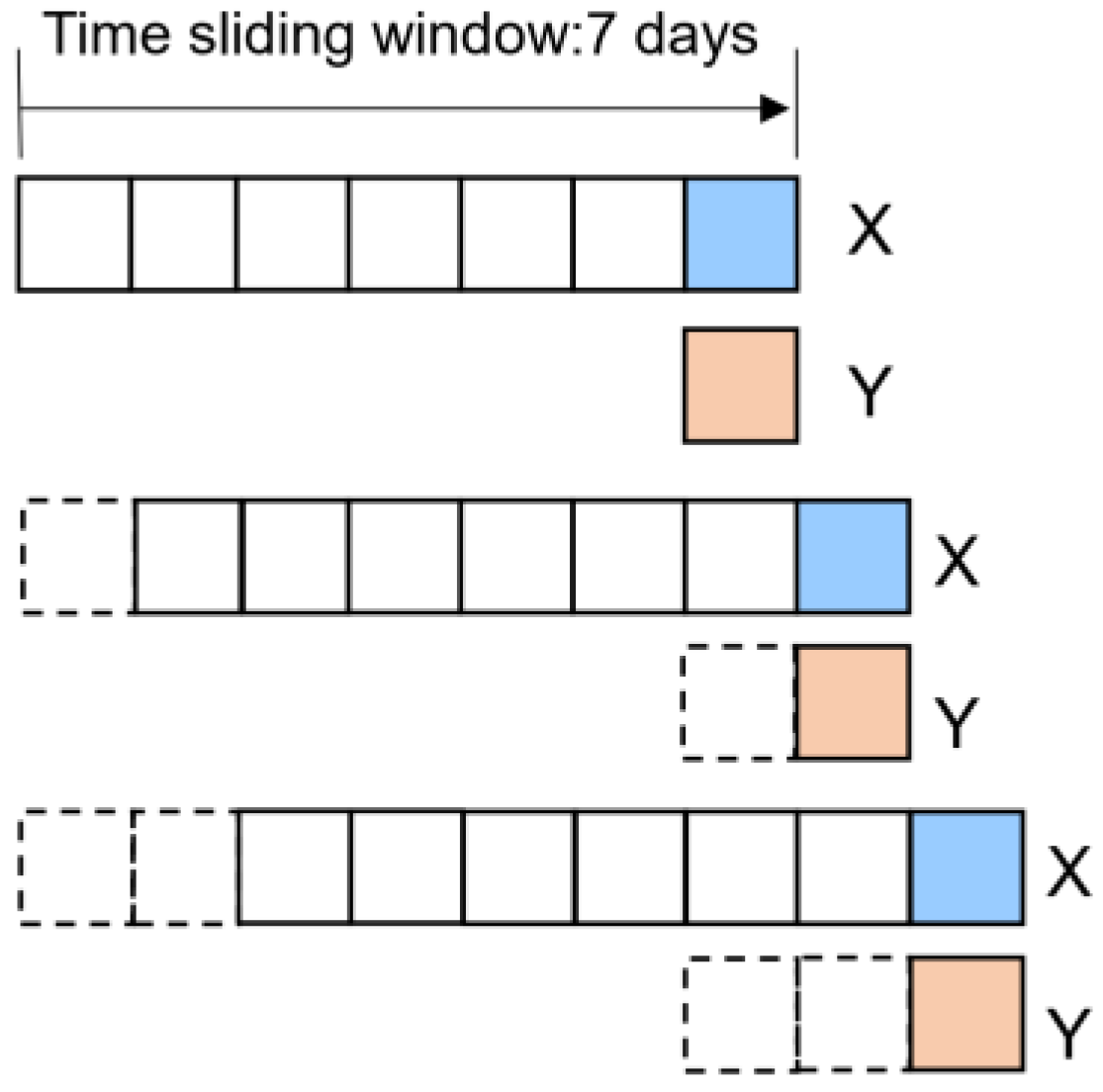
Table 2, which are forecast factors, time lagged variables and the longitude, latitude and altitude of the meteorological stations. Secondly, a time sliding window is applied to all time series (all features) at each station, and a number of batch samples with consistent length of time series will be generated by the time sliding window segmentation technique. Then, the batch samples generated at each station are connected to form the final data set. Among them, the setting of the time sliding window for the segmentation of time-series data is shown in
Figure 2. For the feature data set (X in
Figure 5), the length of the sliding window is set to 7 days, and after the sliding, the shape of the feature data samples in the training set is obtained as (1712 × 2238, 7, 24), where 1712 is the number of sequences generated at a single station after the time sliding window, and 2238 is the total number of stations. For the target data set (Y in
Figure 5), the time-series length is set to 1, the day-by-day sliding is applied through the sliding window, and the shape of the target data sample is (1712 × 2238, 1, 1). So far, the feature data set and the target data set have achieved one-to-one correspondence on each batch. After completing the data set construction, the data set can be directly input into the LSTM and TCN.
3.2. Hyperparameter Settings and Training
For all neural network models (the ED-FCNN, LSTM, TCN and FLT), the common hyperparameters are as follows. The optimizer algorithm in the neural network is the adaptive moment estimation (Adam), and the batch size is set to 64. The number of neurons in the input layer and output layer is determined by the number of features in the input and output neural networks, respectively. The number of neurons in output layer of all model in this study is 1, and the activation function is the Linear function (linear units).
Specifically, the number of neurons in the hidden layer of the neural network in this study is determined by grid search. The number of neurons in the hidden layer is generally set to multiples of 16 and 16, such as 16, 32, 64, etc. Hence, the number of neurons in the hidden layer of the above neural networks is determined by means of grid search. The values of 16, 32, 64, 128 and 256 are set for the grid search, and a cross-validation method adaptive to time series is applied for the grid search, which can avoid the crossover of temporal features in the data, aiming to make the model selection steadier and more robust. Finally, the hyperparameters with the smallest average RMSE of all validation sets are selected. The results of hyperparameters selection of each neural network are as follows: The number of hidden layers is 1, the number of neurons in the hidden layer is 64 and 128 both in ED-FCNN and LSTM, respectively. The network structure of TCN is different from ED-FCNN and LSTM. TCN migrates Convolutional Neural Networks (CNN) to time series. Due to its specific network structure, the hyperparameters of TCN are different from those of ED-FCNN and LSTM. The main hyperparameters of TCN include convolution kernel size, expansion coefficient and convolution kernel number. Therefore, the hyperparameter setting of TCN in this study is: the size of one-dimensional convolution kernels is set as 3, and the dilations are set as 1, 2, 4, 8, 16 and 32, successively, and the number of convolution kernels of TCN is finally determined to be 128.
When training the neural network, the loss function is set to mean absolute error (MAE). Early stopping is selected as the regularization method to prevent the model from over-fitting. The number of model epochs is set to 50 times. If the validation error in training increases instead of decreasing for three consecutive times, the training is stopped and the model with the best performance is stored in the validation set.
3.3. Decaying Average Model
As a contrast, we compare performance of the proposed method with that of the decaying averaging (DA) method, which is an adaptive error correction method of KF type [
37,
38,
39]. The principle of the DA method for error correction is as follows.
where
B(
t) is the lagged average error of temperature forecasts for each leading time
t at the station, and
B(
t−1) is the lagged average error of the day before.
F,
a and
w are the station forecast, observation and weight coefficient, respectively.
By referring to a previous study [
40], the training period is set to 35 days in this study. In the training set, the method of day-by-day rolling update will be adopted at each station, and the weight coefficient corresponding to the minimum average RMSE at all stations is finally selected as the best weight of the corresponding station through comparisons among multiple groups of sensitivity tests. Here, the weight coefficient is set in the range of 0.001–1, with the step size being 0.001.
For a given station and leading time t, the steps of temperature forecast correction are as follows. Firstly, the cold start is carried out when t = 1, that is, B(t − l) = 0. Secondly, the optimal weight coefficient of W in the training period is calculated. Thirdly, the average lagged error B(t) is calculated according to Equation (1). The fourth step is to repeat the third step. After the iterative accumulation during the training period, the obtained error tends to be stable and can represent the situation of systematic error to a certain extent. Finally, the corrected forecast value is obtained by subtracting the latest B(t) from the current forecast.
3.4. Verification Method
The forecast performance for daily maximum temperature of each model is evaluated by using the RMSE, mean absolute error (MAE), the accuracy of temperature forecast (ATF).
where
f is the deep-learning-based regression function,
xn is the input,
f(
xn) is the model forecast,
yn is the observation, and
n is the total number of forecast samples.
ATF is the percentage of the samples (
Nr) whose absolute difference between the forecast value and observed value is no greater than
m °C in the total samples (
Nf) [
19], where
m is the temperature threshold. ATF is calculated as follows.
Following previous studies [
19,
41], m is set to 2 °C in this study, and the higher the ATF value is, the more accurate temperature forecast will be.
5. Conclusions and Discussion
In this study, an ensemble deep neural network model named FLT is developed to forecast the daily maximum temperature over the Chinese mainland by using a stacking generalization approach, and its performance is further compared with three individual neural network models (i.e., ED-FCNN, LSTM and TCN) and a decaying averaging model (i.e., the DA method). To train this model, we use the daily maximum temperature data from 2238 national surface meteorological stations and forecast products from the ECMWF-IFS model in the past 4 years to validate the training effects of the FLT, the 3 individual neural network models and the decaying averaging model. The main findings are summarized as follows.
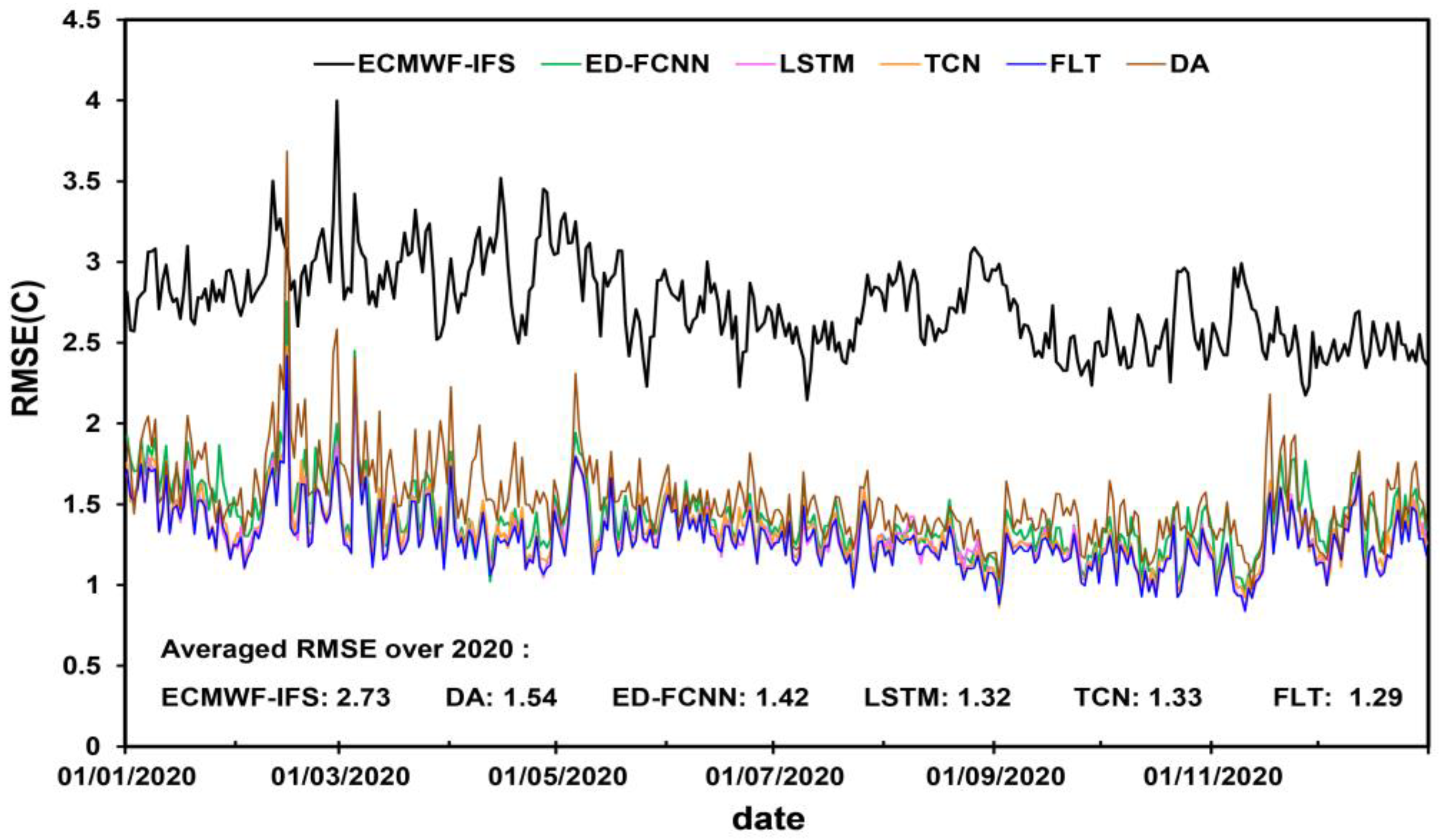
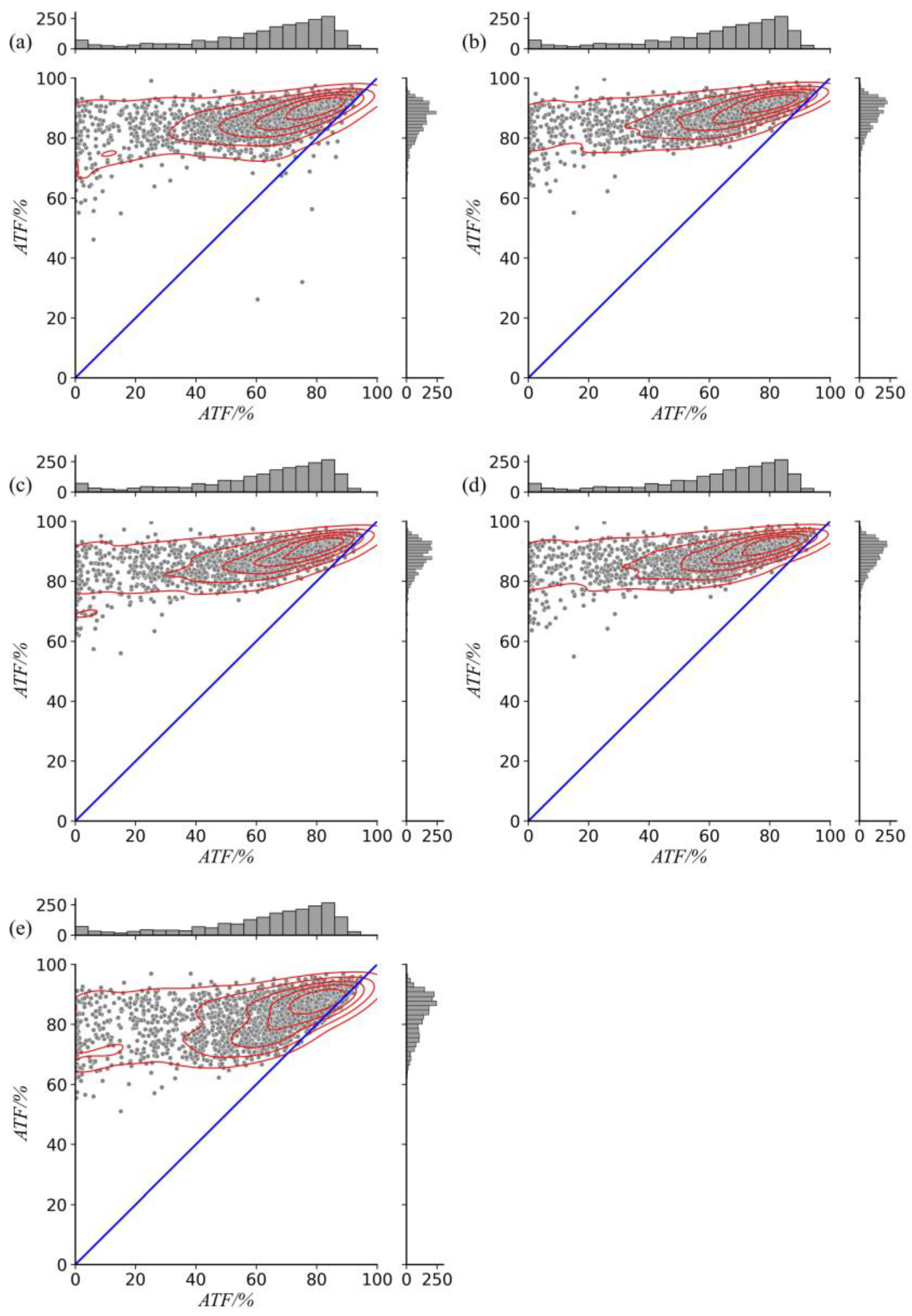
Each neural network model can effectively improve the forecast bias of the ECMWF-IFS model. Specifically, the RMSE (MAE) decrease is between 48.00% and 52.36% (46.50% and 51.50%) and the ATF increase is between 38.89% and 43.12% compared with the ECMWF-IFS model. In addition, the models also exhibit good performance for extreme events. For the extreme temperature events above the 90th percentile (or below the 10th percentile), the RMSE decrease ranges from 60.63% to 66.67% (from 35.63% to 44.06%) and the ATF increase ranges from 81.96% to 89.92% (from 19.40% to 25.12%) compared with the ECMWF-IFS model. Among them, the FLT model yields the best performance compared with other models.
The neural network models can improve the forecast accuracy at almost all stations. All neural models can significantly improve the prediction ability of samples from the ECMWF-IFS model, whose ATFs are less than 60%. The ATFs of each neural network model are significantly concentrated in a relatively high level (85% to 95%) compared with the DA model. In addition, all models can significantly improve the forecast performance of the ECMWF-IFS model in day-by-day, and the forecast performance is better in summer than in winter. This is probably because the cold air activity is stronger and more frequent in winter than in summer, and the forecast ability of neural network models is weaker when the temperature changes abruptly. Compared with the commonly used DA model (1.54), FLT (1.29) improves the day-by-day averaged RMSE by 16.23%.
Different neural network architectures have different adaptability to similar modeling tasks. In this study, the learning effect and forecast performance of the LSTM and the TCN are better than the ED-FCNN. Although two features of month and season that characterize the temporal information have been added to the data samples for the ED-FCNN, the LSTM and the TCN with the input of time-series data set are able to mine the time dependencies in the time-series data, indicating that the construction of the time-series data set is crucial. The ensemble learning model constructed by applying stacked generalization based on different types of neural networks can effectively reduce the forecast bias in the Level-0 model and enhance the model’s generalization ability.
However, some issues in this study still remain to be explored in depth.
For example, the bilinear interpolation method was used to interpolate the forecast data to the stations during the data preprocessing, which inevitably brought some errors. Additionally, the physical quantities input into the model were not in the form of a grid, which might destroy the relatively complete structure of the surface pressure field and the structure of the upper-air synoptic situation field. In future studies, it is suggested that the grid structure of the forecast products can be retained to construct new models based on the new forms of input and output data (grid as input and station as output in this study). In addition, the extraction of spatio-temporal features of meteorological data can also be achieved by fusing the two-dimensional convolutional networks with the RNNs. As to feature selection, this study adopts the combination of variance filtering, correlation analysis and mutual information value, and the effect of other feature selection methods on model effectiveness can be explored in future research.
In terms of model construction, this study selects the size of 7 days for the time window when constructing the time-series data set, while there were no more sensitivity tests on the size of time window. Because the LSTM unit is relatively sensitive to the time-series length, which usually cannot handle the long-range dependence, the time-series length may have some influence on the modeling effect. In addition, this study only compares the effects of different models on modeling effects and explores the ability of different types of neural network frameworks in dealing with the problem of error correction for a model’s temperature forecast. The reasons for how features affect neural networks to make them work have yet to be explored, which is also limited by the uninterpretability of neural networks themselves. This may be the focus of future research work.
In general, the prediction performance of the decreasing average method is between ECMWF-IFS and the neural network, and the improvement of ECMWF-IFS is significant, but it is far less than that of the single neural network, let alone the ensemble neural network model. The deep learning, including mentioned in this paper, belongs to the MOS method. Compared with the MOS method, the deep learning method can extract more complex nonlinear relationships between features and targets. The results of this study show that the ensemble learning methods based on stacked generalization can obtain better prediction results than traditional statistical post-processing methods and single deep learning methods. However, ensemble learning methods are also diverse, and the effects of ensemble methods such as Snapshot Ensembling and Boosting need to be further tested. In addition, this study only verifies the effectiveness of each model to correct the forecast error of daily maximum temperature of the ECMWF-IFS model at the national meteorological stations, and the applicability to other forecast leading time and other meteorological elements (e.g., precipitation) needs to be further verified. Moreover, the effectiveness of their performance on gridded data can also be measured.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}