
Prediction of Concrete Dam Deformation through the Combination of Machine Learning Models



Abstract
:1. Introduction and Background
2. Materials and Methods
2.1. General Approach
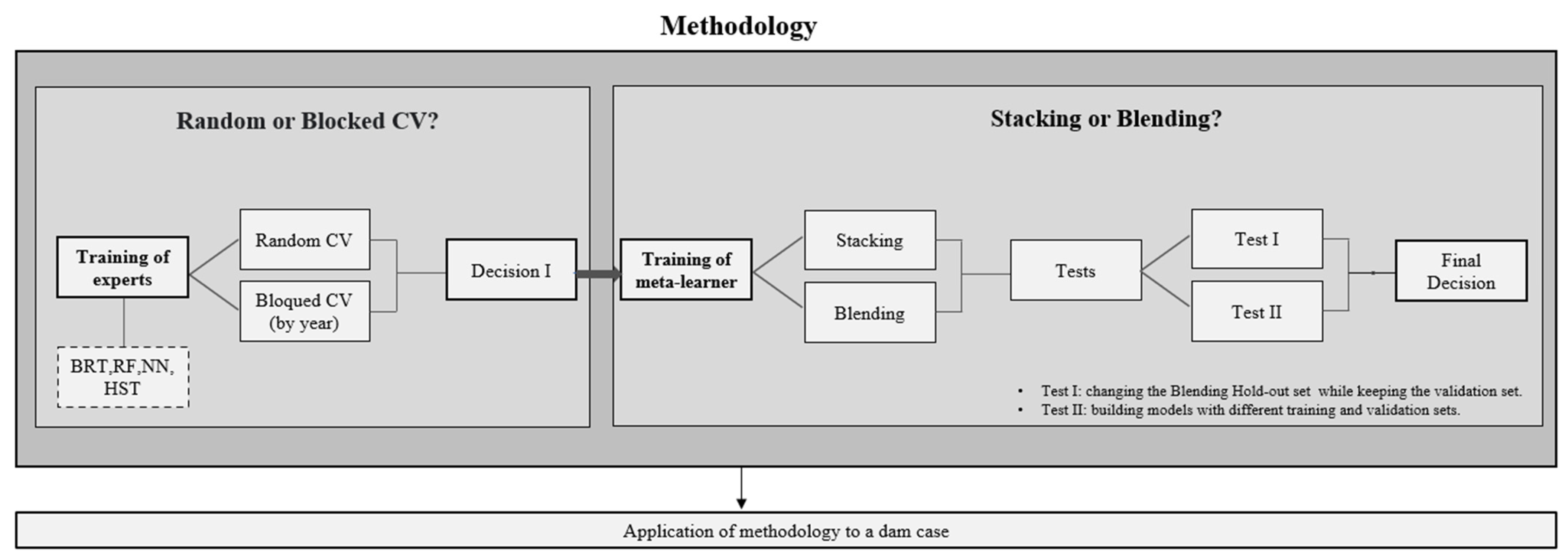
2.2. Methodology
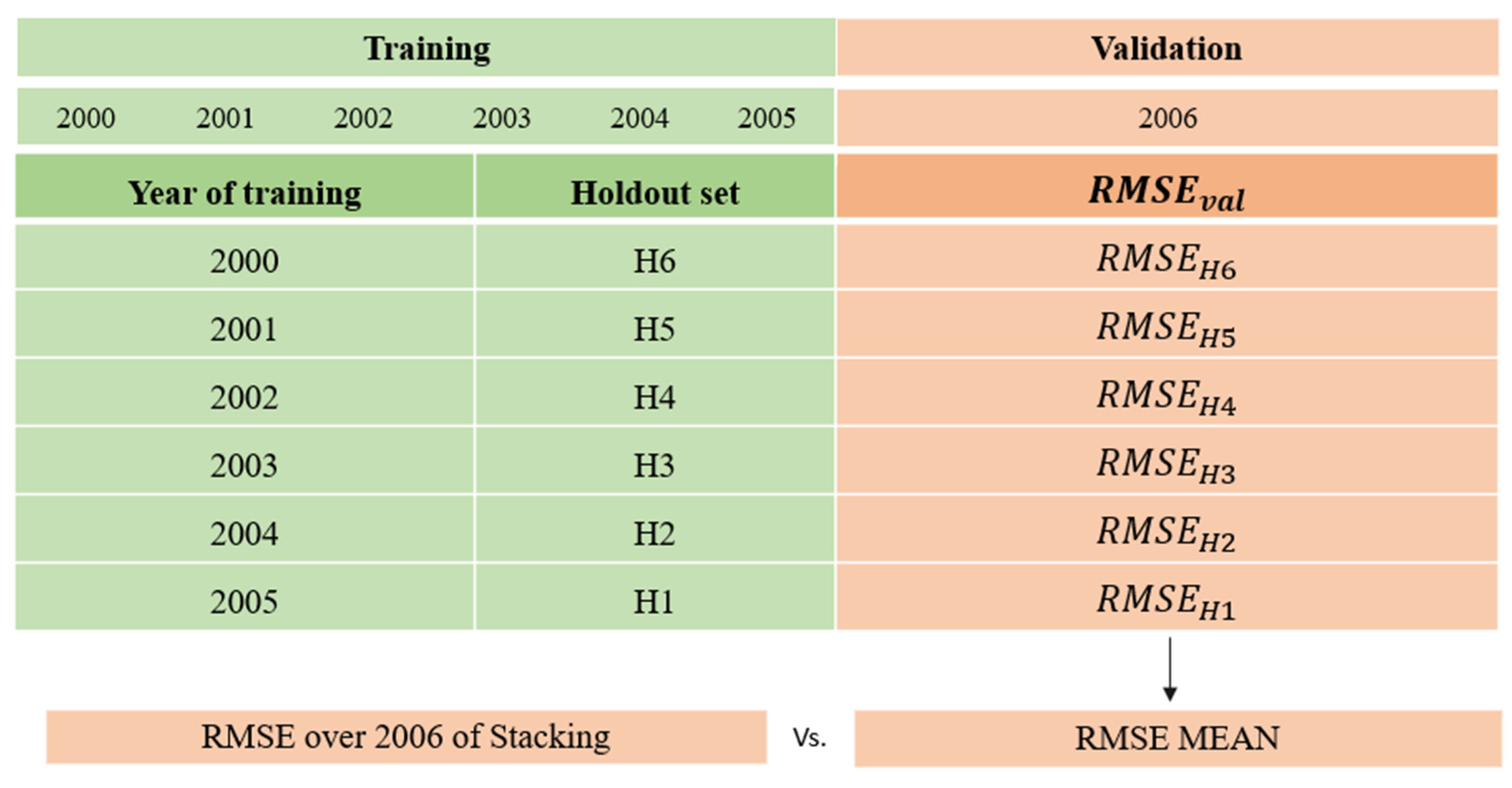
2.2.1. Random or Blocked Cross Validation?
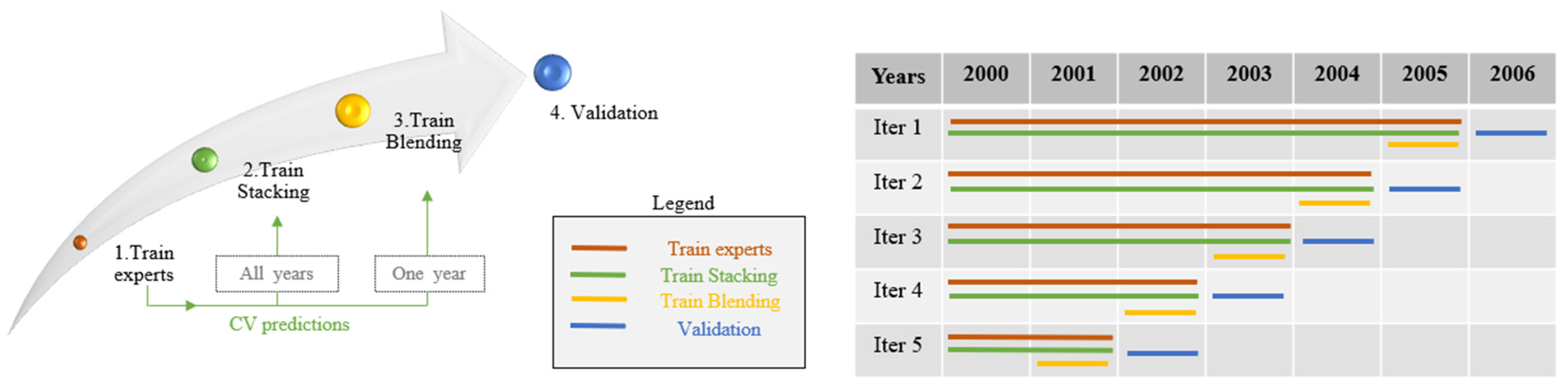
2.2.2. Stacking or Blending?
- The experts are first trained with the data corresponding to the instances between 2000 and 2005.
- The Stacking second-level model is trained with the CV predictions of these experts, which belong to the same years as them.
- The Blending meta-learner is built with the CV predictions of the experts of the last year available in the training.
- Models are validated over the following year.
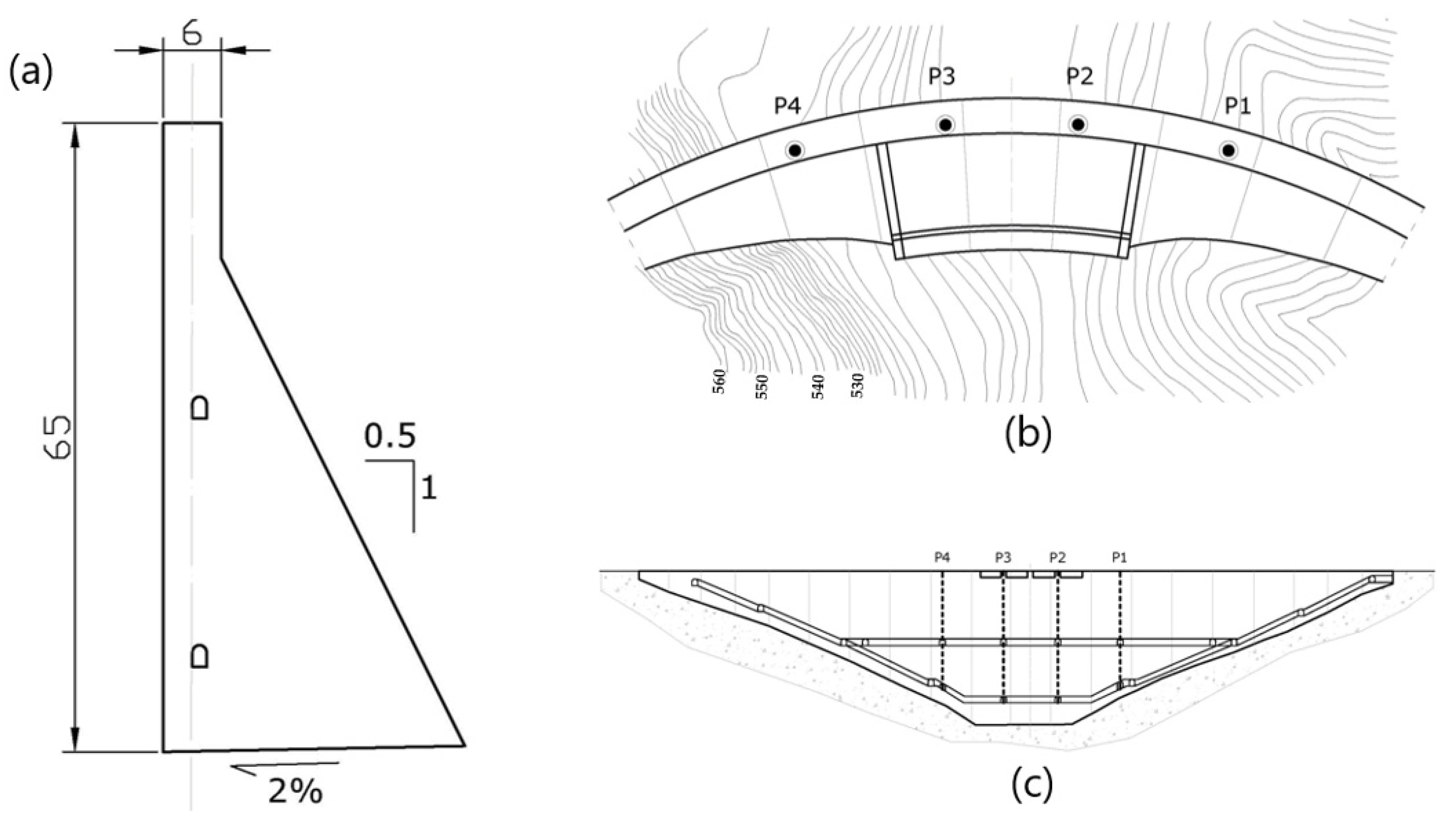
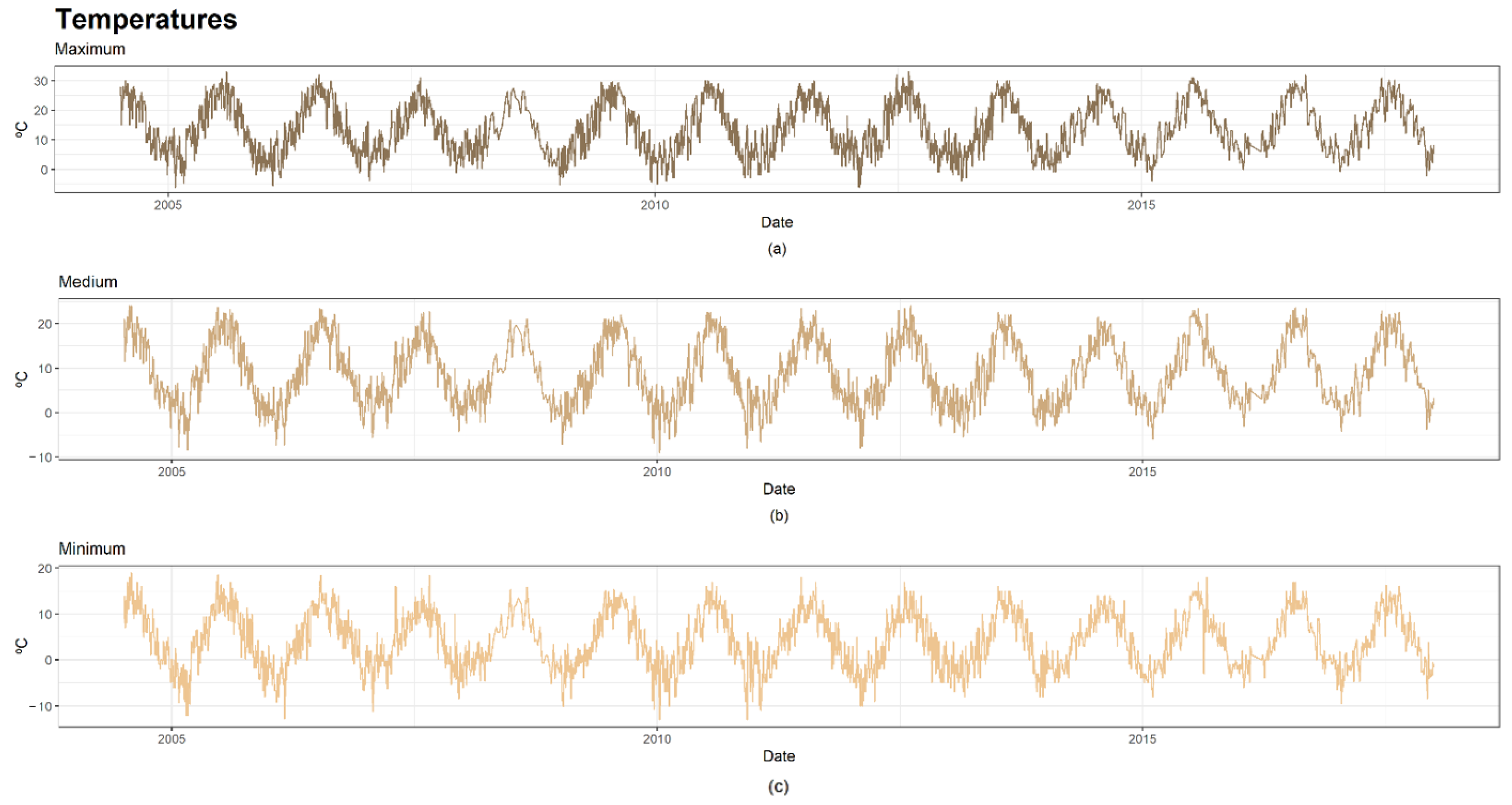
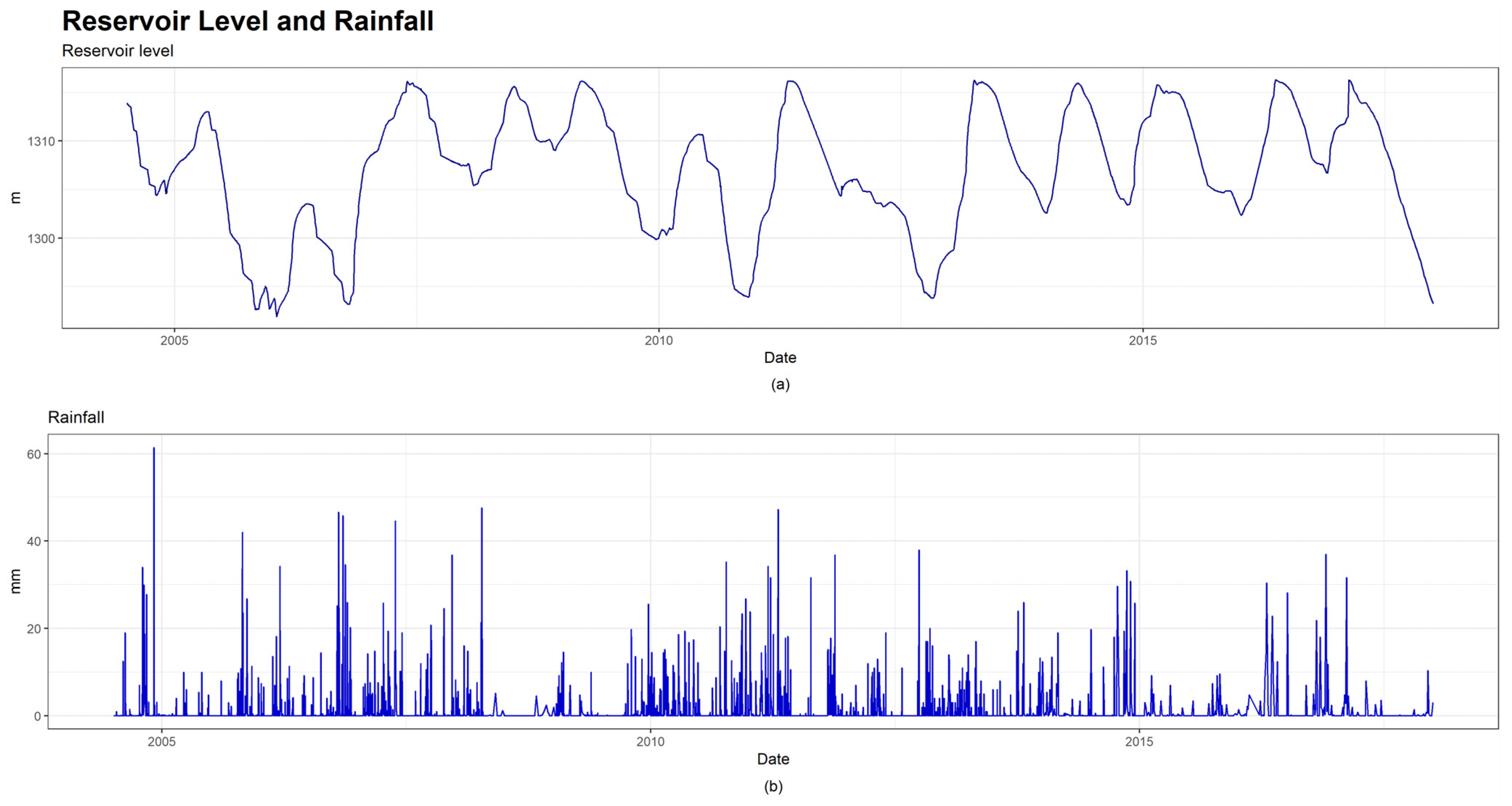
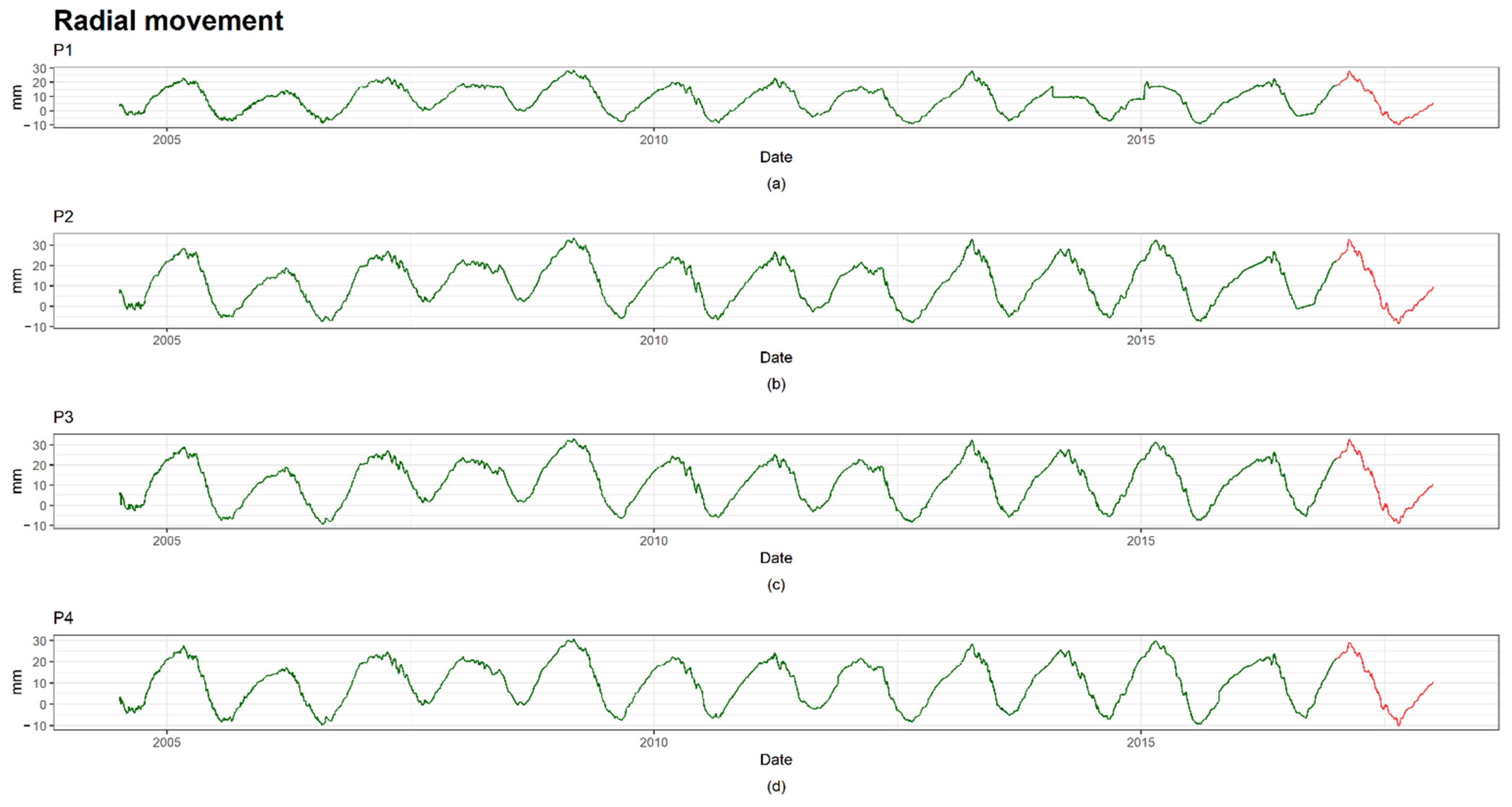
2.3. Dam Case: Description and Available Data
3. Results and Discussion
3.1. Cross Validation
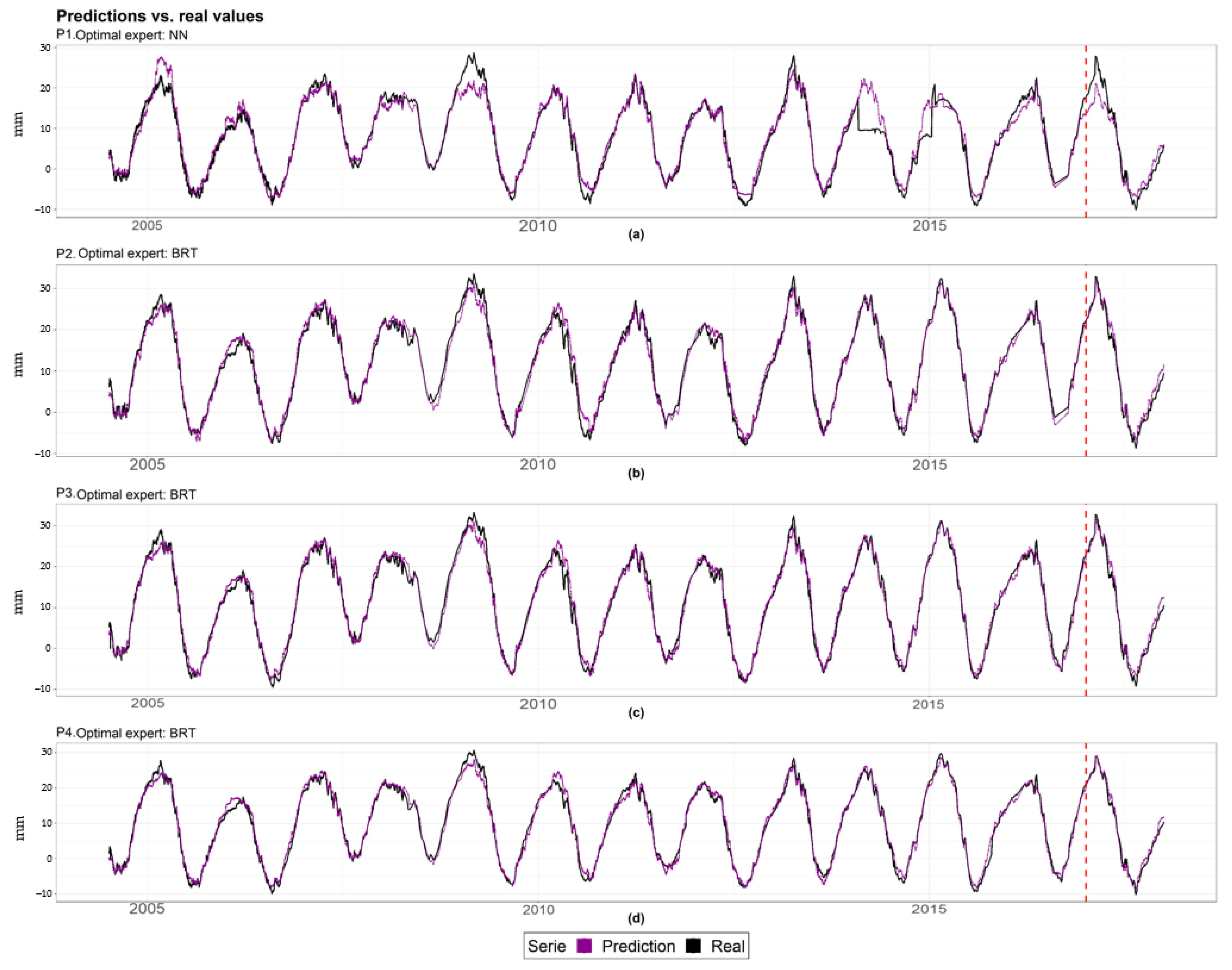
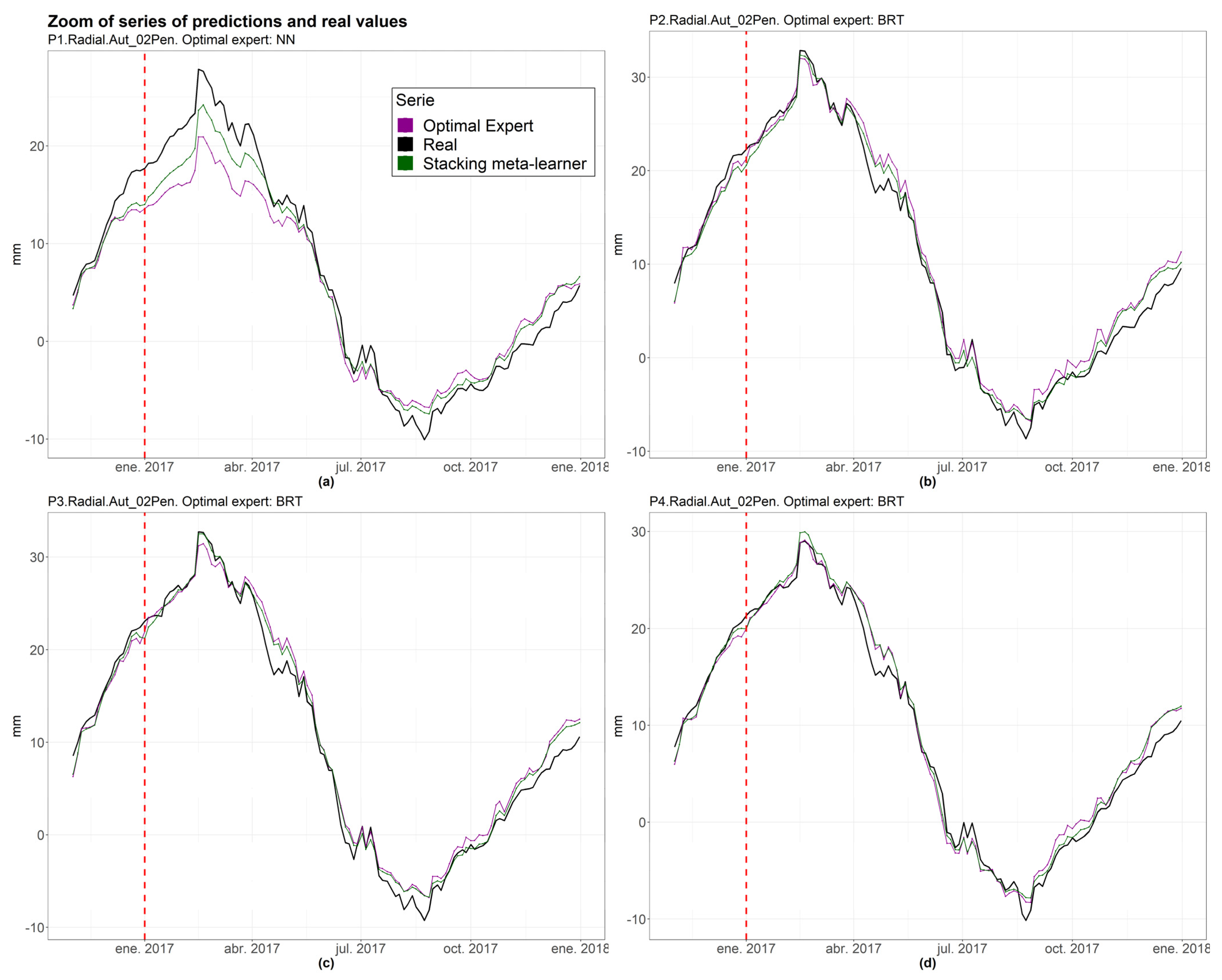
3.2. Experts Committee
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| BRT | Boosted Regression Trees |
| CV | Cross Validation |
| D | matrix representation of the data set |
| D′ | matrix form of prediction vectors of the experts |
| Di,S | relative difference between the expert (i) and the second-level model (S) |
| ER | reduction of the error of Stacking over Blending |
| GLM | Generalized Linear Regression |
| HST | Hydrostatic-Seasonal-Time |
| interactionDepth | hyperparameter of BRT that controls the depth of the tree |
| k | number of experts |
| m | number of instances of the data set |
| n | number of explanatory variables |
| nMinObsInNode | hyperparameter of BRT representing the minimum number of observations to consider in one node |
| NN | Neural Networks |
| nTree | hyperparameter of BRT representing the number of trees |
| RD | relative difference between the Rooted Squared Error over CV and the Validation set |
| RF | Random Forest |
| RMSE | Root-Mean-Square Error |
| RMSEcv | Root-Mean-Square Error over Cross Validation |
| RMSEval | Root-Mean-Square Error over validation |
| RMSEvalB | RMSE of Blending approach in Test II |
| RMSEvalS | the RMSE committed by the Stacking meta-learner in the validation set |
| shrinkage | hyperparameter of BRT that controls overfitting |
| SVM | Support Vector Machine |
References
- Hariri-Ardebili, M.A.; Pourkamali-Anaraki, F. Support vector machine based reliability analysis of concrete dams. Soil Dyn. Earthq. Eng. 2018, 104, 276–295. [Google Scholar] [CrossRef]
- Salazar, F.; Toledo, M.; Gonzalez, J.M.; Oñate, E. Early detection of anomalies in dam performance: A methodology based on boosted regression trees. Struct. Control Health Monit. 2017, 24, e2012. [Google Scholar] [CrossRef]
- Tsihrintzis, G.A.; Virvou, M.; Sakkopoulos, E.; Jain, L.C. Machine Learning Paradigms Applications of Learning and Analytics in Intelligent Systems. Available online: http://www.springer.com/series/16172 (accessed on 13 April 2021).
- Salazar, F.; Morán, R.; Toledo, M.; Oñate, E. Data-Based Models for the Prediction of Dam Behaviour: A Review and Some Methodological Considerations. Arch. Comput. Methods Eng. 2015, 24, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Salazar, F.; Toledo, M.; Oñate, E.; Suárez, B. Interpretation of dam deformation and leakage with boosted regression trees. Eng. Struct. 2016, 119, 230–251. [Google Scholar] [CrossRef] [Green Version]
- Salazar, F.; González, J.M.; Toledo, M.Á.; Oñate, E. A Methodology for Dam Safety Evaluation and Anomaly Detection Based on Boosted Regression Trees. 2016. Available online: https://www.researchgate.net/publication/310608491 (accessed on 5 March 2020).
- Salazar, F.; Toledo, M.; Oñate, E.; Morán, R. An empirical comparison of machine learning techniques for dam behaviour modelling. Struct. Saf. 2015, 56, 9–17. [Google Scholar] [CrossRef] [Green Version]
- Rankovic, V.; Grujović, N.; Divac, D.; Milivojević, N. Development of support vector regression identification model for prediction of dam structural behaviour. Struct. Saf. 2014, 48, 33–39. [Google Scholar] [CrossRef]
- Mata, J. Interpretation of concrete dam behaviour with artificial neural network and multiple linear regression models. Eng. Struct. 2011, 33, 903–910. [Google Scholar] [CrossRef]
- Herrera, M.; Torgo, L.; Izquierdo, J.; Pérez-García, R. Predictive models for forecasting hourly urban water demand. J. Hydrol. 2010, 387, 141–150. [Google Scholar] [CrossRef]
- Kang, F.; Li, J.; Zhao, S.; Wang, Y. Structural health monitoring of concrete dams using long-term air temperature for thermal effect simulation. Eng. Struct. 2018, 180, 642–653. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Wu, T.; Zhang, W.; Jiao, X.; Guo, W.; Hamoud, Y.A. Evaluation of stacking and blending ensemble learning methods for estimating daily reference evapotranspiration. Comput. Electron. Agric. 2021, 184, 106039. [Google Scholar] [CrossRef]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schroder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Bergmeir, C.; Benítez, J.M. On the use of cross-validation for time series predictor evaluation. Inf. Sci. 2012, 191, 192–213. [Google Scholar] [CrossRef]
- Džeroski, S.; Ženko, B. Is Combining Classifiers with Stacking Better than Selecting the Best One? Mach. Learn. 2004, 3, 255–273. [Google Scholar] [CrossRef] [Green Version]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.-W.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2019, 17, 641–658. [Google Scholar] [CrossRef]
- Mohd, L.; Gasim, S.; Ahmed, H.; Mohd, S.; Boosroh, H. Water Resources Development and Management ICDSME 2019 Proceedings of the 1st International Conference on Dam Safety Management and Engineering. Available online: http://www.springer.com/series/7009 (accessed on 13 April 2021).
- Cheng, J.; Xiong, Y. Application of Extreme Learning Machine Combination Model for Dam Displacement Prediction. Procedia Comput. Sci. 2017, 107, 373–378. [Google Scholar] [CrossRef]
- Bin, Y.; Hai-Bo, Y.; Zhen-Wei, G. A Combination Forecasting Model Based on IOWA Operator for Dam Safety Monitoring. In Proceedings of the 2013 5th Conference on Measuring Technology and Mechatronics Automation, ICMTMA 2013, Hong Kong, China, 16–17 January 2013; pp. 5–8. [Google Scholar] [CrossRef]
- Wei, B.; Yuan, D.; Li, H.; Xu, Z. Combination forecast model for concrete dam displacement considering residual correction. Struct. Health Monit. 2017, 18, 232–244. [Google Scholar] [CrossRef]
- Wei, B.; Yuan, D.; Xu, Z.; Li, L. Modified hybrid forecast model considering chaotic residual errors for dam deformation. Struct. Control Health Monit. 2018, 25, e2188. [Google Scholar] [CrossRef]
- Hong, J.; Lee, S.; Bae, J.H.; Lee, J.; Park, W.J.; Lee, D.; Kim, J.; Lim, K.J. Development and Evaluation of the Combined Machine Learning Models for the Prediction of Dam Inflow. Water 2020, 12, 2927. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Berrar, D. Cross-Validation. In Encyclopedia of Bioinformatics and Computational Biology: ABC of Bioinformatics; Elsevier: Amsterdam, The Netherlands, 2018; Volume 1–3, pp. 542–545. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split | Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 |
|---|---|---|---|---|---|
| 1 | Test1 | Train | Train | Train | Train |
| 2 | Train | Test2 | Train | Train | Train |
| 3 | Train | Train | Test3 | Train | Train |
| 4 | Train | Train | Train | Test4 | Train |
| 5 | Train | Train | Train | Train | Test5 |
| Pendulum | Expert | RMSEcv | RMSEval | RD | |||
|---|---|---|---|---|---|---|---|
| Random CV | Blocked CV | Random CV | Blocked CV | Random CV | Blocked CV | ||
| 1 | BRT | 0.435 | 2.2 | 2.522 | 2.331 | −479.77% | −5.95% |
| HST | 2.113 | 2.848 | 2.113 | 2.113 | 0.00% | 25.81% | |
| NN | 1.397 | 2.018 | 3.254 | 3.272 | −132.93% | −62.14% | |
| RF | 0.506 | 2.649 | 3.431 | 3.494 | −578.06% | −31.90% | |
| 2 | BRT | 0.346 | 1.404 | 1.487 | 1.596 | −329.20% | −13.65% |
| HST | 1.853 | 2.080 | 2.249 | 2.249 | −21.38% | −8.15% | |
| NN | 0.933 | 1.446 | 1.359 | 1.385 | −45.58% | 4.22% | |
| RF | 0.437 | 1.925 | 2.073 | 2.117 | −374.77% | −9.98% | |
| 3 | BRT | 0.368 | 1.288 | 1.478 | 1.587 | −301.63% | −23.21% |
| HST | 2.224 | 2.438 | 2.433 | 2.433 | −9.40% | 0.21% | |
| NN | 0.884 | 1.473 | 1.316 | 1.367 | −48.87% | 7.20% | |
| RF | 0.439 | 1.832 | 2.015 | 1.998 | −359.00% | −9.06% | |
| 4 | BRT | 0.361 | 1.299 | 1.433 | 1.314 | −296.95% | −1.15% |
| HST | 2.203 | 2.436 | 2.385 | 2.385 | −8.26% | 2.09% | |
| NN | 0.882 | 1.416 | 1.35 | 1.371 | −53.06% | 3.18% | |
| RF | 0.426 | 1.652 | 1.832 | 1.805 | −330.05% | −9.26% | |
| CV Type | nTree | InteractionDepth | Shrinkage | nMinObsInNode |
|---|---|---|---|---|
| Random | 5000 | 8 | 0.01 | 5 |
| Blocked | 5000 | 2 | 0.01 | 15 |
| Training Year | RMSEval | |||
|---|---|---|---|---|
| Pendulum 1 | Pendulum 2 | Pendulum 3 | Pendulum 4 | |
| 2004 | 4.184 | 2.524 | 2.866 | 2.175 |
| 2005 | 1.342 | 1.257 | 1.090 | 1.203 |
| 2006 | 1.843 | 1.28 | 1.215 | 0.581 |
| 2007 | 2.232 | 1.622 | 1.611 | 1.534 |
| 2008 | 1.775 | 1.527 | 1.167 | 1.181 |
| 2009 | 1.793 | 1.583 | 1.313 | 1.168 |
| 2010 | 1.416 | 1.611 | 1.098 | 1.720 |
| 2011 | 1.485 | 1.357 | 1.021 | 0.576 |
| 2012 | 2.505 | 1.447 | 1.351 | 0.750 |
| 2013 | 3.336 | 1.086 | 0.937 | 0.810 |
| 2014 | 1.495 | 1.126 | 0.960 | 0.757 |
| 2015 | 1.112 | 1.213 | 0.902 | 1.198 |
| 2016 | 1.967 | 1.309 | 1.412 | 0.974 |
| Mean | 2.037 | 1.457 | 1.303 | 1.125 |
| Variance | 0.868 | 0.367 | 0.513 | 0.469 |
| RMSEvalS | 2.035 | 1.1813 | 1.257 | 1.257 |
| Pendulum | Available Years | T years Stacking and Experts | T Year Blending | V Year | RMSEvalS | RMSEvalB | ER |
|---|---|---|---|---|---|---|---|
| 1 | 3 years: [2004–2006] | 2 years: [2004–2005] | 2005 | 2006 | 2.443 | 1.655 | −47.6% |
| 5 years: [2004–2008] | 4 years: [2004–2007] | 2007 | 2008 | 0.960 | 0.988 | 2.8% | |
| 6 years: [2004–2009] | 5 years: [2004–2008] | 2008 | 2009 | 1.454 | 1.317 | −10.4% | |
| 11 years: [2004–2014] | 10 years: [2004–2013] | 2013 | 2014 | 6.864 | 7.444 | 7.8% | |
| 13 years: [2004–2016] | 12 years: [2004–2015] | 2015 | 2016 | 3.171 | 3.330 | 4.8% | |
| 2 | 3 years: [2004–2006] | 2 years: [2004–2005] | 2005 | 2006 | 23.830 | 28.095 | 15.2% |
| 5 years: [2004–2008] | 4 years: [2004–2007] | 2007 | 2008 | 1.389 | 1.152 | −20.6% | |
| 6 years: [2004–2009] | 5 years: [2004–2008] | 2008 | 2009 | 1.948 | 2.714 | 28.2% | |
| 11 years: [2004–2014] | 10 years: [2004–2013] | 2013 | 2014 | 1.232 | 1.435 | 14.1% | |
| 13 years: [2004–2016] | 12 years: [2004–2015] | 2015 | 2016 | 1.055 | 1.157 | 8.8% | |
| 3 | 3 years: [2004–2006] | 2 years: [2004–2005] | 2005 | 2006 | 3.736 | 3.488 | −7.1% |
| 5 years: [2004–2008] | 4 years: [2004–2007] | 2007 | 2008 | 0.908 | 0.974 | 6.8% | |
| 6 years: [2004–2009] | 5 years: [2004–2008] | 2008 | 2009 | 1.393 | 1.139 | −22.4% | |
| 11 years: [2004–2014] | 10 years: [2004–2013] | 2013 | 2014 | 1.048 | 1.639 | 36.1% | |
| 13 years: [2004–2016] | 12 years: [2004–2015] | 2015 | 2016 | 1.238 | 1.347 | 8.1% | |
| 4 | 3 years: [2004–2006] | 2 years: [2004–2005] | 2005 | 2006 | 3.024 | 2.412 | −25.4% |
| 5 years: [2004–2008] | 4 years: [2004–2007] | 2007 | 2008 | 0.892 | 0.797 | −11.9% | |
| 6 years: [2004–2009] | 5 years: [2004–2008] | 2008 | 2009 | 1.433 | 2.096 | 31.6% | |
| 11 years: [2004–2014] | 10 years: [2004–2013] | 2013 | 2014 | 1.094 | 0.954 | −14.7% | |
| 13 years: [2004–2016] | 12 years: [2004–2015] | 2015 | 2016 | 1.088 | 1.241 | 12.3% |
| Pendulum | 1 | ||||
| Model | BRT | NN | RF | HST | Meta-Learner |
| RMSEcv | 2.200 | 2.018 | 2.649 | 2.848 | 2.019 |
| Di,S | −9.02% | 0.00% | −31.27% | −41.13% | −0.05% |
| 2 | |||||
| Model | BRT | NN | RF | HST | Meta-Learner |
| RMSEcv | 1.404 | 1.446 | 1.925 | 2.080 | 1.201 |
| Di,S | 0.00% | −2.97% | −37.07% | −48.08% | 14.48% |
| 3 | |||||
| Model | BRT | NN | RF | HST | Meta-Learner |
| RMSEcv | 1.288 | 1.473 | 1.832 | 2.438 | 1.174 |
| Di,S | 0.00% | −14.36% | −42.24% | −89.29% | 8.85% |
| 4 | |||||
| Model | BRT | NN | RF | HST | Meta-Learner |
| RMSEcv | 1.299 | 1.416 | 1.652 | 2.436 | 1.223 |
| Di,S | 0.00% | −9.01% | −27.17% | −87.53% | 5.85% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alocén, P.; Fernández-Centeno, M.Á.; Toledo, M.Á. Prediction of Concrete Dam Deformation through the Combination of Machine Learning Models. Water 2022, 14, 1133. https://doi.org/10.3390/w14071133
Alocén P, Fernández-Centeno MÁ, Toledo MÁ. Prediction of Concrete Dam Deformation through the Combination of Machine Learning Models. Water. 2022; 14(7):1133. https://doi.org/10.3390/w14071133
Chicago/Turabian StyleAlocén, Patricia, Miguel Á. Fernández-Centeno, and Miguel Á. Toledo. 2022. "Prediction of Concrete Dam Deformation through the Combination of Machine Learning Models" Water 14, no. 7: 1133. https://doi.org/10.3390/w14071133
APA StyleAlocén, P., Fernández-Centeno, M. Á., & Toledo, M. Á. (2022). Prediction of Concrete Dam Deformation through the Combination of Machine Learning Models. Water, 14(7), 1133. https://doi.org/10.3390/w14071133