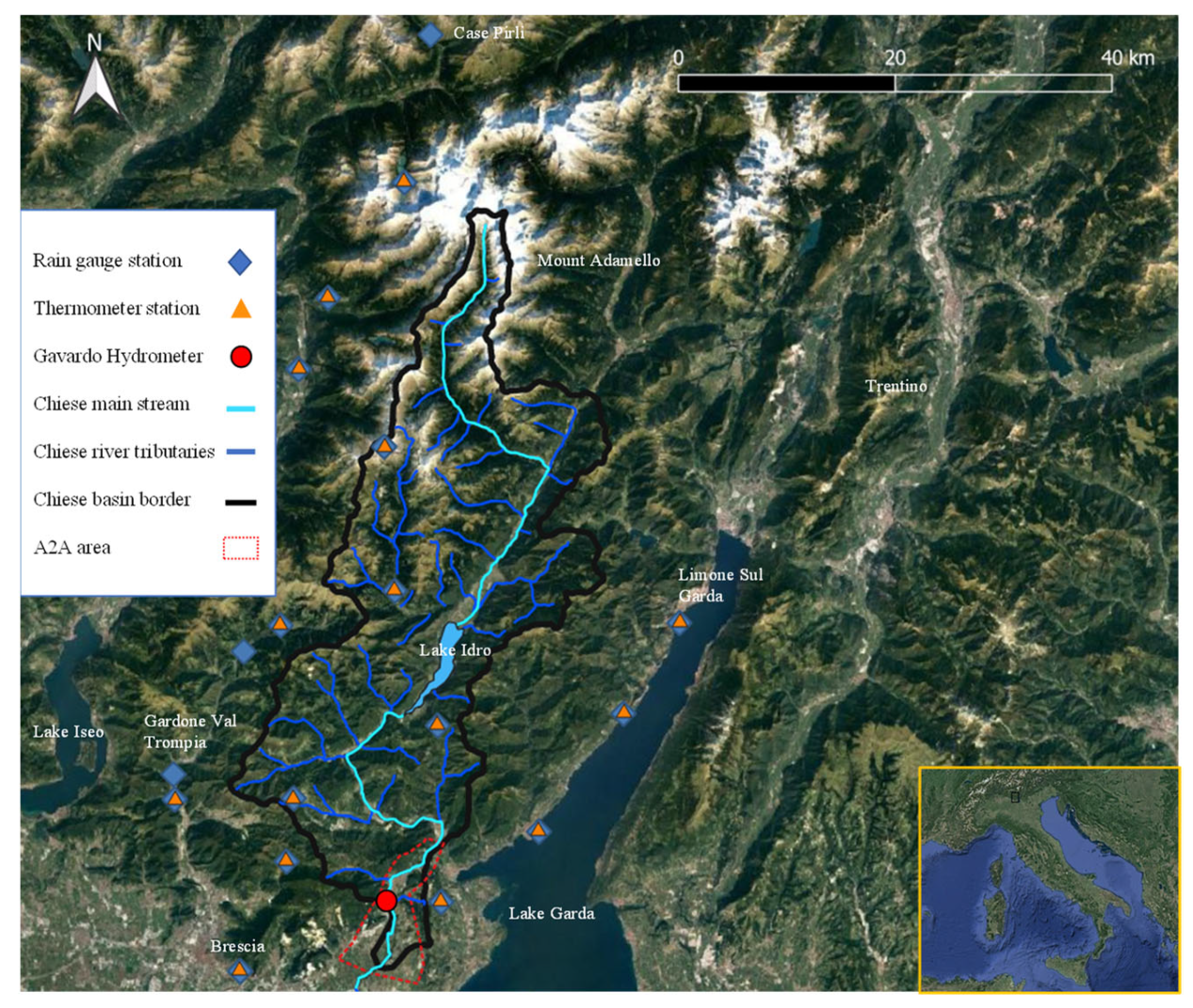
The data were analyzed at the finest resolution, 0.11° (~12.5 km, EUR-11 referring to the models related to the European areas with the finest resolution) and considered for the historical period of 1971–2000 as a baseline. The used coupled Climate models are: CM5-RCA4, ECE-HIRH, ECE-RACM, ECE-RACMr12, ECE-RCA4, IPS-RCA4, Had-RACM, Had-RCA4, MPI-RCA4, and Nor-HIRH, which include three RCMs and six GCMs, the information of which is shown in
Table 1 and
Table 2. ECE-RACMr12 refers to the same model as ECE-RACM but considers a different realization (an ensemble experiment with different initial states from ECE-RACM).
2.3.1. Climate Models’ Performance Evaluations
Work [
23] demonstrated that for small-scale case studies, the averaged climatic variables over the catchment are a good surrogate of the whole catchment climate features, and they can be used for model evaluation and data projection purposes. Hence, together with the ensemble spatial analysis of climate models, this study used a weighted catchment approach, as used in [
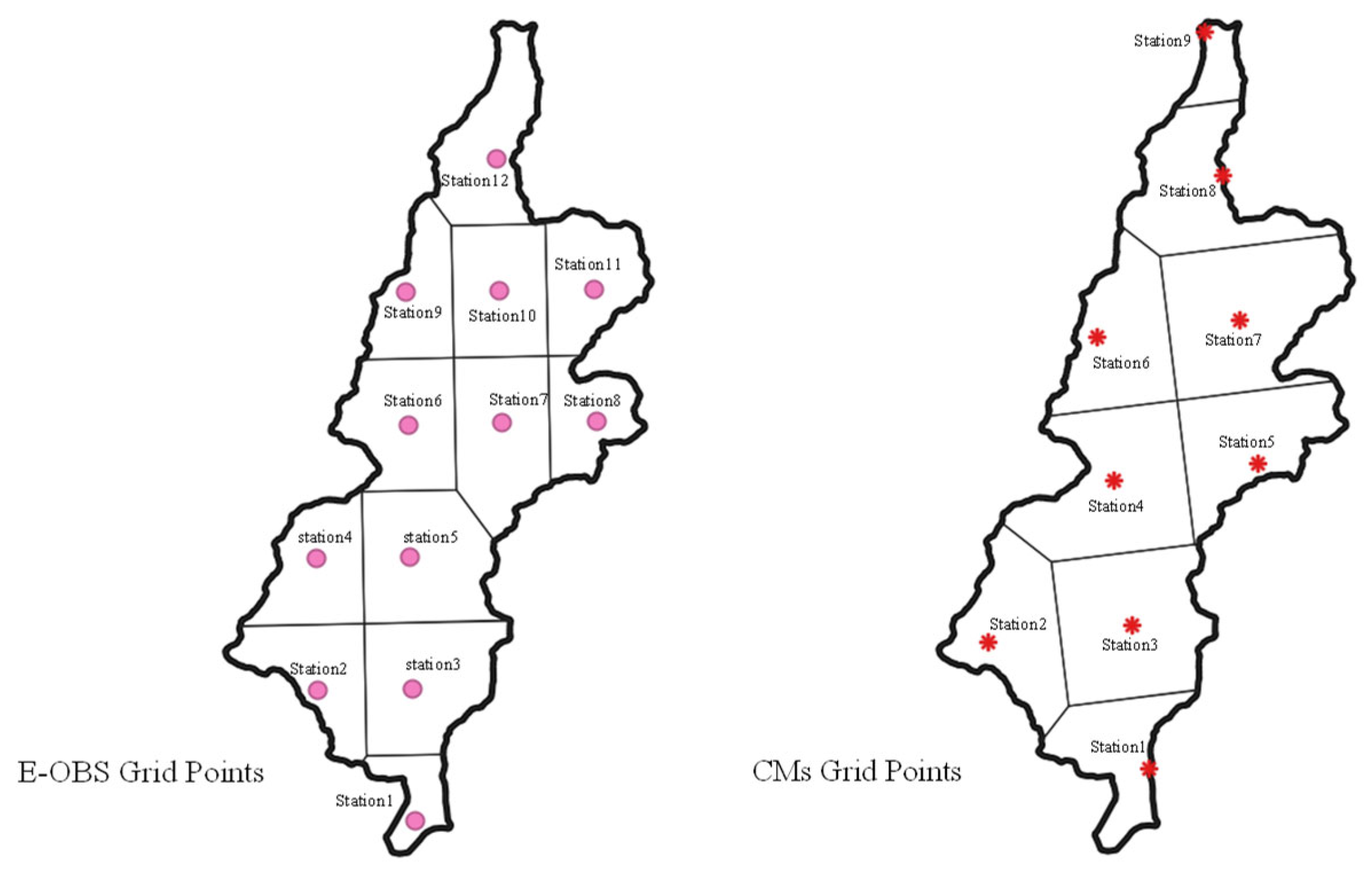
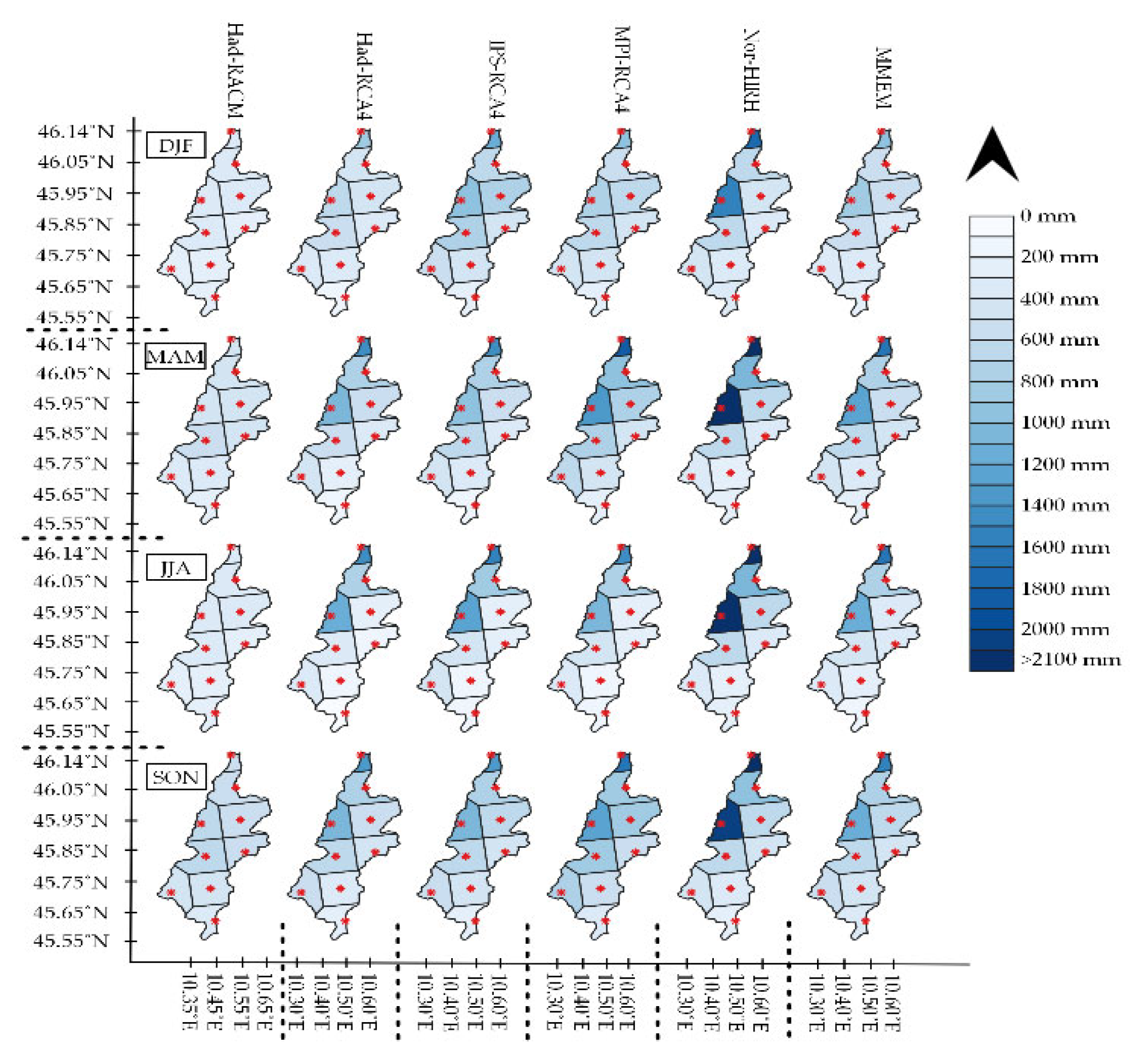
39], to evaluate the RCMs and impact models. In this approach, every grid point within the catchment border represents a fictitious weather station, called a node in
Figure 2, playing the main role in the hydrological analysis of the catchment and in the RCM performance evaluation. To guarantee the good use of CMs’ grid points within the catchment, the longest and shortest east–west and north–south coordinates of real weather gauges were used for the operation of the CMs and finding the region grid points. That is why the outer catchment grid points were also visualized. In our study, all the regional climate models showed the grid points with the same coordinates for both hydro-climatological properties, temperature, and precipitation.
The models were evaluated in two important terms, uncertainty and error, which refer to two different concepts. Error and uncertainty could have an opposite conformity for a CM, meaning that the model could perform with low error but high uncertainty in reproducing or projecting particular catchment data, or vice versa. This is an important issue that has rarely received attention, and the current study provides a solution to overcome this challenge. For the uncertainty assessment, there are different factors affecting the uncertainties in the outputs, including uncertainty in the parameterization, initial and boundary conditions, greenhouse gas emissions scenarios, and models [
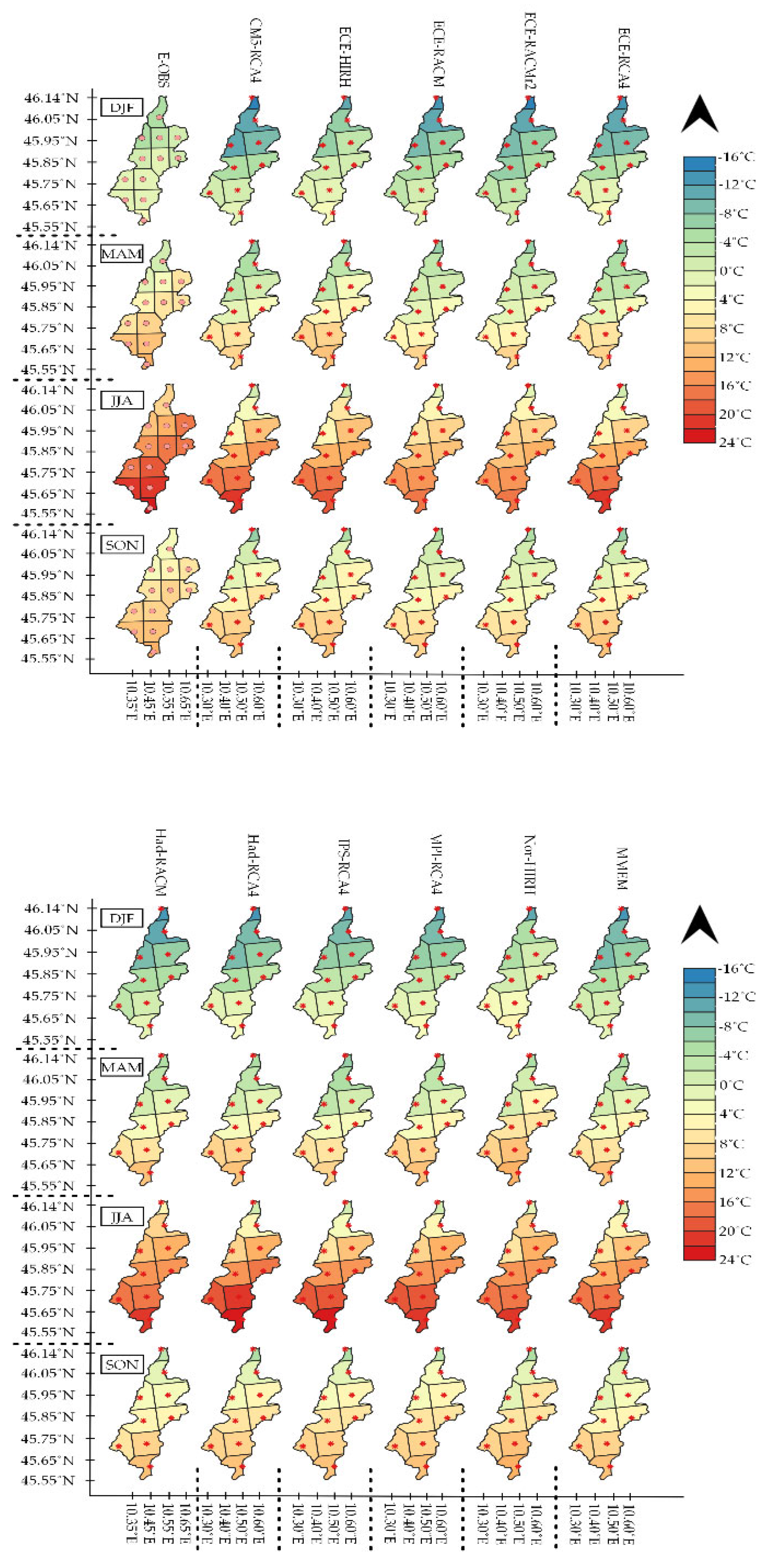
40]. In this study, only uncertainty originating from the interaction of different coupled models was considered. For this purpose, the multi-model ensemble mean (MMEM) model is a new model resulting from averaging all the ensemble members. It was assumed that the MMEM model was the best in terms of covering the uncertainty shortcomings of the model’s outputs. For error assessment, the gridded observational-based daily dataset over the Europe domain called E-OBS was used against CM outputs to evaluate the performance of all the CMs. For this purpose, the last version of E-OBS was downloaded from the source
https://surfobs.climate.copernicus.eu/dataaccess/access_eobs.php#datafiles (accessed on 30 September 2022) for both precipitation and temperature data over a 30-year control period, from 1971 to 2000. The finest spatial resolution of the E-OBS data (0.10°) was chosen, and the E-OBS grid points for both temperature and precipitation were visualized within the selection domain (
Figure 2). As can be seen, 12 fictitious E-OBS stations are located within the catchment border. Due to the finer resolution of E-OBS data, the number of E-OBS grid points is more than that of the CM points within the catchment boundaries.
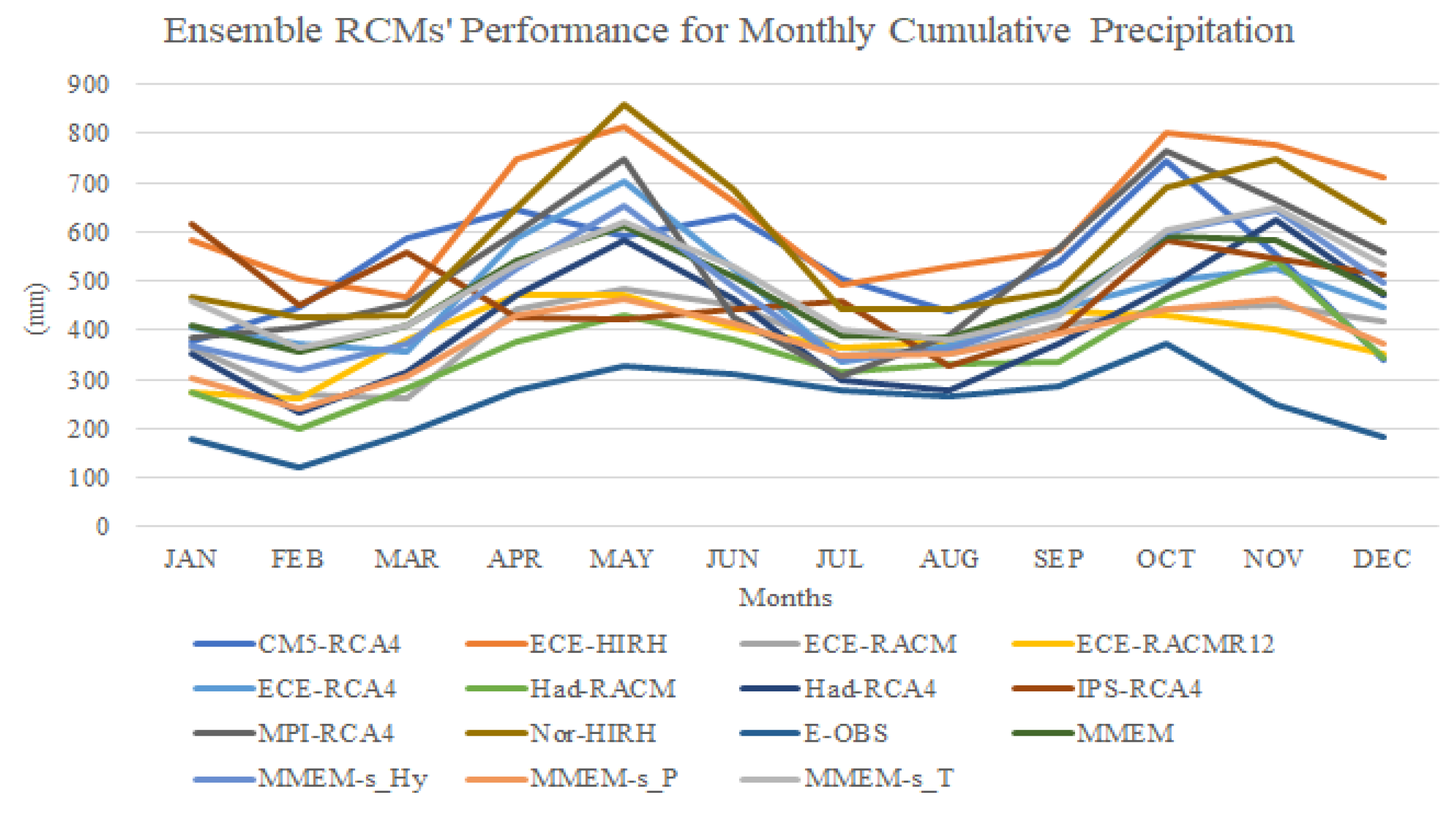
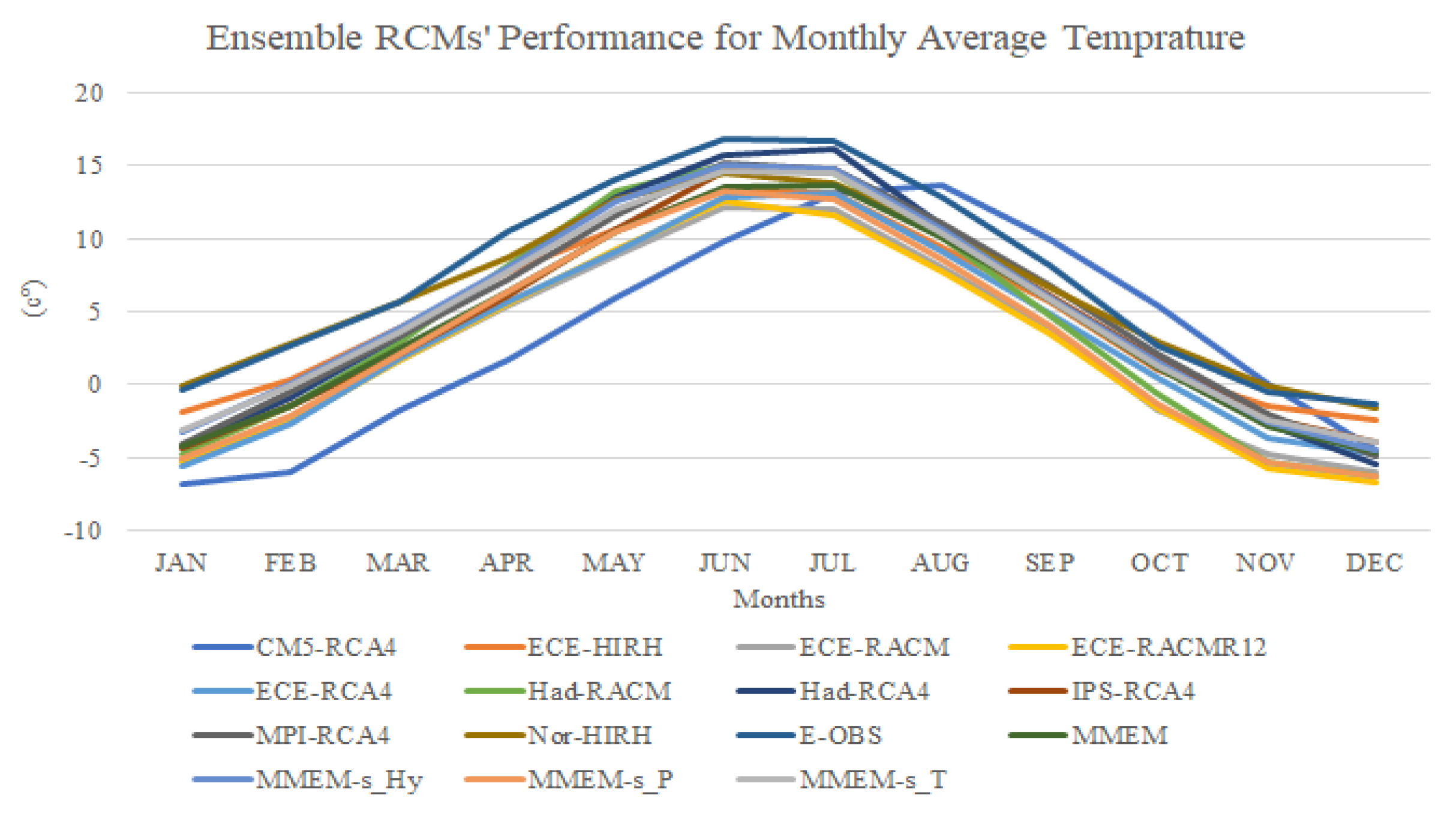
The monthly cumulative precipitation and monthly average temperature values are the target variables for evaluating the CMs. The monthly values of CMs are accessible directly from the source, while the daily E-OBS data should be aggregated over the month scale. In this study, the precipitation and temperature variables for a node
are represented by
, where
x = P (precipitation) or
T (temperature);
,
,
; and
. refer to the number of months, years, E-OBS and CM nodes respectively. For every specific month and year, for example,
(January) and
(year 1971), the current methodology introduces a variable that provides the weighted average catchment value for the two target variables estimated by Equation (1).
where
represents the number of fictitious stations within the catchment, i.e., 9 and 12 for the CMs and E-OBS data.
refers to the weight of every node
calculated by the Thiessen polygons method such that the ratio of the Thiessen polygon area associated with the node to the total area of the catchment provides the weight of the corresponding node. The weights not only specify the significance of the role of the grid points in the hydrological analysis of the catchment, but also evaluate the suitability of CMs’ numerical schemes to the layout of the catchment in case they have different grid schemes.
Figure 3 and
Table 3 show the Thiessen polygons and area information together with the weights and elevation of the fictitious stations (captured from the digital elevation model) for both the CM and E-OBS datasets.
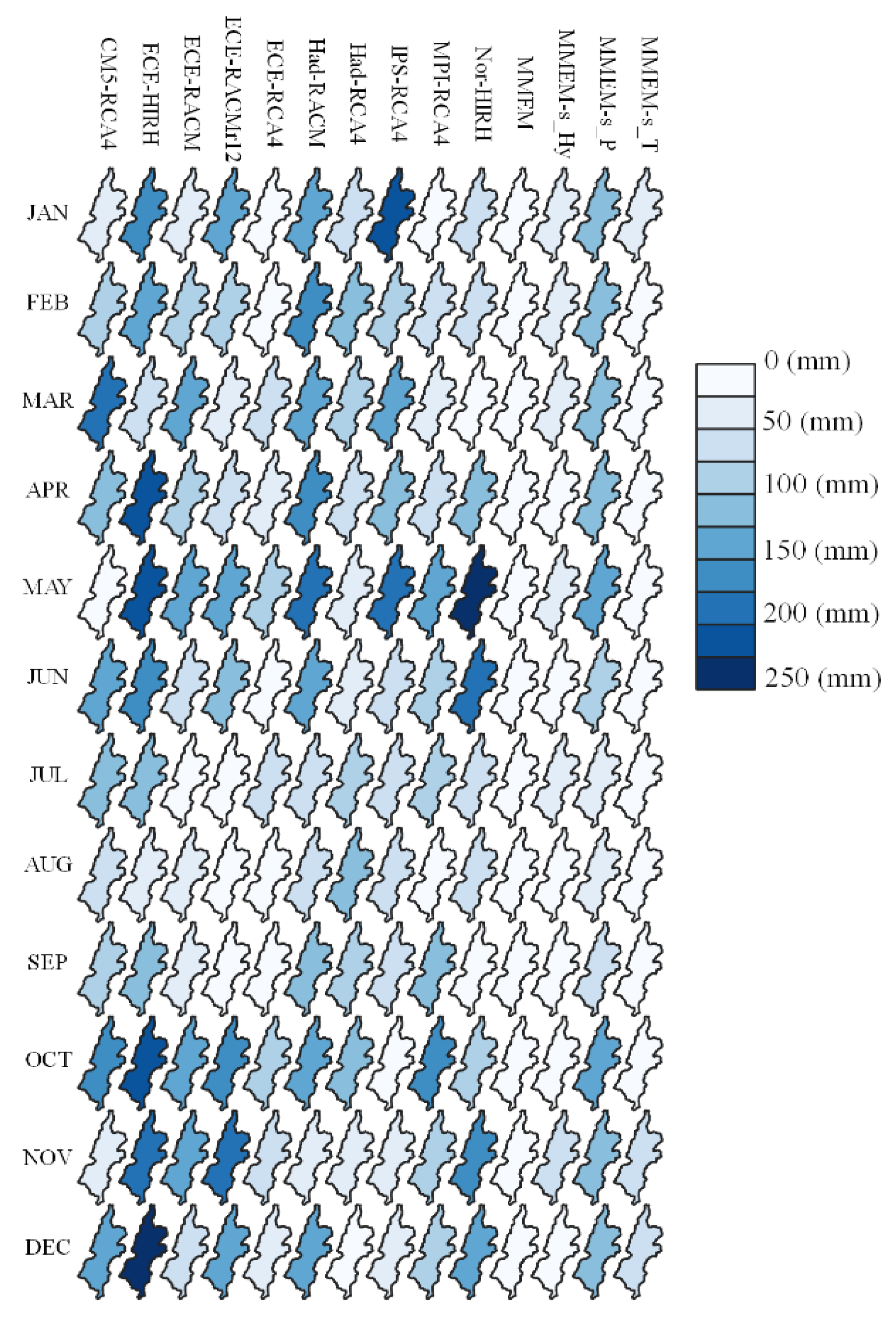
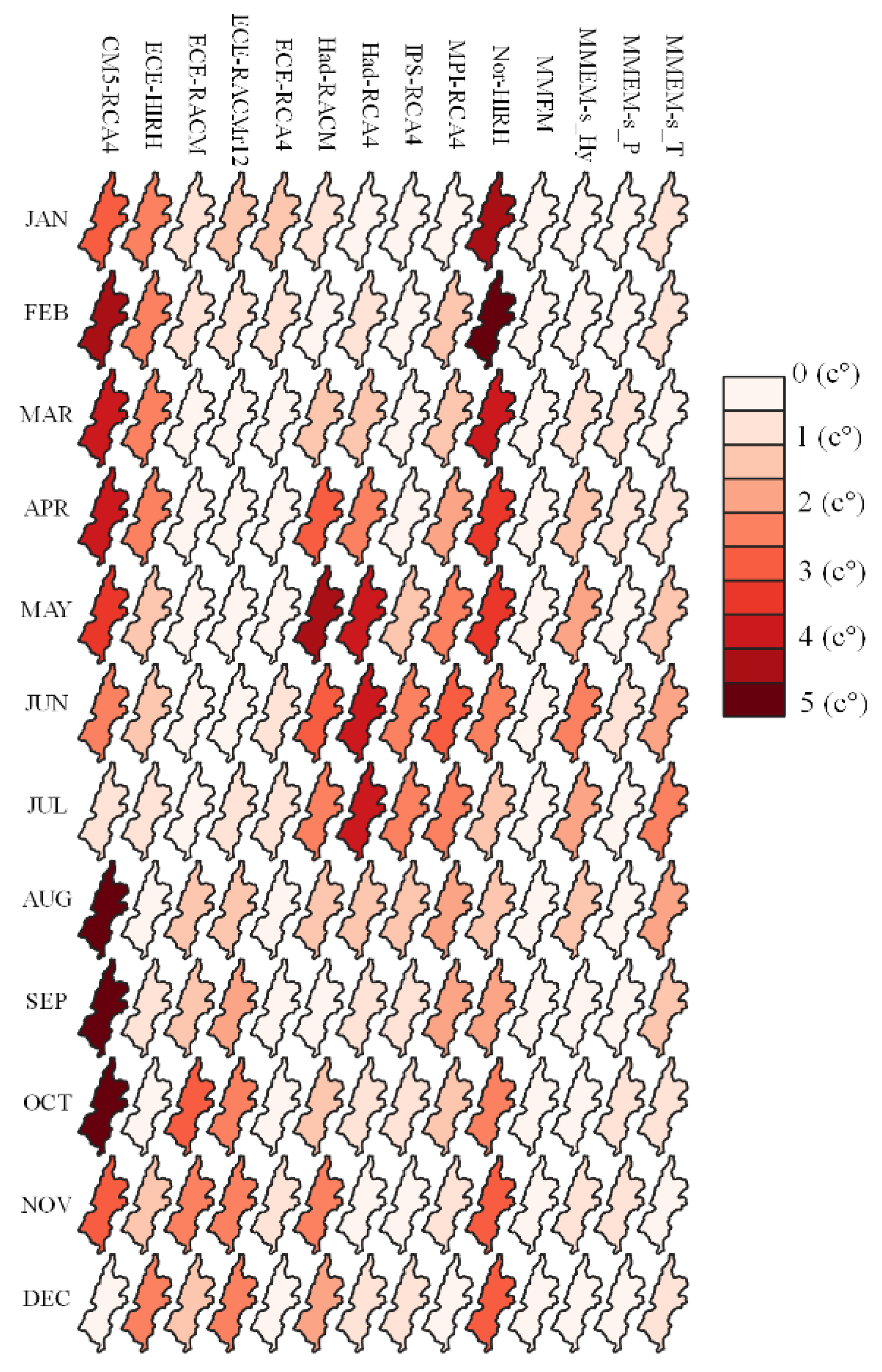
Root Mean Square, Mean, and Standard Deviation Errors (RMSE, ME, and SDE, respectively) are the statistical error indices used to estimate the performance of the climate models in terms of validation. RMSE is calculated after ordering the climate model and E-OBS data associated with the benchmark period of
nyears in ascending order, with the objective of evaluating the extent to which the cumulative frequency of the cumulative rainfall and temperature values obtained from the generic climate model is close to the corresponding cumulative frequency of the E-OBS data. For every specific month
, for example
, the monthly errors for the given precipitation and temperature variables of CM shown by
(
) are calculated by Equation (2) as follows:
where
represents the error of climate model
for simulating month
catchment variable
;
defines the number of years in the control period, which is 30 in the current study; and
and
stand for the E-OBS and climate model precipitation or temperature values in month
, respectively. The representative performance errors of the climate model
, where
varies from one to the number of CMs under study (the 10 downloaded models plus MMEM), are obtained for precipitation and temperature variables by Equation (3):
where
represents the RMSE of the climate model
in terms of precipitation and temperature simulations, respectively. Indeed, the representative error is equal to the average of all months’ RMSE values. Finally,
represents the number of months in a year, which is 12. Other error indices are based on the mean and standard deviation of outputs calculated as follows:
Accordingly, the ME and SDE indices of catchment output
are calculated for every climate model
by Equations (6) and (7):
2.3.2. Ensemble Member Selection for Impact Models Assessment
There are different approaches in the literature for using climate models’ outputs in the hydrological and methodological models projecting future data and showing the impacts of climate change on the environment. The pre-defined CMs could achieve different ranks based on their error performance values. Moreover, the reliability of a model could change for target variable reproduction. For example, while a model shows a small error for generating precipitation data, it could have a high error for the temperature variable. Hence, depending on the type of impact model calculated by CMs’ outputs, the employment of CMs could change. For example, for the hydrological variables, precipitation is the main source of catchment recharge, and temperature plays the main role in evaporation and evapotranspiration. Hence, the reliable CM is the model with the lowest error for reproducing both weighted catchment precipitation and temperature variables. In this study, three weighted dimensionless error metrics are defined to rank the models in different aspects [
23].
In the above-mentioned equations, and are weighting factors for precipitation and temperature errors, respectively, that satisfy . Equations (8)–(10) state the relative performance of different models in the reproduction of target variables. The neutral case is when and in the limiting case, and . The exact values of the weights for the hydrological impact models are obtained after sensitivity analyses and parameters tuning in the hydrological models.
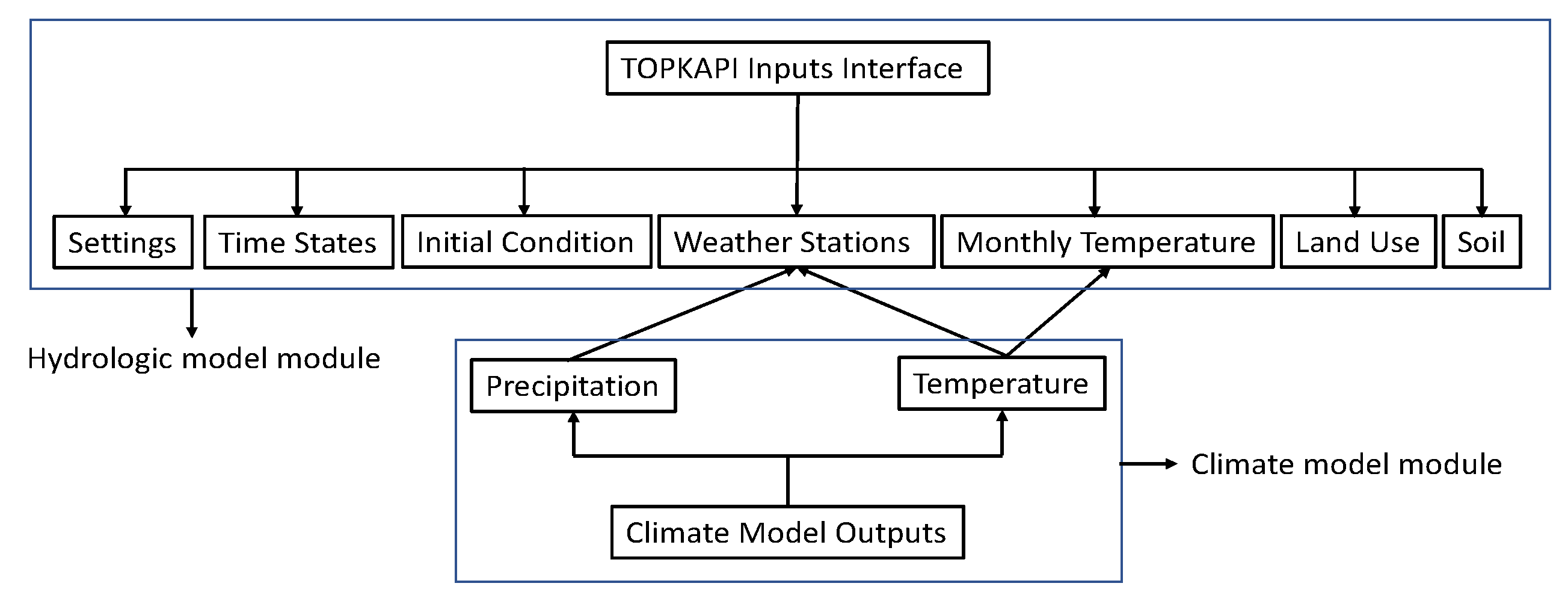
Based on the error values, the CMs are ranked. The first ranked model is the most reliable one in terms of fitting the observed data. However, it may not be the best for covering uncertainty. The ideal case is the time when MMEM is ranked first, as it is the best model in terms of error and uncertainty. It is not guaranteed that the MMEM model always performs with the lowest error, and there could be a case when the MMEM model even has the highest error. In this instance, there is a tradeoff between two concepts of error and uncertainty, meaning that moving towards choosing the model covering uncertainty brings about a model with high error. To tackle this challenge, this study introduces an algorithm to select a subset of ensemble models that have average outputs which are unbiased and balanced for both error and uncertainty (see
Figure 4).
2.3.3. Projection and Climate Change Impacts Assessment
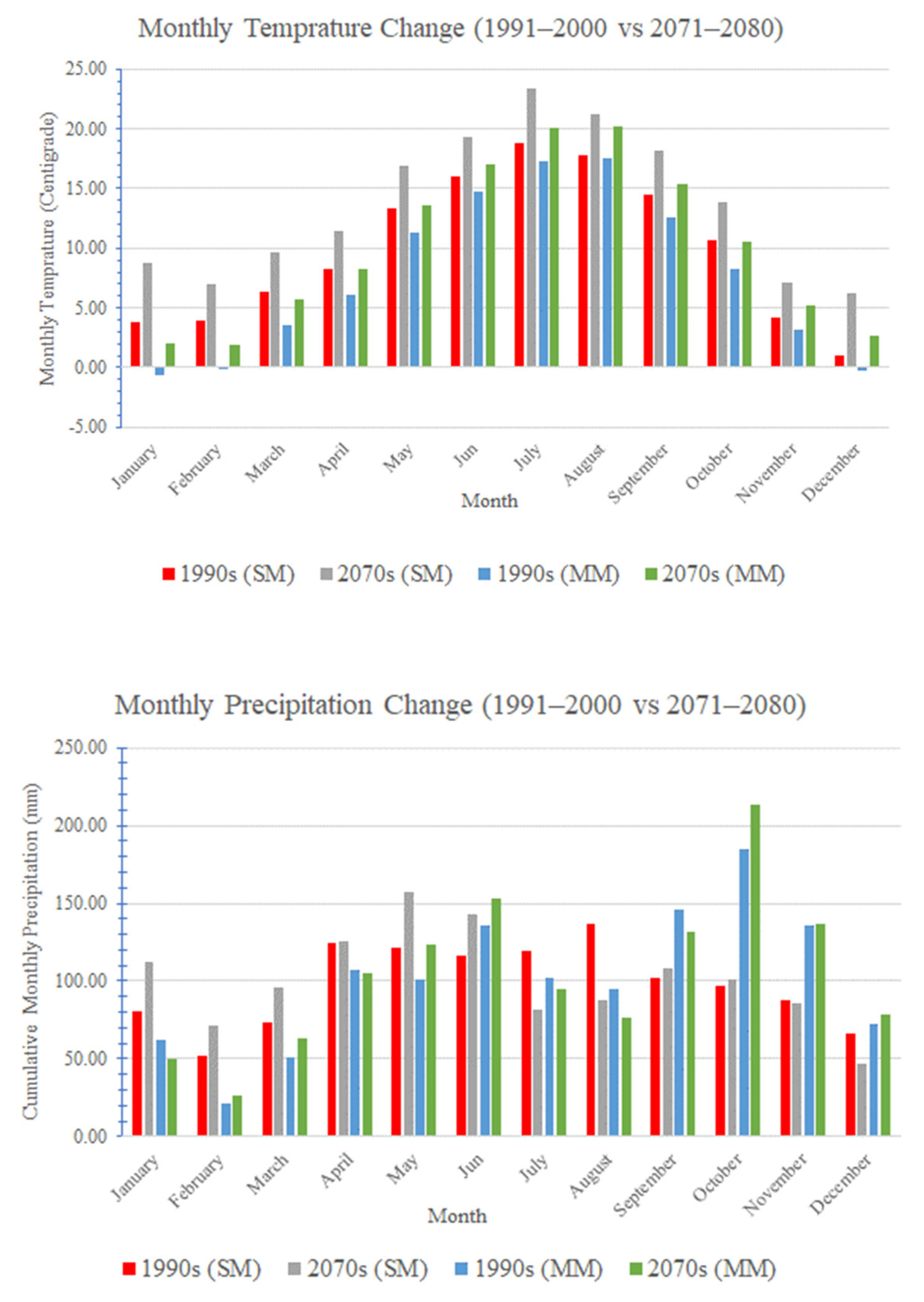
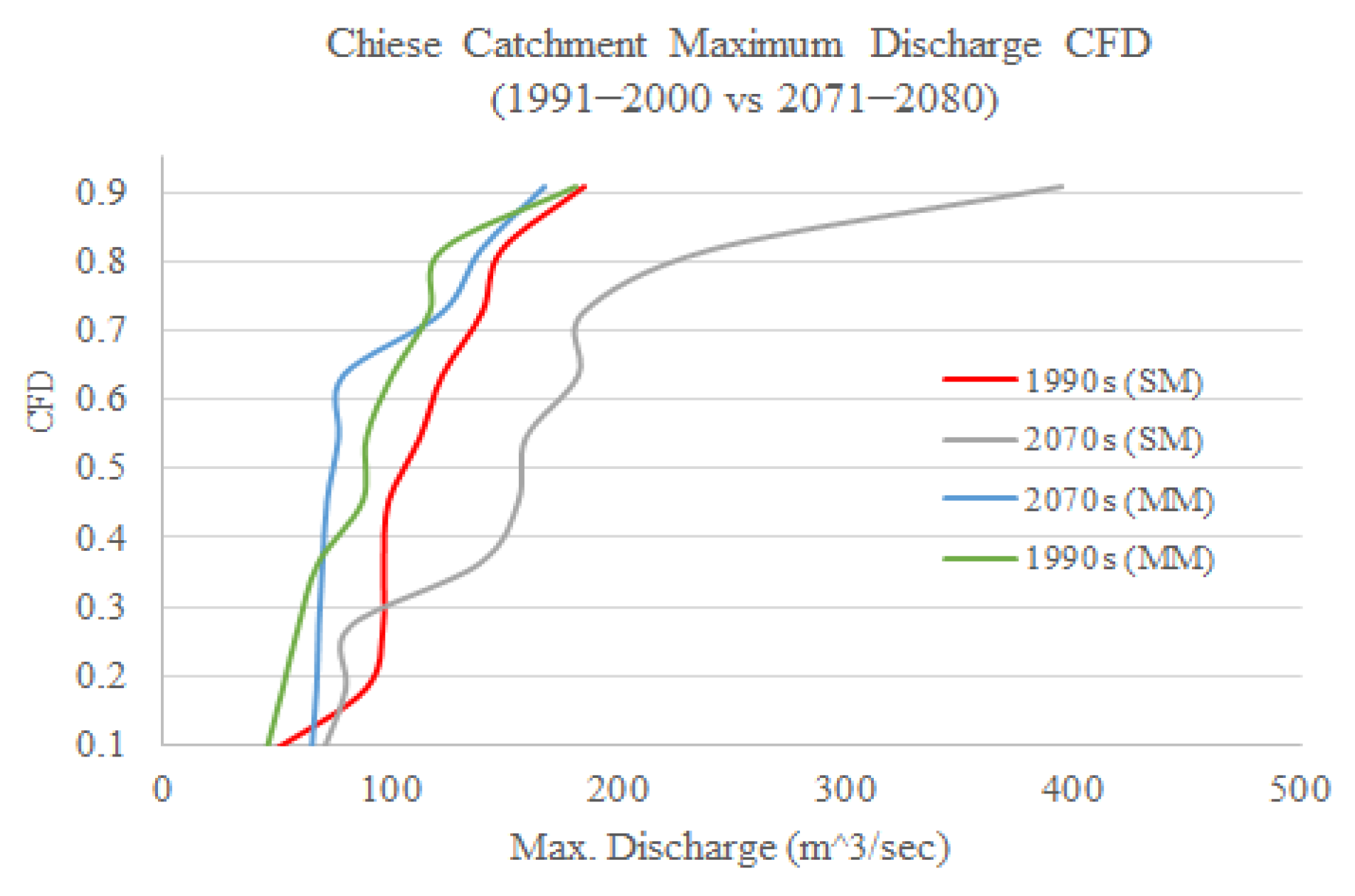
There are 10 climate change impact model assessments in this study, as shown in
Table 4. For all the models, the comparison periods are the 2070s in the future (2071–2080) vs. the 1990s in the historical period of 1991–2000. The aim is to assess the impacts of climate change on some hydro-climatological and hydrological variables under the RCP 4.5 climate change scenario. Every impact model is formed and calculated by its associated and suitable subset ensemble CMs. The relevant weight values for finding the best CMs are written in
Table 4.
As we are dealing with a real project, all of the data generated by the best climate model or the best subset of the ensemble were modified by the bias correction factors to make all the simulations reliable for the decision-makers. There are many methods for the estimation of the bias correction factors [
41]. This study used the linear-scaling method that has parsimony as its main advantage [
10]. According to this method, the CM monthly precipitation data were corrected by multiplicative factors that bring the monthly means of corrected precipitation to match their observed values in the benchmark past period. On the other hand, the temperature data were adjusted through an additive term that brings the corrected average monthly mean temperature to equal the observed values in the benchmark past period. Thus, the corrections were the following for precipitation (
) and temperature (
), respectively:
where
denotes precipitation and
denotes temperature, the overline indicates the mean operation, the subscript of
E-OBS indicates the observed values, subscript
stands for “historic period” (i.e., 1991–2000 in this study), and
is the month index. The corrected historical and future data are given by the following equations:
where, in addition to the previously declared symbols, prime stands for “corrected value”, superscript
indicates a future period (2071–2080 in this study), and
is the year index.
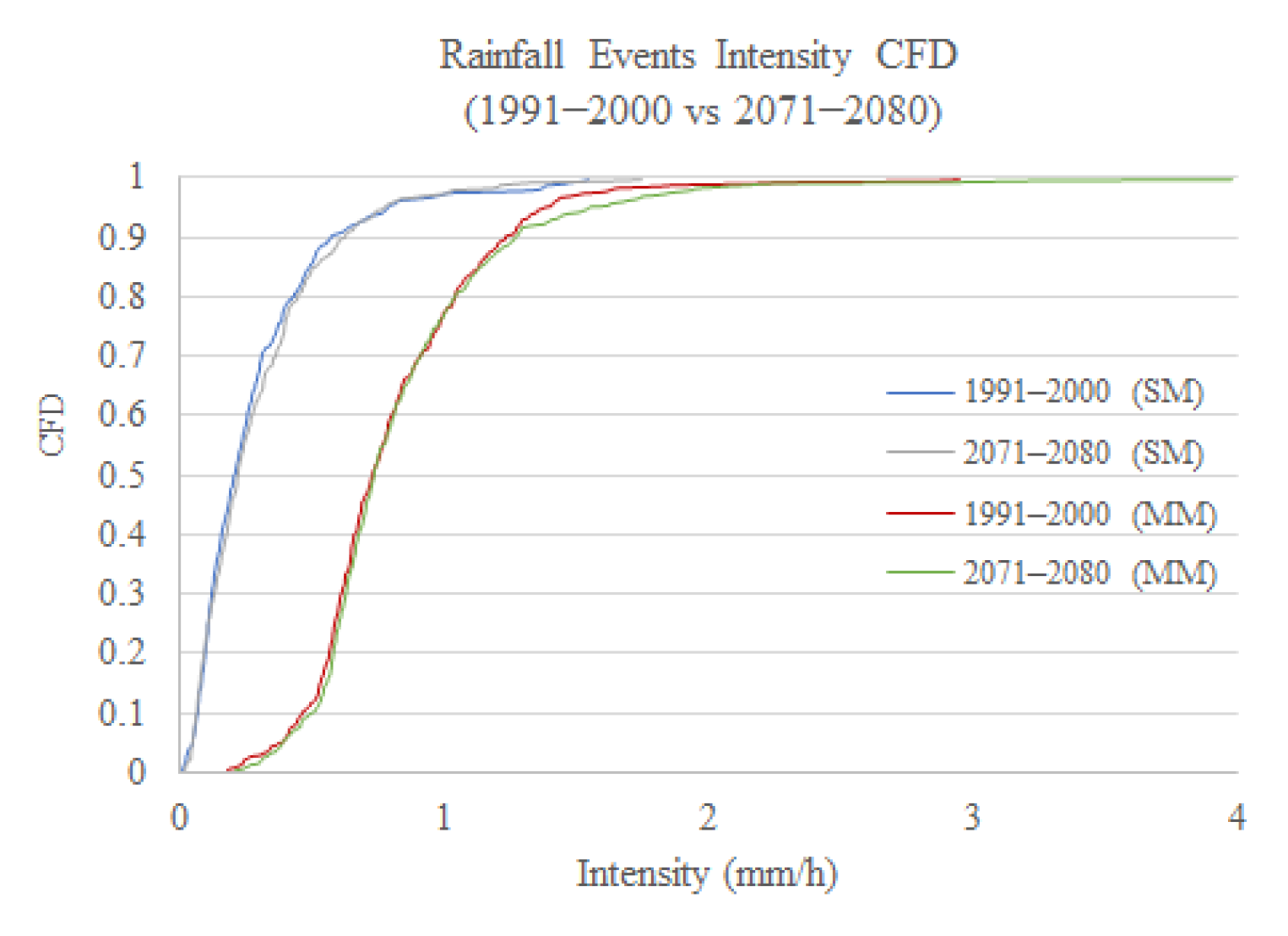
Rainfall event characteristics, including duration, intensity, and depth were assessed and compared. To accomplish this, the hourly data from the best-suited climate model were downloaded and modified by the bias correction factors. Independent rainfall events were selected based on an inter-event time
of about 11 h, estimated based on the concentration and time of the catchment [
42].
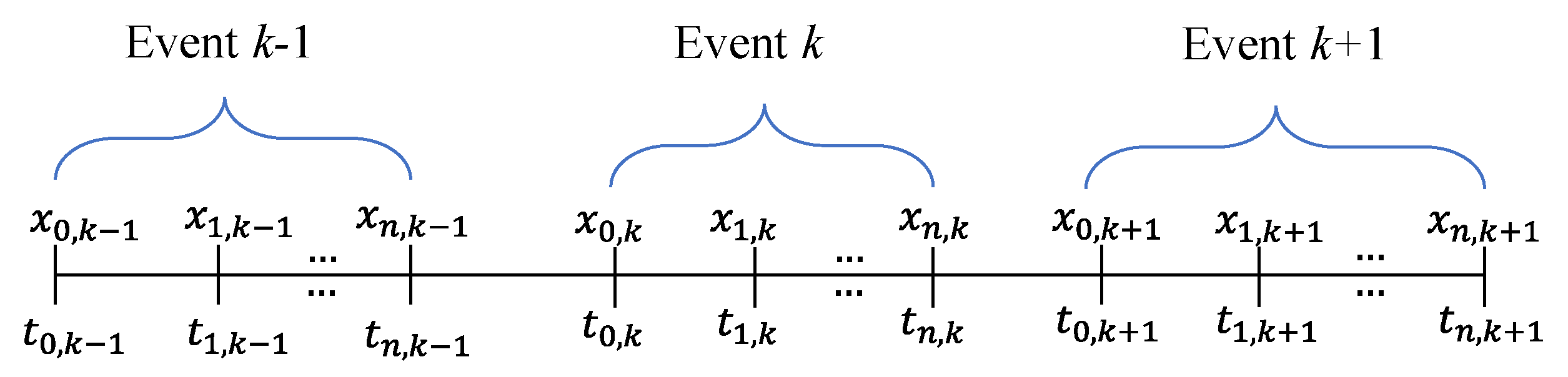
Figure 5 shows the time axis of three independent events where every event takes
hours starting from time
and ending at time
. While
and
, all the time differences within the event
and other subsequent events would be smaller or equal to the threshold. As the result, the duration, intensity, and depth of event
are estimated by Equations (17)–(19).
where,
,
, and
represent the length (hours), depth (mm), and intensity (mm/hours) of the rainfall event,
. Here, the minimum temporal rainfall resolution was assumed to be one hour as the sub-hourly temporal resolution for the precipitation data is not provided by the climate models.
After calculating the lengths, depths, and intensities of rainfall events, they were compared between the future scenario and the historical period based on the cumulative frequency distribution graphs.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}