
Burst Diagnosis Multi-Stage Model for Water Distribution Networks Based on Deep Learning Algorithms



Abstract
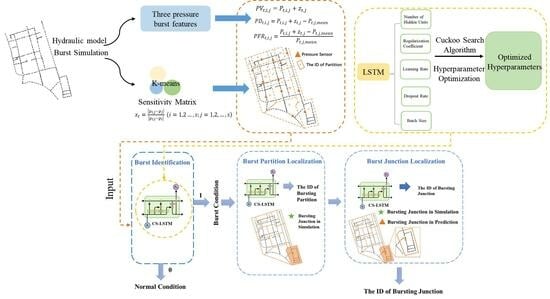
:
1. Introduction
2. Methods
2.1. Overview
2.2. Burst Pressure Feature Extraction
2.2.1. Network Partition and Sensor Layout for Monitoring System
2.2.2. Burst Pressure Features
Burst Simulation
- (1)
- Burst Simulation
- (2)
- Pipe burst conditions
- (3)
- Data noise synthesis based on historic monitoring data
Calculation of Three Different Burst Pressure Features
- (1)
- Pressure Value (PV)
- (2)
- Pressure Difference (PD)
- (3)
- Pressure Fluctuation Ratio (PFR)
2.3. Burst Diagnosis Multi-Stage Model
2.3.1. The Architecture of Burst Diagnosis Multi-Stage Model (BDMM)
2.3.2. CS-LSTM
2.3.3. Model Performance Indexes
Performance Indexes of Burst Identification Module
Performance Indexes of Burst Partition Localization Module
Performance Index of Burst Junction Localization Module
3. Results and Discussion
3.1. Basic Information of the Study Area
3.2. Calculation of Burst Pressure Features
3.3. The Performance of BDMM
3.3.1. Performance of Burst Identification Module
3.3.2. Performance of Burst Partition Localization Module
3.3.3. Performance of Burst Junction Localization Module
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jun, S.; Lansey, K.E. Convolutional Neural Network for Burst Detection in Smart Water Distribution Systems. Water Resour. Manag. 2023, 37, 3729–3743. [Google Scholar] [CrossRef]
- Qi, Z.; Zheng, F.; Guo, D.; Maier, H.R.; Zhang, T.; Yu, T.; Shao, Y. Better Understanding of the Capacity of Pressure Sensor Systems to Detect Pipe Burst within Water Distribution Networks. J. Water Resour. Plann. Manag. 2018, 144, 04018035. [Google Scholar] [CrossRef]
- Wan, X.; Kuhanestani Parisa, K.; Farmani, R.; Keedwell, E. Literature Review of Data Analytics for Leak Detection in Water Distribution Networks: A Focus on Pressure and Flow Smart Sensors. J. Water Resour. Plann. Manag. 2022, 148, 03122002. [Google Scholar] [CrossRef]
- Kammoun, M.; Kammoun, A.; Abid, M. Leak Detection Methods in Water Distribution Networks: A Comparative Survey on Artificial Intelligence Applications. J. Pipeline Syst. Eng. Pract. 2022, 13, 04022024. [Google Scholar] [CrossRef]
- Che, T.-C.; Duan, H.-F.; Lee, P.J. Transient wave-based methods for anomaly detection in fluid pipes: A review. Mech. Syst. Signal Process. 2021, 160, 107874. [Google Scholar] [CrossRef]
- Pérez, R.; Puig, V.; Pascual, J.; Quevedo, J.; Landeros, E.; Peralta, A. Methodology for leakage isolation using pressure sensitivity analysis in water distribution networks. Control Eng. Pract. 2011, 19, 1157–1167. [Google Scholar] [CrossRef]
- Nimri, W.; Wang, Y.; Zhang, Z.; Deng, C.; Sellstrom, K. Data-driven approaches and model-based methods for detecting and locating leaks in water distribution systems: A literature review. Neural Comput. Appl. 2023, 35, 11611–11623. [Google Scholar] [CrossRef]
- Lee, S.J.; Lee, G.; Suh, J.C.; Lee, J.M. Online Burst Detection and Location of Water Distribution Systems and Its Practical Applications. J. Water Resour. Plan. Manag. 2016, 142, 04015033. [Google Scholar] [CrossRef]
- Sanz, G.; Pérez, R. Sensitivity Analysis for Sampling Design and Demand Calibration in Water Distribution Networks Using the Singular Value Decomposition. J. Water Resour. Plan. Manag. 2015, 141, 04015020. [Google Scholar] [CrossRef]
- Corzo, C.M.; Alfonso, L.; Corzo, G.; Solomatine, D. Locating Multiple Leaks in Water Distribution Networks Combining Physically Based and Data-Driven Models and High-Performance Computing. J. Water Resour. Plan. Manag. 2023, 149, 04023066. [Google Scholar] [CrossRef]
- Jian, C.; Gao, J.; Xu, Y. Anomaly Detection and Classification in Water Distribution Networks Integrated with Hourly Nodal Water Demand Forecasting Models and Feature Extraction Technique. J. Water Resour. Plan. Manag. 2022, 148, 04022059. [Google Scholar] [CrossRef]
- Zhou, X.; Tang, Z.; Xu, W.; Meng, F.; Chu, X.; Xin, K.; Fu, G. Deep learning identifies accurate burst locations in water distribution networks. Water Res. 2019, 166, 115058. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Peng, S.; Cheng, R.; Wu, X.; Fang, X. Burst Area Identification of Water Supply Network by Improved DenseNet Algorithm with Attention Mechanism. Water Resour. Manag. 2022, 36, 5425–5442. [Google Scholar] [CrossRef]
- Takudzwa Sikumbuzo, M.; Clement, N.N. A Comparison of Fully-Linear Deep Learning Methods for Pipe Burst Localization in Water Distribution Networks. In Proceedings of the 2023 IST-Africa Conference (IST-Africa), Tshwane, South Africa, 31 May–2 June 2023. [Google Scholar] [CrossRef]
- Birek, L.; Petrovic, D.; Boylan, J. Water leakage forecasting: The application of a modified fuzzy evolving algorithm. Appl. Soft Comput. 2014, 14, 305–315. [Google Scholar] [CrossRef]
- Lauren, M.; Jawad, F.; Liz, V. Flow Forecasting for Leakage Burst Prediction in Water Distribution Systems using Long Short-Term Memory Neural Networks and Kalman Filtering. Sustain. Cities Soc. 2023, 99, 104934. [Google Scholar] [CrossRef]
- Shekofteh, M.; Jalili Ghazizadeh, M.; Yazdi, J. A methodology for leak detection in water distribution networks using graph theory and artificial neural network. Urban Water J. 2020, 17, 525–533. [Google Scholar] [CrossRef]
- Rajabi, M.M.; Komeilian, P.; Wan, X.; Farmani, R. Leak detection and localization in water distribution networks using conditional deep convolutional generative adversarial networks. Water Res. 2023, 238, 120012. [Google Scholar] [CrossRef] [PubMed]
- Romero-Ben, L.; Alves, D.; Blesa, J.; Cembrano, G.; Puig, V.; Duviella, E. Leak detection and localization in water distribution networks: Review and perspective. Annu. Rev. Control 2023, 55, 392–419. [Google Scholar] [CrossRef]
- Min, K.W.; Kim, T.; Lee, S.; Choi, Y.H.; Kim, J.H. Detecting and Localizing Leakages in Water Distribution Systems Using a Two-Phase Model. J. Water Resour. Plann. Manag. 2022, 148, 04022051. [Google Scholar] [CrossRef]
- Soldevila, A.; Boracchi, G.; Roveri, M.; Tornil-Sin, S.; Puig, V. Leak detection and localization in water distribution networks by combining expert knowledge and data-driven models. Neural Comput. Appl. 2022, 34, 4759–4779. [Google Scholar] [CrossRef]
- Zhirong, L.; Jiaying, W.; Hexiang, Y.; Shuping, L.; Tao, T.; Xin, K. Fast Detection and Localization of Multiple Leaks in Water Distribution Network Jointly Driven by Simulation and Machine Learning. J. Water Resour. Plann. Manag. 2022, 148, 05022005. [Google Scholar] [CrossRef]
- Srivastava, D.; Singh, Y.; Sahoo, A. Auto Tuning of RNN Hyper-parameters using Cuckoo Search Algorithm. In Proceedings of the 2019 Twelfth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2019; pp. 1–5. [Google Scholar]
- Yang, X.S.; Deb, S. Engineering optimisation by cuckoo search. Int. J. Math. Model. Numer. Optim. 2010, 1, 330–343. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Math Representation |
|---|---|
| Dataset | Math Representation |
|---|---|
| Dataset | Math Representation |
|---|---|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, S.; Wang, Y.; Fang, X.; Wu, Q. Burst Diagnosis Multi-Stage Model for Water Distribution Networks Based on Deep Learning Algorithms. Water 2024, 16, 1258. https://doi.org/10.3390/w16091258
Peng S, Wang Y, Fang X, Wu Q. Burst Diagnosis Multi-Stage Model for Water Distribution Networks Based on Deep Learning Algorithms. Water. 2024; 16(9):1258. https://doi.org/10.3390/w16091258
Chicago/Turabian StylePeng, Sen, Yuxin Wang, Xu Fang, and Qing Wu. 2024. "Burst Diagnosis Multi-Stage Model for Water Distribution Networks Based on Deep Learning Algorithms" Water 16, no. 9: 1258. https://doi.org/10.3390/w16091258
APA StylePeng, S., Wang, Y., Fang, X., & Wu, Q. (2024). Burst Diagnosis Multi-Stage Model for Water Distribution Networks Based on Deep Learning Algorithms. Water, 16(9), 1258. https://doi.org/10.3390/w16091258