
Least Squares Support Vector Machine for Ranking Solutions of Multi-Objective Water Resources Allocation Optimization Models


Abstract
:1. Introduction
2. Study Area and Methodology
2.1. Study Area
2.2. Methodology
2.2.1. k-Means Clustering Method
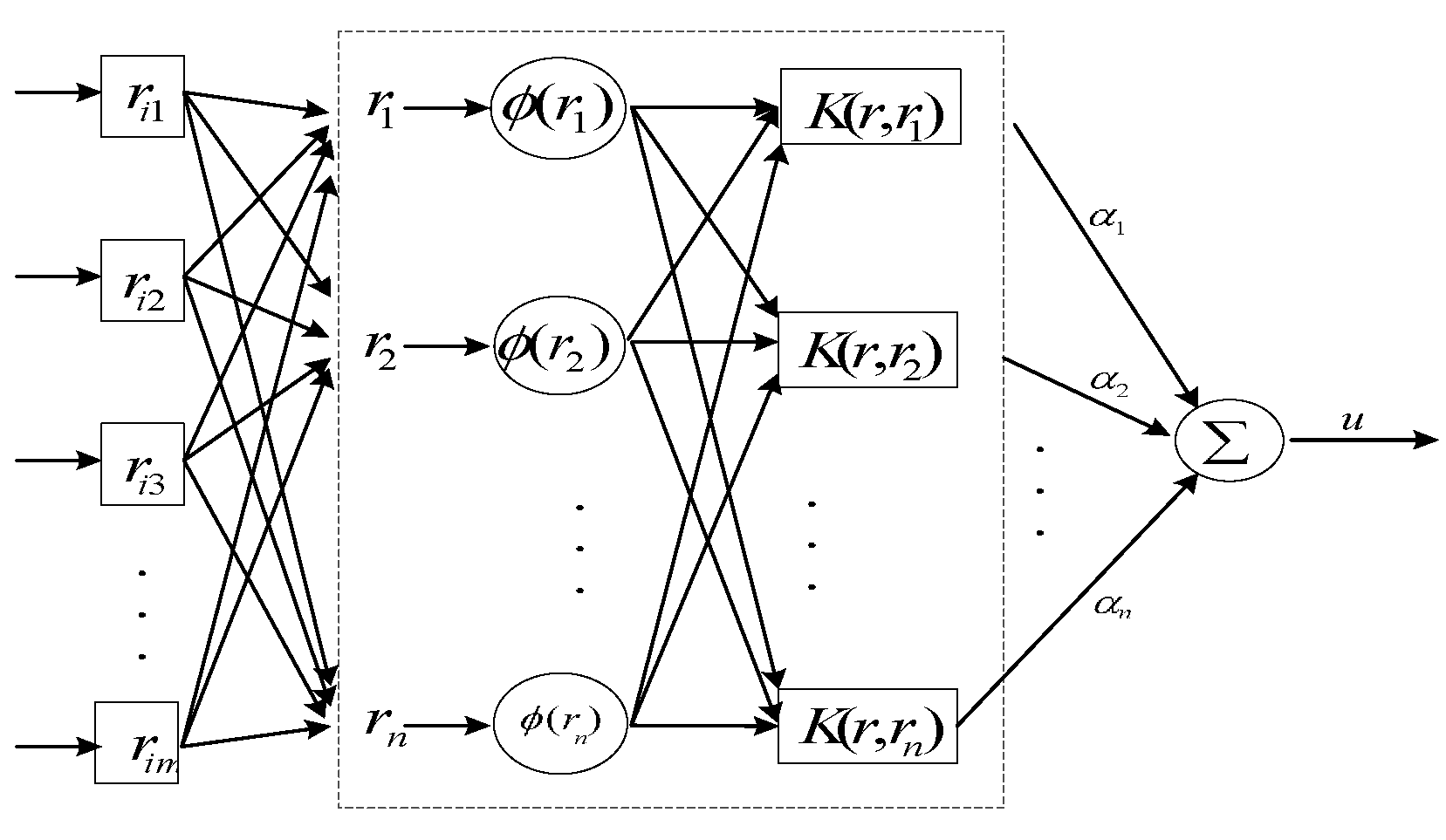
2.2.2. LSSVM Method
2.2.3. Implementation of LSSVM Model
2.2.4. Steps of the Methodology
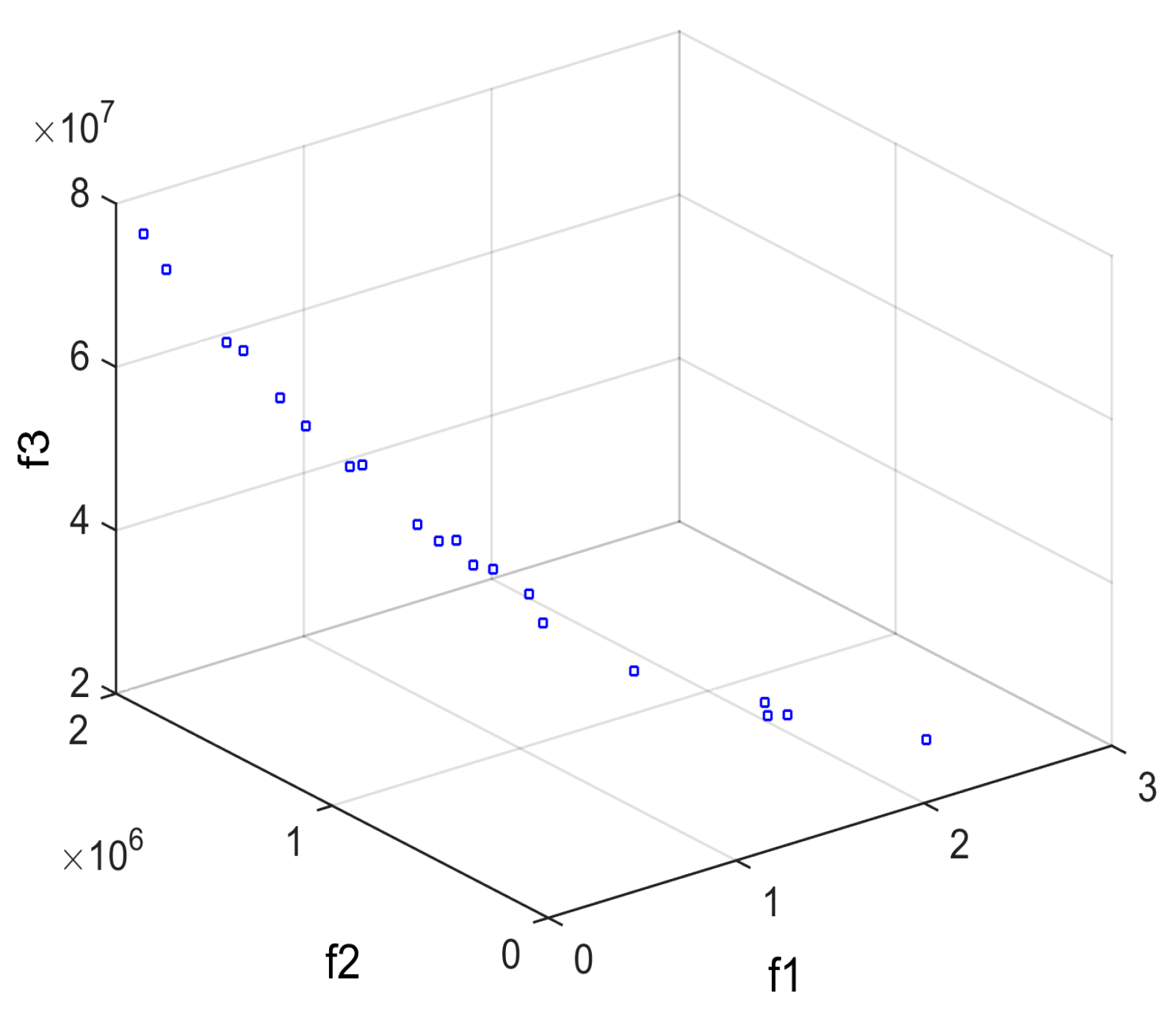
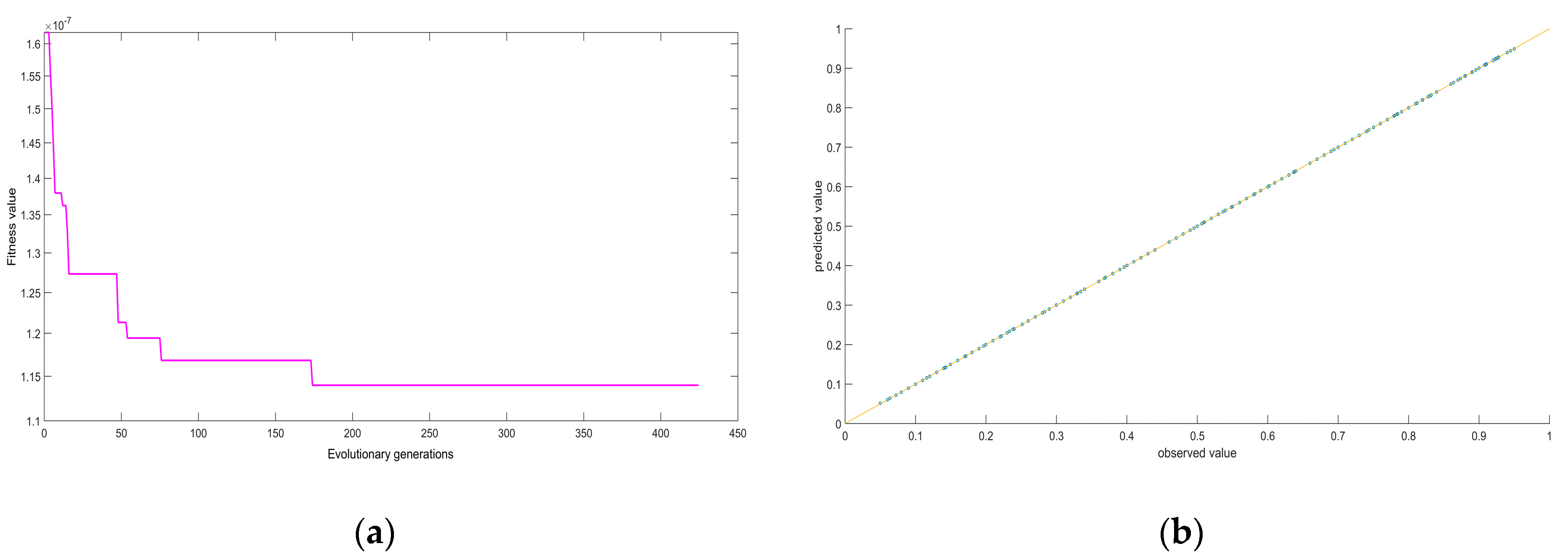
3. Results and Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Liu, D.; Chen, X.; Lou, Z. A model for the optimal allocation of water resources in a saltwater intrusion area: A case study in Pearl River Delta in China. Water Resour. Manag. 2010, 24, 63–81. [Google Scholar] [CrossRef]
- Liu, W.; Liu, L.; Dong, Z. On the use of multi-objective particle swarm optimization for allocation of water resources. In Proceedings of the 2013 Ninth International Conference on Natural Computation (ICNC), Shenyang, China, 23 July 2013; pp. 612–617. [Google Scholar]
- Baltar, A.M.; Fontane, D.G. Use of multiobjective particle swarm optimization in water resources management. J. Water Resour. Plan. Manag. 2008, 134, 257–265. [Google Scholar] [CrossRef]
- Yeh, W.W.G.; Becker, L. Multiobjective analysis of multireservoir operations. Water Resour. Res. 1982, 18, 1326–1336. [Google Scholar] [CrossRef]
- Salman, A.Z.; Al-Karablieh, E.K.; Fisher, F.M. An inter-seasonal agricultural water allocation system (SAWAS). Agric. Syst. 2001, 68, 233–252. [Google Scholar] [CrossRef]
- Shangguan, Z.P.; Shao, M.A.; Horton, R; Lei, T.; Qin, L.; Ma, J. A model for regional optimal allocation of irrigation water resources under deficit irrigation and its applications. Agric. Water Manag. 2002, 52, 139–154. [Google Scholar] [CrossRef]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Coello, C.C.; Lamont, G.B.; Van Veldhuizen, D.A. Evolutionary Algorithms for Solving Multi-Objective Problems, 2nd ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Reed, P.M.; Hadka, D.; Herman, J.D.; Kasprzyk, J.R.; Kollat, J.B. Evolutionary multiobjective optimization in water resources: The past, present, and future. Adv. Water Resour. 2013, 51, 438–456. [Google Scholar] [CrossRef]
- Liu, D.; Guo, S.; Chen, X.; Shao, Q.; Ran, Q.; Song, X.; Wang, Z. A macro-evolutionary multi-objective immune algorithm with application to optimal allocation of water resources in Dongjiang River basins, South China. Stoch. Environ. Res. Risk Assess. 2012, 26, 491–507. [Google Scholar] [CrossRef]
- Kim, T.; Heo, J.-H.; Jeong, C.S. Multi-reservoir system optimization in the Han River basin using multi-objective genetic algorithms. Hydrol. Process. 2006, 20, 2057–2075. [Google Scholar] [CrossRef]
- Guo, J.; Zhou, J.; Zou, Q.; Liu, Y.; Song, L. A novel multi-objective shuffled complex differential evolution algorithm with application to hydrological model parameter optimization. Water Resour. Manag. 2013, 27, 2923–2946. [Google Scholar] [CrossRef]
- Reddy, M.J.; Nagesh Kumar, D. Multi-objective particle swarm optimization for generating optimal trade-offs in reservoir operation. Hydrol. Process. 2007, 21, 2897–2909. [Google Scholar] [CrossRef]
- Liu, W.; Liu, L. Optimal Allocation of Water Resources Based on Multi-Objective Particle Swarm Algorithm and Information Entropy. Appl. Mech. Mater. 2014, 641, 75–79. [Google Scholar] [CrossRef]
- Wang, Q.; Shen, Y.P.; Chen, Y.W. The Support vector machine method for multiple attribute decision making. Syst. Eng. Theory Pract. 2006, 6, 54–58. [Google Scholar]
- Behzad, M.; Asghari, K.; Eazi, M.; Palhang, M. Generalization performance of support vector machines and neural networks in runoff modeling. Expert Syst. Appl. 2009, 36, 7624–7629. [Google Scholar] [CrossRef]
- Guo, J.; Zhou, J.; Qin, H.; Zou, Q.; Li, Q. Monthly streamflow forecasting based on improved support vector machine model. Expert Syst. Appl. 2011, 38, 13073–13081. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Cortes, C.; Vapnik, V. Support vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Wen, X.; Si, J.; He, Z.; Wu, J.; Shao, H.; Yu, H. Support-vector-machine-based models for modeling daily reference evapotranspiration with limited climatic data in extreme arid regions. Water Resour. Manag. 2015, 29, 3195–3209. [Google Scholar] [CrossRef]
- Su, C.; Wang, L.; Wang, X.; Huang, Z.; Zhang, X. Mapping of rainfall-induced landslide susceptibility in Wencheng, China, using support vector machine. Nat. Hazards 2015, 76, 1759–1779. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B.S. Support vector machine in machine condition monitoring and fault diagnosis. Mech. Syst. Signal Process. 2007, 21, 2560–2574. [Google Scholar] [CrossRef]
- Mohammadpour, R.; Shaharuddin, S.; Chang, C.K.; Zakaria, N.A.; Ab Ghani, A.; Chan, N.W. Prediction of water quality index in constructed wetlands using support vector machine. Environ. Sci. Pollut. Res. 2015, 22, 6208–6219. [Google Scholar] [CrossRef] [PubMed]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Samui, P.; Kothari, D.P. Utilization of a least square support vector machine (LSSVM) for slope stability analysis. Sci. Iran. 2011, 18, 53–58. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Benghanem, M. Least squares support vector machine for short-term prediction of meteorological time series. Theor. Appl. Climatol. 2013, 111, 297–307. [Google Scholar] [CrossRef]
- Ismail, S.; Samsudin, R.; Shabri, A. River flow forecasting: A hybrid model of self organizing maps and least square support vector machine. Hydrol. Earth Syst. Sci. Discuss 2010, 7, 8179–8212. [Google Scholar] [CrossRef]
- Shabri, A. Suhartono. Stremflow forecasting using least-squares support vector machines. Hydrol. Sci. J. 2012, 57, 1275–1293. [Google Scholar] [CrossRef]
- Deka, P.C. Support vector machine applications in the field of hydrology: A review. Appl. Soft Comput. 2014, 19, 372–386. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Cao, M.; Zhang, S.; Yin, Y.; Shao, L. Classification and the case matching algorithm of the blast furnace burden surface. In Proceedings of the AIP (American Institute of Physics) Conference, Wuhan, China, 25 February 2017; AIP Publishing: Melville, NY, USA, 2017; p. 080009. [Google Scholar]
- Yu, L.; Yao, X.; Wang, S.; Lai, K.K. Credit risk evaluation using a weighted least squares SVM classifier with design of experiment for parameter selection. Expert Syst. Appl. 2011, 38, 15392–15399. [Google Scholar] [CrossRef]
- De Brabanter, K.; Karsmakers, P.; Ojeda, F.; Alzate, C.; De Brabanter, J.; Pelckmans, K.; Suykens, J.A.K. LS-SVMlab toolbox user’s guide. ESAT-SISTA Technol. Rep. 2011, 10, 146. [Google Scholar]
- Chamkalani, A.; Zendehboudi, S.; Bahadori, A.; Kharrat, R.; Chamkalani, R.; James, L.; Chatzis, I. Integration of LSSVM technique with PSO to determine asphaltene deposition. J. Pet. Sci. Eng. 2014, 124, 243–253. [Google Scholar] [CrossRef]
- Moradkhani, H.; Hsu, K.L.; Gupta, H.V.; Sorooshian, S. Improved streamflow forecasting using self-organizing radial basis function artificial neural networks. J. Hydrol. 2004, 295, 246–262. [Google Scholar] [CrossRef]
- Zhao, J.; Jin, J.; Zhu, J.; Xu, J.; Hang, Q.; Chen, Y.; Han, D. Water Resources Risk Assessment Model based on the Subjective and Objective Combination Weighting Methods. Water Resour. Manag. 2016, 30, 3027–3042. [Google Scholar] [CrossRef]
- Jia, X.; Li, C.; Cai, Y.; Wang, X.; Sun, L. An improved method for integrated water security assessment in the Yellow River basin, China. Stoch. Environ. Res. Risk Assess. 2015, 29, 2213–2227. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Name | f1 | f2 | f3 | Utility Value |
|---|---|---|---|---|
| Ideal point | 1.1491 | 1.5433 | 1.7070 | 0.95 |
| Negative ideal point | −2.4907 | −1.7455 | −1.7995 | 0.05 |
| Model | Training | Testing | ||
|---|---|---|---|---|
| RMSE | RME | RMSE | RME | |
| LSSVM | 2.262 × 10−4 | 0.06731% | 1.025 × 10−4 | 0.0416% |
| RBF network | 3.211 × 10−4 | 0.1448% | 3.159 × 10−4 | 0.1053% |
| Testing Sample NO. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Expected value | 0.07 | 0.15 | 0.25 | 0.35 | 0.45 | 0.55 | 0.65 | 0.75 | 0.85 | 0.93 |
| Simulated value | 0.0699 | 0.1499 | 0.2501 | 0.3502 | 0.4501 | 0.5499 | 0.6499 | 0.7499 | 0.8501 | 0.9301 |
| Relative error (%) | −0.1742 | −0.0910 | 0.0335 | 0.0454 | 0.0171 | −0.0130 | −0.0207 | −0.0078 | 0.0075 | 0.0055 |
| Alternatives NO. | f1 | f2 | f3 | LSSVM | RBF Networks | Information Entropy | ||
|---|---|---|---|---|---|---|---|---|
| (106 Million Yuan/Year) | (104 Tons/Year) | Results | Priority Order | Results | Priority Order | Priority Order | ||
| 1 | 0.2545 | 1.71 | 65.2 | 0.441780 | 18 | 0.397256 | 18 | 18 |
| 2 | 0.6819 | 1.1 | 46.3 | 0.643288 | 10 | 0.637061 | 9 | 11 |
| 3 | 0.9351 | 0.84 | 38 | 0.732777 | 2 | 0.732997 | 2 | 6 |
| 4 | 0.7518 | 1 | 44.2 | 0.676973 | 7 | 0.673814 | 5 | 9 |
| 5 | 0.6397 | 1.16 | 47.8 | 0.620609 | 11 | 0.611983 | 10 | 12 |
| 6 | 1.1993 | 0.65 | 32.9 | 0.749499 | 1 | 0.742739 | 1 | 5 |
| 7 | 1.6858 | 0.46 | 28.2 | 0.689679 | 5 | 0.652028 | 7 | 3 |
| 8 | 0.8246 | 0.81 | 42.8 | 0.723348 | 3 | 0.721588 | 3 | 7 |
| 9 | 0.0994 | 1.96 | 76.2 | 0.416740 | 20 | 0.351093 | 20 | 20 |
| 10 | 0.1415 | 1.89 | 72.5 | 0.419814 | 19 | 0.360474 | 19 | 19 |
| 11 | 0.4118 | 1.48 | 57 | 0.502330 | 15 | 0.475338 | 15 | 15 |
| 12 | 0.7492 | 0.91 | 45 | 0.694340 | 4 | 0.690562 | 4 | 8 |
| 13 | 0.3446 | 1.54 | 60.1 | 0.481052 | 16 | 0.447618 | 16 | 16 |
| 14 | 1.7138 | 0.47 | 26.2 | 0.688663 | 6 | 0.647925 | 8 | 1 |
| 15 | 2.4148 | 0.35 | 20.1 | 0.584945 | 12 | 0.49719 | 14 | 2 |
| 16 | 0.4964 | 1.35 | 53.3 | 0.546941 | 14 | 0.527872 | 13 | 14 |
| 17 | 0.2535 | 1.63 | 65.3 | 0.452988 | 17 | 0.409534 | 17 | 17 |
| 18 | 0.4717 | 1.27 | 54.7 | 0.561099 | 13 | 0.540233 | 12 | 13 |
| 19 | 1.8766 | 0.53 | 24.5 | 0.655651 | 9 | 0.604544 | 11 | 4 |
| 20 | 0.662 | 1 | 47.9 | 0.660599 | 8 | 0.652785 | 6 | 10 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Liu, L.; Tong, F. Least Squares Support Vector Machine for Ranking Solutions of Multi-Objective Water Resources Allocation Optimization Models. Water 2017, 9, 257. https://doi.org/10.3390/w9040257
Liu W, Liu L, Tong F. Least Squares Support Vector Machine for Ranking Solutions of Multi-Objective Water Resources Allocation Optimization Models. Water. 2017; 9(4):257. https://doi.org/10.3390/w9040257
Chicago/Turabian StyleLiu, Weilin, Lina Liu, and Fang Tong. 2017. "Least Squares Support Vector Machine for Ranking Solutions of Multi-Objective Water Resources Allocation Optimization Models" Water 9, no. 4: 257. https://doi.org/10.3390/w9040257
APA StyleLiu, W., Liu, L., & Tong, F. (2017). Least Squares Support Vector Machine for Ranking Solutions of Multi-Objective Water Resources Allocation Optimization Models. Water, 9(4), 257. https://doi.org/10.3390/w9040257