
Introducing State-of-the-Art Deep Learning Technique for Gap-Filling of Eddy Covariance Crop Evapotranspiration Data


 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
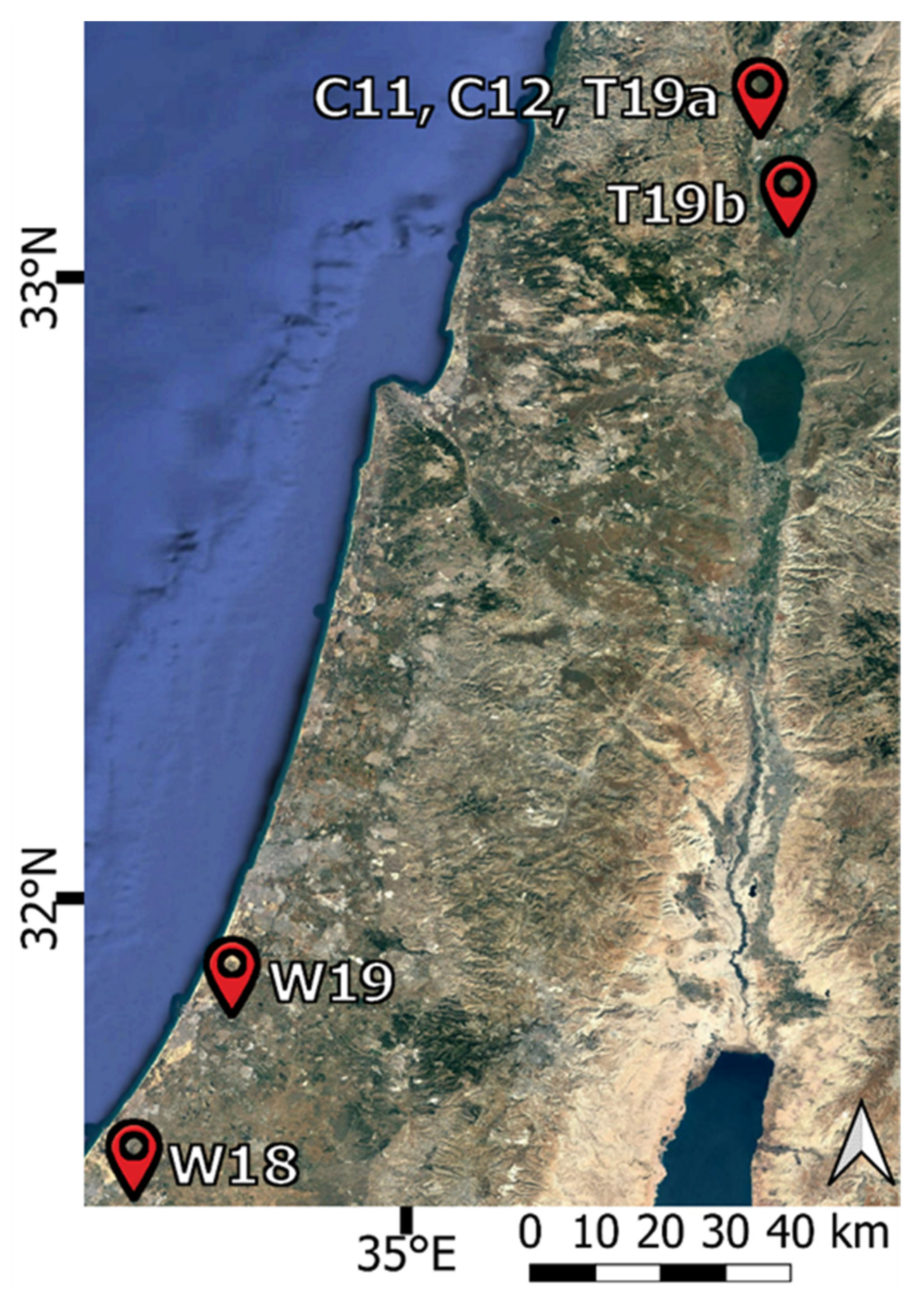
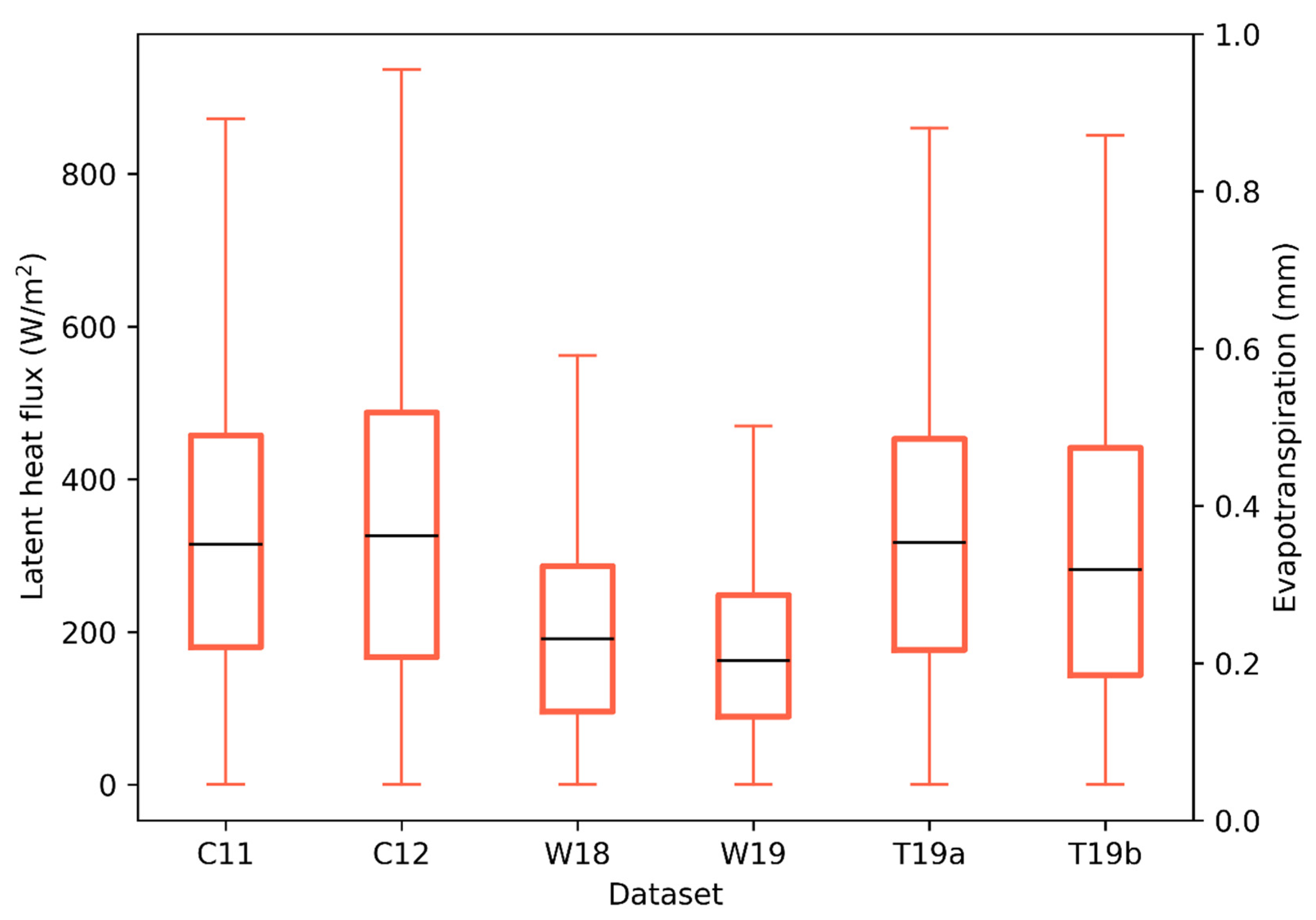
2.1. ET Datasets
2.2. Deep Learning Architecture
2.3. Dataset Processing
2.4. Analyses and Performance Evaluation
2.4.1. Comparison with MDS
2.4.2. Training the Model with or without Wheat Datasets
2.4.3. Sensitivity Analysis of Predictors
2.5. Evaluation Protocol and Metrics
3. Results
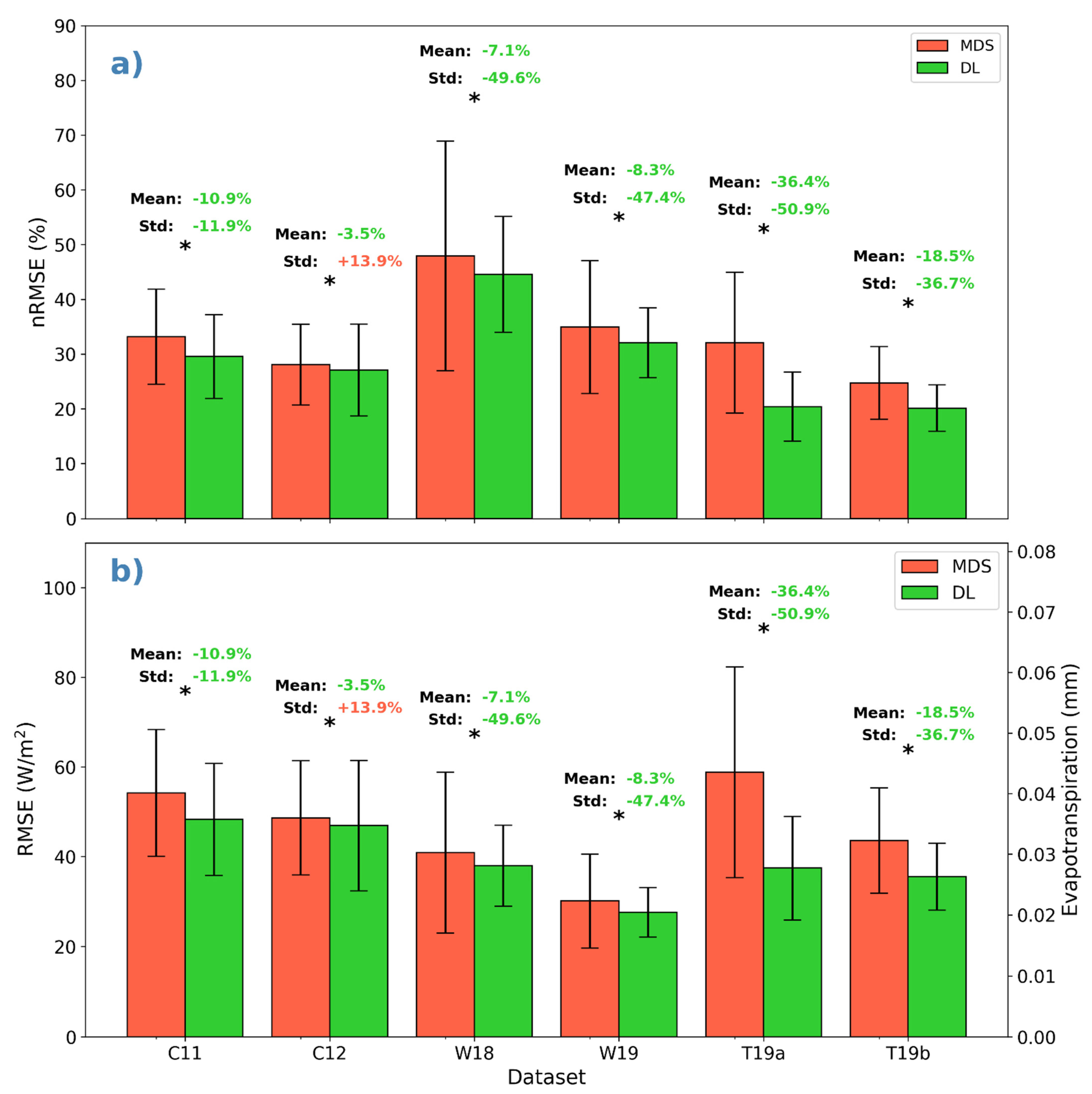
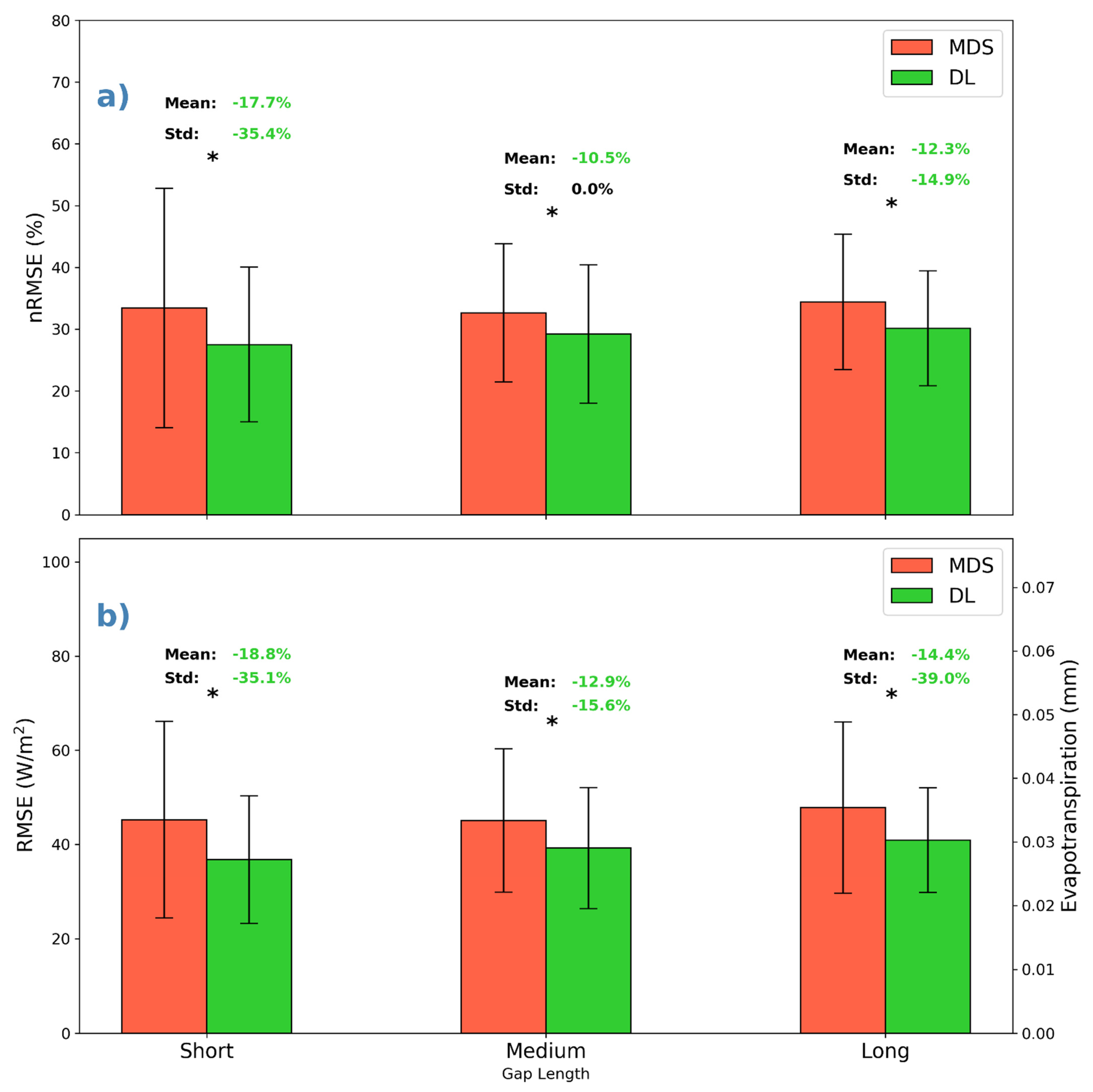
3.1. Comparison with MDS
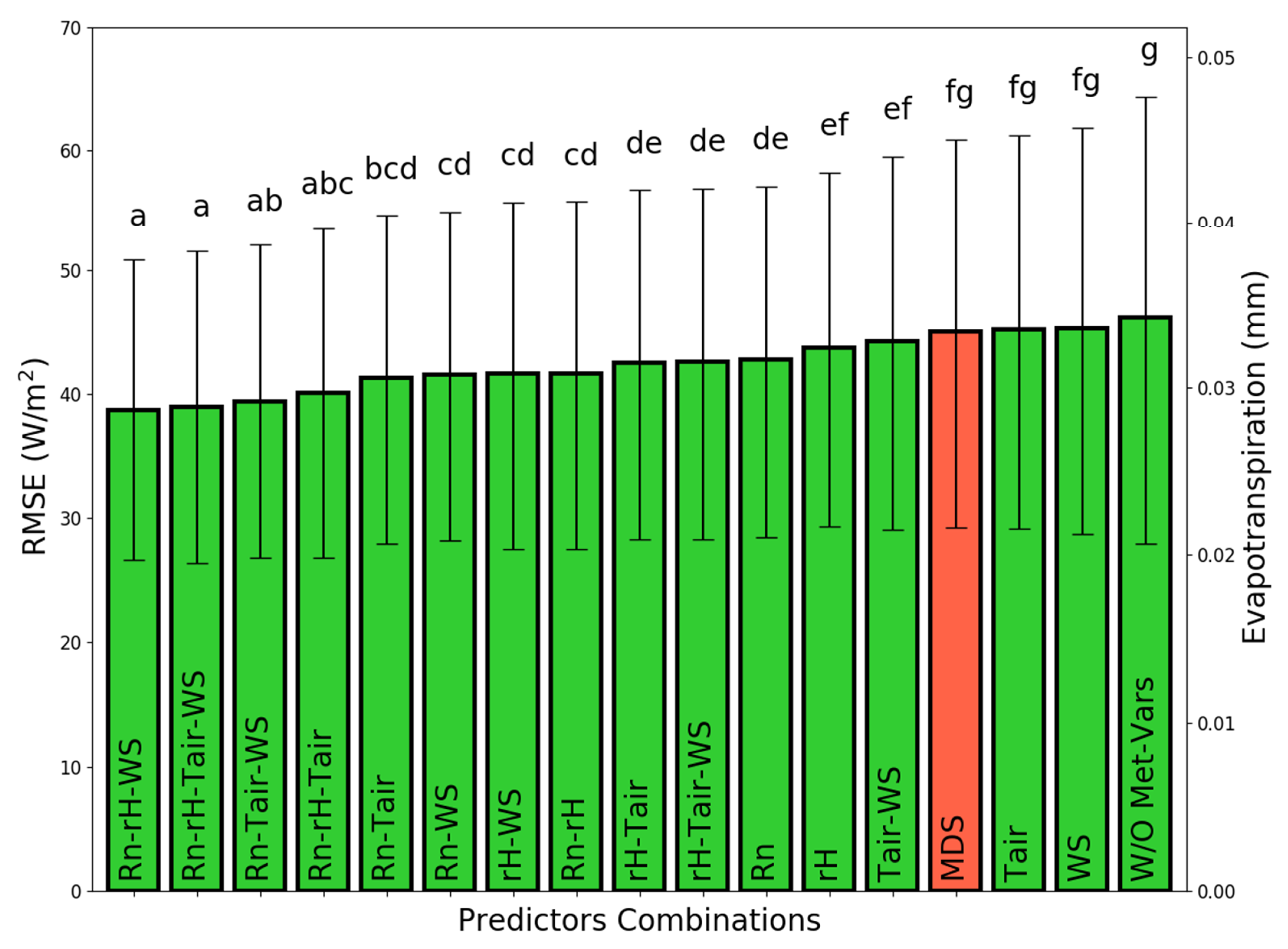
3.2. Sensitivity Analysis of Predictors
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Weksler, S.; Rozenstein, O.; Haish, N.; Moshelion, M.; Walach, R.; Ben-Dor, E. A hyperspectral-physiological phenomics system: Measuring diurnal transpiration rates and diurnal reflectance. Remote Sens. 2020, 12, 1493. [Google Scholar] [CrossRef]
- Aubinet, M.; Vesala, T.; Papale, D. Eddy Covariance: A Practical Guide to Measurement and Data Analysis; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Moffat, A.M.; Papale, D.; Reichstein, M.; Hollinger, D.Y.; Richardson, A.D.; Barr, A.G.; Beckstein, C.; Braswell, B.H.; Churkina, G.; Desai, A.R. Comprehensive comparison of gap-filling techniques for eddy covariance net carbon fluxes. Agric. For. Meteorol. 2007, 147, 209–232. [Google Scholar] [CrossRef]
- Falge, E.; Baldocchi, D.; Olson, R.; Anthoni, P.; Aubinet, M.; Bernhofer, C.; Burba, G.; Ceulemans, R.; Clement, R.; Dolman, H. Gap filling strategies for long term energy flux data sets. Agric. For. Meteorol. 2001, 107, 71–77. [Google Scholar] [CrossRef] [Green Version]
- Reichstein, M.; Falge, E.; Baldocchi, D.; Papale, D.; Aubinet, M.; Berbigier, P.; Bernhofer, C.; Buchmann, N.; Gilmanov, T.; Granier, A. On the separation of net ecosystem exchange into assimilation and ecosystem respiration: Review and improved algorithm. Glob. Chang. Biol. 2005, 11, 1424–1439. [Google Scholar] [CrossRef]
- Lloyd, J.; Taylor, J.A. On the temperature dependence of soil respiration. Funct. Ecol. 1994, 8, 315–323. [Google Scholar] [CrossRef]
- Papale, D.; Valentini, R. A new assessment of European forests carbon exchanges by eddy fluxes and artificial neural network spatialization. Glob. Chang. Biol. 2003, 9, 525–535. [Google Scholar] [CrossRef]
- Braswell, B.H.; Sacks, W.J.; Linder, E.; Schimel, D.S. Estimating diurnal to annual ecosystem parameters by synthesis of a carbon flux model with eddy covariance net ecosystem exchange observations. Glob. Chang. Biol. 2005, 11, 335–355. [Google Scholar] [CrossRef]
- Moffat, A.M. A New Methodology to Interpret High Resolution Measurements of Net Carbon Fluxes Between Terrestrial Ecosystems and the Atmosphere. Ph.D. Thesis, Friedrich Schiller University, Jena, Germany, 2010. [Google Scholar]
- Kim, Y.; Johnson, M.S.; Knox, S.H.; Black, T.A.; Dalmagro, H.J.; Kang, M.; Kim, J.; Baldocchi, D. Gap-filling approaches for eddy covariance methane fluxes: A comparison of three machine learning algorithms and a traditional method with principal component analysis. Glob. Chang. Biol. 2020, 26, 1499–1518. [Google Scholar] [CrossRef]
- Richard, A.; Fine, L.; Rozenstein, O.; Tanny, J.; Geist, M.; Pradalier, C. Filling Gaps in Micro-Meteorological Data. In European Conference on Machine Learning; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Moureaux, C.; Ceschia, E.; Arriga, N.; Béziat, P.; Eugster, W.; Kutsch, W.L.; Pattey, E. Eddy covariance measurements over crops. In Eddy Covariance; Springer: Dordrecht, The Netherlands, 2012; pp. 319–331. [Google Scholar]
- Rosa, R.; Tanny, J. Surface renewal and eddy covariance measurements of sensible and latent heat fluxes of cotton during two growing seasons. Biosyst. Eng. 2015, 136, 149–161. [Google Scholar] [CrossRef]
- Alavi, N.; Warland, J.S.; Berg, A.A. Filling gaps in evapotranspiration measurements for water budget studies: Evaluation of a Kalman filtering approach. Agric. For. Meteorol. 2006, 141, 57–66. [Google Scholar] [CrossRef] [Green Version]
- Boudhina, N.; Zitouna-Chebbi, R.; Mekki, I.; Jacob, F.; Ben Mechlia, N.; Masmoudi, M.; Prévot, L. Evaluating four gap-filling methods for eddy covariance measurements of evapotranspiration over hilly crop fields. Geosci. Instrum. Methods Data Syst. 2018, 7, 151–167. [Google Scholar] [CrossRef] [Green Version]
- Foltýnová, L.; Fischer, M.; McGloin, R.P. Recommendations for gap-filling eddy covariance latent heat flux measurements using marginal distribution sampling. Theor. Appl. Climatol. 2020, 139, 677–688. [Google Scholar] [CrossRef]
- Längkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef] [Green Version]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.; Guo, Z.; Liu, S.; He, X.; Meng, Y.; Xu, Z.; Xia, Y.; Xiao, J.; Zhang, Y.; Ma, Y. Evaluating different machine learning methods for upscaling evapotranspiration from flux towers to the regional scale. J. Geophys. Res. Atmos. 2018, 123, 8674–8690. [Google Scholar] [CrossRef]
- Kljun, N.; Calanca, P.; Rotach, M.; Schmid, H. A simple two-dimensional parameterisation for Flux Footprint Prediction (FFP). Geosci. Model Dev. 2015, 8, 3695–3713. [Google Scholar] [CrossRef] [Green Version]
- Kowalski, A.S.; Anthoni, P.M.; Vong, R.J.; Delany, A.C.; Maclean, G.D. Deployment and evaluation of a system for ground-based measurement of cloud liquid water turbulent fluxes. J. Atmos. Ocean. Technol. 1997, 14, 468–479. [Google Scholar] [CrossRef]
- Moore, C.J. Frequency response corrections for eddy correlation systems. Bound.-Layer Meteorol. 1986, 37, 17–35. [Google Scholar] [CrossRef]
- Webb, E.K.; Pearman, G.I.; Leuning, R. Correction of flux measurements for density effects due to heat and water vapour transfer. Q. J. R. Meteorol. Soc. 1980, 106, 85–100. [Google Scholar] [CrossRef]
- Moncrieff, J.B.; Massheder, J.M.; De Bruin, H.; Elbers, J.; Friborg, T.; Heusinkveld, B.; Kabat, P.; Scott, S.; Soegaard, H.; Verhoef, A. A system to measure surface fluxes of momentum, sensible heat, water vapour and carbon dioxide. J. Hydrol. 1997, 188, 589–611. [Google Scholar] [CrossRef]
- Moncrieff, J.; Clement, R.; Finnigan, J.; Meyers, T. Averaging, detrending, and filtering of eddy covariance time series. In Handbook of Micrometeorology; Springer: Berlin/Heidelberg, Germany, 2004; pp. 7–31. [Google Scholar]
- Vickers, D.; Mahrt, L. Quality control and flux sampling problems for tower and aircraft data. J. Atmos. Ocean. Technol. 1997, 14, 512–526. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wutzler, T.; Lucas-Moffat, A.; Migliavacca, M.; Knauer, J.; Sickel, K.; Šigut, L.; Menzer, O.; Reichstein, M. Basic and extensible post-processing of eddy covariance flux data with REddyProc. Biogeosciences 2018, 15, 5015–5030. [Google Scholar] [CrossRef] [Green Version]
- Reichstein, M.; Moffat, A.M.; Wutzler, T.; Sickel, K. REddyProc: Data Processing and Plotting Utilities of (Half-) Hourly Eddy-Covariance Measurements. R Package Version 0.6–0/r9. 2014, p. 755. Available online: https://www.bgc-jena.mpg.de/bgi/index.php/Services/REddyProcWeb (accessed on 23 February 2022).
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models, I: A discussion of principles. J. Hydrol. 1970, 10, 398–409. [Google Scholar] [CrossRef]
- Ambas, V.T.; Baltas, E. Sensitivity analysis of different evapotranspiration methods using a new sensitivity coefficient. Glob. NEST J. 2012, 14, 335–343. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Site | Region | Crop | Dates | No. of Full Days |
|---|---|---|---|---|---|
| 1 | C11 | Hula Valley | Cotton | 1 June 2011–5 September 2011 | 64 |
| 2 | C12 | Hula Valley | Cotton | 1 June 2012–12 September 2012 | 96 |
| 3 | W18 | Coastal Plain | Wheat | 10 January 2018–8 April 2018 | 65 |
| 4 | W19 | Coastal Plain | Wheat | 21 December 2018–11 April 2019 | 94 |
| 5 | T19a | Hula Valley | Tomato | 2 May 2019–25 July 2019 | 83 |
| 6 | T19b | Hula Valley | Tomato | 24 April 2019–15 August 2019 | 92 |
| # | Site | Air Temperature (°C) | Relative Humidity (%) | Daily Average Net Radiation (W/m2) | Wind Speed (m/s) |
|---|---|---|---|---|---|
| 1 | C11 | 25.6 (18.4, 32.7) | 71.6 (45.8, 95.7) | 178.4 (151.3, 198.0) | 0.6 (0.1, 4.8) |
| 2 | C12 | 27.1 (19.3, 34.4) | 64.2 (35.0, 97.6) | 173.2 (149.0, 187.8) | 0.9 (0.2, 5.8) |
| 3 | W18 | 15.8 (10.2, 23.7) | 75.0 (38.0, 95.1) | 111.6 (44.8, 176.9) | 1.2 (0.4, 4.8) |
| 4 | W19 | 13.8 (7.4, 20.0) | 81.4 (49.8, 95.9) | 82.5 (33.0, 152.5) | 1.7 (0.3, 4.7) |
| 5 | T19a | 26.3 (16.5, 35.4) | 60.7 (24.2, 86.7) | 173.1 (147.2, 206.5) | 1.1 (0.2, 6.1) |
| 6 | T19b | 26.6 (16.7, 35.9) | 63.1 (26.2, 90.7) | 186.4 (122.2, 198.3) | 1.1 (0.2, 4.4) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fine, L.; Richard, A.; Tanny, J.; Pradalier, C.; Rosa, R.; Rozenstein, O. Introducing State-of-the-Art Deep Learning Technique for Gap-Filling of Eddy Covariance Crop Evapotranspiration Data. Water 2022, 14, 763. https://doi.org/10.3390/w14050763
Fine L, Richard A, Tanny J, Pradalier C, Rosa R, Rozenstein O. Introducing State-of-the-Art Deep Learning Technique for Gap-Filling of Eddy Covariance Crop Evapotranspiration Data. Water. 2022; 14(5):763. https://doi.org/10.3390/w14050763
Chicago/Turabian StyleFine, Lior, Antoine Richard, Josef Tanny, Cedric Pradalier, Rafael Rosa, and Offer Rozenstein. 2022. "Introducing State-of-the-Art Deep Learning Technique for Gap-Filling of Eddy Covariance Crop Evapotranspiration Data" Water 14, no. 5: 763. https://doi.org/10.3390/w14050763
APA StyleFine, L., Richard, A., Tanny, J., Pradalier, C., Rosa, R., & Rozenstein, O. (2022). Introducing State-of-the-Art Deep Learning Technique for Gap-Filling of Eddy Covariance Crop Evapotranspiration Data. Water, 14(5), 763. https://doi.org/10.3390/w14050763