
An Improved Transfer Learning Model for Cyanobacterial Bloom Concentration Prediction



Abstract
:1. Introduction
2. Materials and Methods
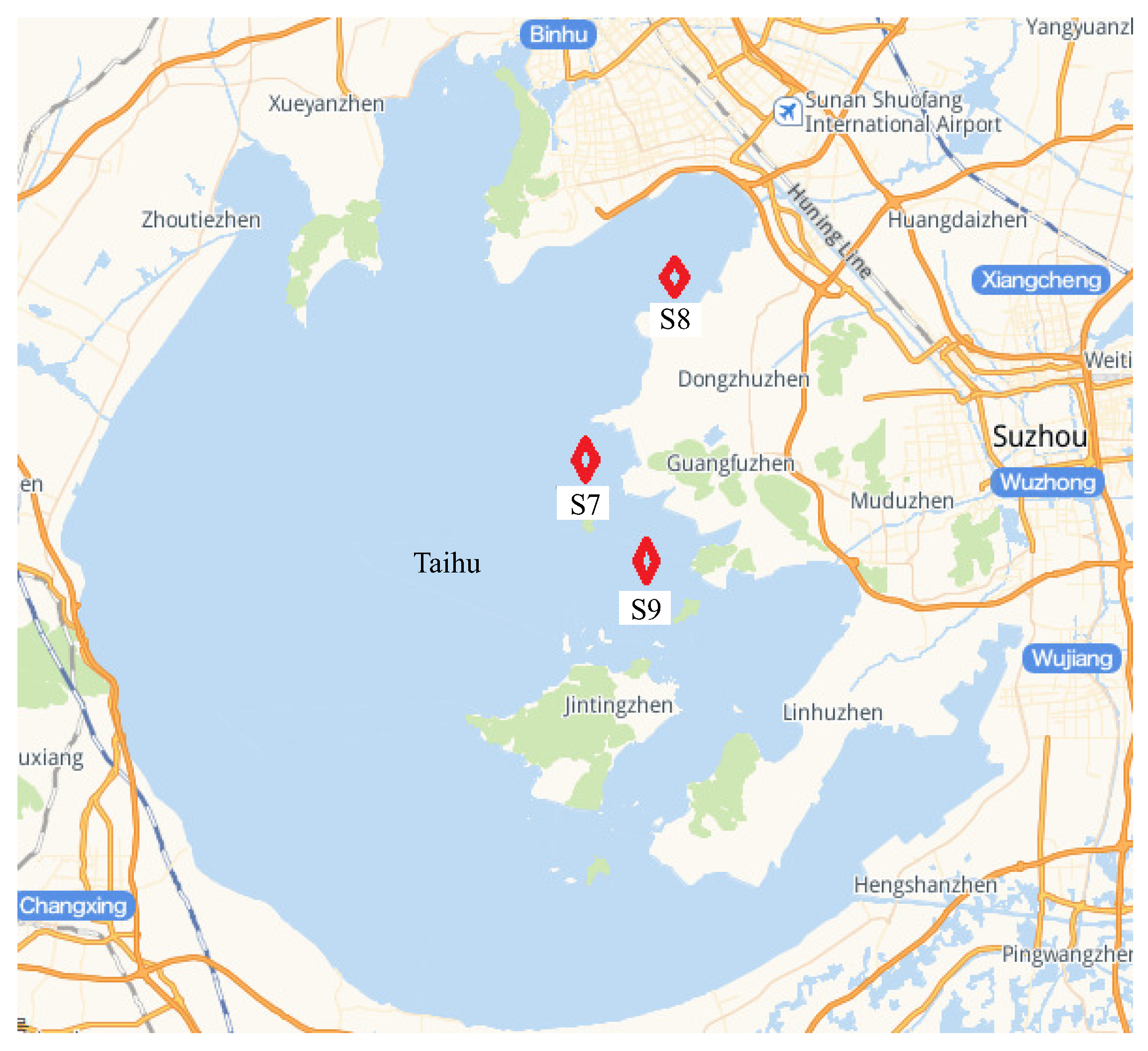
2.1. Research Area and Data Sources
2.2. Proposed Method
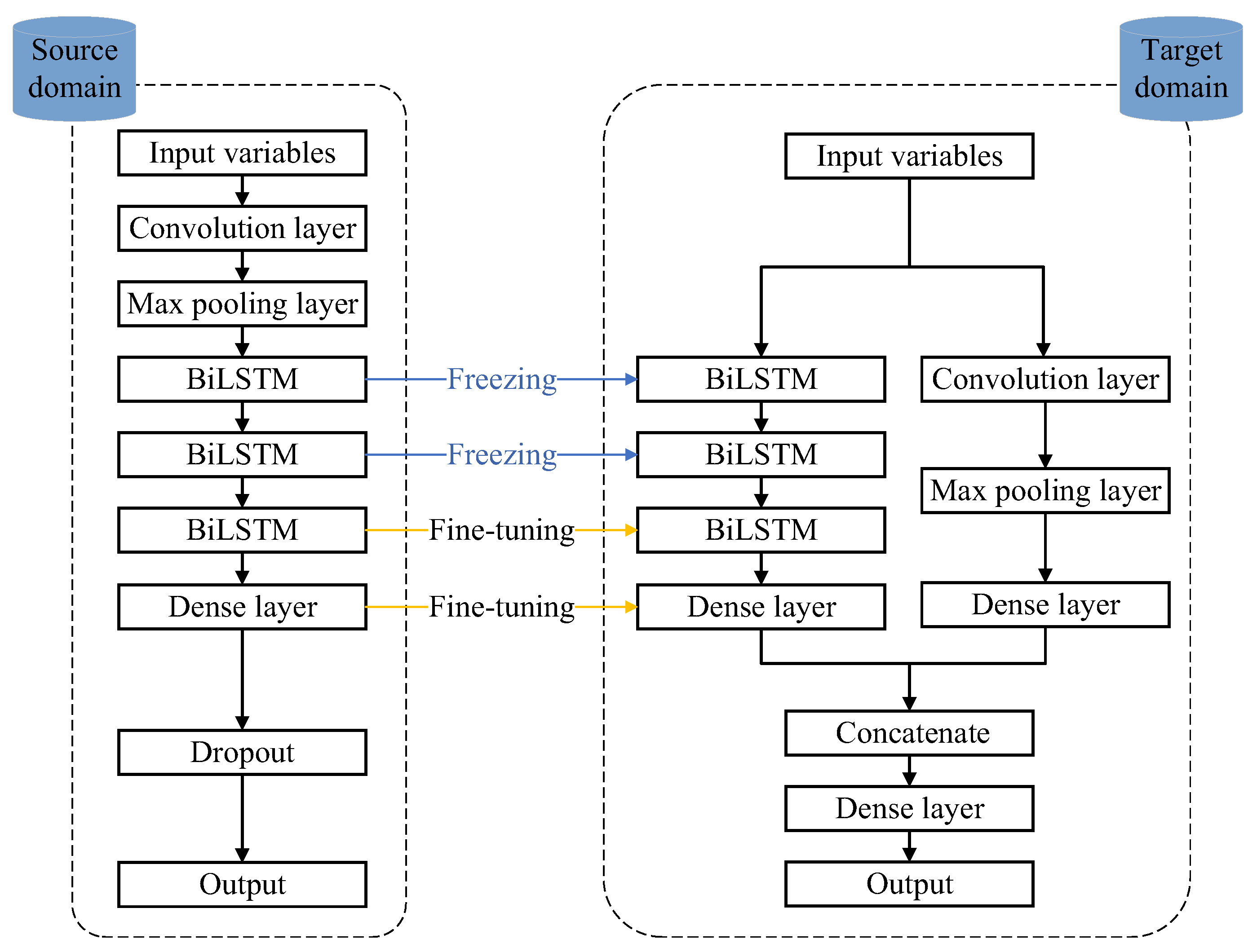
2.2.1. Transfer Learning Method for Modeling
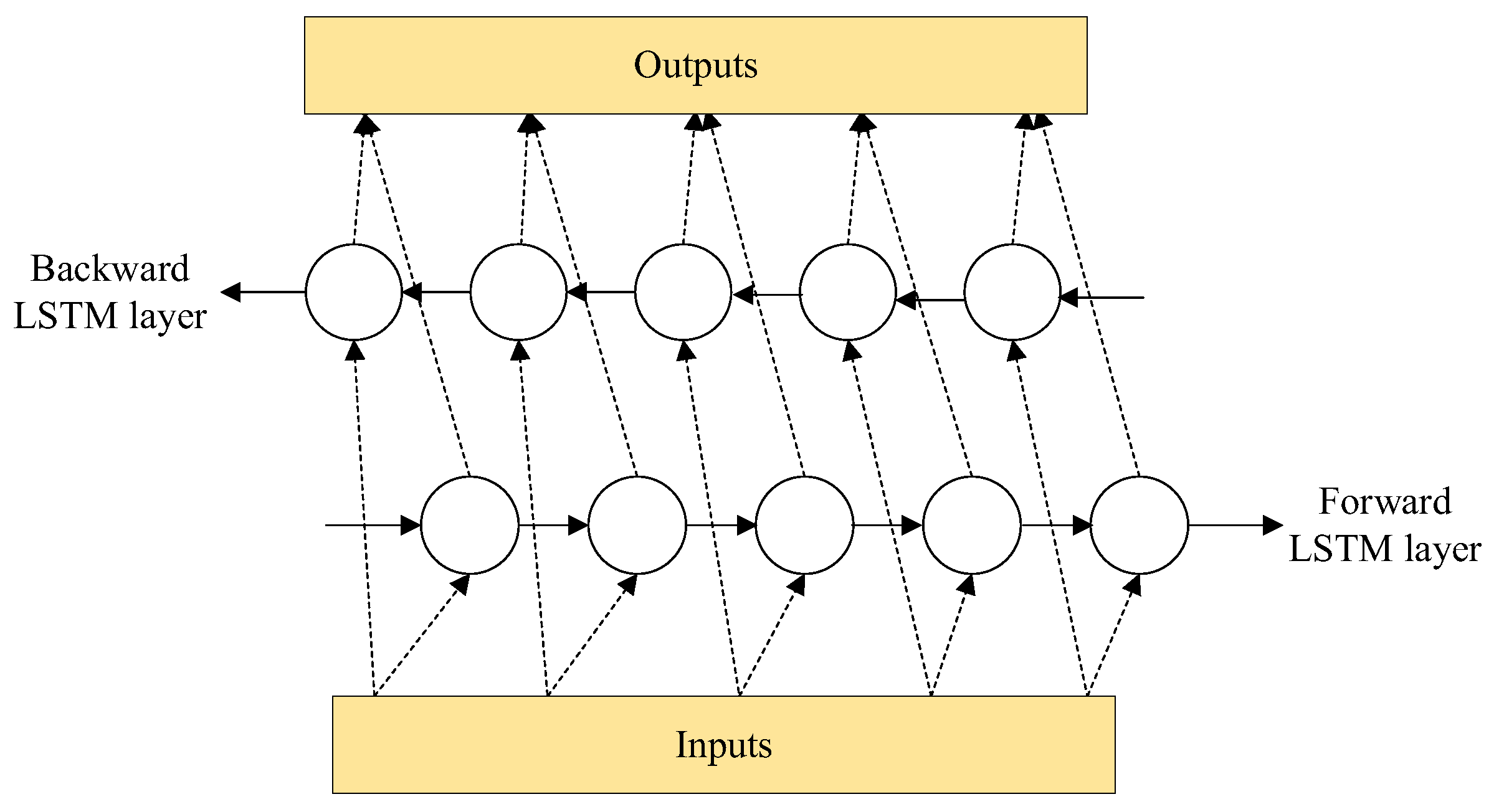
2.2.2. Feature Extraction and Time Series Prediction
2.2.3. Workflow of the Proposed Method
3. Experiments and Discussion
3.1. Evaluation Criteria
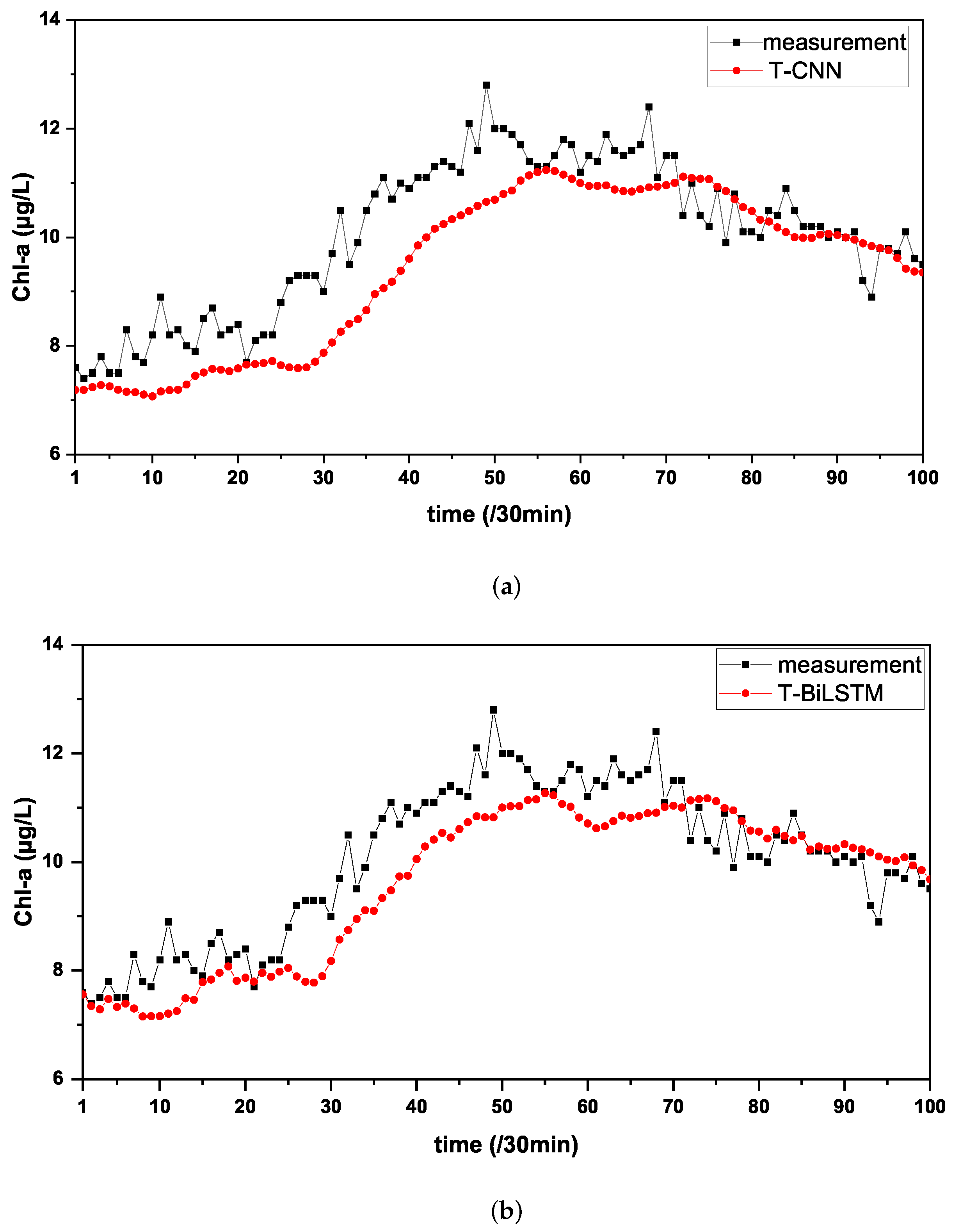
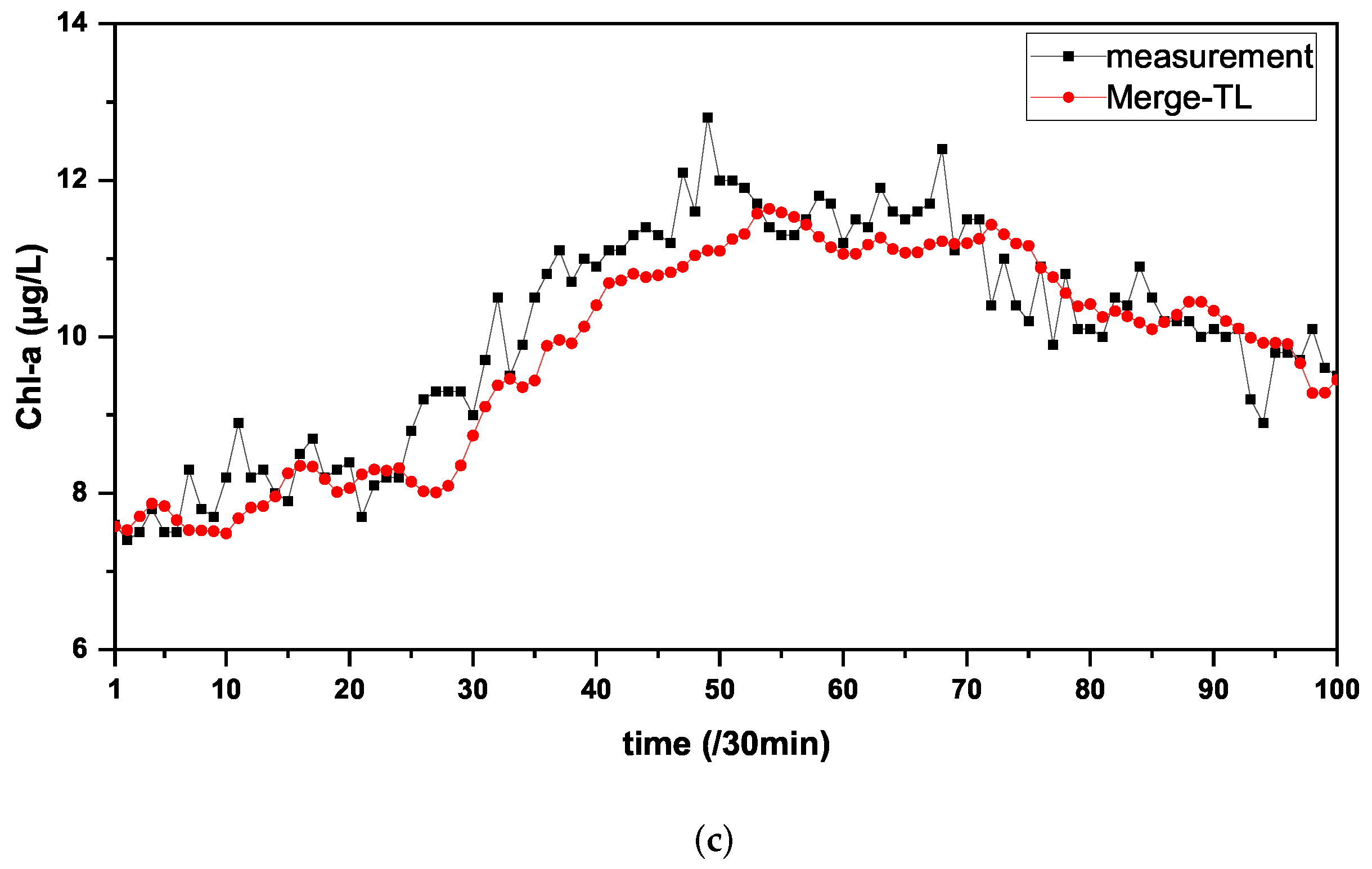
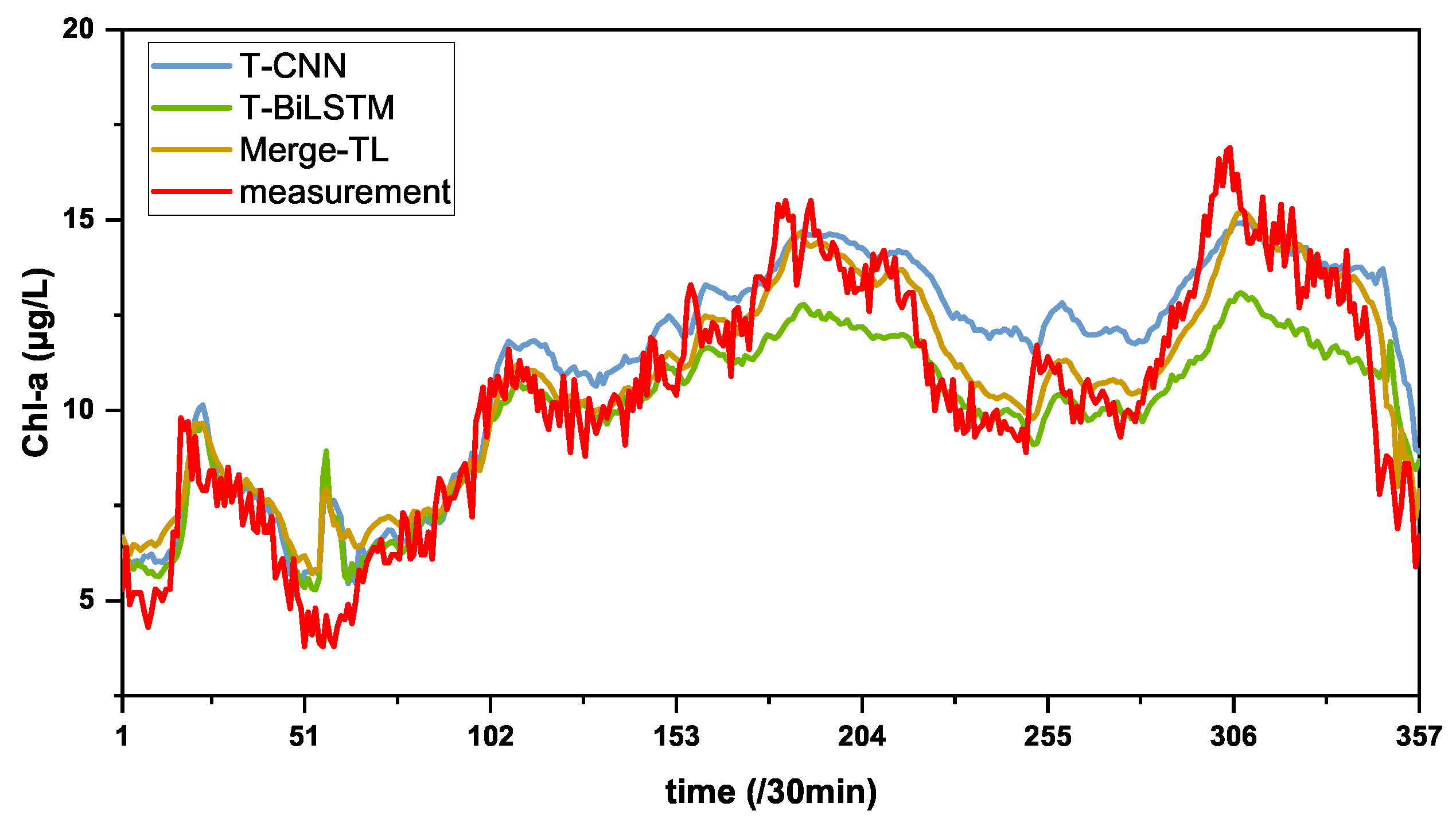
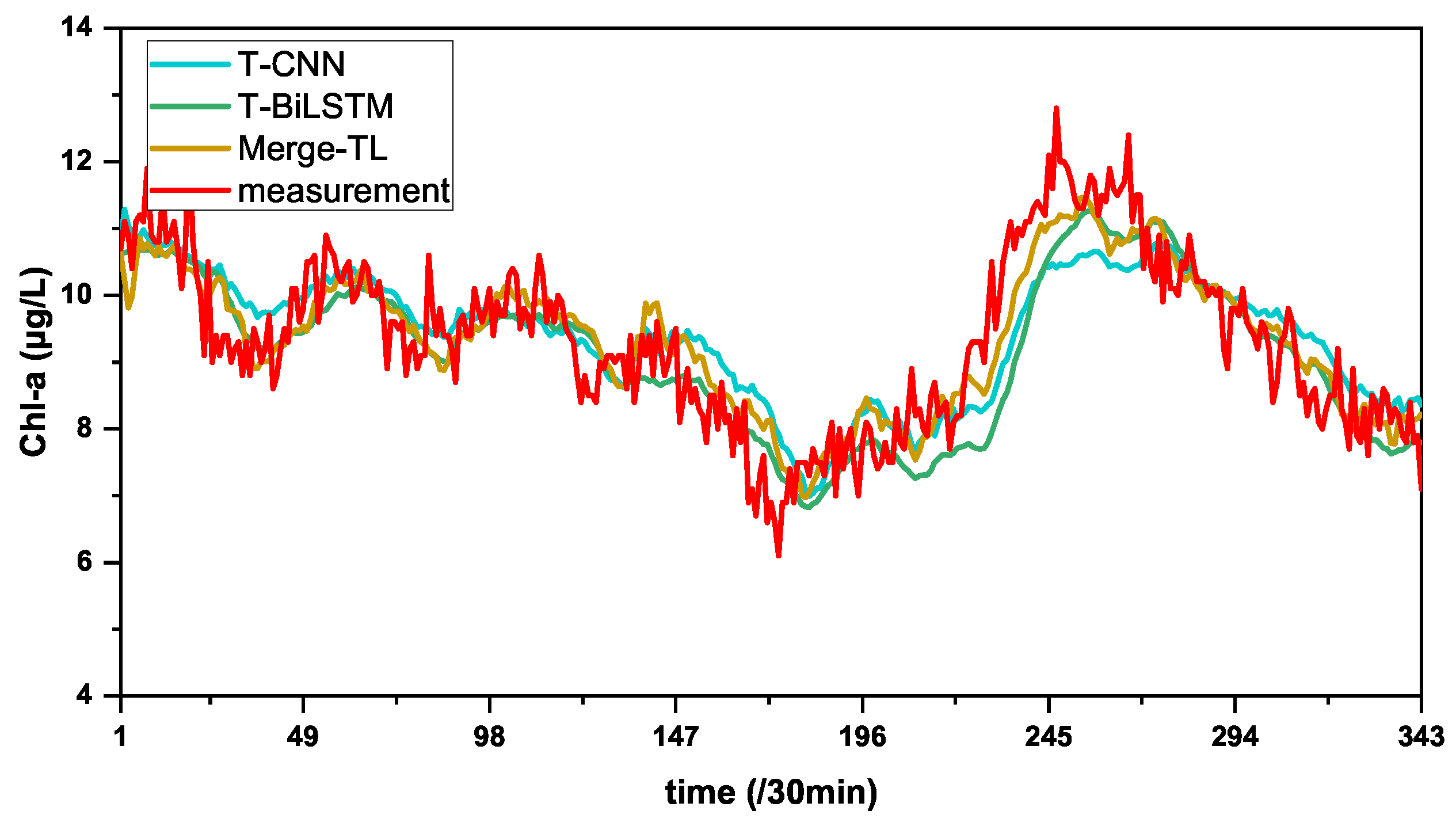
3.2. Comparison Experiment
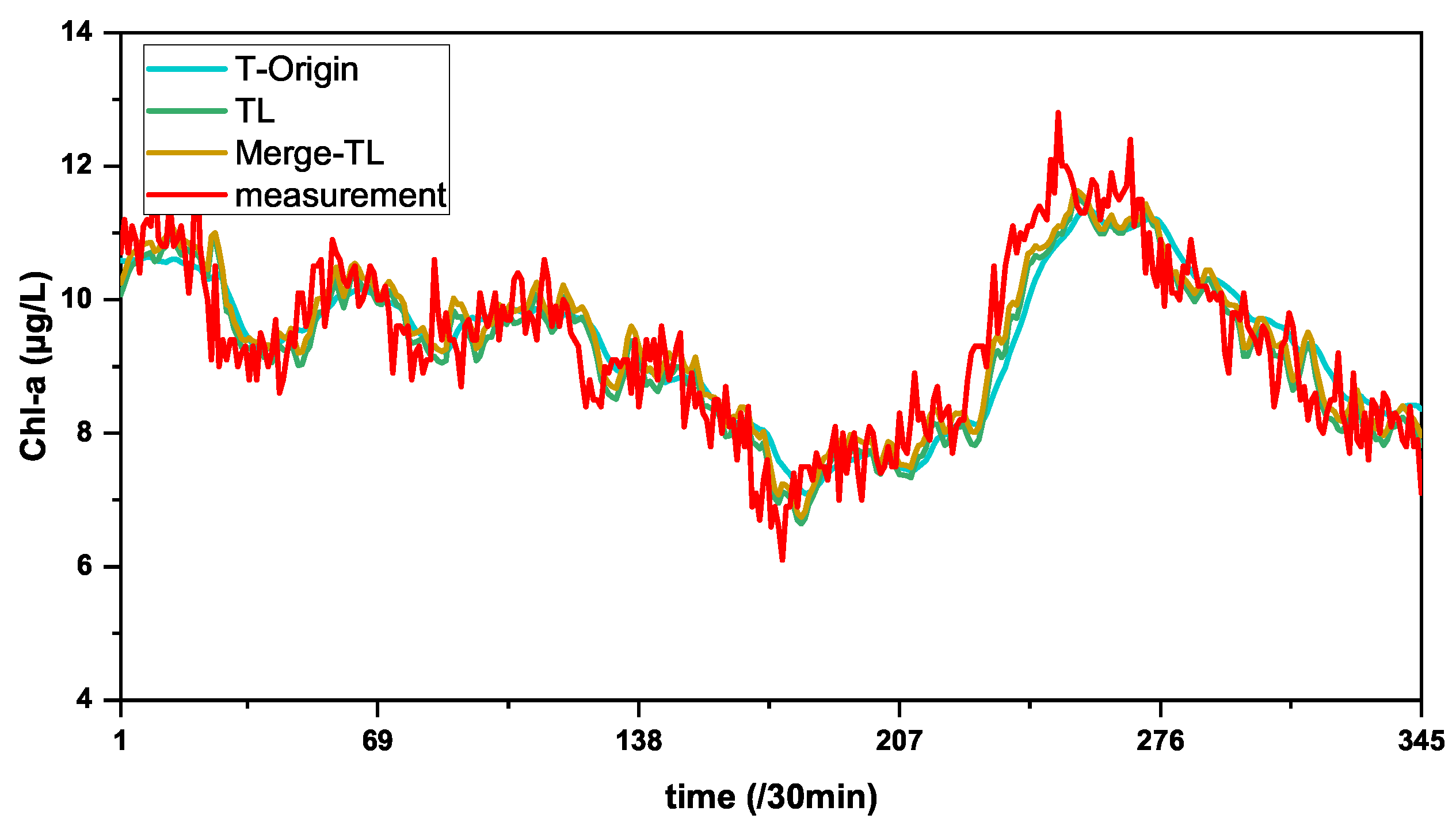
3.3. Ablation Experiments
3.4. Discussion
3.4.1. About the Generalization
3.4.2. About the Prediction Time
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ndlela, L.L.; Oberholster, P.J.; Van Wyk, J.H.; Cheng, P.H. An overview of cyanobacterial bloom occurrences and research in Africa over the last decade. Harmful Algae 2016, 60, 11–26. [Google Scholar] [CrossRef] [PubMed]
- Huo, D.; Gan, N.; Geng, R.; Cao, Q.; Song, L.; Yu, G.; Li, R. Cyanobacterial blooms in China: Diversity, distribution, and cyanotoxins. Harmful Algae 2021, 109, 102106. [Google Scholar] [CrossRef] [PubMed]
- Best, J.; Eddy, F.; Codd, G. Effects of Microcystis cells, cell extracts and lipopolysaccharide on drinking and liver function in rainbow trout Oncorhynchus mykiss Walbaum. Aquat. Toxicol. 2003, 64, 419–426. [Google Scholar] [CrossRef]
- Meng, G.; Sun, Y.; Fu, W.; Guo, Z.; Xu, L. Microcystin-LR induces cytoskeleton system reorganization through hyperphosphorylation of tau and HSP27 via PP2A inhibition and subsequent activation of the p38 MAPK signaling pathway in neuroendocrine (PC12) cells. Toxicology 2011, 290, 218–229. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Chen, J.; Zhang, X.; Xie, P. A review of reproductive toxicity of microcystins. J. Hazard. Mater. 2016, 301, 381–399. [Google Scholar] [CrossRef] [PubMed]
- Yan, T.; Li, X.D.; Tan, Z.J.; Yu, R.C.; Zou, J.Z. Toxic effects, mechanisms, and ecological impacts of harmful algal blooms in China. Harmful Algae 2022, 111, 102148. [Google Scholar] [CrossRef] [PubMed]
- Aguilera, A.; Haakonsson, S.; Martin, M.V.; Salerno, G.L.; Echenique, R.O. Bloom-forming cyanobacteria and cyanotoxins in Argentina: A growing health and environmental concern. Limnologica 2018, 69, 103–114. [Google Scholar] [CrossRef]
- Gorham, T.; Dowling Root, E.; Jia, Y.; Shum, C.; Lee, J. Relationship between cyanobacterial bloom impacted drinking water sources and hepatocellular carcinoma incidence rates. Harmful Algae 2020, 95, 101801. [Google Scholar] [CrossRef]
- Xia, R.; Zhang, Y.; Wang, G.; Zhang, Y.; Dou, M.; Hou, X.; Qiao, Y.; Wang, Q.; Yang, Z. Multi-factor identification and modelling analyses for managing large river algal blooms. Environ. Pollut. 2019, 254, 113056. [Google Scholar] [CrossRef]
- Ranjbar, M.H.; Hamilton, D.P.; Etemad-Shahidi, A.; Helfer, F. Individual-based modelling of cyanobacteria blooms: Physical and physiological processes. Sci. Total Environ. 2021, 792, 148418. [Google Scholar] [CrossRef]
- Havens, K.E.; James, R.T.; East, T.L.; Smith, V.H. N:P ratios, light limitation, and cyanobacterial dominance in a subtropical lake impacted by non-point source nutrient pollution. Environ. Pollut. 2003, 122, 379–390. [Google Scholar] [CrossRef]
- Xu, T.; Yang, T.; Zheng, X.; Li, Z.; Qin, Y. Growth limitation status and its role in interpreting chlorophyll a response in large and shallow lakes: A case study in Lake Okeechobee. J. Environ. Manag. 2022, 302, 114071. [Google Scholar] [CrossRef] [PubMed]
- Menshutkin, V.; Astrakhantsev, G.; Yegorova, N.; Rukhovets, L.; Simo, T.; Petrova, N. Mathematical modeling of the evolution and current conditions of the Ladoga Lake ecosystem. Ecol. Model. 1998, 107, 1–24. [Google Scholar] [CrossRef]
- Muhammetoglu, A.; Soyupak, S. A three-dimensional water quality-macrophyte interaction model for shallow lakes. Ecol. Model. 2000, 133, 161–180. [Google Scholar] [CrossRef]
- Lee, S.; Lee, D. Improved Prediction of Harmful Algal Blooms in Four Major South Korea’s Rivers Using Deep Learning Models. Int. J. Environ. Res. Public Health 2018, 15, 1322. [Google Scholar] [CrossRef] [Green Version]
- Ni, J.; Shen, K.; Chen, Y.; Cao, W.; Yang, S.X. An Improved Deep Network-Based Scene Classification Method for Self-Driving Cars. IEEE Trans. Instrum. Meas. 2022, 71, 5001614. [Google Scholar] [CrossRef]
- Son, H.; Lee, B.; Sung, S. Synthetic Deep Neural Network Design for Lidar-inertial Odometry Based on CNN and LSTM. Int. J. Control. Autom. Syst. 2021, 19, 2859–2868. [Google Scholar] [CrossRef]
- Mutabazi, E.; Ni, J.; Tang, G.; Cao, W. A Review on Medical Textual Question Answering Systems Based on Deep Learning Approaches. Appl. Sci. 2021, 11, 5456. [Google Scholar] [CrossRef]
- Recknagel, F. ANNA—Artificial Neural Network model for predicting species abundance and succession of blue-green algae. Hydrobiologia 1997, 349, 47–57. [Google Scholar] [CrossRef]
- Hill, P.R.; Kumar, A.; Temimi, M.; Bull, D.R. HABNet: Machine Learning, Remote Sensing-Based Detection of Harmful Algal Blooms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3229–3239. [Google Scholar] [CrossRef]
- Cho, H.; Choi, U.; Park, H. Deep learning application to time-series prediction of daily chlorophyll-a concentration. WIT Trans. Ecol. Environ. 2018, 215, 157–163. [Google Scholar]
- Wu, D.; Wang, X.; Wu, S. Jointly modeling transfer learning of industrial chain information and deep learning for stock prediction. Expert Syst. Appl. 2022, 191, 116257. [Google Scholar] [CrossRef]
- Grubinger, T.; Chasparis, G.C.; Natschlager, T. Generalized online transfer learning for climate control in residential buildings. Energy Build. 2017, 139, 63–71. [Google Scholar] [CrossRef] [Green Version]
- Hu, Q.; Zhang, R.; Zhou, Y. Transfer learning for short-term wind speed prediction with deep neural networks. Renew. Energy 2016, 85, 83–95. [Google Scholar] [CrossRef]
- Tian, W.; Liao, Z.; Wang, X. Transfer learning for neural network model in chlorophyll-a dynamics prediction. Environ. Sci. Pollut. Res. 2019, 26, 29857–29871. [Google Scholar] [CrossRef] [PubMed]
- Cao, H.; Han, L.; Li, L. A deep learning method for cyanobacterial harmful algae blooms prediction in Taihu Lake, China. Harmful Algae 2022, 113, 102189. [Google Scholar] [CrossRef]
- Huang, J.; Cui, Z.; Tian, F.; Huang, Q.; Gao, J.; Wang, X.; Li, J. Modeling nitrogen export from 2539 lowland artificial watersheds in Lake Taihu Basin, China: Insights from process-based modeling. J. Hydrol. 2020, 581, 124428. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, W.; Li, D.; Huang, Z.; Shen, Y.; Liu, Y. Cyanobacteria-/cyanotoxin-contaminations and eutrophication status before Wuxi Drinking Water Crisis in Lake Taihu, China. J. Environ. Sci. 2011, 23, 575–581. [Google Scholar] [CrossRef]
- Zhao, K.; Wang, L.; You, Q.; Pan, Y.; Liu, T.; Zhou, Y.; Zhang, J.; Pang, W.; Wang, Q. Influence of cyanobacterial blooms and environmental variation on zooplankton and eukaryotic phytoplankton in a large, shallow, eutrophic lake in China. Sci. Total Environ. 2021, 773, 145421. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, R.; Duan, H.; Loiselle, S.A.; Xu, J. Satellite analysis to identify changes and drivers of CyanoHABs dynamics in Lake Taihu. Water Sci. Technol. Water Supply 2016, 16, 1451–1466. [Google Scholar] [CrossRef]
- Zou, W.; Zhu, G.; Xu, H.; Zhu, M.; Zhang, Y.; Qin, B. Temporal dependence of chlorophyll a-nutrient relationships in Lake Taihu: Drivers and management implications. J. Environ. Manag. 2022, 306, 114476. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Wang, H.; Liu, C.; Zhang, S.; Ding, A.; Xie, E.; Li, J.; Wang, S. Prediction of harmful algal blooms in large water bodies using the combined EFDC and LSTM models. J. Environ. Manag. 2021, 295, 113060. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Xu, Q.; Wang, X.; Xi, B.; Jia, K.; Huo, S.; Liu, H.; Li, C.; Xu, B. Evaluation of a modified monod model for predicting algal dynamics in Lake Tai. Water 2015, 7, 3626–3642. [Google Scholar] [CrossRef] [Green Version]
- Cruz, R.C.; Reis Costa, P.; Vinga, S.; Krippahl, L.; Lopes, M.B. A Review of Recent Machine Learning Advances for Forecasting Harmful Algal Blooms and Shellfish Contamination. J. Mar. Sci. Eng. 2021, 9, 283. [Google Scholar] [CrossRef]
- Han, Z.; Zhao, J.; Leung, H.; Ma, K.F.; Wang, W. A Review of Deep Learning Models for Time Series Prediction. IEEE Sens. J. 2021, 21, 7833–7848. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.; Lin, C.; Tan, Y.; Zhang, J. Improving air quality prediction accuracy at larger temporal resolutions using deep learning and transfer learning techniques. Atmos. Environ. 2019, 214, 116885. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Li, B.; Rangarajan, S. A conceptual study of transfer learning with linear models for data-driven property prediction. Comput. Chem. Eng. 2022, 157, 107599. [Google Scholar] [CrossRef]
- Boureau, Y.L.; Bach, F.; LeCun, Y.; Ponce, J. Learning mid-level features for recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognitio, San Francisco, CA, USA, 13–18 June 2010; pp. 2559–2566. [Google Scholar]
- Ni, J.; Chen, Y.; Chen, Y.; Zhu, J.; Ali, D.; Cao, W. A Survey on Theories and Applications for Self-Driving Cars Based on Deep Learning Methods. Appl. Sci. 2020, 10, 2749. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Hovy, E. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1064–1074. [Google Scholar]
- Ghasemlounia, R.; Gharehbaghi, A.; Ahmadi, F.; Saadatnejadgharahassanlou, H. Developing a novel framework for forecasting groundwater level fluctuations using Bi-directional Long Short-Term Memory (BiLSTM) deep neural network. Comput. Electron. Agric. 2021, 191, 106568. [Google Scholar] [CrossRef]
- Shi, P.; Fang, X.; Ni, J.; Zhu, J. An Improved Attention-Based Integrated Deep Neural Network for PM2.5 Concentration Prediction. Appl. Sci. 2021, 11, 4001. [Google Scholar] [CrossRef]
- Chen, S.; Han, X.; Shen, Y.; Ye, C. Application of Improved LSTM Algorithm in Macroeconomic Forecasting. Comput. Intell. Neurosci. 2021, 2021, 4471044. [Google Scholar] [CrossRef]
- Bai, Y.; Liu, M.D.; Ding, L.; Ma, Y.J. Double-layer staged training echo-state networks for wind speed prediction using variational mode decomposition. Appl. Energy 2021, 301, 117461. [Google Scholar] [CrossRef]
- Sun, W.; Xu, Z. A novel hourly PM2.5 concentration prediction model based on feature selection, training set screening, and mode decomposition-reorganization. Sustain. Cities Soc. 2021, 75, 103348. [Google Scholar] [CrossRef]
- Rajaee, T.; Boroumand, A. Forecasting of chlorophyll-a concentrations in South San Francisco Bay using five different models. Appl. Ocean Res. 2015, 53, 208–217. [Google Scholar] [CrossRef]
- Al Shehhi, M.R.; Kaya, A. Time series and neural network to forecast water quality parameters using satellite data. Cont. Shelf Res. 2021, 231, 104612. [Google Scholar] [CrossRef]
- Le Guen, V.; Thome, N. Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems (NIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Chl-a | Temp | pH | Conduct | Turb | DO | Cyanob |
|---|---|---|---|---|---|---|---|
| (g/L) | (°C) | (S/cm) | (NTU) | (mg/L) | ( cells/L) | ||
| 11 June 2016, 2:00 | 7.0 | 25.13 | 8.61 | 400 | 52.2 | 8.41 | 780.8 |
| 11 June 2016, 2:30 | 5.5 | 25.04 | 8.55 | 402 | 52.2 | 8.24 | 337.0 |
| 11 June 2016, 3:00 | 5.9 | 25.04 | 8.53 | 402 | 50.7 | 8.25 | 382.0 |
| … | … | … | … | … | … | … | … |
| 30 September 2016, 22:30 | 8.8 | 23.42 | 8.24 | 227 | 98.0 | 8.13 | 799.6 |
| 30 September 2016, 23:00 | 8.3 | 23.40 | 8.22 | 275 | 88.1 | 8.10 | 747.3 |
| 30 September 2016, 23:30 | 8.8 | 23.39 | 8.22 | 275 | 92.4 | 8.09 | 705.8 |
| Parameters | Value |
|---|---|
| Convolution layer filters | 32 |
| Convolution layer kernel size | 3 |
| Pooling layer pool size | 2 |
| BiLSTM_layer1 units | 16 |
| BiLSTM_layer2 units | 32 |
| BiLSTM_layer3 units | 64 |
| Activation function | RELU |
| Dropout | 0.5 |
| Methods | MAE | RMSE | MSE | MAPE | |
|---|---|---|---|---|---|
| T-CNN | 0.5292 | 0.6628 | 0.4393 | 5.7125 | 0.7343 |
| T-BiLSTM | 0.5048 | 0.6373 | 0.4062 | 5.3544 | 0.7545 |
| Merge-TL | 0.4336 | 0.5589 | 0.3124 | 4.7179 | 0.8110 |
| Methods | MAE | RMSE | MSE | MAPE | |
|---|---|---|---|---|---|
| T-Origin | 0.4814 | 0.6216 | 0.3864 | 5.2147 | 0.7662 |
| TL | 0.4470 | 0.5749 | 0.3305 | 4.7871 | 0.8000 |
| Merge-TL | 0.4336 | 0.5589 | 0.3124 | 4.7179 | 0.8110 |
| Methods | MAE | RMSE | MSE | MAPE | |
|---|---|---|---|---|---|
| T-CNN | 1.2492 | 1.6564 | 2.7436 | 14.2893 | 0.7107 |
| T-BiLSTM | 1.1205 | 1.5214 | 2.3145 | 11.5404 | 0.7560 |
| Merge-TL | 1.0108 | 1.3572 | 1.8298 | 12.0023 | 0.8061 |
| Methods | MAE | RMSE | MSE | MAPE | |
|---|---|---|---|---|---|
| T-CNN | 0.5761 | 0.7401 | 0.5477 | 6.2951 | 0.6676 |
| T-BiLSTM | 0.5279 | 0.7003 | 0.4904 | 5.6461 | 0.7024 |
| Merge-TL | 0.4679 | 0.5933 | 0.3520 | 5.1302 | 0.7863 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, J.; Liu, R.; Li, Y.; Tang, G.; Shi, P. An Improved Transfer Learning Model for Cyanobacterial Bloom Concentration Prediction. Water 2022, 14, 1300. https://doi.org/10.3390/w14081300
Ni J, Liu R, Li Y, Tang G, Shi P. An Improved Transfer Learning Model for Cyanobacterial Bloom Concentration Prediction. Water. 2022; 14(8):1300. https://doi.org/10.3390/w14081300
Chicago/Turabian StyleNi, Jianjun, Ruping Liu, Yingqi Li, Guangyi Tang, and Pengfei Shi. 2022. "An Improved Transfer Learning Model for Cyanobacterial Bloom Concentration Prediction" Water 14, no. 8: 1300. https://doi.org/10.3390/w14081300
APA StyleNi, J., Liu, R., Li, Y., Tang, G., & Shi, P. (2022). An Improved Transfer Learning Model for Cyanobacterial Bloom Concentration Prediction. Water, 14(8), 1300. https://doi.org/10.3390/w14081300