1. Introduction
Wind energy is an important source of clean energy which is nonpolluting and renewable. Unlike the fossil fuels, wind turbines generate power without emitting greenhouse gases nor toxic waste. According to the Energy Information Administration (EIA) of the US, in March of 2017, the wind and solar power have generated more than 10% of electricity for the first time in the US, and the projections show that this number of percentage will continue to grow steadily. By assessing and characterizing available wind resources, wind resource assessment is a crucial approach in the development, siting, and operation of wind farms. In terms of wind farm development, wind resource assessment provides the estimated wind energy production at prospective wind farms. In particular, the short-term (typically 1–2 years) observation of wind speed at turbine height is first obtained from meteorological towers set up in the prospective sites, and is then used to estimate the short-term wind energy production. Later on, the long-term wind energy production is estimated, most commonly derived from the long-term reanalysis data. In terms of wind farm’s operational performance, wind resource assessment could provide detailed analysis to characterize and evaluate the operation of wind farms.
A widely used method of wind resource assessment for operational wind farms is involved with synoptic pattern analysis, which is a subjective way to examine the dynamical linkage of jet streams and low-level wind resource so as to achieve an improved understanding of fundamental drivers of wind resource. Characterizing the wind resource departure from the expectation would allow to identify other operational factors affecting wind farm performance. In specific, the synoptic pattern analysis method is primarily carried out by subjective inspection of weather maps such that days with similar synoptic patterns in a specific month can be grouped together to form a sub-period. Each sub-period is commonly associated with the favorable, unfavorable or neutral low-level wind resources, respectively. The frequency of occurrence for each sub-period-accompanied synoptic pattern can be thus calculated for a given month. However, the long-term baseline for the frequency of occurrence of these identified synoptic patterns is not yet established. Brayshaw et al. [
1] studied the impact of large-scale atmospheric circulation patterns on wind power generation and potential predictability of wind power over the UK. This study found that the North Atlantic Oscillation (NAO) phases influence the wind power generation of UK and the forecast of future NAO phases would help improve statistical forecasts of monthly wind power generation with months in lead. Another study by Thornton et al. [
2] also confirmed that the large-scale atmospheric circulation patterns are responsible for the varying wind power and changing electricity demand during the winter season of the UK. Moreover, Jerez et al. [
3] also found similar results in NAO impact on renewable energy resources in the southwestern Europe. Hence, in the present study, we desire to establish the climatological frequency of occurrence of certain large-scale atmospheric circulation patterns, associated with various types of wind resources, such that we would enable to compare the wind resource for a given month against the long-term values. This allows us to quantify by how much the wind resource in a specific month exceeds or underperforms the baseline wind resources.
Hence, in the present study, the Cluster Analysis approach is used to group similar synoptic weather patterns into clusters on a month-by-month basis. This enables us to improve the current method of subjective synoptic pattern analysis for operational wind assessment to the next level by explicitly quantifying the departure of wind resources from the baseline values. Detailed description of the Cluster Analysis method is provided in
Section 2.
In this study, wind resource assessment is primarily performed over the Southern Plains of US, given the unique synoptic weather patterns fueling the wind power over this region. It has long been documented that, during the spring and summer time, the Great Plains of the US is characterized by frequent nocturnal low-level jets which are often associated with severe weather events such as thunderstorms [
4,
5,
6,
7,
8,
9]. Specifically, Bonner [
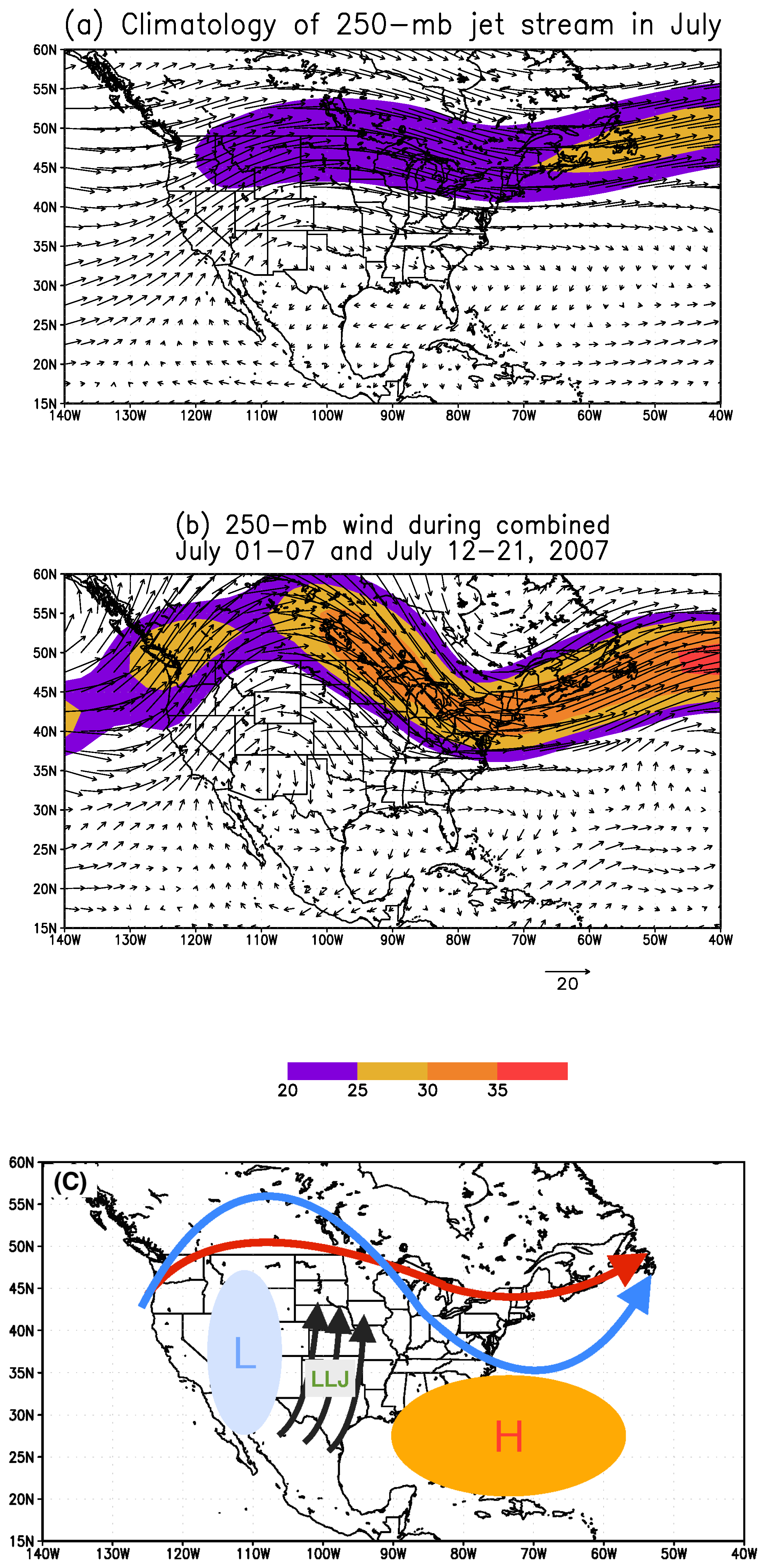
4] examined the geographical distribution and diurnal variations of the low-level jet over the US based on the 2-yr radiosonde data. This study found that the Great Plains low-level jets occur most often from April to September, in particular during the nighttime, and they span over the Great Plains at the horizontal scale. Thus the wind resources of Great Plains are mainly determined by the low-level jet during the spring and summer seasons, and by jet stream during the fall and winter seasons.
The remainder of this study is organized as follows.
Section 2 explains the methodology and data used in this study. In
Section 3, two scenarios featuring favorable and unfavorable wind energy production in the Southern Plains are analyzed respectively. Finally, conclusions and discussion are presented in
Section 4.
2. Methodology and Data
Cluster Analysis is a method used to classify multivariate data into groups in an objective manner [
10,
11]. It is a powerful tool in classifying a variety of meteorology related datasets. For instance, Jimenez et al. [
12], Darby [
13], Kaufmann and Whiteman [
14], Cooter et al. [
15], Beaver and Palazoglu [
16] used cluster analysis to classify the wind patterns; Christiansen [
11], Cheng and Wallace [
17], Kalkstein et al. [
18], Fovell and Fovell [
19], Straus and Molteni [
20], Straus et al. [
21], Fereday et al. [
22], Lorente-Plazas et al. [
23], Garcia-Valero et al. [
24] classified the weather regimes with cluster analysis; and Wolter [
25], DeGaetano [
26], Arnott et al. [
27] applied cluster analysis to other areas of meteorology.
The Cluster Analysis and Principal Component Analysis (PCA) are two distinct approaches for grouping data and there are fundamental differences between them. In our present study, clusters are used in preference to principal components because clusters provide a simple way of partitioning the phase space into localized regions. Cluster centroids are the averages of similar circulation fields, representing physical circulation patterns, while PCA spatial patterns are constrained to be mutually orthogonal so that they do not necessarily resemble physical circulation patterns. In addition, opposite phases of principal components are constrained to have the same spatial pattern, which may not be appropriate for the physical phenomena such as the NAO, whereas clusters are not restricted in this way. Furthermore, while clusters are all approximately the same size, higher PCs account for relatively little of the total variance and thus account for reduced importance. Nevertheless, the PCA approach and cluster analysis could be combined together for clustering as done by Lorente-Plazas et al. [
23], Jimenez et al. [
28].
The hierarchical clustering and
k-means clustering (or partitioning clustering) are the two primary types of cluster analysis methods. The hierarchical clustering builds the classification tree through iteration starting from the single data points and merging pairs based on the similarity criterion. The
k-means clustering starts from the prescribed number of clusters and data points are agglomerated around kernels initially chosen from random seeds. In a sense, the
k-means approach provides an optimal partition, in comparison to the hierarchical clustering [
29]. In the present study, the
k-means cluster analysis approach is adopted to minimize the within-cluster variance summed over all the clusters. Determining the optimal number of clusters is a challenge, nevertheless, abundant research efforts have been made in seeking the optimal number of clusters by assessing the stability of clusters [
30,
31]. The cluster stability is examined by inspecting the global minimum of the within-cluster variance summed over all the clusters. The cluster stability gradually decreases as the number of cluster,
k, increases. This is also termed as Elbow criterion for determining the optimal number of clusters.
k is suggested to locate around a bend in the curve. In the present study, the Elbow criterion is applied to the two selected scenarios and the optimal
k is determined to be 4. However, the Elbow criterion is not always perfect in locating
k in some other cases where a bend in the curve does not really exist. In that case, other criterion for choosing
k should be considered as there is no consensus on ways of finding the optimal number of clusters so far.
The daily data of the National Centers for Environmental Prediction (NCEP)-National Center for Atmospheric Research (NCAR) reanalysis during 1979–2016 (38-yr) is used in this study. The
k-means cluster analysis is performed upon this dataset to form distinct clusters for the selected months, in a sense of climatological cluster. The daily fields of NCEP-NCAR reanalysis are mostly available at 17 vertical pressure levels (
p = 1000, 925, 850, 700, 600, 500, 400, 300, 250, 200, 150, 100, 70, 50, 30, 20 and 10 hPa) on a
grid [
32]. The monthly wind energy production data is taken from the US Energy Information Administration (EIA). The data spans from 2007–2016.
4. Conclusions and Discussion
Wind resource assessment is a vital process for the wind farm development as well as for the operational wind farm performance assessment. Possible operational factors affecting the wind farm performance can be detected through characterizing the wind resource departure from the norm. On top of the existing approach of subjectively inspecting weather maps associated with various wind resource, we are intended to improve wind resource assessment by integrating an objective approach which establishes a climatological frequency of occurrence of large-scale atmospheric circulation patterns (or weather regimes) responsible for wind resources. The k-means cluster analysis is performed upon the NCEP-NCAR daily reanalysis data during 1979–2016 such that clusters associated with dominant weather regimes are detected. These clusters can be used to assist with wind resource assessment by quantifying the baseline frequency of the large-scale atmospheric circulation patterns such that the degree to which the local wind resource departs from the baseline value can be determined.
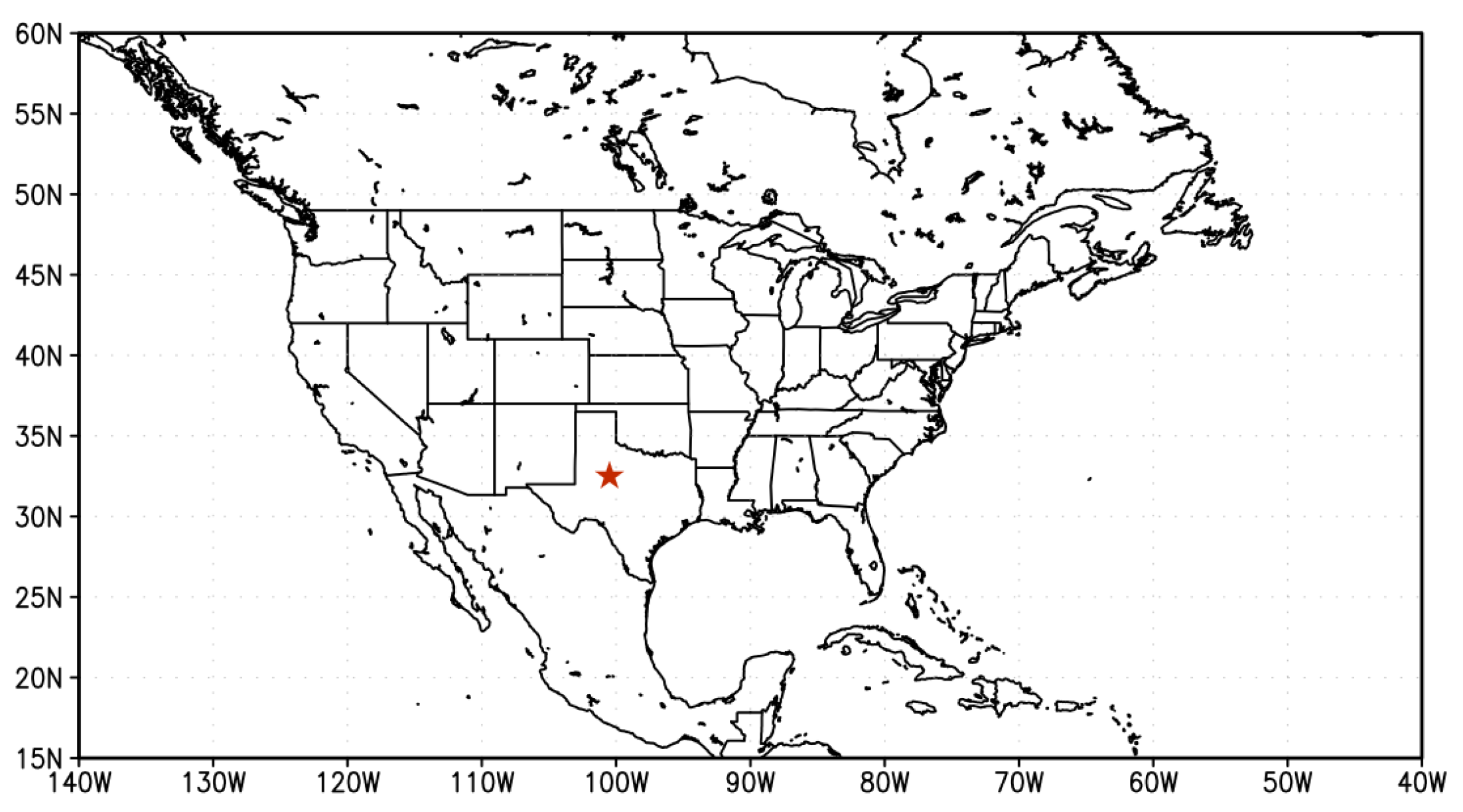
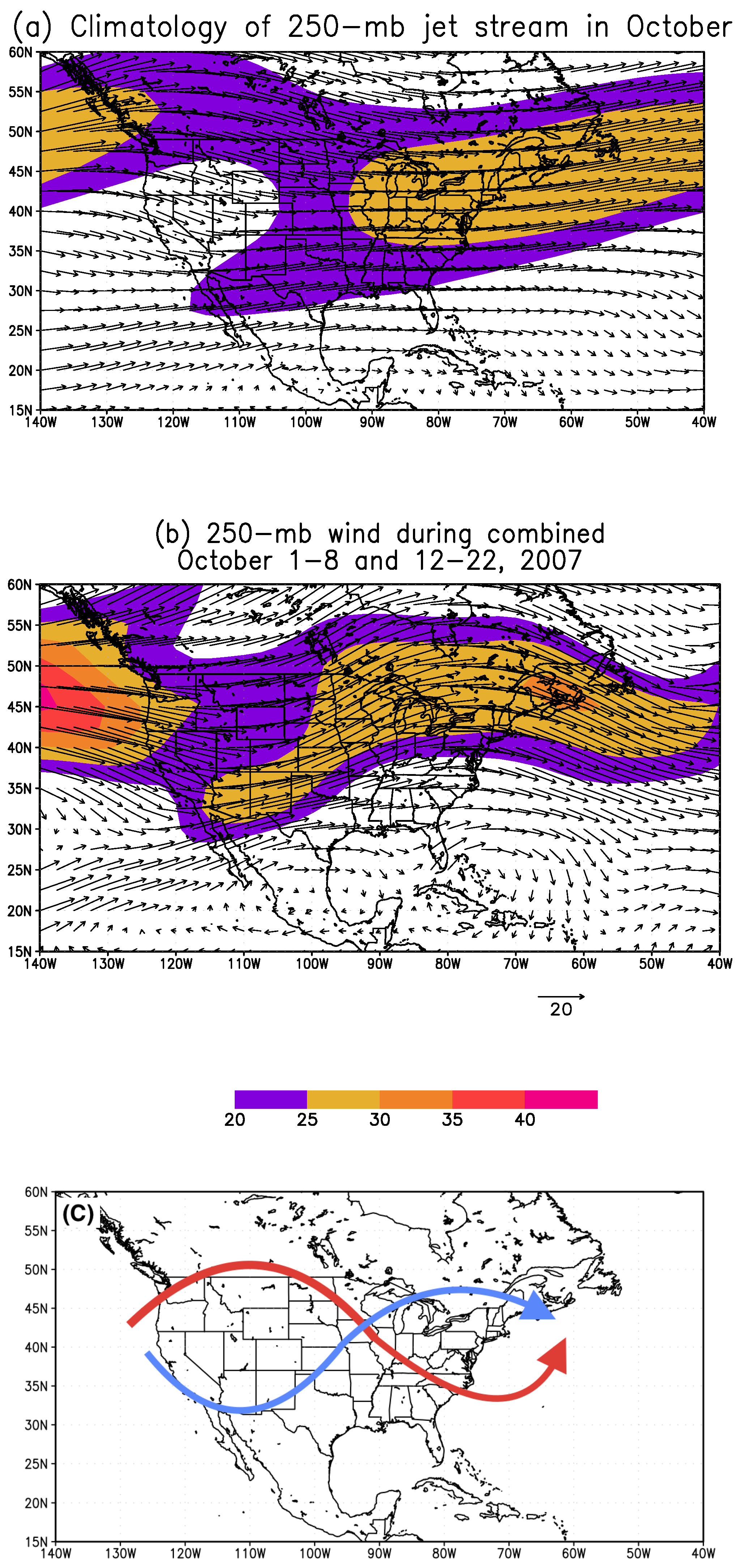
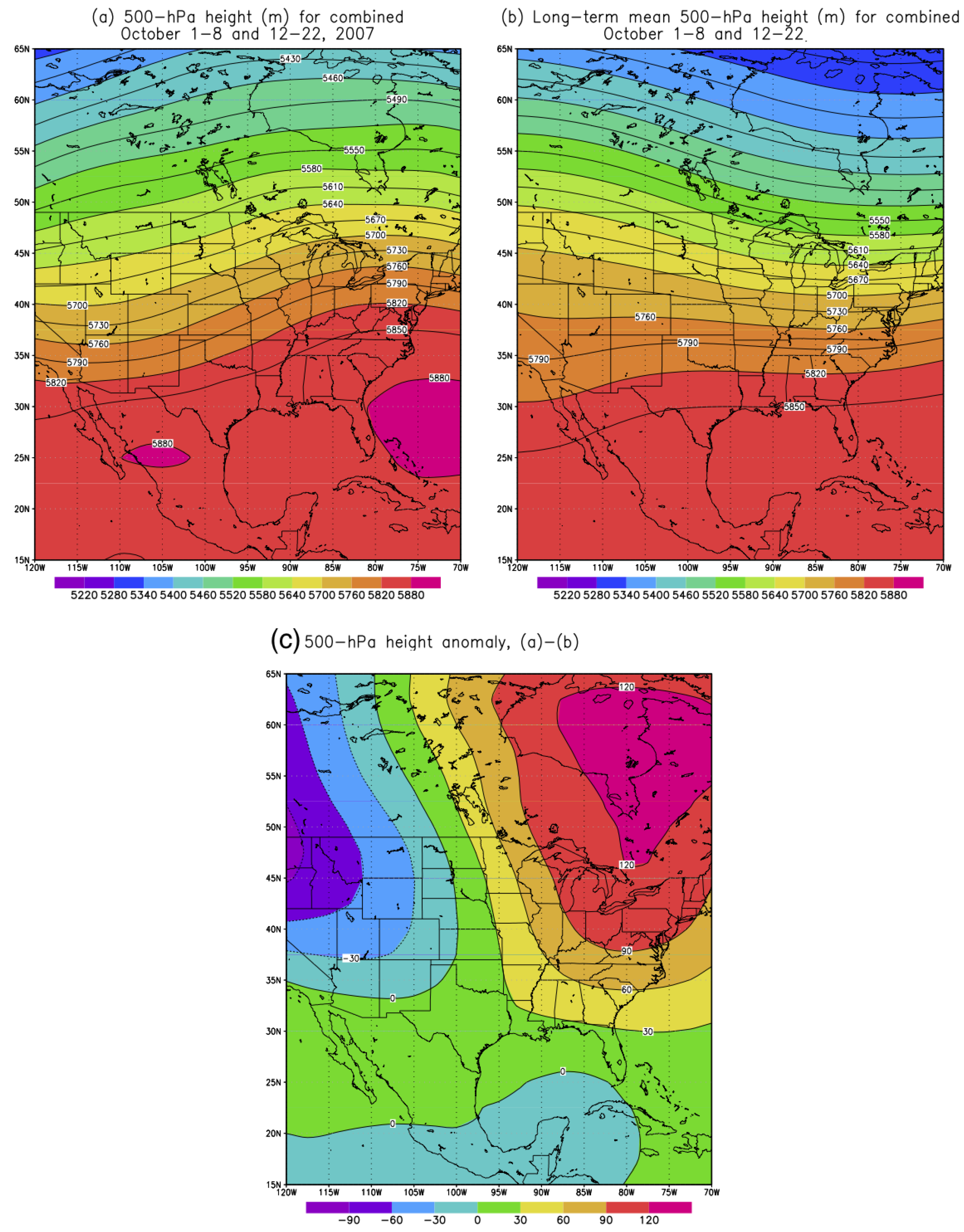
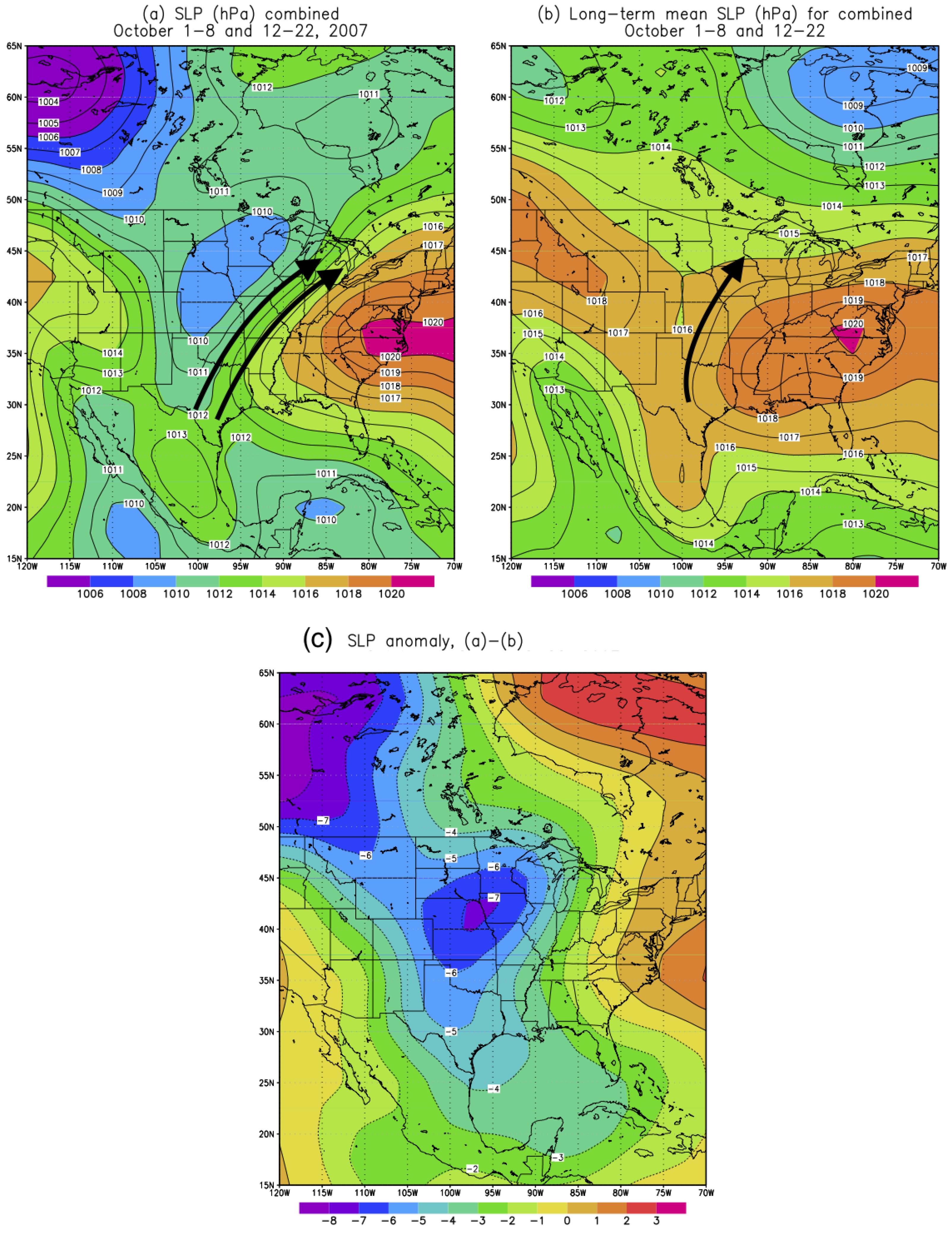
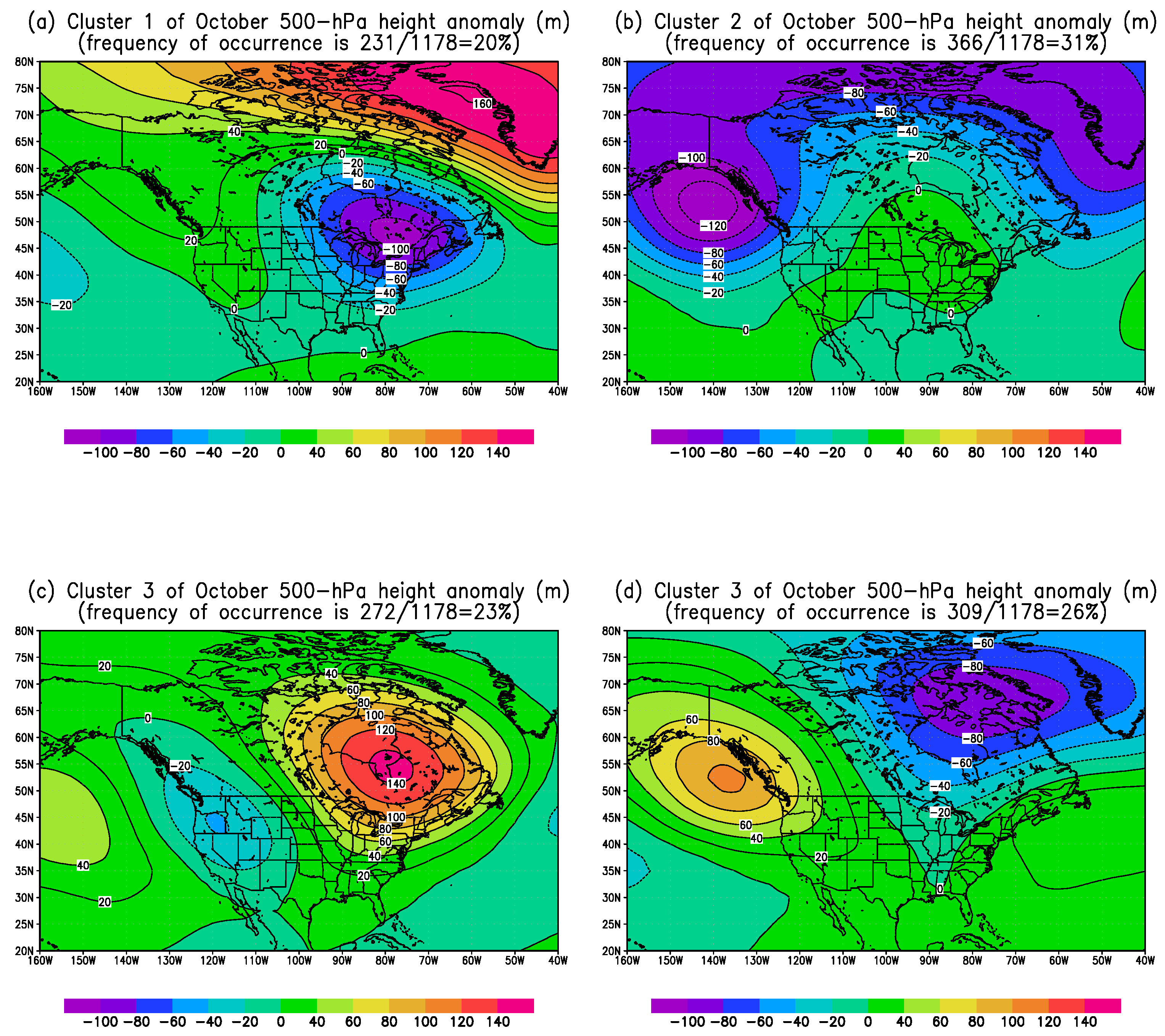
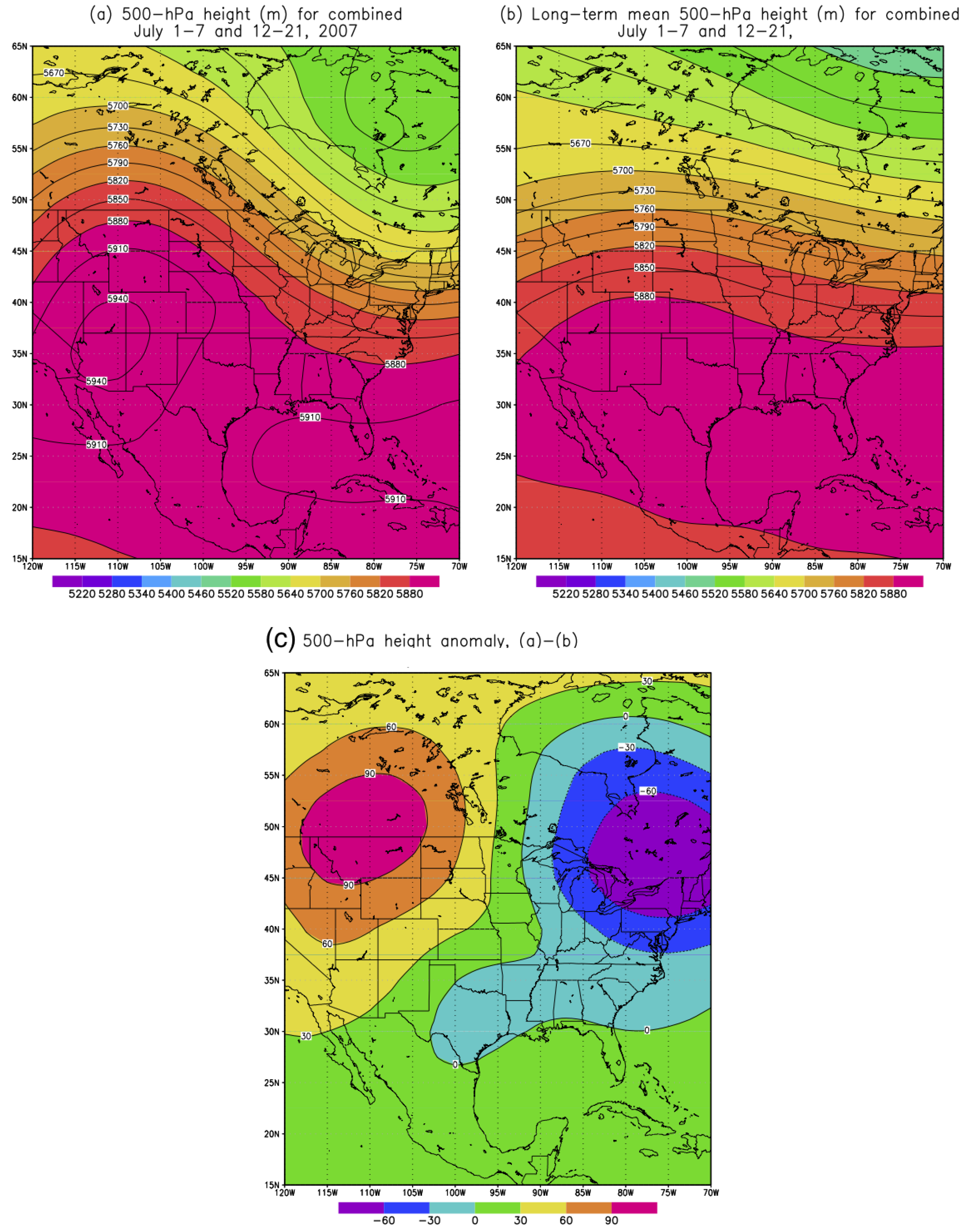
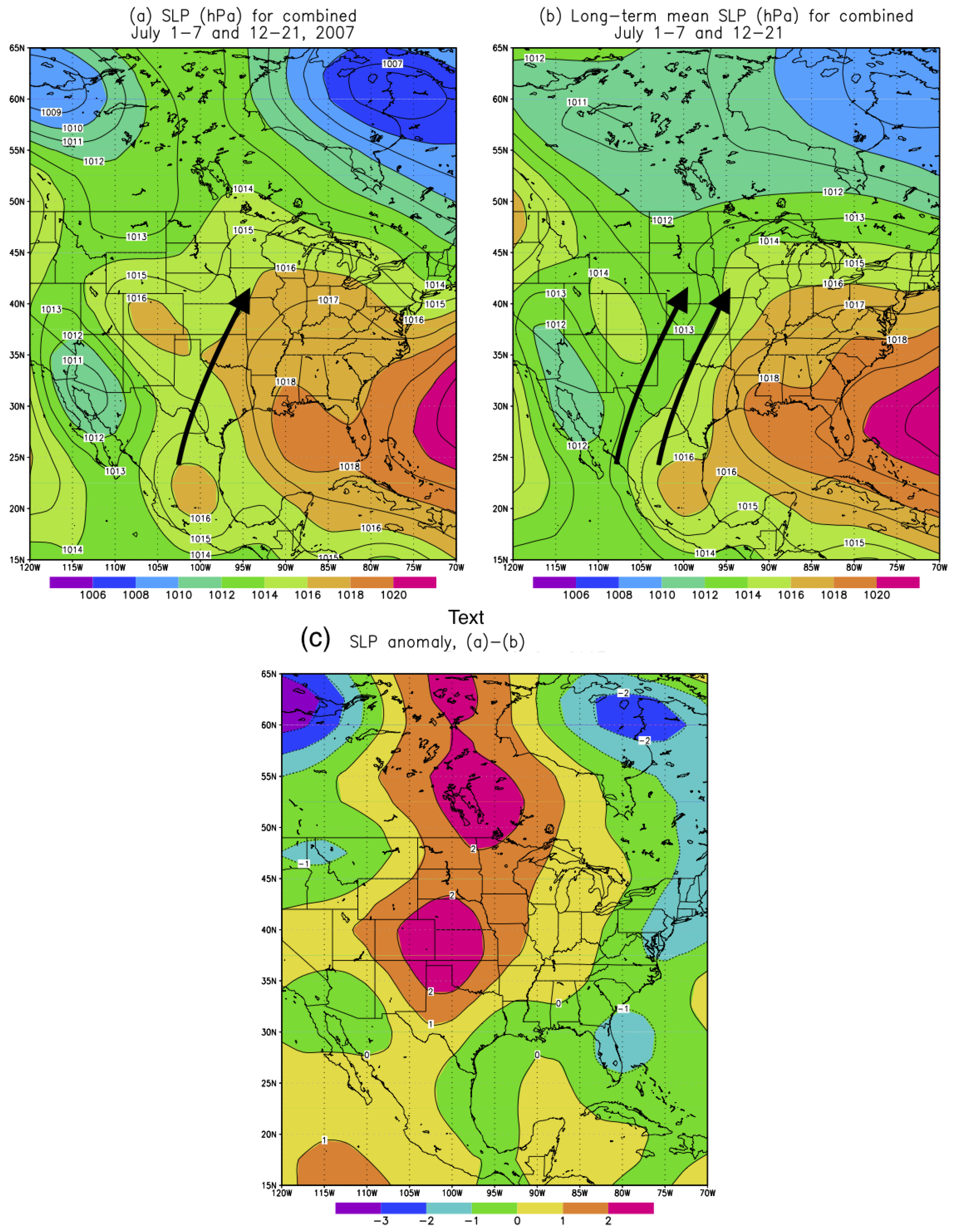
In this study, we chose the Callahan Divide Wind Energy Center of Texas as the study site in the Southern Plains of the US. Two scenarios featuring favorable (October 2007) and unfavorable (July 2007) wind energy production in the Southern Plains are examined in details. For the month of October 2007, the primary jet stream enhances the low-level jet over the Southern Plains which in turn favors the wind energy production in the Callahan Divide wind farm. The frequency of occurrence of the favorable weather pattern to the Callahan Divide wind energy production performance is nearly three times higher than that of the long-term value. In contrast, the July 2007 features well-below-average wind energy production due to the anomalous jet stream which is the amplified version of the climatological summer jet stream. In consequence, the weakened low-level jet is resulted over the Southern Plains leading to the poor wind energy production in Callahan Divide. The dominant weather pattern of July 2007 is found to occur more than twice often as the climatological counterpart.
In summary, compared to the previous approach of wind resource assessment which involves subjectively inspecting daily weather maps, the new approach presented here provides an objective way to perform wind resource assessment. In addition, the new approach is more efficient than the old one in that the clustering process can be automated by programs. Nevertheless, it is important to note that the old approach is not completely discarded by the new approach. Instead, the new approach is a two-stage process which integrates the stage of subjectively inspecting weather maps as the first step. The second step is the automation of clustering. Hence, the new approach presented in this study is proven to make the entire process of wind resource assessment more efficient and complete.
In the present study, even though cluster analysis is only conducted upon the October and July months, as the demonstration of wind resource assessment for two opposite scenarios, the same process can be repeated among other months (not shown) as well in order to establish the baseline frequency values for these months.
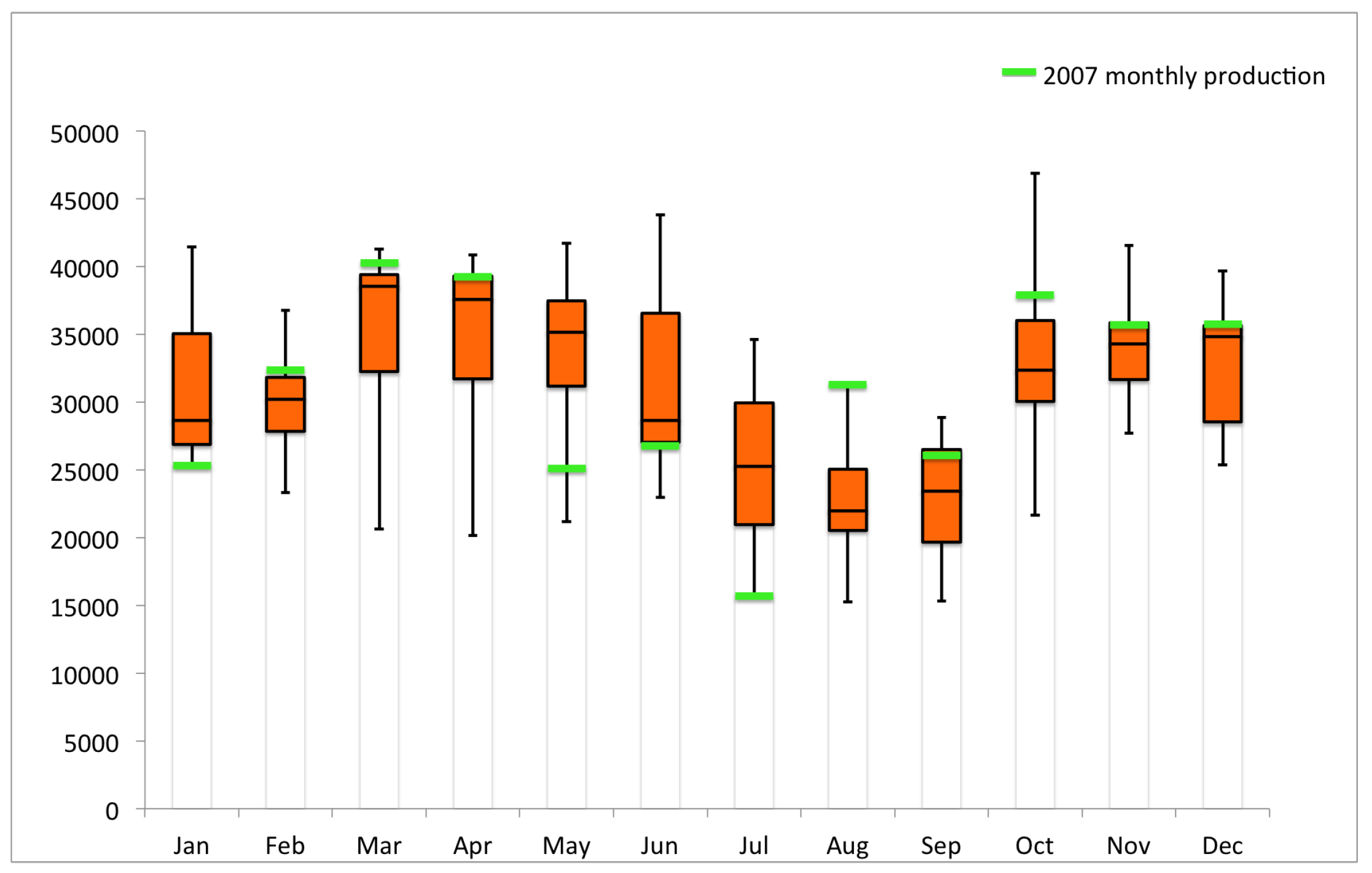
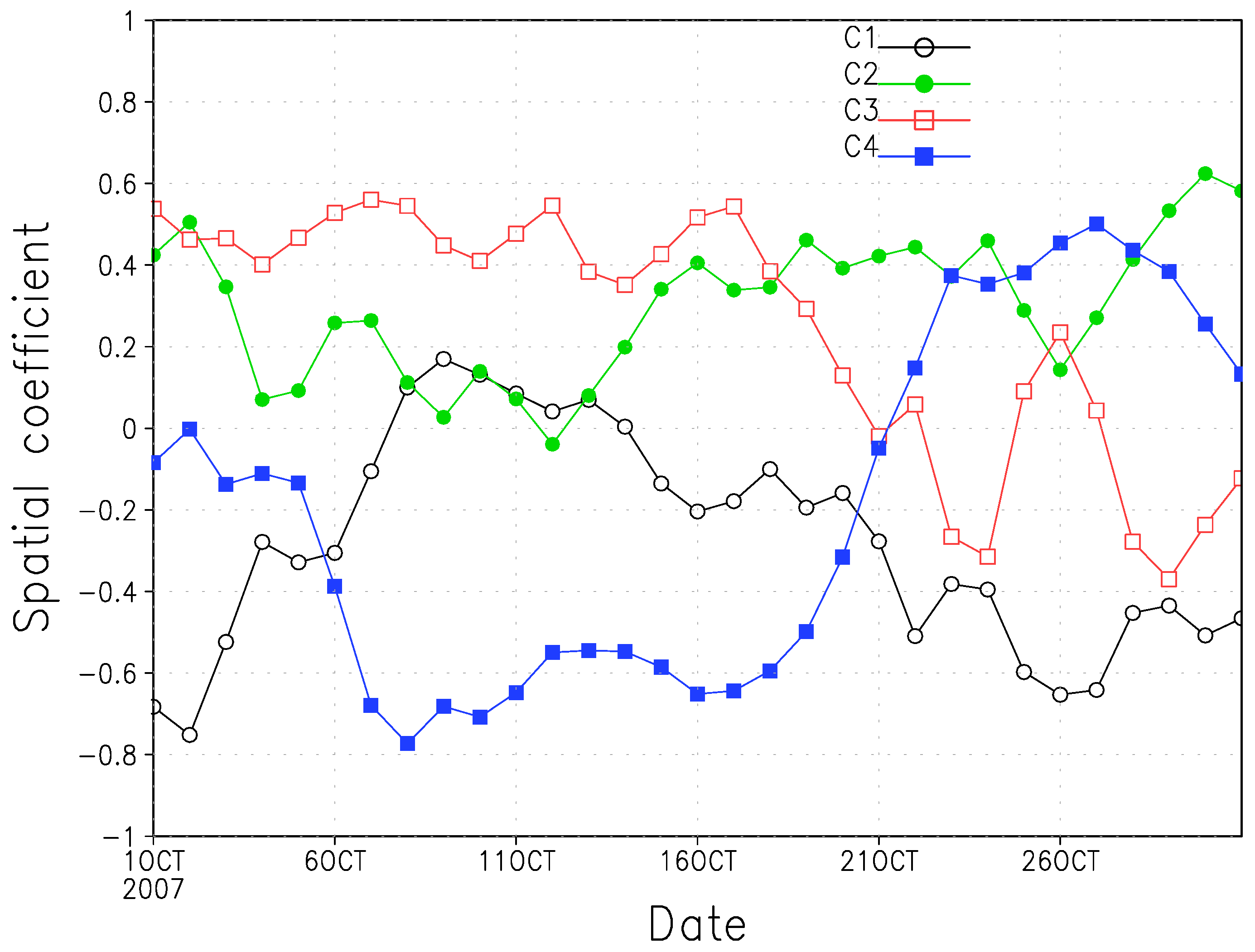
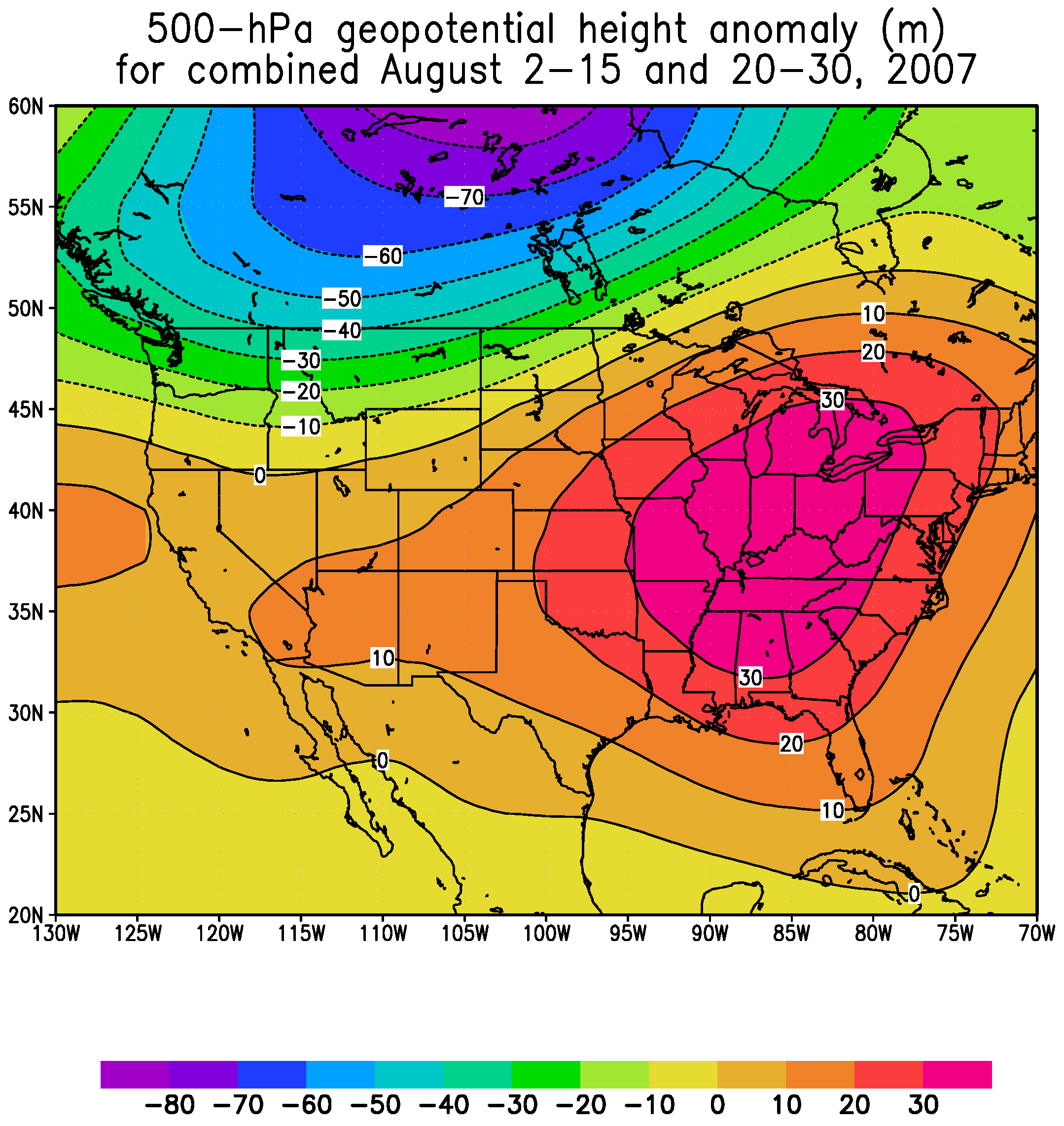
It is noticeable that July and August 2007 feature two extremes of wind energy production in Callahan Divide Energy Center, as shown in
Figure 2, with July 2007 reaching the bottom of the Whisker-box while August 2007 reaching the top. Inspection upon the major clusters derived for August months shows that they are in close resemblance to those of July months. Further synoptic analysis of August 2007 indicates that about 25 out of 31 days during August 2007 are characterized with the anomalous 500-mb height pattern as shown in
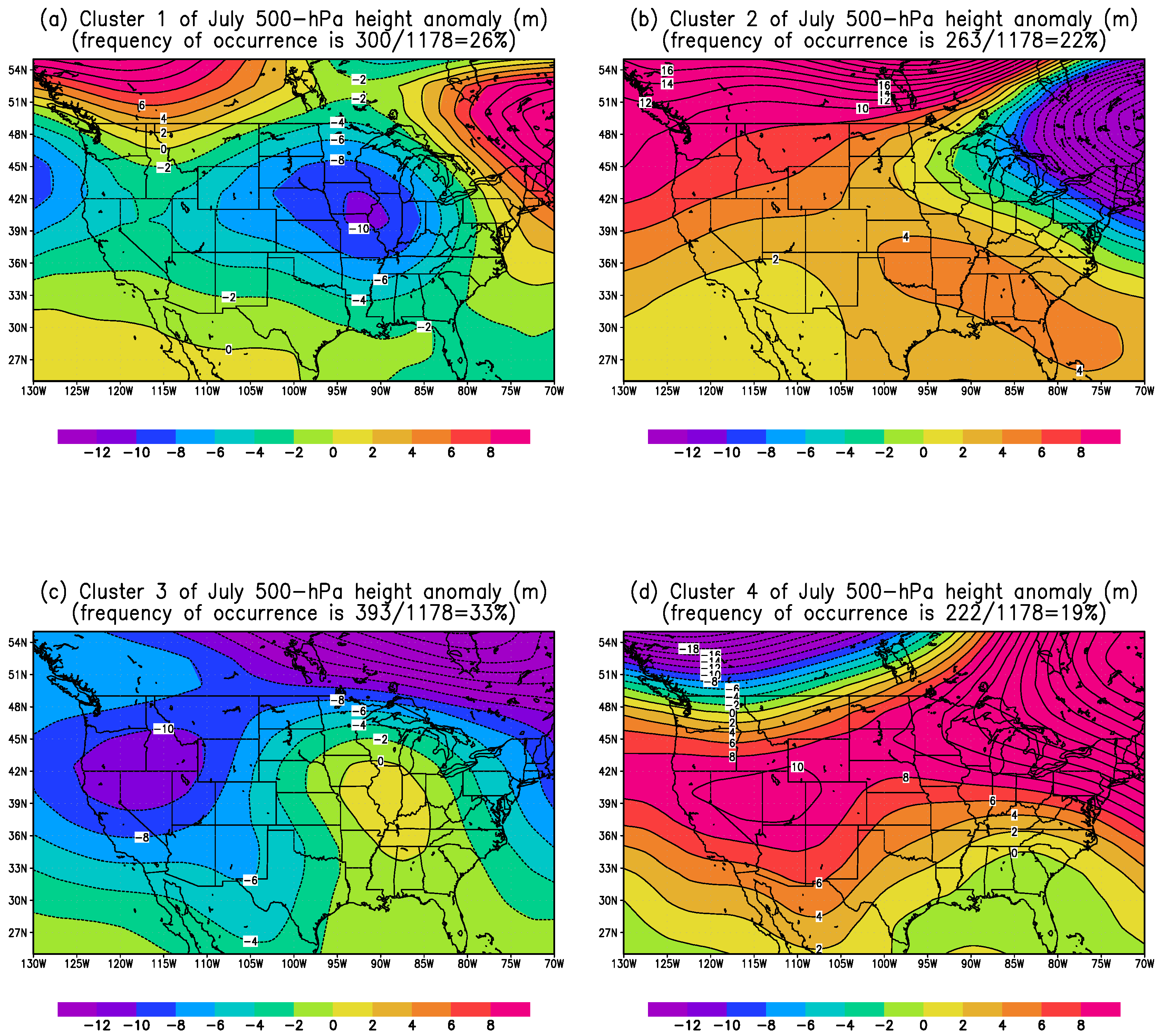
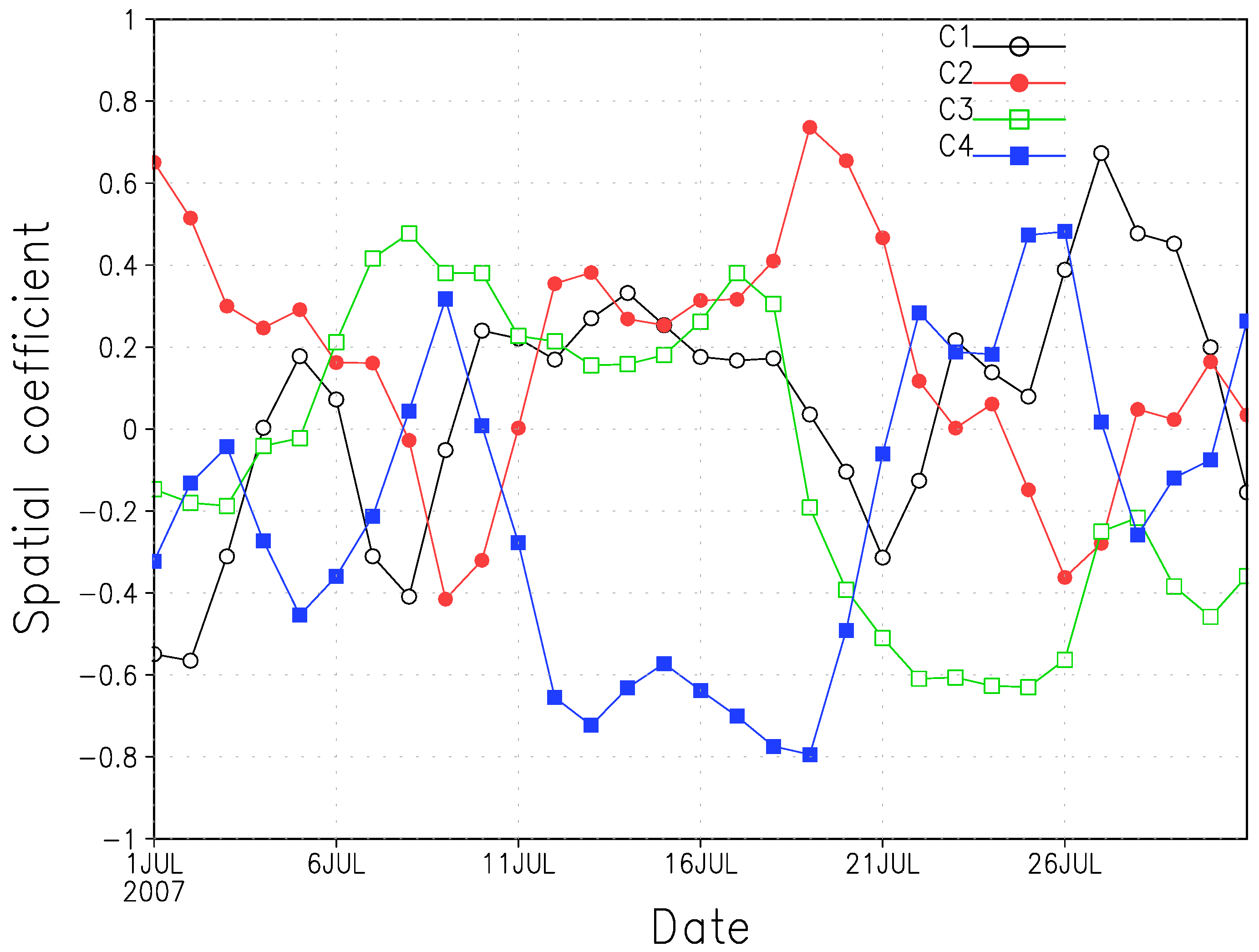
Figure 13. This pattern features high spatial correlation coefficients with cluster 3 among clusters of July months shown in
Figure 11, over the sub-periods of 2–15 August and 20–30 August 2007. This cluster is also largely coincident with cluster 3 of October months as shown in
Figure 6, with a low pressure anomaly dominant over the Western US and high pressure anomaly over the Eastern US. In other words, 25 out of 31 days (81%) during August 2007 are associated with intensified trough over the Western US and amplified ridge over the Eastern US such that the southwesterly over the Southern Plains is greatly strengthened under this configuration and thus excellent wind production is resulted. Simply speaking, in a very similar manner to the October 2007 case, the outstanding wind energy production in Callahan Divide Energy Center during August 2007 is primarily resulted from the favorable jet stream pattern. The comparison between July and August 2007 wind energy performance demonstrates a perfect example where the large-scale atmospheric circulation is the ultimate driver for various wind resources.
With lots of attention being drawn to the impact of global warming, we are curious about how much weather regimes could be altered by global warming. In addition to using the NCEP-NCAR daily reanalysis data between 1979–2016, we have also tested the period of 1979–2007 for cluster detection. The preliminary results show that the patterns of clusters detected from these two sets of long-term reanalysis data resemble each other very closely. In terms of intensity comparison, quantitative discrepancy is observed in some of these detected clusters. For instance, given cluster 3 (favorable to wind production in Southern Plains) detected from October months, the anomalous low center over the Western US is found to be somehow weakened for reanalysis during 1979–2016, in comparison to 1979–2007, whereas the anomalous high center to the East is found to be largely intact between two reanalysis periods. In terms of frequency of occurrence of clusters, small differences are found between clusters detected by two sets of reanalysis data. For instance, for cluster 3 of October months, the frequency of occurrence increases from 21% to 23% whereas for cluster 2 (unfavorable to wind production in Southern Plains) of July months it decreases from 26% to 22%. Hence, further analysis is guaranteed for identifying the underlying mechanisms responsible for this alteration in weather regimes due to climate change.
Given weather regimes of the summer season are weaker and less persistent than the winter and fall seasons, one limitation of the current approach for wind resource assessment is that it is relatively less effective in quantifying the summer wind resources. In other words, there could be times when none of the detected clusters correlates well with the dominant weather pattern of a specific summer month. In that case, additional analysis is required to further classify and quantify the prevailing weather pattern of this specific summer month.
In the present study, the initial seed selection of k-means clustering is carried out by using random seeding for the purpose of simplicity and efficiency. In order to ensure the repeatability and reproducibility of the clustering results, the k-means algorithm is performed over the long-term daily data multiple times. Due to the robustness of the detected weather regimes, the centroids of each identified cluster agree fairly well among these multiple runs. Nevertheless, different choice of initial cluster centers, in particular for those that are far away from the final cluster centers, could result in different clustering results, as k-means algorithm always tends to optimize the cost function. Hence, for the future work, the initial seed selection of k-means is desired to be implemented during the clustering process.
Furthermore, as for the future work, the artificial neural networks (ANN) is planed to classify the large-scale atmospheric circulation, and then be compared against the results with those derived with k-means Cluster Analysis. In particular, we are interested in using the Self-organizing Map (SOM) for cluster analysis. The SOM approach can be used in determining clusters by learning to recognize regularities and correlations between inputs vectors.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












