
Reservoir Sediment Management Using Artificial Neural Networks: A Case Study of the Lower Section of the Alpine Saalach River



Abstract
:1. Introduction
2. Materials and Methods
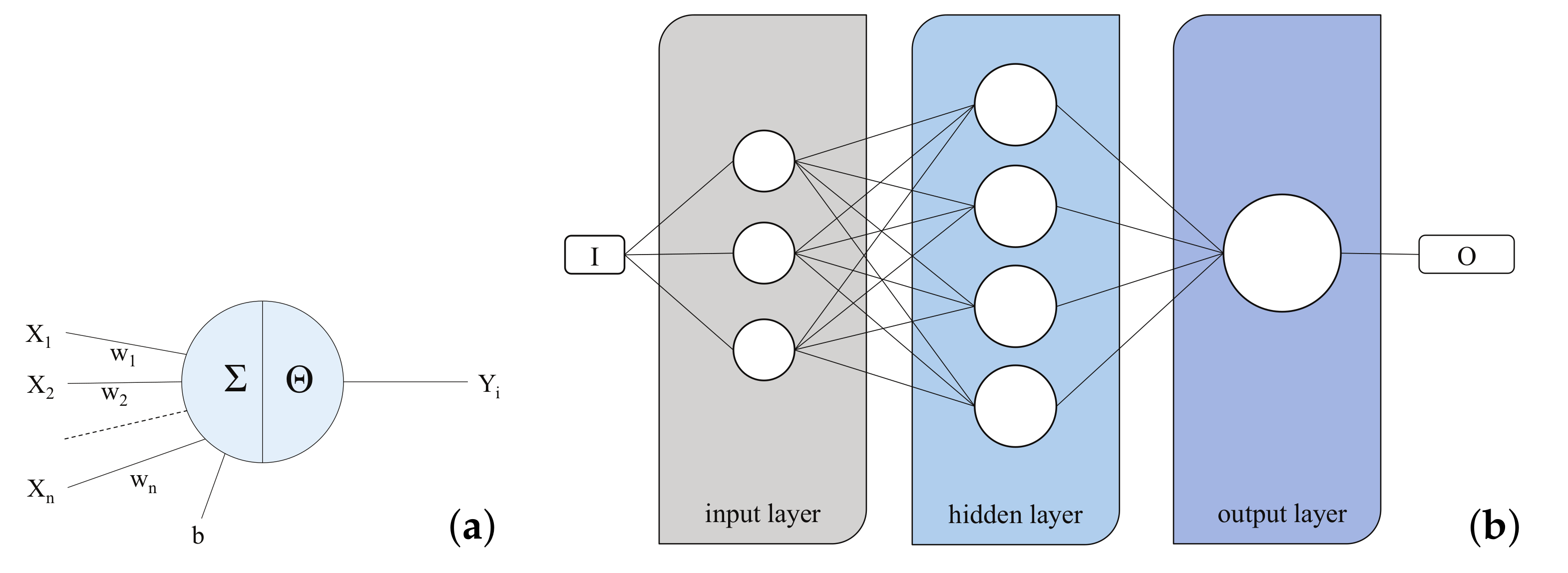
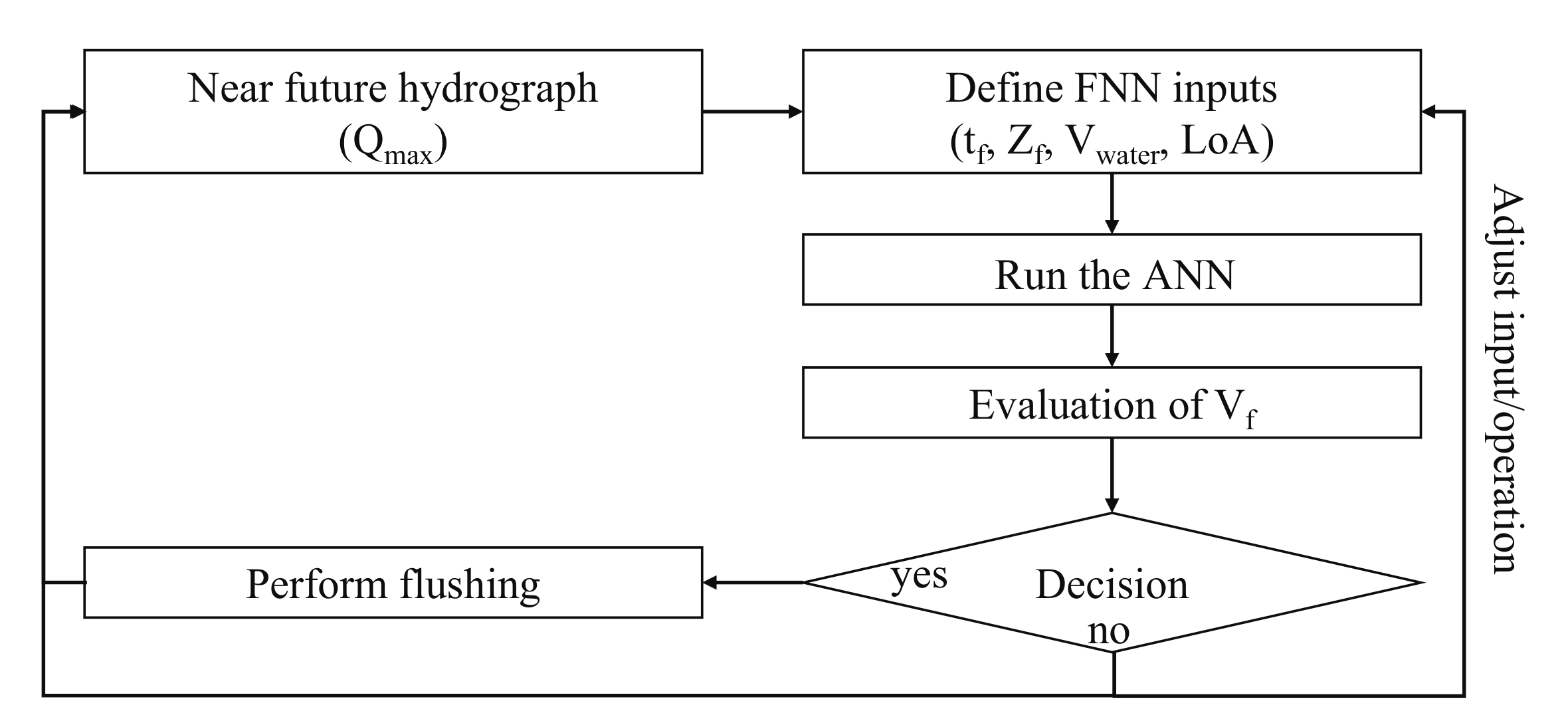
2.1. Artificial Neural Networks
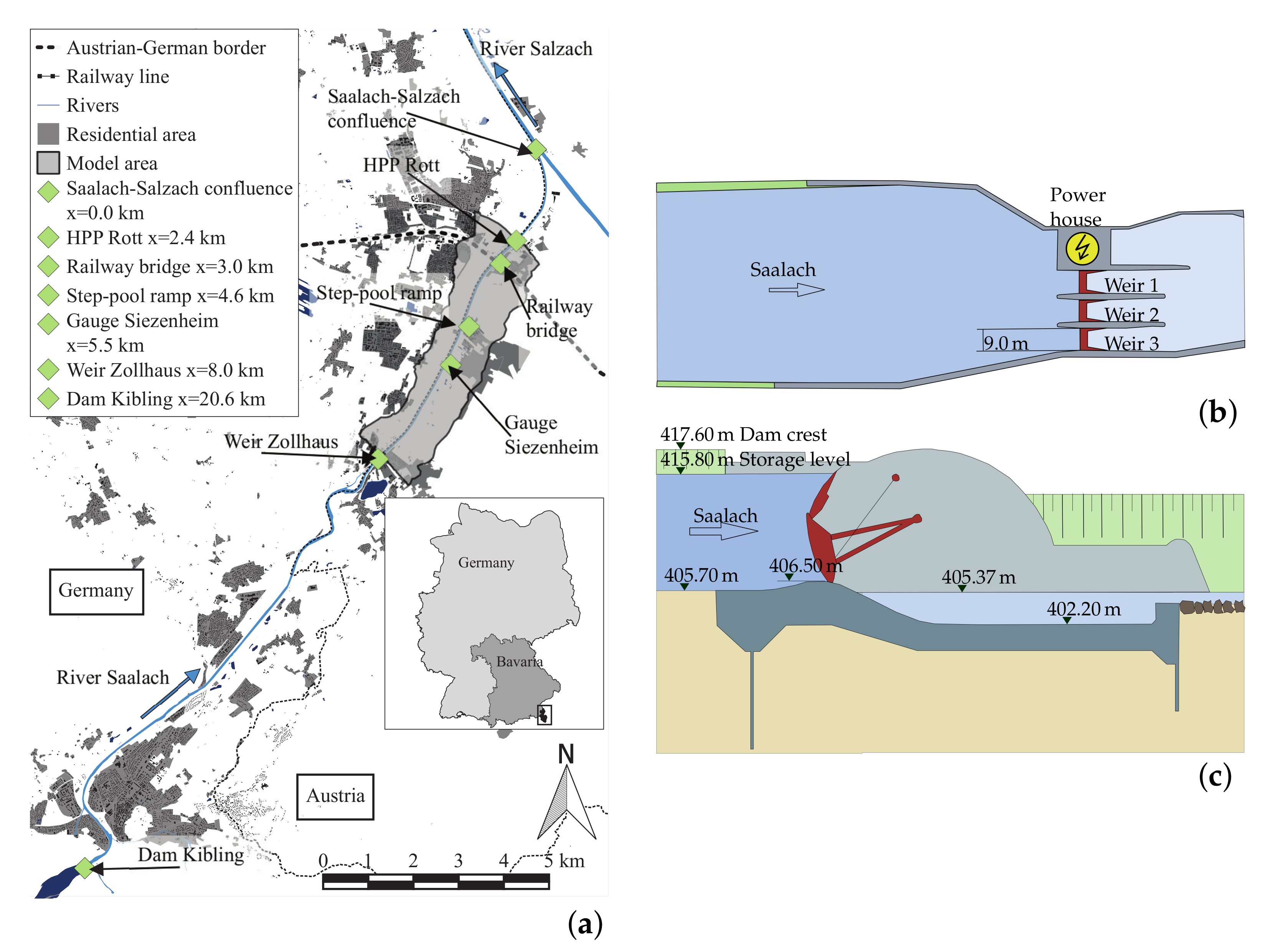
2.2. Study Site
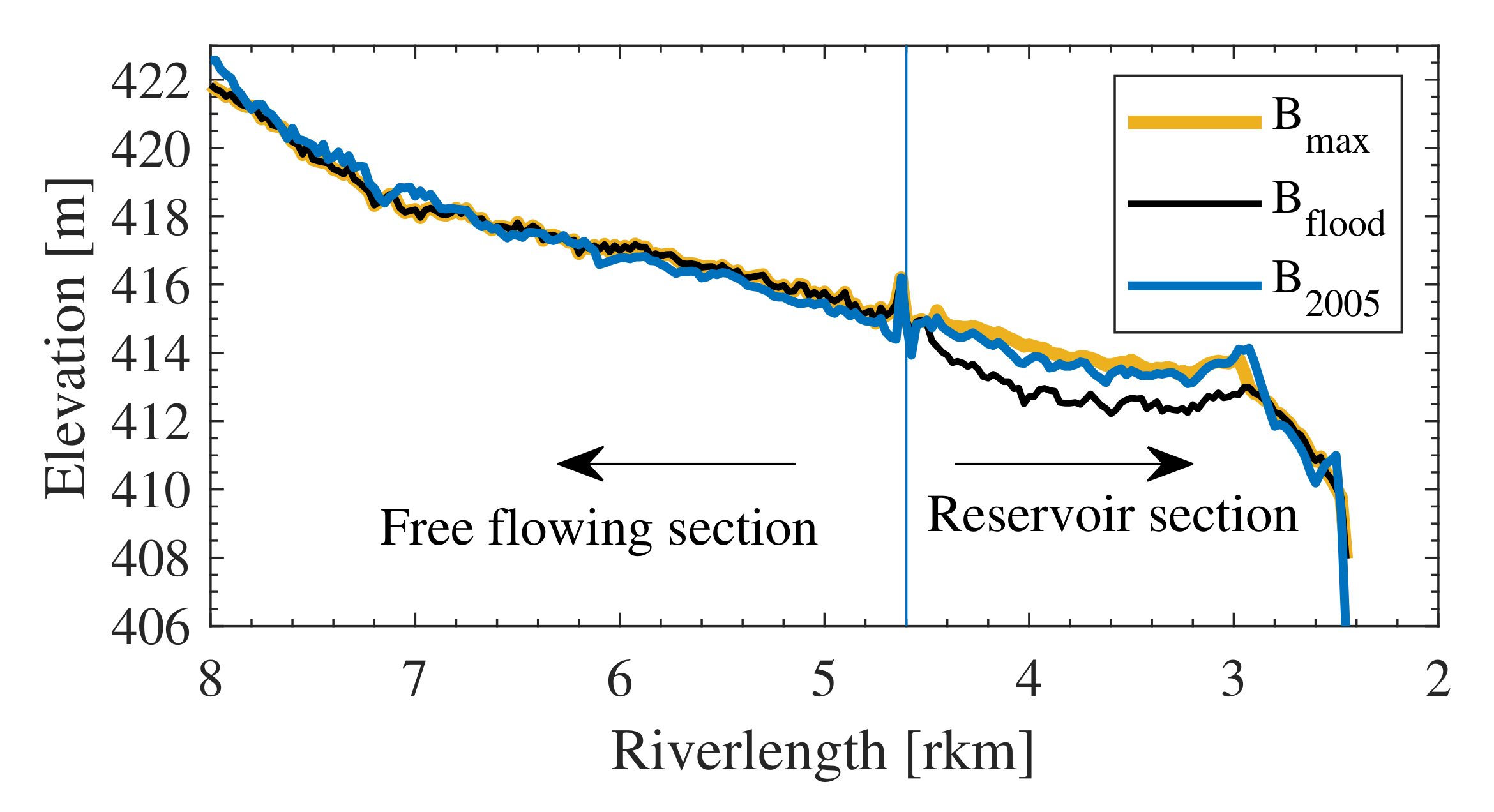
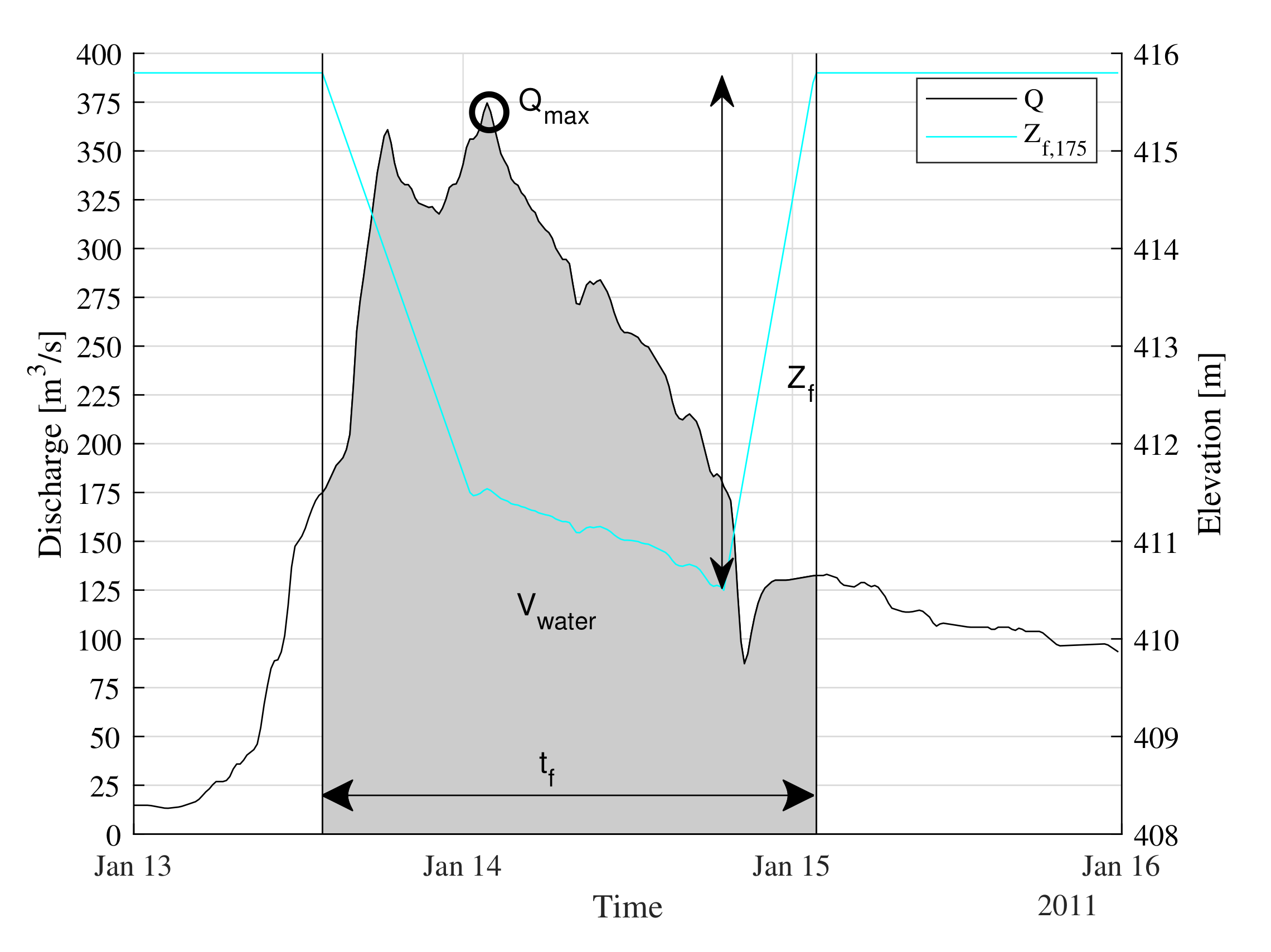
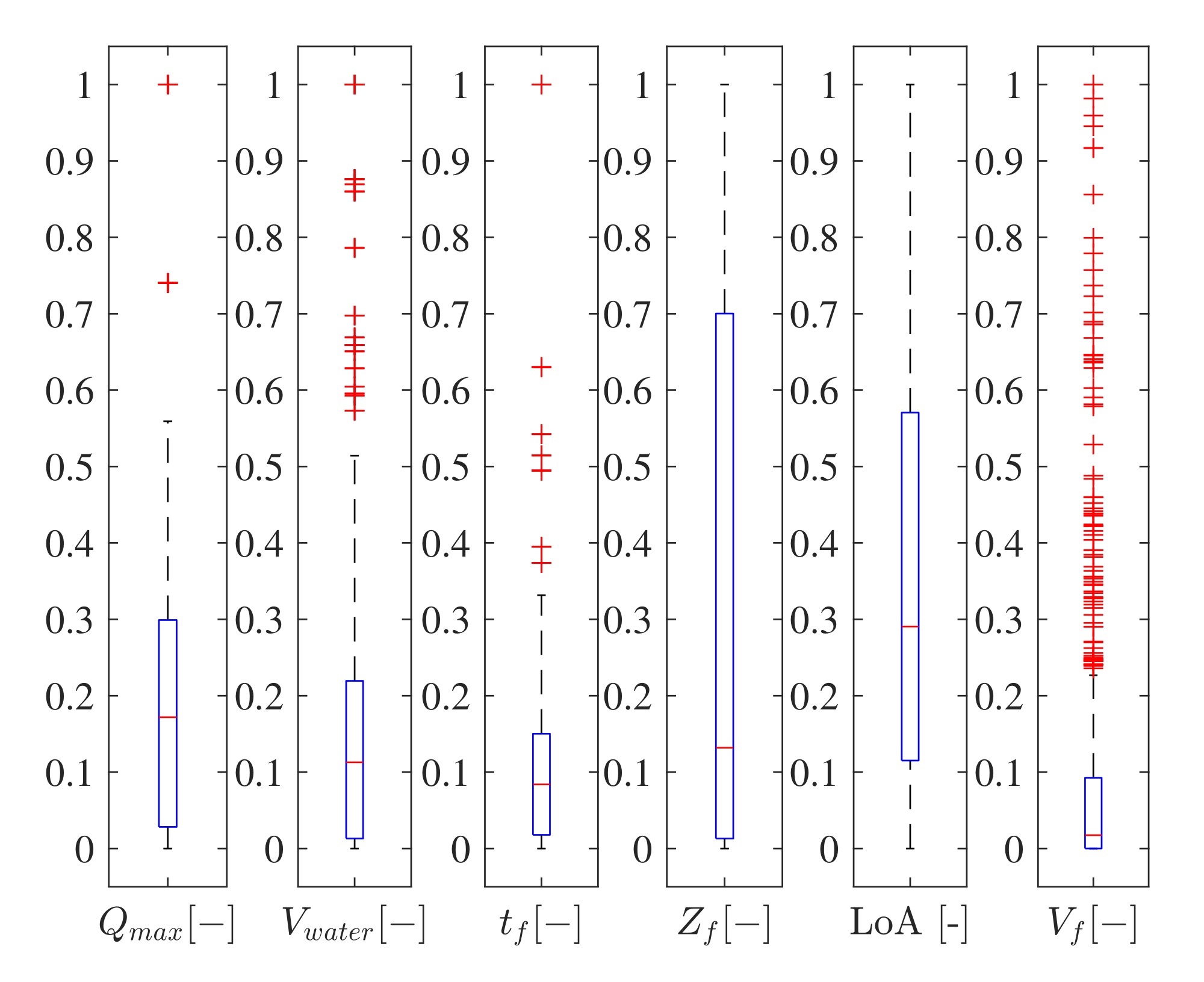
2.3. Data Preparation
2.4. Training Methodology
2.5. Performance Criteria
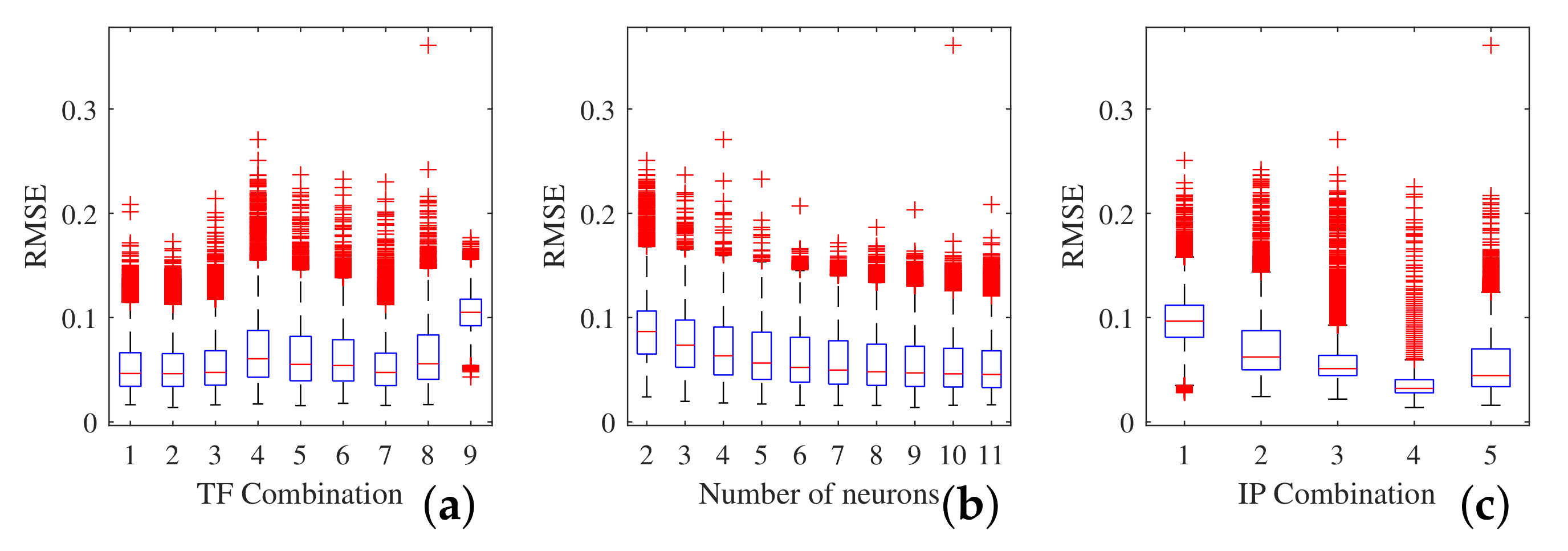
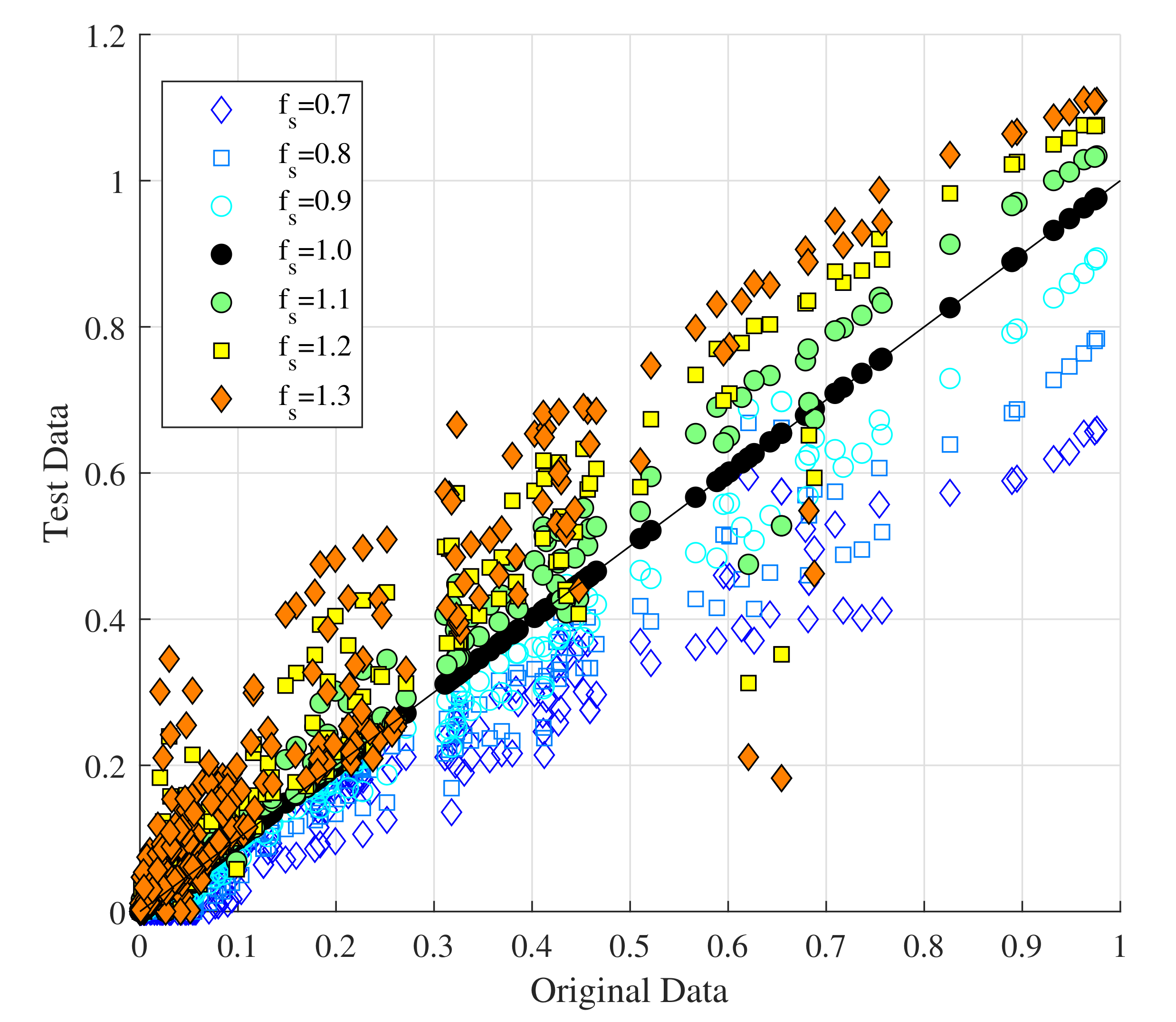
3. Results
3.1. Training
3.2. Sensitivity
4. Discussion
5. Conclusions
- In general, artificial neural networks (ANN) are powerful additional tools for river management.
- A feed-forward neural network can accurately predict the volume of sediment flushed during a single event, based on discrete input parameters.
- The developed ANN can be embedded into existing management structures, providing a decision-support system for reservoir operators.
- Extension of the approach to other study areas and, thus, the inclusion of more data are highly recommended.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Habersack, H.; Hein, T.; Stanica, A.; Liska, I.; Mair, R.; Jäger, E.; Hauer, C.; Bradley, C. Challenges of river basin management: Current status of, and prospects for, the River Danube from a river engineering perspective. Sci. Total Environ. 2016, 543, 828–845. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schleiss, A.J.; Franca, M.J.; Juez, C.; De Cesare, G. Reservoir sedimentation. J. Hydraul. Res. 2016, 54, 595–614. [Google Scholar] [CrossRef]
- Guillén-Ludeña, S.; Manso, P.; Schleiss, A. Multidecadal Sediment Balance Modelling of a Cascade of Alpine Reservoirs and Perspectives Based on Climate Warming. Water 2018, 10, 1759. [Google Scholar] [CrossRef] [Green Version]
- Ludeña, S.G.; Manso, P.; Schleiss, A.J.; Schwegler, B.; Stamm, J.; Fankhauser, A. Sediment balance of a cascade of alpine reservoirs based on multi-decadal data records. E3S Web Conf. 2018, 40, 03012. [Google Scholar] [CrossRef] [Green Version]
- Annandale, G.W.; Morris, G.L.; Karki, P. Extending the Life of Reservoirs: Sustainable Sediment Management for Dams and Run-of-River Hydropower; World Bank Group: Washington, DC, USA, 2016; Available online: http://documents.worldbank.org/curated/en/794841476187802040/Extending-the-life-of-reservoirs-sustainable-sediment-management-for-dams-and-run-of-river-hydropower (accessed on 1 October 2020).
- Reckendorfer, W.; Badura, H.; Schütz, C. Drawdown flushing in a chain of reservoirs—Effects on grayling populations and implications for sediment management. Ecol. Evol. 2019, 9, 1437–1451. [Google Scholar] [CrossRef] [Green Version]
- Isaac, N.; Eldho, T.I. Sediment management studies of a run-of-the-river hydroelectric project using numerical and physical model simulations. Int. J. River Basin Manag. 2016, 14, 165–175. [Google Scholar] [CrossRef]
- Isaac, N.; Eldho, T.I. Sediment removal from run-of-the-river hydropower reservoirs by hydraulic flushing. Int. J. River Basin Manag. 2019, 1–14. [Google Scholar] [CrossRef]
- Reisenbüchler, M.; Bui, M.D.; Skublics, D.; Rutschmann, P. Sediment Management at Run-of-River Reservoirs Using Numerical Modelling. Water 2020, 12, 249. [Google Scholar] [CrossRef] [Green Version]
- Bui, M.D.; Rutschmann, P. Numerical modelling for reservoir sediment management. In Proceedings of the ASIA 2016, Sixth International Conference and Exhibition on Water Resources and Hydropower Development in Asia, Vientiane, Laos, 1–3 March 2016. [Google Scholar]
- Chaudhary, H.P.; Isaac, N.; Tayade, S.B.; Bhosekar, V.V. Integrated 1D and 2D numerical model simulations for flushing of sediment from reservoirs. ISH J. Hydraul. Eng. 2019, 25, 19–27. [Google Scholar] [CrossRef]
- Dépret, T.; Piégay, H.; Dugué, V.; Vaudor, L.; Faure, J.B.; Le Coz, J.; Camenen, B. Estimating and restoring bedload transport through a run-of-river reservoir. Sci. Total Environ. 2019, 654, 1146–1157. [Google Scholar] [CrossRef]
- Gallerano, F.; Cannata, G. Compatibility of Reservoir Sediment Flushing and River Protection. J. Hydraul. Eng. 2011, 137, 1111–1125. [Google Scholar] [CrossRef]
- Ateeq-Ur-Rehman, S. Numerical Modeling of Sediment Transport in Dasu-Tarbela Reservoir using Neural Networks and TELEMAC Model System; Technische Universität München: München, Germany, 2019; Available online: http://mediatum.ub.tum.de/?id=1455875 (accessed on 1 October 2020).
- Esmaeili, T.; Sumi, T.; Kantoush, S.A.; Kubota, Y.; Haun, S.; Rüther, N. Three-Dimensional Numerical Study of Free-Flow Sediment Flushing to Increase the Flushing Efficiency: A Case-Study Reservoir in Japan. Water 2017, 9, 900. [Google Scholar] [CrossRef] [Green Version]
- Shields, A. Application of Similarity Principles and Turbulence Research to Bed-Load Movement; Hydrodynamics Laboratory California Institute of Technology: Pasadena, CA, USA, 1936; Volume 167, Available online: https://authors.library.caltech.edu/25992/1/Sheilds.pdf (accessed on 1 October 2020).
- Wu, W. Depth-Averaged Two-Dimensional Numerical Modeling of Unsteady Flow and Nonuniform Sediment Transport in Open Channels. J. Hydraul. Eng. 2004, 130, 1013–1024. [Google Scholar] [CrossRef]
- Juez, C.; Murillo, J.; García-Navarro, P. Numerical assessment of bed-load discharge formulations for transient flow in 1D and 2D situations. J. Hydroinform. 2013, 15, 1234–1257. [Google Scholar] [CrossRef]
- Sindelar, C.; Gold, T.; Reiterer, K.; Hauer, C.; Habersack, H. Experimental Study at the Reservoir Head of Run-of-River Hydropower Plants in Gravel Bed Rivers. Part I: Delta Formation at Operation Level. Water 2020, 12, 2035. [Google Scholar] [CrossRef]
- Reiterer, K.; Gold, T.; Habersack, H.; Hauer, C.; Sindelar, C. Experimental Study at the Reservoir Head of Run-of-River Hydropower Plants in Gravel Bed Rivers. Part II: Effects of Reservoir Flushing on Delta Degradation. Water 2020, 12, 3038. [Google Scholar] [CrossRef]
- Bieri, M.; Müller, M.; Boillat, J.L.; Schleiss, A.J. Modeling of Sediment Management for the Lavey Run-of-River HPP in Switzerland. J. Hydraul. Eng. 2012, 138, 340–347. [Google Scholar] [CrossRef]
- El Bilali, A.; Taleb, A.; El Idrissi, B.; Brouziyne, Y.; Mazigh, N. Comparison of a data-based model and a soil erosion model coupled with multiple linear regression for the prediction of reservoir sedimentation in a semi-arid environment. Euro-Mediterr. J. Environ. Integr. 2020, 5, 64. [Google Scholar] [CrossRef]
- Garg, V.; Jothiprakash, V. Evaluation of reservoir sedimentation using data driven techniques. Appl. Soft Comput. 2013, 13, 3567–3581. [Google Scholar] [CrossRef]
- Jothiprakash, V.; Garg, V. Reservoir Sedimentation Estimation Using Artificial Neural Network. J. Hydrol. Eng. 2009, 2009. 14, 1035–1040. [Google Scholar] [CrossRef]
- Apaydin, H.; Feizi, H.; Sattari, M.T.; Colak, M.S.; Shamshirband, S.; Chau, K.W. Comparative Analysis of Recurrent Neural Network Architectures for Reservoir Inflow Forecasting. Water 2020, 12, 1500. [Google Scholar] [CrossRef]
- Ateeq-Ur-Rehman, S.; Bui, M.; Rutschmann, P. Variability and Trend Detection in the Sediment Load of the Upper Indus River. Water 2018, 10, 16. [Google Scholar] [CrossRef] [Green Version]
- Tarar, Z.R.; Ahmad, S.R.; Ahmad, I.; Hasson, S.u.; Khan, Z.M.; Washakh, R.M.A.; Ateeq-Ur-Rehman, S.; Bui, M.D. Effect of Sediment Load Boundary Conditions in Predicting Sediment Delta of Tarbela Reservoir in Pakistan. Water 2019, 11, 1716. [Google Scholar] [CrossRef] [Green Version]
- Bui, M.D.; Kaveh, K.; Penz, P.; Rutschmann, P. Contraction scour estimation using data-driven methods. J. Appl. Water Eng. Res. 2015, 3, 143–156. [Google Scholar] [CrossRef]
- Li, X.; Qiu, J.; Shang, Q.; Li, F. Simulation of Reservoir Sediment Flushing of the Three Gorges Reservoir Using an Artificial Neural Network. Appl. Sci. 2016, 6, 148. [Google Scholar] [CrossRef] [Green Version]
- Haykin, S.S. Neural Networks: A Comprehensive Foundation: Solutions Manual; Macmillan College Publishing Company: New York, NY, USA, 1994. [Google Scholar]
- Haykin, S.; Haykin, S. Neural Networks and Learning Machines; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Ateeq-Ur-Rehman, S.; Bui, M.D.; Hasson, S.U.; Rutschmann, P. An Innovative Approach to Minimizing Uncertainty in Sediment Load Boundary Conditions for Modelling Sedimentation in Reservoirs. Water 2018, 10, 1411. [Google Scholar] [CrossRef] [Green Version]
- Bui, V.H.; Bui, M.D.; Rutschmann, P. The Prediction of Fine Sediment Distribution in Gravel-Bed Rivers Using a Combination of DEM and FNN. Water 2020, 12, 1515. [Google Scholar] [CrossRef]
- Bui, V.H.; Bui, M.D.; Rutschmann, P. Combination of Discrete Element Method and Artificial Neural Network for Predicting Porosity of Gravel-Bed River. Water 2019, 11, 1461. [Google Scholar] [CrossRef] [Green Version]
- Kaveh, K.; Bui, M.D.; Rutschmann, P. A new approach for morphodynamic modeling using integrating ensembles of artificial neural networks. In Wasserbau—Mehr als Bauen im Wasser, Proceedings of the 18th Symposium of TU Munich, TU Graz and ETH Zurich, TU Graz, Austria, 11–14 September 2019; Huber, R., Ed.; Rutschmann, Peter: London, UK, 2019; Volume 134, pp. 304–315. Available online: https://www.bgu.tum.de/fileadmin/w00blj/wb/Publikationen/Berichtshefte/Band134.pdf (accessed on 1 October 2020).
- Shahin, M.A.; Maier, H.R.; Jaksa, M.B. Predicting Settlement of Shallow Foundations using Neural Networks. J. Geotech. Geoenviron. Eng. 2002, 128, 785–793. [Google Scholar] [CrossRef]
- Reisenbüchler, M.; Bui, M.D.; Skublics, D.; Rutschmann, P. Enhancement of a numerical model system for reliably predicting morphological development in the Saalach River. Int. J. River Basin Manag. 2020, 18, 335–347. [Google Scholar] [CrossRef]
- Hunziker, R.P. Fraktionsweiser Geschiebetransport; Laboratory of Hydraulics, Hydrology and Glaciology (VAW), ETH Zürich: Zürich, Switzerland, 1995; Volume 11037, p. 191. [Google Scholar] [CrossRef]
- Goler, R.A.; Frey, S.; Formayer, H.; Holzmann, H. Influence of Climate Change on River Discharge in Austria. Meteorol. Z. 2016, 25, 621–626. [Google Scholar] [CrossRef]
- Moulinec, C.; Denis, C.; Pham, C.T.; Rougé, D.; Hervouet, J.M.; Razafindrakoto, E.; Barber, R.W.; Emerson, D.R.; Gu, X.J. TELEMAC: An efficient hydrodynamics suite for massively parallel architectures. Comput. Fluids 2011, 51, 30–34. [Google Scholar] [CrossRef] [Green Version]
- Chiogna, G.; Marcolini, G.; Liu, W.; Pérez Ciria, T.; Tuo, Y. Coupling hydrological modeling and support vector regression to model hydropeaking in alpine catchments. Sci. Total Environ. 2018, 633, 220–229. [Google Scholar] [CrossRef]
- Nourani, V.; Alizadeh, F.; Roushangar, K. Evaluation of a Two-Stage SVM and Spatial Statistics Methods for Modeling Monthly River Suspended Sediment Load. Water Resour. Manag. 2016, 30, 393–407. [Google Scholar] [CrossRef]
- Sakizadeh, M.; Mirzaei, R.; Ghorbani, H. Support vector machine and artificial neural network to model soil pollution: A case study in Semnan Province, Iran. Neural Comput. Appl. 2017, 28, 3229–3238. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Zadeh, H.; Isazadeh, M.; Terzi, O. A comparative study of artificial neural network (MLP, RBF) and support vector machine models for river flow prediction. Environ. Earth Sci. 2016, 75. [Google Scholar] [CrossRef]
- Bishop, P.L.; Hively, W.D.; Stedinger, J.R.; Rafferty, M.R.; Lojpersberger, J.L.; Bloomfield, J.A. Multivariate analysis of paired watershed data to evaluate agricultural best management practice effects on stream water phosphorus. J. Environ. Qual. 2005, 34, 1087–1101. [Google Scholar] [CrossRef] [PubMed]
- Le, T.M.K.; Mäkelä, M.; Schreithofer, N.; Dahl, O. A multivariate approach for evaluation and monitoring of water quality in mining and minerals processing industry. Miner. Eng. 2020, 157, 106582. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Hidden–Output |
|---|---|
| 1 | logsig–purelin |
| 2 | tansig–purelin |
| 3 | radbas–purelin |
| 4 | poslin–purelin |
| 5 | satlin–purelin |
| 6 | satlins–purelin |
| 7 | radbasn–purelin |
| 8 | tribas–purelin |
| 9 | purelin–purelin |
| Parameter | Value |
|---|---|
| Riverbed roughness (Strickler) kst | 35 m/s |
| Form roughness (Strickler) kst,r | Sectional calibrated [22–35] m/s |
| Bedload transport formula | Hunziker [38] |
| Shields-parameter | 0.04 (for all grain classes) |
| Active layer thickness | 0.14 m = dmax |
| Number of grain classes | 8 |
| Mean diameter of the single grain classes [mm] | 0.5, 2, 8, 16, 31.5, 60, 93, 140 |
| Initial Batyhmetry Bi | Threshold Discharge Qf,i [m3/s] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| max | 2005 | flood | 100 | 125 | 150 | 175 | 200 | 225 | 250 | 275 | 300 |
| # | Input Parameters |
|---|---|
| 1 | Qmax, Zf,min |
| 2 | Qmax, Zf,min, tf |
| 3 | Qmax, Zf,min, tf, Vwater |
| 4 | Qmax, Zf,min, tf, Vwater, LoA |
| 5 | Qmax, Zf,min, tf, LoA |
| Qmax | Vwater | tf | Zf,min | LoA | Vf | |
|---|---|---|---|---|---|---|
| [m3/s] | [m3] | [h] | [m] | [/] | [m3] | |
| Min | 100.08 | 2.623·105 | 0.5 | 409.695 | 0.2037 | 5.479·10−5 |
| Max | 1.083·103 | 1.900·108 | 379 | 415.7 | 1.293 | 1.003·105 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reisenbüchler, M.; Bui, M.D.; Rutschmann, P. Reservoir Sediment Management Using Artificial Neural Networks: A Case Study of the Lower Section of the Alpine Saalach River. Water 2021, 13, 818. https://doi.org/10.3390/w13060818
Reisenbüchler M, Bui MD, Rutschmann P. Reservoir Sediment Management Using Artificial Neural Networks: A Case Study of the Lower Section of the Alpine Saalach River. Water. 2021; 13(6):818. https://doi.org/10.3390/w13060818
Chicago/Turabian StyleReisenbüchler, Markus, Minh Duc Bui, and Peter Rutschmann. 2021. "Reservoir Sediment Management Using Artificial Neural Networks: A Case Study of the Lower Section of the Alpine Saalach River" Water 13, no. 6: 818. https://doi.org/10.3390/w13060818
APA StyleReisenbüchler, M., Bui, M. D., & Rutschmann, P. (2021). Reservoir Sediment Management Using Artificial Neural Networks: A Case Study of the Lower Section of the Alpine Saalach River. Water, 13(6), 818. https://doi.org/10.3390/w13060818