


Assessing and Improving the Robustness of Bayesian Evidential Learning in One Dimension for Inverting Time-Domain Electromagnetic Data: Introducing a New Threshold Procedure
 , , , ,
, , , ,  and
and 
Abstract
:1. Introduction
- Demonstrating that BEL1D is an efficient approach for the stochastic inversion of TDEM data.
- Exploring the impact of the accuracy of the forward solver to estimate the posterior distribution, and finding a compromise between accuracy and computational cost.
- Proposing and validating a new thresholding approach to circumvent the need for iterations when the prior uncertainty is large.
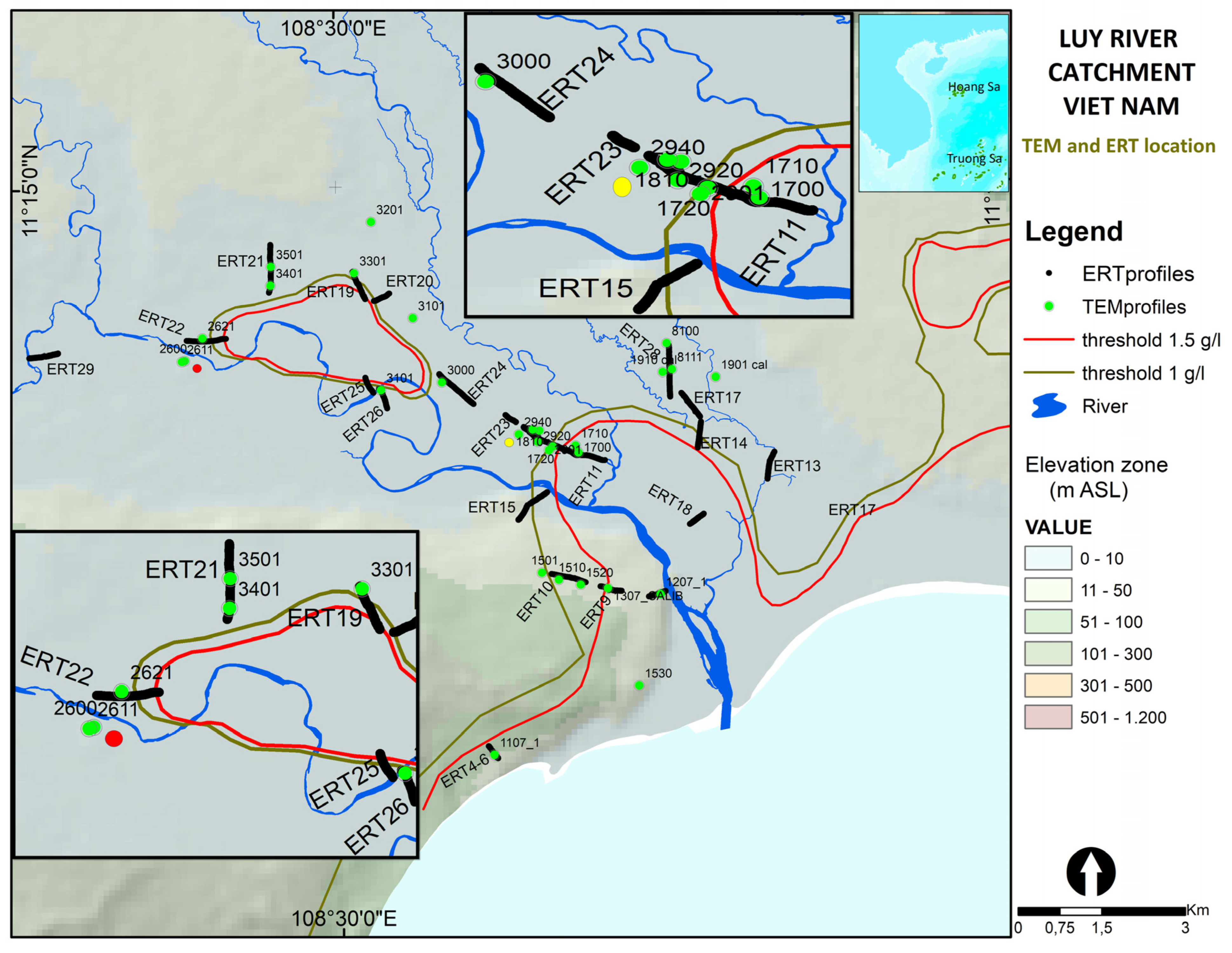
- Applying the new approach to field TDEM data collected in the Luy River catchment in the Binh Thuan province (Vietnam) for saltwater intrusion characterization. This data set was selected because electrical resistivity tomography (ERT) data are available for comparison, but lack sensitivity at greater depth. The case study is also used to illustrate the impact of the selection of the prior on the posterior estimation.
2. Materials and Methods
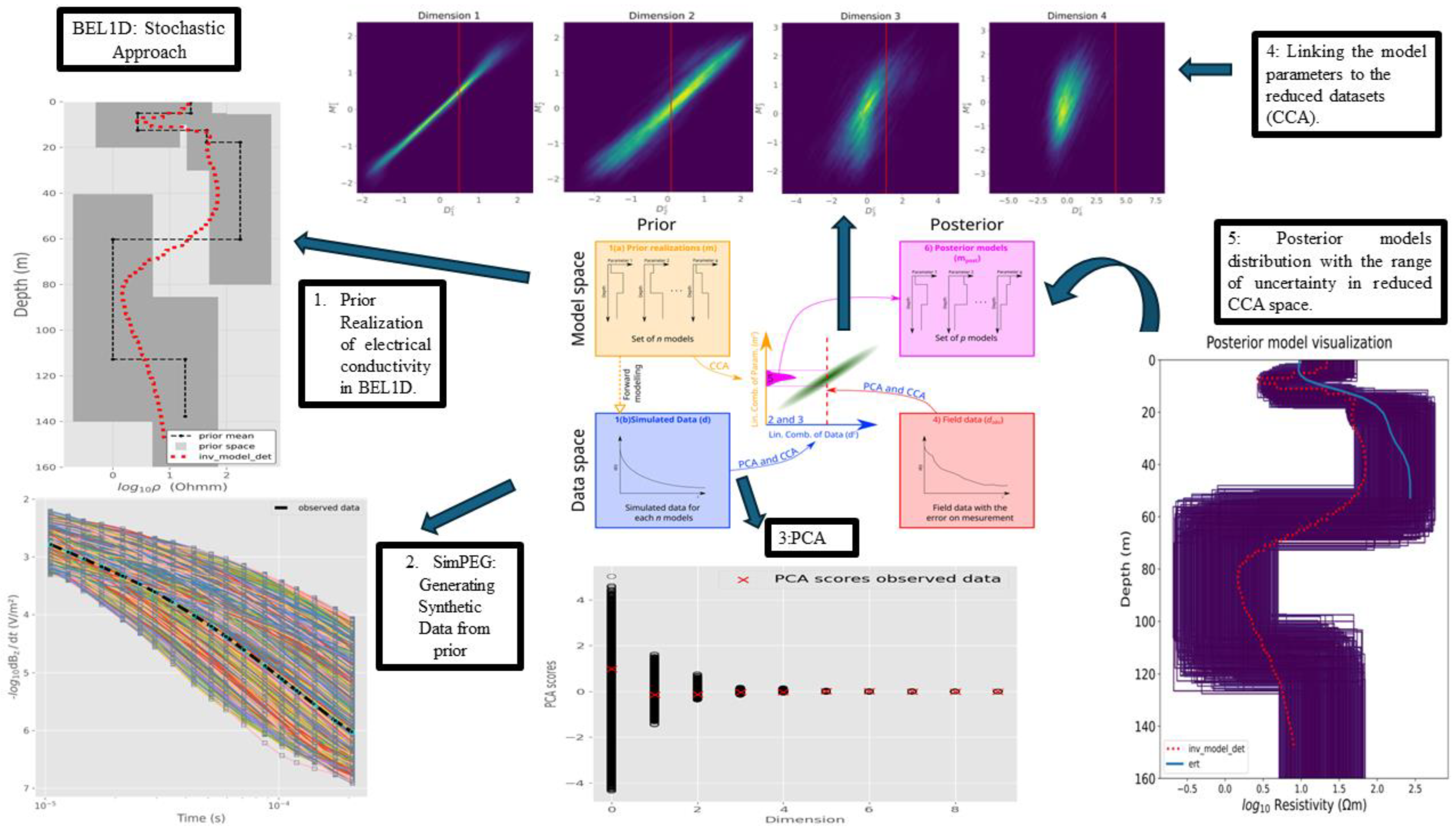
2.1. BEL1D
2.2. SimPEG: Forward Solver
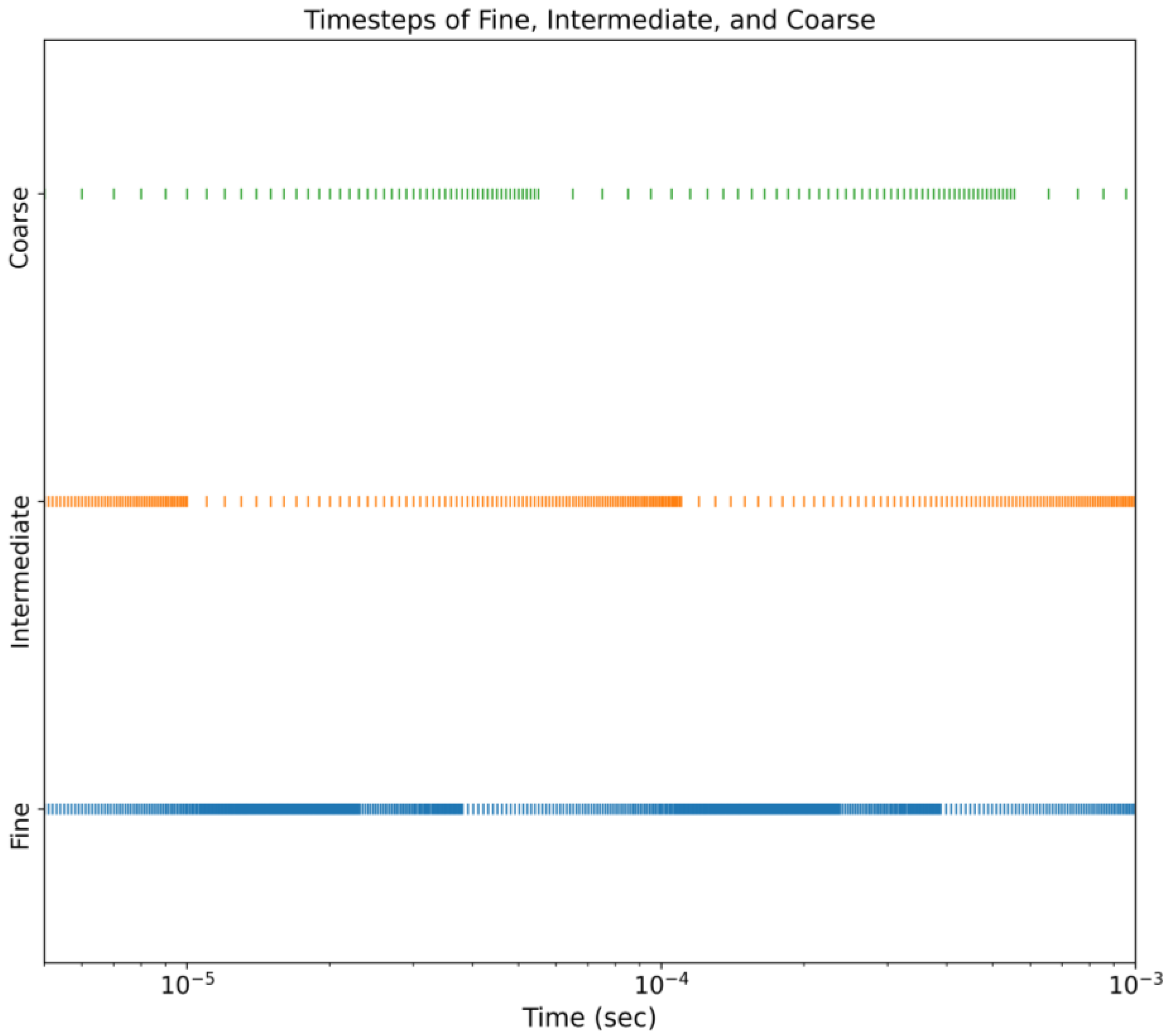
2.2.1. Temporal Discretization
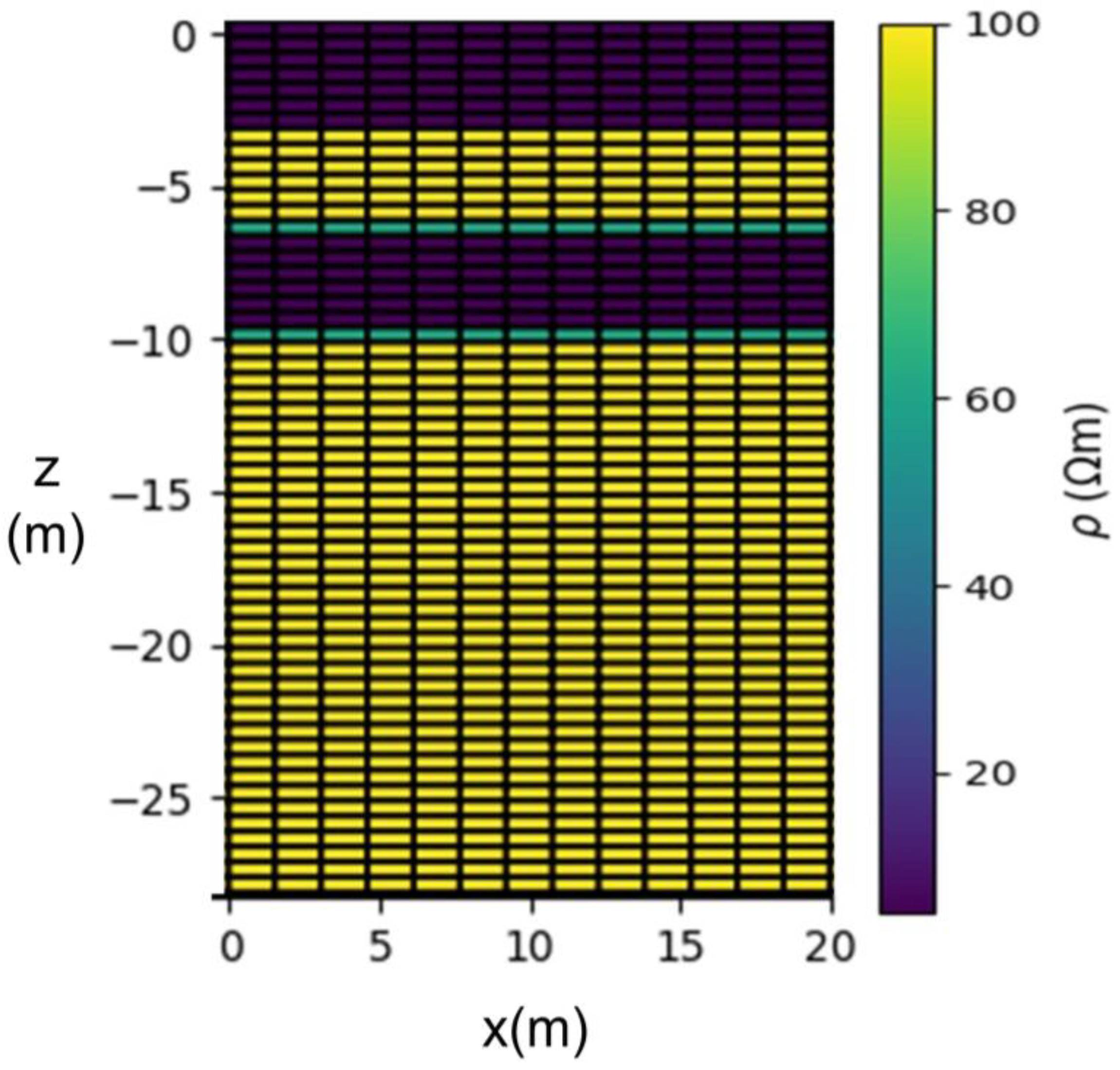
2.2.2. Spatial Discretization
2.3. Synthetic Benchmark
3. Field Site
4. Results
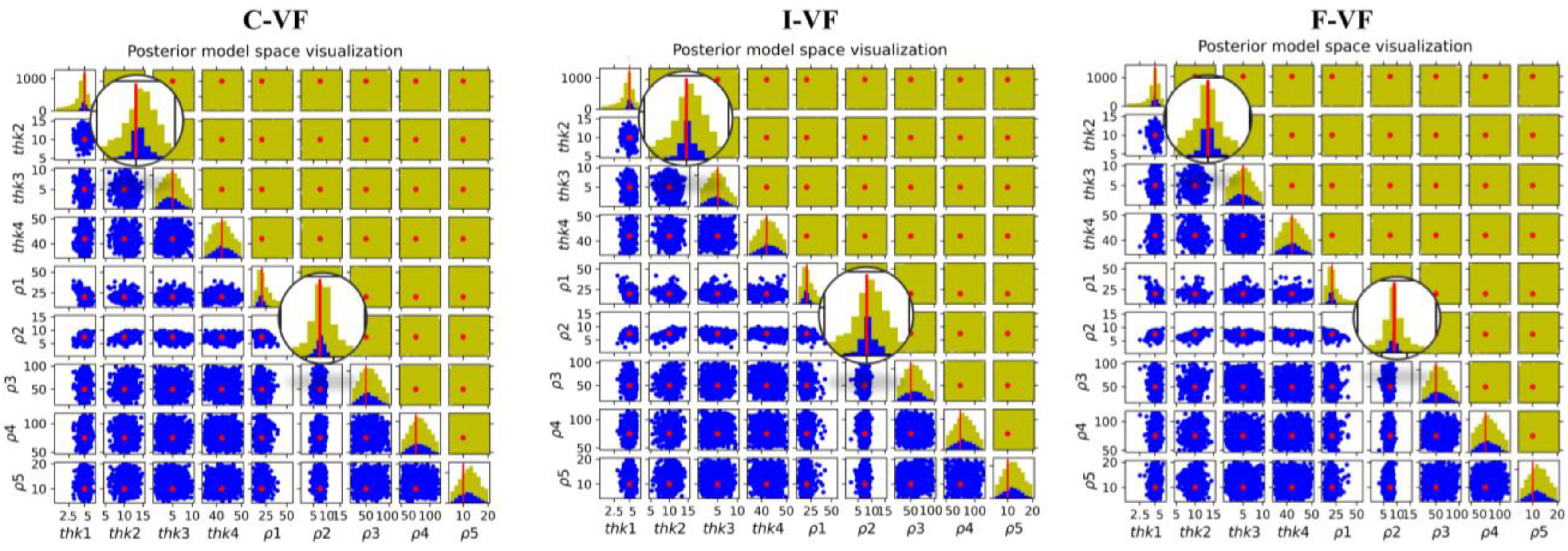
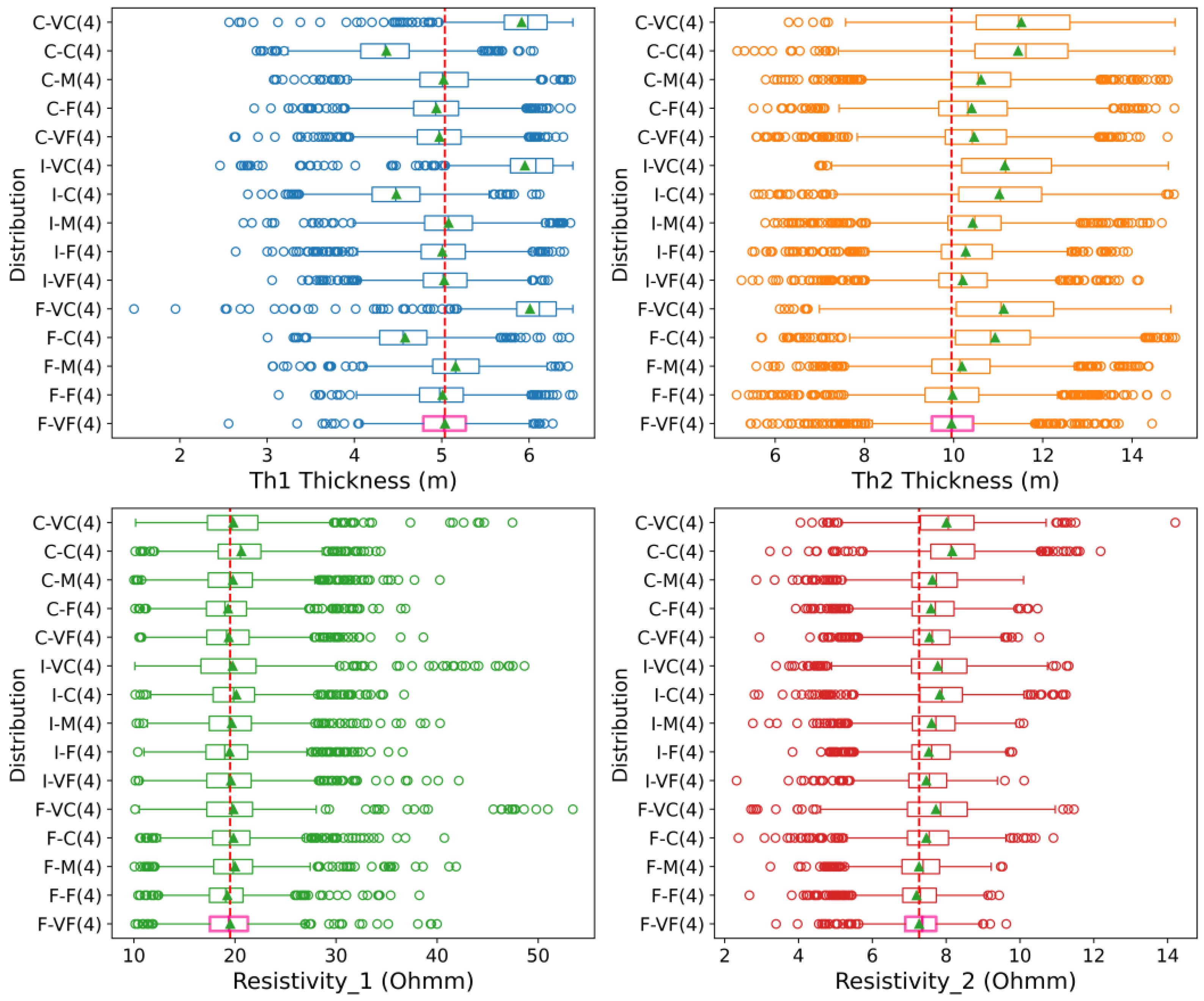
4.1. Impact of Discretization
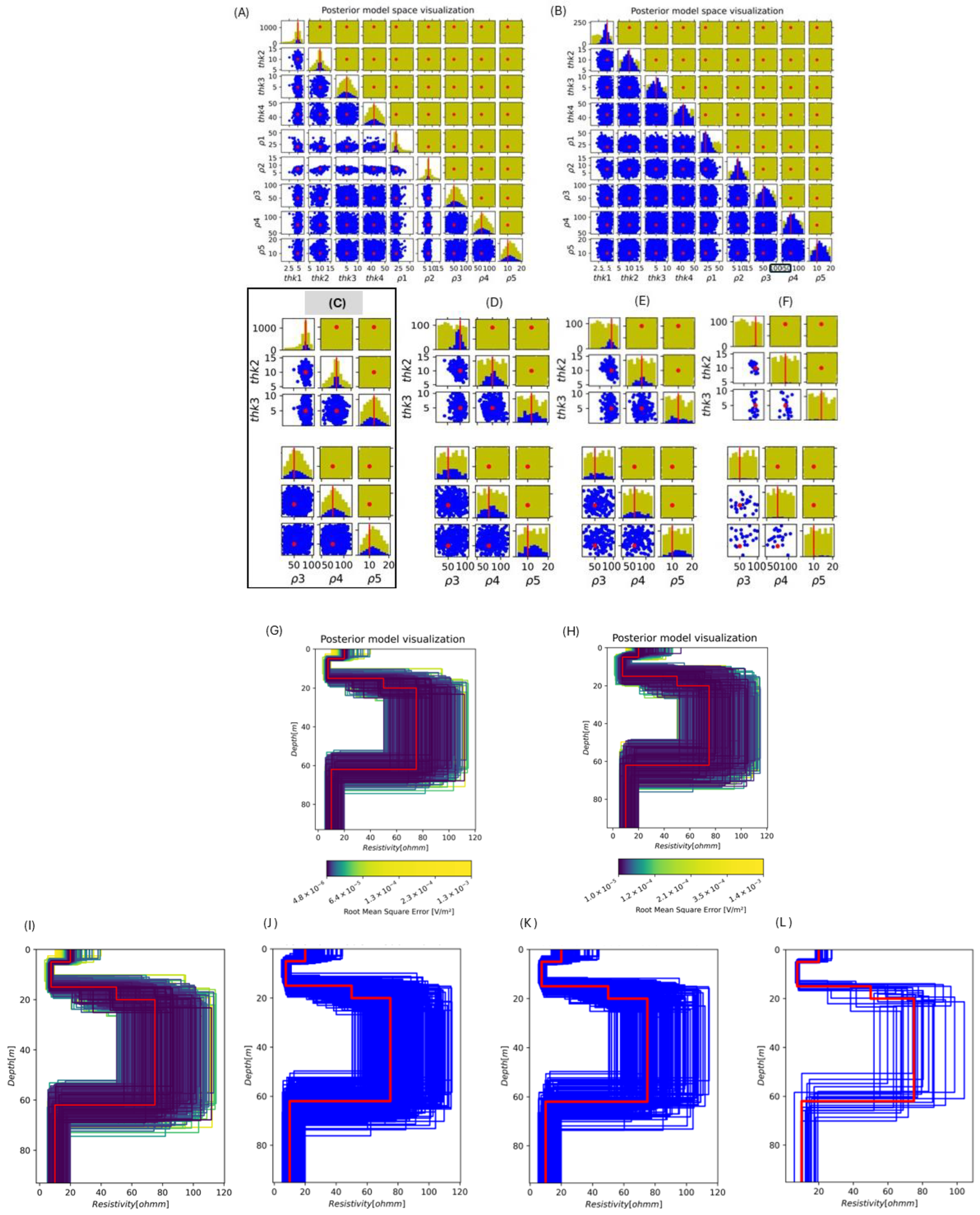
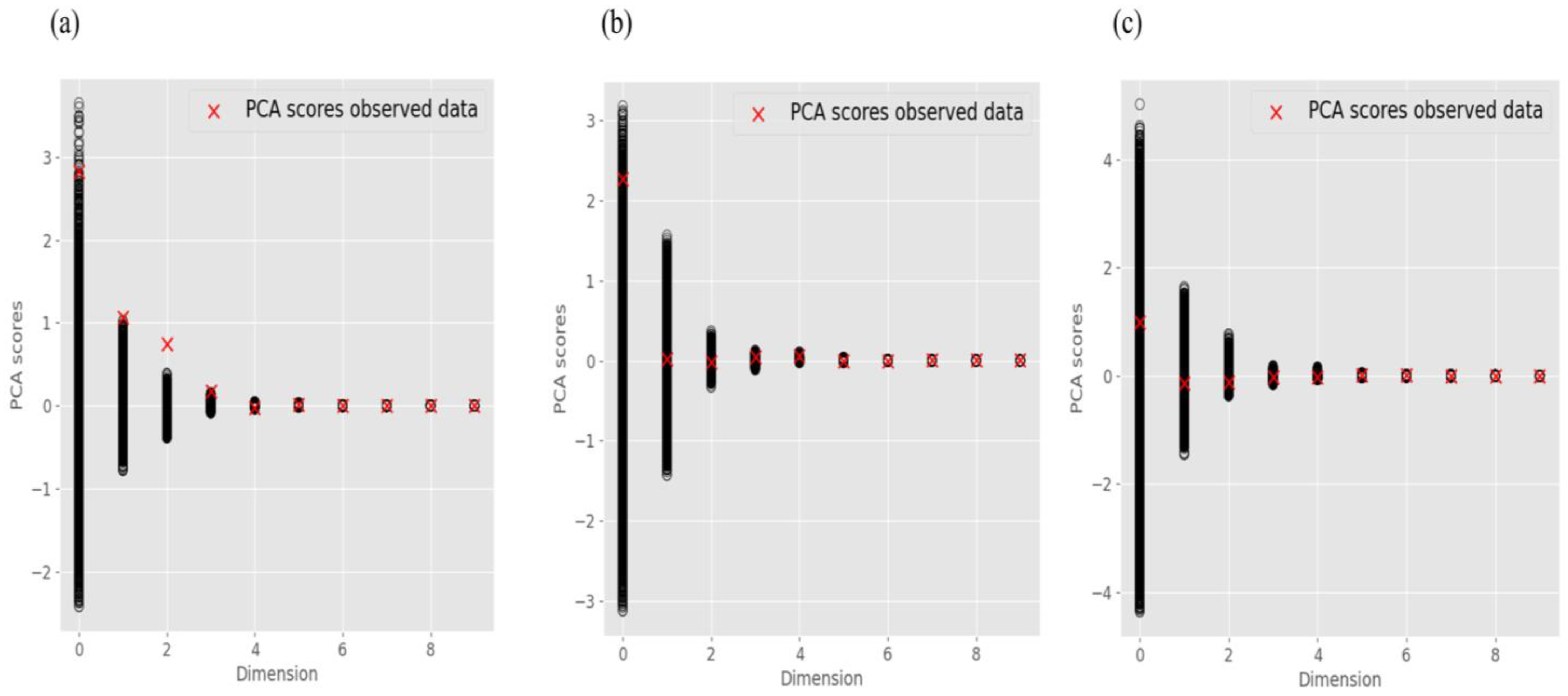
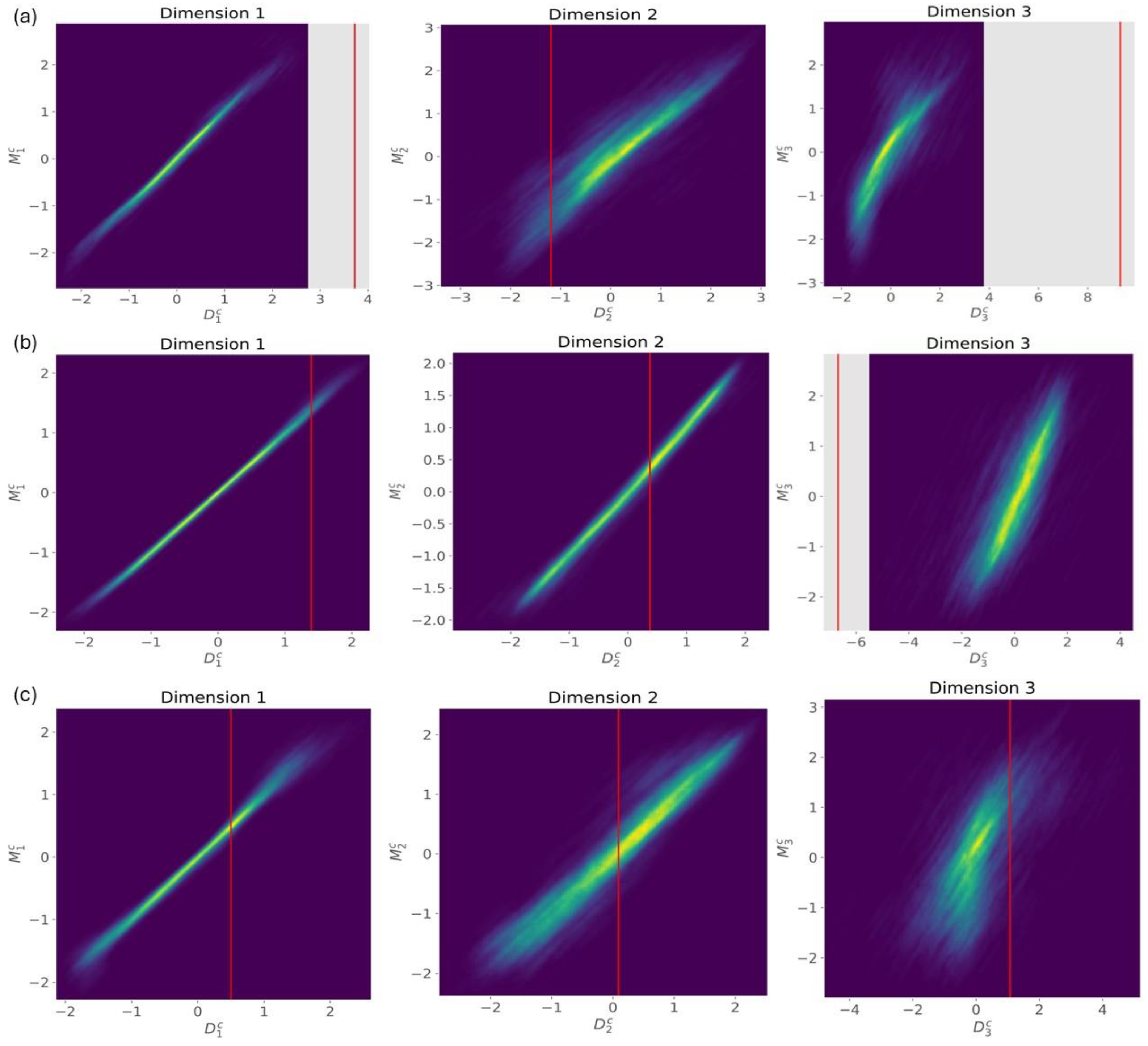
4.2. Impact of the Threshold
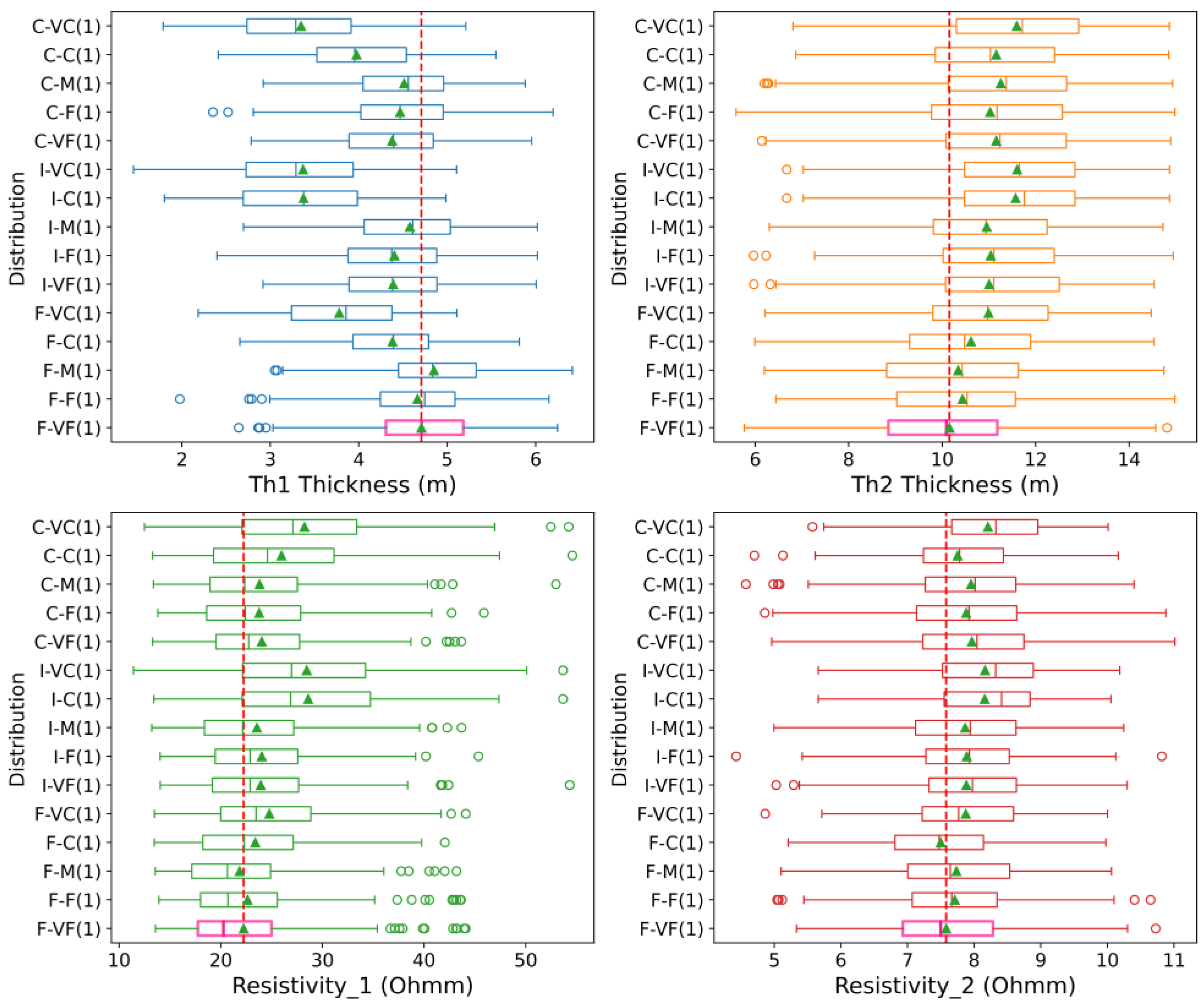
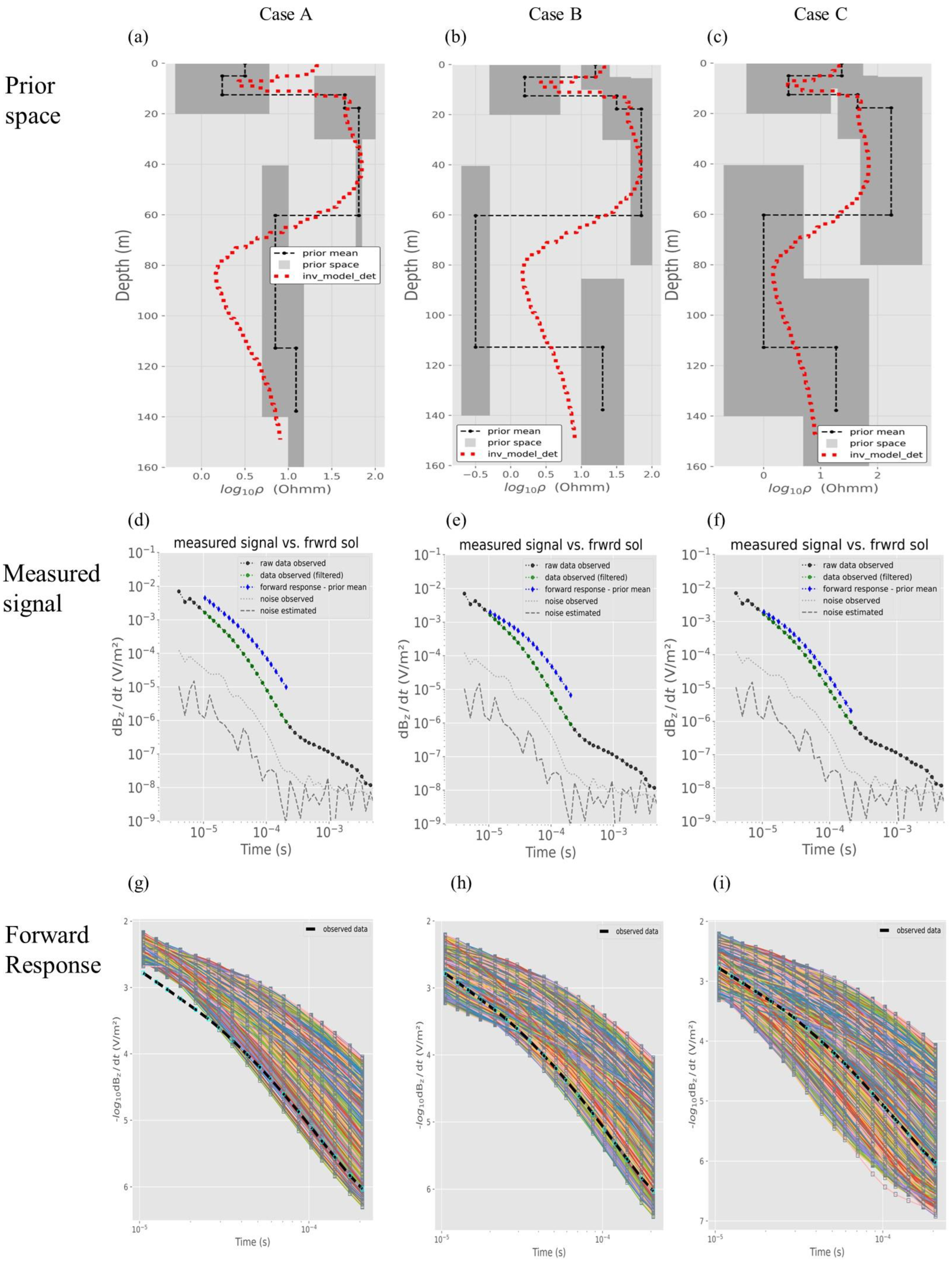
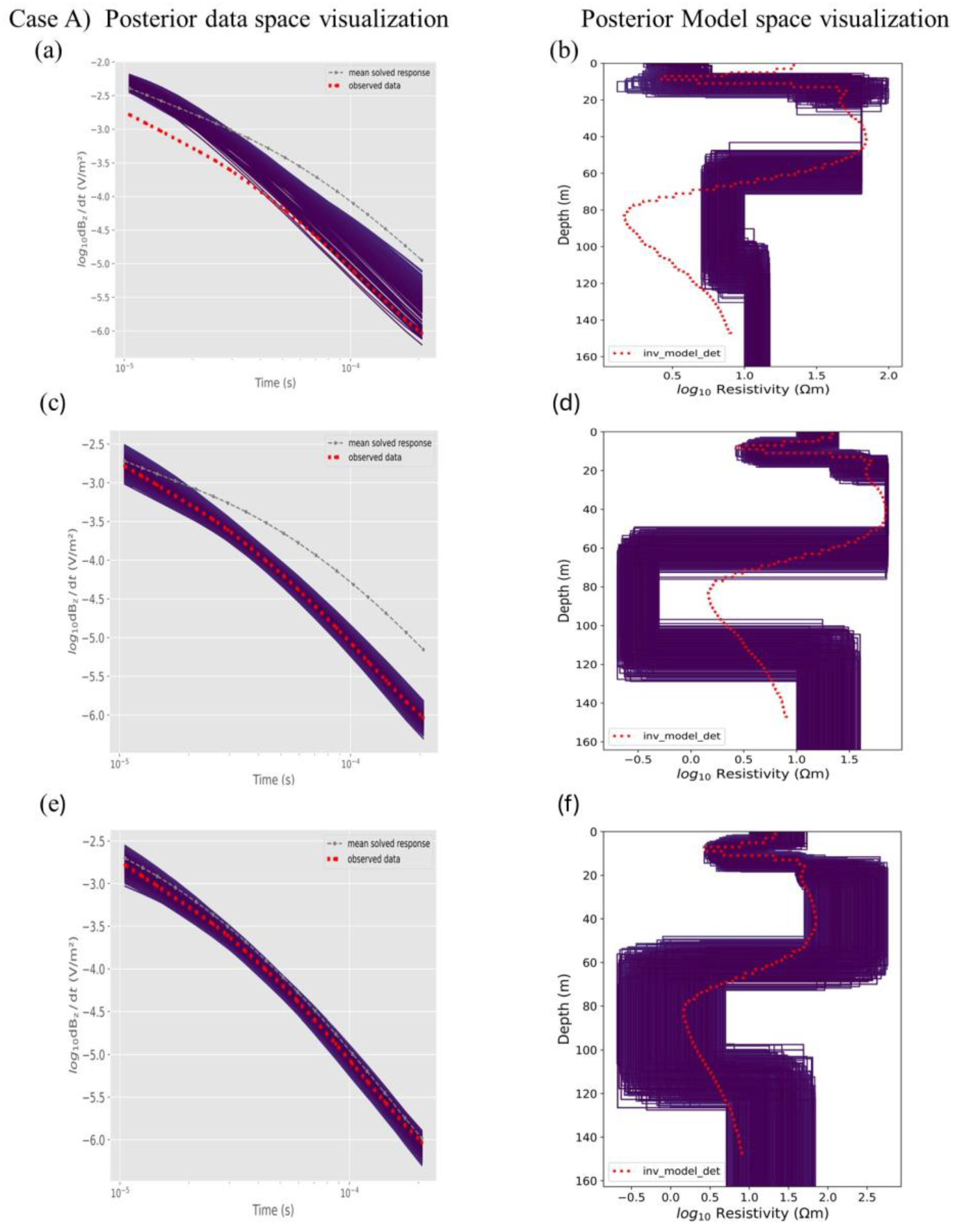
4.3. Impact of the Prior
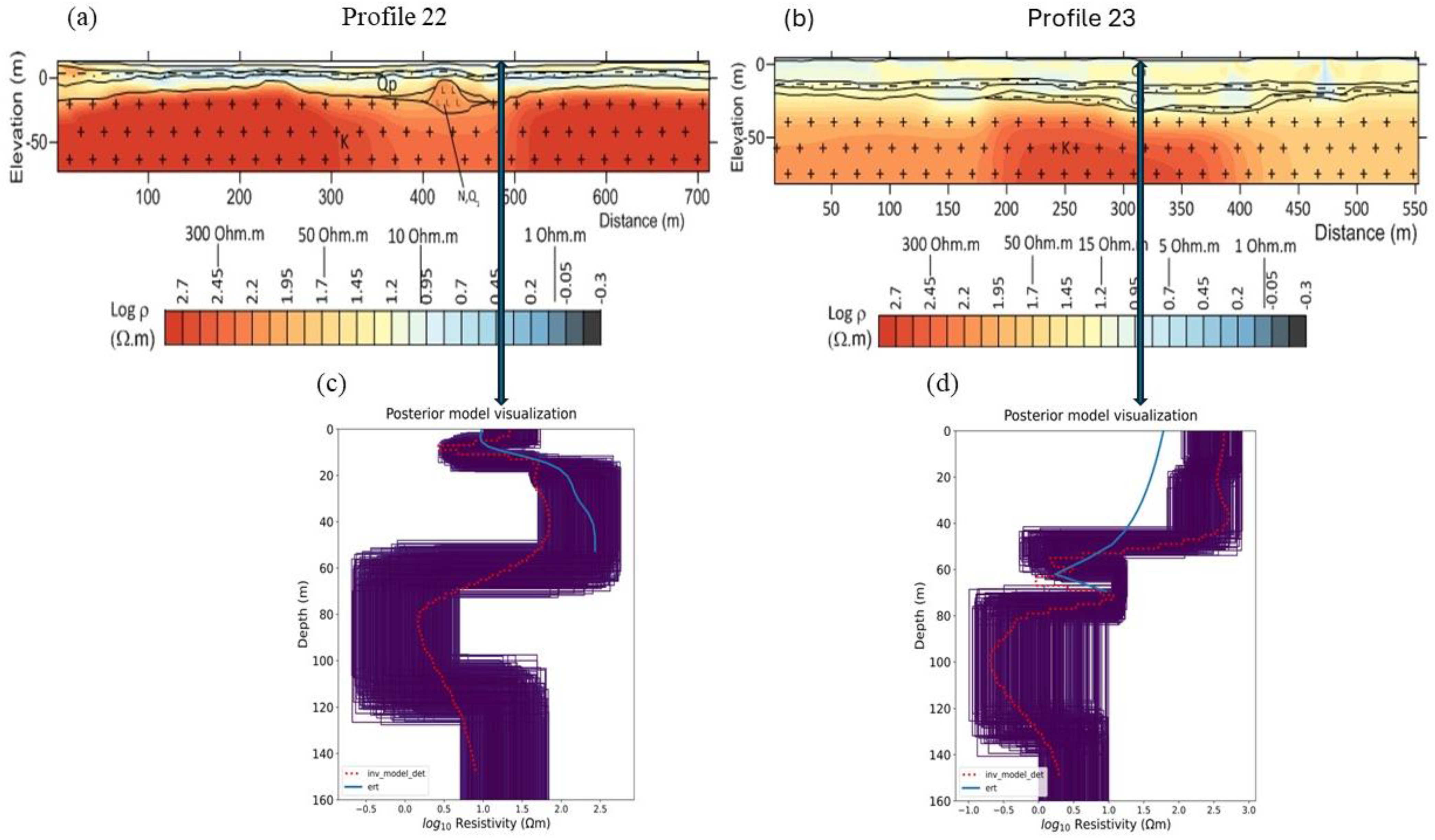
4.4. Field Soundings
4.5. Summary and Discussion
- (1)
- When using a numerical forward model, the temporal and spatial discretization have a significant effect on the retrieved posterior distribution. A semi-analytical approach is recommended when possible. Otherwise, a sufficiently fine temporal and spatial discretization must be retained and BEL1D-T constitutes an efficient and fast alternative for computing the posterior distribution.
- (2)
- BEL1D-T is an efficient and accurate approach for predicting uncertainty with limited computational effort. It was shown to be equivalent to BEL1D-IPR but requires fewer forward models to be computed.
- (3)
- As with any Bayesian approach, BEL1D-related methods are sensitive to the choice of the prior model. The consistency between the prior and the observed data is integrated, and the threshold approach allows for quickly identifying the inconsistent posterior model. We recommend running a deterministic inversion to define the prior model while keeping a wide range for each parameter, allowing for sufficient variability. Our findings illuminate the substantial uncertainty enveloping the deterministic inversion, highlighting the risk of disregarding such uncertainty, particularly in zones of low sensitivity at greater depths. We implement a threshold criterion to ensure all the models within the posterior distribution fit the observed data within a realistic error. Nonetheless, there exists a risk of underestimating uncertainty when the prior distribution is overly restrictive, as detailed in our prior analysis. Relying too much on the deterministic inversion is therefore dangerous, as it might not recover some variations occurring in the field because of the chosen inversion approach. To accommodate a broader prior, it may be imperative to resort to BEL1D-IPR or to increase the sample size significantly, ensuring a comprehensive exploration of the model space and a more accurate reflection of the inherent uncertainties.
- (4)
- For the field case, the results are consistent with ERT and deterministic inversion. Our analysis reveals that the uncertainty reduction at depths greater than 60 m is almost non-existent. It is recommended to avoid interpreting the model parameters at that depth, as the solution is likely highly dependent on the prior.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kemna, A.; Nguyen, F.; Gossen, S. On Linear Model Uncertainty Computation in Electrical Imaging. In Proceedings of the SIAM Conference on Mathematical and Computational Issues in the Geosciences, Santa Fe, NM, USA, 19–22 March 2007. [Google Scholar]
- Hermans, T.; Vandenbohede, A.; Lebbe, L.; Nguyen, F. A Shallow Geothermal Experiment in a Sandy Aquifer Monitored Using Electric Resistivity Tomography. Geophysics 2012, 77, B11–B21. [Google Scholar] [CrossRef]
- Parsekian, A.D.; Grombacher, D. Uncertainty Estimates for Surface Nuclear Magnetic Resonance Water Content and Relaxation Time Profiles from Bootstrap Statistics. J. Appl. Geophys. 2015, 119, 61–70. [Google Scholar] [CrossRef]
- Aster, R.; Borchers, B.; Thurber, C. Parameter Estimation and Inverse Problems; Academic Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Sambridge, M. Monte Carlo Methods in Geophysical Inverse Problems. Rev. Geophys. 2002, 40, 3-1–3-29. [Google Scholar] [CrossRef]
- Yeh, W.W.-G. Review of Parameter Identification Procedures in Groundwater Hydrology: The Inverse Problem. Water Resour. Res. 1986, 22, 95–108. [Google Scholar] [CrossRef]
- McLaughlin, D.; Townley, L.R. A Reassessment of the Groundwater Inverse Problem. Water Resour. Res. 1996, 32, 1131–1161. [Google Scholar] [CrossRef]
- Hidalgo, J.; Slooten, L.J.; Carrera, J.; Alcolea, A.; Medina, A. Inverse Problem in Hydrogeology. Hydrogeol. J. 2005, 13, 206–222. [Google Scholar] [CrossRef]
- Zhou, H.; Gómez-Hernández, J.J.; Li, L. Inverse Methods in Hydrogeology: Evolution and Recent Trends. Adv. Water Resour. 2014, 63, 22–37. [Google Scholar] [CrossRef]
- Sen, M.K.; Stoffa, P.L. Bayesian Inference, Gibbs’ Sampler, and Uncertainty Estimation in Geophysical Inversion. Geophys. Prospect. 1996, 44, 313–350. [Google Scholar] [CrossRef]
- Tarantola, A. Inverse Problem Theory and Methods for Model Parameter Estimation; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2005. [Google Scholar]
- Irving, J.; Singha, K. Stochastic Inversion of Tracer Test and Electrical Geophysical Data to Estimate Hydraulic Conductivities. Water Resour. Res. 2010, 46, W11514. [Google Scholar] [CrossRef]
- Trainor-Guitton, W.; Hoversten, G.M. Stochastic Inversion for Electromagnetic Geophysics: Practical Challenges and Improving Convergence Efficiency. Geophysics 2011, 76, F373–F386. [Google Scholar] [CrossRef]
- De Pasquale, G.; Linde, N. On Structure-Based Priors in Bayesian Geophysical Inversion. Geophys. J. Int. 2017, 208, 1342–1358. [Google Scholar] [CrossRef]
- Ball, L.B.; Davis, T.A.; Minsley, B.J.; Gillespie, J.M.; Landon, M.K. Probabilistic Categorical Groundwater Salinity Mapping from Airborne Electromagnetic Data Adjacent to California’s Lost Hills and Belridge Oil Fields. Water Resour. Res. 2020, 56, e2019WR026273. [Google Scholar] [CrossRef]
- Bobe, C.; Van De Vijver, E.; Keller, J.; Hanssens, D.; Van Meirvenne, M.; De Smedt, P. Probabilistic 1-D Inversion of Frequency-Domain Electromagnetic Data Using a Kalman Ensemble Generator. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3287–3297. [Google Scholar] [CrossRef]
- Tso, C.-H.M.; Iglesias, M.; Wilkinson, P.; Kuras, O.; Chambers, J.; Binley, A. Efficient Multiscale Imaging of Subsurface Resistivity with Uncertainty Quantification Using Ensemble Kalman Inversion. Geophys. J. Int. 2021, 225, 887–905. [Google Scholar] [CrossRef]
- Michel, H.; Hermans, T.; Kremer, T.; Elen, A.; Nguyen, F. 1D Geological Imaging of the Subsurface from Geophysical Data with Bayesian Evidential Learning. Part 2: Applications and Software. Comput. Geosci. 2020, 138, 104456. [Google Scholar] [CrossRef]
- Michel, H.; Hermans, T.; Nguyen, F. Iterative Prior Resampling and Rejection Sampling to Improve 1D Geophysical Imaging Based on Bayesian Evidential Learning (BEL1D). Geophys. J. Int. 2023, 232, 958–974. [Google Scholar] [CrossRef]
- Scheidt, C.; Renard, P.; Caers, J. Prediction-Focused Subsurface Modeling: Investigating the Need for Accuracy in Flow-Based Inverse Modeling. Math. Geosci. 2015, 47, 173–191. [Google Scholar] [CrossRef]
- Satija, A.; Scheidt, C.; Li, L.; Caers, J. Direct Forecasting of Reservoir Performance Using Production Data without History Matching. Comput. Geosci. 2017, 21, 315–333. [Google Scholar] [CrossRef]
- Hermans, T.; Nguyen, F.; Klepikova, M.; Dassargues, A.; Caers, J. Uncertainty Quantification of Medium-Term Heat Storage from Short-Term Geophysical Experiments Using Bayesian Evidential Learning. Water Resour. Res. 2018, 54, 2931–2948. [Google Scholar] [CrossRef]
- Athens, N.D.; Caers, J.K. A Monte Carlo-Based Framework for Assessing the Value of Information and Development Risk in Geothermal Exploration. Appl. Energy 2019, 256, 113932. [Google Scholar] [CrossRef]
- Thibaut, R.; Compaire, N.; Lesparre, N.; Ramgraber, M.; Laloy, E.; Hermans, T. Comparing Well and Geophysical Data for Temperature Monitoring within a Bayesian Experimental Design Framework. Water Resour. Res. 2022, 58, e2022WR033045. [Google Scholar] [CrossRef]
- Park, J.; Caers, J. Direct Forecasting of Global and Spatial Model Parameters from Dynamic Data. Comput. Geosci. 2020, 143, 104567. [Google Scholar] [CrossRef]
- Yin, Z.; Strebelle, S.; Caers, J. Automated Monte Carlo-Based Quantification and Updating of Geological Uncertainty with Borehole Data (AutoBEL v1.0). Geosci. Model Dev. 2020, 13, 651–672. [Google Scholar] [CrossRef]
- Tadjer, A.; Bratvold, R.B. Managing Uncertainty in Geological CO2 Storage Using Bayesian Evidential Learning. Energies 2021, 14, 1557. [Google Scholar] [CrossRef]
- Fang, J.; Gong, B.; Caers, J. Data-Driven Model Falsification and Uncertainty Quantification for Fractured Reservoirs. Engineering 2022, 18, 116–128. [Google Scholar] [CrossRef]
- Thibaut, R.; Laloy, E.; Hermans, T. A New Framework for Experimental Design Using Bayesian Evidential Learning: The Case of Wellhead Protection Area. J. Hydrol. 2021, 603, 126903. [Google Scholar] [CrossRef]
- Yang, H.-Q.; Chu, J.; Qi, X.; Wu, S.; Chiam, K. Bayesian Evidential Learning of Soil-Rock Interface Identification Using Boreholes. Comput. Geotech. 2023, 162, 105638. [Google Scholar] [CrossRef]
- Hermans, T.; Oware, E.; Caers, J. Direct Prediction of Spatially and Temporally Varying Physical Properties from Time-Lapse Electrical Resistance Data. Water Resour. Res. 2016, 52, 7262–7283. [Google Scholar] [CrossRef]
- Pradhan, A.; Mukerji, T. Seismic Bayesian Evidential Learning: Estimation and Uncertainty Quantification of Sub-Resolution Reservoir Properties. Comput. Geosci. 2020, 24, 1121–1140. [Google Scholar] [CrossRef]
- Heagy, L.J.; Cockett, R.; Kang, S.; Rosenkjaer, G.K.; Oldenburg, D.W. A Framework for Simulation and Inversion in Electromagnetics. Comput. Geosci. 2017, 82, WB9–WB19. [Google Scholar] [CrossRef]
- Cockett, R.; Kang, S.; Heagy, L.J.; Pidlisecky, A.; Oldenburg, D.W. SimPEG: An Open Source Framework for Simulation and Gradient Based Parameter Estimation in Geophysical Applications. Comput. Geosci. 2015, 85, 142–154. [Google Scholar] [CrossRef]
- Chongo, M.; Christiansen, A.V.; Tembo, A.; Banda, K.E.; Nyambe, I.A.; Larsen, F.; Bauer-Gottwein, P. Airborne and Ground-Based Transient Electromagnetic Mapping of Groundwater Salinity in the Machile–Zambezi Basin, Southwestern Zambia. Near Surf. Geophys. 2015, 13, 383–396. [Google Scholar] [CrossRef]
- Mohamaden, M.; Araffa, S.A.; Taha, A.; AbdelRahman, M.A.; El-Sayed, H.M.; Sharkawy, M.S. Geophysical Techniques and Geomatics-Based Mapping for Groundwater Exploration and Sustainable Development at Sidi Barrani Area, Egypt. Egypt. J. Aquat. Res. 2023, in press. [Google Scholar] [CrossRef]
- Rey, J.; Martínez, J.M.; Mendoza, R.; Sandoval, S.; Tarasov, V.; Kaminsky, A.; Morales, K. Geophysical Characterization of Aquifers in Southeast Spain Using ERT, TDEM, and Vertical Seismic Reflection. Appl. Sci. 2020, 10, 7365. [Google Scholar] [CrossRef]
- Siemon, B.; Christiansen, A.V.; Auken, E. A Review of Helicopter-Borne Electromagnetic Methods for Groundwater Exploration. Near Surf. Geophys. 2009, 7, 629–646. [Google Scholar] [CrossRef]
- Vilhelmsen, T.N.; Marker, P.A.; Foged, N.; Wernberg, T.; Auken, E.; Christiansen, A.V.; Bauer-Gottwein, P.; Christensen, S.; Høyer, A.-S. A Regional Scale Hydrostratigraphy Generated from Geophysical Data of Varying Age, Type, and Quality. Water Resour. Manag. 2018, 33, 539–553. [Google Scholar] [CrossRef]
- Goebel, M.; Knight, R.; Halkjær, M. Mapping Saltwater Intrusion with an Airborne Electromagnetic Method in the Offshore Coastal Environment, Monterey Bay, California. J. Hydrol. Reg. Stud. 2019, 23, 100602. [Google Scholar] [CrossRef]
- Auken, E.; Foged, N.; Larsen, J.J.; Lassen, K.V.T.; Maurya, P.K.; Dath, S.M.; Eiskjær, T.T. tTEM—A Towed Transient Electromagnetic System for Detailed 3D Imaging of the Top 70 m of the Subsurface. Geophysics 2019, 84, E13–E22. [Google Scholar] [CrossRef]
- Lane, J.W., Jr.; Briggs, M.A.; Maurya, P.K.; White, E.A.; Pedersen, J.B.; Auken, E.; Terry, N.; Minsley, B.K.; Kress, W.; LeBlanc, D.R.; et al. Characterizing the Diverse Hydrogeology Underlying Rivers and Estuaries Using New Floating Transient Electromagnetic Methodology. Sci. Total Environ. 2020, 740, 140074. [Google Scholar] [CrossRef] [PubMed]
- Aigner, L.; Högenauer, P.; Bücker, M.; Flores Orozco, A. A Flexible Single Loop Setup for Water-Borne Transient Electromagnetic Sounding Applications. Sensors 2021, 21, 6624. [Google Scholar] [CrossRef] [PubMed]
- Viezzoli, A.; Christiansen, A.V.; Auken, E.; Sørensen, K. Quasi-3D Modeling of Airborne TEM Data by Spatially Constrained Inversion. Geophysics 2008, 73, F105–F113. [Google Scholar] [CrossRef]
- Linde, N.; Ginsbourger, D.; Irving, J.; Nobile, F.; Doucet, A. On Uncertainty Quantification in Hydrogeology and Hydrogeophysics. Adv. Water Resour. 2017, 110, 166–181. [Google Scholar] [CrossRef]
- Josset, L.; Ginsbourger, D.; Lunati, I. Functional Error Modeling for Uncertainty Quantification in Hydrogeology. Water Resour. Res. 2015, 51, 1050–1068. [Google Scholar] [CrossRef]
- Scholer, M.; Irving, J.; Looms, M.C.; Nielsen, L.; Holliger, K. Bayesian Markov-Chain-Monte-Carlo Inversion of Time-Lapse Crosshole GPR Data to Characterize the Vadose Zone at the Arrenaes Site, Denmark. Vadose Zone J. 2012, 11, vzj2011.0153. [Google Scholar] [CrossRef]
- Calvetti, D.; Ernst, O.; Somersalo, E. Dynamic Updating of Numerical Model Discrepancy Using Sequential Sampling. Inverse Probl. 2014, 30, 114019. [Google Scholar] [CrossRef]
- Köpke, C.; Irving, J.; Elsheikh, A.H. Accounting for Model Error in Bayesian Solutions to Hydrogeophysical Inverse Problems Using a Local Basis Approach. Adv. Water Resour. 2018, 116, 195–207. [Google Scholar] [CrossRef]
- Deleersnyder, W.; Dudal, D.; Hermans, T. Multidimensional Surrogate Modelling for Airborne TDEM Data Accepted Pending Revision. Comput. Geosci. 2024. [Google Scholar] [CrossRef]
- Khu, S.-T.; Werner, M.G.F. Reduction of Monte-Carlo Simulation Runs for Uncertainty Estimation in Hydrological Modelling. Hydrol. Earth Syst. Sci. 2003, 7, 680–692. [Google Scholar] [CrossRef]
- Brynjarsdóttir, J.; O’Hagan, A. Learning About Physical Parameters: The Importance of Model Discrepancy. Inverse Probl. 2014, 30, 114007. [Google Scholar] [CrossRef]
- Hansen, T.M.; Cordua, K.S.; Jacobsen, B.H.; Mosegaard, K. Accounting for Imperfect Forward Modeling in Geophysical Inverse Problems—Exemplified for Crosshole Tomography. Geophysics 2014, 79, H1–H21. [Google Scholar] [CrossRef]
- Deleersnyder, W.; Maveau, B.; Hermans, T.; Dudal, D. Inversion of Electromagnetic Induction Data Using a Novel Wavelet-Based and Scale-Dependent Regularization Term. Geophys. J. Int. 2021, 226, 1715–1729. [Google Scholar] [CrossRef]
- Deleersnyder, W.; Dudal, D.; Hermans, T. Novel Airborne EM Image Appraisal Tool for Imperfect Forward Modelling. Remote Sens. 2022, 14, 5757. [Google Scholar] [CrossRef]
- Bai, P.; Vignoli, G.; Hansen, T.M. 1D Stochastic Inversion of Airborne Time-Domain Electromagnetic Data with Realistic Prior and Accounting for the Forward Modeling Error. Remote Sens. 2021, 13, 3881. [Google Scholar] [CrossRef]
- Minsley, B.J.; Foks, N.L.; Bedrosian, P.A. Quantifying Model Structural Uncertainty Using Airborne Electromagnetic Data. Geophys. J. Int. 2021, 224, 590–607. [Google Scholar] [CrossRef]
- Michel, H. pyBEL1D: Latest Version of pyBEL1D, version 1.1.0; Zenodo: Genève, Switzerland, 14 July 2022. [CrossRef]
- Krzanowski, W.J. Principles of Multivariate Analysis: A User’s Perspective; Oxford University Press: New York, NY, USA, 2000. [Google Scholar]
- Thibaut, R. Machine Learning for Bayesian Experimental Design in the Subsurface. Ph.D. Dissertation, Ghent University, Faculty of Sciences, Ghent, Belgium, 2023. [Google Scholar] [CrossRef]
- Wand, M.P.; Jones, M.C. Comparison of Smoothing Parameterizations in Bivariate Kernel Density Estimation. J. Am. Stat. Assoc. 1993, 88, 520. [Google Scholar] [CrossRef]
- Devroye, L. An Automatic Method for Generating Random Variates with a Given Characteristic Function. SIAM J. Appl. Math. 1986, 46, 698–719. [Google Scholar] [CrossRef]
- Werthmüller, D. An Open-Source Full 3D Electromagnetic Modeler for 1D VTI Media in Python: Empymod. Geophysics 2017, 82, WB9–WB19. [Google Scholar] [CrossRef]
- Yee, K. Numerical Solution of Initial Boundary Value Problems Involving Maxwell’s Equations in Isotropic Media. IEEE Trans. Antennas Propag. 1966, 14, 302–307. [Google Scholar] [CrossRef]
- Haber, E. Computational Methods in Geophysical Electromagnetics; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2014. [Google Scholar] [CrossRef]
- Hyman, J.; Morel, J.; Shashkov, M.; Steinberg, S. Mimetic Finite Difference Methods for Diffusion Equations. Comput. Geosci. 2002, 6, 333–352. [Google Scholar] [CrossRef]
- Hyman, J.M.; Shashkov, M. Mimetic Discretizations for Maxwell’s Equations. J. Comput. Phys. 1999, 151, 881–909. [Google Scholar] [CrossRef]
- Diep, C.-T.; Linh, P.D.; Thibaut, R.; Paepen, M.; Ho, H.H.; Nguyen, F.; Hermans, T. Imaging the Structure and the Saltwater Intrusion Extent of the Luy River Coastal Aquifer (Binh Thuan, Vietnam) Using Electrical Resistivity Tomography. Water 2021, 13, 1743. [Google Scholar] [CrossRef]
- Dieu, L.P.; Cong-Thi, D.; Segers, T.; Ho, H.H.; Nguyen, F.; Hermans, T. Groundwater Salinization and Freshening Processes in the Luy River Coastal Aquifer, Vietnam. Water 2022, 14, 2358. [Google Scholar] [CrossRef]
- Cong-Thi, D.; Dieu, L.P.; Caterina, D.; De Pauw, X.; Thi, H.D.; Ho, H.H.; Nguyen, F.; Hermans, T. Quantifying Salinity in Heterogeneous Coastal Aquifers through ERT and IP: Insights from Laboratory and Field Investigations. J. Contam. Hydrol. 2024, 262, 104322. [Google Scholar] [CrossRef]
- Aigner, L.; Werthmüller, D.; Flores Orozco, A. Sensitivity Analysis of Inverted Model Parameters from Transient Electromagnetic Measurements Affected by Induced Polarization Effects. J. Appl. Geophys. 2024, 223, 105334. [Google Scholar] [CrossRef]
- Hermans, T.; Lesparre, N.; De Schepper, G.; Robert, T. Bayesian Evidential Learning: A Field Validation Using Push-Pull Tests. Hydrogeol. J. 2019, 27, 1661–1672. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temporal Discretization | Total Number of Time Steps | Maximum Size of Time Steps (s) | Weighted Average Length of Time Steps (s) |
|---|---|---|---|
| Fine (F) | 1710 | 10−5 | 0.581 × 10−6 |
| Intermediate (I) | 510 | 10−5 | 1.95 × 10−6 |
| Coarser (C) | 185 | 10−4 | 5.38 × 10−6 |
| Spatial Discretization | Thickness of Grid Cells (in m) |
|---|---|
| Very Fine (VF) | 0.25 |
| Fine (F) | 0.5 |
| Medium (M) | 1 |
| Coarse (C) | 1.5 |
| Very Coarse (VC) | 2 |
| Layers | Thickness (m) | Resistivities (ohmm) |
|---|---|---|
| Layer 1 | 0.5–6.5 (5) | 10–55 (20) |
| Layer 2 | 5–15 (10) | 1–15 (4.5) |
| Layer 3 | 0.5–10 (5) | 20–100 (50) |
| Layer 4 | 35–50 (42) | 50–115 (75) |
| Layer 5 | ∞ (∞) | 5–20 (10) |
| Spatial Discretization | |||||
|---|---|---|---|---|---|
| Time | VF | F | M | C | VC |
| F | 389.02 | 73.88 | 33.4 | 25.92 | 17.7 |
| I | 114.79 | 22.38 | 6.3 | 3.55 | 2.73 |
| C | 44.98 | 11.48 | 3.90 | 2.46 | 2.02 |
| Case A | Case B | Case C | ||||
|---|---|---|---|---|---|---|
| Thickness (m) | Resistivity (ohmm) | Thickness (m) | Resistivity (ohmm) | Thickness (m) | Resistivity (ohmm) | |
| Layer 1 | 0–10 | 2–5 | 0–10 | 10–25 | 0–10 | 10–55 |
| Layer 2 | 5.0–10 | 0.5–6 | 5–10 | 0.5–5 | 5.0–10 | 0.5–15 |
| Layer 3 | 0.5–10 | 20–100 | 0.5–10 | 20–50 | 0.5–10 | 20–100 |
| Layer 4 | 35–50 | 60–70 | 35–50 | 50–100 | 35–50 | 50–600 |
| Layer 5 | 45–60 | 5–10 | 45–60 | 0.2–0.5 | 45–60 | 0.2–10 |
| layer 6 | 0–0 | 10–15 | 0–0 | 10–40 | 0–0 | 5–100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, A.; Aigner, L.; Michel, H.; Deleersnyder, W.; Dudal, D.; Flores Orozco, A.; Hermans, T. Assessing and Improving the Robustness of Bayesian Evidential Learning in One Dimension for Inverting Time-Domain Electromagnetic Data: Introducing a New Threshold Procedure. Water 2024, 16, 1056. https://doi.org/10.3390/w16071056
Ahmed A, Aigner L, Michel H, Deleersnyder W, Dudal D, Flores Orozco A, Hermans T. Assessing and Improving the Robustness of Bayesian Evidential Learning in One Dimension for Inverting Time-Domain Electromagnetic Data: Introducing a New Threshold Procedure. Water. 2024; 16(7):1056. https://doi.org/10.3390/w16071056
Chicago/Turabian StyleAhmed, Arsalan, Lukas Aigner, Hadrien Michel, Wouter Deleersnyder, David Dudal, Adrian Flores Orozco, and Thomas Hermans. 2024. "Assessing and Improving the Robustness of Bayesian Evidential Learning in One Dimension for Inverting Time-Domain Electromagnetic Data: Introducing a New Threshold Procedure" Water 16, no. 7: 1056. https://doi.org/10.3390/w16071056
APA StyleAhmed, A., Aigner, L., Michel, H., Deleersnyder, W., Dudal, D., Flores Orozco, A., & Hermans, T. (2024). Assessing and Improving the Robustness of Bayesian Evidential Learning in One Dimension for Inverting Time-Domain Electromagnetic Data: Introducing a New Threshold Procedure. Water, 16(7), 1056. https://doi.org/10.3390/w16071056