
Feature Extraction and Prediction of Water Quality Based on Candlestick Theory and Deep Learning Methods



Abstract
:1. Introduction
2. Problem Scenario
2.1. Candlestick Graphical Representation of Pollution Process Classification
2.2. Correspondence between Candlestick Characteristics and the Physical Model of Water Quality Diffusion
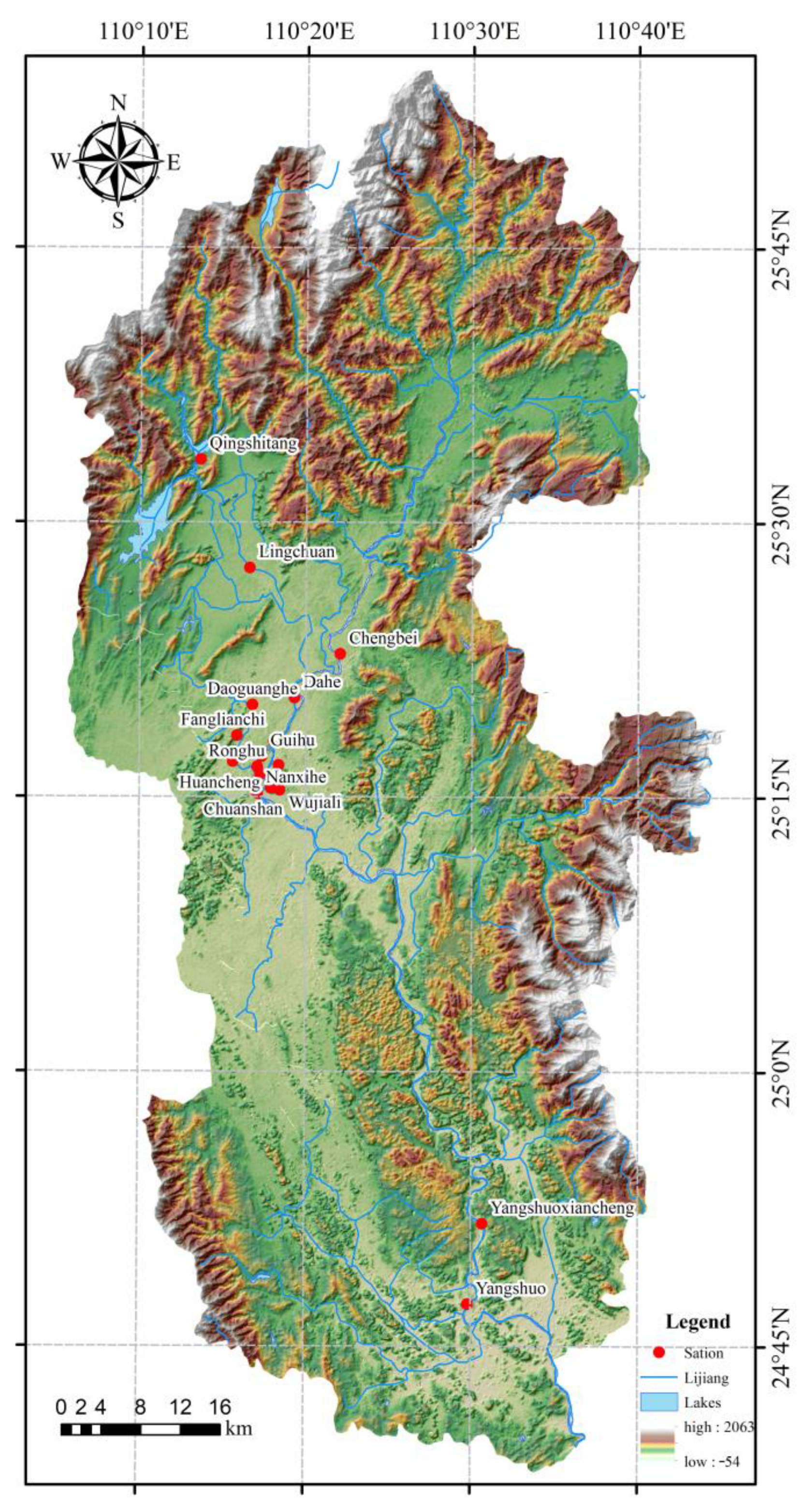
2.3. Research Area
3. Methods
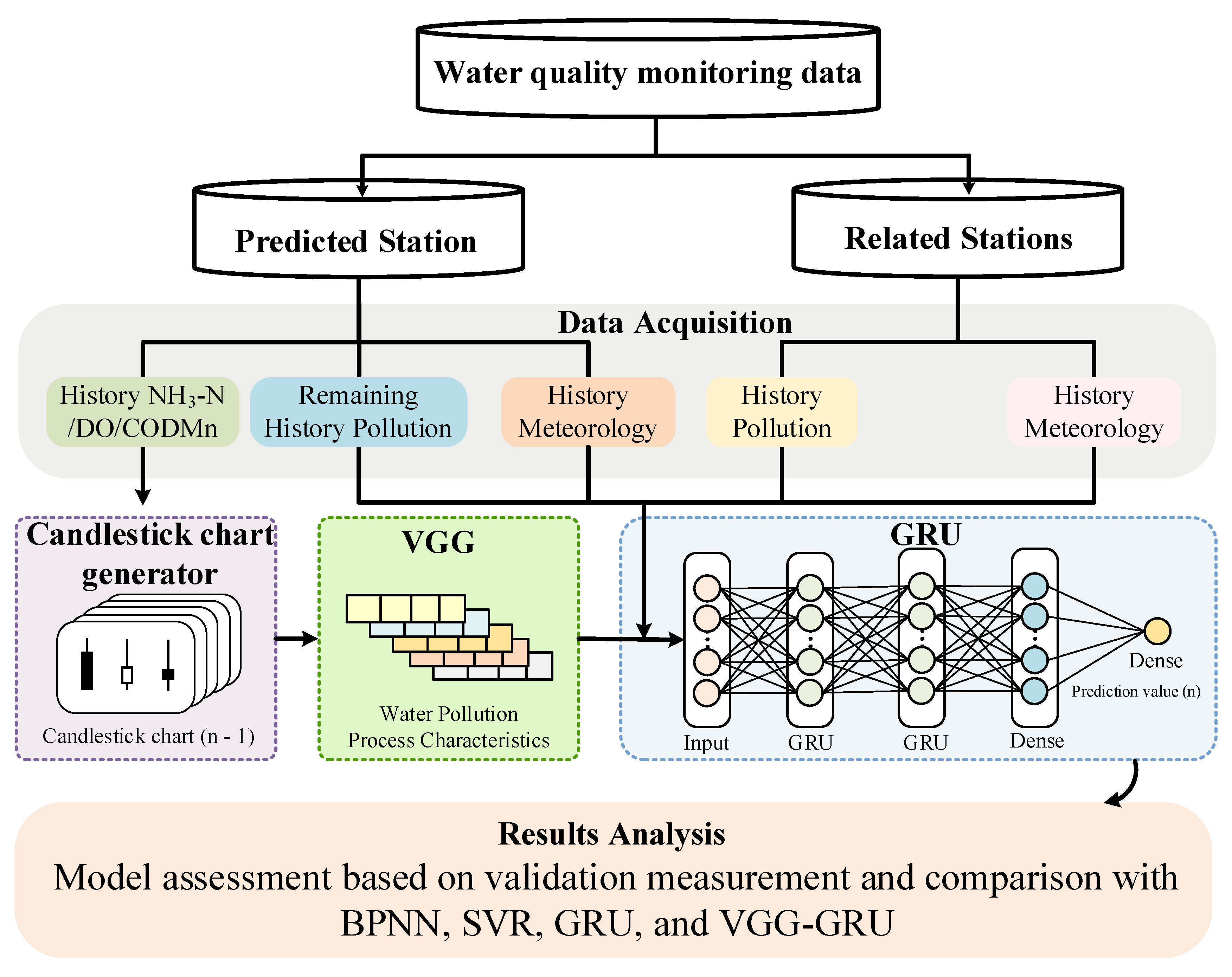
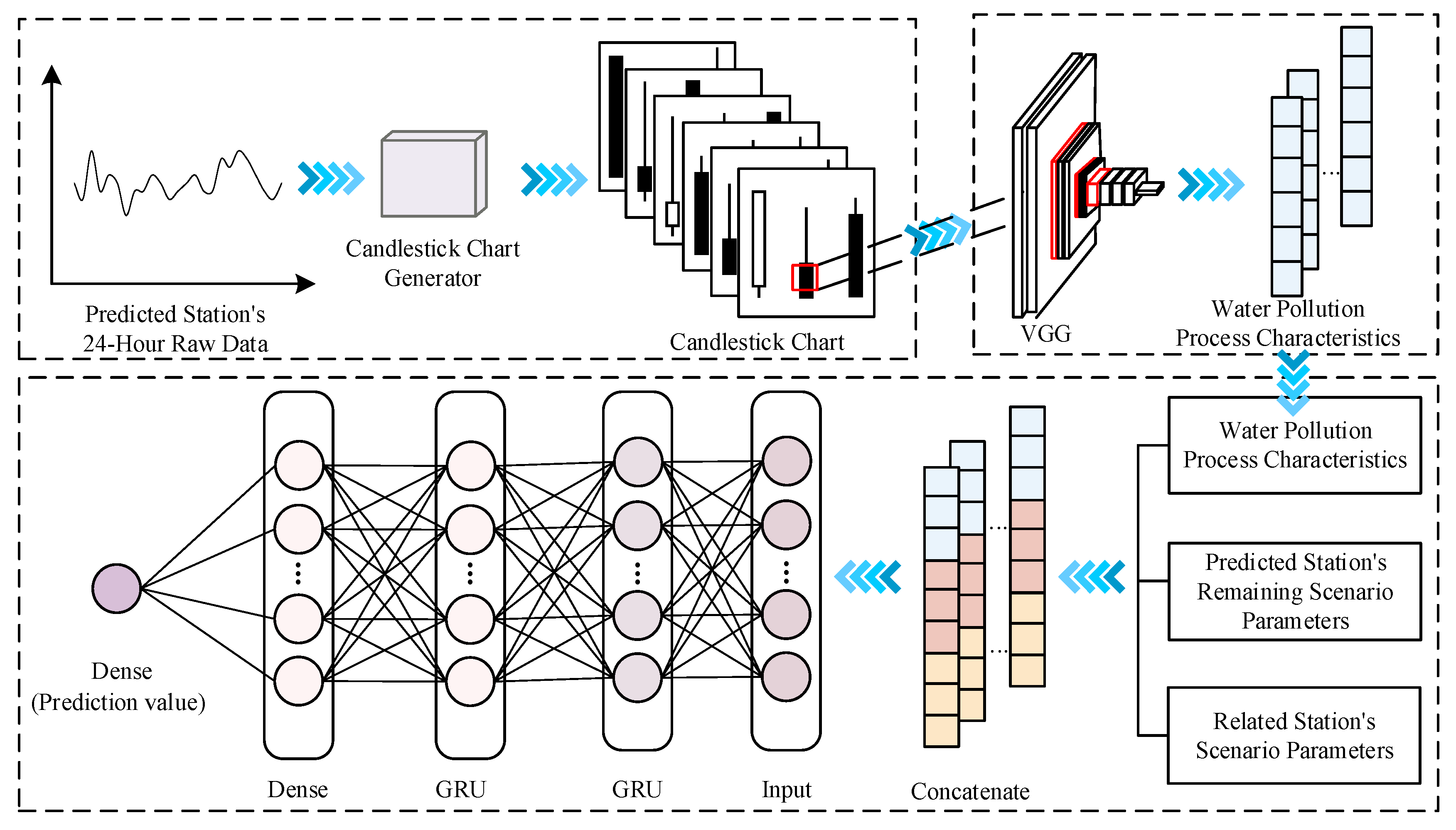
3.1. Framework
3.2. Data Collection and Preprocessing
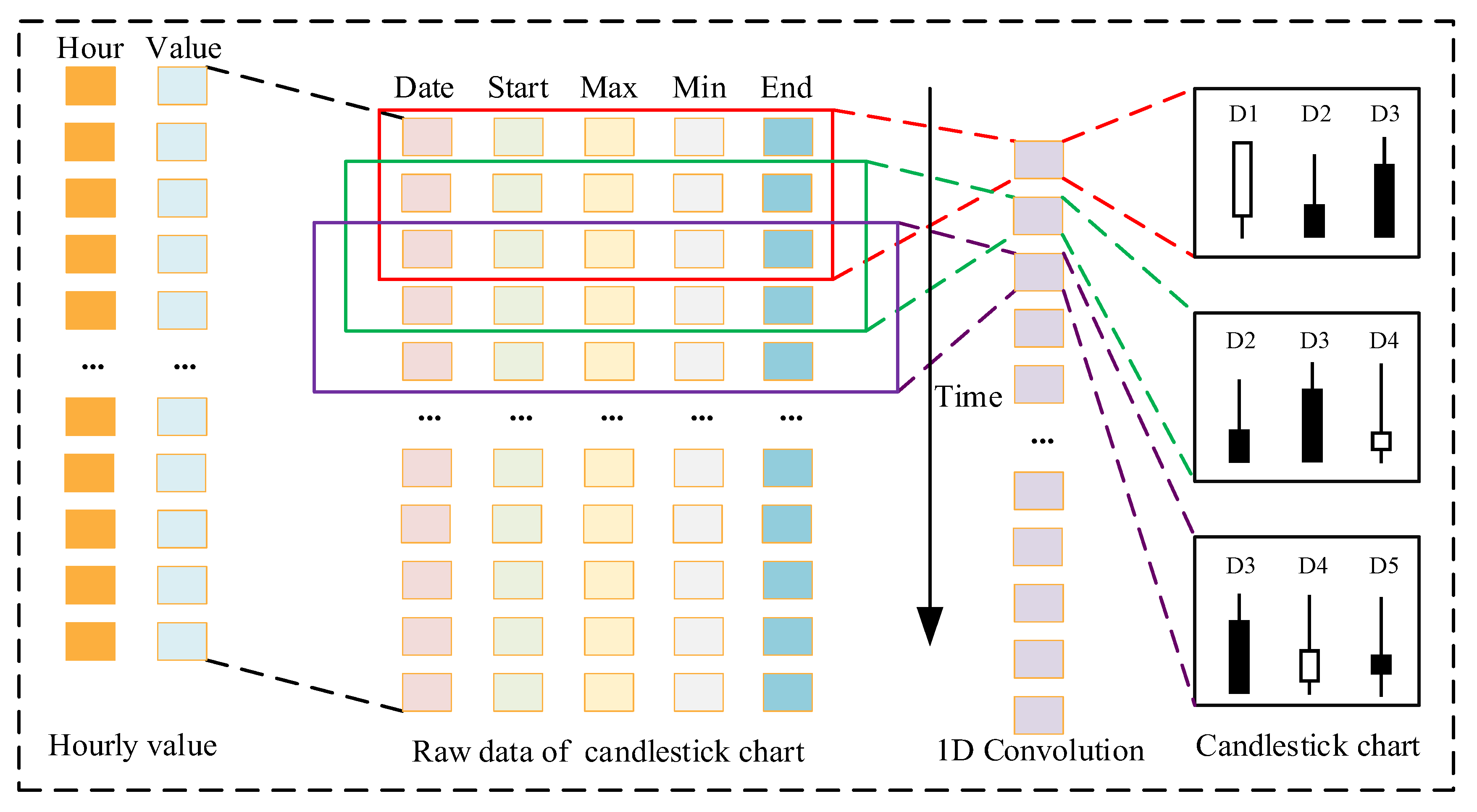
3.3. Design Principle of the Candlestick Chart Generator
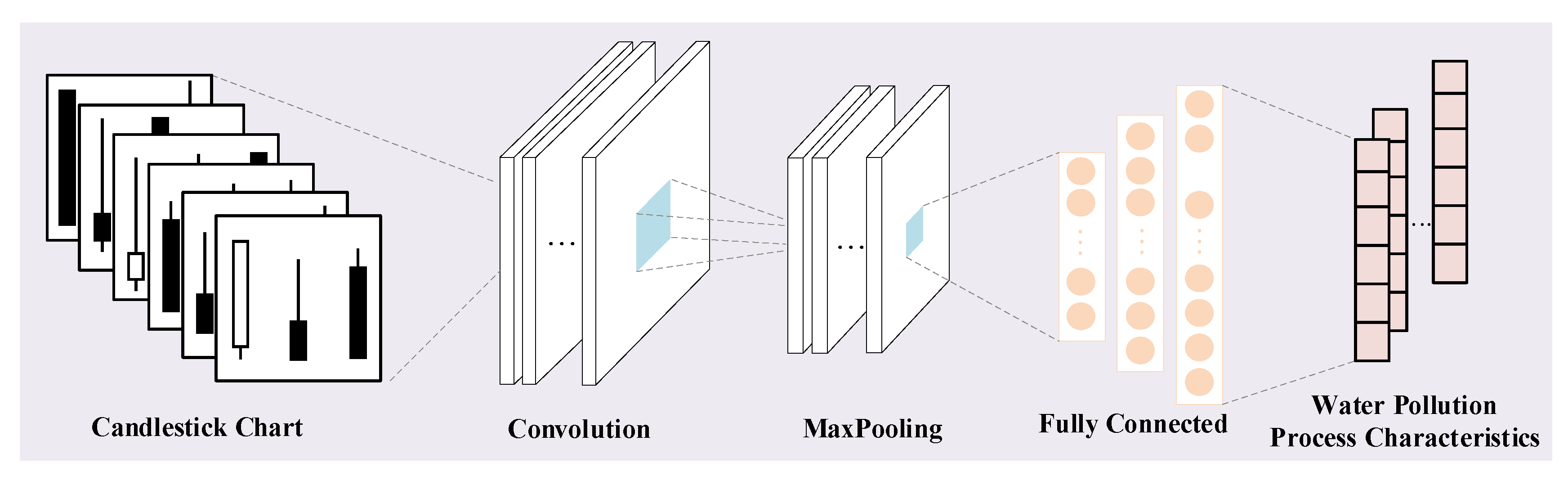
3.4. Feature Extraction of Water Pollution Process Characteristics through VGG
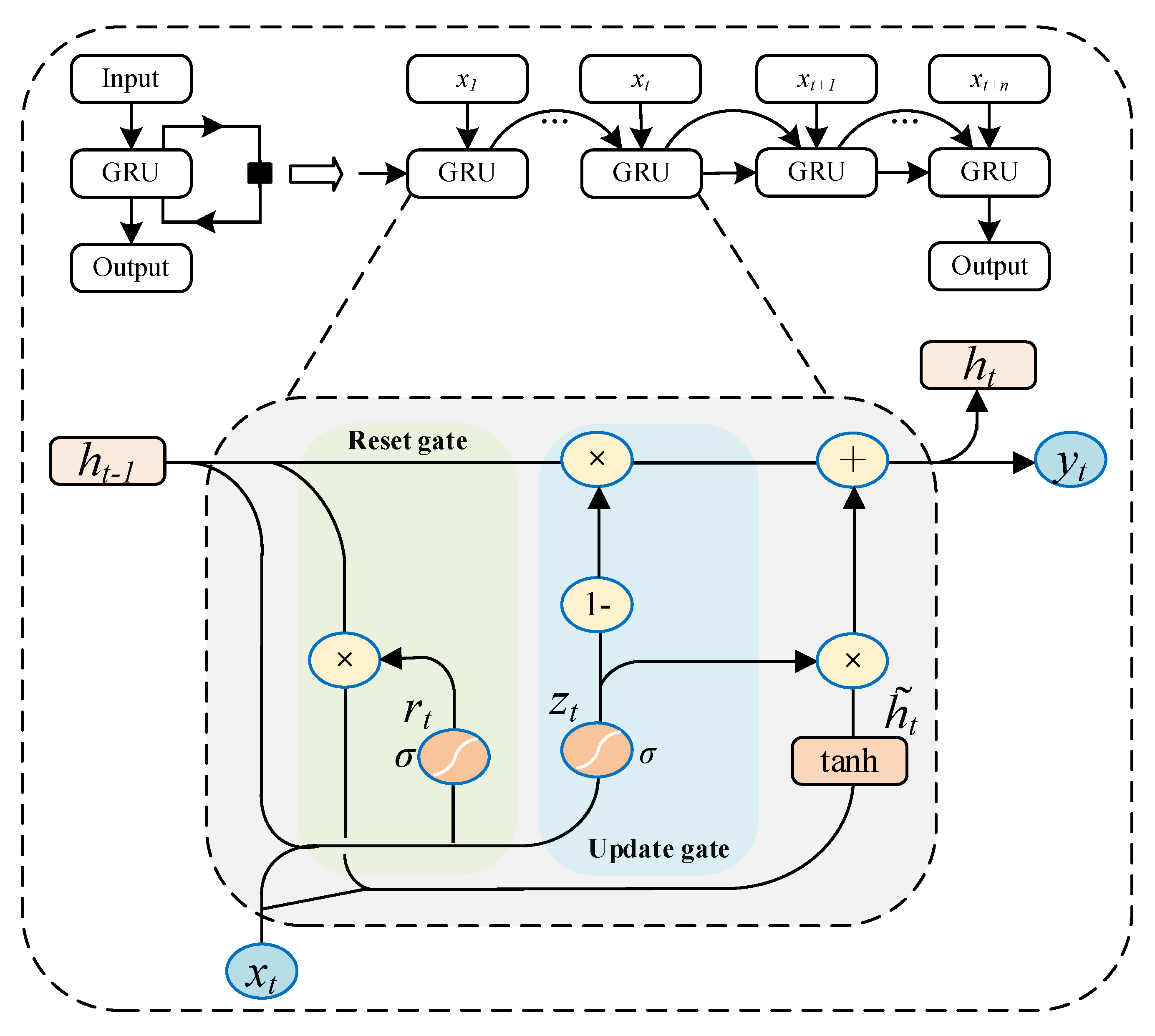
3.5. Time Series Prediction of Water Quality Data through GRU
3.6. The CT-VGG-GRU Model for Water Quality Prediction
4. Experiment Results and Analysis
4.1. Evaluation Criteria
4.2. Network Parameters
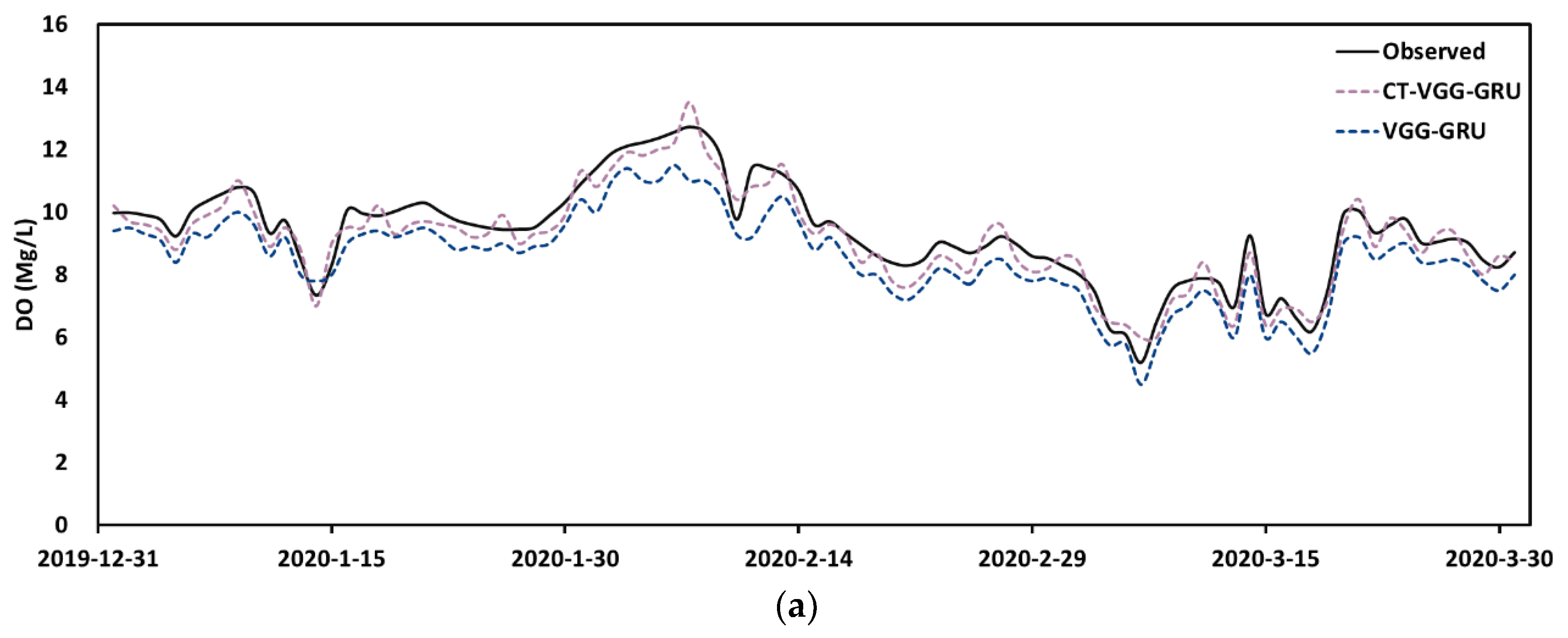
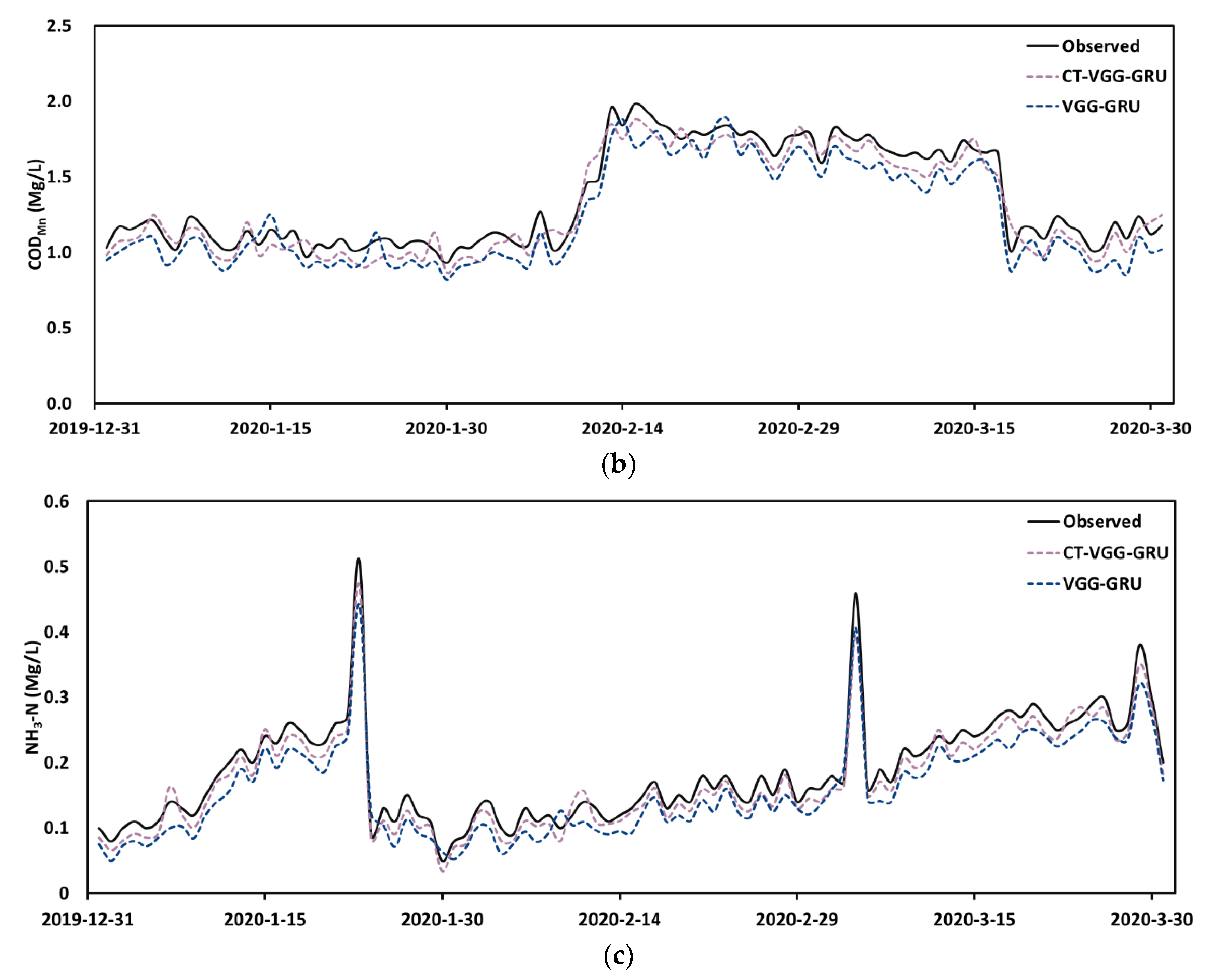
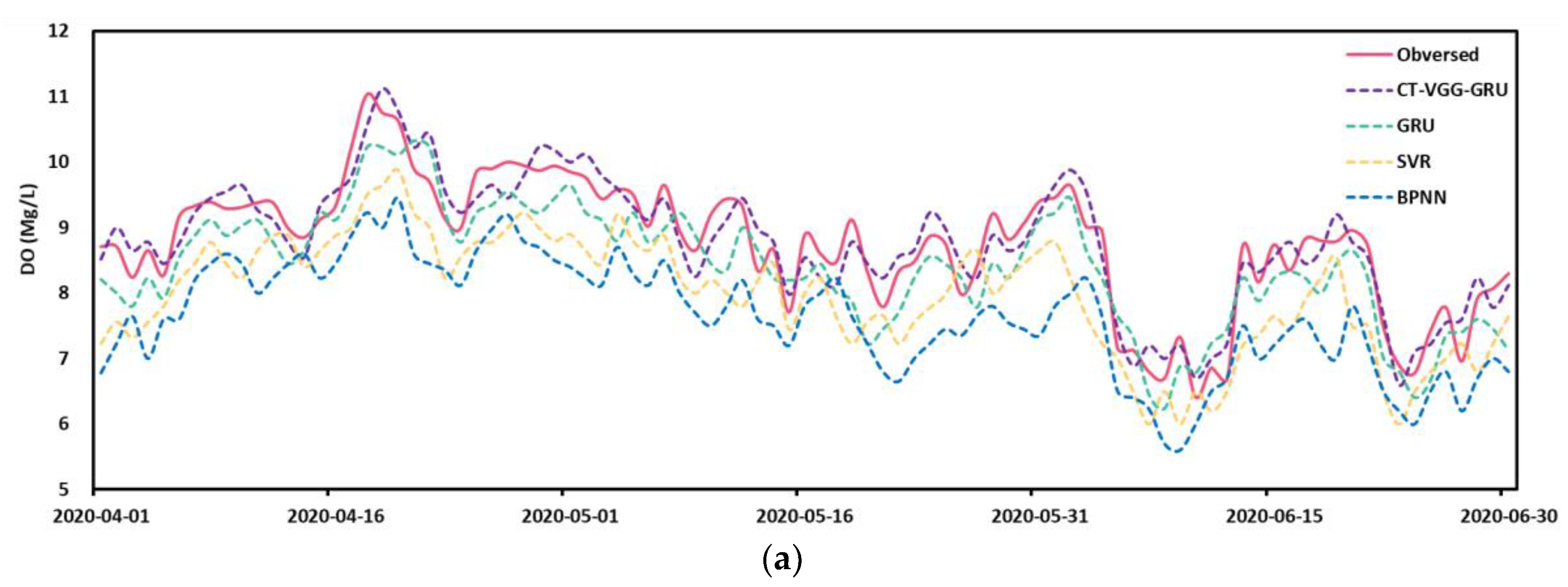
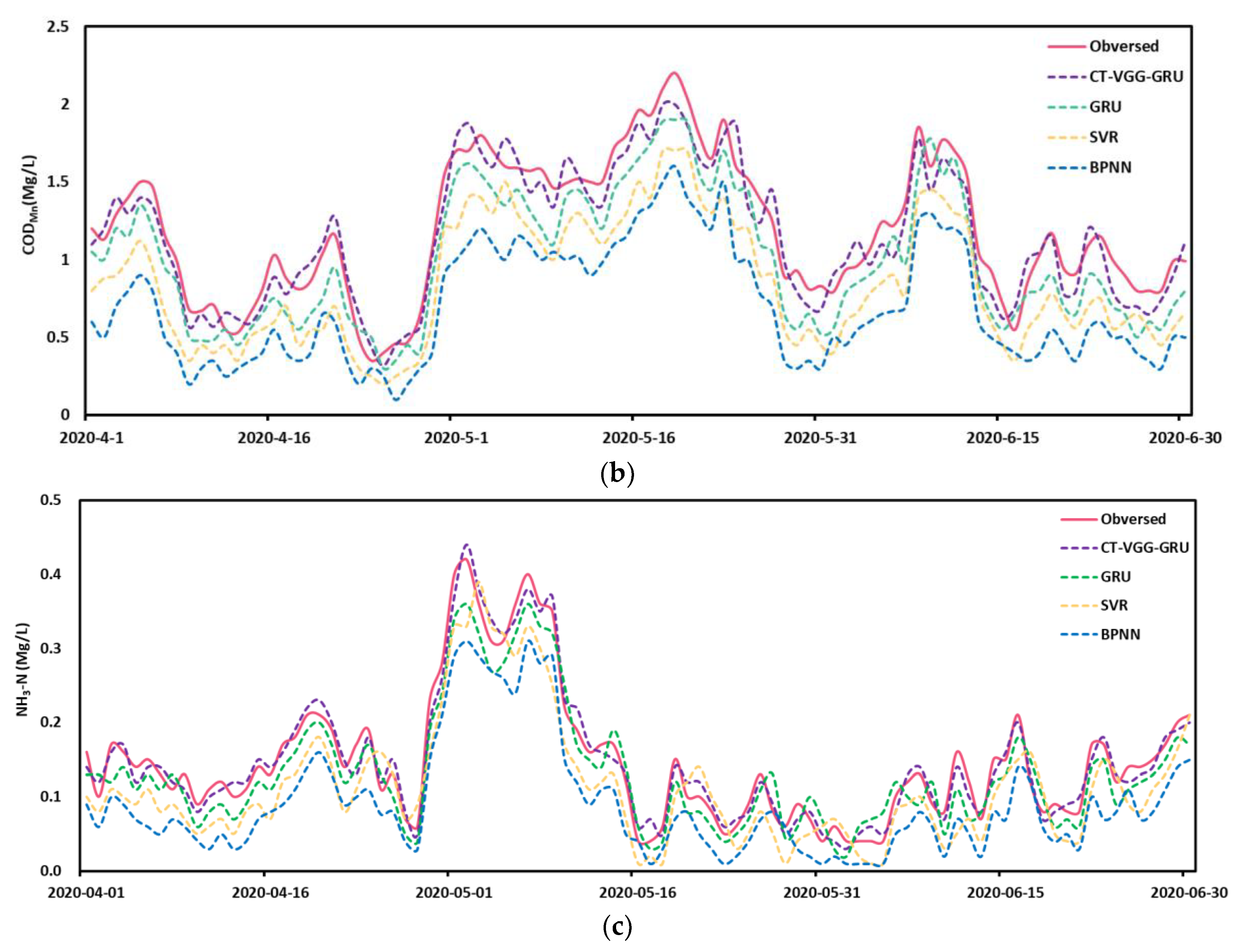
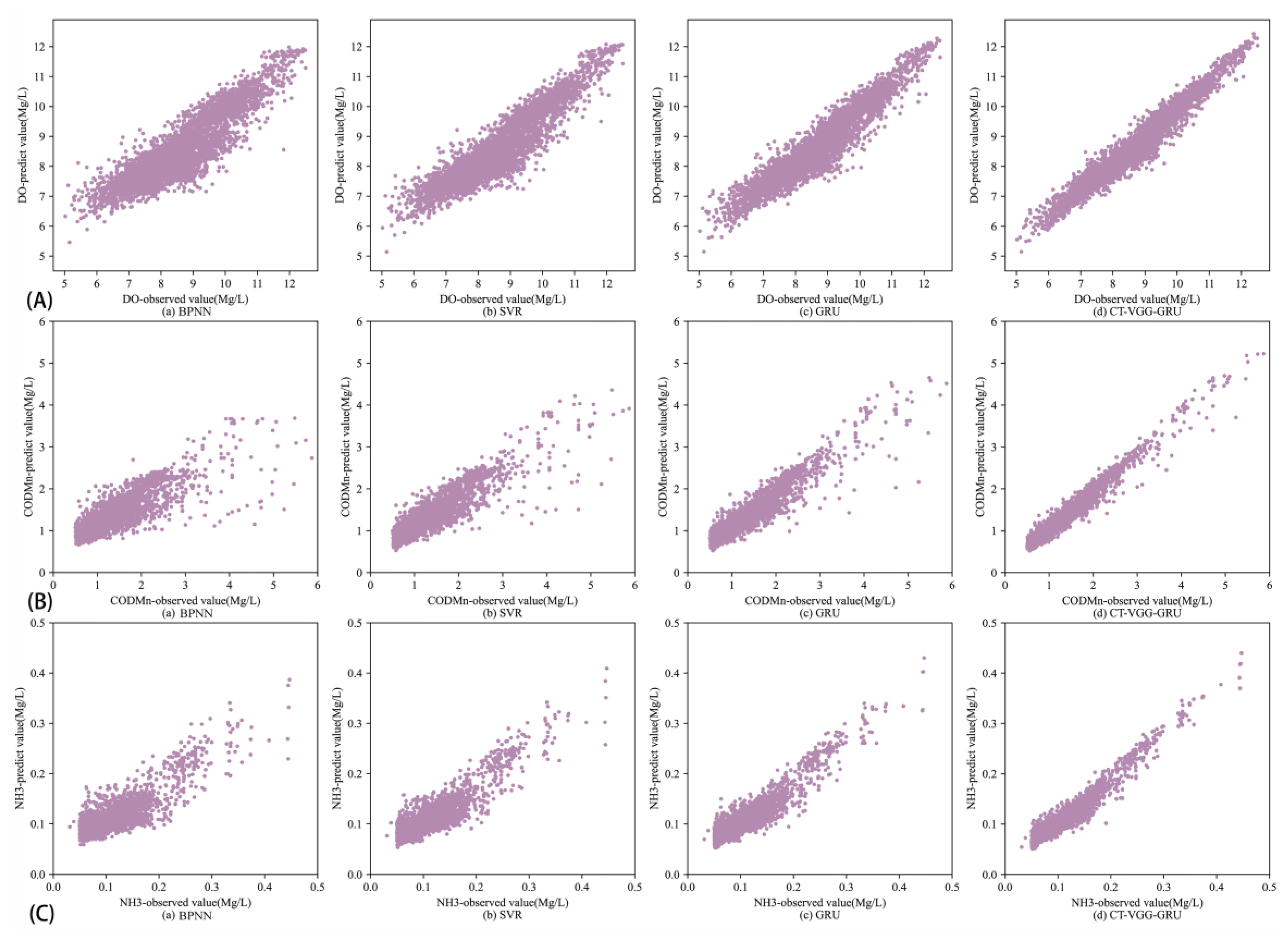
4.3. Prediction Performance
4.4. Comparison of the Proposed Model with Other Methods
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, F.; Zhang, G.; Xu, Y.J. Separating the impacts of climate variation and human activities on runoff in the Songhua River Basin, Northeast China. Water 2014, 6, 3320–3338. [Google Scholar] [CrossRef] [Green Version]
- Wan, H.; Mao, Y.; Cai, Y.; Li, R.; Feng, J.; Yang, H. An SPH-based mass transfer model for simulating hydraulic characteristics and mass transfer process of dammed rivers. Eng. Comput. 2021, 38, 3169–3184. [Google Scholar] [CrossRef]
- Akoko, G.; Le, T.H.; Gomi, T.; Kato, T. A review of SWAT model application in Africa. Water 2021, 13, 1313. [Google Scholar] [CrossRef]
- Aawar, T.; Khare, D. Assessment of climate change impacts on streamflow through hydrological model using SWAT model: A case study of Afghanistan. Model. Earth Syst. Environ. 2020, 6, 1427–1437. [Google Scholar] [CrossRef]
- Ramteke, G.; Singh, R.; Chatterjee, C. Assessing impacts of conservation measures on watershed hydrology using MIKE SHE model in the face of climate change. Water Resour. Manag. 2020, 34, 4233–4252. [Google Scholar] [CrossRef]
- Mbuh, M.J.; Mbih, R.; Wendi, C. Water quality modeling and sensitivity analysis using Water Quality Analysis Simulation Program (WASP) in the Shenandoah River watershed. Phys. Geogr. 2019, 40, 127–148. [Google Scholar] [CrossRef]
- Kouadri, S.; Kateb, S.; Zegait, R. Spatial and temporal model for WQI prediction based on back-propagation neural network, application on EL MERK region (Algerian southeast). J. Saudi Soc. Agric. Sci. 2021, 20, 324–336. [Google Scholar] [CrossRef]
- Wang, X.; Wang, K.; Ding, J.; Chen, X.; Li, Y.; Zhang, W.J. Predicting water quality during urbanization based on a causality-based input variable selection method modified back-propagation neural network. Environ. Sci. Pollut. Res. 2021, 28, 960–973. [Google Scholar] [CrossRef]
- Liang, N.; Zou, Z.; Wei, Y. Regression models (SVR, EMD and FastICA) in forecasting water quality of the Haihe River of China. Desalination Water Treat. 2019, 154, 147–159. [Google Scholar] [CrossRef]
- Su, X.; He, X.; Zhang, G.; Chen, Y.; Li, K. Research on SVR Water Quality Prediction Model Based on Improved Sparrow Search Algorithm. Comput. Intell. Neurosci. 2022, 2022, 7327072. [Google Scholar] [CrossRef]
- Wang, Y.; Yuan, Y.; Pan, Y.; Fan, Z. Modeling daily and monthly water quality indicators in a canal using a hybrid wavelet-based support vector regression structure. Water 2020, 12, 1476. [Google Scholar] [CrossRef]
- Hassanjabbar, A.; Nezaratian, H.; Wu, P. Climate change impacts on the flow regime and water quality indicators using an artificial neural network (ANN): A case study in Saskatchewan, Canada. J. Water Clim. Chang. 2022, 13, 3046–3060. [Google Scholar] [CrossRef]
- Prasad, D.V.V.; Venkataramana, L.Y.; Kumar, P.S.; Prasannamedha, G.; Harshana, S.; Srividya, S.J.; Harrinei, K.; Indraganti, S. Analysis and prediction of water quality using deep learning and auto deep learning techniques. Sci. Total Environ. 2022, 821, 153311. [Google Scholar] [CrossRef]
- Wan, H.; Xu, R.; Zhang, M.; Cai, Y.; Li, J.; Shen, X. A novel model for water quality prediction caused by non-point sources pollution based on deep learning and feature extraction methods. J. Hydrol. 2022, 612, 128081. [Google Scholar] [CrossRef]
- Li, L.; Jiang, P.; Xu, H.; Lin, G.; Guo, D.; Wu, H. Water quality prediction based on recurrent neural network and improved evidence theory: A case study of Qiantang River, China. Environ. Sci. Pollut. Res. 2019, 26, 19879–19896. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Q.; Song, L.; Chen, Y. Attention-based recurrent neural networks for accurate short-term and long-term dissolved oxygen prediction. Comput. Electron. Agric. 2019, 165, 104964. [Google Scholar] [CrossRef]
- Liang, Z.; Zou, R.; Chen, X.; Ren, T.; Su, H.; Liu, Y. Simulate the forecast capacity of a complicated water quality model using the long short-term memory approach. J. Hydrol. 2020, 581, 124432. [Google Scholar] [CrossRef]
- Barzegar, R.; Aalami, M.T.; Adamowski, J. Short-term water quality variable prediction using a hybrid CNN–LSTM deep learning model. Stoch. Environ. Res. Risk Assess. 2020, 34, 415–433. [Google Scholar] [CrossRef]
- Wan, H.; Tan, Q.; Li, R.; Cai, Y.; Shen, X.; Yang, Z.; Shen, X. Incorporating Fish Tolerance to Supersaturated Total Dissolved Gas for Generating Flood Pulse Discharge Patterns Based on a Simulation-Optimization Approach. Water Resour. Res. 2021, 57, e2021WR030167. [Google Scholar] [CrossRef]
- Xu, R.; Deng, X.; Wan, H.; Cai, Y.; Pan, X. A deep learning method to repair atmospheric environmental quality data based on Gaussian diffusion. J. Clean. Prod. 2021, 308, 127446. [Google Scholar] [CrossRef]
- Xie, H.; Zhao, X.; Wang, S. A comprehensive look at the predictive information in Japanese candlestick. Procedia Comput. Sci. 2012, 9, 1219–1227. [Google Scholar] [CrossRef] [Green Version]
- Cagliero, L.; Fior, J.; Garza, P. Shortlisting machine learning-based stock trading recommendations using candlestick pattern recognition. Expert Syst. Appl. 2023, 216, 119493. [Google Scholar] [CrossRef]
- Lan, Q.; Zhang, D.; Xiong, L. Reversal pattern discovery in financial time series based on fuzzy candlestick lines. Syst. Eng. Procedia 2011, 2, 182–190. [Google Scholar] [CrossRef] [Green Version]
- Tsai, C.-F.; Quan, Z.-Y. Stock prediction by searching for similarities in candlestick charts. ACM Trans. Manag. Inf. Syst. 2014, 5, 1–21. [Google Scholar] [CrossRef]
- Lee, K.; Jo, G. Expert system for predicting stock market timing using a candlestick chart. Expert Syst. Appl. 1999, 16, 357–364. [Google Scholar] [CrossRef]
- Chen, S.; Bao, S.; Zhou, Y. The predictive power of Japanese candlestick charting in Chinese stock market. Phys. A Stat. Mech. Its Appl. 2016, 457, 148–165. [Google Scholar] [CrossRef]
- Hung, C.-C.; Chen, Y.-J. DPP: Deep predictor for price movement from candlestick charts. PLoS ONE 2021, 16, e0252404. [Google Scholar] [CrossRef]
- Xu, R.; Liu, X.; Wan, H.; Pan, X.; Li, J. A Feature Extraction and Classification Method to Forecast the PM2. 5 Variation Trend Using Candlestick and Visual Geometry Group Model. Atmosphere 2021, 12, 570. [Google Scholar] [CrossRef]
- Liang, M.; Wu, S.; Wang, X.; Chen, Q. A stock time series forecasting approach incorporating candlestick patterns and sequence similarity. Expert Syst. Appl. 2022, 205, 117595. [Google Scholar] [CrossRef]
- Nison, S. Japanese Candlestick Charting Techniques; New York Institute of Finance: New York, NY, USA, 1991. [Google Scholar]
- Hu, W.; Si, Y.-W.; Fong, S.; Lau, R.Y.K. A formal approach to candlestick pattern classification in financial time series. Appl. Soft Comput. 2019, 84, 105700. [Google Scholar] [CrossRef]
- Farahbod, F. Mathematical investigation of diffusion and decomposition of pollutants as a basic issue in water stream pollution. Arab. J. Geosci. 2020, 13, 918. [Google Scholar] [CrossRef]
- Zhuang, W.; Pang, Y.; Lv, J. Research on the Integration of Two-dimensional Water Quality Model and Geographic Information System. In Proceedings of the 2007 Major Water Conservancy and Hydropower Science and Technology Frontier Academician Forum and the First China Water Conservancy Doctoral Forum Proceedings, Nanjing, China, 11 November 2007; pp. 557–563. [Google Scholar]
- Wang, H.; Yan, W.; Wang, J.; Duan, W. Exploring Distribution Rules and Variation Trends of Precipitation in the Upper Lijiang River from 1951 to 2016, Guangxi Province, China. J. Coast. Res. 2020, 105, 1–5. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Xiong, Q.; Wu, C.; Zou, Q.; Yu, Y.; Yi, H.; Gao, M. A study on water quality prediction by a hybrid CNN-LSTM model with attention mechanism. Environ. Sci. Pollut. Res. 2021, 28, 55129–55139. [Google Scholar] [CrossRef]
- Lin, T.-Y.; RoyChowdhury, A.; Maji, S. Bilinear convolutional neural networks for fine-grained visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1309–1322. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Liao, W.; Chang, Y. Gated recurrent unit network-based short-term photovoltaic forecasting. Energies 2018, 11, 2163. [Google Scholar] [CrossRef] [Green Version]
- Bui, D.T.; Khosravi, K.; Tiefenbacher, J.; Nguyen, H.; Kazakis, N. Improving prediction of water quality indices using novel hybrid machine-learning algorithms. Sci. Total Environ. 2020, 721, 137612. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Candlestick chart |  |  |  |  |  |  |  |  |
| Species | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| Candlestick chart |  |  |  |  |  |  |  |  |
| Species | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| Candlestick chart |  |  |  |  |  |  |  |  |
| Species | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Candlestick chart |  |  |  |  |  |  |  |  |  |
| C0 increase | Y | Y | Y | Y | Y | N | N | N | N |
| C0 decrease | N | N | N | N | N | Y | Y | Y | Y |
| u increase | Y | Y | Y | Y | N | N | N | N | N |
| u decrease | N | N | N | N | Y | Y | Y | Y | Y |
| K increase | N | N | N | N | N | Y | Y | Y | Y |
| K decrease | Y | Y | Y | Y | Y | N | N | N | N |
| Data Category | Parameter | Unit |
|---|---|---|
| Water quality | NH3-N | mg/L |
| TP | mg/L | |
| TN | mg/L | |
| CODMn | mg/L | |
| DO | mg/L | |
| Hydrometeorology | EC | μs/cm |
| PH | Dimensionless | |
| TB | NTC | |
| Q | m3/s | |
| WT | °C | |
| PCP | Mm |
| Parameter | Set of Feasible Values | Optimal Value | MAE | RMSE |
|---|---|---|---|---|
| Neuron number | {16, 32, 64, 128, 256} | 16 | 0.724 | 1.124 |
| 32 | 0.512 | 0.874 | ||
| 64 | 0.347 | 0.547 | ||
| 128 | 0.478 | 0.812 | ||
| 256 | 0.724 | 1.451 | ||
| Time step | {1, 2, 3, 4, 5} | 1 | 0.674 | 0.912 |
| 2 | 0.475 | 0.624 | ||
| 3 | 0.241 | 0.425 | ||
| 4 | 0.382 | 0.824 | ||
| 5 | 0.531 | 1.025 |
| Indicator | Method | MAE | RMSE | SMAPE (%) |
|---|---|---|---|---|
| DO | BPNN | 1.121 | 1.195 | 0.093 |
| SVR | 0.810 | 0.902 | 0.066 | |
| GRU | 0.464 | 0.520 | 0.037 | |
| VGG-GRU | 0.324 | 0.375 | 0.029 | |
| CT-VGG-GRU | 0.284 | 0.315 | 0.022 | |
| CODMn | BPNN | 0.494 | 0.511 | 0.586 |
| SVR | 0.347 | 0.364 | 0.380 | |
| GRU | 0.203 | 0.219 | 0.209 | |
| VGG-GRU | 0.141 | 0.157 | 0.137 | |
| CT-VGG-GRU | 0.113 | 0.122 | 0.108 | |
| NH3-N | BPNN | 0.057 | 0.061 | 0.606 |
| SVR | 0.041 | 0.046 | 0.417 | |
| GRU | 0.027 | 0.029 | 0.241 | |
| VGG-GRU | 0.018 | 0.021 | 0.178 | |
| CT-VGG-GRU | 0.014 | 0.016 | 0.127 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, R.; Wu, W.; Cai, Y.; Wan, H.; Li, J.; Zhu, Q.; Shen, S. Feature Extraction and Prediction of Water Quality Based on Candlestick Theory and Deep Learning Methods. Water 2023, 15, 845. https://doi.org/10.3390/w15050845
Xu R, Wu W, Cai Y, Wan H, Li J, Zhu Q, Shen S. Feature Extraction and Prediction of Water Quality Based on Candlestick Theory and Deep Learning Methods. Water. 2023; 15(5):845. https://doi.org/10.3390/w15050845
Chicago/Turabian StyleXu, Rui, Wenjie Wu, Yanpeng Cai, Hang Wan, Jian Li, Qin Zhu, and Shiming Shen. 2023. "Feature Extraction and Prediction of Water Quality Based on Candlestick Theory and Deep Learning Methods" Water 15, no. 5: 845. https://doi.org/10.3390/w15050845
APA StyleXu, R., Wu, W., Cai, Y., Wan, H., Li, J., Zhu, Q., & Shen, S. (2023). Feature Extraction and Prediction of Water Quality Based on Candlestick Theory and Deep Learning Methods. Water, 15(5), 845. https://doi.org/10.3390/w15050845