

Investigating Machine Learning Applications for Effective Real-Time Water Quality Parameter Monitoring in Full-Scale Wastewater Treatment Plants



Abstract
:1. Introduction
2. Materials and Methods
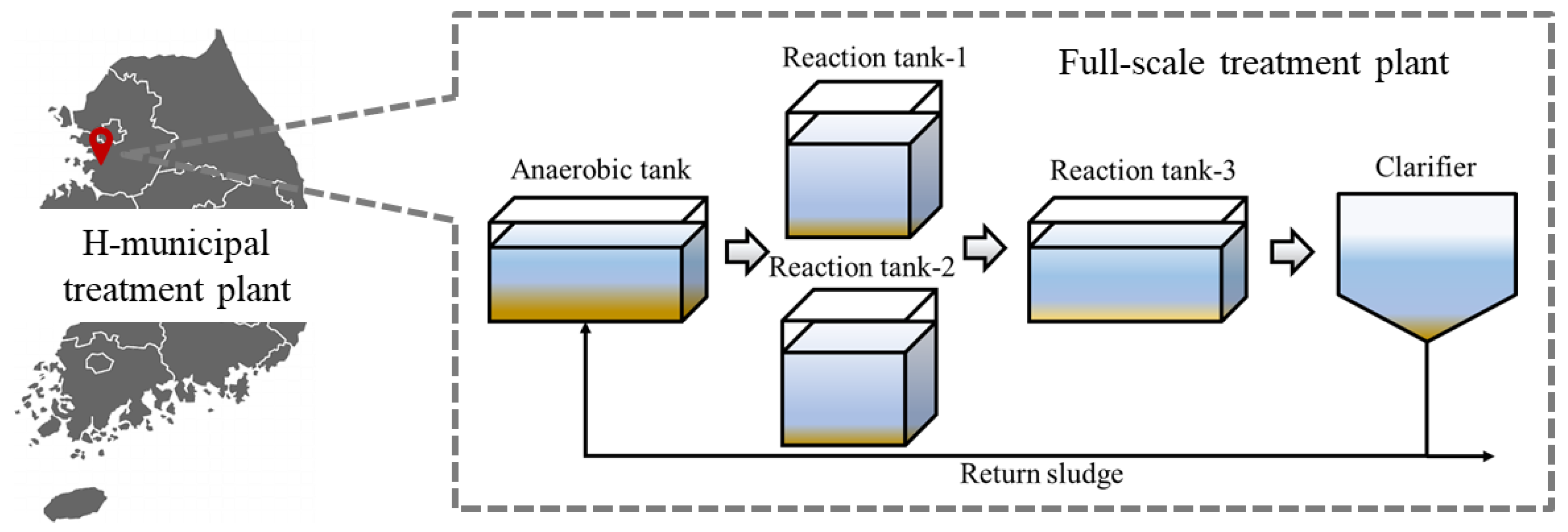
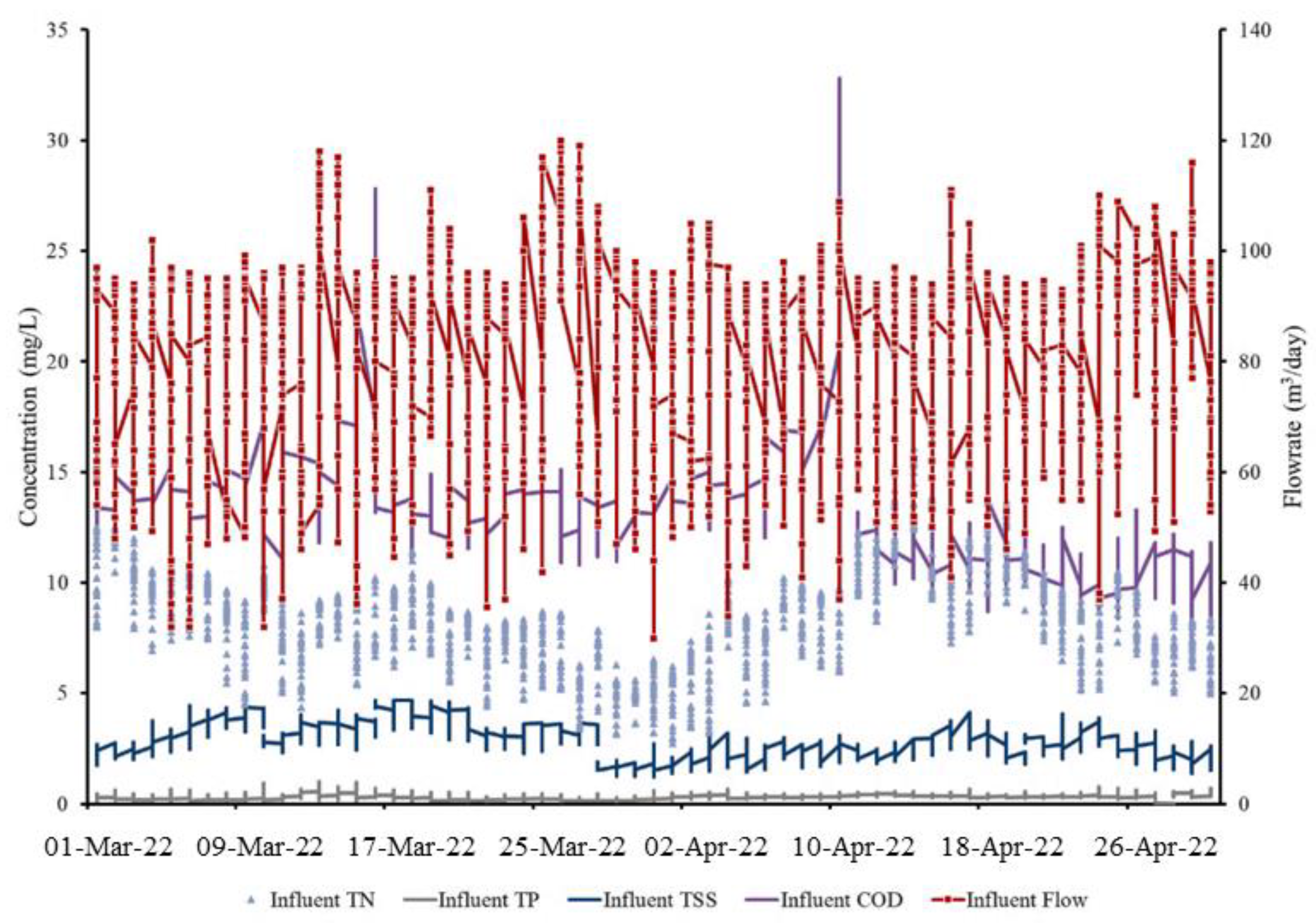
2.1. Target WWTP and Online Data Analysis
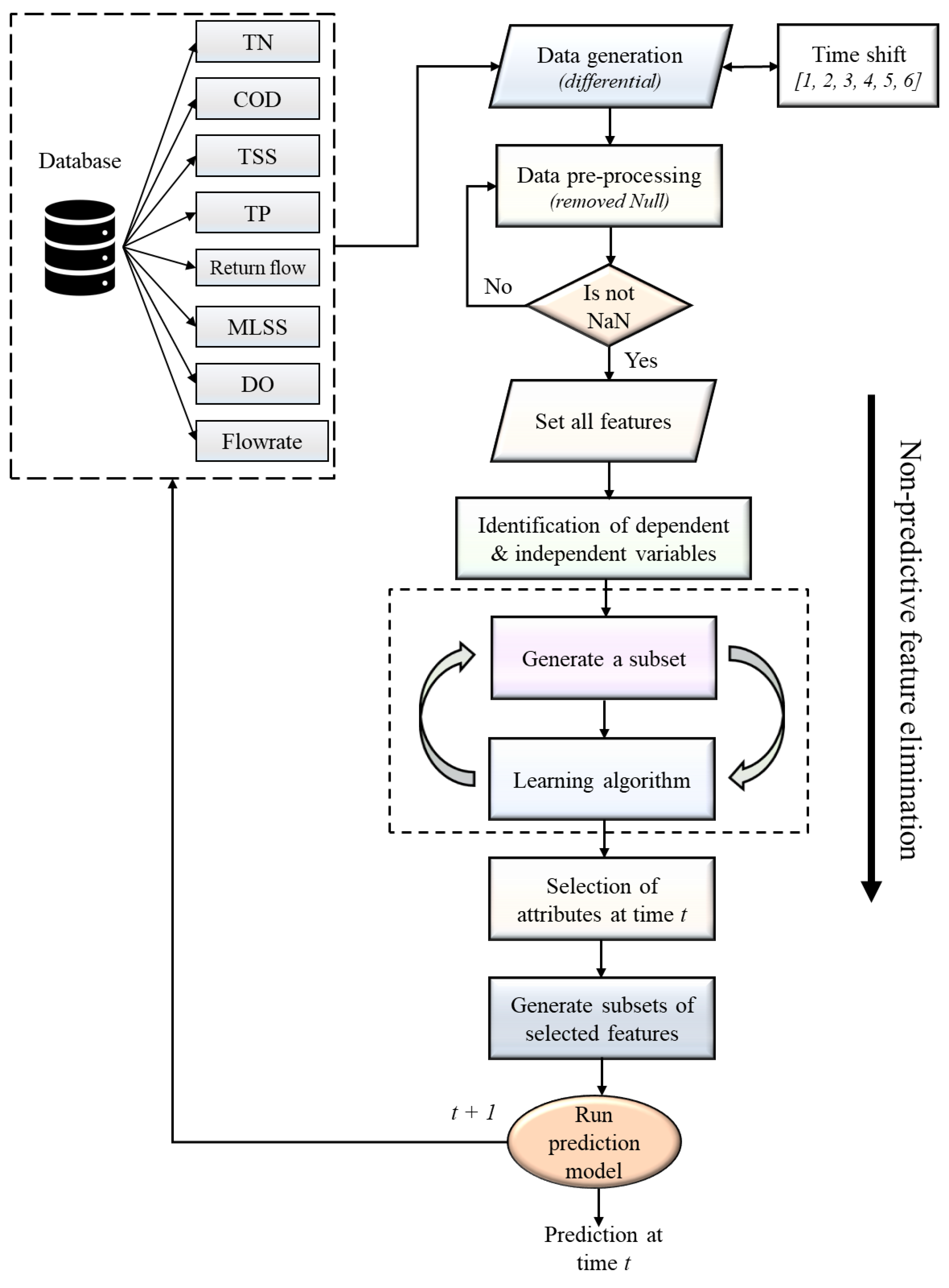
2.2. Selection of Predictive Features
2.3. Prediction Models for Water Quality Parameter
2.3.1. Partial Least Squares (PLS) Model
2.3.2. Stepwise Multiple Linear Regression (MLR) Model
2.3.3. Multilayer Perceptron (MLP) Model
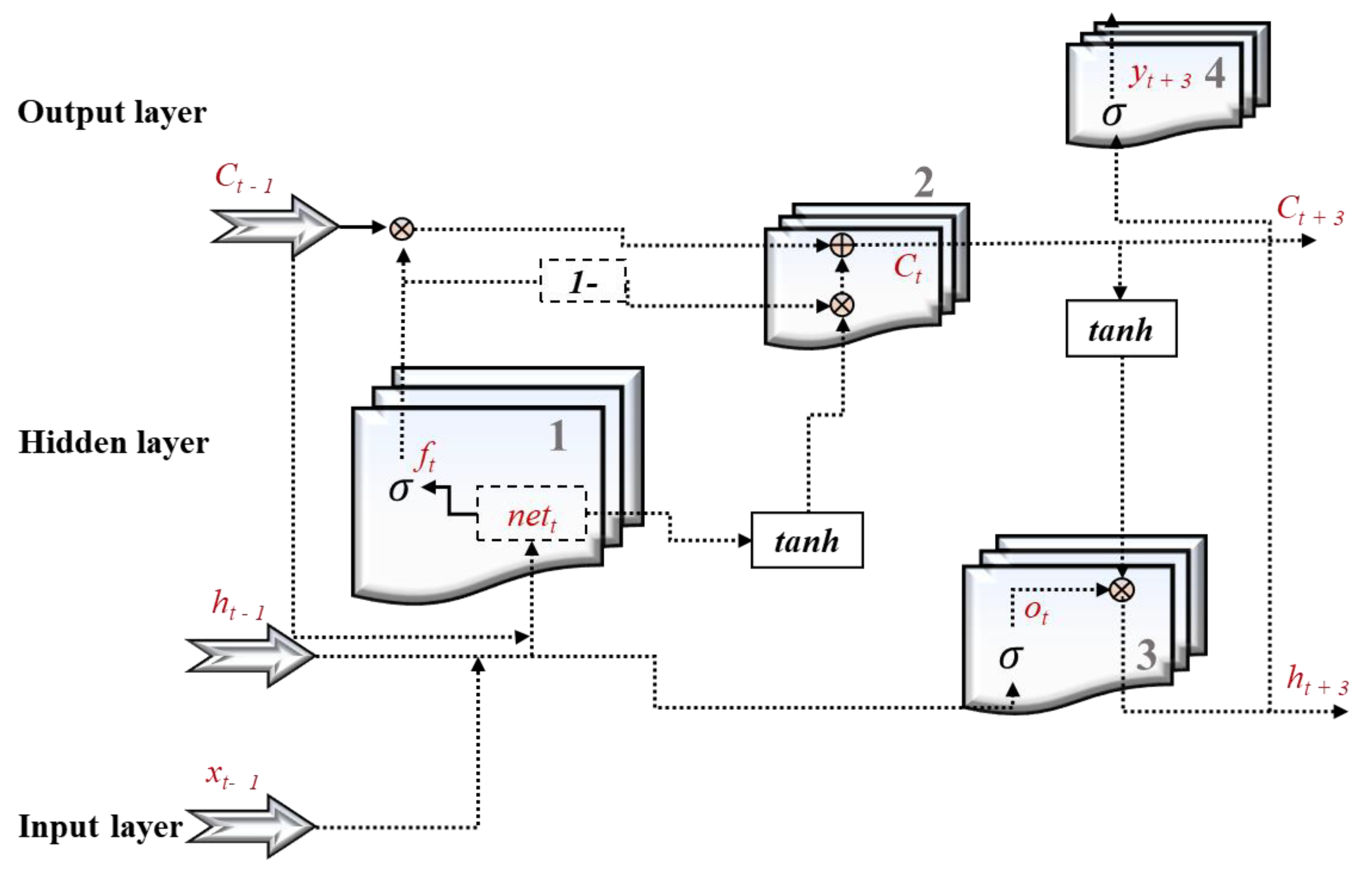
2.3.4. Memory Gated Recurrent Neural Networks
2.3.5. Transformer Multihead Attention Network
2.4. Performance Evaluation
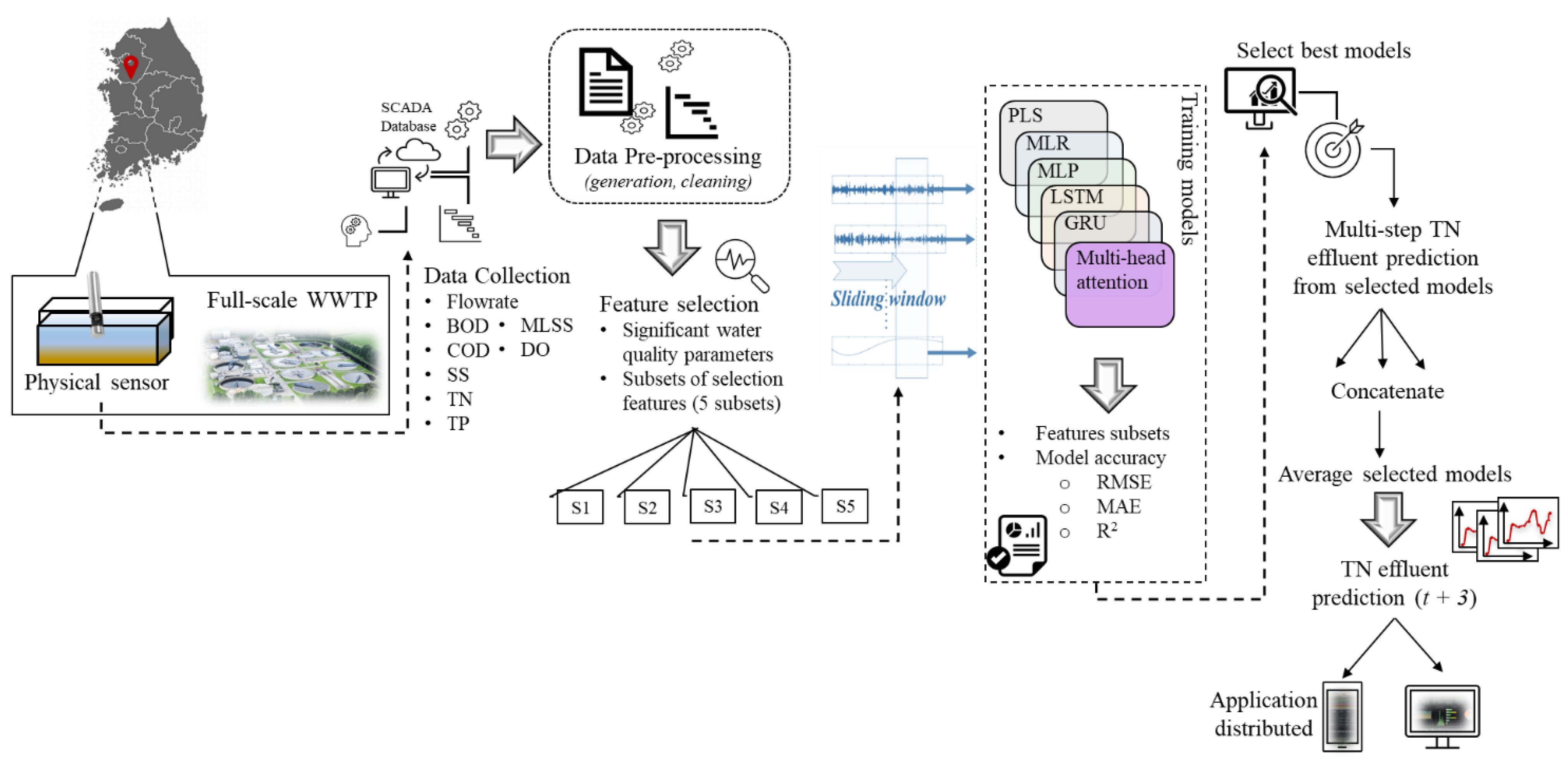
2.5. Proposed Multistep Ahead TN Prediction Methodology
3. Results and Discussions
3.1. Selection of Significant Features for Effluent TN Prediction
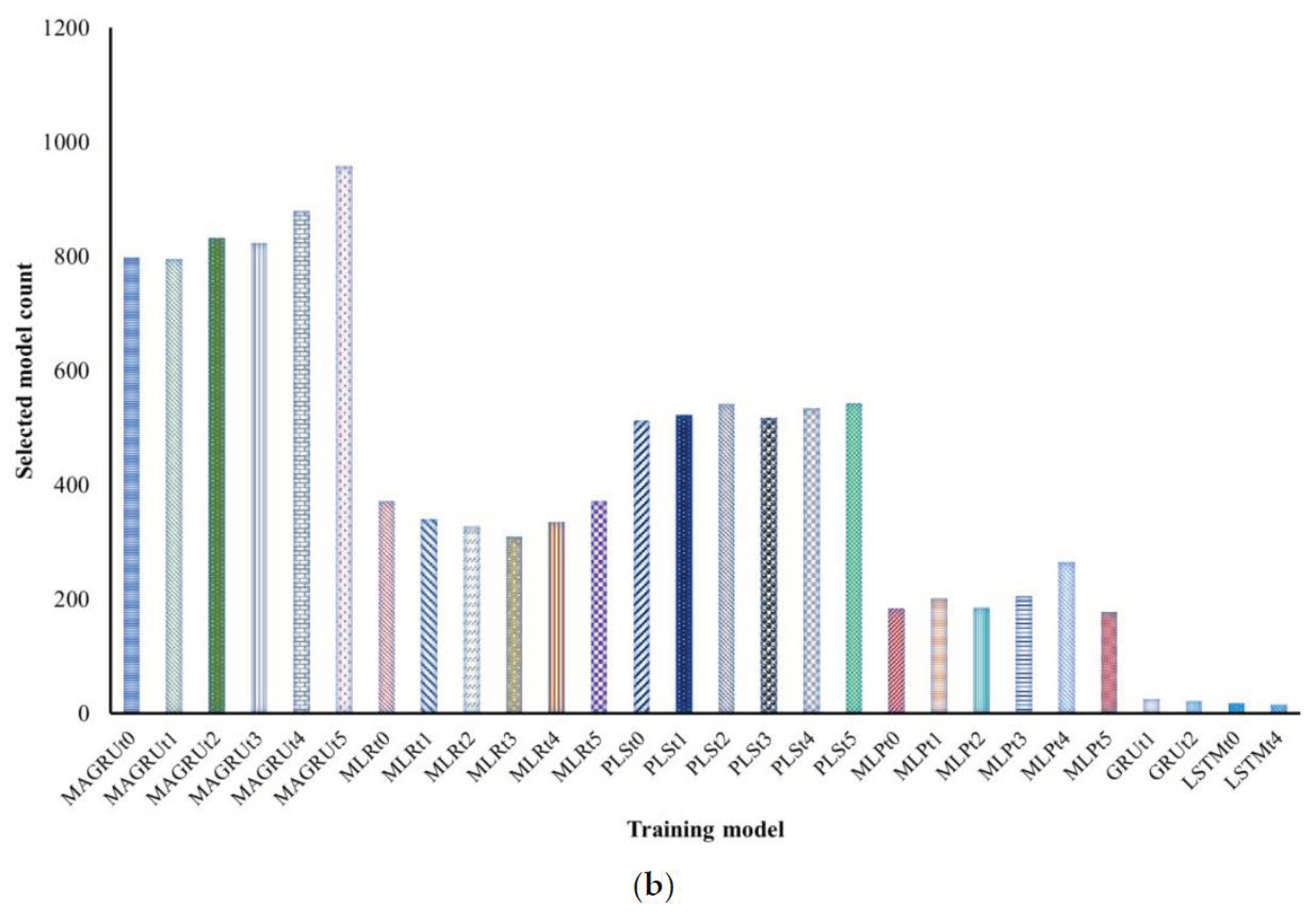
3.2. Determination of the Appropriate Predictive Model Based on Historical Data
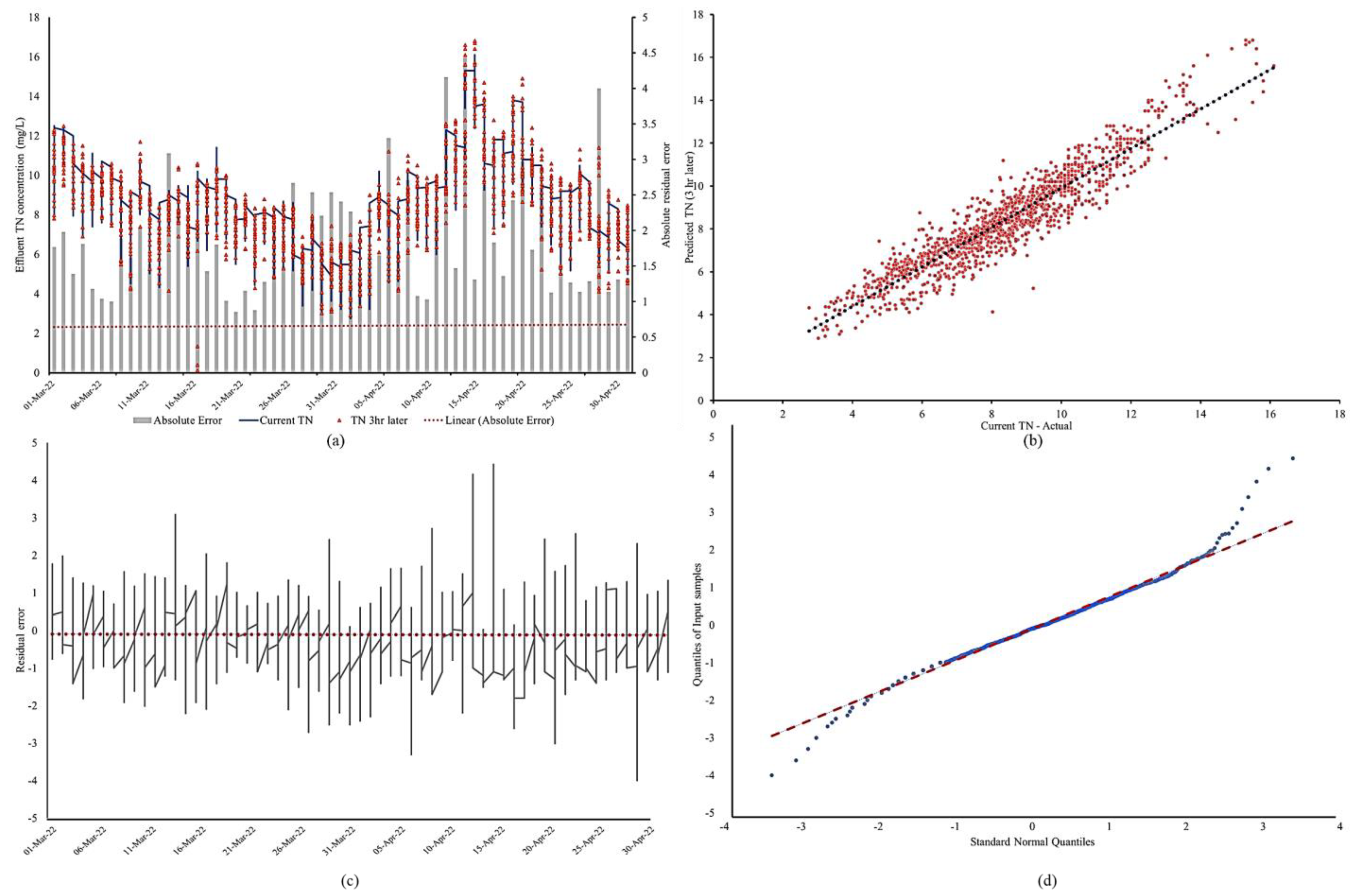
3.3. Hourly and Multistep Effluent TN Prediction
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Safder, U.; Loy-Benitez, J.; Nguyen, H.-T.; Yoo, C. A Hybrid Extreme Learning Machine and Deep Belief Network Framework for Sludge Bulking Monitoring in a Dynamic Wastewater Treatment Process. J. Water Process Eng. 2022, 46, 102580. [Google Scholar] [CrossRef]
- Safder, U.; Tariq, S.; Yoo, C. Multilevel Optimization Framework to Support Self-Sustainability of Industrial Processes for Energy/Material Recovery Using Circular Integration Concept. Appl. Energy 2022, 324, 119685. [Google Scholar] [CrossRef]
- Safder, U.; Rana, M.A.; Yoo, C. Feasibility Study and Performance Assessment of a New Tri-Generation Integrated System for Power, Cooling, and Freshwater Production. Desalin. WATER Treat. 2020, 183, 63–72. [Google Scholar] [CrossRef]
- Vilela, P.; Safder, U.; Heo, S.; Nguyen, H.; Lim, J.Y.; Nam, K.; Oh, T.; Yoo, C. Dynamic Calibration of Process-Wide Partial-Nitritation Modeling with Airlift Granular for Nitrogen Removal in a Full-Scale Wastewater Treatment Plant. Chemosphere 2022, 305, 135411. [Google Scholar] [CrossRef] [PubMed]
- Salgot, M.; Folch, M. Wastewater Treatment and Water Reuse. Curr. Opin. Environ. Sci. Heal. 2018, 2, 64–74. [Google Scholar] [CrossRef]
- Karunanidhi, D.; Aravinthasamy, P.; Subramani, T.; Roy, P.D.; Srinivasamoorthy, K. Risk of Fluoride-Rich Groundwater on Human Health: Remediation Through Managed Aquifer Recharge in a Hard Rock Terrain, South India. Nat. Resour. Res. 2020, 29, 2369–2395. [Google Scholar] [CrossRef]
- Jaramillo, F.; Orchard, M.; Muñoz, C.; Zamorano, M.; Antileo, C. Advanced Strategies to Improve Nitrification Process in Sequencing Batch Reactors—A Review. J. Environ. Manage. 2018, 218, 154–164. [Google Scholar] [CrossRef]
- Safder, U.; Nam, K.; Kim, D.; Shahlaei, M.; Yoo, C. Quantitative Structure-Property Relationship (QSPR) Models for Predicting the Physicochemical Properties of Polychlorinated Biphenyls (PCBs) Using Deep Belief Network. Ecotoxicol. Environ. Saf. 2018, 162, 61. [Google Scholar] [CrossRef]
- Fan, M.; Hu, J.; Cao, R.; Ruan, W.; Wei, X. A Review on Experimental Design for Pollutants Removal in Water Treatment with the Aid of Artificial Intelligence. Chemosphere 2018, 200, 330–343. [Google Scholar] [CrossRef]
- Elkiran, G.; Nourani, V.; Abba, S.I. Multi-Step Ahead Modelling of River Water Quality Parameters Using Ensemble Artificial Intelligence-Based Approach. J. Hydrol. 2019, 577, 123962. [Google Scholar] [CrossRef]
- Zhao, L.; Dai, T.; Qiao, Z.; Sun, P.; Hao, J.; Yang, Y. Application of Artificial Intelligence to Wastewater Treatment: A Bibliometric Analysis and Systematic Review of Technology, Economy, Management, and Wastewater Reuse. Process Saf. Environ. Prot. 2020, 133, 169–182. [Google Scholar] [CrossRef]
- Bagheri, M.; Bazvand, A.; Ehteshami, M. Application of Artificial Intelligence for the Management of Landfill Leachate Penetration into Groundwater, and Assessment of Its Environmental Impacts. J. Clean. Prod. 2017, 149, 784–796. [Google Scholar] [CrossRef]
- Mohammad, A.T.; Al-Obaidi, M.A.; Hameed, E.M.; Basheer, B.N.; Mujtaba, I.M. Modelling the Chlorophenol Removal from Wastewater via Reverse Osmosis Process Using a Multilayer Artificial Neural Network with Genetic Algorithm. J. Water Process Eng. 2020, 33, 100993. [Google Scholar] [CrossRef]
- Poznyak, A.; Chairez, I.; Poznyak, T. A Survey on Artificial Neural Networks Application for Identification and Control in Environmental Engineering: Biological and Chemical Systems with Uncertain Models. Annu. Rev. Control 2019, 48, 250–272. [Google Scholar] [CrossRef]
- Mokhtari, H.A.; Bagheri, M.; Mirbagheri, S.A.; Akbari, A. Performance Evaluation and Modelling of an Integrated Municipal Wastewater Treatment System Using Neural Networks. Water Environ. J. 2020, 34, 622–634. [Google Scholar] [CrossRef]
- Deng, Y.; Zhou, X.; Shen, J.; Xiao, G.; Hong, H.; Lin, H.; Wu, F.; Liao, B.-Q. New Methods Based on Back Propagation (BP) and Radial Basis Function (RBF) Artificial Neural Networks (ANNs) for Predicting the Occurrence of Haloketones in Tap Water. Sci. Total Environ. 2021, 772, 145534. [Google Scholar] [CrossRef]
- Noori, N.; Kalin, L.; Isik, S. Water Quality Prediction Using SWAT-ANN Coupled Approach. J. Hydrol. 2020, 590, 125220. [Google Scholar] [CrossRef]
- Bagheri, M.; Akbari, A.; Mirbagheri, S.A. Advanced Control of Membrane Fouling in Filtration Systems Using Artificial Intelligence and Machine Learning Techniques: A Critical Review. Process Saf. Environ. Prot. 2019, 123, 229–252. [Google Scholar] [CrossRef]
- Ma, J.; Ding, Y.; Cheng, J.C.P.; Jiang, F.; Xu, Z. Soft Detection of 5-Day BOD with Sparse Matrix in City Harbor Water Using Deep Learning Techniques. Water Res. 2020, 170, 115350. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Fitch, P.; Thorburn, P.J. Predicting the Trend of Dissolved Oxygen Based on the KPCA-RNN Model. Water 2020, 12, 585. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Sun, L.; Guo, D.; Zhang, Y.; Wang, W. A Deep Learning Algorithm for Multi-Source Data Fusion to Predict Water Quality of Urban Sewer Networks. J. Clean. Prod. 2021, 318, 128533. [Google Scholar] [CrossRef]
- Farhi, N.; Kohen, E.; Mamane, H.; Shavitt, Y. Prediction of Wastewater Treatment Quality Using LSTM Neural Network. Environ. Technol. Innov. 2021, 23, 101632. [Google Scholar] [CrossRef]
- Xu, R.; Deng, X.; Wan, H.; Cai, Y.; Pan, X. A Deep Learning Method to Repair Atmospheric Environmental Quality Data Based on Gaussian Diffusion. J. Clean. Prod. 2021, 308, 127446. [Google Scholar] [CrossRef]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. arXiv preprint 2017, arXiv:1704.02971. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer: Boston, MA, USA, 1998; ISBN 978-1-4613-7604-0. [Google Scholar]
- Dey, S.K.; Rahman, M.M. Flow Based Anomaly Detection in Software Defined Networking: A Deep Learning Approach with Feature Selection Method. In Proceedings of the 2018 4th International Conference on Electrical Engineering and Information & Communication Technology (iCEEiCT), Bangladesh, 13–15 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 630–635. [Google Scholar]
- Mishra, B.K.; Regmi, R.K.; Masago, Y.; Fukushi, K.; Kumar, P.; Saraswat, C. Assessment of Bagmati River Pollution in Kathmandu Valley: Scenario-Based Modeling and Analysis for Sustainable Urban Development. Sustain. Water Qual. Ecol. 2017, 9–10, 67–77. [Google Scholar] [CrossRef]
- Singh, A.; Jain, A. Adaptive Credit Card Fraud Detection Techniques Based on Feature Selection Method; Springer: Singapore, 2019; pp. 167–178. [Google Scholar]
- Aggarwal, C.C.; Reddy, C.K. (Eds.) Data Clustering; Chapman and Hall/CRC: New York, NY, USA, 2016; ISBN 9781315373515. [Google Scholar] [CrossRef]
- Nkiama, H.; Zainudeen, S.; Saidu, M. A Subset Feature Elimination Mechanism for Intrusion Detection System. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 419. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Gu, B.; Yang, L.; Lu, Y. Hybrid ANN–PLS Approach to Scroll Compressor Thermodynamic Performance Prediction. Appl. Therm. Eng. 2015, 77, 113–120. [Google Scholar] [CrossRef]
- Safder, U.; Nam, K.J.; Kim, D.; Heo, S.K.; Yoo, C.K. A Real Time QSAR-Driven Toxicity Evaluation and Monitoring of Iron Containing Fine Particulate Matters in Indoor Subway Stations. Ecotoxicol. Environ. Saf. 2019, 169, 361–369. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Landslide Susceptibility Assessment and Factor Effect Analysis: Backpropagation Artificial Neural Networks and Their Comparison with Frequency Ratio and Bivariate Logistic Regression Modelling. Environ. Model. Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- Elmaz, F.; Eyckerman, R.; Casteels, W.; Latré, S.; Hellinckx, P. CNN-LSTM Architecture for Predictive Indoor Temperature Modeling. Build. Environ. 2021, 206, 108327. [Google Scholar] [CrossRef]
- Mallick, R.; Yebda, T.; Benois-Pineau, J.; Zemmari, A.; Pech, M.; Amieva, H. A GRU Neural Network with Attention Mechanism for Detection of Risk Situations on Multimodal Lifelog Data. In Proceedings of the 2021 International Conference on Content-Based Multimedia Indexing (CBMI), Lille, France, 28–30 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Kjell, O.N.E.; Sikström, S.; Kjell, K.; Schwartz, H.A. Natural Language Analyzed with AI-Based Transformers Predict Traditional Subjective Well-Being Measures Approaching the Theoretical Upper Limits in Accuracy. Sci. Rep. 2022, 12, 3918. [Google Scholar] [CrossRef] [PubMed]
- Arroyo, D.M.; Postels, J.; Tombari, F. Variational Transformer Networks for Layout Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar] [CrossRef]
- Pei, W.; Baltrušaitis, T.; Tax, D.M.J.; Morency, L.-P. Temporal Attention-Gated Model for Robust Sequence Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June – 1 July 2016. [Google Scholar]
- Hyndman, R.J.; Ahmed, R.A.; Athanasopoulos, G.; Shang, H.L. Optimal Combination Forecasts for Hierarchical Time Series. Comput. Stat. Data Anal. 2011, 55, 2579–2589. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Influent Parameter | Description | Unit | Mean | Standard Deviation |
|---|---|---|---|---|
| Qin | Influent flowrate | m3/day | 83.05 | 16.84 |
| CODin | Chemical oxygen demand | mg/L | 13.06 | 2.43 |
| MLSS | Mixed liquor suspended solids | mg/L | 2892.07 | 335.43 |
| TSSin | Total suspended solids | mg/L | 2.76 | 0.74 |
| TNin | Total nitrogen | mg/L | 8.13 | 2.27 |
| TPin | Total phosphorous | mg/L | 0.35 | 0.16 |
| GRU | LSTM | MAGRU | |
|---|---|---|---|
| General training components | Batch size: 2048 Epochs: 500 Validation split: 0.2 Early stopping patience: 10 Loss function: mean squared error Optimizer: Adam | Batch size: 128 Epochs: 100 Model checkpoint Optimizer: Adam Learning rate: 0.001 | Batch size: 3 Epochs: 100 Validation split: 0.2 Loss function: mean squared error Optimizer: Adam |
| Hyperparameters description | Hidden layer 1: 256 memory cells Hidden layer 2: 128 memory cells Dropout: 0.15 Learning rate: dynamic | Hidden layer 1: 32 neurons (ReLU) Hidden layer 2: 16 neurons (ReLU) Dropout: 0.15 Learning rate: dynamic | Encoder 1: 64 neurons (ReLU) Encoder 2: 64 neurons (ReLU) Hidden layer 1: 16 Time distributed 1: 64 Time distributed 2: 32 Max Pooling: 64 |
| Models/Time | 1 March 2022 02:00 h | 2 March 2022 04:00 h | 10 March 2022 13:00 h | 15 March 2022 22:00 h | 28 March 2022 06:00 h | 5 April 2022 11:00 h | 15 April 2022 09:00 h | 26 April 2022 15:00 h |
|---|---|---|---|---|---|---|---|---|
| Score-MAE | ||||||||
| PLSt0 | 0.561 | 0.808 | 0.861 | 0.572 | 0.715 | 0.427 | 0.432 | 0.503 |
| MLRt0 | 0.577 | 0.708 | 0.716 | 0.564 | 0.631 | 0.435 | 0.441 | 0.432 |
| MLPt0 | 0.772 | 0.979 | 0.788 | 0.645 | 0.881 | 1.386 | 0.706 | 0.437 |
| GRUt0 | 0.973 | 1.013 | 0.893 | 1.054 | 1.068 | 1.475 | 1.825 | 0.969 |
| LSTMt0 | 0.688 | 0.876 | 0.845 | 0.765 | 0.788 | 0.679 | 0.987 | 0.906 |
| MAGRUt0 | 0.436 | 0.398 | 0.550 | 0.425 | 0.961 | 0.374 | 0.588 | 0.416 |
| PLSt1 | 0.400 | 0.553 | 0.878 | 0.593 | 0.595 | 1.357 | 0.446 | 0.672 |
| MLRt1 | 0.478 | 0.545 | 0.730 | 0.562 | 0.482 | 0.928 | 0.428 | 0.554 |
| MLPt1 | 0.530 | 0.756 | 0.640 | 0.492 | 0.575 | 1.648 | 0.656 | 0.541 |
| GRUt1 | 0.626 | 1.015 | 0.885 | 0.676 | 1.080 | 1.484 | 1.853 | 1.375 |
| LSTMt1 | 0.703 | 0.754 | 0.845 | 0.788 | 0.721 | 0.986 | 1.010 | 0.906 |
| MAGRUt1 | 0.304 | 0.423 | 0.551 | 0.321 | 0.359 | 0.369 | 0.669 | 0.411 |
| PLSt2 | 0.459 | 0.611 | 1.788 | 1.763 | 0.539 | 0.312 | 0.484 | 0.369 |
| MLRt2 | 0.513 | 0.550 | 0.932 | 1.053 | 0.473 | 0.434 | 0.427 | 0.434 |
| MLPt2 | 0.653 | 0.574 | 0.637 | 0.955 | 0.599 | 4.601 | 0.716 | 0.426 |
| GRUt2 | 0.941 | 1.004 | 0.935 | 1.057 | 1.061 | 1.476 | 1.887 | 0.876 |
| LSTMt2 | 0.689 | 0.757 | 0.986 | 0.810 | 0.721 | 0.754 | 0.987 | 0.906 |
| MAGRUt2 | 0.395 | 0.593 | 0.406 | 0.264 | 0.631 | 0.330 | 0.584 | 0.481 |
| PLSt3 | 0.425 | 0.401 | 0.846 | 0.589 | 0.570 | 0.417 | 0.518 | 0.356 |
| MLRt3 | 0.479 | 0.489 | 0.695 | 0.568 | 0.468 | 0.470 | 0.426 | 0.431 |
| MLPt3 | 0.495 | 0.733 | 0.655 | 0.608 | 0.660 | 1.737 | 0.549 | 0.457 |
| GRUt3 | 0.940 | 1.037 | 0.889 | 1.183 | 1.075 | 1.477 | 1.856 | 0.877 |
| LSTMt3 | 0.689 | 0.752 | 0.841 | 0.765 | 0.721 | 0.679 | 0.987 | 0.906 |
| MAGRUt3 | 0.404 | 0.398 | 0.453 | 0.557 | 0.350 | 0.330 | 0.628 | 0.313 |
| PLSt4 | 0.405 | 0.428 | 0.844 | 0.525 | 0.544 | 0.303 | 0.843 | 0.407 |
| MLRt4 | 0.479 | 0.486 | 0.700 | 0.556 | 0.484 | 0.439 | 0.601 | 0.444 |
| MLPt4 | 0.523 | 0.519 | 0.851 | 0.588 | 0.605 | 1.954 | 0.968 | 0.417 |
| GRUt4 | 0.942 | 1.006 | 0.895 | 1.074 | 1.082 | 1.477 | 1.884 | 0.924 |
| LSTMt4 | 0.716 | 0.754 | 0.845 | 0.765 | 0.721 | 0.680 | 1.053 | 0.906 |
| MAGRUt4 | 0.408 | 0.389 | 0.371 | 0.492 | 0.367 | 0.390 | 0.611 | 0.307 |
| PLSt5 | 0.514 | 0.409 | 1.006 | 0.542 | 0.551 | 0.830 | 0.926 | 3.337 |
| MLRt5 | 0.571 | 0.489 | 0.806 | 0.563 | 0.525 | 0.580 | 0.609 | 1.384 |
| MLPt5 | 0.764 | 0.673 | 0.819 | 0.599 | 1.119 | 1.249 | 0.683 | 1.421 |
| GRUt5 | 0.946 | 1.026 | 0.893 | 1.050 | 1.066 | 0.499 | 0.881 | 1.461 |
| LSTMt5 | 0.733 | 0.754 | 0.903 | 0.765 | 0.721 | 0.679 | 0.987 | 1.132 |
| MAGRUt5 | 0.376 | 0.406 | 0.447 | 0.427 | 0.494 | 0.286 | 0.438 | 0.305 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Safder, U.; Kim, J.; Pak, G.; Rhee, G.; You, K. Investigating Machine Learning Applications for Effective Real-Time Water Quality Parameter Monitoring in Full-Scale Wastewater Treatment Plants. Water 2022, 14, 3147. https://doi.org/10.3390/w14193147
Safder U, Kim J, Pak G, Rhee G, You K. Investigating Machine Learning Applications for Effective Real-Time Water Quality Parameter Monitoring in Full-Scale Wastewater Treatment Plants. Water. 2022; 14(19):3147. https://doi.org/10.3390/w14193147
Chicago/Turabian StyleSafder, Usman, Jongrack Kim, Gijung Pak, Gahee Rhee, and Kwangtae You. 2022. "Investigating Machine Learning Applications for Effective Real-Time Water Quality Parameter Monitoring in Full-Scale Wastewater Treatment Plants" Water 14, no. 19: 3147. https://doi.org/10.3390/w14193147
APA StyleSafder, U., Kim, J., Pak, G., Rhee, G., & You, K. (2022). Investigating Machine Learning Applications for Effective Real-Time Water Quality Parameter Monitoring in Full-Scale Wastewater Treatment Plants. Water, 14(19), 3147. https://doi.org/10.3390/w14193147