
CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets



Abstract
:1. Introduction
2. Efficient Object Detection Network Design
2.1. YOLOv5 Object Detection Model
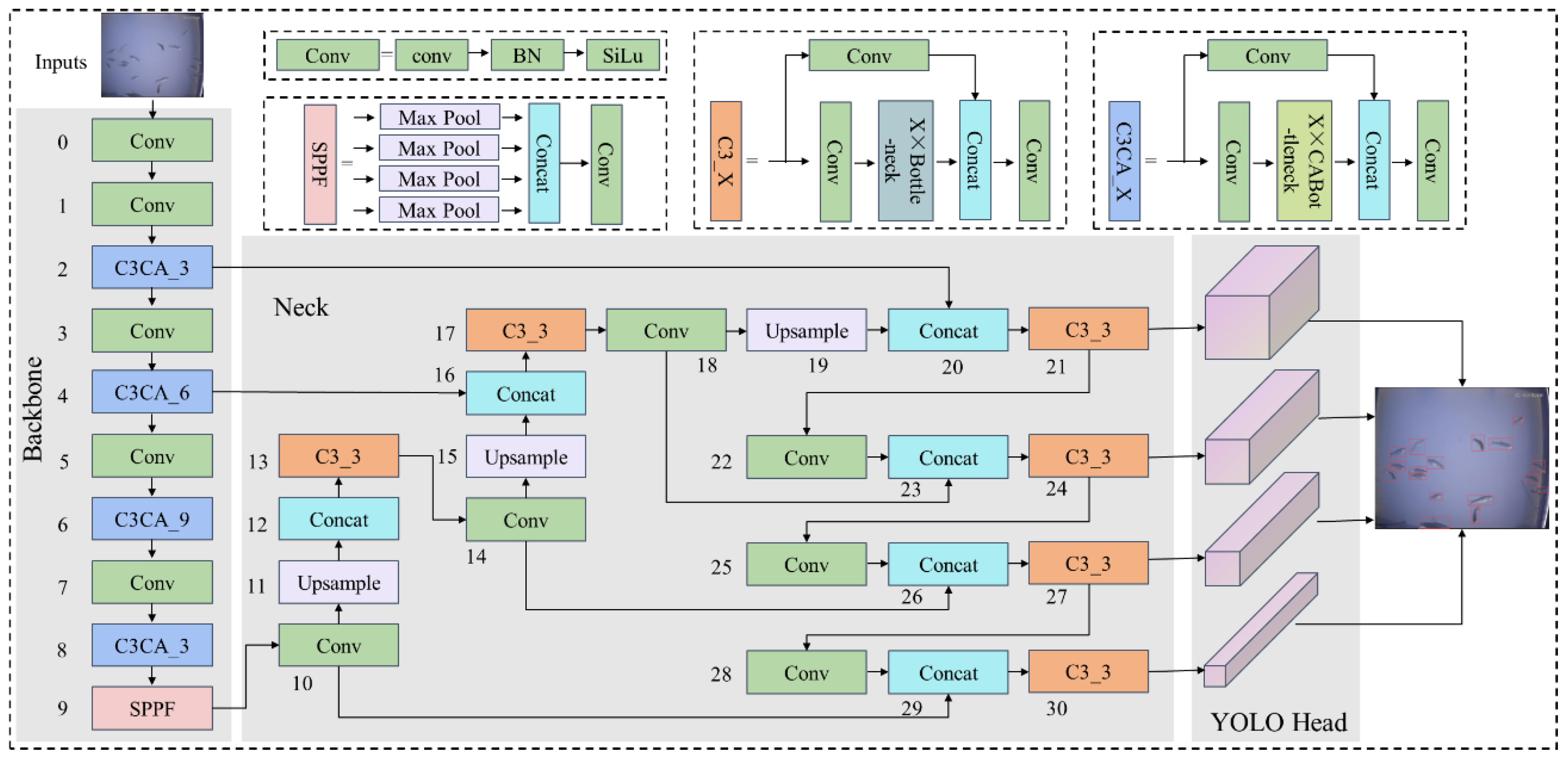
2.2. Improved CME-YOLOv5 Recognition Method
2.2.1. CA Attention Mechanism Module
2.2.2. Multiscale Detection Layer
2.2.3. Optimized Loss Function
3. Dataset
4. Experimental Protocols and Evaluation Measures
4.1. Experimental Platform and Protocols
4.2. Model Evaluation Measures
5. Results and Discussion
5.1. Results Analysis
5.1.1. C3CA Ablation Experiment
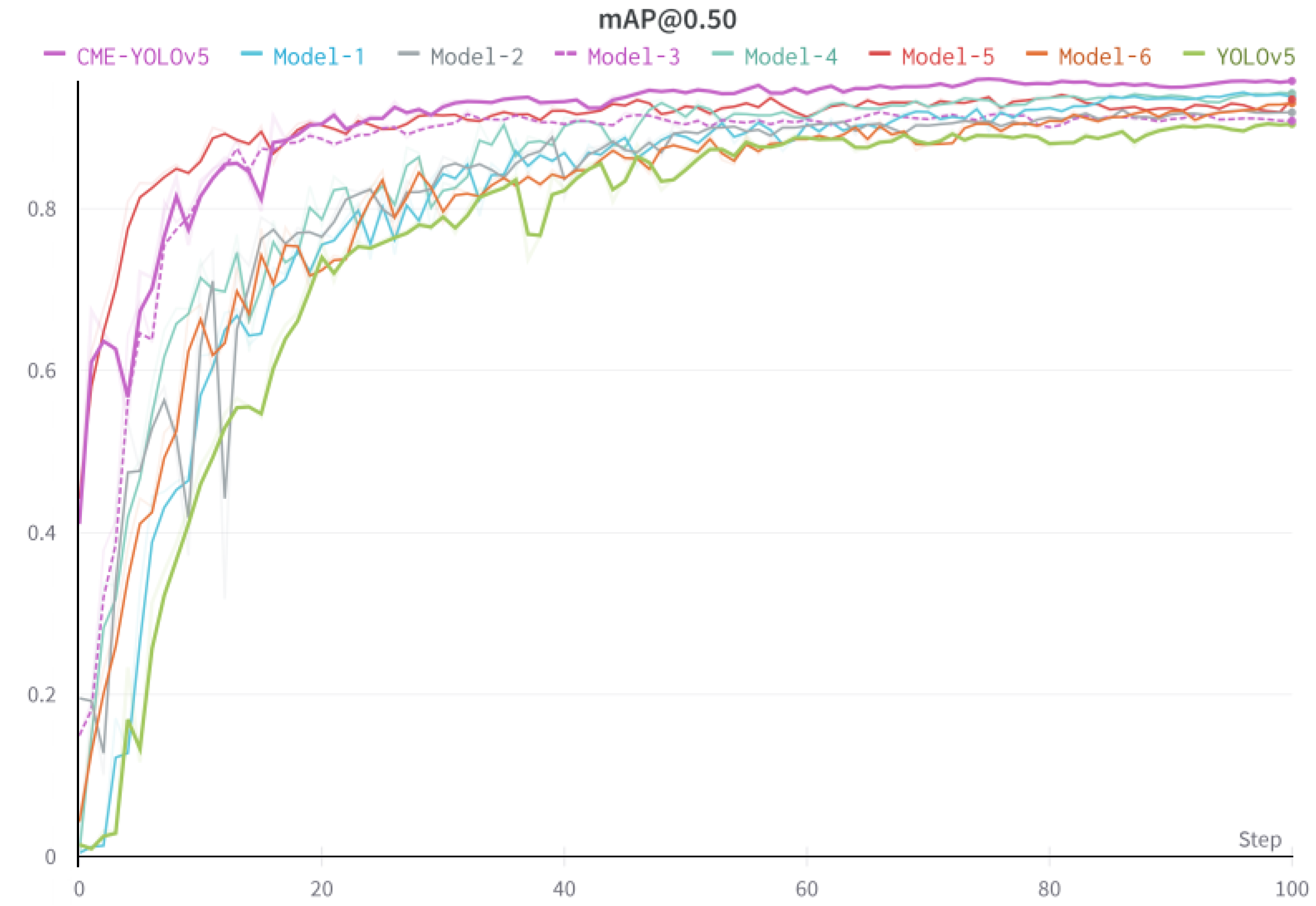
5.1.2. CME-YOLOv5 Ablation Experiment
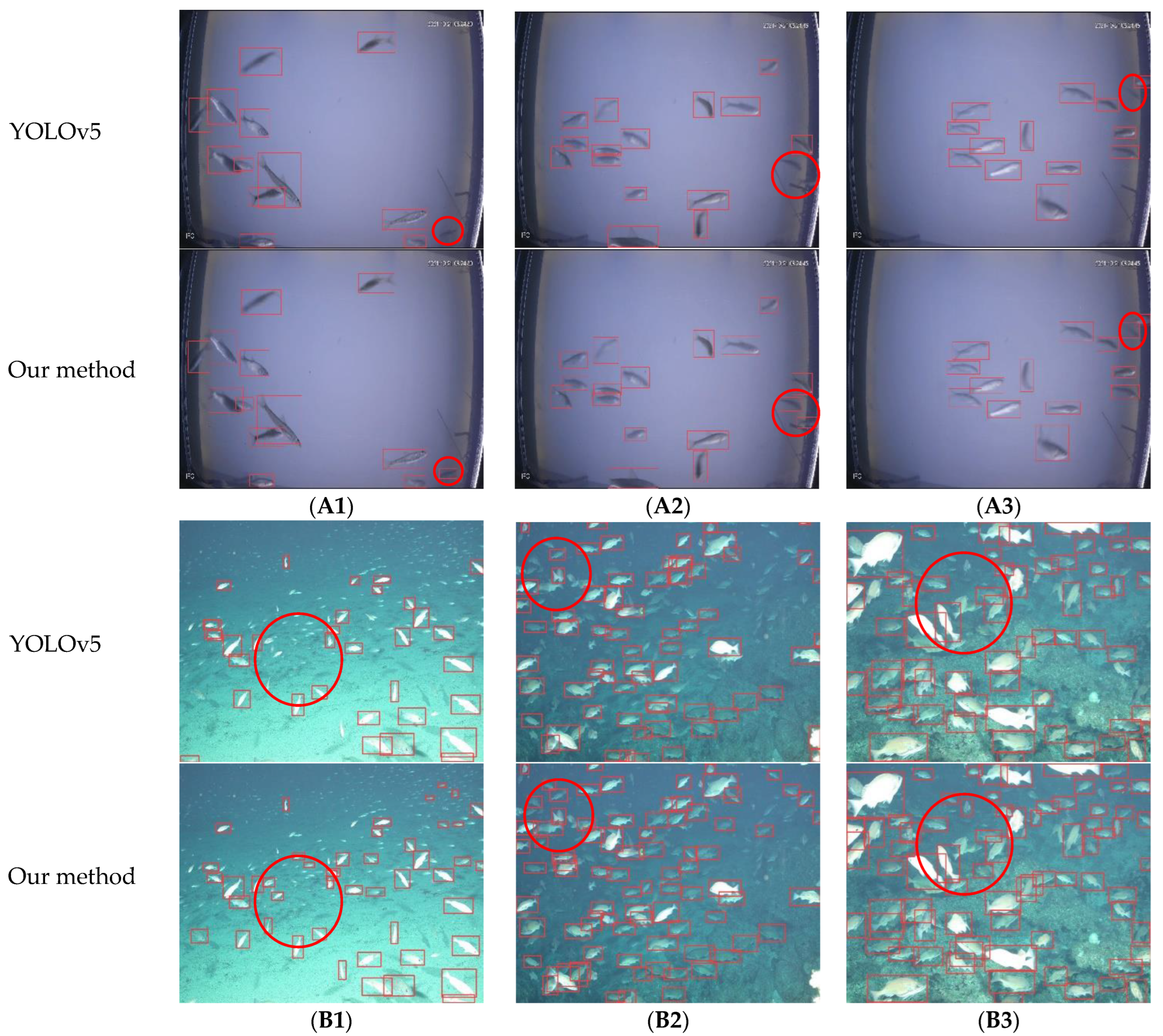
5.1.3. Comparison of Experimental Results
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dimarchopoulou, D.; Keramidas, I.; Sylaios, G.; Tsikliras, A. Ecotrophic Effects of Fishing across the Mediterranean Sea. Water 2021, 13, 482. [Google Scholar] [CrossRef]
- Qi, X. Hanjiang upstream of fishery resources survey. Chin. J. Fish. Res. 2022, 44, 21–32. [Google Scholar]
- Li, K.; Shen, Z.; Chen, Y.; Ye, H. Preliminary study on fish diversity and Protection Countermeasures in Banduo section of the Yellow River. Chin. J. Hydroecol. 2012, 33, 104–107. [Google Scholar]
- Liu, K.; Yu, C.; Yu, N.; Zhang, P.; Jiang, Q.; Niu, W. Current situation and protection analysis of juvenile fish resources in spring and autumn in Zhoushan coastal waters. Fish. Res. 2021, 43, 121–132. [Google Scholar]
- Kelson, S.J.; Hogan, Z.; Jerde, C.L.; Chandra, S.; Ngor, P.B.; Koning, A. Fishing Methods Matter: Comparing the Community and Trait Composition of the Dai (Bagnet) and Gillnet Fisheries in the Tonle Sap River in Southeast Asia. Water 2021, 13, 1904. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Lin, C.; Wei, Y.; Ma, W.; Wu, L.; Liu, D.; Shi, X. Review on monitoring methods of fish passage effect. Chin. J. Ecol. 2019, 38, 586–593. [Google Scholar]
- Wang, L.; Chen, Y.; Tang, L.; Fan, R.; Yao, Y. Object-based convolutional neural networks for cloud and snow detection in high-resolution multispectral imagers. Water 2018, 10, 1666. [Google Scholar] [CrossRef] [Green Version]
- Gadamsetty, S.; Ch, R.; Ch, A.; Iwendi, C.; Gadekallu, T.R. Hash-based deep learning approach for remote sensing satellite imagery detection. Water 2022, 14, 707. [Google Scholar] [CrossRef]
- Pei, Q.; Peng, S.; Liu, Y. Real-time fish detection in fishway based on deep learning. Inf. Commun. 2019, 2, 67–69. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wageeh, Y.; Mohamed, H.E.-D.; Fadl, A.; Anas, O.; ElMasry, N.; Nabil, A.; Atia, A. YOLO fish detection with Euclidean tracking in fish farms. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 5–12. [Google Scholar] [CrossRef]
- Petro, A.B.; Sbert, C.; Morel, J.M. Multiscale retinex. Image Proces. Line 2014, 4, 71–88. [Google Scholar] [CrossRef]
- Fan, W. Ocean Fish Image Recognition And Application Based on Deep Learning. Master’s Thesis, Chongqing Normal University, Chongqing, China, 2019. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yao, L. Underwater Target Recognition Based on Improved YOLOv4 Neural Network. Electronics 2021, 10, 1634. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2004, arXiv:2004.10934. [Google Scholar]
- Qiang, W.; He, Y.; Guo, Y.; Li, B.; He, L. Exploring underwater target detection algorithm based on improved SSD. Xibei Gongye Daxue Xuebao/J. Northwest. Polytech. Univ. 2020, 38, 747–754. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Wu, R.; Bi, X.J. Benthic biometrics identification of coral reefs based on improved YOLOv5. J. Harbin Eng. Univ. 2022, 4, 580–586. [Google Scholar]
- YOLOv5 in PyTorch. Available online: https://github.com/ultralytics/yolov5 (accessed on 6 July 2022).
- Feng, Z.; Xie, Z.; Bao, Z.; Chen, K. Real-time dense small target detection algorithm for uav based on improved YOLOv5. J. Aviation. 1-15[2022-08-02]. Available online: http://kns.cnki.net/kcms/detail/11.1929.V.20220509.2316.010.html (accessed on 6 July 2022).
- Dai, Y.; Zhao, X.; Li, L.; Liu, W.; Chu, X. Infrared dim small target detection algorithm in complex background based on improved yolov5 Infrared technology. Infrared Technol. 2022, 44, 504. [Google Scholar]
- Wang, G.; Ding, H.; Yang, Z.; Li, B.; Wang, Y.; Bao, L. TRC-YOLO: A real-time detection method for lightweight targets based on mobile devices. IET Comput. Vision 2022, 16, 126–142. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Size (Pixels) | mAPval0.5:0.95 | mAPval0.5 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | Params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49 |
| YOLOv5l | 640 | 49 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| Parameters | Configuration | Parameters | Configuration |
|---|---|---|---|
| operating system | Windows10 | initial learning rate | 0.01 |
| CPU | i7-11800H | final learning rate | 0.1 |
| GPU | GeForce RTX3080 | optimizer | SGD |
| CUDA | 11.1 | optimizer momentum | 0.937 |
| image-size | 640 × 640 | batch size | 8 |
| Predicted Value | Positive | Negative |
|---|---|---|
| Real Value | ||
| Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) |
| Framework | Backbone | Neck | mAP |
|---|---|---|---|
| Framework 1 | √ | 93.2 | |
| Framework 2 | √ | 91.7 | |
| Framework 3 | √ | √ | 92.1 |
| Order Number | Model | CA | Multiscale Detection Layer | EIOU | Precision (%) | Recall (%) | [email protected] (%) | Average Detection Time (s) | Model Training Loss |
|---|---|---|---|---|---|---|---|---|---|
| 0 | YOLOv5 | 83.9 | 84.7 | 90.5 | 14.3 | 0.0240 | |||
| 1 | Model 1 | √ | 89.7 | 87.0 | 93.2 | 20.4 | 0.0305 | ||
| 2 | Model 2 | √ | 86.4 | 86.1 | 92.1 | 17.0 | 0.0308 | ||
| 3 | Model 3 | √ | 87.8 | 84.4 | 91.1 | 14.1 | 0.0209 | ||
| 4 | Model 4 | √ | √ | 89.8 | 90.4 | 94.3 | 23.2 | 0.0354 | |
| 5 | Model 5 | √ | √ | 90.1 | 86.5 | 93.8 | 20.4 | 0.0257 | |
| 6 | Model 6 | √ | √ | 85.5 | 88.2 | 93.0 | 16.9 | 0.0275 | |
| 7 | CEM-YOLOv5 | √ | √ | √ | 92.3 | 88.1 | 94.9 | 22.8 | 0.0316 |
| Model | Picture 1 | Picture 2 | Picture 3 | Picture 4 | Picture 5 | Picture 6 | Total Number |
|---|---|---|---|---|---|---|---|
| YOLOv5 | 15 | 12 | 13 | 33 | 68 | 58 | 199 |
| CEM-YOLOv5 | 17 | 13 | 14 | 47 | 83 | 74 | 248 |
| Quantity ratio | 113.3% | 108.3% | 107.7% | 142.4% | 122.1% | 127.6% | 124.6% |
| Model | [email protected] (%) | Average Detection Time (ms) |
|---|---|---|
| SSD | 76.5 | 36.5 |
| Faster R-CNN | 79.6 | 61.5 |
| YOLOv4 | 89.2 | 30.7 |
| YOLOV5 | 90.5 | 14.3 |
| CME-YOLOv5 | 94.9 | 22.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Liu, C.; Lu, X.; Wu, B. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2022, 14, 2412. https://doi.org/10.3390/w14152412
Li J, Liu C, Lu X, Wu B. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water. 2022; 14(15):2412. https://doi.org/10.3390/w14152412
Chicago/Turabian StyleLi, Jianyuan, Chunna Liu, Xiaochun Lu, and Bilang Wu. 2022. "CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets" Water 14, no. 15: 2412. https://doi.org/10.3390/w14152412
APA StyleLi, J., Liu, C., Lu, X., & Wu, B. (2022). CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water, 14(15), 2412. https://doi.org/10.3390/w14152412