Innovative Hybrid Modeling of Wind Speed Prediction Involving Time-Series Models and Artificial Neural Networks

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
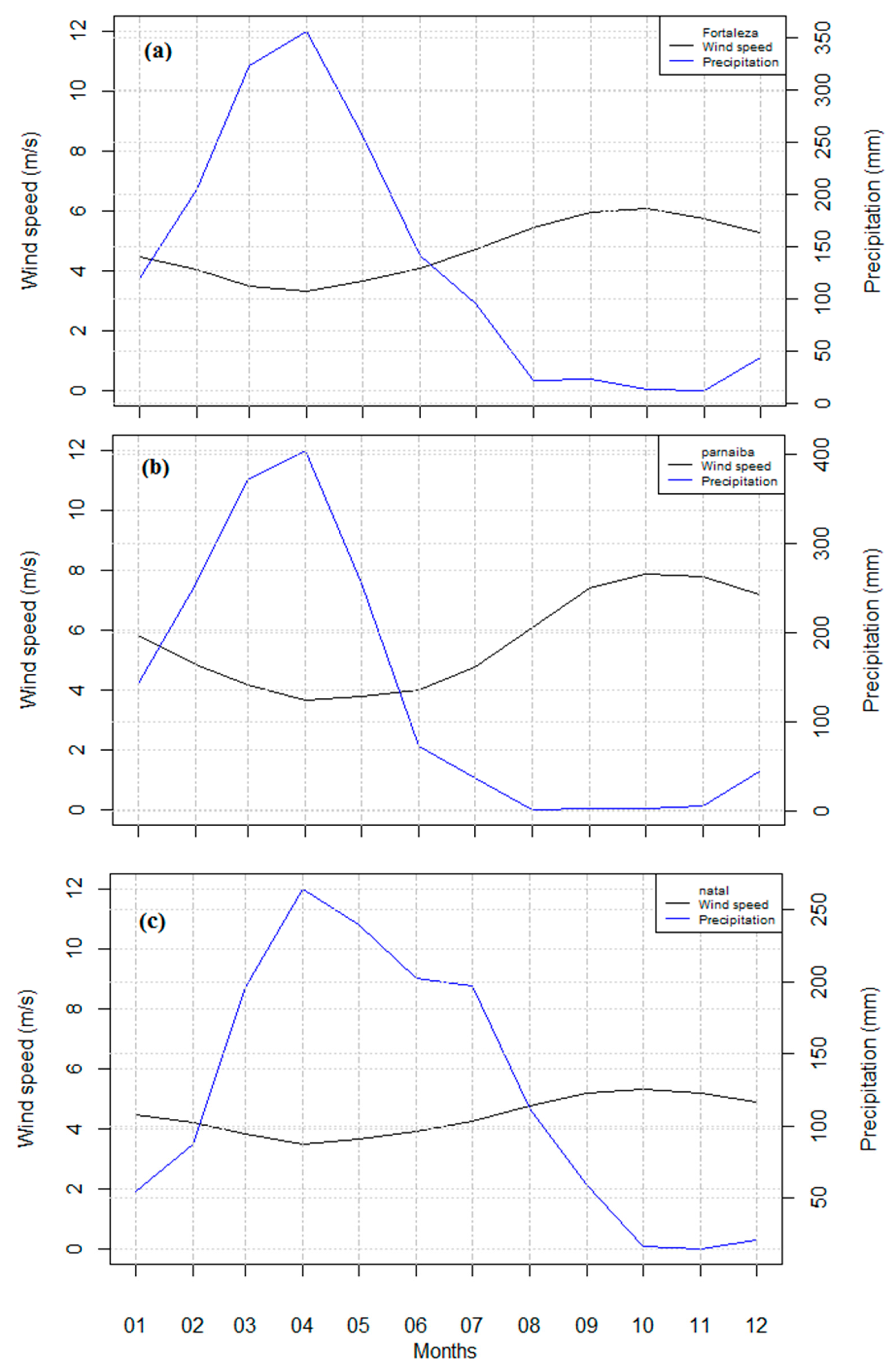
2.1. Regions under Investigation and Wind Speed Data
2.2. Box–Jenkins and Box–Tiao Modeling
2.3. Holt–Winters Model
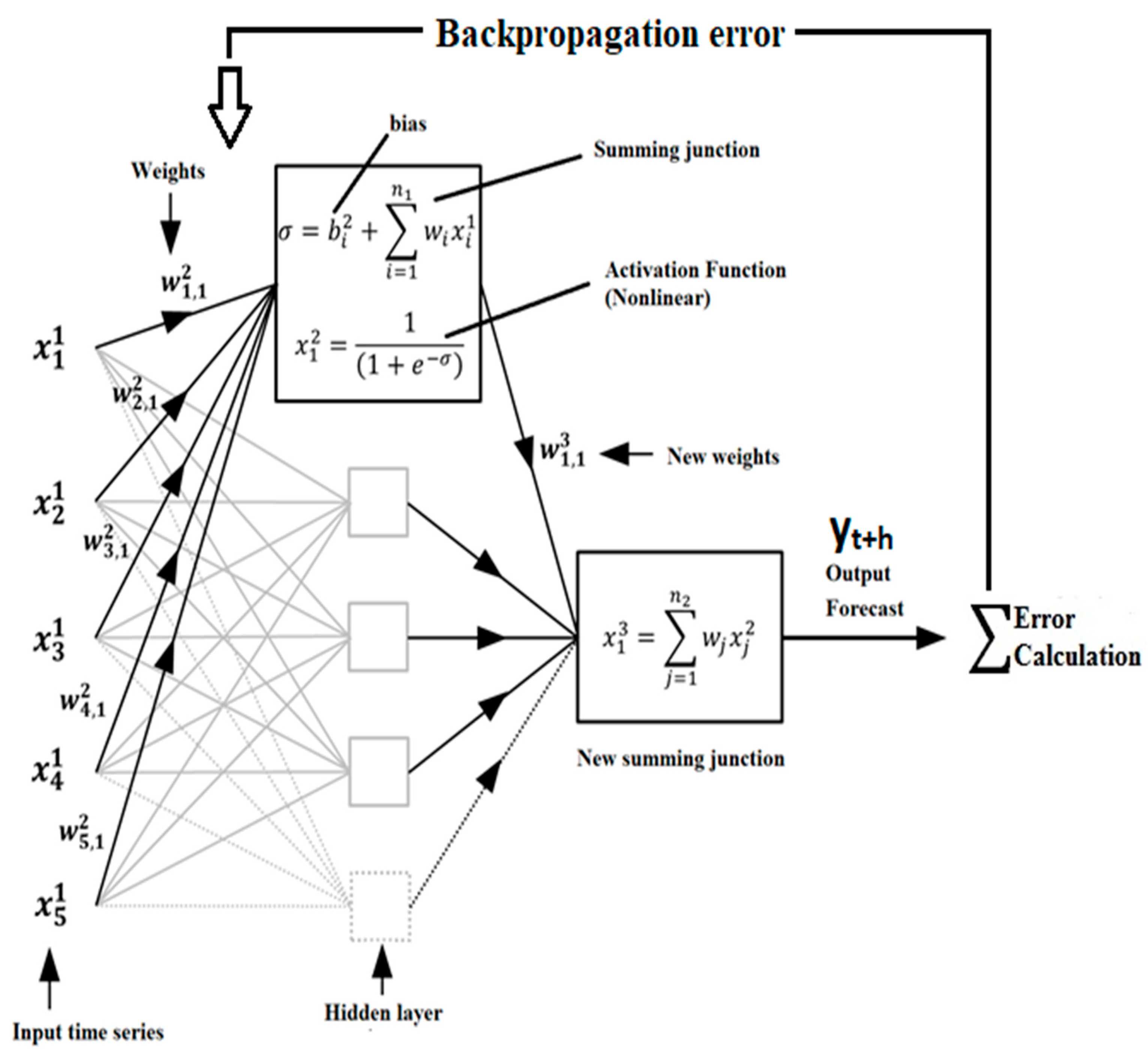
2.4. Artificial Intelligence with Neural Networks
2.5. Hybrid Modelling
2.5.1. Hybrid Model (ARIMA + ANN)
2.5.2. Hybrid Models (ARIMAX + ANN) and (HW + ANN)
2.6. Accuracy Measurements
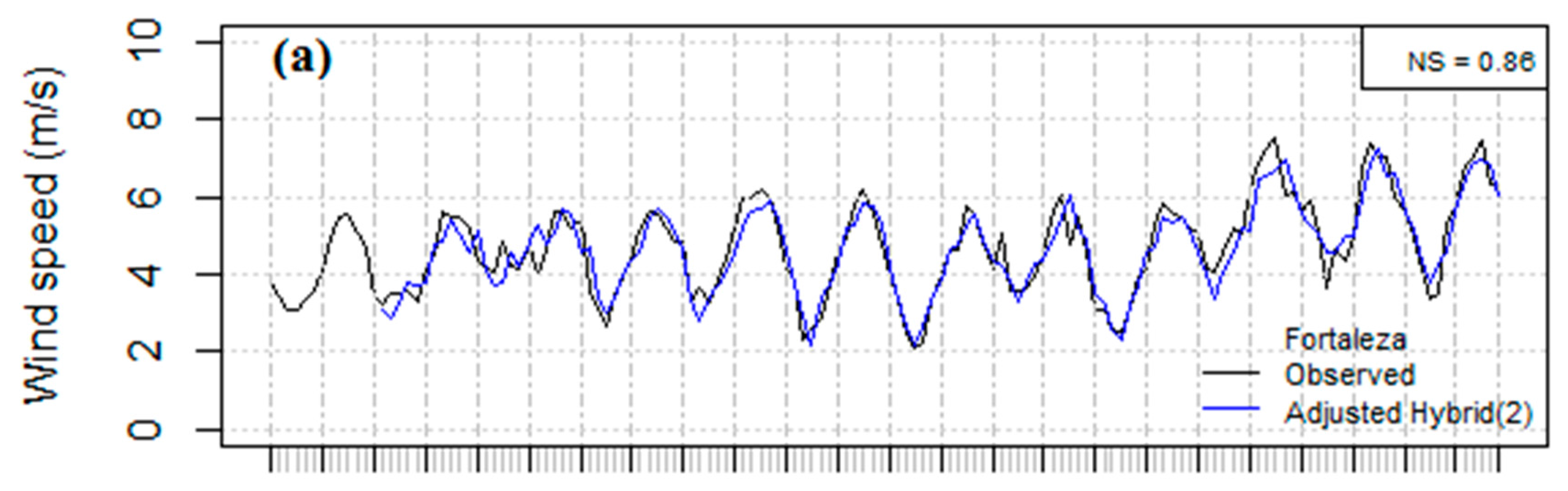
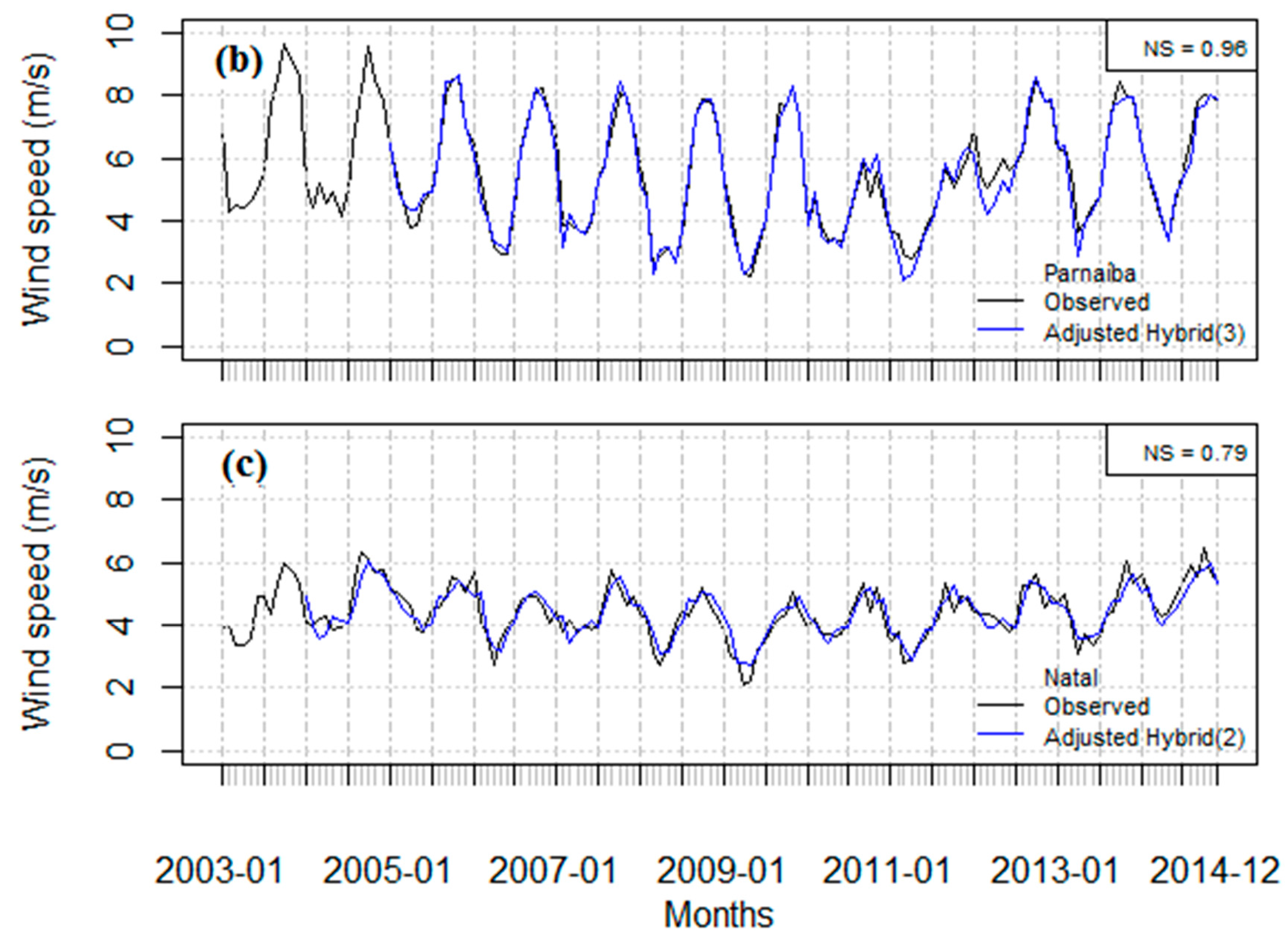
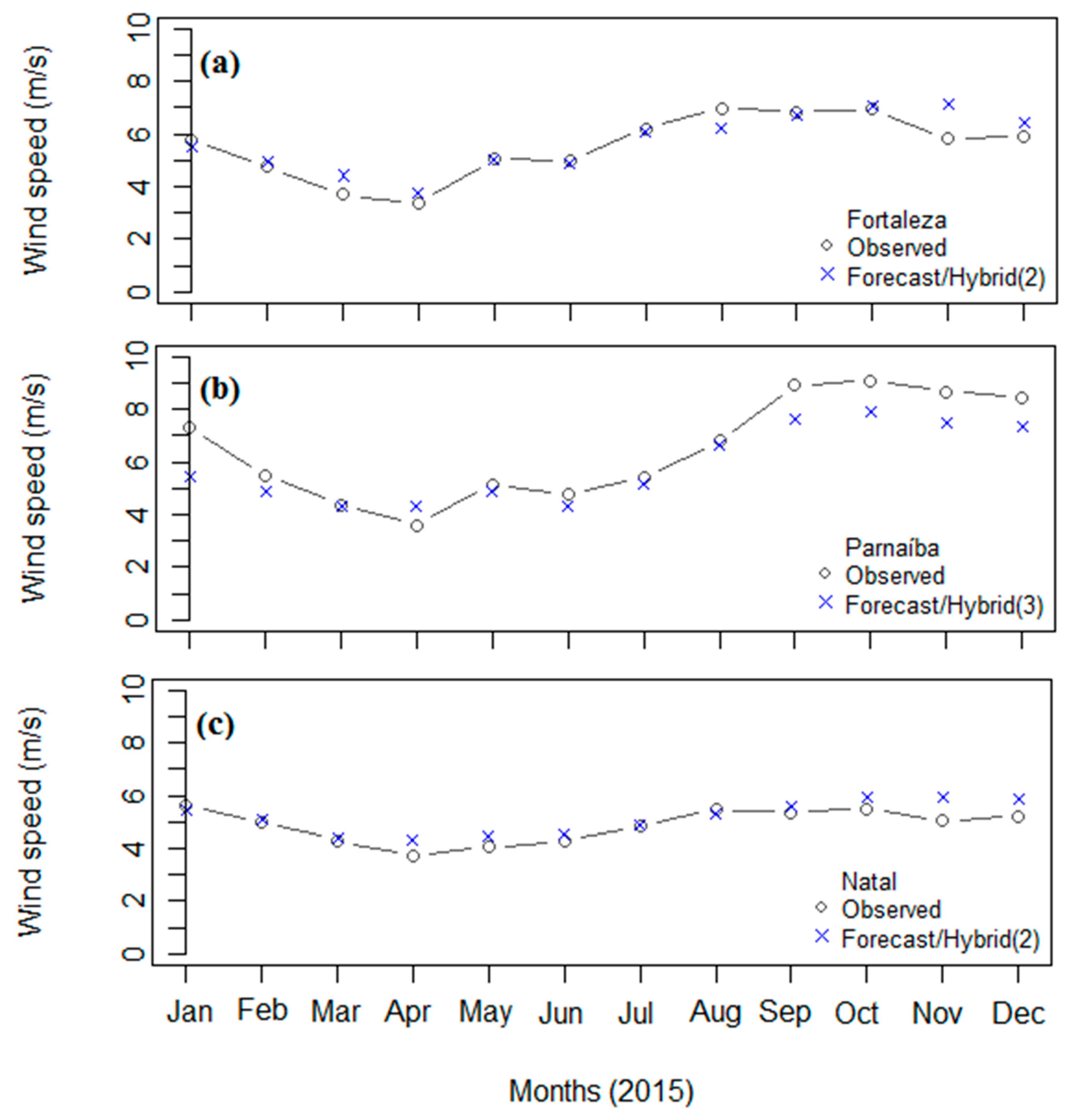
3. Results and Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Nomenclature
| Wt | Time-series adjusted by the ARIMA model. |
| Wt−1, Wt−2, …, Wt−p | Terms of the observed time-series (autoregressive) up to the order p. |
| φ | The coefficient related to the autoregressive stationary filter (p). |
| θ | The coefficient related to the moving averages filter (q). |
| εt | Error (also called residuals) from the ARIMA or ARIMAX model. |
| εt−1, εt−1, εt−1, …, εt−q | (Auto-regressive) errors of the ARIMA model up to the order q. |
| yt | A time-dependent variable (ARIMAX model). |
| ρ | A constant from the ARIMAX model. |
| yt−i | The dependent variable (which is also the wind speed) lagged by i time steps (ARIMAX model). |
| βi | The coefficient of yt−I (ARIMAX model). |
| p | The maximum number of time intervals (ARIMAX model). |
| wj | The exogenous variables (in this case were included in the model: pressure, temperature, and precipitation) (ARIMAX model). |
| ωj | The coefficients of the exogenous variables; r is the maximum number of exogenous variables (ARIMAX model). |
| θj | The coefficient of the term of εt−j which, in turn, represents the error at time t lagged from j. |
| α | Level of significance to applicate tests that identify white noise in Box–Jenkins and Box–Tiao models. |
| at | Series level (in m/s), which is related to how the predicted time-series evolves over time, being identified whether it varies slowly over time or, exceptionally, undergoes sudden variations (HW model). |
| bt | Trend (in m/s2), which is related to the fact that the predicted time-series has growth or decreasing motions that may occur at distinct time intervals (HW model). |
| st | Seasonal component (in m/s), which is related to the fact that the expected time-series has cyclical patterns of variation that repeat at relatively constant intervals of time (HW model). |
| Yt+n | Forecast (in m/s) for n periods ahead (HW model). |
| P | Seasonal period (HW model). |
| n = 1, 2, 3, …, h | Forecast horizon (HW model). |
| Zj | Inputs into neurons j in hidden layers can be linearly combined (ANN model). |
| bj and wi,j | Bias and weight, respectively. These are parameters discovered in the “learning” step from the observed data of the current time-series/ANN model. |
| s(z) | Sigmoid transfer function (ANN model). |
| vadj | The individual value of the adjusted wind speed time-series. |
| vobs | The individual value of the observed wind speed time-series. |
| n | The common order of the time-series (observed and adjusted) to apply the accuracy measures. |
| The observed series average. |
Abbreviations
| ABEEólica | Brazilian Wind Energy Association |
| AIC | Akaike Information Criterion |
| ANN | Artificial Neural Networks |
| ARIMA | Autoregressive Integrated Moving Average |
| ARIMAX | Auto-Regressive Integrated Moving Average and Exogenous inputs |
| HW | Holt–Winters |
| INMET | National Institute of Meteorology |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| METAR | METeorological Aerodrome Report |
| NS | Nash–Sutcliffe Coefficient |
| RMSE | Root Mean Square Error |
| SARIMA | Seasonal-Autoregressive Integrated Moving Average |
| SES | Simple Exponential Smoothing |
References
- Akella, A.K.; Saini, R.P.; Sharma, M.P. Social, economical and environmental impacts of renewable energy systems. Renew. Energy 2009, 32, 390–396. [Google Scholar] [CrossRef]
- Panwar, N.L.; Kaushik, S.C.; Kothari, S. Role of renewable energy sources in environmental protection: A review. Renew. Sustain. Energy Rev. 2011, 15, 1513–1524. [Google Scholar] [CrossRef]
- Dincer, F. The analysis on wind energy electricity generation status, potential and policies in the world. Renew. Sustain. Energy Rev. 2011, 15, 5135–5142. [Google Scholar] [CrossRef]
- Fontoura, C.F.; Brandão, L.E.; Gomes, L.L. Elephant grass biorefineries: Towards a cleaner Brazilian energy matrix? J. Clean. Prod. 2015, 96, 85–93. [Google Scholar] [CrossRef]
- Juárez, A.A.; Araújo, A.M.; Rohatgi, J.S.; De Oliveira Filho, O.D.Q. Development of the wind power in Brazil: Political, social and technical issues. Renew. Sustain. Energy Rev. 2014, 39, 828–834. [Google Scholar] [CrossRef]
- SEINFRACE–Secretariat of Infrastructure of the State of Ceará. Atlas of Wind Power in the State of Ceará. Fortaleza–CE, Brazil. 2001. Available online: http://www.seinfra.ce.gov.br/index.php/downloads/category/6-energia (accessed on 7 February 2018).
- Tammelin, B.; Vihma, T.; Atlaskin, E.; Badger, J.; Fortelius, C.; Gregow, H.; Ljungberg, K. Production of the Finnish wind atlas. Wind Energy 2013, 16, 19–35. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Li, Y.F. An EMD-recursive ARIMA method to predict wind speed for railway strong wind warning system. J. Wind Eng. Ind. Aerodyn. 2015, 141, 27–38. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- Cadenas, E.; Rivera, W. Short term wind speed forecasting in La Venta, Oaxaca, México, using artificial neural networks. Renew. Energy 2009, 34, 274–278. [Google Scholar] [CrossRef]
- Cadenas, E.; Jaramilho, O.A.; Rivera, W. Analysis and forecasting of wind velocity in chetumal, quintana roo, using the single exponential smoothing method. Renew. Energy 2010, 35, 925–930. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Li, Y. Comparison of two new ARIMA-ANN and ARIMA-Kalman hybrid methods for wind speed prediction. Appl. Energy 2012, 98, 415–424. [Google Scholar] [CrossRef]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting, 3rd ed.; Springer: New York, NY, USA, 2016. [Google Scholar]
- Dannecker, L. Energy Time Series Forecasting: Efficient and Accurate Forecasting of Evolving Time Series from the Energy Domain, 1st ed.; Springer: New York, NY, USA, 2015. [Google Scholar]
- Bennet, C.; Stewart, R.A.; Lu, J. Autoregressive with exogenous variables and neural network short-term load forecast models for residential low voltage distribution networks. Energies 2014, 7, 2938–2960. [Google Scholar] [CrossRef]
- Li, Y.; Su, Y.; Shu, L. An ARMAX model for forecasting the power output of a grid connected photovoltaic system. Renew. Energy 2014, 66, 78–89. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 23, 1–22. [Google Scholar]
- Yazici, B.; Yolacan, S. A comparison of various tests of normality. J. Stat. Comput. Sim. 2007, 77, 175–183. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Jennings, C.L.; Kulahci, M. Introduction to Time Series Analysis and Forecasting, 6th ed.; Wiley-Interscience: New York, NY, USA, 2008. [Google Scholar]
- Burton, T.; Sharpe, D.; Jenkins, N.; Ossanvi, E. Wind Energy Handbook, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2011. [Google Scholar]
- Ahrens, C.D. Meteorology Today: An Introduction to Weather, Climate, and the Environment, 9th ed.; Cengage Learning: Boston, MA, USA, 2012. [Google Scholar]
- Tsonis, A.A. An Introduction to Atmospheric Thermodynamics, 2nd ed.; University of Wisconsin: Milwaukee, WI, USA, 2007. [Google Scholar]
- Martins, F.R.; Pereira, E.B. Enhancing information for solar and wind energy technology deployment in Brazil. Energy Policy 2011, 39, 4378–4390. [Google Scholar] [CrossRef]
- Rocha, P.A.C.; de Sousa, R.C.; de Andrade, C.F.; da Silva, M.E.V. Comparison of seven numerical methods for determining Weibull parameters for wind energy generation in the northeast region of Brazil. Appl. Energy 2012, 89, 395–400. [Google Scholar] [CrossRef]
- De Andrade, C.F.; Neto, H.F.M.; Rocha, P.A.C.; da Silva, M.E.V. An efficiency comparison of numerical methods for determining Weibull parameters for wind energy applications: A new approach applied to the northeast region of Brazil. Energy Convers. Manag. 2014, 86, 801–808. [Google Scholar] [CrossRef]
- Rojas, R. Neural Networks: A Systematic Introduction, 1rd ed.; Springer Science & Business Media: Boston, MA, USA, 2013. [Google Scholar]
- Zhang, G.; Patuwo, B.E.; Hu, Y.M. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 4, 35–62. [Google Scholar] [CrossRef]
- Zhang, G. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Saavedra-Moreno, B.; Salcedo-Sanz, S.; Carro-Calvo, L.; Gascón-Moreno, J.; Jiménez-Fernández, S.; Prieto, L. Very fast training neural-computation techniques for real measure-correlate-predict wind operations in wind farms. J. Wind Eng. Ind. Aerodyn. 2013, 116, 49–60. [Google Scholar] [CrossRef]
- Wu, T.; Kareem, A. Modeling hysteretic nonlinear behavior of bridge aerodynamics via cellular automata nested neural network. J. Wind Eng. Ind. Aerodyn. 2011, 99, 378–388. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W. Wind speed forecasting in three different regions of Mexico, using a hybrid ARIMA–ANN model. Renew. Energy 2010, 35, 2732–2738. [Google Scholar] [CrossRef]
- Mohandes, M.A.; Rehman, S. Short term wind speed estimation in Saudi Arabia. J. Wind Eng. Ind. Aerodyn. 2014, 128, 37–53. [Google Scholar] [CrossRef]
- Galanis, G.; Papageorgiou, E.; Liakatas, A. A hybrid Bayesian Kalman filter and applications to numerical wind speed modeling. J. Wind Eng. Ind. Aerodyn. 2017, 167, 1–22. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W. Wind speed forecasting in the south coast of Oaxaca, Mexico. Renew. Energy 2007, 32, 2116–2128. [Google Scholar] [CrossRef]
- Fadare, D.A. The application of artificial neural networks to mapping of wind speed profile for energy application in Nigeria. Appl. Energy 2010, 87, 934–942. [Google Scholar] [CrossRef]
- Camelo, H.N.; Carvalho, P.C.M.; Leal Junior, J.B.V.; Accioly Filho, B.P. Statistical analysis of the wind speed in Ceará State, Brazil. Mag. Technol. 2008, 29, 211–223. Available online: http://periodicos.unifor.br/tec/article/view/38 (accessed on 7 February 2018).
- Chang, W.Y. A literature review of wind forecasting methods. J. Power Energy Eng. 2014, 2, 161–168. [Google Scholar] [CrossRef]
- Okumus, I.; Dinler, A. Current status of wind energy forecasting and a hybrid method for hourly predictions. Energy Convers. Manag. 2016, 123, 362–371. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shapiro–Wilk Test |
| H0: sample comes from a normal population. H1: sample does not come from a normal population. Decision making: if the p-value is greater than α, i.e., p > 0.05 (do not reject H0). |
| Durbin–Watson Test |
| H0: the residues are independents. H1: the residues are not independents. Decision making: if the p-value is greater than α, i.e., p > 0.05 (do not reject H0). |
| Breusch–Pagan Test |
| H0: the residues have homoscedasticity. H1: the residues have heteroscedasticity. Decision making: if the p-value is greater than α, i.e., p > 0.05 (do not reject H0). |
| Local/ARIMA | Shapiro–Wilk | Durbin–Watson | Breusch–Pagan |
| Fortaleza | 0.499 | 0.771 | 0.054 |
| Natal | 0.514 | 0.466 | 0.575 |
| Parnaíba | 0.234 | 0.523 | 0.858 |
| Local/ARIMAX | Shapiro–Wilk | Durbin–Watson | Breusch–Pagan |
| Fortaleza | 0.374 | 0.615 | 0.551 |
| Natal | 0.533 | 0.799 | 0.509 |
| Parnaíba | 0.252 | 0.456 | 0.618 |
| Error (ARIMA) | Fortaleza | Natal | Parnaíba |
| MAE (m/s) | 0.44 | 0.39 | 0.55 |
| RMSE (m/s) | 0.57 | 0.50 | 0.73 |
| MAPE (%) | 9.89 | 9.10 | 10.53 |
| Error (ARIMAX) | Fortaleza | Natal | Parnaíba |
| MAE (m/s) | 0.37 | 0.37 | 0.54 |
| RMSE (m/s) | 0.48 | 0.45 | 0.71 |
| MAPE (%) | 8.48 | 8.47 | 10.40 |
| Error (HW) | Fortaleza | Natal | Parnaíba |
| MAE (m/s) | 0.45 | 0.40 | 0.63 |
| RMSE (m/s) | 0.57 | 0.50 | 0.80 |
| MAPE (%) | 10.10 | 9.44 | 14.21 |
| Error (ANN) | Fortaleza | Natal | Parnaíba |
| MAE (m/s) | 0.46 | 0.36 | 0.93 |
| RMSE (m/s) | 0.66 | 0.53 | 1.29 |
| MAPE (%) | 10.29 | 8.14 | 19.25 |
| Error (Hybrid(1)) | Fortaleza | Natal | Parnaíba |
| MAE (m/s) | 0.39 | 0.32 | 0.53 |
| RMSE (m/s) | 0.49 | 0.42 | 0.71 |
| MAPE (%) | 8.68 | 7.53 | 10.40 |
| Error (Hybrid(2)) | Fortaleza | Natal | Parnaíba |
| MAE (m/s) | 0.36 | 0.31 | 0.51 |
| RMSE (m/s) | 0.46 | 0,38 | 0.68 |
| MAPE (%) | 8.03 | 7.21 | 10.20 |
| Error (Hybrid(3)) | Fortaleza | Natal | Parnaíba |
| MAE (m/s) | 0.44 | 0.37 | 0.22 |
| RMSE (m/s) | 0.56 | 0.45 | 0.33 |
| MAPE (%) | 10.0 | 8.70 | 4.93 |
| Time-Scale | Interval | Applications in the Wind Sector |
|---|---|---|
| Ultra-short-term | Few minutes to 1 h ahead |
|
| Short-term | 1 h to several hours ahead |
|
| Medium-term | Several hours to 1 week ahead |
|
| Long-term | 1 week to 1 year or more ahead |
|
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Do Nascimento Camelo, H.; Sérgio Lucio, P.; Verçosa Leal Junior, J.B.; Von Glehn dos Santos, D.; Cesar Marques de Carvalho, P. Innovative Hybrid Modeling of Wind Speed Prediction Involving Time-Series Models and Artificial Neural Networks. Atmosphere 2018, 9, 77. https://doi.org/10.3390/atmos9020077
Do Nascimento Camelo H, Sérgio Lucio P, Verçosa Leal Junior JB, Von Glehn dos Santos D, Cesar Marques de Carvalho P. Innovative Hybrid Modeling of Wind Speed Prediction Involving Time-Series Models and Artificial Neural Networks. Atmosphere. 2018; 9(2):77. https://doi.org/10.3390/atmos9020077
Chicago/Turabian StyleDo Nascimento Camelo, Henrique, Paulo Sérgio Lucio, João Bosco Verçosa Leal Junior, Daniel Von Glehn dos Santos, and Paulo Cesar Marques de Carvalho. 2018. "Innovative Hybrid Modeling of Wind Speed Prediction Involving Time-Series Models and Artificial Neural Networks" Atmosphere 9, no. 2: 77. https://doi.org/10.3390/atmos9020077
APA StyleDo Nascimento Camelo, H., Sérgio Lucio, P., Verçosa Leal Junior, J. B., Von Glehn dos Santos, D., & Cesar Marques de Carvalho, P. (2018). Innovative Hybrid Modeling of Wind Speed Prediction Involving Time-Series Models and Artificial Neural Networks. Atmosphere, 9(2), 77. https://doi.org/10.3390/atmos9020077