1. Introduction
Evaporation and evapotranspiration play a crucial role in water management in a wide range of human activities and thus there is a strong need for accurate estimates. This need leads to a considerable number of papers and studies that are offering new methods of such estimates or comparison of methods already used in hydrologic engineering applications. The results of estimation could be compared with reference evaporation/evapotranspiration calculated by FAO Penman–Monteith equation
, which is recommended as the standard method [
1,
2]. This equation is considered to be an
etalon to which the results of the other methods can be related and compared. The papers dealing with evaporation or evapotranspiration present the comparison of the
FAO Penman–Monteith method results to other methods proposing the relations between input data less complicated and computationally less demanding. For instance, such a procedure was performed in the study [
3] to find the best estimation of water lost from a covered reservoir. In [
4] it is stated that
provides good agreement with evaporation measured on
dam. In [
5],
is used not only as a reference method and but also a foundation of new numerical models derived by multiple linear regression and design of experiment method, followed by the simplified methodology for the quantification of the evaporation rate of a basin with a photovoltaic system. Similarly, the possibility of reduction of Lake Nasser evaporation using a floating photovoltaic system is described in [
6]. Our research is not focused only on the area of Lake Most, but also on pit lakes that are only planned, therefore it is impossible to use limnological and bathymetric data, such as temperature profile or water depth. Such a situation is considered in [
7], where authors used the
for the computation of the open water evaporation estimation.
FAO Penman–Monteith method is characterized by a strong likelihood of correctly predicting evapotranspiration in a wide range of locations and climates with differing local conditions, e.g., solar radiation, sunshine duration, wind speed, air humidity, air temperature [
8,
9,
10].
Our interest in free water surface evaporation is given by the need for ongoing hydric recultivation of the former Ležáky–Most quarry (Czech Republic), i.e., Lake Most, as well as another planned hydric recultivation in the region. One of the key components of hydric reclamation planning is the securitization of long-term sustainability, which is based on the capability of keeping the stable level of a dimension of the final water level.
Hydric recultivation was proposed to be the best way to deal with the residual of open-cut coal mines in the north-western region of the Czech Republic. After the mine is closed, the void could be filled by surface water runoff and groundwater. In the case that these resources are not strong enough, the pit lake has to be filled artificially and that is the case of the former Most-Ležáky mine and Lake Most. The level of the new lake has been proposed to be stable with a water level at
above sea level assuming the tabulated values of precipitation and evaporation between
and
annually [
11]. However, this assumption fails to be true [
12].
The evolution of artificial pit lakes is affected by a wide range of chemical, physical, and namely hydrological processes such as saturation of the coastal lines, leakage through the bottom, and free surface evaporation. As the lake bottom was sealed before filling, evaporation was supposed to be the main cause of the observed water loss.
Together with the precipitation, the open water
evaporation and vegetation
evapotranspiration form the main components of the water cycle in nature, and it is said that the evaporation over the land surface amounts to about two thirds of the average precipitation, see [
13]. However, these estimates differ from location to location and evaporation measurement or calculation procedures are complicated and burdened with a high degree of uncertainty. This happens due to the complexity of evaporation as a physical phenomenon and several factors that affect this process. The rate of evaporation could be measured or calculated, however, because of the simplification of the evaporation process description, both measurement and computational methods provide only the approximation of actual evaporation. For further discussion about the historical development of
evaporation and
evapotranspiration, see [
14] mentioning 166 models and equations obtained during the last three centuries. The description and characterization of all physical processes affecting evaporation could be found in a classical book by Brutsaert [
15], or Maidment [
16] ( Shuttleworth’s chapter).
For computational methods, there are two ways to handle evaporation, described as
mass transfer or
energy budget methods, see [
13]. Furthermore, the models could be viewed as
temperature-based,
radiation-based,
mass transfer-based, and
combined methods based on the inputs used to calculate the rate of evaporation, for additional details see [
2,
16,
17,
18].
Additionally, within each group, there are several equations, which are widely cited in the technical literature. During the study of various evaporation models in the literature, one can observe several difficulties. One of the main difficulties is the inconsistencies in the used physical units. For instance, according to the time and place of publication of articles or books, the same equation can be encountered with the pressure given in kPa, mbar, Torr or millimeters of mercury column. This variability of units can cause different shapes of the same equations in different sources, even when the same units are used. Furthermore, different types of methods require different type of data. However, in practical applications, we are not able to measure all types of input parameters, therefore the choice of the model depends not only on the modelling quality but mainly on the ability to measure the required input physical quantities.
This is one of the main reasons why the development of new simplified models is still active. The FAO equation is a solid standard, but sometimes too complex to be handled in practice. For instance, in the article [
19], eighteen
temperature-,
radiation-,
mass transfer-based and
combined methods are studied under the condition of climatic change in Germany. The FAO equation is compared with 31 methods under the
humid climate condition in Iran in the paper [
20]. In [
21], five temperature-based methods and three radiation methods are considered.
In this paper, we are looking for the simplification of the FAO equation in terms of the number of input quantities. Our goal is to use less complex models to model the evaporation in the area of Lake Most by calibrating the parameters of the models in the fitting optimization process against the evaporation estimation by FAO using selected statistical measures. The motivation came from the lack of measuring devices in the direct area of the lake. In this paper, we consider models which require only the air temperature, wind speed, and relative humidity. Besides the Lake Most, we are interested also in the planned pit lakes. Therefore, the types of models are limited to those which requires only these basic meteorological data. In this case, it is not possible to measure, for instance, the temperature of the water.
The performance of the considered methods can be evaluated statistically, and several statistical measures could be used. The most commonly used are the Root Mean Square Error (RMSE), Mean absolute error (MAE), and the Mean Bias Error (MBE), see, for instance, [
22]. Additionally, the RMSE and MBE could be combined to calculate the so-called
t-statistic test, which expresses the level of confidence between the models, see [
23]. A quite unusual measure could be found in [
24], it is
mean ratio, which is computed as the average of ratios between the predicted and observed values. Another way to compare two given models is to compute
Pearson’s correlation coefficient (PCC)
r or to compute
coefficient of determination. These two measures are closely connected since
is square of
r. The simplest measure of the prediction quality is the percentage expression of the difference between models. This is a statistical measure that is well known as percent bias (PBIAS). The last class of statistical measures that describe the correspondence of observed and simulated data are agreement indices, such as
Nash–Sutcliffe efficiency (NSE) and
Willmot’s agreement index. These are used, for example, in [
21,
25,
26]. For further discussion of statistical model evaluations, see [
27]. In this paper, we compare several selected statistical measures, namely
, and
. However, we suppose that our methodology can be applied to any chosen distance function. The applicability depends on the ability to solve the corresponding regression problem.
The choice of temperature-based methods in the case of the Lake Most study is not due to the current lack of meteorological data since Kopisty meteostation is located only from the lake. The simplification of the equation is motivated by the further planned hydric recultivations in the region. Planned pit lakes are more distant from Kopisty and therefore the meteorological data provided to the models from Kopisty would not be sufficient. The data provided to the models on new lakes will be measured directly on the area of new lakes. In the case of Lake Most, we can identify the appropriate simplified model because of advantageous location of Kopisty with respect to Lake Most. Therefore, we are interested in the identification of the simplest suitable model with the low demand on input data. The construction of the new weather station in the area closer to the new lake does not make any sense from the financial point of view (because of the presence of Kopisty weather station). On the other hand, to provide better estimations, we should measure the input data as close as possible to the area of interest. The measurement of, for instance, the temperature is relatively cheap. The only question is if the temperature is a sufficient amount of input meteorological data for providing a sufficient estimation. The accuracy of the water loss due to evaporation is crucial for those planned artificial lakes. To provide the best possible estimate, the experiences from the Lake Most will be used. In this paper, we compare several simplified models with respect to different statistical measures, namely , and .
Additionally, to avoid the overfitting of the calibrated model, we adopt the cross-validation methodology [
28]. We randomly split the data into calibration and validation parts. The parameters of the model are optimized on the calibration set and tested on the validation part. Results from the validation part are further analyzed and the best model is chosen concerning results from all cross-validation splittings.
The paper is organized as follows.
Section 2.4 introduces the methods and materials used in our computation. To be more specific, we start with the presentation of the Lake Most in
Section 2.1, and the data provided to the models in
Section 2.2. Afterwards, we review the FAO equation in
Section 2.3 and the simplified models in
Section 2.4. During the calibration process, we use the statistical measures presented in
Section 2.5. The whole methodology is implemented in R programming language, see
Section 2.6 for details. This section also includes the description of the used cross-validation process. The results are presented in
Section 3 and discussed in
Section 4. Finally,
Section 5 concludes the paper.
The paper can be considered to be an extension of our previously published work [
29].
2. Materials and Methods
2.1. Study Area
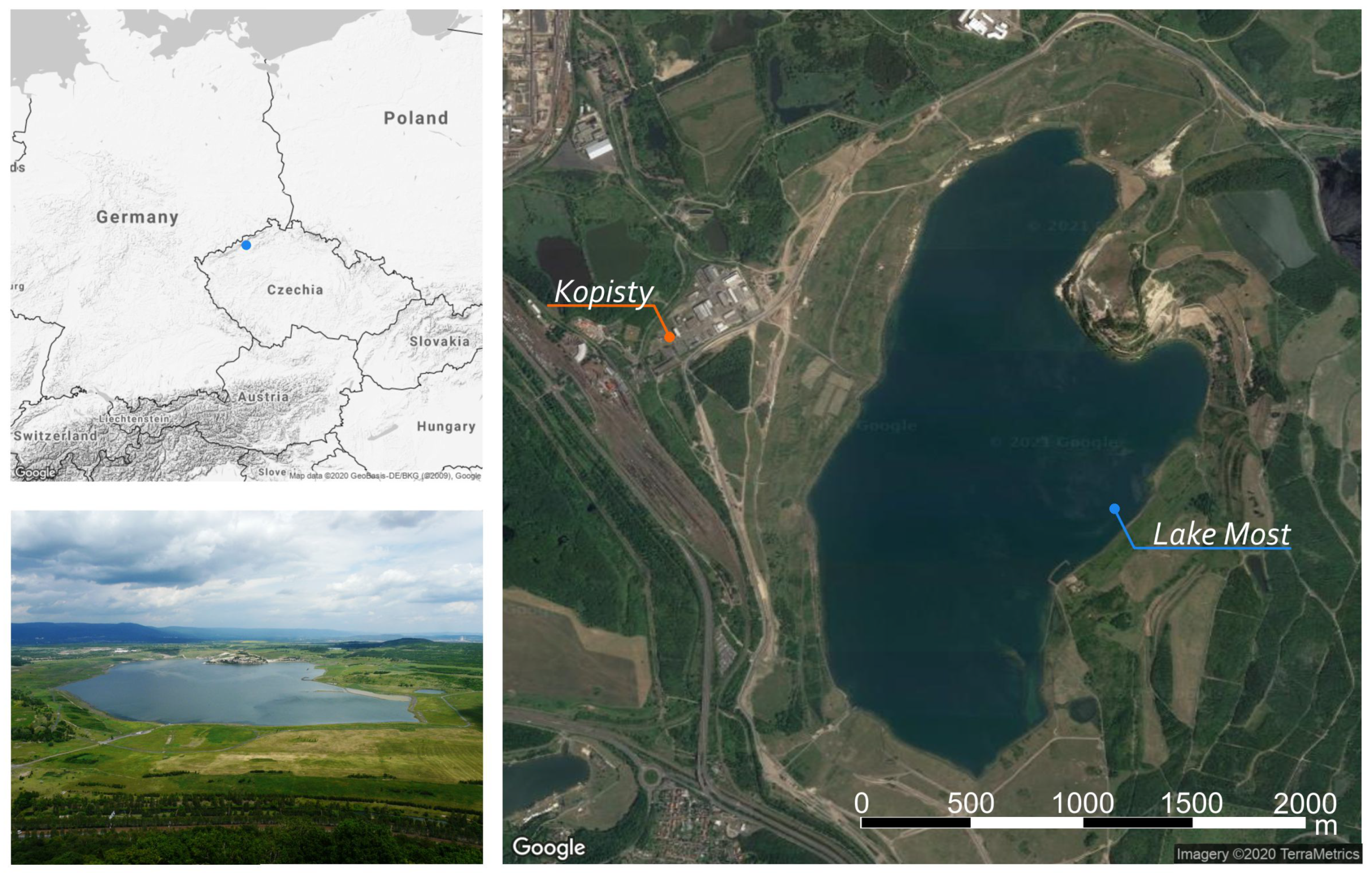
The Lake Most is situated in the North of the Czech Republic near the city of Most 50°C310
N, 13°C360
E, see
Figure 1. It was created by the hydric recultivation of the
Most–Ležáky quarry in the central part of the
North Bohemian brown coal basin. The former mine heavily affected the area of
and the pit lake, as a part of its revitalization, was planned to have a surface area of about
. The project of the revitalization is secured by the state enterprise
Palivový kombinát Ústí (PKU) [
30].
Before the flooding, it was necessary to take technical arrangements such as sealing the bottom of the future lake, construction of an underground sealing wall, and strengthening the shoreline. All these arrangements allow viewing the Lake Most as a closed system without natural inflow or outflow. Due to the absent natural inflow, the residual pit of the lake was filled through an artificial feeder during the period from 2008 to 2014. In the final phase of lake filling, i.e., in the year 2014, the surface level rose from to the required level of above sea level.
After finishing the filling process, Lake Most has an actual surface area of , a coastal line length of , a total water volume of , and a maximum depth of . Throughout the filling of the lake, both operational and basic meteorological data were monitored. The operational data contain data on the achieved altitude of the lake level, its surface area, and especially on the volume of water admitted. The filling of the lake has been finished in 2014 achieving the required surface level of .
2.2. Data and Data Sources
In our research, we are using the meteorological data collected during the years 2015–2019. The collection includes all data necessary for the calculation of the Penman–Monteith equation (see
Section 2.3). These meteorological measurements were performed at the
Kopisty weather station situated approximately
from the lake. The station is operated by
CHMI—Czech Hydrometeorological Institute and the data are recorded at ten-minute intervals. The dataset obtained from
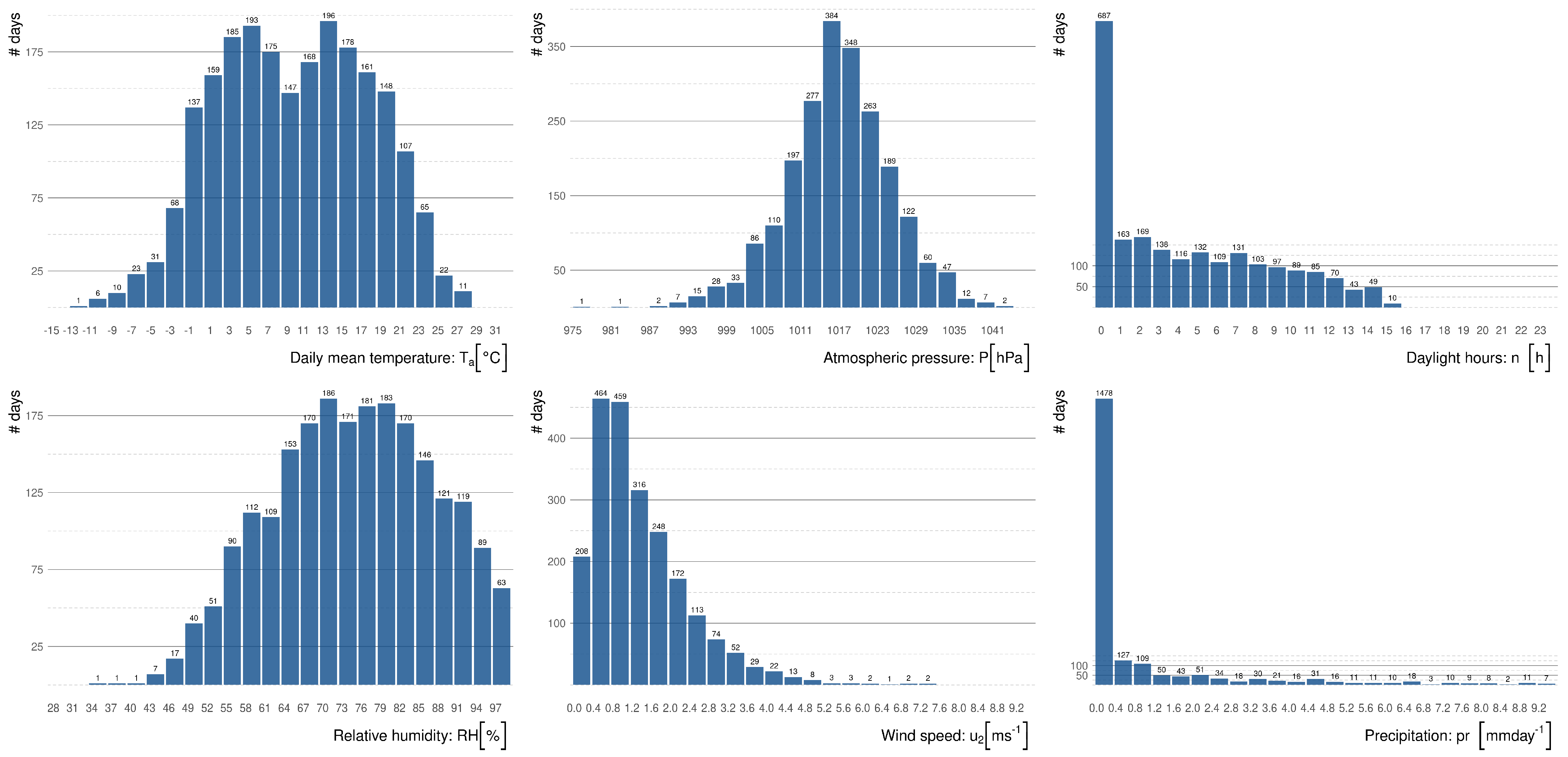
CHMI was statistically processed to be used in the equations to model the evaporation. We present the data basic statistics in
Figure 2. In
Kopisty weather station, the wind speed is measured at
above the ground to avoid the influence of the ground. The air temperature and humidity are measured at
above the ground.
We also included precipitation frequency for the demonstration of the hydrological balance in the area of interest. In comparison with the average temperature and precipitation in the Czech Republic, the area of the planned hydric reclamation is in the area with the temperature strongly above the average and precipitation strongly below normal precipitation, and with the number of hours of sunshine below the typical value in the Czech Republic [
11].
2.3. Penman–Monteith Equation
The
equation is of the form
Please see Section Abbreviations at the end of this paper for the description and physical units of the used variables.
According to
Linacre paper [
31] for daily estimates of the evaporation rate of free water level, the term
G can be neglected, i.e., we set
.
The term
in
, is the difference of saturation vapor pressure and actual vapor pressure. The values
and
are given by
The psychrometric constant
depends on the atmospheric pressure
P in
and on above-mentioned constants
,
and
, with
being ratio molecular weight of water vapor to dry air. To compute its value, the following formula is used
Using this formula, the computed value of depends only on one measured quantity and that is atmospheric pressure P and is given in .
The slope
describes the relationship between saturation vapor pressure and temperature. For a given temperature
, the corresponding
is given by
The resulting unit of is .
The net radiation at the surface
in
is, by [
1], given as the difference incoming net short wave radiation
and outgoing net long wave radiation
, i.e.,
To evaluate , the knowledge of solar radiation and global extraterrestrial radiation, is required.
Extraterrestrial radiation is the amount of radiation incident on a unit of the horizontal surface at the outer boundary of the atmosphere. For places of similar latitude, it is approximately the same, changing only during the year. There is no influence of cloud turbidity or air pollution over the Earth’s atmosphere, and therefore, the dose of solar energy is the highest at any given time. In addition to the solar constant, the angle of incidence of the sun’s rays at a given location of the atmosphere boundary must also be taken into account. Therefore, the value of
is expressed depending on these quantities as
The terms included in Equation (
5) are
The terms
and
could be computed by
where
are
Angström coefficients,
and
are
actual and
maximum possible duration of daylight, respectively. Finally,
denotes
albedo, i.e., the coefficient of reflection.
As the
Angström coefficients are not calculated based on the actual solar radiation measurements here, the
FAO paper [
1] recommendation
and
in Equation (
6) is used. Furthermore, the
free water surface albedo is set as
based on [
1].
The maximum daylight duration
N is computed as
To determine
net longwave radiation , the following formula is used
The above formula (
9) uses the
Stefan-Boltzmann constant
and
in
, which is the
clear-sky radiation.
The value of the
clear-sky radiation is calculated as
where
z is the site
altitude in
above the sea level.
However, despite its complexity of the FAO Penman–Monteith Equation (
1), it is not possible to consider
results to be accurate, since the number of input data to be measured or calculated by empirical formulae based on measured input data. Such an estimation process is affected by measurement and calculation errors. For example, in [
32,
33], one could find sensitivity analysis of the FAO Penman–Monteith equation in different climate conditions.
It should be pointed out that Equation (
1) was derived as a method to determine the
reference rate of evapotranspiration, i.e., the reference rate of evaporation from growing plants with the characteristics of
hypothetical reference crops such as
height,
aerodynamic resistance of their surface, and
albedo. For
real crops, the rate of evapotranspiration is determined from
by multiplying the crop-related coefficient
With the proper coefficient, the
formula could be used to estimate open water evaporation. The values of coefficient
, i.e.,
and
for mid and end season respectively are tabulated in [
1]. Specifically,
for
shallow lakes, i.e., for those with a depth of up to
. For
deep lakes, i.e., with a depth exceeding
, the values
and
are indicated. Therefore, it should be borne in mind that (especially in the case of deep lakes) the result of
could lead to the underestimation of up to
or the overestimation up to
during the season.
Since our research is not focused only on the area of Lake Most, but also on lakes that are only planned and does not exist at present, it is impossible to use limnological and bathymetric data, such as temperature profile or water depth. This leads us to the considerations of the article [
7], which states that in the case of missing
limnological data, the lake coefficient
can be selected and
result itself could be considered to be an open water evaporation estimate. Hence, in all our calibration and validation processes, the equation
serves us as an etalon and all our results are compared against it.
2.4. Evaporation Estimation Methods
Since the FAO Penman–Monteith equation
(see (
1) in
Section 2.3) is very input-intensive and complex in its calculation procedure, many other methods have been derived to determine the rate of evaporation. Depending on the inputs of the method, we divide them into temperature-, radiation-, mass transfer-based, and combined methods.
Temperature-based method equations can be considered the simplest type of equations. They primarily work with a single variable, namely the average mean air temperature . Quite often these equations have a linear form , but they also occur in the form , or the form of exponential formula or . However, the group also includes relations in which the temperature occurs in combination with a member comprising, for instance, relative humidity or theoretical length of the solar day N.
In this section, we selected 7 simple (in comparison to the complexity of FAO Penman–Monteith) evaporation models for the demonstration of our calibration approach.
2.4.1. Regression Derived Relations—Czech Republic
The following three relations are used in the Czech Republic. They are derived by regression between the observed evaporation and mean daily air temperature, using statistical regression to find both
linear and
exponential models. The model relations presented in this section are compared in the paper [
34] with measurements on
evaporation pan placed in the meteorological station
Hlasivo near the city of Tábor 49°C290
N, 14°C450
E) in the South Bohemian Region. This station is operated by
Výzkumný ústav vodohospodářský T. G. Masaryka (VUV, T. G. Masaryk Water Research Institute) and was built in 1957 and has a
evaporation tank,
GGI-3000 pan and
Class-A pan. The pan evaporation measurements here are carried out from May to October, which is due to the temperatures below the freezing point in the winter months. The models are given by
where
is the equation according to Šermer [
35],
according to Beran and Vizina [
36], and
according to Adam Beran from VUV published in the official report
Model průběhu meteorologických veličin pro oblast jezera Most do roku 2050 (The modelling of the course of meteorological quantities for Lake Most area until 2050). In all equations, the evaporation rate is determined in
. Equation (
10) has the form of an exponential function and therefore its results can never be negative. However, it must be mentioned that there are limitations of Equations (
11) and (
12): if the equation produces the negative evaporation estimation, we set the value equal to zero. For instance,
is set on days with the mean temperature below
, since
would be negative in such cases.
To calibrate the models, we present a parametric formulation of the Equations (
10)–(
12) by
where
are unknown parameters, which will be calibrated. We extended models by projection to nonnegative numbers (using the outer max function) to enforce the computed nonnegative evaporation.
2.4.2. Kharrufa
The equation presented by
Kharrufa in [
37] is an example of a nonlinear temperature formula. It is mostly written in the literature in the form
and results in the evaporation rate in
. In (
16), variable
p denotes the percentage of total daytime hours for the daily period out of total daytime hours of the year. This form is used, for instance, in [
38,
39]. The coefficient
was found empirically and it is possible to refine it with respect to the site-specific conditions. For example, in [
34], the form
is given with the formula being calibrated for the conditions of the
Hlasivo weather station in the South Bohemian Region. In this study, the form (
16) with coefficient
is used.
In this paper, we the calibrate model (
16) introducing the parametric version
and calibrate the unknown parameters
.
2.4.3. Hargreaves–Samani
Another method was introduced by
Hargreaves in article [
40] and further modified to the form which can be found in article [
41]. Usually, the
Hargreaves–Samani equation is given in its basic form
In this equation, variable denotes the difference between daily maximum and minimum air temperatures .
Although the formula contains a radiation term
, it is ranked among the temperature-based formulae since the term
here is just a theoretical value calculated according to Formula (
5). Using this computation of
, the
Hargreaves–Samani equation takes any of the following equivalent forms
The difference of these forms is only in the usage of division by the latent heat of vaporization of water , which is performed to obtain the results in millimetres per day.
In this paper, we consider the parametric form of Hargreaves–Samani Equation (
18)
with parameters
. These parameters will be optimized during the calibration process.
2.4.4. Schendel
In contrast to the formulae mentioned above, in which the air temperature is sufficient to calculate the evaporation rate, the air relative humidity
measurement is required in the following
Schendel equation. The formula has a simple form
The equation can be found in the original
Schendel paper [
42]. It is used by many authors, for example, see [
19,
20].
To calibrate this model, we consider the Schendel Equation (
22) in the parametric form
with unknown parameter
.
2.4.5. Priestley–Taylor Equation
A potential evapotranspiration based on the Priestley–Taylor can be considered to be a combined method, which is developed as a combination of the turbulent diffusion method and the method of energy balance [
43]. The basic equation for the computation of the potential evapotranspiration by the Priestley–Taylor method is given by
Please see Section Abbreviations in the end of this paper for the description of the used variables.
In this paper, we optimize the constant parameter in Equation (
22), i.e., we consider a parametric model
where
is unknown parameter.
2.4.6. Turc Equation
The Turc method was developed for the climatic conditions of western Europe [
44]. Several forms of Turc equation could be found in the literature. In this paper, we are considering the one from [
45], i.e.,
The term
total solar radiation is computed using Equation (
6).
In this paper, we calibrate the Turc Equation (
24) with respect to two parameters, namely we work with the parametric model
where the term
and its conditions remains the same as in (
24).
2.5. Statistical Measures
To compare the performance and predictive power of each evaporation estimate method E defined in the previous section against the FAO Penman–Monteith equation, the following statistical measures are used: Nash–Sutcliffe efficiency (NSE), root mean square error (RMSE), mean absolute error (MAE), and percent bias (PBIAS). Each of these measures offers a description of the difference between observed or measured and predicted or calculated values.
One of the most popular measures that assesses model predictive power is
Nash–Sutcliffe efficiency (NSE), see [
46], which tries to capture the extent of errors and their degree of variability. It is given by
where
T is several observations and
is the mean value of FAO Penman–Monteith model given by
The NSE index indicates the relative magnitude of the residual variance (“noise”) compared to the measured data variance (“information”), see [
27]. The index shows, among other things, how well the
scatterplot of the observed and modelled data corresponds to a 1:1 straight line. NSE takes the value
and
indicates a perfect match. The value
means that the model predicts with the same accuracy as the observation mean. Negative values of NSE indicate an
unacceptable model.
To capture the size of individual errors
,
root mean square error (RMSE) and the
mean absolute error (MAE) could be used. They are defined by
Both and also express the model error in units corresponding to the units of the value observed. The value captures the mean error size and similar information is provided by . However, attaches more weight to larger errors and thus suggests the presence of “extreme error”. For both and , it should be noted that their results are always greater than zero, which results in the loss of overvaluation or undervaluation information. For both, their lower value indicates a better model. Concerning the and indicators, the half standard deviation rule is also mentioned; i.e., in a good model, , as well as should be less than half the standard deviation of the observed variable.
The simplest measure of the prediction quality is the difference
or the percentage expression of this difference. This value is called
percent bias and it is computed as
where
is the value of the model in time (day)
.
We used the presented statistical measures to calibrate the parameters of the models, i.e., for each model and measure, we solve the minimization problem
in the case of
(given by Equations (
27)–(
29)), or the maximization problem
in the case of
(given by (
26)). In both problems,
represents the considered parametric model which has to be calibrated, i.e., one of Equations (
13)–(
15), (
17), (
19), (
21), or (
23).
During our experiments on model calibration using different statistical measures, we observed that the maximization of and minimization of produce the same optimizer. The following theorem supports this observation with theoretical proof.
Proof. From the definition of the optimality point
of the optimization problem on the left side of (
32), we can write for all possible parameters
i.e., using the definition (
26)
This inequality can be modified to an equivalent form subtracting 1 from both sides and multiplying by constant negative term
to obtain
We divide this inequality by a positive number of data points
T and apply the square root to both sides. Since both sides of the original inequality are nonnegative values and the square root is an increasing function, the following inequality is equivalent to the previous one
i.e., using the definition (
27)
This is the optimality condition for the solution of the optimization problem on the right side of (
32). □
2.6. Implementation
We have implemented the calibration process in R programming language [
47]. This software provides us with an easy way how to load the data, manipulate them, solve the corresponding optimization problems, and present the results.
The type of the optimization problem depends on the considered model and the selected statistical measure, see (
30) and (
31). We compared several solvers provided by R programming language (both in computational time and the accuracy of the results) and we observed that the
nlminb algorithm from
optim package is the most efficient option for solving the optimization problems. This algorithm is using PORT routines [
48] and our numerical experiments proved the suitability and stability during the solution of both linear and nonlinear models.
To generalize our calibration process, we adopt the
cross-validation methodology [
28]. The modelling with a random subset of data generalizes the results and avoids overfitting. In our case, we perform 10 random permutations of the data (please notice that the statistical measures which we are using are independent of the order in time). We split each permutation into 10 parts—9 of them is used for calibrating the model (i.e., solution of (
30) or (
31)) and the remaining part is used for validation. See
Figure 3, where we demonstrate performed 10 calibration-validation processes on one specific data permutation. We repeat this permutation 100 times and for each of this permutation, we repeat 10 calibration-validation splittings. In total, we obtain 1000 results of the calibration process, which are further analyzed. This method is well known as K-fold cross-validation.
3. Results
We calibrate the models (
Section 2.4) against the FAO Penman–Monteith equation (
Section 2.3) using the criteria (
Section 2.5) and cross-validation process (
Section 2.6). In the comparison of the original models, the calibration process always results in better statistical values, see
Table 1. The value has been obtained using the parameters presented in
Table 2 on the whole data set.
The parameters of the optimal models have been chosen as a mean value of the statistical measure on testing data. As was described in
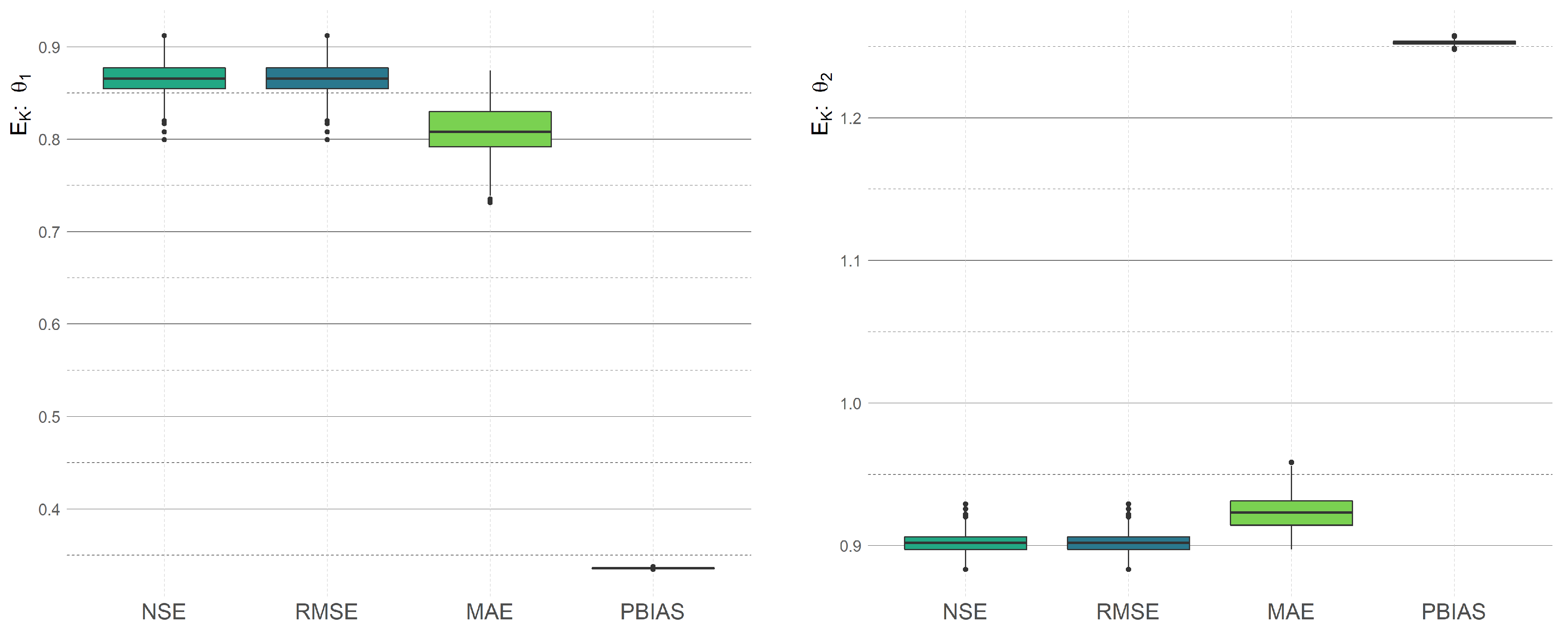
Section 2.6, we are calibrating models on the random part of a given data set and since the optimal parameters depend on this choice, the calibrated parameters are also random variables. Consequently, the new value of the statistical measure is random as well. See
Figure 4, where we demonstrate the
randomness of the statistical value—we plot the statistical measure of the original model on different training data and compare them with the statistical measures obtained by the calibration process on these training data. The final calibrated model has been chosen as a model, which corresponds to the mean value of the obtained calibrations. Each of the presented graphs corresponds to different statistical measures in the calibration.
We calibrated the models with respect to all considered statistical measures and we track the change of other measures. As an example, see
Table 3,
Table 4 and
Table 5 for the results in the case of the Kharrufa model, Hargreaves–Samani model, and Turc model.
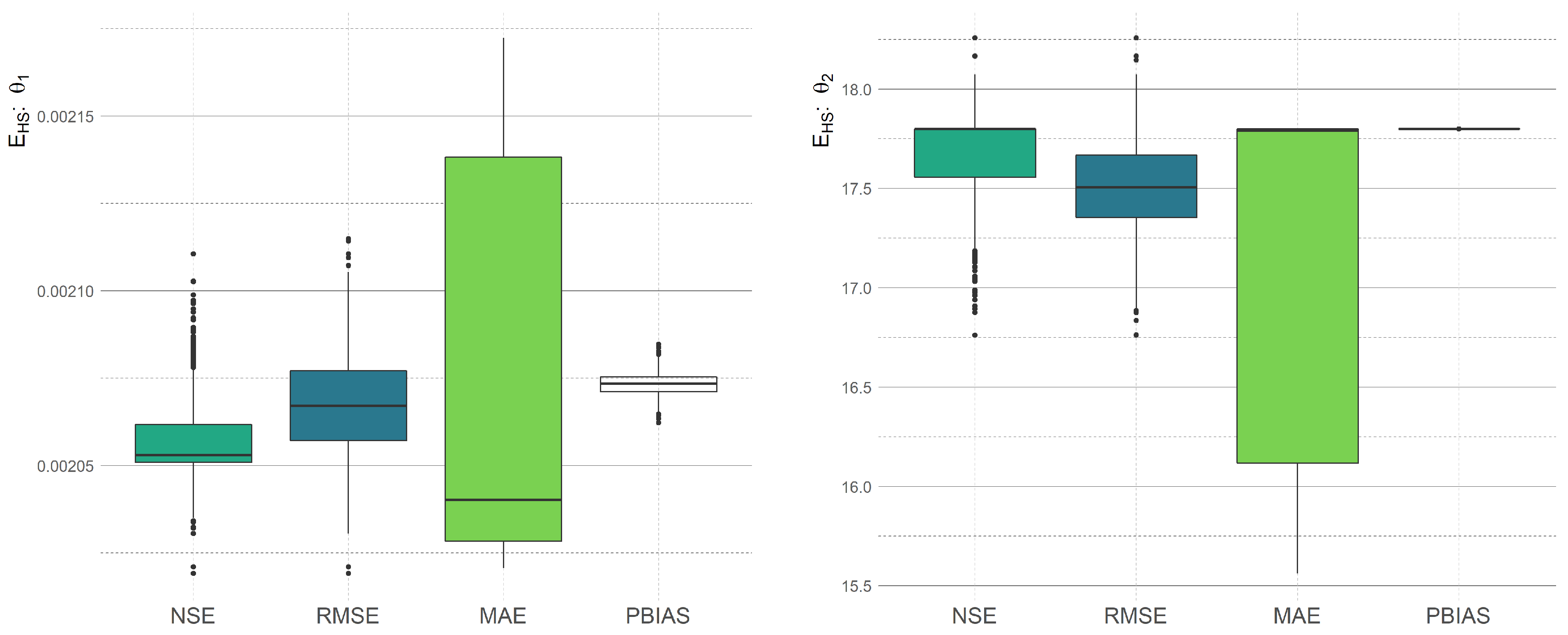
As we mentioned above, the random choice of calibration data in the calibration process causes the randomness of the optimal parameters. In
Figure 5,
Figure 6 and
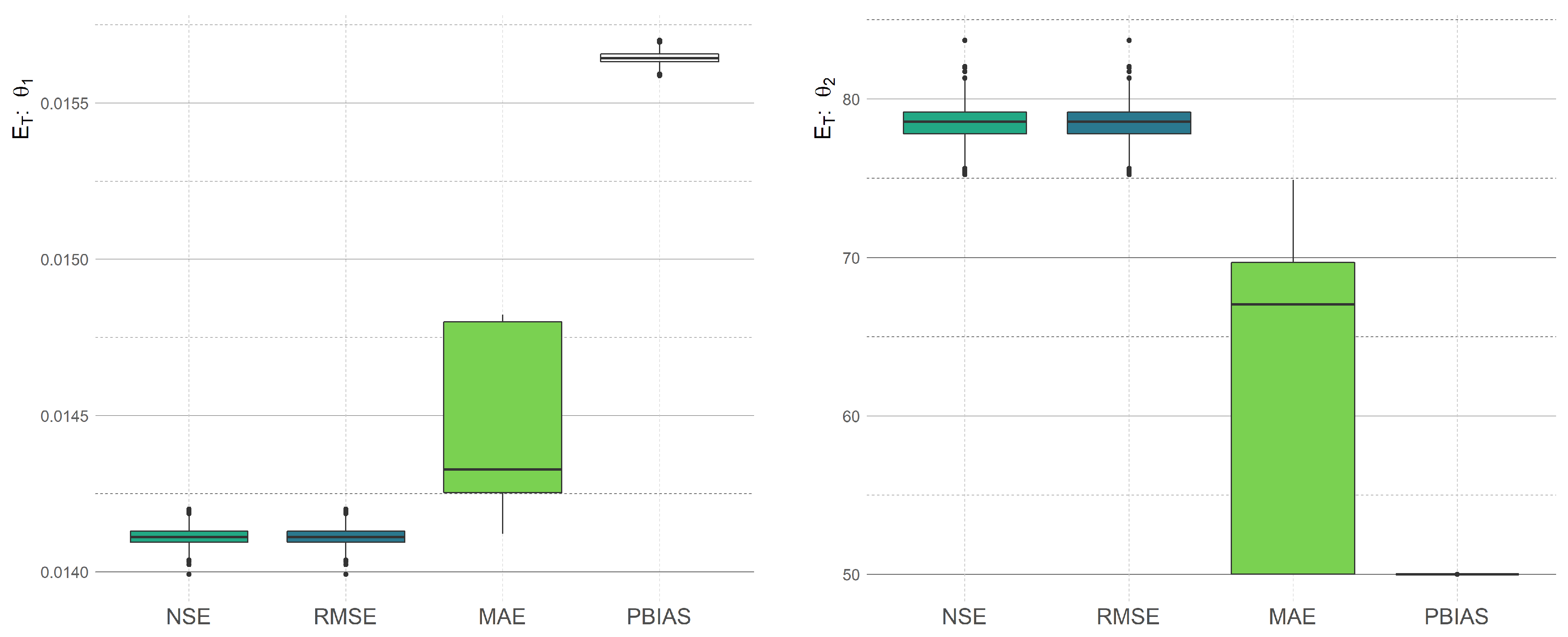
Figure 7, we present the different optimal values of calibrated models with respect to various statistical measures. We can observe that using the cross-validation approach, the final optimal parameters are a random variable as well.
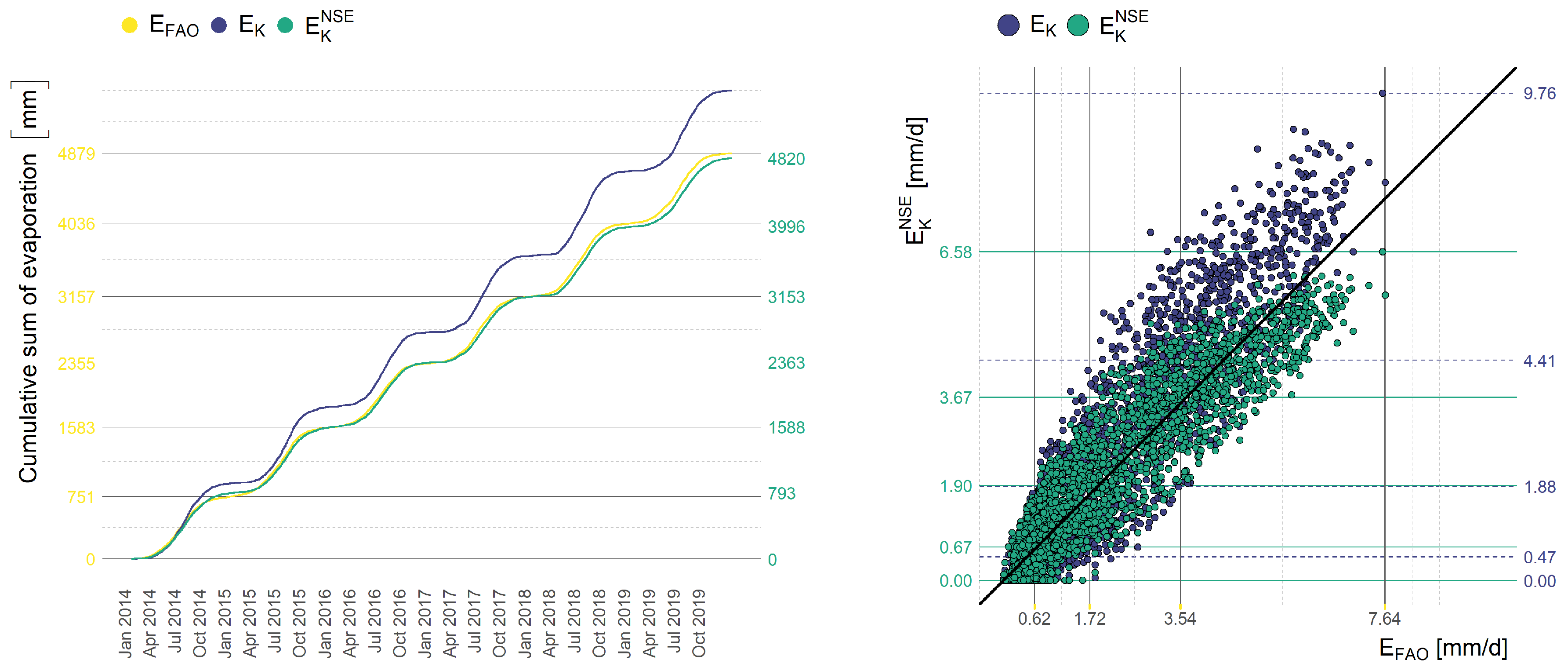
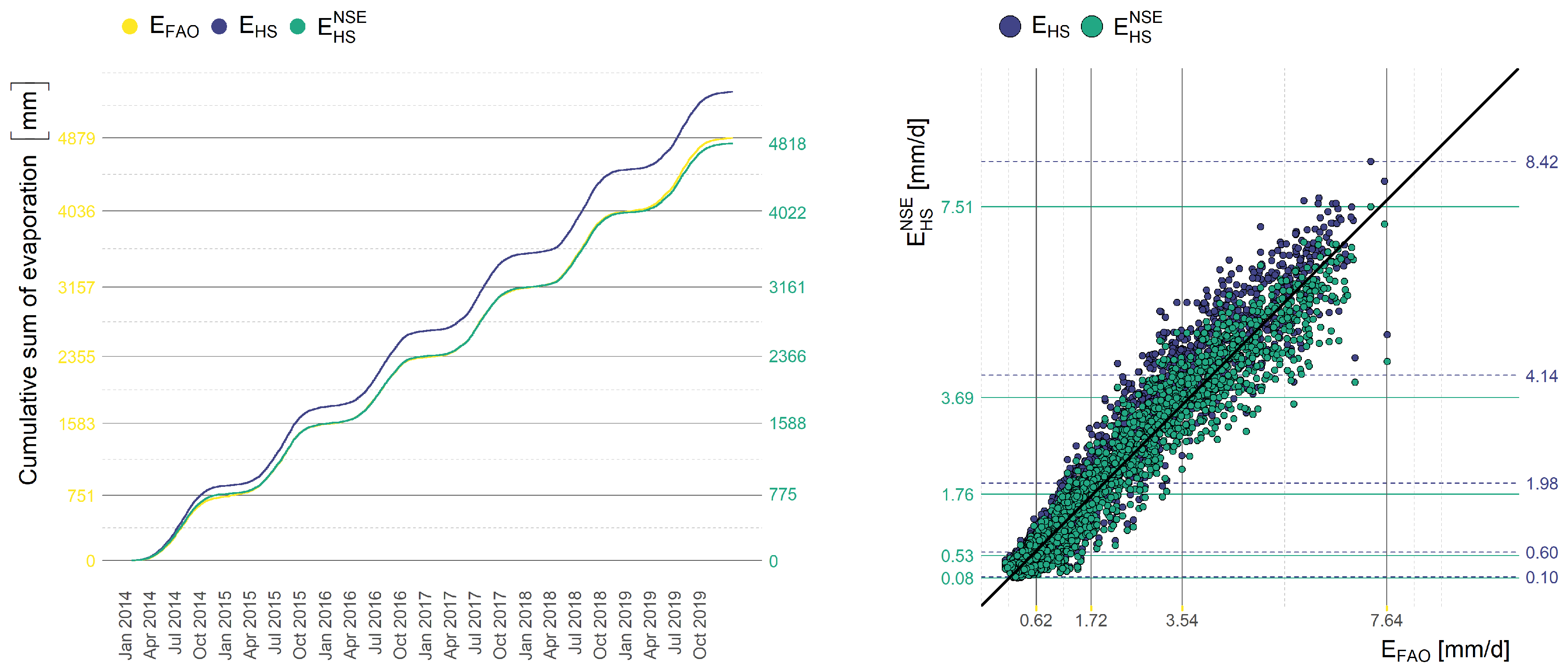
The calibration process fits the model to the values computed by the FAO Penman–Monteith equation. We demonstrate this capability on specific examples.
Figure 8,
Figure 9 and
Figure 10 present the comparison of monthly evaporation computed by FAO Penman–Monteith Equation (
1), Hargreaves–Samani Equation (
16), and calibrated Hargreaves–Samani Equation (
17) in the form of cumulative sum and the scatter plot. The calibration has been performed with respect to NSE.
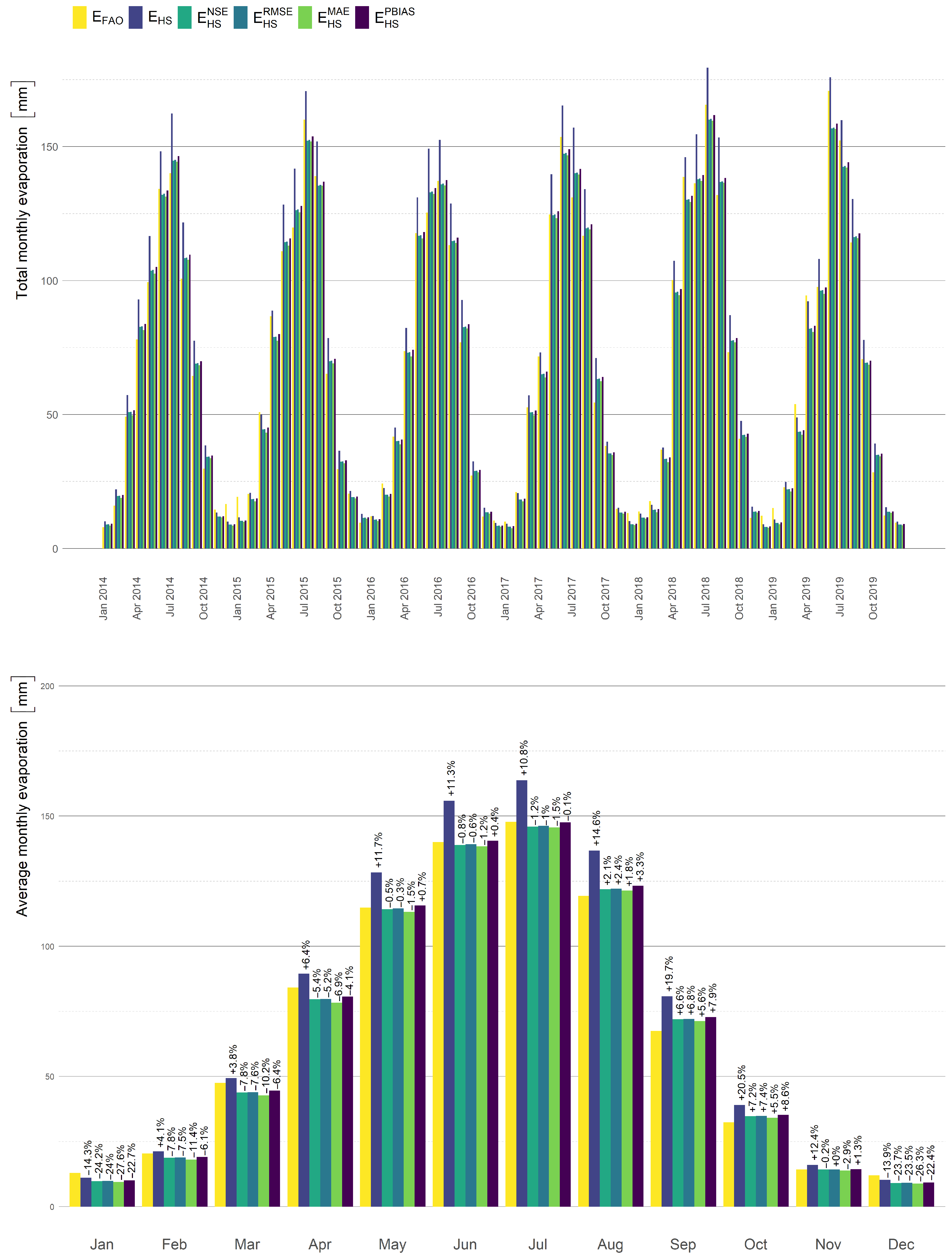
The final result is presented in
Figure 11. Here, we demonstrate the monthly evaporation computed by Hargreaves–Samani equation in the form of a time-line and histogram of evaporation in months. The parameters of the calibrated models can be found in
Table 2 and the improvement of the used statistical measure on the whole data set in
Table 1.
4. Discussion
In our results presented in the previous section, we processed the results of calibration on random data from the cross-validation process (see
Section 2.6). Before the selection of the mean model, we removed the outliers based on the quartile thresholding. For instance, in the case of the Kharrufa equation calibrated with respect to
, we removed 11 outliers more than 1.5 interquartile ranges (IQRs) below the first quartile or above the third quartile.
Our results show that the calibrated parameters depend on the chosen statistical measure, see
Table 2. However, all of them are improving the objective value in comparison with the original equations, see
Table 1.
From the obtained results, we observed that the calibration with respect to one selected measure improves not only this objective measure but also improves the remaining measures. See
Table 3,
Table 4 and
Table 5, where we examined the Kharrufa, Hargreaves–Samani, and Turc model.
The measures presented in
Section 2.5 are defined as the sum of local differences. Our results of cumulative evaporation presented in
Figure 8,
Figure 9 and
Figure 10 show the consequences of the formulation of the objective function in this form—the cumulative evaporation computed by the optimal calibrated model fits the cumulative evaporation computed by the
equation. We observed this property in the case of all measures. However, in the case of daily evaporation (or monthly evaporation), the local difference can be large, see
Figure 11. Evaporation in some months has been underestimated and in other months has been overestimated. In any case, this underestimation and overestimation are always better than in the case of the original equation.
The obtained results follow the equivalency of the calibration process based on
maximization and
minimization, i.e., Theorem 1. Please see
Figure 5,
Figure 6 and
Figure 7, where we demonstrate the density of optimal parameters of the calibrated Kharrufa, Hargreaves–Samani, and Turc equation with respect to the random data split in the cross-validation process. The small difference between
and
is caused by the error of the iterative algorithm: the optimization algorithm has a stopping criterium based on the change of the function value. Since the
and
have different objective functions, the iterative algorithm stops the optimization prematurely (sufficiently approximately) in different optimizers. Especially in the case of
Figure 6, the difference is clearly observable. However, in this case, we are dealing with the Hargreaves–Samani model (
19). We suppose that this difference is caused by the non-linearity of the model (and the non-linearity of used statistical measures). The difference between objective functions in the solutions computed by
and
is approximately
(see
Table 4), which is the value used in the stopping criteria of the iterative optimization algorithm. The situation is similar for
.
The results obtained by our analysis show that the calibrated Hargreaves–Samani and Turc models seem to be the most suitable simplification of the FAO Penman–Monteith equation in the area of Lake Most. However, it is necessary to mention that the final choice of the most suitable calibrated equation for evaporation modelling depends not only on the final value of the statistical measures but also on the input data requirements. Therefore, we suggest using the Hargreaves–Samani equation since this equation requires only the input of the extraterrestrial radiation and the air temperature, see Equation (
18).
Figure 11 presents the final improved evaporation estimation.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}