Machine Learning Approaches to Develop Pedotransfer Functions for Tropical Sri Lankan Soils

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Feature Selection in Waikato Environment for Knowledge Analysis (WEKA) Software
2.2. Approaches Used to Develop Pedotransfer Functions (PTFs)
2.2.1. K-Nearest Neighbor
2.2.2. Artificial Neural Networks
2.2.3. Random Forest
2.3. Using Volumetric Water Content (VWC)10 as an input to Predict VWC33 and VWC1500
2.4. Model Evaluation
3. Results and Discussion
3.1. Selection of Essential Parameters to Estimate Volumetric Water Content (VWC) of Sri Lankan Soils at −10, −33, and −1500 kPa by Selected Machine Learning Algorithms
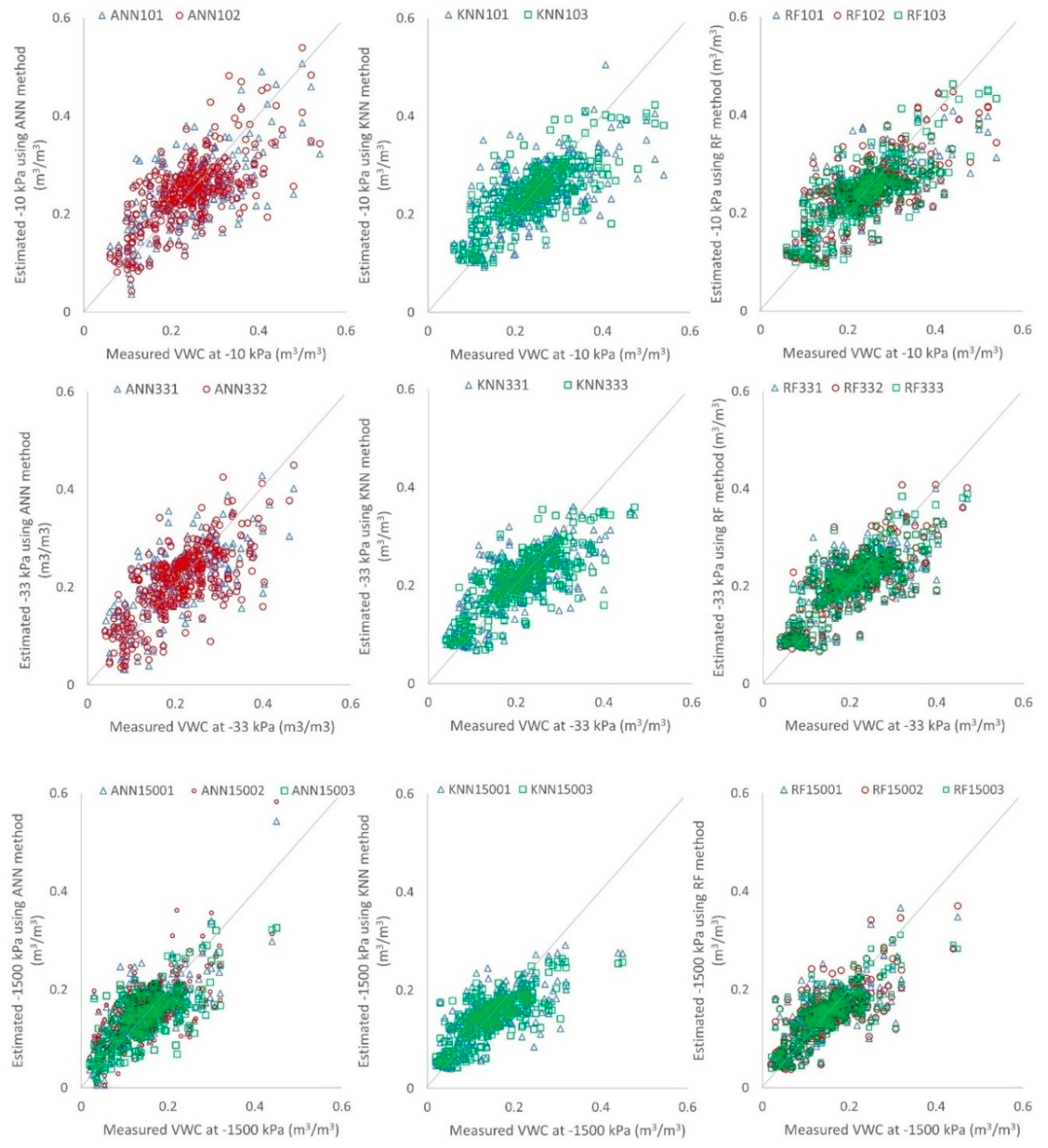
3.2. Development of Pedotransfer Functions (PTFs) to Estimate Volumetric Water Content (VWC) of Tropical Sri Lankan Soils at −10, −33, and −1500 kPa
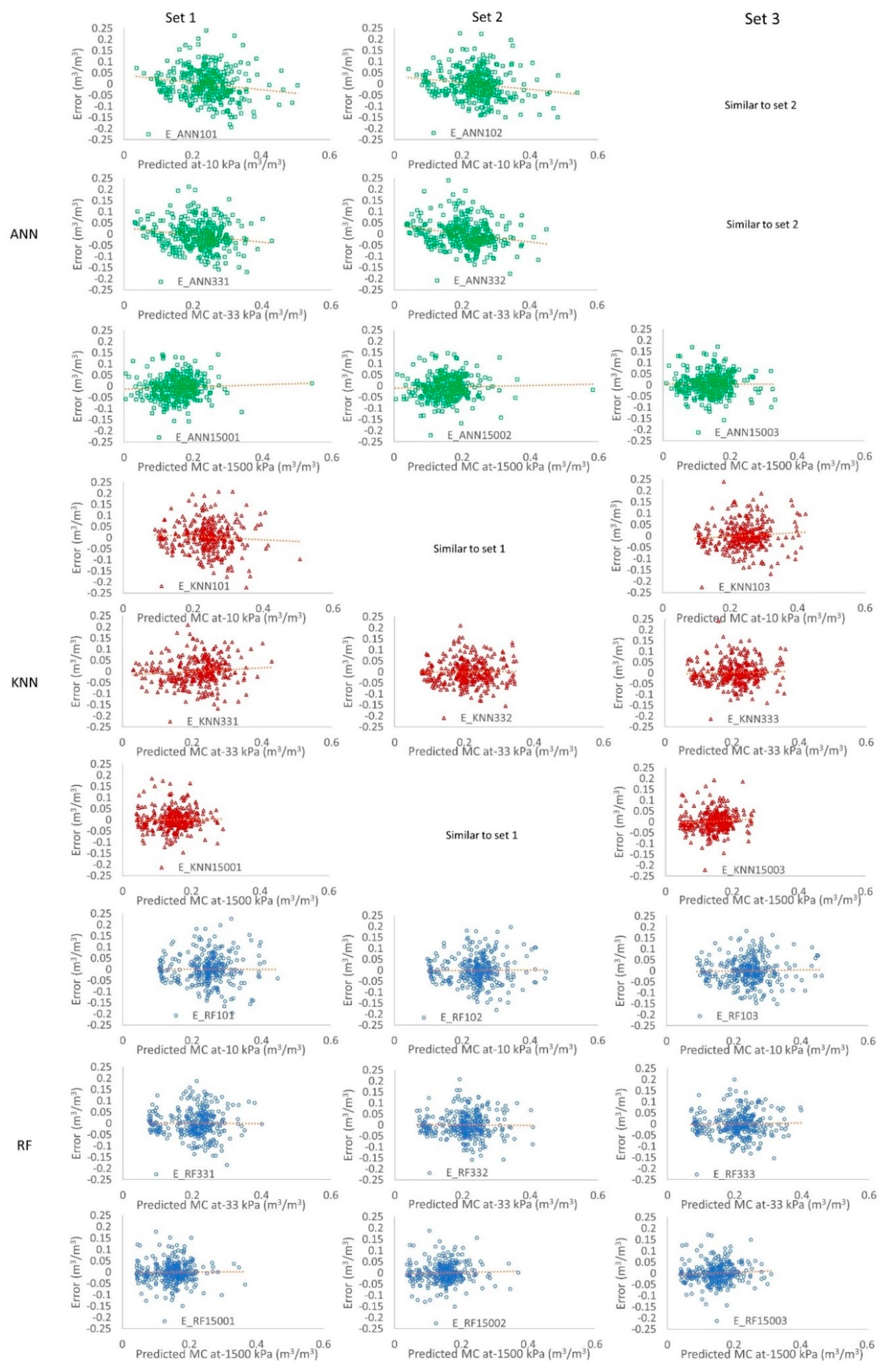
3.3. Error Distribution of Developed Pedotransfer Functions (PTFs) to Estimate Volumetric Water Content (VWC) of Tropical Sri Lankan Soils at −10, −33, and −1500 kPa
3.4. Comparison of the Pedotransfer Functions (PTFs) Developed by Machine Learning Algorithms with Previously Reported PTFs Using MLR Method
3.5. Inclusion of Volumetric Water Content as an Input Parameter
3.6. Functionality of Volumetric Water Content (VWC)-Supported Pedotransfer Functions (PTFs)
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Patil, N.G.; Singh, S.K. Pedotransfer Functions for Estimating Soil Hydraulic Properties: A Review. Pedosphere 2016, 26, 417–430. [Google Scholar] [CrossRef]
- Minasny, B.; Hartemink, A.E. Predicting soil properties in the tropics. Earth-Sci. Rev. 2011, 106, 52–62. [Google Scholar] [CrossRef]
- Rustanto, A.; Booij, M.J.; Wösten, H.; Hoekstra, A.Y. Application and recalibration of soil water retention pedotransfer functions in a tropical upstream catchment: Case study in Bengawan Solo, Indonesia. J. Hydrol. Hydromech. 2017, 65, 307–320. [Google Scholar] [CrossRef]
- Tomasella, J.; Hodnett, M. Pedotransfer functions for tropical soils. In Synchrotron-Based Techniques in Soils and Sediments; Elsevier B.V.: Amsterdam, The Netherlands, 2004; Volume 30, pp. 415–429. [Google Scholar]
- Bouma, J. Using Soil Survey Data for Quantitative Land Evaluation. Adv. Soil Sci. 1989, 9, 177–213. [Google Scholar]
- Gunarathna, M.; Sakai, K.; Nakandakari, T.; Momii, K.; Kumari, M.; Amarasekara, M. Pedotransfer functions to estimate hydraulic properties of tropical Sri Lankan soils. Soil Tillage Res. 2019, 190, 109–119. [Google Scholar] [CrossRef]
- Botula, Y.-D.; Van Ranst, E.; Cornelis, W.M. Pedotransfer functions to predict water retention for soils of the humid tropics: A review. Rev. Bras. Ciênc. Solo 2014, 38, 679–698. [Google Scholar] [CrossRef]
- Nguyen, P.M.; De Pue, J.; Van Le, K.; Cornelis, W. Impact of regression methods on improved effects of soil structure on soil water retention estimates. J. Hydrol. 2015, 525, 598–606. [Google Scholar] [CrossRef]
- Adhikary, P.P.; Chakraborty, D.; Kalra, N.; Sachdev, C.B.; Patra, A.K.; Kumar, S.; Tomar, R.K.; Chandna, P.; Raghav, D.; Agrawal, K.; et al. Pedotransfer functions for predicting the hydraulic properties of Indian soils. Soil Res. 2008, 46, 476–484. [Google Scholar] [CrossRef]
- Botula, Y. Indirect Methods to Predict Hydrophysical Properties of Soils of Lower Congo; Ghent University: Ghent, Belgium, 2013. [Google Scholar]
- Mdemu, M.V. Evaluation and Development of Pedotransfer Functions for Estimating Soil Water Holding Capacity in the Tropics: The Case of Sokoine University of Agriculture Farm in Morogoro, Tanzania. J. Geogr. Geol. 2015, 7, 1–9. [Google Scholar] [CrossRef]
- Mihalikova, M.; Matula, S.; Dolezal, F. Application of k-nearest code for the improvement of class pedotransfer functions and countrywide field capacity and wilting point maps. Soil Water Res. 2014, 9, 1–8. [Google Scholar] [CrossRef]
- Nemes, A.; Schaap, M.G.; Wösten, J.H.M. Functional Evaluation of Pedotransfer Functions Derived from Different Scales of Data Collection. Soil Sci. Soc. Am. J. 2003, 67, 1093. [Google Scholar] [CrossRef]
- Jana, R.B.; Mohanty, B.P. Enhancing PTFs with remotely sensed data for multi-scale soil water retention estimation. J. Hydrol. 2011, 399, 201–211. [Google Scholar] [CrossRef]
- D’Emilio, A.; Aiello, R.; Consoli, S.; Vanella, D.; Iovino, M. Artificial Neural Networks for Predicting the Water Retention Curve of Sicilian Agricultural Soils. Water 2018, 10, 1431. [Google Scholar] [CrossRef]
- Rodríguez-Lado, L.; Rial, M.; Taboada, T.; Cortizas, A.M. A Pedotransfer Function to Map Soil Bulk Density from Limited Data. Procedia Environ. Sci. 2015, 27, 45–48. [Google Scholar] [CrossRef] [Green Version]
- De Souza, E.; Filho, E.I.F.; Batjes, N.H.; Dos Santos, G.R.; Pontes, L.M.; Schaefer, C.E.G.R. Pedotransfer functions to estimate bulk density from soil properties and environmental covariates: Rio Doce basin. Sci. Agric. 2016, 73, 525–534. [Google Scholar] [CrossRef] [Green Version]
- Tayfur, G.; Singh, V.P.; Moramarco, T.; Barbetta, S. Flood Hydrograph Prediction Using Machine Learning Methods. Water 2018, 10, 968. [Google Scholar] [CrossRef]
- Saadi, M.; Oudin, L.; Ribstein, P. Random Forest Ability in Regionalizing Hourly Hydrological Model Parameters. Water 2019, 11, 1540. [Google Scholar] [CrossRef]
- Diez-Sierra, J.; Del Jesus, M. Subdaily Rainfall Estimation through Daily Rainfall Downscaling Using Random Forests in Spain. Water 2019, 11, 125. [Google Scholar] [CrossRef]
- Alizadeh, Z.; Yazdi, J.; Kim, J.H.; Al-Shamiri, A.K. Assessment of Machine Learning Techniques for Monthly Flow Prediction. Water 2018, 10, 1676. [Google Scholar] [CrossRef]
- Chang, L.-C.; Chang, F.-J.; Yang, S.-N.; Kao, I.-F.; Ku, Y.-Y.; Kuo, C.-L.; Amin, I.M.Z.B.M. Building an Intelligent Hydroinformatics Integration Platform for Regional Flood Inundation Warning Systems. Water 2018, 11, 9. [Google Scholar] [CrossRef]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep Learning with a Long Short-Term Memory Networks Approach for Rainfall-Runoff Simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.-W. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Chang, L.-C.; Amin, M.Z.M.; Yang, S.-N.; Chang, F.-J. Building ANN-Based Regional Multi-Step-Ahead Flood Inundation Forecast Models. Water 2018, 10, 1283. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2009; ISBN 978-0-387-84857-0. [Google Scholar]
- Wang, G.; Zhanga, Y.; Yu, N. Prediction of Soil Water Retention and Available Water of Sandy Soils using Pedotransfer Functions. Procedia Eng. 2012, 37, 49–53. [Google Scholar] [CrossRef] [Green Version]
- Merdun, H. Alternative methods in the development of pedotransfer functions for soil hydraulic characteristics. Eurasian Soil Sci. 2010, 43, 62–71. [Google Scholar] [CrossRef]
- Fereshte, H.F. Evaluation of Artificial Neural Network and Regression PTFS in Estimating Some Soil Hydraulic Parameters. ProEnvironment 2014, 7, 10–20. [Google Scholar]
- Sanchez, P.A. Linking climate change research with food security and poverty reduction in the tropics. Agric. Ecosyst. Environ. 2000, 82, 371–383. [Google Scholar] [CrossRef]
- Porter, J.R.; Xie, L.; Challinor, A.J.; Cochrane, K.; Howden, S.M.; Iqbal, M.M.; Lobell, D.B.; Travasso, M.I. Food Security and Food Production Systems. In Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Field, C.B., Barros, V.R., Dokken, D.J., Mach, K.J., Mastrandrea, M.D., Bilir, T.E., Chatterjee, M., Ebi, K.L., Estrada, Y.O., Genova, R.C., Eds.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2014; pp. 485–533. ISBN 9781107641655. [Google Scholar]
- Tito, R.; Vasconcelos, H.L.; Feeley, K.J. Global climate change increases risk of crop yield losses and food insecurity in the tropical Andes. Glob. Chang. Boil. 2017, 24, e592–e602. [Google Scholar] [CrossRef]
- Kang, Y.; Khan, S.; Ma, X. Climate change impacts on crop yield, crop water productivity and food security—A review. Prog. Nat. Sci. 2009, 19, 1665–1674. [Google Scholar] [CrossRef]
- Gaydon, D.S.; Balwinder-Singh; Wang, E.; Poulton, P.L.; Ahmad, B.; Ahmed, F.; Akhter, S.; Ali, I.; Amarasingha, R.; Chaki, A.K.; et al. Evaluation of the APSIM model in cropping systems of Asia. Field Crops Res. 2017, 204, 52–75. [Google Scholar] [CrossRef]
- Zubair, L.; Nissanka, S.P.; Weerakoon, W.M.W.; Herath, D.I.; Karunaratne, A.S.; Agalawatte, P.; Herath, R.M.; Yahiya, S.Z.; Punyawardhene, B.V.R.; Vishwanathan, J.; et al. Climate Change Impacts on Rice Farming Systems in Northwestern Sri Lanka. In Handbook of Climate Change and Agroecosystems; Imperial College Press: London, UK, 2015; pp. 315–352. [Google Scholar] [Green Version]
- Vanuytrecht, E.; Raes, D.; Steduto, P.; Hsiao, T.C.; Fereres, E.; Heng, L.K.; Vila, M.G.; Moreno, P.M. AquaCrop: FAO’s crop water productivity and yield response model. Environ. Model. Softw. 2014, 62, 351–360. [Google Scholar] [CrossRef]
- Gassman, P.W.; Reyes, M.R.; Green, C.H.; Arnold, J.G. The Soil and Water Assessment Tool: Historical Development, Applications, and Future Research Directions. Trans. ASABE 2007, 50, 1211–1250. [Google Scholar] [CrossRef] [Green Version]
- Jones, J.W.; Tsuji, G.Y.; Hoogenboom, G.; Hunt, L.A.; Thornton, P.K.; Wilkens, P.W.; Imamura, D.T.; Bowen, W.T.; Singh, U.; Vries, F.W.T.P. Decision support system for agrotechnology transfer: DSSAT v3. In Understanding Options for Agricultural Production; Springer Science and Business Media: Berlin, Germany, 1998; Volume 7, pp. 157–177. [Google Scholar]
- Keating, B.; Carberry, P.; Hammer, G.; Probert, M.; Robertson, M.; Holzworth, D.; Huth, N.; Hargreaves, J.; Meinke, H.; Hochman, Z.; et al. An overview of APSIM, a model designed for farming systems simulation. Eur. J. Agron. 2003, 18, 267–288. [Google Scholar] [CrossRef] [Green Version]
- Gunarathna, M.; Sakai, K.; Nakandakari, T.; Momii, K.; Kumari, M. Sensitivity Analysis of Plant- and Cultivar-Specific Parameters of APSIM-Sugar Model: Variation between Climates and Management Conditions. Agronomy 2019, 9, 242. [Google Scholar] [CrossRef]
- Gunarathna, M.H.J.P.; Sakai, K.; Kumari, M.K.N. Can crop modeling sucess with estimated soil hydraulic parameters? In Proceedings of the PAWEES-INWEPF International Conference Nara 2018, Nara, Japan, 9–17 May 2018; pp. 461–470. [Google Scholar]
- Gunarathna, M.H.J.P.; Sakai, K. Evaluation of pedotransfer functions for estimating soil moisture constants: A study on soils in dry zone of tropical Sri Lanka. Int. J. Adv. Sci. Eng. Technol. 2018, 6, 15–19. [Google Scholar]
- Senarath, A.; Dassanayake, A.R.; Mapa, R.B. Bench Mark Soils of the Wet Zone: Factsheets; Mapa, R.B., Somasiri, S., Nagarajah, S.L., Eds.; Soil Science Society of Sri Lanka: Kandy, Sri Lanka, 1999. [Google Scholar]
- Dassanayake, A.R.; Somasiri, L.L.W.; Mapa, R.B. Benchmark Soils of the Intermediate Zone: Factsheets; Mapa, R.B., Dassanayake, A.R., Nayakekorale, H.B., Eds.; Soil Science Society of Sri Lanka: Kandy, Sri Lanka, 2005. [Google Scholar]
- Dassanayake, A.R.; De Silva, G.G.R.; Mapa, R.B.; Kumaragamage, D. Benchmark Soils of the Dry Zone of Sri Lanka: Factsheets; Mapa, R.B., Somasiri, S., Dassanayake, A.R., Eds.; Soil Science Society of Sri Lanka: Kandy, Sri Lanka, 2010. [Google Scholar]
- Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H.; Hall, M. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10. [Google Scholar]
- Frank, E.; Hall, M.A.; Witten, I.H. The WEKA Workbench. In Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Pachepsky, Y.; Schaap, M. Data mining and exploration techniques. In Synchrotron-Based Techniques in Soils and Sediments; Elsevier B.V.: Amsterdam, The Netherlands, 2004; Volume 30, pp. 21–32. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Hall, M.; Holmes, G. Benchmarking attribute selection techniques for discrete class data mining. IEEE Trans. Knowl. Data Eng. 2003, 15, 1437–1447. [Google Scholar] [CrossRef]
- Russel, S.J.; Norvig, P. Artificial Intelligence—A modern Approach, 3rd ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2010; ISBN 9780136042594. [Google Scholar]
- Dechter, R.; Pearl, J. Generalized best-first search strategies and the optimality af A. J. ACM 1985, 32, 505–536. [Google Scholar] [CrossRef]
- Liu, H.; Setiono, R. Feature selection via discretization. IEEE Trans. Knowl. Data Eng. 1997, 9, 642–645. [Google Scholar]
- Gheyas, I.A.; Smith, L.S. Feature subset selection in large dimensionality domains. Pattern Recognit. 2010, 43, 5–13. [Google Scholar] [CrossRef] [Green Version]
- Araya, S.N.; Ghezzehei, T.A. Using Machine Learning for Prediction of Saturated Hydraulic Conductivity and Its Sensitivity to Soil Structural Perturbations. Water Resour. Res. 2019, 55, 5715–5737. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Nemes, A.; Rawls, W.J.; Pachepsky, Y.A. Use of the Nonparametric Nearest Neighbor Approach to Estimate Soil Hydraulic Properties. Soil Sci. Soc. Am. J. 2006, 70, 327–336. [Google Scholar] [CrossRef]
- Hart, P.E. The condensed nearest neighbor rule. IEEE Trans. Inf. Theory 1968, 14, 515–516. [Google Scholar] [CrossRef]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-Based Learning Algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- De Sá, A.G.C.; Freitas, A.A.; Pappa, G.L. Multi-label classification search space in the MEKA software. arXiv 2018, arXiv:1811.11353. [Google Scholar]
- Haykin, S. Neural Networks—A Comprehensive Foundation, 2nd ed.; Pearson Education (Singapore) Pte. Ltd.: Delhi, India, 2005. [Google Scholar]
- Van Looy, K.; Bouma, J.; Herbst, M.; Koestel, J.; Minasny, B.; Mishra, U.; Montzka, C.; Nemes, A.; Pachepsky, Y.A.; Padarian, J.; et al. Pedotransfer Functions in Earth System Science: Challenges and Perspectives. Rev. Geophys. 2017, 55, 1199–1256. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Peng, T.; Zhang, C.; Sun, N. Data Pre-Analysis and Ensemble of Various Artificial Neural Networks for Monthly Streamflow Forecasting. Water 2018, 10, 628. [Google Scholar] [CrossRef]
- Jabbari, A.; Bae, D.-H. Application of Artificial Neural Networks for Accuracy Enhancements of Real-Time Flood Forecasting in the Imjin Basin. Water 2018, 10, 1626. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Deep Architectures. In Computer Vision—ECCV 2012; Springer Science and Business Media: Berlin, Germany, 2012; Volume 7700, pp. 437–478. [Google Scholar]
- Sheela, K.G.; Deepa, S.N. Review on Methods to Fix Number of Hidden Neurons in Neural Networks. Math. Probl. Eng. 2013, 2013, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2012; ISBN 978-0-12-381479-1. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar] [CrossRef]
- Zhang, Y.; Schaap, M.G. Weighted recalibration of the Rosetta pedotransfer model with improved estimates of hydraulic parameter distributions and summary statistics (Rosetta3). J. Hydrol. 2017, 547, 39–53. [Google Scholar] [CrossRef] [Green Version]
- Schaap, M.G.; Leij, F.J.; Genuchten, M.T. Van rosetta: A computer program for estimating soil hydraulic parameters with hierarchical pedotransfer functions. J. Hydrol. 2001, 251, 163–176. [Google Scholar] [CrossRef]
- Zambrano-Bigiarini, M. Package ‘hydroGOF: Goodness-of-Fit Functions for Comparison of Simulated and Observed Hydrological Time Series’; R Package Version 0.3-10. Available online: http://hzambran.github.io/hydroGOF/ (accessed on 15 January 2019).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria; Available online: https://www.R-project.org/2018 (accessed on 15 January 2019).
- Schaap, M. Accuracy and uncertainty in PTF predictions. In Synchrotron-Based Techniques in Soils and Sediments; Elsevier B.V.: Amsterdam, The Netherlands, 2004; Volume 30, pp. 33–43. [Google Scholar]
- Nash, J.; Sutcliffe, J. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Willmott, C.J. ON THE VALIDATION OF MODELS. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- Camargo, A.P.; Sentelhas, P.C. Performance evaluation of different potential evapotranspiration estimation methods in the state of Sao Paulo, Brazil. Rev. Bras. Agrometeorol. 1997, 5, 89–97. [Google Scholar] [CrossRef]
- Monteiro, L.A.; Sentelhas, P.C. Calibration and testing of an agrometeorological model for the estimation of soybean yields in different Brazilian regions. Acta Sci. Agron. 2014, 36, 265. [Google Scholar] [CrossRef] [Green Version]
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econ. Stat. 1995, 13, 253–263. [Google Scholar]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series Forecasting: The forecast Package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G.; Bergmeir, C.; Caceres, G.; Chhay, L.; O’Hara-Wild, M.; Petropoulos, F.; Razbash, S.; Wang, E.; Yasmeen, F. Forecast: Forecasting Functions for Time Series and Linear Models. R Package Version 8.7. Available online: http://pkg.robjhyndman.com/forecast/2019 (accessed on 15 March 2019).
- Berg, M.V.D.; Klamt, E.; Van Reeuwijk, L.; Sombroek, W. Pedotransfer functions for the estimation of moisture retention characteristics of Ferralsols and related soils. Geoderma 1997, 78, 161–180. [Google Scholar] [CrossRef]
- Gaiser, T.; Graef, F.; Cordeiro, J.C. Water retention characteristics of soils with contrasting clay mineral composition in semi-arid tropical regions. Soil Res. 2000, 38, 523–536. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B.; Bristow, K.L. Comparison of different approaches to the development of pedotransfer functions for water-retention curves. Geoderma 1999, 93, 225–253. [Google Scholar] [CrossRef]
- Botula, Y.-D.; Nemes, A.; Mafuka, P.; Van Ranst, E.; Cornelis, W.M. Prediction of Water Retention of Soils from the Humid Tropics by the Nonparametric—Nearest Neighbor Approach. Vadose Zone J. 2013, 12, 12. [Google Scholar] [CrossRef]
- Zolfaghari, A.; Taghizadeh-Mehrjardi, R.; Moshki, A.; Malone, B.; Weldeyohannes, A.; Sarmadian, F.; Yazdani, M.; Malone, B. Using the nonparametric k-nearest neighbor approach for predicting cation exchange capacity. Geoderma 2016, 265, 111–119. [Google Scholar] [CrossRef]
- Ahuja, L.R.; Naney, J.W.; Williams, R.D. Estimating Soil Water Characteristics from Simpler Properties or Limited Data. Soil Sci. Soc. Am. J. 2010, 49, 1100. [Google Scholar] [CrossRef]
- Paydar, Z.; Cresswell, H.P. Water retention in Australian soils. II. Prediction using particle size, bulk density, and other properties. Aust. J. Soil Res. 1996, 34, 679–693. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Minimum | Maximum | Mean | SD | Skewness | Kurtosis | CV% | |
|---|---|---|---|---|---|---|---|
| SA (%) | 5.2 | 99.0 | 65.1 | 17.4 | −0.329 | −0.158 | 26.8 |
| SI (%) | 0.0 | 38.6 | 13.1 | 7.7 | 0.703 | 0.503 | 58.8 |
| CL (%) | 1.0 | 61.4 | 21.9 | 13.2 | 0.517 | −0.357 | 60.4 |
| BD (g/cm3) | 1.00 | 2.00 | 1.49 | 0.17 | −0.346 | 0.162 | 11.3 |
| OC (%) | 0.0 | 4.5 | 0.6 | 0.6 | 2.074 | 6.980 | 96.5 |
| VWC10 | 0.06 | 0.54 | 0.24 | 0.09 | 0.434 | 0.419 | 36.9 |
| VWC33 | 0.04 | 0.47 | 0.21 | 0.08 | 0.251 | −0.143 | 39.9 |
| VWC1500 | 0.02 | 0.45 | 0.15 | 0.07 | 0.670 | 1.277 | 46.5 |
| Variable | Sand | Silt | Clay | BD | OC | VWC10 | VWC33 | VWC1500 |
|---|---|---|---|---|---|---|---|---|
| Sand | 1 | |||||||
| Silt | −0.7020 | 1 | ||||||
| Clay | −0.9103 | 0.34429 | 1 | |||||
| BD | 0.42982 | −0.4119 | −0.3274 | 1 | ||||
| OC | −0.1806 | 0.2521 | 0.09184 | −0.3316 | 1 | |||
| VWC10 | −0.7106 | 0.60833 | 0.58319 | −0.3800 | 0.21464 | 1 | ||
| VWC33 | −0.7278 | 0.60326 | 0.60888 | −0.3951 | 0.21325 | 0.96621 | 1 | |
| VWC1500 | −0.7482 | 0.58033 | 0.64906 | −0.404 | 0.28858 | 0.91183 | 0.92891 | 1 |
| Input Level | VWC | ANN | KNN | RF | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SA | SI | CL | BD | OC | SA | SI | CL | BD | OC | SA | SI | CL | BD | OC | ||
| Set 1 | VWC10 | ● | ● | ● | ● | ● | ||||||||||
| VWC33 | ● | ● | ● | ● | ● | |||||||||||
| VWC1500 | ● | ● | ● | ● | ● | |||||||||||
| Set 2 | VWC10 | ● | ● | ● | ● | ● | ● | ● | ||||||||
| VWC33 | ● | ● | ● | ● | ● | ● | ● | ● | ||||||||
| VWC1500 | ● | ● | ● | ● | ● | ● | ● | |||||||||
| Set 3 | VWC10 | ● | ● | ● | ● | ● | ● | ● | ● | ● | ● | ● | ||||
| VWC33 | ● | ● | ● | ● | ● | ● | ● | ● | ● | ● | ● | |||||
| VWC1500 | ● | ● | ● | ● | ● | ● | ● | ● | ● | ● | ||||||
| Set | Method | r | MAE | RMSE | R2 | d | NSE | CI | DM |
|---|---|---|---|---|---|---|---|---|---|
| VWC10 | |||||||||
| 1 | ANN(3) | 0.665 | 0.0532 | 0.0678 | 0.442 | 0.802 | 0.425 | 0.53 | S |
| KNN(11) | 0.665 | 0.0492 | 0.0669 | 0.442 | 0.789 | 0.438 | 0.52 | S | |
| RF(3) | 0.708 | 0.0467 | 0.0631 | 0.502 | 0.812 | 0.502 | 0.57 | - | |
| 2 | ANN(5) | 0.700 | 0.0507 | 0.0648 | 0.490 | 0.824 | 0.475 | 0.58 | S |
| KNN(11) | 0.665 | 0.0492 | 0.0669 | 0.442 | 0.789 | 0.438 | 0.52 | S | |
| RF(5) | 0.732 | 0.0458 | 0.0608 | 0.539 | 0.830 | 0.538 | 0.61 | - | |
| 3 | ANN(3) | 0.700 | 0.0507 | 0.0648 | 0.490 | 0.824 | 0.475 | 0.58 | S |
| KNN(11) | 0.762 | 0.0420 | 0.0581 | 0.580 | 0.843 | 0.577 | 0.64 | NS | |
| RF(7) | 0.764 | 0.0440 | 0.0577 | 0.583 | 0.851 | 0.583 | 0.65 | - | |
| VWC33 | |||||||||
| 1 | ANN(2) | 0.694 | 0.0479 | 0.0614 | 0.478 | 0.820 | 0.455 | 0.57 | S |
| KNN(12) | 0.708 | 0.0446 | 0.0588 | 0.502 | 0.819 | 0.501 | 0.58 | NS | |
| RF(4) | 0.727 | 0.0435 | 0.0572 | 0.529 | 0.829 | 0.529 | 0.60 | - | |
| 2 | ANN(5) | 0.705 | 0.0467 | 0.0605 | 0.497 | 0.833 | 0.473 | 0.59 | S |
| KNN(12) | 0.754 | 0.0425 | 0.0548 | 0.568 | 0.846 | 0.568 | 0.64 | NS | |
| RF(6) | 0.756 | 0.0419 | 0.0545 | 0.572 | 0.851 | 0.572 | 0.64 | - | |
| 3 | ANN(5) | 0.705 | 0.0467 | 0.0605 | 0.497 | 0.833 | 0.473 | 0.59 | S |
| KNN(8) | 0.772 | 0.0398 | 0.0530 | 0.597 | 0.857 | 0.596 | 0.66 | NS | |
| RF(7) | 0.772 | 0.0400 | 0.0530 | 0.596 | 0.858 | 0.595 | 0.66 | - | |
| VWC1500 | |||||||||
| 1 | ANN(3) | 0.711 | 0.0372 | 0.0494 | 0.492 | 0.824 | 0.472 | 0.58 | S |
| KNN(12) | 0.727 | 0.0346 | 0.0475 | 0.528 | 0.826 | 0.528 | 0.60 | NS | |
| RF(4) | 0.748 | 0.0337 | 0.461 | 0.560 | 0.842 | 0.559 | 0.63 | - | |
| 2 | ANN(6) | 0.723 | 0.0367 | 0.0485 | 0.487 | 0.826 | 0.452 | 0.58 | S |
| KNN(12) | 0.727 | 0.0346 | 0.0475 | 0.528 | 0.826 | 0.528 | 0.60 | S | |
| RF(6) | 0.764 | 0.0324 | 0.0446 | 0.584 | 0.855 | 0.584 | 0.65 | - | |
| 3 | ANN(4) | 0.736 | 0.0367 | 0.0482 | 0.519 | 0.834 | 0.512 | 0.60 | S |
| KNN(12) | 0.754 | 0.0335 | 0.0459 | 0.569 | 0.830 | 0.560 | 0.63 | S | |
| RF(6) | 0.777 | 0.0312 | 0.0435 | 0.603 | 0.857 | 0.601 | 0.67 | - | |
| Input Level | Volumetric Water Content at | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| −10 kPa | −33 kPa | −1500 kPa | |||||||
| ANN | KNN | RF | ANN | KNN | RF | ANN | KNN | RF | |
| Set 2 | S | - | S | NS | S | S | NS | - | NS |
| Set 3 | S | S | S | NS | S | S | NS | NS | S |
| Algorithm | Inputs | R | MAE | RMSE | R2 | d | NSE | CI |
|---|---|---|---|---|---|---|---|---|
| ANN-33 | CL, VWC10 | 0.965 | 0.016 | 0.022 | 0.932 | 0.982 | 0.931 | 0.948 |
| KNN-33 | SA, VWC10 | 0.966 | 0.016 | 0.022 | 0.932 | 0.981 | 0.931 | 0.948 |
| RF-33 | SA, SI, BD, VWC10 | 0.971 | 0.015 | 0.020 | 0.943 | 0.984 | 0.941 | 0.955 |
| ANN-1500 | SI, CL, OC, VWC10 | 0.897 | 0.022 | 0.031 | 0.805 | 0.942 | 0.797 | 0.845 |
| KNN-1500 | SA, CL, OC, VWC10 | 0.902 | 0.020 | 0.030 | 0.814 | 0.944 | 0.812 | 0.851 |
| RF-1500 | SA, SI, BD, OC, VWC10 | 0.912 | 0.020 | 0.029 | 0.832 | 0.948 | 0.828 | 0.865 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gunarathna, M.H.J.P.; Sakai, K.; Nakandakari, T.; Momii, K.; Kumari, M.K.N. Machine Learning Approaches to Develop Pedotransfer Functions for Tropical Sri Lankan Soils. Water 2019, 11, 1940. https://doi.org/10.3390/w11091940
Gunarathna MHJP, Sakai K, Nakandakari T, Momii K, Kumari MKN. Machine Learning Approaches to Develop Pedotransfer Functions for Tropical Sri Lankan Soils. Water. 2019; 11(9):1940. https://doi.org/10.3390/w11091940
Chicago/Turabian StyleGunarathna, M.H.J.P., Kazuhito Sakai, Tamotsu Nakandakari, Kazuro Momii, and M.K.N. Kumari. 2019. "Machine Learning Approaches to Develop Pedotransfer Functions for Tropical Sri Lankan Soils" Water 11, no. 9: 1940. https://doi.org/10.3390/w11091940
APA StyleGunarathna, M. H. J. P., Sakai, K., Nakandakari, T., Momii, K., & Kumari, M. K. N. (2019). Machine Learning Approaches to Develop Pedotransfer Functions for Tropical Sri Lankan Soils. Water, 11(9), 1940. https://doi.org/10.3390/w11091940