3.1. General
When the phenomenon to be modelled by the ANN technique is such that experimental observations concerning it are available, in adequate volume, it is customary to use the past data in model development as well as in the validation and the testing of the model. The advantage of this approach is that it enables the use of a large volume of data, generated by several authors at numerous locations, some of which may be far apart. It may be prohibitively expensive and impractical for a single group to experimentally generate data of similar depth and breadth.
The common strategy is to separate the past data randomly into three slots. About 70% of the data is put into the first slot which is used for training the ANN and developing the ANN-based model. The second and the third slots, each comprising of about 15% of the data, are then used, respectively, in validating and testing the model. Examples of this approach abound in the literature. For instance, Bhange et al. [
20] have used 70%, 15%, and 15% of the past data (generated by others) for training, validating, and testing their ANN model. In a similar fashion Perez-Zarate et al. [
21] have used 80% of the past data for ANN training, 10% for validation, and 10% of training. Chen et al. [
12] have also used 70% of past data (generated by others) for model development and the remaining 30% for model validation without using any data of their own.
In the present work we went a step further in ascertaining the robustness of our CH4 model by taking out, randomly, an extra set of five data (out of a total of 76 datasets available in prior art) for use in a second round of model testing before even feeding the remaining 71 datasets to start the modelling process. In the next step, on our asking, the software randomly split the 71 datasets into 49 (70%), 11 (15%), and 11 (15%) datasets for the purpose of training, validation, and testing of the model, respectively. We then used the five datasets (which had been pulled out at the outset), for a second round of testing. We proceeded in like manner in the case of the N2O model.
Needless to say, the steps mentioned above to develop any ANN-based model are possible only when enough numbers of experimental observations are available (on the aspect being modelled) in the prior art. However, if one has to develop an ANN model of any phenomena not studied before, one will be required to first experimentally generate adequate volume of the required data. Thereafter the data will have to be separated in three sets for training, validation, and testing, as explained above. In the instant case adequate prior art was available and doing fresh experiments was not necessary.
3.3. Choice of Input Parameters
Unfortunately, there is no standard, or even similar, protocol used by different authors in their parameter selection. As a result, the variables studied by them differ widely in type as well as numbers. The aspects studied by most of the authors are total organic carbon (TOC), SEC, NPK input, and grain yield (tons per ha). Apart from the fact that only these are the parameters which have been studied by the largest number of authors, they also happen to represent, albeit tenuously, soil properties, nutrient inputs, and a characteristic of the cultivar (yield).
A total of 76 and 30 datasets of these parameters were available vis a vis methane and nitrous oxide emissions respectively.
Table 1 and
Table 2 present the ranges of the values of the six parameters in the available datasets. These were used in the ANN training and validation process. CH
4 and N
2O emissions in their seasonal integrated flux (kg/ha) values were taken as the target data to train the ANNs.
3.4. Development of the ANN Model
The technique of ANN was first reported in its most rudimentary form in 1943 by McCulloch and Pitts [
23]. Its development proceeded slowly for the next 43 years before it received a major boost with the development of the ‘back-propagation’ (BP) algorithm by Rumelhart et al. [
24]. The 1980s was also the time there was a spurt in the development of faster and better computers. These twin happenings have caused tremendous intensification the ANN use in a very large number of areas.
The present work has utilized the multi-layer perceptron (MLP)-ANN protocol, supported by the Levenberg–Marquardt feed-forward BP algorithm. The modelling involved the following steps:
Data collection, identification, and pre-processing of the model input and the target data.
Creating a network in MATLAB R2017b software by selecting the appropriate training functions, adaption learning function, performance function, number of layers, number of neurons, and transfer function.
Training the model with a part of the input and output data.
Assessing the performance of the trained ANN model using the mean squared error (MSE).
Retraining the network in case the performance is not satisfactory, by adjusting the training parameters until a robust network is generated.
Validating the model performance with the remaining data not used for training, and assessing the accuracy of the model in simulating the actual output, in terms of various statistical measures.
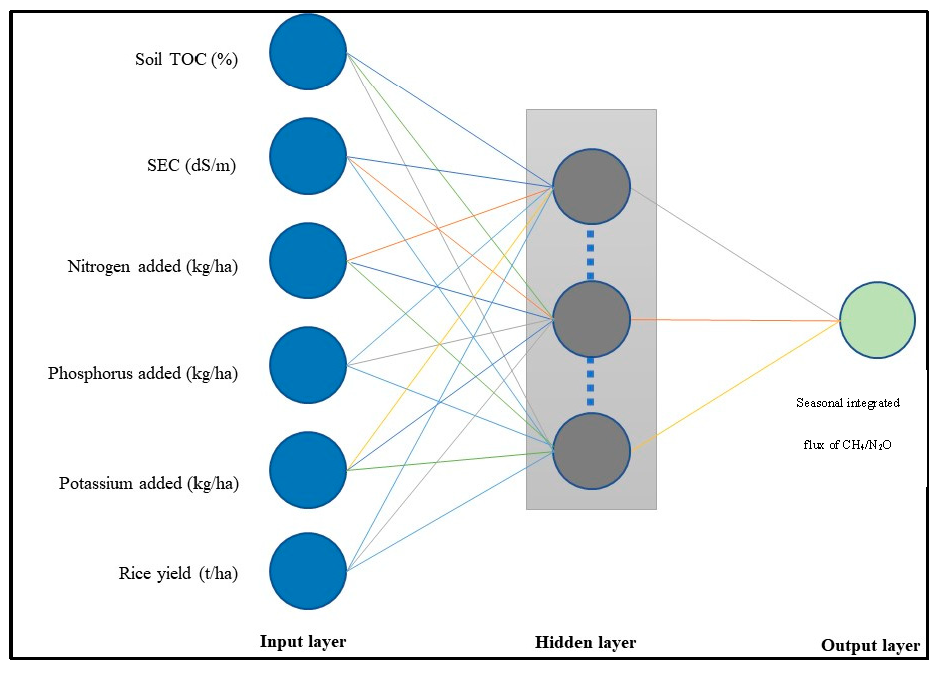
The architecture of the MLP-ANN comprised of three distinct layers: an input layer, an output layer, and unspecified number of hidden layers between the input and the output layers. To train the ANN, data was introduced at the input layer. A hidden layer consisting of 20 neurons was the processing section of the model. It is here that the computation of the weighted sum of the input signals and combination with a bias was carried out. This formed the pre-activation signal for the hidden layer which was then transformed by the hidden layer activation function to form feed forward activation signals that leave the hidden layer. Activation functions were used to transform the activation level of the neurons, which is the weighted sum of the inputs, into a linear output signal. At the output layer, in a similar fashion, the hidden layer activation signals were modified by weights, biases, and an output layer activation function to form the network output. This output was compared with the desired target and the error between the two was calculated. The error associated with the output was propagated back through the model and the network parameters so that the weights and biases were adjusted accordingly. This manner of back propagation computation was continued for several iterations till a minimization of error occurred.
The BP algorithm was used to train feed forward neural networks or multilayer perceptions. It is a method to minimize the cost function by changing weights and biases in the network. To learn and make better predications, a number of epochs (training cycles) were executed where the error determined by the cost function was propagated backward by gradient descent until a sufficiently small error was achieved.
The back-propagation method trained the multilayer neural network by modifying its synaptic connection weights between layers to improve model performance based on the error correction learning function. As needed, the learning function was continuous and differentiable.
The ANN model architecture as used by us is shown in
Figure 1.
As the system being modelled is quite complex, non-linear, and involves the interaction of many inter-related physical and chemical variables that exhibit spatial and temporal variation, we used a trial and error method to select the set of functions which could together give the most optimal network structure.
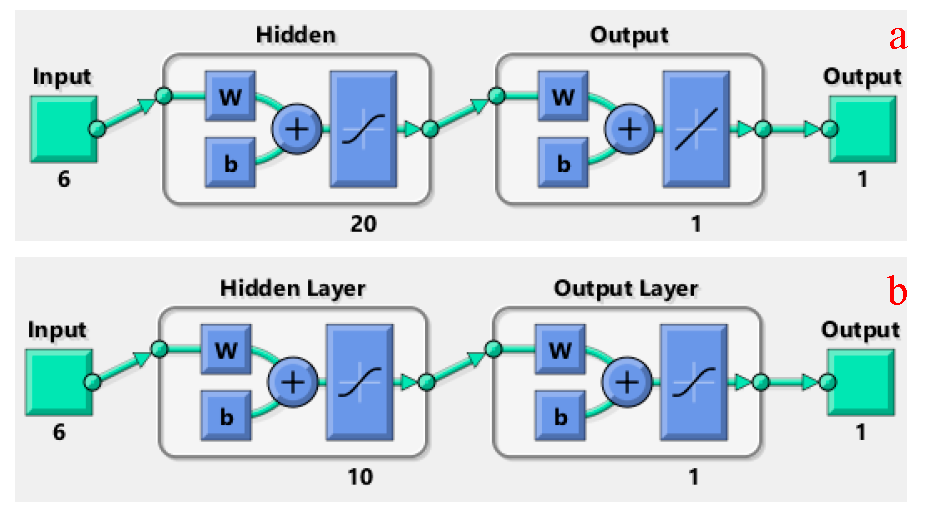
The feedforward network used by us constituted a single hidden layer with 20 neurons and 10 neurons respectively for CH
4 and N
2O emissions, and an output layer (
Figure 2).
The hidden layer was activated by the tan-sigmoid transfer function tansig and output layer by the linear transfer functions purelin. The latter was chosen as it is best suited for solving fitting problems. The network was trained using trainlm, a function which updates weight and bias values according to Levenberg–Marquardt (LM) optimization. As trainlm calculates performance as the mean or sum of squared errors, the mean squared error (MSE) function was chosen as the performance goal function of the network.
3.4.1. Model Training Validation, and Testing
As explained in
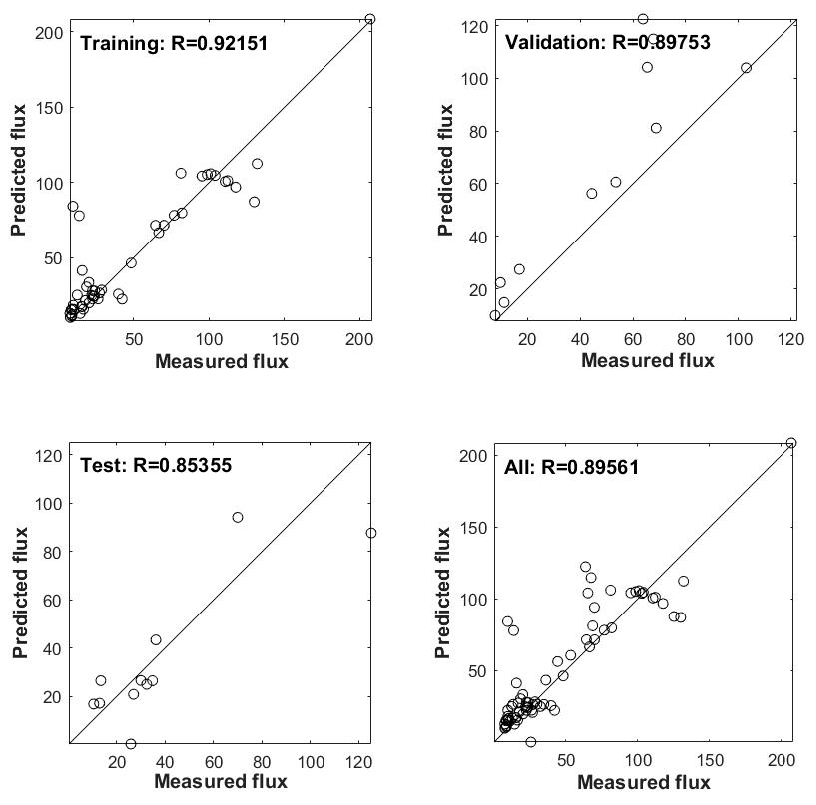
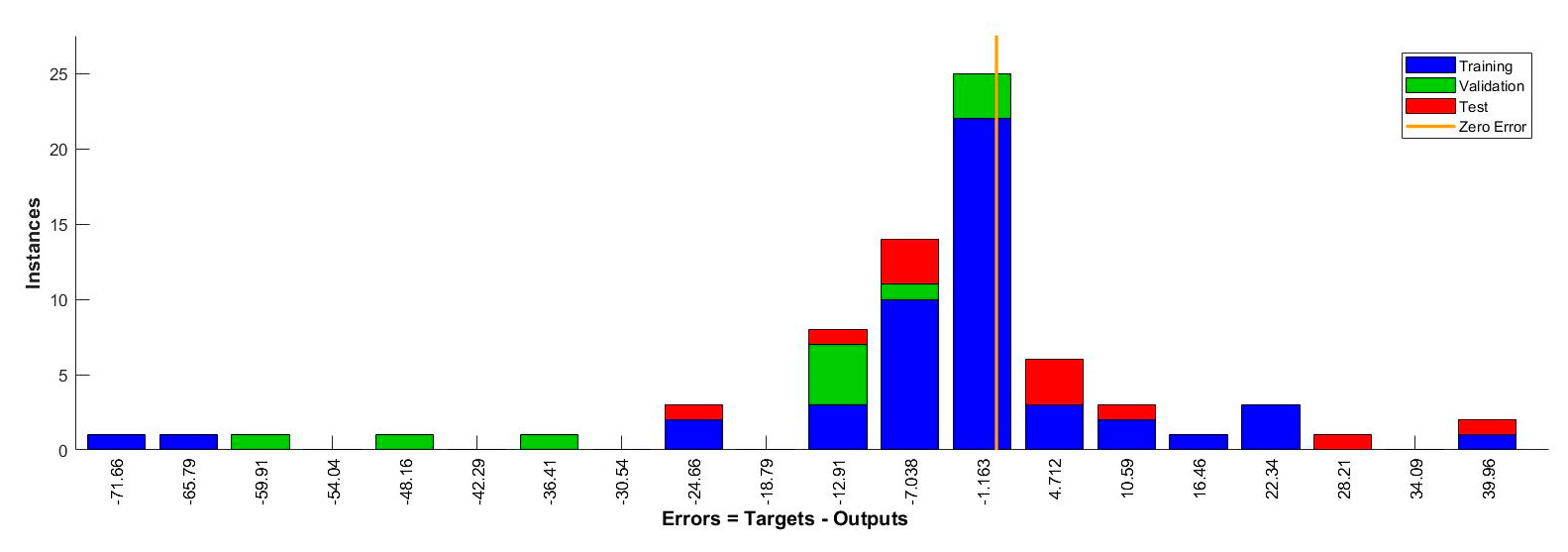
Section 3.1, of the 76 data sets that were obtained from prior art on methane emissions, five were randomly pulled out by us and kept aside for rechecking the model (after it had been validated and tested). The remaining 71 datasets were fed to the ANN software asking it to randomly partition the 71 datasets into sets of 49 (70%), 11 (15%), and 11 (15%) for the purposes of ANN training, model validation, and model testing, respectively. In other words, 49 datasets were used for the ANN training where the network was adjusted according to its error. Eleven datasets were used for validation to measure network generalization, and to halt training when generalization stopped improving as indicated by the increase in mean squared error of the validation samples. The remaining 11 datasets were used for testing. As these data sets had no bearing on the training of the network, they provided an independent measure of network performance during and after training. Thereafter the model performance was re-checked with the five datasets that had been pulled out before commencing the modelling process.
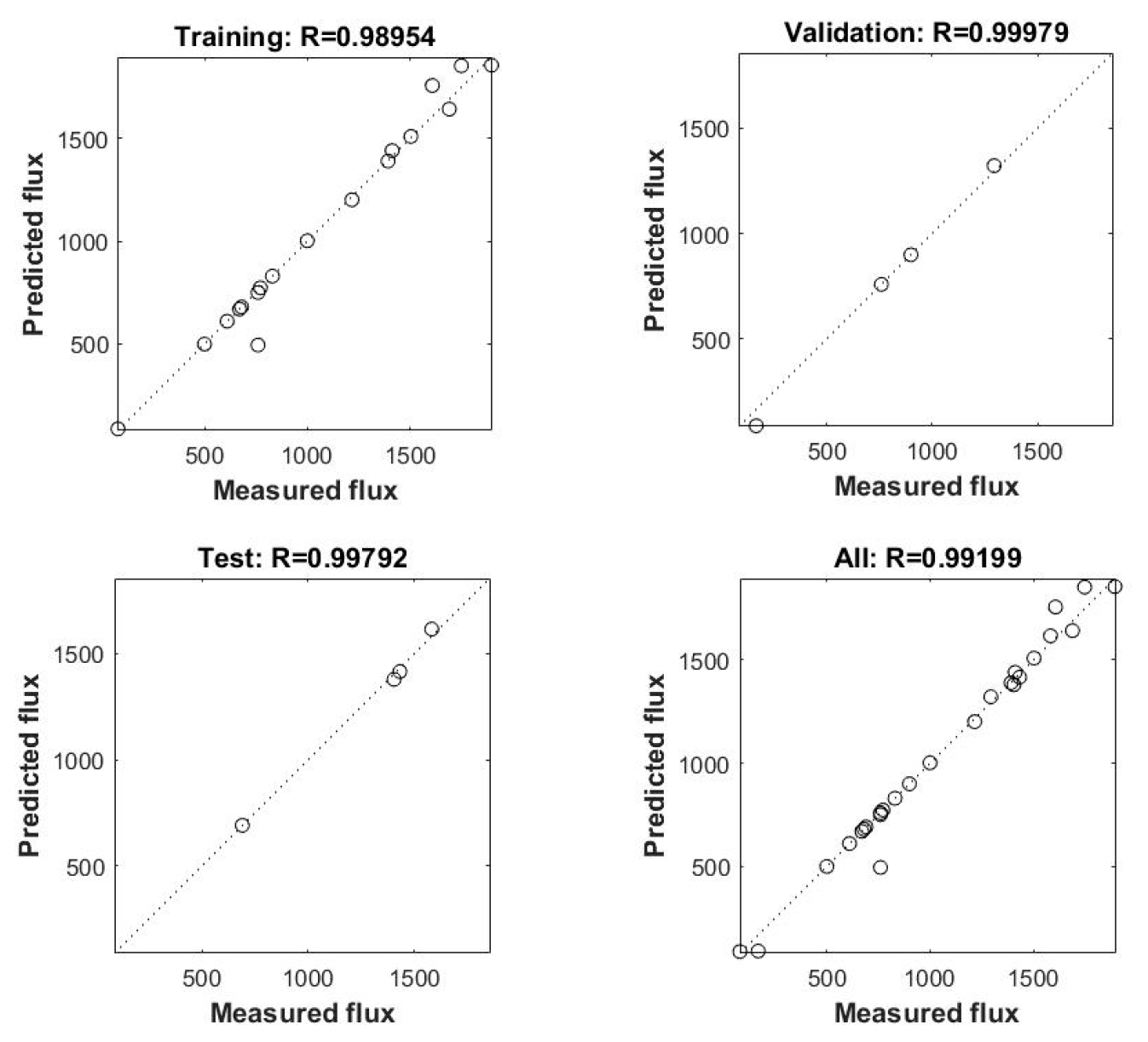
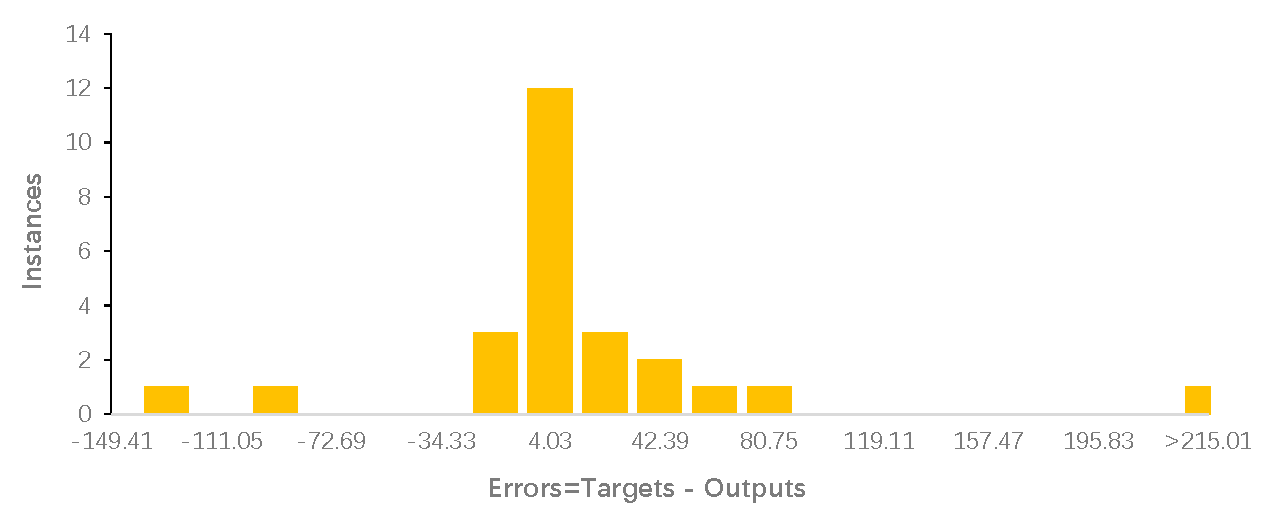
Similarly, for the modelling of nitrous oxide emissions, out of the 30 datasets that were obtained, 26 were used for development of the model and the remaining four were set aside for independent validation. Out of the 26 datasets used in modelling, randomly, 18 were randomly sectioned for training the model, four for validating the model, and the remaining four for testing the model.
3.4.2. Model Simulation
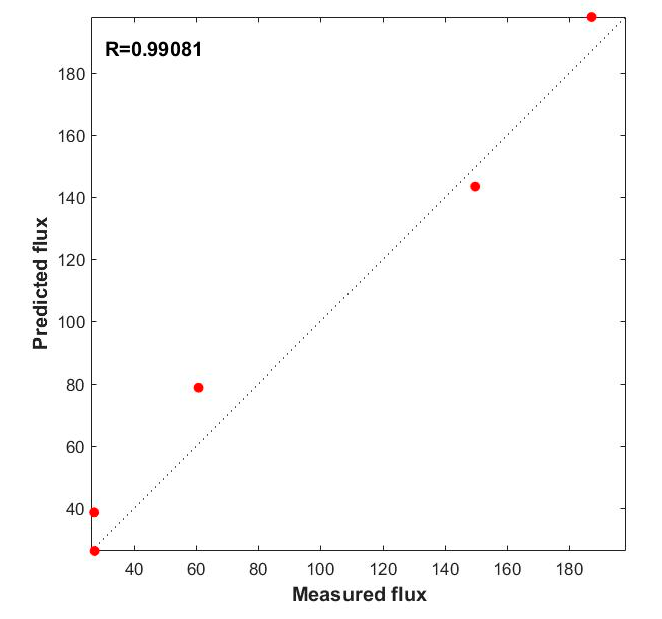
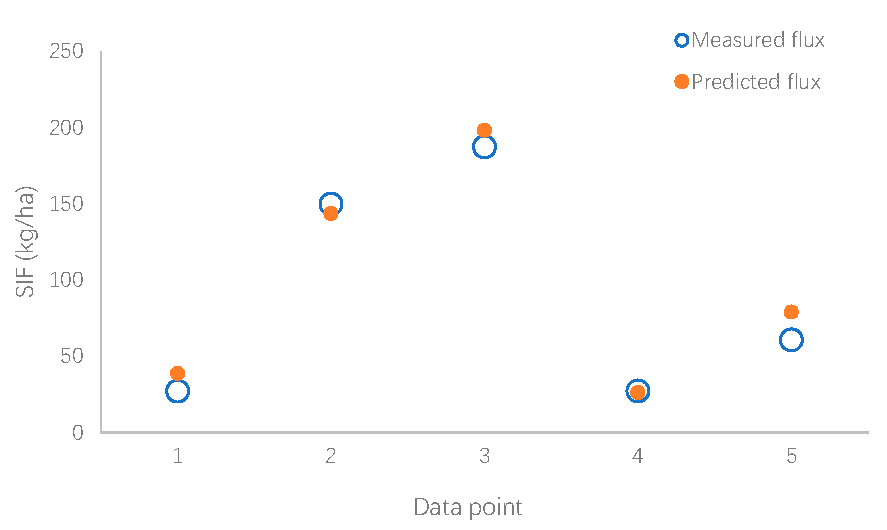
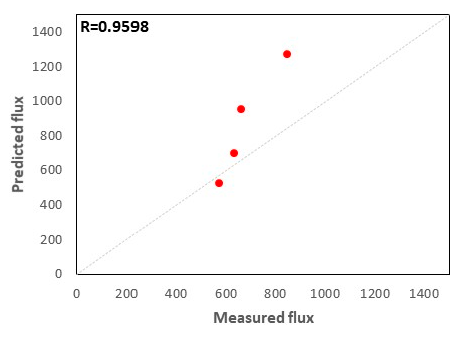
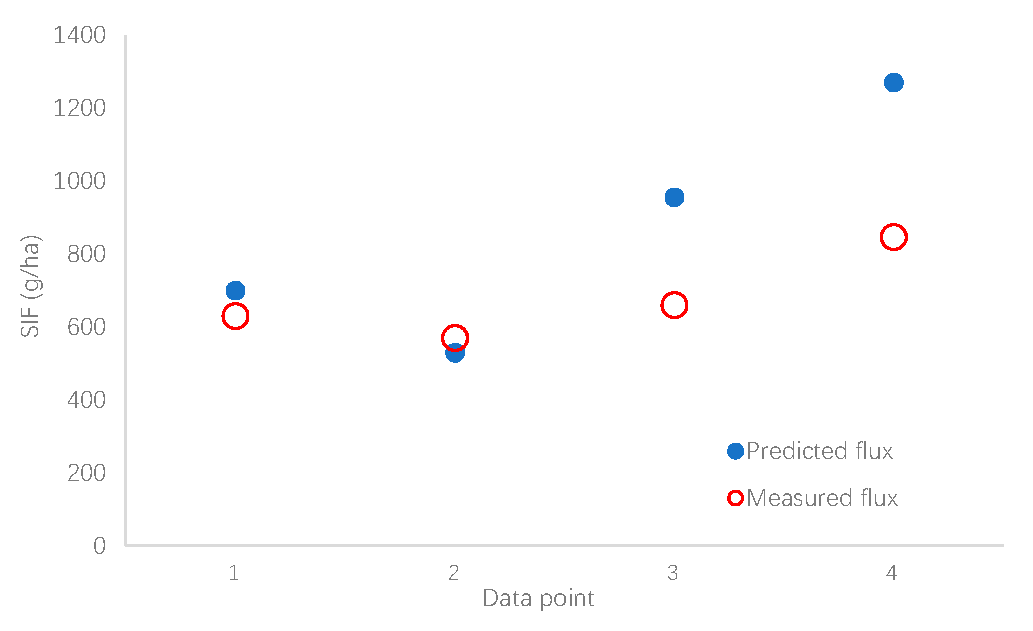
On retraining the network until the MSE was minimized and the correlation coefficients between the inputs and the targets were as close as possible to unity for all the datasets, five datasets from experimental analysis were fed into the trained network. The simulated output of the network was compared with that of the actual experimental values.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}