

Comparison of an Explicit and Implicit Time Integration Method on GPUs for Shallow Water Flows on Structured Grids


Abstract
:1. Introduction
2. Shallow Water Equations
3. Implicit versus Explicit Time-Integration Methods for the Shallow Water Equations
4. Implementation of Numerical Methods for the Shallow Water Equations on GPUs
4.1. Time-Splitting Methods
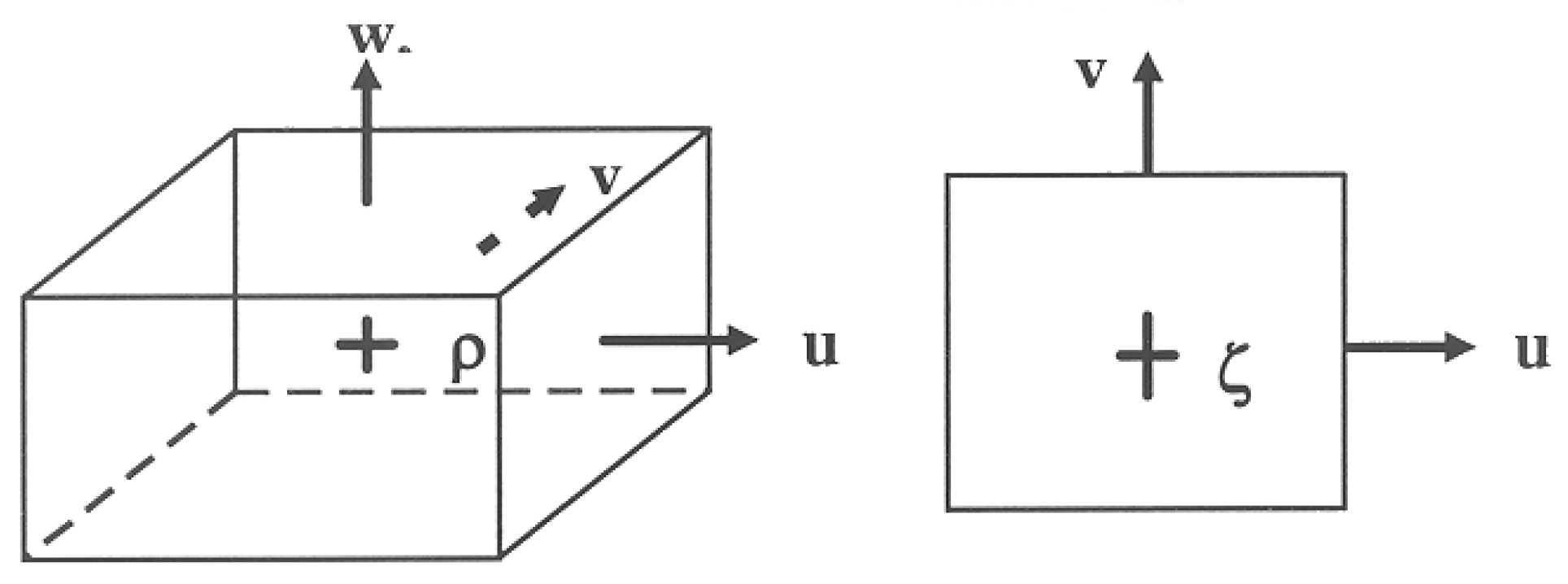
4.2. Discretization and Grid Staggering
4.3. Discretization of the Advection Terms
4.4. Drying and Flooding
4.5. Non-Uniform Grids
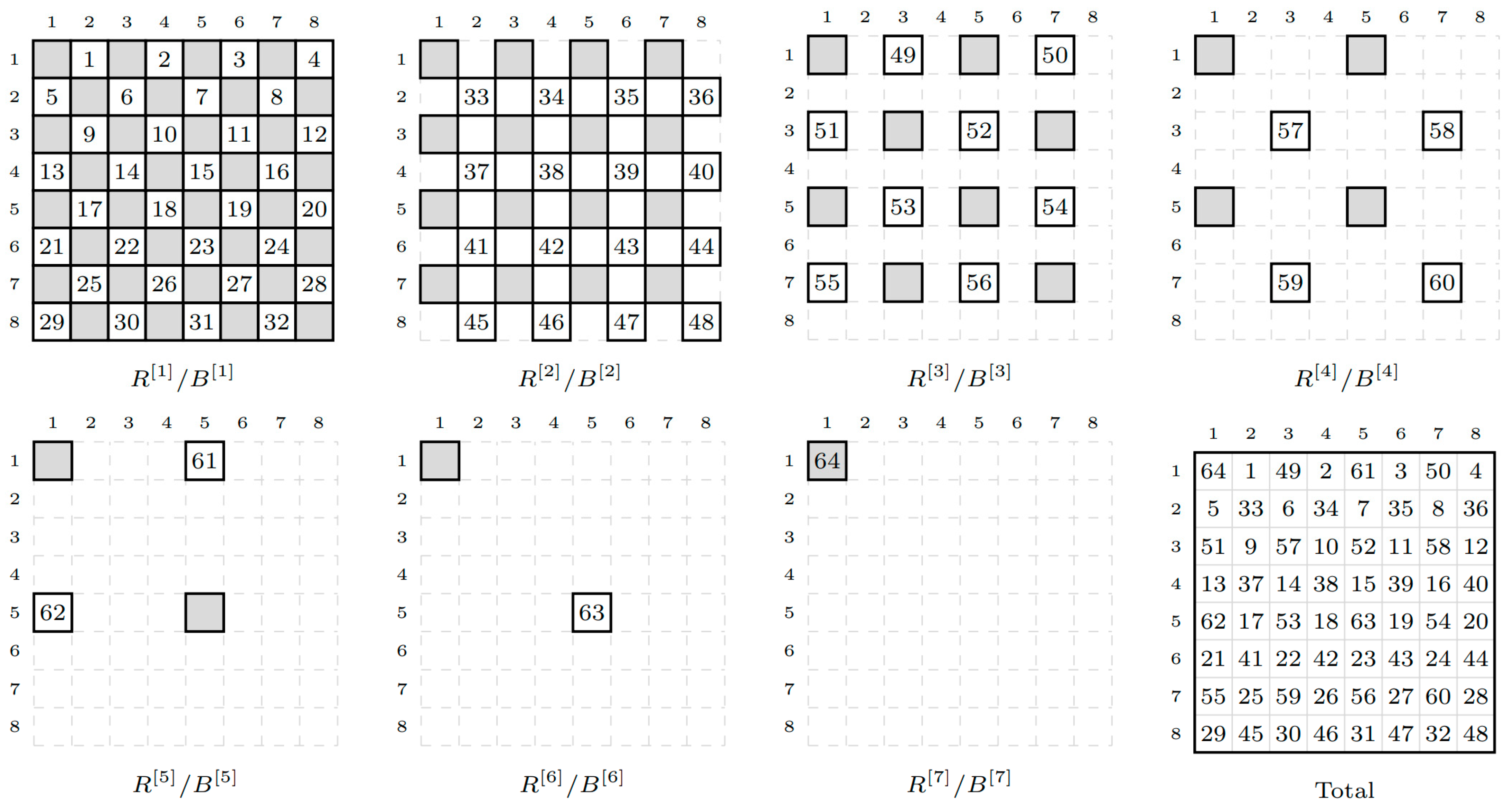
4.6. Solving the Pentadiagonal System
5. GPU Computing
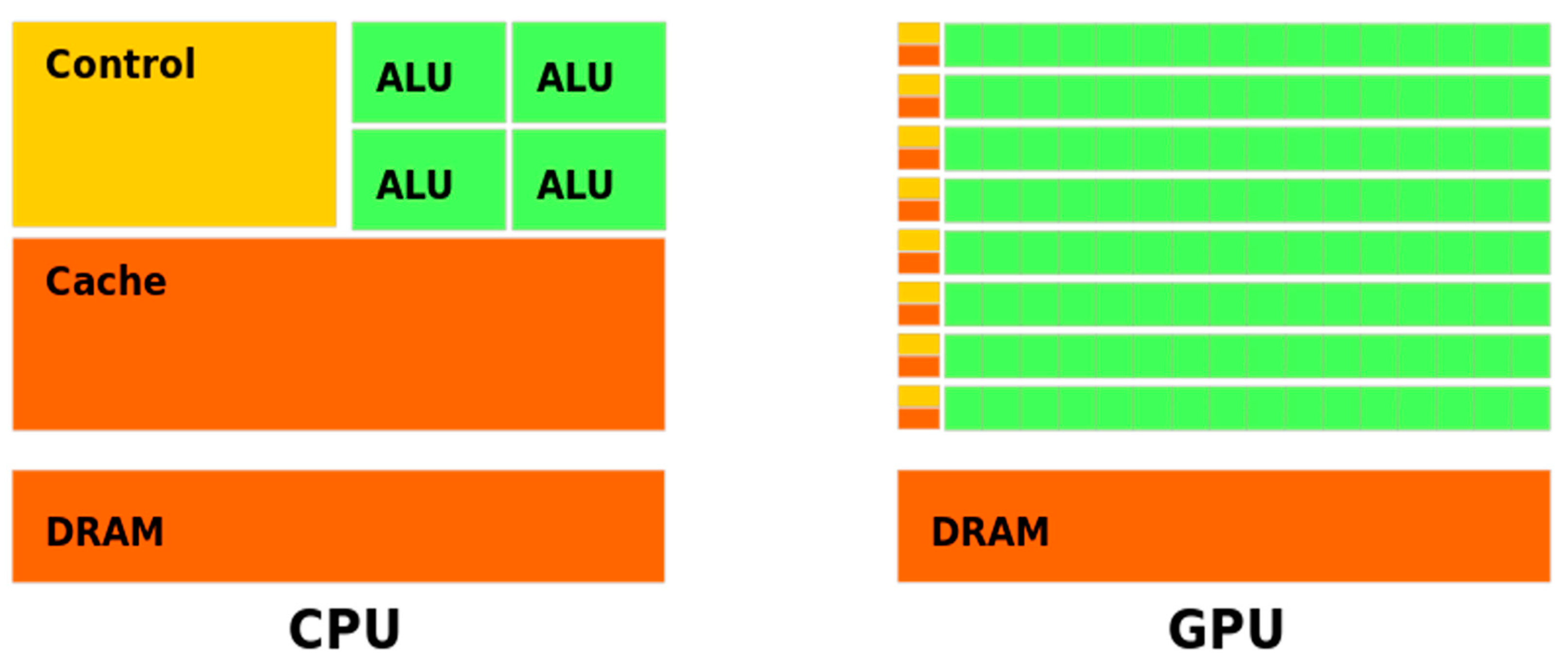
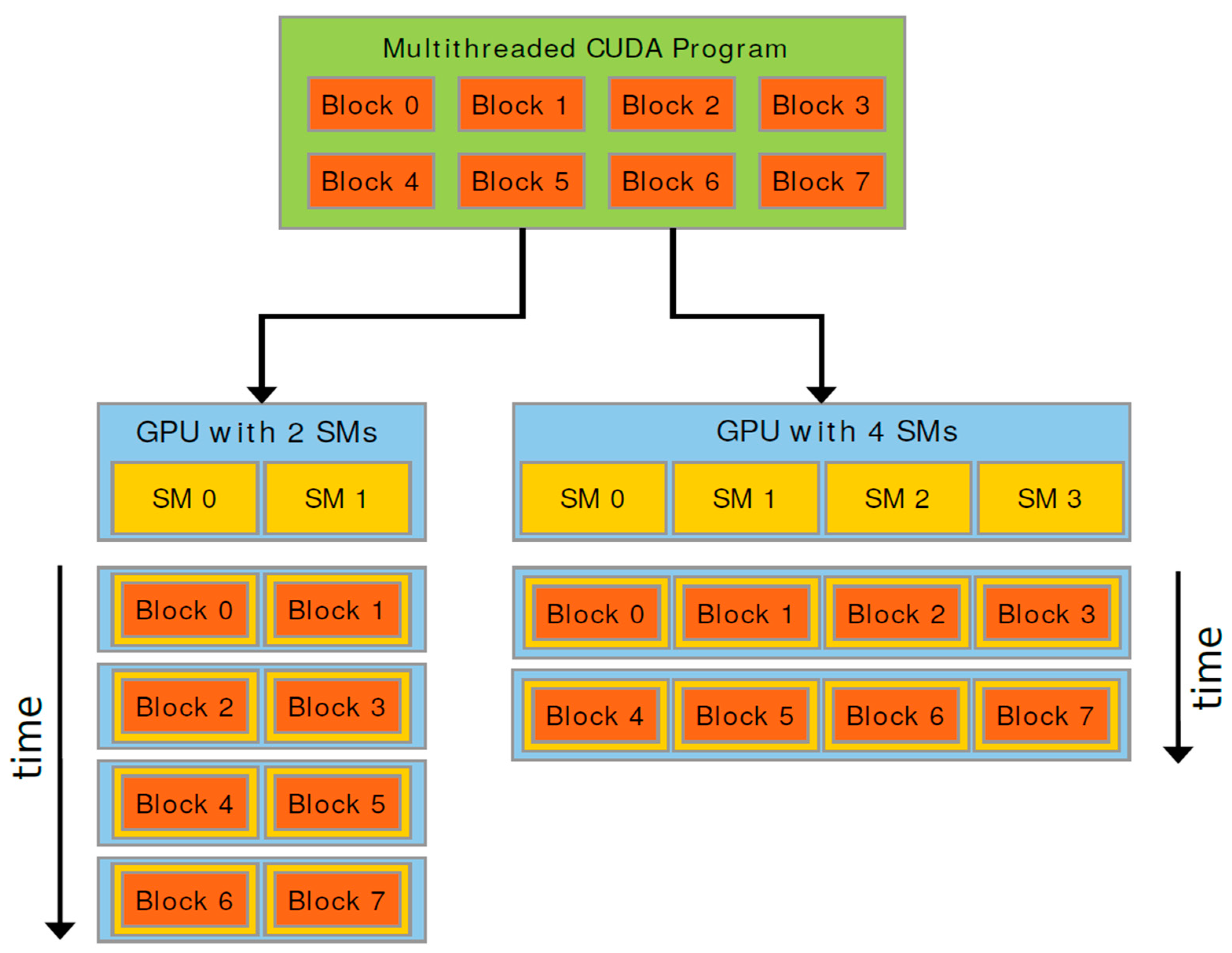
5.1. GPU Architecture
5.2. Code Implementation
6. Model Results
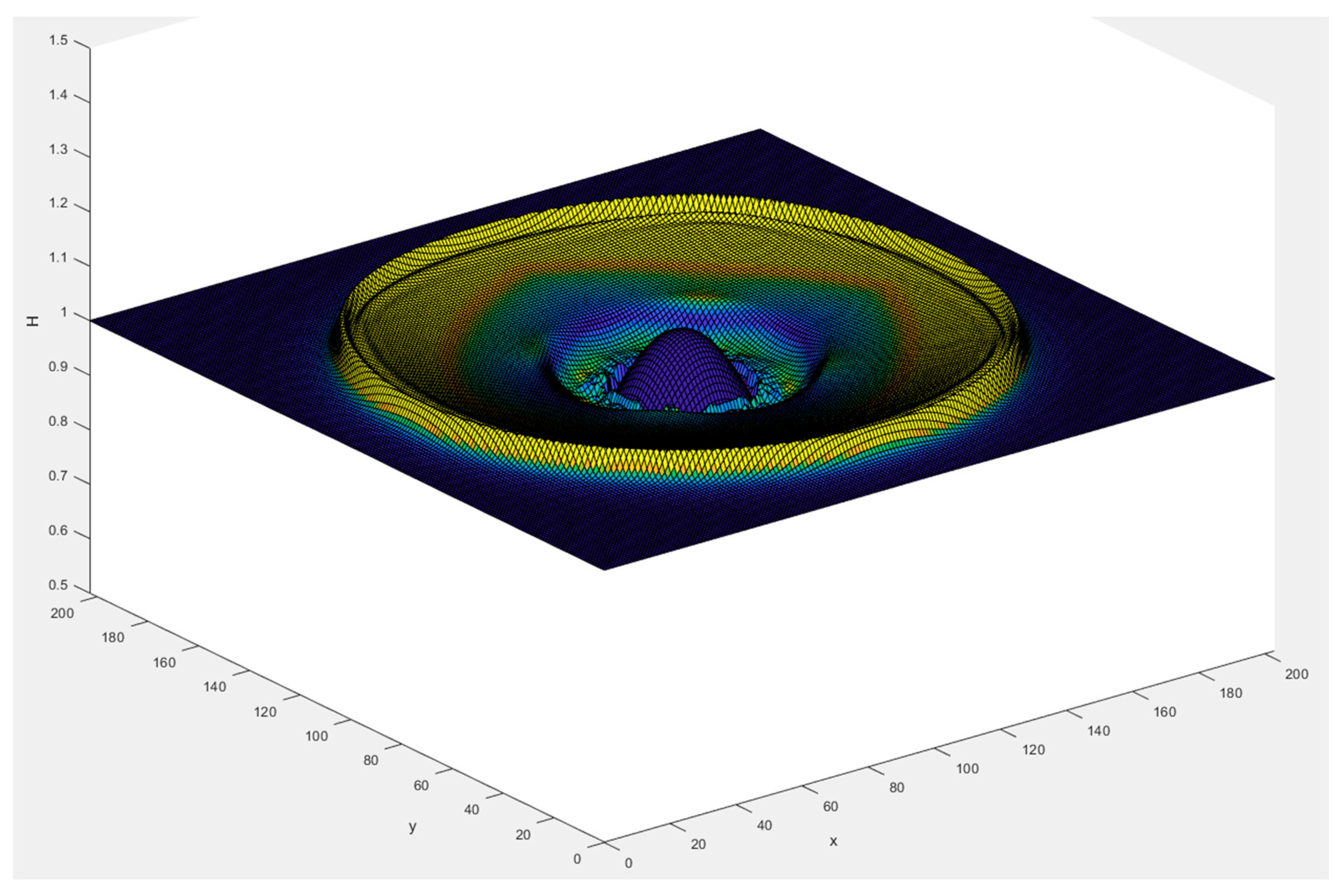
6.1. Test Case 1: Simulation of a Water Droplet
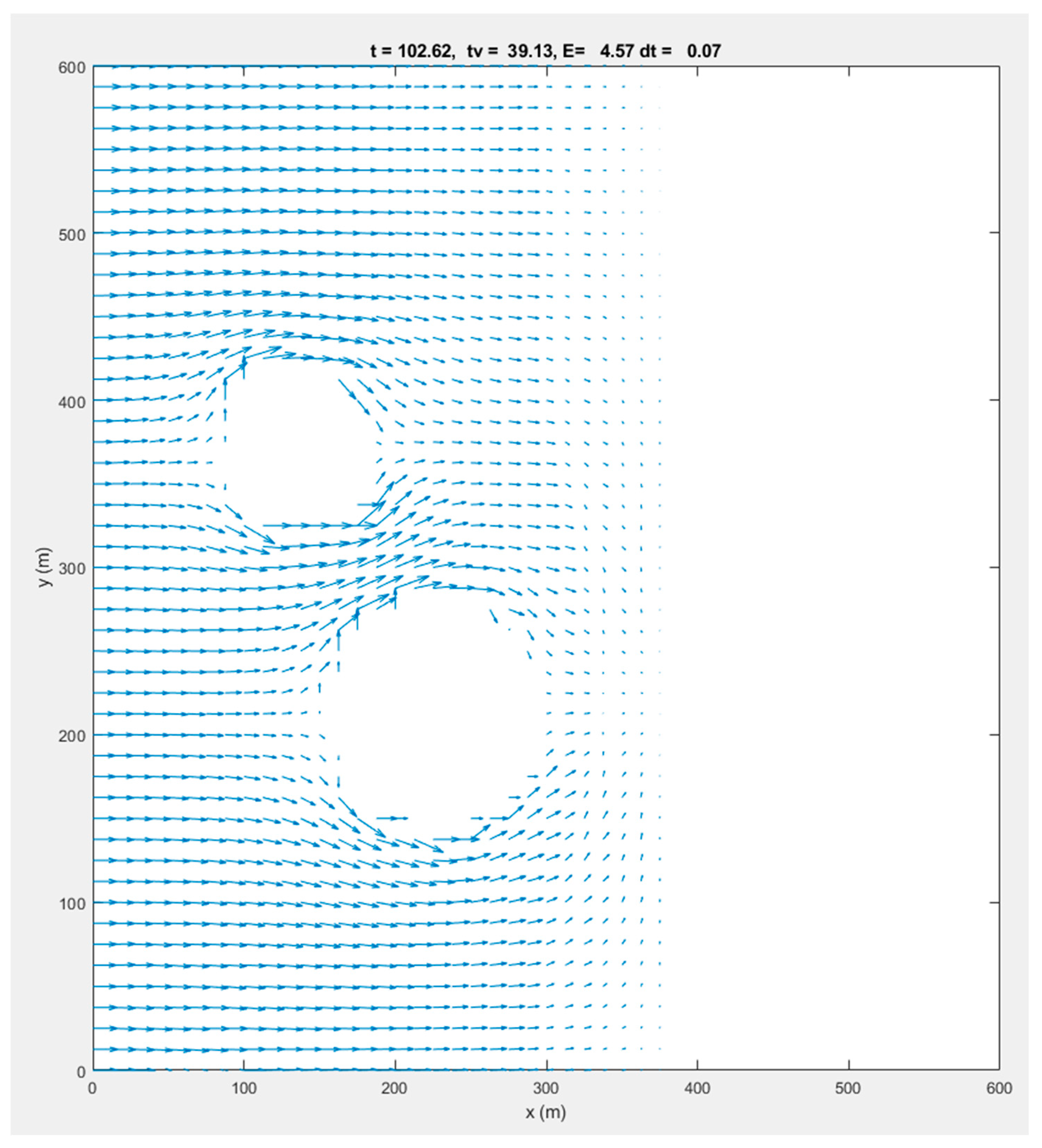
6.2. Test Case 2: Schematized Salt Marsh
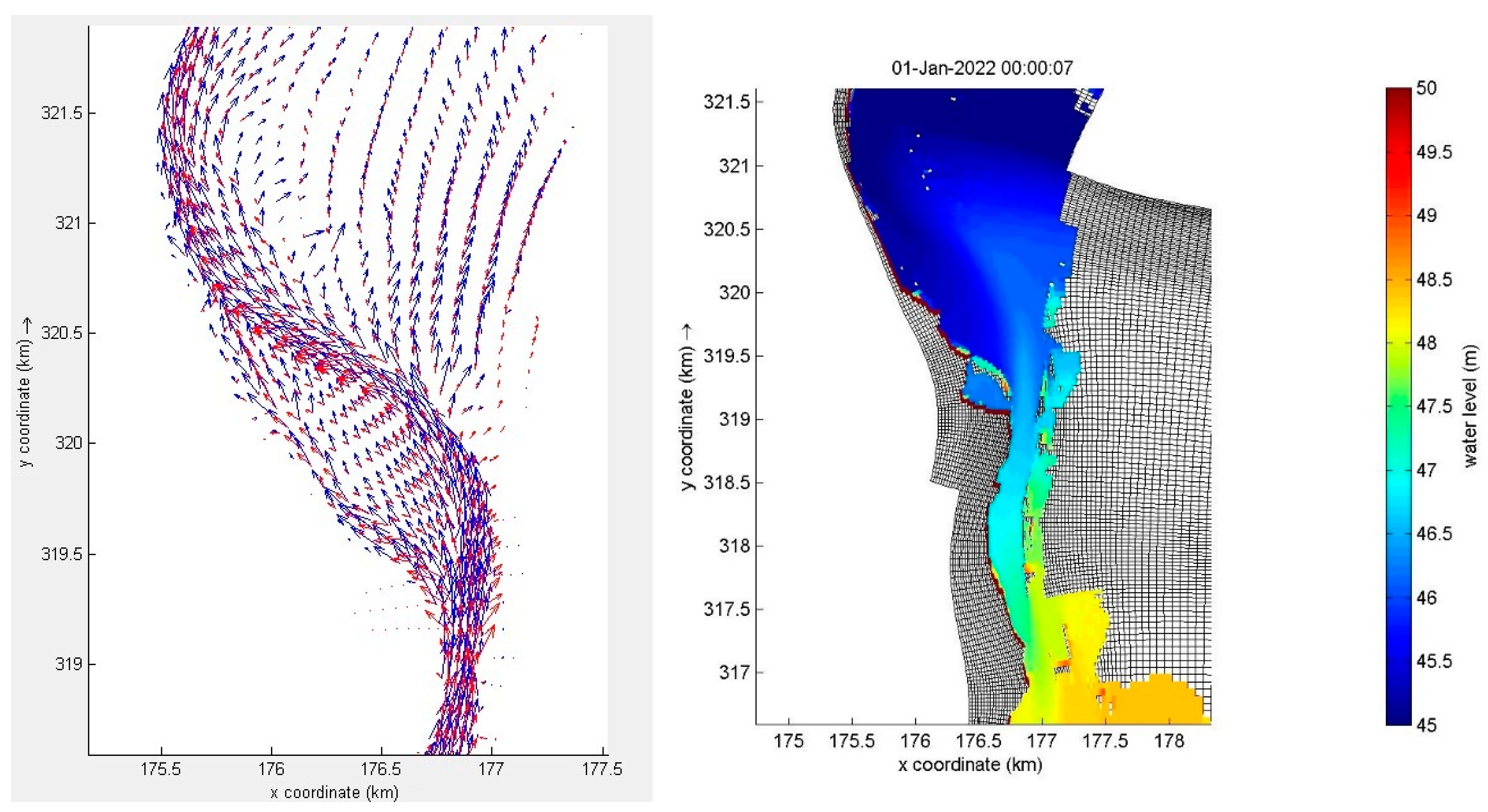
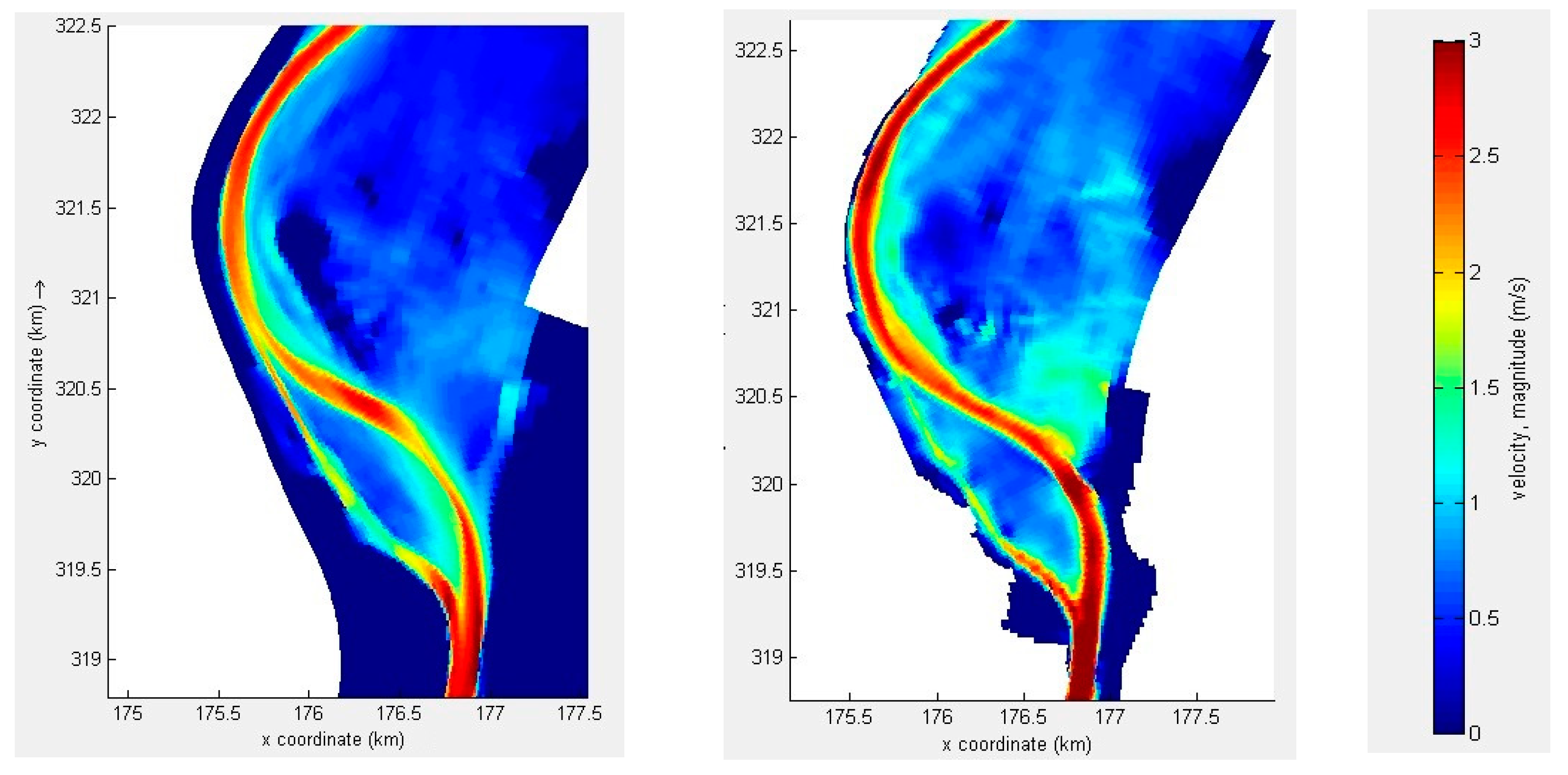
6.3. Test Case 3: River Meuse
6.3.1. Model Description
6.3.2. Model Results
7. Discussion on GPU versus CPU Computing
7.1. Ratio of GPU versus CPU Timings for Other SWE Codes
7.2. Advantages of GPU Computing over CPU Computing
- Fewer numerical approximations: For example, for groynes in Dutch river models, a complex empirical approach is applied in current SWE models [38]. This yields accurate water levels, but currents around groynes are inaccurate. It should be noted that this empirical approach is not meant for simulating accurate currents. With GPU computing, a grid resolution of a few metres becomes possible so that groynes can now be schematized in the bathymetry. Then, this empirical approach is no longer required. In this way, not only water levels but also currents can be computed accurately. The latter is also relevant for morphodynamic scenarios, in which the time evolution of the bathymetry is simulated.
- Easier preprocessing of models: The set-up of operational SWE models in the Netherlands is being done automatically. The coarser the resolution, the more complex the approach. For example:
- Vegetation: For each computation cell, the bed roughness is generated. For example, a grid cell might consist of 30% buildings, 20% hedges and 50% grass, each of which has a different roughness. Via a complex algorithm, this is converted into a roughness coefficient per grid cell. On a high-resolution GPU model, each grid cell will have only one vegetation type.
- Height model: When using 25 m-resolution small levees, heightened roads and traffic bumps may be removed from the height model due to averaging the height values. To fix this, a user can sometimes increase the height artificially, but this requires additional work and can result in mistakes. A high-resolution GPU model does not have this problem because geographical objects, such as roads, speed bumps and levees, show up in the high-resolution grid of approximately 1 m.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Krüger, J.; Westermann, R. Linear algebra operators for GPU implementation of numerical algorithms. ACM Trans. Graph. 2003, 22, 908–916. [Google Scholar] [CrossRef]
- Du, P.; Weber, R.; Luszczek, P.; Tomov, S.; Peterson, G.; Dongarra, J. From CUDA to OpenCL: Towards a performance-portable solution for multi-platform GPU programming. Parallel Comput. 2012, 38, 391–407. [Google Scholar] [CrossRef] [Green Version]
- Klingbeil, K.; Lemarié, F.; Debreu, L.; Burchard, H. The numerics of hydrostatic structured-grid coastal ocean models: State of the art and future perspectives. Ocean. Model. 2018, 125, 80–105. [Google Scholar] [CrossRef] [Green Version]
- Vreugdenhil, C.B. Numerical methods for shallow-water flow. In Water Science and Technology Library; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1994; ISBN 0-7923-3164-8. [Google Scholar]
- Aureli, F.; Prost, F.; Vacondio, R.; Dazzi, S.; Ferrari, A. A GPU-accelerated shallow-water scheme for surface runoff simulations. Water 2020, 12, 637. [Google Scholar] [CrossRef] [Green Version]
- Brodtkorb, A.; Hagen, T.R.; Roed, L.P. One-Layer Shallow Water Models on the GPU. Norwegian Meteorological Institute Report No. 27/2013. 2013. Available online: https://www.met.no/publikasjoner/met-report/met-report-2013/_/attachment/download/1c8711b6-b6c2-45f6-985d-c48f57b1d921:337ce17f6db07903d6f35919717c1d80c8756cc9/MET-report-27-2013.pdf (accessed on 14 March 2023).
- Dazzi, S.; Vacondio, R.; Dal Palu, A.; Mignosa, P. A local time stepping algorithm for GPU-accelerated 2D shallow water models. Adv. Water Resour. 2018, 111, 274–288. [Google Scholar] [CrossRef]
- Fernández-Pato, J.; García-Navarro, P. An Efficient GPU Implementation of a Coupled Overland-Sewer Hydraulic Model with Pollutant Transport. Hydrology 2021, 8, 146. [Google Scholar] [CrossRef]
- García-Feal, O.; González-Cao, J.; Gómez-Gesteira, M.; Cea, L.; Domínguez, J.M.; Formella, A. An Accelerated Tool for Flood Modelling Based on Iber. Water 2018, 10, 1459. [Google Scholar] [CrossRef] [Green Version]
- Guerrero Fernandez, E.; Castro-Diaz, M.J.; Morales de Luna, T. A Second-Order Well-Balanced Finite Volume Scheme for the Multilayer Shallow Water Model with Variable Density. Mathematics 2020, 8, 848. [Google Scholar] [CrossRef]
- Parma, P.; Meyer, K.; Falconer, R. GPU driven finite difference WENO scheme for real time solution of the shallow water equations. Comput. Fluids 2018, 161, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Smith, L.S.; Liang, Q. Towards a generalised GPU/CPU shallow-flow modelling tool. Comput. Fluids 2013, 88, 334–343. [Google Scholar] [CrossRef]
- Xu, S.; Huang, S.; Oey, L.-Y.; Xu, F.; Fu, H.; Zhang, Y.; Yang, G. POM.gpu-v1.0: A GPU-based Princeton Ocean Model. Geosci. Model Dev. 2015, 8, 2815–2827. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.D.; Liang, S.-X.; Sun, Z.-C.; Liu, Z. A GPU accelerated finite volume coastal ocean model. Sci. Direct 2017, 29, 679–690. [Google Scholar] [CrossRef]
- Aackermann, P.E.; Dinesen Pedersen, P.J. Development of a GPU-Accelerated MIKE 21 Solver for the Water Wave Dynamics; Technical University of Denmark: Lyngby, Denmark, 2012. [Google Scholar]
- Zhang, Y.; Jia, Y. Parallelized CCHE2D flow model with CUDA Fortran on Graphics Processing Units. Comput. Fluids 2013, 84, 359–368. [Google Scholar] [CrossRef]
- Esfahanian, V.; Baghapour, B.; Torabzadeh, M.; Chizari, H. An efficient GPU implementation of cyclic reduction solver for high-order compressible viscous flow simulations. Comput. Fluids 2014, 92, 160–171. [Google Scholar] [CrossRef]
- De Jong, M.; Van der Ploeg, A.; Ditzel, A.; Vuik, C. Fine-grain parallel rrb-solver for 5-/9-point stencil problems suitable for GPU-type processors. Electron. Trans. Numer. Anal. 2017, 46, 375–393. [Google Scholar]
- Aissa, M.; Verstraete, T.; Vuik, C. Toward a GPU-aware comparison of explicit and implicit CFD simulations on structured meshes. Comput. Math. Appl. 2017, 74, 201–217. [Google Scholar] [CrossRef]
- Ha, S.; Park, J.; You, D. A GPU-accelerated semi-implicit fractional-step method for numerical solutions of incompressible Navier–Stokes equations. J. Comput. Phys. 2018, 352, 246–264. [Google Scholar] [CrossRef]
- Zolfaghari, H.; Obrist, D. A high-throughput hybrid task and data parallel Poisson solver for large-scale simulations of incompressible turbulent flows on distributed GPUs. J. Comput. Phys. 2021, 437, 110329. [Google Scholar] [CrossRef]
- Morales-Hernandez, M.; Kao, S.-C.; Gangrade, S.; Madadi-Kandjani, E. High-performance computing in water resources hydrodynamics. J. Hydroinf. 2020, 22, 1217–1235. [Google Scholar] [CrossRef] [Green Version]
- Hansen, W. Theorie zur Errechnung des wasserstandes und der Strömingen in Randmeeeren nebst Anwendungen. Tellus 1956, 8, 289–300. [Google Scholar] [CrossRef] [Green Version]
- Heaps, N.S. A two-dimensional numerical sea model. Phil. Trans. Roy. Soc. 1969, 265, 93–137. [Google Scholar]
- Sielecki, A. Mathematical Weather Rev; U.S. Department of Agriculture: Washington, DC, USA, 1968; Volume 96, pp. 150–156.
- Backhaus, J.O. A semi-implicit scheme for the shallow water equations for application to shelf sea modelling. Cont. Shelf Res. 1983, 2, 243–255. [Google Scholar] [CrossRef]
- Casulli, V.; Cheng, R.T. Semi-implicit finite difference methods for three-dimensional shallow water flow. Int. J. Numer. Methods Fluids 1992, 15, 629–648. [Google Scholar] [CrossRef]
- De Goede, E.D. A time splitting method for the three-dimensional shallow water equations. Int. J. Numer. Meth. Fluids 1991, 13, 519–534. [Google Scholar] [CrossRef]
- Wilders, P.; Van Stijn, T.L.; Stelling, G.S.; Fokkema, G.A. A fully implicit splitting method for accurate tidal computations. Int. J. Num. Methods Eng. 1988, 26, 2707–2721. [Google Scholar] [CrossRef]
- Stelling, G.S. On the Construction of Computational Methods for Shallow Water Problems. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 1983. [Google Scholar]
- Jones, J.E. Coastal and shelf-sea modelling in the European context. Oceanogr. Mar. Biol. Annu Rev. 2002, 40, 37–141. [Google Scholar]
- Gerritsen, H.; De Goede, E.D.; Platzek, F.W.; Genseberger, M.; Van Kester, J.A.T.H.M.; Uittenbogaard, R.E. Validation Document Delft3D-FLOW, WL|Delft Hydraulics Report X0356/M3470. 2008. Available online: https://www.researchgate.net/publication/301363924_Validation_Document_Delft3D-FLOW_a_software_system_for_3D_flow_simulations (accessed on 12 March 2023).
- Kernkamp, H.W.J.; Petit, H.A.H.; Gerritsen, H.; De Goede, E.D. A unified formulation for the three-dimensional shallow water equations using orthogonal co-ordinates: Theory and application. Ocean. Dyn. 2005, 55, 351–369. [Google Scholar] [CrossRef]
- Buwalda, F. Suitability of Shallow Water Solving Methods for GPU Acceleration. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2020. Available online: https://repository.tudelft.nl/islandora/search/author%3A%22Buwalda%2C%20Floris%22 (accessed on 18 February 2020).
- De Jong, M.; Vuik, C. GPU Implementation of the RRB-Solver, Reports of the Delft Institute of Applied Mathematics. 2016, Volume 16-06, p. 53. Available online: https://repository.tudelft.nl/islandora/object/uuid%3A40f09247-c706-442e-94cf-a87eabfa59e9 (accessed on 12 March 2023).
- Deltares. Delft3D-FLOW Simulation of Multi-Dimensional Hydrodynamic Flows and Transport Phenomena, Including Sediments; Version 4.05 (15 March 2023); User Manual: Deltares, The Netherlands, 2023; Available online: https://content.oss.deltares.nl/delft3d4/Delft3D-FLOW_User_Manual.pdf (accessed on 12 March 2023).
- Peeters, L. Salt Marsh Modelling: Implemented on a GPU. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2018. Available online: https://repository.tudelft.nl/islandora/object/uuid%3Aab1242b2-72e9-4052-a7e8-bbe77a7a4d5a (accessed on 12 March 2023).
- Rijkswaterstaat. WAQUA/TRIWAQ-Two- and Three-Dimensional Shallow Water Flow Model, Technical Documentation; SIMONA Report Number 99-01. Version 3.16. 2016. Available online: https://iplo.nl/thema/water/applicaties-modellen/watermanagementmodellen/simona/ (accessed on 12 March 2023).
- Deltares. D-Flow Flexible Mesh, Computational Cores and User Interface; Version: 2023 (22 February 2023); User Manual: Deltares, The Netherlands, 2023; Available online: https://content.oss.deltares.nl/delft3d/D-Flow_FM_User_Manual.pdf (accessed on 12 March 2023).
- DHI. 2022. Available online: https://www.mikepoweredbydhi.com/products/mike-21/mike-21-gpu (accessed on 12 March 2023).
- Tygron. 2020. Available online: https://www.tygron.com/nl/2020/09/24/river-deltas-at-high-resolution/ (accessed on 12 March 2023).
- Kurganov, A.; Petrova, G. A Second-Order Well-Balanced Positivity Preserving Central-Upwind Scheme for the Saint-Venant System. 2007. Available online: https://www.math.tamu.edu/~gpetrova/KPSV.pdf (accessed on 12 March 2023).
- Bollerman, A. A Well-Balanced Reconstruction of Wet/Dry Fronts for the Shallow Water Equations. 2013. Available online: https://www.researchgate.net/publication/269417532_A_Well-balanced_Reconstruction_for_Wetting_Drying_Fronts (accessed on 12 March 2023).
- Tygron. 2021. Available online: https://www.tygron.com/en/2021/11/28/tygron-supercomputer-hits-new-record-10-000-000-000/ (accessed on 12 March 2023).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computation Times | |||||||
|---|---|---|---|---|---|---|---|
| GPU | CPU for Expl-H | ||||||
| N | Expl-H | Expl-S | Semi-Impl | CPU1 | CPU2 | CPU6 | CPU12 |
| 100 | 0.02 | 0.02 | 0.12 | 0.31 | 0.17 | 0.07 | 0.10 |
| 196 | 0.02 | 0.02 | 0.18 | 1.21 | 0.63 | 0.25 | 0.27 |
| 388 | 0.03 | 0.04 | 0.54 | 4.76 | 2.40 | 0.93 | 0.87 |
| 772 | 0.11 | 0.13 | 1.80 | 21.5 | 9.93 | 4.23 | 3.99 |
| 1540 | 0.38 | 0.47 | 6.96 | 76.53 | 39.39 | 19.99 | 17.12 |
| 3076 | 1.45 | 1.81 | 27.96 | 308.64 | 161.26 | 76.07 | 68.13 |
| 6148 | 5.76 | 7.24 | 1222.50 | 630.70 | 291.55 | 264.36 | |
| 12,292 | 24.6 | 30.54 | |||||
| GPU | CPU | |||
|---|---|---|---|---|
| Expl-H | Expl-S | Semi-Impl | Delft3D-FLOW | |
| N | Computation Time with Time Step (in Brackets), Both in Seconds | |||
| 96 | 4.3 (0.36) | 5.1 (0.36) | 148.5 (0.5) | 40 (30) |
| 192 | 8.9 (0.18) | 10.7 (0.18) | 293.4 (0.26) | - |
| 384 | 30.2 (0.09) | 36.7 (0.09) | 734.2 (0.14) | - |
| 1056 | 503 (0.03) | 659 (0.03) | 6510.6 (0.05) | 57,600 (3) |
| GPU | CPU | |||||
|---|---|---|---|---|---|---|
| Expl-H | Expl-S | Semi-Impl | WAQUA | Delft3D-FLOW | D-Flow Flexible Mesh | |
| Time Step (in Seconds) | ||||||
| 0.20 | 0.20 | 1.9 | 7.5 | 7.5 | 2.3 | |
| # Cores | Computation Time (in Seconds) | |||||
| 1 | 132 | 164 | 332 | 3380 | 7860 | 10,525 |
| 4 (1 node) | n.a. | n.a. | n.a. | 1475 | 4758 | 4710 |
| 16 (4 nodes) | n.a. | n.a. | n.a. | 400 | 1045 | 1215 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buwalda, F.J.L.; De Goede, E.; Knepflé, M.; Vuik, C. Comparison of an Explicit and Implicit Time Integration Method on GPUs for Shallow Water Flows on Structured Grids. Water 2023, 15, 1165. https://doi.org/10.3390/w15061165
Buwalda FJL, De Goede E, Knepflé M, Vuik C. Comparison of an Explicit and Implicit Time Integration Method on GPUs for Shallow Water Flows on Structured Grids. Water. 2023; 15(6):1165. https://doi.org/10.3390/w15061165
Chicago/Turabian StyleBuwalda, Floris J. L., Erik De Goede, Maxim Knepflé, and Cornelis Vuik. 2023. "Comparison of an Explicit and Implicit Time Integration Method on GPUs for Shallow Water Flows on Structured Grids" Water 15, no. 6: 1165. https://doi.org/10.3390/w15061165
APA StyleBuwalda, F. J. L., De Goede, E., Knepflé, M., & Vuik, C. (2023). Comparison of an Explicit and Implicit Time Integration Method on GPUs for Shallow Water Flows on Structured Grids. Water, 15(6), 1165. https://doi.org/10.3390/w15061165