Comparison of Bootstrap Confidence Intervals Using Monte Carlo Simulations

Abstract
:1. Introduction
2. Materials and Methods
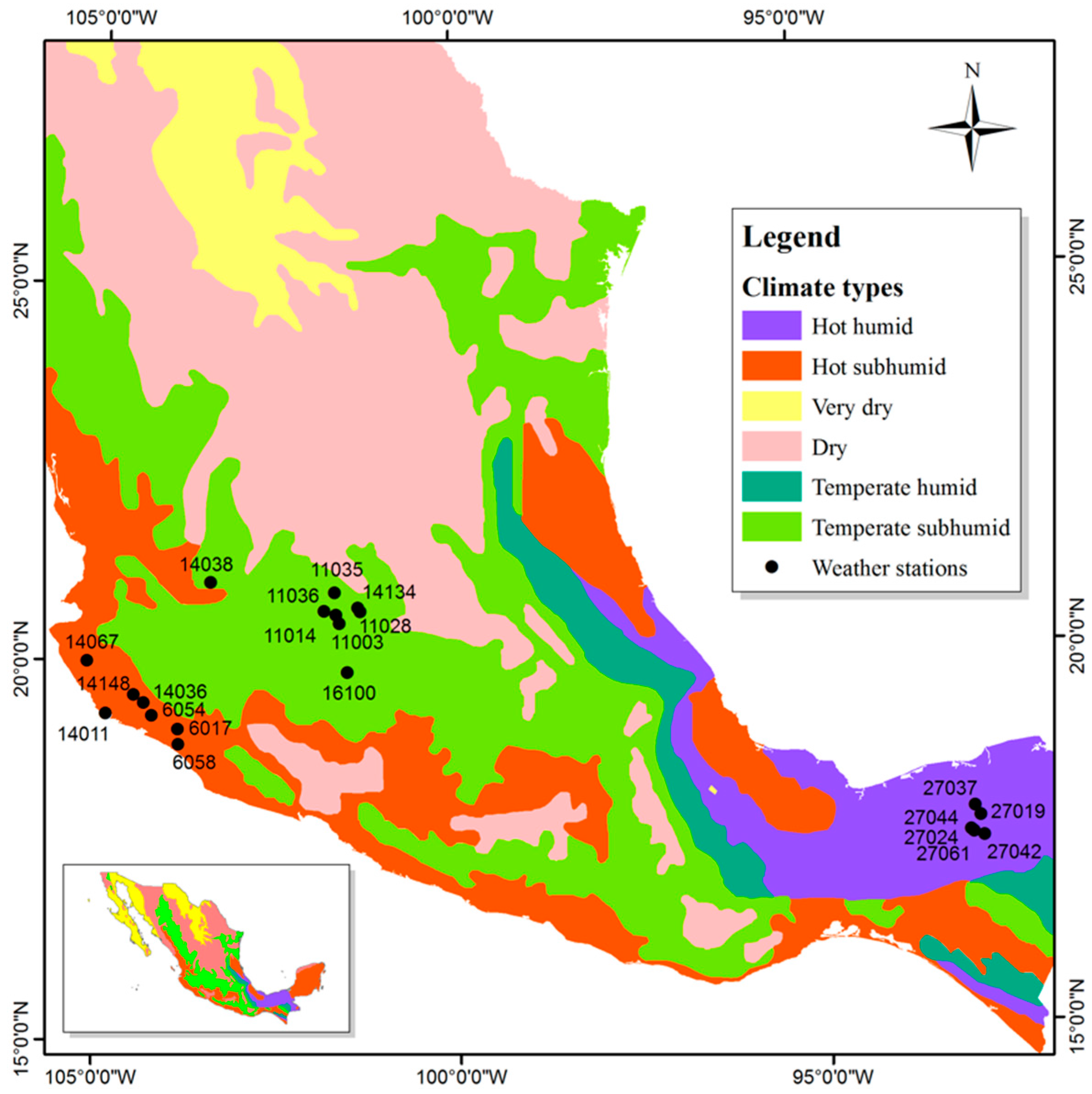
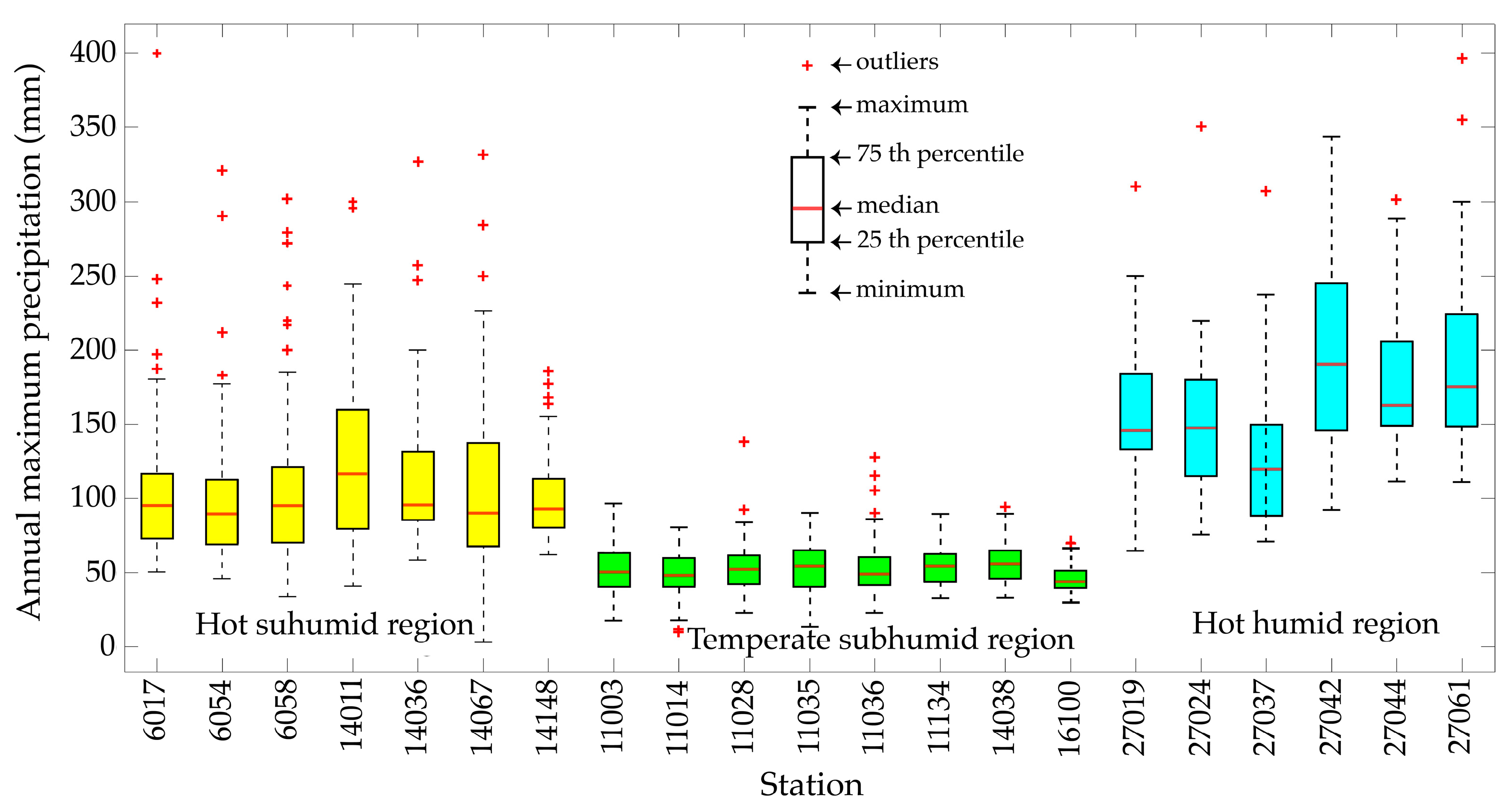
2.1. Climatological Information
2.2. Simulation Software
2.3. Bootstrap Techniques
2.3.1. Percentile Bootstrap (BP)
2.3.2. Bias-Corrected Bootstrap (BC)
2.3.3. Accelerated Bias-Corrected Bootstrap (BCA)
2.3.4. Modified Standard Bootstrap (MSB)
2.4. Modeling the Coverage of Confidence Intervals
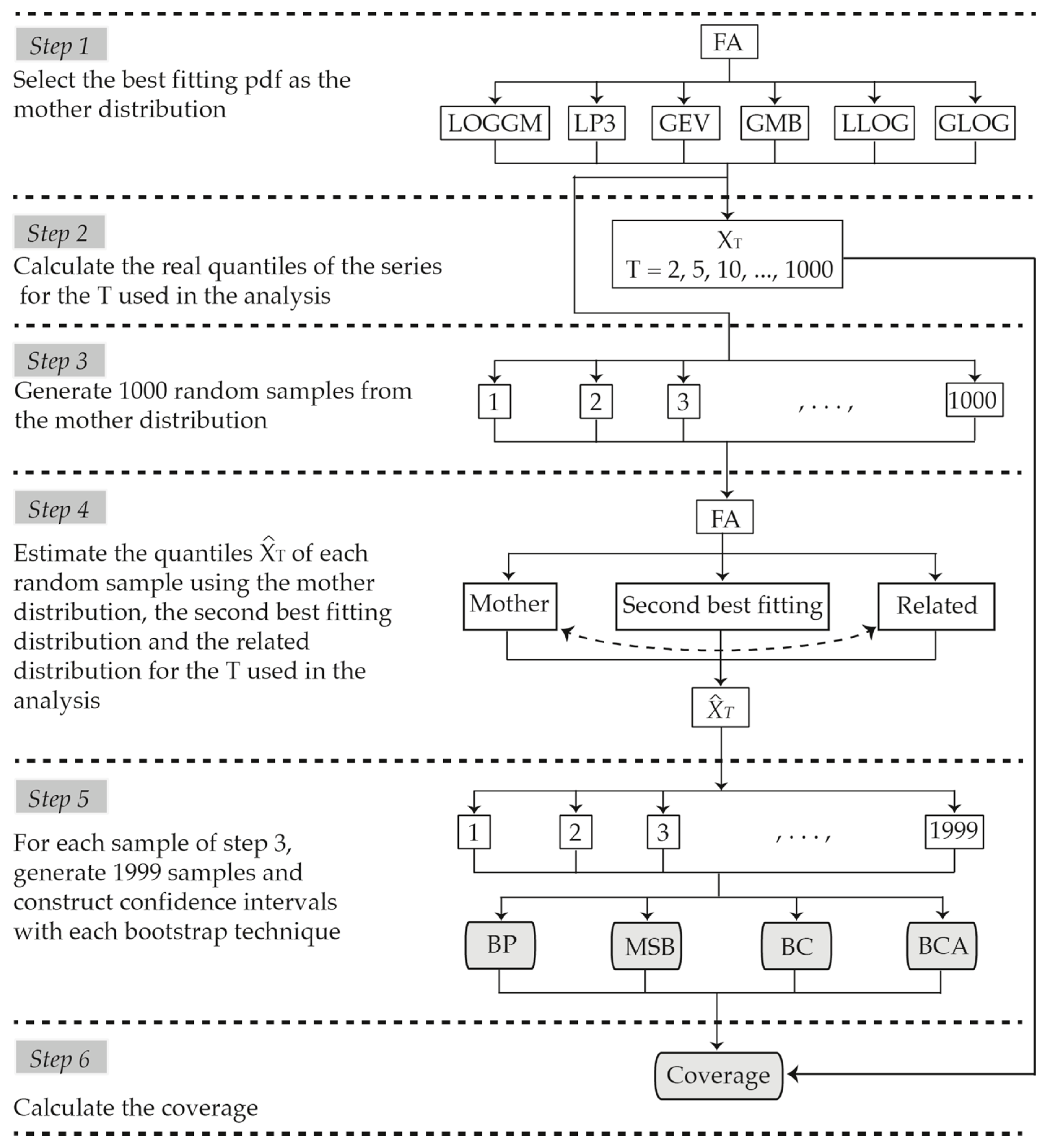
2.5. Procedure for Determining the Level of Coverage
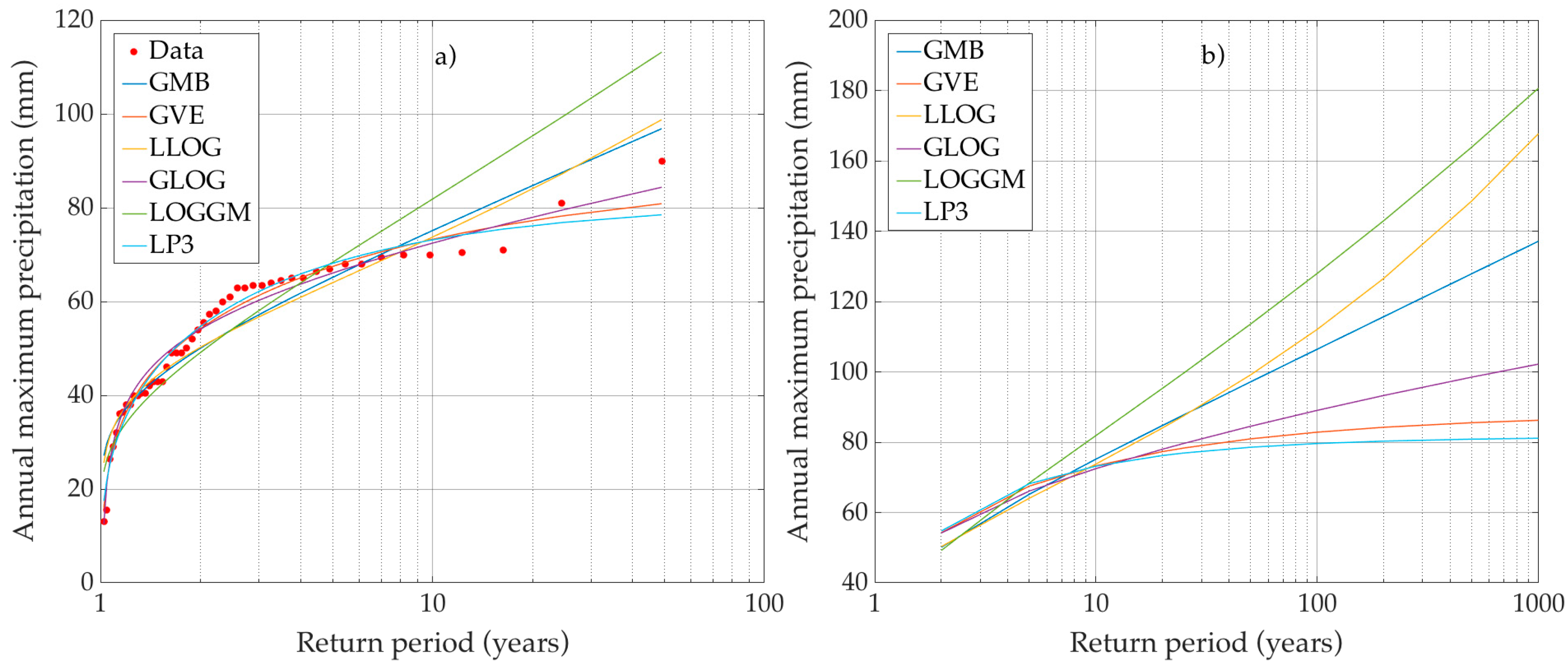
- Select the pdf (mother distribution) to generate the random data.The mother distribution for each site was selected by determining the best fitting pdf to the series of precipitation among a group of six candidates which included both two and three parameter pdf. The pdf used were log-gamma (LOGGM) and log-Pearson type 3 (LP3), Gumbel (GMB) and General Extreme Values (GEV), and log-logistic (LLOG) and generalized logistic (GLOG). The LP3, GLOG, GEV and GMB are among the most commonly used distributions for frequency analysis of extreme rainfalls [29]. The LOGGM and LLOG are two-parameter distributions related to the three parameter LP3 and GLOG distributions, respectively, as the GMB is related to the GEV. Thus, pairs of related two and three-parameter distributions were considered, allowing for the more parsimonious model to be chosen when it provided an adequate fit.Selection of the pdf that best fit the original and simulated series was done by applying the Bayesian Information Criterion (BIC) [30], which assigns a numerical value to each distribution that orders them from best to worst fit. In all cases, the best fitting pdf was selected for the simulations.
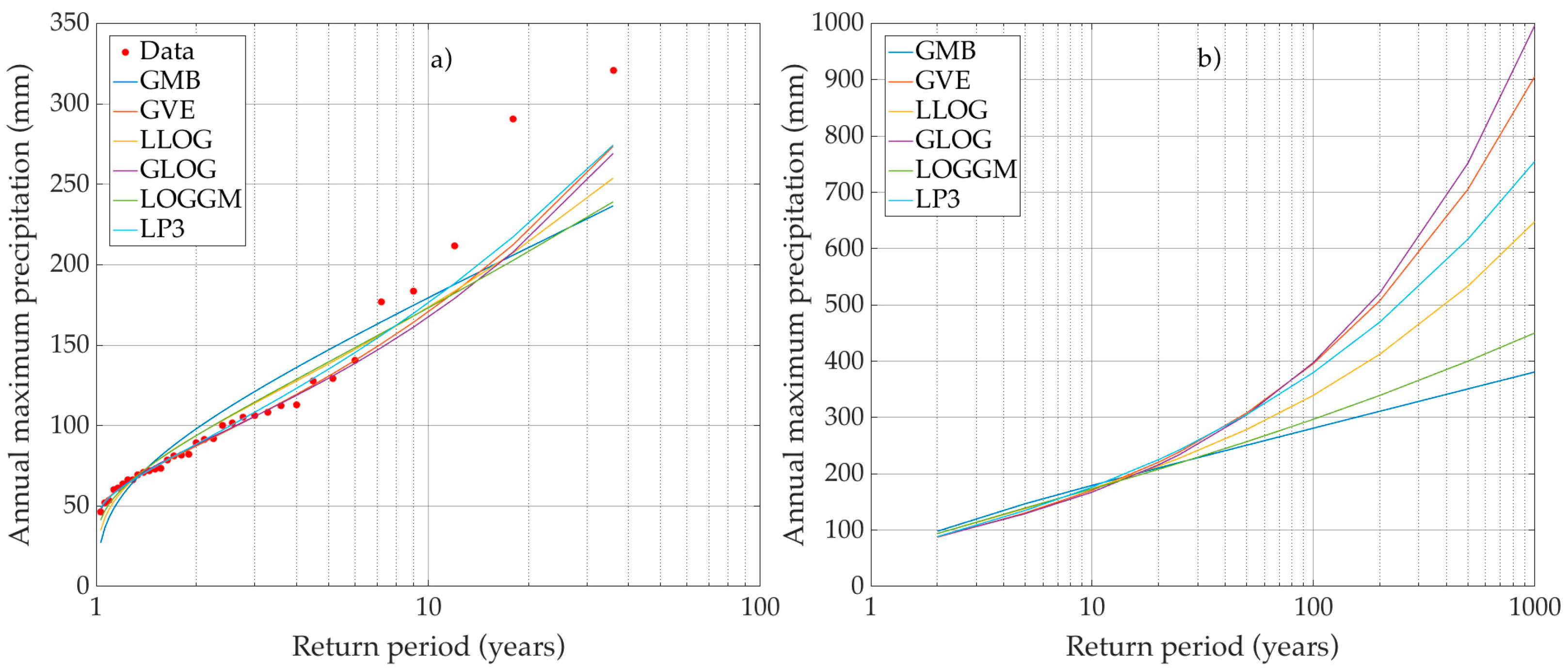
- Calculate the “true value” of the quantile for different return periods .Quantiles corresponding to the return periods 2, 5, 10, 20, 25, 50, 100, 200, 500 and 1000 years were estimated from the original data. These were considered as the true values of the quantiles in the simulations. The quantiles of the GMB, GEV, LLOG and GLOG pdf were calculated with Equations (17)–(20), respectively, where , , and are the estimators of the scale, shape and location parameters of the distributions.No analytical forms exist for the inverse LOGGM or LP3 pdf. However, in these cases, we used SCILAB, which calculates the inverse function of the gamma distribution using the algorithm described by [31] and which served as the basis for calculating the quantiles of the LOGGM and LP3 distributions.
- Generate synthetic samples.One thousand synthetic samples of size were generated from the mother distribution for each of the series that were analyzed.
- Estimate the quantiles .For each of the samples generated, a pdf was fitted to estimate the quantiles corresponding to the return periods analyzed.
- Construct confidence intervals.Confidence intervals were constructed for the quantiles with the BP, BC, BCA and MSB techniques. By generating 1000 synthetic samples, 1000 BP, 1000 BC, 1000 BCA and 1000 MSB intervals were obtained for each return period.
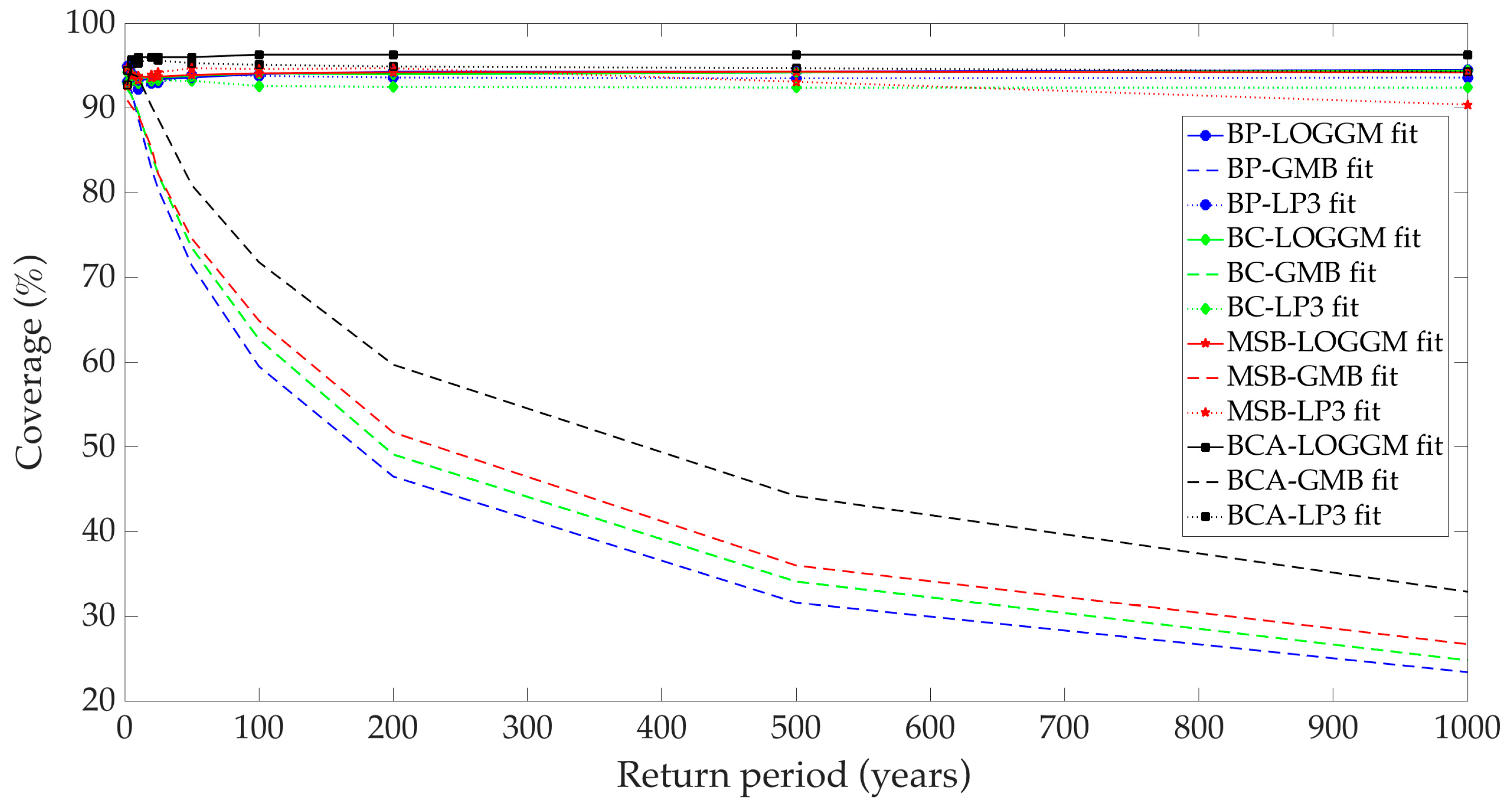
- Calculate coverage.Coverage was calculated as the percentage of times in which the intervals constructed by a bootstrap technique included the real value of the quantile.
3. Results and Discussion
3.1. Frequency Analysis
3.2. Construction of Confidence Intervals
3.3. Comparison of Bootstrap Techniques
4. Conclusions
Author Contributions
Conflicts of Interest
References
- Botto, A.; Ganora, D.; Laio, F.; Claps, P. Uncertainty compliant design flood estimation. Water Resour. Res. 2014, 50, 4242–4253. [Google Scholar] [CrossRef]
- Di Baldasarre, G.; Laio, F.; Montanari, A. Effect of observation errors on the uncertainty of design floods. Phys. Chem. Earth 2011, 42–44, 85–90. [Google Scholar] [CrossRef]
- Hall, M.J.; Van den Boogaard, H.F.P.; Fernando, R.C.; Mynett, A.E. The construction of confidence intervals for frequency analysis using resampling techniques. Hydrol. Earth Syst. Sci. 2004, 8, 235–246. [Google Scholar] [CrossRef]
- Flowers Cano, R.S.; Flowers Robert, J.; Rivera-Trejo, F. Evaluación de criterios de selección de modelos probabilísticos: Validación con series de valores máximos simulados. Tecnol. Cienc. Agua 2014, 5, 189–197. [Google Scholar]
- Cheng, K.-S.; Chiang, J.-L.; Hsu, C.-W. Simulation of probability distributions commonly used in hydrological frequency analysis. Hydrol. Process. 2007, 2, 51–60. [Google Scholar] [CrossRef]
- Silva, A.T.; Naghettini, M.; Portela, M.M. Sobre a estimacao de intervalos de confianca para os quantis de variáveis aleatórias hidrológicas. Recur. Hidr. 2011, 32, 63–76. [Google Scholar] [CrossRef]
- Liu, Y.; Gupta, H.V. Uncertainty in hydrological modeling: Toward an integrated assimilation framework. Water Resour. Res. 2007, 43, W07401. [Google Scholar] [CrossRef]
- Carpenter, J.; Bithell, J. Bootstrap confidence intervals: When, which, what? A practical guide for medical statisticians. Stat. Med. 2000, 19, 1141–1164. [Google Scholar] [PubMed]
- Helsel, D.R.; Hirsch, R.M. Statistical Methods in Water Resources, 1st ed.; Elsevier Science Publishers: Amsterdam, The Netherlands, 1992; 522p, ISBN 0-444-88528-5. [Google Scholar]
- DiCiccio, T.J.; Efron, B. Bootstrap confidence intervals. Stat. Sci. 1996, 11, 189–228. [Google Scholar]
- Davison, A.C.; Hinkley, D.V. Bootstrap Methods and Their Application, 1st ed.; Cambridge University Press: Cambridge, UK, 1997; p. 594. ISBN 978-0-521-57391-7. [Google Scholar]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Kyselý, J. A cautionary note on the use of nonparametric bootstrap for estimating uncertainties in extreme-value models. J. Appl. Meteorol. Climatol. 2008, 42, 3236–3251. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R. Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy. Stat. Sci. 1986, 1, 54–75. [Google Scholar] [CrossRef]
- Kyselý, J. Coverage probability of bootstrap confidence intervals in heavy tailed frequency models, with application to precipitation data. Theor. Appl. Climatol. 2010, 101, 345–361. [Google Scholar] [CrossRef]
- Liu, B.H. Statistical Genomics. Linkeage, Mapping and QTL Analysis, 1st ed.; CRC Press: Boca Raton, FL, USA, 1997; p. 648. ISBN 0849331668. [Google Scholar]
- Lee, S.M.S. Nonparametric confidence intervals based on extreme bootstrap percentiles. Stat. Sin. 2000, 10, 475–496. [Google Scholar]
- Hernández-Abreu, E.; Martínez-Pérez, M. El método bootstrap en la estimación de incertidumbres. BCT INIMET 2012, 1, 8–16. [Google Scholar]
- Correa, J.C.; Sierra, E. Intervalos de confianza para la comparación de dos proporciones. Rev. Colomb. Estad. 2003, 26, 61–75. [Google Scholar]
- Van de Boogaard, H.F.P.; Hall, M.J. The construction of confidence intervals for frequency analysis using resampling techniques: A supplementary note. Hydrol. Earth Syst. Sci. 2004, 8, 1174–1178. [Google Scholar] [CrossRef]
- Comisión Nacional del Agua (CONAGUA). Base de Datos en el Sistema CLIma COMputarizado (CLICOM); Servicio Meteorológico Nacional, Comisión Nacional del Agua: Mexico, Mexico, 2016; (In Spanish). Available online: http://smn.cna.gob.mx/index.php?option=com_content&view=article&id=42&Itemid=75 (accessed on 17 January 2016).
- Efron, B. Censored data and the bootstrap. J. Am. Stat. Assoc. 1981, 76, 312–319. [Google Scholar] [CrossRef]
- Eakin, B.K.; McMillen, D.P.; Buono, M.J. Constructing confidence intervals using the bootstrap: An application to a multi-product cost function. Rev. Econ. Stat. 1990, 72, 339–344. [Google Scholar] [CrossRef]
- Efron, B. Non-Parametric Standard Errors and Confidence Intervals. Available online: https://statistics.stanford.edu/sites/default/files/BIO%2067.pdf (accessed on 15 December 2017).
- Efron, B. The Jackknife, the Bootstrap and Other Resampling Plans; CBMS-NSF Regional Conference Series in Applied Mathematics, Monograph 38; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1982; p. 92. ISBN 9780898711790. [Google Scholar]
- Efron, B. Better Bootstrap Confidence Intervals. Available online: http://oai.dtic.mil/oai/oai?verb=getRecord&metadataPrefix=html&identifier=ADA150798 (accessed on 15 December 2017).
- Efron, B. Transformation theory: How normal is a one parameter family of distributions? Ann. Stat. 1982, 10, 323–339. [Google Scholar] [CrossRef]
- Neter, J.; Wasserman, W. Applied Linear Statistical Models: Regression, Analysis of Variance, and Experimental Designs, 6th ed.; Richard, D., Ed.; Irwin, Inc.: Homewood, IL, USA, 1976; p. 842. ISBN 0256014981. [Google Scholar]
- Nguyen, V.T.V.; Nguyen, T.H. Statistical modeling of extreme rainfall processes (SMExRain): A decision support tool for extreme rainfall frequency analyses. Procedia Eng. 2016, 154, 624–630. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- DiDonato, A.R.; Morris, A.H. Computation of the incomplete gamma function ratios and their inverse. ACM Trans. Math. Softw. 1986, 12, 377–393. [Google Scholar] [CrossRef]
- Instituto Nacional de Ecología-Secretaría de Medio Ambiente y Recursos Naturales (INE-SEMARNAT). Cuarta Comunicación Nacional ante la Convención Marco de las Naciones Unidas sobre el Cambio Climático, 1st ed.; Instituto Nacional de Ecología: Mexico, Mexico, 2010; p. 273. ISBN 978-607-7908-00-5. (In Spanish)
- Laio, F.; Di Baldasarre, G.; Montanari, A. Model selection techniques for the frequency analysis of hydrological extremes. Water Resour. Res. 2009, 45, W07416. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Name | Climate Type | Latitude (° N) | Longitude (° E) | Altitude (masl) | Period of Records | Mean (mm) | Standard Deviation | Skewness Coefficient |
|---|---|---|---|---|---|---|---|---|---|
| 6017 | Madrid | Hot subhumid | 19.1122 | −103.8839 | 195 | 1970–2012 | 112 | 65.4 | 2.38 |
| 6054 | M. Á. Camacho | Hot subhumid | 19.285 | −104.245 | 376 | 1978–2012 | 107 | 62.3 | 2.02 |
| 6058 | Tecomán | Hot subhumid | 18.9083 | −103.8744 | 30 | 1954–2012 | 112 | 62.2 | 1.35 |
| 14011 | Apazulco | Hot subhumid | 19.3064 | −104.8875 | 5 | 1961–2011 | 126 | 62.1 | 0.9 |
| 14036 | Cuautitlán | Hot subhumid | 19.4506 | −104.3592 | 600 | 1958–2011 | 115 | 50.9 | 2.08 |
| 14067 | Higuera Blanca | Hot subhumid | 19.9942 | −105.1625 | 140 | 1956–2002 | 111 | 68 | 1.29 |
| 14148 | Tecomates | Hot subhumid | 19.5583 | −104.5 | 286 | 1961–2006 | 102 | 32 | 1.16 |
| 11003 | Agua Tibia | Temperate subhumid | 20.5103 | −101.6294 | 1720 | 1949–2012 | 53.2 | 15.7 | 0.295 |
| 11014 | Cuerámaro | Temperate subhumid | 20.6256 | −101.6758 | 1732 | 1967–2012 | 49.4 | 16.8 | −0.16 |
| 11028 | Irapuato | Temperate subhumid | 20.6689 | −101.3372 | 1729 | 1923–2011 | 53.8 | 16.5 | 1.55 |
| 11035 | La Sandía | Temperate subhumid | 20.9211 | −101.6974 | 1771 | 1965–2012 | 52.9 | 16.3 | −0.31 |
| 11036 | Adjuntas | Temperate subhumid | 20.6753 | −101.8442 | 1727 | 1944–2012 | 54 | 19.3 | 1.64 |
| 11134 | El Conejo | Temperate subhumid | 20.7158 | −101.3697 | 1740 | 1978–2012 | 54.9 | 15.1 | 0.586 |
| 14038 | Cuixtla | Temperate subhumid | 21.0519 | −103.4389 | 1000 | 1954–2011 | 57.5 | 13.9 | 0.65 |
| 16100 | P. San Isidro | Temperate subhumid | 19.8658 | −101.5189 | 2022 | 1947–1992 | 46.4 | 10.2 | 0.73 |
| 27019 | Jalapa | Hot humid | 17.7233 | −92.8117 | 14 | 1971–2012 | 161 | 44.5 | 0.939 |
| 27024 | La Huasteca | Hot humid | 17.52 | −92.9267 | 80 | 1970–2012 | 150 | 53.4 | 1.59 |
| 27037 | P. Nuevo | Hot humid | 17.8542 | −92.8792 | 21 | 1949–2012 | 127 | 46.8 | 1.33 |
| 27042 | Tapijulapa | Hot humid | 17.4611 | −92.7775 | 44 | 1962–2012 | 200 | 66.9 | 0.417 |
| 27044 | Teapa | Hot humid | 17.5489 | −92.9533 | 51 | 1960–2012 | 178 | 44.1 | 0.891 |
| 27061 | Puyacatengo | Hot humid | 17.5133 | −92.92 | 86 | 1972–2012 | 193 | 62.7 | 1.36 |
| Name | Best pdf | Second Best pdf | |||
|---|---|---|---|---|---|
| Madrid | LP3 | LOGGM | 5.3287144 | 0.1992481 | 3.5390657 |
| M. Á. Camacho | LP3 | GEV | 4.1525277 | 0.2254003 | 3.6213723 |
| Tecomán | LOGGM | LLOG | 82.634782 | 0.0555225 | |
| Apazulco | LOGGM | GMB | 91.842315 | 0.0514029 | |
| Cuautitlán | LP3 | GEV | 4.376189 | 0.1731262 | 3.9173081 |
| Higuera Blanca | GMB | GLOG | 51.898719 | 80.561081 | |
| Tecomates | GEV | LP3 | 0.1945382 | 19.86305 | 85.816749 |
| Agua Tibia | LP3 | GEV | 11.795387 | −0.0914924 | 5.0066864 |
| Cuerámaro | GEV | GLOG | −0.2865803 | 16.660192 | 43.524345 |
| Irapuato | LLOG | LOGGM | 0.1621175 | 3.9415775 | |
| La Sandía | GLOG | LLOG | 0.0823704 | 9.1261126 | 54.169179 |
| Adjuntas | LOGGM | LLOG | 154.81554 | 0.0254319 | |
| El Conejo | LOGGM | GMB | 213.81437 | 0.0185691 | |
| Cuixtla | LOGGM | GMB | 286.73673 | 0.0140327 | |
| P. San Isidro | GMB | LOGGM | 8.2309395 | 41.686879 | |
| Jalapa | LLOG | LOGGM | 0.1493782 | 5.0432277 | |
| La Huasteca | LOGGM | GMB | 236.09342 | 0.0210114 | |
| P. Nuevo | LOGGM | LP3 | 201.45845 | 0.0237352 | |
| Tapijulapa | LOGGM | GMB | 235.16545 | 0.0222989 | |
| Teapa | GMB | LOGGM | 35.105362 | 157.71026 | |
| Puyacatengo | LOGGM | GMB | 313.25914 | 0.0166501 |
| Station | Climate Region | Fitted pdf | Return Period (Years) | Estimated Quantile (mm) | Confidence Intervals (mm) | |||
|---|---|---|---|---|---|---|---|---|
| BP | BC | MSB | BCA | |||||
| 6017 | Hot subhumid | LP3 | 10 | 184 | 140–237 | 145–245 | 146–251 | 140–256 |
| 100 | 384 | 221–720 | 252–927 | 240–957 | 223–1501 | |||
| 1000 | 732 | 300–2166 | 377–3619 | - | 314–8071 | |||
| 6054 | Hot subhumid | LP3 | 10 | 176 | 133–240 | 137–250 | 136–251 | 133–271 |
| 100 | 380 | 206–774 | 232–947 | 226–1201 | 211–1374 | |||
| 1000 | 755 | 282–2487 | 351–5165 | - | 315–9317 | |||
| 6058 | Hot subhumid | LOGGM | 10 | 191 | 155–233 | 157–238 | 158–240 | 155–243 |
| 100 | 358 | 242–543 | 253–574 | 254–606 | 244–608 | |||
| 1000 | 590 | 321–1191 | 345–1328 | 353–1796 | 329–1424 | |||
| 14011 | Hot subhumid | LOGGM | 10 | 213 | 175–259 | 177–262 | 176–263 | 175–266 |
| 100 | 381 | 283–512 | 288–521 | 287–528 | 281–536 | |||
| 1000 | 596 | 408–887 | 417–903 | 416–926 | 405–920 | |||
| 14036 | Hot subhumid | LP3 | 10 | 174 | 145–210 | 149–218 | 147–214 | 145–225 |
| 100 | 317 | 213–522 | 229–642 | 220–570 | 215–789 | |||
| 1000 | 541 | 285–1325 | 323–2169 | 307–2285 | 296–2941 | |||
| 14067 | Hot subhumid | GMB | 10 | 197 | 164–237 | 166–240 | 165–240 | 163–247 |
| 100 | 319 | 260–392 | 262–394 | 262–398 | 253–411 | |||
| 1000 | 439 | 352–543 | 357–550 | 356–555 | 344–572 | |||
| 14148 | Hot subhumid | GEV | 10 | 142 | 122–166 | 124–172 | 123–168 | 123–174 |
| 100 | 234 | 163–365 | 171–404 | 166–392 | 165–436 | |||
| 1000 | 375 | 194–901 | 211–1095 | 211–1695 | 206–1241 | |||
| 11003 | Temperate subhumid | LP3 | 10 | 74.1 | 68.0–80.5 | 68.1–80.5 | 68.4–80.8 | 67.7–81.3 |
| 100 | 92.1 | 79.4–108 | 76.8–105 | 80.0–109 | 78.0–105 | |||
| 1000 | 104 | 83.1–136 | 77.8–129 | 84.1–137 | 81.8–126 | |||
| 11014 | Temperate subhumid | GEV | 10 | 71.2 | 64.7–77.0 | 65.1–77.4 | 65.3–78.1 | 64.6–77.6 |
| 100 | 86.1 | 74.5–100 | 74.1–99.2 | 75.2–101 | 73.6–100 | |||
| 1000 | 93.6 | 77.4–120 | 77.0–119 | 77.1–119 | 77.3–119 | |||
| 11028 | Temperate subhumid | LLOG | 10 | 73.5 | 67.1–81.1 | 67.6–82.3 | 67.1–81.0 | 66.5–84.1 |
| 100 | 108 | 93.2–128 | 94.9–132 | 93.3–128 | 92.3–137 | |||
| 1000 | 158 | 127–200 | 131–208 | 128–200 | 126–222 | |||
| 11035 | Temperate subhumid | GLOG | 10 | 72.5 | 66.7–78.1 | 67.1–78.4 | 67.2–78.7 | 65.9–79.6 |
| 100 | 89.1 | 78.0–104 | 78.1–104 | 78.0–104 | 76.0–108 | |||
| 1000 | 102 | 83.9–134 | 84.1–135 | 83.2–133 | 82.0–140 | |||
| 11036 | Temperate subhumid | LOGGM | 10 | 77.3 | 69.4–86.1 | 69.5–86.4 | 69.6–86.4 | 68.8–87.4 |
| 100 | 111 | 94.5–131 | 95.4–132 | 95.0–132 | 93.7–135 | |||
| 1000 | 147 | 119–181 | 121–185 | 120–183 | 117–190 | |||
| 11134 | Temperate subhumid | LOGGM | 10 | 75.3 | 66.1–85.9 | 66.7–86.8 | 66.4–86.2 | 65.9–87.8 |
| 100 | 102 | 83.7–125 | 84.7–127 | 84.9–126 | 83.2–131 | |||
| 1000 | 129 | 100–168 | 101–171 | 102–170 | 98.6–175 | |||
| 14038 | Temperate subhumid | LOGGM | 10 | 76.0 | 69.6–83.0 | 69.9–83.3 | 69.7–83.3 | 69.4–84.3 |
| 100 | 99.2 | 87.0–113 | 87.5–114 | 87.3–114 | 86.5–115 | |||
| 1000 | 121 | 103–144 | 104–145 | 103–145 | 102–147 | |||
| 16100 | Temperate subhumid | GMB | 10 | 60.2 | 54.3–66.7 | 54.3–66.8 | 54.5–66.9 | 53.9–67.6 |
| 100 | 79.6 | 69.3–91.8 | 69.4–92.0 | 69.5–92.0 | 68.4–92.9 | |||
| 1000 | 98.5 | 83.7–116 | 84.0–117 | 84.1–117 | 82.5–118 | |||
| 27019 | Hot humid | LLOG | 10 | 215 | 191–246 | 193–247 | 190–245 | 190–254 |
| 100 | 308 | 253–386 | 258–392 | 252–384 | 251–411 | |||
| 1000 | 435 | 329–602 | 339–610 | 329–600 | 325–665 | |||
| 27024 | Hot humid | LOGGM | 10 | 217 | 186–253 | 185–252 | 187–255 | 180–264 |
| 100 | 312 | 248–395 | 249–395 | 250–399 | 236–425 | |||
| 1000 | 411 | 307–559 | 308–564 | 311–569 | 289–618 | |||
| 27037 | Hot humid | LOGGM | 10 | 185 | 164–208 | 164–208 | 165–208 | 162–212 |
| 100 | 270 | 226–322 | 229–327 | 229–325 | 224–340 | |||
| 1000 | 362 | 289–453 | 293–465 | 292–460 | 284–488 | |||
| 27042 | Hot humid | LOGGM | 10 | 295 | 257–337 | 258–338 | 259–339 | 257–342 |
| 100 | 434 | 355–531 | 358–542 | 359–534 | 355–544 | |||
| 1000 | 581 | 450–758 | 457–771 | 457–764 | 452–782 | |||
| 27044 | Hot humid | GMB | 10 | 237 | 214–263 | 215–265 | 214–263 | 214–269 |
| 100 | 319 | 279–368 | 280–371 | 279–368 | 277–376 | |||
| 1000 | 400 | 342–472 | 344–475 | 343–473 | 338–483 | |||
| 27061 | Hot humid | LOGGM | 10 | 270 | 234–305 | 235–307 | 237–309 | 230–312 |
| 100 | 375 | 305–450 | 308–456 | 311–461 | 298–470 | |||
| 1000 | 480 | 370–611 | 374–619 | 378–629 | 363–652 | |||
| Station | Mother Distribution | Fitted pdf | Coverage (%) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BP | BC | MSB | BCA | |||||||||||
| Max | Min | Mean | Max | Min | Mean | Max | Min | Mean | Max | Min | Mean | |||
| 6017 | LP3, , , | LP3 | 94 | 89 | 90 | 93 | 90 | 91 | 93 | 51 | 83 | 96 | 93 | 95 |
| LOGGM | 92 | 44 | 71 | 91 | 48 | 73 | 91 | 50 | 73 | 92 | 57 | 79 | ||
| 6054 | LP3, , , | LP3 | 95 | 86 | 88 | 94 | 89 | 90 | 94 | 38 | 78 | 94 | 93 | 93 |
| GEV | 94 | 90 | 91 | 93 | 89 | 91 | 92 | 21 | 75 | 94 | 93 | 93 | ||
| LOGGM | 90 | 40 | 67 | 89 | 44 | 69 | 89 | 46 | 69 | 91 | 54 | 76 | ||
| 6058 | LOGGM, , | LOGGM | 95 | 93 | 94 | 95 | 93 | 94 | 95 | 94 | 93 | 96 | 95 | 93 |
| LLOG | 98 | 91 | 96 | 98 | 83 | 94 | 98 | 90 | 95 | 99 | 90 | 97 | ||
| LP3 | 94 | 92 | 93 | 95 | 91 | 93 | 95 | 90 | 94 | 96 | 93 | 95 | ||
| 11003 | LP3, , , | LP3 | 97 | 94 | 96 | 95 | 92 | 93 | 97 | 95 | 96 | 96 | 92 | 94 |
| GEV | 95 | 94 | 94 | 95 | 93 | 94 | 95 | 94 | 94 | 96 | 94 | 95 | ||
| LOGGM | 99 | 8 | 63 | 99 | 7 | 60 | 99 | 8 | 61 | 99 | 11 | 64 | ||
| 11014 | GEV, , , | GEV | 95 | 93 | 93 | 95 | 91 | 93 | 95 | 92 | 93 | 96 | 94 | 94 |
| GLOG | 99 | 90 | 95 | 99 | 84 | 94 | 99 | 85 | 95 | 100 | 88 | 96 | ||
| GMB | 100 | 1 | 59 | 99 | 0 | 57 | 99 | 0 | 58 | 100 | 1 | 60 | ||
| 11028 | LOGL, , | LOGL | 95 | 95 | 95 | 95 | 94 | 94 | 95 | 95 | 95 | 97 | 95 | 97 |
| LOGGM | 94 | 54 | 84 | 94 | 57 | 84 | 94 | 56 | 84 | 96 | 64 | 88 | ||
| GLOG | 95 | 94 | 94 | 95 | 93 | 94 | 95 | 93 | 94 | 97 | 95 | 96 | ||
| 11035 | GLOG, , , | GLOG | 95 | 93 | 94 | 94 | 92 | 93 | 94 | 93 | 93 | 96 | 93 | 94 |
| LLOG | 100 | 2 | 59 | 100 | 1 | 55 | 100 | 2 | 60 | 100 | 2 | 59 | ||
| 11036 | LOGGM, , | LOGGM | 95 | 94 | 94 | 95 | 94 | 95 | 95 | 94 | 94 | 97 | 94 | 96 |
| LLOG | 98 | 81 | 93 | 98 | 74 | 92 | 98 | 81 | 93 | 99 | 82 | 95 | ||
| LP3 | 95 | 92 | 93 | 94 | 92 | 93 | 94 | 93 | 94 | 96 | 94 | 95 | ||
| 11134 | LOGGM, , | LOGGM | 94 | 94 | 94 | 95 | 94 | 94 | 94 | 94 | 94 | 97 | 94 | 96 |
| GMB | 97 | 94 | 96 | 97 | 95 | 96 | 97 | 94 | 96 | 99 | 95 | 98 | ||
| LP3 | 95 | 92 | 93 | 94 | 90 | 92 | 95 | 93 | 94 | 95 | 93 | 94 | ||
| 14011 | LOGGM, , | LOGGM | 95 | 93 | 94 | 94 | 93 | 94 | 94 | 93 | 94 | 96 | 93 | 96 |
| GMB | 93 | 23 | 67 | 92 | 25 | 68 | 91 | 27 | 69 | 94 | 33 | 75 | ||
| LP3 | 95 | 92 | 94 | 94 | 92 | 93 | 95 | 90 | 94 | 96 | 94 | 95 | ||
| 14036 | LP3, , , | LP3 | 95 | 90 | 91 | 94 | 92 | 93 | 95 | 81 | 91 | 96 | 95 | 95 |
| GEV | 94 | 91 | 92 | 94 | 91 | 92 | 93 | 61 | 87 | 95 | 94 | 95 | ||
| LOGGM | 86 | 25 | 60 | 86 | 28 | 62 | 86 | 28 | 62 | 90 | 35 | 68 | ||
| 14038 | LOGGM, , | LOGGM | 95 | 93 | 94 | 96 | 93 | 94 | 95 | 93 | 94 | 97 | 96 | 96 |
| GMB | 97 | 92 | 95 | 97 | 90 | 94 | 97 | 90 | 94 | 98 | 94 | 97 | ||
| LP3 | 94 | 93 | 93 | 95 | 92 | 93 | 94 | 93 | 94 | 96 | 94 | 95 | ||
| 14067 | GMB, , | GMB | 95 | 93 | 94 | 95 | 94 | 94 | 95 | 94 | 94 | 97 | 95 | 95 |
| GLOG | 99 | 91 | 96 | 97 | 93 | 95 | 97 | 91 | 95 | 99 | 93 | 97 | ||
| GEV | 95 | 89 | 91 | 95 | 89 | 91 | 94 | 90 | 92 | 95 | 92 | 93 | ||
| 14148 | GEV, , , | GEV | 92 | 87 | 89 | 92 | 86 | 88 | 92 | 66 | 86 | 94 | 90 | 92 |
| LP3 | 95 | 82 | 87 | 92 | 85 | 88 | 94 | 76 | 86 | 94 | 91 | 93 | ||
| GMB | 90 | 8 | 57 | 88 | 9 | 57 | 88 | 9 | 57 | 91 | 14 | 64 | ||
| 16100 | GMB, , | GMB | 94 | 94 | 94 | 94 | 94 | 94 | 94 | 94 | 94 | 97 | 95 | 96 |
| LOGGM | 94 | 78 | 87 | 94 | 82 | 88 | 94 | 80 | 87 | 96 | 87 | 92 | ||
| GEV | 94 | 91 | 92 | 94 | 91 | 92 | 94 | 91 | 92 | 95 | 93 | 94 | ||
| 27019 | LLOG, , | LLOG | 95 | 94 | 95 | 95 | 94 | 94 | 96 | 94 | 94 | 97 | 94 | 97 |
| LOGGM | 94 | 63 | 86 | 94 | 67 | 86 | 94 | 66 | 86 | 97 | 73 | 90 | ||
| GLOG | 95 | 93 | 93 | 95 | 92 | 92 | 95 | 90 | 93 | 96 | 95 | 95 | ||
| 27024 | LOGGM, , | LOGGM | 96 | 95 | 95 | 96 | 95 | 95 | 96 | 95 | 95 | 98 | 95 | 97 |
| GMB | 94 | 92 | 93 | 95 | 93 | 94 | 94 | 93 | 93 | 97 | 94 | 96 | ||
| LP3 | 95 | 93 | 93 | 94 | 91 | 92 | 94 | 93 | 94 | 96 | 93 | 94 | ||
| 27037 | LOGGM, , | LOGGM | 95 | 93 | 93 | 95 | 93 | 94 | 95 | 93 | 94 | 96 | 95 | 96 |
| LP3 | 94 | 93 | 93 | 94 | 91 | 92 | 94 | 93 | 94 | 95 | 94 | 95 | ||
| 27042 | LOGGM, , | LOGGM | 95 | 93 | 94 | 96 | 93 | 95 | 96 | 94 | 95 | 97 | 94 | 96 |
| GMB | 95 | 89 | 93 | 94 | 90 | 93 | 95 | 91 | 93 | 97 | 94 | 96 | ||
| LP3 | 95 | 92 | 93 | 94 | 90 | 92 | 95 | 93 | 94 | 96 | 93 | 94 | ||
| 27044 | GMB, , | GMB | 96 | 94 | 95 | 95 | 94 | 95 | 95 | 94 | 95 | 97 | 95 | 97 |
| LOGGM | 94 | 82 | 88 | 95 | 85 | 89 | 94 | 84 | 89 | 96 | 89 | 92 | ||
| GEV | 95 | 93 | 93 | 95 | 92 | 93 | 95 | 93 | 93 | 96 | 95 | 95 | ||
| 27061 | LOGGM, , | LOGGM | 95 | 94 | 94 | 95 | 94 | 94 | 95 | 94 | 94 | 97 | 94 | 96 |
| GMB | 96 | 94 | 95 | 96 | 94 | 95 | 96 | 94 | 95 | 98 | 94 | 97 | ||
| LP3 | 94 | 92 | 93 | 94 | 90 | 92 | 94 | 93 | 93 | 96 | 93 | 94 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flowers-Cano, R.S.; Ortiz-Gómez, R.; León-Jiménez, J.E.; López Rivera, R.; Perera Cruz, L.A. Comparison of Bootstrap Confidence Intervals Using Monte Carlo Simulations. Water 2018, 10, 166. https://doi.org/10.3390/w10020166
Flowers-Cano RS, Ortiz-Gómez R, León-Jiménez JE, López Rivera R, Perera Cruz LA. Comparison of Bootstrap Confidence Intervals Using Monte Carlo Simulations. Water. 2018; 10(2):166. https://doi.org/10.3390/w10020166
Chicago/Turabian StyleFlowers-Cano, Roberto S., Ruperto Ortiz-Gómez, Jesús Enrique León-Jiménez, Raúl López Rivera, and Luis A. Perera Cruz. 2018. "Comparison of Bootstrap Confidence Intervals Using Monte Carlo Simulations" Water 10, no. 2: 166. https://doi.org/10.3390/w10020166
APA StyleFlowers-Cano, R. S., Ortiz-Gómez, R., León-Jiménez, J. E., López Rivera, R., & Perera Cruz, L. A. (2018). Comparison of Bootstrap Confidence Intervals Using Monte Carlo Simulations. Water, 10(2), 166. https://doi.org/10.3390/w10020166