
A Novel Community Detection Method of Social Networks for the Well-Being of Urban Public Spaces



Abstract
:1. Introduction
2. Related Works
3. Basic Notions and Approach
3.1. Terminologies and Notations
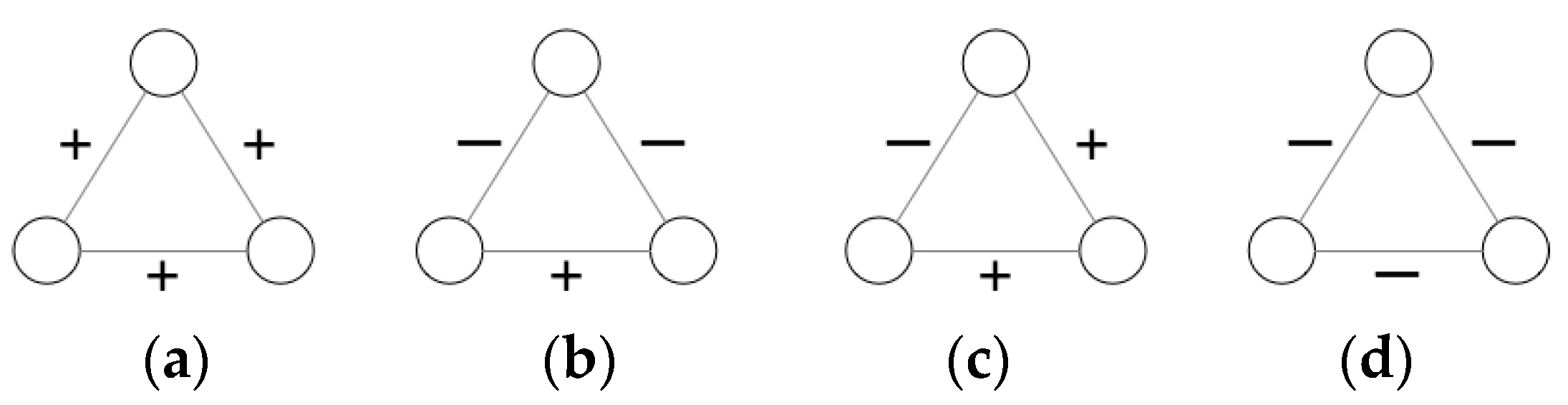
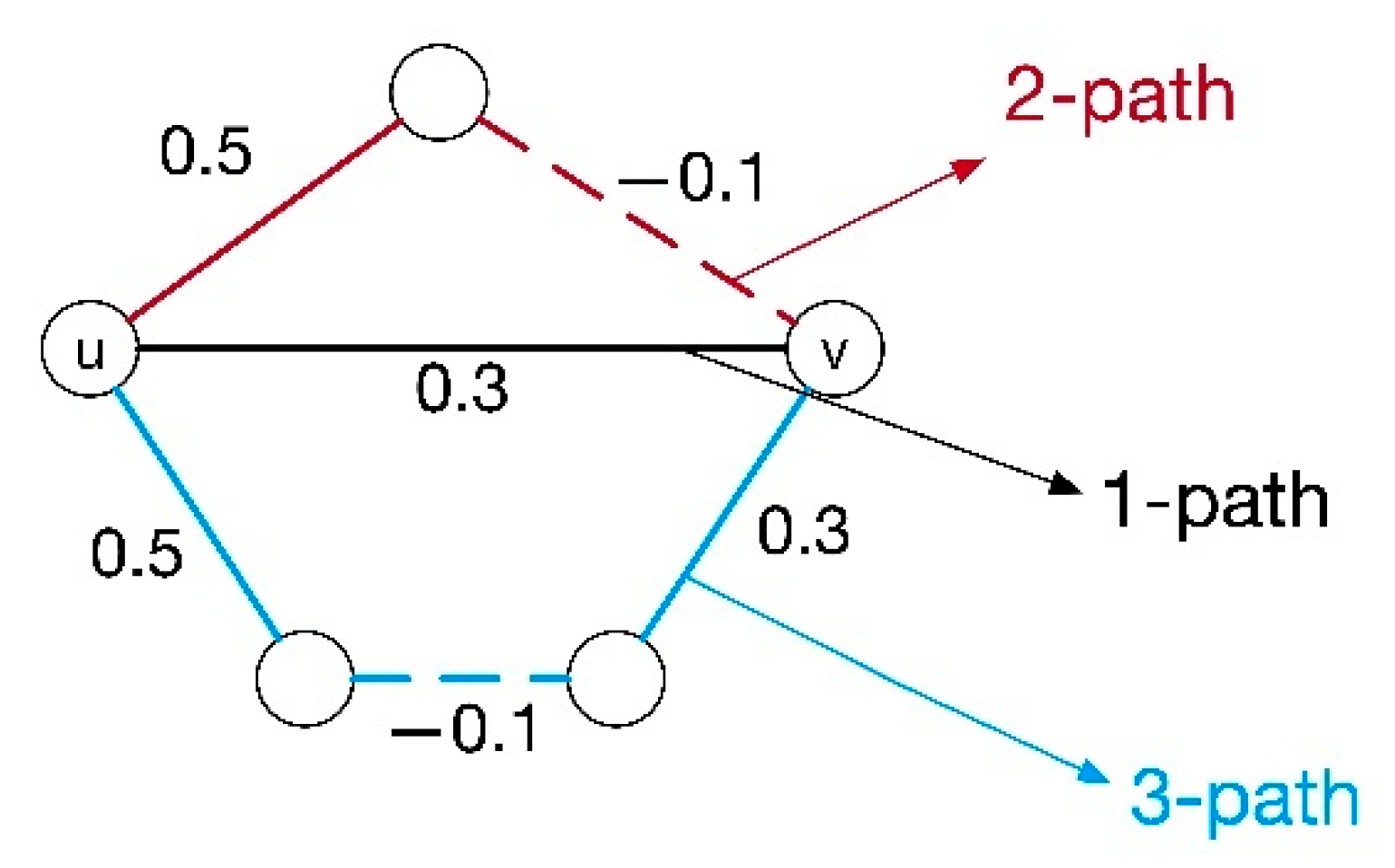
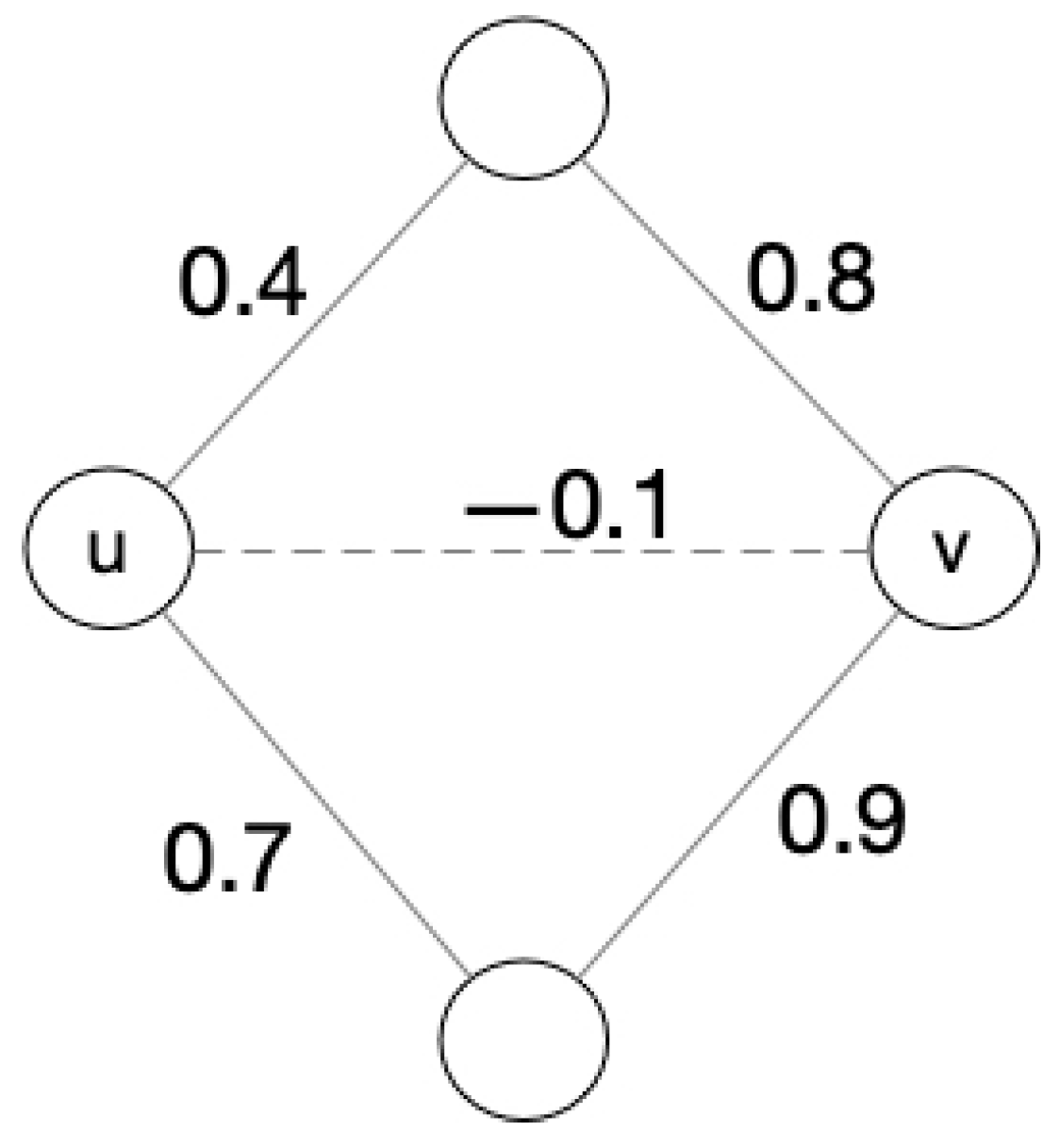
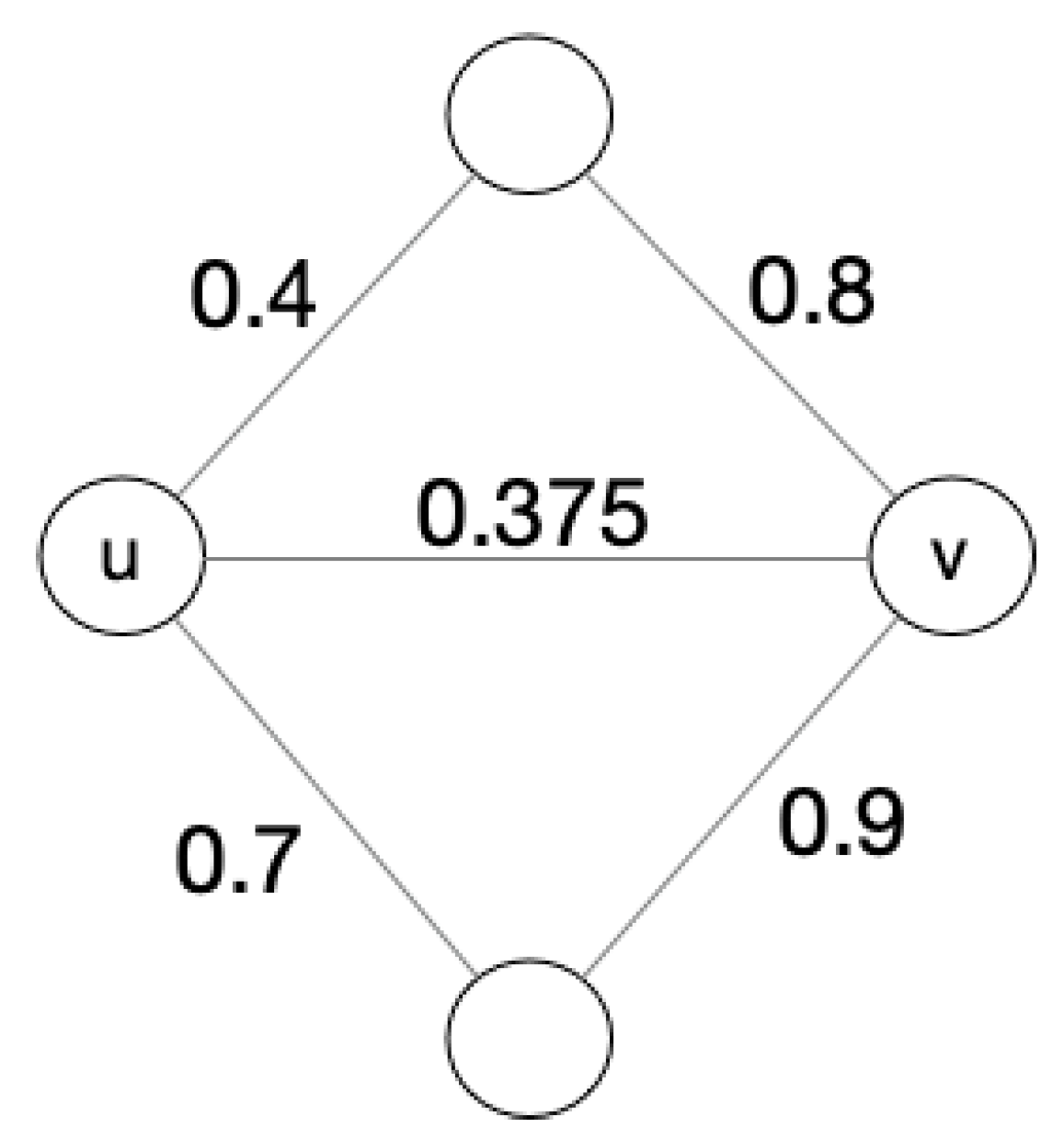
3.1.1. Recalculate the Weights between Friends
3.1.2. γ-Quasi-Cliques
 O1⊆ O2( A1⊇ A2).
O1⊆ O2( A1⊇ A2).| Algorithm 1-Quasi-Cliques Detection |
| formal context f 2: begin 3: Formal Concept Lattice ← Construct FCA(f) 4: for each concept ∈ Formal Concept Lattice: 5: value ← * concept.extent.length 6: flag ← True 7: degree ← degree(all nodes of concept) 8: if value > degree: 9: flag = False 10: if flag is True: 11: QuasiCliques.add(concept) 12: return QuasiCliques 13: End |
3.2. Methodology of Maximal Balanced -Quasi-Cliques Detection
3.2.1. Overview
3.2.2. Optimization of Weight Matrix Computation
3.2.3. Our Maximal Balanced -Quasi-Cliques Detection Method
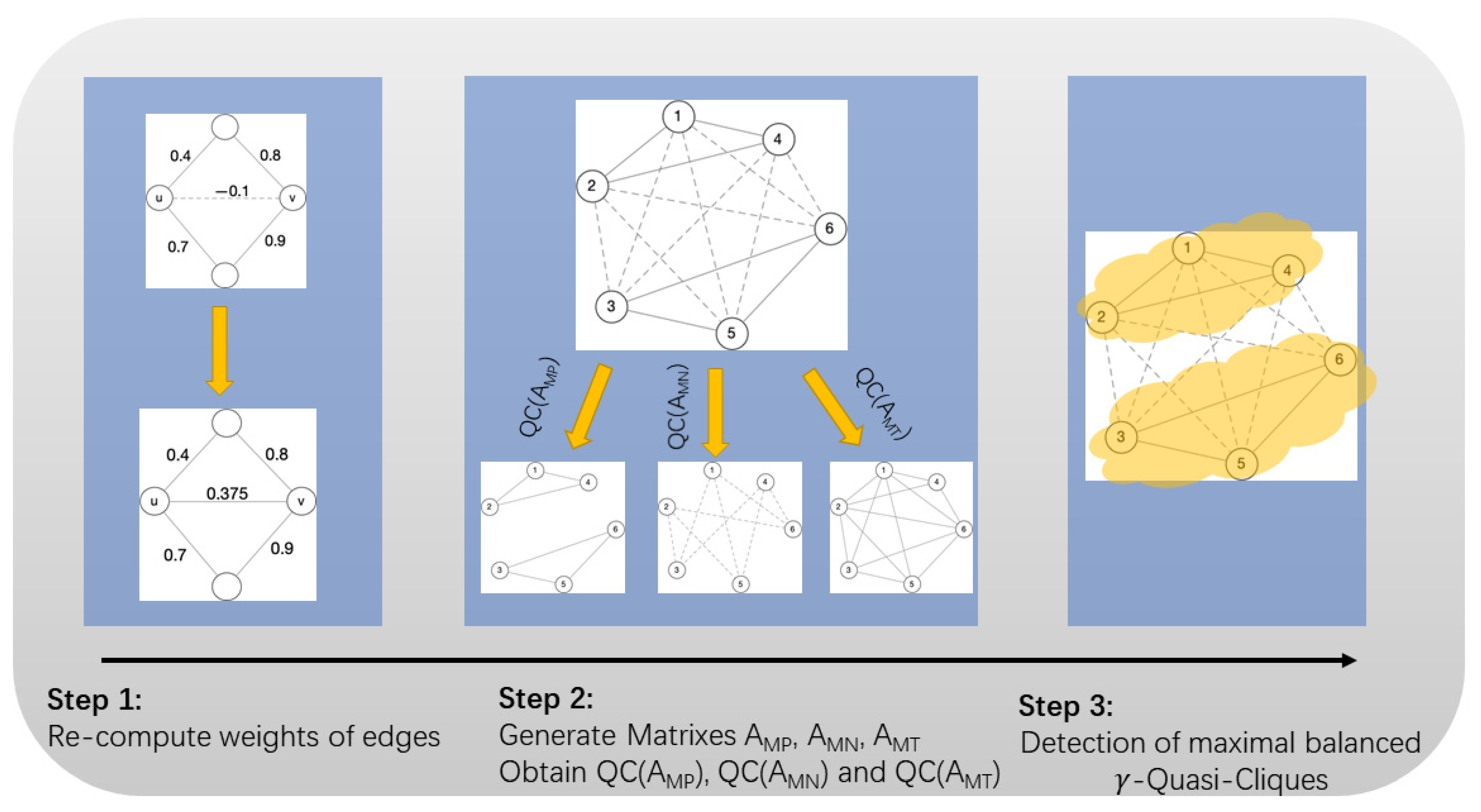
- Step 1 (Complete Weighted Matrix and Prune Data): Make complete weight in the social network graph by Equation (5) and convert it into an adjacency matrix. All elements in the matrix are nonzero after the N power operation of the matrix (N ≤ 6); thus, it is necessary to prune the weight closer to 0 (weight with a more neutral bias). For this, we will provide two thresholds, τ1 and τ2 (given by users).
- If the weight of two nodes is greater than the 1, we regard the edge of these two nodes as a positive edge, noted as 1. If the weight of two nodes is less than 2 (2 is negative), and there is a negative relationship between these two nodes, noted as −1; the remaining nodes are of no relationship and are noted 0. The new adjacency matrix AM is shown in Equation (6).
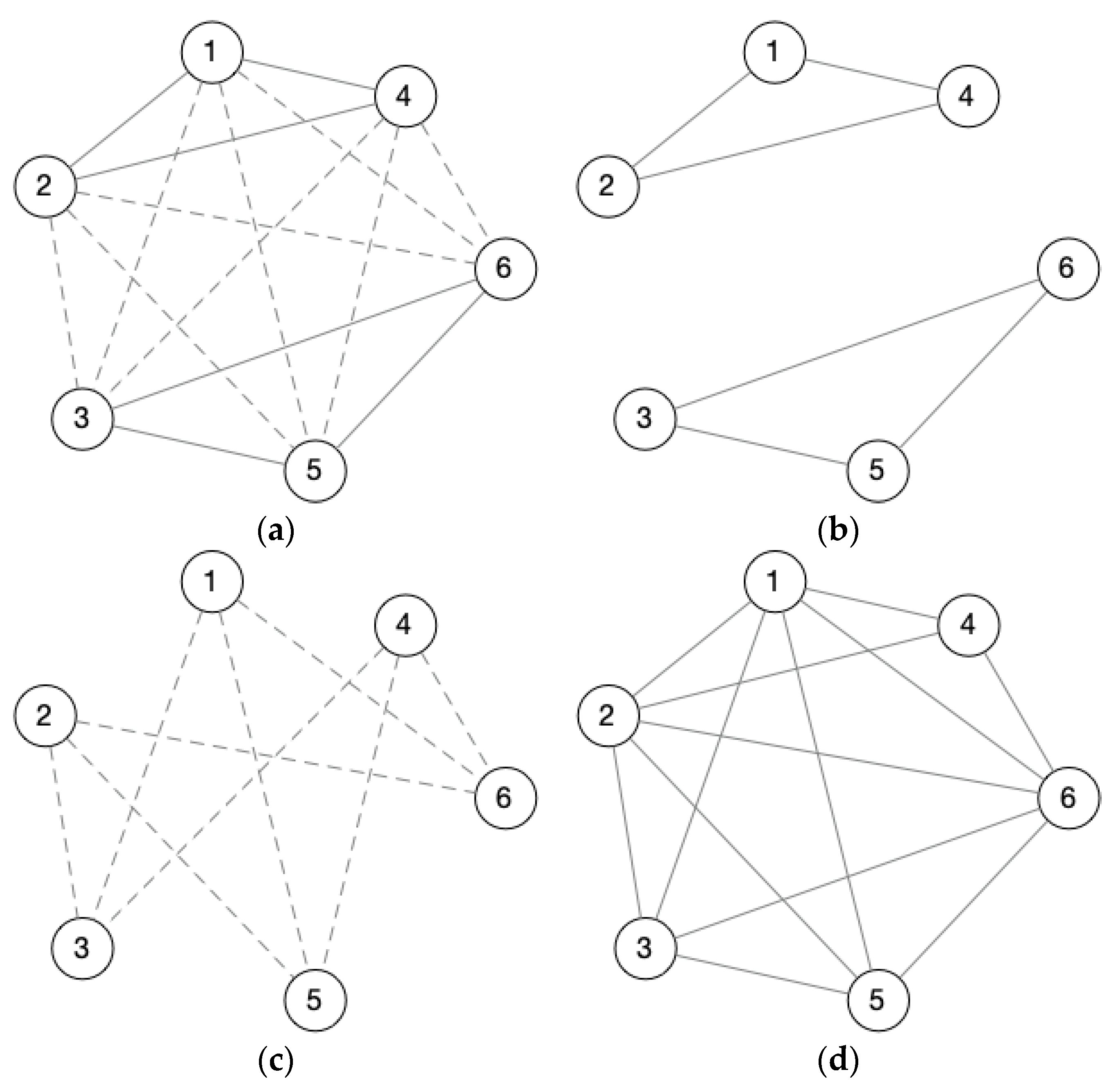
- Step 2 (rebuild the signed matrixes): Since the -Quasi-Cliques Detection method in Section 3.2.1 is assigned to unweighted and normal social networks (the edges do not have positive/negative relations), in this step, we redefine AM as three matrices. All positive edges are stored in AMP, all negative edges are stored in AMN and edges with weights 1 and −1 are regarded as 1 in AMT, which only indicates whether there is a relationship between the nodes.
- Step 3 (-Quasi-Cliques Detection): Using these three matrixes as input values, perform Quasi-cluster detection to obtain Quasi-Cliques sets QC(AMT), QC(AMP), and QC(AMN), if the Quasi-Cliques in quasi-clusters QC(AMP) and QC(AMN) exist in QC(AMT), then they are our final output: Signed -Quasi-Cliques.
Notes: The QC(AMP) is the set of-Quasi-Cliques with positive edges, the QC(AMN) is the set of-Quasi-Cliques with negative edges, the QC(AMT) is the set of-Quasi-Cliques with positive edges and negative edges (regardless of the sign of the edges). If the-Quasi-Clique E1 and-Quasi-Clique E2 are both in the QC(AMP), there are positive relationships among the nodes in E1 and E2, respectively, the E1 and E2 form a-Quasi-Clique in QC(AMN), and there are negative relationships among the nodes in merger set of E1 and E2. Meanwhile, the merger set of E1 and E2 with positive and negative edges is a-Quasi-Clique in QC(AMT), which means that all nodes in E1 and E2 can form a-Quasi-Clique. At this point, this-Quasi-Clique is a maximal balanced-Quasi-Clique.
| Algorithm 2 The overall flow of community detection algorithms |
| graph g, thresholdτ1, τ2 2: begin 3://Complete Weighted Matrix and Prune Data 4: Formal Concept f ← Calculate g by Equation (5) and compare it with threshold τ1, τ2. 5://Rebuild the signed matrixes 6: AMP, AMN, AMT ← Matrix Equation (7) (AM), Matrix Equation (8) (AM), Matrix Equation (9) (AM) 7://Detecting -QuasiCliques 8: -QuasiCliques1, 2, 3 ← Algorithm 1 ( AMP), Algorithm 1 ( AMN), Algorithm 1 ( AMT) 9: for Q1 in QuasiCliques1: 10: for Q2 in QuasiCliques2: 11: if Q1 and Q2 in QuasiCliques3: 12: -Quasi-Cliques ← (Q1, Q2) 13: return Signed -QuasiCliques 14: End |
4. Experiment and Discussion
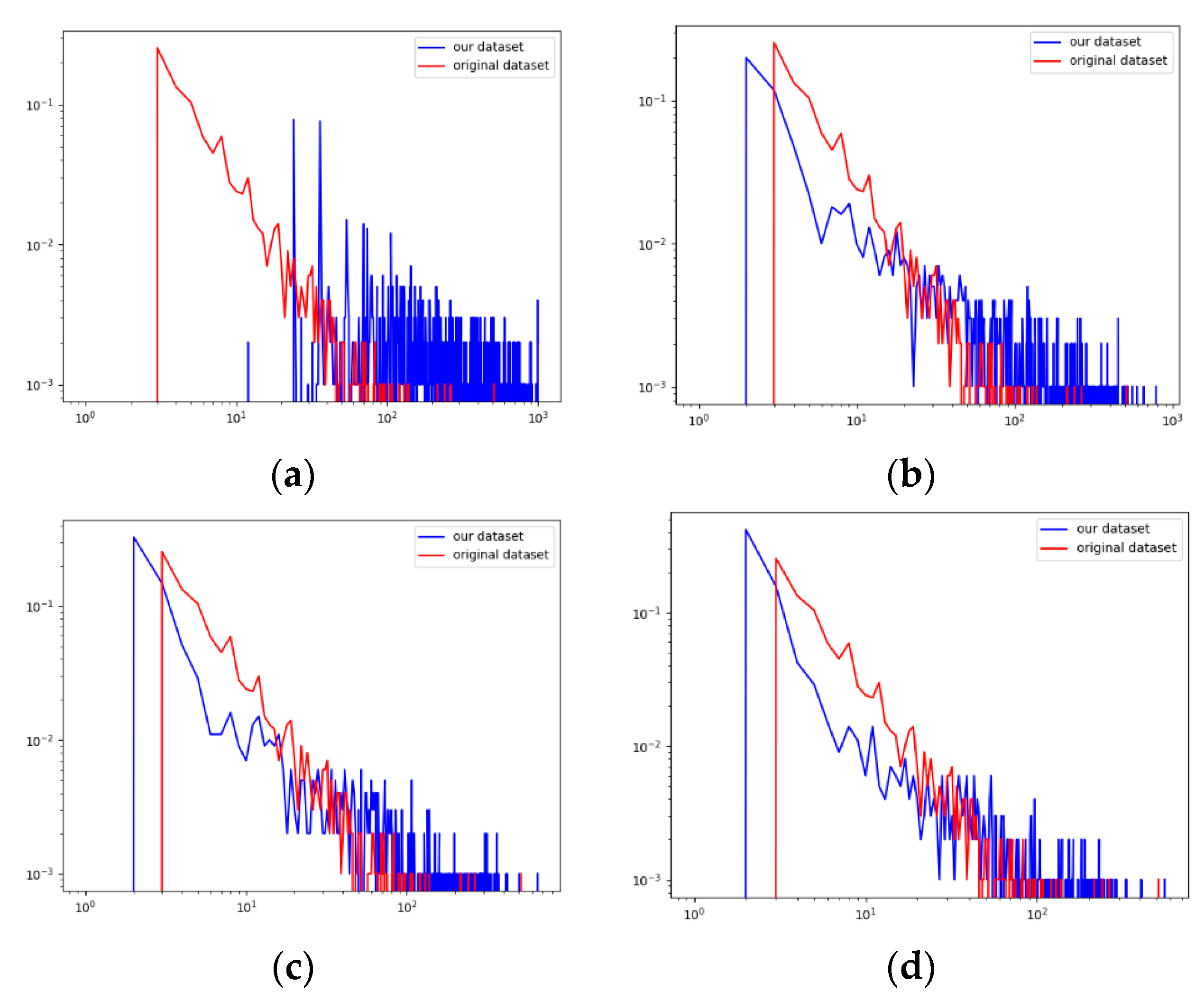
4.1. Recompute Weight Matrix and Threshold Determination
4.1.1. Dataset and Experimental Environment
4.1.2. Threshold Determination
- 1
- The value determination of
- 2
- The value determination of γ
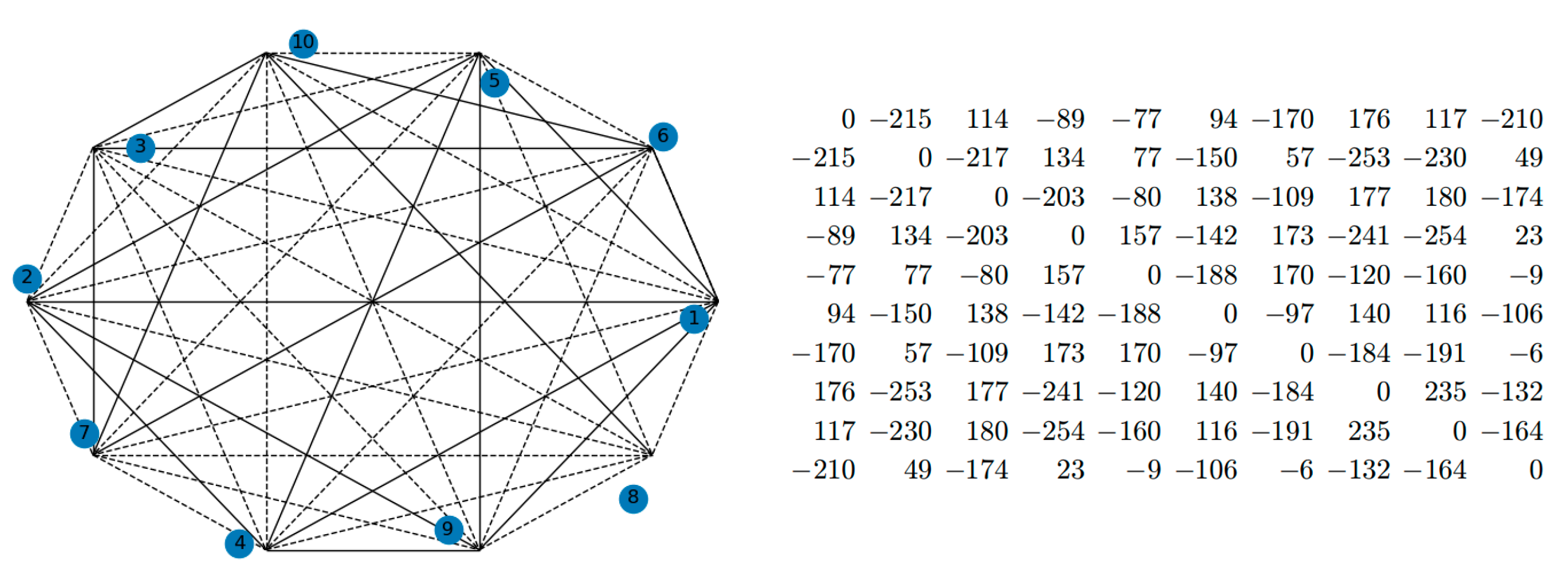
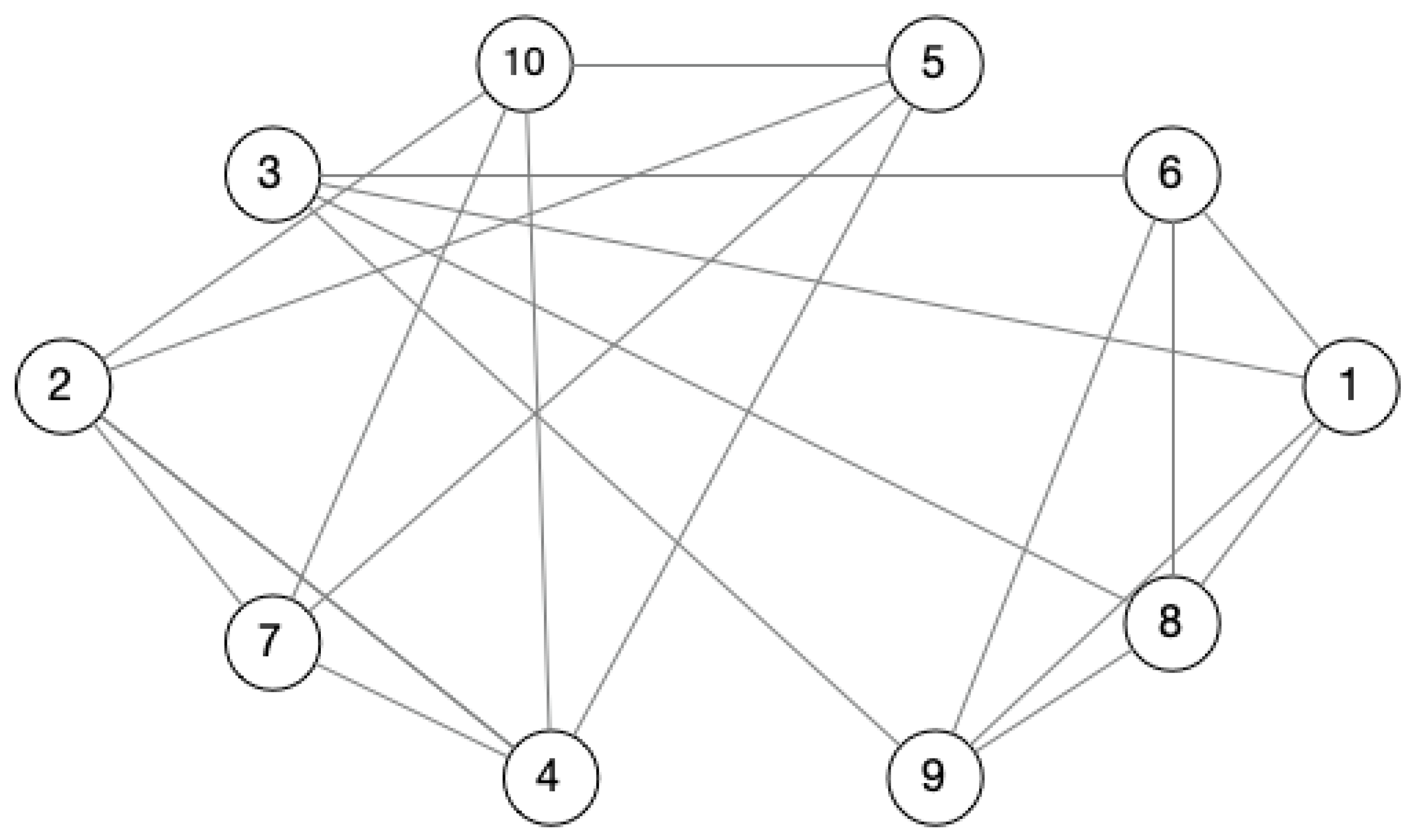
4.2. Case Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ramon, O.; Dennis, B. The third place. Qual. Sociol. 1982, 5, 265–284. [Google Scholar]
- Park, J.; State, B.; Bhole, M.; Bailey, M.C.; Ahn, Y.Y. People, Places, and Ties: Landscape of social places and their social network structures. arXiv 2021, arXiv:2101.04737. [Google Scholar]
- HaoYang, L. Research on Key Technologies of Graph Mining; China Knowledge Network: Beijing, China, 2017. [Google Scholar]
- Jung Hee, W.; Ji Woo, P.; Ahn, J.G. Cancer Patient Specific Driver Gene Identification by Personalized Gene Network and PageRank. KIPS Trans. Softw. Data Eng. 2021, 10, 547–554. [Google Scholar]
- Taejin, K.; Heechan, K.; Soowon, L. Automatic Tag Classification from Sound Data for Graph-Based Music Recommendation. KIPS Trans. Softw. Data Eng. 2021, 10, 399–406. [Google Scholar]
- Yongbin, Q.; Cun-quan, Z. A new multimembership clustering method. J. Ind. Manag. Optim. 2007, 3, 619. [Google Scholar]
- Silviu, M.; Bogdan, C.; Talel, A. Building a Signed Network from Interactions in Wikipedia. In Proceedings of the First ACM SIGMOD Workshop on Databases and Social Networks (DBSocial), Athens, Greece, 12 June 2011; pp. 19–24. [Google Scholar]
- Liu, M.M.; Hu, Q.C.; Guo, J.F.; Chen, J. Link prediction algorithm for signed social networks based on local and global tightness. J. Inf. Processing Syst. 2021, 17, 213–226. [Google Scholar]
- Timo, H. Friends and enemies: A model of signed network formation. Theor. Econ. 2017, 12, 1057–1087. [Google Scholar]
- Cartwright, D.; Harary, F. Structural balance: A generalization of Heider’s theory. Psychol. Rev. 1956, 63, 277. [Google Scholar] [CrossRef] [Green Version]
- Harary, F. On local balance and N-balance in signed graphs. Mich. Math. J. 1955, 3, 37–41. [Google Scholar] [CrossRef]
- Yang, Y.; Park, D.S.; Hao, F.; Peng, S.; Hong, M.P.; Lee, H. Detection of Maximal Balanced Clique in Signed Networks Based on Improved Three-Way Concept Lattice and Modified Formal Concept Analysis. 2021. Available online: https://assets.researchsquare.com/files/rs-277245/v1_covered.pdf?c=1631863443 (accessed on 26 April 2021).
- Yang, Y.; Hao, F.; Park, D.S.; Peng, S.; Lee, H.; Mao, M. Modelling Prevention and Control Strategies for COVID-19 Propagation with Patient Contact Networks. Hum.-Cent. Comput. Inf. Sci. 2021, 11, 45. [Google Scholar]
- Guimei, L.; Limsoon, W. Effective Pruning Techniques for Mining Quasi-Cliques. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Antwerp, Belgium, 15–19 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 33–49. [Google Scholar]
- Fei, H.; Zheng, P.; Laurence, T.Y. Diversified top-k maximal clique detection in Social Internet of Things. Future Gener. Comput. Syst. 2020, 107, 408–417. [Google Scholar]
- Doreian, P.; Mrvar, A. A partitioning approach to structural balance. Soc. Netw. 1996, 18, 149–168. [Google Scholar] [CrossRef]
- Yang, B.; Cheung, W.; Liu, J. Community mining from signed social networks. IEEE Trans. Knowl. Data Eng. 2007, 19, 1333–1348. [Google Scholar] [CrossRef]
- Bansal, N.; Blum, A.; Chawla, S. Correlation clustering. Mach. Learn. 2004, 56, 89–113. [Google Scholar] [CrossRef] [Green Version]
- Sun, R.; Chen, C.; Wang, X.; Zhang, Y.; Wang, X. Stable Community Detection in Signed Social Networks. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Xia, C.; Luo, Y.; Wang, L.; Li, H.-J. A Fast Community Detection Algorithm Based on Reconstructing Signed Networks. IEEE Syst. J. 2022, 16, 614–625. [Google Scholar] [CrossRef]
- Cadena, J.; Vullikanti, A.K.; Aggarwal, C.C. On dense subgraphs in signed network streams. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 51–60. [Google Scholar]
- Li, D.; Liu, J. Modeling influence diffusion over signed social networks. IEEE Trans. Knowl. Data Eng. 2019, 33, 613–625. [Google Scholar] [CrossRef]
- Tsourakakis, C.E.; Chen, T.; Kakimura, N.; Pachocki, J. Novel Dense Subgraph Discovery Primitives: Risk Aversion and Exclusion Queries. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Würzburg, Germany, 6–20 September 2019; Springer: Cham, Switzerland, 2019; pp. 378–394. [Google Scholar]
- Ordozgoiti, B.; Matakos, A.; Gionis, A. Finding large balanced subgraphs in signed networks. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1378–1388. [Google Scholar]
- Qi, X.; Luo, R.; Fuller, E.; Luo, R.; Zhang, C.Q. Signed Quasi-Cliques merger: A new clustering method for signed networks with positive and negative edges. Int. J. Pattern Recognit. Artif. Intell. 2016, 30, 1650006. [Google Scholar] [CrossRef]
- Kleinfeld, J. Could it be a big world after all? The six degrees of separation myth. Society 2002, 12, 2–5. [Google Scholar]
- Hao, F.; Min, G.; Pei, Z.; Park, D.S.; Yang, L.T. K-clique community detection in social networks based on formal concept analysis. IEEE Syst. J. 2015, 11, 250–259. [Google Scholar] [CrossRef]
- Yang, Y.; Hao, F.; Pang, B.; Min, G.; Wu, Y. Dynamic maximal cliques detection and evolution management in social internet of things: A formal concept analysis approach. IEEE Trans. Netw. Sci. Eng. 2021. [Google Scholar] [CrossRef]
- Jo, Y.Y.; Kim, S.W.; Bae, D.H. Efficient sparse matrix multiplication on gpu for large social network analysis. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1261–1270. [Google Scholar]
- Okasaki, C. From fast exponentiation to square matrices: An adventure in types. ACM SIGPLAN Not. 1999, 34, 28–35. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, X. A parallel algorithm for matrix fast exponentiation based on MPI. In Proceedings of the 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA), Shanghai, China, 9–12 March 2018; pp. 162–165. [Google Scholar]
- Kumar, S.; Spezzano, F.; Subrahmanian, V.S.; Faloutsos, C. Edge Weight Prediction in Weighted Signed Networks. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016. [Google Scholar]
- Kumar, S.; Hooi, B.; Makhija, D.; Kumar, M.; Subrahmanian, V.S.; Faloutsos, C. REV2: Fraudulent User Prediction in Rating Platforms. In Proceedings of the 11th ACM International Conference on Web Searchand Data Mining (WSDM), Los Angeles, CA, USA, 5–9 February 2018. [Google Scholar]
- Ferligoj, A.; Kramberger, A. An analysis of the slovene parliamentary parties network. Dev. Stat. Methodol. 1996, 12, 209–216. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subgraph (a) | Subgraph (b) | Subgraph (c) | Subgraph (d) | |
|---|---|---|---|---|
| 1 | Mean(AMP) | Mean(AMP) + Std(AMP) | Mean(AMP) + 2 × Std(AMP) | Mean(AMP) + 3 × Std(AMP) |
| 11,377.463 | 66,294.718 | 119,731.322 | 173,936.850 | |
| 2 | Mean(AMN) | Mean(AMN) − Std(AMN) | Mean(AMN) − 2 × Std(AMN) | Mean(AMN) − 3 × Std(AMN) |
| −1074.750 | −18,230.686 | −35,300.547 | −52,414.579 |
| Subgraph 8(a) | Subgraph 8(b) | Subgraph 8(c) | Subgraph 8(d) | |
|---|---|---|---|---|
| Number of Prune Edges | 707,589 | 858,691 | 879,438 | 887,651 |
| Number of edges | 292,411 | 141,309 | 120,562 | 112,349 |
| Number of Quasi-Cliques | 170 | 127 | 67 | 32 | 8 |
| 168 | 146 | 107 | 65 | 43 |
| QND | 0.168 | 0.127 | 0.107 | 0.065 | 0.043 |
| Node | Frequently Visited Third Place |
|---|---|
| 1 | Coffee, Church |
| 2 | Bar, Coffee, Community Center |
| 3 | Church, Park, Coffee |
| 4 | Park, Bar, Coffee, Community Center |
| 5 | Community Center, Coffee |
| 6 | Park, Church |
| 7 | Bar, Community Center, Coffee |
| 8 | Church, Coffee, Bar |
| 9 | Mall, Church |
| 10 | Park, Community Center, Coffee |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Peng, S.; Park, D.-S.; Hao, F.; Lee, H. A Novel Community Detection Method of Social Networks for the Well-Being of Urban Public Spaces. Land 2022, 11, 716. https://doi.org/10.3390/land11050716
Yang Y, Peng S, Park D-S, Hao F, Lee H. A Novel Community Detection Method of Social Networks for the Well-Being of Urban Public Spaces. Land. 2022; 11(5):716. https://doi.org/10.3390/land11050716
Chicago/Turabian StyleYang, Yixuan, Sony Peng, Doo-Soon Park, Fei Hao, and Hyejung Lee. 2022. "A Novel Community Detection Method of Social Networks for the Well-Being of Urban Public Spaces" Land 11, no. 5: 716. https://doi.org/10.3390/land11050716
APA StyleYang, Y., Peng, S., Park, D. -S., Hao, F., & Lee, H. (2022). A Novel Community Detection Method of Social Networks for the Well-Being of Urban Public Spaces. Land, 11(5), 716. https://doi.org/10.3390/land11050716