Development of Combined Heavy Rain Damage Prediction Models with Machine Learning



Abstract
:1. Introduction
2. Materials and Methods
2.1. Linear Regression Model
2.2. Machine Learning
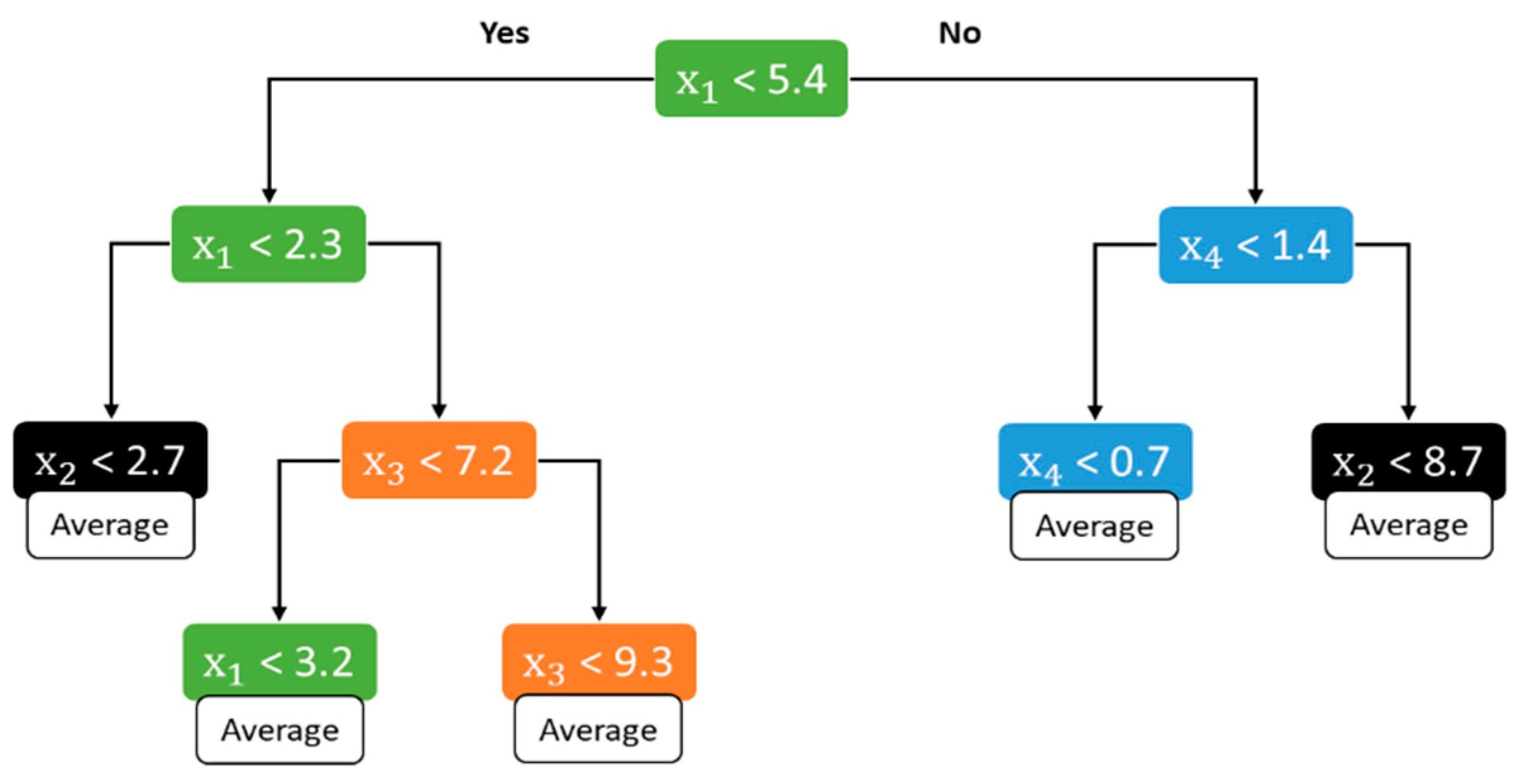
2.2.1. Decision Tree
2.2.2. Random Forest
2.2.3. Support Vector Machine
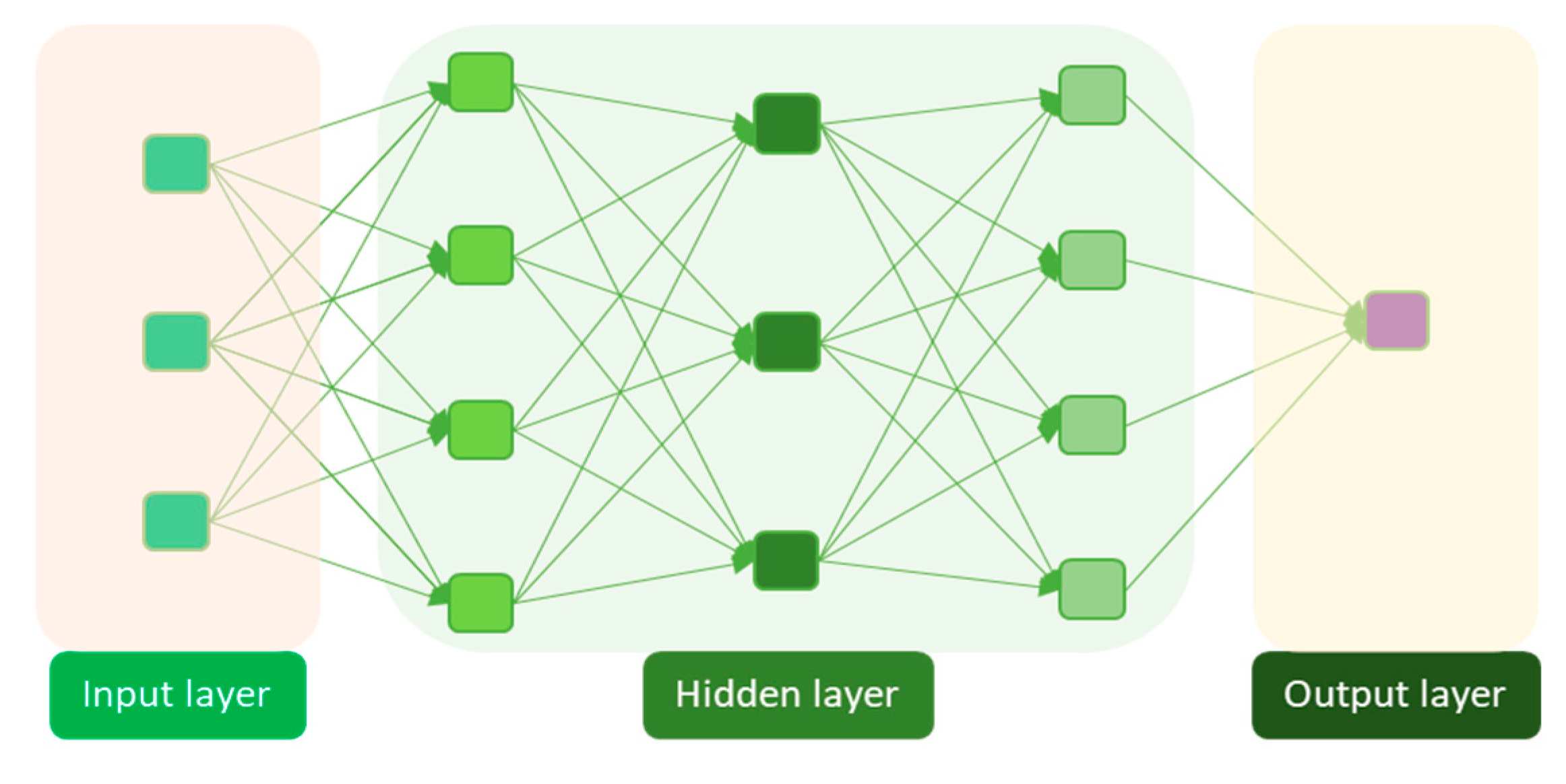
2.2.4. Deep Neural Networks
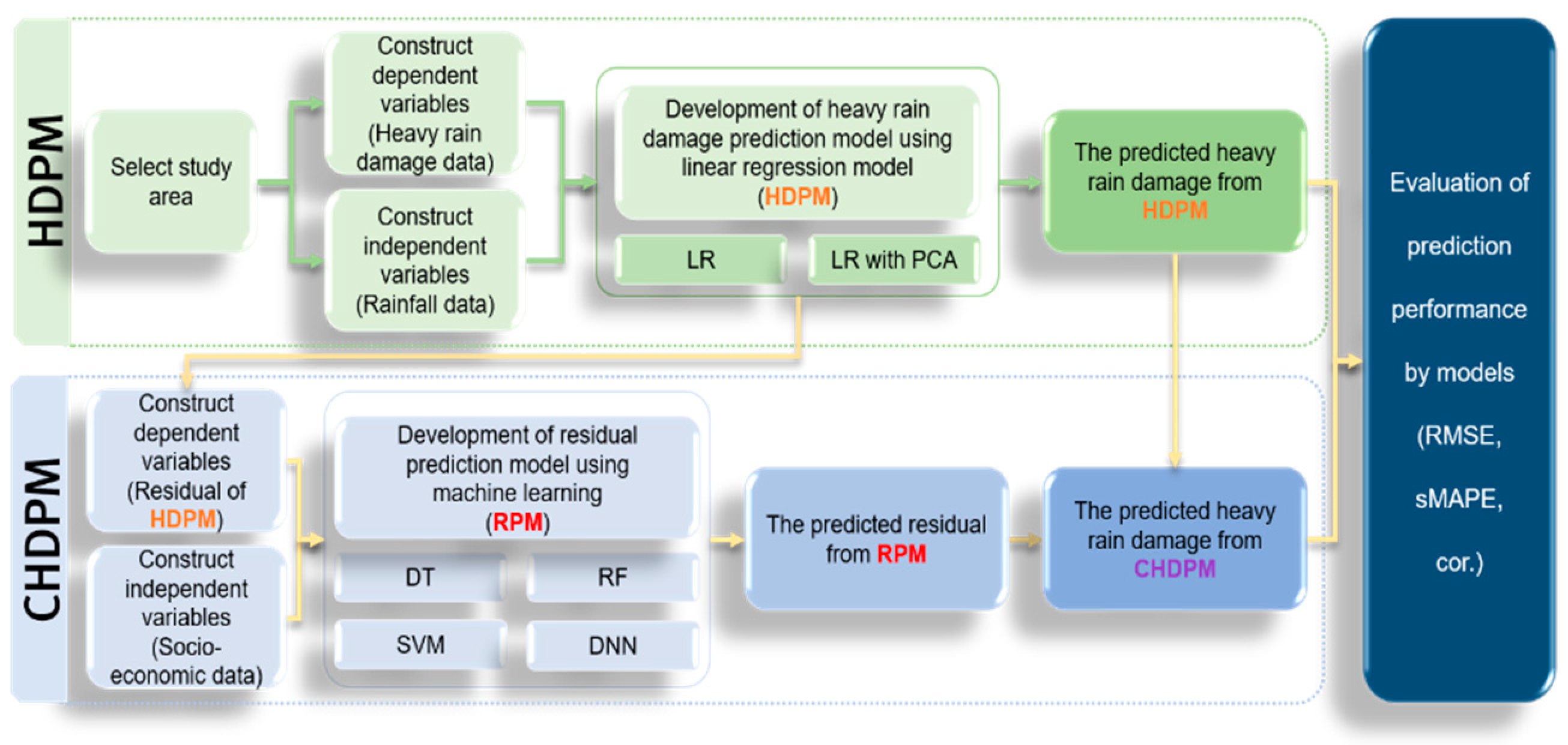
2.3. Proposal of Combined Heavy Rain Damage Prediction Model
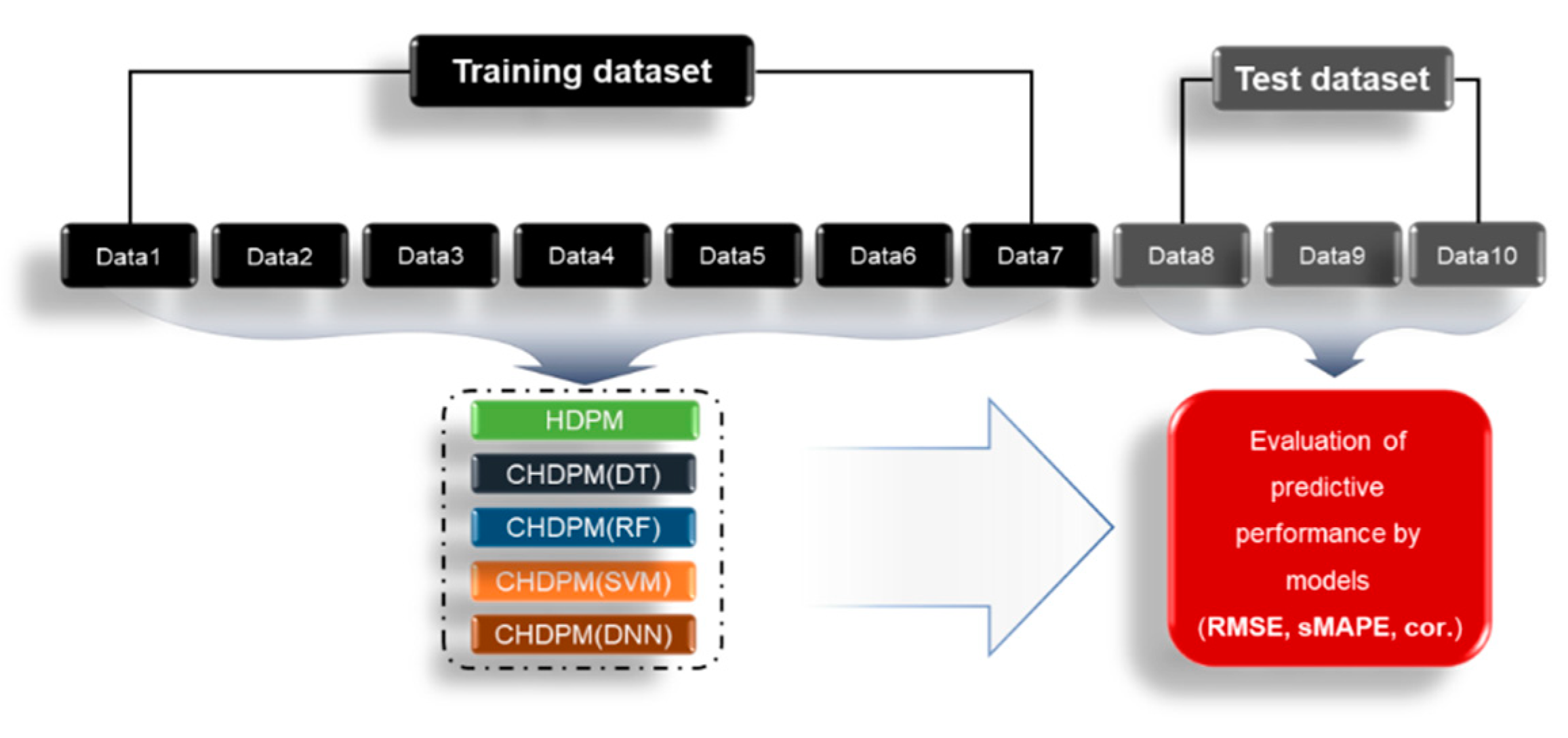
2.4. Evaluation of Predictive Performance by Models
- The total dataset is classified into a training dataset (70%) and test (30%) dataset.
- A model is developed from the training dataset and is applied to the test dataset.
- For each of the models (HDPM and CHDPM), a comparison is made for predictive performance using predictive performance evaluation measures.
3. Heavy Rain Damage Prediction Model
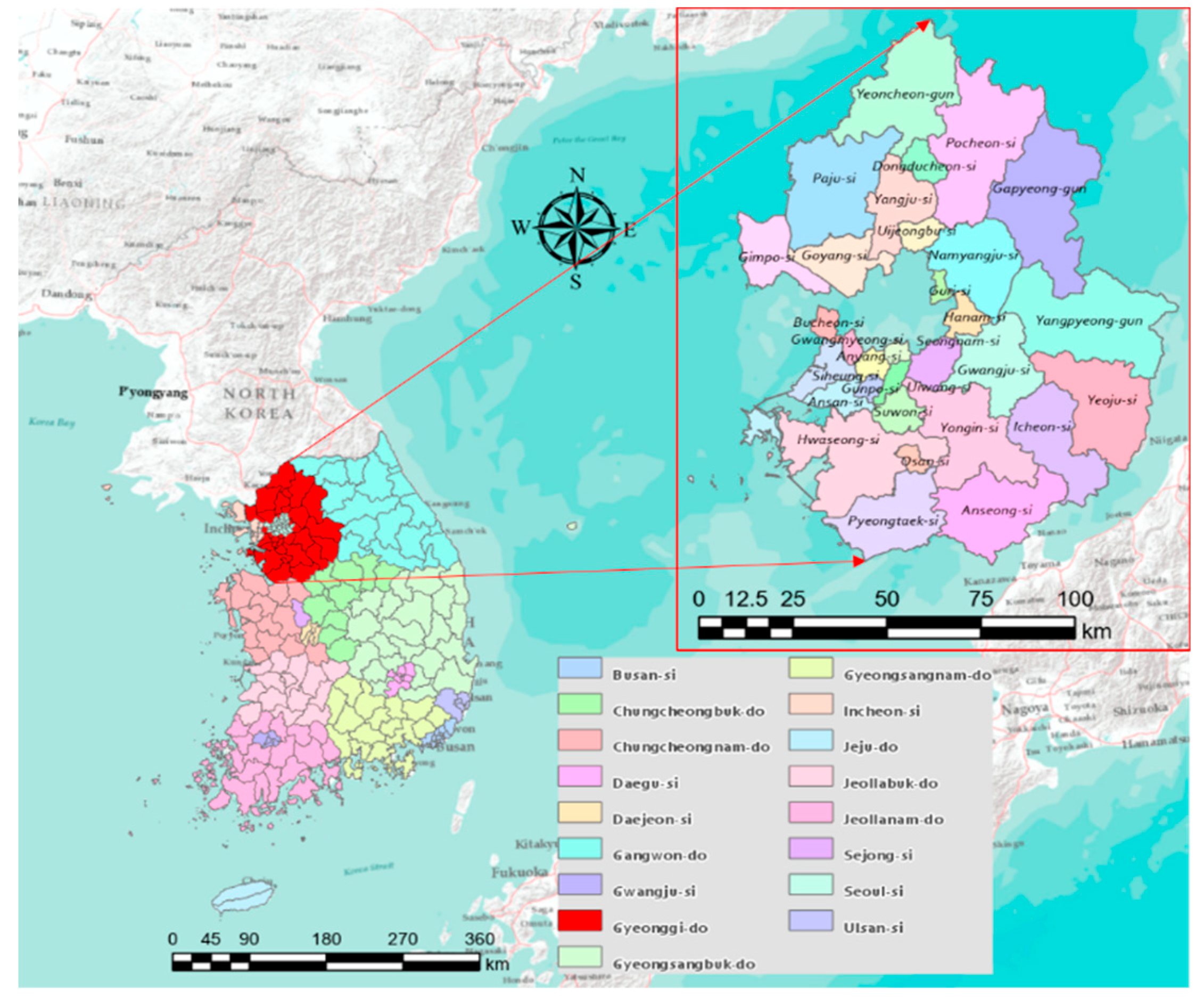
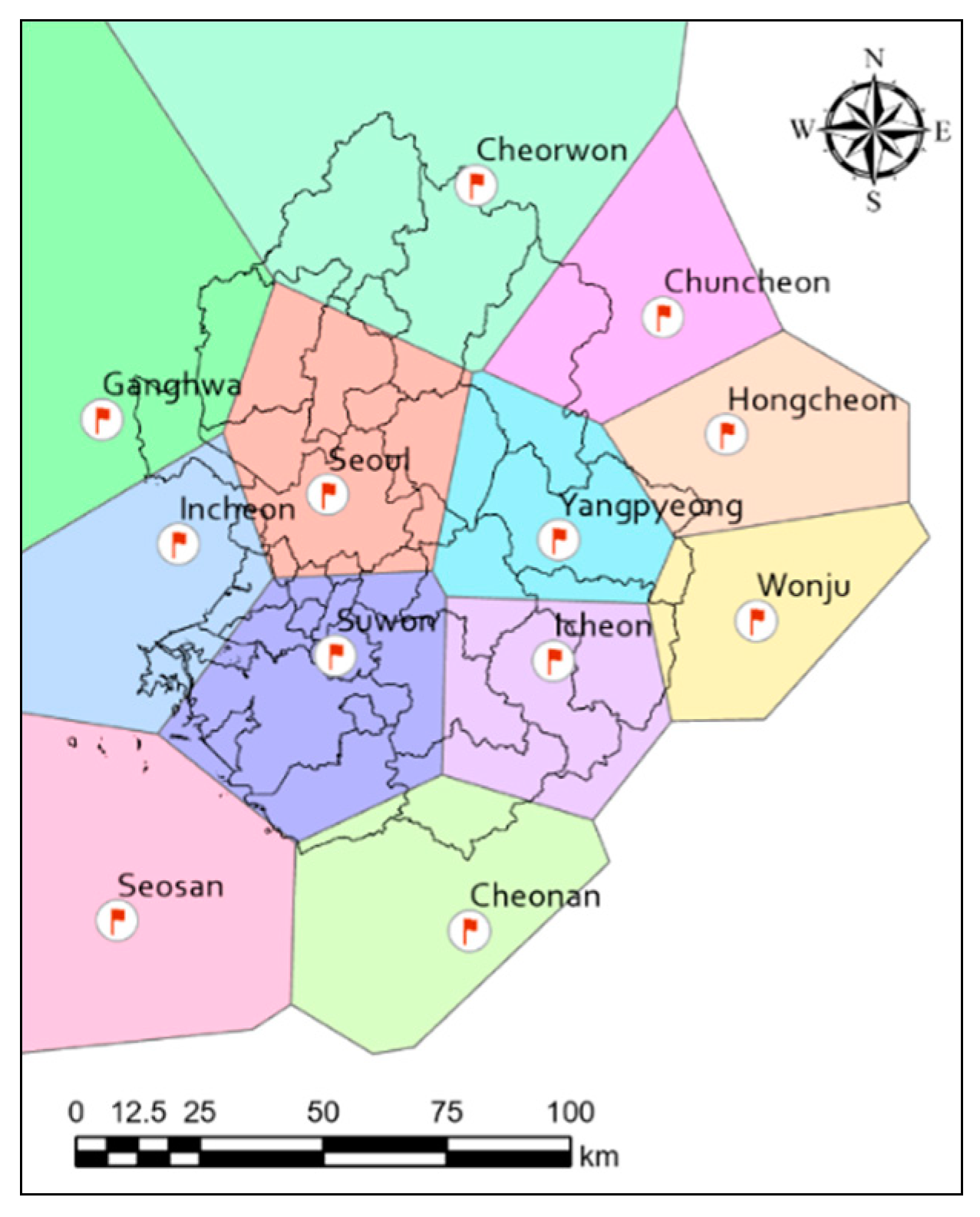
3.1. Study Area
3.2. Dependent and Independent Variables
3.2.1. Dependent Variables
3.2.2. Independent Variables
3.3. Development of HDPM
3.3.1. HDPM Using Linear Regression Model
3.3.2. HDPM Using Principle Component Analysis and Regression Model
4. Combined Heavy Rain Damage Prediction Model
4.1. Dependent and Independent Variables
4.1.1. Dependent Variables for RPM
4.1.2. Independent Variables for RPM
4.2. Development of RPM
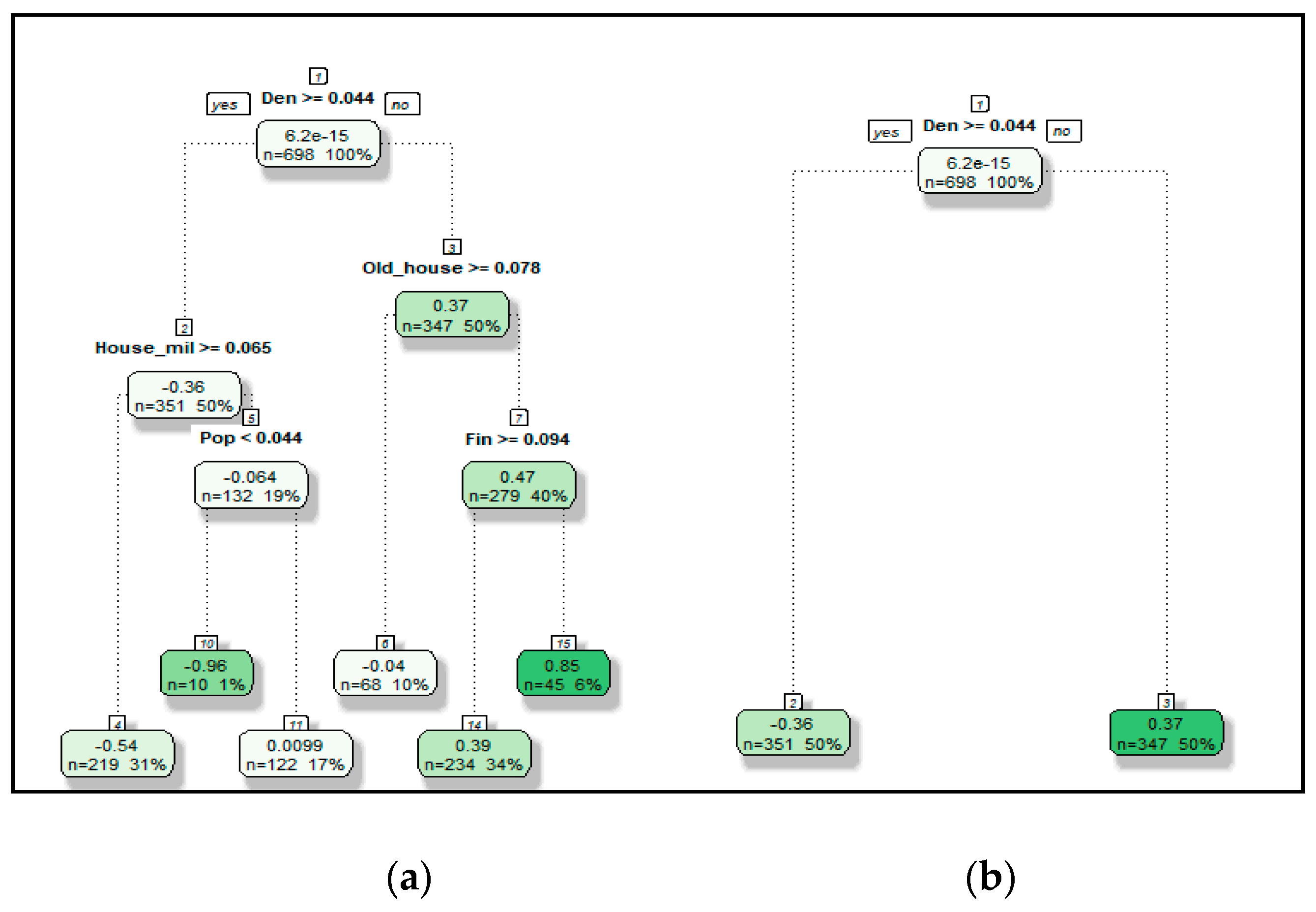
4.2.1. RPM Using Decision Tree
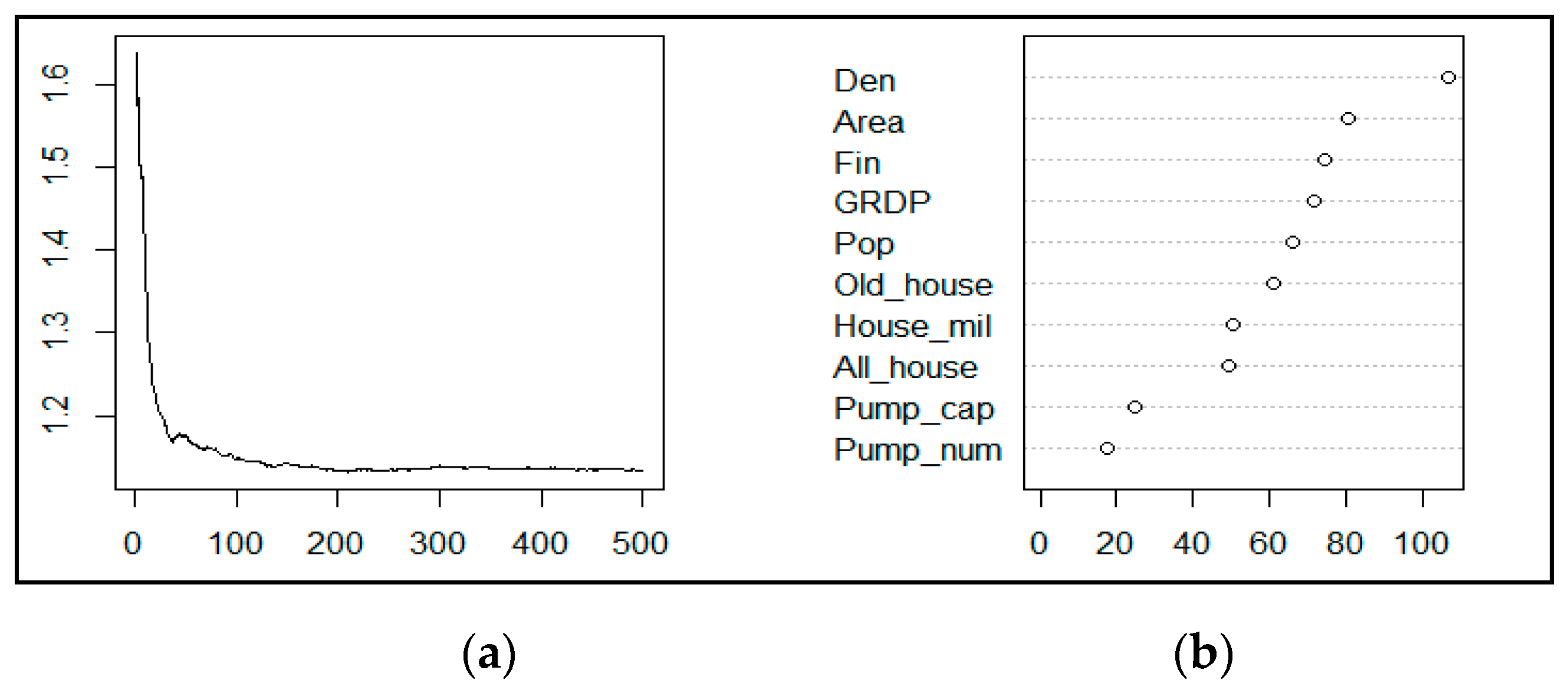
4.2.2. RPM Using Random Forest
4.2.3. RPM Using Support Vector Regression
4.2.4. RPM Using Deep Neural Networks
4.3. Evaluation of Predictive Performance by Models
5. Discussion
5.1. Summary
5.2. Any Other Model
5.3. Future Research Directions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Independent Variables | Min (mm) | Median (mm) | Mean (mm) | Max (mm) | |
|---|---|---|---|---|---|
| Maximum rainfall by duration (1 h) | max1 | 0 | 27.92 | 30.14 | 96.00 |
| Maximum rainfall by duration (2 h) | max2 | 0 | 44.42 | 47.94 | 158.12 |
| Maximum rainfall by duration (3 h) | max3 | 0 | 56.06 | 60.87 | 208.50 |
| Maximum rainfall by duration (4 h) | max4 | 0 | 64.00 | 70.93 | 254.85 |
| Maximum rainfall by duration (5 h) | max5 | 0 | 70.83 | 78.72 | 316.17 |
| Maximum rainfall by duration (6 h) | max6 | 0 | 77.52 | 85.55 | 341.31 |
| Maximum rainfall by duration (7 h) | max7 | 0 | 81.96 | 91.53 | 354.17 |
| Maximum rainfall by duration (8 h) | max8 | 0 | 86.93 | 97.21 | 371.36 |
| Maximum rainfall by duration (9 h) | max9 | 0 | 91.05 | 102.59 | 383.89 |
| Maximum rainfall by duration (10 h) | max10 | 0 | 94.75 | 106.81 | 401.08 |
| Maximum rainfall by duration (11 h) | max11 | 0 | 98.50 | 110.43 | 420.51 |
| Maximum rainfall by duration (12 h) | max12 | 0 | 102.00 | 113.70 | 445.60 |
| Maximum rainfall by duration (13 h) | max13 | 0 | 103.99 | 116.63 | 457.60 |
| Maximum rainfall by duration (14 h) | max14 | 0 | 105.66 | 119.58 | 475.36 |
| Maximum rainfall by duration (15 h) | max15 | 0 | 107.55 | 122.39 | 486.03 |
| Maximum rainfall by duration (16 h) | max16 | 0 | 109.69 | 125.09 | 490.97 |
| Maximum rainfall by duration (17 h) | max17 | 0 | 111.83 | 127.32 | 492.08 |
| Maximum rainfall by duration (18 h) | max18 | 0 | 114.00 | 129.59 | 492.94 |
| Maximum rainfall by duration (19 h) | max19 | 0 | 115.90 | 131.79 | 493.38 |
| Maximum rainfall by duration (20 h) | max20 | 0 | 116.91 | 134.07 | 493.54 |
| Maximum rainfall by duration (21 h) | max21 | 0 | 118.90 | 136.36 | 494.77 |
| Maximum rainfall by duration (22 h) | max22 | 0 | 120.10 | 138.18 | 495.63 |
| Maximum rainfall by duration (23 h) | max23 | 0 | 122.04 | 139.98 | 496.00 |
| Maximum rainfall by duration (24 h) | max24 | 0 | 123.86 | 141.79 | 496.16 |
| Total rainfall | tot | 0 | 194.40 | 243.80 | 1202.40 |
| Antecedent rainfall (1 day before) | pre1 | 0 | 0.38 | 5.97 | 82.75 |
| Antecedent rainfall (2 days before) | pre2 | 0 | 3.72 | 14.43 | 190.00 |
| Antecedent rainfall (3 days before) | pre3 | 0 | 10.76 | 25.52 | 203.04 |
| Antecedent rainfall (4 days before) | pre4 | 0 | 17.26 | 36.13 | 242.19 |
| Antecedent rainfall (5 days before) | pre5 | 0 | 30.27 | 49.43 | 418.00 |
| Antecedent rainfall (6 days before) | pre6 | 0 | 38.04 | 57.70 | 419.50 |
| Antecedent rainfall (7 days before) | pre7 | 0 | 45.89 | 65.85 | 419.50 |
| Independent Variable | VIF | Independent Variable | VIF |
|---|---|---|---|
| Maximum rainfall by duration (2 h) | 4.8146 | Total rainfall | 2.5020 |
| Maximum rainfall by duration (9 h) | 69.7583 | Antecedent rainfall (1 day ago) | 1.0921 |
| Maximum rainfall by duration (13 h) | 339.4480 | Antecedent rainfall (4 days ago) | 3.8679 |
| Maximum rainfall by duration (15 h) | 966.7931 | Antecedent rainfall (5 days ago) | 14.3081 |
| Maximum rainfall by duration (16 h) | 868.9390 | Antecedent rainfall (6 days ago) | 27.3899 |
| Maximum rainfall by duration (20 h) | 90.2535 | Antecedent rainfall (7 days ago) | 14.8949 |
| Principle Components | Standard Deviation | Proportion of Variance | Cumulative Proportion |
|---|---|---|---|
| PC1 | 4.7696 | 0.7109 | 0.7109 |
| PC2 | 2.1376 | 0.1428 | 0.8537 |
| PC3 | 1.1823 | 0.0437 | 0.8974 |
| PC4 | 1.0768 | 0.0362 | 0.9336 |
| PC5 | 0.8601 | 0.0231 | 0.9567 |
| PC6 | 0.6997 | 0.0153 | 0.9720 |
| PC7 | 0.5236 | 0.0086 | 0.9806 |
| ⋮ | ⋮ | ⋮ | ⋮ |
| Independent Variables | Min (mm) | Median (mm) | Mean (mm) | Max (mm) | |
|---|---|---|---|---|---|
| Gross regional domestic product | GRDP | 0 | 0.0792 | 0.1487 | 1 |
| Financial independence rate | Fin | 0 | 0.4055 | 0.4089 | 1 |
| Population density | Den | 0 | 0.0445 | 0.1446 | 1 |
| Population | Pop | 0 | 0.1345 | 0.2442 | 1 |
| Area | Area | 0 | 0.4412 | 0.4041 | 1 |
| Dilapidated dwelling rate | House_mil | 0 | 0.1594 | 0.1919 | 1 |
| Number of houses | All_house | 0 | 0.1536 | 0.2473 | 1 |
| Number of dilapidated dwelling | Old_house | 0 | 0.0424 | 0.0881 | 1 |
| Processing capacity of pumps | Pump_cap | 0 | 0.0056 | 0.0809 | 1 |
| Number of pumps | Pump_num | 0 | 0.0526 | 0.1393 | 1 |
References
- Munich, R.E. NatCatSERVICE Loss Events Worldwide 1980–2014; Munich Reinsurance: Munich, Germany, 2015. [Google Scholar]
- Hoeppe, P. Trends in weather related disasters–Consequences for insurers and society. Weather Clim. Extrem. 2016, 11, 70–79. [Google Scholar] [CrossRef]
- AON. Weather, Climate & Catastrophe Insight: 2018 Annual Report; AON: London, UK, 2018. [Google Scholar]
- MOIS (Ministry of the Interior and Safety). Statistical Yearbook of Natural Disaster 2018; MOIS: Seoul, Korea, 2019.
- Jongman, B.; Winsemius, H.C.; Fraser, S.A.; Muis, S.; Ward, P.J. Assessment and Adaptation to Climate Change-Related Flood Risks. In Oxford Research Encyclopedia of Natural Hazard Science; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Martins, B.; Nunes, A.; Lourenço, L.; Velez-Castro, F. Flash Flood Risk Perception by the Population of Mindelo, S. Vicente (Cape Verde). Water 2019, 11, 1895. [Google Scholar] [CrossRef]
- Re, M. Winter Storms in Europe (II): Analysis of 1999 Losses and Loss Potentials; Munich Re: Munich, Germany, 2002. [Google Scholar]
- Lee, J.; Eo, G.; Choi, C.; Jung, J.; Kim, H.S. Development of Rainfall-Flood Damage Estimation Function using Nonlinear Regression Equation. J. Korean Soc. Disaster Inf. 2016, 12, 74–88. [Google Scholar] [CrossRef]
- Murnane, R.J.; Elsner, J.B. Maximum wind speeds and US hurricane losses. Geophys. Res. Lett. 2012, 39, 16707. [Google Scholar] [CrossRef]
- Zhai, A.R.; Jiang, J.H. Dependence of US hurricane economic loss on maximum wind speed and storm size. Environ. Res. Lett. 2014, 9, 064019. [Google Scholar] [CrossRef]
- Kim, J.; Kim, T.; Lee, B. An Analysis of Typhoon Damage Pattern Type and Development of Typhoon Damage Forecasting Function. J. Korean Soc. Hazard Mitig. 2017, 17, 339–347. [Google Scholar] [CrossRef]
- Choi, C.; Kim, J.; Kim, J.; Kim, H.; Lee, W.; Kim, H.S. Development of Heavy Rain Damage Prediction Function Using Statistical Methodology. J. Korean Soc. Hazard Mitig. 2017, 17, 331–338. [Google Scholar] [CrossRef]
- Kim, K.; Yoon, S. Assessment of Natural Disaster Damage Using Weather Observation Data: Using Multiple Regression Analysis and Artificial Neural Network Analysis. J. Korean Soc. Hazard Mitig. 2017, 17, 57–65. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, T.; Lee, B. Development of Typhoon Damage Prediction Function using Tukey’s Ladder of Power Transformation. J. Korean Soc. Hazard Mitig. 2018, 18, 259–267. [Google Scholar] [CrossRef]
- Pielke, R.A., Jr.; Downton, M.W. Precipitation and damaging floods: Trends in the United States, 1932–1997. J. Clim. 2000, 13, 3625–3637. [Google Scholar] [CrossRef]
- Jeong, J.; Lee, S. Estimating the Direct Economic Damages from Heavy Snowfall in Korea. J. Clim. Res. 2014, 9, 125–139. [Google Scholar] [CrossRef]
- Kim, J.; Woods, P.K.; Park, Y.; Kim, T.; Son, K. Predicting hurricane wind damage by claim payout based on Hurricane Ike in Texas. Geomat. Nat. Hazards Risk 2016, 7, 1513–1525. [Google Scholar] [CrossRef]
- Yang, S.; Son, K.; Lee, K.; Kim, J. Typhoon Path and Prediction Model Development for Building Damage Ratio Using Multiple Regression Analysis. J. Korea Inst. Build. Constr. 2016, 16, 437–445. [Google Scholar] [CrossRef]
- Choo, T.; Kwon, J.; Yun, G.; Yang, D.; Kwak, K. Development of Predicting Function for Wind Wave Damage based on Disaster Statistics: Focused on East Sea and Jeju Island. J. Korean Soc. Environ. Technol. 2017, 18, 165–172. [Google Scholar]
- Oh, Y.; Chung, G. Estimation of Snow Damage and Proposal of Snow Damage Threshold based on Historical Disaster Data. J. Korean Soc. Civ. Eng. 2017, 37, 325–331. [Google Scholar] [CrossRef]
- Kim, J.; Choi, C.; Lee, J.; Kim, H.S. Damage Prediction Using Heavy Rain Risk Assessment: (2) Development of Heavy Rain Damage Prediction Function. J. Korean Soc. Hazard Mitig. 2017, 17, 371–379. [Google Scholar] [CrossRef]
- Kim, D.; Choi, C.; Kim, J.; Joo, H.; Kim, J.; Kim, H.S. Development of a Heavy Rain Damage Prediction Function by Risk Classification. J. Korean Soc. Hazard Mitig. 2018, 18, 503–512. [Google Scholar] [CrossRef]
- Tong, S.; Chang, E. Support vector machine active learning for image retrieval. In Proceedings of the Ninth ACM International Conference on Multimedia, Ottawa, ON, Canada, 1 October 2001; pp. 107–118. [Google Scholar]
- Ahmed, N.K.; Atiya, A.F.; Gayar, N.E.; El-Shishiny, H. An empirical comparison of machine learning models for time series forecasting. Econom. Rev. 2010, 29, 594–621. [Google Scholar] [CrossRef]
- Ak, R.; Fink, O.; Zio, E. Two machine learning approaches for short-term wind speed time-series prediction. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 1734–1747. [Google Scholar] [CrossRef]
- Qu, Y.; Qian, X.; Song, H.; Xing, Y.; Li, Z.; Tan, J. Soil moisture investigation utilizing machine learning approach based experimental data and Landsat5-TM images: A case study in the Mega City Beijing. Water 2018, 10, 423. [Google Scholar] [CrossRef]
- Randall, M.; Fensholt, R.; Zhang, Y.; Bergen Jensen, M. Geographic Object Based Image Analysis of WorldView-3 Imagery for Urban Hydrologic Modelling at the Catchment Scale. Water 2019, 11, 1133. [Google Scholar] [CrossRef]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Goetz, J.N.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci. 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Choi, C.; Park, K.; Park, H.; Lee, M.; Kim, J.; Kim, H.S. Development of Heavy Rain Damage Prediction Function for Public Facility Using Machin Learning. J. Korean Soc. Hazard Mitig. 2017, 17, 443–450. [Google Scholar] [CrossRef]
- Choi, C.; Kim, J.; Kim, J.; Kim, D.; Bae, Y.; Kim, H.S. Development of heavy rain damage prediction model using machine learning based on big data. Adv. Meteorol. 2018, 2018, 5024930. [Google Scholar] [CrossRef]
- Choubin, B.; Borji, M.; Mosavi, A.; Sajedi-Hosseini, F.; Singh, V.P.; Shamshirband, S. Snow avalanche hazard prediction using machine learning methods. J. Hydrol. 2019, 577, 123929. [Google Scholar] [CrossRef]
- Yang, Z.; Ce, L.; Lian, L. Electricity price forecasting by a hybrid model, combining wavelet transform, ARMA and kernel-based extreme learning machine methods. Appl. Energy 2017, 190, 291–305. [Google Scholar] [CrossRef]
- Lee, K.; Kim, H. Forecasting Short-Term Housing Transaction Volumes using Time-Series and Internet Search Queries. KSCE J. Civ. Eng. 2019, 23, 2409–2416. [Google Scholar] [CrossRef]
- Wang, W.; Li, J.; Qu, X.; Han, Z.; Liu, P. Prediction on landslide displacement using a new combination model: A case study of Qinglong landslide in China. Nat. Hazards 2019, 96, 1121–1139. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- MOIS (Ministry of the Interior and Safety). Statistical Yearbook of Natural Disaster 2017; MOIS: Seoul, Korea, 2018.
- NDMI (National Disaster Management Institute). Development of Regional Loss Function Based on Scenario; NDMI: Ulsan, Korea, 2013.
- Kim, J.; Park, J.; Choi, C.; Kim, H.S. Development of Regression Models Resolving High-Dimensional Data and Multicollinearity Problem for Heavy Rain Damage Data. J. Korean Soc. Civ. Eng. 2018, 38, 801–808. [Google Scholar]
- Kim, S.; Ryoo, E.; Jung, M.K.; Kim, J.K.; Ahn, H. Application of support vector regression for improving the performance of the emotion prediction model. J. Intell. Inf. Syst. 2012, 18, 185–202. [Google Scholar]
- Tay, F.E.; Cao, L. Application of support vector machines in financial time series forecasting. Omega 2001, 29, 309–317. [Google Scholar] [CrossRef]
- Lesmeister, C. Mastering Machine Learning with R; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Lewis, N.D.C. Deep Learning Made Easy with R: A Gentle Introduction for Data Science; AusCov: Liverpool, UK, 2016. [Google Scholar]











| Regional Division | Number of Heavy Rain Damage Events | Total Heavy Rain Damage Cost (Unit: 1 Million KRW) |
|---|---|---|
| Gyeonggi-do | 996 | 2,393,552 |
| Jeollanam-do | 762 | 608,826 |
| Gyeongsangbuk-do | 515 | 911,552 |
| Chungcheongnam-do | 440 | 467,558 |
| Gyeongsangnam-do | 429 | 1,259,151 |
| Gangwon-do | 421 | 3,405,380 |
| Jeollabuk-do | 421 | 636,105 |
| Seoul-si | 338 | 218,042 |
| Chungcheongbuk-do | 323 | 1,130,086 |
| Busan-si | 221 | 189,317 |
| Incheon-si | 211 | 79,273 |
| Daejeon-si | 98 | 51,143 |
| Gwangju-si | 90 | 42,507 |
| Ulsan-si | 75 | 44,366 |
| Jeju-do | 63 | 24,879 |
| Daegu-si | 37 | 8735 |
| Sejong-si | 32 | 11,995 |
| Dependent Variable | Min | Median | Mean | Max | |
|---|---|---|---|---|---|
| Heavy rain damage | Total damage | 1.7324 | 4.7885 | 4.8285 | 8.0409 |
| Index | HDPM | CHDPM(DT) | CHDPM(RF) | CHDPM(SVM) | CHDPM(DNN) |
|---|---|---|---|---|---|
| RMSE | 1.0429 | 0.9567 | 1.0051 | 0.9398 | 1.2067 |
| sMAPE | 0.1871 | 0.1651 | 0.1705 | 0.1626 | 0.2038 |
| cor. | 0.6293 | 0.7017 | 0.6829 | 0.7145 | 0.7059 |
| Index | CHDPM (DT) | CHDPM (RF) | CHDPM (SVM) | CHDPM (DNN) |
|---|---|---|---|---|
| RMSE | +8.2656 (%) | +3.6211 (%) | +9.8881 (%) | −15.7050 (%) |
| sMAPE | +11.7575 (%) | +8.8692 (%) | +13.1333 (%) | −8.8805 (%) |
| cor. | +11.5103 (%) | +8.5180 (%) | +13.5353 (%) | +12.1712 (%) |
| Index | CHDPM (SVM) | HDPM2 (DT) | HDPM2 (RF) | HDPM2 (SVM) | HDPM2 (DNN) |
|---|---|---|---|---|---|
| RMSE | 0.9398 | 1.0785 | 0.9677 | 1.0347 | 1.0260 |
| sMAPE | 0.1626 | 0.1833 | 0.1615 | 0.1699 | 0.1670 |
| cor. | 0.7145 | 0.5927 | 0.6744 | 0.6189 | 0.6372 |
| RMSE | sMAPE | Cor. | |
|---|---|---|---|
| HDPM | 9,285,423 | 1.2836 | 0.1559 |
| CHDPM(SVM) | 8,827,218 | 1.1452 | 0.3619 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, C.; Kim, J.; Kim, J.; Kim, H.S. Development of Combined Heavy Rain Damage Prediction Models with Machine Learning. Water 2019, 11, 2516. https://doi.org/10.3390/w11122516
Choi C, Kim J, Kim J, Kim HS. Development of Combined Heavy Rain Damage Prediction Models with Machine Learning. Water. 2019; 11(12):2516. https://doi.org/10.3390/w11122516
Chicago/Turabian StyleChoi, Changhyun, Jeonghwan Kim, Jungwook Kim, and Hung Soo Kim. 2019. "Development of Combined Heavy Rain Damage Prediction Models with Machine Learning" Water 11, no. 12: 2516. https://doi.org/10.3390/w11122516
APA StyleChoi, C., Kim, J., Kim, J., & Kim, H. S. (2019). Development of Combined Heavy Rain Damage Prediction Models with Machine Learning. Water, 11(12), 2516. https://doi.org/10.3390/w11122516